

Abstract
The amount of information contained in a piece of data can be measured by the effect this data has on its observer. Fundamentally, this effect is to transform the observer's prior beliefs into posterior beliefs, according to Bayes theorem. Thus the amount of information can be measured in a natural way by the distance (relative entropy) between the prior and posterior distributions of the observer over the available space of hypotheses. This facet of information, termed “surprise”, is important in dynamic situations where beliefs change, in particular during learning and adaptation. Surprise can often be computed analytically, for instance in the case of distributions from the exponential family, or it can be numerically approximated. During sequential Bayesian learning, surprise decreases like the inverse of the number of training examples. Theoretical properties of surprise are discussed, in particular how it differs and complements Shannon's definition of information. A computer vision neural network architecture is then presented capable of computing surprise over images and video stimuli. Hypothesizing that surprising data ought to attract natural or artificial attention systems, the output of this architecture is used in a psychophysical experiment to analyze human eye movements in the presence of natural video stimuli. Surprise is found to yield robust performance at predicting human gaze (ROC-like ordinal dominance score ∼ 0.7 compared to ∼ 0.8 for human inter-observer repeatability, ∼ 0.6 for simpler intensity contrast-based predictor, and 0.5 for chance). The resulting theory of surprise is applicable across different spatio-temporal scales, modalities, and levels of abstraction.
Keywords: information, surprise, relative entropy, attention, eye movements
1. Introduction
The concept of information is central to science, technology, and many other human endeavors. While several approaches for quantifying information have been proposed, the most prominent one so far has been Claude Shannon's definition introduced over half a century ago [49, 1, 39, 7, 11]. According to this definition, the amount of information contained in a piece of data D is measured by −log2 P(D) bits–a rare piece of data with small probability is considered more informative. Although eminently successful for the development of modern telecommunication and computer technologies, Shannon's definition does not capture all aspects of information. Here we look at information from a different angle. Starting from Bayes theorem, we notice that the fundamental effect that data has on a given observer is to change his/her/its prior beliefs into posterior beliefs. Thus we propose to measure the effect D has on the observer by the distance between his prior and posterior belief distributions. We call this facet of information surprise.
Surprise plays an important role in dynamic situations when the beliefs of the observer change significantly in time, as a result of consecutive applications of Bayes theorem. This can happen in at least two broad categories of situations: either when the beliefs keep changing all the time without converging to a stable value, or when the beliefs progressively converge to a stable value. The first case corresponds to tracking or adaption in a non-stationary environment. The second case corresponds to learning from a stationary data set, when beliefs evolve but finally converge to a stable value. In our framework, adaptation and learning are the results of the same fundamental operation: belief update using Bayes theorem. What distinguishes them is not the basic underlying mathematical operation, but rather the memory span and time scales involved.
In what follows, in Section 2 we first provide the mathematical definition of surprise. In Section 3, we show how surprise can be computed exactly or approximated efficiently in most common situations. In Section 4, we study how surprise changes during learning. In Section 5, we investigate the connections between surprise and other theories of information and novelty, including Shannon's theory of information. In Section 6, we describe a neural network architecture for computing surprise over image and video data in computer vision. Finally, in Section 7, we conduct psychophysical experiments and apply the surprise architecture to the problem of modeling attention and predicting rapid eye movements in humans watching natural stimuli.
The present paper builds on our previously published reports on the same theme [2, 24, 25, 26]. The two key new components here are: (1) a detailed and self-contained treatment of the theory with derivation of closed-form expressions for computing surprise in a number of important cases, analysis of the relationship between surprise and Bayesian learning, and comparison of surprise to other theories of information and novelty; and (2) a detailed presentation of the computational model of attention developed to investigate to which extent Bayesian surprise may predict what attracts human gaze while watching natural video clips. In addition, we also describe new experimental results comparing two variants of our computational model (using either Gaussian data and a Gaussian prior, or Poisson data and a Gamma prior; see below) on two open-access human gaze tracking datasets, and we develop a new temporal analysis that reveals a strong time contingency between the onset of a surprising event in a video clip and the execution of a human gaze shift towards such event. The reader is invited to explore our previous publications for more extensive discussions of the eye-tracking methodologies, general modeling of human saliency maps, and methodologies for comparing human gaze recordings to saliency maps generated by a number of different models available in the literature. All the data collected for the experiments have been made publicly available.
2. Mathematical Definition of Surprise
The definition we propose is best understood within the Bayesian or subjectivist framework of probability theory. In the subjectivist framework, degrees of belief or confidence are associated with hypotheses or models. It can be shown that under a small set of reasonable axioms, these degrees of belief can be represented by real numbers and that when rescaled to the [0,1] interval they must obey the rules of probability and in particular Bayes theorem [12, 48, 6, 31, 16, 32]. The amount of surprise in the data for a given observer can be measured by looking at the changes that take place in going from the prior to the posterior distributions.
Specifically, consider an observer with a prior distribution P(M) over a set 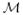 of possible models or hypotheses. The collection of a piece of data D leads to a reevaluation of beliefs and the transformation of the prior probability into a posterior distribution according to Bayes theorem,
of possible models or hypotheses. The collection of a piece of data D leads to a reevaluation of beliefs and the transformation of the prior probability into a posterior distribution according to Bayes theorem,
| (1) |
¿From this equation, the effect of D is clearly to change P(M) to P(M∣D). In other words, we view the data D as an operator acting on the space of distributions over the space of models. Thus, one basic way of measuring information carried by D is to measure the distance between the prior and the posterior distributions. To distinguish it from Shannon's communication information, we call this notion of information the surprise information, or just surprise [2]:
| (2) |
where d is a distance or dissimilarity measure. There are different ways of measuring distance or dissimilarity between probability distributions. In what follows, for standard well-known theoretical reasons such as invariance with respect to reparameterizations, we use the relative entropy or Kullback-Liebler [34] divergence K
| (3) |
where H denotes the entropy.
The alternative version K(P(M∣D), P(M)) of the relative entropy may also be used (and may even be slightly preferable in settings where the “true” or “best” distribution is used as the first argument). While the basic principles in the following derivations apply to both forms, here we use the version in Equation 3 because in general it leads to slightly simpler analytical expressions. This is simply because the prior distribution, which occurs twice in Equation 3, in general has a simpler expression than the posterior distribution which contains additional data-dependent terms. Alternatively, the relative entropy might also be symmetrized by taking [K(P(M), P(M∣D)) + K(P(M∣D), P(M)]/2. Although the symmetric version is rarely used, the analytical formula to be derived could be applied to the symmetric version with the proper and obvious adjustments. The same applies to other variations, such as the Jensen-Shannon divergence [56, 37]. In considering the symmetric version, note, however, that there is no reason why the intuitive notion of surprise ought to be symmetric with respect to the distributions involved. In fact, introspection dictates that the contrary ought to be true. A broad prior distribution followed by a narrow posterior distribution corresponds to a reduction in uncertainty, while a narrow prior distribution followed by a broad posterior distribution corresponds to an increase in uncertainty, and both lead to different subjective experiences.
Equivalently, we can define the single-model surprise by the log-odd ratio
| (4) |
and the surprise by its average
| (5) |
taken with respect to the prior distribution over the model class. In statistical mechanics terminology, surprise can also be viewed as the free energy of the negative log-posterior at a temperature t = 1, with respect to the prior distribution over the space of models [3].
A unit of surprise–the “wow”–can be defined for a single model M as the amount of surprise corresponding to a two-fold variation between the prior and the posterior, i.e., as −log2 P(M)/P(M∣D). Note that unless we use absolute values, this ratio can be positive or negative depending on whether the observer's belief in model M increases or decreases. The total number of wows experienced when simultaneously considering all models is obtained by integrating over and, as a relative entropy, is always positive.
3. Analytical Computation or Approximation of Surprise
As a relative entropy, surprise can always be estimated, at least numerically. But for the concept to be really useful, one ought to be able to compute surprise analytically, at least in the most standard statistical cases.
More precisely, consider a data set D = {d1, …, dN} containing N points. For simplicity, although this does not correspond to any restriction in the general theory, we consider the case of conjugate priors, where the prior and the posterior have the same functional form. In addition to their theoretical interest, conjugate priors are also important for efficient implementations of iterative Bayesian learning where the posterior at iteration t becomes the prior for iteration t + 1. In order to compute surprise in Equation 3 with conjugate priors, we need only to compute general terms of the form
| (6) |
where P1(x) and P2(x) are two distributions with the same functional form. The surprise is then given by
| (7) |
where P1 is the prior and P2 is the posterior. Note also that in this case the symmetric divergence can easily be computed using F(P1, P1) − F(P1, P2) + F(P2, P2) − F(P2, P1). Details for the calculation of F(P1, P2) in the following specific examples are given in the Appendix.
3.1. Discrete Data: Multinomial Model
Consider the case where di is binary. The simplest class of models for D is then M(p), the first order Markov model with a single parameter p representing the probability of emitting a 1. The conjugate prior on p is the Beta distribution (or Dirichlet distribution in the general multinomial case)
| (8) |
with parameters a1 ≥ 0, b1 ≥ 0, and a1 + b1 > 0. The expectation is a1/(a1 + b1). With n successes in the sequence D of N samples, the posterior is a Dirichlet distribution D2(a2, b2) with [3]
| (9) |
The surprise can be computed exactly
| (10) |
where Ψ is the derivative of the logarithm of the Gamma function (see Appendix). When N → ∞, and n = pN with 0 < p < 1 we have
| (11) |
where K(p, a1) is a concise notation to represent the Kullback-Liebler divergence between the empirical distribution (p, 1 − p) and the expectation of the prior (a1/(a1 + b1), b1/(a1 + b1)). Thus asymptotically surprise grows linearly with the number of data points with a proportionality coefficient that depends on the discrepancy between the expectation of the prior and the observed distribution. The same relationship is true in the case of a multinomial model. When the prior is symmetric (a1 = b1), a slightly more precise approximation is provided by
| (12) |
where H(p) denotes the entropy H(p) = −p log p − (1 − p) log(1 − p). For instance, when a1 = 1 then K(D1, D2) ≈ N(1 − H(p)), and when a1 = 5 then K(D1, D2) ≈ N[0.746 − H(p)].
3.2. Discrete Data: Poisson Model
As a second discrete example, consider the case where di is an integer. A simple class of models for D is the class of Poisson models parameterized by λ. The conjugate prior on λ is the Gamma prior
| (13) |
with x ≥ 0, shape a1 > 0, inverse scale b1 > 0. The expectation is a1/b1. With N observations, the posterior is also a Gamma distribution Γ2(a2, b2) with
| (14) |
where m̄ is the sample mean. The surprise can be computed exactly
| (15) |
When N → ∞, Stirling's formula yields the approximation
| (16) |
Thus asymptotically surprise information grows linearly with the number of data points with a proportionality coefficient that depends on the difference between the mean a1/b1 of the prior and mean m̄ of the sample plus an offset.
3.3. Continuous Data: Unknown Mean/Known Variance
When the di are real, we can consider first the case of unknown mean with known variance. We have a family M(μ) of models, with a Gaussian prior . If the data has known variance σ2, then the posterior distribution is Gaussian with parameters given by [16]
| (17) |
where m̄ is the observed mean. In this case
| (18) |
the approximation being valid for large N. In the special case where the prior has the same variance as the data σ1 = σ then the formula simplify a little and yield
| (19) |
the last approximation being valid when N is large. In any case, surprise grows linearly with N with a coefficient that is the sum of the prior variance and the square difference between the expected mean and the empirical mean scaled by the variance of the data.
3.4. Continuous Data: Unknown Variance/Known Mean
When the dis are real, we can also consider the case of unknown variance with known mean. We then have a family M(σ2) of models, with a conjugate scaled inverse gamma prior ([16])
| (20) |
The posterior is then a scaled inverse gamma distribution [16] with
| (21) |
Here σ̄2 = Σ(xi − m)2/N is the observed variance, based on the known mean m. The surprise
| (22) |
For large values of N,
| (23) |
Thus surprise information scales linearly with N, with a coefficient of proportionality that typically depends mostly on the ratio of the empirical variance to the scale parameter , which is roughly the expectation of the prior [the expectation of the prior is provided ν1 > 2]. The effects of very large or very small values of σ̄ or ν1 can also be seen in the formula above. In particular, surprise is largest when the empirical variance σ̄2 goes to 0 or infinity, i.e., is very different from the prior expectation.
3.5. Continuous Data: Unknown Mean/Unknown Variance
Finally, we can consider the case of unknown mean with unknown variance. We have a family M(μ, σ2) of models, with a conjugate prior G1Γ1 = P(μ∣σ2)P(σ2) = G1(μ1, σ2/κ1)Γ1(ν1, s1), product of a normal with a scaled inverse Gamma distribution. Thus the prior has four parameters (μ1, κ1, ν1, s1), with κ1 > 0, ν1 > 0, and s1 > 0. The conjugate posterior has the same form, with similar parameters (μ2, κ2, ν2, s2) satisfying (see for instance [16])
with m̄ = Σxi/N and σ̄2 = Σ(xi − m̄)2/(N − 1). The surprise is
| (24) |
For large values of N,
| (25) |
Surprise information is linear in N with a coefficient that is essentially the sum of the coefficients derived in the unknown mean and unknown variance partial cases.
3.6. Generalization: Exponential Families With Conjugate Priors
The previous examples can be generalized by considering a family M(θ) of models parameterized by the parameter vector θ with a likelihood function associated with the exponential family of distributions ([9])
| (26) |
where h(d), c(θ), wi(θ), and ti(d) are known functions of the respective variables. With N independent data points (D = d1, …, dN)
| (27) |
where , and are the sufficient statistics. The conjugate prior has a similar exponential form
| (28) |
parameterized by the 's. Using Bayes theorem, the posterior has the same exponential form
| (29) |
parameterized by the 's satisfying
| (30) |
Calculation of surprise yields
| (31) |
where EA1[wi(θ)] is the expectation of wi(θ) with respect to the prior. Note that if surprise is defined by K(P(M∣D), P(M), the same calculation yields
| (32) |
Thus for members of the exponential family [9] of distributions, the posterior depends entirely on the sufficient statistics and therefore the surprise also depends crucially on them. The Ti(D) terms typically grow linearly with the data, and so does surprise.
4. Learning and Surprise
There is an immediate connection between surprise and computational learning theory. If we imagine that data points from a training set are presented sequentially, we can consider that the posterior distribution after the N-th point becomes the prior for the next iteration (sequential Bayesian learning). As a system learns from examples with a static distribution, new data points ought to become less and less surprising. Thus in this case we can expect on average surprise to decrease after each iteration. We shall compute the exact rate of decrease using examples taken from the distributions studied in the previous section.
4.1. Learning Curves: Discrete Data
Consider first a sequence of 0-1 examples D = (dN). The learner starts with a Dirichlet prior D0(a0, b0). With each example dN, the learner updates its Dirichlet prior DN(aN, bN) into a Dirichlet posterior DN+1(aN+1, bN+1) with (aN+1, bN+1) = (aN+1, bN) if dN+1 = 1, and (aN+1, bN+1) = (aN, bN + 1) otherwise. When dN+1 = 1, the corresponding surprise is easily computed using Equations 56 and 59 (detailed in Appendix). For simplicity, and without much loss of generality, let us assume that a0 and b0 are integers, so that aN and bN are also integers for any N. Then if dN+1 = 1 the relative surprise is
| (33) |
and similarly in the case dN+1 = 0 by interchanging the role of aN and bN. By using the standard integral bound for series based on monotonically decreasing functions, we have
| (34) |
By combining the last two equations we get
| (35) |
Asymptotically we have aN ≈ a0 + pN and bN ≈ b0 + (1 − p)N (this is exactly true in expectation). Therefore, by taking the first order expansion of log(1 − u) and substituting these approximate values, we see that asymptotically the bound gives
| (36) |
Thus surprise decreases in time with the number of examples as 1/N (Figure 1). A similar calculation can be done for the Poisson model.
Figure 1.

Simulation results corresponding to flips of a 3-sided (red, blue, green) die with a corresponding multinomial learning model. Curves are derived using 400 random samples, drawn from the distribution red = 0.3, blue = 0.3, and green = 0.4. x-axis correspond to learning iterations. y axis correspond to surprise. As predicted by the theory, during Bayesian learning, surprise decreases on average like 1/N (black curve) as learning progresses. (a) curve corresponding to epochs 1-400; (b) magnified view corresponding to epochs 100-400.
4.2. Learning Curves: Continuous Data
In the case of continuous Gaussian data with, for instance, known variance σ2, the learner starts with a Gaussian prior on the mean. With each example dN, the learner updates its Gaussian prior into a Gaussian posterior with
| (37) |
¿From Equation 18, the relative surprise is
| (38) |
Asymptotically
| (39) |
¿From Equation 17, we have , or , which asymptotically behaves like σ2/N.
Combining this asymptotic form with Equation 39, we see that in this case surprise can be expected to decrease like 1/2N, again proportionally to the inverse of the number of data points.
Similar calculations can be done for the general exponential case (Equations 30 and 31) by noticing that, as N → ∞, in a stationary environment Ti(D) ≈ Nt̄i(d), where t̄i(d) is the average value of ti.
5. Relations of Bayesian Surprise to Other Theories of Information and Surprise
5.1. Theories of Information
Several theories have been proposed over the years to try to capture the concept of information and entropy [49, 47, 1, 39, 7, 33, 11] and not all of them can be reviewed here. Shannon's theory has been by far the most successful one, and many of the other theories that have been proposed [47, 1] can be viewed as variations on Shannon's definition. Thus for conciseness here we focus on the relationship of Bayesian surprise to Shannon's definition and then separately on the relationship of Bayesian surprise to other specific definitions of surprise found in the literature.
Shannon theory of communication defines the information contained in D at the level of an individual model M by
| (40) |
with the corresponding entropy
| (41) |
This entropy corresponds to an integral over data, whereas Bayesian surprise corresponds to an integral over models hence at this level surprise and information are dual facets of the data.
Shannon theory can also be applied at the level of the model class . In this case the information carried by D is
| (42) |
where P(D) = P(D∣) = ∫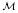
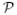 (
(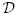 ∣)()⌈ is also called the evidence and plays a key role in Bayesian analysis and model class comparison.
∣)()⌈ is also called the evidence and plays a key role in Bayesian analysis and model class comparison.
The corresponding entropy is given by
| (43) |
For a fixed data set D, the surprise is
| (44) |
and therefore it can also be viewed as the difference between the average Shannon information per model, taken with respect to the prior, and the Shannon information based on the evidence.
If we integrate the surprise with respect to the evidence
| (45) |
we get the Kullback-Liebler divergence K(P(D)P(M), P(D, M)), which is the permuted version of the mutual information MI between and : MI(, ) = K(P(D, M), P(D)P(M)). If surprise is defined by K(P(M∣D), P(M)) then the integral of the surprise is equal to the mutual information between data and models. Note in contrast that the integral over models of the per-model entropy (Equation 41) is not equal to the mutual information, but related to it by a convex inequality, as shown by Equation 44.
In short, Bayesian surprise measures a facet of information that is different and complementary to Shannon's definition.
5.2. Theories of Surprise
The concepts of “surprise” and “surprising event” have also been raised multiple times in the statistical literature [54, 44, 5, 17, 35, 13].
One simple approach corresponds to outlier detection theory, whereby surprising events are defined as rare events, i.e. events having low probability. Such a definition of course is closely related to Shannon's theory of information since, by definition, rare events (P(D) small) have high Shannon information (I(D) = −log P(D) large). While it is easy to see that in many cases, Shannon's I(D) and the Bayesian surprise S(D) are closely related, there exist also specific situations where these two approaches provide clearly distinct answers, and Bayesian surprise matches intuition better. We illustrate here two somewhat extreme classes of examples corresponding to high Shannon information and low surprise, and vice versa.
Many Bits with Few Wows
The most simple example is obtained when contains a single model M. The prior is necessarily given by P(M) = 1, and the posterior distribution is always equal to the prior. Thus if there is data D satisfying P(D) = ε ≪ 1, the Shannon information log ε can be arbitrarily large, whereas the surprise is always zero. For a more complex and instructive example, let = {M1, …, MN} with a uniform prior P(Mi) = 1/N for every i. Assume that for each model Mi, P(D∣Mi) = ε, and hence P(D) = ε; that is, a datum is observed which is unlikely for any of the models. By Bayes theorem, we have immediately P(Mi∣D) = P(Mi) = 1/N. Thus in this case Shannon's information −logε grows to infinity as we decrease the value of ε. On the other hand, the prior and the posterior distributions being identical, the surprise is zero. Thus while the number of wows is zero, the number of bits grows to infinity like −log ε. In this case, although D is a strong outlier, D is a false positive, in the sense that it carries no useful information for discriminating between the alternative hypotheses Mi. Therefore D carries no surprise as its observation leaves the observer's expectations unaffected.
Few Bits with Many Wows
Conversely, consider = {M1, …, MN} with a non-uniform prior given by P(M1) = a and P(Mi) = (1 − a)/(N − 1) for i = 2, …, N. Consider data D with the likelihood P(D∣M1) = (1 − a)/(N − 1) and P(D∣Mi) = a for i = 2, …, N. A simple calculation shows that P(D) = a(1 − a)N/(N − 1) while the posterior distribution is uniform and given by P(Mi) = 1/N for any i. Thus for large N, the Shannon information converges to the constant value I(D) = −log[a(a − 1)] bits, determined by the parameter a. For instance, if a = 0.5 the Shannon information converges to 2 bits. The surprise, however, is given by S(D) = a log Na + (1 − a) log[(1 − a)N/(N − 1)] which, for large values of N, converges to a log N + H(a). Thus while the number of bits is finite, the number of wows grows to infinity like a log N. A data with these properties would go undetected by standard outlier theory, but would be picked up by surprise since it is associated with a significant change from prior to posterior distribution.
Note that examples where D carries few bits but many wows do not require the number N of models to go to infinity. Consider the case N = 2 with P(M1) = a and P(M2) = 1 − a. Assume that P(D∣M1) = b and P(D∣M2) = c. We then have P(D) = ab + (1 − a)c, P(M1∣D) = ba/P(D), and P(M2∣D) = (1 − a)c/P(D). The surprise is equal to log[ab + (1 − a)c] − a log b − (1 − a) log c. By letting either b → 0 or c → 0, but not both, we can easily achieve a diverging amount of surprise in combination with a finite amount of Shannon information.
In any case, in the outlier detection approach, if all possible events or datasets have very low probability, then they are all very “surprising”, which is not very useful in practice. Thus it is clear that whether an event or data set is surprising or not cannot be decided on its probability alone. As a minimum, the probabilities of the other events must also be taken into consideration. Thus another approach, introduced in [54] and further developed in, for instance, [44, 17], tries to compare the probability of an event to the probabilities of all the other possible events by using a “surprise index”. Weaver [54] considers an experiment with n possible outcomes, with probabilities p1, …, pn and defines the Surprise Index by
| (46) |
The SI measures “whether the probability realized, namely, pi is small as compared with the probability that one can expect on the average to realize, namely, E(p). If this ratio is small and SI correspondingly large, then one has a right to be surprised.”[54]. Unlike simple outlier detection, the surprise index does consider an event in the context of other events. However, the surprise index does not consider explicitly prior and posterior distributions and is obviously quite different from the concept of Bayesian surprise described in this paper.
Perhaps closest in spirit to our work, but still different and derived completely independently, is the work of Evans [13, 14] which takes a Bayesian perspective and considers prior and posterior distributions and their ratios. More precisely, consider a family of models parameterized by θ, and a function T(θ) with a set of possible values ti. Evans proposes to introduce a total ordering on the ti and a surprise inference principle by considering that t1 is strictly preferred to t2 if “the relative increase in belief for t1, from a priori to a posteriori, is greater than the corresponding increase for t2.” In turn, this preference ordering is used to determine inferences and applied to estimation, hypothesis testing, and model checking procedures [13]. This statistical work, however, does not take an explicit information theoretic perspective, and does not define surprise as the relative entropy between the prior and posterior distributions.
6. A Neural Network Implementation of Surprise for Computer Vision
Here we describe a neural network architecture for processing and computing surprise over image and video data in bottom-up fashion. The architecture is inspired by the neurobiology of early visual processing in the primate brain [29, 24, 25, 26]. In this section we first describe the low-level, Hubel and Wiesel-like, visual feature detection front-end of the proposed system followed by two alternative surprise computation back-ends operating on the feature responses.
6.1. Low-level visual feature extraction
The proposed system employs a relatively mature and standard low-level feature extraction front-end [30, 28]. This front-end analyzes the incoming input images at several spatial resolutions and along several low-level feature dimensions, including color contrast, luminance contrast, oriented edges, and motion energy. In a manner inspired by how early visual processing is organized in the primate brain, the front-end processing thus decomposes the image into a number of sub-bands. Surprise is then computed at the level where the responses from the low-level feature detectors are integrated, as opposed to directly at the pixel level.
A schematic diagram of the system is given in Fig. 2. Input video frames are analyzed in dyadic image pyramids with 9 scales (from scale 0 corresponding to the original image, to scale 8 corresponding to the image reduced by a factor of 256 horizontally and vertically). The pyramids are constructed by iteratively filtering and decimating the input image. In the implementation used here, pyramids are computed for the following low-level visual features thought to guide human attention [55]: (1) luminance; (2) red-green color opponency; (3) blue-yellow color opponency; (4) four oriented edge filters (using Gabor kernels) spanning 180°; (5) luminance flicker (as computed from the difference between the previous image and the current one); and (6) four directions of motion spanning 360°. Additional details about the implementation of these image pyramids have been published previously [30, 27]. The final feature output is in the form of “feature maps” which are obtained by taking across-scale differences between pairs of levels within each feature pyramid. These differences coarsely approximate center-surround contrast enhancement mechanisms found in the early stages of biological visual processing [23, 51, 21]. Center-surround differences are computed for the following scale pairs: 2-5, 2-6, 3-6, 3-7, 4-7, 4-8. All feature maps are then resampled to scale 4 (where the final combined surprise map is later computed); for 640 × 480 input videos, these maps thus have 40 × 30 pixels. In total, 72 such feature maps are computed (6 for luminance, 12 for color opponencies, 24 for oriented Gabor edges, 6 for flicker, and 24 for motion). Fig. 2C shows all the feature maps computed for the example input image shown.
Figure 2.
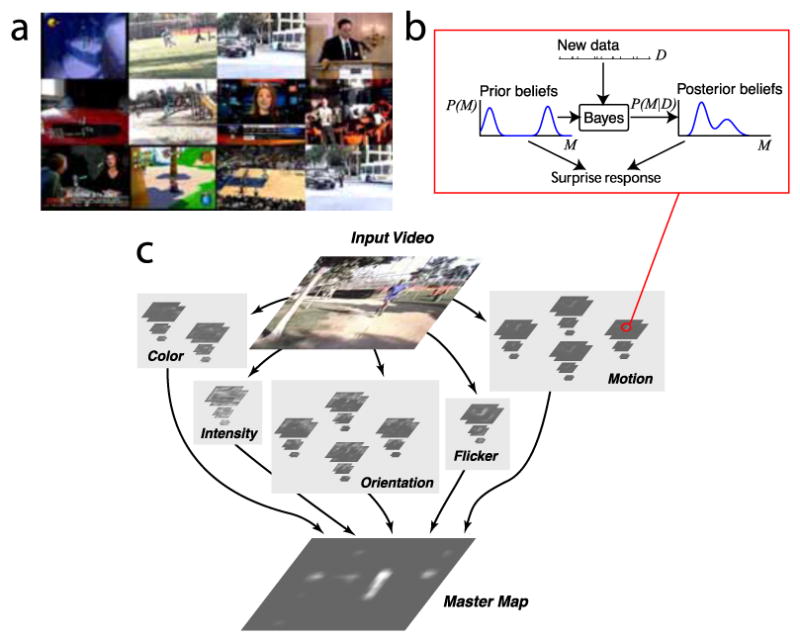
(a) Sample frames of video clips to be processed by the model and for which human eye movement recordings are available (see next section). (b) Computation of surprise at the single-neuron level, each time new data is received from a new video frame. (c) Architecture of the full computational system which analyzes video frames along the dimensions of color, intensity, orientation, flicker, and motion, computing surprise at multiple spatial and temporal scales within each of these feature channels. The surprise output from all feature channels finally gives rise to the master surprise maps. Higher (brighter) values in this map represent the system's prediction of where the strongest attractors of attention currently are in the video inputs (in the example shown, the man running towards the camera is most surprising).
6.2. Surprise computation in feature space
Surprise is computed for every pixel in each of the 72 center-surround feature maps. The underlying motivation is that simulated neurons in the feature maps may establish some very simple beliefs about the world as seen through their spatially- and feature-selective center-surround receptive fields. For instance, a neuron sensitive to red/green opponent contrast at a given location and scale may accumulate over time beliefs about the amount of red/green contrast present in the small portion of the world that is captured by the neuron's receptive field. When new data is observed with each new incoming video frame, the beliefs established thus far are used as prior, and Bayes' rule is applied to compute the posterior. The posterior at one video frame then becomes the prior for the next video frame. Using conjugate priors facilitates this process by ensuring that the posterior has the same functional form as the prior. The current implementation derives prior distributions at time t entirely from past inputs combined through Bayesian learning; however, the theory does not limit what may influence the prior distributions. Other sources such as top-down knowledge, behavioral states, or individual preferences could also influence the prior within the same general framework.
Here we explore two model classes to implement surprise: Gaussian (with a Gaussian conjugate prior) which is formally simple and parallels background adaptation techniques used in computer vision [19], and Poisson (with a Gamma conjugate prior) which may more accurately model incoming neural spike trains from the low-level feature extraction stages [50].
To accommodate for changing data and events at multiple temporal scales, we employ a chained cascade of surprise detectors at every pixel in every feature map, where the output of one surprise detector serves as input to the next detector in the cascade. Our implementation uses 5 such cascaded feature detectors at every pixel and for every feature. The first (fastest) is updated with feature map data from the low-level feature computations, and detector i + 1 samples from i, so that time constants increase exponentially with i. In total, the system thus comprises 72[maps] × (40 × 30) [pixels] × 5[time scales] = 432, 000 surprise detectors.
Finally, to account not only for temporally surprising events (e.g., sudden appearance of an object) but also for spatially surprising items (e.g., a red object among many green objects), we compute surprise both locally over time, and spatially in an instantaneous manner. For local temporal surprise, a single neuron in one of the feature maps is considered, and the prior is established over time from the observations received to date in the receptive field of that one neuron. For spatial surprise, a single neuron is also considered, but its prior is now derived from the compound instantaneous activity of surrounding neurons in the map, at the next faster time scale. For every video frame at time t, location (x, y), feature f, and time scale i, a neighborhood distribution of models is computed as the weighted combination of distributions from the next-faster local models, over a large neighborhood with two-dimensional Difference-of-Gaussians profile (σ+ = 20 and σ− = 3 feature map pixels). As new data arrives, spatial surprise is the KL divergence between prior neighborhood distribution and the posterior after update by local samples from the neighborhood's center. For example, consider a neuron that observes a locally red image patch surrounded by a large green background. That neuron's neighbors would contribute a spatial prior that is strongly suggesting that the world is green. However, when that prior is combined with the local data received by the neuron of interest, which indicates that the world is red, a large difference between prior and posterior arises, and consequently a large spatial surprise (see Fig. 3 for pseudo-code).
Figure 3.

Simplified algorithm to compute surprise over space and time at multiple scales. This algorithm is applied to each of the 72 feature maps. The incoming data is the array of raw feature detector values for the feature map's feature type and center-surround spatial scale.
Our theory does not constrain how temporal and spatial surprises may combine. In previous work [24], we addressed this issue by turning to empirical single-unit recordings of complex cells in striate cortex of anesthetized monkey [40]. From fitting the neural data, total surprise S is given by:
| (47) |
where ST is the temporal and SS the spatial surprise. This formulation resulted from a least-squares fit of a function of the form S = [a1ST + a2SS + a3STSS]a4 to the neural data. We further posit that surprise combines multiplicatively across time scales, such that an event is surprising only if at all relevant time scales, allowing the model to learn periodic stimuli of various frequencies. One caveat with this approach is that stimuli which may fully adapt the surprise detectors at one time scale and yield zero surprise at that scale may effectively zero out potentially surprising events at other time scales. To address this, we introduce below an additional step just before the prior is updated, whereby the variance of the prior is slightly relaxed (increased) prior to the arrival of every video frame. A parameter ζ regulates the amount of relaxation. With 0 < ζ < 1, the variance of the prior will not settle, even if, e.g., the data is stationary, resulting in surprise values that are always non-zero. We finally assume that surprise sums across features, such that a location may be surprising by its color, motion, or other. It is interesting to note that other alternatives may be more desirable, e.g., a max operation across features [36, 57]. However, for the datasets evaluated here, this alternative yields lower ordinal dominance scores (Fig. 5).
Figure 5.

Example maps generated by the computational systems tested. One video frame is shown (clip beverly08, frame 127) with the corresponding master map for each model. Current eye position of one human observer is indicated by the small cyan square (on the person running in the video clip). Ordinal dominance scores are indicated for each system, for both the original and MTV-style dataset. Higher scores indicate better systems, i.e. systems which predict high master map values near the locations selected by human gazes and low map values everywhere else.
The sum is then passed through a saturating sigmoidal nonlinearity to enforce plausible neuronal firing dynamics and yield the final master map used for comparison with human gaze behavior.
6.2.1. Gaussian data with Gaussian prior
With Gaussian models, the data from every low-level feature detector at every location in every video frame is assumed to have a Gaussian distribution with mean given by the feature detector's response to the current frame, and fixed variance which approximates the observation noise at the feature detection stage (which, in turns, reflects sensor noise and possibly neural noise inherent to the feature computation process).
Thus, for each of the 72 feature types (e.g., luminance, red-green opponency, etc), video frame, spatial center-surround feature scale, 2D image location in the rescaled feature map, and temporal scale, we here use the unknown mean / known variance formulation of section 3.3, eq. 17. With the addition of the prior relaxation term 0 < ζ < 1 (which here simply divides the prior's variance , we obtain:
| (48) |
We assume that N = 1 data samples are received for every new video frame, the data sample value (and m̄ since N = 1) are given by the feature detector's response to the current video frame, and the variance σ2 of the data is fixed and reflects noise in the sensor and early stages of processing (we use s̄ = 5 given RGB pixel values in the [0 … 255]3 range). Our simulations use ζ = 0.7. Surprise is computed exactly per eq. 18 (without the approximation for large N).
6.2.2. Poisson data with Gamma prior
In a somewhat more neurally-plausible implementation, we model data received from feature map f at location (x, y) and time t as Poisson distributions M(λ) (which well describe cortical pyramidal cell firing statistics [50]), parameterized by firing rate λ ≥ 0. λ is trivially estimated over the duration of each video frame as simply the feature detector's response λ̅ = f(x, y, t). In contrast with the Gaussian case, here the variance of the sample is not arbitrarily fixed but directly determined by the assumed Poisson nature of the data samples, and thus is equal to the mean λ̅.
As detailed in Section 3.2, the prior P(M) satisfying the conjugate prior property on Poisson data is the Gamma probability density, eq. 13. With the addition of the ζ prior relaxation term (which here again divides the prior's variance, by multiplying both a1 and b1), we slightly modify Eq. 14 and obtain:
| (49) |
We here again assume that N = 1 data samples are received at every video frame. Our simulations here again use ζ = 0.7. Surprise is computed exactly using Eq. 15.
7. An Application of Surprise to Psychophysics and Eye Movements
Developing an ability to rapidly detect surprising events is crucial in allowing living systems to quickly identify potential predators, preys, or mates and in ensuring survival. It is reasonable to postulate that surprising events ought to attract attention mechanisms in living systems, and that the same principle may be useful in the design of artificial systems, for instance in computer vision and surveillance. Indeed, it has been noted that events previously described as novel or salient tend to attract attention [43]. To test the surprise theory, we here present an application to finding surprising objects and events in natural video streams. Using eye-tracking experiments with human subjects, we quantitatively evaluate the extent to which surprising visual events occurring in natural video stimuli may indeed capture attention and gaze of human observers. The application presented here extends previous similar experimentations [24, 25, 26] by adding a new dataset, comparing two different model classes, Gaussian data with a Gaussian prior, and Poisson data with a Gamma prior, and introducing a new temporal analysis which demonstrates a strong time contingency between the onset of a surprising event in the stimuli and the initiation of a human eye movement towards that event.
7.1. Subjects, stimuli and gaze recording methods
Our experiments use the publicly available human eye movement dataset from the NSF-CRCNS data sharing project (crcns.org). This dataset contains two components.
In the first component, we recorded eye movements from eight naïve observers. Each watched a subset from 50 videoclips totaling over 25 minutes of playtime (“original” dataset). Clips comprised outdoors daytime and nighttime scenes of crowded environments, video games, and television broadcast including news, sports, and commercials. Right-eye position was tracked with a 240 Hz video-based device (see [25] for additional methodological details). To maintain interest, observers were instructed to follow the stimuli's main actors and actions, as simple questions would be asked to them at the end of the experiment to test their understanding of the contents of the clips. Here we only retain those clips for which gaze recordings from at least 4 observers were available (to allow for the establishment of an upper bound inter-observer correlation performance, below). Two hundred calibrated eye movement traces (10,192 gaze shifts or “saccades”) were analyzed, corresponding to four distinct observers for each of the 50 clips.
In the second component, the video clips were cut into 1-3s short “clippets” which were then re-assembled in random order into an “MTV-style” set of clips [10]. Another set of 8 observers watched the clips and we here again only retain clips for which recordings are available for at least 4 observers. The goal of the random shuffling of clippets was to abolish some of the long-term cognitive influences on attention and gaze, so that observer's gaze allocation would be more strongly short-term. Here, this dataset is of particular interest because it will help us gauge the extent to which past events beyond a few seconds may influence our modeled low-level vision priors, surprise, and human gaze. In total, 6,648 saccades were analyzed for the MTV-style dataset.
Informed consent was obtained from all subjects prior to the experiments. Each subject watched a subset of the collection of video clips, so that eye movement traces from four distinct subjects were obtained for each clip. Video clips were presented on a 22″ CRT monitor (LaCie, Inc.; 640 × 480, 60.27 Hz double-scan, mean screen luminance 30 cd/m2, room 4 cd/m2, viewing distance 80cm, field of view 28° × 21°). The clips comprised between 164 to 2,814 frames or 5.5s to 93.9s, totaling 46,489 frames or 25:42.7 playback time. Frames were presented on a Linux computer under SCHED_FIFO scheduling which ensured microsecond-accurate timing [15].
Right-eye position was tracked at 240 Hz using a video-based device (IS-CAN RK-464), which robustly estimates gaze from comparative real-time measurements of both the center of the pupil and the reflection of an infrared light source onto the cornea. Saccades were defined by a velocity threshold of 20°/s and amplitude threshold of 2°.
Sampling of master map values around human or random saccade targets used a circular aperture of diameter 5.6°, approximating the size of the fovea and parafovea. Saccade initiation latency was accounted for by subjecting the master maps to a temporal low-pass filter with time constant τ = 500ms. The random sampling process was repeated 100 times.
7.2. Gaze prediction results
We evaluate in Fig. 4 four different attention systems that predict human saccades: one using surprise with Gaussian data and prior (Section 6.2.1), one using surprise with Poisson data and Gamma prior (Section 6.2.2), a simple baseline control system which simply computes local pixel variance in small image patches, and a human inter-observer system — all further described below. In addition, in Fig. 5 we compare these systems with additional previously published systems and with variations on our surprise-based systems.
Figure 4.

Histograms of master map values at saccade endpoints for random (wide green bars) and humans (narrow blue bars), for the “original” (a, b, c) and “MTV-style” (d, e, f) datasets. Human histograms particularly differ from the random ones in that humans gaze towards low master map values (leftmost bins in each histogram) less often than expected by chance, while they gaze towards high mastermap values (rightmost bins) more often than expected by chance. AUC scores indicate significantly different performance levels, and a strict ranking of chance < variance < Gaussian/Gaaussian surprise < Poisson/Gamma surprise < inter-observer.
The Gaussian/Gaussian and Poisson/Gamma surprise systems are as described above. The Variance system simply computes local variance of pixel luminance within 16 × 16 image patches. The resulting variance map has been suggested to already predict human gaze above chance [45]; hence we use this very simple system as a baseline or lower bound. The inter-observer system is built by plotting a Gaussian blob with σ = 3 master map pixels (4.5°), continuously at each of the eye positions of the three observers other than that under test, with some forgetting provided by the master map's temporal low-pass filter. High values on this map would hence be present only at the locations currently gazed at by some human observer. This system allows us to establish an upper bound for how well the other systems might be expected to predict human gaze.
To characterize image regions selected by our observers, we process the video clips through the different systems. Each system outputs a topographic dynamic master response map, assigning in real-time a response value to every input location. A good master map should highlight, more than expected by chance, locations gazed to by our human observers. Hence to score and compare each system, we sample, at the onset of every human saccade made, master map activity around the saccade's future endpoint, and around a uniformly random endpoint. Random sampling is repeated 100 times to evaluate variability. To quantify the extent to which humans may be attracted towards hotspots in the master maps, we use ordinal dominance analysis [4]. To this end, we first normalize master map values sampled at human and random saccade endpoints by the maximum activity in the master map at the time of the saccade. For each system, histograms of master map values at human and random saccade endpoints are then created (Fig. 4). In a manner similar to computing a Receiver Operating Characteristic (ROC) curve, we then sweep a threshold from 0 to 1; for each threshold value we count the percentage of eye positions and random positions which land above threshold (“hits”). The ordinal dominance curve is then created similarly to an ROC curve, with the difference that it plots human hits vs. random hits. This curve indicates how well a simple binary threshold is able to discriminate signal (master map values at human gaze locations) from noise (values at random locations). We finally score each system by computing the area under the curve (AUC) from the ordinal dominance curve. The process is repeated 100 times for the 100 random samples, which allows us to attach a confidence estimate to each AUC value.
An AUC value of 0.5 would indicate a system which is at chance in predicting where human observers looked. Our inter-observer system yields AUC scores of 0.805 ± 0.002 for the first (“original”) dataset and 0.827 ± 0.002 for the second (“MTV-style”) dataset. The surprise and variance systems are hence expected to score between 0.5 and 0.8, with higher scores indicating better ability to predict human gaze. Scores are shown in Fig. 4. All three systems perform significantly above chance level (AUC=0.5; t-test, p < 10−10 or better). Furthermore, both variants of the surprise-based system perform significantly better than the much simpler variance-based system (t-tests on the respective AUC scores, p < 10−10 or better). The Poisson/Gamma surprise system exhibits a small but significant advantage over the Gaussian/Gaussian surprise system in these experiments. These two surprise systems score about half-way between chance and inter-observer.
Fig. 5 shows an example video frame and corresponding master maps for the computational systems studied here, as well as for a few systems evaluated previously [26], and variations on the surprise systems described below. In particular, the Michelson contrast system, as in Mannan et al. [38], is an interesting alternative to our local variance system. However, we find that on these datasets it actually performs slightly below chance level (corresponding to a score of 0.5), indicating that observers tended to preferentially look towards locations with lower contrast than expected by chance. This is in agreement with the original results of Mannan et al., who conclude that a number of local features tested in their experiments (including Michelson contrast, edge density measures, and others) are poor predictors of human fixations. The Entropy and DCT-based information systems are very simplified measures of information in local image patches, and have been previously proposed as gaze predictors [30, 42, 26]. We find that they score above chance, but below surprise. Finally, we evaluated the hypothesis of Zhaoping and colleagues that salience signals may combine across different feature channels according to a maximum rule rather than a sum rule [36, 57]. To this end, we implemented variants of the surprise systems where color, intensity, orientation, flicker and motion sources of surprise combine with a max rule. With the datasets evaluated here, this alternative yields lower AUC scores (Fig. 5). The reason for the lower scores when taking the maximum across features is that this often yields lower gaze target to clutter signal-to-noise ratios. These intriguing results obtained with our free-viewing datasets should be evaluated further with future experiments aimed more directly at addressing the max vs. sum question.
To further investigate the extent to which events detected as surprising by our systems might attract human gaze, we recorded, at the landing location of every saccade, the history of master map values for up to 1,000ms preceding the initiation of the saccade of interest (Fig. 6). In both datasets, a sudden surge of surprise is seen at saccade landing points shortly before saccades are initiated. A similar but weaker surge is observed also for the Variance system, indicating that the sudden appearance of textured objects might also have attracted saccades. However, the surge for the variance system is significantly weaker than for any of the surprise systems. In the MTV-style experiments, a surge of surprise is also observed for random saccades around 500ms prior to human saccades; this reflects the global surge of surprise which is observed at every abrupt jump-cut when the scene changes from one 1-3s clippet to the next. The surge in the random saccade data suggests that humans tended to execute saccades in a manner that was somewhat time-locked to jump-cuts in the stimuli. This is also reflected by the larger surge observed for human saccades in the MTV-style compared to the original dataset.
Figure 6.

History of master map values at locations selected by human saccades, for up to 1,000ms prior to the initiation of each saccade, for the “original” (left) and “MTV-style” (right) datasets. Curves are normalized in pairs (human saccades, solid lines, and random saccades, dashed lines) by the surprise value for human saccades at -1,000ms. This allows easy comparison between the curves for the different systems. Stars indicate time points where the surprise-based systems performed significantly differently from the variance-based system (t-tests, p < 0.05 after Bonferroni correction).
8. Discussion
Bayes theorem is the most fundamental theorem of learning and adaptation, quantifying how the prior distribution over the space of models or hypotheses ought to be revised into a posterior distribution as data is collected. Accordingly, the distance between the prior and posterior distributions is also bound to be a fundamental quantity, that may have escaped systematic attention. Here we have defined this quantity – surprise – and studied its properties systematically.
Surprise is different from Shannon's entropy, which it complements. Surprise is also different from several other definitions of information that have been proposed [1] as alternatives to Shannon's entropy. Most alternative definitions of entropy, such as Rényi's entropies, are actually algebraic variations on Shannon's definition rather than conceptually different approaches.
To measure the effect of data on the observer's prior and posterior distributions, one could envision using the difference between the entropy of the prior and the entropy of the posterior. However, such a difference would only quantify the difference in uncertainty between the prior and posterior distributions. Unlike surprise which is always positive, such a difference could be either positive or negative and therefore less appealing as a measure. More fundamentally, the posterior could, for instance, be very different from the prior, but retain a similar level of entropy. Thus data greatly affecting the observer could appear insignificant by this measure.
In many important cases related to the exponential family of distributions, surprise can be computed analytically and efficiently, both in terms of exact and approximate formula. The analytical results presented here could be extended in several directions including non-conjugate and other prior distributions as well as more complex multidimensional distributions (e.g., inverse Wishart). In general, however, the computation of surprise can be expected to require numerical techniques including Monte Carlo methods to approximate integrals over model classes. In this respect, the computation of surprise should benefit from ongoing progress in Markov chain and other Monte Carlo methods, as well as progress in computing power.
The concept of surprise has its own limitations. In particular, it does not capture all the semantic/relevance aspects of data. If, while surfing the web in search of a car to purchase one stumbles on a picture of Marilyn Monroe, the picture may carry a low degree of relevance, a high degree of surprise, and a low-to-high amount of Shannon information depending on the pixel structure. Thus, relevance, surprise, and Shannon's entropy are three different facets of information that can be present in different combinations. Although there have been several attempts (e.g. [33, 52]), defining relevance remains a central open challenge. Surprise, however, appears remarkable for its simplicity and generality which ought to result in its applicability to areas as diverse as learning, data mining and compression, and the design or reverse engineering of natural or artificial sensory systems.
We have only touched upon the connection between surprise and statistical learning theory [53, 22] by showing that surprise decreases as 1/N during sequential learning in simple cases. This analysis could be extended to more complex settings, such as artificial neural networks. At higher abstraction levels, informal ideas of novelty and surprise have been proposed that could capture attention and trigger learning [43, 20], which may now be formalized in terms of priors and posteriors. Highly surprising data could signal that learning is required and highly unsurprising data could signal that learning is completed, or adaptation no longer necessary.
A surprising training set is a prerequisite for learning. The amount of surprise in training data, however, should not be so excessive as to overwhelm the learning system. Thus information surprise in the training set ought to be calibrated to the capacity of the learning system. Furthermore, when the degree of surprise of the data with respect to the model class becomes low, the data is no longer informative for the given model class. This, however, does not necessarily imply that a good models of the data hase been learnt since the model class itself could be unsatisfactory and in need of a complete overhaul. The process by which a learning system realizes that a model class is unsatisfactory in an alternative free setting–the open-ended aspect of inference–has so far eluded precise formalizations and ought to be the object of future investigations.
As a side note, and to avoid any confusions, it is also worth noting that relative entropy has often been used as a training function for neural networks and other machine learning systems (e.g. [3] and references therein), but in a completely different sense. In a multinomial classification problem, for instance, model parameters can be adjusted in order to minimize the relative entropy Σti log ti − Σti log pi aggregated over all training examples. For a single training example, ti is the 0-1 target representing membership in the i-th class and pi is the probability of membership in the i-th class computed by the learning system. This relative entropy between the vectors t and p has little to do with the relative entropy between the prior and posterior distributions over the parameters of the model that is used to compute p.
In data mining applications, surprise could be used to systematically detect novelty in areas ranging from surveillance to information retrieval. In data compression applications, surprise could be used to guide dynamical encoding of information, allocating more bits to surprising data. For sensory systems, we have described an application of surprise to computer vision and the analysis of human attentional gaze shifts. Human attention is an exceedingly complex phenomenon, under the control of both bottom up and top down influences. Our results are not intended in any way to prove that human brains compute surprise to control eye movements. It is however encouraging to see that the simple bottom-up version of surprise outperforms other state-of-the-art metrics in predicting gaze shifts and that, in principle, top down influences could be incorporated into the surprise framework, simply by modulating the prior distribution. A number of additional theoretical frameworks and computational models have been proposed to explain attention guidance and eye movements, using information-theoretic principles in very restricted scenarios, such as discriminating shape silhouettes or searching for a known target in a noisy environment [46, 41]. While interesting, these approaches still need additional developments before they can be applied to the CRCNS eye-tracking datasets, or other kinds of “real data,” for the purpose of comparison with surprise or other theories. Indeed, such theories and approaches are not yet able to make useful predictions for arbitrary image or video stimuli and observer tasks. This is a fundamental difference between these very interesting but more specialized theories and our new approach: Our surprise theory and associated computational model are capable of making predictions (good or bad) for any set of image or video stimuli and any set of associated eye movement traces (human or other) acquired under any observer task.
Finally, in sensory systems and beyond the visual attention application studied here, surprise may be computed on auditory, olfactory, gustative, somatosensory, or other features, using exactly the same definition. Surprise may be computed at different temporal and spatial scales, and different levels of abstraction. Indeed, detecting surprise in neuronal spike trains or other data streams is a very general operation that does not require understanding the “meaning” carried by the data and therefore may be suitable for learning in deep architectures and other self-organization processes.
Acknowledgments
The work of PB is supported by a Laurel Wilkening Faculty Innovation Award and grants from NSF and NIH. The work of LI is supported by grants from NSF, NGA, HFSP, ONR and DARPA. We wish to thank Mario Blaum and Robert McEliece for encouragement and feedback.
Appendix A: Discrete Case
Multinomial Case (Dirichlet prior)
In the two-dimensional case, consider two Dirichlet distributions D1 = D(a1, b1)(x) = C1xa1−1(1 − x)b1−1 and D2 = D(a2, b2)(x) = C2xa2−1(1 − x)b2−1, with C1 = Γ(a1 + b1)/Γ(a1)Γ(b1), and similarly for C2. To calculate the relative entropy in the two dimensional case, we use the formula ([18])
| (50) |
where B(u, v) is the beta function and Ψ(x) is the derivative of the logarithm of the gamma function Ψ(x) = d(log Γ(x))/dx. A cross term of the form
| (51) |
is equal to
| (52) |
using the fact that C1B(a1, b1) = 1. In particular, the entropy of a two-dimensional Dirichlet distribution such as D1 is obtained by taking: −F(D1, D1).
With some algebra, the Kullback-Liebler divergence between any two Dirichlet distributions is finally given by:
| (53) |
With n successes in the sequence D, the posterior is a Dirichlet distribution D2(a2, b2) with [3]
| (54) |
Using this relation between the prior and the posterior, we get the surprise
| (55) |
Using the general fact that , which implies when n is an integer, we get
| (56) |
Now we have
| (57) |
where
| (58) |
and similarly for the symmetric term. The rest is exactly 0 when a1 and b1 (and hence a2 and b2) are integers, and in general decreases with the size of a1 and b1. This yields the approximation
| (59) |
This approximation is exact when a1 and b1 are integers. Now for x > 0 we have or . Thus,
| (60) |
Now we have,
We can use bounds of the form to estimate this term. Alternatively, one can assume that a1 and b1 are integers and use binomial coefficient approximations, such as those in [8]. In all cases, neglecting constant terms and terms of order log N, if we let n = pN (0 < p < 1) and N go to infinity we have
| (61) |
where H(p) is the entropy of the (p, q) distribution with q = 1 − p. Thus when N → ∞, and n = pN with 0 < p < 1 we have
| (62) |
where K(p, a1) is the relative entropy between the empirical distribution (p, q) and the expectation of the prior . Thus, asymptotically surprise grows linearly with the number of data points with a proportionality coefficient that depends on the discrepancy between the expectation of the prior and the observed distribution. The same relationship can be expected to be true in the case of a multinomial model.
Symmetric Prior (a1 = b1)
Consider now the case of a symmetric prior, then
| (63) |
Using formulas in [18], , thus
| (64) |
the approximation being in the regime n = pN and N → ∞. When a1 is an integer, we also have . Thus when a1 is an integer
| (65) |
As N → ∞ with 0 < p < 1
| (66) |
and therefore
| (67) |
For instance, when a1 = b1 = 1, this gives:
| (68) |
with the asymptotic form
| (69) |
With a uniform symmetric prior, the empirical distribution with maximal entropy brings the least information. When a1 = b1 = 5 this gives R(D1, D2) ≈ N[0.746 − H(p)]. As we increase a1 + b1, keeping a1 = b1, the constant decreases to its asymptotic value log 2 which corresponds to the asymptotic form S(D1, D2) ≈ NK(p, 0.5). The stronger the strength of the uniform prior (the larger a1 + b1), the smaller the surprise created by a die with maximum entropy.
Poisson Case (Gamma Prior)
We consider two Gamma distributions Γ1 = Γ1(a1, b1)x = C1xa1−1e−b1x and Γ2 = Γ2(a2, b2)(x) = C2xa2−1e−b2x with , and similarly for C2. To calculate the relative entropy, we use the formula ([18])
| (70) |
A cross term F(Γ1, Γ2)
| (71) |
is then equal to:
| (72) |
With some algebra, the KL divergence between two Gamma distributions is given by
| (73) |
With N observations in D, the posterior is Gamma and satisfies
| (74) |
With these values, this finally yields the surprise S(Γ1, Γ2)
| (75) |
When N is large, using Stirling's formula, the dominant terms in N log N cancel leaving the approximation
| (76) |
Appendix B: Continuous Case
Unknown Mean/Known Variance
Consider now two Gaussians G1(μ1, σ1) and G2(μ2, σ2). Then, after some algebra, the cross term is given by
| (77) |
here using for simplicity natural logarithms. is the entropy. The Kullback-Liebler divergence can then be obtained
| (78) |
Consider now a data set with N points d1, …, dN with empirical mean m¯. If the data has known variance σ2, then the posterior parameters are given by:
| (79) |
In the general case
| (80) |
when N is large. In the special case where the prior has the same variance has the data σ1 = σ then the formula simplifies a little and yields
| (81) |
when N is large. In any case, surprise grows linearly with N with a coefficient that is the sum of the prior variance and the square difference between the expected mean and the empirical mean scaled by the variance of the data.
Unknown Variance/Known Mean
In the case of unknown variance and known mean, we have a family M(σ2) of models with a conjugate prior for σ2 that is a scaled inverse gamma distribution ([16])
| (82) |
with ν1 > 0 degrees of freedom and scale s1 > 0. F can be computed expanding the integrals and using the fact that . This yields:
| (83) |
The posterior is then a scaled inverse gamma distribution [16] with
| (84) |
where σ̄2 is the empirical variance σ̄2 = Σi(xi − m2)/N, based on the known mean m. The surprise is given by
| (85) |
For large values of N, taking only the leading terms
| (86) |
| (87) |
Thus surprise information scales linearly with N, with a coefficient of proportionality that typically depends mostly on the ratio of the empirical variance to the scale parameters , which is roughly the expectation of the prior [the expectation of the prior is provided ν1 > 2]. The effects of very large of very small values of σ̄, or ν1 can also be seen in the formula above. In particular, surprise is largest when the empirical variance σ̄2 goes to 0 or infinity, i.e. is very different from the prior expectation.
Unknown Mean/Unknown Variance
In the case of unknown mean and unknown variance, we have a family M(μ, σ2) of models with a conjugate prior of the form G1 Γ1 = P(μ∣σ2)P (σ2) = G1(μ1, σ2/κ1)Γ1(ν1, s1). Thus the prior has four parameters (μ1, κ1, ν1, s1), with κ1 > 0, ν1 > 0, and s1 > 0. The conjugate posterior has the same form, with similar parameters (μ2, κ2, ν2, s2) satisfying (see for instance [16])
| (88) |
with m̄ = Σxi/N and σ̄2 = Σ(xi − m̄)2/(N − 1). Computation of F = F(μ1, κ1, ν1, s1; μ2, κ2, ν2, s2) is similar to the two cases treated above and yields:
| (89) |
¿From Equation 89, we can derive the surprise
| (90) |
Substituting the value of the posterior parameters
| (91) |
For simplicity, we can consider the case where μ1 = m̄. Then
| (92) |
In all cases, for large values of N we always have the approximation
| (93) |
Surprise is linear in N with a coefficient that is essentially the sum of the coefficients derived in the unknown mean and unknown variance partial cases.
Appendix C: Exponential Families With Conjugate Priors
Let A1 and A2 denote the parameters of two distributions P1 and P2 in the exponential family. Simple integration yields
| (94) |
where EA1 [wi(θ)] denotes expectation with respect to P1. Surprise S is then derived from F(P1, P1) − F(P1, P2).
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- 1.Aczel J, Daroczy Z. On measures of information and their characterizations. Academic Press; New York: 1975. [Google Scholar]
- 2.Baldi P. A computational theory of surprise. In: Blaum M, Farrell PG, van Tilborg HCA, editors. Information, Coding, and Mathematics. Kluwer Academic Publishers; Boston: 2002. [Google Scholar]
- 3.Baldi P, Brunak S. Bioinformatics: the machine learning approach. Second edition MIT Press; Cambridge, MA: 2001. [Google Scholar]
- 4.Bamber D. The area above the ordinal dominance graph and the area below the receiver operating characteristic graph. Journal of Mathematical Psychology. 1975;12:387–415. [Google Scholar]
- 5.Bartlett MS. The statistical significance of odd bits of information. Biometrika. 1952;39:228–237. [Google Scholar]
- 6.Berger JO. Statistical decision theory and Bayesian analysis. Springer-Verlag; New York: 1985. [Google Scholar]
- 7.Blahut RE. Principles and practice of information theory. Addison-Wesley; Reading, MA: 1987. [Google Scholar]
- 8.Bollobas B. Random Graphs. Academic Press; London: 1985. [Google Scholar]
- 9.Brown LD. Fundamentals of Statistical Exponential Families. Institute of Mathematical Statistics; Hayward, CA: 1986. [Google Scholar]
- 10.Carmi R, Itti L. The role of memory in guiding attention during natural vision. Journal of Vision. 2006;6(9):898–914. doi: 10.1167/6.9.4. [DOI] [PubMed] [Google Scholar]
- 11.Cover TM, Thomas JA. Elements of Information Theory. John Wiley; New York: 1991. [Google Scholar]
- 12.Cox R. Probability, frequency and reasonable expectation. American Journal of Physics. 1964;14:1–13. [Google Scholar]
- 13.Evans M. Bayesian inference procedures derived via the concept of relative surprise. Communications in Statistics. 1997;26(5):1125–1143. [Google Scholar]
- 14.Evans M, Guttman I, Swartz T. Optimality and computations for relative surprise inferences. Canadian Journal of Statistics. 2006;34(1):113–129. [Google Scholar]
- 15.Finney SA. Real-time data collection in linux: A case study. Behav Res Meth, Instr and Comp. 2001;33:167–173. doi: 10.3758/bf03195362. [DOI] [PubMed] [Google Scholar]
- 16.Gelman A, Carlin JB, Stern HS, Rubin DB. Bayesian Data Analysis. Chapman and Hall; London: 1995. [Google Scholar]
- 17.Good I. The surprise index for the multivariate normal distribution. Annals of Mathematical Statistics. 1956:1130–1135. [Google Scholar]
- 18.Gradshteyn IS, Ryzhik IM. Table of integrals, series, and products. Academic Press; New York: 1980. [Google Scholar]
- 19.Grimson WEL, Stauffer C, Romano R, Lee L. Using adaptive tracking to classify and monitor activities in a site. Proc CVPR; Santa Barbara, CA: 1998. [Google Scholar]
- 20.Grossberg S. How hallucinations may arise from brain mechanisms of learning, attention, and volition. Journal of the International Neuropsychological Society. 2000;6:583–592. doi: 10.1017/s135561770065508x. [DOI] [PubMed] [Google Scholar]
- 21.Grossberg S, Raizada R. Contrast-sensitive perceptual grouping and object-based attention in the laminar circuits of primary visual cortex. Vision Research. 2000;40(10-12):1413–1432. doi: 10.1016/s0042-6989(99)00229-1. [DOI] [PubMed] [Google Scholar]
- 22.Hastie T, Tibshirani R, Friedman J. The Elements of Statistical Learning Data Mining, Inference, and Prediction. Springer; New York, NY: 2001. [Google Scholar]
- 23.Hubel DH, Wiesel TN. Receptive fields, binocular interaction and functional architecture in the cat's visual cortex. J Physiol (London) 1962;160:106–54. doi: 10.1113/jphysiol.1962.sp006837. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Itti L, Baldi P. A principled approach to detecting surprising events in video. Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR); San Siego, CA: 2005. pp. 631–637. [Google Scholar]
- 25.Itti L, Baldi P. Advances in Neural Information Processing Systems, Vol. 19 (NIPS*2005) Cambridge, MA: MIT Press; 2006. Bayesian surprise attracts human attention; pp. 1–8. [Google Scholar]
- 26.Itti L, Baldi PF. Bayesian surprise attracts human attention. Vision Research. 2009;49(10):1295–1306. doi: 10.1016/j.visres.2008.09.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Itti L, Dhavale N, Pighin F. Realistic avatar eye and head animation using a neurobiological model of visual attention. In: Bosacchi B, Fogel DB, Bezdek JC, editors. Proc. SPIE 48th Annual International Symposium on Optical Science and Technology; Bellingham, WA: SPIE Press; 2003. pp. 64–78. [Google Scholar]
- 28.Itti L, Koch C. A saliency-based search mechanism for overt and covert shifts of visual attention. Vision Research. 2000;40(10-12):1489–1506. doi: 10.1016/s0042-6989(99)00163-7. [DOI] [PubMed] [Google Scholar]
- 29.Itti L, Koch C. Computational modeling of visual attention. Nat Rev Neurosci. 2001;2(3):194–203. doi: 10.1038/35058500. [DOI] [PubMed] [Google Scholar]
- 30.Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans Patt Anal Mach Intell. 1998;20(11):1254–1259. [Google Scholar]
- 31.Jaynes E. Bayesian methods: General background. In: Justice J, editor. Maximum Entropy and Bayesian Methods in Statistics. Cambridge University Press; Cambridge: 1986. pp. 1–25. [Google Scholar]
- 32.Jaynes ET. Probability Theory. The Logic of Science. Cambridge University Press; 2003. [Google Scholar]
- 33.Jumarie G. Relative Information. Springer Verlag; New York: 1990. [Google Scholar]
- 34.Kullback S. Information theory and statistics. First Edition in 1959 Dover; New York: 1968. [Google Scholar]
- 35.Kvalseth T. Stimulus probability, surprise and reaction time. Proceedings of the Human Factor Society. 1987;1:147–150. [Google Scholar]
- 36.Li Z. A saliency map in primary visual cortex. Trends Cogn Sci. 2002;6(1):9–16. doi: 10.1016/s1364-6613(00)01817-9. ENG. [DOI] [PubMed] [Google Scholar]
- 37.Lin J. Divergence measures based on the Shannon entropy. IEEE Transactions on Information Theory. 1991;37(1):145–151. [Google Scholar]
- 38.Mannan SK, Ruddock KH, Wooding DS. The relationship between the locations of spatial features and those of fixations made during visual examination of briefly presented images. Spat Vis. 1996;10(3):165–188. doi: 10.1163/156856896x00123. [DOI] [PubMed] [Google Scholar]
- 39.McEliece RJ. The Theory of Information and Coding. Addison-Wesley Publishing Company; Reading, MA: 1977. [Google Scholar]
- 40.Müller JR, Metha AB, Krauskopf J, Lennie P. Rapid adaptation in visual cortex to the structure of images. Science. 1999;285(5432):1405–1408. doi: 10.1126/science.285.5432.1405. [DOI] [PubMed] [Google Scholar]
- 41.Najemnik J, Geisler WS. Optimal eye movement strategies in visual search. Nature. 2005;434(7031):387–391. doi: 10.1038/nature03390. [DOI] [PubMed] [Google Scholar]
- 42.Privitera CM, Stark LW. Algorithms for defining visual regions-of-interest: comparison with eye fixations. IEEE Trans Patt Anal Mach Intell. 2000;22(9):970–982. [Google Scholar]
- 43.Ranganath C, Rainer G. Neural mechanisms for detecting and remembering novel events. Nat Rev Neurosci. 2003;4(3):193–202. doi: 10.1038/nrn1052. [DOI] [PubMed] [Google Scholar]
- 44.Redheffer RM. A note on the surprise index. Annals of Mathematical Statistics. 1951;22:128–130. [Google Scholar]
- 45.Reinagel P, Zador AM. Natural scene statistics at the centre of gaze. Network. 1999;10:341–350. [PubMed] [Google Scholar]
- 46.Renninger LW, Coughlan J, Verghese P, Malik J. An information maximization model of eye movements. Adv Neural Inf Process Syst. 2005;17:1121–1128. [PubMed] [Google Scholar]
- 47.Renyi A. On measures of information and entropy. Proceedings of the 4th Berkeley Symposium on Mathematics, Statistics and Probability; 1961. pp. 547–561. [Google Scholar]
- 48.Savage LJ. The foundations of statistics. First Edition in 1954 Dover; New York: 1972. [Google Scholar]
- 49.Shannon CE. A mathematical theory of communication. Bell System Technical Journal. 1948;27:379–423. 623–656. [Google Scholar]
- 50.Softky WR, Koch C. The highly irregular firing of cortical cells is inconsistent with temporal integration of random epsps. J Neurosci. 1993;13(1):334–50. doi: 10.1523/JNEUROSCI.13-01-00334.1993. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Suder K, Worgotter F. The control of low-level information flow in the visual system. Rev Neurosci. 2000;11(2-3):127–146. doi: 10.1515/revneuro.2000.11.2-3.127. [DOI] [PubMed] [Google Scholar]
- 52.Tishby N, Pereira F, Bialek W. The information bottleneck method. In: Hajek B, Sreenivas RS, editors. Proceedings of the 37th Annual Allerton Conference on Communication, Control, and Computing; University of Illinois; 1999. pp. 368–377. [Google Scholar]
- 53.Vapnik V. The Nature of Statistical Learning Theory. Springer Verlag; New York: 1995. [Google Scholar]
- 54.Weaver W. Probability, rarity, interest and surprise. Scientific Monthly. 1948;67(6):390–392. [PubMed] [Google Scholar]
- 55.Wolfe JM, Horowitz TS. What attributes guide the deployment of visual attention and how do they do it? Nat Rev Neurosci. 2004;5(6):495–501. doi: 10.1038/nrn1411. [DOI] [PubMed] [Google Scholar]
- 56.Wong AKC, You M. Entropy distance of random graphs with application to structural pattern recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1985;7:599–609. doi: 10.1109/tpami.1985.4767707. [DOI] [PubMed] [Google Scholar]
- 57.Zhaoping L, May KA. Psychophysical tests of the hypothesis of a bottom-up saliency map in primary visual cortex. PLoS Comput Biol. 2007;3(4):e62. doi: 10.1371/journal.pcbi.0030062. [DOI] [PMC free article] [PubMed] [Google Scholar]