

SUMMARY
The analysis of longitudinal data to study changes in variables measured repeatedly over time has received considerable attention in many fields. This paper proposes a two-level structural equation model for analyzing multivariate longitudinal responses that are mixed continuous and ordered categorical variables. The first-level model is defined for measures taken at each time point nested within individuals for investigating their characteristics that are changed with time. The second level is defined for individuals to assess their characteristics that are invariant with time. The proposed model accommodates fixed covariates, nonlinear terms of the latent variables, and missing data. A maximum likelihood (ML) approach is developed for the estimation of parameters and model comparison. Results of a simulation study indicate that the performance of the ML estimation is satisfactory. The proposed methodology is applied to a longitudinal study concerning cocaine use.
Keywords: latent variables, longitudinal study on cocaine use, maximum likelihood, MCEM algorithm, model comparison, ordered categorical variables
1. INTRODUCTION
In public health and biomedical sciences, it is common to encounter latent variables or constructs that cannot be directly measured by a single observed variable, but instead assessed through a number of observed variables. Structural equation models (SEMs) [1] are a flexible class of models for complex modeling of multivariate correlated data to explain the interrelationships among observed and latent variables. In general, SEMs combine the ideas of factor analysis and regression. They are formulated by two major components. The first component is the measurement equation, which is basically a confirmatory factor analysis model for grouping correlated observed variables to `measure' their corresponding latent variables (factors) and for taking the measurement errors into account. The second component is a regression-type structural equation for assessing the effects of independent latent variables on dependent latent variables of interest. As the number of latent variables is much less than the number of original observed variables, the use of a structural equation with latent variables has its advantages over the application of the ordinary regression model with originally observed variables. Through the use of user-friendly software [2, 3], SEMs have been extensively applied to behavioral, educational, and social–psychological sciences in the past years and to biological and medical sciences in recent years. The basic theory and statistical properties of SEMs are mainly developed in the field of psychometrics for assessing latent constructs. Recently, advanced SEM methodologies have also appeared in mainstream statistical journals; see, for example, [4–10]. Moreover, Sanchez et al. [11] presented a review of the basic theory, including its connection to some latent variables models.
In this paper, we propose a novel, dynamic two-level SEM to analyze multivariate response variables measured at multiple time points. More specifically, let ugt be a random vector for the gth (g=1,…,G) individual measured at time point t (t =1,…,T). A two-level model for ugt will be defined by ugt =yg+vgt, where yg is the second-level random vector that is independent of t, and vgt is the first-level random vector for accounting characteristics that change dynamically with t. A confirmatory factor analysis model with fixed covariates will be defined for yg for accounting characteristics that are invariant with t. A nonlinear SEM with fixed covariates will be defined for vgt, in which the latent variables at every time point are divided into independent and dependent latent variables, and their dynamic relationships over time are assessed by a flexible autoregressive nonlinear structural equation (see equation (5)). Here, latent variables are used to represent latent traits that are related to several observed variables (indicators). To cope with the complex nature of real-world data in substantive research, the proposed model also accommodates mixed continuous and ordered categorical variables, and missing data that are missing at random. A maximum likelihood (ML) approach will be developed for analyzing the proposed model. A Monte Carlo Expectation–Maximization (MCEM) algorithm [12] will be developed for obtaining the ML estimates, and the Louis formula [13] will be used to obtain the standard error estimates. The Bayesian information criterion (BIC) will be used for model comparison. Owing to the complexity of the model, the observed-data likelihood involved in the BIC includes intractable multiple integrals. A procedure based on path sampling [14] will be developed to evaluate the observed-data likelihood.
We illustrate our methodology through a longitudinal data set about cocaine use and related phenomena. Cocaine use is a major social and health problem in the United States. According to the 2002 National Survey on Drug Use and Health [15], an estimated 34 million Americans aged 12 years or older (14.4 per cent) reported cocaine use at least once in their lifetime; among them, an estimated 2 million persons reported cocaine use in the past month. Cocaine is consistently detected in the urine specimens from approximately one-third of arrestees tested across the nation each year [16]. Furthermore, cocaine is the illegal drug mentioned most often in emergency department records [17]. There are various latent traits that influence cocaine use. Specifically, many studies have shown substantial impact of psychiatric problems on cocaine-dependent patients [18–20] and that social support is another key latent trait [21–23].
Although treatment for cocaine use has received considerable attention in recent years [24, 25], the longitudinal phenomena of cocaine use in relation to psychiatric problems and social support have yet to be adequately explicated. To illustrate the application of the proposed methodologies, we analyze the UCLA longitudinal data set collected from cocaine-dependent patients at intake, 1 year, 2 years, and 12 years after treatment [26]. As this data set involves ordered categorical outcomes with missing entries, the proposed two-level SEM is required to assess the longitudinal effects of the latent traits (psychiatric problems and social support) to cocaine use.
Although some specific SEMs or latent variable models have been developed for analyzing longitudinal data, their objectives and/or formulations are quite different from the proposed dynamic two-level nonlinear SEMs. For instance, a standard growth curve model [27, 28] can be viewed as the following confirmatory factor analysis model: xi =Λωi +∊i, where xi is a vector of repeated measures of a univariate response variable, Λ is the factor loading matrix of sequential known values of the growth curve records, and ωi is the latent growth factor containing the `initial status (intercept)' and `rate of change (slope),' and ∊i is the vector of residuals. This is a single-level linear SEM, in which the latent variables in ωi are used to assess the characteristic of change over time rather than latent traits such as `psychiatric problem' and `social support' in our example. Hence, the formulation of a growth curve model is less general, and the interpretation of the latent variables is very different. Dunson [29] recently analyzed multidimensional longitudinal data by developing dynamic latent variable models, which allow mixtures of count, and categorical and continuous response variables. In this model, to assess the changes between the latent variables at different time points, the latent variable ωit at time t for individual i was regressed on the linear terms of the past latent vectors ωi1,…,ωi,t−1 through a regression equation with fixed covariates. Note that Dunson's [29] model is single-level and its latent variables are not divided into independent and dependent latent variables. Compared with Dunson's single-level model, our two-level model includes a second-level model for assessing the individuals' characteristics that are invariant with time. Moreover, latent variables at the first level of our model are divided into independent and dependent latent variables, and the dynamic nonlinear effects of the independent latent variables on the dependent latent variables are assessed through a rather general autoregressive nonlinear structural equation (see equation (5)). Similarly, the multilevel model [30] for the longitudinal profiling of health-care units does not involve an autoregressive nonlinear structural equation among covariates and latent variables. Other longitudinal models in the statistics literature, such as the linear mixed model [31] and the generalized linear mixed model [32], do not involve the latent traits and their associated structural equation. Clearly, the objectives and formulations of these models and our proposed model are very different. Finally, refer to the second remark given in Section 2.3 for the differences of the proposed model and the existing multilevel SEMs.
The contributions of this paper include (i) a novel dynamic two-level nonlinear SEM with fixed covariates for analyzing longitudinal data from mixed continuous and ordered categorical measures and missing data, (ii) a novel utilization of the computational tools, such as the MCEM algorithm [12] and path sampling [14] with the derivation of some new conditional distributions and derivatives for estimation and model comparison of the proposed model, and (iii) a novel application of the developed methodologies to the longitudinal study of cocaine use.
Section 2 presents the two-level SEM for analyzing multivariate random responses with mixed continuous and ordered categorical variables measured at multiple time points. An ML approach for estimation and model comparison in the proposed model framework is discussed in Section 3. A simulation study and a real example using the longitudinal data of cocaine use are presented in Sections 4 and 5, respectively. In Section 6, we discuss some limitations and outline several extensions for further research.
2. THE SEM FOR MULTIVARIATE LONGITUDINAL DATA
Consider a set of observations of a p×1 random vector ugt for individual g 1, …, G, which was measured at multiple time points t =1, …, T. The collection U={ugt :g=1, …, G, t =1, …, T} can be regarded as an observed sample of hierarchical observations that were measured at different time points (first level) and were nested in the individuals (second level). Hence, the following two-level SEM is proposed to model ugt :
| (1) |
where yg and vgt are the random vectors that, respectively, model the second-level effect of the individual g and the first-level effect with respect to the individual g at time t.
2.1. The second-level model
The second-level model for assessing characteristics of individuals that are invariant over time is defined by
| (2) |
where cg0 is a vector of fixed covariates, ωg0 is a vector of latent variables, εg0 is a vector of residual errors, and A0 and Λ0 are matrices of unknown coefficients. We assume that ωg0 is identically and independently distributed (i.i.d.) as N[0,Φ0] and that εg0 is independent of ωg0, and i.i.d. as N[0,Ψ0], where Ψ0 is a diagonal matrix. This is a factor analysis model with covariates [33], which is defined for studying the relationships between the observed variables in ugt and the latent variables in ωg0 with respect to different individuals but common to all time points.
2.2. The first-level model
We define the following measurement model for the more important first-level random vector vgt :
| (3) |
in which the definitions of At, cgt, Λt, ωgt, and εgt are similar to those given in equation (2); except here they are defined at time point t nested within the individual g, and the distribution of εgt is N[0,Ψt], where Ψt is assumed to be a diagonal matrix for brevity. Hence, we assume that the random vector ugt conditional on yg has the following structure:
| (4) |
Conditional on yg, equation (4) accounts for dependency among the observed variables measured for the individual g at a given time point t through the fixed covariates cgt and the shared latent variables ωgt. The relationships between the observed variables and the corresponding fixed covariates and latent variables that change dynamically over time can be assessed by estimating At and Λt.
According to the spirit of SEM, we consider a partition of ωgt into , where ηgt and ξgt are q1-dimensional-dependent and q2-dimensional-independent random latent vectors, respectively, q=q1+q2. Effects of the independent latent variables ξgt on the dependent latent variables ηgt are studied through the following autoregressive nonlinear structural equation: For g=1, …, G, t =1, …, T,
| (5) |
where B0, Bt, and are matrices of unknown coefficients, dg0 is a vector of fixed covariates, which is independent of t, dgt is another vector of fixed covariates, δgt is a vector of residual errors, and is a vector-valued function in which ftj is a differentiable function of the independent latent vector ξgt at the current time point and the latent vectors ωg1, …, ωg,t−1 at previous time points. The residual vector δgt is independent of εgt, ωg1, …, ωg,t−1, and ξgt. Moreover, these residual errors are i.i.d. N[0,Ψδt], where Ψδt is a diagonal matrix. Let ; the distribution of ξg is assumed to be N[0,Φ], where Φ contains the variance-covariance matrix Φtt of ξgt, and the covariance matrix Φtitj of ξgti and ξgtj at different time points ti and tj.
2.3. Remarks
1. The first and second terms of equation (5) allow for direct effects of observed predictors that are invariant over time (dg0) and variant over time (dgt) on the dependent latent variables. The term is very important for assessing the effects of independent latent variables on dependent latent variables to change dynamically over time. It allows various flexible autoregressive structures for recovering the dependency of the dependent latent variable ηgt at the current time point and across both dependent latent variables at previous time points and independent latent variables at previous and current time points. For example, typical special cases are
where Ft is a vector of differentiable functions of ξgt. In the special case (a), ηgt is assessed by the effects of linear-independent latent vectors at all previous time points, the dependent-latent vector at t−1, and finally nonlinear terms of independent latent variables at the current time point. The autoregressive structure (b) allows the dependency of ηgt on the previous endogenous latent vector ηg1, …, ηg,t−1 and a general function Ft (ξgt) of the current exogenous latent vector ξgt. Note that the longitudinal models developed in Dunson [29] and Daniels and Normand [30] do not involve a structural equation in relation to covariates and latent variables.
2. Other multilevel SEMs have been developed to analyze hierarchical data collected from units that are nested within clusters [8, 34]. Owing to different objectives, the formulations of the first-level model for vgt in those multilevel SEMs are quite different and do not accommodate certain important features of our dynamic model. For example, their matrices of coefficient parameters and covariance matrices of errors are variant with cluster g rather than t. Moreover, for t ≠r, their vgt and vgr are assumed to be independent; however, vgt and vgr could be correlated in our model.
2.4. Ordered categorical data and identification of the model
From its definition, ugt is a vector of continuous observations. However, in most substantive research, the continuous measurements of some components of ugt may not be available. Suppose that ugt is composed of a subvector xgt of observed measurements and a subvector wgt of unobserved measurements whose information is given by ordered categorical observations. In the generic sense, the relationship between an ordered categorical variable z and its underlying continuous variable w is defined by z=k+1 if αk≤w<αk+1, for k=0, …, m−1, where {−∞=α0<α1<…<αm=∞} is the set of threshold parameters that define the m categories. A special case with m=2 is the dichotomous or ordered binary variable. Missing data that are missing at random (MAR, [35]) are handled using the procedure given in [36]. Details are not included here for brevity.
The proposed model is not identified without imposing identification conditions. For example, the variance and thresholds associated with each ordered categorical variable are not identifiable; the first- and second-level covariance structures are not identified, and we cannot allow intercepts to simultaneously exist in equations (3) and (5). Existing methods suggested in the SEM literature can be adopted for identifying various components of the current model. For example, the identification problem associated with an ordered categorical variable can be solved by fixing the thresholds α1 and/or αm−1 at some appropriate preassigned values [6, 36], and the covariance structures in the first- and second-level models can be identified by the common practice in structural equation modeling by fixing appropriate elements in Λ0 and Λt at preassigned values [8].
3. AN ML APPROACH
3.1. Estimation
Let α be the parameter vector of the unknown thresholds, and θ be the parameter vector that contains all the unknown distinct structural parameters that are involved in equations (2), (3), and (5). The likelihood function of the observed data involves high-dimensional intractable integrals that are induced by the ordered categorical variables and latent variables. One approach to handle this integral is using adaptive quadrature [34]. In this paper, we use the idea of data augmentation and the MCEM algorithm [12] in the ML estimation.
Let zgt ={zgt j; j =1, …, s} be a vector of ordered categorical observations, and let ugt = {wgt, xgt}, where xgt is a vector of continuous measurements and wgt is the latent continuous measurement corresponding to zgt, ug ={ugt; t =1, …, T}, Z={zgt; g=1, …, G, t =1,…, T}, W={wgt; g=1, …, G, t =1, …, T}, and X={xgt; g=1, …, G, t =1, …, T}. Moreover, let , Ω1={ωg; g=1,…, G}, Ω0={ωg0; g=1, …, G}, and Y={yg;g=1,…, G} be matrices of latent vector at the first and second levels. Further, let , and , then equation (5) can be rewritten as
| (6) |
The observed data set is (X,Z). The observed-data likelihood is very complicated due to the existence of latent quantities (Y,Ω1,Ω2,W). Utilizing the idea of data augmentation, we consider the complete data set, which is equal to {Y,Ω0,Ω1,W,X,Z}={Y,Ω0,Ω1,U,Z}. The complete data likelihood function is equal to
| (7) |
where IRgt (wgt) is an indicator function that takes the value 1 if wgt ∈ Rgt and zero otherwise, and Rgt =[α1,zgt1,α1,zgt1+1)×…×[αs,zgts,αs,zgts+1. Note that for every component wgtj in wgt, there exists one and only one [αj,zgtj,αj,zgtj+1) such that wgtj is in [αj,zgtj,αj,zgtj+1). Hence, the indicator function and the corresponding value of the density function are nonzero. It can be shown from (7) that the complete-data log-likelihood function can be expressed as Lc(Y,Ω0,Ω1,U,Z;α,θ)=L1+L2, where
| (8) |
| (9) |
Note that Lc decomposes into two separable functions, each with distinct sets of parameters. This property simplifies the estimation significantly, although due to the complex function hgt, L1 is still rather complicated. ML estimates of α and θ are obtained using the EM algorithm that consists of the following E-step and M-step at the lth iteration: E-step: Evaluate Q(α,θ|α(l),θ(l))=E{Lc(Y,Ω0,Ω1,U,Z;α,θ)|X,Z,α(l),θ(l)}, in which the expectation is taken with respect to the conditional distribution of (Y,Ω0,Ω1,W) given (X,Z) at (α(l),θ(l)). M-step: Determine (α(l+1),θ(l+1)) by maximizing Q(α,θ|α(l),θ(l)).
Evaluation of the E-step is rather complicated because the conditional expectations involve intractable multiple integrals. Inspired by the MCEM algorithm [12], we solve this problem by simulating a sufficiently large number of observations from the corresponding conditional distributions using a hybrid algorithm that combines the Gibbs sampler [37] and the Metropolis–Hastings (MH) algorithm [38, 39]. In this algorithm, observations are sampled interactively from the following conditional distributions: p(Y|Ω0,Ω1,U,Z,α,θ), p(Ω0|Y,Ω1,U,Z,α,θ), p(Ω1|Y,Ω0,U,Z,α,θ), and p(W|Y,Ω0,Ω1,X,Z,α,θ). Expressions for these conditional distributions are provided in Appendix A.
The M-step updates unknown parameters by maximizing the conditional expectations obtained in the E-step. Structural parameter θ can be updated by maximizing the conditional expectation of L1 and L2 with respect to θ by solving the following system of equations:
| (10) |
Threshold parameters α can be updated according to the method described in Shi and Lee [6], and Lee and Song [8]. The M-step is completed by conditional maximization. Technical details on the derivatives of Q(α,θ|α(l),θ(l)) with respect to components of θ and the corresponding solutions are given in Appendix B. The convergence of the MCEM algorithm is monitored by the following method proposed in Shi and Copas [40]. After the m0th MCEM iteration, is computed, and the convergence is monitored using the following stopping rule: For given small values and (e.g. 0.001), the procedure is stopped if is smaller than some predetermined small value . To avoid the danger of stopping early, a value of larger than 2 is suggested. Convergence is claimed after the stopping rule is satisfied for several consecutive iterations, and is then taken to be the ML estimate. The sample observations of Ω0 and Ω1 simulated at the last iteration of the MCEM algorithm provide estimates of the latent variables. Shi and Copas [40] argued that for a sufficiently large m0, the average of the associative Monte Carlo errors is negligible. To reduce the bias, an appropriate m0 that can control the Monte Carlo errors within a bearable limit is taken. In the simulation study and the example given in Sections 4 and 5, we take m0 =50. Finally, good starting values of some parameters (such as Λt and ∏t) could be obtained from the estimates achieved through separate analysis of the individual model at each time point. As each individual model only involves a comparatively small number of parameters, little computing effort is required.
Standard error estimates of the structural parameters in θ are obtained by the following Louis formula [24] through the simulated observations and the ML estimates:
where expectations are taken with respect to the conditional distribution of (Y,Ω0,Ω1,W) given (X,Z) and (α,θ), and the whole expression is evaluated at . These expectations are difficult to evaluate analytically due to existence of the latent quantities, but they can be approximated, respectively, by the sample mean and the sample covariance matrix of the random sample , generated from using the proposed hybrid algorithm. Details are not given to save space.
3.2. Model comparison
Model comparison is an important issue in SEM analysis. For the current two-level SEM, it is interesting to evaluate competing models that correspond to various hypotheses about the characteristics of the parameters with respect to time changes. In this article, competing models M1 and M2 are compared with the following BIC:
| (11) |
where is the observed-data likelihood evaluated at the ML estimates of αk and θk under Mk, and dk is the dimension of θk. The criterion given in Kass and Raftery [41] can be used for interpreting BIC12.
In obtaining BIC12, we must compute the observed-data log-likelihood which involves complicated multiple integrals. Inspired by its successful application in computing the observed-data likelihood for complex latent variable models [8, 42], we apply path sampling [14] to compute BIC12. Path sampling is a generalization of bridge sampling [43] and gives more accurate results in computing complicated multiple integrals. It is conceptually simple, easy to implement, and applicable to a wide range of models [14].
4. A SIMULATION STUDY
We have conducted an extensive simulation study in different settings to empirically evaluate the performance of the MCEM algorithm. To save space, only the results obtained under the following settings are reported here. A special case of the two-level SEM defined in (2), (4), and (5) with p=9 and G=500 at three time points is considered. For the second-level model associated with individuals, cg0 is a 2×1 vector of covariates, in which the first entry is taken to be 1 to represent the intercept, and the second entry is obtained from observations that are simulated from a standard normal distribution. The true population values of the parameters are given as follows:
In this paper, parameters with an asterisk are fixed to identify the model. For the measurement equation of the first-level model associated with t =1,2,3 (see (3)), no fixed covariates are involved. The true values of parameters in Λt and Ψt are given by
The latent variable in ωgt=(ηgt,ξ1gt,ξ2gt)′ is modeled by the following structural equation:
| (12) |
where the two components in the fixed covariate vector dg0=(d1g0,d2g0)′ are independently generated from the standard bivariate normal distribution, and the fixed covariate dgt (t=1,2,3) are generated from Bernoulli distribution with probability of success 0.6. The true values of the parameters involved in (12) are: b10=1.0,b20=−1.0; and for all t =1,2,3, bt =0.7,βt−1=0.6, γ1t =γ2t =0.6, γ31=−0.4,γ32=−0.6,γ33=−0.8, Ψδt=0.5, (ϕt11,ϕt12ϕt22) in Φtt equal to (1.0,0.3,1.0), and covariances of ξigtj and ξkgtl are all 0.3. Based on the above specifications of the model and the true parameter values, continuous observations of ugt as defined by (4) can be obtained. To consider the model with ordered categorical outcomes, the 5th, 6th, and 9th entries in every ugt were transformed to ordered categorical using the following thresholds (−1.2*,−0.6,0.6,1.2*). Moreover, missing data are considered by randomly deleting some entries in ugt. About 80 per cent of the observations in the data set are fully observed. The total number of parameters in this two-level SEM is 142. In the MCEM algorithm for computing the ML estimates, we generate 100 observations to approximate the conditional expectations at the E-step of each MCEM iteration. Convergence can be monitored by the method of Shi and Copas [40] by using . Convergence is claimed if the stopping rule is satisfied for three consecutive iterations. The algorithm stops at less than 100 MCEM iterations in all 100 replications.
Based on 100 replications, the bias (Bias) and the root mean squares (Rms) between the estimates and the true population values of the parameters were computed as follows:
where θ0(h) is the hth element of the true parameter vector, and is its ML estimate. Standard error (SE) of the estimates were obtained by the arithmetic mean of SE computed through the Louis formula [13] in 100 replications. Simulation results obtained on the basis of 100 replications are presented in Tables I and II. We observe from these tables that the `Bias,' `Rms,' and `SE' are rather small. These results indicate that the empirical performance of the ML estimates obtained by the MCEM algorithm is satisfactory. To save space, results on the nuisance threshold parameters are not presented.
Table I.
Means, root mean squares, and standard errors of the parameter estimates in the first level.
| First level | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Measurement model |
Structural equation |
||||||||||
| Par | Bias | Rms | SE | Par | Bias | Rms | SE | Par | Bias | Rms | SE |
| λ1,21 | 0.004 | 0.029 | 0.025 | b10 | −0.009 | 0.044 | 0.019 | ϕ11 | 0.052 | 0.151 | 0.082 |
| λ1,31 | 0.004 | 0.029 | 0.025 | b20 | 0.017 | 0.047 | 0.020 | ϕ12 | 0.003 | 0.075 | 0.071 |
| λ1,52 | −0.004 | 0.081 | 0.072 | b1 | 0.001 | 0.096 | 0.079 | ϕ13 | 0.043 | 0.091 | 0.068 |
| λ1,62 | −0.008 | 0.074 | 0.057 | b2 | 0.001 | 0.079 | 0.064 | ϕ14 | 0.013 | 0.086 | 0.061 |
| λ1,83 | −0.005 | 0.068 | 0.054 | b3 | −0.010 | 0.075 | 0.070 | ϕ15 | 0.041 | 0.100 | 0.066 |
| λ1,93 | −0.020 | 0.074 | 0.063 | β1 | 0.011 | 0.042 | 0.022 | ϕ16 | 0.008 | 0.078 | 0.063 |
| λ2,21 | −0.000 | 0.018 | 0.016 | β2 | 0.004 | 0.026 | 0.015 | ϕ22 | 0.023 | 0.144 | 0.104 |
| λ2,31 | −0.001 | 0.019 | 0.016 | γ11 | 0.004 | 0.091 | 0.053 | ϕ23 | 0.008 | 0.090 | 0.059 |
| λ2,52 | 0.001 | 0.072 | 0.064 | γ21 | −0.004 | 0.085 | 0.047 | ϕ24 | 0.020 | 0.097 | 0.062 |
| λ2,62 | −0.016 | 0.068 | 0.058 | γ31 | 0.034 | 0.081 | 0.031 | ϕ25 | 0.010 | 0.079 | 0.064 |
| λ2,83 | 0.005 | 0.066 | 0.044 | γ12 | −0.011 | 0.080 | 0.047 | ϕ26 | 0.020 | 0.097 | 0.076 |
| λ2,93 | −0.001 | 0.064 | 0.065 | γ22 | −0.015 | 0.070 | 0.066 | ϕ33 | 0.066 | 0.144 | 0.086 |
| λ3,21 | −0.001 | 0.015 | 0.011 | γ32 | 0.045 | 0.096 | 0.047 | ϕ34 | 0.023 | 0.090 | 0.061 |
| λ3,31 | −0.001 | 0.014 | 0.014 | γ13 | −0.022 | 0.090 | 0.063 | ϕ35 | 0.049 | 0.101 | 0.064 |
| λ3,52 | −0.002 | 0.064 | 0.065 | γ23 | −0.020 | 0.078 | 0.052 | ϕ36 | 0.013 | 0.085 | 0.067 |
| λ3,62 | −0.004 | 0.071 | 0.063 | γ33 | 0.054 | 0.109 | 0.044 | ϕ44 | 0.037 | 0.132 | 0.091 |
| λ3,83 | −0.007 | 0.063 | 0.041 | ϕ45 | 0.017 | 0.088 | 0.066 | ||||
| λ3,93 | 0.001 | 0.071 | 0.070 | ϕ46 | 0.029 | 0.105 | 0.062 | ||||
| ϕ55 | 0.067 | 0.139 | 0.082 | ||||||||
| ϕ56 | 0.014 | 0.077 | 0.060 | ||||||||
| ϕ66 | 0.037 | 0.141 | 0.080 | ||||||||
Table II.
Means, root mean squares, and standard errors of the parameter estimates in the second level.
| Par | Bias | Rms | SE | Par | Bias | Rms | SE | Par | Bias | Rms | SE |
|---|---|---|---|---|---|---|---|---|---|---|---|
| a0,11 | 0.008 | 0.048 | 0.041 | a0,21 | −0.039 | 0.065 | 0.046 | λ0,21 | −0.043 | 0.065 | 0.042 |
| a0,12 | 0.005 | 0.039 | 0.032 | a0,22 | −0.024 | 0.052 | 0.035 | λ0,31 | −0.037 | 0.061 | 0.041 |
| a0,13 | 0.004 | 0.039 | 0.033 | a0,23 | −0.024 | 0.044 | 0.029 | λ0,52 | −0.041 | 0.067 | 0.049 |
| a0,14 | 0.008 | 0.050 | 0.041 | a0,24 | −0.022 | 0.049 | 0.046 | λ0,62 | −0.029 | 0.055 | 0.049 |
| a0,15 | 0.003 | 0.035 | 0.074 | a0,25 | −0.023 | 0.043 | 0.038 | λ0,83 | −0.034 | 0.060 | 0.042 |
| a0,16 | 0.000 | 0.042 | 0.075 | a0,26 | −0.018 | 0.044 | 0.046 | λ0,93 | −0.033 | 0.063 | 0.047 |
| a0,17 | 0.002 | 0.044 | 0.048 | a0,27 | −0.020 | 0.050 | 0.044 | ϕ0,11 | −0.040 | 0.173 | 0.099 |
| a0,18 | 0.004 | 0.040 | 0.034 | a0,28 | −0.015 | 0.036 | 0.032 | ϕ0,12 | −0.024 | 0.103 | 0.073 |
| a0,19 | −0.001 | 0.041 | 0.062 | a0,29 | −0.013 | 0.043 | 0.040 | ϕ0,13 | −0.036 | 0.105 | 0.067 |
| ϕ0,22 | 0.008 | 0.122 | 0.097 | ||||||||
| ϕ0,23 | −0.009 | 0.077 | 0.062 | ||||||||
| ϕ0,33 | 0.015 | 0.126 | 0.088 |
5. AN APPLICATION OF THE SEM APPROACH: THE LONGITUDINAL STUDY OF COCAINE USE
The data set in this example is obtained from a longitudinal study about cocaine use conducted at the UCLA Center for Advancing Longitudinal Drug Abuse Research. Various measures were collected from patients admitted to the West Los Angeles Veterans Affair Medical Center in 1988–1989 and who met the DSM III-R criteria for cocaine dependence [44]. These patients were assessed at baseline, one year after treatment, two years after treatment, and 12 years after treatment (t =t1,t2,t3,t4) in 2002–2003. Among these patients located at the 12-year follow-up, some were confirmed to be deceased, some declined to be interviewed, and some were either out of the country or too ill to be interviewed after one year, two years, or at the 12-year follow-up. Hence, there is a considerable amount of missing data. Seven observed variables at each t are involved in the current analysis: (i) cocaine use (CC), an ordered categorical variable with codings 1–5 to denote days of cocaine use per month that are fewer than 2 days, between 2 and 7 days, between 8 and 14 days, between 15 and 25 days, and more than 25 days, respectively; (ii) Beck inventory (BI), an ordered categorical variable with codings 1–5 to denote scores that are less than 3.0, between 3.0 and 8.0, between 9.0 and 20.0, between 21 and 30, and larger than 30; (iii) depression (DEP), an ordered categorical variable based on the Hopkin Symptom Checklist-58 scores, with codings 1–5 to denote scores that are less than 1.1, between 1.1 and 1.4, between 1.4 and 1.8, between 1.8 and 2.5, and larger than 2.50; (iv) number of friends (NF), an ordered categorical variable with codings 1–5 to denote no friend, 1 friend, 2–4 friends, 5–8 friends, more than 9 friends; (v) `have someone to talk to about problem (TP)'; (vi) `currently employed (EMP)'; and (vii) `alcohol dependence (AD) at baseline.' The last three variables are ordered binary variables with {0,1} for {No,Yes}. The sample size is 223, and the frequencies of all variables at different time points are given in Table III.
Table III.
Frequencies of the ordered categorical variables at different time points in the cocaine use example.
| Categories |
|||||||||
|---|---|---|---|---|---|---|---|---|---|
| Variables | 1 | 2 | 3 | 4 | 5 | No=0 | Yes=1 | Total | |
| t = 1 | CC | 13 | 24 | 38 | 37 | 111 | 223 | ||
| BI | 14 | 35 | 68 | 31 | 12 | 160 | |||
| DEP | 15 | 29 | 29 | 57 | 26 | 156 | |||
| NF | 27 | 30 | 64 | 27 | 8 | 150 | |||
| TP | 30 | 170 | 200 | ||||||
| EMP | 88 | 135 | 223 | ||||||
| AD | 120 | 103 | 223 | ||||||
| t = 2 | CC | 89 | 46 | 23 | 22 | 43 | 223 | ||
| BI | 30 | 47 | 72 | 24 | 10 | 183 | |||
| DEP | 37 | 46 | 40 | 48 | 18 | 189 | |||
| NF | 25 | 27 | 90 | 21 | 18 | 181 | |||
| TP | 15 | 178 | 193 | ||||||
| EMP | 69 | 154 | 219 | ||||||
| AD | 120 | 103 | 223 | ||||||
| t = 3 | CC | 105 | 30 | 25 | 16 | 47 | 223 | ||
| BI | 37 | 44 | 78 | 22 | 11 | 192 | |||
| DEP | 47 | 40 | 47 | 40 | 13 | 187 | |||
| NF | 22 | 22 | 94 | 29 | 23 | 190 | |||
| TP | 9 | 202 | 211 | ||||||
| EMP | 79 | 144 | 223 | ||||||
| AD | 120 | 103 | 223 | ||||||
| t = 4 | CC | 172 | 15 | 14 | 8 | 14 | 223 | ||
| BI | 56 | 63 | 72 | 15 | 16 | 222 | |||
| DEP | 63 | 51 | 43 | 46 | 20 | 223 | |||
| NF | 21 | 37 | 113 | 26 | 23 | 220 | |||
| TP | 22 | 198 | 220 | ||||||
| EMP | 84 | 139 | 223 | ||||||
| AD | 120 | 103 | 223 | ||||||
In this study, we consider observed variables (CC, BI, DEP, NF, TP) and two fixed covariates (EMP, AD) for each individual, which were measured at four time points. The proposed dynamic two-level SEM (see equations (1)–(3) and (5)) is applied to analyze this data set. The second-level model for assessing invariant effects over time is defined by the following two-factor confirmatory factor analysis model:
| (13) |
where yg corresponds to (CC, BI, DEP, NF, TP) of the gth individual, cg0 is fixed at 1.0 so that A0 is a vector of intercepts, ωg0=(ωg01,ωg02)′, Ψ0=diag(0.0*,ψ02,ψ03,ψ04,ψ05),
In this example, parameters with an asterisk were fixed for specifying an identified model. Note that as yg1 is fully defined by CC, λ11,0 and ψ01 are, respectively, fixed at 1.0 and 0.0 according to the usual practice of SEM [2]. In this formulation, ωg01 can be interpreted as the invariant portion of cocaine use and ωg02 can be interpreted as an invariant general latent factor that is not changed over time. The correlation of ωg01 and ωg02 is assessed by ϕ21,0. The first-level model for assessing various dynamic effects that are changed over time is defined by the following nonlinear SEM. The measurement model is defined by
| (14) |
where ωgt =(ηgt,ξ1gt,ξ2gt)′, and
The nonoverlapping structure of Λt is used for achieving a clear interpretation of the latent variables. Based on the meaning of the observed variables and the nonoverlapping structure of Λt, latent variables ηgt,ξ1gt,ξ2gt can be clearly interpreted as `cocaine use (CC),' `psychiatric problems,' and `social support.' In the structural equations of the first-level model, cocaine use was treated as the dependent variable (ηgt), and it is regressed on various independent latent variables, together with fixed covariates EMP(dgt) and AD(dg0) that are variant and invariant over time, respectively. More specifically, the structural equations are defined by
| (15) |
Clearly, (15) is a special case of (5). So far, this dynamic two-level SEM involves 94 unknown parameters. As the sample size is relatively small (n=223), it is not worthwhile to treat the nuisance threshold parameters of the ordered categorical variables as unknown. Hence they are fixed at αjh =Φ*−1 (ρjh), where Φ* is the distribution function of N[0,1], and ρjh are the observed cumulative marginal proportions of the categories with zj<h, see [6, 36].
Let M1 be the two-level model defined as above. To roughly illustrate model comparison with BIC, we compare it with M2, which is a single-level model that is defined by equations (14) and (15) without the second level corresponding to yg as given in (13). In the MCEM algorithm for computing the ML estimates under the competing models, we generate 30+5l observations to approximate the conditional expectations at the E-step of the lth iteration (see [8]). Based on the stopping rule given in Section 4, the algorithm stops at the 202nd MCEM iteration in M1, and is taken as the ML estimate in M1. Fewer MCEM iterations are required to attain the convergence in the simpler model M2. The BIC value for model comparison between M1 and M2 is BIC12=−140.6. According to the interpretation of BIC [41], this result indicates that the two-level model M1 is significantly better than the single-level model M2. The ML estimates and their standard error estimates (which were computed using 5000 simulated observations) of parameters in the first and second level of the selected model M1 are, respectively, presented in path diagrams displayed in Figures 1(a) and (b), while those corresponding to Φ are presented in Table IV. Inspired by the model checking technique in regression and the analysis in Lee and Song [8], we use the following estimated residuals to reveal the adequacy of the measurement models and the structural equation in proposed two-level SEM for fitting the data: , , , and , for t =t2, t3, t4. Plots of the estimated residual in the first level versus, , , and and plots of versus and at t =t1 are presented in Figure 2. Other estimated residual plots have similar behaviors. These plots lie within two parallel horizontal lines that are centered at zero, and no linear or quadratic trends are detected. This roughly indicates that the proposed measurement models and the structural equation are adequate in fitting the data.
Figure 1.

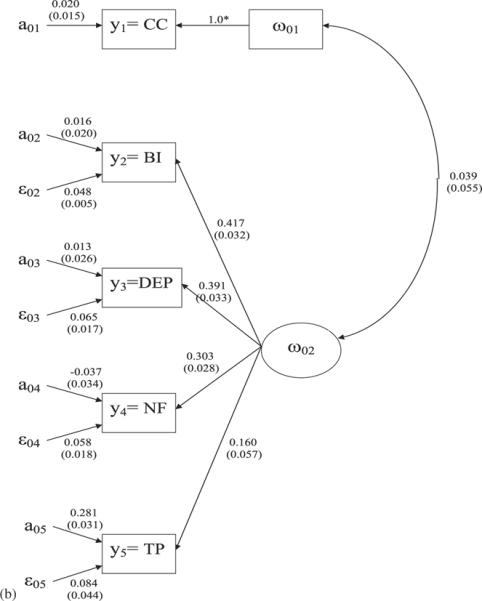
(a) Path diagram and estimates of some parameters of the first-level model in M1, where observed variables are represented by rectangles, latent variables are represented by ellipse, and standard error estimates are in parenthesis. Here, ηt,ξ1t, and ξ2t, respectively, denote `cocaine use (CC),' `psychiatric problems,' and `social support' at t =1,2,3,4. (b) Path diagram and estimates of some parameters of the second-level model in M1, where observed variables are represented by rectangles, latent variables are represented by ellipse, and standard error estimates are in parenthesis.
Table IV.
ML estimates and their standard error estimates (in parenthesis) of Φ [Φtitj] in the cocaine use example.
| t = 1 | 0.601 (0.054) | |||||||
| −0.354 (0.049) | 0.571 (0.056) | |||||||
| t = 2 | 0.317 (0.045) | −0.149 (0.029) | 0.612 (0.065) | Symmetric part | ||||
| −0.283 (0.048) | 0.272 (0.045) | −0.355 (0.040) | 0.469 (0.051) | |||||
| t = 3 | 0.304 (0.053) | −0.426 (0.031) | 0.402 (0.061) | −0.324 (0.045) | 0.689 (0.048) | |||
| −0.166 (0.053) | 0.374 (0.019) | −0.323 (0.051) | 0.271 (0.006) | −0.435 (0.047) | 0.544 (0.052) | |||
| t = 4 | 0.100 (0.047) | −0.155 (0.042) | 0.093 (0.042) | −0.139 (0.039) | 0.204 (0.054) | −0.120 (0.043) | 0.605 (0.034) | |
| −0.007 (0.039) | 0.137 (0.031) | −0.183 (0.056) | 0.235 (0.040) | −0.228 (0.051) | 0.149 (0.037) | −0.277 (0.040) | 0.567 (0.066) |
Figure 2.

Plots of versus , , and , and plots of versus and .
We can conclude from the model comparison result given by BIC12 (=−140.6) value that it is significantly better to include a second-level model yg for incorporating characteristics that are invariant over time to analyze the longitudinal properties of ugt, see equation (1). It follows from equation (13) and Figure 1(b) that the following findings can be achieved: (i) All the factor loading estimates are significant; this indicates substantial associations of the observed variables with the general latent factor. (ii) The correlation between the general latent factor and cocaine use is not significant. (iii) As expected, the intercept estimates corresponding to the ordered categorial variables are close to zero. The intercept estimate corresponding to the dichotomous variable y5 is 0.281. This indicates that y5=0 if the underlying latent continuous variable is less than −0.281; otherwise y5=1. Clearly, the above findings cannot be obtained by a single level model without the multilevel component.
The longitudinal patterns of the more important parameters in the first-level model are displayed in Figures 3(a) and (b). From Figures 1(a) and 3(a) and (b), the following phenomena are observed: (i) As λ32 at all time points (t =t1, t2, t3, t4) are close to 1.0, BI and DEP give equal constant loadings over time to the latent variable `psychiatric problems, ξ1gt.' This indicates that the relationship between `psychiatric problems' and {BI,DEP} are very stable over time (they both measure depression symptoms). (ii) The fixed covariate AD has a positive effect on `cocaine use, CC.' (iii) The fixed covariate EMP has a negative effect on `cocaine use, CC' at all time points (see the line `b1'), which indicates that having a job reduces cocaine use. Also note that the effect of EMP is more substantial during the long-term follow-up period. (iv) The positive effect of the latent variable `social support' on cocaine use at baseline changed quickly to negative effects at two years after intake, as well as years after treatment (see the line γ2). This indicates that social support had a substantial impact on reducing cocaine use during the post-treatment period. (v) Note also that the magnitude of decreases from baseline to one or two years after intake, but rebounds during the long-term follow-up period. This indicates that the impact of `psychiatric problems' is still strong during a long period of time after treatment, although it may be reduced during treatment or shortly after. (vi) It is interesting to find that the variances ϕ11,ϕ22, and ϕ12 are basically constant over time (see Figure 3(b)). (vii) For λ53, γ1, and γ2, their changes are substantial from baseline to one or two years after intake, but less substantial in the subsequent years (see Figures 3(a) and (b)). (viii) The effects of cocaine use from t =t1 to t =t2, and from t =t2 to t =t3 are , and , respectively. After a time difference of 10 years, the corresponding effect from t =t3 to t =t4 is reduced to (see Figure 1(a)). Most of these effects are significant. These findings are consistent with prior literature showing a strong stability of cocaine use over time. The present modeling results also demonstrate a positive association of psychiatric problems with cocaine use during two of the three follow-up points. The increasing negative association of social support with cocaine use is discernible at the later follow-up points, which suggests that social support becomes a stronger factor influencing cocaine use when the treatment effects dissipate at the longer follow-up point, and future studies are needed to further this investigation.
Figure 3.
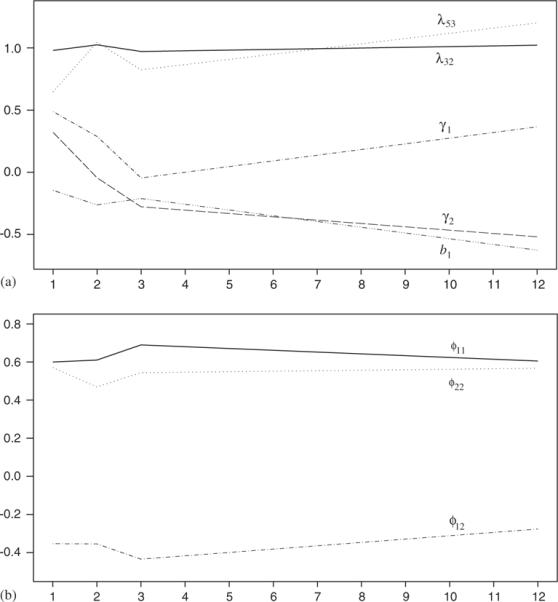
(a) Plots of ML estimates of λ32,λ53,b, γ1, and γ2 at t =t1,t2,t3, and t4 and (b) plots of ML estimates of ϕ11,ϕ12, and ϕ22 at t =t1,t2,t3, and t4.
6. DISCUSSION
An appealing feature of SEMs is the ability to group the correlated observed variables into latent variables so that instead of dealing with a large number of observed variables, we can utilize the structural equation with a much smaller number of latent variables to assess inter-relationships among them. This feature is particularly advantageous in analyzing multivariate longitudinal data, because the comprehensive model that is simultaneously defined at every time point involves p×T observed variables, which may be too large for a regression model. Moreover, the interpretations based on latent variables are more clear and precise than those that are based on the original observed variables. The proposed two-level nonlinear SEM with covariates provides a rather general framework for assessing various characteristics of changes with respect to time.
There are a few limitations of the current approach that indicate areas needing future research. First, similar to many other statistical models, the proposed SEM depends on the assumption that the latent variables and the residual errors are normally distributed. As this assumption may be violated for many types of biomedical data, it is necessary to develop robust methods that are less reliant on this assumption [45]. Second, due to the complexities of the proposed two-level nonlinear SEM with ordered categorical variables, which involves observed data with a correlation structure and missing entries, and the fact that a saturated model does not exist in the context of nonlinear SEM, we do not have a classical likelihood ratio test statistic to assess the goodness-of-fit of the proposed model. In a Bayesian approach with the unknown parameters treated as random, goodness-of-fit of a hypothesized model can be assessed by using Bayesian predictive p-values (BPPs) [46], which required integration over the posterior distribution of the unknown parameters in the model. As it is simple to perform numerically using posterior simulation draws of the parameters within the iterations of a Markov chain Monte Carlo algorithm in the Bayesian estimation, the BPPs have been widely applied in Bayesian analyses of some latent variable models in biostatistics (see [47]) as well as many SEMs (see [48] and the references therein). However, there is a conceptual problem in applying BPPs in an ML analysis, because parameters are not considered as random and the posterior distribution of the unknown parameters is not related to the ML approach. Hence, we propose the BIC for model comparison, and residual plots for model checking (see Figure 2 in the example). Clearly, the development of a more formal statistic for goodness-of-fit of the model in the ML context is an interesting topic for future research. Alternatively, the Bayesian approach can be used. Third, the current ML method cannot handle unordered categorical data. As genotype variables are unordered categorical, it is important to develop methods to handle this kind of data for genetic analysis. Fourth, because the missing data considered here are missing at random, it is necessary to generalize the ML approach in analyzing missing data with a nonignorable missing mechanism.
ACKNOWLEDGEMENTS
This research was supported by a grant (CUHK 450607) from the Research Grant Council of Hong Kong Special Administration Region and grant P30DA016383 from the National Institute on Drug Abuse, Bethesda, MD. Special thanks to Diane M. Herbeck and David Huang for data preparation and to C. P. Chou for valuable comments in improving the manuscript.
Contract/grant sponsor: Research Grant Council of Hong Kong Special Administration Region; contract/grant number: CUHK 450607
Contract/grant sponsor: National Institute on Drug Abuse; contract/grant number: P30DA016383
APPENDIX A: CONDITIONAL DISTRIBUTIONS AND IMPLEMENTATION OF THE E-STEP
Based on the definition and properties of the current model, it can be shown that
where
| (A1) |
where
| (A2) |
in which
where
| (A3) |
and
| (A4) |
where zgt j is jth element of zgt associated with ordered categorical variable wgt j.
The conditional distributions given in (A1) and (A2) are standard normal distributions, drawing observations from them is straightforward. As (A3) is a nonstandard distribution, the MH algorithm is used to simulate observations from (A3). (A4) involves the univariate truncated normal distribution. Simulating observations from this distribution is done by the inverse distribution method proposed in Devroye [49].
To simulate observations from the target density p(ωg|·) in (A3), let , Ψ=diag(Ψ1, …, ΨT), Ψδ=diag(Ψδ1, …, ΨδT), λtm be the mth column of Λt,
and Π*=I–Π, where I is an identity matrix with appropriate dimension. We choose N[·,σ2Σ*] as the proposal distribution, where and
where . be the density function corresponding to the proposal distribution ; the MH algorithm is implemented as follows: At the lth iteration with a current value , a new candidate is generated from and accepting this new candidate with probability min. The variance σ2 can be chosen such that the average acceptance rate is approximately 0.25 or more, see [50].
APPENDIX B: DETAILS IN COMPLETING THE M-STEP
Let , , , , , and B0j be the jth rows of At, A0, Λt, Λ0, Πt, and B0. The derivatives involved in the system of equations given in ∂Q/∂θ=0 are
Conditional on other parameters, the solution of each individual equation in ∂Q/∂θ=0 can be obtained as follows:
Finally, to update the M-step, the conditional expectations involved in the above solutions are approximated by the corresponding observations simulated by the hybrid algorithm at the E-step.
REFERENCES
- 1.Bollen KA. Structural Equation with Latent Variables. Wiley; New York: 1989. [Google Scholar]
- 2.Jöreskog KG, Sörbom D. LISREL 8: Structural Equation Modeling with the SIMPLIS Command Language. Scientific Software International; Hove and London: 1996. [Google Scholar]
- 3.Bentler PM, Wu EJC. EQS6 for Windows User Guide. Multivariate Software, Inc.; Enciuo, CA: 2002. [Google Scholar]
- 4.Yuan KH, Bentler PM. Mean and covariance structures analysis: the oretical and practical improvements. Journal of the American Statistical Association. 1997;92:767–774. [Google Scholar]
- 5.Dunson DB. Bayesian latent variable models for clustered mixed outcomes. Journal of the Royal Statistical Society, Series B. 2000;62:355–366. [Google Scholar]
- 6.Shi JQ, Lee SY. Latent variable models with mixed continuous and polytomous data. Journal of the Royal Statistical Society, Series B. 2000;62:77–87. [Google Scholar]
- 7.Lee SY, Shi JQ. Maximum likelihood estimation of two-level latent variable models with mixed continuous and polytomous data. Biometrics. 2001;57:787–794. doi: 10.1111/j.0006-341x.2001.00787.x. [DOI] [PubMed] [Google Scholar]
- 8.Lee SY, Song XY. Maximum likelihood analysis of a general latent variable model with hierarchically mixed data. Biometrics. 2004;60:624–636. doi: 10.1111/j.0006-341X.2004.00211.x. [DOI] [PubMed] [Google Scholar]
- 9.Guo J, Wall M, Amemiya Y. Latent class regression on latent factor. Biostatistics. 2006;7:145–163. doi: 10.1093/biostatistics/kxi046. DOI: 10.1093/biostatistics/kxi046. [DOI] [PubMed] [Google Scholar]
- 10.Papadopoulos S, Amemiya Y. Correlated samples with fixed and nonnormal latent variables. Annals of Statistics. 2005;33:2732–2757. DOI: 10.1214/009053605000000552. [Google Scholar]
- 11.Sanchez BN, Budtz-Jögensen E, Ryan LM, Hu H. Structural equation models: a review with applications in environmental epidemiology. Journal of the American Statistical Association. 2005;100:1443–1454. [Google Scholar]
- 12.Wei GCG, Tanner MA. A Monte Carlo implementation of the EM algorithm and the poor man's data augmentation algorithm. Journal of the American Statistical Association. 1990;85:699–704. [Google Scholar]
- 13.Louis TA. Finding the observed information matrix when using EM algorithm. Journal of the Royal Statistical Society, Series B. 1982;44:226–233. [Google Scholar]
- 14.Gelman A, Meng XL. Simulating normalizing constant: from importance sampling to bridge sampling to path sampling. Statistical Science. 1998;13:163–185. [Google Scholar]
- 15.Substance Abuse and Mental Health Services Administration . 2002 National Survey on Drug Use & Health Report. SAMHSA, Office of Applied Studies; Rockville, MD: 2003. [Google Scholar]
- 16.National Institute of Justice . 2000 Arrestee Drug Abuse Monitoring: Annual Report. NIJ, Office of Justice Programs; Washington, DC: 2003. [Google Scholar]
- 17.Substance Abuse and Mental Health Services Administration . Emergency Department Trends from the Drug Abuse Warning Network, Final Estimates 1995–2002. SAMHSA, Office of Applied Studies; Rockville, MD: 2003. [Google Scholar]
- 18.Carrol KM, Power ME, Bryant K, Rounsaville BJ. One-year follow-up status of treatment-seeking cocaine abusers. Psychopathology and dependence severity as predictors of outcome. Journal of Nervous and Mental Disease. 1993;181:71–79. doi: 10.1097/00005053-199302000-00001. [DOI] [PubMed] [Google Scholar]
- 19.Browne RA, Monti PM, Myers MG, Martin RA, Rivinus T, Dubreuil MET, Rohsenow DJ. Depression among cocaine abusers in treatment: relation to cocaine and alcohol use and treatment outcome. American Journal of Psychiatry. 1998;155:220–225. doi: 10.1176/ajp.155.2.220. [DOI] [PubMed] [Google Scholar]
- 20.Patkar AA, Thornton CC, Mannelli P, Hill KP, Gottheil E, Vergare MJ, Weinstein SP. Comparison of pretreatment characteristics and treatment outcomes for alcohol, cocaine, and multisubstance-dependent patients. Journal of Additive Diseases. 2004;23:93–109. doi: 10.1300/J069v23n01_08. [DOI] [PubMed] [Google Scholar]
- 21.Hayassy BE, Wasserman DA, Hall SM. Social relationships and abstinence from cocaine in an American treatment sample. Addition. 1995;90:699–710. doi: 10.1046/j.1360-0443.1995.90569911.x. [DOI] [PubMed] [Google Scholar]
- 22.Weisner C, Ray GT, Mertens JR, Satre DD, Moore C. Short-term alcohol and drug treatment outcomes predict long-term outcomes. Drug and Alcohol Dependence. 2003;71:281–294. doi: 10.1016/s0376-8716(03)00167-4. [DOI] [PubMed] [Google Scholar]
- 23.Hser Y. Prediction long-term stable recovery from heroin addiction: findings based on a 33-year follow-up study. Journal of Addiction Diseases. 2007;26:51–60. doi: 10.1300/J069v26n01_07. [DOI] [PubMed] [Google Scholar]
- 24.Crits-Christoph P, Siqueland L, Blaine J, Frank A, Luborsky L, Onken LS, Muenz LR, Thase ME, Weiss RD, Gastfriend DR, Woody GE, Barber JP, Butler SF, Daley D, Salloumn I, Bishop S, Najavits LM, Lis J, Mercer D, Griffin ML, Moras K, Beck AT. Psychosocial treatments for cocaine dependence: National Institute on Drug Abuse Collaborative Cocaine Treatment Study. Archives of General Psychiatry. 1999;56:493–502. doi: 10.1001/archpsyc.56.6.493. [DOI] [PubMed] [Google Scholar]
- 25.Chou CP, Hser YI, Anglin MD. Longitudinal treatment effects among cocaine users: a growth curve modeling approach. Substance Use and Misuse. 2003;38:1323–1343. doi: 10.1081/ja-120018491. [DOI] [PubMed] [Google Scholar]
- 26.Hser Y, Stark ME, Paredes A, Huang D, Anglin MD, Rawson R. A 12-year follow-up of a treated cocaine-dependent sample. Journal of Substance Abuse Treatment. 2006;30:219–226. doi: 10.1016/j.jsat.2005.12.007. [DOI] [PubMed] [Google Scholar]
- 27.Meredith W, Tisak J. Latent curve analysis. Psychometrika. 1990;55:107–122. [Google Scholar]
- 28.Browne MW. Structural latent curve models. In: Cuadras CM, Rao CR, editors. Multivariate Analysis: Future Directions 2. Elsevier; Amsterdam: 1993. pp. 171–179. [Google Scholar]
- 29.Dunson DB. Dynamic latent trait models for multidimensional longitudinal data. Journal of the American Statistical Association. 2003;98:555–563. [Google Scholar]
- 30.Daniels MJ, Normand SLT. Longitudinal profiling of health care units based on continuous and discrete patient outcomes. Biostatistics. 2006;7:1–15. doi: 10.1093/biostatistics/kxi036. DOI: 10.1093/biostatistics/kxi036. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Verbeke G, Molenberghs G. Linear Mixed Models for Longitudinal Data. Springer; New York: 2000. [Google Scholar]
- 32.Diggle DJ, Heagerty P, Liang KY, Zeger SL. Analysis of Longitudinal Data. 2nd edn Oxford University Press; Oxford, U.K.: 2002. [Google Scholar]
- 33.Sammel MD, Ryan LM. Latent variables with fixed effects. Biometrics. 1996;52:220–243. [PubMed] [Google Scholar]
- 34.Rabe-Hesketh S, Skrondal A, Pickless A. Generalized multilevel structural equation modeling. Psychometrika. 2003;69:167–190. [Google Scholar]
- 35.Little RJA, Rubin DB. Statistical Analysis with Missing Data. Wiley; New York: 1987. [Google Scholar]
- 36.Song XY, Lee SY. Bayesian analysis of latent variable models with exponential family outcomes. Statistics in Medicine. 2007;26:681–693. doi: 10.1002/sim.2530. DOI: 10.1002/sim.2530. [DOI] [PubMed] [Google Scholar]
- 37.Geman S, Geman D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1984;6:721–741. doi: 10.1109/tpami.1984.4767596. [DOI] [PubMed] [Google Scholar]
- 38.Metropolis N, Rosenbluth AW, Rosenbluth MN, Teller AH, Teller E. Equations of state calculations by fast computing machine. Journal of Chemical Physics. 1953;21:1087–1091. [Google Scholar]
- 39.Hastings WK. Monte Carlo sampling methods using Markov chains and their application. Biometrika. 1970;57:97–109. [Google Scholar]
- 40.Shi JQ, Copas J. Publication bias and meta-analysis for 2×2 tables: an average Markov chain Monte Carlo EM algorithm. Journal of the Royal Statistical Society, Series B. 2002;64:221–236. [Google Scholar]
- 41.Kass RE, Raftery AE. Bayes factors. Journal of the American Statistical Association. 1995;90:773–795. [Google Scholar]
- 42.Song XY, Lee SY. Model comparison of generalized linear mixed effect models. Statistics in Medicine. 2006;25:1685–1698. doi: 10.1002/sim.2318. DOI: 10.1002/sim.2318. [DOI] [PubMed] [Google Scholar]
- 43.Meng XL, Wong HW. Simulating ratios of normalizing constants via a simple identity: a theoretical exploration. Statistica Sinica. 1996;6:831–860. [Google Scholar]
- 44.Kasarabada DN, Anglin MD, Khalsa-Denison E, Paredes A. Differential effects of treatment modality on psychosocial functioning of cocaine-dependent men. Journal of Clinical Psychology. 1999;55:257–274. doi: 10.1002/(sici)1097-4679(199902)55:2<257::aid-jclp13>3.0.co;2-x. [DOI] [PubMed] [Google Scholar]
- 45.Lee SY, Lu B, Song XY. Semiparametric Bayesian analysis of structural equation models with fixed covariates. Statistics in Medicine. 2008 doi: 10.1002/sim.3098. DOI: 10.1002/sim.3098. [DOI] [PubMed] [Google Scholar]
- 46.Gelman A, Meng XL, Stern H. Posterior predictive assessment of model fitness via realized discrepancies. Statistica Sinica. 1996;6:733–807. [Google Scholar]
- 47.Carlin JB, Wolfe R, Brown CH, Gelman A. A case study on the choice, interpretation and checking of multilevel models for longitudinal binary outcomes. Biostatistics. 2001;2:397–416. doi: 10.1093/biostatistics/2.4.397. [DOI] [PubMed] [Google Scholar]
- 48.Lee SY. Structural Equation Modelling: A Bayesian Approach. Wiley; New York: 2007. [Google Scholar]
- 49.Devroye L. Non-uniform Random Variate Generation. Springer; New York: 1985. [Google Scholar]
- 50.Gelman A, Roberts GO, Gilks WR. Efficient metropolis jumping rules. In: Bernardo JM, Berger JO, Dawid AP, Smith AFM, editors. Bayesian Statistics. vol. 5. Oxford University Press; Oxford: 1995. pp. 599–607. [Google Scholar]