

Abstract
Qualitative research creates mountains of words. U.S. federal funding supports mostly structured qualitative research, which is designed to test hypotheses using semi-quantitative coding and analysis. The authors have 30 years of experience in designing and completing major qualitative research projects, mainly funded by the US National Institute on Drug Abuse [NIDA]. This article reports on strategies for planning, organizing, collecting, managing, storing, retrieving, analyzing, and writing about qualitative data so as to most efficiently manage the mountains of words collected in large-scale ethnographic projects. Multiple benefits accrue from this approach. Several different staff members can contribute to the data collection, even when working from remote locations. Field expenditures are linked to units of work so productivity is measured, many staff in various locations have access to use and analyze the data, quantitative data can be derived from data that is primarily qualitative, and improved efficiencies of resources are developed. The major difficulties involve a need for staff who can program and manage large databases, and who can be skillful analysts of both qualitative and quantitative data.
Keywords: qualitative research, organizing project, field expenses, data base management, semi-quantitative coding
The Problem
Qualitative research creates Mountains of Words. No matter how large or small the project, the qualitative methodology depends primarily upon eliciting self-reports from subjects or observations made in the field that are transcribed into field notes. Even a small qualitative project easily generates thousands of words. Major ethnographic projects easily generate millions of words. Fortunately recent advances in computer technology and software have made it possible to manage these mountains of words more efficiently, as described below. At every step of conducting research using qualitative methods, researchers and research teams face daunting problems of how to organize, collect, manage, store, retrieve, analyze, and give meaning to the information obtained during qualitative research. This article focuses upon strategies and experiences of the authors, who have conducted a wide variety of research projects which are primarily qualitative in their focus, although some have also included quantitative components. This focus reflects their experience in organizing large qualitative projects so as to routinely manage the data flows into a comprehensive database so as to make subsequent analysis of these data as efficient as possible.
Quantitative research projects ask pre-coded questions and assign numeric values to responses; such pre-coded answers can be analyzed by the straightforward methods delineated in programs like SAS, SPSS, or STATA. By contrast, qualitative research is far less structured and cannot be easily converted into numbers that can be analyzed by such statistical packages.
The field of anthropology continues to have a tradition of a lone investigator conducting fieldwork, often in a foreign country, collecting qualitative data which only they know and understand, and must subsequently analyze for publication—but this is quite rare. During the past 25 years, the U.S. federal government, through the various institutes of the National Institutes of Health and Department of Education, has provided increased funding to support qualitative researchers to address numerous topics. Increasingly, researchers who rely primarily upon federal funding to support qualitative research must grapple with review committees and funding decisions which increasingly insist that qualitative researchers obtain and analyze data to build towards (or include) a quantitative component. This is due to the fact that quantitative research constitutes the dominant methodological paradigm for most social science research supported by governments and foundations. Moreover, most scientific theories and hypotheses are formulated to be answered by quantitative approaches. Review committees often want larger samples, inclusion of special populations, and higher levels of abstraction and theory testing than can be accomplished by smaller qualitative research projects. Even when fortunate enough to receive a federal grant to conduct qualitative research, many problems confront the skilled qualitative researcher. Some urban ethnography is now conducted with multiple ethnographers and field workers; this involves training, coordinating, and structuring the work of those who will conduct the actual research, and systematically recording qualitative information that will often be analyzed by persons who did not collect it. We will call this structured qualitative research. By this we mean that the investigator proposes to study a rather specific topic, and outlines in considerable detail the various dimensions or lines of inquiry that the project will be designed to elicit. While many qualitative researchers make substantial attempts to structure their research, so as to obtain rich responses from subjects and well-written field notes, the careful structuring of qualitative protocols, systematic use of databases for storage, retrieval, and management of the mountains of words collected, and other efficiencies described below represent important advances for qualitative researchers to consider.
An additional expectation from grant and peer reviewers is that the investigator will propose specific hypotheses and analyze the qualitative data by employing analytic approaches that are what we call semi-quantitative. This means that some segments of textual data will be coded in such a way that it allows for rough numerical counts or proportions to be reported along with typical quotes from qualitative respondents. That is, a small portion of the Mountains of Words is partially converted from textual data into assigned numbers or variables that can be counted and employed like quantitative data sets. The structured qualitative research reported here has generated a coding system that permits individual interview responses to be converted into numeric codes for subsequent quantitative analysis. This article will report on strategies for planning, organizing, collecting, managing, storing, retrieving, coding, analyzing, and writing so that qualitative methods can most efficiently manage the Mountain of Words collected in large-scale ethnographic projects. With this focus in mind, we will report on strategies for handling textual data, and not with many other important issues that arise in qualitative research. Other articles in this special issue address important topics—which this article only mentions in passing. The authors have also addressed such issues in prior publications.
For example, this article ignores issues associated with human subjects, informed consent1 (Dunlap and Johnson 2005), sampling of respondents, safety in field settings (Dunlap and Johnson 1992; Williams et al 1992;), and many other related issues (although they may be mentioned in passing). Rather, the authors focus upon several key stages or procedures which support structured qualitative research for managing, eliciting, and analyzing Mountains of Words.
Background
The authors have engaged in several major qualitative research projects, with a primary focus upon patterns of illicit drug use and distribution. All of these projects have been funded by the National Institute on Drug Abuse (NIDA). The senior author, Johnson, was trained as a quantitative researcher at Columbia University, but has been associated with several leading ethnographers and qualitative researchers during his career. The second author, Dunlap, was primarily trained as a qualitative researcher at University of California at Berkeley, while the third author, Benoit, has training in historical methods and qualitative research at New York University. All three have worked together on several different qualitative research projects. From 1988 to the present, Johnson and Dunlap have conducted qualitative studies on crack distribution and substance abuse, crack and crime, and several others involving quantitative studies of arrestees. Recently, Dunlap and Johnson have conducted qualitative studies of household violence, transient domesticity, marijuana and blunts, and most recently studies of drug markets in New Orleans and Houston following Hurricane Katrina. Each of these studies has involved very similar qualitative methods for framing research questions, developing qualitative protocols, organizing data, storing and managing textual data, and then analyzing the data. These projects have resulted in close to 100 different publications since 1990 in a wide variety of journals and books. Some of these are cited at different points in the analysis that follows.
We also recognize that many other ethnographers have conducted excellent qualitative studies, and arrived at different solutions and uses of software, and analyzed both qualitative and quantitative data, resulting in the publication of peer-reviewed articles. Such researchers may find our experience helpful at improving their efficiency in managing the Mountain of Words in their future research. Likewise, colleagues conducting research outside the USA and international settings may find these experiences informative.
A central conclusion which has been widely noted by many qualitative researchers is that continuing and recent advances in computer hardware (almost all computers in 2008 have extensive RAM and hard drive storage capacity) (Fielding and Lee 1991), software (Bazeley 2002, MacMillan and Koenig 2004), internet access (Mann and Stewart 2000), and cellular communication technology has transformed the efficiency for managing mountains of words (Mangabeira, Lee and Fielding 2004). The strategies reported below are based on efficient use of some of this technology. Nevertheless, the authors struggle to keep up with and use these technological advances—a struggle that will continue in the foreseeable future. We address how researchers can most efficiently use such technological advances to conduct their qualitative research on a wide range of topics.
In the authors’ experience, most qualitative analysis programs, such as Ethnograph (Sidel and Friese 1998), Atlas (Muhr 2005), Nudist (Crowley, Harré, Tagg 2002), Nvivo (Bazeley 2002), and others have major limitations (see Barry 1998; Brent and Slusarz 2003, Gilbert et al 2004, MacMillan and Koenig 2004) that have proven unsatisfactory for the management of the mountains of words collected in the above-mentioned research projects (also see Manwar, Dunlap, Johnson 1993). The major shortcomings of these programs stem from their being word based. While these programs are efficient in searching for individual words or organizing some collection of words or text, they do so across the entire database. Such programs generate far too many “hits” to systematically retrieve targeted data that is useful for analysis purposes. By contrast, structured qualitative research is organized around questions that are carefully framed by the investigator to systematically elicit answers from respondents. This approach can help qualitative researchers to obtain, store, organize, and analyze the data more efficiently and effectively.
Thus, one of the most fundamental and important decisions in conducting structured qualitative research—which is best made at the beginning of a research project—is the choice of a software program that can integrate information across many different functions and purposes. This allows for one software program to maintain most of the information and data to be collected during qualitative research. During the past nine years, the authors have found one relational database which provides that integrative function. FileMaker_Pro (2007) (now in version 9) is a true relational database that has been successful for managing qualitative data, as well as being a major “storehouse” for answers to individual questions by ethnographic respondents. This product has continuously upgraded its capabilities. Moreover, our staff experience has developed over the years, and they have learned how to employ this program’s capabilities. Staff now can now design, accomplish, and integrate many functions that were previously disconnected in different programs or done by paper and pencil and US mails, as described below.
We currently have three major databases (each is over 60 MB), each containing extensive amounts of qualitative data. We reference our experience and findings from some of these projects to illustrate some of the points made below. These three projects are briefly described here; citations are also provided to published articles that contain more details about the samples and qualitative methods employed.
Marijuana/blunts: This project was a five-year study (2002-2007) in New York City which recruited 100 current and active marijuana users who were longitudinally followed for three to four years; they were re-interviewed on several occasions following a structured qualitative protocol (similar to that described below). In addition, this project developed a quantitative protocol derived from insights gained during the qualitative research in year one. This peer group questionnaire was developed in year two and administered during years two and three; 550 additional respondents completed this protocol (Ream et al 2005, 2006, 2007, 2008). An additional sub-study recruited marijuana/blunts users who allowed their recent purchase of marijuana to be weighed so that price/gm could be calculated (Sifaneck et al 2007).
Transient domesticity: This study was built upon 10 years of previous qualitative research in the 1990s. An entirely qualitative study (2003-2008), it investigates the role of (often transient) male partners in the households of poor African-American women with children. It documents whether and how violence occurs within the male-female relationship, and how drug use and sales activities impact upon household functioning. Ninety-two carefully selected focal subjects (plus partners and other household members) were recruited in years one and two. These subjects completed a baseline protocol, and most have been re-interviewed approximately every six months during the remaining three years.
Katrina project: This study (2006-2010) is in mid-data collection; this article is among the early publications from this project (also see Johnson, Dunlap, Morse 2007). More extensive data analysis is just beginning. This structured qualitative study investigates the reformulation of illicit drug markets among New Orleans evacuees both in New Orleans and in Houston. The staff anticipates that over 150 active drug users and sellers of several illegal drugs will be recruited and interviewed in these two locations. Several focus groups are being conducted. This qualitative project faces the additional difficulty of being conducted at sites (New Orleans and Houston) far removed from the investigator’s work location (New York). Most of the examples provided below are drawn from this project, because of the important advances made in the effective use of the technology and software that make this project innovative. We provide illustrative materials in boxes (labeled as Figures).
Planning structured qualitative research
The most fundamental requirement is to be clear about what the qualitative research project is designed to accomplish. This is especially important when writing a complex application to a federal agency for funding, and hoping that it will be funded after several reviews. The application must propose a specific focus for the research, delineate specific aims, indicate its significance, describe preliminary research, and provide detailed methods and analysis plans. This is where scientific innovation and clarity of purpose are especially important, as only a few applications receive good priority scores, and even fewer receive funding. The aims are provided in the abstract of the Katrina project in Figure 1.
Figure 1.

AIMS and Abstract of Katrina Project
Many qualitative research projects are organized around four types of data collection approaches that yield extensive amounts of textual data:
Field notes -- written observations of the field setting that record what is seen, heard, or observed.
Baseline qualitative protocol -- a carefully developed interview schedule that elicit stories and accounts from respondents. Usually interviews are recorded and transcribed, generating large numbers of words. When carefully recorded and transcribed the questions and answers become the data elements.
Follow-up qualitative protocol – this protocol is very similar to the baseline, but often asks fewer questions, requests updates, and provides information needed to study change across time.
Focus group protocols -- the focus group usually involves three to 10 persons who are asked to address a limited group of questions for which they have the expertise to provide illuminating information. In our experience, the more carefully structured each of these types of data collection approaches, the better the quality of data that is elicited. We consider each of these in some detail below.
Depending upon the aims of the project, many other issues may need further elaboration. In the Katrina project, this involved development of question domains regarding time windows and illicit drug markets being studied. The baseline protocol described below includes questions asked of respondents for the month before Katrina, during the week of the Katrina Hurricane and flooding of New Orleans, a month after evacuation from New Orleans, and in the present (in the past 30 days) at the time of the interview. The 30-day window was chosen to reflect a common time period which persons could recall with some accuracy; in fact many respondents reported their recollections without reference to a 30 day window. Likewise, other questions are focused upon a respondent’s participation as a user and/or seller in various illegal markets: cannabis, heroin, crack/cocaine, and other illicit drugs. Many other details are fleshed out in the research methods section of the application and in the development of protocols and data collection devices—as well in other prior publications (Davis et al 2006; Lewis et al 1992). These aspects need to be systematically asked and their answers recorded in a highly structured fashion in order to obtain roughly comparable data from a wide variety of participating research subjects.
Training and supervising ethnographic staff
No matter how well conceptualized the qualitative research project has been, actual implementation is fraught with many difficulties. A typical problem involves hiring of qualified staff. The reality is that very few persons have all the requisite qualitative skills for studying illegal drug markets in the field. Investigators must often choose between two types of staff. Persons having good educational credentials (e.g. masters or doctoral level training in qualitative research, persons in anthropology or sociology) often lack street contacts and connections with illegal drug users at research sites. By contrast, “street savvy” persons may have excellent contacts within drug user circles, but lack educational credentials, writing skills, and/or training in qualitative research methods. Social workers with several years of experience often have both the credentials and street savvy to become good ethnographers. Over several years and projects, our experience has been that the “street savvy” person often makes the better field worker because such work enhances their employment record, and so they will remain loyal staff members for the duration of the project and often across several projects. The graduate student or well-educated person often has considerable difficulty accessing illicit drug users and markets; they also often leave before the project ends (due to graduation, higher paid jobs, or other reasons). Our best ethnographers have been persons who have recovered from heroin/crack abuse as young adults, but who have gotten bachelor and masters degrees, and have been trained to routinely write rich field notes and conduct high quality interviews with extensive probing.2
Far more important than hiring the “right person” is the investigator’s ability to systematically train all staff in the details of the qualitative research process, and give them time to upgrade their skills, until they accomplish it well. Especially in locations (such as New Orleans and Houston) remote from the investigator’s office (in New York City), having doctoral level consultants or co-investigators who can provide ongoing staff supervision greatly enhances the project. At project startup, all staff needs five days or more of training in various procedures and approaches. This involves both formal training and actual practice sessions. Formal training includes:
in-depth discussion about the practical application and reading of previously published articles about entering the field and conducting research among drug users (Dunlap and Johnson 1998; Dunlap et al 1993),
maintaining personal safety for both subjects and field staff in dangerous situations (Williams et al 1992),
informed consent procedures approved by the institutional review board,
ethical issues that may arise (Dunlap and Johnson 2006),
the basics of observations and field note writing,
the conduct of personal interviews, and conceptualization of the major issues to be researched,
how to account for and record expenses incurred during the study;
plans for regular staff meetings.
The investigator also needs to ensure that all staff members clearly understand the project’s aims and purpose. The investigator must provide considerable clarity about what each staff person is expected to produce in terms of field notes and interviews during a week or month. The initial training usually does not include development of protocols, which comes later. This training also includes instruction in how to follow detailed written procedures for submission of textual data or recordings (described in more detail below).
An important component of training staff occurs via role-playing, so as to develop experience in observation and field note writing, interviewing, and other skills that are expected. When each staff member can effectively demonstrate their skills via role playing, they are sent into the field setting to begin work and practice their skills. Training in observations and writing field notes educates staff about how to enter the field and make the ethnographers’ presence known and accepted. It also leads to discussion about the difficulties and inconsistencies that the main work will entail. After initial training, a most important activity is to provide regular ongoing supervision—biweekly staff conference calls usually can accomplish this. It is easier to monitor quantity of production than the quality of work this way because writing field notes and awaiting transcription of interviews takes more time. Ethnographers also need to conduct their research outside of regular business hours; they need to adjust their work schedule to fit the typical work hours of potential subjects—active drug users and sellers, in the Katrina project.
Recording and managing units of work
As staff begin conducting the qualitative research activity, they need to be trained, directed, and supervised to routinely create units of work. A good operational definition in qualitative research: a unit of work is equivalent to a file—usually written in Microsoft Word—that describes staff effort accomplished at a specific date, time, location, and with a particular focus. This is especially important with regard to field notes. Moreover, each unit of work needs to have “header information” that is standard across all units of work. The field worker records a file name, date, the approximate time, his or her name and location, description of subject(s) or other information as requested. The header used in the Katrina study is provided in figure 2. The controlling feature is the filename, in which is embedded: the type of work done (field note or voice recorded interview, the staff member who collected data, the date it was collected, and whether it refers to a specific respondent or not. The additional information in the header needs to be systematically recorded. The information in the header will become a field in the FileMaker Pro database, which organizes all the units of work for analysis at a later time.
Figure 2.

Example of Header Information and an Observation Only Field Note.
When a field note is written, or other units of work created, it is critically important that each ethnographer maintain every file they generate on their own computer for subsequent cross checking. They should also print out and maintain paper copies of their units of work for ease of cross checking the specific units of work with the staff maintaining the integrating project data base (see below). All field notes and units of work need to be routinely submitted or uploaded electronically to the central data repository of the project (as described below).
Observations and descriptive field notes
One of the most important skills for ethnographers is the ability to enter a field setting, make systematic observations, hold informal conversations with persons present and screen for “persons of interest”--in our case those involved as consumers or sellers of illegal drugs. Sometimes their observations may result in new contacts or in no contacts and yet provide interesting information that needs to be recorded (e.g. a community demonstration against destruction of public housing in New Orleans). At other times staff will conduct informal conversations as they go about their work. A major difficulty can arise here. Staff needs considerable pressure and supervision to routinely generate field notes about each unit of work. In a large-scale qualitative research project, each field note is the rough equivalent of a short interview in a quantitative research project. The ethnographers needs considerable self-discipline to make 1-3 hours of direct observations in the field, and then spend several hours writing field notes based upon those observations. Indeed, writing the field notes may take more time than making the observations. The field notes need to be very descriptive of what was observed, without being judgmental or disrespectful of the behaviors observed or the lifestyle of the people observed. Many staff may lack skills in writing clear sentences, reproducing interactions or informal conversations with potential subjects, and developing extensive and thickly descriptive field notes. It often takes much time and intensive supervision to get staff both trained and systematically supervised to write excellent field notes. Having ethnographers write descriptive field notes is much more important than the grammar and sentence structure. The important issue is whether the field note coveys clearly what happened/was observed. Further, since observations are focused upon persons engaged in illegal behaviors (drug sales), observations will need to include interpretations of the meanings implied by words used by respondents—as well as what might be learned by returning for additional observations later. Our experience has been that each unit of work must have its own field note. Thus, if a field worker makes observations at three different locations, each of those locations needs to result in a separate field note because it is a unique setting and a different unit of work. Due to the need to maintain confidentiality of respondents (who have given informed consent) and potential respondents or persons present in field settings (who do not know of the ethnographer’s role), no cameras of any kind are employed.
Likewise, if the interviewer conducts a personal interview with a subject that covers only the first 25 questions in the protocol, they need to write a field note about that unit of work and clearly indicate that they covered only these 25 questions. It would be another unit of work when they conduct another interview that covers the last set of questions. Two types of field notes will be generated: “Linked field notes” describe contacts with or interviews with a specific person chosen as a research subject. If that subject is contacted or observed in the field on other dates, each different contact should have its own field note with a different file name, but that person’s ID number is recorded in the file name and the header.
“Observation only field notes” result when the ethnographer goes into the field and only observes the general scene and maybe has informal conversations with unknown persons (not research subjects); such a field note should record what was observed (without using actual names). In the Katrina project, staff have found it important to also document that “nothing is happening” or that no one was observed at specific locations where previously active drug distribution was observed.
Across several weeks and months of data collection, numerous field notes get written, and expenses associated with conducting field research and payments for interviews begin to pile up. Keeping track of all these units of work becomes extremely cumbersome and time consuming when using only paper files. Managing paper files was especially problematic in New Orleans, as mail service (both pickup and delivery), was severely disrupted by the flooding of most local post offices. Electricity and especially internet service was far more reliable than conventional mail six months after the Hurricane.
Managing expenses and units of work
During the first nine months of the Katrina project, staff recorded their interviews and field notes and submitted them on diskettes and/or paper files to the central office where the data was stored. This rapidly bogged down all project work because ethnographers spent too much time keeping track of paper work and several paper copies were lost in the mails. Some other mechanism was needed. Fortunately, the organization’s [National Development and Research Institutes, Inc.-NDRI] network and web-based software has now developed to the point where data can be recorded electronically and uploaded successfully across vast distances, with confidentiality ensured by double password protection. As a result, FileMaker Pro was able to integrate two major data management functions that were very time consuming and error prone.
Field expenses
While conducting ethnographic research, staff in New Orleans and Houston drive vast distances to meet with subjects or to make observations, thus incurring mileage expenses. In addition they purchase sodas or food for potential subjects while making observations. When qualitative protocols are conducted, they provide incentives for completing interviews. Previously each of these expenses needed to be recorded on paper receipts and submitted on a timely basis to ensure reimbursement.3 Instead, we now use programmer-developed scripts in FileMaker Pro that computerized the recording of field expenses. Further, each field note was linked to its associated expenses. Ethnographers in Houston and New Orleans go to a specified website on the Internet and enter expense information directly into the project database in New York. Staff members enter each type of expense associated with each unit of work (a field note or personal interview), effectively billing the project for those units of work. For auditing purposes, a reconciliation of expenses is generated and submitted to the fiscal department. The project advances money via funds transfer directly into the ethnographers’ personal bank accounts. This procedure substantially reduces the time devoted to accounting for field expenses and provides nearly instantaneous recording of expenses and advances to the ethnographer. Figure 3 displays a screen shot of the expenses associated with a field note and personal interviews.
Figure 3.
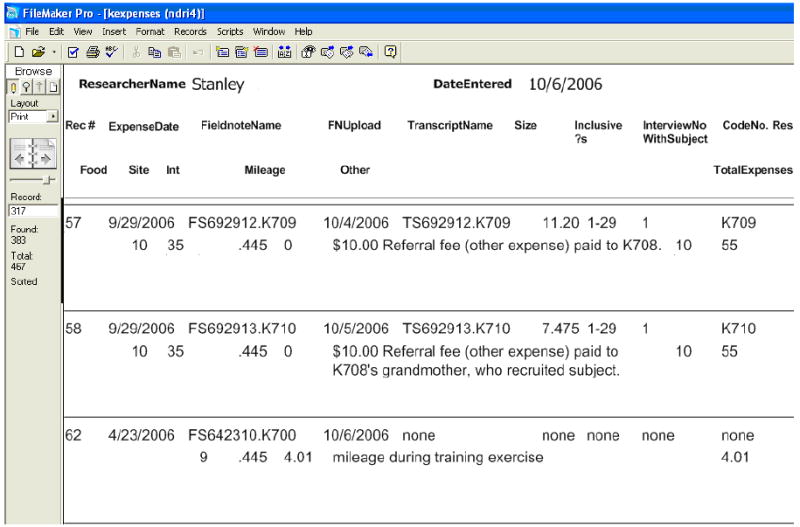
Screen shot from File Maker Pro of Expenses associated with one Field note and two personal interviews.
Uploading field notes and files
The web-based interface now enables ethnographers in remote sites to directly submit their work to the central repository on the NDRI network. On a routine basis, ethnographers now upload each and every field note via the internet. In addition, digital voice files recorded during personal interviews (see below), often 5-20 megabytes in size, are required to be uploaded to the project repository. This means that staff no longer need to mail diskettes or CDs containing their work to New York. Virtually all raw data files submitted by staff members are now stored electronically in the project repository where one administrator is responsible for keeping the data flow organized. Staff conference calls scheduled every two weeks enable the investigators to provide feedback about the quality of work by ethnographic staff, and to discuss emergent findings.
Protocols for eliciting rich qualitative data
After several weeks of ethnographic observations and systematic review of field notes, and drawing upon the collective experience of the research team, staff members collaborate to develop a protocol that is specifically designed to elicit rich qualitative data. This involves several meetings with all staff present, usually several drafts of each question, reorganization of question order, and clarification about the major focus of the project. Two general classes of questions are developed. “Concrete questions” are designed to measure relatively common roles or phenomena, such as demographics (gender, ethnicity, age) and education, residence and residential locations, etc.; these are fairly easy to develop but often elicit answers that may not be straightforward to code. By contrast, “thematic questions” are designed to elicit extensive reports and stories about the focal topics of interest (e.g. drug use patterns, drug sales activity, perceptions of illegal drug markets). Five thematic questions from the 15-page qualitative protocol for the Katrina project are provided in figure 4.
Figure 4.

Questions as written in the structured qualitative protocol. (Five of 101 questions.)
Now let’s talk about during the disaster and before your evacuation from New Orleans. We refer below to DURING KATRINA DISASTER: this began on Aug 29 (Monday) and lasted thru September 6 (Tues) when virtually everyone was evacuated from New Orleans.
In the process of developing structured qualitative protocols, staff develop a lead question about a specific topic, along with several probes to be asked of persons who respond positively. But since all possible probes cannot be included in a protocol, ethnographers also need to be trained to listen carefully, and then ask appropriate probes. This open-ended questioning approach is also seeking the meaning of specific argot terms (e.g. “trees” for marijuana—Johnson et al 2006). A serendipitous observation by the subject may provide an insight about tactics to conceal distribution (e.g. a car wash provides a cover for selling).
A key strategy in the development of probes is to ask respondents to “tell us a story” about that topic, with a follow-up question, “is there anything else?” This strategy is designed to let people talk as much as they want to about that topic and provide further interesting details. In their “story” is the rich data which qualitative methodology is so excellent at obtaining. But a major shortcoming of qualitative methodology is that so many follow-up questions can be generated that the interview becomes very long. Another limitation is that respondents often talk about issues that are “off the topic” of the question; they need to be reminded to address the topic.
The Principal Investigator is responsible for developing and finalizing the written interview protocol for purposes of data collection. Project staff also needs careful instruction and systematic training to read a question as written and if necessary repeat it. Likewise, each staff member must be carefully trained to understand the question in the same way. Every question is discussed in detail, with everyone stating their understanding of the purpose of the question and the domain to be tapped. Staff also needs to follow the order of questions in the protocol. They need to clearly state the question number being asked so that the transcriber types the question number and exact words spoken by the interviewer. [The administrator enters data from the transcript into the correct fields in the database, see below.] After the protocol is developed and the staff trained to conduct the protocol, each ethnographer begins to recruit subjects and conduct personal interviews. While completing the informed consent process, each subject is asked to give a preferred code name which is the only identifying information recorded during interviews. Administration of this protocol serves three important functions: 1) the respondent has time to feel comfortable with the ethnographer, 2) the ethnographer develops rapport with the subject and can elicit more honest answers or disclosures, and 3) the respondent provides rich data—their stories—and answers the questions poised by the ethnographer. With a lengthy qualitative protocol such as that used in the Katrina project (with 100 main questions; each with many probes), a given subject may need two to four interview sessions to complete it.
Recording interviews with digital voice recorders
During the 1990s and early 2000s, our qualitative research team used tape recorders containing cassettes on which interviews were recorded. These cassettes would then be submitted to the central repository, and subsequently transcribed. But such cassettes could be lost, some times had bad recording quality, and other limitations. Another major technological advance, digital voice recorders (DVR), now provide much superior sound quality and recording accuracy for about the same price as cassette recorders. DVRs are more compact and easier to use (with training), and eliminate the need for multiple steps involved with handling recorded cassettes. They are especially valuable in field settings where much background noise may interfere with recording. The quality of recording with a DVR can be improved by having a remote microphone directed at the respondent, and by having the interviewer sit near the recording device when asking questions. One drawback of the digital voice recorder is that it is sometimes easy to unintentionally delete a previously recorded file. A second limitation is that digital voice files grow to be very large and become more difficult to handle. Staff members report that it is best to record for a half to three-quarters of an hour on one digital voice file, take a break, and resume the interview but with a different digital voice file. Thus, one interview often has two related digital voice files. All files are electronic digital files that can be easily stored and transmitted using computer technology.
After the interview is complete, the interviewer connects the digital voice recorder to their computer and copies/transfers that voice file into their computer; it is given a filename parallel to the field note protocol, but the voice digital voice file name begins with V(voice) rather than F (field note). After being stored on the ethnographer’s hard drive, each digital voice file can then be easily uploaded via the Internet to the central data repository for this project. Only the field worker has rights (password protected) to upload files into their location in the repository. The confidentiality and anonymity of both the digital voice file and the associated field notes are maintained but recorded in the central repository for subsequent handling.
Managing the central repository
The central repository is the location where all of the original raw data files submitted by the ethnographic staff are stored on a network hard drive (and backed up to CDs). Each staff member has their own unique location for storing their field notes, digital voice files, and transcripts. One administrative staff person is responsible for managing all of the files.
Every field note and digital voice file uploaded by field staff is entered into a spreadsheet that tracks the progress of that unit of work. This spreadsheet is routinely provided to each field worker in order for them to cross check that the central repository contains all the work they have done; if something is missing, the appropriate files are uploaded again.
Each digital voice file is uploaded via the internet to a transcriber who has been specially trained to maintain the confidentiality of these data and to accurately reproduce the exact words spoken by the interviewer and each research subject. After transcription, a Word file containing the transcript is forwarded to the administrator along with the invoice for that transcript; the administrator then pays for and stores the transcript in the central repository for review by the ethnographer who completed that interview. Each digital voice file and its associated transcripts are also tracked for the timeliness, quality, and accuracy of transcribing. The administrator can also correct misspellings, and/or listen to the audio files to resolve “inaudibles.”
Building an integrated qualitative data base
Careful programming of FileMaker Pro provides a highly structured environment in which the administrator effectively copies text from the transcripts and pastes the contents into a field in the relational database. This relational database systematically links each field note and each transcript with the subject ID number and with the name of the ethnographer who generated it, as well as the expenses associated with that unit of work.
The project database is maintained on a network drive that allows several people to work with the database at the same time. This FileMaker Pro database has been programmed so that each question in the structured interview protocol has a location (or field) in the database where a subject’s answer to that question is to be stored. The administrator reviews the Word transcript, then copies and pastes the answers to each question in the appropriate field in the database. The end result is a database which displays the code names and numbers of subjects interviewed in a row at the top of the screen and the answers to each question (with the questions) in fields below. A screenshot of a portion of one subject’s answers from the database is displayed in figure 5. This also displays the semi-quantitative coding system described below.
Figure 5.

- The question as written in the structured qualitative protocol (two examples)
- Window containing the text addressing that question, both the interviewer’s question and respondent’s answer.
- Semi-quantitative code categories developed for that question.
- Numeric code(s) entered by coder based upon the answer (2) and code categories (3).
- “Info” button provides demographic information about the subject, interviewer, and date.
The administrator also systematically reviews the database for missing information and blank cells. Data may be missing for a given question because the interviewer has not yet completed the interview with that subject, or the question may have been appropriately skipped following skip instructions in the interview protocol. It is also possible that the interviewer failed to ask the question or get a response to a particular item. Follow-up protocols and interviews with the same subjects can be organized in the same manner as the baseline protocol, but with the follow-up questions added to the list of variables, and recorded as separate interviews. Focus group protocols are also entered into the database, but often these subjects were not part of the main qualitative study and hence have no personal interview. Focus group subjects are handled differently, organized according to the questions asked.
The end result is a large and extensive database containing mountains of words. But the structured organization of the data permits the staff members to efficiently conduct analyses with the database, as described next.
Retrieval of relevant responses for a topic
At the end of 2007, approximately 106 Katrina subjects have been recruited and have completed at least one interview, but the majority has completed the full baseline protocol and their responses are entered into the database. FileMaker Pro offers several ways of accessing this data and generating results specific to a given topic. A straight-forward approach is to select 2-4 questions asked, and then read every respondent’s answers to that question on the screen. The analyst can select sections of text (quotes) and paste them into a working file for later use. The “Info” button provides the analyst with a summary of key information about that respondent (code name, gender, ethnicity, age, date of interview, interviewer).
An important function is the query, a procedure for locating responses to specific questions associated with the topic that the analysts wish to address. The analyst specifies the questions in the interview protocol that they wish to obtain. The query will rapidly return all relevant fields for all subjects for that question. The output from a query can be generated as a Word document, or as an Excel file, or in other files which the analyst might desire. If so desired, only specific subsets of respondents can be queried; for instance, a particular query can be limited to include only those subjects interviewed in New Orleans, or only those engaged in heroin use. Depending on the topic chosen, additional questions in the database may be obtained. For example, the qualitative protocol (and database) contains four questions about violence before Katrina, during Katrina, shortly after Katrina, and at the current time. But many more questions inquire about participation in drug markets in these time periods, and they can be queried and analyzed for relationship to violence. Overall the Katrina database makes access to the information extremely easy to retrieve and use for analysis purposes. But the way that analysis is approached will determine what is retrieved and how it will be analyzed.
Qualitative analysis with the textual data
While the database will provide mountains of words regarding a particular topic, the hard work just begins. The analyst will need to carefully read through several screens of narrative or pages of printout narratives, and try to figure out how to use these data in a report they may wish to develop. A purely qualitative analysis will identify and examine certain themes that emerged from a careful reading of the data. Particularly useful quotes may be identified, copied, and used in the written report. This kind of analysis is especially useful in identifying contradictions between respondent reports and what might be obtained in quantitative analysis. For example, one paper from the Transient Domesticity project analyzed qualitative data about beatings in childhood. When asked, “Did you receive beatings while growing up in your household ?” more than half of the subjects denied it. However, ethnographic probing and analysis of their stories revealed that a negative answer did not mean the absence of physical assault. Rather, many of the respondents regarded the physical punishments they received as distinct from being “beaten.” They provided rich stories about how they had been beaten (from the perspective of the analyst). Some legitimated their punishment as “spankings” or as “deserved.” The published report provides quoted materials from several subjects who reported that they had not been beaten, but actually were, during their childhood as depicted by their stories (Dunlap Golub Johnson 2003b; also see Dunlap et al 2003a and Dunlap et al 2006). This suggests that the scientific (and layperson’s) understanding of a phenomenon (beatings) may not mean the same thing to respondents and that a “yes or no” answer in a quantitative survey may provide results that seriously under-count the phenomenon—the better data is elicited by probing the subject.
Semi-quantitative coding
Some questions in the interview protocol and answers stored in the database may be especially amenable to transformation into quantitative codes like those used in typical surveys. Generally these involve demographics or other concrete roles. The analyst can code persons according to gender and levels of education. Our experience indicates that respondent answers about their ethnicity and age are often difficult to code into standard close ended categories. For example, when asked to explain their ethnicity, many people provide extensive answers about their ancestor’s ethnicity and backgrounds. Likewise, the simple question, “how old are you?” often elicits a story about where they were born and a variety of evasive answers, so that a specific age is difficult to code. Asking their date of birth more often elicits a standard answer of month, day, and year—from which a specific numeric age can be calculated and assigned. Other relatively easy to code variables include their reported ZIP code of residence, the neighborhood where they reside, who the occupants of their households are, whether they are employed or not, and descriptions of their job type. Although many words may be available in the qualitative dataset, the answers given by most subjects to questions like these can be classified into categories for which numeric codes can be assigned. These quantitative codes—derived from qualitative data—are most useful in describing the characteristics of the persons sampled and/or providing basic descriptives of their background that may be relevant to analyst efforts to provide a written analysis of the topic. Typically such data are presented as percentages in a table accompanying the qualitative analysis of a topic (see Ream et al 2006).
Most qualitative research, however, is designed to illuminate phenomena that are not so easily transformed into numeric codes. On any given topic and in answers to interviewers’ questions, respondent stories may be highly differentiated and varied in content. The analyst must read through much textual data trying to locate and understand different themes or uniformity that emerge from respondent stories. This includes identifying textual material (appropriate quotes) that exemplify the themes (or categories) relevant for the written report. The analyst needs to define categories for the different themes and may assign some numeric value to each category. We refer to the process as semi-quantitative coding because the actual referent and the phenomena being so classified are diffuse and not widely understood or agreed upon in American culture. The assignment of such (numeric) semi-quantitative codes also grossly simplifies and possibly reifies the answers given by subjects. But if and when the coding scheme has been generated, the analytic staff can encode each respondent’s answer according to those themes, and classify the responses into numbers. Note that many subject files may be missing data or contain textual information that cannot be coded into any of the classifications. Whether and how to use these semi-quantitative codes will remain the task of the analyst developing a paper.
In the Katrina project, the investigators developed one or two semi-quantitative codes (or variables) for each question in the qualitative protocol. In Figure 5, the right side contains the semi-quantitative codes (a list of drugs) developed for this question (with codes 0-19). Well-trained coders read the text on the left and decide which codes on the right are mentioned in the text. They then enter the code number(s) in the box in the middle. If multiple codes are appropriate, the coder enters them separated by a space (in this example codes for cocaine (2) and heroin (4) are entered). While the coding process is relatively straightforward, it is very tedious and time consuming. To read and code the Mountain of Words recorded in the Katrina data base, it took several coders approximately half a year to systematically code the 106 subjects. When the coding process was completed, FileMaker Pro enabled export of these codes into an Excel file which was then converted for use in a quantitative program such as SPSS or SAS. This means that the semi-quantitative codes can now be analyzed quantitatively in conjunction with the extensive qualitative data. Future analyses and publications can provide both qualitative and quantitative analyses of these rich data.
One additional software package—gotomypc.com—now permits all project staff (with appropriate password protection) to access and read (and copy data) from the FileMaker Pro database while working from remote sites (e.g. at home, while traveling, or at offices in New Orleans or Houston) without needing to install FileMaker Pro on their remote computer. Thus, all project staff can work on/with the same database, often at the same time.
Creating quantitative protocols from ethnographic insights
One important outcome of qualitative research is to better inform the development of quantitative protocols to develop better information about phenomena of interest. That is, during the collection and analysis of qualitative data, important insights about social processes are uncovered. These insights can be used to develop detailed close-ended codes for inclusion in a quantitative protocol that can then be administered to many additional respondents. While all quantitative protocols will lack the rich detail obtained in qualitative data, quantitative data and results will provide better information about the numbers and proportions of subjects who were actively involved in that topic. With both quantitative and qualitative data, the analysts can write reports that are richer because they contain both numerically viable information and detailed understanding of phenomena.
As an example, one publication (Sifaneck et al 2007) from the Marijuana/Blunts project highlights how the following hypothesis was tested: Advantaged persons pay much more than the less advantaged for their marijuana in NYC. During the first year of research, ethnographers observed that marijuana retail sales units varied from $5 to $50 and more; both marijuana sellers and consumers reported substantial differences in quality and type of marijuana. No one knew the actual weights and price per gram of retail marijuana purchases; all lacked scientific precision. Ethnographic observations among marijuana smokers recruited from a variety of SES groups in NYC also suggested that white middle class consumers usually purchased “cubes” of high quality marijuana for $50 from concealed delivery services, while smokers in poor communities usually purchased “bags” of lower quality marijuana for $10 - $20. A special subproject was designed to collect both qualitative and quantitative data in a systematic fashion. Among their wide contacts, ethnographers were able to recruit marijuana buyers who allowed 99 purchases to be weighed. Each subject collaborated with the ethnographer to weigh a recent marijuana purchase on a digital scale (accurate to 100th of a gram), and then answered several questions about themselves and the product (gender, ethnicity, SES, dealer type, quality of marijuana, price paid). Independent of the subject’s quality rating, our experienced ethnographers observed and “graded” the quality of the marijuana purchase. Since the subject always retained possession of their marijuana, no legal issues arose. In the analysis of these data, Sifaneck (et al 2007) systematically described the differences (from qualitative data) between “designer” marijuana (usually grown hydroponically with flowering buds preserved by plastic cubes) and “commercial” marijuana (usually grown outdoors, compressed into bricks for transport, and sold in ziplock baggies). Furthermore, designer marijuana was almost exclusively purchased from private delivery services by middle and upper income persons—usually whites with good legal incomes and working in lower Manhattan. Commercial marijuana was sold by a range of distributors including street sellers, storefronts, and some private residences, but rarely by a delivery service. The quantitative analysis of the weights and price data indicate clear differences in price per gram between the purchases of commercial (average $8.20/g) and designer (average $18.02/g) marijuana. Designer purchases were often sold with brand names describing actual strains like Sour Diesel and White Widow; these were only sold in downtown markets to persons who paid $50 (or more) for 2.5 g in a cube. Commercial marijuana purchases were more likely to be made by blacks, uptown (Harlem), via street dealers, and in units of $5, $10, and $20 bags. Imported commercial types Arizona and Chocolate were only found uptown. Logistic regression indicated that the distinction between Designer and Commercial purchases was the most important factor in price paid per gram--more important than [but highly correlated with] gender, ethnicity, dealer type, or location in New York City.
Conclusions
This article provides an overview of the authors’ efforts and experience in efficiently managing Mountains of Words that are collected during large qualitative research projects like the three mentioned above. The planning, organizing, collecting, transcribing, storing, retrieving, coding, and analytic approaches described herein are necessary to facilitate the hard work associated with data analysis and report writing. While the developed procedures may be reasonably efficient and effective in locating and retrieving appropriate and highly relevant qualitative textual segments, the analyst retains the responsibility for all aspects of preparing an article for journal publication. After retrieving a query containing questions and answers that are highly relevant to a given topic, the analyst and research teams will often have to review the text in pages of quoted materials, searching for respondent statements that clearly indicate something about a given theme. Even after identifying such quoted materials, and arranging them according to thematic content, many other issues arise. The analyst will then need to review the relevant scientific literature to frame the key themes or ideas that emerge from ethnographic data, place the research methods and findings within the context of this literature, and write a coherent text or narrative incorporating these qualitative data into an article that makes an important scientific contribution to the published literature. Perhaps such information may provide important guidance for intervention agents and agencies. This article cannot provide more guidance about how to complete such a report.
Researchers planning ethnographic projects in the future will need to be more efficient in the use of limited financial resources. The technological advances for organizing and storing and retrieving data described above can help in this regard. Although the structured qualitative research approach has been useful in managing the mountains of words generated by our projects, we recognize that many other researchers have also been successful in accomplishing the major functions of planning, collecting, storing, and organizing qualitative analysis. Many have used other ethnographic programs, including Ethnograph, Atlas, Nudist, etc. Our experience has been that these programs have severe limitations for retrieving appropriate materials from a large quantity of words collected from respondents. Yet they may be very appropriate for specific types of analysis that ethnographers conduct. Indeed, a variety of other approaches for integrating qualitative and quantitative data analysis are available (MacMillan and Koenig 2004; Mangabeira, Lee and Fielding 2004; Miles and Huberman 1994).
A true relational data base such as FileMaker Pro, which we prefer, has a few drawbacks. The average social scientist will need to master it effectively or have the support of an experienced database programmer to create the appropriate FileMaker Pro database structure and create special reports as needed. Its capabilities are more successfully exploited when operating in a well-networked environment (like a university or major research institution) where well-trained database staff can assist. Nevertheless, the investigators and analysts need to invest a substantial amount of time learning how to use this program efficiently and effectively to conduct both the qualitative and semi-quantitative data analysis described above. Outside of the United States, investigators may also find that the procedures outlined above may prove useful in planning to conduct ethnographic research. The authors would be pleased to provide further elaboration about some of the issues addressed above, and can be contacted at the e-mail address above.
Acknowledgments
Preparation of this paper was supported by grants from the National Institute on Drug Abuse (R01 DA021783-03, 1R01 DA13690-05, R01 DA009056-12, 5T32 DA07233-24), and by National Development and Research Institutes. Points of view, opinions, and conclusions in this paper do not necessarily represent the official position of the U.S. Government or National Development and Research Institutes. The authors acknowledge with appreciation the many contributions to this research by Lawrence Duncan, Stanley Hoogerwerf, Joseph Kotarba, Edward Morse, Gwangi Richardson-Alston, Claudia Jenkins, and Vicki Zaleski.
Footnotes
The specific projects reported below, and all prior research, have been carefully reviewed by the institutional review board; further all persons participating as research subjects have given their informed consent prior to interview and are compensated for their information and time.
Active drug users and/or persons in recovery often lack many essential skills, have difficulty mastering the skill of writing rich field notes, and often leave before the project ends.
This paper receipt worked in all prior projects conducted in NYC. But paper receipts for field expenses are now giving way to similar electronic filing and documentation.
References
- Barry Christine A. Choosing qualitative data analysis software: Atlas/ti and Nudist compared. Sociological Research Online. 1998;3:1–16. [Google Scholar]
- Bazeley P. The evolution of a project involving an integrated analysis of structured qualitative and quantitative data: From N3 to Nvivo. International Journal of Social Research Methodology. 2002;5(3):229–243. [Google Scholar]
- Benoit Ellen, Randolph Doris, Dunlap Eloise, Johnson Bruce D. Code switching and inverse imitation among marijuana-smoking crack sellers. British Journal of Criminology. 2003;43(3):506–525. [Google Scholar]
- Brent Edward, Slusarz Pawel. “Feeling the beat”: intelligent coding advice from metaknowledge in qualitative research. Social Science Computer Review. 2003;21(3):281–303. [Google Scholar]
- Crowley C, Harré R, Tagg C. Qualitative research and computing: methodological issues and practices in using QSR NVivo and NUD* IST. International Journal of Social Research Methodology. 2002;5:193–199. [Google Scholar]
- Davis W Rees, Johnson Bruce D, Liberty Hilary, Randolph Doris. Street drugs: Obtaining reliable self and surrogate reports about the use and sale of crack, powder cocaine, and heroin. In: Cole Spencer., editor. Street Drugs: New Research. Hauppauge, NY: Nova Science Publishers; 2006. pp. 55–79. [Google Scholar]
- Dunlap Eloise, Johnson Bruce D. Ethical and legal dilemmas in ethnographic field research: Three case studies. In: Buchanan David., editor. Ethical and Legal Issues in Research with High-Risk Populations: Addressing Threats of Suicide, Child Abuse, And Violence. Washington, DC: American Psychological Association; 2006. [Google Scholar]
- Dunlap Eloise, Benoit Ellen, Sifaneck Stephen J, Johnson Bruce D. Social constructions of dependency by blunts smokers: Qualitative reports. International Journal of Drug Policy. 2006;17:171–182. doi: 10.1016/j.drugpo.2006.01.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dunlap Eloise, Golub Andrew, Johnson Bruce D. The lived experience of welfare reform in drug-using welfare-needy households in inner-city New York. Journal of Sociology and Social Welfare. 2003a;30(3):39–58. [PMC free article] [PubMed] [Google Scholar]
- Dunlap Eloise, Golub Andrew, Johnson Bruce D. Girls’ sexual development in the inner city: From compelled childhood sexual contact to sex-for-things exchanges. Journal of Child Sexual Abuse. 2003b;12(2):73–96. doi: 10.1300/J070v12n02_04. [DOI] [PubMed] [Google Scholar]
- Dunlap Eloise, Johnson Bruce D, Morse Edward. Illicit drug markets among New Orleans Evacuees before and soon after hurricane Katrina. Journal of Drug Issues. 2007;37(4):981–1006. doi: 10.1177/002204260703700411. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dunlap Eloise, Johnson Bruce D, Sanabria Harry, Holliday Elbert, Lipsey Vickie, Barnett Maurice, Hopkins William, Sobel Ira, Randolph Doris, Chin Ko-lin. Studying crack users and their criminal careers. In: Newman William M, Boudreau Frances A., editors. Understanding Social Life: A Reader in Sociology. Minneapolis: West Publishing; 1993. pp. 43–53. [Google Scholar]
- Dunlap Eloise, Johnson Bruce D. Gaining access to hidden populations: Strategies for gaining cooperation of sellers/dealers in ethnographic research. In: De La Rosa Mario, Segal Bernard, Lopez Richard., editors. Conducting Drug Abuse Research with Minority Populations: Advances and Issues. Wilmington, PA: Hayworth Press; 1998. [Google Scholar]
- Fielding Nigel G, Lee Raymond M. Using Computers in Qualitative Research. Newbury Park, CA: Sage; 1991. [Google Scholar]
- FileMakerPro. 2008 http://www.filemaker.com/
- Gerbert B, Caspers N, Moe J, Clanon K, Abercrombie P, Herzig K. The mysteries and demands of HIV care: Qualitative analyses of HIV specialists’ views on their expertise. AIDS Care. 2004;16:363–376. doi: 10.1080/09540120410001665367. [DOI] [PubMed] [Google Scholar]
- Johnson Bruce D, Bardhi Flutura, Sifaneck Stephen J, Dunlap Eloise. Marijuana argot as subculture threads: Social constructions by users in New York City. British Journal of Criminology. 2006;46(1):46–77. [Google Scholar]
- Lewis Carla, Johnson Bruce D, Golub Andrew L, Dunlap Eloise. Studying crack abusers: Strategies for recruiting the right tail of an ill-defined population. Journal of Psychoactive Drugs. 1992;24(3):323–336. doi: 10.1080/02791072.1992.10471657. [DOI] [PubMed] [Google Scholar]
- MacMillan Katie, Koenig Thomas. The wow factor: Preconceptions and expectations for data analysis software in qualitative research. Social Science Computer Review. 2004;22(2):179–186. [Google Scholar]
- Mangabeira Wilma C, Lee Raymond M, Fielding Nigel G. Computers and Qualitative Research: Adoption, Use, and Representation. Social Science Computer Review. 2004;22:167. [Google Scholar]
- Mann Chris, Stewart Fiona. Internet Communication and Qualitative Research: A Handbook for Researching Online. Sage Publications; 2000. [Google Scholar]
- Manwar Ali, Dunlap Eloise, Johnson Bruce. Qualitative data analysis with HyperText: A case study of New York City crack dealers. Qualitative Sociology. 1994;17(3):283–292. doi: 10.1007/BF02422256. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miles Matthew B, Huberman Michael A. Qualitative data analysis: An expanded sourcebook. Thousand Oaks: Sage Publications; 1994. [Google Scholar]
- Muhr Thomas. ATLAS ti Qualitative Software Package. Berlin: Scientific Software; 2005. [Google Scholar]
- Ream Geoffrey, Johnson Bruce D, Sifaneck Stephen, Dunlap Eloise. Distinguishing blunts users from joints users: A comparison of marijuana use subcultures. In: Cole Spencer., editor. Street Drugs: New Research. Hauppauge, NY: Nova Science Publishers; 2006. pp. 245–273. [Google Scholar]
- Richards Tom. An intellectual history of NUD* IST and NVivo. International Journal of Social Research Methodology. 2002;5:199–214. [Google Scholar]
- Seidel John, Friese S. Ethnograph v 5. 0: A Program for the Analysis of Text Based Data.”. Colorado Springs: Qualis Research Associates; 1998. [Google Scholar]
- Sifaneck Stephen J, Ream Geoffrey, Johnson Bruce D, Dunlap Eloise. Retail marijuana purchases in designer and commercial markets in New York City: Sales units, weights, and prices per gram. Drug and Alcohol Dependence. 2007;90S:S40–S51. doi: 10.1016/j.drugalcdep.2006.09.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Williams Terry, Dunlap Eloise, Johnson Bruce D, Hamid Ansley. Personal safety in dangerous places. Journal of Contemporary Ethnography. 1992;21(3):343–374. doi: 10.1177/089124192021003003. [DOI] [PMC free article] [PubMed] [Google Scholar]