

Abstract
The field of glycobiology is concerned with the study of the structure, properties, and biological functions of the family of biomolecules called carbohydrates. Bioinformatics for glycobiology is a particularly challenging field, because carbohydrates exhibit a high structural diversity and their chains are often branched. Significant improvements in experimental analytical methods over recent years have led to a tremendous increase in the amount of carbohydrate structure data generated. Consequently, the availability of databases and tools to store, retrieve and analyze these data in an efficient way is of fundamental importance to progress in glycobiology. In this review, the various graphical representations and sequence formats of carbohydrates are introduced, and an overview of newly developed databases, the latest developments in sequence alignment and data mining, and tools to support experimental glycan analysis are presented. Finally, the field of structural glycoinformatics and molecular modeling of carbohydrates, glycoproteins, and protein–carbohydrate interaction are reviewed.
Keywords: Glyco-bioinformatics, Databases, Carbohydrates, Glycosylation, Glycoproteins, Molecular modeling, Molecular dynamics simulation
Introduction
The field of glycobiology is concerned with the study of the structures, properties, and biological functions of the family of biomolecules called carbohydrates. These carbohydrates can differ significantly in size ranging from monosaccharides to polysaccharides consisting of many thousands of carbohydrate units. One of the most significant features of carbohydrates is their ability to form branched molecules, which stands in contrast to the linear nature of DNA, RNA, and proteins. Combined with the large heterogeneity of their basic building blocks, the monosaccharides, they exhibit a significantly higher structural diversity than other abundant macromolecules. On the cell surface, carbohydrates (glycans) occur frequently as glycoconjugates, where they are covalently attached to proteins and lipids (aglycons). Glycosylation constitutes the most prevalent of all known post-translational protein modifications. It has been estimated that more than half the proteins in nature are glycoproteins [1]. Carbohydrates (N- or O-glycans) are typically connected to proteins via asparagine (N-linked glycosylation), serine or threonine (O-linked glycosylation). In recent years, it has been shown that glycosylation plays a key role in health and disease and consequently it has gained significant attention in life science research and industry [2–10].
Databases are playing a significant role in modern life science. It is now unthinkable to design research projects without a prior query or consultation of a few databases. In this respect, bioinformatics provides databases and tools to support glycobiologists in their research. Additionally, high throughput analysis of glycomes can only be handled properly with some sort of automated analysis pipeline that requires extensive bioinformatic support to organize the experimental data generated. In parallel, there are bioinformatic groups actively developing mathematical or statistical algorithms and computational methodologies to analyze the data and thus uncover biological knowledge underlying the biological data. Since valuable experimental data are generated at various locations and in projects that target different scientific questions, the different sources of data have to be connected to generate a more complete data repository, which may aid in gaining a clearer understanding of the functions of carbohydrates in an organism. Consequently, data integration is a prerequisite for improving the efficiency of extraction and analysis of biological information, particularly for knowledge discovery and research planning [11].
Significant improvements in experimental analytical methods over recent years—particularly in glycan analysis by mass spectrometry and high performance separation techniques [12–21]—have led to a tremendous increase in the amount of carbohydrate structure data generated. The second source generating new experimental data on a large scale is the increased application of lectin and carbohydrate microarrays to probe the binding preferences of carbohydrates to proteins [22–26]. Consequently, the availability of databases and tools to store, retrieve, and analyze these data in an efficient way is of fundamental importance to progress in glycobiology [13, 15, 18, 27, 28]. Although bioinformatics for glycobiology or glycomics (‘glycoinformatics’) [29] is not yet as well established as in the fields of genomics and proteomics [30, 31], over the past few years, there has been a substantial increase in both the development, and use, of informatics tools and databases in glycosciences [32–42].
In this review, we will first introduce the various representations of carbohydrates used in the literature, then provide an overview of newly developed databases for glycomics, highlighting briefly the most recent glycoinformatic developments in sequence alignment and data mining, and provide an update [38] on tools to support experimental glycan analysis. Finally, we will review the field of (3D) structural glycoinformatics and molecular modeling of carbohydrates, glycoproteins, and protein–carbohydrate interaction.
Graphical representations of carbohydrate structures
The basic units of carbohydrates are the monosaccharides. Whereas the other fundamental building blocks of biological macromolecules (nucleotides and amino acids) are clearly defined and limited in their number, the situation is much more complex for the carbohydrates. This becomes immediately evident by looking at the ten most frequently occurring monosaccharides in mammals [43]: d-GlcNAc, d-Gal, d-Man, d-Neu5Ac, l-Fuc, d-GalNAc, d-Glc, d-GlcA, d-Xyl, and l-IdoA (Fig. 1). Less than half of them are unmodified hexoses (d-Glc, d-Gal, d-Man) or pentoses (d-Xyl). Most of them are modified or substituted on the parent monosaccharides (deoxy: l-Fuc; acidic: d-GlcA, l-IdoA; substituted: d-GlcNAc, d-GalNAc, d-Neu5Ac). Therefore, derivatization is for monosaccharides the rule rather than an exception. The d-form is more common, but some monosaccharides occur more frequently in their l-form. Additionally, each of them can occur in two anomeric forms (α/β) and two ring forms [pyranose (p)/furanose (f)], which results, for example, in eight forms of cyclic galactose (α-d-Galp, α-l-Galp, β-d-Galp, β-d-Galf, etc.).
Fig. 1.

Frequently occurring carbohydrate building blocks in mammalia. For each monosaccharide, the 3D structure, the IUPAC short code, and the symbols used in the Oxford (top) and CFG (bottom) symbolic nomenclature are shown. The acids (last row) are displayed with substituents (O-methyl, sulfate). α-l-IdopA is shown in two conformations (1C4 and 2S0) as they appear in heparin (pdb code 1E0O [53]). The formal charge of the monosaccharide at physiological pH is denoted in parentheses
Simplified representations of complex biological macromolecules are frequently used to communicate or encode information on their structure. One-letter codes are in use to encode nucleic acids (5 nucleotides) or proteins (20 amino acids). Since the number of basic carbohydrate units frequently found in mammals is also very limited, symbolic representations [44, 45] (Figs. 1, 2) are frequently in use and one-letter codes have also been proposed [46, 47]. However, more than 100 different monosaccharides are found in bacteria, as has been revealed by a statistical database analysis [48]. This renders the general representation of monosaccharides by one-letter codes unfeasible, and generally longer abbreviations for the monosaccharide residues have to be used. A standardized International Union of Pure and Applied Chemistry (IUPAC) nomenclature for monosaccharides and oligosaccharide chains exists (http://www.chem.qmul.ac.uk/iupac/2carb/) [49], and full names and short codes for the common monosaccharides and derivatives have been defined (e.g., ‘Glc’ for glucose, ‘GlcNAc’ for N-acetylglucosamine). Typically the short names are derived from the trivial names of the monosaccharides (e.g. ‘Fuc’, systematic name: 6-deoxy-galactopyranose; trivial name: fucose). As already shown, in order to define the full monosaccharide short names, the anomeric descriptor, the d/l identifier and the ring form (p/f) have to be given as well, so the shortest name for ‘α-d-glucopyranose’ would be ‘α-d-Glcp’. An example of a more complex monosaccharide is N-acetyl-α-neuraminic acid; short name: α-d-Neup5Ac or α-Neu5Ac (full IUPAC name: 5-acetamido-3,5-dideoxy-d-glycero-α-d-galacto-non-2-ulopyranosonic acid).
Fig. 2.

Different graphical representations of the N-glycan GlcNAc2Man9. a CFG symbolic representation [45]. b Oxford system [44]. c Chemical drawing. d Extended IUPAC 2D graph representation
The most commonly used graphical and textual representations for carbohydrates are shown in Fig. 2. Each of these shows a different level of information content that is tailored to a particular area of glycoscience research. Glycobiologists will prefer cartoon representations (Fig. 2a, b), whereas synthetic chemists will prefer the ‘chemical’ structural drawings with full atom topology displayed (Fig. 2c). Unfortunately, there are different graphical symbols in use for the same monosaccharides, which is even confusing for scientists working in the field. An agreement on one set of symbols would be very beneficial for the community [50]. From the viewpoint of bioinformatics, the graphical representations are only relevant for structure display in the context of user interfaces. Software tools have been developed that are able to generate on-the-fly cartoon representations from a carbohydrate sequence format (which is a ‘computer representation’ of a carbohydrate structure) [51]. Although carbohydrates have been encoded successfully using the ‘computerized’ extended IUPAC (2D) representation [52] (Fig. 2d), it has been realized that a more flexible and systematic sequence format is required to encode all carbohydrate structures that occur in scientific publications.
Bioinformatic concepts and algorithms
Encoding of carbohydrate structures
There are essentially two possible ways to encode a carbohydrate molecule: as a set of atoms that are connected through chemical bonds, or as a set of building blocks that are connected through linkages. The first approach is used in chemoinformatics and a variety of chemical file formats (e.g., CML [54], InChi [55], SMILES [56]) have been developed for encoding of molecules for storage in chemical databases like PubChem [57] or ChEBI [58]. Figure 3 shows one PubChem entry of sialyl Lewis-X together with additional structural descriptors, like molecular weight. IUPAC full names and InChi and SMILES encoding are computed from the chemical drawing; therefore, encoding of carbohydrates as InChi or auto-generated IUPAC names is possible; however, there are severe limitations. One of the main requirements for databases is to store information in an organized way that facilitates further computational processing. Based on the InChi or IUPAC code, it is, for example, very difficult to derive the monosaccharide composition of sialyl Lewis-X, which is (Neu5Ac)1(Gal)1(GlcNAc)1(Fuc)1. Additionally, since there is more than one entry for sialyl Lewis-X in the PubChem database, the automatic procedures to always generate the same InChi code for the same carbohydrate may need to be improved in order to generate unique IDs for carbohydrates. Although it is possible to develop software that parses InChi codes and assigns knowledge about monosaccharides to a database entry, InChi may not be the first choice for the encoding of carbohydrate structures. Consequently, it would be much more efficient to encode carbohydrates using a residue-based approach similar to the sequences of genes and proteins. However, there are two significant differences: the number of building blocks (residues) may be very large due to frequently occurring modifications of the parent monosaccharides, and the carbohydrate chains frequently contain branches, which means that many carbohydrates are tree-like molecules.
Fig. 3.

PubChem entry of sialyl Lewis-X together with structural descriptors like IUPAC name and InChi and SMILES code
The prerequisite for a residue-based encoding format is a controlled vocabulary of the residue names. For practical reasons, the number of residues should be kept as small as possible. The main difficulty in encoding monosaccharide names in a systematic way is the definition of clear rules about which atoms of a molecule belong to a monosaccharide residue and which are, for example, of type ‘non-monosaccharide’ (e.g., substituent). The following short list will illustrate the dilemma: Glc, Gal, GlcN, GlcNAc, GalNAc, GlcOAc. For a biologist, all of them would be monosaccharides on their own (glucose, galactose, glucosamine, N-acetylglucosamine, etc.) except GlcOAc, which would be a glucose carrying an ‘acetyl’ substituent. From an encoding point of view, it makes more sense that all entries are of type ‘Glc’ or ‘Gal’ and N, NAc, and OAc are substituents, respectively. Even for bacterial monosaccharides, this would result in a reasonably sized ‘monosaccharide base type’ residue list {Glc, Gal, …} and ‘non-monosaccharide’ residue list {N, NAc, OAc, …}, which is much easier to maintain.
Over the years, each database project that aimed to store carbohydrate structures developed a new sequence format (see Table 1). Because of this, translation tools for the different formats were necessary to establish cross-links between the databases. In the context of the EUROCarbDB design study, which aimed at developing standards for glycoinformatics, a new carbohydrate sequence format for use in databases (GlycoCT) [59] has been established as well as a reference database for monosaccharide notation (http://www.monosaccharidedb.org). The GlycomeDB [60] project uses GlycoCT as a standard format for the integration of all open access carbohydrate structure databases (Fig. 4). Recently, as a result of a close collaboration between developers at the Complex Carbohydrate Research Center (CCRC) and EUROCarbDB, the Glyde-II format (http://glycomics.ccrc.uga.edu/GLYDE-II/) was created where concepts of Glyde [61] and GlycoCT [59] were combined in order to define a new standard exchange format for carbohydrate structures [27].
Table 1.
Major carbohydrate structure databases and the sequence formats used
| Database | Encoding | URL |
|---|---|---|
| GlycomeDB [89] | GlycoCT [59] | http://www.glycome-db.org/ |
| EUROCarbDBa | GlycoCT [59] | http://www.ebi.ac.uk/eurocarb/ |
| CarbBanka [52] | IUPAC extended [90] | http://www.boc.chem.uu.nl/sugabase/carbbank.html |
| KEGGa [83] | KCF [91] | http://www.genome.jp/kegg/glycan/ |
| GLYCOSCIENCES.dea [82] | LINUCS [92] | http://www.glycosciences.de/ |
| CFGa [84] | Glycominds Linear Code® [47] | http://www.functionalglycomics.org/ |
| BCSDBa [93] | BCSDB linear code | http://www.glyco.ac.ru/bcsdb3/ |
| GlycoSuiteDB [87] | IUPAC condensed [94] | http://glycosuitedb.expasy.org/ |
| GlycoBase (Dublin)a [86] | Motif based | http://glycobase.ucd.ie/ |
| GlycoBase (Lille)a [95] | Linkage path | http://glycobase.univ-lille1.fr/base/ |
| JCGGDB [96] | CabosML [97] | http://jcggdb.jp/ |
aCurrently queried by GlycomeDB
Fig. 4.

GlycomeDB entry of sialyl Lewis-X. The structure is displayed in a ‘human readable’ encoding (CFG cartoons) at the top and in a ‘computer readable’ sequence format (GlycoCT) at the bottom. Additionally, links to external databases and information on structural motifs are available
Algorithms for structural alignment and similarity of carbohydrate structures
For many applications in glycoinformatics, it is required to classify glycans based on occurring structural motifs or patterns, or to compare two carbohydrates and to establish a similarity score. Despite many efforts, this is still an open problem due to the lack of broadly accepted metrics on carbohydrate structures. Algorithms based on adapting the already established sequence alignment approaches from DNA, RNA, and protein sequences to carbohydrates and establishing a scoring matrix for substitutions have been proposed [62, 63]. However, discovery of biomarkers or more broadly extracting discriminating patterns from sets of carbohydrates poses a great challenge due to their branched nature and the possibility that a significant pattern can be fragmented and distributed across multiple branches of the carbohydrate. Traditional pattern discovery and classification techniques from machine learning have been applied with increasing success to meet this challenge. Markov models were used to discover patterns spanning multiple branches [62, 63]. Then the focus shifted to Support Vector Machines and the search for kernels appropriate for branched structures [64–66]. Recently, a novel statistical approach for motif discovery that currently outperforms all competing methods has been presented [67].
Glycomics ontologies
The information explosion in biology makes it difficult for researchers to stay up-to-date with current biomedical knowledge and to make sense of the massive amounts of online information. Ontologies are increasingly enabling biomedical researchers to accomplish these tasks [68]. An ontology provides a shared vocabulary, which can be used to model a domain of interest, and it defines the type of objects and concepts that exist, and their properties and relations. Ontologies are often represented graphically as a hierarchical structure of concepts (nodes) that are connected by their relationships (edges). Concepts and relationships are assigned unique ontological names. For example, the ontological concepts ‘carbohydrate’ and ‘molecule’ can be connected by the hierarchical relationship ‘is_a’. In this way, ontologies can be used to provide a formal mechanism to categorize objects by specifying their membership in a specific class. The Glycomics Ontology (GlycO) focuses on the glycoproteomics domain to model the structure and functions of glycans and glycoconjugates, the enzymes involved in their biosynthesis and modification, and the metabolic pathways in which they participate. GlycO is intended to provide both a schema and a sufficiently large knowledge base, which will allow classification of concepts commonly encountered in the field of glycobiology in order to facilitate automated information analysis in this domain [69, 70] (for more information, see the web site http://lsdis.cs.uga.edu/projects/glycomics/).
Predicting the size and diversity of glycomes
A hexasaccharide can, in theory, build 1012 structural isomers [71]. Although such large numbers highlight the intrinsic complexity of carbohydrates, the actual number of carbohydrates in nature is probably significantly smaller. Modeling of enzyme kinetics and estimating the size and diversity of the glycome has been of considerable interest to the field of glycobiology. The first attempt to establish mathematical models of N-type glycosylation occurred over 10 years ago [72], by employing the known enzymatic activities of glycosyltransferases involved in the N-type glycosylation pathway and generating all possible carbohydrates resulting from those activities up to the first galactosylation of an oligosaccharide. This work was then extended [73] by using less simplifying assumptions and extending the set of enzymes included in the model. Recent advances have led to the ability to estimate enzyme reaction rates and enzyme concentrations from mass spectrometry data, thereby opening up the possibility to infer changes to the enzyme concentrations in diseased tissues [74]. Similarly, the expression profiles of glycosyltransferases were used to predict the repertoire of potential glycan structures [75, 76]. A recent estimation of the size of the human glycome based on biosynthetic pathway knowledge approximates the upper limit of distinct carbohydrates to be in the range of hundreds of thousands [77]. Currently, there are about 35,000 distinct carbohydrate structures stored in databases [60]; however, nobody knows how many carbohydrate structures have already been discovered or published so far, since no comprehensive database of carbohydrate structures exists. Statistical analyses of the structures stored in GLYCOSCIENCES.de and the Bacterial Carbohydrate Structure Database (BCSDB) have been performed and showed the differences between available structures from the mammalian and bacterial glycome [48]. The ‘chemical analysis’ of the database entries revealed that about 36 chemical building blocks (=monosaccharide + branching level) would be required for the chemical synthesis of 75% of the mammalian glycans [43]. Unfortunately, the situation is much more complex for the bacterial carbohydrates. However, if one would concentrate on the synthesis of a particular subclass of bacterial carbohydrates (e.g., for vaccine development) the diversity becomes much smaller.
Databases and tools for glycobiology
A variety of databases are available to the glycoscientist [32, 36, 78–80]. From the viewpoint of glycoproteins, they can be grouped into databases that contain information on the proteins themselves, databases that store information on the enzymes and pathways that build the glycans, and carbohydrate structure databases [36, 37]. Only limited information is available in databases on glycoforms of glycoproteins.
Carbohydrate structure databases
The complex carbohydrate structure database (CCSD)—often referred to as CarbBank in reference to its query software—was developed and maintained for more than 10 years by the Complex Carbohydrate Research Center of the University of Georgia (USA) [52, 81]. The CCSD was the largest effort during the 1990s to collect the structures of carbohydrates, mainly through retrospective manual extraction from literature. The main aim of the CCSD was to catalog all publications in which complex carbohydrate structures were reported. Unfortunately, funding for the CCSD stopped during the second half of the 1990s and the database was no longer updated. Nevertheless, with almost 50,000 records (from 14,000 publications) relating to approximately 23,500 different carbohydrate sequences, the CCSD is still one of the largest repositories of carbohydrate-related data. Subsets of the CCSD data have been incorporated into almost all recent open access databases, of which the major ones are GLYCOSCIENCES.de (23,233) [82], KEGG Glycan database (10,969) [83], CFG Glycan Database (8,626) [84], Bacterial Carbohydrate Structure Database (BCSDB, 6,789) [85], and GlycoBase (377) [86]. The numbers in parentheses denote the number of distinct carbohydrate sequences (without aglycons) stored in the database (based on GlycomeDB analysis, October 2008). Recently, the JCGGDB, which assembles CabosDB, Galaxy, LipidBank, GlycoEpitope, LfDB, and SGCAL (with 1,490 unique carbohydrate structures) and the GlycoSuiteDB (with about 3,300 unique carbohydrate structures) [87] have become freely accessible as well.
The EUROCarbDB project (http://www.eurocarbdb.org) was a design study that aimed to create the foundations for a new infrastructure of distributed databases and bioinformatics tools where scientists themselves can upload carbohydrate structure-related data. Fundamental ethics of the project were that all data are freely accessible and all provided tools are open source. A prototype of a database application has been developed that can store carbohydrate structures plus additional data such as biological context (organism, tissue, disease, etc.), and literature references. Primary experimental data (MS, HPLC, and NMR) that can serve as evidence or reference data for the carbohydrate structure in question can be uploaded as well (Fig. 5).
Fig. 5.

EUROCarbDB web interface. a The GlycanBuilder Tool [51] serves as an interface for structure input. Various graphical representations are supported and can be changed interactively. b Result of a structure search in the database. The first three entries contain associated MS data as evidence for the structure
Until recently, there was hardly any direct cross-linking between the established carbohydrate databases [88]. This is mainly due to the fact that the various databases use different sequence formats to encode carbohydrate structures [59] (Table 1). Therefore, the situation in glycoinformatics has been characterized by the existence of multiple disconnected and incompatible islands of experimental data, data resources, and specific applications, managed by various consortia, institutions, or local groups [27, 37]. Importantly, no comprehensive and curated database of carbohydrate structures currently exists. From the user’s point of view, the lack of cross-links between carbohydrate databases means that, until recently, they had to visit different database web portals in order to retrieve all the available information on a specific carbohydrate structure. Additionally, the users might have had to acquaint themselves with the different local query options, some of which require knowledge of the encoding of the residues in the respective database.
In 2005, a new initiative was begun to overcome the isolation of the carbohydrate structure databases and to create a comprehensive index of all available structures with references back to the original databases. To achieve this goal, most structures of the freely available databases were translated to the GlycoCT sequence format [59], and stored in a new database, the GlycomeDB [60]. The integration process is performed incrementally on a weekly basis, updating the GlycomeDB with the newest structures available in the associated databases. During the integration process, some automated checks are performed. Structures that contain errors are reported to the administrators of the original database. A web interface has been developed (http://www.glycome-db.org) as a single query point for all open access carbohydrate structure databases [89] (Fig. 4).
Databases for carbohydrate–protein interaction data
Advances in recent years have led to an explosive growth of data from carbohydrate microarray experiments, coming from multiple research laboratories, each employing their own proprietary technology for spotting the array [22, 98–101]. Unfortunately, the often radically different approaches to the spotting of the arrays can change the binding affinities observed. This inhomogeneity in the way the data are generated has caused problems in the comparative analysis and evaluation of the data. Further complications arise from lack of comprehensive applications to manage the data generated in the experiments and also computational approaches to perform analytical studies. There is a clear need in this area for more research and development of computational approaches and tools. Particularly, the standards for reporting glycan array experiments need to be defined [102].
Currently, there is one major public resource for glycan array data provided by the Consortium for Functional Glycomics (CFG) (http://www.functionalglycomics.org). The CFG supported the development of the first robot-produced, publicly available micro-titer-based glycan array. The currently used printed mammalian glycan microarray format (version 4.1) comprises 465 synthetic and natural glycan sequences representing major glycan structures of glycoproteins and glycolipids [103]. In 2008, a pathogen glycan array was also made available for screening, containing 96 polysaccharides derived from Gram-negative bacteria. The protein–glycan interaction core (H) analyzes investigator-generated lectins, antibodies, antisera, microorganisms, or suspected glycan binding proteins (GBP) of human, animal, and microbial origins on the mammalian and pathogen glycan microarrays. Fluorescent reagents are used for detecting primary binding to the glycans on the array. The results of the screening performed by the Core H can be accessed through the consortium web page, and the raw data can be downloaded as an Excel spreadsheet [84] (Fig. 6). The website offers an interactive bar-chart that dynamically displays the glycan structures upon a mouse click on the signal of interest. Links to CFG databases that contain curated information on the GBP and the glycan structures printed on the array are available.
Fig. 6.

Glycan microarray data provided by the Consortium for Functional Glycomics (CFG). a Web interface providing access to the primary data and related information. b The CFG dataset in the GlyAffinity database. Affinity data from different techniques (FAC, SPR, FP) are also available
A second large resource of carbohydrate–protein interaction data is the Lectin Frontier DataBase (LfDB) provided by the Japanese Consortium for Glycobiology and Glycotechnology (JCGG). A significant part of the data may have been generated as part of the structural glycomics project funded by New Energy and Industrial Technology Organization (NEDO) [104]. In contrast to the CFG glycan microarray database, which provides relative fluorescence units (FU), the LfDB provides affinity constants (K a) determined by frontal affinity chromatography [24, 105]. Similar to the CFG website, users can navigate to the experimental data using the lectin as an entry point. The data are also presented as an interactive bar-chart (Fig. 7). Since the site is to a large extent in Japanese, it is somewhat difficult to explore the full functionality of the web-interface at the moment.
Fig. 7.

Lectin Frontier Database. a LfDB web interface providing access to the experimental data and related information. b The LfDB dataset in the GlyAffinity database. Crosslinks via a carbohydrate entry to additional experiments and literature references are shown
Recently, a prototype for an integrated database for protein–carbohydrate interaction, ‘GlyAffinity’, has been developed at the German Cancer Research Center. The database aims at providing a comprehensive repository of curated protein–carbohydrate interaction data from various sources and techniques (Figs. 6b and 7b). The publicly available microarray experiments conducted by the CFG have been acquired and processed. This entailed the parsing of the data, conversion of the carbohydrate structures to the GlycoCT format, and curation of an initial set of approximately 100 experiments for inclusion in the database. The complete contents of the Lectin Frontier DataBase have also been imported and curated, and publications have been scoured for data and manually entered. The Leffler Laboratory (Lund, Sweden) provided access to their primary data, which has been processed and partially imported, and initial steps have been taken to include the data generated by the Feizi Laboratory (London, UK). Access to the data is provided through an interactive web-interface, which offers options to locate data either by lectin or carbohydrate structure. Each lectin entry is classified according to the established hierarchical lectin family scheme [106–108] and provides a list of experiments conducted with their experimental conditions and technique. The pages of the individual experiments feature the full list of carbohydrates, their recorded affinity, and the possibility to detect standard motifs.
A current limitation in making full use of protein–carbohydrate interaction data is the lack of systematic analysis methods for extracting information, most importantly the deduction of the binding epitope. Recently, the development of a novel algorithm to detect the occurrence of significant motifs in carbohydrate microarray experiments has been reported [109]. The approach entails the selection of 63 commonly occurring carbohydrate motifs (e.g., Lewis-X, terminal beta-GalNAc, etc.) and processing the complex carbohydrates found on the CFG microarray to detect their presence. Subsequent analysis of the occurrences of a motif in the carbohydrate structures of a particular experiment together with the fluorescence intensity measured yields information about the specificity the lectin exhibits towards a subset of the motifs.
Protein databases
Carbohydrates are frequently covalently attached to or interact non-covalently with proteins, and the biosynthesis of carbohydrates involves the action of hundreds of different enzymes. Consequently, databases that contain information on enzymes, biological pathways, glycoproteins, and lectins are of major interest to a glycobiologist (Table 2). The CAZy database [110] provides a comprehensive repository of carbohydrate active enzymes classified by sequence similarity into distinct families. The CAZy database is highly curated, and its family classification system [111] is frequently used in glycobiology. EC numbers are also annotated in the database, which relates structural features to the observed functions of the enzymes. Cross-links to access 3D structures of the enzymes from the Protein Data Bank (PDB) [112] are also available. BRENDA [113] is broader in its scope and offers information on all known enzymes identified by their EC number. A valuable resource for biochemical pathways is the Kyoto Encyclopedia of Genes and Genomes (KEGG) [83] (http://www.genome.jp/kegg/). KEGG PATHWAY is a database that represents molecular interaction networks, including metabolic pathways, regulatory pathways, and molecular complexes. The integration of carbohydrate structures from the KEGG GLYCAN database into the glycan-related pathways makes it possible to relate carbohydrate structures to genes. A variety of other carbohydrate-related tools are available, which makes KEGG an important informatics resource for glycobiology. The KEGG enzymes are also encoded as EC numbers. Other databases containing information on carbohydrate active enzymes are the GlycoGene Database (GGDB) [114], the CFG glycosyltransferase database [84], and the CERMAV glycosyltransferase database [115]. Curated databases of Glycan Binding Proteins (Lectins) are maintained by the CFG (GBP molecules DB), CERMAV (Lectines DB), and JCGG (Lectin Frontier DB) [96]. More detailed information on animal lectins can be found on the website “A genomics resource for animal lectins” (http://www.imperial.ac.uk/research/animallectins/), which also offers valuable data on lectin families and their roles in recognition processes. GlycoEpitope is an integrated database of carbohydrate antigens and antibodies [116] and is available now in the context of the JCGGDBs. The various databases that provide information on enzymes and lectins frequently provide direct links to entries in the Protein Data Bank if available. The O-GlycBase database [117] offers a curated set of experimentally verified O-glycosylated proteins. GlycoProtDB, which is part of JCGGDB, provides information on glycoproteins from C. elegans N2 and mouse tissues [118]. A very valuable information resource on glycoproteins is GlycoSuiteDB [87] cross-linked with UniProt/SWISS-PROT [119].
Table 2.
Protein databases that contain carbohydrate related information (see also [32])
| Name | Content | URL |
|---|---|---|
| CAZy [110] | Carbohydrate active enzymes | http://www.cazy.org/ |
| BRENDA [113] | Enzymes | http://www.brenda-enzymes.org/ |
| JCGGDB [96] | Glyco genes, glycoproteins, lectin affinity, MS data, epitopes | http://jcggdb.jp/ |
| CFG [84] | Glycans, lectins, glycosyltransferases | http://www.functionalglycomics.org/ |
| Glyco3D [115, 120] | 3D structures of carbohydrates, glycosyltransferases and lectins | http://www.cermav.cnrs.fr/glyco3d/ |
| O-GlycBase [117] | Curated set of O-and C-glycosylated proteins | http://www.cbs.dtu.dk/databases/OGLYCBASE/ |
| UniProt/SWISS-PROT [121] | Annotated proteins (lectins, glycoproteins, enzymes) | http://www.uniprot.org/ |
| RCSB Protein Data Bank [112] | 3D structures of lectins, glycoproteins, enzymes | http://www.rcsb.org/pdb/ |
Software tools for glycan analysis
Over the years, the increased application of a variety of methods for glycan analysis have led to the development of many software tools that aim to assist in the interpretation of the experimental data generated. High-throughput methods are mainly based on mass spectrometry (MS) and high performance liquid chromatography (HPLC) due to their sensitivity. Many of these methods rely on reference data of known carbohydrates from databases. Nuclear magnetic resonance (NMR) spectroscopy has always played a key role in the de novo determination of carbohydrate structures [122], and some new tools that aim at decreasing the time needed for NMR peak assignment have been recently developed (Table 3).
Table 3.
New free software tools for glycan analysis (see also [38])
| Name | Content | URL |
|---|---|---|
| GlycoWorkbench [136] | Glycan MS spectra annotation | |
| Glyco-Peakfinder [132] | Determination of glycan compositions from their mass signals | |
| GlycoPep ID [142] | Identifying the peptide moiety of glycopeptides generated using a nonspecific enzyme | http://hexose.chem.ku.edu/predictiontable.php |
| GlycoMiner [138] | Glycopeptide composition analysis | http://www.chemres.hu/ms/glycominer/index.php |
| AutoGU [86] | HPLC analysis | |
| ProspectND | NMR spectra processing | http://www.eurocarbdb.org/applications/nmr-tools |
| CCPN Tools [148] | Annotation of NMR spectra | http://www.ccpn.ac.uk/ |
| CASPER [146] | Structure determination of oligosaccharides and regular polysaccharides |
Automatic interpretation of MS data remains a challenging task due to the technique only being able to report masses of the fragments observed. This information can be used to calculate a set of potential compositions the carbohydrate could have, which then give rise to a set of potential carbohydrates that satisfy the composition constraints. One of the first tools to deduce potential carbohydrate compositions from MS data is the GlycoMod online service [123]. The number of compositions matching a certain mass value scales exponentially with the number of different monomers; therefore, taxonomic and biosynthetic information have to be incorporated in the assignment process so that smart choices can be made based upon a given composition. The Cartoonist tool [124–127] uses a set of archetypal structures in combination with a set of rules for their potential modification to generate all types of glycans that could be possibly synthesized by mammalian cells. Archetypes and rules have been compiled by a group of experts and represent the current knowledge on biosynthetic pathways in mammalian organisms. The number of matching structures is thus greatly reduced by avoiding implausible molecules. Cartoonist has been extended over the years, and now uses a well-tested library of structures, scoring routines to establish confidence scores in an annotation, and knowledge of biochemical pathways to aid the interpretation of spectra. Cartoonist is used as an analysis tool for the glycan profiling service of the CFG.
De novo sequencing tools based on MSn fragmentation data are STAT [128], OSCAR [129] StrOligo [130], and GLYCH [131]. Glyco-Peakfinder [132] is a new web-service for the de novo determination of the composition of glycan-derived MS signals independent of the source of spectral data. Library-based sequencing methods—similar to those applied in proteomics—are also applied in glycomics, where experimental peaks of MS2 spectra are compared with online calculated theoretical fragments from user-definable carbohydrate sequences deposited in databases (glyco-fragment mass fingerprinting). Such an approach is supported by the GlycoSearchMS service [133], where Glyco-Fragment [134] is used to calculate fragment-libraries of all carbohydrates contained in GLYCOSCIENCES.de. GlycosidIQ™ [135] is a similar mass fingerprinting tool developed for interpretation of oligosaccharide mass spectrometric fragmentation based on matching experimental data with theoretically fragmented oligosaccharides generated from the database GlycoSuiteDB [87]. However, the success of such an approach depends on the comprehensiveness of experimentally determined glycan structures included in the database. GlycoWorkbench [136], one of the most recent tools for the computer-assisted annotation of mass spectra of glycans, has been developed as an open source project in the context of the EUROCarbDB project. The main task of GlycoWorkbench is to evaluate a set of structures proposed by the user by matching the corresponding theoretical list of fragment masses against the list of peaks derived from the spectrum. For annotation, GlycoWorkbench uses a database of carbohydrate structures derived from GLYCOSCIENCES.de, CarbBank, and CFG glycan. The tool provides an easy to use graphical interface, a comprehensive and increasing set of structural constituents, an exhaustive collection of fragmentation types, and a broad list of annotation options. Mass spectra annotated with GlycoWorkbench can be uploaded into the EUROCarbDB MS database. GlyQuest [137] and GlycoMiner [138] are new tools that support high-throughput composition and primary structure determination of N-glycans attached to peptides, based on CID (collision induced dissociation) MS/MS (tandem mass spectrometric data). Also new is SysBioWare [139], a general software platform for carbohydrate assignment based on MS data. More specialized applications have been reported for the analysis of glycosaminoglycans [140], in silico fragmentation of peptides linked to N-glycans [141], and identifiying the peptide moiety of sulfated or sialylated carbohydrates [142]. Of further interest for bioinformatic developers might be the OpenMS [143] initiative that provides an open source framework for mass spectrometry and TOPPView [144], an open source viewer for MS data.
The development of robust high-performance liquid chromatography (HPLC) technologies continues to improve the detailed analysis and sequencing of glycan structures released from glycoproteins. In the context of the EUROCarbDB project, an analytical tool (autoGU) [86] was developed to assist in the interpretation, assignment, and annotation of HPLC-glycan profiles. AutoGU assigns provisional structures to each integrated HPLC peak and, when used in combination with exoglycosidase digestions, progressively assigns each structure automatically based on the footprint data. The software is assisted by GlycoBase, a relational database originally developed at the Oxford Glycobiology Institute, which contains the HPLC elution positions for over 350 2-AB labelled N-glycan structures together with digestion pathways. The system is suitable for automated analysis of N-linked sugars released from glycoproteins and allows detection of the carbohydrates at femtomolar concentrations [18].
ProSpectND is an advanced integrated NMR data processing and inspection tool, originally developed at the University of Utrecht and refined during the EUROCarbDB project. It allows batch processing of spectra simulations and automated graphics generation. CASPER is a tool for calculating chemical shifts of oligo- and polysaccharides as well as N- and O-glycans. The tool already has a long history [145, 146] and has recently received a major upgrade. CASPER can also be used for determining the primary structures of carbohydrates by simulating spectra of a set of possible structures and comparing them with the supplied experimental data to find the best match. The Collaborative Computing Project for the NMR community (CCPN) has developed a powerful data model for NMR experiments [147] and an assignment package for NMR spectra of proteins and peptides (CcpNmr Analysis) [148]. As a result of an intensive EUROCarbDB/CCPN collaboration, support for (branched) carbohydrates was added to the CCPN data model and CcpNmr Analysis software. Additionally, CASPER can be used to automatically assign NMR signals to carbohydrate atoms in connection with CcpNmr Analysis. CCPN project files can be directly uploaded into the EUROCarbDB NMR database.
Prediction and statistical analysis of glycosylation sites
Glycosylation is the most common post-translational modification of proteins [1]. Initial analyses yielded a consensus sequence motif for N-type glycosylation, Asn-X-Ser/Thr, with any amino acid at X except proline. Every N-type glycosylation site adheres to this motif, but its sole presence in the amino acid sequence is only a necessity and not sufficient to predict the presence of a glycan. The situation becomes further complicated when one considers mucin-type or other types of O-glycosylation where the glycan is usually attached to a serine or threonine. Research in this area over the last 10 years has resulted in a series of approaches for the prediction of glycosylation sites (Table 4). All strategies for the prediction of glycosylation sites are of a statistical nature: NetCGlyc [149], NetNGlyc [150], NetOGlyc [151], and YinOYang [150] all use neural networks for the prediction of glycosylation sites; big-Pi [152] employs scoring functions based on amino acid properties; GPI-SOM [153] uses a Kohonen map; CKSAAP_OGlySite [154], and EnsembleGly [155] use a Support Vector Machine based approach; and GPP [156], the currently best performing predication tool, uses a hybrid combinatorial and statistical learning approach based on random forests. Training datasets for the statistical learning approaches are usually derived from the PDB or O-GLYCBASE [117].
Table 4.
Tools for prediction and analysis of glycosylation sites
| Name | Description | URL |
|---|---|---|
| Big-Pi [152] | GPI-anchors | http://mendel.imp.ac.at/sat/gpi/gpi_server.html |
| GPI-SOM [153] | GPI-anchors | http://gpi.unibe.ch/ |
| NetCGlyc [149] | C-mannosylation | http://www.cbs.dtu.dk/services/NetCGlyc/ |
| NetNGlyc [150] | N-glycosylation | http://www.cbs.dtu.dk/services/NetNGlyc/ |
| NetOGlyc [151] | O-glycosylation | http://www.cbs.dtu.dk/services/NetOGlyc/ |
| YinOYang [150] | O-beta-GlcNAc-ylation | http://www.cbs.dtu.dk/services/YinOYang/ |
| EnsembleGly [155] | O-, N- and C-glycosylation | http://turing.cs.iastate.edu/EnsembleGly/ |
| CKSAAP_OGlySite [154] | Mucin-type O-glycosylation | http://bioinformatics.cau.edu.cn/zzd_lab/CKSAAP_OGlySite/ |
| GPP [156] | O- and N-glycosylation | http://comp.chem.nottingham.ac.uk/glyco/ |
| GlySeq [159] | Statistical analysis of glycosylation sites based on sequence | http://www.dkfz.de/spec/glycosciences.de/tools/glyseq/ |
| GlyVicinity [159] | Statistical analysis of glycosylation sites based on 3D structures | http://www.dkfz.de/spec/glycosciences.de/tools/glyvicinity/ |
The mechanism of acceptor site selection for the covalent attachment of carbohydrates by a series of glycosyl transferases in the case of C-type and O-type glycosylation, and by the oligosaccharyltransferase (OST) for N-type glycosylation, is still not completely understood. This has led to studies on the statistical and structural properties of amino acids in the neighborhood of glycosylation sites. Conformational and statistical properties of N-type glycosylation sites were analyzed based on glycosylated proteins found in the PDB [157]. Statistical properties of O-type glycosylation were analyzed based on entries of the O-GLYCBASE [158]. The GlySeq and GlyVicinity online services [159] allow for interactive exploration of the statistical and conformational properties of glycosylation sites and their surroundings.
Carbohydrate 3D structures and molecular modeling
Complex carbohydrates represent a particularly challenging class of molecules in terms of describing their three-dimensional (3D) structure. Due to their inherent flexibility, these molecules very often exist in solution as an ensemble of conformations rather than as a single well-defined structure. Traditionally, NMR methods, especially Nuclear Overhauser Effect (NOE) measurements, have been widely used to study oligosaccharide conformation in solution [160, 161]. Unfortunately, many oligosaccharide NOEs cannot be resolved or are difficult to assign. Additionally, there are often too few inter-residue NOEs to make an unambiguous 3D structure determination possible. In general, the interpretation of structural experimental data frequently needs to be supported by molecular modeling methods [162, 163]. One of the main aims of computer modeling of carbohydrates is to generate reasonable 3D models that can be used to rationalize experimentally derived observations. Conformational analysis by computational methods consequently plays a key role in the determination of 3D structures of complex carbohydrates.
In recent years, a variety of modeling methods have been applied to the conformational analysis of carbohydrates [164]. Of these, the calculation of conformational maps for disaccharides using systematic search methods, and molecular dynamics (MD) simulations of oligosaccharides in explicit solvent, are by far the most popular methods in modeling of carbohydrate 3D structures [165–168]. Although quantum mechanics (ab initio) methods are used for modeling of carbohydrate conformation, these methods are still computationally too demanding to be used routinely to study or predict the 3D structure of complex carbohydrates. Quantum mechanics methods are mainly used to study chemical reactions [169–171], to calculate force constants and atom charges to be used as force field parameters [172, 173], or for the conformational analysis of smaller carbohydrates [174–176].
In general, molecular modeling methods are applied in glycobiology at various levels of required expertise and computer equipment. Simple model building using a molecular builder will already give one valuable insight: complex carbohydrates look in 3D very different from the impression one gets by looking at chemical drawings or cartoon representations. Also, the simple overlay in 3D of a new carbohydrate ligand onto an existing one in a crystal structure can give valuable first insight into a possible binding mode. However, one has to be aware of the limitations of such basic modeling approaches: molecular builders generate one reasonable conformation out of many; and manually overlaying two carbohydrates in a binding site is a strong bias towards one predefined binding mode and alternative binding modes are unlikely to be discovered. The other extremes would be to perform a complete conformational analysis of a complex carbohydrate based on extensive MD simulations in explicit solvent, which may take weeks of calculation time, and GBytes of simulation data need to be analyzed afterwards, or to screen the complete protein surface for carbohydrate binding sites using extensive dockings based on genetic search algorithms. Recently, even high-level Car-Parinello-based ab initio MD simulations combined with metadynamics simulation have been applied to carbohydrates [170, 177, 178]. The question which modeling method would work best for solving a specific scientific problem is not always straightforward to answer. For example, if exploring the accessible conformational space of a carbohydrate is of major interest then the MD simulation could also be performed in gas phase at higher temperatures instead of running an extensive MD simulation in explicit solvent at room temperature. However, for some systems, the use of explicit solvent is necessary,while for others, one would reach the same conclusions based on gas phase simulations, but with much less computational cost. As is the case with ‘experimental’ methods, ‘experience’ is the key to successful application of molecular modeling methods in most cases.
Since the beginning of the 1990s, more and more crystal structures have been reported where carbohydrates are covalently attached to a (glyco) protein or constitute the ligand in a protein–carbohydrate complex [179, 180]. These experimentally determined 3D structures are freely accessible from the Protein Data Bank (PDB) [112]. So, over recent years, the PDB has become a very valuable resource for obtaining conformational properties of carbohydrates [181]. However, it has to be kept in mind that crystals are often grown under non-physiological conditions, and flexible molecules like carbohydrates may change conformation due to strong forces induced by crystallographic packing.
A variety of reviews and book chapters on conformational analysis of carbohydrates have been published and are recommended for further reading [46, 165, 166, 182].
Databases containing 3D structures of carbohydrates
The two major databases where experimentally determined carbohydrate structures are stored are the Cambridge Structural Database (CSD, http://www.ccdc.cam.ac.uk/products/csd/) and the Protein Data Bank (PDB, http://www.rcsb.org/pdb/). Many crystal structures of small oligosaccharides [183] are also accessible through the Glyco3D web interface (http://www.cermav.cnrs.fr/glyco3d/).
The PDB [112] currently contains more than 60,000 3D structures of biomolecules, of which about 4,000 contain carbohydrates [184]. Most of the carbohydrates in the PDB are either connected covalently to a (glyco)protein, or the carbohydrate forms a complex with a lectin, enzyme, or antibody. Isolated carbohydrates are only rarely found in the PDB. When looking at the carbohydrate structures of a PDB entry, one has to keep in mind that frequently only fragments of the original carbohydrates may be resolved (Fig. 8). Additionally, the 3D structures of the carbohydrates in the PDB do not always meet high quality standards; therefore, one has to look at the structures with care. It has been recognized that, in order to improve the quality of the 3D structures contained in the PDB, theoretical validation procedures for carbohydrates have to be established [184–186]. Despite these limitations, the PDB is an important source of information on carbohydrate 3D structures [187]. Unfortunately, due to the lack of a consistently used nomenclature for carbohydrates in PDB files, it is difficult to find the entries of interest. To overcome this problem, the GLYCOSCIENCES.de web portal [187] and the Glycoconjugate Data Bank: Structures (http://www.glycostructures.jp) [188] offer convenient ways to search for carbohydrate structures in the PDB.
Fig. 8.
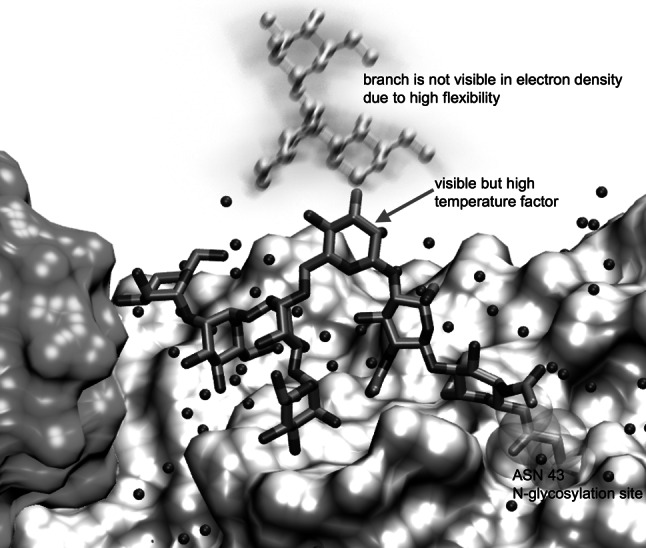
N-Glycosylation site of Phanerochaete chrysosporium Laminarinase 16A (pdb code 2W52 [189]). Although the resolution of the X-ray crystal structure is rather high (1.56 Å), parts of the N-glycan are not visible in the electron density due to the high flexibility of the branch linked to position 3 of the core mannose
Statistical analysis of structural parameters of the carbohydrates present in the PDB entries can be performed with the tools GlySeq, GlyVicinity, GlyTorsion, and carp (http://www.glycosciences.de/tools) [159]. GlySeq checks the type of amino acids that are in the sequence neighborhood of N- and O-glycosylation sites, GlyVicinity performs an analysis of the population of amino acids in the spatial vicinity of carbohydrate residues, and GlyTorsion provides access to the torsion angles of the glycosidic linkages. Using the carp tool (CArbohydrate Ramachandran Plot), these torsions can be compared to theoretical Ramachandran-type conformational maps stored in GlycoMapsDB [185]. This service can be used by crystallographers to cross-check or validate the carbohydrate 3D structures similar to the Ramachandran plot analysis that is routinely used to evaluate the backbone torsions of protein structures.
Molecular modeling of carbohydrates over the Internet
Easy-to-use and freely available Web-based tools [32, 190] are available to generate an initial model of a carbohydrate 3D structure. SWEET-II [191] is a frequently used carbohydrate 3D builder that is available on the GLYCOSCIENCES.de [82] website, which also provides the GlyProt [192] tool for in silico glycosylation of proteins derived from the PDB. A very nice builder for carbohydrates and glycoproteins is also available at the GLYCAM website (http://www.glycam.com). The first molecular builder for carbohydrates was probably POLYS [193] and the latest development in this field is FSPS (fast sugar structure prediction software) [194]. However, it is unclear whether POLYS or FSPS are available to the scientific community via a website or for download. A web-portal to perform MD simulations of carbohydrates over the Internet [195] was recently shut down because the glycoinformatics group that maintained the service was closed [42].
Molecular dynamics simulation
Despite the significant limitations that still exist, the use of molecular dynamics (MD) simulations has turned out to be an excellent methodology to study the conformational properties of carbohydrates and other biomolecules [163, 196–199]. Although quantum mechanics-based MD simulations have recently become feasible, most applications of MD are still based on force fields. The development of carbohydrate force fields in itself is a challenging task and is still in progress [172, 173, 200]. Because carbohydrates are polar molecules, the proper treatment of atom charges is likely to be of significant importance particularly for modeling of intermolecular interactions [201]. The discussion about including extra terms for (exo) anomeric effects into force fields has a long tradition in carbohydrate modeling [202–205]. The solvent model used for the MD simulation also has a significant effect on the results [206]. In order to make the outcome of an MD simulation more reliable, the theoretical results should always be compared to experimental results if possible. It has to be kept in mind that disagreement between computational and experimental results does not necessarily mean that the force field used is inappropriate for the simulation of carbohydrate structures. It can also mean that other simulation parameters used are not appropriate (e.g., simulation time, solvent model) or possibly that there is a significant error in the experimental results themselves. However, experimental results are very important for validating the quality of theoretical calculations. In recent years, MD simulations have been used to study conformations of complex carbohydrates [206–209], glycolipids [200, 210, 211], glycopeptides [212], glycoproteins [213, 214], protein–carbohydrate complexes [215–217], protein–glycopeptide interaction [218], carbohydrate–ion interaction [219], and carbohydrate–water interaction [220].
The MD simulation of a complex oligosaccharide or glycoprotein in a solvent box is computationally very expensive, and CPU time of many weeks or months may be required in order to simulate a timescale of only a few nanoseconds [221] (Fig. 9). The timescales of most of the published MD simulations involving carbohydrates are in the range of up to 50 ns. However, in order to achieve convergence for the rotamer populations of the exocylic C–C torsions, the length of an MD simulation should be longer than 100 ns [206, 222]. Although water models like TIP5P are a better approximation of water, in most MD simulations much simpler water models, like SPC or TIP3P [223, 224], are used because of calculation speed and because most force field parameters have been tailored to these simple models. The trajectory files of an MD simulation are typically many GBytes in size. With the availability of supercomputers terabytes of MD data can be produced easily within a short time. The current bottleneck in the application of MD simulations is therefore hard disk space and the requirement to analyze and interpret very quickly the huge amount of data produced. Analysis tools that are part of the MD software distributions [225–227], and which have been mainly developed for the analysis of proteins, are frequently used for the analysis of MD trajectories of carbohydrates. However, because of the limitations of the available tools, glycoscientists tend to develop their own ‘in-house’ analysis software. Recently, ‘Conformational Analysis Tools’ (CAT) [228], a novel software for the analysis of MD trajectories, has been made publicly available. CAT is optimized for the efficient conformational analysis of carbohydrates, glycoproteins, and protein–carbohydrate complexes. In summary, MD simulations provide valuable additional information on the conformational dynamics of the system investigated, which is frequently not available from experimental methods. However, although performing simple MD simulations is straightforward in most cases, the correct setup and interpretation of the results requires expert knowledge, and the limitations of the method have to be taken into account.
Fig. 9.
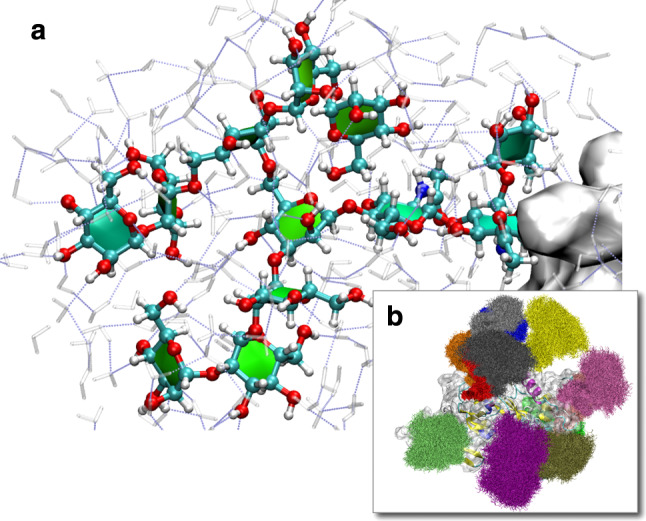
MD simulation of SIV gp120 glycoprotein (M. Frank, unpublished). Complete N-glycans were modeled at 13 glycosylation sites based on the X-ray structure (pdb code 2BF1 [229]). a Solvation shell of a selected N-glycan on the protein surface. b A significant surface area of the protein is shielded by the N-glycans. The molecular system has more than 100,000 atoms (4,832 protein atoms, 3,432 carbohydrate atoms, 30,665 water molecules, 4 chloride ions). Water molecules are not shown for clarity
Modeling protein–carbohydrate interaction
One of the major challenges in molecular modeling at the moment is the development of efficient and accurate methods to estimate the binding affinity of protein–carbohydrate complexes [46]. The application of docking methods to study protein–carbohydrate interaction has lately significantly increased [230–236]. Typically, a flexible ligand is docked to a rigid receptor; however, examples are reported where receptor flexibility has been included in the docking protocol [237–239]. Next to an efficient searching algorithm, the availability of a robust scoring function is critical for the success of docking [240]. Bridging water molecules and CH–π interactions [241–243] play a major role in the interaction of a carbohydrate and a protein. However, for various reasons, it is difficult to include these factors into the scoring functions of available standard docking software (e.g. AutoDOCK) [244]. Therefore, despite the many successful applications of docking methods, there are still significant problems with respect to the correct prediction of carbohydrate binding sites and relative affinities in some cases.
If a 3D structure of a protein–carbohydrate complex is available (e.g. an X-ray structure), MD simulations can be performed to study the local interactions (hydrogen bonding, hydrophobic interactions, water bridges) in more detail [245, 246] or to calculate free energy [247–249] and entropy changes upon binding [250]. Since polar OH groups of carbohydrates quite frequently like to bind in areas where water molecules are also found on the protein surface, an investigation of the water binding sites is of particular interest [251–253].
Conclusion
From the bioinformatics point of view, carbohydrates are a particularly challenging class of biomolecules. Like nucleic acids or proteins, they are assembled from a set of molecular building blocks; however, due to multiple linkage types and sites, even linear carbohydrates are much more complex. Additionally, complex carbohydrates frequently contain one or more branches, which renders most of the sequence algorithms developed for genes not applicable to carbohydrates, and so more complicated tree-based algorithms have to be developed and applied. As a result, established bioinformatics groups seem to neglect carbohydrates to a large extent, and only a few glycoinformatic pioneers face the challenge to develop computer algorithms for carbohydrate sequences.
Significant improvements in glycan analysis and the application of carbohydrate microarrays in glycomics research have led to a significant increase in the amount of experimental data generated. Unfortunately, because of the lack of an established glycoinformatics infrastructure and standards in the field, each research group or consortium has developed their own storage formats, databases, and tools. This renders data integration and exchange very difficult. In recent years, it has become obvious that this situation needs to be changed in the future, and centrally integrated, curated, and comprehensive databases are required for glycomics, similar to proteomics and genomics [27, 38, 254]. Despite this insight, it is very difficult to establish a global glycoinformatics infrastructure at the moment due to the lack of funding and leadership. This is particularly unfortunate because, in recent years, the field has made significant progress: a standard glycan sequence format (GlycoCT) has been developed; and GlycomeDB integrates globally all carbohydrate structure databases and makes the structures searchable for scientists through one central web-interface. In the context of the EUROCarbDB project, standards, tools, and databases have been developed to store carbohydrate structures, analytical data, biological context, and literature references. Recently, a database prototype (GlyAffinity) that aims at integrating all types of protein–carbohydrate interaction data has been developed; the bioinformatic cores of the Consortium for Functional Glycomics (CFG) and the Japan Consortium for Glycobiology and Glycotechnology (JCGG) are making available a vast amount of experimental data; and the EuroGlycoArrays Consortium has just entered the field and will provide more experimental data for the community. Last but not least, in recent years, people working in the field have really started to talk to each other, which is an important catalyst for establishing bioinformatics standards and fueling data integration.
Over the years, established methods in structural glycobiology, like X-ray crystallography, NMR, and molecular modeling, have provided valuable insights into the three-dimensional structures of carbohydrates, glycoproteins and protein–carbohydrate complexes. This has further improved our understanding of the functions of glycans, and may help to design better enzymes, drugs, or vaccines [10, 255–258]. It has been realized within the PDB consortium [112] that the data representation and validation of carbohydrates in the PDB needs to be revised. Working groups have been established recently to develop a new format for representing carbohydrates in the PDB, and to recommend new computational tools to be developed [259], as well as to develop standards for glycomics databases and experimental reporting [260].
For a long time glycobiology has been the cinderella field in life sciences: “an area that involves much work but, does not get to show off at the ball with her cousins, the genomes and proteins” [261]. This has changed dramatically over the last 10 years. Large collections of new glycomics data are available that are ready to be integrated into the large data collections of proteomics and genomics. Bioinformatics standards for glycomics have been established and, in the context of the EUROCarbDB project, strategies and concepts for data sharing have been worked out and initial discussions with bioinformatic groups from the proteomics field have taken place. It has been realized that the topics currently discussed in proteomics on data sharing [262] are very similar to the aims of EUROCarbDB. Therefore, the next steps will be to establish a closer collaboration with bioinformatic groups in proteomics and genomics which will hopefully result in the long-term establishment of glycoinformatic concepts at the European Bioinformatics Institute (EMBL-EBI) or the National Center for Biotechnology Information (NCBI) and a bioinformatics center in Japan. In conclusion, bioinformatics for glycomics has evolved beautifully over recent years and is ready to be invited to show up at the ball with proteomics and genomics in order to waltz together.
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
References
- 1.Apweiler R, Hermjakob H, Sharon N. On the frequency of protein glycosylation, as deduced from analysis of the SWISS-PROT database. Biochim Biophys Acta. 1999;1473:4–8. doi: 10.1016/s0304-4165(99)00165-8. [DOI] [PubMed] [Google Scholar]
- 2.Marth JD, Grewal PK. Mammalian glycosylation in immunity. Nat Rev Immunol. 2008;8:874–887. doi: 10.1038/nri2417. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Varki A. Sialic acids in human health and disease. Trends Mol Med. 2008;14:351–360. doi: 10.1016/j.molmed.2008.06.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Ohtsubo K, Marth JD. Glycosylation in cellular mechanisms of health and disease. Cell. 2006;126:855–867. doi: 10.1016/j.cell.2006.08.019. [DOI] [PubMed] [Google Scholar]
- 5.Jaeken J, Matthijs G. Congenital disorders of glycosylation: a rapidly expanding disease family. Annu Rev Genomics Hum Genet. 2007;8:261–278. doi: 10.1146/annurev.genom.8.080706.092327. [DOI] [PubMed] [Google Scholar]
- 6.Jefferis R. Recombinant antibody therapeutics: the impact of glycosylation on mechanisms of action. Trends Pharmacol Sci. 2009;30:356–362. doi: 10.1016/j.tips.2009.04.007. [DOI] [PubMed] [Google Scholar]
- 7.Li H, d’Anjou M. Pharmacological significance of glycosylation in therapeutic proteins. Curr Opin Biotechnol. 2009;20:678–684. doi: 10.1016/j.copbio.2009.10.009. [DOI] [PubMed] [Google Scholar]
- 8.Kawasaki N, Itoh S, Hashii N, Takakura D, Qin Y, Huang X, Yamaguchi T. The significance of glycosylation analysis in development of biopharmaceuticals. Biol Pharm Bull. 2009;32:796–800. doi: 10.1248/bpb.32.796. [DOI] [PubMed] [Google Scholar]
- 9.Arnold JN, Wormald MR, Sim RB, Rudd PM, Dwek RA. The impact of glycosylation on the biological function and structure of human immunoglobulins. Annu Rev Immunol. 2007;25:21–50. doi: 10.1146/annurev.immunol.25.022106.141702. [DOI] [PubMed] [Google Scholar]
- 10.Hecht ML, Stallforth P, Silva DV, Adibekian A, Seeberger PH. Recent advances in carbohydrate-based vaccines. Curr Opin Chem Biol. 2009;13:354–359. doi: 10.1016/j.cbpa.2009.05.127. [DOI] [PubMed] [Google Scholar]
- 11.Yu U, Lee SH, Kim YJ, Kim S. Bioinformatics in the post-genome era. J Biochem Mol Biol. 2004;37:75–82. doi: 10.5483/bmbrep.2004.37.1.075. [DOI] [PubMed] [Google Scholar]
- 12.Krishnamoorthy L, Mahal LK. Glycomic analysis: an array of technologies. ACS Chem Biol. 2009;4:715–732. doi: 10.1021/cb900103n. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Haslam SM, Julien S, Burchell JM, Monk CR, Ceroni A, Garden OA, Dell A. Characterizing the glycome of the mammalian immune system. Immunol Cell Biol. 2008;86:564–573. doi: 10.1038/icb.2008.54. [DOI] [PubMed] [Google Scholar]
- 14.Zaia J. Mass spectrometry and the emerging field of glycomics. Chem Biol. 2008;15:881–892. doi: 10.1016/j.chembiol.2008.07.016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Ruhaak LR, Deelder AM, Wuhrer M. Oligosaccharide analysis by graphitized carbon liquid chromatography-mass spectrometry. Anal Bioanal Chem. 2009;394:163–174. doi: 10.1007/s00216-009-2664-5. [DOI] [PubMed] [Google Scholar]
- 16.Turnbull JE, Field RA. Emerging glycomics technologies. Nat Chem Biol. 2007;3:74–77. doi: 10.1038/nchembio0207-74. [DOI] [PubMed] [Google Scholar]
- 17.Geyer H, Geyer R. Strategies for analysis of glycoprotein glycosylation. Biochim Biophys Acta. 2006;1764:1853–1869. doi: 10.1016/j.bbapap.2006.10.007. [DOI] [PubMed] [Google Scholar]
- 18.Royle L, Campbell MP, Radcliffe CM, White DM, Harvey DJ, Abrahams JL, Kim YG, Henry GW, Shadick NA, Weinblatt ME, Lee DM, Rudd PM, Dwek RA. HPLC-based analysis of serum N-glycans on a 96-well plate platform with dedicated database software. Anal Biochem. 2008;376:1–12. doi: 10.1016/j.ab.2007.12.012. [DOI] [PubMed] [Google Scholar]
- 19.Karlsson H, Larsson JM, Thomsson KA, Hard I, Backstrom M, Hansson GC. High-throughput and high-sensitivity nano-LC/MS and MS/MS for O-glycan profiling. Methods Mol Biol. 2009;534:117–131. doi: 10.1007/978-1-59745-022-5_9. [DOI] [PubMed] [Google Scholar]
- 20.Domann PJ, Pardos-Pardos AC, Fernandes DL, Spencer DI, Radcliffe CM, Royle L, Dwek RA, Rudd PM. Separation-based glycoprofiling approaches using fluorescent labels. Proteomics. 2007;7(Suppl 1):70–76. doi: 10.1002/pmic.200700640. [DOI] [PubMed] [Google Scholar]
- 21.Wada Y, Azadi P, Costello CE, Dell A, Dwek RA, Geyer H, Geyer R, Kakehi K, Karlsson NG, Kato K, Kawasaki N, Khoo KH, Kim S, Kondo A, Lattova E, Mechref Y, Miyoshi E, Nakamura K, Narimatsu H, Novotny MV, Packer NH, Perreault H, Peter-Katalinic J, Pohlentz G, Reinhold VN, Rudd PM, Suzuki A, Taniguchi N. Comparison of the methods for profiling glycoprotein glycans—HUPO Human Disease Glycomics/Proteome Initiative multi-institutional study. Glycobiology. 2007;17:411–422. doi: 10.1093/glycob/cwl086. [DOI] [PubMed] [Google Scholar]
- 22.Liu Y, Palma AS, Feizi T. Carbohydrate microarrays: key developments in glycobiology. Biol Chem. 2009;390:647–656. doi: 10.1515/BC.2009.071. [DOI] [PubMed] [Google Scholar]
- 23.Horlacher T, Seeberger PH. Carbohydrate arrays as tools for research and diagnostics. Chem Soc Rev. 2008;37:1414–1422. doi: 10.1039/b708016f. [DOI] [PubMed] [Google Scholar]
- 24.Hirabayashi J. Concept, strategy and realization of lectin-based glycan profiling. J Biochem. 2008;144:139–147. doi: 10.1093/jb/mvn043. [DOI] [PubMed] [Google Scholar]
- 25.Pilobello KT, Slawek DE, Mahal LK. A ratiometric lectin microarray approach to analysis of the dynamic mammalian glycome. Proc Natl Acad Sci USA. 2007;104:11534–11539. doi: 10.1073/pnas.0704954104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Raman R, Raguram S, Venkataraman G, Paulson JC, Sasisekharan R. Glycomics: an integrated systems approach to structure-function relationships of glycans. Nat Methods. 2005;2:817–824. doi: 10.1038/nmeth807. [DOI] [PubMed] [Google Scholar]
- 27.Packer NH, von der Lieth C-W, Aoki-Kinoshita KF, Lebrilla CB, Paulson JC, Raman R, Rudd P, Sasisekharan R, Taniguchi N, York WS. Frontiers in glycomics: Bioinformatics and biomarkers in disease. An NIH White Paper prepared from discussions by the focus groups at a workshop on the NIH campus, Bethesda, MD (September 11–13, 2006) Proteomics. 2008;8:8–20. doi: 10.1002/pmic.200700917. [DOI] [PubMed] [Google Scholar]
- 28.Andersson B (2006) European Science Foundation Policy Briefing
- 29.von der Lieth CW, Lutteke T, Frank M (eds) (2009) Bioinformatics for glycobiology and glycomics: an Introduction. Wiley, New York
- 30.Kersey P, Apweiler R. Linking publication, gene and protein data. Nat Cell Biol. 2006;8:1183–1189. doi: 10.1038/ncb1495. [DOI] [PubMed] [Google Scholar]
- 31.Mulder NJ, Kersey P, Pruess M, Apweiler R. In silico characterization of proteins: UniProt, InterPro and Integr8. Mol Biotechnol. 2008;38:165–177. doi: 10.1007/s12033-007-9003-x. [DOI] [PubMed] [Google Scholar]
- 32.Lutteke T. Web Resources for the Glycoscientist. Chembiochem. 2008;9:2155–2160. doi: 10.1002/cbic.200800338. [DOI] [PubMed] [Google Scholar]
- 33.Mahal LK. Glycomics: towards bioinformatic approaches to understanding glycosylation. Anticancer Agents Med Chem. 2008;8:37–51. doi: 10.2174/187152008783330806. [DOI] [PubMed] [Google Scholar]
- 34.Mamitsuka H. Informatic innovations in glycobiology: relevance to drug discovery. Drug Discov Today. 2008;13:118–123. doi: 10.1016/j.drudis.2007.10.013. [DOI] [PubMed] [Google Scholar]
- 35.Aoki-Kinoshita KF. An introduction to bioinformatics for glycomics research. PLoS Comput Biol. 2008;4:e1000075. doi: 10.1371/journal.pcbi.1000075. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Ranzinger R, Herget S, Lutteke T, Frank M (2009) Carbohydrate Structure Databases. In: Cummings RD, Pierce JM (eds) Handbook of glycomics. Elsevier, Amsterdam, pp 211–233
- 37.von der Lieth C-W. Databases and Informatics for Glycobiology and Glycomics. In: Kamerling JP, editor. Comprehensive glycoscience—from chemistry to systems biology. Oxford: Elsevier; 2007. pp. 329–346. [Google Scholar]
- 38.von der Lieth C-W, Lutteke T, Frank M. The role of informatics in glycobiology research with special emphasis on automatic interpretation of MS spectra. Biochim Biophys Acta. 2006;1760:568–577. doi: 10.1016/j.bbagen.2005.12.004. [DOI] [PubMed] [Google Scholar]
- 39.Aoki-Kinoshita KF, Kanehisa M. Bioinformatics approaches in glycomics and drug discovery. Curr Opin Mol Ther. 2006;8:514–520. [PubMed] [Google Scholar]
- 40.Perez S, Mulloy B. Prospects for glycoinformatics. Curr Opin Struct Biol. 2005;15:517–524. doi: 10.1016/j.sbi.2005.08.005. [DOI] [PubMed] [Google Scholar]
- 41.Marchal I, Golfier G, Dugas O, Majed M. Bioinformatics in glycobiology. Biochimie. 2003;85:75–81. doi: 10.1016/S0300-9084(03)00068-3. [DOI] [PubMed] [Google Scholar]
- 42.von der Lieth C-W, Bohne-Lang A, Lohmann KK, Frank M. Bioinformatics for glycomics: status, methods, requirements and perspectives. Brief Bioinform. 2004;5:164–178. doi: 10.1093/bib/5.2.164. [DOI] [PubMed] [Google Scholar]
- 43.Werz DB, Ranzinger R, Herget S, Adibekian A, von der Lieth C-W, Seeberger PH. Exploring the structural diversity of mammalian carbohydrates (“glycospace”) by statistical databank analysis. ACS Chem Biol. 2007;2:685–691. doi: 10.1021/cb700178s. [DOI] [PubMed] [Google Scholar]
- 44.Harvey DJ, Merry AH, Royle L, Campbell MP, Dwek RA, Rudd PM. Proposal for a standard system for drawing structural diagrams of N- and O-linked carbohydrates and related compounds. Proteomics. 2009;9:3796–3801. doi: 10.1002/pmic.200900096. [DOI] [PubMed] [Google Scholar]
- 45.Varki A, Freeze HH, Manzi AE (2009) Overview of glycoconjugate analysis. Curr Protoc Protein Sci Chapter 12, Unit 12.1 12.1.1–8 [DOI] [PubMed]
- 46.DeMarco ML, Woods RJ. Structural glycobiology: a game of snakes and ladders. Glycobiology. 2008;18:426–440. doi: 10.1093/glycob/cwn026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Banin E, Neuberger Y, Altshuler Y, Halevi A, Inbar O, Nir D, Dukler A. A novel Linear Code((R)) nomenclature for complex carbohydrates. TIGG. 2002;14:127–137. [Google Scholar]
- 48.Herget S, Toukach PV, Ranzinger R, Hull WE, Knirel YA, von der Lieth C-W. Statistical analysis of the Bacterial Carbohydrate Structure Data Base (BCSDB): characteristics and diversity of bacterial carbohydrates in comparison with mammalian glycans. BMC Struct Biol. 2008;8:35. doi: 10.1186/1472-6807-8-35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.McNaught AD. Nomenclature of carbohydrates (recommendations 1996) Adv Carbohydr Chem Biochem. 1997;52:43–177. doi: 10.1016/S0065-2318(08)60089-X. [DOI] [PubMed] [Google Scholar]
- 50.Varki A, Cummings RD, Esko JD, Freeze HH, Stanley P, Marth JD, Bertozzi CR, Hart GW, Etzler ME. Symbol nomenclature for glycan representation. Proteomics. 2009;9:5398–5399. doi: 10.1002/pmic.200900708. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Ceroni A, Dell A, Haslam SM. The GlycanBuilder: a fast, intuitive and flexible software tool for building and displaying glycan structures. Source Code Biol Med. 2007;2:3. doi: 10.1186/1751-0473-2-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Doubet S, Bock K, Smith D, Darvill A, Albersheim P. The Complex Carbohydrate Structure Database. Trends Biochem Sci. 1989;14:475–477. doi: 10.1016/0968-0004(89)90175-8. [DOI] [PubMed] [Google Scholar]
- 53.Pellegrini L, Burke DF, von Delft F, Mulloy B, Blundell TL. Crystal structure of fibroblast growth factor receptor ectodomain bound to ligand and heparin. Nature. 2000;407:1029–1034. doi: 10.1038/35039551. [DOI] [PubMed] [Google Scholar]
- 54.Murray-Rust P, Mitchell JB, Rzepa HS. Communication and re-use of chemical information in bioscience. BMC Bioinformatics. 2005;6:180. doi: 10.1186/1471-2105-6-180. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.McNaught A (2006) The IUPAC International Chemical Identifier:InChl. Chemistry International (IUPAC) 28 [DOI] [PMC free article] [PubMed]
- 56.Weininger D. Smiles, a chemical language and information—system 1. Introduction to methodology and encoding rules. J Chem Inf Comput Sci. 1988;28:31–36. [Google Scholar]
- 57.Wang Y, Xiao J, Suzek TO, Zhang J, Wang J, Bryant SH. PubChem: a public information system for analyzing bioactivities of small molecules. Nucleic Acids Res. 2009;37:W623–W633. doi: 10.1093/nar/gkp456. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Degtyarenko K, de Matos P, Ennis M, Hastings J, Zbinden M, McNaught A, Alcantara R, Darsow M, Guedj M, Ashburner M. ChEBI: a database and ontology for chemical entities of biological interest. Nucleic Acids Res. 2008;36:D344–D350. doi: 10.1093/nar/gkm791. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Herget S, Ranzinger R, Maass K, von der Lieth C-W. GlycoCT-a unifying sequence format for carbohydrates. Carbohydr Res. 2008;343:2162–2171. doi: 10.1016/j.carres.2008.03.011. [DOI] [PubMed] [Google Scholar]
- 60.Ranzinger R, Herget S, Wetter T, von der Lieth C-W. GlycomeDB - integration of open-access carbohydrate structure databases. BMC Bioinform. 2008;9:384. doi: 10.1186/1471-2105-9-384. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Sahoo SS, Thomas C, Sheth A, Henson C, York WS. GLYDE-an expressive XML standard for the representation of glycan structure. Carbohydr Res. 2005;340:2802–2807. doi: 10.1016/j.carres.2005.09.019. [DOI] [PubMed] [Google Scholar]
- 62.Aoki KF, Yamaguchi A, Ueda N, Akutsu T, Mamitsuka H, Goto S, Kanehisa M. KCaM (KEGG Carbohydrate Matcher): a software tool for analyzing the structures of carbohydrate sugar chains. Nucleic Acids Res. 2004;32:W267–W272. doi: 10.1093/nar/gkh473. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Aoki KF, Mamitsuka H, Akutsu T, Kanehisa M. A score matrix to reveal the hidden links in glycans. Bioinformatics. 2005;21:1457–1463. doi: 10.1093/bioinformatics/bti193. [DOI] [PubMed] [Google Scholar]
- 64.Hizukuri Y, Yamanishi Y, Nakamura O, Yagi F, Goto S, Kanehisa M. Extraction of leukemia specific glycan motifs in humans by computational glycomics. Carbohydr Res. 2005;340:2270–2278. doi: 10.1016/j.carres.2005.07.012. [DOI] [PubMed] [Google Scholar]
- 65.Kuboyama T, Hirata K, Aoki-Kinoshita KF, Kashima H, Yasuda H. A gram distribution kernel applied to glycan classification and motif extraction. Genome Inform. 2006;17:25–34. [PubMed] [Google Scholar]
- 66.Yamanishi Y, Bach F, Vert JP. Glycan classification with tree kernels. Bioinformatics. 2007;23:1211–1216. doi: 10.1093/bioinformatics/btm090. [DOI] [PubMed] [Google Scholar]
- 67.Hashimoto K, Takigawa I, Shiga M, Kanehisa M, Mamitsuka H. Mining significant tree patterns in carbohydrate sugar chains. Bioinformatics. 2008;24:i167–i173. doi: 10.1093/bioinformatics/btn293. [DOI] [PubMed] [Google Scholar]
- 68.Rubin DL, Shah NH, Noy NF. Biomedical ontologies: a functional perspective. Brief Bioinform. 2008;9:75–90. doi: 10.1093/bib/bbm059. [DOI] [PubMed] [Google Scholar]
- 69.Thomas CJ, Sheth A, York WS (2006) In: Proceedings of the International Conference on formal ontology in information systems (FOIS) IOS (in press)
- 70.York WS, Kochut KJ, Miller JA (2009) Integration of glycomics knowledge and data. In: Cummings RD, Pierce JM (eds) Handbook of glycomics. Elsevier, Amsterdam, pp 179–195
- 71.Laine RA. A calculation of all possible oligosaccharide isomers both branched and linear yields 1.05 × 10(12) structures for a reducing hexasaccharide: the Isomer Barrier to development of single-method saccharide sequencing or synthesis systems. Glycobiology. 1994;4:759–767. doi: 10.1093/glycob/4.6.759. [DOI] [PubMed] [Google Scholar]
- 72.Umana P, Bailey JE. A mathematical model of N-linked glycoform biosynthesis. Biotechnol Bioeng. 1997;55:890–908. doi: 10.1002/(SICI)1097-0290(19970920)55:6<890::AID-BIT7>3.0.CO;2-B. [DOI] [PubMed] [Google Scholar]
- 73.Krambeck FJ, Betenbaugh MJ. A mathematical model of N-linked glycosylation. Biotechnol Bioeng. 2005;92:711–728. doi: 10.1002/bit.20645. [DOI] [PubMed] [Google Scholar]
- 74.Krambeck FJ, Bennun SV, Narang S, Choi S, Yarema KJ, Betenbaugh MJ. A mathematical model to derive N-glycan structures and cellular enzyme activities from mass spectrometric data. Glycobiology. 2009;19:1163–1175. doi: 10.1093/glycob/cwp081. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Kawano S, Hashimoto K, Miyama T, Goto S, Kanehisa M. Prediction of glycan structures from gene expression data based on glycosyltransferase reactions. Bioinformatics. 2005;21:3976–3982. doi: 10.1093/bioinformatics/bti666. [DOI] [PubMed] [Google Scholar]
- 76.Suga A, Yamanishi Y, Hashimoto K, Goto S, Kanehisa M. An improved scoring scheme for predicting glycan structures from gene expression data. Genome Inform. 2007;18:237–246. doi: 10.1142/9781860949920_0023. [DOI] [PubMed] [Google Scholar]
- 77.Joshi HJ (2008) Deutsches Krebsforschungszentrum, PhD Thesis, University of Heidelberg
- 78.Brooksbank C, Camon E, Harris MA, Magrane M, Martin MJ, Mulder N, O’Donovan C, Parkinson H, Tuli MA, Apweiler R, Birney E, Brazma A, Henrick K, Lopez R, Stoesser G, Stoehr P, Cameron G. The European Bioinformatics Institute’s data resources. Nucleic Acids Res. 2003;31:43–50. doi: 10.1093/nar/gkg066. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Wheeler DL, Barrett T, Benson DA, Bryant SH, Canese K, Chetvernin V, Church DM, Dicuccio M, Edgar R, Federhen S, Feolo M, Geer LY, Helmberg W, Kapustin Y, Khovayko O, Landsman D, Lipman DJ, Madden TL, Maglott DR, Miller V, Ostell J, Pruitt KD, Schuler GD, Shumway M, Sequeira E, Sherry ST, Sirotkin K, Souvorov A, Starchenko G, Tatusov RL, Tatusova TA, Wagner L, Yaschenko E. Database resources of the National Center for Biotechnology Information. Nucleic Acids Res. 2008;36:D13–D21. doi: 10.1093/nar/gkm1000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.Whitfield EJ, Pruess M, Apweiler R. Bioinformatics database infrastructure for biotechnology research. J Biotechnol. 2006;124:629–639. doi: 10.1016/j.jbiotec.2006.04.006. [DOI] [PubMed] [Google Scholar]
- 81.Doubet S, Albersheim P. CarbBank. Glycobiology. 1992;2:505–507. doi: 10.1093/glycob/2.6.505. [DOI] [PubMed] [Google Scholar]
- 82.Lutteke T, Bohne-Lang A, Loss A, Goetz T, Frank M, von der Lieth C-W. GLYCOSCIENCES.de: an Internet portal to support glycomics and glycobiology research. Glycobiology. 2006;16:71R–81R. doi: 10.1093/glycob/cwj049. [DOI] [PubMed] [Google Scholar]
- 83.Hashimoto K, Goto S, Kawano S, Aoki-Kinoshita KF, Ueda N, Hamajima M, Kawasaki T, Kanehisa M. KEGG as a glycome informatics resource. Glycobiology. 2006;16:63R–70R. doi: 10.1093/glycob/cwj010. [DOI] [PubMed] [Google Scholar]
- 84.Raman R, Venkataraman M, Ramakrishnan S, Lang W, Raguram S, Sasisekharan R. Advancing glycomics: Implementation strategies at the consortium for functional glycomics. Glycobiology. 2006;16:82R–90R. doi: 10.1093/glycob/cwj080. [DOI] [PubMed] [Google Scholar]
- 85.Toukach FV, Knirel YA. New database of bacterial carbohydrate structures. Glycoconjugate J. 2005;22:216–217. [Google Scholar]
- 86.Campbell MP, Royle L, Radcliffe CM, Dwek RA, Rudd PM. GlycoBase and autoGU: tools for HPLC-based glycan analysis. Bioinformatics. 2008;24:1214–1216. doi: 10.1093/bioinformatics/btn090. [DOI] [PubMed] [Google Scholar]
- 87.Cooper CA, Joshi HJ, Harrison MJ, Wilkins MR, Packer NH. GlycoSuiteDB: a curated relational database of glycoprotein glycan structures, their biological sources. 2003 update. Nucleic Acids Res. 2003;31:511–513. doi: 10.1093/nar/gkg099. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88.Toukach P, Joshi HJ, Ranzinger R, Knirel Y, von der Lieth C-W. Sharing of worldwide distributed carbohydrate-related digital resources: online connection of the Bacterial Carbohydrate Structure DataBase and GLYCOSCIENCES.de. Nucleic Acids Res. 2007;35:D280–D286. doi: 10.1093/nar/gkl883. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89.Ranzinger R, Frank M, von der Lieth CW, Herget S. Glycome-DB.org: a portal for querying across the digital world of carbohydrate sequences. Glycobiology. 2009;19:1563–1567. doi: 10.1093/glycob/cwp137. [DOI] [PubMed] [Google Scholar]
- 90.McNaught AD. International Union of Pure and Applied Chemistry and International Union of Biochemistry and Molecular Biology. Joint Commission on Biochemical Nomenclature. Nomenclature of carbohydrates. Carbohydr Res. 1997;297:1–92. doi: 10.1016/S0008-6215(97)83449-0. [DOI] [PubMed] [Google Scholar]
- 91.Hattori M, Okuno Y, Goto S, Kanehisa M. Development of a chemical structure comparison method for integrated analysis of chemical and genomic information in the metabolic pathways. J Am Chem Soc. 2003;125:11853–11865. doi: 10.1021/ja036030u. [DOI] [PubMed] [Google Scholar]
- 92.Bohne-Lang A, Lang E, Forster T, von der Lieth C-W. LINUCS: linear notation for unique description of carbohydrate sequences. Carbohydr Res. 2001;336:1–11. doi: 10.1016/S0008-6215(01)00230-0. [DOI] [PubMed] [Google Scholar]
- 93.Toukach FV. Bacterial carbohydrate structure database version 3. Glycoconjugate J. 2009;26:856. [Google Scholar]
- 94.Cooper CA, Harrison MJ, Wilkins MR, Packer NH. GlycoSuiteDB: a new curated relational database of glycoprotein glycan structures and their biological sources. Nucleic Acids Res. 2001;29:332–335. doi: 10.1093/nar/29.1.332. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95.Maes E, Bonachera F, Strecker G, Guerardel Y. SOACS index: an easy NMR-based query for glycan retrieval. Carbohydr Res. 2009;344:322–330. doi: 10.1016/j.carres.2008.11.001. [DOI] [PubMed] [Google Scholar]
- 96.Shikanai T, Shimma YS, Suzuki YS, Fujita NF, Kaji HK, Sato TS, Togayachi AT, Kameyama AK, Tateno HT, Hirabayashi J, Okuda S, Kawasaki T, Takahashi N, Kato K, Furukawa K, Yasugi E, Nishijima M, Kinoshita K, Nishihara S, Yamada I, Mizuno M, Shirai T, Kato M, Yamaguchi Y, Hagiya E, Yoshida K, Taniguchi N, Narimatsu H. Japan consortium for glycobiology and glycotechnology database. Glycoconjugate J. 2009;26:856–856. [Google Scholar]
- 97.Kikuchi N, Kameyama A, Nakaya S, Ito H, Sato T, Shikanai T, Takahashi Y, Narimatsu H. The carbohydrate sequence markup language (CabosML): an XML description of carbohydrate structures. Bioinformatics. 2005;21:1717–1718. doi: 10.1093/bioinformatics/bti152. [DOI] [PubMed] [Google Scholar]
- 98.Yue T, Haab BB. Microarrays in glycoproteomics research. Clin Lab Med. 2009;29:15–29. doi: 10.1016/j.cll.2009.01.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 99.Powell AK, Zhi ZL, Turnbull JE. Saccharide microarrays for high-throughput interrogation of glycan-protein binding interactions. Methods Mol Biol. 2009;534:313–329. doi: 10.1007/978-1-59745-022-5_22. [DOI] [PubMed] [Google Scholar]
- 100.Culf AS, Cuperlovic-Culf M, Ouellette RJ. Carbohydrate microarrays: survey of fabrication techniques. Omics. 2006;10:289–310. doi: 10.1089/omi.2006.10.289. [DOI] [PubMed] [Google Scholar]
- 101.Smith DF, Cummings RD (2009) Glycan-binding proteins and glycan microarrays. In: Cummings RD, Pierce JM (eds) Handbook of glycomics. Elsevier, Amsterdam, pp 139–160
- 102.Orchard S, Salwinski L, Kerrien S, Montecchi-Palazzi L, Oesterheld M, Stumpflen V, Ceol A, Chatr-aryamontri A, Armstrong J, Woollard P, Salama JJ, Moore S, Wojcik J, Bader GD, Vidal M, Cusick ME, Gerstein M, Gavin AC, Superti-Furga G, Greenblatt J, Bader J, Uetz P, Tyers M, Legrain P, Fields S, Mulder N, Gilson M, Niepmann M, Burgoon L, De Las Rivas J, Prieto C, Perreau VM, Hogue C, Mewes HW, Apweiler R, Xenarios I, Eisenberg D, Cesareni G, Hermjakob H. The minimum information required for reporting a molecular interaction experiment (MIMIx) Nat Biotechnol. 2007;25:894–898. doi: 10.1038/nbt1324. [DOI] [PubMed] [Google Scholar]
- 103.Blixt O, Head S, Mondala T, Scanlan C, Huflejt ME, Alvarez R, Bryan MC, Fazio F, Calarese D, Stevens J, Razi N, Stevens DJ, Skehel JJ, van Die I, Burton DR, Wilson IA, Cummings R, Bovin N, Wong CH, Paulson JC. Printed covalent glycan array for ligand profiling of diverse glycan binding proteins. Proc Natl Acad Sci USA. 2004;101:17033–17038. doi: 10.1073/pnas.0407902101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 104.Hirabayashi J. Lectin-based structural glycomics: glycoproteomics and glycan profiling. Glycoconjugate J. 2004;21:35–40. doi: 10.1023/B:GLYC.0000043745.18988.a1. [DOI] [PubMed] [Google Scholar]
- 105.Tateno H, Nakamura-Tsuruta S, Hirabayashi J. Frontal affinity chromatography: sugar-protein interactions. Nat Protoc. 2007;2:2529–2537. doi: 10.1038/nprot.2007.357. [DOI] [PubMed] [Google Scholar]
- 106.Van Damme EJM, Peumans WJ, Pusztai, A, Bardocz S (1998) Handbook of plant lectins: properties and biomedical applications, Wiley, Chichester
- 107.Kilpatrick DC. Handbook of animal lectins: properties and biomedical applications. Chichester: Wiley; 2000. [Google Scholar]
- 108.Varki A, Cummings RD, Esko JD, Freeze H, Hart G (ed) (2008) Essentials of glycobiology. Cold Spring Harbor Laboratory, New York [PubMed]
- 109.Porter A, Yue T, Heeringa L, Day S, Suh E, Haab BB. A motif-based analysis of glycan array data to determine the specificities of glycan-binding proteins. Glycobiology. 2009;20:369–380. doi: 10.1093/glycob/cwp187. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 110.Cantarel BL, Coutinho PM, Rancurel C, Bernard T, Lombard V, Henrissat B. The Carbohydrate-Active EnZymes database (CAZy): an expert resource for Glycogenomics. Nucleic Acids Res. 2009;37:D233–D238. doi: 10.1093/nar/gkn663. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 111.Campbell JA, Davies GJ, Bulone V, Henrissat B. A classification of nucleotide-diphospho-sugar glycosyltransferases based on amino acid sequence similarities. Biochem J. 1997;326(Pt 3):929–939. doi: 10.1042/bj3260929u. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 112.Berman H, Henrick K, Nakamura H, Markley JL. The worldwide Protein Data Bank (wwPDB): ensuring a single, uniform archive of PDB data. Nucleic Acids Res. 2007;35:D301–D303. doi: 10.1093/nar/gkl971. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 113.Chang A, Scheer M, Grote A, Schomburg I, Schomburg D. BRENDA, AMENDA and FRENDA the enzyme information system: new content and tools in 2009. Nucleic Acids Res. 2009;37:D588–D592. doi: 10.1093/nar/gkn820. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 114.Kikuchi N, Narimatsu H. Bioinformatics for comprehensive finding and analysis of glycosyltransferases. Biochim Biophys Acta. 2006;1760:578–583. doi: 10.1016/j.bbagen.2005.12.024. [DOI] [PubMed] [Google Scholar]
- 115.Breton C, Snajdrova L, Jeanneau C, Koca J, Imberty A. Structures and mechanisms of glycosyltransferases. Glycobiology. 2006;16:29R–37R. doi: 10.1093/glycob/cwj016. [DOI] [PubMed] [Google Scholar]
- 116.Kawasaki T, Nakao H, Takahashi E, Tominaga T. GlycoEpitope: the integrated database of carbohydrate antigens and antibodies. TIGG. 2006;18:267–272. [Google Scholar]
- 117.Gupta R, Birch H, Rapacki K, Brunak S, Hansen JE. O-GLYCBASE version 4.0: a revised database of O-glycosylated proteins. Nucleic Acids Res. 1999;27:370–372. doi: 10.1093/nar/27.1.370. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 118.Kaji H, Kamiie J, Kawakami H, Kido K, Yamauchi Y, Shinkawa T, Taoka M, Takahashi N, Isobe T. Proteomics reveals N-linked glycoprotein diversity in Caenorhabditis elegans and suggests an atypical translocation mechanism for integral membrane proteins. Mol Cell Proteomics. 2007;6:2100–2109. doi: 10.1074/mcp.M600392-MCP200. [DOI] [PubMed] [Google Scholar]
- 119.Jung E, Veuthey AL, Gasteiger E, Bairoch A. Annotation of glycoproteins in the SWISS-PROT database. Proteomics. 2001;1:262–268. doi: 10.1002/1615-9861(200102)1:2<262::AID-PROT262>3.0.CO;2-#. [DOI] [PubMed] [Google Scholar]
- 120.Imberty A, Gerber S, Tran V, Perez S. Data-Bank of 3-Dimensional Structures of Disaccharides, a Tool to Build 3-D Structures of Oligosaccharides.1. Oligo-Mannose Type N-Glycans. Glycoconjugate J. 1990;7:27–54. doi: 10.1007/BF01050401. [DOI] [Google Scholar]
- 121.Boutet E, Lieberherr D, Tognolli M, Schneider M, Bairoch A. UniProtKB/Swiss-Prot: The Manually Annotated Section of the UniProt KnowledgeBase. Methods Mol Biol. 2007;406:89–112. doi: 10.1007/978-1-59745-535-0_4. [DOI] [PubMed] [Google Scholar]
- 122.Gerwig GJ, Vliegenthart JF. Analysis of glycoprotein-derived glycopeptides. Exs. 2000;88:159–186. doi: 10.1007/978-3-0348-8458-7_11. [DOI] [PubMed] [Google Scholar]
- 123.Cooper CA, Gasteiger E, Packer NH. GlycoMod–a software tool for determining glycosylation compositions from mass spectrometric data. Proteomics. 2001;1:340–349. doi: 10.1002/1615-9861(200102)1:2<340::AID-PROT340>3.0.CO;2-B. [DOI] [PubMed] [Google Scholar]
- 124.Goldberg D, Sutton-Smith M, Paulson J, Dell A. Automatic annotation of matrix-assisted laser desorption/ionization N-glycan spectra. Proteomics. 2005;5:865–875. doi: 10.1002/pmic.200401071. [DOI] [PubMed] [Google Scholar]
- 125.Goldberg D, Bern M, Li B, Lebrilla CB. Automatic determination of O-glycan structure from fragmentation spectra. J Proteome Res. 2006;5:1429–1434. doi: 10.1021/pr060035j. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 126.Goldberg D, Bern M, Parry S, Sutton-Smith M, Panico M, Morris HR, Dell A. Automated N-glycopeptide identification using a combination of single- and tandem-MS. J Proteome Res. 2007;6:3995–4005. doi: 10.1021/pr070239f. [DOI] [PubMed] [Google Scholar]
- 127.Goldberg D, Bern M, North SJ, Haslam SM, Dell A. Glycan family analysis for deducing N-glycan topology from single MS. Bioinformatics. 2009;25:365–371. doi: 10.1093/bioinformatics/btn636. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 128.Gaucher SP, Morrow J, Leary JA. STAT: a saccharide topology analysis tool used in combination with tandem mass spectrometry. Anal Chem. 2000;72:2331–2336. doi: 10.1021/ac000096f. [DOI] [PubMed] [Google Scholar]
- 129.Lapadula AJ, Hatcher PJ, Hanneman AJ, Ashline DJ, Zhang H, Reinhold VN. Congruent strategies for carbohydrate sequencing. 3. OSCAR: an algorithm for assigning oligosaccharide topology from MSn data. Anal Chem. 2005;77:6271–6279. doi: 10.1021/ac050726j. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 130.Ethier M, Saba JA, Spearman M, Krokhin O, Butler M, Ens W, Standing KG, Perreault H. Application of the StrOligo algorithm for the automated structure assignment of complex N-linked glycans from glycoproteins using tandem mass spectrometry. Rapid Commun Mass Spectrom. 2003;17:2713–2720. doi: 10.1002/rcm.1252. [DOI] [PubMed] [Google Scholar]
- 131.Tang HX, Mechref Y, Novotny MV. Automated interpretation of MS/MS spectra of oligosaccharides. Bioinformatics. 2005;21:I431–I439. doi: 10.1093/bioinformatics/bti1038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 132.Maass K, Ranzinger R, Geyer H, von der Lieth C-W, Geyer R. “Glyco-peakfinder”—de novo composition analysis of glycoconjugates. Proteomics. 2007;7:4435–4444. doi: 10.1002/pmic.200700253. [DOI] [PubMed] [Google Scholar]
- 133.Lohmann KK, von der Lieth C-W. GlycoFragment and GlycoSearchMS: web tools to support the interpretation of mass spectra of complex carbohydrates. Nucleic Acids Res. 2004;32:W261–W266. doi: 10.1093/nar/gkh392. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 134.Lohmann KK, von der Lieth C-W. GLYCO-FRAGMENT: A web tool to support the interpretation of mass spectra of complex carbohydrates. Proteomics. 2003;3:2028–2035. doi: 10.1002/pmic.200300505. [DOI] [PubMed] [Google Scholar]
- 135.Joshi HJ, Harrison MJ, Schulz BL, Cooper CA, Packer NH, Karlsson NG. Development of a mass fingerprinting tool for automated interpretation of oligosaccharide fragmentation data. Proteomics. 2004;4:1650–1664. doi: 10.1002/pmic.200300784. [DOI] [PubMed] [Google Scholar]
- 136.Ceroni A, Maass K, Geyer H, Geyer R, Dell A, Haslam SM. GlycoWorkbench: a tool for the computer-assisted annotation of mass spectra of glycans. J Proteome Res. 2008;7:1650–1659. doi: 10.1021/pr7008252. [DOI] [PubMed] [Google Scholar]
- 137.Gao HY. Generation of asparagine-linked glycan structure databases and their use. J Am Soc Mass Spectrom. 2009;20:1739–1742. doi: 10.1016/j.jasms.2009.05.012. [DOI] [PubMed] [Google Scholar]
- 138.Ozohanics O, Krenyacz J, Ludanyi K, Pollreisz F, Vekey K, Drahos L. GlycoMiner: a new software tool to elucidate glycopeptide composition. Rapid Commun Mass Spectrom. 2008;22:3245–3254. doi: 10.1002/rcm.3731. [DOI] [PubMed] [Google Scholar]
- 139.Vakhrushev SY, Dadimov D, Peter-Katalinic J. Software platform for high-throughput glycomics. Anal Chem. 2009;81:3252–3260. doi: 10.1021/ac802408f. [DOI] [PubMed] [Google Scholar]
- 140.Tissot B, Ceroni A, Powell AK, Morris HR, Yates EA, Turnbull JE, Gallagher JT, Dell A, Haslam SM. Software tool for the structural determination of glycosaminoglycans by mass spectrometry. Anal Chem. 2008;80:9204–9212. doi: 10.1021/ac8013753. [DOI] [PubMed] [Google Scholar]
- 141.Clerens S, Van den Ende W, Verhaert P, Geenen L, Arckens L. Sweet Substitute: a software tool for in silico fragmentation of peptide-linked N-glycans. Proteomics. 2004;4:629–632. doi: 10.1002/pmic.200300572. [DOI] [PubMed] [Google Scholar]
- 142.Irungu J, Go EP, Dalpathado DS, Desaire H. Simplification of mass spectral analysis of acidic glycopeptides using GlycoPep ID. Anal Chem. 2007;79:3065–3074. doi: 10.1021/ac062100e. [DOI] [PubMed] [Google Scholar]
- 143.Sturm M, Bertsch A, Gropl C, Hildebrandt A, Hussong R, Lange E, Pfeifer N, Schulz-Trieglaff O, Zerck A, Reinert K, Kohlbacher O. OpenMS—an open-source software framework for mass spectrometry. BMC Bioinform. 2008;9:163. doi: 10.1186/1471-2105-9-163. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 144.Sturm M, Kohlbacher O. TOPPView: an open-source viewer for mass spectrometry data. J Proteome Res. 2009;8:3760–3763. doi: 10.1021/pr900171m. [DOI] [PubMed] [Google Scholar]
- 145.Jansson PE, Kenne L, Widmalm G. Casper—a computer-program used for structural-analysis of carbohydrates. J Chem Inf Comput Sci. 1991;31:508–516. doi: 10.1021/ci00004a013. [DOI] [PubMed] [Google Scholar]
- 146.Jansson PE, Stenutz R, Widmalm G. Sequence determination of oligosaccharides and regular polysaccharides using NMR spectroscopy and a novel Web-based version of the computer program CASPER. Carbohydr Res. 2006;341:1003–1010. doi: 10.1016/j.carres.2006.02.034. [DOI] [PubMed] [Google Scholar]
- 147.Fogh RH, Vranken WF, Boucher W, Stevens TJ, Laue ED. A nomenclature and data model to describe NMR experiments. J Biomol NMR. 2006;36:147–155. doi: 10.1007/s10858-006-9076-z. [DOI] [PubMed] [Google Scholar]
- 148.Vranken WF, Boucher W, Stevens TJ, Fogh RH, Pajon A, Llinas P, Ulrich EL, Markley JL, Ionides J, Laue ED. The CCPN data model for NMR spectroscopy: development of a software pipeline. Proteins Struct Funct Bioinf. 2005;59:687–696. doi: 10.1002/prot.20449. [DOI] [PubMed] [Google Scholar]
- 149.Julenius K. NetCGlyc 1.0: prediction of mammalian C-mannosylation sites. Glycobiology. 2007;17:868–876. doi: 10.1093/glycob/cwm050. [DOI] [PubMed] [Google Scholar]
- 150.Gupta R, Brunak S (2002) Prediction of glycosylation across the human proteome and the correlation to protein function. Pac Symp Biocomput pp 310–322 [PubMed]
- 151.Hansen JE, Lund O, Tolstrup N, Gooley AA, Williams KL, Brunak S. NetOglyc: prediction of mucin type O-glycosylation sites based on sequence context and surface accessibility. Glycoconjugate J. 1998;15:115–130. doi: 10.1023/A:1006960004440. [DOI] [PubMed] [Google Scholar]
- 152.Eisenhaber B, Bork P, Yuan Y, Loffler G, Eisenhaber F. Automated annotation of GPI anchor sites: case study C. elegans . Trends Biochem Sci. 2000;25:340–341. doi: 10.1016/S0968-0004(00)01601-7. [DOI] [PubMed] [Google Scholar]
- 153.Fankhauser N, Maser P. Identification of GPI anchor attachment signals by a Kohonen self-organizing map. Bioinformatics. 2005;21:1846–1852. doi: 10.1093/bioinformatics/bti299. [DOI] [PubMed] [Google Scholar]
- 154.Chen YZ, Tang YR, Sheng ZY, Zhang Z. Prediction of mucin-type O-glycosylation sites in mammalian proteins using the composition of k-spaced amino acid pairs. BMC Bioinform. 2008;9:101. doi: 10.1186/1471-2105-9-101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 155.Caragea C, Sinapov J, Silvescu A, Dobbs D, Honavar V. Glycosylation site prediction using ensembles of Support Vector Machine classifiers. BMC Bioinform. 2007;8:438. doi: 10.1186/1471-2105-8-438. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 156.Hamby SE, Hirst JD. Prediction of glycosylation sites using random forests. BMC Bioinformatics. 2008;9:500. doi: 10.1186/1471-2105-9-500. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 157.Petrescu AJ, Milac AL, Petrescu SM, Dwek RA, Wormald MR. Statistical analysis of the protein environment of N-glycosylation sites: implications for occupancy, structure, and folding. Glycobiology. 2004;14:103–114. doi: 10.1093/glycob/cwh008. [DOI] [PubMed] [Google Scholar]
- 158.Thanka Christlet TH, Veluraja K. Database analysis of O-glycosylation sites in proteins. Biophys J. 2001;80:952–960. doi: 10.1016/S0006-3495(01)76074-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 159.Lutteke T, Frank M, von der Lieth C-W. Carbohydrate Structure Suite (CSS): analysis of carbohydrate 3D structures derived from the PBD. Nucleic Acids Res. 2005;33:D242–D246. doi: 10.1093/nar/gki013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 160.Widmalm G. General NMR spectroscopy of carbohydrates and conformational analysis in solution. In: Kamerling JP, editor. Comprehensive glycoscience - from chemistry to systems biology. Oxford: Elsevier; 2007. pp. 101–132. [Google Scholar]
- 161.Jimenez-Barbero J, Diaz MD, Nieto PM. NMR structural studies of oligosaccharides related to cancer processes. Anticancer Agents Med Chem. 2008;8:52–63. doi: 10.2174/187152008783330879. [DOI] [PubMed] [Google Scholar]
- 162.Lutteke T, Frank M (2009) Synergy of computational and experimental methods in carbohydrate 3D structure determination and validation. In: von der Lieth CW, Lutteke T, Frank M (eds) Bioinformatics for glycobiology and glycomics: an introduction. Wiley, New York, pp 389–412
- 163.Weimar T, Woods RJ. Combining NMR and simulation methods in oligosaccharide conformational analysis. In: Jimenez-Barbero J, Peters T, editors. NMR spectroscopy of glycoconjugates. Weinheim: Wiley; 2003. pp. 111–144. [Google Scholar]
- 164.Frank M (2009) Conformational analysis of carbohydrates—a historical overview. In: von der Lieth CW, Lutteke T, Frank M (eds) Bioinformatics for glycobiology and glycomics: an introduction. Wiley, New York, pp 337–357
- 165.Frank M (2009) Predicting Carbohydrate 3D Structures Using Theoretical Methods. In: von der Lieth CW, Lutteke T, Frank M (eds.) Bioinformatics for glycobiology and glycomics: an introduction. Wiley, New York, pp 359–388
- 166.Perez S. Molecular modeling in glycoscience. In: Kamerling JP, editor. Comprehensive glycoscience - from chemistry to systems biology. Oxford: Elsevier; 2007. pp. 347–388. [Google Scholar]
- 167.Stortz CA. Disaccharide conformational maps: how adiabatic is an adiabatic map? Carbohydr Res. 1999;322:77–86. doi: 10.1016/S0008-6215(99)00207-4. [DOI] [PubMed] [Google Scholar]
- 168.von der Lieth C-W, Kozar T, Hull WE. A (critical) survey of modelling protocols used to explore the conformational space of oligosaccharides. THEOCHEM. 1997;395:225–244. doi: 10.1016/S0166-1280(96)04953-6. [DOI] [Google Scholar]
- 169.Krupicka M, Tvaroska I. Hybrid quantum mechanical/molecular mechanical investigation of the beta-1, 4-galactosyltransferase-I mechanism. J Phys Chem B. 2009;113:11314–11319. doi: 10.1021/jp904716t. [DOI] [PubMed] [Google Scholar]
- 170.Dong H, Nimlos MR, Himmel ME, Johnson DK, Qian X. The effects of water on beta-d-xylose condensation reactions. J Phys Chem A. 2009;113:8577–8585. doi: 10.1021/jp9025442. [DOI] [PubMed] [Google Scholar]
- 171.Greig IR, Zahariev F, Withers SG. Elucidating the nature of the Streptomyces plicatus beta-hexosaminidase-bound intermediate using ab initio molecular dynamics simulations. J Am Chem Soc. 2008;130:17620–17628. doi: 10.1021/ja805640c. [DOI] [PubMed] [Google Scholar]
- 172.Kirschner KN, Yongye AB, Tschampel SM, Gonzalez-Outeirino J, Daniels CR, Foley BL, Woods RJ. GLYCAM06: a generalizable biomolecular force field. Carbohydrates. J Comput Chem. 2008;29:622–655. doi: 10.1002/jcc.20820. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 173.Guvench O, Hatcher E, Venable RM, Pastor RW, MacKerell AD. CHARMM Additive All-Atom Force Field for Glycosidic Linkages between Hexopyranoses. J Chem Theory Comput. 2009;5:2353–2370. doi: 10.1021/ct900242e. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 174.Schnupf U, Willett JL, Bosma W, Momany FA. DFT conformation and energies of amylose fragments at atomic resolution. Part 1: syn forms of alpha-maltotetraose. Carbohydr Res. 2009;344:362–373. doi: 10.1016/j.carres.2008.11.017. [DOI] [PubMed] [Google Scholar]
- 175.Spiwok V, Tvaroska I. Conformational free energy surface of alpha-N-acetylneuraminic acid: an interplay between hydrogen bonding and solvation. J Phys Chem B. 2009;113:9589–9594. doi: 10.1021/jp8113495. [DOI] [PubMed] [Google Scholar]
- 176.Remko M, von der Lieth C-W. Conformational structure of some trimeric and pentameric structural units of heparin. J Phys Chem A. 2007;111:13484–13491. doi: 10.1021/jp075330l. [DOI] [PubMed] [Google Scholar]
- 177.Biarnes X, Ardevol A, Planas A, Rovira C, Laio A, Parrinello M. The conformational free energy landscape of beta-D-glucopyranose. implications for substrate preactivation in beta-glucoside hydrolases. J Am Chem Soc. 2007;129:10686–10693. doi: 10.1021/ja068411o. [DOI] [PubMed] [Google Scholar]
- 178.Laio a, Gervasio FL (2008) Metadynamics: a method to simulate rare events and reconstruct the free energy in biophysics, chemistry and material science. Reports on Progress in Physics 71
- 179.Qasba PK, Ramakrishnan B. X-ray crystal structures of glycosyltransferases. In: Kamerling JP, editor. Comprehensive glycoscience—from chemistry to systems biology. Oxford: Elsevier; 2007. pp. 251–281. [Google Scholar]
- 180.Buts L, Loris R, Wyns L. X-Ray crystallography of lectins. In: Kamerling JP, editor. Comprehensive glycoscience - from chemistry to systems biology. Oxford: Elsevier; 2007. pp. 221–249. [Google Scholar]
- 181.Lutteke T, von der Lieth CW. Data mining the PDB for glyco-related data. Methods Mol Biol. 2009;534:293–310. doi: 10.1007/978-1-59745-022-5_21. [DOI] [PubMed] [Google Scholar]
- 182.Vliegenthart JFG, Woods RJ (ed) (2006) NMR spectroscopy and computer modeling of carbohydrates. American Chemical Society, Washington, DC
- 183.Jeffrey GA. Crystallographic studies of carbohydrates. Acta Crystallogr Sect B Struct Sci. 1990;46(Pt 2):89–103. doi: 10.1107/S0108768189012449. [DOI] [PubMed] [Google Scholar]
- 184.Lutteke T. Analysis and validation of carbohydrate three-dimensional structures. Acta Crystallogr D Biol Crystallogr. 2009;65:156–168. doi: 10.1107/S0907444909001905. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 185.Frank M, Lutteke T, von der Lieth C-W. GlycoMapsDB: a database of the accessible conformational space of glycosidic linkages. Nucleic Acids Res. 2007;35:287–290. doi: 10.1093/nar/gkl907. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 186.Crispin M, Stuart DI, Jones EY. Building meaningful models of glycoproteins. Nat Struct Mol Biol. 2007;14:354. doi: 10.1038/nsmb0507-354a. [DOI] [PubMed] [Google Scholar]
- 187.Lutteke T, von der Lieth C-W. The protein data bank (PDB) as a versatile resource for glycobiology and glycomics. Biocatal Biotransform. 2006;24:147–155. doi: 10.1080/10242420600598269. [DOI] [Google Scholar]
- 188.Nakahara T, Hashimoto R, Nakagawa H, Monde K, Miura N, Nishimura S. Glycoconjugate Data Bank: structures—an annotated glycan structure database and N-glycan primary structure verification service. Nucleic Acids Res. 2008;36:D368–D371. doi: 10.1093/nar/gkm833. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 189.Vasur J, Kawai R, Andersson E, Igarashi K, Sandgren M, Samejima M, Stahlberg J. X-ray crystal structures of Phanerochaete chrysosporium Laminarinase 16A in complex with products from lichenin and laminarin hydrolysis. Febs Journal. 2009;276:4282–4293. doi: 10.1111/j.1742-4658.2009.07099.x. [DOI] [PubMed] [Google Scholar]
- 190.Berteau O, Stenutz R. Web resources for the carbohydrate chemist. Carbohydr Res. 2004;339:929–936. doi: 10.1016/j.carres.2003.11.008. [DOI] [PubMed] [Google Scholar]
- 191.Bohne A, Lang E, von der Lieth C-W. SWEET - WWW-based rapid 3D construction of oligo- and polysaccharides. Bioinformatics. 1999;15:767–768. doi: 10.1093/bioinformatics/15.9.767. [DOI] [PubMed] [Google Scholar]
- 192.Bohne-Lang A, von der Lieth C-W. GlyProt: in silico glycosylation of proteins. Nucleic Acids Res. 2005;33:W214–W219. doi: 10.1093/nar/gki385. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 193.Engelsen SB, Cros S, Mackie W, Perez S. A molecular builder for carbohydrates: application to polysaccharides and complex carbohydrates. Biopolymers. 1996;39:417–433. doi: 10.1002/(SICI)1097-0282(199609)39:3<417::AID-BIP13>3.3.CO;2-R. [DOI] [PubMed] [Google Scholar]
- 194.Xia J, Margulis C. A tool for the prediction of structures of complex sugars. J Biomol NMR. 2008;42:241–256. doi: 10.1007/s10858-008-9279-6. [DOI] [PubMed] [Google Scholar]
- 195.Frank M, Gutbrod P, Hassayoun C, von der Lieth C-W. Dynamic molecules: molecular dynamics for everyone. An Internet-based access to molecular dynamic simulations: Basic concepts. J Mol Model. 2003;9:308–315. doi: 10.1007/s00894-003-0144-y. [DOI] [PubMed] [Google Scholar]
- 196.Klepeis JL, Lindorff-Larsen K, Dror RO, Shaw DE. Long-timescale molecular dynamics simulations of protein structure and function. Curr Opin Struct Biol. 2009;19:120–127. doi: 10.1016/j.sbi.2009.03.004. [DOI] [PubMed] [Google Scholar]
- 197.Alonso H, Bliznyuk AA, Gready JE. Combining docking and molecular dynamic simulations in drug design. Med Res Rev. 2006;26:531–568. doi: 10.1002/med.20067. [DOI] [PubMed] [Google Scholar]
- 198.Karplus M, McCammon JA. Molecular dynamics simulations of biomolecules. Nat Struct Biol. 2002;9:646–652. doi: 10.1038/nsb0902-646. [DOI] [PubMed] [Google Scholar]
- 199.Almond A (2006) Biomolecular dynamics: testing microscopic predictions against macroscopic experiments. In: Vliegenthart JFG, Woods RJ (eds.) NMR spectroscopy and computer modeling of carbohydrates, vol. 930. American Chemical Society, Washington, DC, pp 156–169
- 200.Tessier MB, DeMarco ML, Yongye AB, Woods RJ. Extension of the GLYCAM06 biomolecular force field to lipids, lipid bilayers and glycolipids. Mol Simul. 2008;34:349–363. doi: 10.1080/08927020701710890. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 201.Tschampel SM, Kennerty MR, Woods RJ. TIP5P-consistent treatment of electrostatics for biomolecular simulations. J Chem Theory Comput. 2007;3:1721–1733. doi: 10.1021/ct700046j. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 202.Takahashi O, Yamasaki K, Kohno Y, Ueda K, Suezawa H, Nishio M. The origin of the generalized anomeric effect: possibility of CH/n and CH/pi hydrogen bonds. Carbohydr Res. 2009;344:1225–1229. doi: 10.1016/j.carres.2009.04.011. [DOI] [PubMed] [Google Scholar]
- 203.Lii JH, Chen KH, Johnson GP, French AD, Allinger NL. The external-anomeric torsional effect. Carbohydr Res. 2005;340:853–862. doi: 10.1016/j.carres.2005.01.032. [DOI] [PubMed] [Google Scholar]
- 204.Asensio JL, Hidalgo A, Cuesta I, Gonzalez C, Canada J, Vicent C, Chiara JL, Cuevas G, Jimenez-Barbero J. Experimental evidence for the existence of non-exo-anomeric conformations in branched oligosaccharides: NMR analysis of the structure and dynamics of aminoglycosides of the neomycin family. Chemistry. 2002;8:5228–5240. doi: 10.1002/1521-3765(20021115)8:22<5228::AID-CHEM5228>3.0.CO;2-L. [DOI] [PubMed] [Google Scholar]
- 205.Tvaroska I, Carver JP. The anomeric and exo-anomeric effects of a hydroxyl group and the stereochemistry of the hemiacetal linkage. Carbohydr Res. 1998;309:1–9. doi: 10.1016/S0008-6215(98)00114-1. [DOI] [Google Scholar]
- 206.Taha HA, Castillo N, Roy PN, Lowary TL. Conformational studies of methyl beta-D-Arabinofuranoside using the AMBER/GLYCAM approach. J Chem Theory Comput. 2009;5:430–438. doi: 10.1021/ct800384h. [DOI] [PubMed] [Google Scholar]
- 207.Olsson U, Sawen E, Stenutz R, Widmalm G. Conformational flexibility and dynamics of two (1-- > 6)-linked disaccharides related to an oligosaccharide epitope expressed on malignant tumour cells. Chemistry. 2009;15:8886–8894. doi: 10.1002/chem.200900507. [DOI] [PubMed] [Google Scholar]
- 208.Sanchez-Medina I, Frank M, von der Lieth CW, Kamerling JP. Conformational analysis of the neutral exopolysaccharide produced by Lactobacillus delbrueckii ssp. bulgaricus LBB.B26. Org Biomol Chem. 2009;7:280–287. doi: 10.1039/b810468a. [DOI] [PubMed] [Google Scholar]
- 209.Yongye AB, Gonzalez-Outeirino J, Glushka J, Schultheis V, Woods RJ. The conformational properties of methyl alpha-(2, 8)-Di/Trisialosides and their N-Acyl analogues: implications for anti-neisseria meningitidis B vaccine design. Biochemistry. 2008;47:12493–12514. doi: 10.1021/bi800431c. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 210.Jedlovszky P, Sega M, Vallauri R. GM1 ganglioside embedded in a hydrated DOPC membrane: a molecular dynamics simulation study. J Phys Chem B. 2009;113:4876–4886. doi: 10.1021/jp808199p. [DOI] [PubMed] [Google Scholar]
- 211.DeMarco ML, Woods RJ. Atomic-resolution conformational analysis of the GM3 ganglioside in a lipid bilayer and its implications for ganglioside-protein recognition at membrane surfaces. Glycobiology. 2009;19:344–355. doi: 10.1093/glycob/cwn137. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 212.Fernandez-Tejada A, Corzana F, Busto JH, Jimenez-Oses G, Jimenez-Barbero J, Avenoza A, Peregrina JM. Insights into the geometrical features underlying beta-O-GlcNAc glycosylation: water pockets drastically modulate the interactions between the carbohydrate and the peptide backbone. Chemistry. 2009;15:7297–7301. doi: 10.1002/chem.200901204. [DOI] [PubMed] [Google Scholar]
- 213.Blanchard V, Frank M, Leeflang BR, Boelens R, Kamerling JP. The structural basis of the difference in sensitivity for PNGase F in the de-N-glycosylation of the native bovine pancreatic ribonucleases B and BS. Biochemistry. 2008;47:3435–3446. doi: 10.1021/bi7012504. [DOI] [PubMed] [Google Scholar]
- 214.Choi Y, Lee JH, Hwang S, Kim JK, Jeong K, Jung S. Retardation of the unfolding process by single N-glycosylation of ribonuclease A based on molecular dynamics simulations. Biopolymers. 2008;89:114–123. doi: 10.1002/bip.20867. [DOI] [PubMed] [Google Scholar]
- 215.Xu D, Newhouse EI, Amaro RE, Pao HC, Cheng LS, Markwick PR, McCammon JA, Li WW, Arzberger PW. Distinct glycan topology for avian and human sialopentasaccharide receptor analogues upon binding different hemagglutinins: a molecular dynamics perspective. J Mol Biol. 2009;387:465–491. doi: 10.1016/j.jmb.2009.01.040. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 216.Mackeen MM, Almond A, Deschamps M, Cumpstey I, Fairbanks AJ, Tsang C, Rudd PM, Butters TD, Dwek RA, Wormald MR. The conformational properties of the Glc3Man unit suggest conformational biasing within the chaperone-assisted glycoprotein folding pathway. J Mol Biol. 2009;387:335–347. doi: 10.1016/j.jmb.2009.01.043. [DOI] [PubMed] [Google Scholar]
- 217.Mark P, Baumann MJ, Eklof JM, Gullfot F, Michel G, Kallas AM, Teeri TT, Brumer H, Czjzek M. Analysis of nasturtium TmNXG1 complexes by crystallography and molecular dynamics provides detailed insight into substrate recognition by family GH16 xyloglucan endo-transglycosylases and endo-hydrolases. Proteins. 2009;75:820–836. doi: 10.1002/prot.22291. [DOI] [PubMed] [Google Scholar]
- 218.Gunnerson KN, Pereverzev YV, Prezhdo OV. Atomistic simulation combined with analytic theory to study the response of the P-selectin/PSGL-1 complex to an external force. J Phys Chem B. 2009;113:2090–2100. doi: 10.1021/jp803955u. [DOI] [PubMed] [Google Scholar]
- 219.Eriksson M, Lindhorst TK, Hartke B. Differential effects of oligosaccharides on the hydration of simple cations. J Chem Phys. 2008;128:105105. doi: 10.1063/1.2873147. [DOI] [PubMed] [Google Scholar]
- 220.Ramadugu SK, Chung YH, Xia JC, Margulis CJ. When sugars get wet. A comprehensive study of the behavior of water on the surface of oligosaccharides. J Phys Chem B. 2009;113:11003–11015. doi: 10.1021/jp904981v. [DOI] [PubMed] [Google Scholar]
- 221.Nadas J, Li C, Wang PG. Computational structure activity relationship studies on the CD1d/glycolipid/TCR complex using AMBER and AUTODOCK. J Chem Inf Model. 2009;49:410–423. doi: 10.1021/ci8002705. [DOI] [PubMed] [Google Scholar]
- 222.Gonzalez-Outeirino J, Kirschner KN, Thobhani S, Woods RJ. Reconciling solvent effects on rotamer populations in carbohydrates—a joint MD and NMR analysis. Can J Chem. 2006;84:569–579. doi: 10.1139/V06-036. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 223.Jorgensen WL, Tirado-Rives J. Potential energy functions for atomic-level simulations of water and organic and biomolecular systems. Proc Natl Acad Sci USA. 2005;102:6665–6670. doi: 10.1073/pnas.0408037102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 224.Dill Ka, Truskett TM, Vlachy V, Hribar-Lee B (2005) Modeling water, the hydrophobic effect, and ion solvation. Ann Rev Biophy Biomol Struct 34:173–199 [DOI] [PubMed]
- 225.Brooks BR, Brooks CL, 3rd, Mackerell AD, Jr, Nilsson L, Petrella RJ, Roux B, Won Y, Archontis G, Bartels C, Boresch S, Caflisch A, Caves L, Cui Q, Dinner AR, Feig M, Fischer S, Gao J, Hodoscek M, Im W, Kuczera K, Lazaridis T, Ma J, Ovchinnikov V, Paci E, Pastor RW, Post CB, Pu JZ, Schaefer M, Tidor B, Venable RM, Woodcock HL, Wu X, Yang W, York DM, Karplus M. CHARMM: the biomolecular simulation program. J Comput Chem. 2009;30:1545–1614. doi: 10.1002/jcc.21287. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 226.Case DA, Cheatham TE, 3rd, Darden T, Gohlke H, Luo R, Merz KM, Jr, Onufriev A, Simmerling C, Wang B, Woods RJ. The Amber biomolecular simulation programs. J Comput Chem. 2005;26:1668–1688. doi: 10.1002/jcc.20290. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 227.Van der Spoel D, Lindahl E, Hess B, Groenhof G, Mark AE, Berendsen HJC. Gromacs: fast, flexible, and free. J Comput Chem. 2005;26:1701–1718. doi: 10.1002/jcc.20291. [DOI] [PubMed] [Google Scholar]
- 228.Conformational Analysis Tools (CAT), URL: http://www.md-simulations.de/CAT/
- 229.Chen B, Vogan EM, Gong H, Skehel JJ, Wiley DC, Harrison SC. Structure of an unliganded simian immunodeficiency virus gp120 core. Nature. 2005;433:834–841. doi: 10.1038/nature03327. [DOI] [PubMed] [Google Scholar]
- 230.Chen Y, Shoichet BK. Molecular docking and ligand specificity in fragment-based inhibitor discovery. Nat Chem Biol. 2009;5:358–364. doi: 10.1038/nchembio.155. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 231.Reina JJ, Diaz I, Nieto PM, Campillo NE, Paez JA, Tabarani G, Fieschi F, Rojo J. Docking, synthesis, and NMR studies of mannosyl trisaccharide ligands for DC-SIGN lectin. Org Biomol Chem. 2008;6:2743–2754. doi: 10.1039/b802144a. [DOI] [PubMed] [Google Scholar]
- 232.Takaoka T, Mori K, Okimoto N, Neya S, Hoshino T. Prediction of the structure of complexes comprised of proteins and glycosaminoglycans using docking simulation and cluster analysis. J Chem Theory Comput. 2007;3:2347–2356. doi: 10.1021/ct700029q. [DOI] [PubMed] [Google Scholar]
- 233.Nurisso A, Kozmon S, Imberty A. Comparison of docking methods for carbohydrate binding in calcium-dependent lectins and prediction of the carbohydrate binding mode to sea cucumber lectin CEL-III. Molecular Simulation. 2008;34:469–479. doi: 10.1080/08927020701697709. [DOI] [Google Scholar]
- 234.Guerrini M, Guglieri S, Casu B, Torri G, Mourier P, Boudier C, Viskov C. Antithrombin-binding octasaccharides and role of extensions of the active pentasaccharide sequence in the specificity and strength of interaction. Evidence for very high affinity induced by an unusual glucuronic acid residue. J Biol Chem. 2008;283:26662–26675. doi: 10.1074/jbc.M801102200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 235.de Geus DC, van Roon AMM, Thomassen EAJ, Hokke CH, Deelder AM, Abrahams JP. Characterization of a diagnostic Fab fragment binding trimeric Lewis X. Proteins Struct Funct Bioinform. 2009;76:439–447. doi: 10.1002/prot.22356. [DOI] [PubMed] [Google Scholar]
- 236.Laederach A, Reilly PJ. Modeling protein recognition of carbohydrates. Proteins. 2005;60:591–597. doi: 10.1002/prot.20545. [DOI] [PubMed] [Google Scholar]
- 237.Voss C, Eyol E, Frank M, von der Lieth C-W, Berger MR. Identification and characterization of riproximin, a new type II ribosome-inactivating protein with antineoplastic activity from Ximenia americana. FASEB J. 2006;20:1194–1196. doi: 10.1096/fj.05-5231fje. [DOI] [PubMed] [Google Scholar]
- 238.Moitessier N, Westhof E, Hanessian S. Docking of aminoglycosides to hydrated and flexible RNA. J Med Chem. 2006;49:1023–1033. doi: 10.1021/jm0508437. [DOI] [PubMed] [Google Scholar]
- 239.Landon MR, Amaro RE, Baron R, Ngan CH, Ozonoff D, McCammon JA, Vajda S. Novel druggable hot spots in avian influenza neuraminidase H5N1 revealed by computational solvent mapping of a reduced and representative receptor ensemble. Chem Biol Drug Des. 2008;71:106–116. doi: 10.1111/j.1747-0285.2007.00614.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 240.Hill AD, Reilly PJ. A Gibbs free energy correlation for automated docking of carbohydrates. J Comput Chem. 2008;29:1131–1141. doi: 10.1002/jcc.20873. [DOI] [PubMed] [Google Scholar]
- 241.Raju RK, Ramraj A, Hillier IH, Vincent MA, Burton NA. Carbohydrate-aromatic pi interactions: a test of density functionals and the DFT-D method. Phys Chem Chem Phys. 2009;11:3411–3416. doi: 10.1039/b822877a. [DOI] [PubMed] [Google Scholar]
- 242.Spiwok V, Lipovova P, Skalova T, Vondrackova E, Dohnalek J, Hasek J, Kralova B. Modelling of carbohydrate-aromatic interactions: ab initio energetics and force field performance. J Comput Aided Mol Des. 2005;19:887–901. doi: 10.1007/s10822-005-9033-z. [DOI] [PubMed] [Google Scholar]
- 243.Vandenbussche S, Diaz D, Fernandez-Alonso MC, Pan W, Vincent SP, Cuevas G, Canada FJ, Jimenez-Barbero J, Bartik K. Aromatic–carbohydrate interactions: an NMR and computational study of model systems. Chemistry. 2008;14:7570–7578. doi: 10.1002/chem.200800247. [DOI] [PubMed] [Google Scholar]
- 244.Kerzmann A, Fuhrmann J, Kohlbacher O, Neumann D. BALLDock/SLICK: A new method for protein-carbohydrate docking. Journal of Chemical Information and Modeling. 2008;48:1616–1625. doi: 10.1021/ci800103u. [DOI] [PubMed] [Google Scholar]
- 245.Meynier C, Guerlesquin F, Roche P. Computational studies of human galectin-1: role of conserved tryptophan residue in stacking interaction with carbohydrate ligands. J Biomol Struct Dyn. 2009;27:49–58. doi: 10.1080/07391102.2009.10507295. [DOI] [PubMed] [Google Scholar]
- 246.Mishra NK, Kulhanek P, Snajdrova L, Petrek M, Imberty A, Koca J. Molecular dynamics study of Pseudomonas aeruginosa lectin-II complexed with monosaccharides. Proteins. 2008;72:382–392. doi: 10.1002/prot.21935. [DOI] [PubMed] [Google Scholar]
- 247.Fujimoto YK, Terbush RN, Patsalo V, Green DF. Computational models explain the oligosaccharide specificity of cyanovirin-N. Protein Sci. 2008;17:2008–2014. doi: 10.1110/ps.034637.108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 248.Das P, Li JY, Royyuru AK, Zhou RH. Free energy simulations reveal a double mutant avian H5N1 virus hemagglutinin with altered receptor binding specificity. J Comput Chem. 2009;30:1654–1663. doi: 10.1002/jcc.21274. [DOI] [PubMed] [Google Scholar]
- 249.Cai W, Sun T, Liu P, Chipot C, Shao X. Inclusion mechanism of steroid drugs into beta-cyclodextrins. Insights from free energy calculations. J Phys Chem B. 2009;113:7836–7843. doi: 10.1021/jp901825w. [DOI] [PubMed] [Google Scholar]
- 250.Diehl C, Genheden S, Modig K, Ryde U, Akke M. Conformational entropy changes upon lactose binding to the carbohydrate recognition domain of galectin-3. J Biomol NMR. 2009;45:157–169. doi: 10.1007/s10858-009-9356-5. [DOI] [PubMed] [Google Scholar]
- 251.Gauto DF, Di Lella S, Guardia CM, Estrin DA, Marti MA. Carbohydrate-binding proteins: Dissecting ligand structures through solvent environment occupancy. J Phys Chem B. 2009;113:8717–8724. doi: 10.1021/jp901196n. [DOI] [PubMed] [Google Scholar]
- 252.Di Lella S, Ma L, Ricci JC, Rabinovich GA, Asher SA, Alvarez RM. Critical role of the solvent environment in galectin-1 binding to the disaccharide lactose. Biochemistry. 2009;48:786–791. doi: 10.1021/bi801855g. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 253.Kadirvelraj R, Foley BL, Dyekjaer JD, Woods RJ. Involvement of water in carbohydrate-protein binding: concanavalin A revisited. J Am Chem Soc. 2008;130:16933–16942. doi: 10.1021/ja8039663. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 254.Seeberger PH. Chemical glycobiology: why now? Nat Chem Biol. 2009;5:368–372. doi: 10.1038/nchembio0609-368. [DOI] [PubMed] [Google Scholar]
- 255.Shaikh FA, Withers SG. Teaching old enzymes new tricks: engineering and evolution of glycosidases and glycosyl transferases for improved glycoside synthesis. Biochem Cell Biol. 2008;86:169–177. doi: 10.1139/O07-149. [DOI] [PubMed] [Google Scholar]
- 256.Vliegenthart JF. Carbohydrate based vaccines. FEBS Lett. 2006;580:2945–2950. doi: 10.1016/j.febslet.2006.03.053. [DOI] [PubMed] [Google Scholar]
- 257.Debeljak N, Sytkowski AJ. Erythropoietin: new approaches to improved molecular designs and therapeutic alternatives. Curr Pharm Des. 2008;14:1302–1310. doi: 10.2174/138161208799316393. [DOI] [PubMed] [Google Scholar]
- 258.von Itzstein M, Thomson R (2009) Anti-influenza drugs: the development of sialidase inhibitors. Handb Exp Pharmacol 111–154 [DOI] [PubMed]
- 259.CFG Workshop on Leveraging Glycan Array Screens with Biological, Computational and structural data. http://glycomics.scripps.edu/CFGWorkshopOct2009.html
- 260.CFG Workshop on Analytic and Bioinformatic Glycomics, http://glycomics.scripps.edu/CFGWorkshopApril2009.html
- 261.Hurtley S, Service R, Szuromi P. Cinderella’s coach is ready. Science. 2001;291:2337–2337. doi: 10.1126/science.291.5512.2337. [DOI] [Google Scholar]
- 262.Rodriguez H, Snyder M, Uhlen M, Andrews P, Beavis R, Borchers C, Chalkley RJ, Cho SY, Cottingham K, Dunn M, Dylag T, Edgar R, Hare P, Heck AJ, Hirsch RF, Kennedy K, Kolar P, Kraus HJ, Mallick P, Nesvizhskii A, Ping P, Ponten F, Yang L, Yates JR, Stein SE, Hermjakob H, Kinsinger CR, Apweiler R. Recommendations from the 2008 International Summit on Proteomics Data Release and Sharing Policy: the Amsterdam principles. J Proteome Res. 2009;8:3689–3692. doi: 10.1021/pr900023z. [DOI] [PMC free article] [PubMed] [Google Scholar]