

Abstract
The study measured listener sensitivity to increments of a target inter-onset interval (IOI) embedded within isochronous tone sequences that featured a single accented tonal component. The sequences consisted of six 1000-Hz tone bursts separated by silent intervals to establish equal tonal IOIs of 200 ms within the sequence. Tone burst durations within the sequences were 50 ms, except one tone had a longer duration of 100 ms to produce a perception of accent. Duration DLs in ms for increments of a single sequence IOI were measured adaptively by adjusting the duration of the silent interval between two tones. Sequence position of the target IOI differed across conditions. Listeners included young normal-hearing adults and older adults with and without hearing loss. Discrimination performance of the two older listener groups was equivalent and significantly poorer than that of the younger listeners in each discrimination condition. The age-related discrimination deficits were independent of sequence locations of both the target interval and the accented tonal component. Comparative DLs collected for target intervals in unaccented tone sequences with equal tone durations revealed that the detrimental effects of accent on temporal discrimination were primarily restricted to the older listeners.
Keywords: Aging, temporal discrimination, tone sequences, accent
1. Introduction
Many older people experience difficulty in listening tasks that examine various aspects of auditory temporal processing. Most of the experimental tasks used relatively simple stimuli and asked listeners to detect brief temporal gaps between successive sounds (e.g., Schneider et al., 1994; Snell, 1997; Schneider and Hamstra, 1999), or discriminate changes in the duration of time intervals separating pairs of stimulus markers (Abel et al., 1990; Fitzgibbons and Gordon-Salant, 1994; Grose et al, 2006). Other studies examined listeners’ abilities to recognize or discriminate changes in the temporal ordering of sounds in a sequence (Trainor and Trehub, 1989; Fitzgibbons and Gordon-Salant, 1998; Shrivastav et al., 2008). In each of the tasks, older listeners were shown to exhibit poorer performance than their younger-hearing counterparts, with some of the observations indicating that the age effects were more pronounced when testing was conducted with sounds of brief duration, or stimulus sequences that featured rapid presentation rates. Additionally, most of the studies concluded that the diminished temporal sensitivity observed for older listeners was largely independent of factors related to the sensorineural hearing loss exhibited by some of the participants.
Other related research efforts have focused on questions about the extent to which the temporal processing limitations, as measured with simple stimuli, are relevant to the processing of more complex auditory patterns, such as those associated with extended sequences of either speech or non-speech sounds. For example, speech recognition studies have shown consistently that older listeners exhibit considerable difficulty understanding stimuli that have been temporally altered in some manner. This observation is most evident for listening tasks that utilize sentence-length speech samples presented at rapid presentation rates, produced either by fast talkers or time-compression techniques applied to speech waveforms (Wingfield et al., 1985; Gordon-Salant and Fitzgibbons, 1993; Tun, 1998). The specific sources of these age-related problems with rapid speech are unknown, but are likely to be varied and complex. Part of the problem relates to the inherent acoustic complexity of the speech signal itself. Additionally, other contributing factors, including the prevalence of sensorineural hearing loss among older listeners, potential age-related declines in cognitive processing, and the complex effects of speech semantic and syntactic factors, can each exert a significant influence on speech recognition performance. However, in terms of acoustic properties, rapid speech can be viewed as auditory sequences with reduced durations of component sound segments and silence intervals, together with consequent shifts in overall sequence timing characteristics. Thus, any loss of sensitivity to these altered temporal properties of the speech sequences could be expected to contribute to the processing difficulties of older listeners.
Unfortunately, little information about the specific temporal processing limitations among older listeners is available from studies using stimulus sequences comprised of speech sounds. There are, however, some potentially relevant findings that come from psychoacoustic discrimination experiments conducted with non-speech stimulus sequences. One general outcome of these experiments revealed that estimates of listener temporal sensitivity measured for sound segments within sequences can differ substantially from measures collected for the same segments presented is isolation. This result is particularly evident for performance measures collected from groups of older listeners. For example, one initial experiment (Fitzgibbons and Gordon-Salant, 1995) compared younger and older listeners’ duration discrimination thresholds for simple isolated tone bursts to corresponding thresholds measured for the same tone bursts when embedded as components within sentence-length sequences of multiple tones that featured varying degrees of spectral complexity. Older listeners in this study revealed substantially poorer discrimination performance for tonal components within sequences compared to tones presented in isolation. By comparison, younger listeners in the experiments showed nearly equivalent discrimination performance for isolated tones and tones within the sequences. These results indicate that, for older listeners, measures of discrimination performance observed for simple sounds are not always good predictors of performance expected for sounds presented within the context of more complex sequential patterns.
Other findings revealed that older listeners also exhibit reduced ability to perceive changes in the overall timing characteristics of auditory sequences. This evidence comes from experiments that assessed listener sensitivity to changes in the tempo of stimulus sequences consisting of five identical tone bursts separated equally by silent intervals (Fitzgibbons and Gordon-Salant, 2001). With these stimuli, silent intervals within sequences were co-varied across discrimination trials to measure listeners’ discrimination thresholds for small changes in sequence tempo, with the measurements collected for each of several baseline sequence presentation rates. Compared to younger listeners, older listeners in this experiment exhibited consistently poorer tempo discrimination, with the largest age-related performance differences observed for sequences with the fastest sequence presentation rates. Additionally, these experiments revealed exaggerated performance difficulties among older listeners when the listening task was changed from one of overall tempo discrimination to one of discriminating changes in the duration of a single interval separating two components of the sequence. Again, for these single-interval discrimination conditions, the performance of older listeners was poorest for sequences that featured the fastest presentation rates.
These collective findings from the discrimination experiments indicate that listener sensitivity to stimulus durational cues is essential for processing both the properties of individual components within sound sequences and the rate characteristics of the sequences as a whole. In a similar manner, sensitivity to segment durations is required for speech processing, with both vowel and silent-interval durations being examples of important temporal cues underlying listener recognition of certain consonant phoneme attributes. Segment durations also play a role in defining the stress or accent patterns in speech sequences. That is, while analysis of stressed sounds in speech samples reveal several correlated acoustic changes (e.g., shifts in voice frequency and intensity), the predominant change observed is the elongation of sound durations (Fant et al., 1991; Pickett, 1999). These duration changes, in conjunction with age-related losses in temporal sensitivity, could lead to processing difficulties for older listeners when presented with unfamiliar stress patterns within samples of speech (e.g., accented speech). Research on this topic is presently limited in scope, although at least one investigation reports that older listeners do have problems recognizing accented English sentences (Burda et al., 2003). This observation points to a need for more information about the attributes of accented sound sequences that influence processing performance among older listeners. The present study addresses this topic by investigating aging and listener sensitivity to the temporal properties of accented stimulus sequences.
There is some indication suggesting that even young listeners may experience some degree of difficulty in processing the temporal attributes of stimulus sequences that include an accented, or stressed, component. For example, Hirsh et al. (1990) used isochronous sequences of six tone bursts separated by silent intervals and measured the ability of young listeners to discriminate changes in the duration of a single inter-tone interval at different sequence locations. The stimulus sequences featured one tonal component that was accented by virtue of having a frequency that was elevated relative to the other equal-frequency tonal components. Results obtained from some of the young listeners revealed that discrimination performance for the target interval within sequences was reduced when the interval was located adjacent to the accented tonal component. This observation prompted Hirsh et al. to hypothesize that the presence of accent within an auditory sequence could affect listeners’ temporal processing ability. The present experiments examine this hypothesis by using accented tonal sequences to compare the temporal discrimination performance of both younger and older listeners. One objective of the experiments is to determine the relative effects of listener age and hearing sensitivity, and sequential accent, on temporal discrimination. This is examined by comparing listener discrimination performance with accented and unaccented stimulus sequences. A second objective of the experiments is to determine if the effects of sequence accent on temporal discrimination are localized to regions of stimulus accent or distributed across locations of the stimulus patterns.
2. Materials and methods
2.1. Participants
A total of 45 adults participated in the experiments. These were assigned to three groups of 15 each based on age (young adults: 18-40 years; older adults: 65+ years) and hearing status (normal hearing vs. hearing loss, defined below). The first group, younger normal-hearing (Yng Norm) included individuals aged 18-25 years (Mean = 20.2 years) with normal hearing sensitivity. Normal hearing sensitivity was defined as pure tone thresholds ≤ 20 dB HL from 250-4000 Hz (re: ANSI, 2004) and was used for two of the three listener groups. The second group, older normal-hearing (Older Norm), included older adults aged 66-81 years (Mean = 70.9 years). The third group, older hearing-impaired (Older HI) included adults aged 65-80 years (Mean = 74.9 years) with bilateral mild-to-moderate sloping high-frequency sensorineural hearing losses from 250-4000 Hz. These older listeners with hearing loss had a negative history of otologic disease, noise exposure, and family history of hearing loss. The probable etiology of hearing loss in these older listeners was presbycusis. Although individuals in the two older groups met the selection criteria for age, the older hearing-impaired listeners were slightly older than the older listeners with normal hearing [t(28) = −2.573, p<.05]. Table 1 presents the mean pure tone air conduction thresholds and associated standard deviations for the three listener groups.
Table 1.
Mean pure tone air conduction thresholds (and standard deviations), from 250 – 4000 Hz, in dB HL (re: ANSI, 2004), for the three listener groups.
| Listener Group | |||
|---|---|---|---|
| Frequency | Young Norm |
Older Norm |
Older Hrg Imp |
| 250 | 6.3 (4.4) | 9.4 (6.6) | 17.9 (8.0) |
| 500 | 6.3 (3.9) | 10.9 (5.5) | 23.2 (11.0) |
| 1000 | 5.7 (5.3) | 13.4 (6.2) | 27.5 (15.0) |
| 2000 | 6.3 (5.8) | 13.1 (7.3) | 39.6 (13.5) |
| 4000 | 3.0 (4.9) | 13.1 (8.5) | 58.2 (9.5) |
Additional criteria for subject selection included monosyllabic word recognition scores in quiet exceeding 80% (Northwestern University Auditory Test No. 6), normal middle ear function as assessed by tympanometry, and acoustic reflex thresholds that were within the 90th percentile for a given pure tone threshold (Gelfand et al., 1990). All listeners were in general good health, with no history of stroke or neurological impairment and possessed sufficient motor skills to provide responses using a computer keyboard. Additionally, all listeners passed a screening test for general cognitive awareness (Pfeiffer, 1977). Most of the listeners reported some degree of childhood exposure to musical instruments, but none received formal musical training as adults, or currently practiced as musicians. The listeners had not participated previously as subjects in listening experiments.
2.2 Stimuli
All tonal sequences for the experiments were generated using an inverse fast-Fourier-transform (FFT) procedure with a digital signal processing board (Tucker-Davis Technologies, AP2) and a 16-bit D/A converter (Tucker-Davis Technologies DD1, 20-kHz sampling rate) that was followed by low-pass filtering (Frequency Devices 901F, 6000-Hz cutoff, 90 dB/octave). For control conditions, samples of unaccented stimulus sequences were constructed using six 1000-Hz tone bursts that were separated equally by silent intervals of 150 ms; tone burst durations were 50 ms, which included 5-ms cosine-squared rise/fall envelopes. As constructed, the interval separating successive tonal onsets (the inter-onset interval, or IOI) was fixed at 200 ms to produce an overall sequence duration of 1.05 s, a value that approximates that of a short speech sentence. Stimulus sequences for the accented conditions included the same 50-ms tone bursts, except one tone burst (the 2nd, 3rd, or 4th in different conditions) had a longer fixed duration of 100 ms; this longer tone was followed by a shorter inter-tone silent interval (100 ms) to preserve the uniform 200-ms tonal IOI for all sequences. These component duration changes were sufficient to produce a perception of accent in the sequence, with the tone duration increment being consistent with the relative degree of increase in duration observed for stressed syllables in spoken English (Fant et al., 1991). Figure 1 (panel a) shows a schematic diagram of the unaccented and accented stimulus sequences.
Fig. 1.
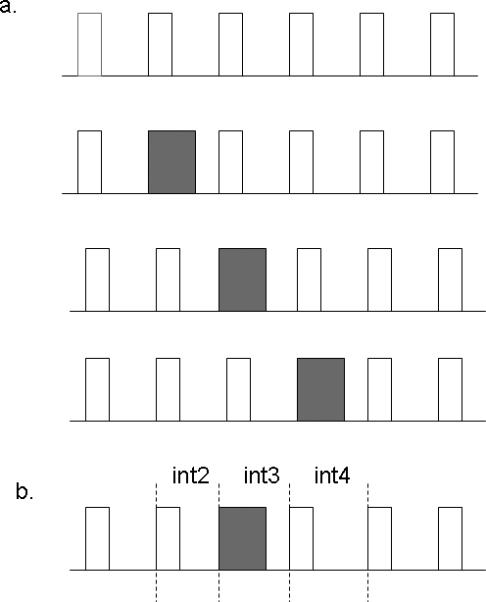
Schematic diagram of stimulus conditions. Panel a shows unaccented (top row) and single accented tones in different sequence locations (rows 2 through 4); Panel b shows an accented sequence with the three possible target IOI positions.
The unaccented and accented tone sequences served as reference stimuli in experimental conditions that measured a listener's duration difference limen (DL) for increments of a single tonal inter-tone silent interval within a sequence, designated as the target interval. For each discrimination condition, reference and comparison sequences presented during a discrimination trial were the same, except the single target interval in the comparison sequence was longer, and was varied adaptively to measure a duration DL in ms. Variations of the target interval produced corresponding shifts in the overall sequence duration, while other sequence IOIs and all tone durations were preserved at their original values. For the control conditions, the reference and comparison sequences for discrimination trials were the unaccented sequences with equal tone burst durations. For the accent conditions, both the reference and comparison sequences of discrimination trials featured the same longer 100-ms tone at the same sequence location. For each type of reference sequence, accented or unaccented, discrimination testing was conducted for target intervals at each of three sequence positions, following the 2nd, 3rd, or 4th tonal component (see Figure 1, panel b). Also, it should be noted that the target interval for all discrimination testing in the present experiments is designated as a tonal IOI, rather than an inter-tone silent interval. The rationale for this designation stems directly from the collective findings of earlier studies, which have documented the relevance of component onset separations for listener discrimination of time intervals within isochronous tone sequences (Hirsh et al., 1990; Drake and Botte, 1993; Fitzgibbons and Gordon-Salant, 2001).
3 Procedure
The measurement of DLs for the target IOIs was obtained using an adaptive three-interval, two-alternative forced-choice procedure. Each discrimination trial contained three listening intervals spaced 750 ms apart. The first listening interval of each trial contained a sample of the reference tonal sequence, with the second and third listening intervals containing samples of the reference and comparison tone sequences in either order selected randomly across listening trials. For each condition, the reference and comparison tone sequences of a listening trial differed only by the duration of the target IOI, which was always longer in the comparison sequence. The sequence location of the target IOI was also fixed across a series of listening trials. Listeners used a keyboard to respond to the comparison sequence in the second or third listening interval of each trial. Each listening interval of a trial was marked by a visual display that also provided correct-interval feedback for each trial.
Estimates for all duration DLs in ms were obtained using an adaptive rule for varying the IOI in the comparison sequence such that the IOI decreased in magnitude following two consecutive correct responses by the listener and increased in magnitude following each incorrect response. IOI was altered by varying the silent interval between tones. Threshold estimates derived by this adaptive rule corresponded to values associated with 70.7% correct discrimination (Levitt, 1971). Testing in each condition was conducted in 50-trial blocks with a target IOI starting value 1.4 times its reference 200-ms value, and a step size for IOI change that decreased logarithmically over trials to produce rapid convergence on threshold values. Following the first three reversals in direction of IOI change, a threshold estimate was calculated by averaging reversal-point IOI values associated with the remaining even-numbered reversals. An average of four threshold estimates was used to calculate a final threshold in ms; the reference 200-ms IOI was subtracted from this threshold to derive the DL for each listener in each condition. Prior to data collection, each listener received four to six practice blocks of trials for each condition, with each listener showing performance stability after three to four blocks of trials in each condition.
Overall, there were twelve discrimination conditions. Three of these used the unaccented reference tone sequences with the duration DLs measured separately for the 2nd, 3rd, and 4th sequence position of the target interval. Nine conditions used the accented tone sequences, with each of the three target interval positions tested for each of the three sequence locations (2nd, 3rd, or 4th) of the 100-ms accented tonal component. Listeners were tested individually in a sound-treated booth, with the sequence conditions tested in a different randomly selected order for each listener. Stimulus levels were 85 dB SPL in order to provide clear audibility for all listeners, including the older listeners with relatively mild degrees of hearing loss in the frequency region of the stimuli. Testing was monaural in the listener's preferred ear using an insert earphone (Etymotic ER-3A) that was calibrated in a 2-cm3 coupler (B&K DB0138). All listening was conducted in two-hour sessions over the course of several weeks. Total test time varied across listeners, but averaged about 4 h. Listeners were reimbursed for their listening time and travel costs. The experiments were approved by the University of Maryland Institutional Review Board for Human Subjects Research.
3. Results
For the purpose of analysis and comparison of results across conditions, absolute values (ms) of the duration DLs measured for the target intervals were divided by the 200-ms reference IOI for the sequences to produce relative IOI DL values (i.e., Weber fractions). All results are shown in Fig.2, which displays the mean relative DLs in percent as a function of sequence target interval position for each listener group, with error bars in the figure representing standard errors of means. Results for conditions with no sequence accent and each of the three sequence accent components are shown in the separate panels of the figure. An analysis of variance (ANOVA) was conducted on the individual relative DL values using a repeated measures design with two within-subject variables (sequence accent condition and target interval position) and one between-subjects variable (listener group). Results of the analysis revealed significant main effects of sequence condition [F(3,228) = 22.6, p< .001], target interval position [F(2,228) = 17.1, p < .001], and listener group [F(2,38) = 26.3, p < .001]. Significant interactions between sequence condition and listener group [F(6,228) = 2.60, p < .021] and between sequence condition and target interval position [F(6,228) = 5.60, p < .001] were also observed. The three-way interaction between sequence condition, target interval position, and listener group was not significant (p>.05).
Fig. 2.

Mean relative IOI DLs in percent as a function of target interval position for each listener group, shown separately in each panel for each sequence accent condition. Error bars represent one standard error of the mean.
Analysis of simple effects revealed significant performance differences among the listener groups for each of the sequence conditions. The relevant results for this analysis are shown in Fig. 3, which displays the relative DLs for the three listener groups in each sequence accent condition, with the data collapsed across the target interval positions. For these displayed data, the analysis revealed that the relative DLs of the younger listeners were significantly smaller than those of the two older listener groups in each sequence accent condition (p<.01). Additionally, there was no significant difference in performance between the two older groups for any condition. The performance equivalence between the older groups of listeners indicates that factors related to mild hearing loss had no systematic influence on discrimination performance.
Fig. 3.

Mean relative IOI DLs of the three listener groups in each sequence accent condition (collapsed across target interval position). Error bars represent one standard errors of the mean.
Corresponding analysis of simple effects was conducted to examine the interaction between stimulus accent condition and the target interval position within the sequence. The relevant data for this analysis are displayed in Fig. 4, which shows the mean relative DLs for each target interval position and stimulus accent condition, with the data collapsed across listener groups. Analysis of these results indicated that discrimination was poorer in each of the accented sequence conditions compared to the sequence condition with no accent (p<.05). Also, there was a significant influence of target interval position on discrimination, with the DLs being smaller for the 2nd target interval position compared to the other two positions (p< .05). One exception to this outcome was for the tone 2 accent condition, which produced DLs that were independent of target interval position.
Fig. 4.

Mean relative IOI DLs in percent in the three target interval positions shown for each accent condition (data collapsed across listener group). Error bars represent one standard error of the mean.
A final analysis of results compared performance in accented vs. unaccented sequence conditions for the younger and older listeners. For this analysis, performance measures for the two older listener groups were collapsed, as no significant performance differences between the groups were observed in the data. The relevant results for this analysis are displayed in Fig. 5, which shows the mean relative DLs in percent of the younger and older listeners as a function of target interval position for both the unaccented sequences and the accented sequences (collapsed across component accent location). Statistical analysis of these results (t-test) revealed that older listeners exhibited significant decreases in discrimination performance for accented compared to unaccented sequence conditions at each target interval position (p< .01). For the younger listeners, a significant performance decrement for the accented conditions was evident only the 2nd target interval position.
Fig. 5.

Mean relative IOI DLs in percent as a function of target interval position of the younger and older listeners (normal and hearing-impaired groups combined) in the unaccented and accented sequence conditions (collapsed across accent conditions). Error bars represent one standard error of the mean.
4. Discussion
The experiments were designed to investigate questions about the influence of accent within auditory stimulus sequences on listeners’ abilities to discriminate temporal properties of the sound patterns. For purposes of experimental control, all stimuli were created as sequences of brief tone bursts of equal frequency, intensity, and inter-onset interval separation. Tone bursts of the sequences were also equal in duration for the case of unaccented patterns, or featured a single elongated component for accented patterns. Both types of stimulus patterns were used to assess the ability of younger and older listeners to discriminate changes in the duration of a single tonal inter-onset interval (target) fixed at different positions within a sequence. Discrimination testing revealed age-related differences in temporal sensitivity and consequent effects of sequential accent. Some of the results also showed an influence of sequence target position on discrimination performance, but this effect was inconsistent across stimulus accent conditions.
4.1 Younger listeners
The discrimination results collected from the younger listeners in conditions with the unaccented sequences served as baseline measures for the assessment of temporal sensitivity across different target interval positions within a sequence. These results showed relative IOI DLs for the target intervals ranging from 4.5% to 6.3%, with a small, but insignificant, increase from 2nd to 4th target interval locations. This outcome is essentially the same as observed by Hirsh et al. (1990) for younger listeners, who reported IOI DLs of 5%-6% for corresponding 200-ms sequence IOIs across a range of sequence positions. It is worth noting that the component tone burst durations for the isochronous sequences used by Hirsh et al. (20ms) and the present experiments (50ms) differed, but the measured DLs were equivalent between the studies for the same baseline sequence IOI. This performance equivalence points to the relevance of component inter-onset interval, rather than absolute component durations, or inter-tone silent interval, in listeners’ discrimination of intervals within the isochronous patterns. It should be noted also that the present IOI DLs of the younger listeners with the unaccented sequences are considerably smaller than corresponding IOI DLs reported previously for simple sequences comprised of only two identical tone bursts separated by a silent interval (Fitzgibbons et al., 2007). Thus, it appears that, for stimuli of the present experiments, the repetition of the same interval within the isochronous sequences of identical tones served to enhance listener temporal sensitivity relative to that observed previously for a single sequence interval.
The accented stimulus patterns featured a single longer tonal component at different sequence locations across conditions. However, for the younger listeners, the presence of an accent within the stimulus sequences did not produce substantial changes in discrimination performance, compared to the unaccented conditions. For example, averaged across target interval positions, the mean relative IOI DLs for the younger listeners ranged from 6.9% to 7.9% across conditions of differing sequence accent location from the 2nd to 4th tonal component. These results in the accent conditions reflect an average performance decrement relative to that measured for the unaccented sequences, but the discrimination differences were generally small and insignificant. One exception was for target intervals at the 2nd sequence position, where the difference in the IOI DLs between accented and unaccented conditions was somewhat larger than observed for the other target interval locations. This difference can be attributed primarily to the somewhat better discrimination observed for the early target interval position with the unaccented sequences. For the accented sequence conditions, discrimination performance of the younger listeners was equivalent for each target interval position, as shown in Fig. 5.
Generally, the results for the younger listeners do not provide strong support for the premise that discrimination of a target interval within accented sequences might be influenced by the proximity of the target to the accented sequence component. Under this hypothesis, the largest discrimination deficits would be anticipated for target interval positions that coincided with that of the 100-ms sequence component. This result was not evident in the data. Thus, the present findings differ somewhat from those of Hirsh et al. (1990), which reported poorer discrimination of target intervals located adjacent to an accented component of their stimulus sequences. It should be noted, however, that Hirsh et al. introduced accent in their sequences by imposing a frequency shift to a selected tonal component. Additionally, both the magnitude of the frequency shift and its location within the sequence were additional factors found to influence listener discrimination performance. Therefore, although changes in both component frequency and duration are observed as correlates of component accent, the specific effects of each parameter on listeners’ temporal sensitivity are not well understood, and may differ.
4.2 Older Listeners
Discrimination testing of the older listeners with the baseline unaccented sequences revealed fairly consistent results for the conditions with different target interval positions. Mean IOI DLs for these older listeners fell within a range of 9.0% to 10.2% across the target interval locations, with no significant performance differences observed for listener groups with and without hearing loss. In specific conditions where discrimination differences were evident between the older listener groups, it was the group with mild hearing loss that demonstrated somewhat better temporal sensitivity. However, no systematic effects of listener hearing status on temporal discrimination performance across sequence conditions emerged in the test results. This outcome is not entirely surprising given the high audibility levels of the stimuli and the relatively mild degrees of hearing loss among the older listeners at the stimulus frequency region. Nevertheless, the absence of hearing-loss effects in the present results is consistent with observations reported in earlier investigations of aging and temporal discrimination (e.g., Schneider et al., 1994; Fitzgibbons & Gordon-Salant, 2001; Grose et al., 2006). The DLs of the older listeners with the unaccented sequences were significantly larger than those of the younger listeners for each of the target interval positions within the sequences.
For the accent conditions, the mean DLs of the older listeners fell within a narrow range of 12.4% to 13.5% across the different sequence locations for the accented tonal component. As depicted in Fig. 3, these values are significantly larger than corresponding values for the younger listeners in each position of sequence accent. Where performance differences across target interval positions existed, they were generally reflected by smaller DLs for the early target position 2 within sequences. This interval position effect, however, was observed inconsistently, and was not evident at all when the accented tonal component also coincided with the early sequence position. Thus, results for the older listeners, like those for the younger listeners, did not provide support for the idea that discrimination would be influenced by the proximity of the target interval to the accented sequence component. Instead, the results indicate that the presence of accent within a sequence, rather than its location, has the more important influence on temporal discrimination. This general effect of accent on discrimination performance is most evident in the comparisons of DLs measured for the unaccented and accented sequence conditions, as displayed in Fig. 5. These DL comparisons revealed that older listeners exhibited a significant performance decrement for the accented vs. unaccented conditions, independent of the target interval position. By comparison, the performance measures of the younger listeners revealed relatively small effects of sequence accent, and better temporal sensitivity in each sequence condition.
It is interesting to observe that the presence of a single longer tonal component in the stimulus patterns influenced discrimination of target intervals at various sequence positions, both preceding and following the longer tone. This result, pertaining primarily to the older listeners, was not anticipated, in part due to the observations reported previously by Hirsh et al. (1990) for their younger listeners. Additionally, for the present stimuli, the lengthening in duration of a tonal component to produce accent was implemented in a manner that preserved the equality of component onset-to-onset timing within each accented sequence. The preservation of sequence timing was considered important because the introduction of variable timing within sequences was observed previously to have an important independent influence on discrimination performance of older listeners (Fitzgibbons and Gordon-Salant, 2004). Despite the uniformity of timing, the longer tonal component, followed by a shorter silent interval, did introduce a degree of rhythmic irregularity within the sequences that appears to have been particularly disruptive to the temporal sensitivity of older listeners. Thus, it is possible that older listeners find it difficult to ignore global stimulus attributes, such as rhythmic structure, when attempting to process the temporal dimensions of individual sequence components.
5. Conclusions
The discrimination experiments used simple isochronous tone sequences to examine the influence of a single longer accented tone on discrimination of a targeted sequence interval. The results showed that the presence of an accented sequence component had a detrimental effect on listeners’ discrimination performance, with the reduction in temporal sensitivity being pronounced for older listeners and minimal for younger listeners. Small differences in hearing sensitivity among older listeners in the stimulus frequency region had no systematic influence on discrimination performance. Discrimination performance with the accented sequences was largely independent of accent location, or the proximity of accent and the targeted temporal interval. Collectively, the current findings suggest that the rhythmic characteristics of stimulus sequences can influence the processing of individual pattern components, particularly for older listeners. The application of these findings to the processing problems of older listeners with accented speech is not straightforward, especially given the added temporal and spectral complexity of speech. Nevertheless, it is reasonable to expect that the influences of accent on temporal sensitivity with the non-speech sequences would operate as well in limiting listener processing of temporal cues in accented speech sequences.
Acknowledgments
This research was supported by Grant R37AG09191 from the National Institute Aging. The authors are grateful to Helen Hwang and Keena James for their assistance in data collection and analysis.
Abbreviations
- IOI
inter-onset interval
- DL
difference limen
- SPL
sound pressure level
- HL
hearing loss
- FFT
Fast Fourier Transform
- ANOVA
Analysis of Variance
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Abel SM, Krever EM, Alberti PW. Auditory detection, discrimination, and speech processing in ageing, noise-sensitive and hearing-impaired listeners. Scand. Audiol. 1990;19:43–54. doi: 10.3109/01050399009070751. [DOI] [PubMed] [Google Scholar]
- ANSI . ANSI S3.6-2004, “American National Standard Specification for Audiometers”. American National Standards Institute; New York: 2004. [Google Scholar]
- Burda AN, Scherz JA, Hagerman CF, Edwards HT. Age and understanding speakers with Spanish or Taiwanese accents. Percept. Motor Skills. 2003;97:11–20. doi: 10.2466/pms.2003.97.1.11. [DOI] [PubMed] [Google Scholar]
- Fant G, Kruchenberg A, Nord L. Durational correlates of stress in Swedish, French and English. J. Phonetics. 1991;19:351–365. [Google Scholar]
- Fitzgibbons PJ, Gordon-Salant S. Age effects on measures of auditory duration discrimination. J. Speech Hear. Res. 1994;37:662–670. doi: 10.1044/jshr.3703.662. [DOI] [PubMed] [Google Scholar]
- Fitzgibbons PJ, Gordon-Salant S. Age effects on duration discrimination with simple and complex stimuli. J. Acoust. Soc. Am. 1995;98:3140–3145. doi: 10.1121/1.413803. [DOI] [PubMed] [Google Scholar]
- Fitzgibbons PJ, Gordon-Salant S. Auditory temporal order perception in younger and older adults. J. Speech Lang. Hear. Res. 1998;41:1052–1060. doi: 10.1044/jslhr.4105.1052. [DOI] [PubMed] [Google Scholar]
- Fitzgibbons PJ, Gordon-Salant S. Aging and temporal discrimination in auditory sequences. J. Acoust. Soc. Am. 2001;109:2955–2963. doi: 10.1121/1.1371760. [DOI] [PubMed] [Google Scholar]
- Fitzgibbons PJ, Gordon-Salant S. Age effects on discrimination of timing in auditory sequences. J. Acoust. Soc. Am. 2004;116:1126–1134. doi: 10.1121/1.1765192. [DOI] [PubMed] [Google Scholar]
- Fitzgibbons PJ, Gordon-Salant S, Barrett J. Age-related differences in discrimination of an interval separating onsets of successive tone bursts as a function of interval duration. J. Acoust. Soc. Am. 2007;122:458–466. doi: 10.1121/1.2739409. [DOI] [PubMed] [Google Scholar]
- Gelfand S, Schwander T, Silman S. Acoustic reflex thresholds in normal and cochlear-impaired ears: Effect of no-response rates on 90th percentiles in a large sample. J. Speech Hear. Disord. 1990;55:198–205. doi: 10.1044/jshd.5502.198. [DOI] [PubMed] [Google Scholar]
- Gordon-Salant S, Fitzgibbons PJ. Temporal factors and speech recognition performance in young and elderly listeners. J. Speech Hear. Res. 1993;36:1276–1285. doi: 10.1044/jshr.3606.1276. [DOI] [PubMed] [Google Scholar]
- Grose JH, Hall JW, Buss E. Temporal processing deficits in the presenescent auditory system. J. Acoust. Soc. Am. 2006;119:2305–2315. doi: 10.1121/1.2172169. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hirsh IJ, Monahan CB, Grant KW, Singh PG. Studies in auditory timing: I. Simple patterns. Percept. Psychophys. 1990;47:215–226. doi: 10.3758/bf03204997. [DOI] [PubMed] [Google Scholar]
- Levitt H. Transformed up-down methods in psychoacoustics. J. Acoust. Soc. Am. 1971;49:467–477. [PubMed] [Google Scholar]
- Pfeiffer E. A short portable mental status questionnaire for the assessment of organic brain deficit in elderly patients. J. Am. Geriatric Soc. 1977;23:433–441. doi: 10.1111/j.1532-5415.1975.tb00927.x. [DOI] [PubMed] [Google Scholar]
- Pickett JM. The Acoustics of Speech Communication. Allyn and Bacon; Needham Heights, MA: 1999. pp. 75–98. [Google Scholar]
- Schneider BA, Pichora-Fuller MK, Kowalchuk D, Lamb M. Gap detection and the precedence effect in young and old adults. J. Acoust. Soc. Am. 1994;95:980–991. doi: 10.1121/1.408403. [DOI] [PubMed] [Google Scholar]
- Schneider BA, Hamstra SJ. Gap detection thresholds as a function of tonal duration for younger and older listeners. J. Acoust. Soc. Am. 1999;106:371–380. doi: 10.1121/1.427062. [DOI] [PubMed] [Google Scholar]
- Shrivastav MN, Humes LE, Aylsworth L. Temporal order discrimination of tonal sequences by younger and older adults: The role of duration and rate. J. Acoust. Soc. Am. 2008;124:462471. doi: 10.1121/1.2932089. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Snell KB. Age-related changes in temporal gap detection. J. Acoust. Soc. Am. 1997;101:2214–2220. doi: 10.1121/1.418205. [DOI] [PubMed] [Google Scholar]
- Trainor LJ, Trehub SE. Aging and auditory temporal sequencing: Ordering the elements of repeating tone patterns. Percept. Psychophys. 1989;45:417–426. doi: 10.3758/bf03210715. [DOI] [PubMed] [Google Scholar]
- Tun PA. Fast, noisy speech: Age differences in processing rapid speech with background noise. Psychol. Aging. 1998;13:424–434. doi: 10.1037//0882-7974.13.3.424. [DOI] [PubMed] [Google Scholar]
- Wingfield A, Poon LW, Lombardi L, Lowe D. Speed of processing normal aging: effects of speech rate, linguistic structure, and processing time. J. Geront. 1985;40:579–585. doi: 10.1093/geronj/40.5.579. [DOI] [PubMed] [Google Scholar]