

Abstract
It is common in longitudinal studies for scheduled visits to be accompanied by as-needed visits due to medical events occurring between scheduled visits. If the timing of these as-needed visits is related to factors that are associated with the outcome but are not among the regression model covariates, naively including these as-needed visits in the model yields biased estimates. In this paper, the authors illustrate and discuss the key issues pertaining to inverse intensity rate ratio (IIRR)-weighted generalized estimating equations (GEE) methods in the context of a study of Kenyan mothers infected with human immunodeficiency virus type 1 (1999–2005). The authors estimated prevalences and prevalence ratios for morbid conditions affecting the women during a 1-year postpartum follow-up period. Of the 484 women under study, 62% had at least 1 as-needed visit. Use of a standard GEE model including both scheduled and unscheduled visits predicted a pneumonia prevalence of 2.9% (95% confidence interval: 2.3%, 3.5%), while use of the IIRR-weighted GEE predicted a prevalence of 1.5% (95% confidence interval: 1.2%, 1.8%). The estimate obtained using the IIRR-weighted GEE approach was compatible with estimates derived using scheduled visits only. These results highlight the importance of properly accounting for informative follow-up in these studies.
Keywords: data analysis; data interpretation, statistical; epidemiologic methods; follow-up studies; generalized estimating equation; generalized linear model; longitudinal studies; models, statistical
Longitudinal studies typically examine the effect of an exposure on an outcome over a prespecified period of time. A large and varied body of statistical literature exists for the case in which outcomes are observed at the same small set of times for each individual. In some studies, however, the outcome may be observed at different times for each individual, and the choice of times may not be independent of the outcome. In this situation, often referred to as outcome-dependent or informative follow-up, methods designed for regular follow-up schedules, such as generalized estimating equations (GEE) (1), may fail to produce unbiased results. The bias will be similar to that caused by informative missing data or informative cluster size (2).
We examined data from a prospective cohort study in which patients were scheduled to come into the study clinic on a specific visit schedule but were also allowed to come to the clinic off-schedule if needed. Other examples of outcome-dependent follow-up include administrative database cohorts, for which there is no regular observation schedule, and cohorts with scheduled visits with poor visit adherence.
Proper estimation of the association between an exposure and an outcome must account for the dependence of the visit times on a set of measured predictors, either baseline or time-dependent. One way of doing this is to include the entire set of measured predictors of visit times as covariates in the model for outcome, and thus remove the informativeness of follow-up. However, inference is then drawn for a scientific question that is not of interest. This can clearly be seen in a situation where the predictors of visit times are mediators in the relation between exposure and outcome.
Without altering the model for outcome, the inverse intensity rate ratio (IIRR)-weighted method incorporated into GEE (3–5) allows for proper inference in situations where visit times are a mixture of scheduled and as-needed visits and where the occurrence of visits is predicted by past outcome, cumulative exposure, and other measured variables such as causal intermediates in the model for outcome.
In this paper, we describe the application of the IIRR-weighted GEE method to estimation of prevalences and prevalence ratios for morbid conditions during the first year postpartum among Kenyan women infected with human immunodeficiency virus type 1 (HIV-1). Of 484 women under study, 62% had at least 1 as-needed visit. Overall, the women accumulated 5,423 visits, with almost 20% of those being as-needed visits.
MATERIALS AND METHODS
Study setting and population
Data for this case study were collected as part of a prospective cohort study conducted in Nairobi, Kenya, from July 1999 to June 2005, and are described in detail elsewhere (6, 7). HIV-1-seropositive women were enrolled during pregnancy. Our analysis goal was to estimate the prevalences and prevalence ratios of several illnesses during the first year postpartum. Initially, between 1999 and 2002, 216 women were enrolled for monthly visits to the study clinic, with a predefined follow-up period of 12 months after delivery. Subsequently, from 2002 to 2005, 319 additional women were included with a predefined follow-up period of 24 months, with visits taking place monthly for the first 12 months and then every 3 months for an additional 12 months. In addition, women with health complaints arising between scheduled visits were seen in the clinic on an as-needed basis.
At enrollment, baseline sociodemographic and medical information was collected for all women using a standardized questionnaire. At 32 weeks of gestation, a physical examination was conducted, and blood was collected for measurement of CD4 cell counts and hemoglobin and HIV-1 RNA levels. Measurement of CD4 cell counts and HIV-1 RNA levels was repeated at 1, 3, 6, 9, and 12 months postpartum in all women and at 18 and 24 months postpartum in the women followed for the extended study period.
Diagnoses of morbid conditions were based on self-reported history of illness and clinical examination findings at each clinic visit. Clinical determination of illness was based on World Health Organization diagnostic guidelines in use at the clinic site by study physicians (8).
Follow-up
Of the 535 women enrolled during pregnancy, 501 (94%) were followed to delivery and 484 (90%) had a least 1 follow-up visit during the first year postpartum, either as scheduled (479 women; 99% of the 484) or as needed (302 women; 62% of the 484). These 484 women comprised the data set for our analysis.
Data were collected on 5,423 separate encounters occurring in the first year postpartum, for an average of 11.2 visits per woman. Women accrued a total of 4,516 scheduled visits (an average of 9.3 visits per woman) and 907 as-needed visits (an average of 1.9 visits per woman). Figure 1 shows the distribution of scheduled and as-needed visits in the 484 women during the first year postpartum. The measured predictors of the timing of visits were maternal demographic and socioeconomic baseline characteristics and time-varying clinical factors.
Figure 1.

Distribution of numbers of scheduled and as-needed study visits among 484 Kenyan mothers infected with human immunodeficiency virus type 1, 1999–2005.
Baseline characteristics of the cohort are presented in Table 1.
Table 1.
Baseline Characteristics of a Cohort of 484 Kenyan Mothers Infected With Human Immunodeficiency Virus Type 1, 1999–2005
| No. of Women | Mean or No. | IQR or % | |
| Demographic factors | |||
| Age, years | 484 | 25.3 | 22.0–28.0a |
| Higher than primary education | 476 | 194 | 41.0 |
| Marital status | 484 | ||
| Monogamous marriage | 385 | 79.5 | |
| Polygamous marriage | 43 | 8.9 | |
| Single | 42 | 8.7 | |
| Widowed | 3 | 0.6 | |
| Divorced/separated | 11 | 2.3 | |
| Flush toilet in the home | 484 | 235 | 48.6 |
| Single room in the home | 482 | 369 | 76.6 |
| Nulliparous | 480 | 107 | 22.3 |
| Clinical factors | |||
| CD4 count, cells/mm3 | 476 | 477.5 | 303.8–618.0 |
| CD4 count <200 cells/mm3 | 476 | 50 | 10.5 |
| HIV-1 RNA level, log10 copies/mL | 461 | 4.6 | 4.2–5.2 |
| Body mass indexb | 476 | 24.7 | 24.5–26.2 |
Abbreviations: HIV-1, human immunodeficiency virus type 1; IQR, interquartile range.
Interquartile range (25th–75th percentiles).
Weight (kg)/height (m)2.
Outcome-dependent follow-up
We first illustrate an outcome-dependent follow-up situation while estimating the prevalence of morbidity. Simplistically, assume that women with a current low CD4 count (for instance, <200 cells/mm3) are more likely to come into the clinic for an as-needed visit than women with a higher CD4 count. Designate Z(t) the binary low/high CD4 count variable. Next, assume that a morbid condition such as pneumonia and CD4 count are negatively correlated. If we were to include the as-needed visits in the analysis of pneumonia and we ignored the dependence of visits on CD4 counts, the prevalence of pneumonia would be overestimated for the study population. We would have an overrepresentation of observations on women currently suffering from pneumonia but too few observations on women currently pneumonia-free. If we include the low/high CD4 count as an exposure variable in the regression model, we correctly estimate the prevalence of pneumonia among women with a low CD4 count and the prevalence of pneumonia among women with a high CD4 count. That, however, may not be the quantity of interest. We may instead be interested in the overall prevalence of pneumonia in the population, regardless of the women's CD4 count.
We next extend this example to the case where we are interested in estimating an association, such as the prevalence ratio for pneumonia associated with viral load X(t). We further assume that viral load and CD4 count are correlated. If we ignored the dependence of visits on CD4 counts and analyzed directly the viral load and pneumonia in all available visits, the contrast estimates could be biased for the study population. The reason is the differential association in women with a high CD4 count and women with a low CD4 count and their differential numbers of contributed observations. As in the case of estimating prevalence, if we added the low/high CD4 count variable to viral load as an additional covariate, we would correctly estimate the prevalence ratio for pneumonia associated with viral load among women with a low CD4 count and among women with a high CD4 count. However, this is again not what we intended to estimate.
A parallel can be drawn between our studied situation of informative follow-up in a mixture of discrete times (scheduled visits) and continuous times (as-needed visits) and missingness classification (9) in discrete time, when visit times come from a finite set of points. At time t, the outcome Y(t) is missing at random given covariates X(t) of the outcome model and covariates Z(t) of the visit-times model, but it is informative missingness given covariates of the outcome model X(t) alone. Missing data approaches are not directly applicable in our situation, however, because the number of time points is infinite.
Bůžková and Lumley (3) described a method of longitudinal data analysis for generalized linear models with follow-up dependent on outcome-related variables, utilizing an IIRR-weighted GEE approach.
We used 3 types of GEEs to estimate the prevalences and prevalence ratios of morbid conditions in the HIV-1-infected women during the first year postpartum. To compute estimators based on combined scheduled and as-needed visits, we used the IIRR-weighted GEE method, denoted method A. For comparison, we used GEE to compute estimators based on scheduled visits alone—method B—an appropriate (i.e., consistent) but possibly imprecise approach in situations where the number of as-needed visits is large relative to the number of scheduled visits. We also computed GEE estimators based on combined scheduled and as-needed visits, not adjusting for outcome-dependent follow-up—denoted method C—as could often be the analyst approach. If there truly is outcome-dependent follow-up, this method is biased and inconsistent. Data were analyzed using R (10). We used bootstrapping for all 3 methods to empirically estimate the standard error of coefficient estimates. In method A, with each bootstrapped sample, we first reestimated the weights and then the parameters of the outcome model.
IIRR-weighted GEE
Following the notation of Bůžková and Lumley (3), consider a model for the mean of the outcome Yi(t)
| (1) |
for individual i ∈ {1, …, n} at any time t ∈ [0, τ], with τ being the end of the study, where the link function g(·) is known, monotonic, and differentiable and μi(t) = E[Yi(t)|Xi(t)]. The parameter of major interest is β0, a p-dimensional vector of regression coefficients, estimating the association between the possibly time-varying exposure and the outcome. The link function can be a linear, log, or logit function, depending on the targeted inference. Here, we will use the linear link for estimating morbidity prevalence and the log link for estimating the prevalence ratio for morbidity. Our approach is a very flexible approach that could be applied to many types of data. We do not impose any assumptions about the specific distribution of the outcome, nor do we need to specify the correlation structure of the outcome over time.
The goal of this analysis is to estimate the prevalence of 7 morbid conditions: pneumonia, malaria, tuberculosis, upper respiratory tract infection, bronchitis, mastitis, and diarrhea. For each morbid condition, we propose a simple prevalence model,
| (2) |
where the parameter of interest is the 1-dimensional β01. Referring to equation 1, Xi(t) = 1 for all t's and i's, and the link function g(·) is an identity function. If we wished to model time-specific prevalence, we could consider, for example, a model
| (3) |
where {t1, t2} is a set of times in which prevalence can change stepwise, or a model
| (4) |
allowing for a continuous piecewise-linear time effect with β02 representing the slope up to time t1 and β03 representing the slope afterwards.
We also wish to estimate the prevalence ratio for each of the morbid conditions associated with the following 5 exposures, each in a separate model: higher age at delivery (>25 years), having a flush toilet, breastfeeding, CD4 count, and HIV-1 viral load. The model for the prevalence ratio is associating a morbid condition and a correlate through a model
| (5) |
where β0 = (β01, β02)T, with the parameter of major interest being the contrast parameter β02, Xi(t) = (1, Correlatei(t))T, and the link function g(·) is a log function.
The estimating function used resembles GEE with working independence that is being weighted by the subject and time-specific inverse weights. As is any weighted GEE method, pioneered for studies with dropout data (11), the IIRR-weighted GEE method is a 2-step method. First, estimate time- and person-specific inverse weights from a model for visit times. Generally speaking, the inverse weights represent the likelihood of having a visit. The likelihood can take the form of probability, intensity rate, or intensity rate ratios. The higher the likelihood of a visit, the lower the weight given to the particular data point. The weighting approach has been used extensively in literature related to coarsened (i.e., incompletely observed) data. The weights help us to standardize the observed data to the underlying population. In the given example on outcome-dependent follow-up for morbidity prevalence, the weights would weight down data with low CD4 counts versus data with high CD4 counts. Second, estimate the parameter of interest by means of the GEE approach, employing the weights obtained in the first step. Because of the use of estimated weights in the GEE, the model-based variance of the GEE estimators is not valid; instead, variance can be obtained by implementing the formulas of Bůžková and Lumley (3) or by using bootstrapping.
Inverse probability weighting methods (11, 12) rely on the fact that the visit times come from a prespecified set of discrete time points. A logistic regression model can be used to estimate the probability of not missing a specific visit, to further estimate a probability for each subject's missingness profile. However, with as-needed visits coming from a continuous time span, a different approach is needed, using time-to-events modeling. Specifically, we use a proportional rate model for the visit times, a model similar to but more flexible than a proportional hazards model (13).
Calculation of IIRR weights
First we introduce the notation for the model for visit times. For each individual i, the outcome is measured at Ki visit times 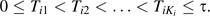 . These are scheduled visit times as well as as-needed visit times. We denote Ci the dropout time and
. These are scheduled visit times as well as as-needed visit times. We denote Ci the dropout time and
the number of observations by time t, where an indicator function I(event) is 1 or 0 according whether the event happens. The underlying uncensored process is Ni*, with Ni(t) = Ni*(min(t, Ci)), and the at-risk indicator is ξi(t) = I(Ci > t).
For the ith individual at time t, we define the IIRR weights as 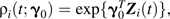 , where γ0 comes from a model for visit times that is very similar to a Cox proportional hazards model: a proportional rate model
, where γ0 comes from a model for visit times that is very similar to a Cox proportional hazards model: a proportional rate model
| (6) |
where Λ0(·) is an arbitrary nondecreasing function of time t (13). These inverse weights are proportional to the probability that individual i has an observation at time t under the intensity rate model defined in equation 6, with Zi(t) being the set of predictors. The true γ0 and thus the true weights are unknown but can be estimated from the data based on the intensity rate model.
We use baseline characteristics as well as time-varying factors as predictors of the timing of visits. Specifically, the time-invariant predictors are age at baseline, higher than primary education (Edu), living in a single room at home (SR), having a flush toilet at home (FT), and being a primigravida (Prim), denoting Z1i = (Agei, Edui, SRi, FTi, Primi). Time-varying predictors are breastfeeding (BF), last value carried forward of viral load in log10 copies per mL (VL), and last value carried forward of CD4 count in hundreds of cells per mm3 (CD4), as well as the last observed value of the 7 morbid conditions (Morb*), denoting Z2i(t) = (BFi(t), VLi(t), CD4i(t), Morbi*(t)). We note that the direct current outcome cannot be used as a predictor. We set different parameters for scheduled and as-needed visits, allowing for compliance with the scheduled visits to be associated with predictors in a different way than coming in for an as-needed visit. We define a model for visit times as follows:
 |
(7) |
with Λ0(·) being an arbitrary nondecreasing function of time t. Generally speaking, each γvj with v ∈ {0, 1}, j ∈ {1, …, 9} is the rate ratio for intensity of visiting associated with a given predictor for scheduled and as-needed visits, respectively.
An important assumption of Bůžková and Lumley (3) is that the ith woman's probability of making a clinic visit at time t depends on Zi(t), Xi(t), Yi(t) only through Zi(t). Zi(t) may contain any variables available at or before time t, such as Xi(t) and previous outcome, except for the current outcome Yi(t). If this assumption does not hold, the estimation approach yields inconsistent estimates. Investigators should use caution while planning a priori in order to measure variables with good predictive ability for the visit timing—including, for example, mediating variables.
RESULTS
Based on the model defined in equation 7, the IIRR weights in our data ranged from 0.24 to 2.05.
Table 2 shows the estimated prevalences of the 7 morbid conditions during the first year postpartum, based on the model defined in equation 2. The 95% confidence intervals were based on an empirical estimator of the standard error of the prevalence estimate using 1,000 bootstrap resamples of the data set.
Table 2.
Estimated Prevalence (%) of Morbid Conditions During the First Year Postpartum in a Cohort of 484 Kenyan Mothers Infected With Human Immunodeficiency Virus Type 1, 1999–2005
| Method Aa |
Method Bb |
Method Cc |
||||
| % | 95% CI | % | 95% CI | % | 95% CI | |
| Pneumonia | 1.48 | 1.20, 1.76 | 1.61 | 1.20, 2.01 | 2.89 | 2.31, 3.47 |
| Malaria | 2.10 | 1.86, 2.34 | 2.08 | 1.59, 2.56 | 3.15 | 2.59, 3.72 |
| Tuberculosis | 0.58 | 0.37, 0.79 | 0.66 | 0.27, 1.06 | 0.88 | 0.43, 1.33 |
| Upper respiratory tract infection | 11.39 | 10.74, 12.04 | 11.36 | 10.27, 12.45 | 14.65 | 13.44, 15.87 |
| Bronchitis | 1.43 | 1.15, 1.71 | 1.35 | 0.99, 1.71 | 1.73 | 1.35, 2.11 |
| Mastitis | 1.09 | 0.88, 1.31 | 1.00 | 0.66, 1.35 | 1.10 | 0.77, 1.43 |
| Diarrhea | 3.58 | 2.84, 4.31 | 3.12 | 2.43, 3.82 | 3.64 | 2.93, 4.35 |
Abbreviations: CI, confidence interval; GEE, generalized estimating equations.
Method A used both scheduled and as-needed visits in an inverse intensity rate ratio-weighted GEE approach.
Method B used scheduled visits alone in a GEE approach.
Method C used both scheduled and as-needed visits in a GEE approach but neglected the possible dependence of the visit times and the outcome.
Upper respiratory tract infections had the highest prevalence, with 11.39%, followed by diarrhea (3.58%) and malaria (2.10%). The prevalences of pneumonia and bronchitis were both approximately 1.4%. Mastitis had a prevalence of 1.09%, and tuberculosis had the lowest prevalence (0.58%).
Method A provided estimates fairly similar to those of method B, a correct but possibly imprecise method. We note that method A always yielded a narrower confidence interval than method B. Comparing methods B and C with method A, the estimates of pneumonia prevalence were almost doubled: 1.61% (95% confidence interval (CI): 1.20, 2.01) and 2.89% (95% CI: 2.31, 3.47), respectively. The estimated prevalence of upper respiratory tract infection was more than 3% higher when using method C. Prevalence estimates of malaria and bronchitis were also highly elevated when using method C. For tuberculosis, mastitis, and diarrhea, the estimates based on methods B and C were more comparable, suggesting that follow-up may not be very informative with these outcomes. However, method A did not lose precision, even in this case of no strong informative follow-up, and can be validly used.
We also considered time-varying prevalence as suggested above in the Materials and Methods section, using the IIRR-weighted GEE approach. Only mastitis prevalence showed some variability over time, decreasing from 2.63% during the first month postpartum to 0.8% during the second half of the year, using a piecewise linear model (3) with cutoff points of 1, 4, and 6 months.
Table 3 shows estimated prevalence ratios for the 7 morbid conditions associated with a set of 5 cofactors during the first year postpartum. The standard error estimates were again obtained by bootstrapping, using 1,000 resamples. Higher age at delivery was associated with an increased prevalence of pneumonia (prevalence ratio (PR) = 2.04, 95% CI: 1.51, 2.78), whereas breastfeeding was associated with a lower prevalence (PR = 0.64, 95% CI: 0.46, 0.88). Tuberculosis prevalence was associated with higher age at delivery, not breastfeeding, a lower CD4 count, and a higher viral load. The prevalences of bronchitis and mastitis were lower when women had a flush toilet in the home (PR = 0.59 (95% CI: 0.39, 0.90) and PR = 0.38 (95% CI: 0.22, 0.66), respectively). Diarrhea was also associated with having a flush toilet. Women with higher CD4 counts as well as lower viral loads had lower prevalences of pneumonia, tuberculosis, and diarrhea.
Table 3.
Estimated Prevalence Ratios for 7 Morbid Conditions Associated With a Set of 5 Cofactors During the First Year Postpartum in a Cohort of 484 Kenyan Mothers Infected With Human Immunodeficiency Virus Type 1, 1999–2005
| Method Aa |
Method Bb |
Method Cc |
||||
| PR | 95% CI | PR | 95% CI | PR | 95% CI | |
| Pneumonia | ||||||
| Age >25 years | 2.04** | 1.51, 2.78 | 1.91** | 1.20, 3.05 | 1.45* | 1.03, 2.04 |
| Flush toilet | 0.84 | 0.70, 1.01 | 0.91 | 0.57, 1.44 | 1.31 | 0.89, 1.94 |
| Breastfeeding | 0.64* | 0.46, 0.88 | 0.72 | 0.45, 1.14 | 0.72† | 0.50, 1.03 |
| CD4 countd | 0.82** | 0.75, 0.89 | 0.76** | 0.65, 0.87 | 0.57** | 0.52, 0.62 |
| Viral loade | 1.81** | 1.48, 2.21 | 1.74** | 1.24, 2.45 | 1.85** | 1.52, 2.25 |
| Malaria | ||||||
| Age >25 years | 1.29 | 0.91, 1.81 | 1.18 | 0.79, 1.77 | 1.23 | 0.92, 1.64 |
| Flush toilet | 0.87 | 0.63, 1.22 | 0.83 | 0.55, 1.24 | 0.74* | 0.55, 1.00 |
| Breastfeeding | 0.99 | 0.72, 1.35 | 0.93 | 0.62, 1.38 | 0.88 | 0.66, 1.18 |
| CD4 count | 0.85** | 0.80, 0.90 | 0.92 | 0.84, 1.01 | 0.93* | 0.87, 0.99 |
| Viral load | 0.83† | 0.67, 1.02 | 0.97 | 0.76, 1.24 | 1.15 | 0.95, 1.39 |
| Tuberculosis | ||||||
| Age >25 years | 2.87** | 1.65, 4.99 | 2.32* | 1.07, 5.01 | 1.78* | 1.06, 2.99 |
| Flush toilet | 1.04 | 0.62, 1.75 | 1.24 | 0.59, 2.60 | 1.84* | 1.09, 3.12 |
| Breastfeeding | 0.21** | 0.12, 0.37 | 0.28** | 0.12, 0.66 | 0.75 | 0.44, 1.26 |
| CD4 count | 0.63** | 0.48, 0.83 | 0.52** | 0.39, 0.70 | 0.60** | 0.50, 0.72 |
| Viral load | 3.06** | 2.10, 4.46 | 2.69** | 1.53, 4.75 | 2.04** | 1.38, 3.02 |
| Upper respiratory tract infection | ||||||
| Age >25 years | 1.00 | 0.88, 1.13 | 0.90 | 0.76, 1.06 | 1.02 | 0.90, 1.16 |
| Flush toilet | 0.94 | 0.83, 1.06 | 0.96 | 0.82, 1.13 | 0.90 | 0.80, 1.03 |
| Breastfeeding | 0.99 | 0.87, 1.12 | 0.99 | 0.84, 1.16 | 0.95 | 0.83, 1.07 |
| CD4 countd | 0.99 | 0.96, 1.01 | 0.98 | 0.95, 1.02 | 0.99 | 0.96, 1.01 |
| Viral loade | 1.09* | 1.00, 1.18 | 1.11* | 1.00, 1.23 | 1.06† | 0.98, 1.15 |
| Bronchitis | ||||||
| Age >25 years | 1.31 | 0.88, 1.94 | 1.42 | 0.86, 2.34 | 0.97 | 0.65, 1.45 |
| Flush toilet | 0.59** | 0.39, 0.90 | 0.61† | 0.36, 1.02 | 0.61* | 0.40, 0.93 |
| Breastfeeding | 0.94 | 0.63, 1.40 | 1.07 | 0.65, 1.77 | 0.94 | 0.63, 1.40 |
| CD4 count | 1.00 | 0.95, 1.10 | 0.98 | 0.88, 1.08 | 1.02 | 0.94, 1.10 |
| Viral load | 1.35* | 1.04, 1.76 | 1.43* | 1.01, 2.01 | 1.15 | 0.89, 1.50 |
| Mastitis | ||||||
| Age >25 years | 0.61† | 0.36, 1.06 | 0.71 | 0.39, 1.30 | 0.63 | 0.37, 1.07 |
| Flush toilet | 0.38** | 0.22, 0.66 | 0.39** | 0.20, 0.75 | 0.52* | 0.30, 0.90 |
| CD4 count | 0.90* | 0.81, 1.00 | 0.92† | 0.81, 1.05 | 0.98 | 0.89, 1.09 |
| Viral load | 0.80† | 0.60, 1.07 | 0.79 | 0.57, 1.10 | 0.78† | 0.59, 1.04 |
| Diarrhea | ||||||
| Age >25 years | 1.12 | 0.86, 1.46 | 1.13 | 0.81, 1.57 | 1.02 | 0.77, 1.33 |
| Flush toilet | 0.59** | 0.44, 0.78 | 0.58** | 0.41, 0.82 | 0.59** | 0.44, 0.78 |
| Breastfeeding | 1.29† | 0.97, 1.71 | 1.28† | 0.92, 1.79 | 1.40* | 1.06, 1.85 |
| CD4 count | 0.94* | 0.89, 1.00 | 0.95† | 0.89, 1.02 | 0.80* | 0.75, 0.85 |
| Viral load | 1.43** | 1.18, 1.73 | 1.33** | 1.06, 1.66 | 1.82** | 1.51, 2.19 |
* P ≤ 0.05; **P ≤ 0.01; †P > 0.05 and P ≤ 0.10 (borderline-significant).
Abbreviations: CI, confidence interval; PR, prevalence ratio.
Method A used both scheduled and as-needed visits in an inverse intensity rate ratio-weighted GEE approach.
Method B used scheduled visits alone in a GEE approach.
Method C used both scheduled and as-needed visits in a GEE approach but neglected the possible dependence of the visit times and the outcome.
Per 100-cells/mm3 increase.
Log10 copies/mL.
Comparing the 3 methods, method A provided estimates fairly similar to those of method B, with usually tighter confidence intervals. Comparing methods B and C, some estimates of prevalence ratio were very different, and different conclusions would be derived. For instance, the prevalence ratio for tuberculosis associated with breastfeeding changed from 0.28 to 0.75 and lost statistical significance; the prevalence ratio for bronchitis associated with viral load decreased from 1.43 to 1.15 and also lost statistical significance.
DISCUSSION
Our objective in this paper was to provide an accessible account of an application of the IIRR-weighted GEE approach to the real analytical problem of informative follow-up in cohort studies. This should encourage greater use of this method in cohort studies with irregular follow-up.
Table 2 shows that adjusting for informative follow-up when studying serious conditions that need acute treatment, such as pneumonia and malaria, had a large effect on the prevalence estimates. The use of both scheduled and as-needed visits in a naive GEE approach (method C) that ignored informative follow-up provided biased estimates. On the other hand, when estimating the prevalence of diseases that were self-resolving and did not necessarily require a visit, such as mastitis and diarrhea, the impact of adjusting for irregular follow-up was lowest. Prevalence estimates obtained by implementing method C were then more comparable to the estimates obtained by the IIRR-weighted GEE approach (method A). Estimates obtained by the IIRR-weighted GEE approach were validated by estimates obtained by applying GEE to scheduled visits alone (method B) and were often more precise because more information was accounted for.
We emphasize that the IIRR-weighted GEE approach and GEE using scheduled visits alone are both valid (i.e., unbiased) approaches when as-needed visit times are informative about the outcome. A naive GEE approach applied to both scheduled and as-needed visits provides biased estimates. Utilizing a larger data set, the IIRR-weighted GEE approach often is more precise than the GEE approach based on scheduled visits alone, giving somewhat smaller standard errors.
In the case where there are no scheduled visits but as-needed visits only, the IIRR-weighted GEE approach is still a valid method that can provide unbiased estimates. It is extremely important to pay attention to the mechanics of the visit times, as naive GEE (using the only available visits that are all as-needed visits) can provide highly biased estimates. We note that using naive GEE on as-needed visits would often be the choice of an analyst.
In this paper, we describe an estimation procedure that is appropriate for drawing inferences about population averages, such as prevalence, and population contrast parameters, such as prevalence ratios. Under certain circumstances, an analysis using as-needed visits alone may be of interest. It would correctly address questions related to modeling of clinical resources. However, the proposed method is not intended for this purpose, because its primary aim is to infer population estimates.
The approach that we took for the prevalence of morbid conditions can be similarly applied when the incidence of morbid conditions is of interest, once incidence outcome variables have been defined. Relative risks of morbidity would be examined instead of prevalence ratios. However, defining an incidence of a morbid condition in situations where measurements are available at irregular times may be fairly complicated.
Lin et al. (14) addressed outcome-dependent follow-up in generalized linear models with inverse intensity weighting. Their estimation procedure requires estimation of a smooth hazard rate in the model for visit times. This approach complicates estimation but, more importantly, rules out visit times that have a positive probability, as occurs with scheduled visits. Bůžková and Lumley have described extension of the IIRR-weighted GEE approach to semiparametric regression with an unspecified intercept for linear models (4) and log-linear models (5). A conceptually different approach to addressing informative follow-up is to use latent variables linking the model for a longitudinal outcome and the model for visit times. The approaches of Sun et al. (15) and Liang et al. (16) are for linear models only and use a latent variable that is constant in time and thus cannot handle the common situations of informative follow-up due to dependence on the last observed outcome or other time-varying factors. Using the latent variable concept, an estimation procedure that is valid in situations where informative follow-up can change over time or is valid for generalized linear models is yet to be discovered.
Unlike the use of unknown latent variables to link the model for the outcome with the model for visit times, the approach of using weights to adjust for informative follow-up assumes that variables effecting the visit times are measured. This is true for both the IIRR-weighted GEE approach and the more established inverse probability weighting approach. Another assumption of the IIRR-weighted GEE is that the visit times do not depend on the current outcome. The visit times can, however, depend on the last observed outcome. As with inverse probability weighting approaches, when weights are unstable, the method should be used with caution (17).
The estimation procedure can be implemented in many software packages with relative ease—the same level of ease as with the inverse probability weighting approach. The model for visit times can be fitted with standard software for the Cox proportional hazards model to obtain estimates of γ0, which can then be used to compute the weights. The weights can then be used in any method for solving weighted GEEs or fitting generalized linear models. A simplified code is supplied in the Appendix. Some programming is needed for the estimate of covariance, but this can be avoided by using the bootstrap for inference.
The IIRR-weighted GEE approach is a very flexible modeling method. Being a GEE method, the correlation structure of the outcome does not need to be correctly specified. The method is consistent if only the mean model is correct (1). The intensity rate model is also very flexible, allowing the baseline intensity function to have discontinuities that correspond to times of positive probabilities of having a scheduled visit. This allows the use of our method on data with a combination of scheduled and as-needed visits. A thorough explanation of the intensity rate model and a comparison with the Cox proportional hazards model can be found in the paper by Lin et al. (13).
In our study, when using all combined data from scheduled and as-needed visits without adjusting for outcome-dependent follow-up in the naive GEE approach, we greatly overestimated the prevalences of all morbid conditions. This overestimating occurs when people come in for as-needed visits more often when they experience a given morbid condition than when they do not. Properly accounting for the nonrandom nature of irregular visits is essential to unbiased estimates of disease prevalence. We believe that using IIRR weighting in GEE is a straightforward way to improve these studies.
Acknowledgments
Author affiliations: Department of Biostatistics, School of Public Health, University of Washington, Seattle, Washington (Petra Bůžková, Elizabeth R. Brown); Department of Medicine, School of Medicine, University of Washington, Seattle, Washington (Grace C. John-Stewart); and Department of Epidemiology, School of Public Health, University of Washington, Seattle, Washington (Grace C. John-Stewart).
The acquired immunodeficiency syndrome studies were funded by National Institutes of Health grants K24 HD054314-03, R01 HD3412, and AI27757 (Grace C. John-Stewart) and National Institutes of Health grant R01 AI029168 (Elizabeth R. Brown).
The authors thank Phelgona A. Otieno and the study team for conducting the study. They also thank Dr. Joseph A. Delaney for his insightful advice regarding manuscript preparation.
Conflict of interest: none declared.
Glossary
Abbreviations
- CI
confidence interval
- GEE
generalized estimating equations
- HIV-1
human immunodeficiency virus type 1
- IIRR
inverse intensity rate ratio
- PR
prevalence ratio
APPENDIX
The R code for obtaining inverse intensity rate ratio-weighted estimates is as follows:
gamma.hat<-coxph(Surv(start.time, stop.time, visit)∼Z, data=visit.times.dat)$coef
iirr<-1/exp(Z %*% gamma.hat)
beta.hat<-summary(lm(morbidity∼1, weights=iirr))$coef[1,]
beta.hat<-summary(glm(morbidity∼correlate, family=quasipoisson,weights=iirr,
data=morbidity.dat))$coef[2,]
prev.ratio<-exp{beta.hat}
References
- 1.Liang KY, Zeger SL. Longitudinal data analysis using generalized linear models. Biometrika. 1986;73(1):13–22. [Google Scholar]
- 2.Hoffman EB, Sen PK, Weinberg CR. Within-cluster resampling. Biometrika. 2001;88(4):1121–1134. [Google Scholar]
- 3.Bůžková P, Lumley T. Longitudinal data analysis for generalized linear models with follow-up dependent on outcome-related variables. Can J Stat. 2007;35(4):485–500. [Google Scholar]
- 4.Bůzková P, Lumley T. Semiparametric modeling of repeated measurements under outcome-dependent follow-up. Stat Med. 2009;28(6):987–1003. doi: 10.1002/sim.3496. [DOI] [PubMed] [Google Scholar]
- 5.Bůžková P, Lumley T. Semiparametric loglinear regression for longitudinal measurements subject to irregular, biased follow-up. J Stat Plan Inference. 2008;138(8):2450–2461. [Google Scholar]
- 6.Otieno PA, Brown ER, Mbori-Ngacha DA, et al. HIV-1 disease progression in breast-feeding and formula-feeding mothers: a prospective 2-year comparison of T cell subsets, HIV-1 RNA levels, and mortality. J Infect Dis. 2007;195(2):220–229. doi: 10.1086/510245. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Walson JL, Brown ER, Otieno PA, et al. Morbidity among HIV-1-infected mothers in Kenya: prevalence and correlates of illness during 2-year postpartum follow-up. J Acquir Immune Defic Syndr. 2007;46(2):208–215. doi: 10.1097/QAI.0b013e318141fcc0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.World Health Organization. Integrated Management of Adolescent and Adult Illness. Interim Guidelines for First-Level Facility Health Workers at Health Centre and District Outpatient Clinic. Geneva, Switzerland: World Health Organization; 2004. ( http://www.who.int/hiv/pub/imai/en/acutecarerev2_e.pdf). (Accessed April 10, 2009) [Google Scholar]
- 9.Rubin DB. Inference and missing data. Biometrika. 1976;63(3):581–592. [Google Scholar]
- 10.R Development Core Team. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Project for Statistical Computing; 2007. ( http://www.R-project.org). (Accessed May 12, 2009) [Google Scholar]
- 11.Robins JM, Rotnitzky A, Zhao LP. Analysis of semiparametric regression-models for repeated outcomes in the presence of missing data. J Am Stat Assoc. 1995;90(429):106–121. [Google Scholar]
- 12.Rotnitzky A, Robins JM, Scharfstein DO. Semiparametric regression for repeated outcomes with nonignorable nonresponse. J Am Stat Assoc. 1998;93(444):1321–1339. [Google Scholar]
- 13.Lin DY, Wei LJ, Yang I, et al. Semiparametric regression for the mean and rate functions of recurrent events. J R Stat Soc B Series. 2000;62(4):711–730. [Google Scholar]
- 14.Lin H, Scharfstein DO, Rosenheck RA. Analysis of longitudinal data with irregular, outcome-dependent follow-up. J R Stat Soc Series B. 2004;66(3):791–813. [Google Scholar]
- 15.Sun J, Sun L, Liu D. Regression analysis of longitudinal data in the presence of informative observation and censoring times. J Am Stat Assoc. 2007;102(480):1397–1406. [Google Scholar]
- 16.Liang Y, Lu W, Ying Z. Joint modeling and analysis of longitudinal data with informative observation times. Biometrics. 2009;65(2):377–384. doi: 10.1111/j.1541-0420.2008.01104.x. [DOI] [PubMed] [Google Scholar]
- 17.Cole SR, Hernán MA. Constructing inverse probability weights for marginal structural models. Am J Epidemiol. 2008;168(6):656–664. doi: 10.1093/aje/kwn164. [DOI] [PMC free article] [PubMed] [Google Scholar]