

Abstract
Genetic investigations often involve the testing of vast numbers of related hypotheses simultaneously. To control the overall error rate, a substantial penalty is required, making it difficult to detect signals of moderate strength. To improve the power in this setting, a number of authors have considered using weighted p-values, with the motivation often based upon the scientific plausibility of the hypotheses. We review this literature, derive optimal weights and show that the power is remarkably robust to misspecification of these weights. We consider two methods for choosing weights in practice. The first, external weighting, is based on prior information. The second, estimated weighting, uses the data to choose weights.
Key words and phrases: Bonferroni correction, multiple testing, weighted p-values
1. INTRODUCTION
Testing for association between genetic variation and a complex disease typically requires scanning hundreds of thousands of genetic polymorphisms. In a multiple testing situation, such as a genome-wide association study (GWAS), the null hypothesis is rejected for any test that achieves a p-value less than a predetermined threshold (usually on the order of 10−8). Data from these investigations has renewed interest in the multiple testing problem. The introduction of the false discovery rate and a procedure to control it by Benjamini and Hochberg (1995) inspired hope that this would be an effective way to control error while increasing power (Storey and Tibshirani, 2003; Sabatti, Service and Freimer, 2003). To further bolster power, recent statistical methods have been proposed that up-weight and down-weight hypotheses, based on prior likelihood of association with the phenotype (Genovese, Roeder and Wasserman, 2006; Roeder et al., 2006; Roeder, Wasserman and Devlin, 2007; Wang, Li and Bucan, 2007). Such prior information is often available in practice.
Weighted procedures multiply the threshold by the weight w, for each test, raising the threshold when w > 1 and lowering it if w < 1. To control the overall rate of false positives, a budget must be imposed on the weighting scheme, so that the average weight is one. If the weights are informative, the procedure improves power substantially, but, if the weights are uninformative, the loss in power is usually small. Surprisingly, aside from this budget requirement, any set of nonnegative weights is valid (Genovese, Roeder and Wasserman, 2006). While desirable in some respects, this flexibility makes it difficult to select weights for a particular analysis.
The first such weighting scheme appears to be Holm (1979). Related ideas can be found in Benjamini and Hochberg (1997), Chen et al. (2000), Genovese, Roeder and Wasserman (2006), Kropf et al. (2004), Rosenthal and Rubin (1983), Schuster, Kropf and Roeder (2004), Westfall and Krishen (2001), Westfall, Kropf and Finos (2004), Blanchard and Roquain (2008) and Roquain and van de Wiel (2008), among others. Several of these approaches use data dependent weights and yet maintain familywise error control. There are, of course, other ways to improve power aside from weighting. Some notable recent approaches include Rubin, Dudoit and van der Laan (2006), Storey (2007), Donoho and Jin (2004), Signoravitch (2006), Westfall, Krishen and Young (1998), Westfall and Soper (2001), Efron (2007) and Sun and Cai (2007). Of these, our approach is closest to Rubin, Dudoit and van der Laan (2006).
In some cases, the optimal weights can be estimated from the data. An approach developed by Westfall, Kropf and Finos (2004) utilizes quadratic forms to construct such weights; however, this approach assumes the individual measurements are normally distributed. This approach is suited to applications such as microarray data for which the observations are approximately normally distributed. We are interested in applications such as tests for genetic association. In this setting the individual observations are discrete, but the test statistics are approximately normally distributed.
In general, p-value weighting raises several important questions. How much power can we gain if we guess well in the weight assignment? How much power can we lose if we guess poorly? In this paper we show that the optimal weights have a simple parametric form and we investigate various approaches for estimating these weights. We also show the power is very robust to misspecification of the weights. In particular, in Section 3 we show that (i) sparse weights (few large weights and minimum weight close to 1) lead to huge power gains for well specified weights, but minute power loss for poorly specified weights; and (ii) in the nonsparse case, under weak conditions, the worst case power for poorly specified weights is typically better than the power obtained using equal weights.
We consider two methods for choosing the weights: (i) external weights, where prior information (based on scientific knowledge or prior data) singles out specific hypotheses (Section 4) and (ii) estimated weights where the data are used to construct weights (Section 5). External weights are prone to bias, while estimated weights are prone to variability. The two robustness properties reduce concerns about bias and variance.
To motivate this work consider an example (Figure 1) of external weighting that arises in genetic epidemiology. To identify variants of genes that induce greater susceptability to disease, two types of studies (linkage and association) are often performed. Whole genome linkage analysis has been conducted for most major diseases. These data can be summarized by a linkage trace, a smooth stochastic process {Z(s): s ∈ [0, L]} where each s corresponds to a location on the genome. At points that correspond to a variant of a gene of interest, the mean of the process μ(s) = E(Z(s)) is a large positive value; however, due to extensive spatial correlation in the process, μ(s) is also nonzero in the vicinity of the variant. Tests for association between genetic polymorphisms and disease status for each of many genetic markers across the genome are also of interest. Like linkage analysis, the association statistics {Tj: j = 1, …, m} map to spatial locations {sj: j = 1, …, m} on the genome. The number of tests m can be large, on the order of 1,000,000. Until recently, whole genome association analysis was prohibitively expensive, but technological advances have now made such studies feasible. Due to the multiple testing correction, it is difficult to achieve sufficient power to obtain definitive results in these studies. The linkage trace provides one obvious source of information from which the weights can be constructed; see Section 6 for further elaboration. Unlike linkage analysis, however, the spatial correlation in association tests is weak. For this reason, other choices such as genetic pathways could offer a more promising source for weights in the future.
Fig. 1.

Linkage trace and weights for 6 chromosomes. The trace is the linkage statistic plotted as a function of position on the chromosome. The shading indicates which p-values were up/down weighted. The upspike is the association test statistic. The 3 downspikes indicate tests that were rejected using the binary weights.
2. BACKGROUND
2.1 Multiple Testing
Consider a multiple testing situation in which m tests are being performed. Suppose m0 of the null hypotheses are true and m1 = m − m0 null hypotheses are false. We can categorize the m tests as in Table 1. In this notation F is the number of false positives. To control the familywise error rate, it is traditional to bound P (F > 0) at α. When the tests are independent, the simplest way to control this probability is to reject only those tests for which the p-value is less than α/m; this is called the Bonferroni procedure.
Table 1.
2 × 2 classification of m hypothesis tests
| H0 rejected | H0 not rejected | Total | |
|---|---|---|---|
| H0 true | F | m0 – F | m0 |
| H0 false | T | m1 – T | m1 |
| Total | S | m – S | m |
In 1995 Benjamini and Hochberg (BH) introduced a new approach to multiple hypothesis testing that controls the false discovery rate (FDR), defined as the expected fraction of false rejections among those hypotheses rejected. Let P(1) < ··· < P(m) be the ordered p-values from m hypothesis tests, with P(0) ≡ 0. Then, the BH procedure rejects any null hypothesis for which P ≤ T with
This quantity is of more scientific relevance than the overall type I error rate in GWAS. Also, the procedure is more powerful than the Bonferroni method. Adaptive variants of the procedure can increase power further at little additional computational expense; see Benjamini, Krieger and Yekutieli (2006) and Storey (2002).
BH controls the false discovery rate at level αm0/m, where m0 is the number of true null hypotheses. With certain dependence assumptions on the p-values, this is true regardless of how many nulls are true and regardless of the distribution of the p-values under the alternatives (Benjamini and Yekutieli, 2001; Blanchard and Roquain, 2009; Sarkar, 2002). Under some distributional assumptions, Genovese and Wasserman (2002) show that, asymptotically, the BH method corresponds to rejecting all p-values less than a particular p-value threshold u*. Specifically, u* is the solution to the equation H (u) = βu and , where A0 = m0/m and H is the (common) distribution of the p-value under the alternative. The key result is that α/m ≤ u* ≤ α, which shows that the BH method is intermediate between Bonferroni (corresponding to α/m) and uncorrected testing (corresponding to α). If A0 is close to 0, however, as it usually is in GWA, then β is a very large quantity and the power of the FDR is not much improved over the Bonferroni procedure.
The power of the BH method can be improved with adaptations. Blanchard and Roquain (2008) have given numerical comparisons of different adaptive procedures under dependence. Romano, Shaikh and Wolf (2008) have considered improving the adaptive procedure of Benjamini, Krieger and Yekutieli (2006) using the bootstrap. Sarkar and Heller (2008) have noted that the adaptive procedure of Benjamini et al. may not perform well compared to Storey’s (2002) procedure for certain parameter choices.
2.2 Weighted Multiple Testing
We are given hypotheses H = (H1, …, Hm) and standardized test statistics T = (T1, …, Tm), where Tj ~ N(ξj, 1). Likewise, . For a two-sided hypothesis, Hj = 1 if ξj ≠ 0 and Hj = 0 otherwise. For the sake of parsimony, unless otherwise noted, results will be stated for a one-sided test where Hj = 1 if ξj > 0, although the results extend easily to the two-sided case. Let θ = (ξ1, …, ξm) denote the vector of means.
The p-values associated with the tests are P = (P1, …, Pm), where Pj = Φ̄(Tj), Φ̄ = 1 − Φ and Φ denotes the standard Normal CDF. Let P(1) ≤ ··· ≤ P(m) denote the sorted p-values and let T(1) ≥ ··· ≥ T(m) denote the sorted test statistics.
A rejection set 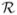 is a subset of {1, …, m}. Say that controls familywise error at level α if ℙ( ∩
is a subset of {1, …, m}. Say that controls familywise error at level α if ℙ( ∩ 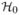 ) ≤ α, where = {j: Hj = 0}. The Bonferroni rejection set is = {j: Pj < α/m} = {j: Tj > zα/m} where we use the notation zβ = Φ̄−1 (β).
) ≤ α, where = {j: Hj = 0}. The Bonferroni rejection set is = {j: Pj < α/m} = {j: Tj > zα/m} where we use the notation zβ = Φ̄−1 (β).
The weighted Bonferroni procedure (Rosenthal and Rubin, 1983; Genovese, Roeder and Wasserman, 2006) is as follows. Specify nonnegative weights w = (w1, …, wm) and reject hypothesis Hj if
| (1) |
In the following lemma we show that as long as m−1Σj wj ≡ w̄ = 1, the rejection set controls familywise error at level α. The second lemma includes a simple modification that will be needed later.
Lemma 2.1
If w̄ = 1, then controls familywise error at level α.
Lemma 2.2
Suppose that Wj = g(Vj, c), j = 1, …, m, for some random variables V1, …, Vm, some constant c and some function g. Further, suppose that Vj has a known distribution H whenever j ∈ and that Pj is independent of Vj for all j ∈ . The rule that rejects when Pj ≤ αWj/m controls familywise error at level α if c is chosen to satisfy 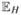 (g(Vj, c)) ≤ 1.
(g(Vj, c)) ≤ 1.
Genovese, Roeder and Wasserman (2006) also showed that false discovery methods benefit by weighting. Recall that the false discovery proportion (FDP) is
where the ratio is defined to be 0 if the denominator is 0. The false discovery rate (FDR) is FDR = 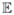 (FDP). Benjamini and Hochberg (1995) proved FDR ≤ α if = {j: P(j) ≤ T} where T = max{j: P(j) ≤ j α/m}. Genovese, Roeder and Wasserman (2006) showed that FDR ≤ α if the Pj ’s are replaced by Qj = Pj/wj provided w̄ = 1. This paper focuses on familywise error using the weighted procedure (1). Similar results hold for FDR and other familywise controlling procedures such as Holm’s test.
(FDP). Benjamini and Hochberg (1995) proved FDR ≤ α if = {j: P(j) ≤ T} where T = max{j: P(j) ≤ j α/m}. Genovese, Roeder and Wasserman (2006) showed that FDR ≤ α if the Pj ’s are replaced by Qj = Pj/wj provided w̄ = 1. This paper focuses on familywise error using the weighted procedure (1). Similar results hold for FDR and other familywise controlling procedures such as Holm’s test.
3. POWER, ROBUSTNESS AND OPTIMALITY
The optimal weights, derived below, can be re-expressed as optimal cutoffs for testing. Specifically, rejecting when Pj/wj ≤ α/m is the same as rejection when Tj > ξj/2 + c/ξj. This result can be obtained from Spjøtvoll (1972) and is identical to the result in Rubin, Dudoit and van der Laan (2006) obtained independently. The remainder of the paper, which shows some good properties of the weighted method, can thus also be considered as providing support for their method for selecting test specific cutoffs. In particular, Rubin et al. (2006)’s simulations indicate that even poorly specified estimates of the cutoffs ξj/2 + c/ξj can still perform well. In this section we provide insight into why this is true.
The power of a single, one-sided alternative in the unweighted case (wj = 1) is
The power1 in the weighted case is
| (2) |
Weighting increases the power when wj > 1 and decreases the power when wj < 1 for the jth alternative.
Given θ = (ξ1, …, ξm) and w = (w1, …, wm), we define the average power
where . More generally, if ξ is drawn from a distribution Q and w = w(ξ) is a weight function, we define the average power ∫π( ξ, w(ξ))I (ξ > 0) dQ(ξ)/∫I (ξ > 0) dQ(ξ). If we take Q to be the empirical distribution of (ξ1, …, ξm), then this reduces to the previous expression. In this formulation we require w(ξ) ≥ 0 and ∫ w(ξ) dQ(ξ) = 1.
In the following theorem we see that the set of optimal weight functions form a one parameter family indexed by a constant c.
Theorem 3.1
Given θ = (ξ1, …, ξm), the optimal weight vector w = (w1, …, wm) that maximizes the average power subject to wj ≥ 0 and w̄ = 1 is w = (ρc(ξ1), …, ρc(ξm)), where
| (3) |
and c ≡ c(θ) is defined by the condition
| (4) |
The proof, essentially a special case of Spjøtvoll (1972), is in the Appendix. Figure 2 displays the function ρc(ξ) for various values of c (the function is normalized to have maximum 1 for easier visualization). The result generalizes to the case where the alternative means are random variables with distribution Q in which case c is defined by ∫ ρc(ξ) dQ(ξ) = 1.
Fig. 2.

Optimal weight function ρc(ξ) for various c. In each case m = 1000 and α = 0.05. The functions are normalized to have maximum 1.
Lemma 3.2
The power at an alternative with mean ξ under optimal weights is Φ̄(c/ξ − ξ/2). The average power under optimal weights, which we call the oracle power, is
where m1 =Σj I (ξj > 0).
The oracle power is not attainable since the optimal weights depend on θ = (ξ1, …, ξm). In practice, the weights will either be chosen by prior information or by estimating the ξ’s. This raises the following question: how sensitive is the power to correct specification of the weights? Now we show that the power is very robust to weight misspecification.
Property I
Sparse weights (minimum weight close to 1) are highly robust. If most weights are less than 1 and the minimum weight is close to 1, then correct specification (large weights on alternatives) leads to large power gains but incorrect specification (large weights on nulls) leads to little power loss.
Property II
Worst case analysis. Weighted hypothesis testing, even with poorly chosen weights, typically does as well or better than Bonferroni except when the the alternative means are large, in which both have high power.
Let us now make these statements precise. Also, see Genovese, Roeder and Wasserman (2006) and Roeder et al. (2006) for other results on the effect of weight misspecification.
Property I
Consider first the case where the weights take two distinct values and the alternatives have a common mean ξ. Let ε denote the fraction of hypotheses given the larger of the two values of the weights B. Then, the weight vector w is proportional to
where k = εm and B > 1, and, hence, the normalized weights are
where
We say that the weights are sparse if ε is small. Provided B is considerably less than 1/ε, most weights are near 1 in the sparse case.
Rather than investigate the average power, we focus on a single alternative with mean ξ. The power gain by up-weighting this hypothesis is the power under weight w1 minus the unweighted power π( ξ, w1) − π( ξ, 1). Similarly, the power loss for down-weighting is ρ(ξ, 1) − π( ξ, w0). The gain minus the loss, which we call the robustness function, is
The gain outweighs the loss if and only if R(B, ε) > 0 (Figure 3).
Fig. 3.

Robustness function for m = 1000. In this example, ξ = zα/m which has power 1/2 without weighting. The gain of correct weighting far outweighs the loss for incorrect weighting as long as the fraction of large weights ε is small.
In the sparse weighting scenario k is small and w0 ≈ 1 by assumption, consequently, an analysis of R(B, ε) sheds light on the effect of weighting on power, without the added complications involved in a full analysis of average power.
Theorem 3.3
Fix B > 1. Then, limε→0 R(B, ε) > 0. Moreover, there exists ε*(B) > 0 such that R(B, ε) > 0 for all ε < ε*(B).
We can generalize this beyond the two-valued case as follows. Let w be any weight vector such that w̄ = 1. Now define the (worst case) robustness function
We will see that R(ξ) > 0 under weak conditions and that the maximal robustness is obtained for ξ near the Bonferroni cutoff zα/m.
Theorem 3.4
A necessary and sufficient condition for R(ξ) > 0 is
| (5) |
where B = min{wj: wj > 1}, b = min{wj }. Moreover,
where
and, as b → 1, μ({ξ: R(ξ) < 0}) → 0 and infξ R(ξ) → 0.
Based on the theorem, we see that there is overwhelming robustness as long as the minimum weight is near 1. Even in the extreme case b = 0, there is still a safe zone, an interval of values of ξ over which R(ξ) > 0.
Lemma 3.5
Suppose that B ≥ 2. Then there exists ξ* > 0 such that RB,b(ξ) > 0 for all 0 ≤ ξ ≤ ξ* and all b. An upper bound on ξ* is zα/m − 1/(zα/m − zBα/m).
Property II
Even if the weights are not sparse, the power of the weighted test tends to be acceptable.
The result holds even though the weights themselves can be very sensitive to changes in θ. Consider the following example. Suppose that θ = (ξ1, …, ξm) where each ξ is equal to either 0 or some fixed number ξ. The empirical distribution of the ξj ’s is thus Q = (1 − a)δ0 + aδξ, where δ denotes a point mass and a is the fraction of nonzero means. The optimal weights are 0 for ξj = 0 and 1/a for ξj = ξ. Let Q̃ = (1 − a − γ)δ0 + γδu + aδξ, where u is a small positive number. Since we have only moved the mass at 0 to u, and u is small, we would hope that w(ξ) will not change much. But this is not the case. Set , where
This arrangement yields weights w0 and w1 on u and ξ such that w0/w1 = K. For example, if m = 1000, α = 0.05, a = 0.1, γ = 0.1, K = 1000 and c = 0.1, then u = 0.03 and ξ = 9.8. The optimal weight on ξ under Q is 10 but under Q̃ it is 0.00999 and so is reduced by a factor of 1001. More generally, we have the following result which shows that the weights are, in a certain sense, a discontinuous function of θ.
Lemma 3.6
Fix α and m. For any δ > 0 and ε > 0 there exists Q = (1 − a)δ0 + aδξ and Q̃ = (1 − a − γ)δ0 + γδu + aδξ such that d(Q, Q̃) < δ, and ρ̃(ξ)/ρ(ξ) < ε, where a = α/4, d(Q, Q̃) = supξ |Q(−∞, ξ], Q̃(−∞, ξ]| is the Kolmogorov–Smnirnov distance, ρ is the optimal weight function for Q and ρ̃ is the optimal weight function for Q̃.
Fortunately, this feature of the weight function does not pose a serious hurdle in practice because it is possible to have high power even with poor weights. In Figure 4 the plots on the left show the power as a function of the alternative mean ξ. The dark solid line shows the lowest possible power assuming the weights were estimated as poorly as possible (under conditions specified below). The lighter solid line is the power of the unweighted (Bonferroni) method. The dotted line shows the power under theoretically optimal weights. The worst case weighted power is typically close to or larger than the Bonferroni power except for large ξ when they are both large.
Fig. 4.

Power as a function of the alternative mean ξ. In these plots, a = 0.01, m = 1000 and α = 0.05. There are (1 − a)m nulls and ma alternatives with mean ξ. The left plots show what happens when the weights are incorrectly computed assuming that a fraction γ of nulls are actually alternatives with mean u. In the top plot, we restrict 0 < u < ξ. In the second and third plots, no restriction is placed on u. The top and middle plots have γ = 0.1, while the third plot has γ = 1 − a (all nulls misspecified as alternatives). The dark solid line shows the lowest possible power assuming the weights were estimated as poorly as possible. The lighter solid line is the power of the unweighted (Bonferroni) method. The dotted line is the power under the optimal weights. The vertical line in the top plot is at ξ*. The weighted method beats unweighted for all ξ < ξ*. The right plot shows the least favorable u as a function of ξ. That is, mistaking γm nulls for alternatives with mean u leads to the worst power. Also shown is the line u = ξ.
To begin formal analysis, assume that each mean is either equal to 0 or ξ for some fixed ξ > 0. Thus, the empirical distribution is Q = (1 − a) δ0 + aδξ, where δ denotes a point mass and a is the fraction of nonzero ξj ’s. The optimal weights are 1/a for hypotheses whose mean is ξ. To study the effect of misspecification error, consider the case where γm nulls are mistaken for alternatives with mean u > 0. This corresponds to misspecifying Q to be Q̃ = (1 − a − γ) δ0 + γδu + aδξ. We will study the effect of varying u, so let π(u) denote the power at the true alternative ξ as a function of u. Also, let πBonf denote the power using equal weights (Bonferroni). Note that changing Q = (1− a) δ0 + aδξ to Q = (1− a) δ0 + aδξ′ for ξ′ ≠ ξ does not change the weights.
As the weights are a function of c, we first need to find c as a function of u. The normalization condition (4) reduces to
| (6) |
which implicitly defines the function c(u). First we consider what happens when u is restricted to be less than ξ.
Theorem 3.7
Assume that α/m ≤ γ + a ≤ 1. Let Q = (1 − a)δ0 + aδξ and Q̃ = (1 − a − γ)δ0 + γδu + aδξ with 0 ≤ u ≤ ξ. Let C(ξ) = sup0≤u≤ ξc(u) and define ξ0 = zα/(m(γ+a)):
-
For ξ ≤ ξ0, C(ξ) = ξξ0 − ξ2/2. For ξ> ξ0, C(ξ) is the solution to
In this case, .
-
Let , where q = α(1 − α)/(mγ). For ξ< ξ*,
(7) For ξ ≥ ξ* we have(8) (9) (10) The factor is the worst case power deficit due to misspecification. Now we drop the assumption that u ≤ ξ.
Theorem 3.8
Let Q = (1 − a)δ0 + aδξ and let Qu ≡ (1 − a − γ)δ0 + γδu + aδξ. Let πu denote the power at ξ using the weights computed under Qu.
-
The least favorable u is , where c* solves
and .
- The minimal power is
A sufficient condition for infu πu to be larger than the power of the Bonferroni method is .
4. CHOOSING EXTERNAL WEIGHTS
One approach to choosing external weights (or test statistic cutoffs) is to use empirical Bayes methods to model prior information while being careful to preserve error control as in Westfall and Soper (2001), for example. Here we consider a simple method that takes advantage of the robustness properties we have discussed. We will focus here on the two-valued case. Thus,
where k = εm, w1 = B/(εB + (1 − ε)) and w0 = 1/(εB + (1 − ε)). In practice, we would typically have a fixed fraction of hypotheses ε that we want to give more weight to. The question is how to choose B. We will focus on choosing B to produce weights with good properties at interesting values of ξ. Now large values of ξ already have high power. Very small values of ξ have extremely low power and benefit little by weighting. This leads us to focus on constructing weights that are useful for a marginal effect, defined as the alternative ξ0 that has power 1/2 when given weight 1. Thus, the marginal effect is ξ0 = zα/m. In the rest of this section then we assume that all nonzero ξj ’s are equal to ξ0. Of course, the validity of the procedure does not depend on this assumption being true.
Fix 0 < ε < 1 and vary B. As we increase B, we will eventually reach a point B0(ε) where R(B, ε) < 0, which we call the turnaround point. Formally, B0(ε) = sup{B: R(B, ε) > 0}. The top panel in Figure 5 shows B0(ε) versus εwhich shows that for small ε we can choose B large without loss of power. The bottom panel shows R(B, ε) for ε = 0.1. Ideally, for a given ε, one chooses B near B*(ε), the value of B that maximizes R(B, ε).
Fig. 5.

Top plot: turnaround point B0(ε) versus ε. Bottom plot shows the robustness function R(B, 0.1) versus B. The turnaround point B0(ε) is shown with a vertical dotted line.
Theorem 4.1
Fix 0 < ε < 1. As a function of B, R(B, ε) is unimodal and satisfies R(1, ε) = 1, R′(1, ε) > 0 and R(∞, ε) < 0. Hence, B0(ε) exists and is unique. Also, R(B, ε) has a unique maximum at some point B*(ε) and R(B*(ε), ε) > 0.
When ε is very small, B can be large, provided w0 ≈ 1. For example, suppose we want to increase the chance of rejecting one particular hypothesis so that ε= 1/m. Then,
and
The next results show that binary weighting schemes are optimal in a certain sense. Suppose we want to have at least a fraction ε with high power 1 − β and otherwise we want to maximize the minimum power.
Theorem 4.2
Consider the following optimization problem: Given 0 < ε < 1 and 0 < β < 1/2, find a vector w = (w1, …, wm) that maximizes minj π(ξm, wj ) subject w̄ = 1, and #{j: π(wj, ξm) ≥ 1 − β}/m ≥ ε. The solution is given by c = Φ̄(zα/m + z1−β ), B = cm(1 − ε)/(α − εcm), w1 = B/(εB + (1 − ε)), w0 = 1/(εB + (1 − ε)) and k = εm.
If our goal is to maximize the number of alternatives with high power while maintaining a minimum power loss, the solution is given as follows.
Theorem 4.3
Consider the following optimization problem: Given 0 < β < 1/2, find a vector w = (w1, …, wm) that maximizes #{j: π(wj, ξm) ≥ 1 − β} subject to w̄ = 1, and minj π(wj, ξm) ≥ δ. The solution is
and k = mε.
A special case that falls under this theorem permits the minimum power to be 0. In this case w0 = 0 and ε= 1/w1.
5. ESTIMATED WEIGHTS
In practice, ξj is not known, so it must be estimated to utilize the weight function. A natural choice is to build on the two stage experimental design (Satagopan and Elston, 2003; Wang et al., 2006) and split the data into subsets, using one subset to estimate ξi, and hence w(ξi ), and the second to conduct a weighted test of the hypothesis (Rubin, Dudoit and van der Laan, 2006). This approach would arise naturally in an association test conducted in stages. It does lead to a gain in power relative to unweighted testing of stage 2 data; however, it is not better than simply using the full data set without weights for the analysis (Rubin, Dudoit and van der Laan, 2006). These results are corroborated by Skol et al. (2006) in a related context. They showed that it is better to use stages 1 and 2 jointly, rather than using stage 2 as an independent replication of stage 1.
To gain a strong advantage with data-based weights, prior information is needed. One option is to order the tests (Rubin, Dudoit and van der Laan, 2006), but with a large number of tests this can be challenging. The type of prior information readily available to investigators is often nonspecific. For instance, SNPs might naturally be grouped, based on features that make various candidates more promising for this disease under investigation. For a brain-disorder phenotype we might cross-classify SNPs by categorical variables such as functionality, brain expression and so forth. The SNPs in one group may seem most promising, a priori, while those in another seem least promising. Intermediate groups may be somewhat ambiguous. It is easy to imagine additional variables that further partition the SNPs into various classes that help to separate the more promising SNPs from the others. While this type of information lends itself to grouping SNPs, it does not lead directly to weights for the groups. Indeed, it might not even be possible to choose a natural ordering of the groups. What is needed is a way to use the data to determine the weights, once the groups are formed.
Until recently, methods for weighted multiple-testing required that prior weights be developed independently of the data under investigation (Genovese, Roeder and Wasserman, 2006; Roeder, Wasserman and Devlin, 2007). Here we provide a data-based estimate of weights based on results of grouped analysis. One way to implement this approach is to follow these steps:
Partition the tests into subsets
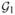 , …,
, …, 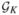 , with the kth group containing rk elements, ensuring that rk is at least 20–30.
, with the kth group containing rk elements, ensuring that rk is at least 20–30.Calculate the sample mean and variance for the test statistics in each group.
-
Label the ith test in group k, Tik. At best, only a fraction of the elements in each group will have a signal, hence, we assume that for i = 1, …, rk the distribution of the test statistics is approximated by a mixture modelor
where ξk is the signal size for those tests with a signal in the kth group. This is an approximation because the signal is likely to vary across tests. The mixture of normals is only appropriate when the tests are one-sided. For two-sided alternatives, the χ2 is the natural approach. This test squares the noncentrality parameter, effectively removing any ambiguity about the direction of the associations.
-
Estimate (πk, ξk) using the method of moments estimator (for details see the Appendix). Because ξk has no meaning when πk = 0, the ξ̂k is set to 0 when π̂k is close to zero. For the normal model the estimators are
(11) provided π̂k > 1/rk; otherwise ξ̂k = 0.
For the χ2 model they are(12) provided Yk > 1 and 1/rk < π̂k < (rk − 1)/rk; otherwise ξ̂k = 0.
-
For each of the k groups, construct weights w(ξ̂k ). It is apparent in Figure 1 that if |ξ̂k| < δ, for δ near 0, then w(ξ̂k) ≈ 0 and it is unlikely that any tests in the kth group will be significant, regardless of the p-value. The stochastic quantity δ depends upon the relative values of (ξ̂1, …, ξ̂K ), and the number of elements in each group. For this reason we have found that smoothing the weights generally improves the power of the procedure. We suggest using a linear combination such as
with γ = 0.01 or 0.05. The larger the choice of γ, the more evenly distributed the weights across groups. Alternatively, one could smooth the weights by using a Stein shrinkage estimator or bagging procedure to obtain a more robust estimator of (ξ1, …, ξK ) (Hastie, Tibshirani and Friedman, 2001). Regardless of how the weights are smoothed, one should renorm them to ensure the weights sum to m. Each test in group k receives the weight ŵk. Another effect of the smoothing is to ensure that each group gets a weight greater than 0.
This weighting scheme relies on data-based estimators of the optimal weights, but with a partition of the data sufficiently crude to preserve the control of family-wise error rate. The approach is an example of the “sieve principle” (Bickel et al., 1993). The sieve principle works because the number of parameters estimated is far less than the number of observations. Thus, many observations are used to estimate each parameter. Consequently, parameters are estimated with substantially less variability than if they were estimated using only the test statistics from the particular gene under investigation. Because the weights are determined by the size of the tests in the entire cluster, the probability of upweighting simply because a single test is large, due to chance, is small.
6. EXAMPLES
6.1 Binary Weights
In a study of nicotine dependence, Saccone et al. (2007) used binary weights in a candidate gene study. Their study involved 3713 genetic variants (single nucleotide polymorphisms or SNPs) encompassing 348 genes. The genes were divided into two types: 52 nicoinic and dopaminergic receptor genes; and 296 other candidate genes. Each SNP associated with a gene in the first group was allocated ten times the weight of a gene in the other category. Using a generous false discovery rate (α = 0.4), they identified 39 SNPs; 78% of these were nicotine receptors, in contrast to the fraction of nicotine receptors overall (15%).
6.2 Independent Data Weights
For family-based study designs, tests of association are based on transmission data. In these studies, data are available from which one can compute the potential power to detect a signal at each SNP tested; see Ionita-Laza et al. (2007) for a detailed explanation of this unique feature of family-based data. Because the data used to calculate the power are independent of the test statistics for association, these data are available for construction of the weights. Motivated by this possibility, Ionita-Laza et al. (2007) developed a weighting scheme. Using independent data, they ranked the SNPs from most to least promising, in terms of power. They then constructed an exponential weighting scheme, based on simulations of genetic models. The scheme results in a small number of SNPs receiving a top weight, successively more SNPs receiving correspondingly lower weights, and finally a large number receiving the lowest weight. In their simulations they found that the power of the test can often be doubled using this procedure. Using the FHS data, they apply the technique to a genome-wide association study with 116,204 SNPs and 923 participants. The phenotype of interest is height. Using their weighting scheme, they obtained one significant result with weights and none without weights.
6.3 Linkage Weights
Finding variation in the genetic code that increases the risk for complex diseases, such as Type II diabetes and schizophrenia, is critically important to the advancement of genetic epidemiology. In the Introduction we describe a means by which weights could be extracted from linkage data. Here we illustrate the idea with both data and simulations.
In the analysis of 955 cases and 1498 controls enrolled in a genome-wide association study, McQueen and colleagues (2008) used weights derived from published linkage results. They combined results from 11 linkage studies on bipolar disorder to obtain Z scores corresponding to the locations of each association test. From the linkage results they computed weighted p-values using the cummulative normal weight function (Roeder et al., 2006). Although none of their results were genome-wide significant, they obtained promising results in four regions. Three of these are obtained due to strong p-values in combination with a linkage peak. One signal did not correspond to a linkage peak, but continued to be in the top tier of p-values, after weights were applied.
To illustrate how binary weights could be derived from such linkage data, we present a realistic synthetic example. Using the methods described in Roeder et al. (2006), we create a linkage trace that captures many of the features found in actual linkage traces. In this simulation we generate a full genome (23 chromosomes) and place 20 disease variants at random, one per chromosome. The signals from these variants were designed to yield weak signals with broad peaks. Next, we simulated 100,000 normally distributed association test statistics mapped to the same genome. Again, 20 of these tests were generated under the alternative hypothesis of association. These signals were also weak.
To illustrate the synthetic data, six typical chromosomes are displayed in Figure 1. Each displayed chromosome has one true signal, with the association test statistic at that location indicated by an upspike; none of the association tests generated under the null hypothesis are plotted. Without weights, only 2 of the 20 signals could be detected using a Bonferonni correction. Using binary weights, as described above, with ε = 0.05 and B = 10, we discover 5 of the 20 signals. In the left column of the figure all three signals were discovered, while in the right column none were discovered (indicated by presence of a down-spike). Comparing the top row, we see that both signals were up-weighted in the correct location, but the association signal was not strong enough in the top right chromosome to achieve significance. Alternatively, in the bottom left panel the association statistic was substantial enough to reject the null hypothesis without the benefit of up-weighting.
To examine the robustness of the procedure to choice of weights, we tried 4 choices of ε (0.01, 0.05, 0.1, 0.2) with 1 ≤ B ≤ 50. We made no false discoveries with any of these choices. The power is displayed in Figure 6. To assist in the choice of parameters, we have found it helpful to examine the number of discoveries for each choice. In this example, the number of discoveries varied between 2 (unweighted, i.e., B = 1) to 6 (ε = 0.2, B ≥ 10). Five discoveries were made for a broad range of choices. In principle, choosing (ε, B) to maximize the number of discoveries can inflate the error rate. In our simulations we have found that searching within the family of weights defined by 1 or 2 parameters, such as this binary weight system based upon a linkage trace, tends to provide very close to nominal protection against false discoveries.
Fig. 6.

Power as a function of B and ε.
7. DISCUSSION
Several authors have explored the effect of weights on the power of multiple testing procedures [e.g., Westfall, Kropf and Finos (2004)]. These investigations show that the power of multiple testing procedures can be increased by using weighted p-values. Here we derive the optimal weights for a commonly used family of tests and show that the power is remarkably robust to misspecification of these weights.
The same ideas used here can be applied to other testing methods to improve power. In particular, weights can be added to the FDR method, Holm’s step-down test, and the Donoho and Jin (2004) method. Weighting ideas can also be used for confidence intervals. Another open question is the connection with Bayesian methods which have already been developed to some extent in Efron et al. (2001).
GWAS for some phenotypes such as Type 1 diabetes have yielded exciting results (Todd et al., 2007), while results for other complex diseases have been much less successful. Presumably, many studies do not have sufficient power to detect the genetic variants associated with the phenotypes, even though thousands of cases and controls have been genotyped. To bolster power, we recommend up-weighting and down-weighting hypotheses, based on prior likelihood of association with the phenotype. For instance, Wang, Li and Bucan (2007) describe pathway-based approaches for the analysis of GWAS.
Multiple testing arises in GWAS analyses in other contexts as well. Frequently, multiple tests, assuming different genetic models, are applied to each genetic marker. Multiple markers in a neighborhood can be analyzed simultaneously to increase the signal, using haplotypes, multivariate models and fine-mapping techniques. Data are often collected in multiple stages of the experiment, and at each stage promising markers are tested for association. In summary, many questions concerning multiple testing remain open in the context of GWAS.
Acknowledgments
The authors thank Jamie Robins for helping us to clarify several issues. Research supported in part by National Institute of Mental Health Grant MH057881 and NSF Grant AST 0434343.
APPENDIX
Proof of Lemma 2.1
The familywise error is
Proof of Lemma 2.2
The familywise error is
Proof of Theorem 3.1
Let C denote the set of hypotheses with ξj > 0. Power is optimized if wj = 0 for j ∉C. The average power is
with constraint
Choose w to maximize
by setting the derivative to zero
The w that solves these equations is given in (3). Finally, solve for c such that Σi wi = m.
Proof of Theorem 3.4
The first statement follows easily by noting that the worst case corresponds to choosing weight B in the first term in R(ξ) and choosing weight b in the second term in R(ξ). The rest follows by Taylor expanding Rb,B (ξ) around b = 1.
Proof of Lemma 3.5
With b = 0, Rb,B (ξ) ≥ 0 when
| (13) |
With B ≥ 2, (13) holds at ξ = 0. The left-hand side is increasing in ξ for ξ near 0, but (13) does not hold at ξ = zα/m. So (13) must hold in the interval [0, ξ*]. Rewrite (13) as Φ̄(zBα/m − ξ) − Φ̄(zα/m − ξ) ≥ Φ̄(zα/m − ξ). We lower bound the left-hand side and upper bound the right-hand side. The left-hand side is . The right-hand side can be bounded using Mill’s ratio: Φ̄(zα/m − ξ) ≤ φ(zα/m − ξ)/(zα/m − ξ). Set the lower bound greater than the upper bound to obtain the stated result.
Proof of Lemma 3.6
Choose K > 1 such that 1/(K + 1) < 1/a − ε. Choose 1 > γ > (2α − a)/K. Choose a small c > 0. Let and , where
Then ρ(ξ) = 1/a and ρ̃( ξ) = 1/(K + 1). Now d(Q, Q̃) = γ. Taking K sufficiently large and γ sufficiently close to (2α − a)/K makes γ< δ.
It is convenient to prove Theorem 3.8 before proving Theorem 3.7.
Proof of Theorem 3.8
Let c* solve
| (14) |
We claim first that, for any c > c*, there is no u such that the weights average to 1. Fix c > c*. The weights average to 1 if and only if
| (15) |
Since c > c* and since the second term is decreasing in c, we must have
The function r(u) = Φ̄(c/u + u/2) is maximized at . So . But . Hence, . This implies c < c*, which is a contradiction. This establishes that supu c(u) ≤ c*. On the other hand, taking c = c* and solves equation (15). Thus, c* is indeed the largest c that solves the equation which establishes the first claim. The second claim follows by noting that
Now set this expression equal to α/m and solve.
Proof of Theorem 3.7
Define c* as in (14). If , then the the proof proceeds as in the previous proof. So we first need to establish for which values of ξ is this true. Let . We want to find out when the solution of r(c) = α/m is such that , or, equivalently, c ≤ ξ2/2. Now r is decreasing in c. Since γ + a ≥ α/m, r(−∞) ≥ α/m. Hence, there is a solution with c ≤ ξ2/2 if and only if r(ξ2/2) ≤ α/m. But r(ξ2/2) = (γ + a) Φ̄ (ξ), so we conclude that there is such a solution if and only if (γ + a) Φ̄ (ξ) ≤ α/m, that is, ξ ≥ zα/(m(γ +a)) = ξ0.
Now suppose that ξ < ξ0. We need to find u ≤ ξ to make c as large as possible in the equation v(u, c) ≡ γΦ̄ (u/2 + c/u) + aΦ̄ (ξ/2 + c/ξ) = α/m. Let u* = ξ and c* = ξzα/(m(γ +a)) − ξ2/2. By direct substitution, v(u*, c*) = α/m for this choice of u and c and, clearly, u* ≤ ξ as required. We claim that this is the largest possible c*. To see this, note that v(u, c) < v(u, c*). For ξ ≤ ξ0, v(u, c*) is a decreasing function of u. Hence, v(u, c) < v(u, c*) ≤ v(u*, c*) = α/m. This contradicts the fact that v(u, c) = α/m.
For the second claim, note that the power of the weighted test beats the power of Bonferroni if and only if the weight w = (m/α) Φ̄ (ξ/2 + C(ξ)/2) ≥ 1, which is equivalent to
| (16) |
When ξ ≤ ξ0, C(ξ) = ξξ0 − ξ2/2. By assumption, γ + a ≤ 1 so that zα/(m(γ +a)) ≤ zα/m and now suppose that ξ0 <ξ ≤ ξ*. Then C(ξ) is the solution to . We claim that (16) still holds. Suppose not. Then, since r(c) is decreasing in c, r(ξzα/m − ξ2/2) > r(C(ξ)) = α/m. But, by direct calculation, r(ξzα/m − ξ2/2) > α/m implies that ξ > ξ*, which is a contradiction. Thus, (7) holds.
Finally, we turn to (8). In this case, . The worst case power is . The latter is increasing in ξ and so is at least , as claimed. The next two equations follow from standard tail approximations for Gaussians. Specifically, a Gaussian quantile zβ/m can be written as , where Lm = c loga(m) for constants a and c [Donoho and Jin (2004)]. Inserting this into the previous expression yields the final expression.
Proof of Theorem 4.2
Setting π(w, ξm) =Φ̄(Φ̄−1 (wα/m) − ξm) equal to 1 − β implies w = (m/α) Φ̄ (z1−β + zα/m), which is equal to w1 as stated in the theorem. The stated form of w0 implies that the weights average to 1. The stated solution thus satisfies the restriction that a fraction ε have power at least 1 − β. Increasing the weight of any hypothesis whose weight is w0 necessitates reducing the weight of another hypothesis. This either reduces the minimum power or forces a hypothesis with power 1 − β to fall below 1 − β. Hence, the stated solution does in fact maximize the minimum power.
Footnotes
Contributor Information
Kathryn Roeder, Email: roeder@stat.cmu.edu, Professor of Statistics, Department of Statistics, Carnegie Mellon University, 5000 Forbes Avenue, Pittsburgh, PA 15213, USA.
Larry Wasserman, Email: wasserman@stat.cmu.edu, Professor of Statistics, Carnegie Mellon University, 5000 Forbes Avenue, Pittsburgh, PA 15213, USA.
References
- Benjamini Y, Hochberg Y. Controlling the false discovery rate: A practical and powerful approach to multiple testing. J Roy Statist Soc Ser B. 1995;57:289–300. MR1325392. [Google Scholar]
- Benjamini Y, Hochberg Y. Multiple hypotheses testing with weights. Scand J Statist. 1997;24:407–418. MR1481424. [Google Scholar]
- Benjamini Y, Krieger AM, Yekutieli D. Adaptive linear step-up procedures that control the false discovery rate. Biometrika. 2006;93:491–507. MR2261438. [Google Scholar]
- Benjamini Y, Yekutieli D. The control of the false discovery rate in multiple testing under dependency. Ann Statist. 2001;29:1165–1188. MR1869245. [Google Scholar]
- Bickel P, Klaassen C, Ritov Y, Wellner J. Technical report. Johns Hopkins Series in the Mathematical Statistics; Baltimore, Maryand: 1993. Efficient and adaptive estimation for semiparametric models. MR1245941. [Google Scholar]
- Blanchard G, Roquain E. Two simple sufficient conditions for FDR control. Electron J Stat. 2008;2:963–992. MR2448601. [Google Scholar]
- Blanchard G, Roquain E. Adaptive FDR control under independence and dependence. J Mach Learn Res. 2009 To appear. [Google Scholar]
- Chen JJ, Lin KK, Huque M, Arani RB. Weighted p-value adjustments for animal carcinogenicity trend test. Biometrics. 2000;56:586–592. doi: 10.1111/j.0006-341x.2000.00586.x. [DOI] [PubMed] [Google Scholar]
- Donoho D, Jin J. Higher criticism for detecting sparse heterogeneous mixtures. Ann Statist. 2004;32:962–994. MR2065195. [Google Scholar]
- Efron B. Simultaneous inference: When should hypothesis testing problems be combined? Ann Appl Statist. 2007;2:197–223. MR2415600. [Google Scholar]
- Efron B, Tibshirani R, Storey JD, Tusher V. Empirical Bayes analysis of a microarray experiment. J Amer Statist Assoc. 2001;96:1151–1160. MR1946571. [Google Scholar]
- Genovese C, Wasserman L. Operating characteristics and extensions of the false discovery rate procedure. J R Stat Soc Ser B Stat Methodol. 2002;64:499–517. MR1924303. [Google Scholar]
- Genovese CR, Roeder K, Wasserman L. False discovery control with p-value weighting. Biometrika. 2006;93:509–524. MR2261439. [Google Scholar]
- Hastie T, Tibshirani R, Friedman J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer; New York: 2001. MR1851606. [Google Scholar]
- Holm S. A simple sequentially rejective multiple test procedure. Scand J Statist. 1979;6:65–70. MR0538597. [Google Scholar]
- Ionita-Laza I, McQueen M, Laird N, Lange C. Genomewide weighted hypothesis testing in family-based association studies, with an application to a 100K scan. Am J Hum Genet. 2007;81:607–614. doi: 10.1086/519748. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kropf S, Läuter J, Eszlinger M, Krohn K, Paschke R. Nonparametric multiple test procedures with data-driven order of hypotheses and with weighted hypotheses. J Statist Plann Inference. 2004;125:31–47. MR2086887. [Google Scholar]
- McQueen M, et al. Personal communication. 2008.
- Roeder K, Bacanu S-A, Wasserman L, Devlin B. Using linkage genome scans to improve power of association in genome scans. Am J Hum Genet. 2006;78:243–252. doi: 10.1086/500026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roeder K, Wasserman L, Devlin B. Improving power in genome-wide association studies: Weights tip the scale. Genet Epidemiol. 2007;31:741–747. doi: 10.1002/gepi.20237. [DOI] [PubMed] [Google Scholar]
- Romano JP, Shaikh AM, Wolf M. Control of the false discovery rate under dependence using the bootstrap and subsampling. TEST. 2008;17:417–442. MR2470085. [Google Scholar]
- Roquain E, van de Wiel M. Multi-weighting for FDR control. 2008. Available at arXiv:0807.4081. [Google Scholar]
- Rosenthal R, Rubin D. Ensemble-adjusted p-values. Psychol Bull. 1983;94:540–541. [Google Scholar]
- Rubin D, Dudoit S, van der Laan M. A method to increase the power of multiple testing procedures through sample splitting. Stat Appl Genet Mol Biol. 2006;5 doi: 10.2202/1544-6115.1148. Art. 19 (electronic). MR2240850. [DOI] [PubMed] [Google Scholar]
- Sabatti C, Service S, Freimer N. False discovery rate in linkage and association genome screens for complex disorders. Genetics. 2003;164:829–833. doi: 10.1093/genetics/164.2.829. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Saccone S, Hinrichs AL, Saccone N, Chase G, Konvicka K, Madden P, Breslau N, Johnson E, Hatsukami D, Pomerleau O, Swan G, Goate A, Rutter J, Bertelsen S, Fox L, Fugman D, Martin N, Montgomery G, Wang J, Ballinger D, Rice J, Bierut L. Cholinergic nicotinic receptor genes implicated in a nicotine dependence association study targeting 348 candidate genes with 3713 SNPs. Hum Mol Genet. 2007;16:36–49. doi: 10.1093/hmg/ddl438. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sarkar S, Heller R. Comments on: Control of the false discovery rate under dependence using the bootstrap and subsampling. TEST. 2008;17:450–455. MR2470085. [Google Scholar]
- Sarkar SK. Some results on false discovery rate in stepwise multiple testing procedures. Ann Statist. 2002;30:239–257. MR1892663. [Google Scholar]
- Satagopan J, Elston R. Optimal two-stage genotyping in population-based association studies. Genet Epidemiol. 2003;25:149–157. doi: 10.1002/gepi.10260. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schuster E, Kropf S, Roeder I. Micro array based gene expression analysis using parametric multivariate tests per gene—a generalized application of multiple procedures with data-driven order of hypotheses. Biom J. 2004;46:687–698. MR2108612. [Google Scholar]
- Signoravitch J. Technical report. Harvard Biostatistics; 2006. Optimal multiple testing under the general linear model. [Google Scholar]
- Skol A, Scott L, Abecasis G, Boehnke M. Joint analysis is more efficient than replication-based analysis for two-stage genome-wide association studies. Nat Genet. 2006;38:390–394. doi: 10.1038/ng1706. [DOI] [PubMed] [Google Scholar]
- Spjøtvoll E. On the optimality of some multiple comparison procedures. Ann Math Statist. 1972;43:398–411. MR0301871. [Google Scholar]
- Storey JD. A direct approach to false discovery rates. J R Stat Soc Ser B Stat Methodol. 2002;64:479–498. MR1924302. [Google Scholar]
- Storey JD. The optimal discovery procedure: A new approach to simultaneous significance testing. J R Stat Soc Ser B Stat Methodol. 2007;69:347–368. MR2323757. [Google Scholar]
- Storey J, Tibshirani R. Statistical significance for genome-wide studies. Proc Natl Acad Sci USA. 2003;100:9440–9445. doi: 10.1073/pnas.1530509100. MR1994856. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sun W, Cai TT. Oracle and adaptive compound decision rules for false discovery rate control. J Amer Statist Assoc. 2007;102:901–912. MR2411657. [Google Scholar]
- Todd J, Walker N, Cooper J, Smyth D, Downes K, Plagnol V, Bailey R, Nejentsev S, Field S, Payne F, Lowe C, Szeszko J, Hafler J, Zeitels L, Yang J, Vella A, Nutland S, Stevens H, Schuilenburg H, Coleman, Maisuria M, Meadows W, Smink LJ, Healy B, Burren O, Lam A, Ovington N, Allen J, Adlem E, Leung H, Wallace C, Howson J, Guja C, Ionescu-Tirgovi C, Simmonds M, Heward J, Gough S, Dunger D, Wicker L, Clayton D Genetics of Type 1 Diabetes in Finland. Wellcome Trust Case Control Consortium. Robust associations of four new chromosome regions from genome-wide analyses of type 1 diabetes. Nat Genet. 2007;39:857–864. doi: 10.1038/ng2068. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang H, Thomas D, Pe’er I, Stram D. Optimal two-stage genotyping designs for genome-wide association scans. Genet Epidemiol. 2006;30:356–368. doi: 10.1002/gepi.20150. [DOI] [PubMed] [Google Scholar]
- Wang K, Li M, Bucan M. Pathway-based approaches for analysis of genomewide association studies. Am J Hum Genet. 2007;81:1278–1283. doi: 10.1086/522374. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Westfall P, Krishen A, Young S. Using prior information to allocate significance levels for multiple endpoints. Stat Med. 1998;17:2107–2119. doi: 10.1002/(sici)1097-0258(19980930)17:18<2107::aid-sim910>3.0.co;2-w. [DOI] [PubMed] [Google Scholar]
- Westfall PH, Krishen A. Optimally weighted, fixed sequence and gatekeeper multiple testing procedures. J Statist Plann Inference. 2001;99:25–40. MR1858708. [Google Scholar]
- Westfall PH, Kropf S, Finos L. IMS Lecture Notes Monogr Ser. Vol. 47. IMS; Beachwood, OH: 2004. Weighted FWE-controlling methods in high-dimensional situations. Recent Developments in Multiple Comparison Procedures; pp. 143–154. MR2118598. [Google Scholar]
- Westfall PH, Soper KA. Using priors to improve multiple animal carcinogenicity tests. J Amer Statist Assoc. 2001;96:827–834. MR1963409. [Google Scholar]