

Abstract
Carboxylesterase (CES) is predominantly responsible for the detoxification of a wide range of drugs and narcotics, and catalyze several reactions in cholesterol and fatty acid metabolism. Studies of the genetic and biochemical properties of primate CES may contribute to an improved understanding of human disease, including atherosclerosis, obesity and drug addiction, for which non-human primates serve as useful animal models. We cloned and sequenced baboon CES1 and CES2 and used in vitro and in silico methods to predict protein secondary and tertiary structures, and examined evolutionary relationships for these enzymes with other primate and mouse CES orthologs. We found that baboon CES1 and CES2 proteins retained extensive similarity with human CES1 and CES2, shared key structural features reported for human CES1, and showed family specific sequences consistent with their multimeric and monomeric subunit structures respectively.
Keywords: cDNA sequence, amino acid sequence, 3-D structure
Introduction
Carboxylesterases (CES; E.C.3.1.1.1) exist as a family of enzymes which have been implicated in the catalysis of a broad range of hydrolytic and transesterification reactions [54]. Diverse substrates include xenobiotics (carboxyl esters, thioesters and aromatic amides), anticancer drugs such as CPT-11 and capecitabine, narcotics such as heroin and cocaine, and clinical drugs such as lovastatin and lidocaine [48, 56]. CES detoxifies numerous organophosphate and carbamate compounds used as chemical weapons (sarin, tabun and soman) or insecticides (malathion), usually by ‘suicide-inactivation’ at the CES active site [1, 31]. The enzyme has also been associated with cholesterol and fatty acid metabolism through demonstrated activities for several reactions: cholesterol:ester hydrolase [19]; fatty acyl CoA hydrolase [60]; acyl CoA:cholesterol acyl transferase [2]; acyl carnitine hydrolase [23]; and fatty acyl: ethyl ester synthase [13], and has been linked with the assembly of low density lipoprotein particles in liver [63]. CES is predominantly localized in the endoplasmic reticulum (ER), has an N-terminal hydrophobic signal peptide consistent with a trafficking role through the ER and forms complexes with β-glucuronidase, consistent with a partnering role in phase II drug metabolism [45, 68].
Two major forms of human CES have been reported: CES1 is the major liver enzyme and also is found in lung epithelia, macrophages and other tissues [59]; and CES2 is the major intestinal enzyme and is widely distributed in tissues including liver, kidney, heart and skeletal muscle [30]. Three-dimensional structural analyses of several human CES1 complexes have shown that the active site is highly promiscuous enabling catalysis of many diverse reactions for a wide range of substrates [4, 5, 34, 48, 56]. In addition to the active site, human CES1 has at least two ligand binding sites, the ‘side-door’ and ‘Z-site’, where fatty acids and cholesterol analogues respectively, are bound. The trimer-hexamer subunit structure for CES1 is proposed to play an important role in the regulation of catalysis through ligand binding, which may influence access to the active site by shifting this equilibrium [48]. Genomic structures for the genes encoding these enzymes have been determined: CES1 is located on chromosome 16 contains 14 exons and spans about 30 kb [7, 30, 59]; and CES2 is also located on chromosome 16 contains 15 exons and spans about 11 kb [8, 34, 57]. Their close proximity and sequence similarity (47% identity for human CES1 and CES2 cDNAs) imply that they arose from a common ancestor [22, 44, 54–56]. Three other CES genes (CES3, CES4 and CES7) also map to human chromosome 16 [37, 53, 66].
This paper reports the cDNA and deduced amino acid sequences, subunit structures and predicted secondary and tertiary structures for baboon CES1 and CES2, and describes the structural and likely evolutionary relationships for these enzymes from several primate species, including humans. The baboon and other non-human primate species are used as animal models for studying several human diseases [52], including atherosclerosis and related arterial diseases [6, 33], obesity [11] and drug addiction and toxicity [38, 50]. Given the major role of CES in the metabolism of drugs and narcotics [48, 56], and in catalyzing several reactions of cholesterol and fatty acid metabolism [2, 12, 19, 23, 60], these and related studies may lead to a better understanding of genetic and biochemical factors contributing to these common diseases.
Methods
cDNA cloning and sequencing
Total RNA was extracted from archived baboon liver. First strand cDNA synthesis from total RNA was performed with an Oligo (dT) Primer (Ambion, Austin,TX) and Superscript III Reverse Transcriptase (Invitrogen, Carlsbad,CA) according to the manufacturer’s instructions. CES1 baboon cDNA was PCR amplified from one first strand cDNA sample using forward primer (5’ – AAAACTGTCGCCCTTCCACG -3’) and reverse (5’ – TTCCCCAGCCACGGTAAGATGCCT -3’) designed from rhesus sequence data [28, 51]. CES2 baboon cDNAs were PCR amplified as 3 overlapping fragments from each first strand sample using: fragment 1 (698 bp – 2532 bp) forward primer (5’ – TTTGCTCAAGCGGTTCCTTC -3’) and reverse primer (5’ – TCATGTGCGGTGGCCTGATGTTCT -3’); fragment 2 (1171 bp – 2532 bp) forward primer (5’ – AACCGAGACCAGCGAGCCGACCAT -3’) and reverse primer (5’ – TCATGTGCGGTGGCCTGATGTTCT -3’); and fragment 3 (2429 bp – 3862 bp) forward primer (5’ – GCGGACTCCATGTTTGTGATCCCT -3’) and reverse primer (5’ – ACTTAGGTGTGGGCAACATTCTTC -3’) designed from human sequence data [27]. Baboon CES1 and CES2 cDNAs were sequenced from the PCR fragments and a tiling path of sequencing primers for each gene was constructed (Table 1). cDNA samples for each baboon were sequenced using these primers and Big Dye v3.1 chemistry (Applied Biosystems Cat. No. 4337455). Sequencing products were purified using Exonuclease I (10ul/ul, USB Cat. No. 70073Z) and Shrimp Alkaline Phosphatase (SAP) (1u/ul, USB Cat. No. 70092Z) and analyzed on an automated sequencer (Applied Biosystems 3100) using Sequence Analysis software (Applied Biosystems 3100). Sequence data were imported into Sequencher (Gene Codes, Inc.) for alignment. Gene sequences were deposited with GenBank (accession numbers xxx and xxx).
Table 1.
Baboon cDNA CES1 and CES2 Sequencing Primers
| Name | Position | Direction | Sequence (5’ – 3’) |
|---|---|---|---|
| CES1_15WG | 89 | Forward | AAAACTGTCGCCCTTCCACG |
| CES1_2 | 384 | Forward | CGTGGCAGGGCAGGTACTCTCAGA |
| CES1_3 | 759 | Forward | CATCTTTGGAGAGTCAGCGGGAGG |
| CES1_4 | 1166 | Forward | AGCAGGAGTTTGGCTGGATTATTC |
| CES1_5 | 1596 | Forward | GGTGATGAAATTCTGGGCCAACTT |
| CES1_8 | 388 | Reverse | TAGCTCTGAGAGTACCTGCCCTGC |
| CES1_9 | 760 | Reverse | TCCTCCCGCTGACTCTCCAAAGAT |
| CES1_10 | 1165 | Reverse | AATAATCCAGCCAAACTCCTGCTT |
| CES1_11 | 1596 | Reverse | AAGTTGGCCCAGAATTTCATCACC |
| CES1_12 | 1855 | Reverse | TCCCTTTCACAAGATACCCCAGTC |
| CES1_16WG | 1892 | Reverse | TTCCCCAGCCACGGTAAGATGCCT |
| Name | Position | Direction | Sequence (5’ – 3’) |
|---|---|---|---|
| CES2_4 | 2036 | Forward | CAAGTTGACTCTGAGGCCCTGGTG |
| CES2_5 | 2429 | Forward | GCGGACTCCATGTTTGTGATCCCT |
| CES2_13 | 1814 | Reverse | AAAGTGGGCGATATTCTGCTGGAC |
| CES2_15 | 2532 | Reverse | TCATGTGCGGTGGCCTGATGTTCT |
| CES2_24 | 2533 | Forward | GAACATCAGGCCACCGCACATGAA |
| CES2_25 | 2543 | Forward | CCACCGCACATGAAGGCAGACCAT |
| CES2_36 | 2663 | Reverse | ATTTCTCGCAAAGTTGGCCCAGTA |
| CES2_40 | 1136 | Forward | TCTCTGGGTGAACAGCAGCGTGTC |
| CES2_41 | 1515 | Forward | GCCAAGTCAATGTGACCATCCCTT |
| CES2_45 | 2865 | Reverse | GCACAGGGAGCTACAGCTCTGTGT |
Phylogenetic Studies and Sequence Divergence
Phylogenetic trees were constructed using an amino acid alignment from a ClustalW-derived alignment of primate and mouse CES protein sequences, obtained with default settings and corrected for multiple substitutions [10, http://www.ebi.ac.uk/clustalw/], and used to predict likely evolutionary relationships for these enzymes. Table 2 provides a summary of the Genbank (http://www.ncbi.nlm.nih.gov/Genbank/), UniProtKB/Swiss-Prot (http://au.expasy.org/sprot/) and predicted in silico CES sequences [27] used in alignment studies. Also included are the baboon CES1 and CES2 sequences reported here. The extent of divergence for mammalian CES1 and CES2 amino acid sequences was determined using the SIM-Alignment tool for Protein Sequences [http://au.expasy.org/tools/sim-prot.html].
Table 2.
| Mammal | CES Gene |
CES Lineage |
GenBank mRNA (or *N-scan ID) |
UNIPROT ID |
No of Amino Acids |
Chromosome Location (or * Scaffold) |
Strand |
|---|---|---|---|---|---|---|---|
| Human | CES1 | CES1 | L07765 | P23141 | 567 | 16:54,394,465–54,424,468 | negative |
| Chimp | CES1 | CES1 | *16.56.002 | 567 | 16:55,223,013–55,237,148 | negative | |
| Orangutan | CES1 | CES1 | CR857194 | Q5R545 | 566 | ||
| Baboon | CES1 | CES1 | 567 | ||||
| Rhesus | CES1 | CES1 | *20.55.002 | 566 | 20:54,008,925–54,141,457 | negative | |
| Mouse | CES1 | CES1 | NP067431 | Q8VCC2 | 565 | 8:95,826,807–95,861,053 | negative |
| Mouse | CES3 | CES1 | NM053200 | Q8VCT4 | 565 | 8:95,690,157–95,721,618 | negative |
| Mouse | CES22 | CES1 | NP598421 | Q64176 | 562 | 8:95,725,306–95,753,320 | negative |
| Mouse | CESN | CES1 | NP031980 | P23953 | 551 | 8:95,623,067–95,655,157 | negative |
| Rat | CES3 | CES1 | X51974 | P16303 | 565 | 19:14,928,590–14,966,890 | negative |
| Pig | EST1 | CES1 | X63323 | Q29550 | 566 | ||
| Cow | CES1 | CES1 | NP031980 | Q0VC13 | 558 | 18:25,100,195–25,140,384 | negative |
| Dog | CES1 | CES1 | AB023629 | Q95N05 | 565 | 2:63,156,760–63,185,822 | positive |
| Cat | CES1 | CES1 | AB114676 | Q766D7 | 566 | *15028:171,921–202,675 | negative |
| Rabbit | EST1 | CES1 | AF036930 | P12337 | 565 | ||
| Human | CES2 | CES2 | BX538086 | O00748 | 559 | 16:65,525,828–65,536,493 | positive |
| Chimp | CES2 | CES2 | *20.66.008 | 559 | 16:66,639,936–66,650,303 | positive | |
| Baboon | CES2 | CES2 | 561 | ||||
| Rhesus | CES2 | CES2 | *20.66.008 | 561 | 20:65,225,907–65,236,896 | positive | |
| Mouse | CES2 | CES2 | NP663558 | Q91WG0 | 561 | 8:107,371,033–107,378,161 | positive |
| Mouse | CES5 | CES2 | BC055622 | Q8BK48 | 559 | 8:107,450,221–107,457,611 | positive |
| Mouse | CES6 | CES2 | NP598721 | Q8QZR3 | 558 | 8:107,257,972–107,265,313 | positive |
| Rat | CES2 | CES2 | AB010632 | O70177 | 560 | 1:267,885,132–267,894,795 | positive |
| Rat | CES2.1 | CES2 | AB010570 | O70631 | 561 | 1:267,887,436–267,894,795 | positive |
| Rat | CES6 | CES2 | AY034877 | Q8K3R0 | 558 | 19:37,855–44,723 | negative |
| Hamster | CES2 | CES2 | D28566 | Q64419 | 561 | ||
| Hamster | CES6 | CES2 | D50577 | O35533 | 559 | ||
| Rabbit | EST2 | CES2 | P14943 | 532 | |||
| Cow | CES2 | CES2 | BC102288 | Q3T0R6 | 533 | 18:31,817,564–31,829,262 | positive |
In silico CES gene and gene product identification
BLAT (BLAST-Like Alignment Tool) in silico studies were undertaken using the UC Santa Cruz [http://genome.ucsc.edu/cgi-bin/hgBlat] web site with the default settings [27]. UniProtKB/Swiss-Prot Database [http://au.expasy.org] and GenBank [http://www.ncbi.nlm.nih.gov/Genbank/] sequences (see Table 2) were used to interrogate the human, chimp, rhesus, mouse, rat, cow, dog and cat genome sequences [27] and gene locations were observed for each CES sequence examined for those regions showing identity with the respective CES gene products.
Purification of CES1 and CES2 and native MW studies
Baboon liver samples stored at −80°C were extracted into 50mM Tris-HCl buffer pH 8.0 containing 0.1% Triton-X 100 ( buffer A) (20% w/v) using an Ultra-Turrax homogenizer and centrifuged at 4°C for 30 min at 15,000g. Extracts (~ 5µl) were then subjected to electrophoresis on Titan III cellulose acetate plates at 4°C using 50mM Tris-citrate buffer pH 7.0 at 150 V for 60 min. Edges of the plate were cut and histochemically stained for CES activity using α-napthyl acetate as substrate, Fast Blue RR salt and 1% agarose-overlay in 50mM Tris-HCl pH 8.0 buffer [26]. Cellulose acetate particles were scraped from the unstained plate for the CES1 and CES2 activity zones, and gently extracted into 0.25 mls of Buffer A and centrifuged at 2,000g for 10 min at 4°C. Supernatants containing isozymically purified CES1and CES2 were then subjected to gradient-PAGE (4–20%) in a Tris-Glycine pH 8.5 buffer at 150V for 4.45 hours at 4°C and histochemically stained for CES activity. Native MW standards were run simultaneously with the purified CES1 and CES2 samples and these lanes stained for protein with Coomassie Blue G-250 (0.25%w/v in a solution of 30% methanol/10% acetic acid and distilled water) and destained in the methanol/acetic acid solution. Native MWs for baboon liver CES1 and CES2 were determined from a linear plot of log10MW for the protein standards and migration distance.
Predicted Secondary and Tertiary Structures for Baboon CES Gene Products
Predicted secondary structures for baboon CES1 and CES2 were obtained using the PSIPRED v2.5 web site tools provided by Brunel University [36, http://bioinf.cs.ucl.ac.uk/psipred/psiform.html]. Predicted tertiary structures for baboon CES1 and CES2 were obtained using the SWISS MODEL web tools [http://swissmodel.expasy.org/workspace/index.php?func=modelling_simple1] [21, 28, 43, 67]. The reported human CES1 tertiary structures [3, 4, 48] served as the reference for obtaining the predicted baboon CES1 and CES2 tertiary structures.
Results
Baboon liver CES1 and CES2 cDNA Sequences
We isolated and sequenced cDNAs for baboon CES1 and CES2 and lodged the respective sequences with GenBank (these will be deposited upon acceptance of the manuscript for publication xxx). Based on an alignment with the human CES1 sequence [7, 19, 30] (data not shown), the baboon CES1 cDNA sequence includes 21 bp of the 108 bp 5′ untranslated region (UTR), the entire coding sequence, and 47 bp of the 212 bp 3′UTR. We also sequenced 1980 bp of the baboon CES2 cDNA. An alignment of the baboon CES2 cDNA sequence with the reported human CES2 cDNA sequence [8, 53, 57, 59] (data not shown) showed that the sequence includes 57 bp of 1192 bp 5’ UTR, the entire coding sequence and 237 bp of the 1085 bp 3’ UTR. Alignments of baboon CES1 and CES2 cDNAs with the corresponding sequences for human CES1 and CES2 showed 95% and 92% sequence identities respectively with both the non-coding and coding regions of the genes.
Alignments of baboon CES1 and CES2 with human and other primate CES1 and CES2 amino acid sequences
The deduced amino acid sequences for baboon liver CES1 and CES2 are shown in Figure 1 together with previously reported sequences for human CES1 [7, 19, 30] and human CES2 [8, 53, 57, 59], and with deduced sequences for orangutan CES1 [62], chimp CES1 and CES2, and rhesus CES1 and CES2. The latter four sequences were obtained by in silico interrogation of the chimp and rhesus genomes using human CES1, human CES2, baboon CES1 and baboon CES2 sequences, respectively [27]. Alignments of baboon CES1 with human CES1 and of baboon CES2 with human CES2 showed 94% and 90% sequence identities respectively, while other primate CES1 amino acid sequences are 93% or more identical with human CES1 whereas other primate CES2 sequences are 86% or more identical with human CES2 (Table 3). The deduced amino acid sequence for baboon CES2 was two residues longer (Met310 and Lys546 within the 561 amino acid sequence) than for human CES2 (559 residues). Human CES1 occurs as two major isoforms containing 567 and 568 residues for isoforms 1 and 2 respectively [2, 7], in comparison with the reported baboon CES1 sequence which contains 567 amino acid residues. Since the human CES-isoform 1 was used to describe the tertiary structure for this enzyme [3, 4, 15, 48], these residue numbers are cited in the following text for comparing amino acid sequences of several primate CES1 proteins. The primate CES forms examined in this present study were between 559–567 residues in length, of which 228 residues (~40%) were identical. Of particular interest were the key residues involved in determining the catalytic, microlocalization and regulatory functions for these enzymes which will be dealt with in more detail below and in the discussion section.
Figure 1. Alignment of primate CES1 and CES2 amino acid sequences.

The sequence is annotated with: sequence identities: * identical residues : 1 and . 2 alternative residues observed; residues involved in microsomal processing at N- and C- termini (bold red); N-glycosylation residues at 79NAT (CES1) and potential N-glycosylation sites (green highlight); active site residues Ser; Glu; and His. (red highlight); AS: active site; Side door and gate residues (boxed red font); cholesterol binding Gly residue for human CES1 (light blue font); Z site (boxed black font); disulfide bond Cys residues for human CES1 S---S (blue font); charge clamp residues identified for human CES1 −.....+ (red highlight); helix (human CES1) or predicted helix. (yellow highlight); sheet (human CES1) or predicted sheet structures (gray highlight).
Table 3.
| CES | hCES1 | cCES1 | oCES1 | bCES1 | rCES1 | hCES2 | cCES2 | bCES2 | rCES2 |
|---|---|---|---|---|---|---|---|---|---|
| hCES1 | 100 | 95 | 94 | 94 | 93 | 45 | 45 | 44 | 43 |
| cCES1 | 95 | 100 | 93 | 92 | 91 | 45 | 44 | 44 | 42 |
| oCES1 | 94 | 93 | 100 | 93 | 93 | 45 | 44 | 45 | 43 |
| bCES1 | 94 | 92 | 93 | 100 | 95 | 45 | 45 | 44 | 42 |
| rCES1 | 93 | 91 | 93 | 95 | 100 | 45 | 45 | 44 | 42 |
| hCES2 | 45 | 45 | 45 | 45 | 45 | 100 | 97 | 90 | 87 |
| cCES2 | 45 | 44 | 44 | 45 | 45 | 97 | 100 | 90 | 86 |
| bCES2 | 44 | 44 | 45 | 44 | 44 | 90 | 90 | 100 | 94 |
| rCES2 | 43 | 42 | 43 | 42 | 42 | 87 | 86 | 94 | 100 |
Primate: h, Human; c, Chimp; o, Orangutan; b, Baboon; r, Rhesus
Predicted Secondary and Tertiary Structures for Baboon and other Primate CES Gene Products
Analyses of predicted secondary structures for human CES2, and for baboon and other primate CES1 and CES2 proteins were compared with the previously reported secondary structure for human CES1 [3, 4, 48] (Figure 1). The α-helix/β-sheet predominant CES structure is readily apparent with a high degree of similarity in secondary structures for the CES gene products examined. Consistent structures were apparent near key residues or functional domains including the α-helix within the N-terminal signal peptide (residues 2–13 and 3–24 for human CES1 and CES2, respectively); the β-sheet and α-helix structures bordering the active site Ser228 (human CES1) and the active site and nearby Z site (Glu354 and Gly356 respectively); the α-helix structures bordering the ‘side door’ site; and the α-helix located near the ‘gate’ at the CES1 and CES2 C-terminus end [3, 4, 48). In addition, two random coil regions (residues 51 –115 and 169 –188 for human CES1) are retained for all forms of primate CES1 and CES2 which have been shown for human CES1 to contain 2 charge clamp sites: Lys79…Glu183; and Glu73…Arg186); an N-glycosylation site at 79NAT; a second potential N-glycosylation site for all 4 forms of primate CES2 (111NMT for human CES2), and one of the disulfide bridges (87Cys –S-S-117Cys) reported for human CES1 [3, 4, 48] . Predicted 3-D structures for baboon CES1 and CES2 (Figure 2) showed a high degree of similarity with human CES1 [3, 4, 48]. The rainbow based color code (red for carboxyl-end and deep blue for amino terminus end) illustrated the high degree of conservation observed for both baboon CES1 and CES2 secondary and tertiary structures despite having <45% sequence identity.
Figure 2.

Predicted tertiary structures for baboon CES1 and CES2
Subunit Structures for Baboon Liver CES1 and CES2
Baboon liver CES1 exhibited gradient PAGE migration properties consistent with being a mixture of two multi-subunit structures, trimers (~170kD) and hexamers (340kD), whereas liver and intestine CES2 behaved as a monomer, based upon subunit MWs of ~62kD for both enzymes (Figure 3) [7, 8]. This is consistent with the results reported for human CES1 and CES2 as trimers/hexamers and monomers, respectively [44]. Baboon intestine CES1 exhibited similar properties to liver CES1 but with two higher MW zones indicating further aggregation of subunits for this enzyme. A monomeric subunit structure for baboon CES2 is further supported by the amino acid replacements observed at the subunit-subunit binding sites of human CES1 [15] for the corresponding residues in human and baboon CES2 (Figure 1). The CES2 amino acid charge clamp residue substitutions interfere with monomer-monomer binding: CES1 Glu183, which binds to Lys78 in human and baboon, is substituted in CES2 by Lys190 in human, baboon and other primates (Figure 1); and CES1 Arg193, which in human and baboon binds to Glu72, is substituted in CES2 by Thr200 (Figure1) human, baboon and other primates. In addition, the CES1 79Asn in human and baboon has been replaced by 87Asp (Figure 1) in CES2 for the 4 primate enzymes examined, preventing carbohydrate binding to the amide group and sialic acid stacking which is essential for trimer-hexamer formation [15]. The loss of two charge clamps and the carbohydrate binding site for CES2 may contribute significantly to the disruption of monomer-monomer binding leading to the observed single subunit structure for human and baboon CES2.
Figure 3.
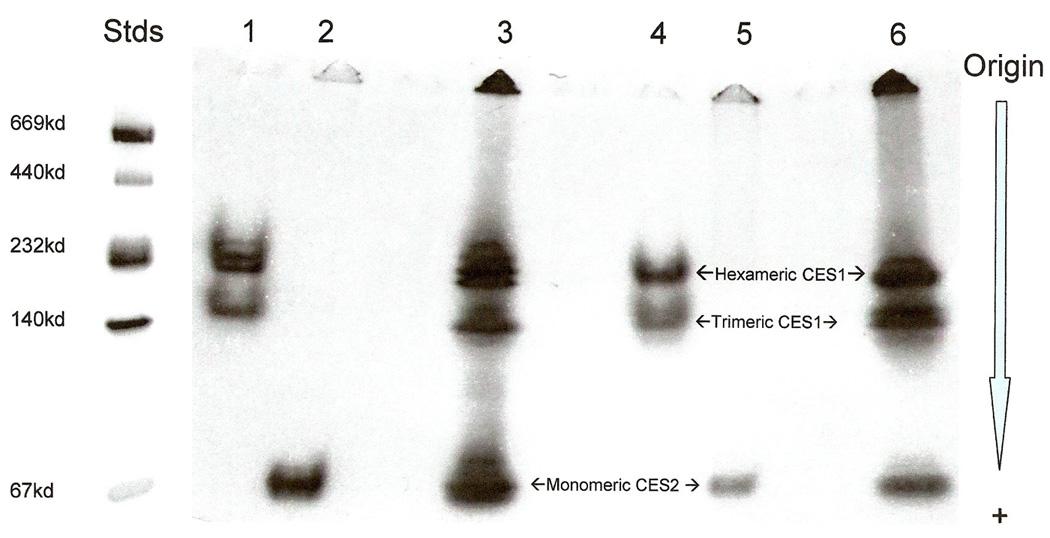
Gradient PAGE zymogram of baboon liver and intestine CES1 and CES2. 1: Baboon intestine CES1; 2: Baboon intestine CES2; 3: Baboon intestine CES1 and CES2; 4: Baboon liver CES1; 5: Baboon liver CES2; 6: Baboon liver CES1 and CES2. Stds: Native protein MW standards.
Phylogeny of Mammalian CES1 and CES2 Sequences
A phylogenetic tree (Figure 4) was calculated by the progressive alignment of nine primate and two mouse CES1 and CES2 amino acid sequences which shows clustering into two main groups (or families) for the CES1 and CES2 ‘like’ genes. Primate CES2 genes are apparently undergoing a more rapid rate of amino acid sequence divergence than primate CES1 genes and non-primate CES1 and CES2 genes, which is further substantiated by comparing the percentage of sequence identities for human and chimp CES1 and CES2 with those for baboon and rhesus CES1 and CES2 (Table 3). In each case, a significantly lower percentage of identity was observed for baboon and rhesus CES2 with human and rhesus CES2 than for the same inter-species comparisons for primate CES1.
Figure 4.

Phylogenetic tree of primate (human; chimp; baboon; and rhesus) and mouse CES sequences. Each branch of the tree is labeled with the gene name and followed by the species name. O designates a Catarrhine common ancestor estimated to occur at ~ 25 million years ago [21, 46]; X designates the eutherian common ancestor estimated to occur at ~ 100 million years ago [41, 64]. The line joining the CES1 and CES2 eutherian common ancestors designates the separation for the 2 separate lines of evolution following the proposed gene duplication event at ~ 360 million years ago [22].
Gene Locations for Mammalian CES1 and CES2 Genes
Table 2 summarizes the known or predicted CES1 and CES2 gene locations for 3 primate species and for 5 non-primate eutherian mammals based upon published reports for human [7, 8, 30, 57, 59], mouse [14, 16, 17, 39] and rat CES1 and CES2 [18, 47], and BLAT interrogation of the genomes for human, chimp [27, 35], rhesus [49], mouse [39], rat [47], cow, dog and cat [27]. With the exception of rat CES2 (CES2 ‘like’) and CES3 (CES1 ‘like’) genes, which are located on chromosomes 1 and 19 respectively, CES1 and CES2 genes from the other 5 mammalian genomes examined were syntenic. In addition, ten of eleven mammalian CES1 genes were transcribed on the negative strand, and nine of ten CES2 genes were transcribed on the positive strand.
Discussion
Three dimensional structures for human CES1 have been determined at high resolution (2.8Å) [3, 4, 48] and the enzyme shown to be divided into three functional domains: the catalytic domain contains the active site ‘triad’ and the carbohydrate binding site; the αβ domain provides the majority of the hydrophobic internal structure and assists in forming the trimeric subunit structure for this enzyme; and the regulatory domain which may regulate substrate binding, product release and the trimer-hexamer equilibrium. Three ligand binding sites have been described, designated as the active site, the side door and the Z-site. The side door apparently assists with the release of product (eg. fatty acids) following catalysis, whereas the Z-site is proposed to play a role in regulating catalysis following ligand binding by shifting the trimer-hexamer equilibrium towards trimer, and opening up the active site to substrate and subsequent catalysis [15]. Several key amino acid residues or sequences have been strictly conserved among primate CES1 and CES2 (Figure 1), which correlate with their proposed functions, based on the 3-D studies conducted on human CES1 [see 3, 4, 49]: the active site ‘triad’ (Ser221, Glu354 and His468) [12]; Gly356 or the Z-site, which binds cholesterol-like compounds; Cys95/Cys123 and Cys280/Cys291, the sites for disulfide bond formation [32]; and two microsomal targeting sequences, including the hydrophobic N-terminus signal peptides for CES1 (residues 1–18) and CES2 (residues 1–26) [61] and the C-terminal endoplasmic reticulum (ER) retention sequences His-X-Glu-Leu (HXEL), which functions in protein retrieval from the Golgi apparatus and in CES retention in the ER lumen [40, 51].
There are other conserved amino acid residues or sequences which appear to be CES1 or CES2 specific among the primate sequences examined, and correlate with the functions proposed by the human CES1 tertiary structure studies [3, 4, 48]. The high-mannose N-glycosylation site reported for human CES1 (Asn79-Ala80-Thr81) [15] was retained for all primate CES1 sequences whereas another potential carbohydrate binding site was observed for all primate CES2 sequences at Asn111-X112-Thr113. A second potential carbohydrate binding site was also found for human and chimp CES2 at 276NLS (Figure 1). Given the roles described for N-glycosylation in maintaining human CES1 activity [29] and in stabilizing the N-terminal structure [15], it is likely that these potential sites for primate CES2 are also subject to N-glycosylation in vivo to assist with the stability for this enzyme. The charge clamps that perform key roles in maintaining the trimeric-hexameric subunit structures for human CES1 [15] are retained by baboon and rhesus CES1. Chimp and orangutan CES1, however, have retained only one of these clamps (Glu183 binding to Lys78 in the adjacent CES1 subunit), whereas the second charge clamp (Arg193 binding to Glu72 in the adjacent CES1 subunit) will not function as for human CES1 because of the Arg193 substitution by 193Pro. The monomeric subunit structure for baboon CES2 (Figure 3) is consistent with a previous report for human CES2 [45], and may be explained by the absence of key residues supporting two charge clamps previously reported for human CES1 [15]. The four primate CES2 sequences examined have undergone amino acid substitutions for those residues contributing to the human CES1 charge clamps: human CES1 Glu183 and Arg186 have been replaced for primate CES2 by amino acids that would not support charge clamp formation: Glu183 → Lys183; and Arg186 → Thr183 (Figure 1). It would appear that the respective multimeric and monomeric subunit structures for CES1 and CES2 have been retained for all primate species examined. This is likely to have a major influence on the kinetics and biochemical roles for these enzymes. Bencharit and coworkers [3, 4] have proposed that ligand binding to the CES1 ‘Z-site’ shifts the trimer-hexamer equilibrium towards the trimer facilitating substrate binding and enzyme catalysis. They also proposed that ligand binding to this site may play a role in facilitating the hydrolysis of cholesterol esters and in the allosteric activation of esterase catalysis. As a monomer, primate CES2 would behave quite differently and may serve a distinct set of roles in drug and lipid metabolism in the body.
Human CES1 Met425 has been described as the most important residue in regulating the release of fatty acids following hydrolysis of cholesterol esters and serving as a ‘gate’ at the ‘side door’ of human CES1, where Phe426 serves as a switch’ and Phe551 acts as an aromatic releasing residue also in the ‘side door’ region [3, 4, 48]. The 424VMF ‘side door’ amino acid residues (Figure 1) have been retained for all five primate CES1 sequences examined, whereas only the human CES1 425MF amino acids have been retained for the four primate CES2 sequences. This may reflect a change in the kinetics or specificity in regulating fatty acid or other acyl-product release for primate CES2 as compared with CES1. In addition, the key residue at the human CES1 ‘gate’, 551Phe, has been conserved for all primate CES1 sequences examined, whereas another hydrophobic amino acid (human CES2 542Leu) has replaced the human CES1 551Phe residue in all four primate CES2 sequences. The significance of this change in ‘gate’ residue for primate CES2 remains to be determined however it may influence product release following acyl hydrolysis or transesterifcation. The deduced amino acid sequence for baboon and rhesus CES2 was two residues longer (Met310 and Lys546 within the 561 amino acid sequence for baboon CES2) than for human and chimp CES2 (559 residues) (Figure 1). Human, chimp and baboon CES1 contained 567 amino acid residues; whereas, orangutan and rhesus CES1 were one residue shorter (566). The N-terminal microsomal signal peptides for human and baboon CES1, which facilitates retention of the enzyme within the ER [42, 51, 61], were identical in sequence between human CES1 isoform 2 and baboon CES1, and both contained an extra residue (Ala18) prior to Gly19 which is immediately prior to the cleavage site for human CES1 isoform 1. This is in contrast to most mammalian CES1 and CES2 products which have N-terminal signal peptides containing a bulky aromatic residue followed by a small neutral residue prior to the cleavage site [61].
There were three major predicted secondary structure differences observed between primate CES1 and CES2, involving longer helices for the four primate CES2 proteins, in comparison with primate CES1: (1) The helix following the primate CES1 ‘side door’ residues (human CES1 424VMF) was extended into the ‘side door’ region for primate CES2 proteins (415MF for human CES2); (2) The CES1 N-terminus helix (human CES1 residues 2–14) was considerably lengthened for the primate CES2 proteins (human CES2 residues 3–23); and (3) The CES1 C-terminus helix (human CES1 residues 540–554) was significantly extended for primate CES2, including forming a second smaller predicted helix at or near the HTEL terminus for three of the four primate CES2 structures (human CES2 residues 531–549 and 554–557 respectively (Figure 1). The role of these longer helices for primate CES2 in comparison with primate CES1 awaits 3-dimensional structural analysis of primate CES2.
The phylogenetic tree reported for primate CES1 and CES2 (together with mouse CES3 and CES2 included as outgroups) (Figure 4) was obtained by the progressive alignment of 8 primate CES amino acid sequences and shows a cluster into two main groups (or families) consistent with CES1 and CES2 being products of ancestral gene duplication events. This is similar to previously published phylogenetic trees for mammalian CES [44, 55, 56] and is consistent with the results of a recent study of marsupial (opossum) and eutherian CES, which indicated that CES gene duplication events which generated ancestral mammalian CES genes predated the common ancestor for eutherian and marsupial mammals [22]. This study proposed that several ancient gene duplication events took place prior to the evolutionary appearance of mammals, generating five ancestral genes for CES1, CES2, CES3, CES6 and CES7. The timing of the CES1/CES2 gene duplication event has been estimated at ~ 330 MY ago following the appearance of tetrapods during vertebrate evolution [22]. In addition to these ancestral CES gene duplication events, it is apparent that several more recent gene duplications have occurred for mammalian CES1 and CES2. For example, mouse CES1 ‘like’ and CES2 ‘like’ genes exist as multiple copies which are closely linked on chromosome 8 [5, 23]; rat CES1 ‘like’ and CES2 ‘like’ genes also occur as multiple copies although in this case, they are localized on chromosomes 19 and 1, respectively [17, 47]; and a second CES1 ‘like’ gene has been reported in human, designated as CES4, and localized on chromosome 16 within 80 kilo bases of CES1 [9, 27, 66].
The tissue distribution profiles and differential kinetic properties for human (and baboon) CES1 and CES2 may assist in determining their respective metabolic roles in the body. Mammalian liver is predominantly responsible for drug and xenobiotic clearance from the body where CES1 plays the major role, following the absorption of drugs and xenobiotics into the circulation [24, 45]. In contrast, mammalian intestine CES2 is predominantly responsible for first pass clearance of several drugs and xenobiotics, with activity occurring mostly in the ileum and jejunum and processed via CES2 [25]. CES1 and CES2 also serve distinct roles in prodrug activation, as shown for the anti-cancer drug irinotecan (CPT-11) which is converted to its active form SN-38 predominantly by CES2 [24, 25]. It is readily apparent that these specific roles for human CES1 and CES2 will have been retained for these enzymes from other primate sources, including the baboon, given the structural similarities observed for human and other primate CES1 and CES2 proteins, respectively.
In conclusion, the results of the present study indicate that primate CES1 and CES2 have very similar amino acid sequences with the corresponding human enzymes and share key conserved sequences and structures that have been reported for human CES1, and have family specific sequences consistent with their multimeric and monomeric subunit structures respectively. Predicted secondary and tertiary structures for baboon CES1 and CES2 showed a high degree of conservation with human CES1. Phylogeny studies using primate and other mammalian CES1 and CES2 amino acid sequences showed that these two CES classes have undergone sequence divergence during mammalian and primate evolution, with primate CES2 showing higher amino acid substitution rates than that for primate CES1.
Acknowledgements
This project was supported by NIH Grants P01 HL028972 and P51 RR013986. In addition, this investigation was conducted in facilities constructed with support from Research Facilities Improvement Program Grant Numbers 1 C06 RR13556, 1 C06 RR15456, 1 C06 RR017515. Thanks to Mary Jo Avialiotis and Mari Hui for their expert assistance.
REFERENCES
- 1.Ahmad S, Forgash AJ. Nonoxidative enzymes in the metabolism of insecticides. Drug Metab Rev. 1976;5:141–164. [PubMed] [Google Scholar]
- 2.Becker A, Bottcher A, Lackner KJ, Fehringer P, Notka F, Aslanidis C, Schmitz G. Purification, cloning and expression of a human enzyme with acyl coenzyme A: cholesterol acyltransferase activity, which is identical to liver carboxylesterase. Arterioscler Thromb. 1994;14:1346–1355. doi: 10.1161/01.atv.14.8.1346. [DOI] [PubMed] [Google Scholar]
- 3.Bencharit S, Edwards CC, Morton CL, Howard-Williams EL, Kuhn P, Potter PM, Redinbo MR. Multisite promiscuity in the processing of endogenous substrates by human carboxylesterase 1. J Mol Biol. 2006;363:201–214. doi: 10.1016/j.jmb.2006.08.025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Bencharit S, Morton CL, Xue Y, Potter PM, Redinbho MR. Structural basis of heroin and cocaine metabolism by a promiscuous human drug-processing enzyme. Nature Struct Biol. 2003;10:349–356. doi: 10.1038/nsb919. [DOI] [PubMed] [Google Scholar]
- 5.Berning W, De Looze SM, von Deimling O. Identification and development of a genetically closely linked carboxylesterase gene family of the mouse liver. Comp Biochem Physiol. 1985;30B:859–865. doi: 10.1016/0305-0491(85)90475-4. [DOI] [PubMed] [Google Scholar]
- 6.Blangero J, MacCleur JW, Kammerer CM, Mott GE, Dyer TD, MacGill HC., Jr Genetic analysis of apolipoprotein A-1 in two dietary environments. Am J Hum Genet. 1990;47:414–428. [PMC free article] [PubMed] [Google Scholar]
- 7.CES1 Gene Card GC16M054395 http://www.genecards.org/cgi-bin/carddisp.pl?gene=CES1
- 8.CES2 Gene Card GC16P065525 http://www.genecards.org/cgi-bin/carddisp.pl?gene=CES2
- 9.CES4 Gene Card GC16P054352 http://www.genecards.org/cgi-bin/carddisp.pl?gene=CES4
- 10.Chenna R, Sugawara H, Koike T, Lopez R, Gibson TJ, Higgins DG, Thompson JD. Multiple sequence alignment with the Clustal series of programs. Nucleic Acids Res. 2003;31:3497–3500. doi: 10.1093/nar/gkg500. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Comuzzie AG, Cole SA, Martin L, Carey KD, Mahaney MC. The baboon as a nonhuman primate model for the study of the genetics of obesity. Obesity Res. 2003;11:75–80. doi: 10.1038/oby.2003.12. [DOI] [PubMed] [Google Scholar]
- 12.Cygler M, Schrag JD, Sussman JL, Harel M, Silman L, Gentry MK, Doctor BP. Relationship between sequence conservation and three-dimensional structure in a large family of esterases, lipases and related proteins. Protein Sci. 1993;2:366–382. doi: 10.1002/pro.5560020309. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Diczfalusy MA, Bjorkkem I, Einarsson C, Hillebrant CG, Alexson SE. Characterization of enzymes involved in formation of ethyl esters of long-chain fatty acids. J Lipid Res. 2001;42:1025–1032. [PubMed] [Google Scholar]
- 14.Dolinsky VW, Sipione S, Lehner R, Vance DE. The cloning and expression of murine triacylglycerol hydrolase cDNA and the structure of the corresponding gene. Biochim Biophys Acta. 2001;1532:162–172. doi: 10.1016/s1388-1981(01)00133-0. [DOI] [PubMed] [Google Scholar]
- 15.Fleming CD, Bencharit S, Edwards CC, Hyatt JL, Trurkan L, Bai B, Fraga C, Morton CL, Howard-Williams EL, Potter PM, Redinbo BM. Structural insights into drug processing by human carboxylesterase 1: tamoxifen, Mevaststin, and inhibition by Benzil. J Mol Biol. 2005;352:165–177. doi: 10.1016/j.jmb.2005.07.016. [DOI] [PubMed] [Google Scholar]
- 16.Furihata T, Hosokawa M, Nakata F, Satoh T, Chiba K. Purification, molecular cloning and functional expression of inducible acylcarnitine hydrolase in C57BL/6J mouse belonging to the carboxylesterase gene family. Arch Biochem Biophys. 2003;416:101–109. doi: 10.1016/s0003-9861(03)00286-8. [DOI] [PubMed] [Google Scholar]
- 17.Furihata T, Hosokawa M, Fujii A, Derkel M, Satoh T, Chiba K. Dexamethosone-induced methylprednisolone hemisuccinate hydrolase: its identification as a member of the rat carboxylesterase 2 family and its unique presence in plasma. Biochem Pharm. 2005;69:1287–1297. doi: 10.1016/j.bcp.2005.01.017. [DOI] [PubMed] [Google Scholar]
- 18.Furihata T, Hosokawa M, Masuda M, Satoh T, Chiba K. Hepatocyte nuclear factor-4α plays pivotal roles in the regulation of mouse carboxylesterase 2 gene transcription in mouse liver. Arch Biochem Biophys. 2006;447:107–117. doi: 10.1016/j.abb.2006.01.015. [DOI] [PubMed] [Google Scholar]
- 19.Ghosh S. Cholesteryl ester hydrolase in human monocyte/macrophage: cloning, sequencing and expression of full-length cDNA. Physiol Genomics. 2000;2:1–8. doi: 10.1152/physiolgenomics.2000.2.1.1. [DOI] [PubMed] [Google Scholar]
- 20.Goodman M, Porter CA, Czelusniak J, Page SL, Schneider H, Shoshani J, Gunnel G, Groves CP. Toward a phylogenetic classification of primates based on DNA evidence complimented by fossil evidence. Mol Phylogenet Evol. 1998;9:585–598. doi: 10.1006/mpev.1998.0495. [DOI] [PubMed] [Google Scholar]
- 21.Guex N, Peitsch MC. (1997) SWISS-MODEL and the Swiss-PdbViewer: An environment for comparative protein modelling. Electrophoresis. 1997;18:2714–2723. doi: 10.1002/elps.1150181505. [DOI] [PubMed] [Google Scholar]
- 22.Holmes RS, Chan J, Cox LA, Murphy WJ, VandeBerg JL. Opossum carboxylesterases: sequences, phylogeny and evidence for CES duplication events predating the marsupial-eutherian common ancestor. BMC Evol Biol. 2008;8:54. doi: 10.1186/1471-2148-8-54. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Hosokawa M, Furihata T, Yaginuma Y, Yamamoto N, Kayano N, Fujii A, Nagahara Y, Satoh T, Chiba K. Genomic structure and transcriptional regulation of the rat, mouse and human carboxylesterase genes. Drug Metab Rev. 2007;39:1–15. doi: 10.1080/03602530600952164. [DOI] [PubMed] [Google Scholar]
- 24.Humerickhouse R, Lohrbach K, Li L, Bosron WF, Dolan ME. Characterization of CPT-11 hydrolysis by human liver carboxylesterase isoforms h-CE1 and hCE-2. Cancer Res. 2000;60:1189–1192. [PubMed] [Google Scholar]
- 25.Imai T. Human carboxylesterase isozymes: catalytic properties and rational drug design. Drug Metab Pharmacogenet. 2006;21:173–185. doi: 10.2133/dmpk.21.173. [DOI] [PubMed] [Google Scholar]
- 26.Kakenko A, Demop K, Onoe T. Heterogeneity of esterases and cell types in rat liver. Biochim Biophys Acta. 1972;284:128–135. doi: 10.1016/0005-2744(72)90052-6. [DOI] [PubMed] [Google Scholar]
- 27.Kent WJ, Sugnet CW, Furey TS, Roskin KM, Pringle TH, Zahler AM, Hussler D. The human genome browser at UCSC. Genome Res. 2002;12:994–1006. doi: 10.1101/gr.229102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Kopp J, Schwede T. The SWISS-MODEL Repository of annotated three-dimensional protein structure homology models. Nucleic Acids Res. 2004;32:D230–D234. doi: 10.1093/nar/gkh008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Kroetz DL, McBride OW, Gonzalez FJ. Glycosylation-dependent activity of Baculovirus-expressed human liver carboxylesterases: cDNA cloning and characterization of two highly similar enzyme forms. Biochem. 1993;32:11606–11617. doi: 10.1021/bi00094a018. [DOI] [PubMed] [Google Scholar]
- 30.Langmann T, Becker A, Aslanidis C, Notka F, Ullrich H, Schwer H, Schmitz G. Structural organization and characterization of the promoter region of a human carboxylesterase gene. Biochim Biophys Acta. 1997;1350:65–74. doi: 10.1016/s0167-4781(96)00142-x. [DOI] [PubMed] [Google Scholar]
- 31.Leinweber FJ. Possible physiological roles of carboxyl ester hydrolases. Drug Metab Rev. 1987;18:379–439. doi: 10.3109/03602538708994129. [DOI] [PubMed] [Google Scholar]
- 32.Lockridge O, Adkins S, La Due BN. Location of disulfide bonds within the sequence of human serum cholinesterase. J Biol Chem. 1987;262:12945–12952. [PubMed] [Google Scholar]
- 33.MacCleur JW, Kammerer CM, VandeBerg JL, Cheng M-L, Mott GE, McGill Jnr HC. Detecting genetic effects on lipoprotein phenotypes in baboon: a review of methods and preliminary findings. Genetica. 1987;73:159–168. doi: 10.1007/BF00057446. [DOI] [PubMed] [Google Scholar]
- 34.Marsh S, Xiao M, Yu J, Ahluwalia R, Minton M, Freimuth RR, Kwok P-Y, McLeod HL. Pharmacogenomic assessment of carboxylesterases 1 and 2. Genomics. 2004;84:661–668. doi: 10.1016/j.ygeno.2004.07.008. [DOI] [PubMed] [Google Scholar]
- 35.McBrearty S, Jablonski NG. First fossil chimpanzee. Nature. 2005;437:105–108. doi: 10.1038/nature04008. [DOI] [PubMed] [Google Scholar]
- 36.McGuffin LJ, Bryson K, Jones DT. The PSIPRED protein structure prediction server. Bioinformatics. 2000;16:404–405. doi: 10.1093/bioinformatics/16.4.404. [DOI] [PubMed] [Google Scholar]
- 37.Miyazaki M, Kamiie K, Soeta S, Taira H, Yamashita T. Molecular cloning and characterization of a novel carboxylesterase-like protein that is physiologically present at high concentrations in the urine of domestic cats (Felis Catus) Biochem J. 2003;370:101–110. doi: 10.1042/BJ20021446. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Morgan D, Grant KA, Gage HD, Mach RH, Kaplan JR, Prioleau O, Nader SH, Buchheimer N, Ehrenkaufer RL, Nader MA. Social dominance in monkeys: dopamine D2 receptors and cocaine self-administration. Nature Neuroscience. 2002;5:169–174. doi: 10.1038/nn798. [DOI] [PubMed] [Google Scholar]
- 39.Mouse Genome Browser. 2007 http://mouse.perlegen.com/cgi-bin/gbrowse/mouse_b04/?name=CES3.
- 40.Munro S, Pelham HR. A C-terminal signal prevents secretion of luminal ER proteins. Cell. 1987;48:899–907. doi: 10.1016/0092-8674(87)90086-9. [DOI] [PubMed] [Google Scholar]
- 41.Murphy WJ, Eizirik E, Johnson WE, Zhang YP, Ryder OA, O'Brien SJ. Molecular phylogenetics and the origins of placental mammals. Nature. 2001;409:614–618. doi: 10.1038/35054550. [DOI] [PubMed] [Google Scholar]
- 42.Ozols J. Isolation, properties, and the complete amino acid sequence of a second form of 60-kDa glycoprotein esterase. Orientation of the 60-kDa proteins in the microsomal membrane. J Biol Chem. 1989;264:12533–12545. [PubMed] [Google Scholar]
- 43.Peitsch MC. Protein modeling by E-mail. Bio Technology. 1995;13:658–660. [Google Scholar]
- 44.Pindel EV, Kedishvili NY, Abraham TL, Brzezinski MR, Zhang J, Dean RA, Bosron WF. Purification and cloning of a broad substrate specificity human liver carboxylesterase that catalyzes the hydrolysis of cocaine and heroin. J Biol Chem. 1997;272:14769–14775. doi: 10.1074/jbc.272.23.14769. [DOI] [PubMed] [Google Scholar]
- 45.Potter PM, Wolverton JS, Morton CL, Wierdl M, Danks M. Cellular localization domains of a rabbit and human carboxylesterase: influence on irinotecan (CPT-11) metabolism by the rabbit enzyme. Cancer Res. 1998;58:3627–3632. [PubMed] [Google Scholar]
- 46.Raaum R, Sterner KN, Noviello CM, Stewart C-B, Disotell TR. Catarrhine primate divergence dates estimated from complete mitochondrial genomes: concordance with fossil and nuclear DNA evidence. J Hum Evol. 2005;48:237–257. doi: 10.1016/j.jhevol.2004.11.007. [DOI] [PubMed] [Google Scholar]
- 47.Rat Genome Database. 2007 http://rgd.mcw.edu/tools/genes/genes_view.cgi?id=621508.
- 48.Redinbo MR, Potter PN. Mammalian carboxylesterases: from drug targets to protein therapeutics. Drug Discov Today. 2005;10:313–320. doi: 10.1016/S1359-6446(05)03383-0. [DOI] [PubMed] [Google Scholar]
- 49.Rhesus macaque genome sequencing and analysis consortium. Evolutionary and biomedical insights from the rhesus macaque genome. Science. 316:222–234. doi: 10.1126/science.1139247. [DOI] [PubMed] [Google Scholar]
- 50.Ricaurte GA, Yuan J, Hatzidimitriou G, Cord BJ, McCann UD. Severe dopaminergic neurotoxicity in primates after a common recreational dose regimen of MDMA ("Ecstasy") Science. 2002;297:2260–2263. doi: 10.1126/science.1074501. [DOI] [PubMed] [Google Scholar]
- 51.Robbi M, Beaufay H. The COOH terminus of several liver carboxylesterases targets these enzymes to the lumen of the endoplasmic reticulum. J Biol Chem. 1991;266:20498–20503. [PubMed] [Google Scholar]
- 52.Rogers J, Hixson JE. Baboons as an animal model for genetic studies of common human disease. Am J Human Genetics. 1997;61:489–493. doi: 10.1086/515527. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Sanghani SP, Quinney SK, Fredenberg TB, Davis WI, Murry DJ, Bosron WF. Hydrolysis of irinotecan and its oxidative metabolites, 7-ethyl-10-[4-N(5-aminopentanoic acid)-1-piperidino] carbonyloxycampothecin and 7-ethyl-10-[4-(1-piperidino)-1 amino]-carbonyloxycamptothecin, by human carboxylesterases CES1A1, CES2, and a newly expressed carboxylesterase isoenzyme, CES3. Drug Metab Dispos. 2004;32:505–511. doi: 10.1124/dmd.32.5.505. [DOI] [PubMed] [Google Scholar]
- 54.Satoh T, Hosokawa M. The mammalian carboxylesterases: from molecules to functions. Ann Rev Pharmacol Toxicol. 1998;38:257–288. doi: 10.1146/annurev.pharmtox.38.1.257. [DOI] [PubMed] [Google Scholar]
- 55.Satoh T, Hosokawa M. Structure, function and regulation of carboxylesterases. Chem-Biol Interactions. 2006;162:195–211. doi: 10.1016/j.cbi.2006.07.001. [DOI] [PubMed] [Google Scholar]
- 56.Satoh H, Taylor P, Bosron WF, Sanghani SP, Hosokawa M, La Du BN. Current progress on esterases: from molecular structure to function. Drug Metab Dispos. 2002;30:488–493. doi: 10.1124/dmd.30.5.488. [DOI] [PubMed] [Google Scholar]
- 57.Schewer H, Langmann T, Daig R, Becker A, Aslandis C, Schmitz G. Molecular cloning and characterization of a novel putative carboxylesterase, present in human intestine and liver. Biochem Biophys Res Commun. 1997;233:117–120. doi: 10.1006/bbrc.1997.6413. [DOI] [PubMed] [Google Scholar]
- 58.Schwede T, Kopp J, Guex N, Peitsch MC. SWISS-MODEL: an automated protein homology-modeling server. Nucleic Acids Res. 2003;31:3381–3385. doi: 10.1093/nar/gkg520. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Shibita F, Takagi Y, Kitajima M, Kuroda T, Omura T. Molecular cloning and characterization of a human carboxylesterase gene. Genomics. 1993;17:76–82. doi: 10.1006/geno.1993.1285. [DOI] [PubMed] [Google Scholar]
- 60.Tsujita T, Okuda H. Palmitoyl-coenzyme A hydrolyzing activity in rat kidney and its relationship with carboxylesterase. J Lipid Res. 1993;34:1773–1781. [PubMed] [Google Scholar]
- 61.von Heijne G. Patterns of amino acids near signal-sequence cleavage sites. Eur J Biochem. 1983;133:17–21. doi: 10.1111/j.1432-1033.1983.tb07424.x. [DOI] [PubMed] [Google Scholar]
- 62.Wambutt R, Huebner D, Mewes HW, Amid C, Osanger a, Fobo G, Han R, Wiemann S. The German cDNA Consortium. Submitted to EMBL/Gen/DDBJ Databases. 2004 [Google Scholar]
- 63.Wang H, Gilham D, Lehner R. Proteomic and lipid characterization of apo-lipoprotein B-free luminal lipid droplets from mouse liver microsomes: implications for very low density lipoprotein assembly. J Biol Chem. 2007;282:33218–33226. doi: 10.1074/jbc.M706841200. [DOI] [PubMed] [Google Scholar]
- 64.Woodburne MO, Rich TH, Springer MS. The evolution of tribospheny and the antiquity of mammalian clades. Mol Phylogenet Evol. 2003;28:360–385. doi: 10.1016/s1055-7903(03)00113-1. [DOI] [PubMed] [Google Scholar]
- 65.Xu G, Zhang W, Ma MK, MacLeod HL. Human carboxylesterase 2 is commonly expressed in tumor tissue and is correlated with the activation of irinotecan. Clin Cancer Res. 2002;8:2605–2611. [PubMed] [Google Scholar]
- 66.Yan B, Matoney L, Yang D. Human carboxylesterases in term placentae: enzymatic characterization, molecular cloning and evidence for existence for multiple forms. Placenta. 1999;20:599–607. doi: 10.1053/plac.1999.0407. [DOI] [PubMed] [Google Scholar]
- 67.Yang Z, Rannala B. Bayesian estimation of species divergence times under a molecular clock using multiple fossil calibrations with soft bounds. Mol Biol Evol. 2005;23:212–226. doi: 10.1093/molbev/msj024. [DOI] [PubMed] [Google Scholar]
- 68.Zhen L, Rusiniak ME, Swank RT. The beta-glucuronidase propeptide contains a serpin-related octamer necessary for complex formation with egasyn esterase and for retention within the endoplasmic reticulum. J. Biol Chem. 1995;270:11912–11920. doi: 10.1074/jbc.270.20.11912. [DOI] [PubMed] [Google Scholar]