

Abstract
A dynamic regime provides a sequence of treatments that are tailored to patient-specific characteristics and outcomes. In 2004 James Robins proposed g-estimation using structural nested mean models for making inference about the optimal dynamic regime in a multi-interval trial. The method provides clear advantages over traditional parametric approaches. Robins’ g-estimation method always yields consistent estimators, but these can be asymptotically biased under a given structural nested mean model for certain longitudinal distributions of the treatments and covariates, termed exceptional laws. In fact, under the null hypothesis of no treatment effect, every distribution constitutes an exceptional law under structural nested mean models which allow for interaction of current treatment with past treatments or covariates. This paper provides an explanation of exceptional laws and describes a new approach to g-estimation which we call Zeroing Instead of Plugging In (ZIPI). ZIPI provides nearly identical estimators to recursive g-estimators at non-exceptional laws while providing substantial reduction in the bias at an exceptional law when decision rule parameters are not shared across intervals.
Keywords: adaptive treatment strategies, asymptotic bias, dynamic treatment regimes, g-estimation, optimal structural nested mean models, pre-test estimators
1 Introduction
In a study aimed at estimating the mean effect of a treatment on a time-dependent outcome, dynamic treatment regimes are an obvious choice to consider. A dynamic regime is a function that takes treatment and covariate history as arguments; the value returned by the function is the treatment to be given at the current time. A dynamic regime provides a sequence of treatments that are tailored to patient-specific characteristics and outcomes. A recently proposed method of inference (Robins, 2004) is g-estimation using structural nested mean models: this method is semi-parametric and is robust to certain types of mis-specification and in this regard it is superior to traditional parametric approaches. However, g-estimation of certain structural nested mean models is asymptotically biased under specific data distributions which Robins has termed the exceptional laws. At exceptional laws, g-estimators of parameters for optimal structural nested mean models are asymptotically biased and exhibit non-regular behaviour.
The aim of this paper is to provide a means of reducing the asymptotic bias of g-estimators in the presence of exceptional laws. Exceptional laws are discussed in the optimal dynamic regimes literature only by Robins, (2004); there, a method of detecting these laws and improving coverage of confidence intervals, but not the bias of point estimates, is proposed.
Structural nested mean models and g-estimation are discussed in section 2.1, followed by a detailed explanation of exceptional laws in g-estimation in section 2.2. Section 3.2 describes a method of reducing the asymptotic bias due to exceptional laws which we call Zeroing Instead of Plugging In (ZIPI), with theoretical properties derived in section 3.3. Sections 3.4 and 3.5 compare ZIPI to g-estimation and to the Iterative Minimization for Optimal Regimes (IMOR) method proposed by Murphy (2003). Section 4 concludes.
2 Inference via g-estimation and exceptional laws
2.1 Inference for optimal dynamic regimes: structural nested mean models and g-estimation
We consider the estimation of treatment effect in a longitudinal study. All of the methods discussed in this paper may be extended to a finite number of treatment intervals. We focus on the two-interval case where a single covariate is used to determine the optimal rule at each interval.
Notation
Notation is adapted from Murphy (2003) and Robins (2004). Treatments are taken at K fixed times, t1,…,tK. Lj are the covariates measured prior to treatment at the beginning of the jth interval, while Aj is the treatment taken subsequent to having measured Lj. Y is the outcome observed at the end of interval K; larger values of Y are favorable. Random variables are upper case; specific values, or fixed functions are lower-case. Denote a variable Xj at tj and its history, (X1, X2,…,Xj), by X̄j. Finally, denote a treatment decision at tj that depends on history, L̄j, Āj−1, by Dj ≡ dj(L̄j, Āj−1).
In the two-interval case, treatments are taken at two fixed times, t1 and t2, with outcome measured at t3. The covariates measured prior to treatment at the beginning of the first and second intervals, i.e. at t1 and t2, are L1 and L2, respectively. In particular, L1 represents baseline covariates and L2 includes time-varying covariates which may depend on treatment received at t1. The treatment given subsequent to observing Lj is Aj, j = 1, 2. Response Y is measured at t3. Thus, the data are, chronologically, (L1, A1, L2, A2, Y).
Throughout this paper, models are explained in terms of potential outcomes: the value of a covariate or the outcome that would result if a subject were assigned to a treatment possibly different from the one that they actually received. In the two-interval case we denote by L2(a1) a subject’s potential covariate at the beginning of the second interval if treatment a1 is taken by that subject, and Y(a1, a2) denotes the potential end-of-study outcome if regime (a1, a2) is followed.
Potential outcomes adhere to the axiom of consistency: L2(a1) ≡ L2 whenever treatment a1 is actually received and Y(a1, a2) ≡ Y whenever (a1, a2) is received. That is, the actual and counterfactual covariates (or outcome) are equal when the potential regime is the regime actually received.
We use the following definitions: an estimator ψ̂n of the parameter ψ† is -consistent if with respect to any distribution P in the model. Similarly, if under P, , and E|T| < ∞ then E(T) is the asymptotic bias of ψ̂n under P, which we denote AsyBiasp(ψ̂n). If for some law P in the model, AsyBiasp(ψ̂n) = 0, then ψ̂n is said to be asymptotically unbiased under P. (We will usually suppress the and the P in our notation.) As shall be seen, g-estimators are -consistent under all laws, however they are not asymptotically unbiased under certain distributions of the data, which, following Robins (2004), we term ‘exceptional laws’ (see section 2.2).
Assumptions
To estimate the effect of a dynamic regime, we require the stable unit treatment value assumption (Rubin, 1978), which states that a subject’s outcome is not influenced by other subjects’ treatment allocation. In addition we assume that there are no unmeasured confounders (Robins, 1997), i.e. for any regime āK,
In a trial in which sequential randomization is carried out, the latter assumption always holds. In two intervals for any a1, a2 we have that A1 ╨ (L2(a1), Y(a1, a2)) | L1 and A2 ╨ Y(a1, a2) | (L1, A1 = a1, L2), that is, conditional on history, treatment received in any interval is independent of any future potential outcome.
Without further assumptions, the optimal regime may only be estimated from among the set of feasible regimes (Robins, 1994), i.e. those treatment regimes that have positive probability; in order to make non-parametric inference about a regime we require some subjects to have followed it.
Structural nested mean models and g-estimation
Robins (2004, p. 209–214) produced a number of estimating equations for finding optimal regimes using structural nested mean models (SNMM) (Robins, 1994). We use a subclass of SNMMs called the optimal blip-to-zero functions, denoted by γj(l̄j, āj), defined as the expected difference in outcome when using the “zero” regime instead of treatment aj at tj, in subjects with treatment and covariate history l̄j, āj−1 who subsequently receive the optimal regime. The “zero” regime, which we denote 0j, can be thought of as placebo or standard care; the optimal strategy at time j is denoted . The optimal treatment regime subsequent to being prescribed aj (or 0j) at tj may depend on prior treatment and covariate history i.e. what is optimal subsequent to tj may depend both on the treatment received at tj and on (l̄j, āj−1). In the two-interval case, the blip functions are:
At the last (here, the second) interval there are no subsequent treatments, so the blip γ2(·) is simply the expected difference in outcomes for subjects having taken treatment a2 as compared to the zero regime, 02, among subjects with history l̄2, a1. At the first interval, the blip γ1(·) is the expected (conditional) difference between the counterfactual outcome if treatment a1 was given in the first interval and optimal treatment was given in the second and the counterfactual outcome if the zero regime was given in the first interval and optimal treatment was given in the second interval.
We will use ψ to denote the parameters of the optimal blip function model, and ψ† to denote the true values. For example, a linear blip implies that, conditional on prior treatment and covariate history, the expected effect of treatment aj on outcome, provided optimal treatment is subsequently given, is quadratic in the covariate lj and linear in the treatment received in the previous interval. Note that in this example, the blip function is a simple function of the covariates multiplied by the treatment indicator aj.
Non-linear SNMMs are possible and may be preferable for continuous doses of treatment. For example, the SNMMs corresponding to the models in Murphy (2003) for both continuous and binary treatments are quadratic functions of treatment. It is equally possible to specify SNMMs where parameters are common across intervals. For instance, in a two-interval setting, the following blips may be specified: γ1(l1, a1) = a1(ψ0 + ψ1l1) and γ2(l̄2, ā2) = a2(ψ0 + ψ1l2). In this example, the same parameters, ψ0 and ψ1, are used in each interval j and thus are said to be shared. The implied optimal decision rules are I[ψ0+ψ1lj > 0] for intervals j = 1, 2. Practically, sharing of parameters by blip functions/decision rules would be appropriate if the researcher believes that the decision rule in each interval is the same function of the covariate lj (and thus does not depend on the more distant past). Note that if aj takes multiple levels then we are free to allow the blip function to take different functional forms for different values of aj.
Robins (2004, p. 208) proposes finding the parameters ψ of the optimal blip-to-zero function via g-estimation. For two intervals, let
H1(ψ) and H2(ψ) are equal in expectation, conditional on prior treatment and covariate history, to the potential outcomes and Y(A1, 02), respectively. For the purpose of constructing an estimating procedure, we must specify a function Sj(aj) = sj(aj, L̄j, Āj−1) ∈ ℝdim(ψj) which depends on variables that are thought to interact with treatment to influence outcome. For example, if the optimal blip at the second interval is linear, say γ2(l̄2, ā2) = a2(ψ0 + ψ1l2 + ψ2a1 + ψ3l2a1), a common choice for this function is since the blip suggests that the effect of the treatment at t2 on outcome is influenced by covariates at the start of the second interval and by treatment at t1. Let
| (1) |
For distributions that are not “exceptional” (see definition in the next section), if , then E[U(ψ†)] = 0 is an unbiased estimating equation from which consistent estimators ψ̂ of ψ† may be found. Robins proves that estimates found by solving (1) are consistent provided either the expected counterfactual model, E[Hj(ψ)|L̄j, Āj−1] is correctly specified, or the treatment model, pj(aj|L̄j, Āj−1), used to calculate E[Sj(Aj)|L̄j, Āj−1], is correctly specified. Since, for consistency, only one of the models need be correct, this procedure is said to be doubly-robust. At exceptional laws the estimates are consistent but not asymptotically normal and not asymptotically unbiased (see next section). At non-exceptional laws the estimators are asymptotically normal under standard regularity conditions but are not in general efficient without a special choice of the function Sj(Aj).
A less efficient, singly-robust version of equation (1) simply omits the expected counterfactual model:
| (2) |
Estimates found via equation (2) are consistent provided the model for treatment allocation, pj(aj|L̄j, Āj−1), is correctly specified.
Recursive, closed-form g-estimation
Exact solutions to equations (1) and (2) can be found when optimal blips are linear in ψ and parameters are not shared between intervals. For details of the recursive procedure, see Robins (2004) or Moodie et al. (2007). An algorithm for solving the doubly-robust estimating equation (1) in the two-interval case is as follows, using ℙn to denote the empirical average operator:
Estimate the nuisance parameters of the treatment model at time 2; i.e., estimate α2 in p2(a2|L̄2, A1; α2).
Assume a linear model for the expected counterfactual, E[H2(ψ2)|L̄2, A1; ς2]. Express the least squares estimate ς̂2(ψ2) of the nuisance parameter ς2, explicitly as a function of the data and the unknown parameter, ψ2.
- To find ψ̂2, solve ℙnU2(ψ2) = 0; i.e. solve
Estimate the nuisance parameters of the treatment model at time 1; i.e. estimate α1 in p1(a1|L1; α1). Plug ψ̂2 into H1(ψ1, ψ2) so that only ψ1 is unknown.
Assuming a linear model for E[H1(ψ1, ψ̂2)|L1; ς1], the least squares estimate ς̂1(ψ1, ψ̂2) of ς1 can again be expressed directly in terms of ψ1, ψ̂2 and the data.
- Solve ℙnU1(ψ1, ψ̂2) = 0 to find ψ̂1; i.e. solve
2.2 Asymptotic bias under exceptional laws
The distribution function of the observed longitudinal data is exceptional with respect to a blip function specification if, at some interval j, there is a positive probability that the true optimal decision is not unique (Robins 2004, p. 219). Suppose, for example, that the blip function is linear, depending only on the current covariate and the previous treatment: γj(l̄j, āj; ψ) = aj(ψj0 + ψj1lj + ψj2aj−1). The distribution is exceptional if it puts positive probability on values lj and aj−1 such that and so γj(l̄j, āj; ψ†) = γj(l̄j, (āj−1, 0j); ψ†) = 0 for all aj, indicating that treatment 0j and any other treatment aj are equally good, so that for some individuals the optimal rule at time j is not unique. The combination of three factors make a law exceptional for a given blip model: (i) the form of the assumed blip model, (ii) the true values of the blip model parameters ψ†, and (iii) the distribution of treatments and covariates. For a law to be exceptional, then, condition (i) requires the specified blip function to include at least one covariate such as prior treatment; conditions (ii) and (iii) require that the true blip function has value 0 with positive probability, that is, there is some subset of the population in which the optimal treatment is not unique. Thus a law is exceptional with respect to a blip model specification.
Exceptional laws may easily arise in practice: in the case of no treatment effect, for a blip function that includes at least one component of treatment and covariate history, every distribution is an exceptional law. More generally, it may be the case that a treatment has no effect in a sub-group of the population under study. For example, in a study of a reduced-salt diet on blood pressure, the treatment (diet) will have little or no impact on the individuals in the study who are not salt-sensitive. The examples presented in the following sections focus on blip functions with discrete covariates, however asymptotic bias may be observed when variables included in the modelled blip function are continuous but do not affect response (i.e., the true coefficient is zero).
Robins (2004, p. 308) uses a simple scenario to explain the source of the asymptotic bias at exceptional laws. Define the function (x)+ ≡ I(x > 0)x = max(0, x). Suppose an i.i.d. sample X1,…,Xn is drawn from a normal distribution 𝒩(η†, 1), and we wish to estimate (η†)+. The MLE of (η†)+ is (X̄)+, where X̄ is the sample mean. In the usual frequentist vein, suppose that under repeated sampling a collection of sample means, X̄(1), X̄(2),…,X̄(k), are found. If η† = 0, then since E[X̄] = 0, on average half of the sample means will be negative and half positive. However, in calculating (X̄)+ we set the negative statistics to zero so E[(X̄)+] ≥ 0 = E[X̄] = η†. Further, with Z ~ N(0, 1). Thus, by definition, (X̄)+ is consistent for (η†)+. However, if η† = 0, then the asymptotic distribution of (X̄)+ consists of a mixture of a standard Normal distribution left-truncated at 0, and and a point mass at 0, hence in this case AsyBias((X̄)+) = (2π)−1/2; if η† ≠ 0 then AsyBias((X̄)+) = 0; see Robins (2004, p. 309).
Now consider the usual two-interval set-up, with linear optimal blips γ1(l1, a1) = a1(ψ10 + ψ11l1) and γ2(l̄2, a1, a2) = a2(ψ20 + ψ21l2 + ψ22a1 + ψ23l2a1). Let g2(ψ2) = ψ20 + ψ21l2 + ψ22a1 + ψ23l2a1. The g-estimating function for is consistent and asymptotically normal, so . The sign of determines the true optimal treatment at the second interval: ; the estimated rule is . The g-estimating equation solved for ψ1 at the first interval contains:
So
The quantity in H1(ψ), or with more intervals, in Hj(ψj), corresponds to I[η > 0]η in the simple Normal problem described above. By using an asymptotically biased estimate of in H1(ψ), the g-estimating equation for ψ1 becomes asymptotically biased after plugging in ψ̂2 for ψ2.
In this paper, we consider only binary treatments. However, the generalization to a larger number of discrete treatments is trivial and the issue of asymptotic bias remains. When the blip models are linear, asymptotic bias may be observed when the assumed blip models contain only discrete variables or when the true effect of the continuously-distributed covariates included in the assumed model is zero.
In the case of continuous treatments taking values in an interval one would typically assume a non-linear blip model, since otherwise optimal treatment will always be either the maximum or minimum value; see Robins (2004), p.218. Here again, the optimal treatment at time 2, and hence the estimating equation at time 1, U1(ψ1, ψ2) will again be not everywhere differentiable with respect to ψ2. Consequently at exceptional laws asymptotic bias will be present.
Simulated example: Asymptotic bias with good estimation of the optimal decision rule
Consider a concrete example: the treatment of mild psoriasis in women aged 20–40 with randomly assigned treatments A1 (topical vitamin D cream) and A2 (oral retinoids) and covariates/response L1 a visual analog scale of itching, L2 a discrete symptom severity score where 1 indicates severe itching, and Y a continuous scale measuring relief and acceptability of side effects. The data were generated as follows: treatment in each interval takes on the value 0 or 1 with equal probability L1 ~ 𝒩(0, 3); L2 ~ round(𝒩(0.75, 0.5)); and Y ~ 𝒩(1, 1) − |γ1(l1, a1)| − |γ2(l̄1, ā2)| (see, for example, Murphy, 2003, p. 339). Suppose that the blip function is linear. For example, taking and ; whenever even though not all components of equal zero. Table 1 summarizes the results of the simulations, including the bias of the first-interval g-estimates (absolute and relative to standard error) and the coverage of Wald and score confidence intervals for n = 250 and 1000. Note that the optimal rule in the first interval is , so that the sign of the blip parameter determines the optimal decision. The bias in the first interval estimate of is not negligible. Coverage is incorrect in smaller samples in part because of slow convergence of the estimated covariance matrix but perhaps also because of the exceptional law. Our results are consistent with the general observation that score intervals provide coverage closer to the nominal level than Wald intervals.
Table 1.
Summary statistics of g-estimates and Robins’ (2004) proposed method of detecting exceptional laws from 1000 datasets of sample sizes 250 and 1000.
| n | ψ† | Mean(ψ̂) | |Bias| | |t|a | rMSEb | Cov.c | Cov.d |
|---|---|---|---|---|---|---|---|
| 250 | |||||||
| ψ10 = 1.6 | 1.657 | 0.057 | 0.306 | 0.245 | 95.1 | 94.2 | |
| ψ11 = 0.0 | −0.001 | 0.001 | 0.027 | 0.057 | 94.2 | 94.7 | |
| ψ20 = −3.0 | −3.001 | 0.001 | 0.001 | 0.424 | 92.5 | 94.5 | |
| ψ21 = 2.0 | 2.006 | 0.006 | 0.017 | 0.460 | 92.0 | 93.5 | |
| ψ22 = 1.0 | 1.004 | 0.004 | 0.003 | 0.615 | 93.5 | 93.6 | |
| ψ23 = 0.0 | −0.001 | 0.001 | 0.008 | 0.693 | 94.2 | 94.7 | |
| : Mean (Range): 63.8 (30.4, 92.0) | |||||||
| 1000 | |||||||
| ψ10 = 1.6 | 1.629 | 0.029 | 0.321 | 0.121 | 95.5 | 95.4 | |
| ψ11 = 0.0 | −0.001 | 0.001 | 0.026 | 0.028 | 96.1 | 95.2 | |
| ψ20 = −3.0 | −3.001 | 0.001 | 0.017 | 0.203 | 95.3 | 95.3 | |
| ψ21 = 2.0 | 2.002 | 0.002 | 0.007 | 0.225 | 94.2 | 94.7 | |
| ψ22 = 1.0 | 1.000 | 0.000 | 0.002 | 0.298 | 95.4 | 94.9 | |
| ψ23 = 0.0 | −0.006 | 0.006 | 0.032 | 0.348 | 94.5 | 95.2 | |
| : Mean (Range): 35.7 (28.2, 70.2) | |||||||
|t| = |Bias(ψ̂)/SE(ψ̂)|
Root of the mean squared error (rMSE)
Coverage of 95% Wald confidence intervals
Coverage of 95% score confidence intervals
Estimated proportion of sample with non-unique optimal rules (see section 2.3)
In this example, the bias, though evident, is not large relative to the true value of the parameter. In such cases, the bias may have little impact on the estimation of the optimal decision rules, since the estimated optimal rules are of the form I[ψ̂10 + ψ̂11L1 > 0]. As the next example shows, this will not always be the case.
Simulated example: Asymptotic bias with poor estimation of the optimal decision rule
Suppose now that, in fact, for every patient the optimal outcome does not depend on whether the topical vitamin D cream (A1) is applied, so that , and the optimal treatment at t1 is not unique. The second interval parameters remain as above. In this case, the bias in the estimates of the first-interval blip function parameters result in a treatment rule which will lead us to apply the topical vitamin D cream, even though this is unnecessary. Table 2 demonstrates that in approximately 10% of the simulated datasets, one or both of ψ̂10 and ψ̂11 were found to be significantly different from 0 in independent, 0.05-level tests. When the tests falsely rejected one or both of the null hypotheses and , the estimated optimal decision rule in the first interval would lead to unnecessary treatment for half of the individuals in a similar population! The non-smooth (and implicit) nature of the optimal decision rule parameterization (Murphy, 2003; Robins et al., 2008, §4.4.1) is such that even small bias in the parameter estimates can lead to serious consequences in the resulting decision rule. Henceforth, we focus on the bias in the blip parameter estimates, keeping in mind that poor estimates of these can lead to treatment being applied unnecessarily, due to the indirect parameterization of the optimal decision rules.
Table 2.
Consequences of biased blip function parameters: summary of the number of incorrect decisions made from 1000 datasets of sample sizes 250, 350, 500, 750, and 1000.
| n | Bias | % of false rejectionsa |
% of individuals incorrectly treated,b median (range) |
|
|---|---|---|---|---|
| ψ10 | ψ11 | |||
| 250 | 0.068 | 0.002 | 9.1 | 100.0 (9.2, 100.0) |
| 350 | 0.048 | 0.001 | 7.8 | 53.4 (74.4, 100.0) |
| 500 | 0.040 | 0.000 | 9.4 | 52.2 (4.4, 100.0) |
| 750 | 0.039 | 0.001 | 10.1 | 52.8 (45.2, 100.0) |
| 1000 | 0.026 | 0.000 | 7.8 | 53.0 (2.8, 100.0) |
Fraction of times that at least one of ψ10, ψ11 was significantly different from 0 at the 0.05 level in 1000 simulated datasets.
Summary of the number of individuals in the simulated dataset who would have been affected by the bias (received an incorrect treatment recommendation at the first interval) when at least one of ψ10, ψ11 was significantly different from 0 at the 0.05 level.
Simulated examples: Visual display
Robins (2004, pp. 313–315) proves that under the scenario of an exceptional law such as the above, estimates ψ̂1 are -consistent but are neither asymptotically normal nor asymptotically unbiased. For a graphical interpretation of asymptotic bias and consistency coinciding, we examine bias maps; these plots depict the bias of a parameter as sample size and another parameter are varied. Bias maps throughout this article focus on the absolute bias in ψ̂10 as a function of sample size and one of the second interval parameters, , or . The plots represent the average bias over 1000 data sets, computed over a range of 2 units (on a 0.1 unit grid) for each parameter at sample sizes of 250, 300,…,1000. Note that there are several combinations of parameters that lead to exceptional laws: as well as (−3.0, 2.0, 1.0, 0.0) if p(A1 = L2 = 1) > 0, exceptional laws occur with (−2.0, 2.0, 1.0, 0.0) and (−3.0, 3.0, 1.0, 0.0) if p(A1 = 0, L2 = 1) > 0.
The results of Robins (2004) imply that estimators of are asymptotically unbiased and consistent, for parameters that do not change with n and a non-exceptional law. Consistency may be visualized by looking at a horizontal cross-section of any one of the bias maps in Figure 1: eventually, sample size will be great enough that bias of first-interval estimates is smaller than any fixed, positive number. However, if we consider a sequence of data generating processes in which the ψ2’s decrease with increasing n, so that is O(n−1/2), then AsyBias(ψ̂1) > 0. Contours of constant bias can be found along the lines on the bias map traced by plotting against n. Note that the asymptotic bias is bounded. In finite samples, the proximity to the exceptional law and the sample size both determine the bias of the estimator (Figure 1).
Figure 1.

Absolute bias of ψ̂10 as sample size varies at and near exceptional laws. In each figure, one of ψ20, ψ21, ψ22, ψ23 is varied while the remaining are fixed at −3.0, 2.0, 1.0, or 0.0, respectively. Note that there are several combinations of parameters that lead to exceptional laws: as well as (−3.0, 2.0, 1.0, 0.0) with p(A1 = L2 = 1) > 0, exceptional laws occur with (−2.0, 2.0, 1.0, 0.0) and (−3.0, 3.0, 1.0, 0.0) if p(A1 = 0, L2 = 1) > 0.
In Figure 2, L2 is not rounded (representing, say, a visual analog scale of itching rather than a severity score) so that and the law is not exceptional. Virtually no small- or large-sample bias is observed for n ≥ 250. For a law to not be exceptional, it is sufficient for the blip function to contain a continuous covariate (with no point-masses in its distribution function) that interacts with treatment to affect the response, i.e., that has a non-zero coefficient in the blip function. However in finite samples, to avoid the bias that arises through truncation, it is also necessary that the derivative of the blip function with respect to a continuous covariate , is large (that is, greater than kn−1/2 for some k) whenever γj(L̄j, Āj) is in a neighbourhood of zero, so as to be able to distinguish a unique optimal regime from those that are not unique.
Figure 2.

Lack of bias of ψ̂10 for large samples (n ≥ 250) for non-exceptional laws. In each figure, one of ψ20, ψ21, ψ22, ψ23 is varied while the other three parameters are fixed at −3.0, 2.0, 1.0, or 0.0, respectively. L2 is continuous Normal so that p(A1 = L2 = 1) = p(A1 = 0, L2 = 1) = 0 and its coefficient in the blip function is sufficiently far from zero that no optimal rules appear to be non-unique in samples of size 200 or greater.
Asymptotic bias calculation for two intervals
As before, we express the blip as γj(L̄j, Āj; ψj) = Ajgj(L̄j, Āj−1; ψj). Thus for binary treatment Aj, the corresponding optimal rule is I[gj(L̄j, Āj−1; ψj) > 0]. Exceptional laws exist when and the specification of gj(L̄j, Āj−1; ψj) includes at least one component of L̄j, Āj−1.
Robins (2004, p. 315) calculates the asymptotic bias of ψ̂1 found using equation (2) on two intervals for linear blips in the special case where exceptional laws occur when Lj = Aj−1 = 1. We generalize the result here. Assume a linear blip with g2(L̄2, A1; ψ2) = ψ2 · X2, where X2 includes at least one element from L1, L2, A1 so that g2(L̄2, A1; ψ2) = 0 whenever ψ2 · X2 = 0. Similarly let X1 denote the covariates included in the first interval blip function, with g1(L1; ψ1) = ψ1 · X1.
Since ψ̂1 solves , it follows that
where ; here the superscript g indicates that the quantity is used to determine bias of g-estimators. As indicated by the notation, does not depend on ψ1 when blips are linear.
Since , this term does not contribute to the asymptotic bias, so it is sufficient to focus on . First observe the following:
The last step follows because
by Slutsky’s Theorem, as ψ̂2 is consistent and asymptotically normal.
We now partition the space of the covariates X2, according to whether is positive, negative or zero, considering each case separately. We also introduce the definition h(X1) ≡ {S1(A1) − E[S1(A1) | L1]} in order to simplify the notation:
and thus this case contributes no asymptotic bias. The first equality here follows by Lemma 19.24 in van der Vaart (1998): the set of functions
with ψ2 ranging over a compact set satisfy a Lipschitz condition and are thus P-Donsker (this assumes finite second moments, see Examples 19.7 and 19.25); the equality then follows from the Lemma cited because
via the continuous mapping theorem (again assuming finite second moments). The second equality follows since , hence
again by the continuous mapping theorem. Turning to the second term:
thus this term also does not contribute to the asymptotic bias. As in the previous case, the first equality here follows from a similar application of Lemma 19.24 in van der Vaart (1998); the second again follows from the continuous mapping theorem. The third term is as follows:
again by applying Lemma 19.24. Thus
where Σ2 is such that , and we have used the formula for the expectation of a truncated normal distribution. Thus
| (3) |
which is bounded.
For more than two intervals, the asymptotic bias calculation is more complex. Consider a three-interval problem where non-unique optimal rules exist at the last interval. The asymptotic bias calculation at the second (middle) interval proceeds as above, so that, the asymptotic bias in ψ̂2 is
Note that in the recursive estimation setting, . The asymptotic bias calculation at the first interval can be found by examining . This function is more complex than that derived above because both the regular estimator ψ̂3 and the asymptotically biased, non-regular estimator ψ̂2, are plugged in.
Doubly-robust g-estimation is more efficient than singly-robust estimation and has the advantage that blip functions which do not allow for covariate and treatment interactions do not lead to exceptional laws. The doubly-robust g-estimating equation (1) can be expressed in terms of the singly-robust equation (2):
If either the model E[Hj(ψ) | L̄j, Āj−1] or E[Sj(Aj) | L̄j, Āj−1]} (which depends on parameters of the probability-of-treatment model) is correctly specified, then E[Uj(ψ)] = 0. It is not hard to show that under correct specification of the propensity score model, p(aj | L̄j, Āj−1), the asymptotic bias in ψ̂1 resulting from the doubly-robust equation (1) is also given by (3).
It is possible that if the propensity score model is incorrectly specified, but the model for E[H2(ψ2) | L̄2, A1] is correct, then additional bias terms might arise. However, this is an unlikely scenario in practice as, with linear blips, correct specification of the model for E[H2(ψ2) | L̄2, A1] is complex (see Moodie et al. 2007, Web Appendix).
2.3 Detecting exceptional laws
It is not necessary for all parameters to equal zero for a law to be exceptional, thus a simple F-test is not a sufficient check. Robins (2004, p. 317) suggests the following steps for when parameters are not shared across intervals:
Compute g-estimates of ψj for j = 1,…,K and Wald confidence intervals about each parameter.
At each interval j, compute as the number of optimal rules possible at time j for each subject i under all values ψj in the confidence set. For example, if all values of ψj in the confidence set give the same optimal rule for subject i then .
If the fraction of that is greater than 1, denoted by pop,j, is small (e.g. pop,j < 0.05) then the law at interval j is likely not exceptional and inference based on Wald confidence sets is reliable for earlier intervals m < j.
The idea behind this approach is that if there are few instances for which , then the confidence set is far away from values of ψj that, in combination with the distribution of covariate and treatment history, would produce an exceptional law. In our simulations, Robins’ method detects exceptional laws in all samples in which they are present (Table 1) so that in all cases, score confidence intervals are recommended. In general, the score confidence intervals improve coverage at both time intervals, particularly in smaller samples.
This method may save the analyst having to find a more computationally-intensive confidence set if score intervals are not recommended, but could itself be quite time-consuming. We suggest here some additional guidelines:
When parameters are not shared, exceptional laws at the kth interval do not affect the regularity of estimates for ψj, j > k; hence it is sufficient to consider only for the intervals k,…,K.
If, at every interval, the Wald confidence interval for the parameter of at least one continuous variable (with no “spikes” or point-masses) excludes zero, the law is likely not exceptional.
If at any interval, the hypothesis of no effect of treatment is not rejected (i.e., the Wald confidence set for the vector ψj includes the vector 0), the law is likely exceptional.
If a law is exceptional, Wald confidence intervals will not have the correct coverage; score confidence intervals will still be uniformly of the correct level (Robins 2004, p. 222). However the asymptotic bias remains.
3 Bias-correction at exceptional laws: Zeroing Instead of Plugging In (ZIPI)
3.1 Exceptional laws: an issue of subpopulations
In this section, we propose a modification to g-estimation (when there is no parameter sharing) that detects exceptional laws and reduces bias in the presence of an exceptional law. The method relies on the supposition that – at any interval j – the sample of study participants is drawn from two populations, and , where those who are members of do not have a unique optimal treatment decision in interval j, while there is only a single optimal treatment for all those belonging to . Let denote the members of the sample drawn from , and define similarly. The method that we propose attempts to determine an individual’s membership in or and then treats the data collected on individuals from the two groups differently. In practice, and are unknown and must be estimated.
3.2 Zeroing Instead of Plugging In
As seen in section 2.2, bias enters the g-estimating equation of through the inclusion of the upwardly-biased estimate of into H1(ψ) when is at or close to zero. Our algorithm searches for individuals for whom it is likely that and then uses the “better guess” of zero for instead of the estimate obtained by plugging in ψ̂2 for . We call this Zeroing Instead of Plugging In (ZIPI). Specifically, ZIPI is performed by starting at the last interval:
Compute ψ̂K using the usual g-estimation (singly- or doubly-robust). Set j = K.
Estimate by calculating the 95% (or 80%, or 90%, etc.) Wald confidence interval, Wji, about gj(l̄j,i, āj−1,i; ψ̂j) for each individual i in the sample. Let , and .
- For individual i, set
I.e., if at any interval k, k ≥ j, the confidence interval about gk(L̄k,i, Āk−1,i; ψ̂k) includes zero, is set to 0 in , otherwise it is estimated by plugging in ψ̂k. Using as defined above, find the ZIPI estimate for by replacing Hj−1,i with in equation (1) or (2).
Repeat steps 2–4 with j replaced by j − 1 until all parameters have been estimated.
The last interval ZIPI estimator, ψ̂K, is equal to the usual recursive g-estimator and thus is always consistent and asymptotically normal. Table 3 compares g-estimation with ZIPI using different confidence levels to select individuals who are likely to have non-unique optimal rules, keeping to the simulation scenario used in Table 1 and Figure 1. The bias reduction observed by using 0 instead of the estimate I[gj(L̄2,i, A1,i; ψ̂2) > 0]gj(L̄2,i, A1,i; ψ̂2) is good at and far from exceptional laws, with performance dependent on the level of the confidence interval used to estimate and . Coverage is very close to the nominal level.
Table 3.
Parameter estimates under exceptional laws: summary statistics of g-estimation using Zeroing Instead of Plugging In (ZIPI) and the usual g-estimates from 1000 datasets of sample sizes 250, 500 and 1000 using 80%, 90%, and 95% CIs for ZIPI. Second interval parameter estimates are omitted for all but 80% CI exclusions since the exclusions affect only first-interval parameters when using ZIPI (see section 3.2).
| CI exclusion |
ZIPI |
Usual g-estimation |
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ψ† | Mean(ψ̂) | SE | |t|a | rMSE | Cov.b | Mean(ψ̂) | SE | |t|a | rMSE | Cov.b | |
| n = 250 | |||||||||||
| 80% | ψ10 = 1.6 | 1.631 | 0.167 | 0.174 | 0.229 | 94.3 | 1.659 | 0.179 | 0.322 | 0.243 | 95.7 |
| ψ11 = 0.0 | −0.001 | 0.042 | 0.031 | 0.057 | 94.3 | −0.001 | 0.042 | 0.029 | 0.057 | 94.6 | |
| ψ20 = −3.0 | −2.991 | 0.299 | 0.016 | 0.413 | 92.8 | −2.991 | 0.299 | 0.016 | 0.413 | 93.3 | |
| ψ21 = 2.0 | 1.977 | 0.325 | 0.095 | 0.461 | 92.3 | 1.977 | 0.325 | 0.095 | 0.461 | 92.4 | |
| ψ22 = 1.0 | 0.992 | 0.444 | 0.020 | 0.606 | 94.2 | 0.992 | 0.444 | 0.020 | 0.606 | 94.3 | |
| ψ23 = 0.0 | 0.014 | 0.505 | 0.015 | 0.696 | 93.1 | 0.014 | 0.505 | 0.015 | 0.696 | 93.4 | |
| 90% | ψ10 = 1.6 | 1.622 | 0.165 | 0.126 | 0.227 | 94.3 | |||||
| ψ11 = 0.0 | −0.001 | 0.042 | 0.031 | 0.057 | 94.1 | ||||||
| 95% | ψ10 = 1.6 | 1.617 | 0.164 | 0.098 | 0.225 | 94.4 | |||||
| ψ11 = 0.0 | −0.001 | 0.042 | 0.030 | 0.057 | 94.2 | ||||||
| n = 500 | |||||||||||
| 80% | ψ10 = 1.6 | 1.615 | 0.118 | 0.108 | 0.164 | 92.6 | 1.636 | 0.126 | 0.281 | 0.172 | 94.2 |
| ψ11 = 0.0 | 0.000 | 0.030 | 0.003 | 0.041 | 94.8 | 0.000 | 0.030 | 0.002 | 0.041 | 94.7 | |
| ψ20 = −3.0 | −2.998 | 0.212 | 0.006 | 0.288 | 93.5 | −2.998 | 0.212 | 0.006 | 0.288 | 94.1 | |
| ψ21 = 2.0 | 1.993 | 0.233 | 0.047 | 0.317 | 93.7 | 1.993 | 0.233 | 0.047 | 0.317 | 93.9 | |
| ψ22 = 1.0 | 0.996 | 0.314 | 0.013 | 0.432 | 93.9 | 0.996 | 0.314 | 0.013 | 0.432 | 94.3 | |
| ψ23 = 0.0 | −0.002 | 0.360 | 0.018 | 0.495 | 93.3 | −0.002 | 0.360 | 0.018 | 0.495 | 93.7 | |
| 90% | ψ10 = 1.6 | 1.609 | 0.117 | 0.062 | 0.161 | 93.2 | |||||
| ψ11 = 0.0 | 0.000 | 0.030 | 0.003 | 0.041 | 94.9 | ||||||
| 95% | ψ10 = 1.6 | 1.605 | 0.116 | 0.032 | 0.160 | 93.3 | |||||
| ψ11 = 0.0 | 0.000 | 0.030 | 0.002 | 0.041 | 94.9 | ||||||
| n = 1000 | |||||||||||
| 80% | ψ10 = 1.6 | 1.616 | 0.083 | 0.180 | 0.114 | 94.9 | 1.632 | 0.090 | 0.348 | 0.121 | 95.3 |
| ψ11 = 0.0 | −0.001 | 0.021 | 0.041 | 0.028 | 94.8 | −0.001 | 0.021 | 0.042 | 0.028 | 95.1 | |
| ψ20 = −3.0 | −2.995 | 0.150 | 0.025 | 0.207 | 93.4 | −2.995 | 0.150 | 0.025 | 0.207 | 93.7 | |
| ψ21 = 2.0 | 1.997 | 0.165 | 0.030 | 0.225 | 93.8 | 1.997 | 0.165 | 0.030 | 0.225 | 94.0 | |
| ψ22 = 1.0 | 0.992 | 0.222 | 0.036 | 0.305 | 94.2 | 0.992 | 0.222 | 0.036 | 0.305 | 94.5 | |
| ψ23 = 0.0 | 0.003 | 0.255 | 0.003 | 0.348 | 94.8 | 0.003 | 0.255 | 0.003 | 0.348 | 95.0 | |
| 90% | ψ10 = 1.6 | 1.611 | 0.083 | 0.127 | 0.113 | 95.1 | |||||
| ψ11 = 0.0 | −0.001 | 0.021 | 0.042 | 0.028 | 94.8 | ||||||
| 95% | ψ10 = 1.6 | 1.608 | 0.082 | 0.089 | 0.112 | 95.1 | |||||
| ψ11 = 0.0 | −0.001 | 0.021 | 0.042 | 0.028 | 94.7 | ||||||
|t| = |Bias(ψ̂)/SE(ψ̂)|
Coverage of 95% Wald confidence intervals
In finite samples, some misclassification of individuals into and will always occur if type I error is held fixed and both sets are non-empty. In this context, a type I error consists of falsely classifying subject i as having a unique rule when in fact he does not: . Correspondingly, type II error is the incorrect classification of subject i as having a non-unique optimal regime when in truth his optimal rule is unique: . An unfortunate consequence is that ZIPI introduces bias where none exists using ordinary recursive g-estimation in regions of the parameter space that are moderately close to the exceptional laws (Figure 3); see section 3.3 for further explanation of this phenomenon. As sample size increases, the magnitude of the bias and the region of “moderate proximity” to the exceptional law, where bias is observed, decrease. The maximum bias observed using ZIPI is smaller than the bias observed using usual g-estimation: 0.033 with 80% confidence interval (CI) selection and 0.040 with 95% CI selection as compared to 0.060 with g-estimation (Figure 1, Figure 3–Figure 4).
Figure 3.

Absolute bias of ψ̂10 as sample size varies at and near exceptional laws using Zeroing Instead of Plugging In (ZIPI) when 95% confidence intervals suggest exceptional laws. In each figure, one of ψ20, ψ21, ψ22, ψ23 is varied while the other three parameters are fixed at −3.0, 2.0, 1.0, or 0.0, respectively.
Figure 4.

Absolute bias of ψ̂10 as sample size varies at and near exceptional laws using Zeroing Instead of Plugging In (ZIPI) when 80% confidence intervals suggest exceptional laws. In each figure, one of ψ20, ψ21, ψ22, ψ23 is varied while the other three parameters are fixed at −3.0, 2.0, 1.0, or 0.0, respectively.
ZIPI falls into the class of pre-test estimators that are frequently used in a variety of statistical settings (variable or model selection constitutes a common example). The ZIPI procedure requires a large number of correlated significance tests, since the algorithm requires a testing of all individuals at all intervals but the first. Control of the type I error under multiple testing has been well-studied, however many methods of controlling family-wise error rate significantly reduce the power of the tests. The false discovery rate (FDR) of Benjamini & Hochberg (1995) provides a good alternative that has been shown to work well for correlated tests (Benjamini & Yekutieli, 2001). However even in better-understood scenarios, the optimal choice of threshold is a complicated problem; see, for example, Giles et al. (1992) or Kabaila & Leeb (2006).
3.3 Consistency and asymptotic bias of ZIPI estimators
ZIPI estimators are similar to ordinary g-estimators at non-exceptional laws, with the added benefit of reduced asymptotic bias at exceptional laws.
Theorem 1
Under non-exceptional laws, ZIPI estimators converge to the usual recursive g-estimators and therefore are asymptotically consistent, unbiased, and normally distributed.
The proof is trivial. Of greater interest is the performance of ZIPI estimators under exceptional laws. We begin assuming that and are known for all j.
Theorem 2
When the distribution is exceptional and are known at every interval, ZIPI estimators are asymptotically consistent, unbiased, and normally distributed.
Proof
The statement is proved for the singly-robust [equation (2)] in a two-interval context. The generalization to K intervals or to the use of equation (1) follows readily.
Decompose the usual first-interval g-estimation function into two components:
For , g2(l̄2,i, a1,i; ) ≠ 0 and so . For , on the other hand, since
is upwardly biased for , as described in section 2.2 and by Robins (2004).
Now let if subject i belongs to and otherwise. The ZIPI estimating equation [corresponding to the g-estimating equation (2)] is
, and therefore ZIPI estimators calculated under known are consistent and asymptotically unbiased for any ψ in the parameter space and at any law, exceptional or otherwise.
Of course, and are not known and must always be estimated. Typically, some misclassification will occur. Recall a type I error is that of using the estimate ψ̂2 rather than 0 in H1,i(ψ1) and a type II error is that of using 0 when a plug-in estimate would have been desired. We now calculate the asymptotic bias and compare this to the result of section 2.2 to demonstrate that even when and are estimated, ZIPI exhibits less asymptotic bias than recursive g-estimation. As with ordinary g-estimation, generalization of the expression for the asymptotic bias for K > 2 intervals is not trivial because of the need to use both regular and asymptotically biased plug-in estimates.
Theorem 3
When the distribution law is exceptional and are estimated, two-interval ZIPI estimators have smaller asymptotic bias than the usual recursive g-estimators provided estimates are not shared across intervals, and .
Proof
Since for some μ > 0 for all subjects with a unique optimal rule at the second interval, it follows that there exists a sample size such that the power to detect whether is effectively equal to 1 if classification of individuals into is performed using 1 − ε confidence intervals for fixed type I error ε. However, 100ε% of the people with non-unique treatment rules will be falsely classified as belonging to .
Assume linear blips, so when laws are exceptional, where the true values of ψ1, ψ2 are denoted by . Define , a quantity in ZIPI estimation similar to in the usual g-estimation procedure. Since, asymptotically, the only form of misclassification error in ZIPI is type I, consists of three components:
If and , ;
- If and ,
; - If ,
.
Similar to the calculation of section 2.2, the asymptotic bias of ψ̂1 is proportional to . The classification procedure in ZIPI incorrectly fails to use zeros for 100ε% of the sample with . Therefore we rewrite in terms of of recursive g-estimation:
It follows directly that the asymptotic bias of first-interval ZIPI estimates at exceptional laws is
In finite samples both type I and type II error will be observed, which leads to additional bias in the ZIPI estimates. When sample size is not sufficient for power to equal 1, is decomposed into four components (two of which are zero in expectation). If type II error is denoted by β, then, approximately, for two-intervals the bias will be proportional to
When covariates are integer-valued as in our simulations, there is good separation of g2(L̄2, A1; ψ̂2) between those people with unique rules and those without; in this instance, simulations suggest that choosing a relatively large (e.g., 0.20) type I error provides a good balance between bias reduction at and near exceptional laws (Figure 3–Figure 4). In general, we expect that it is preferable to have low type II error rather than low type I error. When a type I error is made, the ZIPI procedure will incorrectly assume an individual does have a unique regime and fail to plug in a zero, making the ZIPI estimate numerically more similar to the usual g-estimate, which is known to be unbiased (though not asymptotically so). When a type II error is made, the individual is incorrectly believed to have non-unique optimal rules at the second stage. and H1,i(ψ1, ψ̂2) will be equal only if individual i happened to receive the optimal treatment at the second interval, and so the impact of the misclassification resulting from type II error will depend on the distribution of treatments at the second interval.
3.4 ZIPI versus simultaneous (non-recursive) g-estimation
With ZIPI g-estimation proving both theoretically and in simulation to be asymptotically less biased than recursive g-estimation when parameters are not shared between intervals, it is a natural choice. The assumption of unshared parameters is in many cases appropriate, even when the number of intervals is large. For example, when studying the effect of breastfeeding in infant growth, blips at different intervals are not expected to share parameters as effects are thought to vary by developmental stage of infancy (Kramer et al., 2004). However, it is plausible that blip functions for a treatment given over several intervals for a chronic condition may share parameters. The question then arises as to whether ZIPI outperforms simultaneous (non-recursive) g-estimation.
If parameters are shared across intervals, that is, ψj = ψj′ for some j ≠ j′, recursive methods may still be used by pretending otherwise, using a recursive form of g-estimation (the usual or ZIPI) then averaging the interval-specific estimates of ψ†. Such inverse covariance weighted recursive g-estimators have the advantage of being easier to compute than simultaneous estimators and are also doubly-robust under non-exceptional laws (Robins 2004, p. 221); note that the definition of exceptional laws is the same whether or not parameters are assumed to be shared. On the other hand, simultaneous g-estimation searches for estimates of the shared parameters directly without needing to average estimates from different intervals.
Robins (2004, p. 221–222) recommends simultaneous g-estimation for non-exceptional laws when there are few subjects who change treatment from one interval to the next: with few changes of treatment at a particular interval j, estimates ψ̂j are extremely variable. If there are a moderate number of treatment changes from one interval to the next (recursive) ZIPI estimation may be useful for the purposes of bias reduction in large samples. Figure 5 compares ZIPI with 80% confidence intervals used to estimate membership in or , recursive g-estimation, and simultaneous g-estimation, for varying sample sizes, for data as before: L1 ~ 𝒩(0, 3); L2 ~ round(𝒩(0.75, 0.5)); Y ~ 𝒩(1, 1)−|γ1(L1, A1)|−|γ2(L̄2, Ā2)| but we now impose stationarity so that γ1(L1, A1) = A1(ψ0 + ψ1L1) and γ2(L̄2, Ā2) = A2(ψ0 + ψ1L2 + ψ22A1 + ψ23L2A1). Note the sharing of ψ0 and ψ1 between the blips of both intervals.
Figure 5.
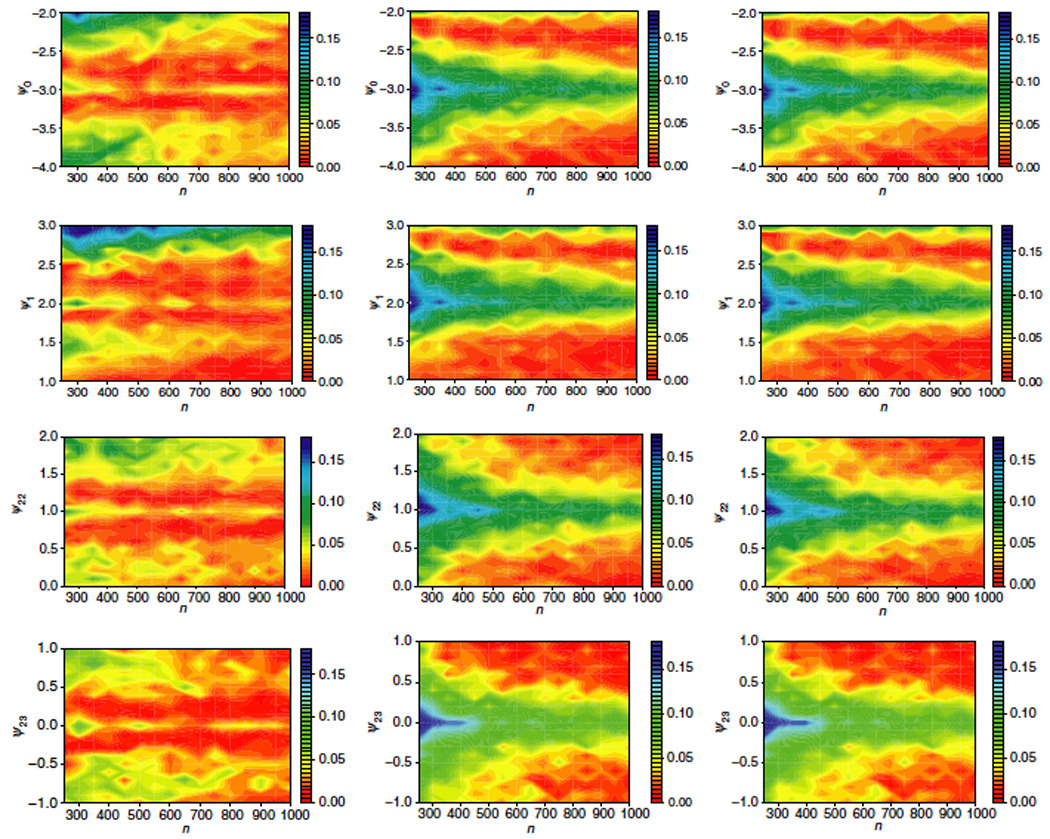
Absolute bias in ψ̂0 as n varies about exceptional laws assuming stationarity: inverse-covariance weighted ZIPI estimates with 80% CIs, inverse-covariance weighted recursive g-estimates, and simultaneous g-estimates [left, center, and right columns]. Rows: the true value of one of ψ0, ψ1, ψ22, ψ23 is varied; the rest are fixed at −3.0, 2.0, 1.0, or 0.0, respectively.
In our simulations, simultaneous and recursive g-estimation are similar in terms of both bias and variability. Relative to simultaneous g-estimation, the recursive methods are easier to implement and do not suffer from the possibility of multiple roots under linear blip functions. At non-exceptional laws, ZIPI produces nearly identical estimates to the doubly-robust recursive g-estimation which, as noted above, is locally efficient. In our simulations, ZIPI’s performance at exceptional laws varied by situation, performing much better when ψ1 = 2 as compared to when ψ1 = 3 (Figure 5), indicating that inverse-covariance weighted ZIPI estimators are not always less biased than simultaneous g-estimators.
3.5 ZIPI versus Iterative Minimization for Optimal Regimes
It is worth noting that the asymptotic bias due to exceptional laws is also present in the Iterative Minimization for Optimal Regimes (IMOR) (Murphy, 2003) method as well. This is not surprising since IMOR and g-estimation are very closely related (Moodie et al., 2007). As observed with the usual g-estimation, ZIPI outperforms IMOR when parameters are not shared across intervals (Table 4). Nevertheless, when parameters are shared and the sample is not very large, IMOR may prove to be less biased at exceptional laws than ZIPI, as in the previous subsection.
Table 4.
Parameter estimates under exceptional laws: summary statistics of g-estimation using Zeroing Instead of Plugging In (ZIPI) and the IMOR from 1000 datasets of sample sizes 250, 500 and 1000 using 80% CIs for ZIPI.
| ZIPI |
IMOR |
||||||||
|---|---|---|---|---|---|---|---|---|---|
| n | ψ† | Mean(ψ̂) | SE | rMSE | Cov.a | Mean(ψ̂) | SE | rMSE | Cov.a |
| 250 | |||||||||
| ψ10 = 1.6 | 1.628 | 0.167 | 0.233 | 93.3 | 1.643 | 0.193 | 0.259 | 95.9 | |
| ψ11 = 0.0 | 0.002 | 0.042 | 0.058 | 93.6 | −0.002 | 0.043 | 0.059 | 92.7 | |
| ψ20 = −3.0 | −3.017 | 0.296 | 0.409 | 92.4 | −3.042 | 0.391 | 0.524 | 95.7 | |
| ψ21 = 2.0 | 2.011 | 0.325 | 0.451 | 92.1 | 2.040 | 0.381 | 0.516 | 94.1 | |
| ψ22 = 1.0 | 1.022 | 0.442 | 0.606 | 94.6 | 1.046 | 0.496 | 0.675 | 94.4 | |
| ψ23 = 0.0 | −0.020 | 0.507 | 0.693 | 94.9 | −0.047 | 0.516 | 0.699 | 95.1 | |
| 500 | |||||||||
| ψ10 = 1.6 | 1.625 | 0.118 | 0.160 | 95.0 | 1.640 | 0.137 | 0.180 | 96.7 | |
| ψ11 = 0.0 | 0.000 | 0.030 | 0.041 | 94.4 | 0.000 | 0.030 | 0.041 | 94.6 | |
| ψ20 = −3.0 | −2.993 | 0.212 | 0.288 | 93.4 | −2.997 | 0.276 | 0.369 | 95.5 | |
| ψ21 = 2.0 | 1.995 | 0.234 | 0.319 | 93.6 | 2.000 | 0.269 | 0.362 | 94.5 | |
| ψ22 = 1.0 | 0.994 | 0.313 | 0.419 | 95.7 | 1.000 | 0.349 | 0.470 | 96.0 | |
| ψ23 = 0.0 | 0.009 | 0.361 | 0.482 | 95.8 | 0.002 | 0.363 | 0.488 | 96.3 | |
| 1000 | |||||||||
| ψ10 = 1.6 | 1.608 | 0.083 | 0.116 | 92.7 | 1.619 | 0.097 | 0.129 | 95.3 | |
| ψ11 = 0.0 | 0.000 | 0.021 | 0.028 | 96.2 | 0.000 | 0.021 | 0.028 | 96.2 | |
| ψ20 = −3.0 | −3.010 | 0.151 | 0.206 | 93.8 | −3.020 | 0.197 | 0.265 | 95.9 | |
| ψ21 = 2.0 | 2.009 | 0.166 | 0.227 | 94.0 | 2.017 | 0.191 | 0.258 | 95.2 | |
| ψ22 = 1.0 | 1.015 | 0.222 | 0.305 | 94.0 | 1.023 | 0.249 | 0.342 | 94.0 | |
| ψ23 = 0.0 | −0.013 | 0.256 | 0.347 | 94.0 | −0.018 | 0.258 | 0.353 | 94.3 | |
Coverage of 95% Wald confidence intervals
4 Discussion
In this paper, we have discussed the asymptotic bias of optimal decision rule parameter estimators in the presence of exceptional laws. We also presented suggestions to reduce the computational burden of trying to detect exceptional laws using the method of Robins (2004). We introduced Zeroing Instead of Plugging In, a recursive form of g-estimation, that is to be preferred over recursive g-estimation whenever parameters are not shared between intervals if there is a possibility of laws being exceptional.
The ZIPI algorithm provides an all-or-nothing adjustment, using weights of zero or one for each individual depending on the estimated unique-rule class membership. Other approaches to bias reduction were considered, including weighting by each individual’s probability of having a unique optimal rule, but the improvement in the estimates was unremarkable. We will pursue other methods such as, for example, weighted averaging of the ZIPI and usual g-estimates in the pursuit of a method that works well both with shared and unshared parameters. The efficacy of the ZIPI procedure has not been tested in the case of non-linear blip functions for, say, estimating the optimal rules for a binary outcome. This, too, shall be investigated.
Future work will also include determination of the optimal choice of threshold in ZIPI; simulations suggest that when there is reasonably good separation of people with unique rules and those without, a relatively large probability of type I error (e.g., 0.20) works well. When the distinction between those individuals with unique rules and those without is smaller, controlling the type I error in the class-membership testing through the false-discovery rate or a comparable procedure may be desirable. We will also investigate using the ZIPI procedure with type I error that systematically decreases with increasing sample size while maintaining high power to detect individuals with unique optimal rules.
Oetting et al. (2008) have performed the most comprehensive study of sample size requirements for a two-interval, two-treatment sequential multiple assignment randomized trial (SMART) (Collins et al., 2007) yet. In this study, sample size calculations were based on testing for a difference between the best and next-best strategy by considering the difference in mean response under the two treatment strategies. Earlier sample size calculations for testing between strategies were derived by Murphy (2005). To date, no thorough study has been performed for the sample size requirements for testing optimal strategies selected via g-estimation, and so the impact of parameter sharing on sample size and efficiency is not well understood. However it is assumed that the ‘reward’ for the additional assumption of shared parameters would be increased efficiency (under correct specification). A future direction of research will be the investigation of the properties of g-estimators and required sample sizes under both shared and unshared parameter assumptions.
We conclude by observing that one of g-estimation’s primary points of appeal is that, unlike traditional approaches such as dynamic programming, estimates are asymptotically unbiased under the null hypothesis of no treatment effect even if the distribution law of the complete longitudinal data is not known, provided the true law is not exceptional. However for a blip function that includes at least one component of treatment and covariate history, under the hypothesis of no treatment effect, every distribution is an exceptional law and therefore g-estimation is asymptotically biased under the null for all such blip functions and laws. Thus when primary concern is in performing a valid test of the null hypothesis of no treatment effect, we may consider fitting a “null” blip model which does not include any covariates (using the doubly robust estimator), proceeding to richer blip models only if the “null” blip model cannot be rejected.
Acknowledgements
Erica Moodie is supported by a University Faculty Award and a Discovery Grant from the Natural Sciences and Engineering Research Council of Canada (NSERC). Thomas Richardson acknowledges support by NSF grant DMS 0505865 and NIH R01 AI032475. We wish to thank Dr. James Robins for his insights and valuable discussion. We also thank Dr. Moulinath Banerjee, the associate editor and anonymous referees for helpful comments.
Contributor Information
Erica E. M. Moodie, Department of Epidemiology, Biostatistics, and Occupational Health, McGill University
Thomas S. Richardson, Department of Statistics, University of Washington
References
- Benjamini Y, Hochberg Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B Stat. Methodol. 1995;57:289–300. [Google Scholar]
- Benjamini Y, Yekutieli D. The control of the false discovery rate in multiple testing under dependency. Ann. Statist. 2001;29:1165–1188. [Google Scholar]
- Collins LM, Murphy SA, Strecher V. The Multiphase Optimization STrategy (MOST) and the Sequential Multiple Assignment Randomized Trial (SMART): New methods for more potent e-health interventions. American Journal of Preventative Medicine. 2007;32(5S):S112–S118. doi: 10.1016/j.amepre.2007.01.022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Giles DEA, Lieberman O, Giles JA. The optimal size of a preliminary test of linear restrictions in a misspecified regression model. J. Amer. Statist. Assoc. 1992;87:1153–1157. [Google Scholar]
- Kabaila P, Leeb H. On the large-sample minimal coverage probability of confidence intervals after model selection. J. Amer. Statist. Assoc. 2006;101:619–629. [Google Scholar]
- Kramer MS, Guo T, Platt RW, Vanilovich I, Sevkovskaya Z, Dzikovich I, Michaelsen KF, Dewey K. Feeding effects on growth during infancy. The Journal of Pediatrics. 2004;145:600–605. doi: 10.1016/j.jpeds.2004.06.069. [DOI] [PubMed] [Google Scholar]
- Moodie EEM, Richardson TS, Stephens DA. Demystifying optimal dynamic treatment regimes. Biometrics. 2007;63:447–455. doi: 10.1111/j.1541-0420.2006.00686.x. [DOI] [PubMed] [Google Scholar]
- Murphy SA. Optimal dynamic treatment regimes. J. R. Stat. Soc. Ser. B Stat. Methodol. 2003;65:331–366. [Google Scholar]
- Murphy SA. An experimental design for the development of adaptive treatment strategies. Stat. Med. 2005;24:1455–1481. doi: 10.1002/sim.2022. [DOI] [PubMed] [Google Scholar]
- Oetting AI, Levy JA, Weiss RD, Murphy SA. Statistical methodology for a SMART design in the development of adaptive treatment strategies. In: Shrout P, editor. Causality and psychopathology: finding the determinants of disorders and their cures. Arlington VA: American Psychiatric Publishing, Inc.; 2008. [Google Scholar]
- Robins JM. Correcting for non-compliance in randomized trials using structural nested mean models. Comm. Statist. Theory Methods. 1994;23:2379–2412. [Google Scholar]
- Robins JM. Causal inference from complex longitudinal data. In: Berkane M, editor. Latent variable modeling and applications to causality. New York: Springer-Verlag; 1997. pp. 69–117. [Google Scholar]
- Robins JM. Optimal structural nested models for optimal sequential decisions. In: Lin DY, Heagerty PJ, editors. Proceedings of the Second Seattle Symposium on Biostatistics; New York: Springer-Verlag; 2004. pp. 189–326. [Google Scholar]
- Robins JM, Orellana L, Rotnitzky A. Estimation and extrapolation of optimal treatment and testing strategies. Stat. Med. 2008;27:4678–4721. doi: 10.1002/sim.3301. [DOI] [PubMed] [Google Scholar]
- Rubin DB. Bayesian inference for causal effects: The role of randomization. Ann. Statist. 1978;6:34–58. [Google Scholar]
- van der Vaart A. Asymptotic Statistics. Cambridge: Cambridge University Press; 1998. [Google Scholar]