

Abstract
Regression quantiles can be substantially biased when the covariates are measured with error. In this paper we propose a new method that produces consistent linear quantile estimation in the presence of covariate measurement error. The method corrects the measurement error induced bias by constructing joint estimating equations that simultaneously hold for all the quantile levels. An iterative EM-type estimation algorithm to obtain the solutions to such joint estimation equations is provided. The finite sample performance of the proposed method is investigated in a simulation study, and compared to the standard regression calibration approach. Finally, we apply our methodology to part of the National Collaborative Perinatal Project growth data, a longitudinal study with an unusual measurement error structure.
Keywords: Correction for attenuation, Growth curves, Longitudinal data, Measurement error, Quantile regression, Regression calibration, Regression quantiles
1. INTRODUCTION AND MOTIVATION
Quantile regression, proposed by Koenker and Bassett (1978), has emerged as an important statistical methodology. By estimating various conditional quantile functions, quantile regression complements the focus of classical least squares regression on the conditional mean and offers a systematic strategy for examining how covariates influence the entire response distribution. It has been used in a wide range of applications including economics, biology, ecology, and finance.
Often, the covariates of interest, here denoted by x, are not observable and instead are measured with error. It is well known that such errors can sometimes lead to substantial attenuation of estimated effects in mean regression (Carroll et al. 2006). As we illustrate in Section 5, the regression quantiles can also be seriously biased when the covariates contain measurement errors. This paper aims at developing statistical methods and theory that yield consistent quantile estimation in the presence of covariate measurement error.
There is some work on measurement error in quantile regression. He and Liang (2000) considered the case that errors in the response y and x are independent and follow the same symmetric distribution. Their approach yields consistent estimates. However, the equal distribution assumption is very strong and difficult to verify in practice. Chesher (2001) used a small error variance approximation approach, which does not require distributional assumptions on the response y. However, it does not yield consistent estimation, and the calculation is difficult when the error distribution depends on the covariates. Hu and Schennach (2008) and Schennach (2008) proved nonparametric identification of a nonparametric quantile function under various settings where there is an instrumental variable measured on all sampling units. There are many differences between our approach and theirs in terms of generality: our model is less general. There are also differences in implementation: they use sieve-based estimation, which requires choice of tuning constants such as the number of sieve terms as well as constraints on the sieve basis functions in order to estimate densities such as that of the response given the true covariates; our method relies on a simple, straightforward but novel EM-type implementation.
We consider a family of linear quantile regression models
| (1) |
where yi is the response for the ith individual, xi is its corresponding covariate, and εi is the error term, whose τ th quantile is zero conditional on xi. The distribution of εi may depend on xi. Moreover, we assume that Model (1) holds for all the τ’s, that is, all the conditional quantiles are linear in xi with quantile-specific coefficient β0,τ. A special case of Model (1) is the well-known location scale model,
| (2) |
where εi ~ Fε is independent of xi. This location-scale model implies that the τ th conditional quantile coefficient .
An outline of this paper is as follows. Section 2 describes the basic methodology, while in Section 3 we describe the algorithm in detail. Section 4 gives asymptotic theory. Section 5 describes a simulation study. In Section 6 we apply our methodology to the National Collaborative Perinatal Project (NCPP) investigating the effect of body size in childhood on body size in adulthood. Section 7 gives concluding remarks. Technical details are given in an Appendix.
2. SEMIPARAMETRIC JOINT ESTIMATING EQUATIONS
2.1 Preliminaries and the Case That x Is Observed
Suppose {yi, xi} is a random sample from Model (1) with sample size n, where x = (x1 … xp)⊤ is a p-dimensional covariate. Then an estimating equation for β0,τ can be written as
| (3) |
where Ψτ(u) = τ − I{u < 0}, I{·} denotes the indicator function, and βτ ∈ Rp is a p-dimensional unknown coefficient vector. Actually, of course, the indicator function means that (3) may not have an exact zero, and what instead is done is to recast the issue as a minimization problem, and then use linear programming to solve this minimization problem. Thus, (3) is a slight abuse of notation, but since everything else involving observed data is an estimating equation that will have a zero, we will use the estimating equation nomenclature. The solution of equations (3) is proven to be a consistent estimate of β0,τ. When x is measured with error and instead only a surrogate wi is observed, naively replacing xi by the observed wi will result in substantial bias. We construct new estimating equations which take the measurement errors into account, and result in consistent estimation of β0,τ. The new estimating equations take the form
| (4) |
where f (x|yi, wi) is the conditional density of x given the observed (yi, wi). The integration in (4) makes the function continuous in its argument. The summand of (4) is Ex{Ψτ (y − x⊤βτ)x|y, w}, the conditional mean of the original score function given the observed y and w. Letting Ψnew(y, w, βτ) = ∫x Ψτ(y − x⊤βτ)x · f (x|y, w) dx, it is easy to show that Ey[Ψnew(y, w, β0,τ)|w] ≡ 0 for all w. Therefore, Ψnew(y, w, βτ) is an unbiased estimating function, that is, has mean zero, and will be the basis for constructing estimating equations. We further impose the usual surrogacy condition that f (y|x, w) = f (y|x), which means the contaminated w does not provide additional information about the response y if the true covariate x is known.
2.2 Two Technical Challenges
Although Equation (4) provides valid estimating equations for the coefficients of interests, β0,τ, solving such equations is challenging, mainly due to the following two reasons. First, unlike the classical approaches in mean regression, the conditional density f (x|yi, wi) does not have any prespecified parametric form. To get a better understanding of this, we can rewrite the conditional density f (x|yi, wi) under the surrogacy condition by
| (5) |
In the spirit of quantile regression, we leave the error distribution of εi in Model (1) unspecified. Therefore, f (y|x), and consequently, f (x|yi, wi) does not have a parametric form. However, we get around this problem by noting that we can link the conditional density f (y|x) to Model (1) by the following equation:
| (6) |
where τy = {τ ∈(0, 1): x⊤β0(τ) = y}, and β0(τ) is the true quantile coefficient viewed as a function of τ. To make the presentation clear, we note that β(τ) = (β1(τ), …, βp(τ))⊤ ∈ Rp × (0, 1) is p-dimensional quantile coefficient process on the interval (0, 1), and βτ = (βτ,1, …, βτ,p)⊤ ∈ Rp is its evaluation specifically at quantile level τ. They are unknown parameters in the estimating equations, while the previously defined β0(τ) and β0,τ are the corresponding true values.
Equation (6) is derived from the fact that the conditional quantile function x⊤β0(τ) is the inverse function of the conditional distribution function F(y|x). The density function is hence the reciprocal of the first derivative of the quantile function at the corresponding quantile level. This formulation reveals the second challenge in solving the estimating equations—the conditional density f (x|yi, wi) involves the entire quantile coefficient process β0(τ). In other words, the estimating equations (4) need to be solved jointly for all the τ’s, even if one is interested in a particular quantile level τ. Following the arguments above, we extend (4) to a semiparametric joint estimating equations
| (7) |
where f {x|yi, wi; β(τ)} = f {yi|x; β(τ)}f (x|wi)/∫xf{yi|x; β(τ)}f (x|wi) dx, and f {yi|x; β(τ)} is the conditional density function of yi given x that is induced by quantile function x⊤β(τ), that is, f {yi|x; β(τ)} = F′{yi|x; β(τ)} and F{yi|x; β(τ)} = inf{τ ∈ (0, 1): x⊤β(τ) > y}. We use f {x|y, w; β(τ)} and f {y|x; β(τ)} to indicate their dependence on the entire unknown quantile process β(τ). The aforementioned true densities f (x|y, w) and f (y|x) can be written as f (x|y, w) = f {x|y, w; β0(τ)} and f (y|x) = f {y|x; β 0(τ)}. We note that the estimating function of (7), ∫x[τ − I{y − x⊤β(τ) < 0}] · x · f {x|y, w; β(τ)} dx, is a function of τ, and its conditional mean at β0(τ),
| (8) |
for all the τ and w, the estimating equations (7) are hence unbiased joint estimating equations. On the other hand, we say that the estimating equations (7) are semiparametric, since the conditional quantile function of y is a parametric function of x at given τ, but the coefficients β(τ) are nonparametric functions of τ. The estimating equations (7) involve the infinite dimensional parametric space β(τ) ∈ Rp × (0, 1).
2.3 The Continuous Case
To estimate β0(τ), we assume that they are smooth functions on (0, 1), and approximate β(τ) in (7) by natural linear splines with common internal knots Ω = {ε = τ1 < τ2 < ··· < τkn = 1 − ε}. Let
be the set of quantile coefficients at quantile levels Ω. We define a natural linear spline 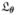 (τ): [0, 1] → Rp as p continuous, piecewise linear functions on [0,1] which satisfies (τk) = βτk, and is subject to the constraints that
. With a sufficient numbers of knots, that is, kn → ∞ and ε → 0, the difference between β(τ), and its spline approximation (τ) is negligible (de Boor 2001). Consequently, we also approximate the conditional density function f {x|yi, wi; β(τ)} by
(τ): [0, 1] → Rp as p continuous, piecewise linear functions on [0,1] which satisfies (τk) = βτk, and is subject to the constraints that
. With a sufficient numbers of knots, that is, kn → ∞ and ε → 0, the difference between β(τ), and its spline approximation (τ) is negligible (de Boor 2001). Consequently, we also approximate the conditional density function f {x|yi, wi; β(τ)} by
| (9) |
where
In other words, we approximate the quantile function x⊤β(τ) by its spline approximation x⊤ (τ). In this way, we only need to solve the estimating equations (7) for the grid of internal knots, τk’s. We hence reduce the infinite dimensional estimating equations (7) to a finite dimensional case
| (10) |
where Ψ(yi − x⊤θ) = {Ψτ1(yi −x⊤βτ1),…, Ψτkn(yi − x⊤ × βτkn)}⊤ is a kn-dimensional vector, and ⊗ stands for Kronecker product. We note that Ψ(yi − x⊤ θ) ⊗ x is a kn × p dimensional vector, which consists of kn sets of original estimating functions {Ψτk(yi − x⊤βτk)x}k = 1,…,kn on quantile levels Ω; while f (x|yi, wi; θ) is the approximated conditional density of x given the observed (yi, wi). We call (10) the working estimating equations, which can be viewed as a spline approximation of the unbiased semiparametric joint estimating equations defined in (7). Solving such equations directly is not easy since they involve integration. In the next section, we outline an iterative EM-type algorithm to obtain the solution of (10).
3. ESTIMATION ALGORITHM
3.1 Preliminaries
The crux of all measurement error problems which have a likelihood flavor is the estimating of the distribution of x given w. Our method, as well as many others, depends on being able to estimate this distribution reasonably well. In practice, this distribution needs to be estimated, and estimating the distribution of x given w depends on the context of the problem.
In nutritional epidemiology, it is fairly common to use parametric and semiparametric methods to transform the observed w-data to normality, and to then assume that the measurement error model is additive with x normally distributed; see Nusser et al. (1990, 1997a, 1997b). In other cases, with replicates of the observed but error-prone predictor, the transformation is to normality and homoscedasticity of the measurement errors (Eckert, Carroll, and Wang 1997), with a flexible model for the distribution of x. See also Carriquiry (2003) for other methods. In the simulation study presented later section, we used this additive transformation model as the basis for estimating f (x|w).
In some instances, when it can be assumed that w = x + u where there are replicated values of w, the distribution of the measurement errors u as well as the latent variable x can be estimated nonparametrically (Li and Vuong 1998; Delaigle, Hall, and Meister 2008), and hence so too can the distribution of x given u be estimated nonparametrically. In the next subsection, we first assume that the crucial distribution is known, and then show how the method is modified when it is estimated. We conjecture that interesting and possibly not parametric-rate properties arise when the distribution of x given w is estimated non-parametrically.
3.2 Basic Algorithm
In this section, we outline an iterative algorithm to obtain a solution of the working estimating equations (10). We will establish in the next section the consistency property of the resulting estimates. The algorithm can be viewed as an nonparametric analogue of the EM algorithm, since the basic components involve iteratively updating the conditional distribution f (x|yi, wi, θ) and quantile coefficients θ. However, we do not have specific likelihood functions to work with as in classical EM algorithms. Let ν be the indicator of iteration steps, the main steps of the algorithm are the following:
Step 1. Set initial values of θ based on uncorrected quantile regression.
-
Step 2. Update the distribution f (ν)(x|yi, wi) based on the , that is,where
-
Step 3. Estimate based on the new estimating function Ψnew(yi, wi;βτ) evaluated at f (ν)(x|yi, wi). In order to perform this step, we have to make a numerical approximation to an integral. We do this via translating the problem into a weighted quantile regression problem. Let x̃i = (x̃i,1, x̃i,2, …, x̃i,m) is a fine grid of possible xi values, akin to a set of abscissas in Gaussian quadrature. Then the new sample estimating equations are
which is a weighted quantile regression with response yi over the covariates x̃i,j with weights f (ν)(xi,j|yi, wi).
Note that the original quantile regression estimating function Ψτ(y − x⊤βτ)x can be viewed as the first derivative of the logarithm of an asymmetric Laplace distribution (Koenker and Machado 1999)
with respect to βτ. The convergence of the proposed algorithm follows from classical results on the EM algorithm (McLachlan and Krishnan 2008, page 19).
The estimation algorithm involves a turning parameter, the number of quantile levels. The necessary number of quantile levels depends on the underlying distribution of y. In our numerical investigations, we found 40 evenly spaced quantile levels worked well even for heavy-tail distributions such as the log-normal. However, when the dimension of x exceeds 2, evaluating f (ν)(x|y, w) on a fine grid of x in Step 3 could be computationally undesirable. Instead, we can simulate x̃i,j from the conditional density of x given w to ensure a sufficient number of x̃i,j with high densities, and then use importance weights to adjust the bias due to the difference between f (ν)(x|y, w) and f (x|w). This Monte Carlo integration approach can be implemented to reduce the computational burden. We delay until Section 6 the details of this modified algorithm implementing MC integration.
3.3 When the Distribution of x Given w Is Estimated
Denoting f̃ (x|w) as the estimated conditional distribution of x given w, we further approximate the working estimating equations (10) by
| (11) |
in which f̃ (x|yi, wi; θ) is the conditional distribution of x given yi and wi with f̃(x|wi) and θ. The working estimating equations (11) involve two approximations: (a) β(τ) is approximated by a linear spline; and (b) the conditional density f (x|w) is approximated by its estimator. The estimation algorithm remains unchanged except that we need to replace the f (x|wi) in Step 2 by f̃(x|wi). Once f (x|w) is estimated, it stays the same in all the iterations. The iteration converges to the solution of the approximated working estimation equations (11), which we denote as θ̂n. Let β̂n(τ) = 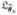 (τ) be the natural linear spline extended from θ̂n. We show in next section that β̂n(τ) is a consistent estimator of β0(τ) under certain conditions, especially that f̃ (x|w) is a consistent estimator of f (x|w), kn → ∞ and knn−1 → 0.
(τ) be the natural linear spline extended from θ̂n. We show in next section that β̂n(τ) is a consistent estimator of β0(τ) under certain conditions, especially that f̃ (x|w) is a consistent estimator of f (x|w), kn → ∞ and knn−1 → 0.
4. ASYMPTOTIC PROPERTIES
For a vector x, we use ||x|| to denote its Euclidean norm, and use |x| for its componentwise absolute values. By |a| < 1, we mean that each component of a is bounded by ±1.
In this section, we first list and discuss sufficient conditions for the consistency of β̂n(τ), with the main result summarized in Theorem 1. We first introduce the conditions on the covariates (x, w).
Assumption 1
The covariate x has bounded support 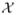 , and:
, and:
the conditional density f (x|w) is bounded away from infinity for all (x, w);
- there exists a consistent estimator f̂(x|w) of f (x|w), such that, ∀x,
Remark 1
Assumption 1(i) is quite mild. The assumption that x has compact support is needed in the proof, but we think the reason is more to do with the method of proof than to the actual requirement. Our simulations does not obey this restriction, although due to the nature of the data, our empirical example does obey the restriction.
Recall that β0(τ) is the true quantile coefficient function, and β0,τ is the true value at quantile level τ, then for any x ∈ , x⊤β0(τ) defines a conditional quantile function. We further define a functional
, which is the density of y given x at the τ th quantile. We call this the conditional quantile density function. Its reciprocal is known as the sparsity function (Welsh 1988 and Koenker and Xiao 2004). With these definitions, we now introduce the smoothness conditions on β0(τ).
Assumption 2
The true coefficient β0(τ) are smooth functions on (0, 1), and for any x ∈ ,
0 < hx(τ) < ∞ and limτ→0 hx(τ) = limτ→1 hx(τ) = 0;
- there exist constants M and ν1,ν2 > −1 such that its first derivative is bounded by
(12)
Remark 2
The first condition of Assumption 2 implicitly assumes that the conditional density f (y|x) is continuous, bounded away from zero and infinity, and diminishes to zero as τ goes to 0 and 1. The assumption that 0 < hx(τ) < ∞ is fairly standard. The equivalent version of this assumption is that 0 < f (εi) < ∞, and this is commonly assumed in the quantile regression literature; see, for example, Portnoy (2003) and Koenker (2004). The second condition is on the tail behavior of f (y|x), noting that determines how smooth the density function diminishes as the quantile level goes to the two ends. The condition (12) is fairly general, and covers a wide range of distribution families, such as exponential, Gaussian, and Student t distributions.
We now make two further definitions:
-
Recall that is defined at (4), and let be it expectation at the τ th quantile.
Recall that Sn(θ) is defined at (10). Let Sn(βτ) be the p× 1 subset of Sn(θ) that corresponds to the τ th quantile, and let S(βτ) = E{Sn(βτ)} be its expectation.
We make the following assumptions.
Assumption 3
The true coefficient β0,τ is the unique solution to the equation S0(βτ) = 0, for all τ ∈ (0, 1), and there exist a that uniquely solves the equation S(βτ) = 0, for all τ ∈ (0, 1).
Assumption 4
There exists a compact set Θ ∈ Rp, such that
Remark 3
Assumption 3 is the identifiability condition that is commonly assumed in the quantile regression literature, while Assumption 4 is used to ensure that the solution to the approximated working estimating equations is confined to a compact set Θ, which is a standard condition for M and Z estimators.
Moreover, if we are willing to assume that the difference between the true coefficient process β0(τ) and its spline approximation is negligible, that is, β0(τ) are linear natural splines with a fixed number of knots K, we obtain the asymptotic normality of θ̂n. The results are summarized in Theorem 2 below. Additional assumptions for asymptotic normality are listed as follows.
Assumption 2*
The coefficients β0(τ) are continuous linear splines on [0, 1] with internal knots Ω= {0 < τ1 < τ2 < ··· < τK<1}.
Let Ψnew(yi, wi, θ) = ∫xΨ(yi − x⊤ θ) ⊗ x · f (x|yi,wi; θ) dx, then . We further denote Vn = var{Sn(θ0)} and . We make the following additional assumptions.
Assumption 5
There exists a nonnegative definite matrix V such that Vn → V as n → ∞.
Assumption 6
There exists a positive definite matrix D, such that Dn → D in probability as n → ∞.
Theorem 1
Under Assumptions 1–4, for kn → ∞, knn−1 → 0, β̂n (τ) is a consistent estimator of β0(τ), that is,
Theorem 2
Under Assumptions 1, 2*, and 3–6,
in distribution as n → ∞, where Σ = D−1VD−1.
The proofs of the two theorems are provided in the Appendix.
5. SIMULATION STUDY
5.1 Model Setup
To understand the effects of measurement errors and to demonstrate the performance of our method, we used a location-scale quantile regression model
| (13) |
where εi = Normal(0, 1). It follows that the actual quantile function of y given x is βτ, 1 + βτ, 2x with βτ, 1 ≡ 0 and βτ, 2 = 2 + 0.5Φ−1(τ). We further assume that the xi’s are measured with error following one of two models:
Model I (Additive).
Model II (Multiplicative).
In Model I, w and x follow normal distributions, while in Model II, they follow log-normal distributions. We kept the variances of x in Model I or log(x) in Model II and ε to be 1, so that the two models have a constant signal-noise ratio. For each model, we assumed the measurement error Ui follows a normal distribution with mean 0 and variances and 0.5. These choices correspond to moderate and larger attenuation which equal R = 4/5 and R = 2/3, respectively.
Regression model scale
It is important to note that the model (13) for the quantile regression function is in the original scale of xi. In Model II, we are merely stating that the measurement errors are multiplicative.
5.2 Estimation of f (x|w)
To estimate the conditional density of x given w, we assume that the wi’s were observed from the following model:
| (14) |
where the function Λ(·) is the Box–Cox transformation function, that is, Λ(Z, λ) = log(Z) if λ= 0 and = (Zλ − 1)/λ otherwise.
The true power parameters λ in Models I and II are 1 and 0, respectively, but are assumed unknown. We estimate λ by maximizing the log-likelihood function of the wi’s, that is,
where Λ̄ is the sample mean. This is a transformation that tries to make Λ (w, λ) = Normal(μ, σ2). For understanding the measurement error, we assume that there exists a subset of 100 replicates (wi,1, wi,2) for estimating . With replicates, the variance can be estimated by half of the sample variance of the difference of the transformed wi,1 and wi,2, that is, Λ(wi,1, λ̂) − Λ(wi,2, λ̂), so that
With the estimated λ̂ and σ̂2, the estimated f (x|w) is
| (15) |
where Φ(·) is the density function of the standard normal distribution, and μ̂ and ŝ are the estimated conditional mean and standard deviation of the transformed Λ(x, λ̂) given the observed w. Let Λ̄w and be the sample mean and variance of Λ(wi, λ̂). Then is an unbiased estimator of the variance of x. It then follows that μ̂ and ŝ in the density (15) are
5.3 Estimators Considered
We performed 100 simulations with n = 500 for each of these models, and computed four estimators:
the naive estimator that replaces x by w;
the regression calibration estimator, which replaces x by an estimate mean of x given w via the linear regression of x on w, or log(x) on log(w). Specifically, we replace xi in Model I by (1 − R̂)w̄ + R̂wi, and replace xi in Model II by , where R̂ and and are estimated based on the set of replicates. When applied to ordinary linear regression, the regression calibration estimator is consistent for estimating (β1, β2), that is, for the mean regression curve;
our method with 40 evenly spaced quantile levels (internal knots), but assuming f (x|w) is known;
our method with 40 evenly spaced quantile levels (internal knots), and the conditional density f (x|w) is estimated based on Model (14).
When applying the proposed estimation algorithm, we chose Ω to be a set of 40 evenly spaced quantile levels, the convergence criterion is set to be the average of |θ̂(ν) − θ̂(ν−1)| < 0.01, and the maximum iteration steps is 50. In approach (d), the power λ is estimated using the wi’s, while the variance is estimated using the 100 pairs of replicates ( ).
5.4 Simulation Results and Discussion
In Figures 1 and 2, we present the resulting estimated slope (Figure 1) and intercept (Figure 2) functions from the four approaches, both Models I and II and with attenuation R = 4/5. The top panel plots the mean of the estimated slope functions with the red solid line representing the true slope function. The middle panel illustrates the sample distributions of β̂τ,(k) − βτ from approaches (a)–(d) under Model I at selected quantile levels 0.1, 0.5, and 0.9, where β̂τ,(k) is the estimated coefficient from the kth Monte Carlo sample, and βτ is the true value. The bottom panel is its counterpart for Model II. As expected, the naive estimator (dotted gray lines) is badly biased for both normally distributed x and skewed x. The regression calibration estimator (dashed gray lines) worked fairly well for normally distributed x, however, it is badly biased for skewed x. Such bias is more evident under more severe contamination. The proposed method successfully corrected the bias, and brings the estimates fairly close to the true values with all the quantile levels. Moreover, the difference between the estimates using the true f (x|w) and the estimated f (x|w) are small. Similar results (not presented in this paper) were obtained for the more severe attenuation rate R = 2/3.
Figure 1.

Comparison of the estimated slope coefficients from methods (a)–(d) under the contamination rate R = 0.8. In sub-figure (a), the black curve is the true coefficient function. The gray solid and dashed lines are the estimated coefficient functions from the proposed method using the true and estimated f (x|w) respectively. The gray dotted line is the estimated coefficients from the naive method; the gray dash-dotted line is that of the regression calibration method. Note that the box plots are box plots of biases.
Figure 2.

Comparison of the estimated intercept coefficients from methods (a)–(d) under the contamination rate R = 0.8. In sub-figure (a), the black curve is the true coefficient function. The gray solid and dashed lines are the estimated coefficient functions from the proposed method using the true and estimated f (x|w), respectively. The gray dotted line is the estimated coefficients from the naive method; the gray dash-dotted line is that of the regression calibration method. Note that the box plots are box plots of biases.
5.5 Simulation When the Estimated f (x|w) Deviates From the True Function
In the previous simulation study, the conditional density f (x|w) is estimated in the correct model setting. The mean difference between the estimates from the true density and the estimated density is rather small. It is of interest to assess how sensitive the method is to the estimation of f (x|w). To do this, we replace the density function of U in both Models I and II by a t distribution with 3 degrees of freedom, that is:
Model I*.
Model II*.
The scalar is used to maintain the same error variance as in the previous simulation. We repeated exactly the same estimation procedure (d) assuming U is Gaussian. Consequently, the estimated f (x|w) deviates systematically from the underlying true density. In Figure 3, we plot the resulting estimated slope functions under misspecified Models I and II with attenuation R = 4/5, and compare them with the naive and regression calibration estimates. The solid dark-gray lines are estimated coefficients from the misspecified f (x|w), and the long-dashed dark-gray lines are those from the correctly estimated ones. As expected, the estimated coefficients from the misspecified f (x|w) do exhibit some modest bias, but still much less biased than the naive estimates (the dotted light-gray lines) and those from regression calibration (the dot-dashed light-gray lines).
Figure 3.

Comparison of the estimated slope coefficients when the measurement error model is misspecified with moderately contaminated rate R = 4/5. The subfigure on the left compares the estimated slope functions of Model I, while the one on the right compares those Model II. In all the subfigures, the sold black lines are the true slope coefficients. The solid dark-gray lines are estimators using the proposed method but with the misspecified f (x|w), and the dashed dark-gray ones are estimators using the proposed method for the correct model. As a comparison, the dotted light-gray lines are the naive estimates and the dot-dashed light-gray ones are from regression calibration.
6. APPLICATION
6.1 Data, Model, and Algorithm
We applied our method to part of the National Collaborative Perinatal Project (NCPP; Terry, Wei, and Essenman 2007). The data set included 232 women who were born at Columbia Presbyterian Medical Center from 1959–1963. Their growth measurements, weight, and height were carefully taken by clinical researchers at birth and at 4 months, 1 year, and 7 years. These ages are known to be critical times for growth. The public health researchers were interested in studying the long-term impact of early growth on adult body size. We consider therefore the quantile regression model
| (16) |
where Y is an individual subject’s body mass index (BMI) at age 20, 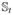 stands for her weight at age t, and (t1, t2, t3, t4) are the four target ages at birth, 4 months, 1 year, and 7 years.
stands for her weight at age t, and (t1, t2, t3, t4) are the four target ages at birth, 4 months, 1 year, and 7 years.
However, these subjects did not in fact all attend clinic at exactly these scheduled times. Since children grow relatively quickly especially at young ages, one or two week’s deviation from the target time may result in substantial measurement error in St. If we pretend the actual observation times are the true ones, the coefficient estimates will therefore be biased, as we have demonstrated in our simulations. We apply our method to obtain consistent estimation of the βτ’s.
Model for f (x|w)
Suppose 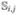 is the jth measurement of the ith subject taken at age ti,j. We assume that they are observed from a underlying weight path of the ith subject, denoted as
is the jth measurement of the ith subject taken at age ti,j. We assume that they are observed from a underlying weight path of the ith subject, denoted as 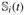 . Let T0 = (t1, t2, t3, t4) be the set of target ages; and Ti = (ti,1, ti,2, ti,3, ti,4) be the actual measurement ages of the ith subject. Note that
. Let T0 = (t1, t2, t3, t4) be the set of target ages; and Ti = (ti,1, ti,2, ti,3, ti,4) be the actual measurement ages of the ith subject. Note that 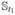 is birth weight and is accurately measured at birth, that is, ti,1 ≡ t1. We have three covariates of interest that are unobserved, denoted as xi = {
is birth weight and is accurately measured at birth, that is, ti,1 ≡ t1. We have three covariates of interest that are unobserved, denoted as xi = {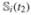 ,
, 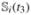 ,
, 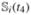 }⊤. In addition, we denote wi =
}⊤. In addition, we denote wi = 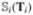 = {
= {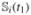 ,
, 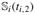 ,
, 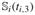 ,
, 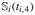 }⊤ as the actual weights at birth and the individual measurement times ti,2, ti,3, and ti,4. Finally, we estimate the density f (xi|wi) by the following linear mixed model:
}⊤ as the actual weights at birth and the individual measurement times ti,2, ti,3, and ti,4. Finally, we estimate the density f (xi|wi) by the following linear mixed model:
| (17) |
We further assume that
Model (17) assumes that the logarithm of is a Gaussian process with mean μi(t) = αi,0 + αi,1t + αi,2t2 + αi,3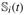 and variance
. The covariance between and
and variance
. The covariance between and 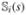 is (1, t, t2, )Σα (1, s, s2, )⊤. The log-transform on
is (1, t, t2, )Σα (1, s, s2, )⊤. The log-transform on 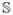 is used due to the skewness of weight.
is used due to the skewness of weight.
It then follows that xi has a log-normal distribution, that is,
| (18) |
where
Algorithmic Details
We choose to be a set of 40 evenly spaced quantile levels. The initial estimate is obtained by regressing Y over the observed weights assuming the all the ti,j = tj, the target ages. Note that x is three dimensional in this example, so evaluating f (xi|wi) on a three-dimensional grid can be computationally undesirable. Consequently, we modify Step 3 in our iterative algorithm by using an importance sampling strategy as follows:
Step 3′(a). For each subject i, generate m = 500 x̃i,j’s from the log-normal distribution in (18), the conditional distribution of xi given wi.
- Step 3′(b). Calculate the importance sampling weights forx̃i,j as
- Step 3′(c). Estimate ’s by solving the following weighted estimating equations:
We used the same convergence rule as in the simulation study.
6.2 Results
The resulting coefficient estimates are presented in Figure 4 (the solid lines). In Figure 4, for comparison we also plot the estimated coefficients from two alternative approaches. The long-dashed lines are the estimated coefficients from the original uncorrected quantile regression. Another possible approach to correct for measurement error is to fit an interpolation spline for each individual growth path, and use its fitted values at the target ages (t2, t3, t4) as x, the true weights of interests. This approach smooths individual paths to reduce the measurement errors, and has been used in Terry, Wei, and Essenman (2007). The resulting coefficient estimates using this interpolation approach are displayed in Figure 4 as short-dashed lines. We note that the estimated coefficients from our method differ considerably from the naive estimator, especially the coefficients for weights at 1 year and 7 years. In contrast, the fits from the interpolation approach agree with the naive estimators fairly well. Comparing with our estimates, both the naive estimates and the interpolation approach appear to underestimate the impact of weight at age 4 months at upper quantiles, but overestimate the impact of weights at 1 and 7 years at upper quantiles. We performed a bootstrap analysis and found that the differences between two estimates for weight at 1 year are significantly different from each other at quantile levels from 0.71 to 0.85 (as presented in Table 1). The observed differences for weight at 7 years are comparably smaller, and not of statistical significance.
Figure 4.

Estimated coefficients in the NCPP study and its comparison to original QR estimates and the interpolation approach.
Table 1.
Differences between naive and the proposed estimates, and their bootstrap standard errors. β̂ is the estimated coefficient using the proposed method, while β̂(a) is that from the naive estimation. The standard error of (β̂ − β̂(a)) is calculated based on 50 bootstrap sample
| Quantile level (τ) |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Weight at | 0.66 | 0.68 | 0.71 | 0.73 | 0.76 | 0.78 | 0.80 | 0.83 | 0.85 | |
| 1 yr | β̂ − β̂(a) | 0.48 | 0.61 | 0.66 | 0.76 | 0.74 | 0.79 | 0.84 | 1.04 | 0.98 |
| Bootstrap SE | 0.40 | 0.41 | 0.37 | 0.36 | 0.39 | 0.42 | 0.40 | 0.40 | 0.50 | |
| p-value | 0.114 | 0.069 | 0.038 | 0.019 | 0.029 | 0.030 | 0.018 | 0.005 | 0.024 | |
| 7 yrs | β̂ − β̂(a) | −0.19 | −0.17 | −0.12 | −0.09 | −0.08 | −0.12 | −0.09 | −0.16 | −0.12 |
| Bootstrap SE | 0.10 | 0.10 | 0.10 | 0.10 | 0.11 | 0.10 | 0.09 | 0.09 | 0.15 | |
| p-value | 0.969 | 0.960 | 0.883 | 0.827 | 0.767 | 0.881 | 0.828 | 0.958 | 0.973 | |
6.3 Further Investigation via Simulated NCPP-Like Data
To understand the observed differences seen in the NCPP example, we generated synthetic data sets based on the estimated models (16), (17), and (18). To mimic the NCPP data, we chose the same sample size, n = 232, and use the original birth weight and actual measurement ages ti,2, ti,3, and ti,4 for all the subjects. We then generated the weights 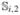 ,
, 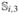 , and
, and 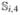 from the estimated model (17). In addition, we generated xi, the underlying “true” weights at ages 4 months, 1 year, and 7 years from the estimated model (17). Finally, we generated BMI at 20 years from the estimated quantile model (16) by
from the estimated model (17). In addition, we generated xi, the underlying “true” weights at ages 4 months, 1 year, and 7 years from the estimated model (17). Finally, we generated BMI at 20 years from the estimated quantile model (16) by
where β̂k(·) are smoothed the quantile coefficient process from the estimated quantile models (16), and ui are iid random draws from Uniform(0, 1). The generated datasets follow the distribution characterized by Models (16), (17), and (18).
We generated 20 synthetic data sets, and repeatedly estimated the coefficients using the naive approach, the interpolation approach and our proposed method. The results are presented in Figure 5. In Figure 5, the solid gray line represents the true co-efficient process that is used to generate the synthetic data sets. The solid black lines are the estimated coefficients using our approach, the long-dashed lines are those from naive estimation, and the short-dashed lines used the interpolation approach. The naive estimates are close to the true values except for the birth weight coefficient, for which the naive estimates seriously underestimated the efficient at the upper quantiles. In contrast, our method appeared to largely correct the bias, as we had hoped and as the simulation led us to expect.
Figure 5.

Estimated coefficients using synthetic data sets and its comparison to original QR estimates and the interpolation approach.
7. DISCUSSION
In this paper, we have proposed a new method to estimate linear quantile regression models when the covariates are measured with error. The method is based on constructing estimating equations jointly for all quantile levels τ ∈ (0, 1), and avoids specifying a distribution for the response given the true covariates. The heart of the algorithm is an EM-type computation. The resulting estimated coefficients are consistent and, if the underlying function is characterized by a spline, asymptotically normally distributed. Numerical results show that the new estimator is promising in terms of correcting the bias arising from the errors-in-covariates, and compares favorably with alternative approaches.
In both simulation studies and an empirical data example, we estimated the conditional density f(x|w) based on a Gaussian model with appropriate transformation to accommodate possible heteroscedasticity and skewness. There are many other ways to estimate this distribution when the scale is known such that w has mean x, for example, deconvolution with or without heteroscedasticity; see Staudenmayer, Ruppert, and Buonaccorsi (2008) for multiple references to the rapidly growing de-convolution literature as well as a semiparametric Bayesian approach. Our results show that use of these methods will still lead to consistent estimation of the quantile function, although asymptotic distributions would have to be addressed separately if such deconvolution approaches were to be used.
The methodology can be extended to longitudinal or clustered data within the working independence context; see for example He, Zhu, and Fung (2002). In such an approach, one ignores the correlations but fixes up the estimated covariance matrix to account for the correlated responses, using so-called sandwich method. That is, each individual contributes an estimating function to the overall estimating equation, and it is those estimating functions to which the sandwich method is applied.
Acknowledgments
Wei’s research was supported by the National Science Foundation (DMS-096568) and a career award from NIEHS Center for Environmental Health in Northern Manhattan (ES009089). Carroll’s research was supported by a grant from the National Cancer Institute (CA57030) and by Award Number KUS-CI-016-04, made by King Abdullah University of Science and Technology (KAUST). The authors thank Dr. Mary Beth Terry for kindly providing the NCPP adult data.
APPENDIX
Recall that β(τ) is a (p + 1) dimensional unknown quantile co-efficient function on (0, 1), and θ = {βτk:τk ∈ Ω} is the set of its quantile coefficients on the quantile level set Ω. Without loss of generosity, we assume in our proof that τk = k/(kn +1) such that Ω = {1/(kn +1), 2/(kn +1), …, kn/(kn +1)}. Recall that Sn(θ) are the working estimating equations defined in (10), and S(θ) is its expectation. Similarly, we denote as the estimating equations defined in (4) at quantile levels Ω, and S0(θ) its expectation. With this notation, we introduce Lemmas A.1 and A.2 which will be used for the proof of consistency.
Lemma A.1
Under Assumptions 1–2, we have
| (A.1) |
Proof
We first decompose ||S(θ0)− S0(θ0)|| as
| (A.2) |
By construction, f(x|yi, wi, θ0) = 0 for yi ≥ x⊤β0,kn/(kn+1), therefore,
| (A.3) |
The second last equation above is followed by the surrogacy condition, and the last equation is due to the fact that Prob(yi > x⊤β0,kn/(kn+1) = 1/(kn+1) for all i’s. Since Ex(||x|| |wi) is bounded for all the i’s according to Assumption 1, it follows that . Using similar arguments, we can also show that . In what follows, we show that . Note that I can be bounded by
Since x has bounded support as indicated in Assumption 1, a sufficient condition for
, according to Scheffe’s theorem (Scheffe 1947), is that, for any x ∈ , the following holds:
Since f(x|yi, wi; θ0) = f(yi|x; θ0)f(x|w)/∫xf(yi|x; θ0)f(x|w) dx and f(x|yi, wi;β0(τ)}= f{yi|x; β0(τ)}f(x|w)/∫xf{yi|x; β0(τ)}f(x|w)dx, it again suffices to show that ∀x ∈ ,
| (A.4) |
Let Fx(yi)= inf{τ: x⊤β0,τ ≥ yi} be the quantile rank of yi with respect to the probability measure induced by the quantile function x⊤β0(τ), and let be the density of y at the τ th quantile. For any yi that is bounded between x⊤β0,1/(kn+1) and x⊤β0,kn/(kn+1), there exist a ki such that x⊤β0,ki/(kn+1) ≤ yi ≤ (x⊤β0,(ki+1)/(kn+1). Consequently, the left side of (A.4) is equivalent to
| (A.5) |
According to Assumption 2,
| (A.6) |
Since ν1, ν2 > −1, (A.4) is implied by (A.6) and (A.5). The proof of Lemma A.1 is hence complete.
Lemma A.2
Recall that S̃n(θ) and Sn(θ) are two sets of score functions defined in (10) and (11), respectively. Let S(θ) be the expectation of Sn(θ). Then under Assumptions 1–4, for kn → ∞, knn−1→ 0, we have the following uniform convergence:
| (A.7) |
Proof
We first bound the left side of (A.7) by
According to Assumption 1, f(x|w) is bounded away from infinity, and supw |f̃(x|w) − f(x|w)| → 0 for any x as n goes to infinity. Therefore, for any i,
which further implies that |f̃(x|yi, wi; θ) − f(x|yi, wi; θ)= op(1) for all i. Due to the boundness of x, it follows from Sheffe’s theorem that
| (A.8) |
Therefore, to show (A.7), we only need to show that, for any ε,
| (A.9) |
as n → ∞. In what follows, we will show (A.9) using Huber’s chaining augment. Without loss of generality, we assume Θ × Ω= ∪k{β: |β − β0,τk| < 1}. We partition the parameter space Θ × Ω into Ln disjoint small cubes Γl with diameters less than qn = C1kn/n, for some constant C1. Let ξl be the center of the lth cube Γl. The probability of the left side of (A.9) is bounded by the sum of the following two probabilities, P1 + P2, where
We first note that
Moreover, under Assumption 1, there exist a constant C such that
Let gi(z) be the density of (x⊤ ξl −yi) given (yi, ξl, wi). Then gi(z) is also continuous and bounded away from zero and infinity. Following the mean value theorem, for any i there exist such that . It follows that .
On the other hand, a sufficient condition for is that maxi |f(x|yi, wi; θ) − f(x|yi, wi; ξl)| = op(1). Due to the boundedness of f(x|w), it again suffices to show that
where f(y|x; θ) and f(y|x; ξl) are two density functions that are induced by the quantile functions x⊤ (τ) and x⊤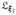 (τ). Moreover, denote Fθ(y) = inf{τ: x⊤ (τ) > y} and Fξl(y) = inf{τ: x⊤(τ)>y} as the inverse functions of x⊤ (τ) and x⊤(τ). Since |θ − ξl| = O(kn/n), supτ|x⊤ (τ) − x⊤(τ)| = o(1). Let θ[k] and ξl[k] stand for the subset of coefficients θ and ξl at the quantile level k/(kn+1), then by construction,
(τ). Moreover, denote Fθ(y) = inf{τ: x⊤ (τ) > y} and Fξl(y) = inf{τ: x⊤(τ)>y} as the inverse functions of x⊤ (τ) and x⊤(τ). Since |θ − ξl| = O(kn/n), supτ|x⊤ (τ) − x⊤(τ)| = o(1). Let θ[k] and ξl[k] stand for the subset of coefficients θ and ξl at the quantile level k/(kn+1), then by construction,
And (τ) has the same format. The difference between x⊤ (τ) and x⊤(τ) is then bounded by
Since |θ − ξl|O(kn/n) implies maxk |θ[k] − ξl[k]| = O(kn/n), then the boundness above implies supτ|x⊤ (τ) − x⊤(τ)| = op(1). Consequently, if we denote Ln = min(x⊤ θ[1], x⊤ξl[1]) and Un =max(x⊤θ[kn], x⊤ξl[kn]), then we have supy∈[Ln,Un]|Fθ(y) − Fξl(y)| = o(1). Since we can write
and
for y ∈ [Ln, Un]. supy∈[Ln,Un]|f(y|x; θ) − f(y|x; ξl) = o(1). Moreover, by construction, f(y|x; θ) = f(y|x; ξl) = 0 for any y > Un or y < Ln. Combining these facts, we have maxi |f(yi|x; θ) − f(yi|x; ξl)|=op(1), which in turn implies knSS2 =op(1). Following a similar argument, we can also show that, supθ∈Γ l||S(θ) − S(ξl)|| = o(1). It then follows that P1 = o(1).
Let 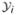 (l, k, m) = ∫xΨτ(yi − x⊤βτ k)xm · f(x|yi, wi; θ) dxIθ ∈ Γl. A sufficient condition for P2 = o(1) is that, for any βτk and xm,
(l, k, m) = ∫xΨτ(yi − x⊤βτ k)xm · f(x|yi, wi; θ) dxIθ ∈ Γl. A sufficient condition for P2 = o(1) is that, for any βτk and xm,
Under Assumption 5, |(l, k, m)| < C for all the i’s. Applying Bernstein’s inequality to the probability term above, we have
We now have shown that both P1 and P2 =o(1), which in turn implies that the uniform convergence (A.7) holds. Lemma A.2 is hence proved.
Proof of Consistency
Recall that β̂τk is the (p + 1)-dimensional estimated coefficient vector at quantile level τk based on the working estimating equations (10), and β̂j, τk is its jth component. We further define βj(τ) as the piece-wise linear function with β̂j(τk) = β̂j,τk, ∀,τk ∈ Ω. To simplify the notation, we also denote as the p × kn dimensional estimated coefficient matrix.
For any δ > 0, we define a compact set Bτ ={β ∈ ℝp+1:||β − β0,τ||<δ}, where β0,τ is the true coefficients at the quantile level τ. We denote as its complementary set. Note that Sn(θ) are the working estimating equations defined in (10), and let S(θ) be its expectation. We define the distance
| (A.10) |
between the norm of the working estimating equations evaluated at the true coefficients θ0 and the minimized norm when θ stays outside of Bτ ⊗ Ω. In what follows, we show that dn(δ) > 0 under Assumptions 1 to 4.
Recall in Assumption 3 that θ0 is the unique solution of S0(θ) =0, we have S0(θ0) = 0. Therefore, the convergence of (A.1) stated in Lemma A.1 is equivalent to . Moreover, since is the unique solution of S(θ) = 0 according to Assumption 3, it follows that . Due to the continuity of S(·) and the uniqueness of θ*, we have , as n goes to infinity. Consequently, there exist Kδ, such that when kn > Kδ, we have that , in other words, θ* ∈ Bτ × Ω for kn > Kδ. Due to the uniqueness of θ*, for any kn > Kδ, we have
| (A.11) |
On the other hand, due to the continuity of S(·), for sufficiently larger kn, we also have
| (A.12) |
Combining these (A.12) and (A.11), we have
| (A.13) |
for sufficiently large kn.
We now define the random event that
which, together with Assumption 4, implies that
| (A.14) |
and
| (A.15) |
Since θ̂n is the minimizer of ||S̃n(θ)||, we have ||S̃n(θ̂n)|| < ||S̃n(θ0)||, which, together with (A.14), shows that . Following Lemma A.2, limn → ∞ pr(En) = 1, which implies
By the definition of Bτ and the fact that , this in turn implies that limn→∞pr(θ̂n ∈ Bτ) = 1, that is,
The consistency of β̂n(τ) is hence proved.
Proof of Asymptotic Normality
Recall that , where Ψnew(yi, wi, θ) =∫xΨ(yi −x⊤ θ) ⊗ x · f(x|yi, wi; θ) dx, and S̃n(θ) is its approximation replacing f(x|wi) in f(x|yi, wi; θ) by its estimate f̃(x|wi). Following a similar argument as in Lemma A.2, we can show that for any decreasing sequence dn →0, we have
| (A.16) |
Theorem 1 implies, for fixed K, that θ̂n is a consistent estimator of θ0. The uniform convergence (A.16) hence implies
| (A.17) |
Note that n1/2S̃n(θ̂n)= op(1), and ||S̃n(θ̂n) − ||S̃n(θ̂n)|| = op(1), which is implied by (A.8) and Assumption 4, it follows that Sn(θ̂n) ≈ 0 for large enough n. On the other hand, S(θ0) = 0 under Assumption 3. Therefore, the convergence (A.17) is equivalent to
Taylor expanding S(θ̂n) around S(θ0), we have
Theorem 2 follows immediately from the Central Limit Theorem.
Contributor Information
Ying Wei, Email: ying.wei@columbia.edu, Assistant Professor, Department of Biostatistics, Columbia University, 722 West 168th St., New York, NY 10032.
Raymond J. Carroll, Email: carroll@stat.tamu.edu, Distinguished Professor of Statistics, Nutrition and Toxicology, Department of Statistics, Texas A&M University, TAMU 3143, College Station, TX 77843-3143
References
- Carriquiry AL. Estimation of Usual Intake Distributions of Nutrients and Foods. Journal of Nutrition. 2003;133:601–608. doi: 10.1093/jn/133.2.601S. [DOI] [PubMed] [Google Scholar]
- Carroll RJ, Ruppert D, Stefanski LA, Crainiceanu CM. Measurement Error in Nonlinear Models: A Modern Perspective. 2. Boca Raton, FL: Chapman & Hall/CRC Press; 2006. [Google Scholar]
- Chesher A. Working Paper CWP02/01. University College London, Dept. of Economics; 2001. Parameter Approximations for Quantile Regressions With Measurement Error. [Google Scholar]
- de Boor C. A Practical Guide to Splines, Applied Mathematical Sciences. New York: Springer-Verlag; 2001. [Google Scholar]
- Delaigle A, Hall P, Meister A. On Deconvolution With Repeated Measurements. The Annals of Statistics. 2008;36:665–685. [Google Scholar]
- Eckert RS, Carroll RJ, Wang N. Transformations to Additivity in Measurement Error Models. Biometrics. 1997;53:262–272. [PubMed] [Google Scholar]
- He X, Liang H. Quantile Regression Estimates for a Class of Linear and Partially Linear Errors-in-Variables Models. Statistica Sinica. 2000;10:129–140. [Google Scholar]
- He X, Zhu ZY, Fung WK. Estimation in a Semiparametric Model for Longitudinal Data With Unspecified Dependence Structure. Biometrika. 2002;89:579–590. [Google Scholar]
- Hu Y, Schennach SM. Identification and Estimation of Non-classical Nonlinear Errors-in-Variables Models With Continuous Distributions Using Instruments. Econometrica. 2008;76:195–216. [Google Scholar]
- Koenker R. Quantile Regression for Longitudinal Data. Journal of Multivariate Analysis. 2004;91:74–89. [Google Scholar]
- Koenker R, Bassett GJ. Regression Quantiles. Econometrica. 1978;46:33–50. [Google Scholar]
- Koenker R, Machado J. Goodness of Fit and Related Inference Processes for Quantile Regression. Journal of the American Statistical Association. 1999;94:1296–1309. [Google Scholar]
- Koenker R, Xiao ZJ. Unit Root Quantile Autoregression Inference. Journal of the American Statistical Association. 2004;99:775–787. [Google Scholar]
- Li T, Vuong Q. Nonparametric Estimation of the Measurement Error Model Using Multiple Indicators. Journal of Multivariate Analysis. 1998;65:139–165. [Google Scholar]
- McLachlan GJ, Krishnan T. The EM Algorithm and Extensions. New York: Wiley; 2008. [Google Scholar]
- Nusser SM, Carriquiry AL, Dodd KW, Fuller WA. A Semiparametric Transformation Approach to Estimating Usual Intake Distributions. Journal of the American Statistical Association. 1997a;91:1440–1449. [Google Scholar]
- Nusser SM, Carriquiry AL, Jensen HH, Fuller WA. A Transformation Approach to Estimating Usual Intake Distributions. In: Milliken GA, Schwenke JR, Manhattan KS, editors. Applied Statistics in Agriculture: Proceedings of the 1990 Kansas State University Conference on Applied Statistics in Agriculture. Kansas State University; 1990. pp. 120–132. [Google Scholar]
- Nusser SM, Fuller WA, Guenther PM. Estimating Usual Dietary Intake Distributions: Adjusting for Measurement Error and Nonnormality in 24-Hour Food Intake Data. In: Lyberg L, Biemer P, Collins M, DeLeeuw E, Dippo C, Schwartz N, Trewin D, editors. Survey Measurement and Process Quality. New York: Wiley; 1997b. pp. 689–709. [Google Scholar]
- Portnoy S. Censored Regression Quantiles. Journal of American Statistical Association. 2003;98:1001–1012. [Google Scholar]
- Scheffe H. A Useful Convergence Theorem in Probability Distributions. Annals of Mathematical Statistics. 1947;18:434–458. [Google Scholar]
- Schennach SM. Quantile Regression With Mismeasured Covariates. Econometric Theory. 2008;24:1010–1043. [Google Scholar]
- Staudenmayer J, Ruppert D, Buonaccorsi JP. Density Estimation in the Presence of Heteroskedastic Measurement Error. Journal of the American Statistical Association. 2008;103:726–736. [Google Scholar]
- Terry MB, Wei Y, Essenman D. Maternal, Birth, and Early Life Influences on Adult Body Size in Women” (with discussions) The American Journal of Epidemiology. 2007;166:5–13. doi: 10.1093/aje/kwm094. Author reply, 17–18. [DOI] [PubMed] [Google Scholar]
- Welsh AH. Asymptotically Efficient Estimation of the Sparsity Function at a Point. Statistics and Probability Letters. 1988;6:427–432. [Google Scholar]