

Abstract
We discuss briefly the very interesting concept of Brownian distance covariance developed by Székely and Rizzo (2009) and describe two possible extensions. The first extension is for high dimensional data that can be coerced into a Hilbert space, including certain high throughput screening and functional data settings. The second extension involves very simple modifications that may yield increased power in some settings. We commend Székely and Rizzo for their very interesting work and recognize that this general idea has potential to have a large impact on the way in which statisticians evaluate dependency in data.
Keywords: Brownian distance covariance, Correlation, Hilbert spaces, U-statistics
1 Introduction and Assessment
The Brownian distance covariance and correlation proposed by Székely and Rizzo (2009) (abbreviated SR hereafter) is a very useful and elegant alternative to the standard measures of correlation and is based on several deep and non-trivial theoretical calculations developed earlier in Székely, Rizzo and Bakirov (2007) (abbreviated SRB hereafter). We congratulate the group on this very original and elegant work. The main result is that a single, simple statistic 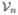 (X, Y) can be used to assess whether two random vectors X and Y, of possibly different respective dimensions p and q, are dependent based on an i.i.d. sample.
(X, Y) can be used to assess whether two random vectors X and Y, of possibly different respective dimensions p and q, are dependent based on an i.i.d. sample.
The proposed statistic (X, Y) estimates an interesting population parameter 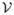 (X, Y) that the authors demonstrate can also be expressed as the covariance between independent Brownian motions W and W′, with p and q dimensional indices, evaluated at X and Y, respectively. Specifically, let W: ℝp ↦ ℝ be a real valued, tight, mean-zero Gaussian process with covariance |s|p + |t|p −|s − t|p, for s, t ∈ ℝp, where |·|r is the standard Euclidean norm in ℝr. Let W′ be similarly defined but for indices s, t ∈ ℝq and norm |·|q. It can be shown that (X, Y) = E[W (X)W (X′)W′(Y)W′(Y′)], where (X′, Y′) is an independent copy of (X, Y), and where W ans W′ are independent of both (X, Y) and (X′, Y′). This justifies the designation “Brownian distance covariance.”
(X, Y) that the authors demonstrate can also be expressed as the covariance between independent Brownian motions W and W′, with p and q dimensional indices, evaluated at X and Y, respectively. Specifically, let W: ℝp ↦ ℝ be a real valued, tight, mean-zero Gaussian process with covariance |s|p + |t|p −|s − t|p, for s, t ∈ ℝp, where |·|r is the standard Euclidean norm in ℝr. Let W′ be similarly defined but for indices s, t ∈ ℝq and norm |·|q. It can be shown that (X, Y) = E[W (X)W (X′)W′(Y)W′(Y′)], where (X′, Y′) is an independent copy of (X, Y), and where W ans W′ are independent of both (X, Y) and (X′, Y′). This justifies the designation “Brownian distance covariance.”
By replacing Brownian motion with other stochastic processes, a very wide array of alternative forms of correlation between vectors X and Y can be generated. In the special case where p = q = 1 and the stochastic processes W and W′ are the non-random identify functions centered respectively at E(X) and E(Y), (X, Y) = E[W (X)W (X′)W′(Y)W′(Y′)] = Cov2(X, Y), which is the standard Pearson product-moment covariance squared. Thus the results obtained by SR not only have a profound connection to Brownian motion, but also include traditional measures of dependence as special cases, while, at the same time, have the potential to generate many useful new measures of dependence through the use of other stochastic processes besides Brownian motion. This raises the very real possibility that a broadly applicable and unified theoretical and methodological framework for testing dependence could be developed.
The SR paper is therefore not only important for the specific results contained therein but also for the possibly far reaching consequences for future statistical research in both theory and applications. For the remainder of the paper, we describe two possible extensions of these results. The first extension is for high dimensional data that can be coerced into a Hilbert space, including certain high throughput screening and functional data settings. The second extension involves very simple modifications that may yield increased power in some settings. We first present some initial results and consequences of SR and SRB that will prove useful in later developments. We then present the Hilbert space extension with a few example applications. Some modifications leading to potential variations in power will then be described. The paper will then conclude with a brief discussion.
2 Some Initial Results
We now present a few initial results which will be useful in later sections. For a paired sample of size n, (X1, Y1), …, (Xn, Yn), of realization of (X, Y), where X and Y are random variables from arbitrary normed spaces with respective norms ||·||X and ||·||Y, define, analogously to SR,
and Vn(X, Y) = T1 + T2 − 2T3. Also define
and V0(X, Y) = T10+T20−2T30. Also let Vn(X) = Vn(X, X) and V0(X) = V0(X, X); and let Vn(Y) = Vn(Y, Y) and V0(Y) = V0(Y, Y). This allows us to define also and , provided the denominators are non-zero (and defined to be zero otherwise). The main distinction between this and the definitions in SR is the use of arbitrary normed spaces.
Because this has a standard U-statistic structure, we have the following general result, the proof of which follows from standard theory for U-statistics (see, e.g., Chapter 12 of van der Vaart, 1998):
Lemma 1
Provided and , then and .
Remark 1
In the special case where X and Y are from finite-dimensional Euclidean spaces, we know from Theorems 1–4 of SR that Vn(X, Y), Vn(X), Vn(Y), V0(X, Y), V0(X) and V0(Y) are all non-negative; that and ; that V0(X) = 0 or V0(Y) = 0 only when X or Y is trivial; that Vn(X) = 0 or Vn(Y) = 0 only when the X’s or Y ’s in the sample are all identical; that 0 ≤ Rn(X, Y), R0(X, Y) ≤ 1; and that V0(X, Y) = 0 only when X and Y are independent.
We now wish to generalize the above results in the finite-dimensional context to a class of norms more broad than Euclidean norms. These results will be useful for later sections. Let A and B be respectively p × p and q × q symmetric, positive definite matrices. Let a “tilde” placed over T1, T2, T3, Vn, V0, etc., denote the quantity obtained by replacing |x|p with and |y|q with in Vn, V0, etc.. For example . We now have the following very simple extension:
Lemma 2
Let A and B be symmetric and positive definite. Then Ṽn(X, Y), Ṽn(X), Ṽn(Y), Ṽ0(X, Y), Ṽ0(X) and Ṽ0(Y) are all non-negative; and all of the other results in Remark 1 remain true with a “tilde” placed over the given quantities. Moreover, Ṽ0(X, Y) = 0 if and only if V0(X, Y) = 0.
Proof
For a symmetric, positive definite matrix C, let C1/2 denote the symmetric square root of C, i.e., C1/2C1/2 = C. Note that such a square root always exists and, moreover, is always positive definite. Now define U = A1/2X and V = B1/2Y, and note that |U|p = ||X||A,p and |V|q = ||Y||B,q. Now replace X and Y in the quantities listed in Remark 1 with U and V. By the symmetry properties of these norms, the first part of the lemma up to just before the last sentence is proved. The last sentence follows from the simple observation that U and V are independent if and only if X and Y are independent by the positive definiteness of A1/2 and B1/2. Since V0(X, Y) = 0 if and only if X and Y are independent, we now conclude that Ṽ0(X, Y) = 0 if and only if X and Y are independent. The entire lemma now follows.
The third initial result involves some non-trivial properties of independent components in the finite dimensional setting. Suppose for X ∈ ℝp and Y ∈ ℝq, where p = p1 + p2 and q = q1 + q2, we have
where X(1), X(2) ∈ ℝp1, X(3) ∈ ℝp2, Y (1), Y (2) ∈ ℝq1, y(3) ∈ ℝq2; and suppose also that the two vectors X̃ = ([X(2)]T, [X(3)]T)T and Ỹ = ([Y (2)]T, [Y (3)]T)T are mutually independent and also independent of X(1) and Y (1). We have the following somewhat surprising result:
Lemma 3
V0(X, Y) = V0(X(1), Y(1)).
Proof
For any t ∈ ℝp and s ∈ ℝq, with , t1 ∈ ℝp1, t2 ∈ ℝp2, s1 ∈ ℝq1, and s2 ∈ ℝq2, the independence assumptions and standard characteristic function properties yield
Combining this with Theorems 1 and 2 of SR, we obtain that
Note that the right-hand side is invariant with respect to the distributions of X̃ and Ỹ, and thus we can replace X̃ and Ỹ with degenerate random variables fixed at zero. Doing the same on the left-hand side yields the desired result.
3 High Dimensional Extensions
The basic idea we propose is to extend the results to Hilbert spaces which can be approximated by sequences of finite-dimensional Euclidean spaces. We will give a few examples shortly. First, we give the conditions for our results. Assume X is a random variable in a Hilbert space HX with inner produce 〈·, ·〉X and norm ||·||X. A superscript * will be used to denote adjoint. Say that X is “finitely approximable” if there exists a sequence Xm ∈ HX such that for each m ≥ 1, there exists a linear map Mm: Hx ↦ ℝpm for which is symmetric and positive definite on ℝpm, pm is non-decreasing, Xm = Mm(Um) for some sequence of Euclidean random variables Um, and that as m → ∞. Note that we can assume that is the identity without loss of generality. This follows since we can always replace Um with Ũm = AmUm and Mm with , where , to yield Xm = M̃mŨm with being the identity.
Example 1
Let X be functional data with realizations that are functions in the Hilbert space HX = L2[0, 1] consisting of functions f: [0, 1] ↦ ℝ satisfying . Specifically, we will assume that
where Z1, Z2, … are independent random variables with mean zero and variance 1; φ1, φ2, … form an orthonormal basis in L2[0, 1]; and λ1, λ2, … are fixed constants satisfying . This formulation can yield a large variety of tight stochastic processes and can be a realistic model for some kinds of functional data.
Let pm = m, Um = (λ1Z1, …, λmZm)T, and, for any vector a ∈ ℝpm, . Clearly, Xm = Mm(Um) is in HX almost surely, since is bounded almost surely. Moreover, for any f ∈ L2[0, 1], it can be shown that
and thus is the identity by the orthonormality of the basis and is therefore positive definite. Since ,
as m → ∞. Thus X is finitely approximable.
Example 2
This is basically the same as Example 1, except that we will not require the basis functions to be orthogonal. Specifically, let X(t) be as given in (1), with the basis functions satisfying , for all i ≥ 1, but not necessary being mutually orthogonal. Let , for i, j ≥ 1, and define Am to be the m × m matrix with entry ai,j for row i and column j for 1 ≤ i, j ≤ m. Assume that A is positive definite for each m ≥ 1 and also assume that . If we now follow parallel calculations to those done in Example 1, we can readily deduce that with , we have Mm and defined as before, but with instead of the identity, while also as before. The increased flexibility enlarges the scope of stochastic processes achievable to include, for example, Brownian motion.
Example 3
Let X = (X(1), X(2), …)T be an infinitely long Euclidean vector in ℓ2, i.e., almost surely; and assume that, after permuting the indices if necessary,
as m → ∞. It is fairly easy to see that if we let Xm be a vector with the first m elements being identical to the first m elements of X but with all remaining elements equal to zero, then , as m → ∞, and all of the remaining conditions for finite approximability are satisfied. This example may be applicable to certain high throughput screening settings where the vector of measurements may be arbitrarily high-dimensional.
The following lemma tells us that the range-related properties of Brownian distance covariance are preserved for finitely approximable random variables:
Lemma 4
Assume that X and Y are both finitely approximable random variables in Hilbert spaces. Then Vn(X, Y), Vn(X), Vn(Y), V0(X, Y), V0(X) and V0(Y) are all non-negative; ; and 0 ≤ Rn(X, Y), R0(X, Y) ≤ 1.
Proof
Let Xm and Ym be sequences such that and as m → ∞. Using simple algebra, we can verify that V0(Xm, Ym) → V0(X, Y) which implies V0(X, Y) ≥ 0. Similar arguments verify the desired results for V0(X), V0(Y) and R0(X, Y). Now, for a sample of size n, (X1, Y1), …, (Xn, Yn), we can create a sequence of samples (X1m, Y1m), …, (Xnm, Ynm), such that by finite approximability. Let be the same as Vn(X, Y) but with the m’th approximating sample replacing the sample observations. Since convergence in mean implies convergence in probability, we can apply basic algebra to verify that as m → ∞. Similar arguments verify the desired results for Vn(X), Vn(Y) and Rn(X, Y), and this completes the proof.
Our ultimate goal in this section, however, is to show that R0(X, Y) has the same implications for assessing dependence for finitely approximable Hilbert spaces as it does for finite dimensional settings. This is actually quite challenging, and we are only able to achieve part of the goal in this paper. The following is our first result in this direction:
Lemma 5
Suppose X and Y are random variables in finitely approximable Hilbert spaces. Then R0(X, Y) > 0 implies that X and Y are dependent.
Proof
Assume that R0(X, Y) > 0 but that X and Y are independent. By finite approximability, there exists a sequence of paired random variables (Xm, Ym) such that Xm and Ym are independent for each m ≥ 0, , and . This implies that R0(Xm, Ym) = 0 for all m ≥ 0. Since also R0(Xm, Ym) → R0(X, Y), we have a contradiction. Hence X and Y are dependent.
If we could also show that R0(X, Y) = 0 implies independence, we would have essentially full homology with the finite dimensional case. It is unclear how to show this in general, and it may not even be true in general. However, it is certainly true for an interesting special case which we now present.
Let X and Y be random variables in finitely approximable Hilbert spaces. Suppose there exists linear maps M: HX ↦ HX and N: HY ↦ HY with adjoints for which both M*M and N*N are identities, and that MX = X1 + X2 and NY = Y1 + Y2, where and and are finite-dimensional subspaces of HX and HY, respectively, and that X2 and Y2 are mutually independent and independent of (X1, Y1). We will call a random pair (X, Y) that satisfies these conditions “at most finitely dependent.” For example, paired functional data (X, Y) could be at most finitely dependent if all possible dependencies between the two populations X and Y are attributable to at most a few principle functions (or principle components) in each population and that the remaining components are independent noise.
Example 4
Suppose that we are interested in determining whether X and Y are independent, where X is either a functional observation or some other very high dimensional observation and Y is a continuous outcome of interest such as a time to an event. Suppose also that X is finitely approximable and that any potential dependence of Y on X is solely due to a latent set of finite principle components of X. Such a pair (X, Y) would be at most finitely dependent.
The following lemma on finitely dependent data is the final result of this section:
Lemma 6
Suppose that X and Y are finitely approximable random variables in Hilbert spaces and that (X, Y) is at most finitely dependent. Then R0(X, Y) ≥ 0 and the inequality is strict if and only if X and Y are dependent.
Proof
Note first that and, similarly, ||NY ||Y = ||Y ||Y. Since R0(X, Y) is a function involving only the norms of X and Y, we can assume without loss of generality that N and M are identities. Thus we will simply assume that X = X1 + X2 and Y = Y1 + Y2 hereafter. Let (X2m, Y2m) be a sequence of paired random variables in HX × HY such that and , and where, for each m ≥ 1, X2m and Y2m are mutually independent and also independent of (X1, Y1).
Now let X̂m = X1+X2m and Ŷm = Y1+Y2m, and note that both X̂m and Ŷm are finite dimensional with R0(X̂m, Ŷm) → R0(X, Y). Let p1 and q1 be the respective dimensions of X1 and Y1, p2m and q2m be the respective dimensions of X2m and Y2m, and let pm = p1 + p2m and qm = q1 + q2m. Let be the projection of X2m onto be the projection of Y2m onto , and let and . By the finite-dimensionality of X1, X2m, Y1 and Y2m, there exists linear maps , A2m: ℝp2m ↦ HX, , and B2m: ℝq2m ↦ HY, such that and are all identities and that X1 = A1U1, , Y1 = B1Z1, , and , for random vectors U1, , Z1, , and , where and are mutually independent and independent of (U1, Z1).
If we let and , the above formulation yields that ||X̂m||X = |Ûm|pm and ||Ŷm||Y = |Ẑ|qm. By Lemma 3, we now have that R0(Ûm, Ẑm) = R0(U1, Z1) which does not depend on m. Since and are both identities, we also have that R0(U1, Z1) = R0(X1, Y1), and thus R0(X̂m, Ŷm) = R0(Ûm, Ẑm) → R0(X1, Y1), as m → ∞. This now implies that R0(X, Y) = R0(X1, Y1), which yields the desired result.
4 Increasing Power
We now briefly discuss the issue of power of tests based on Rn(X, Y). By Lemma 2, we observe that there are many different versions of the statistic Rn(X, Y), based on different choices of matrices A and B in the norms ||·||A,p and ||·||B,q, that all have the ability to assess general dependence. Is it possible to choose A and B in a way that provides optimal power for certain fixed or contiguous alternatives? The answer should be yes since it appears that A and B could potentially be selected to emphasize dependence for certain subcomponents of X and Y while deemphasizing dependence for other subcomponents. The answer to this question, unfortunately, seems to be very hard to pin down rigorously. We do not pursue this further here, but it does seem to be a potentially important issue that deserves further attention.
5 Discussion
We have briefly proposed two generalizations of the Brownian distance covariance, one based on alternative norms to Euclidean norms, and the other based on infinite dimensional data. The first generalization raises the possibility of fine-tuning the statistics proposed in SR to increase power, and the second generalization opens the door for applicability of the results in SR to a broader array of data types, including infinite dimensional data and data with dimension increasing with sample size. However, for both of these generalizations, there remain many open questions that could lead to important further improvements. In either case, the results of SR are very important both practically and theoretically and should result in many important future developments in both the application and theory of statistics.
Acknowledgments
This research was supported in part by U.S. National Institutes of Health grant CA075142.
References
- Székely GJ, Rizzo ML. Brownian distance covariance. Annals of Applied Statistics. 2009 doi: 10.1214/09-AOAS312. In press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Székely GJ, Rizzo ML, Bakirov NK. Measuring and testing dependence by correlation of distances. Annals of Statistics. 2007;35:2769–2794. [Google Scholar]
- van der Vaart AW. Asymptotic Statistics. Cambridge University Press; New York: 1998. [Google Scholar]