

Abstract
This study examines the storage vs. composition of Spanish inflected verbal forms in L1 and L2 speakers of Spanish. L2 participants were selected to have mid-to-advanced proficiency, high classroom experience, and low immersion experience, typical of medium-to-advanced foreign language learners. Participants were shown the infinitival forms of verbs from either Class I (the default class, which takes new verbs) or Classes II and III (non-default classes), and were asked to produce either first-person singular present-tense or imperfect forms, in separate tasks. In the present tense, the L1 speakers showed inflected-form frequency effects (i.e., higher frequency forms were produced faster, which is taken as a reflection of storage) for stem-changing (irregular) verb-forms from both Class I (e.g., pensar-pienso) and Classes II and III (e.g., perder-pierdo), as well as for non-stem-changing (regular) forms in Classes II/III (e.g., vender-vendo), in which the regular transformation does not appear to constitute a default. In contrast, Class I regulars (e.g., pescar-pesco), whose non-stem-changing transformation constitutes a default (e.g., it is applied to new verbs), showed no frequency effects. L2 speakers showed frequency effects for all four conditions (Classes I and II/III, regulars and irregulars). In the imperfect tense, the L1 speakers showed frequency effects for Class II/III (-ía-suffixed) but not Class I (-aba-suffixed) forms, even though both involve non-stem-change (regular) default transformations. The L2 speakers showed frequency effects for both types of forms. The pattern of results was not explained by a wide range of potentially confounding experimental and statistical factors, and does not appear to be compatible with single-mechanism models, which argue that all linguistic forms are learned and processed in associative memory. The findings are consistent with a dual-system view in which both verb class and regularity influence the storage vs. composition of inflected forms. Specifically, the data suggest that in L1, inflected verbal forms are stored (as evidenced by frequency effects) unless they are both from Class I and undergo non-stem-changing default transformations. In contrast the findings suggest that at least these L2 participants may store all inflected verb-forms. Taken together, the results support dual-system models of L1 and L2 processing in which, at least at mid-to-advanced L2 proficiency and lower levels of immersion experience, the processing of rule-governed forms may depend not on L1 combinatorial processes, but instead on memorized representations.
Keywords: regular, irregular, morphology, Spanish, storage, composition, stem-change, inflection, frequency effects
Introduction
Certain basic questions regarding the acquisition and use of adult-learned second language (L2) still remain unresolved, including the following: (a) What neurocognitive (brain and psychological) mechanisms underlie the acquisition and use of L2, and do these differ between different aspects of language, for example in the basic linguistic distinction between rule-governed and idiosyncratic mappings? (b) Are the neurocognitive mechanisms underlying L2, including those subserving idiosyncratic and rule-governed mappings, the same or different from those underlying first language (L1)?
Here we examine aspects of these questions regarding the computation of rule-governed and idiosyncratic linguistic mappings, focusing on the issue of storage versus composition: (a) Are linguistic forms in L2 stored and retrieved from memory or are they composed from their parts (e.g., walk + -ed), and does this differ between rule-governed mappings (e.g., in English regular past-tense formation, as in walk-walked) and idiosyncratic, i.e., not entirely predictable, mappings (e.g., in English irregular past-tense formation, as in teach-taught)? (b) Is the pattern of storage versus composition in idiosyncratic and rule-governed mappings the same or different in L2 as in L1? Here we report results from an empirical study that is designed to elucidate these questions.
Theoretical models from several fields, including Second Language Acquisition (SLA), cognitive psychology, and cognitive neuroscience have addressed these questions. For the most part, these models have focused on the question of whether the neurocognition of L2 is the same as or different from that of L1. The models can be classified into three broad types: those that hold that the neurocognitive mechanisms are the same in L1 and L2, those that claim they are different between L1 and L2, and those that suggest that there is a partial overlap between the two.
Models hypothesizing that L1 and L2 are supported by the same acquisition and processing mechanisms include models that espouse a “dual-system” perspective (Abutalebi, 2008; Indefrey, 2006) as well as those that take a “single-mechanism” view (Ellis, 2005). In L1, dual-system models of language (Clahsen, 1999; Marslen-Wilson & Tyler, 1998; Pinker, 1999; Pinker & Ullman, 2002; Ullman, 2001a) posit a mental lexicon and a mental grammar, which depend on distinct neurocognitive substrates. The mental lexicon stores (at least) all idiosyncratic word-specific information, including arbitrary sound-meaning pairings (e.g., the meaning of cat) and what unpredictable morphologically-related forms a word takes (e.g., in irregular morphology, such as in English irregular past-tense formation). The mental grammar underlies rule-governed composition, across linguistic domains, including syntax and morphology (e.g., in regular morphology, such as in English regular past-tense formation). Single-mechanism models of L1, by contrast, posit that rules are only descriptive entities, and that an associative memory with broad anatomic distribution gradually learns the entire statistical structure of the language, from arbitrary mappings to rule-like mappings (Bates & MacWhinney, 1989; Elman et al., 1996; MacDonald, Pearlmutter, & Seidenberg, 1994; McClelland & Patterson, 2002; Seidenberg, 1997). Thus models hypothesizing that L2 depends on the same neurocognitive mechanisms as L1 differ according to their underlying assumptions: Such models that assume a dual-system perspective (Abutalebi, 2008; Indefrey, 2006) suggest that the neurocognitive distinction between idiosyncratic and rule-governed mappings should exist similarly in L2 and in L1. In contrast, according to single-mechanism models that do not make a neurocognitive distinction between these two types of mappings (Ellis, 2005), both types of mappings should depend on the same neurocognitive mechanisms in both L1 and L2.
On the opposite end of the spectrum, some models hold that L1 and L2 rely on largely (DeKeyser, 2000, 2003) or entirely (Bley-Vroman, 1989) different mechanisms. For Bley-Vroman, this distinction is based on the unavailability of Universal Grammar (UG) in later language learning. For DeKeyser, the dissociation is tied to the psychological distinction between implicit (not available to conscious awareness) and explicit (available to conscious awareness) processes, with the claim being that implicit, L1-like learning is not available in L2 acquisition. These models do not generally specify whether the L2 linguistic system is subserved by single or dual mechanisms, nor do they distinguish explicitly between idiosyncratic and rule-governed forms (Bley-Vroman, 1989; DeKeyser, 2003). However, the fact that Bley-Vroman (1989) takes a UG perspective (e.g., Chomsky, 1980) suggests the assumption of some sort of dual-system model for L1. DeKeyser has not to our knowledge taken an explicit stance with regard to single vs. dual systems in L1.
Finally, some models suggest a partial overlap between the mechanisms underlying L1 and L2. These models generally subscribe to a dual-system view. According to the declarative/procedural (DP) model of language (Ullman, 2001b, 2001c, 2004, 2005a), L1 idiosyncratic knowledge relies on the declarative memory brain system, which subserves the learning and use of knowledge about facts and events, may be specialized for the binding of arbitrary relations, and is rooted in particular temporal lobe structures. In contrast, rule-governed representations generally rely on the procedural memory system, which subserves the implicit learning of new, and the control of established, motor and cognitive ‘skills’ and ‘habits’, especially those involving rules and sequences, and is rooted in frontal/basal-ganglia brain circuits. However, according to the DP model, not only can rule-governed forms be composed by the procedural memory system, they can also rely on lexical/declarative memory. For example, they can be memorized as chunks in the mental lexicon, with the likelihood of such memorization depending on various item- and subject-specific factors (Ullman, 2004, 2007). On this view, stored and composed representations of even the same form can be found within as well as between individuals (Ullman, 2004, 2005b; Walenski & Ullman, 2005).1 In L2, the DP model (Ullman, 2001b, 2005a) posits that idiosyncratic knowledge, as in L1, relies on the declarative memory system. However, due to age-related and other factors that may affect learning in declarative and/or procedural memory, L2 learners should rely more than L1 speakers on declarative memory for rule-governed mappings, at least at lower levels of experience. This reliance can take various forms, including memorization as chunks (e.g., “walked”, “the cat”) and learning rules in declarative memory (such as explicitly learned verbalizable “rules”) (Ullman, 2005a, 2006). However, with increasing experience (and accompanying proficiency), it is predicted that the grammar will undergo “proceduralization”, and thus will become increasingly L1-like in its neurocognitive mechanisms. It should be noted that this cognitive-neuroscience perspective offers an understanding of declarative vs. procedural memory that is not isomorphic to explicit vs. implicit knowledge as they are generally understood in SLA, but rather overlaps somewhat with these concepts: declarative memory is at least partially, but is not necessarily, explicit, whereas procedural memory is only one type of implicit memory system (Ullman, 2005a).
The shallow-structure hypothesis (SSH) (Clahsen & Felser, 2006b, 2006c; Silva & Clahsen, 2008) offers a very similar view to the DP model. The SSH currently posits that L2 lexical/semantic processing is similar to that of L1, whereas L2 morphological and syntactic processing depend more on lexical, pragmatic and world knowledge than in L1 (Clahsen & Felser, 2006c; Silva & Clahsen, 2008). However, “word-level processing and morphosyntactic feature matching between adjacent or locally related words might be more easily mastered as grammatical proficiency increases and can eventually become native-like” (Clahsen & Felser, 2006c). Thus, the SSH makes analogous claims to the DP model: lexical knowledge is stored in both L1 and L2; there is a dissociation between L1 and L2 in the representation of morphological and syntactic processing, with more reliance on storage and less on combinatorial processing in L2 than in L1; but L1-like composition for rule-governed structures in morphology and certain aspects of syntax may be available in advanced L2 for domains in which learners are highly proficient.
Paradis (1994; 2004; 2009), like the DP model, emphasizes a greater dependence on declarative than procedural memory in L2 as compared to L1, and in low- as compared to high-proficiency L2. However, his view differs from the DP model in that he assumes isomorphic relations between explicit knowledge and declarative memory, and between implicit knowledge and procedural memory. Moreover, Paradis discusses the increased reliance on procedural memory at high proficiency largely in terms of greater automatization and implicitness across various domains of language, including at least portions of the lexicon. To our knowledge Paradis does not discuss the distinction between storage and composition.
Regular and Irregular Morphology
To investigate the issue of storage vs. composition in L2 and L1 we examined the contrast between regular and irregular inflectional morphology. A large body of research has examined this contrast in L1, and to a lesser extent in L2, especially in English past-tense formation (Clahsen, 1999; Joanisse & Seidenberg, 1999; Pinker, 1999; Pinker & Ullman, 2002; Rumelhart & McClelland, 1986; Ullman, 1997, 2001c). Regulars and irregulars can be well-matched on frequency and other factors that might influence representation and processing. However, regulars and irregulars differ crucially in one respect: irregular past-tense formation is at least partly idiosyncratic, with verbs undergoing various types of stem (and other) changes (e.g., bring-brought, sing-sang), and so must depend at least in part on memorized representations, whereas regular past-tense formation can be described by a simple default rule, -ed-affixation of the unchanged stem.
In L1, dual-system and single-mechanism models make different claims regarding the computation of regulars and irregulars. According to dual system models, regular inflected forms can be composed, while irregular inflected forms must depend on stored representations (Halle & Marantz, 1993; Pinker, 1999; Ullman, 2001a)–though, as noted above, on some views regulars can also be stored, as a function of various item- and subject-specific factors (Prado & Ullman, 2009; Ullman, 2004, 2007; Ullman, Miranda, & Travers, 2008). Thus we should emphasize that on a dual-system view regulars are not defined as those inflected forms that are composed; rather regulars are defined independently – in the case of English past-tense, regulars are those forms that take the default –ed-affixation of an unchanged stem – and may be either composed or stored. In contrast, single-mechanism models assume that all inflected forms are represented and processed in a distributed associative memory (Elman, 1996; Plunkett & Marchman, 1993; Rumelhart & McClelland, 1986).
There have been fewer explicit claims regarding the computation of regulars and irregulars in L2. According to the DP model, in L2 irregulars (as in L1) always depend on stored representations, whereas regulars show different patterns at different levels of experience and proficiency: at lower levels regulars will tend to be stored, while at higher levels they will be increasingly composed (Ullman, 2001b, 2005a). The same basic pattern is expected by the SSH (Clahsen & Felser, 2006b). Although we are not aware of any claims regarding the computation of regular/irregular morphology made by the other L2 models discussed above, one can extrapolate from their broader claims. Models arguing for the same neurocognitive mechanisms in L2 as in L1 would expect that regulars and irregulars follow the same pattern of computation in L2 and L1, though the composition of regulars (in both L2 and L1) may be predicted by dual-system (Abutalebi, 2008; Indefrey, 2006) but not single-mechanism views (Ellis, 2005). In contrast, Bley-Vroman (1989) would presumably expect that any composition of regulars in L1 would not also be found in L2. DeKeyser (2000; 2003) might make similar predictions. It is not clear to us what Paradis (1994; 2004; 2009) would predict regarding this issue.
Spanish Verbal Inflectional Morphology
Whereas in English past-tense inflection the regular/irregular contrast is relatively simple, inflectional systems are more complex in many other languages. In the present study we examine the storage/composition distinction in Spanish verbal morphology, focusing on present-tense and imperfect inflection.
Spanish verbs are traditionally divided into three verb classes (also referred to as conjugation or morphological classes), which are distinguished by the thematic vowel – -a- (Class I), -e- (Class II), and -i- (Class III) – in the infinitival form of the verb (e.g., hablar, comer, mentir). Class I contains many more verbs than Classes II and III, and appears to be the default verb-class, with new verbs being assigned to it (J. Harris, 1969); e.g., escanear, ‘to scan’.
Additionally, and of particular interest here, a division can be made between inflected verb forms that either undergo phonological stem changes (e.g., venir-vengo, pensar-pienso) or do not (e.g., hablar-hablo). Consistent with the definition of regularity in English past-tense inflection, we refer to transformations in Spanish verbal inflection that contain stem changes as irregular2 and to non-stem-changing transformations as regular3. Note that because in Spanish both stem-changing and non-stem-changing forms usually take the same (default) affix (e.g., piens-o, habl-o), the affix – unlike in English – is generally not useful for defining the notion of regularity.
Although the distinction between regular and irregular as defined here – i.e., no-stem-change vs. stem-change – is logically independent of verb class, the two do appear to interact. Specifically, regular transformations (that is, with no stem changes) appear to be the default for all inflections of Class I verbs, with the vast majority of verbs, including new ones, following this pattern. In contrast, Class II and III verbs show a preponderance and an apparent default of regular (non-stem-changing) transformations only for some inflections.
In order to begin to tease apart the influence of verb class (default Class I vs. non-default Classes II and III) and regularity (regular, i.e., no stem-changing vs. irregular, i.e., stem-changing) on the storage vs. composition of inflected forms, the present paper examines two inflectional transformations: first-person singular present tense and imperfect.
In Spanish first-person singular present tense (almost) all verbs take an -o suffix, but differ in whether or not their stems change. For example, and of particular interest here, certain verbs of all three verb-classes undergo an e-ie stem-change (pescar-pesco vs. pensar-pienso; vender-vendo vs. perder-pierdo; sumergir-sumerjo vs. mentir-miento), with the stem-change occurring only in present-tense forms in which the syllable containing the e is stressed (pensár, ‘to think’ - piénso, piénsas, piénsa, pensámos, pensáis, piénsan).4 Additionally, whereas the vast majority of Class I verbs, including new ones, undergo no stem-changes in the present tense, and non-stem-changing (regular) transformations appear to be the default, such a preponderance of non-stem-changing transformations does not hold in Class II and III verbs in the present tense, where no default is obvious. Therefore, first-person singular present-tense forms in Spanish allow the examination of the effects on storage/composition of verb class (default Class I vs. non-default Classes II/III) and regularity (non-stem-changes, i.e., regulars vs. stem-changes, i.e., irregulars), where the regular (non-stem-change) transformation constitutes the default in (the default) Class I but not in (the non-default) Classes II/III.
In the Spanish imperfect tense, by contrast, all (but three) verbs in all three classes undergo class-wide regular (non-stem-change) transformations. These vary only in their affixes between classes, with -aba- for Class I verbs and -ía- for Class II and III verbs (e.g., for first- and third-person singular, hablar-hablaba vs. comer-comía and mentir-mentía). Regular (non-stem-changing) transformations thus constitute the default in both the default (Class I) and non-default (Classes II/III) classes. Therefore, imperfect forms in Spanish allow us to examine the effects on storage/composition of verb class (default Class I vs. non-default Classes II/III) when (almost) all forms are regulars (non-stem-changing) and the regular transformation is the default in both the default and non-default verb classes.
Thus, by examining (first-person singular) present-tense and imperfect Spanish inflection, one can probe the contributions of and interactions between class (default vs. non-default) and regularity (regular, that is, non-stem-changing, vs. irregular, that is, stem-changing), thereby going beyond a simple regular/irregular distinction.
Previous Evidence
A variety of different methods have been used to examine the neurocognition of regular and irregular inflectional morphology, particularly in L1, but also in L2. Different methodologies are appropriate for investigating different questions. For example, although some neurolinguistic techniques are well-suited for probing for the existence of distinct neural systems, they are not well-suited for testing the representational and computational bases of inflected forms.
Here we use a method that is both appropriate and has been widely used for examining the storage/composition distinction in inflectional morphology: testing for inflected-form frequency effects. This method is based on the finding that lexical forms that are encountered more frequently – i.e., that have a higher frequency in the language – are more successfully or more rapidly accessed in memory (Forster & Chambers, 1973; Rubenstein, Garfield, & Milliken, 1970). Thus stored forms, including inflected ones, should show frequency effects. That is, once access to their stems is controlled for (by controlling for lemma frequency), higher frequency inflected forms should be accessed more successfully or faster than less frequent forms. Composed forms, on the other hand, should not show this effect. Therefore the presence of inflected-form (also called surface-form or full-form) frequency effects can be used as a diagnostic of the storage and retrieval of inflected forms from memory, while the absence of such effects suggests their composition (see Discussion for an alternative explanation of the absence of frequency effects for regulars).
In L1, a number of studies have reported frequency effects for irregular but not regular inflected forms. This pattern has been observed both for English past-tense forms (Beck, 1997; Prasada, Pinker, & Snyder, 1990; Seidenberg & Bruck, 1990; Ullman, 1999) and for German plurals (Clahsen, Eisenbeiss, & Sonnenstuhl, 1997; Penke & Krause, 2002) and past participles (Clahsen, Hadler, & Weyerts, 2004). However, consistent with the view that certain item- and subject-related factors can lead to the storage of regulars (Pinker & Ullman, 2002; Ullman, 1999, 2004), some studies have found frequency effects for regulars, for example for higher frequency forms (Alegre & Gordon, 1999; Prado & Ullman, 2009). Other studies have reported frequency effects for regulars in English noun plurals (Sereno & Jongman, 1997), Finnish partitive noun plurals (Bertram, Laine, Harald Baayen, Schreuder, & Hyona, 2000), and Dutch verbs (inflected for past tense, perfect participle, and present participle) (H. Baayen, Schreuder, de Jong, & Knott, 2002), though it remains unclear to what extent these results could have been influenced by factors that have independently been shown to affect the storage of regulars, such as (but not limited to) higher vs. lower frequency regulars and female vs. male subjects (Alegre & Gordon, 1999; Prado & Ullman, 2009; Ullman, 2001a, 2004, 2008).
We are aware of only one frequency effects study of inflectional morphology in a Romance language. The study investigated adult Spanish verbal inflection in L1. Like the current study, it examined frequency effects in the production (from the infinitive) of Spanish first-person singular present-tense forms (Class I vs. Class II/III verbs, in each case contrasting non-stem-changing and e-ie stem-changing verbs) and imperfect forms (Class I vs. Class II verbs) (Brovetto, 2002; Brovetto & Ullman, 2003). RTs of correct forms constituted the dependent variable. No significant frequency effects were found, in any of the four present-tense or two imperfect-tense conditions. It should be noted however, that the study examined only 20 verbs per condition (vs. 32 in the current study), and used simple correlations to test for frequency effects (vs. mixed-effects models in the current study).
Fewer studies have investigated inflected-form frequency effects in L2. In an early paper, Beck (1997) examined the production of regular and irregular English past-tense forms (from verb stems) by L1 speakers and by L2 learners with a variety of native languages. The L2 learners' length of residence (LOR) ranged from two months to 13 years. The L1 speakers showed past-tense frequency effects (with response time – RT – as the dependent variable) on irregulars but not regulars, whereas the L2 speakers, surprisingly, showed frequency effects on neither verb-type. Birdsong and Flege (2001) examined regular and irregular English past-tense and plural forms in a selection task (participants were asked to choose the best form to fit each sentence) in “end-state” L2 learners of English (LOR of 10 to 16 years) with native languages of either Spanish or Korean. They reported frequency effects for irregulars but not for regulars. L1 speakers were not examined. In a third study, L1 English speakers and L2 learners whose native language was Spanish or Chinese (mean LOR of 7.3 years) performed an English past-tense production task (from verb stems). Frequency effects (with RT of correct forms as the dependent measure) were found on irregulars but not regulars in L1, but on both verb-types in L2 (Babcock, Stowe, Maloof, Brovetto, & Ullman, In preparation; Brovetto, 2002; Brovetto & Ullman, 2001). The same pattern was found by Neubauer and Clahsen (2009) in their lexical decision study of past participles in German, in which the L2 speakers (native speakers of Polish) had a mean LOR of 3.1 years. Thus overall, the evidence from previous L2 studies of frequency effects have painted a somewhat mixed picture, albeit one in which the data seem to be most consistent with the dual-system view that high-experience L2 learners show an L1-like pattern in storing irregular but not regular inflected forms, whereas somewhat lower-experience L2 learners rely on memorized representations for both types of forms (Ullman, 2005a).
Although the examination of frequency effects is particularly well suited for investigating the storage/composition distinction, it is not the only technique that can elucidate this issue, which has also been probed with priming. In priming studies, participants are presented with a prime word prior to being presented with a target word, on which they are asked to perform some task (e.g., lexical decision or naming). In L1, priming studies have often found that regularly inflected and related forms of the same word (e.g., stem, infinitive, other regularly inflected forms) fully prime each other (for example, regularly inflected forms facilitate the task as much as presenting the identical word as the prime), whereas irregular forms do not.5 This pattern, which is generally interpreted as suggesting the decomposition of regulars but not irregulars, has been found in different languages in L1, e.g., for English past tense (Marslen-Wilson & Tyler, 1998; Münte, Say, Clahsen, Schiltz, & Kutas, 1999) and for German past participles and plurals (Sonnenstuhl, Eisenbeiss, & Clahsen, 1999).
We are aware of three L1 priming studies of inflectional morphology in Romance languages that have used this approach: one in Portuguese, one in Italian, and one in French. Like the present study, all three examined verbal morphology. In Romance languages such as Portuguese, Italian, and French, verbs are generally – as in Spanish – categorized into verb classes, one of which (Class I) seems to be the default. Also like Spanish, within each class an inflectional transformation for a given verb can either undergo stem changes (i.e., it is irregular) or not (i.e., it is regular) in addition to affixation. A cross-modal priming study of Portuguese (Veríssimo & Clahsen, 2009) examined the priming of infinitives on first-person singular present-tense targets in three conditions: (a) regular (non-stem-changing) Class I verbs (limitar-limito); (b) regular Class III verbs (adquirir-adquiro) and (c) stem-changing (irregular) Class I verbs (afogar (pronounced af[u]gar)-afogo (af[ɔ]go)). Full priming effects were found for the regular Class I condition only, with partial priming for the other two conditions. In contrast, an Italian cross-modal priming study (Orsolini & Marslen-Wilson, 1997) found that irregularly inflected past tense forms primed infinitives (scesero-scendere) and past participles (presero-preso) as much as did regularly inflected forms (giocarono-giocare and amarono-amato).
However, the “regular” condition (with no stem-change) included both default-class (Class I) and non-default-class verbs, possibly reducing priming for regulars overall and obscuring any effect of verb class. Finally, an investigation of French verbal inflection (Meunier & Marslen-Wilson, 2004) used both a cross-modal priming task (Experiment 1) and a masked priming task (Experiment 2) to compare four conditions (with inflected forms as primes for infinitives): (a) non-stem-changing (regular) Class I verbs (aimerons-aimer); (b) Class I verbs that undergo a fully predictable stem-change (sème-semer); (c) Class III verbs with idiosyncratic stem-changes common to at least 10 verbs (peignent-peindre); and (d) verbs from all three verb classes (Class I, II and III) with idiosyncratic alternations that “typically only apply to one or two verbs” (iront-aller, meurt-mourir, prenons-prendre). No differences in priming were found between regular pairs and any of the three types of irregular pairs for priming in the lexical decision task in either experiment. In sum, the findings from priming studies of verbal inflection in Romance languages are thus far somewhat inconsistent.
Finally, we are aware of only two priming studies of inflectional morphology in L2. An English past-tense priming study of L1 and L2 participants (native languages Chinese or German; LOR between 10 and 19 months) found that whereas L1 speakers showed full priming effects for regulars, L2 speakers did not (Silva & Clahsen, 2008). A German past-participle priming study of L1 and L2 participants (native language Polish; LOR 3.1 years) revealed the same pattern of results (Neubauer & Clahsen, 2009). Thus the two previous priming studies of L2 appear to be most consistent with the dual-system view that in L1 regulars but not irregulars are decomposed, whereas at least lower-experience L2 learners may rely more on storage for regulars (Ullman, 2005a). However, additional studies of L2 are clearly needed, particularly in more complex languages such as Spanish.
The Current Study
The primary goal of the current study is to provide evidence regarding the storage vs. composition of inflected forms in L1 and L2 Spanish verbal morphology, in order to elucidate, in both L1 and L2, the effect on the storage/composition distinction of two factors: regularity (regular/non-stem-change vs. irregular/stem-change) and verb-class (default Class I vs. non-default Class II/III). We examined inflected-form frequency effects in a production task of first-person singular present-tense and imperfect-tense forms in L1 and L2 Spanish. By probing both present and imperfect inflection we could also examine the contrast between regular transformations which appear to be the default in Class I but not in Class II/III (present-tense), and those which appear to be the default in both Class I and Class II/III (imperfect-tense), thus providing insight as to whether storage vs. composition is also affected by whether or not a regular/non-stem-change transformation is (or appears to be) the default, even in non-default classes (Class II/III). In the present tense, we tested verbs from four conditions: (a) Class I non-stem-changing verbs (that is, default-class regular verbs, whose transformation appears to be the default in this class), (b) Class I e-ie stem-changing verbs (default class irregular verbs), (c) Class II/III non-stem-changing verbs (non-default class regular verbs, whose transformation does not appear to be the default in these classes), and (d) Class II/III e-ie stem-changing verbs (non-default class irregular verbs). In these contrasting conditions we were thus able to examine the contributions of both verb-class (default Class I vs. non-default Class II/III) and regularity (regular/non-stem-change vs. irregular/stem-change) to the storage vs. composition of inflected forms in an inflectional paradigm in which regular (non-stem-change) transformations constitute the clear default in Class I but not Class II/III verbs. In the imperfect we tested Class I and Class II/III verbs, all regular (non-stem-changing), allowing us to examine apparently default regular transformations in both default (Class I) and non-default (Class II/III) classes. Finally, in this study we focused on typical medium-to-advanced foreign language learners. Thus the L2 participants were selected to have relatively high levels of classroom experience (mean of about 7 semesters; see below) together with a small amount of immersion experience (mean of about 9 months).
As discussed above, in L1, dual-system models claim that regulars can be composed while irregulars must be stored, whereas single-mechanism models claim that all inflected forms are learned in an associative memory. On the assumption that all forms stored in memory should show frequency effects (see Discussion for an alternative single-mechanism view), we therefore considered the following predictions of these models. Single-mechanism models predict that all inflected forms – both present and imperfect – should show frequency effects in L1. In contrast, according to dual-system models at least certain regular forms should not show frequency effects due to their composition. However, which regular forms do or do not show frequency effects will depend on the roles of both verb class and regularity (as well as default transformations) on composition vs. storage. Because these roles were unknown, and indeed their elucidation was a primary goal of the study, several outcomes were considered on a dual system perspective: For present-tense forms we considered four possible outcomes: (a) frequency effects (suggesting storage) are found for all forms other than Class I regular verbs (hablar-hablo), suggesting that verbs in both the default class and with a regular transformation (which also is the default transformation6) are composed, while all others are stored; (b) all Class II/III forms (e.g., vender-vendo, mentir-miento) and no Class I forms (pescar-pesco, pensar-pienso) show frequency effects, independent of stem-change (regularity), suggesting that verb-class alone can determine storage vs. composition, at least in this case, where the regular transformation does not appear to be the default in Class II/III; (c) the irregular (stem-changing; e.g., pensar-pienso, mentir-miento) but not the regular (pescar-pesco, vender-vendo) forms show frequency effects, independent of class, suggesting that stem-change (regularity) is the crucial factor in the storage of inflected forms, and that even the apparently non-default Class II/III regular forms are composed; (d) none of the four conditions yield frequency effects, suggesting that all forms rely on composition (Halle & Marantz, 1993). For imperfect forms we considered two possible outcomes on a dual-system perspective: (a) Class II/III (tener-tenía, vivir-vivía) but not Class I (hablar-hablaba) forms show frequency effects, suggesting that class defaultness can fully determine the storage of inflected forms, even when Class II/III inflections follow regular (non-stem-changing) default transformations; (b) neither condition yields frequency effects, suggesting that verb-class does not determine storage vs. composition, but rather regular default transformations can rely on composition, even in non-default classes.
Different L2 models make different predictions regarding the pattern of L2 frequency effects. Models that posit the same neurocognitive mechanisms in L2 and L1 may expect the same pattern of frequency effects in L2 and L1, supporting either dual-system (Abutalebi, 2008; Indefrey, 2006) or single-mechanism (Ellis, 2005) perspectives depending on the pattern of frequency effects. Models that posit distinct mechanisms for L1 and L2 (Bley-Vroman, 1989; DeKeyser, 2000, 2003) should instead expect a different pattern of frequency effects in L1 and L2, in particular with at least certain regulars showing frequency effects in L2 but not L1. Finally, according to both the DP model and SSH, frequency effects are predicted in L2 for at least all types of inflected forms which show frequency effects in L1. Given the status of the L2 group under investigation, namely with medium-to-high proficiency, according to the DP model and the SSH two outcomes are possible for regular forms which do not show frequency effects in L1: (a) such forms should show frequency effects in L2, suggesting that these L2 participants have not (yet) reached the point of (largely) depending on composition; or (b) such forms should show the same lack of frequency effects as in L1, suggesting that the L2 participants have (already) reached an L1-like level of composition. Either outcome will crucially shed light on whether the amount and type of exposure and level of proficiency in these participants does or does not lead to L1-like composition.
Method
Participants
We tested 32 adults: 17 native Spanish speakers (with English as their L2) and 15 native English speakers with Spanish as their L2. All participants were given both a telephone screening questionnaire, and, if they met the criteria for the study, a full questionnaire (just prior to testing) asking for a range of detailed information, including age, education, handedness, medical history, and language background. All had normal or corrected hearing and vision, and all had at least some college education. None of the participants had any known developmental, neurological, or psychiatric disorders. All participants were right-handed (Oldfield, 1971).
Because the study aimed to examine late L2 learners of Spanish as compared to L1 Spanish speakers, all participants' first significant exposure7 to their L2 occurred after 17 years of age, i.e., after the putative critical period. Thus, all L2 Spanish participants (L1 English) were first significantly exposed to Spanish after age 17, and similarly, all L1 Spanish participants were first significantly exposed to English after age 17. In addition, participants were not significantly exposed to any languages other than their native language before age 17. All participants gave written informed consent, and were paid for their participation in the study.
The L2 Spanish participants were initially selected according to their level of L2 experience (see below),8 and were subsequently evaluated for oral proficiency in Spanish with the Simulated Oral Proficiency Interview9 (SOPI; Center for Applied Linguistics (CAL), Washington, DC). To maintain as much homogeneity as possible within the L2 group, outliers (>2 standard deviations from the mean on the SOPI, with ratings converted to numerical scores following Henning (1992)), were excluded from analysis. One such participant was excluded; the final N for the study was therefore 31 participants (19 females, 12 males). Thus, the L2 participants were selected on the basis of both their experience and their proficiency in the L2. See Table 1 for demographic information on the participant groups and proficiency information for the L2 Spanish speakers. Following are additional details about each of the participant groups:
Table 1. Participant Background Information. Means (and Standard Deviations).
| L1 Spanish (n=17) |
L2 Spanish (n=14) |
|
|---|---|---|
| Age in years | 26.5 (5.4) | 23.6 (3.5) |
| Years of education | 17.5 (3.2) | 16.5 (1.7) |
| L2 proficiency (SOPI) score (min=0.1, max=3.0) | n/a | 2.4 (0.33) |
| L2 self-rating (5-point scale) | ||
| Listening | n/a | 3.8 (0.7) |
| Reading | n/a | 3.7 (0.7) |
| Speaking | n/a | 3.6 (0.9) |
| Writing | n/a | 3.4 (0.9) |
Note. Years of education is defined as the number of years of formal education. The L1 and L2 groups did not differ in years of education (t(29)=1.06, p=.30) but differed marginally in age (t(29)=1.73, p=.095).
L1 Spanish (L1)
This group, which consisted of 17 L1 Spanish speakers (9 females, 8 males), was selected both to serve as a control group for the L2 group and to provide new evidence regarding frequency effects in L1 Spanish inflectional morphology. These participants lived in Spanish-speaking countries (16 participants lived in Latin America and 1 in Spain) until at least age 17, and were living in the U.S. at the time of the study. Their average LOR in the U.S. (it should be emphasized that these participants were tested only in Spanish) was 2.6 years, and all continued to use Spanish on a regular basis (average of 42% of time at work, 59% of time at home, and 70% of time visiting friends).
L2 Spanish (L2)
This group comprised 14 American English native speakers learning Spanish as an L2 (10 females, 4 males). They had completed an average of 6.9 semesters of instructed Spanish (SD=1.6), plus one to two semesters in an immersion situation in Spanish-speaking countries (mean number of months=9.4, SD=3.6). The average level of Spanish proficiency for this group was Advanced Mid, as measured by the SOPI (range: Intermediate High to Advanced High).
Tasks and Materials
We have used similar production (i.e., generation) tasks to examine the neurocognition of morphology in English L1 and L2 and in Spanish L1 (Babcock et al., In preparation; Brovetto, 2002; Brovetto & Ullman, 2001; Prado & Ullman, 2009). The method of this study is similar to that of the study carried out by Brovetto and Ullman (Brovetto, 2002; Brovetto & Ullman, 2001) on L1 Spanish speakers (unlike the present study, they did not examine L2 Spanish speakers). The procedure in the studies is similar, and the verbs used here were adapted from those developed by Brovetto and Ullman. Additional verbs were selected, and some verbs were replaced because they were deemed to be especially problematic for learners of Spanish as an L2.
Present tense
The present-tense task included 128 verbs (see Appendix A): 71 from Brovetto and Ullman (Brovetto, 2002; Brovetto & Ullman, 2001) and 57 additional verbs. To avoid verb-stem decomposition, the verbs were selected to have monomorphemic stems.10 Half (64) of the stimuli were Class I verbs, and half were of Classes II and III (both Class II and III verbs were used to provide enough verbs). In each set (Classes I or II/III), half the verbs were stem-changing (irregular) and half were not (regular), and all contained -e- in the position that might undergo a stem-change (the penultimate syllable in the infinitive).11 Thus there were four sets of verbs representing the contrast between verb-class (I or II/III) and verb-type (non-stem-changing/regular vs. stem-changing/irregular): 32 Class I regulars (e.g., pescar-pesco), 32 Class I irregulars (e.g., pensar-pienso), 32 Class II/III regulars (e.g., vender-vendo), and 32 Class II/III irregulars (e.g., perder-pierdo).
The four sets of verbs were matched group-wise on surface form (first-person singular present-tense inflected form) frequency (overall mean: 1.54; range: 0-6.75; F(3,124)=.187, p=.905); infinitival frequency (mean: 3.39; range: 0-6.74; F(3,124)=.478, p=.698); and lemma frequency (sum of frequencies of all forms of a given verb; mean: 5.18; range: 0.69-8.74; F(3,124)=.988, p=.401). For each form, the frequency value was taken from the 5-million-word LEXESP frequency count (Sebastián Gallés, Cuetos Vega, Carreiras Valiña, & Martí Antonin, 2000). For frequency values for the present-tense task, this count alone was employed (and not the two other counts that were also used for the imperfect tense; see below), since it crucially contains part-of-speech information, and thus we were able to distinguish first-person singular verb forms from, for example, noun homographs (i.e., beso can be either a noun or verb). As in our other work (e.g., Babcock et al., In preparation; Prado & Ullman, 2009), the raw frequency values were increased by 1 (to avoid ln of 0) and natural logarithm (ln)-transformed. All frequency-based analyses (including the matching statistics just above, and all frequency effects analyses) were performed on these ln-transformed values. The verbs across the four conditions were also matched group-wise on length of the infinitive and of the inflected (surface) form (number of phonemes, with diphthongs counted as one phoneme), and therefore approximately on phonological complexity, which single-mechanism theorists have argued might explain empirical differences between regular and irregular verbs (McClelland & Patterson, 2002). Other item-based factors were considered as covariates in the analyses (see Analysis and Table 2).
Table 2. Potential Subject- and Item-level Covariates Considered.
| Variable | Comments |
|---|---|
| Subject-Level | |
| Age | Measured in number of years. |
| Education | Formal education, measured in number of years. |
| Sex | Male or female. |
| Item-Level | |
| Item Order | A measure of how many verbs were presented prior to a given verb. Including item order in the model allows one to account for variability attributable to presentation order (e.g., due to practice effects within the task), enhancing prediction accuracy and decreasing the size of the residual error in the regression models. Order is likely to be more influential for earlier items, with order effects diminishing rapidly as participants become more comfortable with the task; therefore the natural logarithm of item order was used. Note that item order for each verb was calculated separately for each of the two presentation orders. |
| Follows Same Inflectional Type | A binary variable indicating whether or not the previous verb presented was of the same inflectional type (for present tense, only regular vs. irregular; for imperfect tense, Class I vs. Class II/III). This variable was examined because repeating a similar response versus producing a different type of response may affect response times. Calculated separately for each presentation order. |
| Phonological Length of Inflected Form | Computed as the number of phonemes, with diphthongs counted as one phoneme. Included because longer spoken forms may require more time for syllabification and articulatory planning than shorter ones (Levelt, Roelofs, & Meyer, 1999), and because word length has been shown to predict performance on single-word processing measures such as lexical decision and single-word reading (Balota, Cortese, Sergent-Marshall, Spieler, & Yap, 2004). |
| Initial Fricative | A binary variable describing whether the initial sound of the participant's response was a fricative. Included because this can affect computer-recorded response time measurements (fricatives tend to be detected more slowly than sonorants, nasals, vowels, and plosives) (Kessler, Treiman, & Mullennix, 2002). |
| Initial Plosive | A binary variable describing whether the initial sound of the participant's response was a plosive. Included because this can affect computer-recorded response time measurements (plosives tend to be detected faster than fricatives but more slowly than sonorants, nasals and vowels) (Kessler et al., 2002). |
| Plausible Non-Monomorphemic Verb Stem | A binary variable indicating whether the meaning of the verb stem might plausibly be derivable from a prefix and root, and thus the verb stem might be decomposed. Included because such verbs could be processed differently from verbs with actual monomorphemic stems. |
| Number of Verb Stem Repetitions | A variable indicating the number of times the stem of any given stimulus (infinitive) had been seen already in the particular presentation order. Included because in some cases more than one stimulus (verb) shared a given stem (e.g., cometer, prometer), and response times may be affected by such repetitions. Calculated separately for each presentation order. |
| Existence of Other Forms | A binary variable describing whether the participant's response (1st person singular form) also exists as another part of speech (i.e., as a noun or an adjective) at a minimum frequency threshold (frequency of at least 1 in the frequency count used for analyses). Included because it is possible that the processing of an inflected form may be affected by the existence of other – non-verbal – words with the same surface form (Prado & Ullman, 2009). Calculated only for items in the present-tense task. |
| Same-class Neighborhood Strength | A measure indicating the number of neighboring “friends” minus the number of neighboring “enemies” in the same verb class (I or II/III), at a minimum frequency threshold (of at least 1 in the frequency count used for analyses). Same-class neighbors are defined as verbs in the same class as the given verb that have the same rime in the final syllable of the infinitival stem. “Friends” are neighbors undergoing the same inflectional transformation (i.e., also regular, or also undergoing the irregular e-ie transformation) as the response. “Enemies” are neighbors undergoing any type of inflectional transformation different from that of the correct response of the given verb (Brovetto, 2002; Brovetto & Ullman, 2001). Included to account for the potential influence of phonologically similar verbs of the same conjugation class on a given form stored in memory (Prado & Ullman, 2009). |
| Opposite-class Neighborhood Strength | A measure indicating the number of neighboring “enemies” minus the number of neighboring “friends” in the opposite verb class (I or II/III) of the given verb, at a minimum frequency threshold of 1 in the frequency count used for analyses. Opposite-class neighbors are defined as verbs in the opposite class (Class II/III for Class I verbs, and vice versa) that have the same rime in the final syllable of the infinitival stem. Included to account for the potential influence of phonologically similar verbs of the opposite conjugation class on a given form stored in memory (Prado & Ullman, 2009). |
Imperfect Tense
The imperfect task consisted of 64 verbs (see Appendix B): 12 from Brovetto and Ullman (Brovetto, 2002; Brovetto & Ullman, 2001), and 52 additional verbs. As in the present-tense task, the verbs were selected to have monomorphemic stems (see note 10). These constituted 32 verbs of verb-class I, all of which undergo only non-stem-change (regular) transformations in all tenses, and 32 verbs of verb-classes II and III. The latter were selected such that all undergo a stem-change (irregular) transformation in some tense (other than imperfect). This decision was made (a) in response to Brovetto and Ullman's (L1) data, which yielded no frequency effects for either Class I or II verbs (all of which were verbs that undergo only regular transformations in all tenses), in case having other irregular forms increases the likelihood of a verb's regular forms also being stored; and (b) because Spanish students (i.e., the participants in the L2 group) learn many more Class II and III verbs that are irregular (in some form) than regular, presumably because they are more frequent than entirely regular Class II/III verbs.
The Class I and II/III verbs were matched group-wise on surface frequency (i.e., of each -aba- or -ía- suffixed form; overall mean: 8.11; range: 0.40-25.64; t(62)=.262, p=.794), infinitival frequency (mean: 6.16; range: 3.33-8.21; t(62)=.284, p=.787), and lemma frequency (mean: 6.13; range: 2.94-7.83; t(62)=.931; p=.355). For the imperfect tense we used the sum of three frequency counts12 (ln-transformed, with 1 added first): the 20-million-word 20th century count from Corpus del español (Davies, 2002), the 2-million-word Alameda & Cuetos count (1995) and the 5-million-word LEXESP count (Sebastián Gallés et al., 2000). Unlike first-person singular present-tense forms, no homographs exist for imperfect forms in Spanish, allowing us to benefit from this much larger combined frequency count, even though as a result the surface frequency counts were based on third-person as well as first-person forms, which are identical. The verbs were also matched group-wise on length (number of phonemes) of the infinitive and the surface form. As with the present tense, other item-based factors were considered as covariates in the analyses (see below).
Procedure
The same procedure was used for both present-tense and imperfect-tense tasks. The two tasks were administered separately, and the order of task presentation was counter-balanced across participants within each group (L1 and L2). In each task, two mirror-image stimulus presentation orders were used (i.e., each was the reverse order of the other), with presentation order being counterbalanced within each group (L1 and L2 participants) and task order. Presentation order was pseudo-randomized, with no more than 4 verbs of either verb-class (I or II/III) or verb-type (regular or irregular, for present only) presented in a row.
The infinitive of the target verb was presented visually on a computer screen, as a single word. Participants were asked to say, out loud, the form of the verb that they would use to describe something that they currently do (present-tense form) or that they used to do regularly in the past (imperfect form). Participants were instructed to answer as quickly and accurately as possible, and were allowed up to 5 seconds for each verb to give their response. Practice items (present tense: 4; imperfect: 4) were provided after instruction. In addition, at the beginning of each task participants were presented with pre-items (present tense: 6; imperfect: 10). The pre-items, which were indistinguishable from the experimental items but were not included in analyses, were included to avoid initial task effects. Responses were digitally recorded, and RTs were collected via a voice trigger.
Analysis
Frequency effects were examined only on RTs; as in our previous studies of frequency effects, a high rate of correct responses precluded sufficient variability for analyses on accuracy (e.g., Prado & Ullman, 2009). Also as in our previous studies, RT analyses were performed only on correct first-responses (82.83% of all first responses for present tense; 96.22% of all first responses for imperfect tense). During testing, the experimenter noted items whose RTs were not triggered by a participant's response (1.49% of correct first responses for present tense; 1.68% for imperfect). These RTs were excluded from analysis. As in our previous research (Gelfand, Walenski, Moffa, Lee, & Ullman, Under Revision; Prado & Ullman, 2009), RTs faster than 500 ms were discarded as being likely due to timer error (7.15% of correct first responses for present; 12.41% for imperfect).13 Extreme outliers for each participant – that is, responses whose RTs were more than 3.5 standard deviations from the given participant's mean – were also excluded (1.06% of correct first responses for present; 0.94% for imperfect). Significance of all effects was assessed using α=0.05. All p-values are reported as two-tailed. In all analyses, degrees of freedom were computed using the Satterthwaite approximation.
The RT data were analyzed using mixed-effects regression models. This statistical method allows each individual RT from each participant and item to be entered into one model, without averaging RTs (which results in a substantial loss of information) and allows various item- and subject-level covariates that may influence the pattern of results to also be included in the same model. Mixed-effects models account for subject variability by including the baseline performance (model intercept) of each participant as a random variable. For more complete discussions of this statistical method and for similar analyses see especially (R. H. Baayen, Davidson, & Bates, 2008), as well as Prado and Ullman (2009).
Two mixed-effects models were constructed, one for present tense and one for imperfect. These included ln-transformed RT as the dependent variable; inflected-form frequency (as described above), verb-class (Class I vs. Class II/III), and verb-type (for present tense only: regular vs. irregular) as item-level variables; and participant group (L1 vs. L2) as a subject-level variable. The independent variables were entered into the model as interactions between participant group, verb-class, verb-type (for present tense), and frequency, generating separate frequency coefficients for each participant group on each item type.
Thirteen potentially confounding item- and subject-level variables (e.g., see Babcock et al., In preparation; Prado & Ullman, 2009) were examined for possible inclusion as covariates (Table 2). Each of these variables was included as a covariate only if it met certain specific conditions (see below) that suggested it might confound the results. Thus, only a subset of potential covariates was actually included in analyses, reducing the risk of overfitting the data.
The following steps were taken to determine whether each variable would or would not be included as a covariate in analyses. It was assessed whether each potential covariate was unbalanced and/or associated. A factor was considered unbalanced if it differed (p ≤.1) between L1 and L2 for subject-level variables (e.g., age), or among the sets of verbs (for present, among the 4 verb sets; for imperfect, between the 2 verb-classes) for item-level variables (e.g., length). Whether or not a factor was unbalanced was determined by t-tests/one-way ANOVAs (for continuous variables; e.g., age) or Fisher's exact tests (for categorical variables; e.g., whether or not the word began with a fricative). For subject-level variables, only age was found to be imbalanced (for both present tense and imperfect, since these were given to the same participants; F(29)=1.73, p=.094). For the present-tense, the following item-level variables were unbalanced: number of verb stem repetitions (F(3)=6.80, p<.0001 for presentation order 1; F(3)=4.90, p<.0001 for presentation order 2), same-class neighborhood strength (F(3)=22.54, p<.0001) and opposite-class neighborhood strength (F(3)=12.18, p<.0001). For the imperfect-tense, the following item-level variables were unbalanced: number of verb stem repetitions (t(62)=2.33, p=.023 for both presentation orders), same-class neighborhood strength (t(62)=2.96, p=.004) and opposite-class neighborhood strength (t(62)=4.17, p<.0001). Association was tested with separate correlations (Pearson's r) between each potential covariate and either the mean subject scores over all verbs (for subject-level covariates), or the mean item RTs over all participants (for item-level covariates), with mean RTs computed as the mean ln-transformed RTs. A covariate was considered to be associated if it predicted performance (p≤.1). For present-tense the following were associated: sex (r(31)=0.369, p=.041), follows same inflectional type (r(128)=0.15, p=.089 for presentation order 1; note that for presentation order 2, p=.177), and existence of other forms (r(128)=-0.23, p=.008). For imperfect-tense the following were associated: sex (r(31)=0.32, p=.079), education (r(31)=-0.32, p=.077), and opposite-class neighborhood strength (r(64)=-0.33, p=.008). All potential covariates that were either unbalanced or associated were then entered as fixed main effects into the mixed-effects models (for present tense or imperfect) described above. Because the criteria for covariate inclusion were very liberal – either associated or unbalanced – it is likely that any potentially confounding covariates (of those that were considered) were included.
Results
Present Tense
For L1 speakers, present-tense14 regular (non-stem-changing) forms showed significant inflected-form frequency effects on Class II/III but not Class I verbs (see Figure 1),15 with significant differences between the verb-classes in these effects (p=.032). In contrast, irregular (stem-changing) forms showed frequency effects in both verb-classes (I and II/III), with no differences between the verb-classes in the magnitude of these effects (p=.634). Additionally, within Class I, the difference between the effects (i.e., the slopes) for regulars and irregulars was significant (p = .022). In contrast, there was no difference between the frequency effects for regulars and irregulars in Class II/III forms (p=.776). The interaction between verb-class (I vs. II/III), verb-type (regular vs. irregular) and frequency was borderline significant (p=.054), despite the fact that it is a three-way interaction, suggesting that the frequency effect pattern differed by verb-type (regular vs. irregular) between the verb classes (Class I vs. Class II/III), and vice versa.
Figure 1.
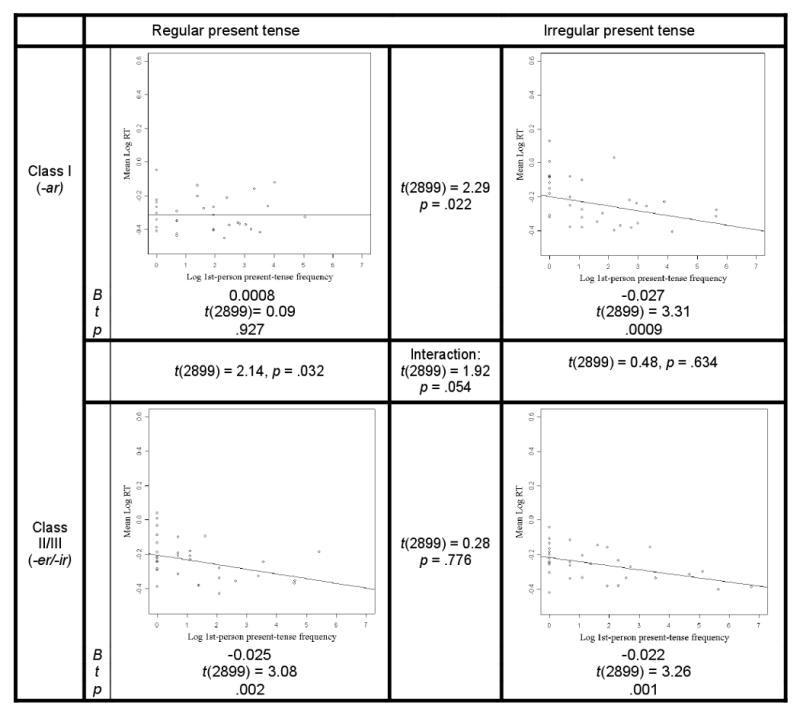
L1 present-tense frequency effects for regular and irregular Class I and Class II/III forms.
The L2 speakers showed a different pattern, with significant frequency effects (ps < .0001) for all four sets of verbs (see Figure 2), with no significant differences between any of the slopes (ps >.159). Moreover, the interaction between verb-class, verb-type and frequency was not significant (p=.102).
Figure 2.
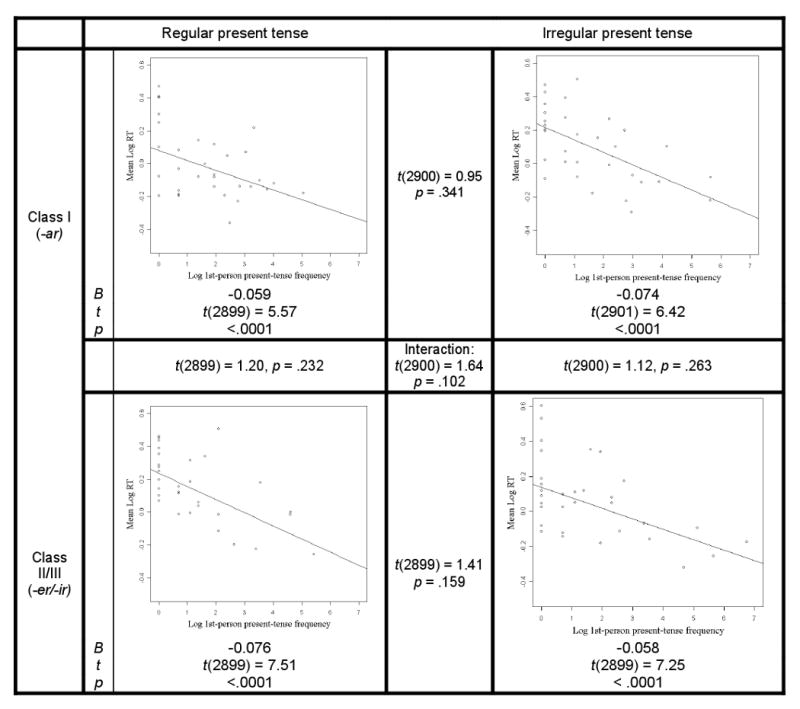
L2 present-tense frequency effects for regular and irregular Class I and Class II/III forms.
These results do not appear to be explained by confounding statistical factors. First, the lack of frequency effects for Class I regular inflected forms in L1 was not due to a lack of variability (e.g., from RT floor effects) among these items: the variance in RTs for the Class I regulars did not differ either from that for the Class I irregulars (Fvar(31,31)=1.83, p=.097, for the F-test of equality of variance) or from that of the Class II/III regulars (Fvar(31,31)=1.53, p=.242). Additionally, Class I regulars in L1 yielded the highest level of accuracy (98%; other L1 conditions, 96% or less; L2 conditions, 88% or less). Moreover, there were slightly more L1 than L2 participants. Thus, despite the fact that the statistical power was actually greatest for the Class I regulars in L1 (i.e., more RTs with correct first responses than the other conditions, and more participants than in the L2 conditions), it was only this condition that did not show frequency effects.
Imperfect Tense
For the imperfect tense,16 L1 speakers showed no frequency effects for Class I inflected forms (p=.172) but did show frequency effects for Class II/III forms (p=.002), although the difference between the two was not significant (p=.317); see Figure 3. In contrast, for L2 speakers, both Class I and Class II/III inflected forms evidenced significant (ps < .0003) frequency effects (Figure 4); there was no significant difference in the magnitude of these effects (p=.424). Due to the lack of a significant difference between the Class I and Class II/III effects, despite the frequency effects found for the former but not the latter in L1, we also examined group (L1 vs. L2) differences (which were generated by the same regression model). These revealed that the L2 speakers showed significantly more reliable effects than the L1 speakers for Class I forms (t(1596)=2.18, p=.029) but not for Class II/III forms (p=.565).
Figure 3.
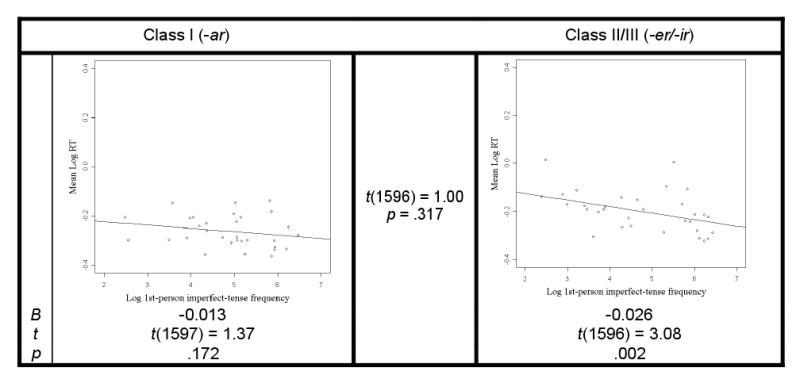
L1 imperfect-tense frequency effects for Class I and Class II/III forms.
Figure 4.
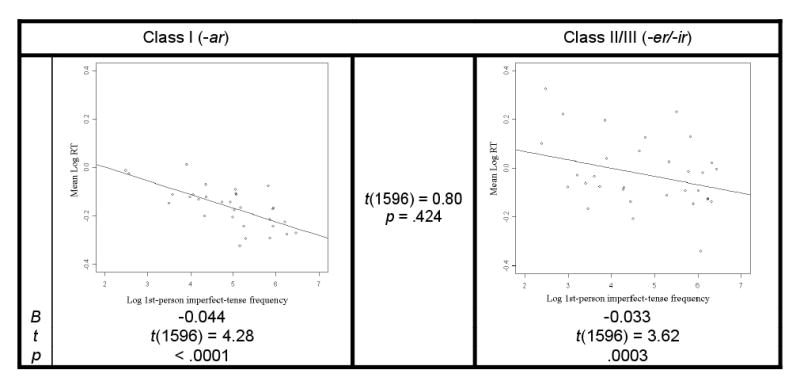
L2 imperfect-tense frequency effects for Class I and Class II/III forms
As with the present tense, these results do not appear to be attributable to confounding statistical factors. Again, the absence of frequency effects for Class I inflected forms in L1 was not explained by lower variability among these items: the variance in RTs did not differ between Classes I and II/III (Fvar(31,31)=1.24, p=.550). Additionally, even though accuracy was highest among Class I forms for L1 (99%; Class II/III for L1: 98%; L2 conditions: 95% or less), and so power was greatest in this condition (more RTs for correct first-responses, as well as more L1 than L2 participants), it was the only condition in the imperfect tense that failed to yield frequency effects.
Discussion
In summary, the following pattern was observed. In the present tense, among the L1 Spanish participants, only Class I regular (non-stem-changing) forms did not show frequency effects; frequency effects were found on Class II/III regulars as well as on irregular (stem-changing) forms in both Class I and Class II/III verbs.17 For the L2 group, on the other hand, all four conditions (Class I and Class II/III, regulars and irregulars) yielded frequency effects. For the imperfect tense, for the L1 group Class II/III but not Class I inflected forms showed frequency effects, whereas among the L2 participants frequency effects were found on Class I as well as Class II/III verbs.
These results do not appear to be explained by confounding experimental or statistical factors. First, the verb sets were matched on surface, infinitival and lemma frequency, as well as phonological length of both the surface and infinitival forms. Second, neither differences in RT variability nor in accuracy explained the results. Third, the data were not accounted for by 13 potential explanatory subject-level or item-level variables: age; education; sex; item order; whether or not an item followed another item of the same inflectional type; phonological length of the inflected form; whether or not the initial sound of the response was a fricative; whether or not the initial sound of the response was a plosive; whether the verb stem is plausibly non-monomorphemic; the number of times a given verb stem had already been presented; whether or not the response also exists as another part of speech; and finally, two measures of phonological neighborhood strength (see Table 2). Finally, it might be suggested that the frequency counts were more appropriate for the L1 than the L2 subjects, potentially leading to a greater likelihood of false negatives (lack of frequency effects) for the L2 than the L1 subjects (because the frequency counts would be less representative of the input for L2 subjects, and thus noisier). However, this pattern was not observed, and in fact, the L2 subjects showed equivalent or more reliable frequency effects as compared to the L1 subjects.
The data do not appear to be fully compatible with a single-mechanism view, which expects all verb forms to be learned, represented and processed in an associative memory system. At first blush at least, this view would expect frequency effects to be found for all verb forms (see Introduction), a pattern that was not observed. However, it has been argued by single-mechanism theorists that, at least in English, because regulars have similar stem-past phonological transformations, the general phonological pattern is learned in associative memory, leaving little or no influence to individual word frequencies (Daugherty & Seidenberg, 1992; Seidenberg, 1992). Nevertheless, it is not clear how this could account for the data observed here. First, to our knowledge this argument has not been made (nor have the relevant simulations been performed) for Spanish or other Romance languages, let alone for the particular inflections, verb-classes and regular/irregular contrasts examined here. Second, we held neighborhood strength constant in our analyses (see Table 2 and Analysis section). Third, all (but three) Class II and III verbs in Spanish are inflected with the -ía- suffix in the imperfect, yet even these verbs showed frequency effects in L1, suggesting that the lack of frequency effects among the Class I forms cannot easily be explained by effects of consistency.
The results may thus be interpreted in light of a dual-system view, in which the lack of frequency effects suggests composition. The findings suggest that in L1 Spanish present tense, at least for first-person singular, only Class I (the default class) regular inflected forms (i.e., non-stem-changing, which are the default transformation in Class I) are composed, whereas irregular (stem-changing) forms from all verb-classes, as well as regulars in Classes II and III (where they do not appear to constitute a default transformation), are stored.18 In L1 Spanish imperfect, at least for first-person singular, Class I (-aba-suffixed) forms appear to be composed, whereas Class II/III (-ía-suffixed) forms are stored, even though in both cases the verbs undergo regular (non-stem-changing) default transformations. These are new findings for L1 Spanish.
The results from L1 Spanish seem to support a dual-system view in which both verb-class and regularity influence the storage vs. composition of inflectional morphology. Specifically, the data suggest that verbal inflected forms that are both from (default) Class I and undergo regular (non-stem-changing) default transformations are composed. All other forms, that is, all irregulars (stem-changing forms), and even regulars (non-stem-changing forms) that follow default transformations in non-default classes (Class II/III),19 are stored.
Taken together, the L1 and L2 findings in the present study do not appear to be readily compatible either with perspectives that maintain that the mechanisms underlying L1 and L2 processing are distinct (Bley-Vroman, 1989; DeKeyser, 2000, 2003), nor that they are the same (Abutalebi, 2008; Ellis, 2005; Indefrey, 2006), given that the patterns of frequency effects in L1 and L2 (only) partially overlapped. Note that although the pattern of frequency effects of L2 participants taken alone appears to be compatible with a single-mechanism perspective, they must be interpreted in light of the L1 results, which do not appear to be consistent with this perspective. Instead, the data from this study seem to be most compatible with dual-system views that claim partial overlap of the mechanisms underlying L1 and L2. Specifically, the results are in line with the views espoused by the DP model (Ullman, 2001b, 2005a) and SSH (Clahsen & Felser, 2006a, 2006b). These models hypothesize (see Introduction) that whereas the L1 and L2 processing of idiosyncratic forms is similar, relying on lexical processes, the L2 processing of rule-governed structures depends less on L1 grammatical processes, and more on lexical (and other) processes, especially at lower levels of experience. It remains to be seen whether highly proficient and experienced L2 Spanish speakers come to show an L1-like processing pattern (e.g., a lack of frequency effects, suggesting online composition) for default-class regular forms in Spanish, as these models would also predict. Note that although Paradis has not made specific claims regarding the processing of regular and irregular inflectional morphology, it is possible that the pattern of results of L1 and L2 regular and irregular morphology could be incorporated into his model.
The data obtained here are consistent with previous studies of L1 and L2. We are aware of no other frequency effect (or priming) studies of regular/irregular verbal inflection in Spanish L1 (other than the study discussed above that is very similar to the study presented here, but showed no frequency effects, likely due to a lack of statistical power; see Introduction). However, three event-related potential (ERP) studies of L1 Spanish regular/irregular verbal inflection have been published. One study found ERP priming effects between infinitives and regular (non-stem-changing) but not irregular (with both e-ie and o-ue stem-changes) first-person singular present-tense forms, suggesting memorized lexical entries for irregular but not regular inflected forms (Rodriguez-Fornells, Munte, & Clahsen, 2002). However, it should be noted that verbs from all three verb-classes (with the majority being Class I verbs) were included in both the regular and irregular conditions. Similarly, in another ERP study of first-person singular present-tense forms, irregulars (including both e-ie and o-ue stem-changes) showed reduced ERP priming effects as compared to regulars (though again, both regulars and irregulars included all three verb classes, with a majority of Class I verbs) (De Diego Balaguer, Sebastian-Galles, Diaz, & Rodriguez-Fornells, 2005). Finally, an ERP violation study presented L1 Spanish speakers with third-person plural present-tense forms of Class III irregular verbs that take an e-i stem-change (e.g., medir-miden) (Linares, Rodriguez-Fornells, & Clahsen, 2006). Correctly (miden) and incorrectly (meden) inflected forms showed amplitude differences in a negativity interpreted as an N400, which has been linked to lexical-semantic processing and declarative memory. No regulars were tested in this study. Thus previous studies of L1 Spanish regular/irregular verbal morphology are consistent with a dual-system perspective, and are compatible with the findings reported here, even though they focused only on present tense, and did not attempt to tease apart the regular/irregular distinction from the distinction between the default (Class I) and non-default (Classes II and III) verb classes.
We are not aware of any previous studies of Spanish regular/irregular verbal inflectional morphology in L2. However, the L2 results reported here are largely compatible with previous findings on L2 regular/irregular verbal inflectional morphology in other languages. These studies suggest that, except at quite high levels of experience (e.g., LOR of 10 to 16 years in Birdsong & Flege, 2001), L2 speakers generally show frequency effects for both regulars and irregulars, and reduced priming for regulars (see Introduction). ERP studies examining lexical/semantic and syntactic processing are consistent with this pattern: L2 and L1 speakers do not differ in their lexical/semantic processing, but show differences in syntactic processing, except at relatively high levels of L2 proficiency (Gillon Dowens, Vergara, Barber, & Carreiras, In Press; Hahne, 2001; Ojima, Nakata, & Kakigi, 2005; Osterhout, McLaughlin, Kim, Greenwald, & Inoue, 2004; Rossi, Gugler, Friederici, & Hahne, 2006; Weber-Fox & Neville, 1996) (for reviews, see Steinhauer, White, & Drury, 2009; Ullman, 2001b, 2005a). Overall, these data, like those from the current study, are consistent with dual-system views of partial overlap of L1 and L2 neural mechanisms, and specifically with the DP model (Ullman, 2001b, 2005a) and SSH (Clahsen & Felser, 2006a, 2006b).
It is of interest that in the current study, the L2 group had relatively high proficiency (medium-to-advanced) but low immersion experience (mean of about 9 months), as compared to other studies (see above). In addition, the L2 participants examined here had high levels of classroom experience (average of about 7 college semesters). The pattern of results found for this L2 group therefore has at least two interesting implications. First, the finding that these participants still showed frequency effects for inflected forms that did not evidence signs of storage in L1 suggests that perhaps immersion rather than classroom experience may be critical for achieving native-like (e.g., procedural) grammatical processing in L2 (e.g., as found in the high LOR participants reported by Birdsong & Flege, 2001). Indeed, this view is compatible with a recent ERP study of artificial language, in which implicit (immersion-like) but not explicit (classroom-like) instruction yielded L1-like ERP patterns of grammatical processing (Kara Morgan-Short, 2007; Kara Morgan-Short, Steinhauer, Sanz, & Ullman, 2007; K. Morgan-Short, Steinhauer, Sanz, & Ullman, In Preparation). Second, the pattern found here suggests that (at least some types of) experience may play a more important role than proficiency alone in achieving L1-like neurocognitive processing of L2 grammar (Ullman, 2001b, 2005a).
In sum, we examined inflected-form frequency effects in Spanish present and imperfect tense in both L1 and L2 speakers. The results suggest that in L1 both verb-class and regularity affect the storage vs. composition of inflected forms: consistent with a dual-system view, only those inflected forms that are from the default class (Class I) and that undergo a regular (non-stem-changing) transformation seem to be composed, while all other inflected forms are stored. In contrast, in L2 Spanish all verbal inflected forms are stored, at least in L2 speakers with mid-to-high levels of proficiency and with substantial classroom experience, though with a low amount of immersion experience. The results are not compatible with L2 perspectives suggesting that the mechanisms underlying L1 and L2 processing are either the same or different. In contrast, they are consistent with the view that while the processing of idiosyncratic forms depends on lexical (and perhaps declarative) memory in both L1 and L2, at least at lower levels of L2 experience rule-governed forms are processed not by L1 combinatorial processes, but rather also depend on lexical memory.
Acknowledgments
We thank Claudia Brovetto and John Stowe for their contributions to the project. Preliminary results from this study were presented at the annual meeting of the American Association for Applied Linguistics in 2008. Support for this project was provided to MTU by the NIH under RO1 MH58189 and RO1 HD049347, by the NSF under Doctoral Dissertation Improvement Grant 0519133, and to HWB by the NIH under Ruth L. Kirschstein National Research Service Award 5 F31MH68143-04 from the NIMH.
Appendix A
Present-tense Items
| Class I Regulars | Class I Irregulars | Class II/III Regulars | Class II/III Irregulars | ||||
|---|---|---|---|---|---|---|---|
| Infinitive | First-person singular | Infinitive | First-person singular | Infinitive | First-person singular | Infinitive | First-person singular |
| agregar | agrego | acertar | acierto | acceder | accedo | adherir | adhiero |
| apelar | apelo | alentar | aliento | agredir | agredo | advertir | advierto |
| aumentar | aumento | apretar | aprieto | aprender | aprendo | ascender | asciendo |
| besar | beso | arrendar | arriendo | beber | bebo | asentir | asiento |
| cenar | ceno | atravesar | atravieso | ceder | cedo | atender | atiendo |
| cosechar | cosecho | calentar | caliento | cometer | cometo | conferir | confiero |
| delegar | delego | cerrar | cierro | compeler | compelo | consentir | consiento |
| doblegar | doblego | comenzar | comienzo | comprender | comprendo | convertir | convierto |
| echar | echo | confesar | confieso | conceder | concedo | defender | defiendo |
| enfrentar | enfrento | despertar | despierto | convencer | convenzo | descender | desciendo |
| enrejar | enrejo | empedrar | empiedro | converger | converjo | diferir | difiero |
| entregar | entrego | empezar | empiezo | deber | debo | digerir | digiero |
| entrenar | entreno | enmendar | enmiendo | depender | dependo | discernir | discierno |
| esperar | espero | enterrar | entierro | ejercer | ejerzo | divertir | divierto |
| fomentar | fomento | fregar | friego | emerger | emerjo | encender | enciendo |
| frenar | freno | gobernar | gobierno | emprender | emprendo | entender | entiendo |
| heredar | heredo | helar | hielo | exceder | excedo | extender | extiendo |
| intentar | intento | merendar | meriendo | expeler | expelo | herir | hiero |
| manejar | manejo | negar | niego | expender | expendo | hervir | hiervo |
| mezclar | mezclo | pensar | pienso | mecer | mezo | inferir | infiero |
| numerar | numero | quebrar | quiebro | ofender | ofendo | ingerir | ingiero |
| observar | observo | regar | riego | prender | prendo | invertir | invierto |
| pecar | peco | remendar | remiendo | pretender | pretendo | mentir | miento |
| pegar | pego | restregar | restriego | proceder | procedo | perder | pierdo |
| pescar | pesco | reventar | reviento | prometer | prometo | preferir | prefiero |
| presentar | presento | segar | siego | proteger | protejo | querer | quiero |
| quedar | quedo | sembrar | siembro | repeler | repelo | requerir | requiero |
| revelar | revelo | sentar | siento | sorprender | sorprendo | sentir | siento |
| rezar | rezo | sosegar | sosiego | sumergir | sumerjo | sugerir | sugiero |
| secar | seco | temblar | tiemblo | tejer | tejo | tender | tiendo |
| sospechar | sospecho | tentar | tiento | temer | temo | trascender | trasciendo |
| tensar | tenso | tropezar | tropiezo | vender | vendo | verter | vierto |
Appendix B
Imperfect-tense Items
| Class I | Class II/III | ||
|---|---|---|---|
| Infinitive | First-person singular | Infinitive | First-person singular |
| abrazar | abrazaba | abrir | abría |
| ahorrar | ahorraba | caber | cabía |
| amar | amaba | caer | caía |
| atacar | atacaba | competir | competía |
| ayudar | ayudaba | concebir | concebía |
| bailar | bailaba | conducir | conducía |
| bañar | bañaba | conseguir | conseguía |
| cambiar | cambiaba | construir | construía |
| caminar | caminaba | corregir | corregía |
| cantar | cantaba | cubrir | cubría |
| cocinar | cocinaba | deducir | deducía |
| conspirar | conspiraba | describir | describía |
| cortar | cortaba | despedir | despedía |
| criticar | criticaba | dormir | dormía |
| cruzar | cruzaba | elegir | elegía |
| doblar | doblaba | escoger | escogía |
| explorar | exploraba | escribir | escribía |
| fumar | fumaba | medir | medía |
| gritar | gritaba | morir | moría |
| levantar | levantaba | oler | olía |
| limpiar | limpiaba | pedir | pedía |
| molestar | molestaba | proferir | profería |
| narrar | narraba | reducir | reducía |
| olvidar | olvidaba | rendir | rendía |
| pagar | pagaba | repetir | repetía |
| publicar | publicaba | resolver | resolvía |
| quitar | quitaba | romper | rompía |
| sacar | sacaba | servir | servía |
| tocar | tocaba | sustituir | sustituía |
| tomar | tomaba | traducir | traducía |
| trabajar | trabajaba | traer | traía |
| viajar | viajaba | vestir | vestía |
Footnotes
Note that the access of stored forms is thought to take primacy over the computation of composed forms, though such primacy does not necessarily lead to faster retrieval than composition, and thus simple reaction times cannot be used to distinguish storage from composition (Pinker & Ullman, 2002; Ullman, 2001a, 2007).
There are also other types of transformations in Spanish verbal inflection that are usually considered irregular (e.g., suppletive forms such as ser-fui) which are not examined here.
On this view, because a given verb (e.g., pensar) may take both irregular (stem-changing; e.g., pensar-pienso) and regular (non-stem-changing; e.g., pensar-pensamos) transformations, it is not the case that a given verb is necessarily intrinsically regular or irregular.
The status of the e-ie stem-change is controversial, given that it is partially predictable (it can occur only when the syllable containing the e is stressed) but not completely predictable (it occurs only for some verbs that present this environment). Some analyses assume rule-based derivation for these stem changes (J. W. Harris, 1985), while others suggest that the modified stem may be memorized (Clahsen, Aveledo, & Roca, 2002).
Here we focus on studies that examine priming between forms of the same word, and thus do not discuss other types of priming paradigms, such as those that examine priming between an inflected form and a stem homograph (e.g., Allen & Badecker, 1999; Laudanna, Badecker, & Caramazza, 1992).
In this study we examine regular inflectional transformations that are (a) in the default class and constitute the default transformation (Class I regulars in the present tense); (b) not in the default class but do constitute the default transformation (Class II/III regulars in the imperfect tense); and (c) not in the default class but do not apparently constitute the default transformation (Class II/III regulars in the present tense). However, we do not examine regular inflectional transformations that are in the default class but do not constitute the default transformation, and indeed, we are not aware of any such transformations.
“Significant exposure” was defined as having any family members or caretakers who spoke the L2 to them, having attended a bilingual or international school with the L2 as a language of instruction, or living in a country in which the L2 is spoken.
Two additional groups of L2 participants were also tested: a group of 16 participants with 2-4 semesters of classroom experience and no immersion experience, and a group of 7 participants with a very high level of immersion experience. These groups are not the focus of this paper, and are not discussed further.
The SOPI elicits spoken language in a variety of simulated situations. It is based on the speaking proficiency guidelines of the American Council on the Teaching of Foreign Languages (ACTFL). See http://www.cal.org/topics/ta/sopi.html for more information on the SOPI. We administered a computer-adapted version of the test developed in the Brain and Language Lab (Georgetown University) which exactly replicated the SOPI but presented the visual and audio prompts via a self-timed PowerPoint presentation rather than via a booklet and master tape. The entire test session was digitally recorded for each participant. The test results were assessed by two raters who were trained either with CAL's Multi-media Rater Training Program and/or in CAL workshops; if these two ratings did not match, the test was independently rated by a third trained rater to obtain a final rating.
All of the verbs met a simple definition of monomorphemic, namely that their meanings were not transparently derivable from any prefix and verb. However, to obtain enough verbs that satisfied the specified phonological constraints and that covered a wide frequency range, we had to include a number of verbs which, though we judged them to be not derivable, might nonetheless be argued to be so – from a prefix and either a verb (e.g., aprender, to learn, might possibly be derivable from a- and prender, to take) or even other parts of speech (e.g., enterrar, to bury, might be derivable from en- and the noun tierra, earth). We addressed this concern statistically; see Analysis and Table 2.
Because the task hinges on the e-ie stem-change, the non-stem-changing verbs also had to be ‘potential’ stem-changing verbs, in order to avoid simple strategies (e.g., change the stem of any verb with an e in penultimate syllable in the infinitive). This meant that it was difficult to avoid including non-stem-changing verbs whose infinitival forms rhyme with those of stem-changing verbs, even though inflected forms of such “rhyming regulars” may show an increased likelihood of memorization, at least in English (Ullman, 2001a). However, we managed to select the non-stem-changing verbs such that within each class (i.e., Class I and Class II/III) slightly more than half (17/32) of the non-stem-changing verbs do not rhyme with (e-ie) irregulars in the same class (i.e., for -ar regulars, 17 have no rhyming irregular -ar verbs, and analogously for the Class II/III verbs).
Of the three counts, only LEXESP provided lemma information, so the lemma frequency counts were based only on this source.
We also ran each of the models reported in Results with 350, 400 and 450 ms cutoffs, and found the same patterns of significance for each verb type as with a 500 ms cutoff.
Although this study focuses on frequency effects, here we also present mean response times (and standard errors), in milliseconds. L1 Class I (-ar) regulars: 838.4 (14.4); irregulars: 898.0 (17.9). L1 Class II/III (-er/-ir) regulars: 921.7 (18.9); irregulars: 895.7 (16.2). L2 Class I (-ar) regulars: 1154.7 (26.9); irregulars: 1238.6 (38.1). L2 Class II/III (-er/-ir) regulars: 1327.7 (35.1); irregulars: 1254.2 (35.6).
In each scatterplot, the line represents the prediction of the mixed-effects model with regard to the effect of frequency on the dependent variable (log of reaction time), with the effect of all covariates removed. Each point on the graph represents the mean log response time for the relevant group of participants (L1 or L2) on that item. For further details, see Prado and Ullman (2009).
Mean response times (and standard errors), in milliseconds: L1 Class I (-ar) verbs: 731.4 (10.5); Class II/III (-er/-ir): 774.5 (12.9). L2 Class I (-ar) verbs: 797.9 (11.5): Class II/III (-er/-ir): 927.6 (16.5).
The present-tense Class II/III regulars (non-stem-changing forms) are mostly (30 out of 32) Class II (–er) verbs whereas as the present-tense Class II/III irregulars (stem-changing) are mostly (20 out of 32) Class III (–ir) verbs. This imbalance was due to the need to match verbs (groupwise) between regulars and irregulars on frequency. Therefore the frequency effects found on Class II/III regulars must be due primarily to Class II (-er) verbs, so we do not know whether regular Class III (-ir) verbs would also show frequency effects. However, because Class II and III verbs appear to be equally unpredictable in general (J. Harris, 1969), and given that all other Class II/III inflected forms show frequency effects, whether regular or irregular, it seems reasonably likely that Class III (-ir) regular verbs would also show frequency effects.
The finding that all e-ie stem-changing inflected forms appear to be stored also suggests that the controversy regarding the composition vs. retrieval of phonologically-changed stems (see Note 4) is moot, since this controversy seems to be relevant only for changed stems which then undergo composition.
These results were obtained for default regulars (i.e., which constitute the default transformation) whose affix in the non-default Classes II/III (-ía-) was different from that in the default Class I (-aba-). It remains an open question as to whether the same result would also be found for default regulars whose affix in Classes II/III and Class I is the same, as is the case, for example, in the future (e.g., hablar-hablaré, comer-comeré, mentir-mentiré) and conditional (e.g., hablar-hablaría, comer-comería, mentir-mentiría) tenses. Additionally, it should be noted that the results here were found for Class I verbs that were regular in all tenses (not just in the imperfect), and Class II/III verbs that were irregular in at least one form in one tense (but not in the imperfect). It thus remains open as to whether the same result would also be found for other combinations (e.g., Class I verbs in which at least one other form is irregular, etc.).
References
- Abutalebi J. Neural aspects of second language representation and language control. Acta Psychologica. 2008;128(3):466–478. doi: 10.1016/j.actpsy.2008.03.014. [DOI] [PubMed] [Google Scholar]
- Alameda JR, Cuetos F. Diccionario de frecuencias de las unidades lingüísticas del castellano. Oviedo, Spain: Publicaciones de la Universidad de Oviedo; 1995. [Google Scholar]
- Alegre M, Gordon P. Frequency Effects and the Representational Status of Regular Inflections. Journal of Memory and Language. 1999;40:41–61. [Google Scholar]
- Allen M, Badecker W. Stem homograph inhibition and stem allomorphy: Representing and processing inflected forms in a multilevel lexical system. Journal of Memory and Language. 1999;41(1):105–123. [Google Scholar]
- Baayen H, Schreuder R, de Jong N, Knott A. Dutch inflection: the rules that prove the exception. In: Nooteboom S, Weerman F, Wijnen F, editors. Storage and Computation in the Language Faculty. Dordrecht, Netherlands: Kluwer Academic; 2002. pp. 61–92. [Google Scholar]
- Baayen RH, Davidson DJ, Bates DM. Mixed-effects modeling with crossed random effects for subjects and items. Journal of Memory and Language: Emerging Data Analysis Techniques. 2008:1–23. [Google Scholar]
- Babcock L, Stowe J, Maloof C, Brovetto C, Ullman MT. Frequency effects, age of arrival and amount of exposure in second language learning: A study of English past-tense production In preparation. [Google Scholar]
- Balota DA, Cortese MJ, Sergent-Marshall SD, Spieler DH, Yap MJ. Visual Word Recognition of Single-Syllable Words. Journal of Experimental Psychology: General. 2004;133(2):283–316. doi: 10.1037/0096-3445.133.2.283. [DOI] [PubMed] [Google Scholar]
- Bates EA, MacWhinney B. Functionalism and the competition model. In: MacWhinney B, Bates E, editors. The crosslinguistic study of sentence processing. Cambridge, UK: Cambridge University Press; 1989. pp. 3–73. [Google Scholar]
- Beck ML. Regular verbs, past tense and frequency: Tracking down a potential source of NS/NNS competence differences. Second Language Research. 1997;13(2):93–115. [Google Scholar]
- Bertram R, Laine M, Harald Baayen R, Schreuder R, Hyona J. Affixal homonymy triggers full-form storage, even with inflected words, even in a morphologically rich language. Cognition. 2000;74(2):B13–25. doi: 10.1016/s0010-0277(99)00068-2. [DOI] [PubMed] [Google Scholar]
- Birdsong D, Flege JE. BUCLD 25: Proceedings of the 25th Annual Boston University Conference on Language Development. Boston, MA: Cascadilla Press; 2001. Regular-irregular dissociations in the acquisition of English as a second language; pp. 123–132. [Google Scholar]
- Bley-Vroman R. What is the logical problem of foreign language learning? In: Gass SM, Schacter J, editors. Linguistic perspectives on second language acquisition. Cambridge: Cambridge University Press; 1989. pp. 41–68. [Google Scholar]
- Brovetto C. The representation and processing of verbal morphology in first and second language. Georgetown University; Washington, DC: 2002. Unpublished Ph D. [Google Scholar]
- Brovetto C, Ullman MT. First vs second language: A differential reliance on grammatical computations and lexical memory; Paper presented at the CUNY 2001 Conference on Sentence Processing; Philadelphia, PA. 2001. Mar, [Google Scholar]
- Brovetto C, Ullman MT. The mental representation and processing of Spanish verbal morphology; Paper presented at the The 7th Hispanic Linguistics Symposium; The University of New Mexico, Albuquerque. 2003. Mar, [Google Scholar]
- Chomsky N. Rules and representations. The Behavioral and Brain Sciences. 1980;3:1–61. [Google Scholar]
- Clahsen H. Lexical entries and rules of language: A multidisciplinary study of German inflection. Behavioral and Brain Sciences. 1999;22(6):991–1060. doi: 10.1017/s0140525x99002228. [DOI] [PubMed] [Google Scholar]
- Clahsen H, Aveledo F, Roca I. The development of regular and irregular verb inflection in Spanish child language. Journal of Child Language. 2002;29(3):591–622. doi: 10.1017/s0305000902005172. [DOI] [PubMed] [Google Scholar]
- Clahsen H, Eisenbeiss S, Sonnenstuhl I. Morphological structure and the processing of inflected words. Theoretical Linguistics. 1997;23(3):201–249. [Google Scholar]
- Clahsen H, Felser C. Continuity and shallow structures in language processing: A reply to our commentators. Applied Psycholinguistics. 2006a;27(1):107–126. [Google Scholar]
- Clahsen H, Felser C. Grammatical Processing in Language Learners. Applied Psycholinguistics. 2006b;27(1):3–42. [Google Scholar]
- Clahsen H, Felser C. How native-like is non-native language proceessing? Trends in Cognitive Science. 2006c;10(12):564–570. doi: 10.1016/j.tics.2006.10.002. [DOI] [PubMed] [Google Scholar]
- Clahsen H, Hadler M, Weyerts H. Speeded production of inflected words in children and adults. Journal of Child Language. 2004;31:687–712. doi: 10.1017/s0305000904006506. [DOI] [PubMed] [Google Scholar]
- Daugherty K, Seidenberg M. Rules or connections? The past tense revisited; Paper presented at the Milwaukee Rules Conference; Milwaukee. 1992. [Google Scholar]
- Davies M. Corpus del Español (100 million words, 1200s-1900s) 2002 Version http://www.corpusdelespanol.org/). Available online at http://www.corpusdelespanol.org.
- De Diego Balaguer R, Sebastian-Galles N, Diaz B, Rodriguez-Fornells A. Morphological processing in early bilinguals: an ERP study of regular and irregular verb processing. Cognitive Brain Research. 2005;25(1):312–327. doi: 10.1016/j.cogbrainres.2005.06.003. [DOI] [PubMed] [Google Scholar]
- DeKeyser RM. The robustness of critical period effects in second language acquisition. Studies in Second Language Acquisition. 2000;22:499–533. [Google Scholar]
- DeKeyser RM. Implicit and explicit learning. In: Doughty CJ, Long MH, editors. The handbook of second language acquisition. Malden, MA: Blackwell; 2003. pp. 313–348. [Google Scholar]
- Ellis NC. At the interface: dynamic interactions of explicit and implicit language knowledge. Studies in Second Language Acquisition. 2005;27(2):305–352. [Google Scholar]
- Elman JL. Rethinking innateness. In: Elman JL, editor. Rethinking innateness: A connectionist perspective on development. Cambridge, Mass.: MIT Press; 1996. [Google Scholar]
- Elman JL, Bates EA, Johnson MH, Karmiloff-Smith A, Parisi D, Plunkett K. Rethinking innateness: A connectionist perspective on development. Cambridge, Massachusetts: The MIT Press; 1996. [Google Scholar]
- Forster KI, Chambers SM. Lexical access and naming time. Journal of Verbal Learning and Verbal Behavior. 1973;12:627–635. [Google Scholar]
- Gelfand MP, Walenski M, Moffa M, Lee S, Ullman MT. The Influence of Handedness on Language: Storage versus Composition Differences in Left- and Right-Handers Under Revision. [Google Scholar]
- Gillon Dowens M, Vergara M, Barber H, Carreiras M. Morpho-syntactic processing in late L2 learners. Journal of Cognitive Neuroscience. doi: 10.1162/jocn.2009.21304. In Press. [DOI] [PubMed] [Google Scholar]
- Hahne A. What's different in second-language processing? Evidence from event-related brain potentials. Journal of Psycholinguistic Research. 2001;30(3):251–266. doi: 10.1023/a:1010490917575. [DOI] [PubMed] [Google Scholar]
- Halle M, Marantz A. The View From Building 20. Cambridge, MA: MIT Press; 1993. Distributed morphology and the pieces of inflection. [Google Scholar]
- Harris J. Spanish Phonology. Cambridge: MIT Press; 1969. [Google Scholar]
- Harris JW. Spanish diphthongisation and stress: a paradox resolved. Phonology Yearbook. 1985;2:31–85. [Google Scholar]
- Henning G. The ACTFL Oral Proficiency Interview: Validity Evidence. System. 1992;20(3):365–372. [Google Scholar]
- Indefrey P. A Meta-analysis of Hemodynamic Studies on First and Second Language Processing: Which Suggested Differences Can We Trust and What Do They Mean? Language Learning. 2006;56(Suppl 1):279–304. [Google Scholar]
- Joanisse MF, Seidenberg MS. Impairments in verb morphology after brain injury: a connectionist model. Proceedings of the National Academy of Sciences of the United States of America. 1999;96(13):7592–7597. doi: 10.1073/pnas.96.13.7592. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kessler B, Treiman R, Mullennix J. Phonetic Biases in Voice Key Response Time Measurements. J Mem Lang. 2002;47:145–171. [Google Scholar]
- Laudanna A, Badecker W, Caramazza A. Processing inflectional and derivational morphology. Journal of Memory and Language. 1992;31(3):333–348. [Google Scholar]
- Levelt WJ, Roelofs A, Meyer AS. A theory of lexical access in speech production. Behavioral and Brain Sciences. 1999;22(1):1–38. 38–75. doi: 10.1017/s0140525x99001776. discussion. [DOI] [PubMed] [Google Scholar]
- Linares RE, Rodriguez-Fornells A, Clahsen H. Stem allomorphy in the Spanish mental lexicon: Evidence from behavioral and ERP experiments. Brain and Language. 2006;97:110–120. doi: 10.1016/j.bandl.2005.08.008. [DOI] [PubMed] [Google Scholar]
- MacDonald MC, Pearlmutter NJ, Seidenberg MS. Lexical nature of syntactic ambiguity resolution. Psychological Review. 1994;101(4):676–703. doi: 10.1037/0033-295x.101.4.676. [DOI] [PubMed] [Google Scholar]
- Marslen-Wilson W, Tyler LK. Rules, representations, and the English past tense. Trends in Cognitive Sciences. 1998;2(11):428–435. doi: 10.1016/s1364-6613(98)01239-x. [DOI] [PubMed] [Google Scholar]
- McClelland JL, Patterson K. Rules or connections in past-tense inflections: what does the evidence rule out? Trends in Cognitive Sciences. 2002;6(11):465–472. doi: 10.1016/s1364-6613(02)01993-9. [DOI] [PubMed] [Google Scholar]
- Meunier F, Marslen-Wilson W. Regularity and irregularity in French verbal inflection. Language and Cognitive Processes. 2004;19(4):561–580. [Google Scholar]
- Morgan-Short K. Unpublished Dissertation. Georgetown University; Washington, D.C.: 2007. A Neurolinguistic Investigation of Late-Learned Second Language Knowledge: The Effects of Explicit and Implicit Conditions. [Google Scholar]
- Morgan-Short K, Steinhauer K, Sanz C, Ullman M. Effects of explicit and implicit training conditions on L2 knowledge: An event-related potential study. Paper presented at the EuroSLA; xNewcastle, England. 2007. Sep, [Google Scholar]
- Morgan-Short K, Steinhauer K, Sanz C, Ullman MT. An ERP investigation of second language processing: Effects of proficiency and explicit and implicit training In Preparation. [Google Scholar]
- Münte TF, Say T, Clahsen H, Schiltz K, Kutas M. Decomposition of morphologically complex words in English: Evidence from event-related brain potentials. Cognitive Brain Research. 1999;7(3):241–253. doi: 10.1016/s0926-6410(98)00028-7. [DOI] [PubMed] [Google Scholar]
- Neubauer K, Clahsen H. Decomposition of inflected words in a second language: An experimental study of German participles. Studies in Second Language Acquisition. 2009;31:403–435. [Google Scholar]
- Ojima S, Nakata H, Kakigi R. An ERP study on second language learning after childhood: Effects of proficiency. Journal of Cognitive Neuroscience. 2005;17(8):1212–1228. doi: 10.1162/0898929055002436. [DOI] [PubMed] [Google Scholar]
- Oldfield RC. The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia. 1971;9(1):97–113. doi: 10.1016/0028-3932(71)90067-4. [DOI] [PubMed] [Google Scholar]
- Orsolini M, Marslen-Wilson W. Representing morphological irregularity in the mental lexicon: Evidence from Italian. Language and Cognitive Processes 1997 [Google Scholar]
- Osterhout L, McLaughlin J, Kim A, Greenwald R, Inoue K. Sentences in the Brain: Event Related Potentials as Real Time Reflections of Sentence Comprehension and Language Learning. In: Carreiras M, Clifton J, editors. The On-line Study of Sentence Comprehension: Eye Tracking, ERP and Beyond. 2004. pp. 271–308. [Google Scholar]
- Paradis M. Neurolinguistic aspects of implicit and explicit memory: Implications for bilingualism and SLA. In: Ellis NC, editor. Implicit and explicit learning of languages. London, UK: Academic Press; 1994. pp. 393–419. [Google Scholar]
- Paradis M. A neurolinguistic theory of bilingualism. Amsterdam: John Benjamins; 2004. [Google Scholar]
- Paradis M. Declarative and procedural determinants of second languages. Vol. 40. Amsterdam: John Benjamins; 2009. [Google Scholar]
- Penke M, Krause M. German noun plurals: A challenge to the dual-mechanism model. Brain and Language. 2002;81(1-3):303–311. doi: 10.1006/brln.2001.2526. [DOI] [PubMed] [Google Scholar]
- Pinker S. Words and rules: The ingredients of language. New York: Basic Books; 1999. [Google Scholar]
- Pinker S, Ullman MT. The past and future of the past tense. Trends in Cognitive Sciences. 2002;6(11):456–463. doi: 10.1016/s1364-6613(02)01990-3. [DOI] [PubMed] [Google Scholar]
- Plunkett K, Marchman V. From rote learning to system building: Acquiring verb morphology in children and connectionist nets. Cognition. 1993;48:21–69. doi: 10.1016/0010-0277(93)90057-3. [DOI] [PubMed] [Google Scholar]
- Prado E, Ullman MT. Can imageability help us draw the line between storage and composition? Journal of Experimental Psychology: Language, Memory, and Cognition. 2009;35(4):849–866. doi: 10.1037/a0015286. [DOI] [PubMed] [Google Scholar]
- Prasada S, Pinker S, Snyder W. Some evidence that irregular forms are retrieved from memory but regular forms are rule-generated. Paper presented at the 31st Annual Meeting of the Psychonomics Society; New Orleans. 1990. Nov 16-18, [Google Scholar]
- Rodriguez-Fornells A, Munte TF, Clahsen H. Morphological priming in Spanish verb forms: An ERP repetition priming study. Journal of Cognitive Neuroscience. 2002;14(3):443–454. doi: 10.1162/089892902317361958. [DOI] [PubMed] [Google Scholar]
- Rossi S, Gugler MF, Friederici AD, Hahne A. The impact of proficiency on syntactic second-language processing of German and Italian: Evidence from event-related potentials. Journal of Cognitive Neuroscience. 2006;18(12):2030–2048. doi: 10.1162/jocn.2006.18.12.2030. [DOI] [PubMed] [Google Scholar]
- Rubenstein H, Garfield L, Milliken JA. Homographic entries in the internal lexicon. Journal of Verbal Learning and Verbal Behavior. 1970;9:487–492. [Google Scholar]
- Rumelhart DE, McClelland JL. On learning the past tenses of English verbs. In: McClelland JL, Rumelhart DE, PDP Research Group, editors. Parallel distributed processing: Explorations in the microstructures of cognition (Vol 2: Psychological and biological models, pp 272-326. Cambridge, MA: Bradford/MIT press; 1986. [Google Scholar]
- Sebastián Gallés N, Cuetos Vega F, Carreiras Valina MF, Martí Antonin MA. LEXESP: Léxico informatizado del espanol. Barcelona, Spain: Universitat de Barcelona; 2000. [Google Scholar]
- Seidenberg M. Connectionism without tears. In: Davis S, editor. Connectionism: Theory and Practice. New York: Oxford University Press; 1992. pp. 84–137. [Google Scholar]
- Seidenberg M, Bruck M. Consistency effects in the generation of past tense morphology. Paper presented at the Thirty-First Annual Meeting of the Psychonomic Society; New Orleans. 1990. [Google Scholar]
- Seidenberg MS. Language acquisition and use: Learning and applying probabilistic constraints. Science. 1997;275:1599–1603. doi: 10.1126/science.275.5306.1599. [DOI] [PubMed] [Google Scholar]
- Sereno JA, Jongman A. Processing of English inflectional morphology. Memory and Cognition. 1997;25(4):425–437. doi: 10.3758/bf03201119. [DOI] [PubMed] [Google Scholar]
- Silva R, Clahsen H. Morphologically complex words in L1 and L2 processing: Evidence from masked priming experiments in English. Bilingualism: Language and Cognition. 2008;11(2):245–260. [Google Scholar]
- Sonnenstuhl I, Eisenbeiss S, Clahsen H. Morphological priming in the German mental lexicon. Cognition. 1999;72(3):203–236. doi: 10.1016/s0010-0277(99)00033-5. [DOI] [PubMed] [Google Scholar]
- Steinhauer K, White EJ, Drury JE. Temporal dynamics of late second language acquisition: Evidence from event-related brain potentials. Second Language Research. 2009;25(1):13–41. [Google Scholar]
- Ullman MT. Acceptability ratings of regular and irregular past tense forms: Evidence for a dual-system model of language from word frequency and phonological neighbourhood effects. Language and Cognitive Processes. 1999;14(1):47–67. [Google Scholar]
- Ullman MT. The declarative/procedural model of lexicon and grammar. Journal of Psycholinguistic Research. 2001a;30(1):37–69. doi: 10.1023/a:1005204207369. [DOI] [PubMed] [Google Scholar]
- Ullman MT. The neural basis of lexicon and grammar in first and second language: the declarative/procedural model. Bilingualism: Language and Cognition. 2001b;4(1):105–122. [Google Scholar]
- Ullman MT. A neurocognitive perspective on language: The declarative/procedural model. Nature Reviews Neuroscience. 2001c;2:717–726. doi: 10.1038/35094573. [DOI] [PubMed] [Google Scholar]
- Ullman MT. Contributions of memory circuits to language: The declarative/procedural model. Cognition. 2004;92(1-2):231–270. doi: 10.1016/j.cognition.2003.10.008. [DOI] [PubMed] [Google Scholar]
- Ullman MT. A cognitive neuroscience perspective on second language acquisition: The declarative/procedural model. In: Sanz C, editor. Mind and Context in Adult Second Language Acquisition: Methods, Theory and Practice. Washington, DC: Georgetown University Press; 2005a. pp. 141–178. [Google Scholar]
- Ullman MT. More is sometimes more: Redundant mechanisms in the mind and brain. APS Observer. 2005b;18(12):7, 46. [Google Scholar]
- Ullman MT. The declarative/procedural model and the shallow-structure hypothesis. Journal of Applied Psycholinguistics. 2006;27(1):97–105. [Google Scholar]
- Ullman MT. The biocognition of the mental lexicon. In: Gaskell MG, editor. The Oxford Handbook of Psycholinguistics. Oxford, UK: Oxford University Press; 2007. pp. 267–286. [Google Scholar]
- Ullman MT, Corkin S, Coppola M, Hickok G, Growdon JH, Koroshetz WJ, et al. A neural dissociation within language: Evidence that the mental dictionary is part of declarative memory, and that grammatical rules are processed by the procedural system. Journal of Cognitive Neuroscience. 1997;9(2):266–276. doi: 10.1162/jocn.1997.9.2.266. [DOI] [PubMed] [Google Scholar]
- Ullman MT, Miranda RA, Travers ML. Sex differences in the neurocognition of language. In: Becker JB, Berkley KJ, Geary N, Hampson E, Herman J, Young E, editors. Sex on the Brain: From Genes to Behavior. New York: Oxford University Press; 2008. pp. 291–309. [Google Scholar]
- Veríssimo J, Clahsen H. Morphological priming by itself: A study of Portuguese conjugations. Cognition. 2009;112:187–194. doi: 10.1016/j.cognition.2009.04.003. [DOI] [PubMed] [Google Scholar]
- Walenski M, Ullman MT. The science of language. The Linguistic Review. 2005;22(2-4):327–346. [Google Scholar]
- Weber-Fox CM, Neville HJ. Maturational constraints on functional specializations for language processing: ERP and behavioral evidence in bilingual speakers. Journal of Cognitive Neuroscience. 1996;8(3):231–256. doi: 10.1162/jocn.1996.8.3.231. [DOI] [PubMed] [Google Scholar]