

Despite the successes of genomics, little is known about how genetic information produces complex organisms. A look at the crucial functional elements of fly and worm genomes could change that.
Supplementary information
The online version of this article (doi:10.1038/459927a) contains supplementary material, which is available to authorized users.
Model answers: modENCODE explained
The National Human Genome Research Institute's modENCODE project (the model organism ENCyclopedia Of DNA Elements) was set up in 2007 with the goal of identifying all the sequence-based functional elements in the genomes of two important experimental organisms, Caenorhabditis elegans and Drosophila melanogaster. Armed with modENCODE data, geneticists will be able to undertake the comprehensive molecular studies of regulatory networks that hold the key to how complex multicellular organisms arise from the list of instructions coded in the genome. In this issue, modENCODE team members outline their plan of campaign. Data from the project are to be made available on http://www.modencode.org and elsewhere as the work progresses.
Supplementary information
The online version of this article (doi:10.1038/459927a) contains supplementary material, which is available to authorized users.
The primary objective of the Human Genome Project was to produce high-quality sequences not just for the human genome but also for those of the chief model organisms: Escherichia coli, yeast (Saccharomyces cerevisiae), worm (Caenorhabditis elegans), fly (Drosophila melanogaster) and mouse (Mus musculus). Free access to the resultant data has prompted much biological research, including development of a map of common human genetic variants (the International HapMap Project)1, expression profiling of healthy and diseased cells2 and in-depth studies of many individual genes. These genome sequences have enabled researchers to carry out genetic and functional genomic studies not previously possible, revealing new biological insights with broad relevance across the animal kingdom3,4.
Nevertheless, our understanding of how the information encoded in a genome can produce a complex multicellular organism remains far from complete. To interpret the genome accurately requires a complete list of functionally important elements and a description of their dynamic activities over time and across different cell types. As well as genes for proteins and non-coding RNAs, functionally important elements include regulatory sequences that direct essential functions such as gene expression, DNA replication and chromosome inheritance.
Although geneticists have been quick to decode the functional elements in the yeast S. cerevisiae, with its small compact genome and powerful experimental tools5,6, our understanding of the more complex genomes of human, mouse, fly and worm is still rudimentary. Intrinsic signals that define the boundaries of protein-coding genes can only be partly recognized by current algorithms, and signals for other functional elements are even harder to find and interpret. Experimental approaches, notably the sequencing of complementary DNA and expressed sequence tags, have been invaluable, but unfortunately these data sets remain incomplete7. Non-coding RNA genes present an even greater challenge8,9,10, and many remain to be discovered, particularly those that have not been strongly conserved during evolution. Flies and worms have roughly the same number of known transcription factors as humans11, but comprehensive molecular studies of gene regulatory networks have yet to be tackled in any of these species.
In an attempt to remedy this situation, the National Human Genome Research Institute (NHGRI) launched the ENCODE (Encyclopedia of DNA Elements) project in 2003, with the goal of defining the functional elements in the human genome. The pilot phase of the project focused on 1% of the human genome and a parallel effort to foster technology development12. The initial ENCODE analysis revealed new findings but also made clear just how complex the biology is and how our grasp of it is far from complete13. On the basis of this experience, the NHGRI launched two complementary programmes in 2007: an expansion of the human ENCODE project to the whole genome (http://www.genome.gov/ENCODE) and the model organism ENCODE (modENCODE) project to generate a comprehensive annotation of the functional elements in the C. elegans and D. melanogaster genomes (http://www.modencode.org; http://www.genome.gov/modENCODE).
These two model organisms, with their ease of husbandry and genetic manipulation, are pillars of modern biological research, and a systematic catalogue of their functional genomic elements promises to pave the way to a more complete understanding of the human genome. Studies of these animals have provided key insights into many basic metazoan processes, including developmental patterning, cellular signalling, DNA replication and inheritance, programmed cell death and RNA interference (RNAi). The genomes are small enough to be investigated comprehensively with current technologies and findings can be validated in vivo. The research communities that study these two organisms will rapidly make use of the modENCODE results, deploying powerful experimental approaches that are often not possible or practical in mammals, including genetic, genomic, transgenic, biochemical and RNAi assays. modENCODE, with its potential for biological validation, will add value to the human ENCODE effort by illuminating the relationship between molecular and biological events.
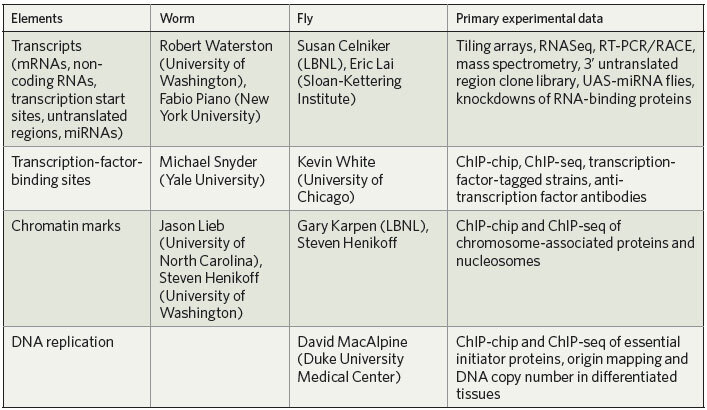
The modENCODE project (Table 1) complements other systematic investigations into these highly studied organisms. In both organisms, RNAi collections have been developed and used to uncover novel gene functions14,15,16,17,18. Mutants are being recovered through insertional mutagenesis19 and targeted deletions (http://celeganskoconsortium.omrf.org; http://www.shigen.nig.ac.jp/c.elegans), with the eventual goal of one for every known gene. Genome sequences of related species are now also available for both fly20,21 and worm22, and multiple independent wild isolates are being characterized (T. MacKay, personal communication, http://www.dpgp.org23; R.H.W.). First-generation catalogues have been assembled of gene expression patterns during development and in different tissues24,25,26,27,28,29,30,31,32,33,34.
Table 1.
modENCODE CONSORTIUM
Research and analysis
The modENCODE project will operate as an open consortium and participants can join on the understanding that they will abide by the set criteria (http://www.genome.gov/26524644). An important aim of the project is to respond to the needs of the broader Drosophila and C. elegans scientific communities, and several avenues will be open for suggestions on which experiments to prioritize. For example, researchers can visit http://www.modencode.org/Vote.shtml now to help prioritize transcription factors for studies using chromatin immunoprecipitation followed by DNA microarray or DNA sequencing (ChIP-chip and ChIP-seq), and can also indicate whether they have useful antibodies. We will seek community input on other issues as the opportunities arise.
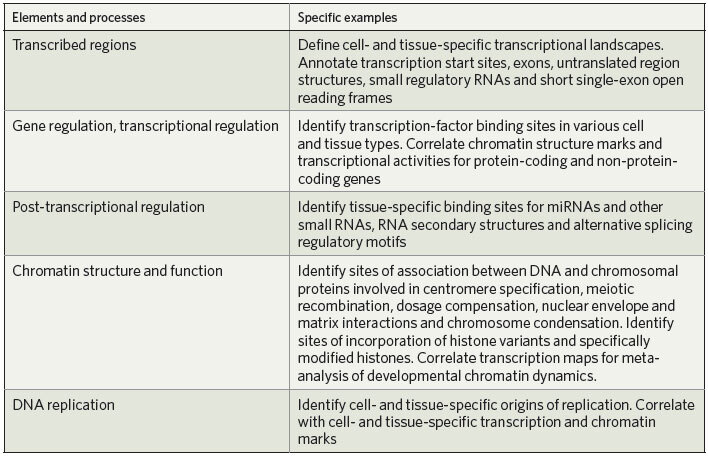
The core of the modENCODE project consists of ten groups who use high-throughput methods to identify functional elements (see Table 1). A Data Coordinating Center (DCC) will collect, integrate and display the data. Together, the groups expect to identify the principal classes of functional element for D. melanogaster and C. elegans. They will work closely together to complete the precise annotation of protein-coding genes, identify small RNAs and non-coding RNA transcripts, map transcription start sites, identify promoter motif elements, elucidate functional elements within 3′ untranslated regions, and identify alternatively spliced transcripts as well as the signals required for splicing. Genomic sites bound by sequence-specific transcription factors will also be comprehensively identified. Charting the chromatin 'landscapes' will include the characterization of key histone modifications and variants, nucleosome phasing, RNA polymerase II isoforms and proteins involved in dosage compensation, centromere function, replication, homologue pairing, recombination and associations of chromosomes with the nuclear envelope.
Integrative analysis of these data across the different types of functional element will be used to reveal fundamental principles of fly and worm genome biology and to begin to uncover the emergent properties of these complex genomes. Some topics the modENCODE groups, along with interested members of the wider community, intend to explore are outlined below, but these are only a beginning. Our intention is to create a resource that will provide the foundation for ongoing analysis by scientists for years to come.
Our two model organisms share many similarities with other metazoans, including humans. They also differ from other organisms in some striking ways, particularly in details of the establishment and maintenance of cellular identity, centromere biology and heterochromatin function. To help understand how the similarities and differences in worm and fly biology are reflected in their genome sequences and how they are specified by genome function at the molecular level, we will carry out comparative analyses of transcription, splicing, cis-regulatory and post-transcriptional elements and chromatin function. We will subsequently investigate how our findings apply to the control of gene expression in the human genome.
We also plan to use genome-wide data on pre- and post-transcriptional functional elements to expand our understanding of gene-regulatory networks. We will study how these two layers of control complement or reinforce each other during development. For example, the availability of full-length transcripts and promoter structures for microRNA (miRNA) genes will enable us to develop models of regulatory circuits that integrate the upstream regulation of miRNA genes with that of other regulatory factors (such as transcription factors) and the effects of miRNAs on their downstream targets. We will search global patterns identified in the regulatory programs for emerging principles of gene regulation within and across species; as part of this endeavour, we will evaluate evidence for the modular structure of regulatory networks.
Because several developmental stages and diverse tissues will be sampled in both animals, we will be able to investigate the global and dynamic activities of functional elements across the entire genome in multiple cell types and stages of differentiation. We aim to define the characteristics and rules that distinguish regulatory programs in different cell types and developmental stages at the DNA, chromatin, and post-transcriptional levels. This will enable us to identify the types of element that function together in various spatio-temporal environments and find new types of functional element, perhaps including those used in restricted developmental contexts.
An important objective is to generate specific biological hypotheses that can be refined and tested experimentally by the broader scientific community. For example, these analyses might identify transcribed regions with novel regulatory roles, structural regions that function in the establishment of chromatin structure or three-dimensional conformation, enhancers far away from the gene they control, and alternative promoter regions. In addition, we will use comparative analyses of the sequenced genomes from different species to clarify the extent of conservation and the functional constraints associated with potential new classes of element and to characterize their evolutionary signatures21.
Another objective of the modENCODE project is the creation of reference data sets of maximum utility. We have agreed that, whenever possible, a common set of reagents will be used to facilitate comparison of data sets generated by different groups. For example, the fly and worm groups using ChIP-chip and related methods to map the genome-wide distributions of histone modifications will use a common set of validated antibodies. In addition, we will use common fly and worm strains, and in the case of Drosophila, the common cell lines Kc167, S2-DRSC, CME W1 Cl.8+ and ML-DmBG3-c2.
The fly and worm genomes are about a thirtieth of the size of their mammalian counterparts, making current methods for high-throughput genomic analysis cost-effective. We will use high-density tiling DNA microarrays to interrogate the genome on a single microarray (C. elegans, 26 base pair (bp) median spacing; D. melanogaster, 38 bp median spacing) at a resolution sufficient for ChIP-chip experiments. Denser arrays (D. melanogaster, 7 bp median spacing), which promise higher resolution, will be used in a move to high-throughput sequencing platforms such as the Illumina Genome Analyzer to generate sufficient sequence coverage for transcript mapping and miRNA and ChIP experiments.
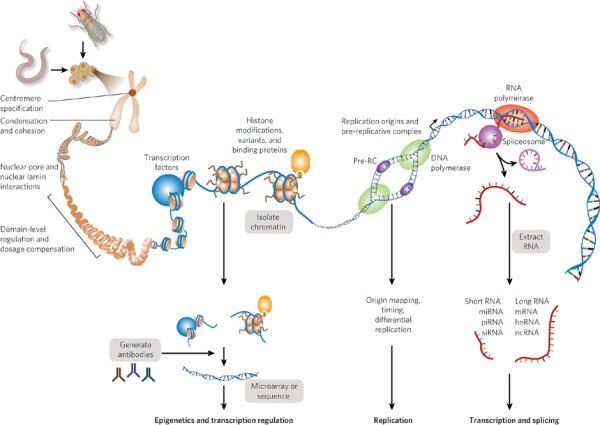
The biological significance of the genomic features identified will be tested in experiments designed to evaluate the accuracy and functionality of subsets of the structural and regulatory annotations. For example, we will carry out ChIP experiments on extracts from whole animals or cells that lack selected regulators (using mutants or RNAi). The tissue-specific DNA-binding patterns of selected regulators will be validated in transgenic animals. Figure 1 summarizes the DNA elements to be interrogated and the methods to be used.
Figure 1. DNA element functions and identification process.
Data management and accessibility
Data generated by the modENCODE Consortium, including those from validation experiments, will be collected, quality checked, integrated and distributed through the modENCODE DCC (http://www.modencode.org). The DCC will collate detailed metadata for each submitted data set to ensure broad and long-term usability. Where appropriate, the data will also be submitted to public databases, for example, GenBank (http://www.ncbi.nlm.nih.gov) and the Gene Expression Omnibus (http://www.ncbi.nlm.nih.gov/geo) or Array Express (http://www.ebi.ac.uk/microarray-as/aer/entry) and the University of California, Santa Cruz Genome Bioinformatics Site (http://genome.ucsc.edu). The DCC will also work closely with WormBase (http://www.wormbase.org) and FlyBase (http://www.flybase.org) to facilitate integration of the modENCODE data with selected data from these databases and with other information about these organisms.
All data will be available for bulk download through an FTP site and through a number of Generic Model Organism Database tools (http://www.gmod.org): BioMart (http://www.biomart.org) will provide powerful data-mining capabilities, and InterMine (http://www.intermine.org) will provide a flexible interface for complex querying of the data, a library of canned queries, and powerful list-based tools and operations (http://intermine.modencode.org). As for the ENCODE pilot project data (http://www.genome.gov/10005107), new data can be examined alongside existing data using interactive genome browsers35 for both the fly (http://www.modencode.org/cgi-bin/gbrowse/fly) and the worm (http://www.modencode.org/cgi-bin/gbrowse/worm).
The Drosophila and C. elegans communities have thrived because of their open culture. In keeping with this tradition and with those of the genome sequencing projects, HapMap and the ENCODE pilot project, modENCODE is a 'community resource project' subject to the NHGRI's data-sharing policy. The success of this policy is based on mutual and independent responsibilities for the production and use of the resource. We will release data rapidly (Table 2), before publication, once they have been established to be reproducible (verification; see http://www.modencode.org/'PublicationPolicylink' for the criteria), even if the data have not been sampled to determine if there is biological meaning (validation). In turn, users are asked to recognize the source of the data and to respect the legitimate interest of the resource producers to publish an initial report of their work (see http://www.genome.gov/modencode for more details). Finally, the funding agencies recognize the need to support the analysis and dissemination of the data.
Table 2.
GLOBAL ANALYSIS GOALS
In addition, a variety of physical resources (for example, DNA constructs and transgenic strains) will be produced that are likely to be of use to the broader community and to which that community will have unrestricted access. We expect to cooperate with data users in the worm and fly communities to set the gold standard for data release and openness.
Conclusion
The Human Genome Project benefited enormously from the technology developed and the experience acquired in sequencing the significantly smaller genomes of model organisms, particularly C. elegans and D. melanogaster. The modENCODE project is dedicated to the next phase of decoding the information stored in these genomes: the comprehensive identification of sequence-based functional elements. Having laid the foundation for the discovery of many of the genetic programs underlying metazoan development and behaviour, Drosophila and Caenorhabditis will serve as ideal model systems to identify DNA-based functional elements on a genome-wide basis. In the future, these data will provide a powerful platform for characterizing the functional networks that direct multicellular biology, thereby linking genomic data with the biological programs of higher organisms, including humans.
Supplementary information A full list of names and addresses of current consortium participants is linked to the online version of this feature at http://tinyurl.com/modENCODE
Supplementary information
Supplementary Information. (PDF 71 kb)
Acknowledgements
We thank Brenda Andrews and Tim Hughes for discussions on the status of yeast functional genomics.
Footnotes
Correspondence should be addressed to S.E.C. (celniker@fruitfly.org).
References
- 1.Sabeti PC, et al. Nature. 2007;449:913–918. doi: 10.1038/nature06250. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Neve RM, et al. Cancer Cell. 2006;10:515–527. doi: 10.1016/j.ccr.2006.10.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Chintapalli VR, Wang J, Dow JA. Nature Genet. 2007;39:715–720. doi: 10.1038/ng2049. [DOI] [PubMed] [Google Scholar]
- 4.Nichols CD. Pharmacol. Ther. 2006;112:677–700. doi: 10.1016/j.pharmthera.2006.05.012. [DOI] [PubMed] [Google Scholar]
- 5.Ross-Macdonald P, et al. Nature. 1999;402:413–418. doi: 10.1038/46558. [DOI] [PubMed] [Google Scholar]
- 6.Boone C, Bussey H, Andrews BJ. Nature Rev. Genet. 2007;8:437–449. doi: 10.1038/nrg2085. [DOI] [PubMed] [Google Scholar]
- 7.Celniker SE, Rubin GM. Annu. Rev. Genomics Hum. Genet. 2003;4:89–117. doi: 10.1146/annurev.genom.4.070802.110323. [DOI] [PubMed] [Google Scholar]
- 8.Tupy JL, et al. Proc. Natl Acad. Sci. USA. 2005;102:5495–5500. doi: 10.1073/pnas.0501422102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Ruby JG, et al. Cell. 2006;127:1193–1207. doi: 10.1016/j.cell.2006.10.040. [DOI] [PubMed] [Google Scholar]
- 10.Ruby JG, et al. Genome Res. 2007;17:1850–1864. doi: 10.1101/gr.6597907. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Reece-Hoyes JS, et al. Genome Biol. 2005;6:R110. doi: 10.1186/gb-2005-6-13-r110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.The ENCODE Project Consortium Science306, 636–640 (2004). [DOI] [PubMed]
- 13.Birney E, et al. Nature. 2007;447:799–816. doi: 10.1038/nature05874. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Boutros M, et al. Science. 2004;303:832–835. doi: 10.1126/science.1091266. [DOI] [PubMed] [Google Scholar]
- 15.Kamath RS, et al. Nature. 2003;421:231–237. doi: 10.1038/nature01278. [DOI] [PubMed] [Google Scholar]
- 16.Rual JF, et al. Genome Res. 2004;14:2162–2168. doi: 10.1101/gr.2505604. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Sonnichsen B, et al. Nature. 2005;434:462–469. doi: 10.1038/nature03353. [DOI] [PubMed] [Google Scholar]
- 18.Dietzl G, et al. Nature. 2007;448:151–156. doi: 10.1038/nature05954. [DOI] [PubMed] [Google Scholar]
- 19.Bellen HJ, et al. Genetics. 2004;167:761–781. doi: 10.1534/genetics.104.026427. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Clark AG, et al. Nature. 2007;450:203–218. doi: 10.1038/nature06341. [DOI] [PubMed] [Google Scholar]
- 21.Stark A, et al. Nature. 2007;450:219–232. doi: 10.1038/nature06340. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Stein LD, et al. PLoS Biol. 2003;1:E45. doi: 10.1371/journal.pbio.0000045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Hillier LW, et al. Nature Methods. 2008;5:183–188. doi: 10.1038/nmeth.1179. [DOI] [PubMed] [Google Scholar]
- 24.Tomancak P, et al. Genome Biol. 2002;3:research0088.1–0088.14. doi: 10.1186/gb-2002-3-12-research0088. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Arbeitman MN, et al. Science. 2002;297:2270–2275. doi: 10.1126/science.1072152. [DOI] [PubMed] [Google Scholar]
- 26.Stuart JM, Segal E, Koller D, Kim SK. Science. 2003;302:249–255. doi: 10.1126/science.1087447. [DOI] [PubMed] [Google Scholar]
- 27.Li TR, White KP. Dev. Cell. 2003;5:59–72. doi: 10.1016/S1534-5807(03)00192-8. [DOI] [PubMed] [Google Scholar]
- 28.Stolc V, et al. Science. 2004;306:655–660. doi: 10.1126/science.1101312. [DOI] [PubMed] [Google Scholar]
- 29.Manak JR, et al. Nature Genet. 2006;38:1151–1158. doi: 10.1038/ng1875. [DOI] [PubMed] [Google Scholar]
- 30.Tomancak P, et al. Genome Biol. 2007;8:R145. doi: 10.1186/gb-2007-8-7-r145. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Jiang M, et al. Proc. Natl Acad. Sci. USA. 2001;98:218–223. doi: 10.1073/pnas.98.1.218. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Reinke V, Gil IS, Ward S, Kazmer K. Development. 2004;131:311–323. doi: 10.1242/dev.00914. [DOI] [PubMed] [Google Scholar]
- 33.Baugh LR, Hill AA, Slonim DK, Brown EL, Hunter CP. Development. 2003;130:889–900. doi: 10.1242/dev.00302. [DOI] [PubMed] [Google Scholar]
- 34.Kim SK, et al. Science. 2001;293:2087–2092. doi: 10.1126/science.1061603. [DOI] [PubMed] [Google Scholar]
- 35.Stein LD, et al. Genome Res. 2002;12:1599–1610. doi: 10.1101/gr.403602. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary Information. (PDF 71 kb)