

Abstract
Neurons perform computations, and convey the results of those computations through the statistical structure of their output spike trains. Here we present a practical method, grounded in the information-theoretic analysis of prediction, for inferring a minimal representation of that structure and for characterizing its complexity. Starting from spike trains, our approach finds their causal state models (CSMs), the minimal hidden Markov models or stochastic automata capable of generating statistically-identical time series. We then use these CSMs to objectively quantify both the generalizable structure and the idiosyncratic randomness of the spike train. Specifically, we show that the expected algorithmic information content (the information needed to describe the spike train exactly) can be split into three parts describing (1) the time-invariant structure (complexity) of the minimal spike-generating process, which describes the spike train statistically, (2) the randomness (internal entropy rate) of the minimal spike-generating process, and (3) a residual pure noise term not described by the minimal spike generating process. We use CSMs to approximate each of these quantities. The CSMs are inferred non-parametrically from the data, making only mild regularity assumptions, via the Causal State Splitting Reconstruction (CSSR) algorithm. The methods presented here complement more traditional spike train analyses by describing not only spiking probability, and spike train entropy, but also the complexity of a spike train’s structure. We demonstrate our approach using both simulated spike trains and experimental data recorded in rat barrel cortex during vibrissa stimulation.
I. INTRODUCTION
The recognition that neurons are computational devices is one of the foundations of modern neuroscience (McCulloch & Pitts, 1943). However, determining the functional form of such computation is extremely difficult, if only because while one often knows the output (the spikes) the input (synaptic activity) is almost always unknown. Often, therefore, scientists must draw inferences about the computation from its results, namely the output spike trains and their statistics. In this vein, many researchers have used information theory to determine, via calculation of the entropy rate, a neuron’s channel capacity, i.e., how much information the neuron could conceivably transmit, given the distribution of observed spikes (Rieke et al., 1997). However, entropy quantifies randomness, and says little about how much structure a spike train has, or the amount and type of computation which must have, at a minimum, taken place to produce this structure. Here, and throughout this paper, we mean “computational structure” information-theoretically, i.e., the most compact effective description of a process capable of statistically reproducing the observed spike trains. The complexity of this structure is the number of bits needed to describe it. This is different from the algorithmic information content of a spike train, which is the number of bits needed to reproduce the latter exactly, describing not only its regularities, but also its accidental, noisy details.
Our goal is to develop rigorous yet practical methods for determining the minimal computational structure necessary and sufficient to generate neural spike trains. We are able to do this through non-parametric analysis of the directly-observable spike trains, without resorting to a priori assumptions about what kind of structure they have. We do this by identifying the minimal hidden Markov model (HMM) which can statistically predict the future of the spike train without loss of information. This HMM also generates spike trains with the same statistics as the observed train. It thus defines a program which describes the spike train’s computational structure, letting us quantify, in bits, the structure’s complexity.
From multiple directions, several groups, including our own, have shown that minimal generative models of time series can be discovered by clustering histories into “states”, based on their conditional distributions over future events (Crutchfield & Young, 1989; Grassberger, 1986; Jaeger, 2000; Knight, 1975; Littman et al., 2002; Shalizi & Crutchfield, 2001). The observed time series need not be Markovian (few spike trains are), but the construction always yields the minimal HMM capable of generating and predicting the original process. Following Shalizi (2001); Shalizi & Crutchfield (2001), we will call such a HMM a “Causal State Model” (CSM). Within this framework, the model discovery algorithm called Causal State Splitting Reconstruction, or CSSR (Shalizi & Klinkner, 2004) is an adaptive non-parametric method which consistently estimates a system’s CSM from time-series data. In this paper we adapt CSSR for use in spike train analysis.
CSSR provides us with non-parametric estimates of the time- and history- dependent spiking probabilities found by more familiar parametric analyses. Unlike those analyses, it is also capable, in the limit of infinite data, of capturing all the information about the computational structure of the spike-generating process contained in the spikes themselves. In particular, the CSM quantifies the complexity of the spike-generating process by showing how much information about the history of the spikes is relevant to their future, i.e., how much information is needed to reproduce the spike train statistically. This is equivalent to the log of the effective number of statistically-distinct states of the process (Crutchfield & Young, 1989; Grassberger, 1986; Shalizi & Crutchfield, 2001). While this is not the same as the algorithmic information content, we show that CSMs can also approximate the average algorithmic information content, splitting it into three parts: (1) The generative process’s complexity in our sense; (2) the internal entropy rate of the generative process, the extra information needed to describe the exact state transitions the undergone while generating the spike train; and (3) the residual randomness in the spikes, unconstrained by the generative process. The first of these quantifies the spike train’s structure, the last two its randomness.
Below, we give precise definitions of these quantities, both their ensemble averages (§II.C) and their functional dependence on time (§II.D). The time-dependent versions allow us to determine when the neuron is traversing states requiring complex descriptions. Our methods put hard numerical lower bounds on the amount of computational structure which must be present to generate the observed spikes. They also quantify, in bits, the extent to which the neuron is driven by external forces. We demonstrate our approach using both simulated and experimentally recorded single-neuron spike trains. We discuss the interpretation of our measures, and how they add to our understanding of neuronal computation.
II. THEORY AND METHODS
Throughout this paper we treat spike trains as stochastic binary time series, with time divided into discrete, equal-duration bins steps (typically at one millisecond resolution); “1” corresponds to a spike and “0” to no spike. Our aim is to find a minimal description of the computational structure present in such a time series. Heuristically, the structure present in a spike train can be described by a “program” which can reproduce the spikes statistically. The information needed to describe this program (loosely speaking the program length) quantifies the structure’s complexity. Our approach uses minimal, optimally predictive HMMs, or Causal State Models (CSMs), reconstructed from the data, to describe the program. (We clarify our use of “minimal” below.) The CSMs are then used to calculate various measures of the computational structure, such as its complexity.
The states are chosen so that they are optimal predictors of the spike train’s future, using only the information available from the train’s history. (We discuss the limitations of this below.) Specifically the states St are defined by grouping the histories of past spiking activity which occur in the spike train into equivalence classes, where all members of a given equivalence class are statistically equivalent in terms of predicting the future spiking . ( denotes the sequence of random observables, i.e., spikes or their absence, between t′ and t > t′ while Xt denotes the random observable at time t. The notation is similar for the states.) This construction ensures that the causal states are Markovian, even if the spike train is not (Shalizi & Crutchfield, 2001, Lemma 6, p. 839). Therefore, at all times t the system and its possible future evolution(s) can be specified by the state St. Like all HMMs, a CSM can be represented pictorially by a directed graph, with nodes standing for the process’s hidden states and directed edges the possible transitions between these states. Each edge is labeled with the observable/symbol emitted during the corresponding transition (“1” for a spike and “0” for no spike), and the probability of traversing that edge given that the system started in that state. The CSM also specifies the time-averaged probability of occupying any state (via the ergodic theorem for Markov chains).
The theory is described in more detail below, but at this point examples may clarify the ideas. Figures 1 A and B show two simple CSMs. Both are built from simulated ≈ 40 Hz spike trains 200 seconds in length (1 msec time bins, p = 0.04 IID at each time when spiking is possible). However, spike trains generated from the CSM in Figure 1 B have a 5 msec refractory period after each spike (when p = 0), while the spiking rate in non-refractory periods is still 40 Hz (p = 0.04). The refractory period is additional structure, represented by the extra states. State A represents the status of the neuron during 40 Hz spiking, outside of the refractory periods. While in this state, the neuron either emits no spike (Xt+1 = 0), staying in state A, or emits a spike (Xt+1 = 1) with probability p = 0.04 and moves to state B. The equivalence class of past spiking histories defining state A therefore includes all past spiking histories for which the most recent five symbols are 0, symbolically {*00000}. State B is the neuron’s state during the first msec of the refractory period. It is defined by the set of spiking histories {*1}. No spike can be emitted during a refractory period so the transition to state C is certain and the symbol emitted is always ‘0’. In this manner the neuron proceeds through states C to F and back to state A whereupon it is possible to spike again.
FIG. 1.
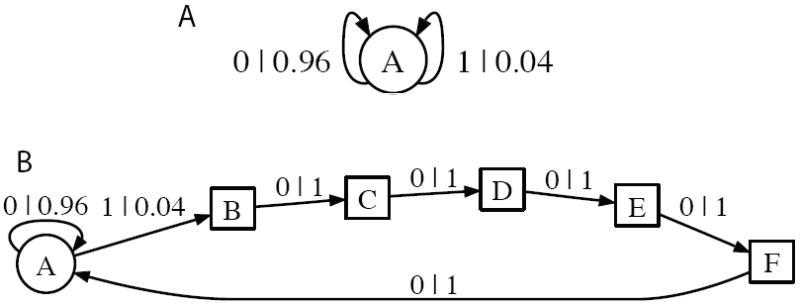
Two simple CSMs reconstructed from 200 sec of simulated spikes using CSSR. States are represented as the nodes of a directed graph. The transitions between states are labeled with the symbol emitted during the transition (1 = spike, 0 = no spike) and the probability of the transition given the origin state. (A) The CSM for a 40 Hz Bernoulli spiking process consists of a single state A which always transitions back to itself, emitting a spike with probability p = 0.04 per msec. (B) CSM for 40 Hz Bernoulli spiking process with a 5 msec refractory period imposed after each spike. State A again spikes with probability p = 0.04. Upon spiking the CSM transitions through a deterministic chain of states B–F (squares) which represent the refractory period. The increased structure of the refractory period requires a more complex representation.
The rest of this section is divided into four subsections. First, we briefly review the formal theory behind CSMs (for details, see Shalizi (2001); Shalizi & Crutchfield (2001)) and discuss why they can be considered a good choice for understanding the structural content of spike trains. Second, we describe the Causal State Splitting Reconstruction (CSSR) algorithm used to reconstruct CSMs from observed spike trains (Shalizi & Klinkner, 2004). We emphasize that CSSR requires no a priori knowledge of the structure of the CSM which is discovered from the spike train. Third, we discuss two different notions of spike train structure, namely statistical complexity and algorithmic information content. These two measures can be interpreted as different aspects of a spike train’s computational structure, and each can be related to the reconstructed CSM. Fourth and finally, we show how the reconstructed CSM can be used to predict spiking, measure the neural response and detect the influence of external stimuli.
A. Causal State Models
The foundation of the theory of causal states is the concept of a predictively sufficient statistics. A statistic, η, on one random variable, X, is sufficient for predicting another random variable, Y, when η(X) and X have the same information1 about Y, I[X; Y] = I[η(X); Y]. This holds if and only if X and Y are conditionally independent given η(X): ℙ(Y∣X, η(X)) = ℙ(Y∣η(X)). This is a close relative of the familiar idea of parametric sufficiency; in Bayesian statistics, where parameters are random variables, parametric sufficiency is a special case of predictive sufficiency (Bernardo & Smith, 1994). Predictive sufficiency shares all of parametric sufficiency’s optimality properties (Bernardo & Smith, 1994). However, a statistic’s predictive sufficiency depends only on the actual joint distribution of X and Y, not on any parametric model of that distribution. Again as in the parametric case, a minimal predictively sufficient statistic ε is one which is a function of every other sufficient statistic η, i.e., ε(X) = h(η(X)) for some h. Minimal sufficient statistics are the most compact summaries of the data which retain all the predictively-relevant information. A basic result is that a minimal sufficient statistic always exists and is (essentially) unique, up to isomorphism (Bernardo & Smith, 1994; Shalizi & Crutchfield, 2001).
In the context of stochastic processes, such as spike trains, ε is the minimal sufficient statistic of the history for predicting future of the process, . This statistic is the optimal predictor of the observations. The sequence of values of the minimal sufficient statistic, , is another stochastic process. This process is always a homogeneous Markov chain, whether or not the Xt process is (Knight, 1975; Shalizi & Crutchfield, 2001). Turned around, this means that the original Xt process is always a random function of a homogeneous Markov chain, whose latent states, named the causal states by Crutchfield & Young (1989), are optimal, minimal predictors of the future of the time series.
A causal state model or causal state machine is a stochastic automaton or HMM constructed so that its Markov states are minimal sufficient statistics for predicting the future of the spike train, and consequently can generate spike trains statistically identical to those observed. 2 Causal state reconstruction means inferring the causal states from the observed spike train. Following Crutchfield & Young (1989); Shalizi & Crutchfield (2001), the causal states can be seen as equivalence classes of spike-train histories which maximize the mutual information between the state(s) and the future of the spike train . Because they are sufficient, they predict the future of the spike train as well as it can be predicted from its history alone. Because they are minimal, the number of states or equivalence classes is as small as it can be without discarding predictive power.3
Formally, two histories, x− and y−, are equivalent when . The equivalence class of x− is [x−]. Define the function which maps histories to their equivalence classes:
The causal states are the possible values of ε, i.e., the equivalence classes; each corresponds to a distinct distribution for the future. The state at time t is . Clearly, ε(x−) is a sufficient statistic. It is also minimal, since if η is sufficient, then η(x−) = η(y−) implies ε(x−) = ε(y−). One can further show (Shalizi & Crutchfield, 2001, Theorem 3) that ε is the unique minimal sufficient statistic, meaning that any other must be isomorphic to it.
In addition to being minimal sufficient statistics, the causal states have some other important properties which make them ideal for quantifying structure (Shalizi & Crutchfield, 2001). (1) As mentioned, {St} is a Markov process, and one can write the observed process X as a random function of the causal state process, i.e., X has a natural hidden-Markov-model representation. (2) The causal states are recursively calculable; there is a function T such that St+1 = T(St, Xt+1) — see Appendix A. (3) CSMs are closely related to the “predictive state representations” of controlled dynamical systems (Littman et al., 2002); see Appendix C.
B. Causal State Splitting Reconstruction
Our goal is to find a minimal sufficient statistic for the spike train, which will form a hidden Markov model. As stated previously, the states of this model are equivalence classes of spiking histories . In practice, we need an algorithm which can both cluster histories into groups which preserve their conditional distribution of futures, and find the history length Λ at which the past may be truncated while preserving the computational structure of the spike train. The former is accomplished by the CSSR algorithm (Shalizi & Klinkner, 2004) for inferring causal states from data by building a recursive next-step-sufficient statistic.4 We do the latter by minimizing Schwartz’s Bayesian Information Criterion (BIC) over Λ.
To save space, we just sketch the CSSR algorithm here.5 CSSR starts by treating the process as an independent, identically-distributed sequence, with one causal state. It adds states when statistical tests show that the current set of states is not sufficient. Suppose we have a sequence of length N from a finite alphabet A of size k. We wish to derive from this an estimate ε̂ of the minimal sufficient statistic ε. We do this by finding a set Σ of states, each of which will be a set of strings, or finite-length histories. The function ε̂ will then map a history x− to whichever state contains a suffix of x− (taking “suffix” in the usual string-manipulation sense). Although each state can contain multiple suffixes, one can check (Shalizi & Klinkner, 2004) that the mapping ε̂ will never be ambiguous.
The null hypothesis is that the process is Markovian on the basis of the states in Σ,
| (1) |
for all a ∈ A. In words, adding an extra piece of history does not change the conditional distribution for the next observation. We can check this with standard statistical tests, such as χ2 or Kolmogorov-Smirnov. In this paper, we used a KS test of size α = 0.01.6 If we reject this hypothesis, we fall back on a restricted alternative hypothesis, that we have the right set of conditional distributions, but have matched them with the wrong histories. That is,
| (2) |
for some s* ∈ Σ, but . If this hypothesis passes a test of size α, then s* state to which we assign the history7. Only if the (2) is itself rejected do we create a new state, with the suffix .8
The algorithm itself has three phases. Phase I initializes Σ to a single state, which contains only the null suffix 0̸. (That is, 0̸ is a suffix of any string.) The length of the longest suffix in Σ is L; this starts at 0. Phase II iteratively tests the successive versions of the null hypothesis, Eq. 1, and L increases by one each iteration, until we reach some maximum length Λ. At the end of II, ε̂ is (approximately) next-step sufficient. Phase III makes ε̂ recursively calculable, by splitting the states until they have deterministic transitions. Under mild technical conditions (a finite true number of states, etc.), CSSR converges in probability on the correct CSM as N → ∞, provided only that Λ is long enough to discriminate all of the states. The error of the predicted distributions of futures , measured by total variation distance, decays as N−1/2. Section 4 of Shalizi & Klinkner (2004) details CSSR’s convergence properties. Comparisons of CSSR’s performance with that of more traditional expectation maximization based approaches can also be found in Shalizi & Klinkner (2004) as can time complexity bounds for the algorithm. Depending upon the machine used, CSSR can process an N = 106 time series in under a minute.
1. Choosing Λ
CSSR requires no a priori knowledge of the CSM’s structure, but does need a choice of of Λ; here pick it by minimizing the BIC of the reconstructed models over Λ, i.e.,
| (3) |
where ℒ is the likelihood, N is the data length and d is the number of model parameters, in our case the number of predictive states 9 BIC’s logarithmic-with-N penalty term helps keep the number of causal states from growing too quickly with increased data size, which is why we use it instead of the Akaike Information Criterion (AIC). Also, BIC is known to be consistent for selecting the order of Markov chains and variable-length Markov models (Csiszár & Talata, 2006), both of which are sub-classes of CSMs.
Writing the observed spike train as , and the state sequence as , the total likelihood of the spike train is
| (4) |
the sum over all possible causal state sequences of the joint probability of the spike train and the state sequence. Since the states update recursively, st+1 = T(st, xt+1), the starting state s0 and the spike train fix the entire state sequence . Thus the sum over state sequences can be replaced by a sum over initial states
| (5) |
with the state probabilities ℙ(S0 = si) coming from the CSM. By the Markov property,
| (6) |
Selecting Λ is now straightfoward: for each value of Λ, we build the CSM from the spike train, calculate the likelihood using Eq. 5 and 6, and pick the value, and CSM, minimizing Eq. 3. We try all values of Λ up to a model-independent upper bound. For a wide range of stochastic processes, Marton & Shields (1994) showed that the length m of subsequences for which probabilities can be consistently and non-parametrically estimated can grow as fast as log N/h, where h is the entropy rate, but no faster. CSSR estimates the distribution of the next symbol given the previous Λ symbols, which is equivalent to estimating joint probabilities of blocks of length m = Λ + 1. Thus Marton and Shield’s result limits the usable values of Λ:
| (7) |
Using Eq. 7 requires the entropy rate h. The latter can either be upper bounded as the log of the alphabet size (here, log 2 = 1), or by some other, less pessimistic, estimator of the entropy rate (such as the output of CSSR with Λ = 1). Use of an upper bound on h results in a conservative maximum value for Λ. For example, a 30 minute experiment with 1 msec time bins lets us use at least Λ ≈ 20 by the most pessimistic estimate of h = 1; the actual maximum value of Λ may be much larger. We use Λ ≤ 25 in this paper but see no indication that this can’t be extended further, if need be.
2. Condensing the CSM
For real neural data, the number of causal states can be very large — hundreds or more. This creates an interpretation problem, if only because it is hard to fit such a CSM on a single page for inspection. We thus developed a way to reduce the full CSM while still accounting for most of the spike train’s structure. Our “state culling” technique found the least-probable states and selectively removed them, appropriately redirecting state transitions and reassigning state occupation probabilities. By keeping the most probable states, we focus on the ones which contribute the most to the spike train’s structure and complexity. Again, we used BIC as our model selection criterion.
First, we sorted the states by probability, finding the least probable state (“remove” state) with a single incoming edge from a state (its “ancestor”) with outgoing transitions to two different states, the remove state and a second, “keep” state. We redirected both of the ancestor’s outgoing edges to the keep state. Second, we reassigned the remove state’s outgoing transitions to the keep state. If the outgoing transitions from the keep state were still deterministic (at most a single 0 emitting edge and a single 1 emitting edge), we stopped. If the transitions were non-deterministic, we merged states reached by emitting 0s with each other (likewise those reached by 1s), repeating this until termination. Third, we checked that there existed a state sequence of the new model which could generate the observed spikes. If there was, we accepted the new CSM. If not, we rejected the new CSM and chose the next lowest probability state from the original CSM to remove.
This culling was iterated until removing any state made it impossible for the CSM to generate the spike train. At each iteration, we calculated BIC (as described in the previous section), and ultimate chose the culled CSM with the minimum BIC. This gave a culled CSM for each value of Λ; the final one we used was chosen after also minimizing BIC over Λ. The CSMs shown below in the results section paper result from this minimizing of BIC over Λ and state culling.
3. ISI Bootstrapping
While we do model selection with BIC, we also want to do model checking or adequacy-testing. For the most part, we do this by using the CSM to bootstrap point-wise confidence bounds on the interspike interval (ISI) distribution, and checking their coverage of the empirical ISI distribution. Because this distribution is not used by CSSR in reconstructing the CSM, it provides a check on the latter’s ability to accurately describe the spike-train’s statistics.
Specifically, we generated confidence bounds as follows. To simulate one spike train, we picked a random starting state according to the CSM’s inferred state-occupation probabilities, and then ran the CSM forward for N time-steps, N being the length of the original spike train. This gives a binary time-series, where a “1” stands for a spike and a “0” for no-spike, and gave us a sample of inter-spike intervals from the CSM. This in turn gave an “empirical” ISI distribution. Repeated over 104 independent runs of the CSM, and taking the 0.005 and 0.995 quantiles of the distributions at each ISI length, gives 99% pointwise confidence bounds. (Pointwise bounds are necessary because of the ISI distribution often modulates rapidly with ISI length.) If the CSM is correct, the empirical ISI will, by chance, lie outside the bounds at ≈ 1% of the ISI lengths.
If we split the data into training and validation sets, a CSM reconstructed from the training set can be used to bootstrap ISI confidence bounds, which can be compared to the ISI distribution of the test set. We discuss this sort of of cross validation, as well as an additional test based on the time rescaling theorem, in Appendix B.
C. Complexity and Algorithmic Information Content
The algorithmic information content of a sequence is the length of the shortest complete (input-free) computer program which will output exactly and then halt (Cover & Thomas, 1991) 10. In general, is strictly uncomputable, but when is the realization of a stochastic process , the ensemble-averaged algorithmic information essentially coincides with the Shannon entropy (“Brudno’s theorem”; see Badii & Politi (1997)), reflecting the fact that both are maximized for completely random sequences (Cover & Thomas, 1991). Both the algorithmic information and the Shannon entropy can be conveniently written in terms of a minimal sufficient statistic Q:
| (8) |
The equality holds because Q is a function of , so .
The key to determining a spike train’s expected algorithmic information is thus to find a minimal sufficient statistic. By construction, causal state models provide exactly this; a minimal sufficient statistic for is the state sequence (Shalizi & Crutchfield, 2001). Thus the ensemble-averaged algorithmic information content, dropping terms o(n) and smaller, is
| (9) |
Going from the first to the second line uses the causal states’ Markov property. Assuming stationarity, Eq. 9 becomes
| (10) |
This separates terms representing structure from those representing randomness.
The first term in Eq. 10 is the complexity, C, of the spike-generating process (Crutchfield & Young, 1989; Grassberger, 1986; Shalizi et al., 2004).
| (11) |
C is the entropy of the causal states, quantifying the structure present in the observed spikes. This is distinct from the entropy of the spikes themselves, which quantifies not their structure but their randomness (and is approximated by the other two terms). Intuitively, C is the (time-averaged) amount of information about the past of the system which is relevant to predicting its future. For example, consider again the IID 40 Hz Bernoulli process of Figure 1 A. With p = 0.04, this has an entropy of 0.24 bits/msec, but because it can be described by a single state, the complexity is zero. (That state emits either a “0” or a “1”, with respective probabilities 0.96 and 0.04, but either way the state transitions back to itself.) In contrast, adding a 5 ms refractory period to the process means six states are needed to describe the spike trains (Figure 1 B). The new structure of the refractory period is quantified by the higher complexity, C = 1.05 bits.
The second and third terms in Eq. 10 both describe randomness, but of distinct kinds. The second term, the internal entropy rate J, quantifies the randomness in the state transitions; it is the entropy of the next state given the current state.
| (12) |
This is the average number of bits per time-step needed to describe the sequence of states the process moved through (beyond those given by C). The last term in Eq. 10 accounts for any residual randomness in the spikes which is not captured by the state transitions.
| (13) |
For long trains, the entropy of the spikes, , is approximately the sum of these two terms, . Computationally, C represents the fixed generating structure of the process, which needs to be described once, at the beginning of the time series, and n(J + R) represents the growing list of details which pick out a particular time series from the ensemble which could be generated; this needs, on average, J + R extra bits per time-step. (Cf. the “sophistication” of Gács et al. (2001).)
Consider again the 40 Hz Bernoulli process. As there is only one state, the process always stays in that state. Thus the entropy of the next state J = 0. However, the state sequence yields no information about the emitted symbols (the process is IID), so the residual randomness R = 0.24 bits/msec — as it must be, since the total entropy rate is 0.24 bits/msec. In contrast, the states of the 5 msec refractory process are informative about the process’s future. The internal entropy rate J = 0.20 bits/msec and the residual randomness R = 0. All of the randomness is in the state transitions, because they uniquely define the output spike train. The randomness in the state transition is confined to state A, where the process “decides” whether it will stay in A, emitting no spike, or emit a spike and go to B. The decision needs, or gives, 0.24 bits of information. The transitions from B through F and back to A are fixed and contribute 0 bits, reducing the expected J.
The important point is that the structure present in the refractory period makes the spike train less random, lowering its entropy. Averaged over time, the mean firing rate of the process is p = 0.0333. Were the spikes IID, the entropy rate would be 0.21 bits/msec, but in fact J + R = 0.20 bits/msec. This is because a minimal description of a long sequence , the generating process only needs to be described once (C), while the internal entropy rate and randomness need to be updated at each time step (n(J + R)). Simply put, a complex, structured spike train can be exactly described in fewer bits than one which is entirely random. The CSM lets us calculate this reduction in algorithmic information, and quantify the structure by means of the complexity.
D. Time-Varying Complexity and Entropies
The complexity and entropy are ensemble-averaged quantities. In the previous section the ensemble was the entire time series, and the averaged complexity and entropies were analogous to a mean firing rate. The time-varying complexity and entropies are also of interest, for example their variation after stimuli. A peri-stimulus time histogram (PSTH) shows how the firing probability varies with time; the same idea works for the complexity and entropy.
Since the states form a Markov chain, and any one spike train stays within a single ergodic component, we can invoke the ergodic theorem (Gray, 1988), and (almost surely) assert that
| (14) |
for arbitrary integrable functions f(St, St+1, Xt+1).
In the case of the mean firing rate, the function to time-average is l(t) ≡ Xt+1. For the time averaged-complexity, internal entropy and residual randomness, the functions (respectively c, j and r) are
| (15) |
and time-varying entropy h(t) = j(t) + r(t).
The PSTH averages over an ensemble of stimulus presentations, rather than time:
| (16) |
with M being number of stimulus presentations, and t re-set to zero at each presentation. Analogously, the “PSTH” of the complexity is
| (17) |
For the entropies, replace c with j, r or h as appropriate. Similar calculations can be made with any well-defined ensemble of reference times, not just stimulus presentations; we will also calculate c and the entropies as functions of the time since the latest spike.
We can estimate the error these time-dependent quantities as the standard error of the mean as a function of time, where st is the sample standard deviation in each time bin t and M is the number of trials. The probabilities appearing in the definitions of c(t), j(t), r(t) also have some estimation errors, either because of sampling noise or, more interestingly, because the ensemble is being distorted by outside influences. The latter creates a gap between their averages (over time or stimuli) and what the CSM predicts for those averages. In the next section, we explain how to use this to measure the influence of external drivers.
E. The Influence of External Forces
If we know that St = s, the CSM predicts that firing probability is λ(t) = ℙ(Xt+1 = 1∣St = s). By means of the CSM’s recursive filtering property (Appendix A), once a transient regime has passed, the state is always known with certainty. Thereafter, the CSM predicts what the firing probability should be at all times, incorporating the effects of the spike train’s history. As we show in the next section, these predictions give good matches to the actual response function in simulations where the spiking probability depends only on the spike history. But real neurons’ spiking rates generally also depend on external processes, e.g., stimuli. As currently formulated, the CSM is (or, rather, converges on) the optimal predictor of the future of the process given its own past. Such an “output only” model does not represent the (possible) effects of other processes, and so ignores external covariates and stimuli. Presently, determining the precise form of spike trains’ responses to external forces is best left to parametric models.
However, we can use output-only CSMs to learn something about the computation: the PSTH-calculated entropy rate HPSTH(t) = JPSTH(t) + RPSTH(t) quantifies the extent to which external processes drive the neuron. (The PSTH subscript is henceforce supressed.) Suppose we know the true firing probability λtrue(t). At each time step, the CSM predicts the firing probability λCSM(t). If λCSM(t) = λtrue(t), then the CSM correctly describes the spiking and the PSTH entropy rate is
| (18) |
However, if λCSM(t) ≠ λtrue(t), then the CSM mis-describes the spiking, because it neglects the influence of external processes. Simply put, the CSM has no way of knowing when the stimuli happen. The PSTH entropy rate calculated using the CSM becomes
| (19) |
Solving λtrue(t),
| (20) |
The discrepancy between λCSM(t) and λtrue(t) indicates how much of the apparent randomness in the entropy rate is actually due to external driving. The true PSTH entropy rate Htrue(t) is
| (21) |
The difference between HCSM(t) and Htrue(t) quantifies, in bits, the driving by external forces as a function of the time since stimulus presentation.
| (22) |
This stimulus-driven entropy ΔH is the relative entropy or Kullback-Leibler divergence D(Xtrue ∥XCSM) between the true distribution of symbol emissions and that predicted by the CSM. Information-theoretically, this relative entropy is the error in our prediction of the next state due to assuming the neuron is running autonomously when it’s actually externally driven. Since every state corresponds to a distinct distribution over future behavior, this is our error in predicting the future due to ignorance of the stimulus.11
III. RESULTS
We now present a few examples. (All of them use a time-step of 1 millisecond.) We begin with idealized model neurons to illustrate our technique. We recover CSMs for the model neurons using only the simulated spike trains as input to our algorithms. From the CSM we calculate the complexity, entropies, and, when appropriate, stimulus-driven entropy (Kullback-Leibler divergence between the true and CSM predicted firing probabilities) of each model neuron. We then analyze spikes recorded in vivo from a neuron in layer II/III of rat SI (barrel) cortex. We use spike trains recorded both with and without external stimulation of the rat’s whiskers. See Andermann & Moore (2006) for experimental details.
A. Model neuron with a “soft” refractory period and bursting
We begin with a refractory, bursting model neuron, whose spiking rate depends only on the time since the last spike. The baseline rate is 40 Hz. Every spike is followed by a 2 msec “hard” refractory period, during which spikes never occur. The spiking rate then rebounds to twice its baseline, to which it slowly decays. (See dashed line in the first panel of Figure 3 B.) This history dependence mimics that of a bursting neuron, and is, intuitively, more complex than the simple refractory period of the model in Figure 1.
FIG. 3.
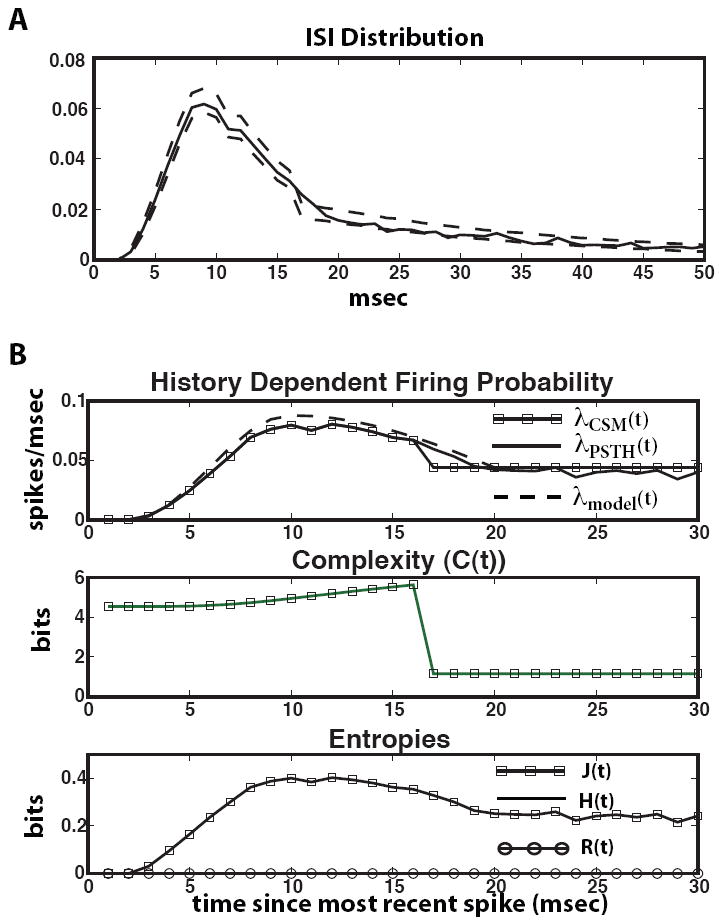
“Soft” refractory and bursting model ISI distribution and time dependent firing probability, complexity and entropies. (A) ISI distribution and 99% confidence bounds bootstrapped from the CSM. (B) First panel: Firing probability as a function of time since the most recent spike. Line with squares = firing probability predicted by CSM. Solid line = firing probability deduced from PSTH. Dashed line = model firing rate used to generate spikes. Second panel: Complexity as a function of time since most recent spike. Third panel: Entropies as a function of time since most recent spike. Squares = internal entropy rate, circles = residual randomness, solid line = entropy rate. (overlaps squares)
Figure 2 shows the 17-state CSM reconstructed from a 200 second spike train (at 1 msec resolution) generated by this model. It has a complexity of C = 3.16 bits (higher than that of the model in Figure 1, as anticipated), an internal entropy rate of J = 0.25 bits/msec and a residual randomness of R = 0 bits/msec. The CSM was obtained with Λ = 17 (selected by BIC). Figure 3 A shows how the 99% ISI bounds bootstrapped from the CSM enclose the empirical ISI distribution, with the exception of one short segment.
FIG. 2.
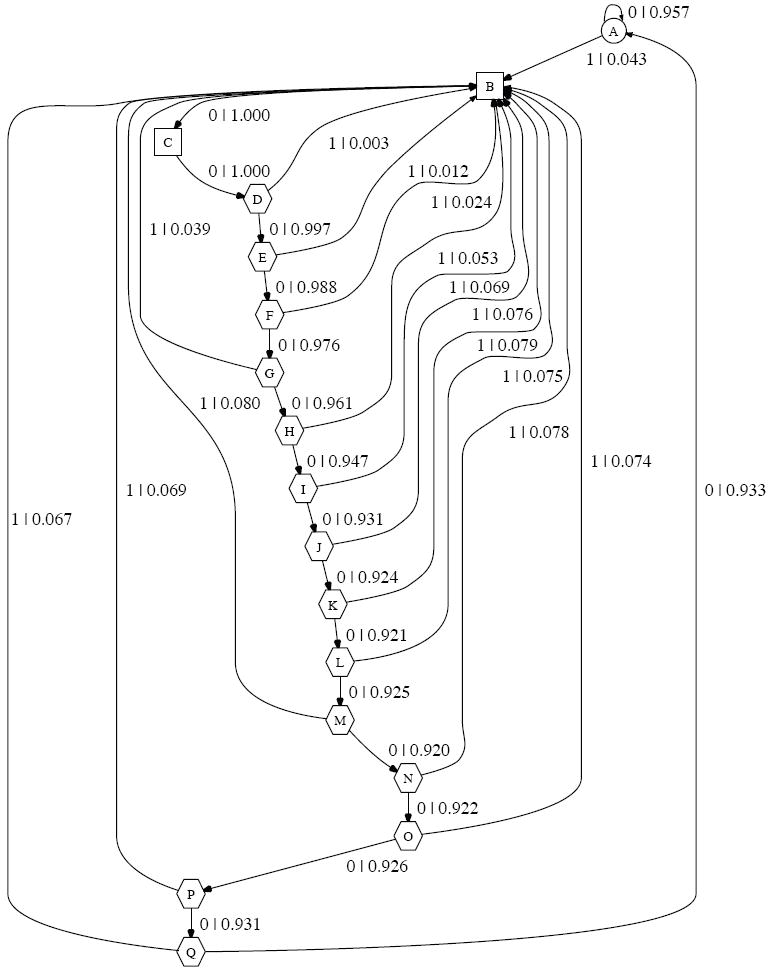
CSM reconstructed from a 200 sec simulated spike train with a “soft” refractory/bursting structure. C = 3.16, J = 0.25, R = 0. State A (circle) is the baseline 40 Hz spiking state. Upon emitting a spike the transition is to state B. States B and C (squares) are “hard” refractory states from which no spike may be emitted. States D through Q (hexagons) compromise a refractory/bursting chain from which if a spike is emitted the transition is back to state B. Upon exiting the chain the CSM returns to the baseline state A.
The CSM is easily interpreted. State A is the baseline state. When it emits a spike, the CSM moves to state B. There are then two deterministic transitions, to C and then D, which never emit spikes; this is the hard 2 msec refractory period. Once in D it is possible to spike again, and if that happens, the transition is back to state B. However, if no spike is emitted, the transition is to state E. This is repeated, with varying firing probabilities, as states E through Q are traversed. Eventually, the process returns to A and so to baseline.
Figure 3 B plots the firing rate, complexity, and internal entropies as functions of the time since the last spike conditional on no subsequent spike emission. This lets us compare the firing rate predicted by the CSM (solid line squares) to the specification of the model which generated the spike train (dashed line) and a PSTH calculated by triggering on the last spike (solid line). Except at 16 and 17 msec post spike, the CSM-predicted firing rate agrees with both the generating model and the PSTH. The discrepancy arises because the CSM only discerns the structure in the data, and most of the ISIs are shorter than 16 msec. There is much closer agreement between the CSM and the PSTH if firing rates are plotted as a function of time since a spike without conditioning on no subsequent spike emission (not shown).
The second and third panels of Figure 3 plot the time-dependent complexity and entropies. The complexity is much higher after the emission of a spike than during baseline, because the states traversed (B-Q) are less probable, and represent the additional structures of refractoriness and bursting. The time-dependent entropies (third panel) show that just after a spike, the refractory period imposes temporary determinism on the spike train, but burstiness increases the randomness before the dynamics return to the baseline state.
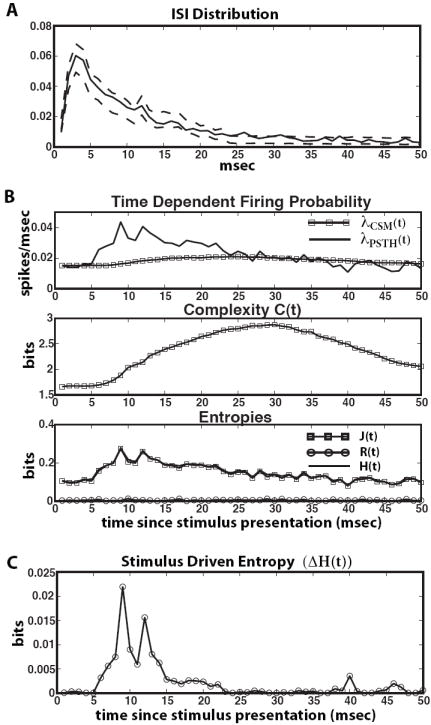
B. Model neuron under periodic stimulation
Figure 4 shows the CSM for a periodically-stimulated model neuron. This CSM was reconstructed from 200 seconds of spikes with a baseline firing rate of 40 Hz (p = 0.04). Each second, the firing rate rose over the course of 5 msec to p = 0.54 spikes/msec, falling slowly back to baseline over the next 50 msec. This mimics the periodic presentation of a strong external stimulus. (The exact inhomogeneous firing rate used was λ(t) = 0.93[e−t/10− e−t/2] + 0.04 with t in msec. See Figure 5 B, first panel, dashed line.) In this model, the firing rate does not directly depend on the spike train’s history, but there is a sort of history dependence in the stimulus time-course, and this is what CSSR discovers.
FIG. 4.
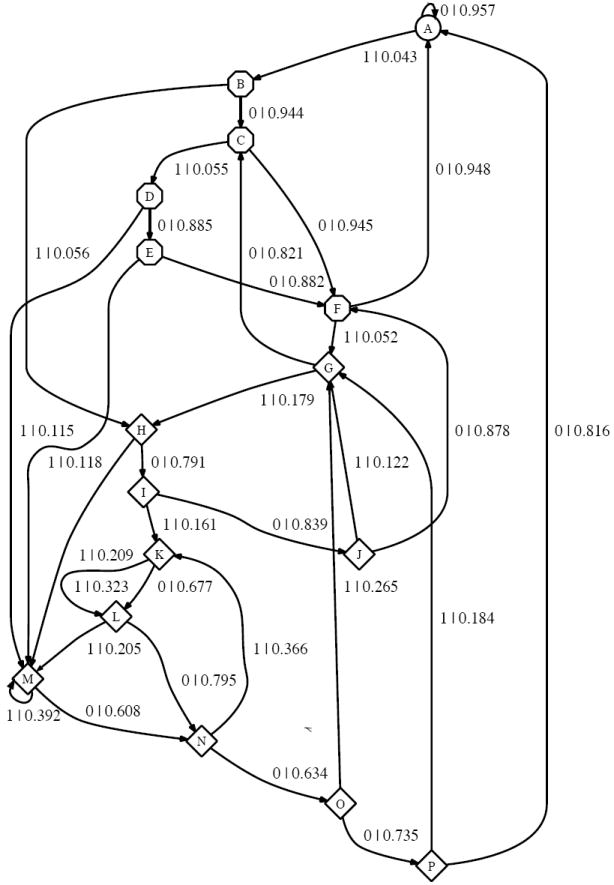
16-state CSM reconstructed from 200 sec of simulation of periodically-stimulated spiking. C = 0.89, J = 0.27, R = 0.0007. State A is the baseline state. States B through F (octagons) are “decision” states in which the CSM evaluates whether a spike indicates a stimulus or was spontaneous. Two spikes within 3 msec cause the CSM to transition to states G through P, which represent the structure imposed by the stimulus. If no spikes are emitted within 5 (often fewer) sequential msec, the CSM goes back to the baseline state A.
FIG. 5.
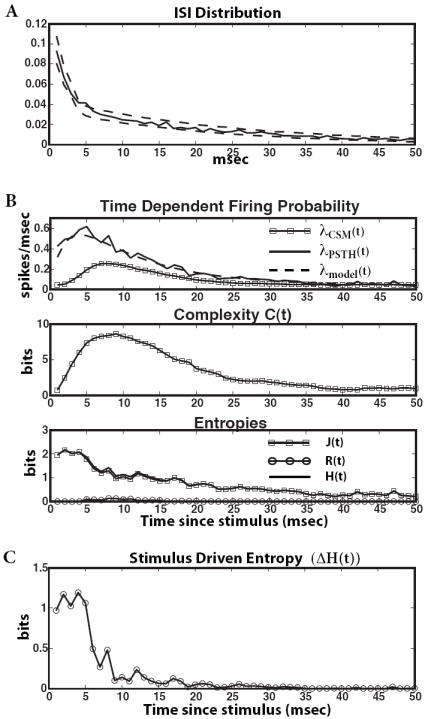
Stimulus model ISI distribution and time-dependent complexity and entropies. (A) ISI distribution and 99% confidence bounds. (B) First panel: Firing probability as a function of time since stimulus presentation. Second panel: Time dependent complexity. Third panel: time-dependent entropies. (C) The stimulus-driven entropy is > 1 bit, indicating strong external drive. See text for discussion.
BIC selected Λ = 7, giving a 16 state CSM with C = 0.89 bits, J = 0.27 bits/msec and R = 0.0007 bits/msec. The baseline is again state A and if no spike is emitted then the process stays in A. Spikes are either spontaneous and random, or stimulus-driven. Because the stimulus is external, it is not immediately clear which of these two causes produced a given spike. Thus, if a spike is emitted, the CSM traverses states B through F, deciding, so to speak, whether or not the spike is due to a stimulus. If two spikes happen within 3 msec of each other, then the CSM decides that it is being stimulated and goes to one of states G, H or M. States G through P represent the response to the stimulus. The CSM moves between these states until no spike is emitted for 3 msec, when it returns to the baseline, A.
The ISI distribution from the CSM matches that from the model (Figure 5 A). However, because the stimulus doesn’t depend on spike train’s history, the CSM makes inaccurate predictions during stimulation. The first panel of Figure 5 B plots the firing rate as a function of time since stimulus presentation, comparing the model (dashed line) and the PSTH (solid line) with the CSM’s prediction (line with squares). The discrepancy between these is due to the CSM having no way of knowing that an external stimulus has been applied until several spikes in a row have been emitted (represented, as we just say, by states B–F)12. Despite this, c(t) shows that something more complex than simple random firing is happening (second panel of Figure 5 B), as do j(t) and r(t) (third panel). Further, something is clearly wrong with the entropy rate, because it should be upper-bounded by h = 1 bit/msec (when p = 0.5). The fact that h(t) exceeds this bound indicates an external force, not fully captured by the CSM, is at work.
As discussed in Methods (§II.E), drive from the stimulus can be quantified with a relative entropy (Figure 5 C). Stimuli are presented at t = 1 msec, where ΔH(t) > 1 bit. It is not until ≈ 25 msec post-stimulus that ΔH(t) ≈ 0 and the CSM once again correctly describes the internal entropy rate. Thus, as expected, the stimulus strongly influences neuronal dynamics immediately after its presentation. The true internal entropy rate Htrue(t) is slightly less than 1 bit/msec shortly after stimulation, when the true spiking rate has a maximum of pmax = 0.54. The fact that the CSM gives an inaccurate value for J actually lets us find the number of bits of information gain supplied by the stimulus, e.g., ΔH > 1 bit immediately after the stimulus is presented.
C. Spontaneously Spiking Barrel Cortex Neuron
We reconstructed a CSM from 90 seconds of spontaneous (no vibrissa deflection) spiking recorded from a layer II/III FSU barrel cortex neuron. CSSR, using Λ = 21, discovered a CSM with 315 states, a complexity of C = 1.78 bits, and internal entropy rate of J = 0.013 bits/msec. After state culling (§II.B.2), the reduced CSM, plotted in Figure 6, has 14 states, C = 1.02, J = 0.10 bits/msec, and residual randomness of R = 0.005 bits/msec. We focus on the reduced CSM from this point onwards.
FIG. 6.
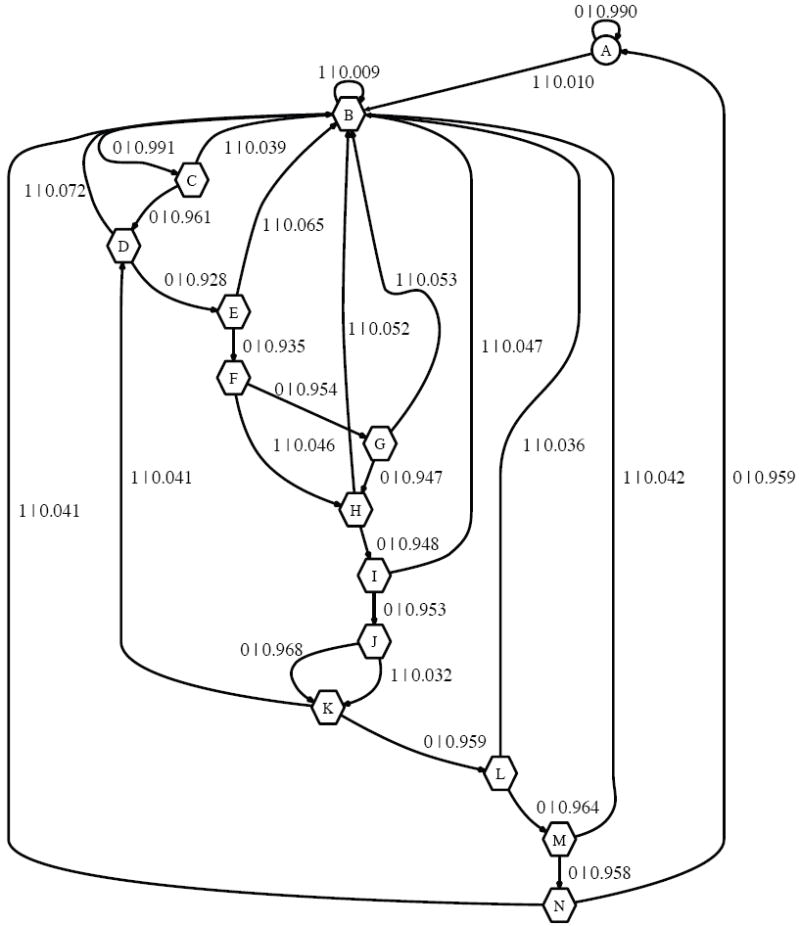
14-state CSM reconstructed from 90 sec of spiking recorded from a spontaneously spiking (no stimulus) neuron located in layer II/III of rat barrel cortex. C = 1.02, J = 0.10, R = 0.005. State A (circle) is baseline 10 Hz spiking. States B through N comprise a refractory/bursting chain similar to, but with a somewhat more intricate structure than, that of the model neuron in Figure 2
This CSM resembles that of the spontaneously-firing model neuron of §III.A and Fig. 2. The complexity and entropies are lower than those of our model neuron because the mean spike rate is much lower, and so simple descriptions suffice most of the time. (Barrel cortex neurons exhibit notoriously low spike rates, especially during anesthesia.) There is a baseline state A which emits a spike with probability p = 0.01, i.e., 10 Hz. When a spike is emitted, the CSM moves to state B and then on through the chain of states C through N, return to A if no spike is subsequently emitted. However, the CSM can emit a second or even third spike after the first, and indeed this neuron displays spike doublets and triplets. In general, emitting a spike moves the CSM to B, with some exceptions that show the structure to be more intricate than the model neuron’s.
Figure 7 A shows the CSM’s 99% confidence bounds almost completely enclosing the empirical ISI distribution. The first panel of Figure 7 B plots the history-dependent firing probability predicted by the CSM as a function of the time since the latest spike, according to both the PSTH and the CSM’s prediction. They are highly similar in the first 13 msec post-spike, indicating that the CSM gets the spiking statistics right in this epoch. The CSM and PSTH the diverge after this, for two reasons. First, as with the model neuron, there are few ISIs of this length. Most of the ISIs are either shorter, due to the nueron’s burstiness, or much longer, due to the low baseline firing rate. Secondly, 90 seconds is not very much data. We show in Figure 10 that a CSM reconstructed from a longer spike train does capture all of the structure. We present the results of this shorter spike train to emphasize that, as a non-parametric method, CSSR only uncovers the statistical structure in the data, no more, no less.
FIG. 7.
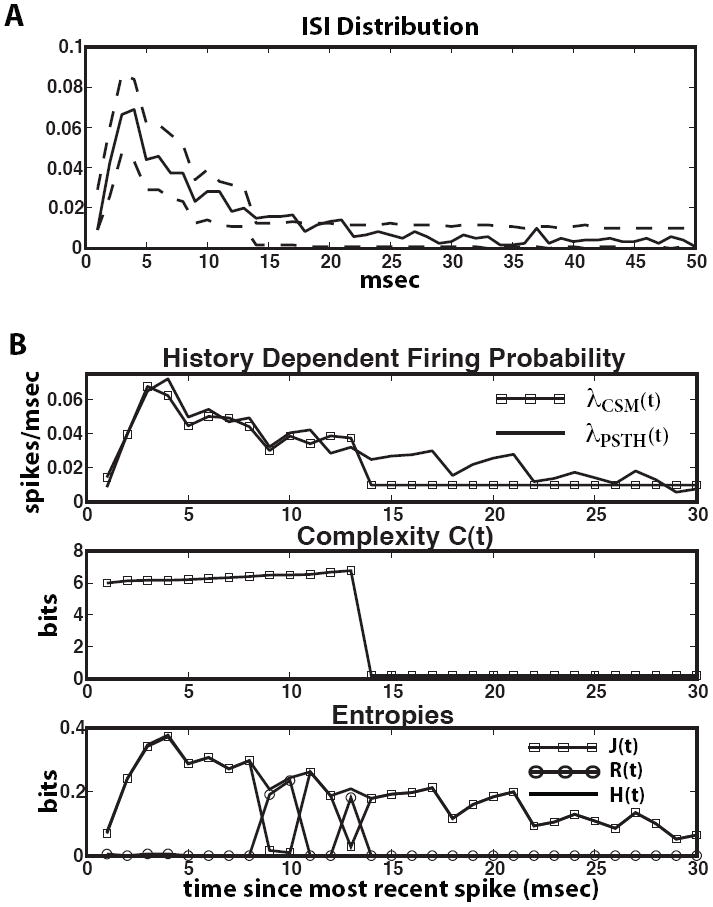
Spontaneously spiking barrel cortex neuron. (A) ISI distribution and 99% bootstrapped confidence bounds. (B) First panel: Time dependent firing probability as a function of time since most recent spike. See text for explanation of discrepancy between CSM and PSTH spike probabilities. Second Panel: Complexity as a function of time since most recent spike. Third Panel: Entropy rates as a function of time since most recent spike.
FIG. 10.
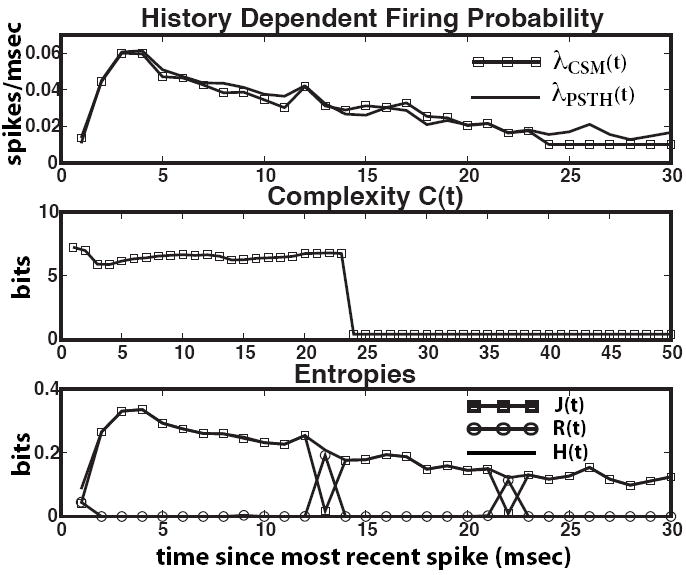
Firing probability, complexity and entropies of the stimulated barrel cortex neuron as a function of time since the most recent spike.
Finally, the second and third panels of Figure 6 B show, respectively, the complexity and entropies as functions of the time since the latest spike. As with the model of §III.A, the structure in the process occurs after spiking, during the refractory and bursting periods. This is when the complexity is largest, and also when the entropies vary most.
D. Periodically Stimulated Barrel Cortex Neuron
We reconstructed CSMs from 335 seconds of spike trains taken from the same neuron used above, but recorded while it was being periodically stimulated by vibrissa deflection. BIC selected Λ = 25, giving the 29-state CSM shown in Figure 8. (Before state culling, the original CSM had 1916 states, C = 2.55 and J = 0.11.) The reduced CSM has a complexity of C = 1.97 bits, an internal entropy rate of J = 0.10 bits/msec, and a residual randomness of R = 0.005 bits/msec. Note that C is higher when the neuron is being stimulated as opposed to when it is spontaneously firing, indicating more structure in the spike train.
FIG. 8.
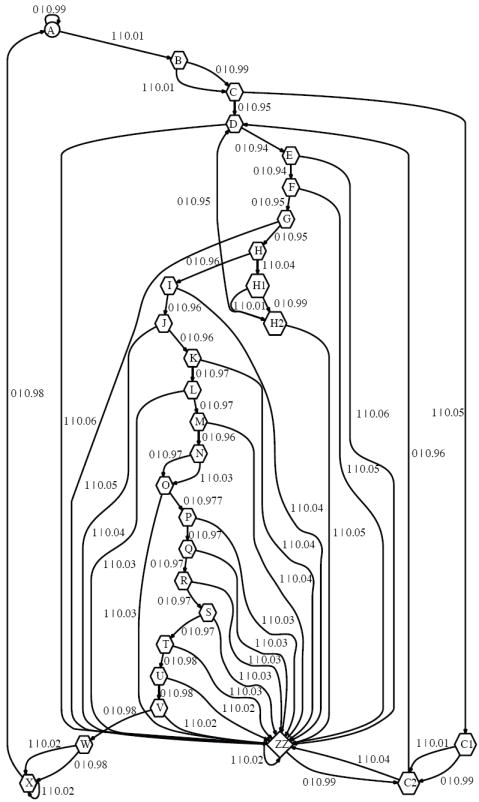
29-state CSM reconstructed from 335 seconds of spikes recorded from a layer II/III barrel cortex neuron undergoing periodic (125 msec inter-stimulus interval) stimulation via vibrissa deflection. C = 1.97, J = 0.11, R = 0.004. Most of the states are devoted to refractory/bursting behavior, however states “C1”, “C2” and “ZZ” represent the structure imposed by the external stimulus. See text for discussion.
While at first the CSM may seem to only represents history-dependent refractoriness and bursting, ignoring the external stimulus, this is not quite true. Once again, there is a baseline state A, and most of the other states (B–X) comprise a refractory/bursting chain, like this neuron has during spontaneous firing. However, the transition upon A emitting a spike is not back to B and then down the chain again, but to either state C1, and subsequently C2, or more often to state ZZ. These three states represent the structure induced by the external stimulus, as we saw with the model stimulated neuron of §III.B and Figure 4. (The state ZZ is comparable to the state M of the model stimulated neuron: both loop back to themselves if they emit a spike.) Three states are enough because, in this experiment, barrel cortex neurons spike extremely sparsely, 0.1–0.2 spikes per stimulus presentation.
Figure 9 A plots the ISI distribution, nicely enclosed by the bootstrapped confidence bounds. Figure 9 B shows the firing rate, complexity and entropies as functions of the time since stimulus presentation (averaged over all presentations). These plots look much like those in Figure 7 B. However, there is a clear indication that something more complex takes place after stimulation: the CSM’s firing-rate predictions are wrong. The stimulus-driven entropy ΔH turns out to be as large as 0.02 bits within 5–15 msec post-stimulus. This agrees with the known ≈ 5–10 msec stimulus propagation time between vibrissae and barrel cortex (Andermann & Moore, 2006). The reason that ΔH is so much smaller for the real neuron than the stimulated model neuron of §III.B is that the former’s firing rate is much lower. Although the firing rate post-stimulus can be almost twice as large as the CSM’s prediction, the actual rate is still low, max λ(t) ≈ 0.04 spikes/msec. Most of the time the neuron does not spike, even when stimulated, so on average, the stimulus provides little information per presentation. For completeness, Figure 10 shows the spike probability, complexity and entropies as functions of the time since the latest spike. Averaged over this ensemble, the CSM’s predictions are highly accurate.
FIG. 9.
Stimulated barrel cortex neuron ISI distribution and time-dependent complexity and entropies. (A) ISI distribution and 99% confidence bounds. (B) First panel: Firing probability as a function of time since stimulus presentation. Second panel: Time-dependent complexity. Third panel: time-dependent entropies. (C) The stimulus driven entropy (maximum of 0.02 bits/msec) is low because the number of spikes per stimulus (≈ 0.1 – 0.2) is very low and hence the stimulus does not supply much information.
IV. DISCUSSION
The goal of this paper was to present methods for determining the structural content of spike trains while making minimal a priori assumptions as to the form which that structure takes. We use the CSSR algorithm to build minimal, optimally predictive hidden Markov models (CSMs) from spike trains, Schwartz’s Bayesian Information Criterion to find the optimal history length Λ of the CSSR algorithm, and bootstrapped confidence bounds on the ISI distribution from the CSM to check goodness-of-fit. We demonstrated how CSMs can estimate a spike train’s complexity, thus quantifying its structure, and its mean algorithmic information content, quantifying the minimal computation necessary to generate the spike train. Finally we showed how to quantify, in bits, the influence of external stimuli upon the spike-generating process. We applied these methods both to simulated spike trains, for which the resulting CSMs agreed with intuition, and to real spike trains recorded from a layer II/II rat barrel cortex neuron, demonstrating increased structure, as measured by the complexity, when the neuron was being stimulated.
We are unaware of any other practical techniques for quantifying the complexity and computational structure of a spike train as we define them. Intuitively, neither random (Poisson), nor highly ordered (e.g., strictly periodic, as in Olufsen et al. (2003)) spike trains should be thought of as complex since they do not possess structure requiring a sophisticated program to generate. Instead, complexity lies between order and disorder (Badii & Politi, 1997), in the non-random variation of the spikes. Higher complexity means a greater degree of organization in neural activity than would be implied by random spiking. It is the reconstruction of the CSM through CSSR which allows us to calculate the complexity.
Our definition of complexity stands in stark contrast to other complexity measures which assign high values to highly disordered systems. Some of these, such as Lempel Ziv complexity (Amigo et al., 2002, 2004; Jimenez-Montano et al., 2002; Szczepanski et al., 2004) and context free grammar complexity (Rapp et al., 1994) have been applied to spike trains. However, both of these are measures of the amount of information required to reproduce the spike train exactly, and take on very high values for completely random sequences. These “complexity” measures are therefore much more similar to total algorithmic information content and even to the entropy rate than to our sort of complexity.
Our measure of complexity is the entropy of the distribution of causal states. This has the desired property of being maximized for structured, rather than ordered or disordered systems, because the causal states are defined statistically, as equivalence classes of histories conditioned on future events. Other researchers have also calculated complexity measures which are entropies of state distributions, but have defined their states differently. Amigo et al. (2002) uses the observables (symbol strings) present in the spike train to define a k-th order Markov process and calls each individual length k string which appears in the spike train a state. Gorse and Taylor (1990) similarly use single suffix symbol strings to define the states of a Markov process. In both cases, IID Bernoulli sequences could exhibit up to 2k states (in long enough sequences), and possess an extremely high “complexity”. However, all of these states make the same prediction for the future of the process. The minimal representation is a single causal state, a CSM with a complexity of zero.
It should be noted that there are also many works which model spike trains using HMMs, but in which the hidden states represent macro-states of the system (awake/asleep, Up/Down, etc.), and spiking rates are modeled separately in each macro-state (Abeles et al., 1995; Achtman et al., 2007; Chen et al., 2008; Danoczy et al., 2004; Jones et al., 2007). Although the graphical representation of such HMMs may look like those of CSMs, the two kinds of states have very different meanings. Finally, there are also state space methods which model the dynamical state of the system as a continuous hidden variable, the most well known of which is the linear Gaussian model with Kalman filtering. These have been extensively applied to neural encoding and decoding problems (Eden et al., 2007; Smith et al., 2004; Srinivasan et al., 2007). Interestingly, for a univariate Gaussian ARMA model in state-space form, the Kalman filter’s one-step-ahead prediction and mean-squared prediction error are, jointly, minimal-sufficient for next-step prediction, and since they can be updated recursively they in fact constitute the minimal sufficient statistic, and hence the causal state in this special case.
Neurons are driven by their afferent synapses. Although as discussed in Appendix C, there is a parallel “transducer” formalism for generating CSMs which take external influences into account, this is not yet computationally implemented, and our current approach reconstructs CSMs only from the spike train. Since the history of the neuron under study is typically connected with the history of the network in which it is located, this CSM will, in general, reflect more than a neuron’s internal biophysical properties. Nonetheless, in both our model neurons and in the real barrel cortex neuron, states not interpretable as simple refractoriness or bursting appeared when a stimulus was present, proving we can detect stimulus-driven complexity. Further, we showed that the CSM can be used to determine the extent (in bits) to which a neuron is driven by external stimuli.
The methods presented here complement more established modes of spike-train analysis, which have different goals. Parametric methods, such as PSTHs or maximum likelihood estimation (Brown et al., 2004; Truccolo et al., 2005) generally focus on determining a neuron’s firing rate (mean, instantaneous or history-dependent), and on how known external covariates modulate that rate. They have the advantage of requiring less data than non-parametric methods such as CSSR, but the disadvantage, for our purposes, of imposing the structure of the model at the outset. When the experimenter wants to know how a neuron encodes a particular aspect of a covariate, e.g., how neurons in the sensory periphery or primary sensory cortices encode stimuli, parametric methods have proved highly illuminating. However, in many cases the identity or even existence of relevant external covariates is uncertain. For example, one could envision using CSMs to analyze recordings in pre-frontal cortex during different cognitive tasks, or to perhaps compare spiking structure during different attentional states. In both cases, the relevant external covariates are not at all clear, but CSMs could still be used to quantify changes in computational structure, for single neurons or for groups of them. For neural populations one can envision generating distributions (over the population) of complexities and examining how these distributions change in different cortical macro-states. This would be entirely analagous to analyzing distributions of firing rates or tuning curves.
In addition to calculations of the complexity, the whole array of mutual-information analyses can be applied to CSMs, but instead of calculating mutual information between the spikes and the covariates (which could include other spike trains), one can calculate the mutual information between the covariates and the causal states. The advantage is that the causal states represent the behavioral patterns of the spike-generating process, and so are closer to the actual state of the system than the spikes (output observables) are themselves. Results on calculating the mutual information between the causal states of different neurons (informational coherence) in a large simulated network show that synchronous neuronal dynamics are more effectively revealed than when calculated directly from the spikes (Klinkner et al., 2006).
In closing, our methods provide a way to understand structure in spike trains, and should be considered as complements to traditional analysis methods. We rigorously define structure, and show how to discover it from the data itself. Our methods go beyond those which seek to describe the observed variation in the spiking rates by also describing the underlying computational process (in the form of a CSM) needed to generate that variation. A CSM can show not only that the spike rate has changed, but also show exactly how it has changed.
Acknowledgments
The authors thank Mark Andermann and Christopher Moore for the use of their data. RH thanks Emery Brown, Anna Dreyer and Christopher Moore for valuable discussions. CRS thanks Anthony Brockwell, Dave Feldman, Chris Genovese, Rob Kass and Alessandro Rinaldo for valuable discussions.
Appendix A
Filtering with CSMs
A common difficulty with hidden Markov models is that predictions can only be made from a knowledge of the state, which must itself be guessed at from the time series, since it is, after all, hidden. This creates the state estimation or filtering problem. Under strong assumptions (linear Gaussian stochastic dynamics, linearly observed through IID additive Gaussian noise) the Kalman filter is an optimal yet tractable solution. For non-linear processes, however, optimal filtering essentially amounts to maintaining a posterior distribution over the states and updating it via Bayes’s rule (Ahmed, 1998). (This distribution is sometimes called the process’s “information state”.)
One convenient and important feature of CSMs is that this whole machinery of filtering is unnecessary, because of their recursive-updating property. Given the state at time t, St, and the observation at time t + 1, Xt+1, the state at time t + 1 is fixed, St+1 = T(St, Xt+1) for some transition function T. Clearly, if the state is known with certainty at any time, it will remain known. However, the same recursive updating property also allows us to show that the state does become certain, i.e., that after some finite (but possibly random) time τ, is either 0 or 1 for all states s. For Markov chains of order k, clearly τ ≤ k; under more general circumstances ℙ(τ ≥ t) goes to zero exponentially or faster.
Thus, after a transient period, the state is completely unambiguous. This will be useful to us in multiple places, including understanding the computational structure of the process and predicting the firing rate of the neuron. It also leads to considerable numerical simplifications, compared to approaches which demand conventional filtering. Further, recursive filtering is easily applied to a new spike train, not merely the one from which the CSM was reconstructed. This helps in cross-validating CSMs, as discussed in the next appendix.
Appendix B
Cross-Validation
It is often desirable to cross-validate a statistical model by spliting one’s data set in two, using one part (generally the larger) as a training set for the model and the other part to validate the model by some statistical test. In the case of CSMs it is particularly important to check the validity of the BIC used to regularize the Λ control-setting.
One possible test is the ISI bootstrapping of §II.B.3. A second, somewhat stronger, goodness-of-fit test is based on the time rescaling theorem of Brown et al. (2002). This test rescales the interspike intervals as a function of the integrated history-dependent spiking rate over the ISI:
| (B1) |
where the {tk} are the spike times and λ(t) is the history-dependent spiking rate from the CSM. If the CSM describes the data well, then rescaled ISI’s {τk} should follow a uniform distribution. This can be tested using either a Kolmogorov Smirnov test or by plotting the empirical CDF of the rescaled times against the CDF of the uniform distribution (Kolmogorov Smirnov or “KS” plot) (Brown et al., 2002).
Figure 11 gives cross-validation results for the rat barrel cortex neuron, during both spontaneous firing and periodic vibrissae deflection. 90 seconds of spontaneously firing spikes were split into a 75 second training set and a 15 second validation set. The 335 seconds of stimulus-evoked firing were split into a 270 second training set and a 65 second validation set. Panels A and B show the ISI bootstrapping results for the spontaneous and stimulus evoked firing respectively. The dashed lines are 99% confidence bounds from a CSM reconstructed from the training set and the solid line is the ISI distribution of the validation set. The ISI distribution largely falls within these bounds for both the spontaneous and stimulus evoked data.
FIG. 11.
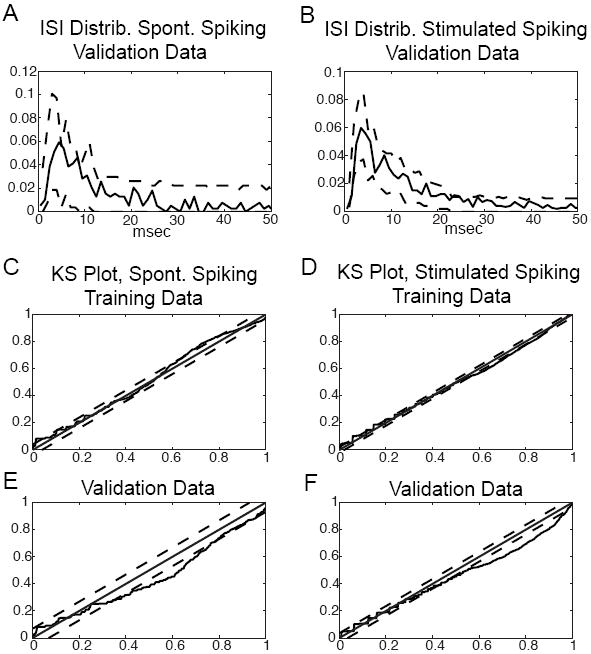
Cross validation of CSMs reconstructed from spontaneously firing and stimulus evoked rat barrel cortex on an independent validation training set. (A,B) ISI distribution of spontaneously and stimulus evoked firing validation sets and 99% confidence bounds bootstrapped from CSM. (C-D) Time rescaling plots of training data sets for spontaneously firing and stimulus evoked firing respectively. Dashed lines are 95% confidence bounds and the solid line is the rescaled ISIs. The solid line along the digagonal is for visual comparison to an ideal fit. (E-F) Similar time rescaling plots for the validation data sets.
Panels C-F display the time rescaling test. Panels C and D show the time rescaling plots for the spontaneous and stimulus evoked training data respectively. The dashed lines are 95% confidence bounds. The spontaneous KS plot largely falls within the bounds. The stimulus-evoked does not, but this is expected because, as discussed, the CSM does not completely capture the imposition of the external stimulus. (The jagged “steps” in both plots result from the 1 msec temporal discretization.) Panels E and F show the time rescaling plots for, respectively, the spontaneous and stimulus evoked validation data. The fits here are somewhat worse. In the stimulated case, this is not surprising. In the spontaneous case the cause is likely non-stationarity in the data, a problem shared with other spike train analysis techniques, such as the Generalized Linear Model approaches described in the next Appendix. It should be emphasized that the point of reconstructing CSMs is not to obtain perfect fits to the data, but instead to estimate the structure inherent in the spike train, and the cross-validation results should be viewed in this light.
Appendix C
Causal State Transducers and Predictive State Representations
Mathematically, CSMs can be expanded to include the influence of external stimuli on the process, yielding causal state transducers, which are optimal representations of the history-dependent mapping from inputs to outputs (Shalizi, 2001, ch. 7). Such causal state transducers are a type of partially-observable Markov decision process, closely related to predictive state representations (PSRs) (Littman et al., 2002). In both formalisms, the right notion of “state” is a statistic, a measurable function of the observable past of the process. Causal states represent this through an equivalence relation on the space of observable histories. For PSRs, the representation is through “tests”, i.e., a distinguished set input/output sequence pairs; the idea is that states can be uniquely characterized by their probabilities of producing the output sequences conditional on the input sequences.
An algorithm for reconstructing causal state transducers would begin by estimating probability distributions of future histories conditioned on both the history of the spikes and the history of an external covariate Y, e.g. , and otherwise be entirely parallel to CSSR. This has not yet implemented.
Footnotes
See Cover & Thomas (1991) for information-theoretic definitions and notation.
Some authors use “hidden Markov Model” only for models where the current observation is independent of all other variables given the current state, and call the broader class which includes CSMs “partially observable Markov model”.
There may exist more compact representations, but then the states, or their equivalents, can never be empirically identified — see Shalizi & Crutchfield (2001, thm. 3, p. 846), or Löhr & Ay (2009).
A next-step-sufficient statistic contains all the information needed for optimal one-step-ahead prediction, , but not necessarily for longer predictions. CSSR relies on the theorem that if η is next-step sufficient, and it is recursively calculable, then η is sufficient for the whole of the future (Shalizi & Crutchfield, 2001, pp. 842–843). CSSR first finds a next-step sufficient statistic, and then refines it to be recursive.
In addition to Shalizi & Klinkner (2004), which gives pseudocode, some details of convergence, and applications to process classification, are treated in Klinkner & Shalizi (2009); Shalizi et al. (2009). An open-source C++ implementation is available at http://bactra.org/CSSR/. The CSMs generated by CSSR can be displayed graphically, as we do in this paper, with the open-source program dot (http://www.graphviz.org/)
For finite N, decreasing α tends to yield simpler CSMs with fewer states. In a sense, it is a sort of regularization coefficient. The influence of this regularization diminishes as N increases. For the data used in the Results section of this paper, varying α in the range 0.001 < α < 0.1 made little difference.
If more than one such state s* exists, we chose the one for which ℙ̂(Xt∣Ŝ = s*) differs least, in total variation distance, from, , which is plausible and convenient. However, which state we chose is irrelevant in the limit N → ∞, so long as the difference between the distributions is not statistically significant.
The conceptually similar algorithm of Kennel & Mees (2002) in effect always creates a new state, which leads to more complex models, sometimes infinitely more complex ones; see Shalizi & Klinkner (2004).
The number of independent parameters d involved in describing the CSM will be (number of states)*(number of symbols - 1) since the sum of the outgoing probabilities for each state is constrained to be 1. Thus, for a binary alphabet, d = number of states.
The algorithmic information content is also called the Kolmogorov complexity. We do not use this term, to avoid confusion with our “complexity” C the information needed to reproduce the spike train statistically rather than exactly (Eq. 11). See Badii & Politi (1997) for a detailed comparison of complexity measures.
Cf. the informational coherence introduced by Klinkner et al. (2006) to measure of information-sharing between neurons, by quantifying the error in predicting the distribution of the future of one neuron due to ignoring its coupling with another.
In effect, this part of the CSM implements Bayes’s rule, balancing the increased likelihood of a spike after a stimulus against the low a priori probability or base-rate of stimulation.
References
- Abeles M, Bergman H, Gat I, Meilijson I, Seidemann E, Tishby N, Vaadia E. Cortical ativity flips among quasi-stationary states. Proc Natl Acad Sci USA. 1995;92:8616–8620. doi: 10.1073/pnas.92.19.8616. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Achtman N, Afshar A, Santhanam G, Yu BM, Ryu SI, Shenoy KV. Free paced high-performance brain-computer interfaces. Journal of Neural Engineering. 2007;4:336–347. doi: 10.1088/1741-2560/4/3/018. [DOI] [PubMed] [Google Scholar]
- Ahmed NU. Linear and nonlinear filtering for scientists and engineers. Singapore: World Scientific; 1998. [Google Scholar]
- Amigo JM, Szczepanski J, Wajnryb E, Sanchez-Vives MV. On the Number of States of the Neuronal Sources. Biosystems. 2002;68:57–66. doi: 10.1016/s0303-2647(02)00156-9. [DOI] [PubMed] [Google Scholar]
- Amigo JM, Szczepanski J, Wajnryb E, Sanchez-Vives MV. Estimating the Entropy Rate of Spike Trains via Lempel-Ziv Complexity. Neural Computation. 2004;16:717–736. doi: 10.1162/089976604322860677. [DOI] [PubMed] [Google Scholar]
- Andermann ML, Moore CI. A sub-columnar direction map in rat barrel cortex. Nature Neuroscience. 2006;9:543–551. doi: 10.1038/nn1671. [DOI] [PubMed] [Google Scholar]
- Badii R, Politi A. Complexity: Hierarchical structures and scaling in physics. Cambridge, England: Cambridge University Press; 1997. [Google Scholar]
- Bernardo JM, Smith AFM. Bayesian Theory. New York: Wiley; 1994. [Google Scholar]
- Brown EN, Barbieri R, Ventura V, Kass RE, Frank LM. The time rescaling theorem and its application to neural spike train data analysis. Neural Computation. 2002;14:325–346. doi: 10.1162/08997660252741149. [DOI] [PubMed] [Google Scholar]
- Brown EN, Kass RE, Mitra PP. Multiple neural spike train data analysis: State-of-the-art and future challanges. Nature Neuroscience. 2004;7:456–461. doi: 10.1038/nn1228. [DOI] [PubMed] [Google Scholar]
- Chen Z, Vijayan S, Barbieri R, Wilson MA, Brown EN. Discrete- and continuous-time probablistic models and inference algorithms for neuronal decoding of Up and Down states. In review at Neural Computation. 2008 doi: 10.1162/neco.2009.06-08-799. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cover TM, Thomas JA. Elements of Information Theory. New York: Wily; 1991. [Google Scholar]
- Crutchfield JP, Young K. Inferring statistical complexity. Physical Review Letters. 1989;63:105–108. doi: 10.1103/PhysRevLett.63.105. [DOI] [PubMed] [Google Scholar]
- Csiszár I, Talata Z. Context tree estimation for not necessarily finite memory processes, via BIC and MDL. IEEE Transactions on Information Theory. 2006;52:1007–1016. [Google Scholar]
- Danoczy MG, Hahnloser RHR. Advances in Neural Information Processing Systems (NIPS 2005) Cambridge: Massachusetts MIT Press; 2005. Efficient Estimation of Hidden State Dynamics. [Google Scholar]
- Eden UT, Frank LM, Barbieri R, Solo V, Brown EN. Dynamic analysis of neural encoding by point process adaptive filtering. Neural Computation. 2004;16:971–998. doi: 10.1162/089976604773135069. [DOI] [PubMed] [Google Scholar]
- Gács P, Tromp JT, Vitanyi PMB. Algorithmic statistics. IEEE Transactions on Information Theory. 2001;47:2443–2463. [Google Scholar]
- Gorse D, Taylor JG. A General Model of Stochastic Neural Processing. Biological Cybernetics. 1990;63:299–306. [Google Scholar]
- Grassberger P. Toward a quantitative theory of self-generated complexity. International Journal of Theoretical Physics. 1986;25:907–938. [Google Scholar]
- Gray RM. Probability, random processes, and ergodic properties. New York: Springer-Verlag; 1988. [Google Scholar]
- Jaeger H. Observable operator models for discrete stochastic time series. Neural Computation. 2000;12:1371–1398. doi: 10.1162/089976600300015411. [DOI] [PubMed] [Google Scholar]
- Jimenez-Montano MA, Ebeling W, Pohl T, Rapp PE. Entropy and Complexity of Finite Sequences and Fluctuating Quantities. Biosystems. 2002;64:23–32. doi: 10.1016/s0303-2647(01)00171-x. [DOI] [PubMed] [Google Scholar]
- Jones LM, Fontanini A, Sadacca BF, Katz DB. Natural stimuli evoke dynamic sequences of states in sensory cortical ensembles. Proc Natl Acad Sci USA. 2007;104:18772–18777. doi: 10.1073/pnas.0705546104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kennel MB, Mees AI. Context-tree modeling of observed symbolic dynamics. Physical Review E. 2002;66:056209. doi: 10.1103/PhysRevE.66.056209. [DOI] [PubMed] [Google Scholar]
- Klinkner KL, Shalizi CR. CSSR: A nonparametric algorithm for predicting and classifying time series. 2009 Manuscript in preparation. [Google Scholar]
- Klinkner KL, Shalizi CR, Camperi MF. Measuring shared information and coordinated activity in neuronal networks. In: Weiss Y, Schölkopf B, Platt JC, editors. Advances in neural information processing systems 18 (NIPS 2005) Cambridge, Massachusetts: MIT Press; 2006. pp. 667–674. [Google Scholar]
- Knight FB. A predictive view of continuous time processes. Annals of Probability. 1975;3:573–596. [Google Scholar]
- Littman ML, Sutton RS, Singh S. Predictive representations of state. In: Dietterich TG, Becker S, Ghahramani Z, editors. Advances in neural information processing systems 14 (NIPS 2001) Cambridge, Massachusetts: MIT Press; 2002. pp. 1555–1561. [Google Scholar]
- Löhr W, Ay N. On the Generative Nature of Prediction. Advances in Complex Systems. 2009 forthcoming. [Google Scholar]
- Marton K, Shields PC. Entropy and the consistent estimation of joint distributions. Annals of Probability. 1994;22:960–977. [Google Scholar]; Correction. Annals of Probability. 24(1996):541–545. [Google Scholar]
- McCulloch WS, Pitts W. A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biophysics. 1943;5:115–133. [PubMed] [Google Scholar]
- Olufsen MS, Whittington MA, Camperi M, Kopell N. New Roles for the Gamma Rhythm: Population Tuning and Processing for the Beta Rhythm. Journal of Computation Neuroscience. 2003;14:33–54. doi: 10.1023/a:1021124317706. [DOI] [PubMed] [Google Scholar]
- Rapp PE, Zimmerman ID, Vining EP, Cohen N, Albano AM, Jimenez-Montano MA. The Algorithmic Complexity of Neural Spike Trains Increases During Focal Seizures. Journal of Neuroscience. 1994;14:4731–4739. doi: 10.1523/JNEUROSCI.14-08-04731.1994. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rieke F, Warland D, de Ruyter van Steveninck R, Bialek W. Spikes: Exploring the neural code. Cambridge, Massachusetts: MIT Press; 1997. [Google Scholar]
- Shalizi CR. PhD thesis, University of Wisconsin-Madison. 2001. Causal architecture, complexity and self-organization in time series and cellular automata. [Google Scholar]
- Shalizi CR, Crutchfield JP. Computational mechanics: Pattern and prediction, structure and simplicity. Journal of Statistical Physics. 2001;104:817–879. [Google Scholar]
- Shalizi CR, Klinkner KL. Blind construction of optimal nonlinear recursive predictors for discrete sequences. In: Chickering M, Halpern JY, editors. Uncertainty in artificial intelligence: Proceedings of the twentieth conference (UAI 2004) Arlington, Virginia: AUAI Press; 2004. pp. 504–511. [Google Scholar]
- Shalizi CR, Klinkner KL, Haslinger R. Quantifying self-organization with optimal predictors. Physical Review Letters. 2004;93:118701. doi: 10.1103/PhysRevLett.93.118701. [DOI] [PubMed] [Google Scholar]
- Shalizi CR, Rinaldo A, Klinkner KL. Adaptive nonparametric prediction and bootstrapping of discrete time series. 2009 Manuscript in preparation. [Google Scholar]
- Singh S, Littman ML, Jong NK, Pardoe D, Stone P. Learning predictive state representations. In: Fawcett T, Mishra N, editors. Proceedings of the Twentieth International Conference on Machine Learning (ICML-2003. AAAI Press; 2003. pp. 712–719. [Google Scholar]
- Smith AC, Frank LM, Wirth S, Yanike M, Hu D, Kubota Y, Graybiel AM, Suzuki WA, Brown EN. Dynamic analysis of learning in behavioral experiments. Journal of Neuroscience. 2002;24:447–461. doi: 10.1523/JNEUROSCI.2908-03.2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Srinivasan L, Eden UT, Mitter SK, Brown EN. General purpose filter design for neural prosthetic devices. Journal of Neurophysiology. 2007;98:2456–2475. doi: 10.1152/jn.01118.2006. [DOI] [PubMed] [Google Scholar]
- Szczepanski J, Amigo JM, Wajnryb E, Sanchez-Vives MV. Characterizing spike trains with Lempel-Ziv complexity. Neurocomputing. 2004;58:79–84. [Google Scholar]
- Truccolo W, Eden UT, Fellow MR, Donoghue JP, Brown EN. A point process framework for relating neural spiking activity to spiking history, neural ensemble and covariate effects. Journal of Neurophysiology. 2005;93:1074–1089. doi: 10.1152/jn.00697.2004. [DOI] [PubMed] [Google Scholar]