

Summary
We consider partially linear models of the form Y = XTβ + ν(Z) + ε when the response variable Y is sometimes missing with missingness probability π depending on (X, Z), and the covariate X is measured with error, where ν(z) is an unspecified smooth function. The missingness structure is therefore missing not at random, rather than the usual missing at random. We propose a class of semiparametric estimators for the parameter of interest β, as well as for the population mean E(Y). The resulting estimators are shown to be consistent and asymptotically normal under general assumptions. To construct a confidence region for β, we also propose an empirical-likelihood-based statistic, which is shown to have a chi-squared distribution asymptotically. The proposed methods are applied to an AIDS clinical trial dataset. A simulation study is also reported.
Some key words: Confidence region, Empirical likelihood, Estimating equation, Measurement error, Missing data, Missing not at random, Nonparametric regression, Semiparametric estimation
1 Introduction
The partially linear model assumes that the response variable Y depends on variable X in a linear way but is related to another independent variable Z in an unspecified form:
| (1.1) |
where X is a p-vector covariate, Z is a scalar covariate, the function ν(·) is unknown, and the model error ε has mean zero conditional on (X, Z).
There is a substantial literature on kernel-based methods for partially linear models and their generalisations; see for example Engle et al. (1986), Speckman (1988), Robinson (1988), Severini & Staniswalis (1994), Zeger & Diggle (1994), Opsomer & Ruppert (1999) and Härdle et al. (2000), among many others. Liang et al. (1999) considered model (1.1) with error-prone X. Recently, missing-data issues have been considered, with Liang, et al. (2004) considering the case in which X in (1.1) is missing at random, while in Wang et al. (2004) the response Y is missing at random.
In this paper, we consider the missing response case, but in addition we allow some of the components of X to be measured with error. Our motivation is from AIDS clinical trials, where the response, variable viral load RNA, can be missing. In addition, the covariates, CD4 measurements, are measured with error. Measurement error in predictors causes a bias in the estimated regression coefficient. While Liang et al. (1999) considered the measurement error problem, they did not allow for missing responses.
We assume that we can observe a surrogate W related to X by
| (1.2) |
If δ = 1 indicates that Y is observed and δ = 0 indicates that Y is missing, we assume that the measurement error U is independent of (Y, Z, X, δ) and with E(U) = 0, cov(U) = Σuu. We first assume that Σuu is known, and later extend the results to the general case.
It is important to stress that, under the setting considered in this paper, see (2.1) below, the missingness of Y is allowed to depend on (X, Z), but not otherwise on W. Since the true X is not observable, Y is therefore not missing at random. Since we will make no further assumption, such as on the distribution of X or on the missing data probabilities, what we are dealing with here is conceptually quite different from most studies of missing data in which missing at random or missing completely at random is assumed.
2 Estimation And Main Results
2.1 Known measurement error covariance matrix
As described previously, we assume that, if X were observed, the missing data mechanism would follow the missing at random mechanism in the sense that
| (2.1) |
for some unknown π(X, Z). Since we also assume that the measurement errors U are independent of (Y, Z, X, δ), pr(δ = 1∣X, Z, Y, W) = π(X, Z). Furthermore, we assume that {(Yi, Wi, Zi, δi), i = 1, ⋯, n} are independent and identically distributed.
We use locally constant smoothers with fixed bandwidths for simplicity in presenting the derivations of the theoretical results: extensions to local polynomial estimation are straightforward, with no change in the limiting distribution of the estimator of β. In what follows, we write A⊗2 = AAT. Also, define mx(z) = E(δX∣Z = z)/E(δ∣Z = z), mw(z) = E(δW∣Z = z)/E(δ∣Z = z) and my(z) = E(δY∣Z = z)/E(δ∣Z = z). Let X̃i = Xi − mx(Zi), W̃i = Wi − mw(Zi), Ỹi = Yi − my(Zi), and denote cov(X̃δ) by ΣX∣Z.
Note that δY = δXTβ + δν(Z) + δε. From our assumptions, it follows that E(δY∣Z) = E(δXT∣Z)β + E(δ∣Z)ν(Z). If X is observed and mx(z) and my(z) are known, one can obtain a least-squares-type estimator of β as
The expectation of the ith term in the second summation is E{π(X, Z)X̃Ỹ } = ΣX∣Zβ. It is easily shown that this estimator is consistent and asymptotically normal(Wang et al., 2004).
The above formula cannot be applied directly when X is measured with error, and mx(z) and my(z) are unknown. However, by our assumptions, E(δW∣Z) = E(δX∣Z). We thus propose an estimator of β that corrects for attenuation:
| (2.2) |
where m̂w(z) and m̂y(z) are nonparametric regression estimators. Let K(·) be a symmetric density function and h be a suitable bandwidth, and define Kh(z) = K(z/h)/h. These estimators take the form
| (2.3) |
Remark 1
Alternative estimators are readily constructed, but generally suffer from complications. For example, since Y − E(Y∣Z) = {X − E(W∣Z) }Tβ + ε, an obvious approach is to estimate E(W∣Z) and E(Y∣Z) using all the data. The former is easy: any nonparametric regression will do. However, the latter is problematic, because of the missing responses, the possibility that missingness depends on X and the fact that X is unobserved. There does not appear to be an easy way to estimate E(Y∣Z) consistently under the current conditions. Note that one of the most important features of the proposed approach is that, through use of the standard measurement error model (1.2), it can handle the not missing at random case with ease and still provide -consistent estimators, as shown in the theorems that follow.
Before presenting our first main result, we note that throughout the paper we make some general assumptions that are listed in the Appendix.
THEOREM 1. Assume that {(Yi, Wi, Zi, δi), i = 1, …, n} are independent and identically distributed. Under Assumptions A1-A7 in the Appendix, n1/2(β̂n − β) is asymptotically normally distributed with mean 0 and covariance matrix , where
The proof of Theorem 1 and those of Theorems 2 and 3 given below generally use a technique similar to that used by Liang et al. (2004) to prove their Theorems 1 and 2. We omit the details, which can be found in an earlier version of this article, available from the authors.
Remark 2
In typical nonparametric kernel regression, bandwidth selection plays a key role in the performance of nonparametric estimators in terms of their bias and variance. In partially linear models, β is of main interest, and ν(z) is a nuisance function. Based on Assumption A2, only the rate of order n−1/5 is needed to lead to the same limit distribution for estimating β. In implementing our proposed estimation procedure, we adopt Ruppert et al.'s (1995) method of choosing the bandwidth. Our limited experience indicates that the numerical performance of the resulting estimators of β is stable around the selected bandwidth.
From the proof of Theorem 1, it is seen that Σβ can be estimated via a standard sandwich method as follows. Let
and . Then it is easily shown that Σ̂β is a consistent estimator of Σβ.
2.2 Estimated measurement error covariance matrix
The covariance matrix Σuu is generally unknown and needs to be estimated. The usual method of doing so (Carroll et al., 1995, Ch.3) is by partial replication, so that we observe Wij = Xi + Uij, j = 1, …, mi. For notational simplicity, we assume that mi ≡ 2. Extension to more general settings is straightforward; see Liang et al. (1999) for a related discussion. Let W̅i be the sample mean of the replicates Wij. A consistent, unbiased method-of-moments estimator for Σuu is
The corresponding estimator of β is
| (2.4) |
where m̂w̅(z) is the locally constant estimator of mw(z) based on the data {(W̅i, Zi), i = 1, …, n}. We now present the following theorem.
THEOREM 2. Under the general conditions of Theorem 1, the estimator β̂n,2 given in (2.4) is consistent and asymptotically normal with covariance matrix , where
By a straightforward but tedious derivation, Theorem 2 can be proved in a manner similar to Theorem 1.
The standard error estimators can also be derived. A consistent estimator of ΣX∣Z in this case is defined as
The Γ* can be estimated as follows. Let
Then a consistent estimator of Γ* is the sample covariance matrix of the Riδi's (Liang et al., 1999).
3 Estimation of The Mean E(Y)
It is of interest to estimate the mean E(Y) = θ. Cheng (1994) studied this problem in the purely nonparametric regression case, while Wang et al. (2004) studied the partially linear model with X observed. Here we construct three estimators of θ when X is not observed. The methods are analogous to those of Wang et al. (2004) in the case in which X is observed. We obtain that the three estimators are asymptotically equivalent.
In a manner similar to Cheng (1994), we can construct two estimators of θ as follows:
where is a nonparametric regression estimator of ν(z) based on the completely observed data of . One can easily show that ν̂n(z) − ν(z) = op(n−1/3), in a way similar to Liang et al. (1999). This rate satisfies our assumption to establish the asymptotic normality of the estimators of θ.
Let , s(z) = E(δ∣Z = z) and P(Z, δ) = δ/s(Z). We define a third estimator of θ as
Note that, if we try to substitute sn(z) by an estimator of π(x, z), a problem arises because X is measured with error, so that the exact X is not available for estimating π(X, Z). In the following theorem, we establish the asymptotic normality of the three estimators, showing that they are asymptotically equivalent.
THEOREM 3. In addition to the assumptions of Theorem 1, assume that nh4 → 0. Then n1/2(θ̂n,● − θ) asymptotically has a normal distribution with mean 0 and variance , where ● indicates “ave”, “est”, or “wei”.
4 Inference Based On Empirical Likelihood
Based on our estimators of the covariance matrix or its bootstrap version, one can give a confidence region for either β or θ = E(Y). Although we have confirmed that the estimator Σ̂β given in §2 is consistent, its finite-sample behaviour may be affected by the need to plug in several estimated terms. Furthermore, the confidence region derived by this procedure is based on a normal approximation, which may be optimistic in small samples. An alternative method is to use the empirical likelihood principle, see Owen (2000), Qin (1994), Qin & Lawless (1994) and Chen (1994). In the remainder of this section, we assume that the εi are independent and identically distributed and independent of (Wi, Zi). We need only to study the empirical-likelihood-based confidence interval for β since the case of θ is similar and simpler.
Let F be the distribution function which assigns probability pi at points (Wi, Yi, Zi). Then and pi ≥ 0 for each i. Our semiparametric empirical likelihood ratio is defined as follows. Note that E[δ{W̃(Ỹ − W̃Tβ) + Σuuβ }] = 0. The empirical likelihood ratio function for β may be defined as
if mw(z) and my(z) are known. In our model setting, a modified empirical likelihood ratio function is defined as
| (4.1) |
THEOREM 4. Under Assumptions A1-A7, −2 log{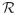 n(β)} converges in distribution to a chi-squared distribution with p degrees of freedom.
n(β)} converges in distribution to a chi-squared distribution with p degrees of freedom.
Based on this result, a confidence region of β can be given by {β : −2log{n(β)} ≤ cα}, where cα denotes the α quantile of the chi-squared distribution. When Σuu is unknown, we need replication data in the usual way. In the special case of mi = 2, as in §2, we can then replace Wi by W̅i and Σuuβ by 1/2Σ̂uuβ. The resulting statistic still has the property given in Theorem 4. A justification of this last assertion can be easily obtained by using the fact that
where W̅ir = W̅i − mw(Zi).
We used software R in our numerical work described below. We developed our code using El. s, a function written by A. B. Owen, for implementing the proposed empirical likelihood method.
5 A Simulation Study
To evaluate the performance of the proposed methods, we conducted a small scale simulation experiment. We generated n = 100 and n = 500 observations from model (1.1), assuming that Y∣X, Z ∼ N{β0 + β1X + ν(Z), σ2(X, Z) } and that the probability of Y being observed equals pr(δ = 1∣Y, X, Z) = Φ {α0 + α1X + ν1(Z) }, where Φ(·) is the standard normal cumulative distribution function. We also assumed that the measurement error follows W = X + U, where U ∼ N(0, 0.04). In our simulations, two replications for each X were obtained. We set α0 = β0 = 0, β1 = 1, α1 = 2, X ∼ Un(0, 1), Z ∼ Un(0, 1), independent of X, and ν(z) = 4{exp(−3.25z) − 4 exp(−6.5z) + 3 exp(−9.75z) }. We considered the following four cases.
Case 1: Here ν1(z) = 0.75z and σ2(x, z) = 0.25.
Case 2: Here ν1(z) = sin(z2) and σ2(x, z) = 0.25.
Case 3: Here ν1(z) = 0.75z and σ2(x, z) = 0.1{sin2(2πx3) + 0.5z + 0.3}. This case illustrated the effect of heteroscedastic error on the estimators and confidence intervals.
Case 4: Here ν1(z) = 0.75z and the error ε follows , where is a chi-squared variable with 2 degrees of freedom. This case illustrated the effect of asymmetric error on the estimators and confidence intervals.
The reliability ratio, defined as var(X)/{var(X) + var(U)/2}, is 0.806 for all the 4 cases. In our nonparametric estimation procedure, we selected bandwidths as in Remark 2. We used the quartic kernel, K(u) = 15/16(1 − u2)2I(|u|≤1). We generated 1, 000 datasets in each of the four cases. In each case, approximately 35% of the Y's are missing. To estimate the variance of U, we generated replicate samples of W. We computed the naive and correction-for-attenuation estimates of the parametric components, and their asymptotic and empirical-likelihood-based confidence intervals.
The results are given in Table 1(a). The column ‘Estimate’ gives the average of 1,000 estimated coefficients based on the naive and our proposed methods and the column ‘R2’ gives the coefficients of determination in the (Y, W, Z) naive and (Y, X, Z) analyses; for the latter, R2 can be calculated directly when X is observable, as is the case in simulations, or can be estimated by 1−RSS/Syy, with and . Our numerical experience indicates that the results of these two R2's are generally close to each other. We present the estimated values of R2 here and in our data analysis later. The columns ‘midpoint’ and ‘length’ give the average midpoint and length of the confidence intervals. The column ‘CI(ME)’ gives the confidence intervals using the empirical likelihood and normal approximation methods when the measurement errors are accounted for. The lower and upper values are the averages of 1,000 simulated corresponding lower and upper values. The column ‘Coverage (ME)’ gives the corresponding coverage probabilities of the 1,000 datasets.
Table 1.
Simulation study. Point estimates for β1, with true value 1, together with the coefficients of determination (R2) and the 95% confidence intervals based on the empirical likelihood (EL) and normal approximation (Norm) methods. Also displayed are the averages of the lower and upper endpoints of the confidence intervals, their average midpoints, their average lengths, and the associated coverage probabilities for the simulated data (a) when X and Z are independent, and (b) when X and Z are strongly correlated.
| Estimate | R2 | Confidence Interval | Midpoint | Length | Coverage | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | Case | Naive | ME | Naive | X observed | EL | Norm | EL | Norm | EL | Norm | EL | Norm |
| (a) X and Z are independent | |||||||||||||
| 100 | 1 | 0.649 | 1.027 | 0.464 | 0.525 | (0.511, 1.624) | (0.438, 1.615) | 1.072 | 1.027 | 1.114 | 1.177 | 93.7 | 94.3 |
| 2 | 0.643 | 1.021 | 0.467 | 0.525 | (0.500, 1.627) | (0.438, 1.605) | 0.969 | 1.021 | 1.126 | 1.167 | 94.0 | 94.7 | |
| 3 | 0.655 | 1.042 | 0.861 | 0.915 | (0.806, 1.318) | (0.740, 1.324) | 1.082 | 1.042 | 0.522 | 0.544 | 95.7 | 92.7 | |
| 4 | 0.657 | 1.048 | 0.473 | 0.532 | (0.505, 1.676) | (0.364, 1.733) | 1.090 | 1.048 | 1.171 | 1.369 | 96.3 | 94.3 | |
| 500 | 1 | 0.665 | 1.007 | 0.446 | 0.502 | (0.793, 1.221) | (0.793, 1.221) | 0.981 | 1.007 | 0.427 | 0.428 | 94.7 | 94.8 |
| 2 | 0.658 | 0.997 | 0.445 | 0.501 | (0.786, 1.217) | (0.777, 1.218) | 1.006 | 0.997 | 0.432 | 0.441 | 95.8 | 94.5 | |
| 3 | 0.660 | 1.000 | 0.858 | 0.917 | (0.913, 1.071) | (0.916, 1.083) | 1.007 | 1.000 | 0.158 | 0.167 | 93.7 | 95.8 | |
| 4 | 0.663 | 1.003 | 0.446 | 0.502 | (0.788, 1.144) | (0.785, 1.221) | 0.990 | 1.003 | 0.363 | 0.436 | 94.8 | 94.9 | |
| (b) X and Z are strongly correlated | |||||||||||||
| 100 | 1 | 0.569 | 1.082 | 0.65 | 0.688 | (0.306, 2.016) | (-0.001, 2.165) | 1.061 | 1.082 | 1.71 | 2.166 | 92.7 | 97.0 |
| 2 | 0.589 | 1.094 | 0.641 | 0.677 | (0.357, 1.916) | (0.256, 1.931) | 0.971 | 1.094 | 1.569 | 1.675 | 96.3 | 95.0 | |
| 3 | 0.568 | 1.088 | 0.879 | 0.922 | (0.530, 1.907) | (0.044, 2.132) | 1.019 | 1.088 | 1.377 | 2.088 | 94.6 | 96.7 | |
| 4 | 0.564 | 0.983 | 0.645 | 0.674 | (0.261, 2.082) | (-0.296, 2.445) | 1.172 | 0.983 | 1.821 | 2.741 | 94.7 | 97.7 | |
| 500 | 1 | 0.586 | 1.013 | 0.631 | 0.665 | (0.725, 1.227) | (0.720, 1.306) | 1.026 | 1.013 | 0.522 | 0.586 | 94.8 | 94.2 |
| 2 | 0.582 | 1.005 | 0.631 | 0.664 | (0.716, 1.221) | (0.715, 1.296) | 0.981 | 1.005 | 0.544 | 0.581 | 95.6 | 94.5 | |
| 3 | 0.582 | 0.991 | 0.912 | 0.942 | (0.897, 1.062) | (0.892, 1.125) | 0.993 | 0.991 | 0.168 | 0.233 | 98.6 | 95.3 | |
| 4 | 0.586 | 1.011 | 0.630 | 0.664 | (0.728, 1.228) | (0.727, 1.295) | 1.023 | 1.011 | 0.510 | 0.568 | 96.4 | 94.6 | |
The results are generally in accord with the theory. The impact of the measurement errors on the estimates is substantial. When measurement errors are ignored, the estimators are significantly biased and attenuate to zero. For moderate sample size, the empirical-likelihood-based confidence intervals appear to be superior to those based on the normal approximation. The improvement is greater when the error is nonnormal or its variance is not constant.
At the referee's request, we repeated the procedure above except that X and Z are correlated. We used X = Z + e with e ∼ N(0, 0.06), so that the correlation coefficient of X and Z is 0.76, and the reliability ratio is about 0.877. The results are presented in Table 1(b). We can draw the same general conclusion as that from the case where X and Z are independent. The main difference is that the confidence intervals are generally much wider than in the independent X and Z case, as expected.
6 Analysis of A Dataset From An Aids Study
In this section we present an illustrative analysis of the pediatric AIDS clinical trial group PACTG 338 study. One of the purposes of this study is to investigate the effectiveness of antiretroviral medicines, and to see how increasing CD4 cell counts decrease the amount of HIV in the blood, the HIV viral load. We are interested in understanding the pathogenesis of HIV infection and in evaluation of antiretroviral therapies by characterising the relationship between viral load and CD4 cell counts. Our preliminary investigations suggested that viral load depends linearly on CD4 cell count but nonlinearly on treatment time; see Liang et al. (2004) for a related discussion. We therefore model the relationship between viral load and CD4 cell counts by model (1.1). Let Yij be the viral load and let Xij be the CD4 cell count for subject i at treatment time Zij. The Xij are measured with error (Liang et al., 2003). Here we treat Yij as measured without error except for being partially missing. The model we used is
where Wij are the observed CD4 cell counts. The first part of this model was applied by Zeger & Diggle (1994) to investigate the relationship between the CD4 cell count, Yij, and time, Zij, and other covariates, Xij. If there is no correlation, this longitudinal model reduces to model (1.1).
The PACTG 338 study consists of 297 children, who were clinically stable and who had not had prior treatment with protease inhibitors. They were subjected to a regimen containing a 2- or 3-drug protease inhibitor containing regimen, i.e., ritonavir plus 1 or 2 nucleoside analogues, or to a dual nucleoside analogue regimen. There were 2287 observations, among which 404 (17.6%) viral load RNA values were missing. The ranges of viral load (log10) and CD4 cell counts are (2.6, 6.21) and (51, 3284); the mean and median of CD4 cell counts are 824.55 and 746; the mean and median of HIV RNA levels are 3.518 and 3.346; and the specimens were obtained on weeks 0, 4, 8, 12, 24, 36, 48, 60, 72 and 84. See Nachman et al. (2000) for a detailed explanation of the study. The CD4 cell counts are used to follow response to HIV medications, as a measure of adherence to treatment and most importantly to guide decisions regarding opportunistic infection prophylaxis. Some patients may fail to go to clinical trial centres for a HIV viral load measurement when they feel that their immunity is strong enough or too weak. Therefore, the assumption that the missing RNA levels depend on true CD4 cell counts and not on measured counts and treatment time appears to be at least reasonable.
We ignored the correlation structure when computing the estimates, using the so-called working independence assumption. As pointed out in equation (2) of Lin & Carroll (2001), working independence has some model-robustness advantages over estimation methods that account for correlation, with a corresponding loss of efficiency. To reduce the marked skewness of CD4 cell counts, and make treatment times equal space, we take log-transformations of both variables. We used the same kernel function as in the simulation study in §5, and obtained a bandwidth of h = 0.124 in the same manner as described there. We assumed that the measurement errors Uij were independent and normally distributed with mean zero and variance . In the absence of validation or replication data, as in Lin & Carroll (2000), we conducted a sensitivity analysis by taking to be one quarter and one half of the variance of W.
We applied the methods proposed in §2 and 4, assuming , which naively ignores measurement error, and . For β, we give estimated values, along with the normal approximation, bootstrap and empirical likelihood confidence intervals in the full-data part of Table 2. The bootstrap intervals were based on 200 replications. The R2's shown in the table: are calculated as was described in §5 for the coefficient of determination in the (Y, X, Z) regression analysis if X were observed. The estimated values of β corresponding to and increased by 31.2% and 48.8% in absolute value, respectively, compared to the naive estimate, and the confidence intervals were widened accordingly. As expected, when the possibility of measurement errors was taken into account, we found a somewhat stronger negative association between viral load and CD4 cell counts. Whether or not there is correlation between within-subjects observations, the bootstrap method generally produces correct confidence intervals, while other two approaches can lead to incorrect, typically too optimistic, confidence intervals. However, in this special case, any correlation effect appears to be minimal since all three methods produced similar confidence intervals with the empirical-likelihood intervals being slightly shorter, as in the simulation studies, while the normal and bootstrap intervals are virtually identical.
Table 2.
AIDS study. Estimates of β, with the 95% confidence intervals (CI) based on the normal approximation (Norm), empirical likelihood (EL), and bootstrap methods. Also given are the estimated R2's of the coefficient of determination for the (Y, X, Z) regression analysis if X were observed.
| Full data | ||||||
| Estimate of β | -0.125 | -0.164 | -0.186 | |||
| R2 | 0.331 | 0.422 | 0.436 | |||
| CI(Norm) | (-0.144, -0.106) | (-0.207, -0.121) | (-0.244, -0.128) | |||
| CI(EL) | (-0.132, -0.109) | (-0.183, -0.128) | (-0.221, -0.130) | |||
| CI(Boot) | (-0.143, -0.107) | (-0.205, -0.123) | (-0.245, -0.127) | |||
| Independent data | ||||||
| Estimate of β | -0.129 | -0.159 | -0.212 | |||
| R2 | 0.138 | 0.162 | 0.214 | |||
| CI(Norm) | (-0.190, -0.068) | (-0.236, -0.082) | (-0.320, -0.104) | |||
| CI(EL) | (-0.181, -0.068) | (-0.226, -0.076) | (-0.310, -0.114) | |||
Since our approximate confidence intervals assumed working independence, which may well not be the case in the current data analysis, we also demonstrate how they perform for data that actually do satisfy the assumption of having independent observations. For this purpose, we took one observation from each child at random, and repeated the exercise 1,000 times. The results are presented in the independent-data part of Table 2. All the entries were computed in the same way as for the full data except that they are the averages of 1,000 estimates. Again, the two methods produced similar results with the empirical-likelihood intervals being slightly shorter.
The curve of the estimated nonparametric function of treatment time and the corresponding confidence bands for the case of are shown in Fig. 1. The results for the other cases of and are similar and are therefore not shown. The confidence bands were obtained by 200 bootstrap replications, in which patients were resampled. The plot indicates that the viral load RNA levels rapidly decrease after initial antiviral treatment, then become flat and even rebound a little bit and finally decrease rapidly.
Figure 1.

AIDS study. The solid curve represents the estimated values of ν(z) based on the complete observations, and the dotted lines are the confidence intervals.
7 Discussion
The point estimation methods and normal limit distributions are readily extended to longitudinal and repeated measures contexts, if one uses working independence, i.e. ignores the correlation structure when computing the estimator but uses it in computing asymptotic covariance matrices. However, as was suggested in our data analysis, how to employ the empirical likelihood procedure for correlated data appears to be a difficult issue, and is currently under our investigation.
The proposed estimators are based on the observed data, but exclude the observed covariates (W, Z) when Y is missing except that all the Ws are used to estimate Σuu when its estimation is desired. Although we have not derived the efficiency bound for the estimator of β, we conjecture that little gain, if any, can be obtained if we include those observations (W, Z) associated with missing Y's; see Bickel et al. (1993, p 146) for a related result.
Acknowledgments
The authors thank the editor and a referee for their helpful suggestions and constructive comments. Liang's research was partially supported by two grants from the National Institute of Allergy and Infectious Diseases. Wang and Carroll's research was partially supported by a grant from the National Cancer Institute, and by the Texas A&M Center for Environmental and Rural Health via a grant from the National Institute of Environmental Health Sciences. The work of Raymond Carroll occurred during a visit to the Centre of Excellence for Mathematics and Statistics of Complex Systems at the Australian National University, whose support is gratefully acknowledged.
Appendix
Technical details
Assumption A1. The matrix E{π(X, Z)X̃X̃T} is positive-definite, E(ε∣X, Z) = 0, and E(|ε|3∣X, Z) < ∞.
Assumption A2. The bandwidths used in estimating mw(z) and my(z) are of order n−1/5.
Assumption A3. The function K(·) is a bounded symmetric density function with compact support and satisfies ∫ K(u)du = 1, ∫ K(u)udu = 0 and ∫ u2K(u)du = 1.
Assumption A4. The density function of Z, fz(z), is bounded away from zero and has bounded continuous second derivatives.
Assumption A5. The functions my(z) and mw(z) have bounded and continuous second derivatives.
Assumption A6. The probability function π(x, z) is bounded away from zero on the support of (X, Z), and has bounded continuous second partial derivatives.
Assumption A7. The random variable U satisfies E(‖U‖3) < ∞.
We first point out the following facts, which can easily be shown by Assumptions A2-A5:
| (A.1) |
In the rest of the Appendix, we prove Theorem 4. We first present a lemma, whose proof can be found in Liang et al. (1999).
LEMMA A1. Assume that random variables ai and bi satisfy Eai = 0 and ‖bi‖ = op(n−1/4). Then
where ξi are independent variables with zero conditional mean and finite variance.
Proof of Theorem 4. Let
A standard simplification as in Owen (2000, p 61) yields that
| (A.2) |
where a = (a1, …, ap)T is the solution of the equation
| (A.3) |
Mimicking the proof Theorem 3.2 of Owen (2000), we have
| (A.4) |
On the other hand, based on the assumptions, Theorem 1 and the strong law of large numbers, we have
| (A.5) |
Note that
The second term is op(n−1/2) since |aTΩi| = op(1) and
It then follows from (A.3) that
| (A.6) |
A similar argument using yields that
Therefore, we have
| (A.7) |
Consider n(β). Using a Taylor expansion of log(1 + x) on x, we have
The remainder term Qn is bounded by . Using (A.7) and (A.6), we have
Write Ω̃i = ({Wi − mw(Zi)}[Yi − my(Zi) − {Wi − mw(Zi)}Tβ] + Σuuβ) δi. Then Ω̃i − Ωi can be expressed as
It follows from (A.1) that
On the other hand, Lemma A1 implies that
These results imply that and asymptotically have the same normal distribution, and and and have the same limiting value. The proof is thus complete.
Contributor Information
Hua Liang, Email: hliang@bst.rochester.edu, Department of Biostatistics and Computational Biology, University of Rochester Medical Center, Rochester, New York 14642, U.S.A..
Suojin Wang, Email: sjwang@stat.tamu.edu, Department of Statistics, Texas A&M University, College Station, Texas 77843, U.S.A..
Raymond J. Carroll, Email: carroll@stat.tamu.edu, Department of Statistics, Texas A&M University, College Station, Texas 77843, U.S.A..
References
- Bickel PJ, Klaassen CJ, Ritov Y, Wellner J. Efficient and Adaptive Estimation for Semiparametric Models. Baltimore: Johns Hopkins University Press; 1993. [Google Scholar]
- Bickel PJ, Ritov Y. Efficient estimation in the errors in variables model. Ann Statist. 1987;15:513–40. [Google Scholar]
- Carroll RJ, Ruppert D, Stefanski LA. Measurement Error in Nonlinear Models. New York: Chapman and Hall; 1995. [Google Scholar]
- Chen SX. Empirical likelihood confidence intervals for linear regression coefficients. J Mult Anal. 1994;49:24–40. [Google Scholar]
- Cheng PE. Nonparametric estimation of mean functionals with data missing at random. J Am Statist Assoc. 1994;89:81–7. [Google Scholar]
- Engle RF, Granger CWJ, Rice J, Weiss A. Semiparametric estimates of the relation between weather and electricity sales. J Am Statist Assoc. 1986;81:310–20. [Google Scholar]
- Härdle W, Liang H, Gao J. Partially Linear Models. Heidelberg: Springer Physica-Verlag; 2000. [Google Scholar]
- Liang H, Härdle W, Carroll RJ. Estimation in a semiparametric partially linear errors-in-variables model. Ann Statist. 1999;27:1519–35. [Google Scholar]
- Liang H, Wang S, Robins JM, Carroll RJ. Estimation in partially linear models with missing covariates. J Am Statist Assoc. 2004;99:357–67. [Google Scholar]
- Liang H, Wu HL, Carroll RJ. The relationship between virologic and immunologic responses in AIDS clinical research using mixed-effect varying-coefficient semiparametric models with measurement error. Biostatistics. 2003;4:297–312. doi: 10.1093/biostatistics/4.2.297. [DOI] [PubMed] [Google Scholar]
- Lin X, Carroll RJ. Nonparametric function estimation for clustered data when the predictor is measured without/with error. J Am Statist Assoc. 2000;95:520–34. [Google Scholar]
- Lin X, Carroll RJ. Semiparametric regression for clustered data using generalized estimating equations. J Am Statist Assoc. 2001;96:1045–56. [Google Scholar]
- Nachman SA, Stanley K, Yogev R, et al. Nucleoside analogs plus ritonavir in stable antiretroviral therapy experienced HIV infected children: a randomized controlled trial. J Am Med Assoc. 2000;283:492–8. doi: 10.1001/jama.283.4.492. [DOI] [PubMed] [Google Scholar]
- Newey WK. The asymptotic variance of semiparametric estimators. Econometrica. 1994;62:1349–82. [Google Scholar]
- Opsomer JD, Ruppert D. A root-n consistent backfitting estimator for semiparametric additive modelling. J Comp Graph Statist. 1999;8:715–32. [Google Scholar]
- Owen AB. Empirical Likelihood. London: Chapman and Hall/CRC; 2000. [Google Scholar]
- Qin J. Semi-empirical likelihood ratio confidence intervals for the difference of two sample means. Ann Statist. 1994;46:117–26. [Google Scholar]
- Qin J, Lawless J. Empirical likelihood and general estimating equations. Ann Statist. 1994;22:300–25. [Google Scholar]
- Robinson PM. Root-n-consistent semiparametric regression. Econometrica. 1988;56:931–54. [Google Scholar]
- Ruppert D, Sheather SJ, Wand MP. An effective bandwidth selector for local least squares regression. J Am Statist Assoc. 1995;90:1257–70. [Google Scholar]
- Severini TA, Staniswalis JG. Quasilikelihood estimation in semiparametric models. J Am Statist Assoc. 1994;89:501–11. [Google Scholar]
- Speckman P. Kernel smoothing in partial linear models. J R Statist Soc B. 1988;50:413–36. [Google Scholar]
- Stefanski LA, Carroll RJ. Conditional scores and optimal scores in generalized linear measurement error models. Biometrika. 1987;74:703–16. [Google Scholar]
- Wang QH, Linton O, Härdle W. Semiparametric regression analysis with missing response at random. J Am Statist Assoc. 2004;99:334–45. [Google Scholar]
- Zeger SL, Diggle PJ. Semiparametric models for longitudinal data with application to CD4 cell numbers in HIV seroconverters. Biometrics. 1994;50:689–99. [PubMed] [Google Scholar]