

Abstract
Recent research has demonstrated an asymmetry between the origins and endpoints of motion events, with preferential attention given to endpoints rather than beginnings of motion in both language and memory. Two experiments explore this asymmetry further and test its implications for language production and comprehension. Experiment 1 shows that both adults and 4-year-old children detect fewer within-category changes in source than goal objects when tested for memory of motion events; furthermore, these groups produce fewer references to source than goal objects when describing the same motion events. Experiment 2 asks whether the specificity of encoding source/goal relations differs in both spatial memory and the comprehension of novel spatial vocabulary. Results show that endpoint configuration changes are detected more accurately than source configuration changes by both adults and young children. Furthermore, when interpreting novel motion verbs, both age groups expect more fine-grained lexical distinctions in the domain of endpoint configurations compared to that of source configurations. These studies demonstrate that a cognitive-attentional bias in spatial representation and memory affects both the detail of linguistic encoding during the use of spatial language and the specificity of hypotheses about spatial referents that learners build during the acquisition of the spatial lexicon.
Keywords: spatial cognition, spatial memory, spatial language, motion, source, goal, language acquisition, verb learning, path verb
Introduction
This paper presents a joint investigation of the linguistic and non-linguistic representation of motion. Linguistically, the representation of motion consists of several core components, including the Figure (i.e., the moving object), the Path (the trajectory of motion), the Ground (a reference object with respect to which motion Paths are defined) and the Manner of motion (the specific details about the gait, speed, etc. of the moving object; Talmy, 1985). For instance, the English sentence George sailed from Myconos to Santorini via Paros mentions the Figure (the NP George), the Manner of motion (sailed), the Path (the PPs from NP, to NP, via NP) and the corresponding Ground objects (the NPs Myconos, Santorini, Paros). As the example illustrates, there are different types of linguistic Path expressions: FROM Paths (e.g., from Myconos), in which the Figure moves away from the Ground that functions as the Source, TO Paths (to Santorini), in which the Figures moves to the Ground that functions as a Goal, and VIA Paths (via Paros), in which the Figure moves past the Ground object (Jackendoff, 1983). These motion components seem to map onto features of the underlying non-linguistic representation of motion that often seem to be available early on in life (Pulverman, Sootsman, Golinkoff & Hirsh-Pasek, 2003; Pruden, Hirsh-Pasek, Maguire, Meyers & Golinkoff, 2004).
Of particular interest for present purposes is the fact that not all motion paths are born equal. Specifically, recent research has demonstrated an asymmetry between Source and Goal paths, with preferential attention given to Goals compared to Sources of motion in both language and non-linguistic representation. Beginning with the linguistic evidence, both adults and young children are more likely to mark endpoints (into a pot) than origins (out of a bowl) in their linguistic descriptions of motion for events containing salient Source and Goal objects (e.g., a toy plane flying out of a bowl into a pot; Lakusta & Landau, 2005).1 Corpus analyses similarly point to higher frequencies of Goal compared to Source modifiers (Arnold, 2001; Stefanowitsch & Rohlde, 2004). The Source-Goal asymmetry also emerges in the speech of children with Williams syndrome (Landau & Zukowski, 2003), in the production data of brain-damaged patients (Ihara & Fujita, 2000 on Japanese), and in the spontaneous gestures of children that are congenitally deaf and have never been exposed to a conventional language (Zheng & Goldin-Meadow, 2002). Further evidence suggests that this bias may characterize the nature of the spatial linguistic system itself, not simply the way spatial language is used. For instance, it seems that, typically, when languages have an expression that marks a Source (e.g., out), they also have a separate expression marking the corresponding Goal (in) - but the reverse is not necessarily true (e.g., English under or behind lack corresponding Source expressions; Regier, 1997). Additionally, languages seem to make finer distinctions within Goal rather than Source spatial-semantic fields (see Regier & Zheng, 2007, for evidence from Arabic, English and Chinese). Other evidence that Goals may be more basic than Sources is that, in many languages, terms for Locations (e.g., over, between) are co-opted for marking Goal paths (The airplane is over the ocean/ The ball went over the fence) but not Source paths (Jackendoff, 1983; Levinson, 2003). On the basis of distributional and semantic facts, some linguists have proposed incorporating many Goal paths into the argument structure of verbs (thereby treating them as verb arguments) but assigning Source paths adjunct status (Nam, 2004; Filip, 2003; Markovskaya, 2006 - but see Arsenijevič, 2005; Gehrke, 2005 for criticism).
The linguistic asymmetry between Source and Goal motion paths also surfaces in the acquisition of spatial vocabulary. Even though both Source and Goal expressions are acquired early (Clark & Carpenter, 1994), young children have a bias towards interpreting novel verbs as referring to Goal-directed actions: for instance, if presented with a scene in which an object moves from a toy character to another and are told that this is `ziking', 3- and 4-year-olds interpret the verb to mean `give', even though the event is also compatible with a (Source-oriented) `take' interpretation (Fisher, Hall, Rakowitz & Gleitman, 1994). Other studies show that, when children are shown a motion event and given Source/Goal verbs (e.g., pull/hook) as `hints' about how to describe the event, they are more likely to add Goal than Source modifiers to these verbs in producing sentences describing the event (Lakusta & Landau, 2005). In addition, young children have been reported to find it easier to answer questions about the path of an object that moved `to' a landmark than `from' a landmark (Freeman, Sinha & Stedmon, 1980); this pattern has been interpreted in terms of an “allative” bias - i.e., the tendency to encode motions towards a goal, rather than away from a source. Finally, it has been pointed out that children learning English, Dutch, Korean and Tzotzil Mayan tend to overgeneralize separation words that refer to FROM paths (e.g., uit in Dutch, out in English, kkenayta in Korean) but make rather specific distinctions for joining words that encode TO paths (e.g., op in Dutch, on in English, nehta in Korean; Bowerman, 1996; Bowerman, Lourdes de León & Choi, 1995).
Crucially, the asymmetry in salience between origins and endpoints seems to characterize non-linguistic motion representations as well. For instance, prelinguistic infants are more sensitive to Goal than Source changes in processing motion events (Lakusta, Wagner, O'Hearn & Landau, 2007). Furthermore, both preschool children and adults remember reference objects better if these objects serve as endpoints than origins of motion (Lakusta & Landau, 2007). Relatedly, adults have been shown to discriminate better between spatial configurations at Goals (e.g., putting a lid onto vs. into a pot) compared to configurations at Sources (taking a lid off of vs. out of a pot; Regier & Zheng, 2007).
This paper explores further the asymmetry between the non-linguistic representation of Source and Goal paths and tests its implications for the production and comprehension of spatial vocabulary. One question left open by previous research concerns the specificity in the non-linguistic encoding of landmarks that serve as Goals or Sources of motion. Prior studies demonstrating the relative richness of Goal representations in memory have used a change-detection paradigm in which Source or Goal objects were substituted by objects of a different category: for instance, in one of the target events, an agent was shown going to/away from a TV, while in the memory phase the TV was switched to a cart (Lakusta & Landau, 2007). In these studies, the locus of the Source vulnerability might be within the representation of the landmark object itself, the spatial relation, and/or the (inferable) event associated with the object (different activities are associated with a TV set vs. a cart, and when these objects function as Goals, these activities lie in the future and may thus be foregrounded compared to cases when these objects function as Sources). To test specifically whether the granularity in the representation of landmark objects differs depending on whether these objects function as Sources or Goals of motion, one would need to substitute a Source or Goal object with another object of the same kind (thus keeping the event type constant). Within-category object substitutions are generally detected less frequently than across-category object substitutions during memory tests (Mandler & Johnson, 1976) – so such a task would offer a stringent criterion for a representational difference between Source and Goal objects.
From a linguistic perspective, it would be useful to use the same environments to test whether the linguistic description of the very same object would be different depending on whether that object served as the beginning or endpoint of a motion event. A representational deficiency that targets Source objects is compatible with two different (but related) linguistic predictions: Source objects may be mentioned less frequently than Goal objects – other things being equal; and Source objects may be described in less detail compared to Goal objects. Both of these predictions would support a tight homology between linguistic and non-linguistic representations of motion events.
A separate, perhaps more important question concerns the specificity of spatial relations encoded in Source and Goal representations. As mentioned already, spatial configurations at endpoints of motion are discriminated better compared to configurations at starting points (cf. Regier & Zheng, 2007, for adult data). If attention to endpoints trumps attention to beginnings of motion, this asymmetry should surface in a variety of different cognitive tasks (e.g., spatial memory, as well as spatial perception) and across several age groups (e.g., in children, as well as adults). Furthermore, the asymmetry should characterize a variety of sub-types of Goal/Source relations (e.g., attachment to/ detachment from surfaces, as well as insertion in/removal from containers). These hypotheses, if confirmed, would extend and clarify the scope of the Source-Goal asymmetry in the non-linguistic representation of motion paths.
On the linguistic side, we know that the difference in granularity in the representation of Source and Goal relations has consequences for language use: Goal expressions are referentially more specific than Source expressions in adults' path vocabularies cross-linguistically (Regier & Zheng, 2007). Developmental research has also observed in passing that children's production of spatial terms seems to follow the same pattern (Bowerman, 1996; Bowerman et al., 1995). A novel, and exciting possibility, is that this loss of specificity could affect hypotheses about the meanings of novel spatial terms in one's language: learners should expect more fine-grained lexical distinctions for the very same spatial configuration if that configuration occurs at the endpoint compared to the beginning of a motion event. So far, a systematic test of this prediction looking at children's and adults' comprehension of novel path predicates (including different sub-types of Source and Goal paths) is lacking.
This paper reports data from two studies with adults and 4- to 5-year-olds addressing these questions. The first study asks whether the specificity of encoding Source/Goal objects differs in spatial memory (Experiment 1a) and in spatial language used to describe motion events (Experiment 1b). The second study asks whether the specificity of encoding Source/Goal relations differs in spatial memory (Experiment 2a) and in the comprehension of novel spatial vocabulary (Experiment 2b). To anticipate the findings, the first study shows that landmark objects are less likely to be remembered if they function as Sources compared to Goals, even for the same motion event; correspondingly, landmark objects are less likely to be mentioned linguistically if they appear as Sources compared to Goals (and there is a trend for such Source objects to be described in less detail compared to Goal objects). The second study shows that spatial relations are less likely to be remembered accurately if they participate in Source compared to Goal paths; furthermore, this vulnerability has a counterpart in the comprehension of novel labels for these relations - with novel Source labels taken to be less precise than novel Goal labels (even though some sub-types of Source relations are less impacted by loss of specificity than others in both memory and language).
Together, these studies enrich our understanding of the Source-Goal asymmetry in two ways. First, they clarify the locus of vulnerability (landmark object vs. spatial relation) in the non-linguistic representation of Source paths, either by keeping spatial relation constant and changing the landmark object (Experiment 1) or by keeping object type constant and changing the relation (including comparisons between multiple relations; Experiment 2). This more precise picture of the extent and kind of degradation in the representation of Source paths adds to the explicitness of theories of spatial representation. Second, the present studies offer novel evidence for the implications of the Source-Goal asymmetry for spatial language – specifically, they show that the differential robustness of non-linguistic Source /Goal representations affects the production (Experiment 1) and comprehension (Experiment 2) of spatial vocabulary. Even though production and comprehension are different linguistic processes, they are both important (and converging) pieces of evidence for the nature of spatial language: production of known spatial terms captures the resources of the developing (in the case of children) or mature (in the case of adults) spatial-linguistic system and comprehension of newly-heard motion expressions reflects the assumptions novel and more experienced (i.e., adult) learners bring to the interpretation of spatial language. Furthermore, each of these tasks is as parallel as possible to the corresponding non-linguistic task (production of known spatial terms to describe Source/Goal objects parallels the memory encoding of such objects in Experiment 1; comprehension of novel spatial terms that describe Source/Goal relations parallels the memory encoding of such relations in Experiment 2).
Finally, the Source-Goal facts reported here contribute to broader theories about the relationship between language and cognition. To the extent that there are similarities in the granularity of motion path representations in memory and language, these support the existence of a strong homology between linguistic and non-linguistic representations (even though this homology may not be absolute). From a developmental perspective, to the extent that children and adults behave similarly in our battery of tasks, our data support the presence of commonalities in the underlying conceptual representations of objects and motion (and their expression in spatial language) throughout human development.
Experiment 1a: Encoding Source/Goal objects in memory
The first experiment sought to replicate and extend prior evidence for the Source-Goal asymmetry. Specifically, it asked whether objects that serve as endpoints of motion are remembered better than objects that serve as motion origins. The memory task included within-category substitutions of Source or Goal objects (i.e., for motion to/from an object X, another object of the same category was substituted for X). This design makes it possible to preserve the purpose, trajectory and spatial configuration of motion while altering only the type of ground object. Manner of motion events (e.g., flying, crawling) were chosen as targets since they are not inherently Source- or Goal-oriented (but see Nam, 2004). Results from this experiment will serve as background for the investigation of the linguistic encoding of Sources and Goals in the next study.
Participants
Sixteen adults and 14 children (age range: 4;4–5;8, means: 4;7) participated. Adults were undergraduates at the University of Delaware and received course credit for participation. Children were recruited at daycares in the Newark (DE) area. Data from an additional group of five children were collected but excluded from analyses because these children exhibited a response bias (they consistently said that memory items were different from the original events).
Materials
A basic test set of 12 animated motion clips was created. All clips involved an animate agent moving in a particular way from an inanimate Source object to another, also inanimate, Goal object (e.g., a fairy flew from a tree to a flower- see Panel A of Figure 1). Clip duration ranged between 3s and 11s (depending on how long it took for the action to be naturally completed). A second basic set of test clips was then created by reversing the roles of Goal and Source objects from the first set (e.g., a fairy flew from a flower to a tree). Goal and Source objects entered into several different Goal or Source paths (e.g., into/out of, under/from under, towards/away from the target object; for a full list, see Table 1). Within each list, the position (left-right) of Source and Goal objects was counterbalanced.
Fig. 1.

Sample test clips for Experiment 1a. In Panel (A), a fairy is flying from a tree to a flower. Panel (B) shows a Goal change (the flower has been substituted by another flower). In the corresponding Source version of this event (not shown), the fairy is flying from the flower to the tree; for the Source change, the flower is changed to a different kind (as in Panel B above).
Table 1.
Test and filler stimuli for Experiment 1. An asterisk indicates materials in the child version.
| Test items |
|---|
| The target object is in italics (for half of the items, the target object is the origin and for the other half the endpoint of motion). For half of the participants, the role of the target object (origin-endpoint) was reversed from the present list. |
| 1. A snake crawls from the space under a table to the space under a chair.* |
| 2. A man on crutches hops from the front of a house to the space behind a fence. |
| 3. A man tiptoes from inside a room to a staircase outside.* |
| 4. A man skates on ice from a tent into a cave. |
| 5. A bird flies from the top of a trash can to the top of a building.* |
| 6. A car drives from a church to a garage.* |
| 7. A dolphin swims away from a diving board on one end of a pool towards two flags on the other end.* |
| 8. A bug flies from the window onto an armoire.* |
| 9. A baby crawls from under a desk to the space under a bed. |
| 10. A mouse jumps from behind a bush onto the rim of a well. |
| 11. A couple dances from a gazebo to a tree.* |
| 12. A fairy flies from a tree onto a flower.* |
| Filler items |
|---|
| 13. A witch on a broomstick flies from the rooftop of a house to the moon. |
| 14. A spaceship flies from one planet to another.* |
| 15. A school bus drives from a stop sign towards a traffic light.* |
| 16. A butterfly flies in the air between a country house and a plant.* |
| 17. A frog jumps around in the space between a bench and a slide. |
| 18. Three ghosts fly around in a circle.* |
A filler set of 6 motion clips which resembled the set of test items was added. Three of these fillers included motion with a Source and a Goal and the remaining three involved motion in place between 2 landmark objects (e.g., a frog jumping around in the area between a bench and a swing; see Table 1). The result was two stimulus lists with 18 items each. These lists were reversed for a total of 4 presentation orders. For children, a fixed subset of the items was used (8 test and 4 filler items per presentation list; see Table 1 for details) so as to keep sessions reasonably short.
For the memory test, a set of variants was created by substituting a target (Source or Goal) object in each of the test clips with another object from the same category (e.g., in the fairy clip, the flower was changed to a different kind of flower). The target object (e.g., the flower) that underwent a change served as a Goal object for the event in one of the basic stimulus lists and as a Source object in the other. Half of the changes in each of the two basic lists involved Goals and the other half Sources. Fillers remained the same in the memory task. In the memory phase, items were presented in the same order as in the first phase of the experiment.
Procedure
Adults were told that they would see a series of clips and would have to try and remember them because they would be given a memory task later. They were also told that, in the memory task, they would be shown a second set of clips and they would have to say whether the clips were the same or different from the first set. The memory task was administered once participants had finished viewing all the clips. In the first presentation phase, after each target clip, a blank slide was displayed and participants had to press the space bar to advance to the next clip. In the memory phase, each variant clip was displayed exactly as before (and in the same order as the corresponding events in the main phase of the experiment); however, blank slides remained up for only 2s during which participants had to make their verbal response (“Same” or “Different”). Then the display advanced automatically to the next clip.
The procedure was simplified for children so that the memory variant for each event was seen immediately after viewing a particular clip. Specifically, after presenting each target slide, the experimenter showed children a clip showing a clock that was ticking. Children were asked to try to remember what happened in the previous `cartoon' while the clock was ticking. They were told that, after the clock was done, they would see another cartoon and they would have to say whether it was the same or different from the one they saw before the clock. The ticking clock stayed up for 5s, during which the experimenter told children to think about what happened and `remember'. Children were shown two practice trials, one of which involved a change in Goal and the other a change in Source, and were given feedback.
Results and Discussion
Preliminary analyses found no order effects so different orders were collapsed in what follows. Results from this study are presented in Figure 2. As the Figure shows, the proportion of correct responses on the filler trials was high in both adults and children (M = .78 and .69 respectively). Most importantly, there was an asymmetry in the detection of Goal vs. Source object changes in both age groups.2 Matched-pair comparisons of the proportion of adults' correct responses revealed a significant difference between Source and Goal Changes (t(15)=−4.33, p =.0006; MS = .40, MG = .67). Furthermore, adults' performance on Goal changes differed from chance (t(15)=2.45, p=.02, two-tailed), while on Source changes it did not (t(15)=−1.9, p=.06, two-tailed, n.s.).
Fig. 2.

Memory performance (Experiment 1a)
In the children's data, a matched-pairs comparison also showed the Source-Goal difference to be significant (t(13)= 4.59, p=.05; MS = .50, MG = .70). As in the adult data, children's performance on the Goal Changes was different from chance performance (t(13)=2.75, p=.01, two-tailed), while performance on the Source Changes was not (t(13)=0.0, p=1, two-tailed, n.s.).3
These results confirm prior evidence about the asymmetrical representation of Source and Goal information (Lakusta & Landau, 2007): in committing motion events to memory, Source objects are encoded in much less detail than Goal objects. Extending earlier results, the present data show that the Source-Goal object asymmetry holds even when other aspects of the motion event are kept the same (including the event, relation and type of object involved). Furthermore, the lack of encoding detail characterizes Source object representations in both adults' and 4-year-olds' spatial memories. These findings throw light on the locus of Source vulnerability in a way that has not been possible before. Specifically, they show that this vulnerability lies (at minimum) within the landmark object itself: in other words, the object's role in a motion event (beginning vs. endpoint of the event) determines the specificity of memory encoding for that object.
Experiment 1b: Encoding Source/Goal objects in language
This experiment asked whether the same events used in Experiment 1a would give rise to a linguistic asymmetry between Source and Goal objects – specifically, whether Source objects would be mentioned less frequently and/or described in less detail compared to Goal objects (thereby reflecting the downgrading of Source representations revealed in Experiment 1a). The test events are most naturally described in English by manner of motion verbs (jump, fly, crawl) that take neither Source nor Goal modifiers as arguments (Jackendoff, 1990; but see Nam, 2004, for a different analysis). Thus any preference for one or the other type of modifier in the linguistic description of these events cannot be due to the nature of the verb itself.
Participants
Sixteen adults and 17 children (age range: 4;2–5;3, means: 4;4) participated. Participants were recruited from the same populations as in Experiment 1a. None of them had participated in the earlier study.
Materials
Materials were as in the previous experiment (the variants of test items used in the memory phase were not included). As in the previous study, children saw a shorter, fixed set of 12 events.
Procedure
Participants watched the clips and were asked to describe them. After each target clip, a blank slide was displayed and participants had to make their response. No timing or length restrictions were placed on subjects' responses. Then participants pressed the space bar to advance to the next clip. Responses were tape-recorded and later transcribed and coded.
Results and Discussion
Only results on participants' productions on test items are reported. For these items, linguistic responses predominantly included a Manner of motion verb (e.g., fly, jump, run, walk): Manner verbs were included in 81% of all adults' and 67% of all children's responses. Path verbs such as go and leave were also occasionally included in adults' (M = .12) and children's (M = .18) utterances (the remaining 7% and 15% of responses respectively included non-motion verbs such as sit or kiss, general motion verbs such as move, or no verb at all).
Source or Goal information was (optionally) expressed in a prepositional phrase or particle. Figure 3 presents the frequency of Source and Goal marking in the linguistic productions elicited. As the Figure shows, there is a marked asymmetry in the encoding of Sources (“from the flower”) and Goals (“to the tree”) in adults' utterances (MS = .56 vs. MG = .78); in children's speech, Source marking is extremely rare (MS = .03 vs. MG = .54). Matched-pairs comparisons reveal that the Source-Goal difference is significant in both the adult (t(15) = −4.64, p=.0003) and the child production data (t(16) = 8.19, p<.0001).4
Fig. 3.
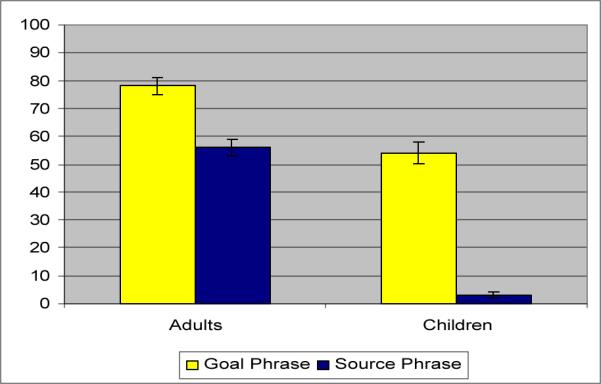
Linguistic performance (Experiment 1b)
A close look at the adult data reveals that the most frequently used Goal preposition was to (M = .48 of Goal-marked responses), followed by into (M = .16), towards (M = .06), under/underneath (M = .05) and others used less frequently (behind, in, on, over, past plus NP). Source marking was done primarily through the use of from NP (M = .75 of all Source-marked responses) or from under/underneath NP (M= .07), with occasional uses of out of NP, off NP, the verb leave + NP and the particle away (each less than .05 of Source-marked responses). In the child data, Goal-marked sentences included to NP (M = .61 of all such responses) and a variety of other terms (down NP, in NP, inside, on NP, over NP, up NP) that were used much less frequently (for each of these terms, M <.06). The (vanishingly rare) Source expressions were restricted to (away) from NP and out of NP.
Finally, it was hypothesized that Source objects might be described in less linguistic detail than Goal objects. This possibility was only explored in the adult production data, since these data contained a sufficiently high number of Source and Goal paths. Even though adults mostly encoded ground objects as a simple NP such as the flower, they occasionally offered additional information either about properties of the object (from a scary mansion/into a red barn) or about path-related aspects of the ground object's axial structure (from the top of/to the top of the garbage can). There were 27 instances where such additional information was offered (about 13% of the total responses on test items). Of these, 10 involved Source and 17 Goal paths (the difference is marginally significant, t(15) = −1.8, p = .08).
These results show that Goal objects have an advantage over Source objects during linguistic communication in both adults and young language learners – a finding consistent with prior reports of linguistic Source-Goal asymmetries (cf. Lakusta & Landau, 2005; Landau & Zukowski, 2003). Unlike prior studies, the present data show that this asymmetry surfaces even when the motion events, relations and objects are held constant: in other words, the same object within a single event becomes linguistically more noteworthy when it serves as a Goal than a Source. Relatedly, there was a trend to describe objects in greater visual detail when they served as Goals compared to Sources. The vulnerability of Sources seems to be especially pronounced in children's linguistic data, where Source modifiers are almost non-existent.
Taken together, Experiments 1a and 1b show strong parallels between the non-linguistic and linguistic representations of the objects that serve as beginnings and endpoints of motion, with endpoints being more privileged in both language and memory.
Experiment 2a: Encoding Source/Goal relations in memory
Let us turn to the question whether adults and children remember specific spatial configurations more accurately if these configurations participate in Goal compared to Source relations (cf. Regier & Zheng, 2007). These results form the background for the investigation of the same issues in novel word interpretation in the next experiment.
A related question is whether different spatial relations (e.g., Containment vs. Support) might affect the type of spatial information retained in processing TO and FROM motion paths. Containment expressions (e.g., in) are acquired earlier than other expressions of spatial location cross-linguistically – perhaps for conceptual reasons (Johnston & Slobin, 1978). Furthermore, it appears that infants develop earlier sensitivity to Containment events compared to Support events (Casasola & Cohen, 2002; Casasola, Cohen & Chiarello, 2003; cf. Lakusta et al., 2007). Thus one might expect memory for Containment relations to be more robust compared to other spatial relations – and the type of spatial relation to interact with the Source-Goal asymmetry in memory.
Participants
Twelve adults and 12 children (age range: 5;0–5;11, means: 5;6) participated. Adults were undergraduates at the University of Delaware and received course credit for participation. Children were recruited at daycares in the Newark (DE) area.
Materials
Materials consisted of short animated clips showing an inanimate self-propelled figure (a soccer ball) move smoothly with respect to an abstract three-dimensional ground object. Real objects were not used as landmarks because such objects have predictable affordances (e.g., chairs are for sitting) and such affordances would affect how people process and remember an agent's interactions with such objects. The choice of a Figure object (soccer ball) was motivated by the flexibility of paths the object could follow. For each clip, both a Goal and a Source version were created; these versions were identical except for including opposite paths (e.g., the ball moved ontoGOAL vs. off the top ofSOURCE an object; see Panels A in Figure 4). There was only one reference object (Source or Goal) per clip so as to minimize competing demands on attention. The position of the ground objects with respect to the ball (up, down, left, right) was counterbalanced across events.
Fig. 4.

Sample test stimuli for Experiment 2a. The top panels show the Goal version of the event, with target path A (a ball goes onto the object) and its variant B (the ball goes over the object). The bottom panels show the corresponding Source version, with target path A and its variant B.
Variants of this first set of events were also created for use in the memory test. The variants depicted the same figure (the soccer ball) moving with respect to an object of a different color but of the same kind as in the original event. The change in color was done so as to prevent complete visual identity and to encourage a generalization across spatial events. (This feature will be particularly important in Experiment 2b.) Crucially, in the variants the ball followed a different trajectory (e.g., in the Goal version, the ball ended up over the ground object; in the Source version, it started off over the ground object; see Panels B in Figure 4). Changes in trajectories between the original and variants were subtle so as to avoid ceiling effects.
A total of 32 test events were used (each with a Goal and Source version), with 8 events selected for each of 4 distinct types of Spatial Relation: Support (the ball moved ontoGOAL /off ofSOURCE the ground object); Containment (the ball moved intoGOAL/out ofSOURCE the ground object); Contact (the ball moved to and touched the side of the ground objectGOAL/the ball moved from the side of the ground objectSOURCE); and Cover (the ball moved under and touched the ground objectGOAL vs. the ball moved from under the ground objectSOURCE). With the exception of Containment, these relations involve contact between the figure and one surface of the ground object (the uppermost, horizontal surface for Support, the vertical side for Contact and the lower, horizontal surface for Cover). In the memory variants, Containment events were changed to similar Support events. For instance, a Goal event in which the ball went into a container was converted into an event in which the ball ended up on the rim of the container (in the corresponding Source version, the target event in which the ball went out of the container was modified such that the ball went off the rim of the container.) The remaining three relations were modified such that there was no contact between the figure and the ground object (Support turned into simple Superimposition, Contact turned into Proximity, and Cover was modified so that it did not involve touching). Table 2 gives examples of the four spatial relations and their memory variants and Figure 5 provides sample test items for illustration.
Table 2.
Spatial relations used in Experiment 2a (test items and their variants only).
| Spatial relation with ground object X | ||||
|---|---|---|---|---|
| Test items | Support | Containment | Contact | Cover (touching) |
| Goal Version | Onto X | Into X | To one side of X | Under X (touching) |
| Source Version | Off the top of X | Out of X | From one side of X | From under X (touching) |
| Variants | Superimposition | Support | Proximity | Cover (no touching) |
|---|---|---|---|---|
| Goal Version | Over X | Onto X | Towards one side of X | Underneath X (not touching) |
| Source Version | Off the area over X | Off of X | Off the area on X's side | From underneath X (not touching) |
Fig. 5.
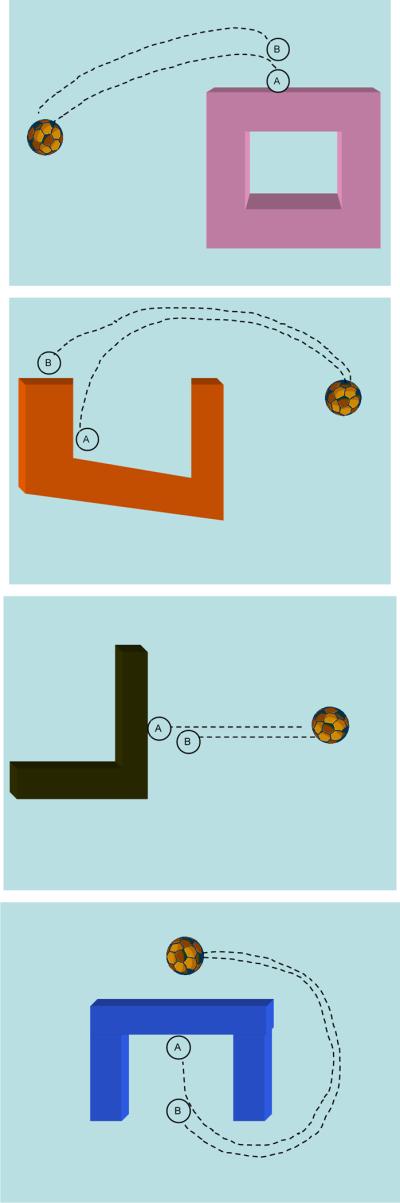
Sample spatial relations for test items in Experiment 2a. From top: Support, Containment, Contact, Cover. Trajectory A represents the target event and B the variant (color changes in the ground objects between targets and variants are not shown). For Goal Versions, trajectories A and B were towards the ground object, and for Source Versions, they were away from the object.
A set of 32 filler events were created such that 8 corresponded to each of the following 4 Spatial Relations: Encirclement (the ball went around the ground object); Inclusion (the ball went between two identical elongated objects); Occlusion (the ball went behind the ground object); and Traversing (the ball went along the ground object). There was also a corresponding set of 32 variants for the filler items. Only the color of the ground object changed between the fillers and their variants; the spatial relation stayed the same. Overall, fillers (and their variants) resembled the target events in every way possible.
Test events were distributed into two basic lists such that only one version of each event was included per list, and 8 items (4 Source and 4 Goal) were included in each list for each of the 4 Spatial Relations. This yielded 32 test items per list. Each list also included all 32 fillers for a total of 64 items arranged in a pseudo-random order. The two lists were then reversed for a total of 4 presentation orders.
Procedure
Adult participants were told that they would watch pairs of events, each involving a soccer ball and some abstract object, and that their task was to say whether the two events in each pair were the same or different. Participants were also told that the second event would always involve an abstract object of a different color than the first event but that this change should not affect their decision about whether the two events were the same or different.
To block verbal encoding, adults were given a counting task during inspection of the events. Specifically, in the beginning of each trial, a different two-digit odd number appeared on the screen for 2s and adults were asked to start counting forward starting from that number. Next the target motion event was displayed. The event lasted for 2s, during which the beginning and endpoint configurations remained on the screen for an equal amount of time (500ms). Participants then saw a masking slide depicting 4 horizontal lines of five soccer balls each (1s) and then a variant of the first event. As before, the event lasted for 2s, during which the beginning and endpoint configurations remained on the screen for 500ms each. Finally, a slide with a question mark appeared and stayed on for 2s. This served as the prompt for participants' verbal response. After 2s, the display proceeded automatically to the next trial. The question of interest was whether participants would be more likely to detect the change between targets and variants for test events (Panels A and B in Figure 4) when these events appeared in their Goal compared to their Source version.
For children, this procedure was modified in a number of ways. Children saw a fixed subset of the full stimulus set (8 test items, with 2 items – one Source and one Goal - per Spatial Relation, plus 8 fillers – 2 of each type). As with adults, each child saw both a Source and a Goal version of each test event. The display proceeded more slowly: motion in all clips lasted for 2s and beginning-endpoint configurations remained on the screen for an additional 1s each. There was no masking slide between target clip and variant. Most importantly, we added some motivation for the comparisons children were asked to make. Specifically, in the beginning of each session, we introduced two animals, a lion and a mouse (clipart characters), and told children that they would watch some games the lion liked to play with his ball and toys. Children were also told that the mouse wanted to play the same games with its own ball and toys but that the mouse was small and might not be able to do it right. For all target events, a lion appeared on the lower right-hand corner of the screen, and for all variants, a mouse appeared in the same position. While the target event was displayed, the experimenter told children to look at the lion's ball. Then as the variant unfolded, the experimenter asked whether the mouse's ball was “doing the same” or not. These verbal prompts were repeated for each event and children had to give a “Yes”/ “No” response. Unlike adults, no time restriction was placed on children's responses.
Before the main session, all participants saw 4 practice items (2 same and 2 different) and were given feedback on their responses. None of the practice items included changes in spatial relations similar to those tested in the main phase of the experiment.
Results and Discussion
Results are given in Figure 6. As shown in the Figure, performance in the filler (No Change) trials was high in both adults and children (M = .88 and .84 respectively). Crucially, spatial configurations at the endpoints of motion were remembered better compared to configurations at starting points by both adults and children. Matched-pairs comparisons revealed that performance on Source vs. Goal Changes differed significantly for adults (t(11)=−4.8, p=.0005), with Source Changes detected 72% of the time and Goal Changes 85% of the time. For children, a matched-pairs comparison revealed a similar asymmetry (t(11)=3.5, p=.0045), with Source Changes detected 31% of the time and Goal Changes 66% of the time.
Fig. 6.

Memory performance (Experiment 2a)
Since the stimulus set included different types of specific spatial configurations, the next question was whether Spatial Relation affected subjects' responses for test items (preliminary analyses revealed no effect of Spatial Relation on accuracy in filler items for either age group). Beginning with adults, an ANOVA was conducted with Spatial Relation (Support, Containment, Contact, Cover) and Change (Source, Goal) as within-subjects variables. As expected, the analysis revealed a main effect of Change (F(1, 11)=11.76, p=.006) but also a main effect of Spatial Relation (F(3, 11)= 5.69, p=.003) and no interaction. The effect of Spatial Relation is due to the higher success rate with Containment (M = .93) compared to Support (M=.71), Contact (M=.71) and Cover (M=.75; differences confirmed statistically in matched-pairs comparisons, p's<.05). A similar ANOVA on children's responses also returned a main effect of Spatial Relation (F(3,9)=5.44, p=.02) (Change was not included as an additional factor, since children saw only one Source and one Goal change per Spatial Relation): children were successful 70% of the time with Containment, but only 41% of the time for each of the other three spatial relations (the difference between Containment and each of the other three relations is statistically significant; all p's<.05).
There are at least two possible explanations for this advantage of Containment. First, as already discussed, Containment spatial relations may be more basic and thus better discriminated than relations involving a figure and a surface ground (such as Contact, Support or Cover). This possibility is consistent with evidence that Containment expressions are acquired earlier than other expressions of spatial location cross-linguistically (Johnston & Slobin, 1978), as well as with studies showing that infants develop earlier sensitivity to Containment events compared to Support events (Casasola & Cohen, 2002; Casasola, Cohen & Chiarello, 2003; cf. Lakusta et al., 2007).
A second, theoretically less interesting explanation is that, in the present stimuli, Containment items included a more radical transformation of the original motion trajectory than the other three types of item. Specifically, in Support, Contact and Cover events, targets and variants were identical, except that the variant was a truncated version of the target: target events involved contact in either the beginning or the endpoint configuration (e.g., the ball went toGOAL/away fromSOURCE the object), while variants simply lacked the portion of the event that involved contact (e.g., the ball went towardsGOAL the object but did not reach it/the ball went away fromSOURCE the area surrounding the object; see Figure 5). In Containment events, by contrast, the paths for targets and variants did not overlap with each other but were visually more distinct (see again Figure 5). This might have made the path discrimination more successful for these items for both adults and young children. These data cannot at present adjudicate between these two possibilities but the issue is currently being pursued in further work (see also next experiment).5
Experiment 2b: Encoding Source/Goal relations in language
The question of interest now is whether the asymmetric representation of Source and Goal relations uncovered in the previous experiment corresponds to a difference in the granularity of semantic hypotheses about the meaning of novel Source and Goal expressions. To address this question, this experiment tested how English speakers generalize a novel path verb's denotation when the verb is ostensively introduced in the context of a scene showing a Source vs. a Goal path. The expectation was that, if the verb was taken to encode a Source relation, it would be more likely to support generalizations to novel paths that differed subtly from the original one (along the lines of path changes used in Experiment 2a) than if it was taken to encode a Goal relation. As in the previous experiment, it was also of interest whether verbs encoding motion with respect to a container would exhibit different extension patterns compared to verbs encoding other kinds of spatial relation.
Path verbs were chosen as examples of novel spatial vocabulary because such verbs are infrequent in English (cf. enter, exit, approach, leave, reach, cross) and are not typically acquired by children until later in life (see Papafragou & Selimis, 2007a; cf. the linguistic results from Experiment 1b above). Furthermore, even though their distribution is restricted in English, path verbs are canonically used to express motion in several other languages such as Greek (Papafragou, Massey & Gleitman, 2002) and Spanish (Gennari, Sloman, Malt & Fitch, 2002). In the present study, novel verbs were embedded in transitive frames (V + NPdirect object) which have been shown to encourage path-verb conjectures for novel motion verbs in both English-speaking adults and children (Naigles & Terrazas, 1998; Skordos & Papafragou, 2009).
Participants
Twelve adults and 12 5-year-old children (age range: 5;0–5;11, means: 5;6) participated. Participants were chosen from the same broad populations as in the previous Experiments. None had taken part in the previous studies.
Materials
Materials were the same as in Experiment 2a. We also created a list of monosyllabic novel verbs (snerge, glorp, etc.) to name the spatial actions displayed.
Procedure
Adults were told that they would see a set of clips showing pairs of events each involving a ball and a toy (toy was introduced as a superordinate for all reference objects). The experimenter would name the first event in each pair using a new, `mystery' word, and they would have to decide whether the next event in the pair could be named with the same word or not. Participants were cautioned that there would be a different-colored toy between the first and second clip in each pair but they could still decide that the new word applied. As soon as the target event began, the experimenter said: Look! The ball is glorping the toy! During the display of the variant, adults were asked: Is the ball glorping THIS toy? Two additional differences were introduced to the procedure of Experiment 2a to accommodate the linguistic instructions: (a) the motion path was slower (2s) for all target and variant events so that the new word could be introduced, and (b) timing was removed from the response slide.
As in Experiment 2a, children were introduced to the lion and mouse characters. Children were told that the lion would use some funny words and that the child's task was to help the experimenter understand what the lion said. While the target items played, the lion introduced the novel verb (Look! My ball is V-ing the toy!). While the variants played, children were asked if the mouse's ball was V-ing that toy. The timing of the display was the same as in the child version of Experiment 2a. For both age groups, Source and Goal versions of the same event (e.g., Panels A in Figure 4) were named with the same novel verb.
Results and Discussion
Results are given in Figure 7. The Figure presents the proportion of `correct' (conservative) responses, i.e., cases in which participants rejected the novel label when the Goal or Source relation was changed (test items) and accepted the novel label when there was no change (filler items). As the Figure shows, both adults and children successfully extended the novel verb in No Change trials (M=.96 and .84 respectively). Turning to the test items, both age groups were more likely to extend a novel verb across two subtly different motion paths if those paths were Sources rather than Goals. For adults, a matched-pairs comparison revealed that the Source-Goal difference is significant (t(11)=-3.5, p=.0047), with Source Changes eliciting correct responses 48% of the time and Goal Changes 71% of the time. A similar analysis on children's responses also revealed that the Source-Goal difference is significant (t(11)=-2.9, p=.01), with Source Changes prompting correct responses 25% of the time and Goal Changes 52% of the time.
Fig. 7.

Linguistic performance (Experiment 2b)
The next question was whether different spatial relations led to different patterns of verb generalization on the part of adults and children. Attention focused on test items because preliminary analyses revealed that there was no effect of Spatial Relation on success with filler items in either age group. Beginning with adults, an ANOVA with Change (Source, Goal) and Spatial Relation (Support, Containment, Contact, Cover) as within-subjects factors returned a main effect of Change (F(1, 11)=13.20, p=.004), a main effect of Spatial Relation (F(3, 11)=7.45, p=.001) and no interaction. A closer look reveals that the effect of Spatial Relation is due to adults' higher success rate with Containment events (M=.78) compared to Support (M=.53), Contact (M=.48) and Cover events (M=.55; differences confirmed statistically in matched-pairs comparisons, with p's<.05). For children, an ANOVA with Spatial Relation as a within-subjects factor revealed a similar effect of Spatial Relation (F(3, 9)=8.48, p=.0054), with Containment items being the most successful (M=.62) compared to Support (M=.29), Contact (M=.29) and Cover items (M=.33; differences confirmed statistically in matched-pairs comparisons, p's <.05). This asymmetry within Spatial Relations reflects the asymmetry observed in the memory task (Experiment 2a): when children and adults generalize novel spatial terms, they are more conservative with Containment terms (i.e., such terms are denotationally more precise) compared to Support, Contact or Cover terms.
Comparison of Experiments 2a and 2b
Finally, responses in the test items of Experiments 2a and 2b were compared to see how non-linguistic and linguistic path representations are related. Of interest was whether word extension judgments would parallel event identity judgments in the memory task for the very same set of events and changes.
Beginning with adults, an ANOVA with Change (Source, Goal) and Spatial Relation (Support, Containment, Contact, Cover) as within-subjects factors and Experiment (Non-Linguistic, Linguistic) as a between-subjects factor found a main effect of Change (F(1,22)=23.68, p<.0001; MS=.60, MG=.78), a main effect of Spatial Relation (F(3, 20)= 12.78, p<.0001; MSupport=.61, MContainment=.86, MContact=.60, MCover=.61), and a main effect of Experiment (F(1, 22)=6.21, p=.02; MNL = .77, ML=.58). There were no interactions among these factors. Overall, adults appeared less restrictive in their interpretation of novel spatial items compared to judgments of identity of the very same spatial scenes; put differently, adults applied the same spatial expressions to scenes that were not always judged to be visually identical. This happened even though adults had more time to inspect the events in the linguistic version (recall that presentation time was lengthened to accommodate the sentence introducing the novel verb) and despite the fact that both the word extension and the identity task involved essentially a judgment about whether the two events in each pair were of `the same kind'. Furthermore, in both tasks the variant was never identical to the target (the landmark object changed in color, and participants were warned about the change) so both tasks involved type rather than token identity. This shows that what counts as `the same event' for linguistic-naming purposes differs from what counts as `the same' in terms of visual detail: criteria for word extension are more abstract than simple perceptual identity (cf. Landau & Stecker, 1990; Malt, Sloman, Gennari, Shi & Wang, 1999; Papafragou & Selimis, 2007b, for related results).
For children, an ANOVA using Change (Source, Goal) and Experiment as factors revealed only a main effect of Change (F(1, 21)=24.71, p<.0001). Finally, an ANOVA using Spatial Relation (Support, Containment, Contact, Cover) and Experiment as factors returned only a main effect of Spatial Relation (F(3, 19)=10.23, p=.003). For children, even though there is a small difference between the non-linguistic (memory) and the linguistic data (in the same direction as in the adult data), this difference is not significant. Children's relatively low performance on the memory task may have been responsible for the tighter coupling between linguistic and non-linguistic results in this group.
General Discussion
Taken together, the present results offer new evidence for the asymmetry between Source and Goal motion paths. Both adults and young children remember objects and relations better if these occur at the endpoint than at the beginning of motion (Experiments 1a and 2a). This bias in spatial representation and memory affects both the spatial language produced in descriptions of motion events (Experiment 1b) and the specificity of hypotheses about spatial referents that learners build during the comprehension of novel spatial terminology (Experiment 2b).
These results confirm prior data on the Source-Goal asymmetry in language and cognition (Lakusta & Landau, 2005; Zheng & Regier, 2007; Bowerman et al., 1995; cf. Introduction). They also extend prior findings in two important ways. First, they allow us to be more precise about the nature of the representational deficit associated with non-linguistic Source paths. Specifically, it was found that this deficit is associated with the representations of both the landmark object and the spatial relation that jointly define Source paths: the very same landmark object or relation was likely to be remembered better if it served as a Goal than a Source for a single event. This points to a close interrelatedness of landmark objects and relations in the representation of motion paths – an interrelatedness which is to be expected, since many spatial relations exploit specific affordances of landmark objects (e.g., Containment presupposes that the landmark object can function as a container).
Second, these studies demonstrate that vulnerabilities associated with Source compared to Goal objects/relations also appear in language. Going beyond previous studies that have demonstrated a linguistic Source-Goal asymmetry (e.g., Lakusta & Landau, 2005), the present data show that the very same landmark object was more likely to be mentioned if it served as a Goal than a Source for a single event; relatedly, there was a trend to describe the very same landmark object in less detail if it functioned as a Source compared to a Goal. More importantly, both 4-year-old children and adults assumed that novel verbs for Source relations were broader in meaning compared to novel verbs for Goal relations.6 Since the non-linguistic and linguistic asymmetries between Source and Goal path representations surface in similar ways across closely matched tasks (Experiments 1a–b, Experiments 2a–b), it follows that the loss of granularity of Source compared to Goal objects and relations in memory impacts the granularity of encoding the corresponding objects and relations during the production and comprehension of path vocabulary.
A particularly noteworthy aspect of the present findings is the behavior of sub-types of Source and Goal relations. As shown in Experiment 2a, among spatial relations found in Source paths, the representation of Containment in memory seems to be spared compared to other relations such as Support or Cover; Containment is also privileged in the domain of Goal paths (ibid.). The asymmetry extends to the representation of landmark objects: details of objects that act as containers are remembered better than details of objects that act as cover or support (see footnote 5 on Experiment 1a). The asymmetry also has a linguistic counterpart: in the adult data, Containment paths were encoded by more specific novel verbs compared to other relations such as Cover or Support (Experiment 2b). The special status of Containment in the present data squares well with other evidence, both non-linguistic and linguistic: infants develop earlier sensitivity to Containment events compared to Support events (Casasola & Cohen, 2002; Casasola et al., 2003; cf. Lakusta et al., 2007), and containment expressions are among the first spatial terms to be acquired cross-linguistically (Johnston & Slobin, 1973). Even though the status of Containment needs to be confirmed by further work, these initial results contribute to a more nuanced picture of how motion paths are encoded in both language and cognition, and suggest potentially distinct developmental trajectories for different spatial relations in both non-linguistic and linguistic representation.
The present data in support of the Source-Goal asymmetry (as well as the specific facts pertaining to Containment) are consistent with the presence of broad homologies between spatial cognition and language (Quinn, 2007; Regier, 1996; Landau & Jackendoff, 1993; Hayward & Tarr, 1995; Crawford, Regier & Huttenlocher, 2000; Regier & Carlson, 2001). At the same time, these data point to interesting asymmetries between linguistic and non-linguistic tasks. As Experiment 2 showed, what counts as the same is not identical for purposes of word extension vs. visual identity, since adults extend a novel predicate to scenes which are judged not to be visually identical. This suggests that, even though the roots of the Source-Goal asymmetry may lie in a cognitive-attentional bias, the linguistic manifestations of the asymmetry are subject to language-internal principles (such as the more abstract principles governing naming) and may not align perfectly with the non-linguistic effects of the bias. Similar results documenting a divergence between naming and (non-linguistic) categorization have been reported for a variety of domains including space (Landau & Stecker, 1990; Papafragou & Selimis, 2007b), artifacts (Malt et al., 1999), entity construal (Li, Dunham & Carey, 2009), and others.
The present data also contribute to theories of how children process objects and their location/motion in space, and how they acquire words to describe such objects and spatial relations. Classic theories of language learning have assumed that spatial language relies on underlying conceptual representations of objects and locations/motions (available to both adults and children), and that such fundamentals of spatial cognition constrain the learners' hypotheses about possible spatial meanings (cf. H. Clark, 1973; Jackendoff, 1983; Miller & Johnson-Laird, 1976). However, we still lack a full model of what these spatial concepts might be and how they specifically affect the linguistic categorization of space. This paper attempted to link one aspect of the development of spatial language to the way the perceptual/conceptual organization of space and motion works in children. Results show that, in this as in other areas, a spatial-cognitive bias (the Goal bias) appears to be treated in a similar way by children and adults – thereby suggesting continuity between the types of cognitive representations and processes available to humans as they develop. Furthermore, this underlying spatial bias was shown to constrain young (and more experienced, i.e., adult) learners' use of spatial terminology, as well as conjectures about possible meanings for newly-heard spatial expressions – precisely as expected by the classical learning theories described above.
The present methods and results can be generalized in a number of ways to further explore the nature of spatial language. First, recall that languages differ in the way they map elements such as Source and Goal paths onto linguistic forms: English typically encodes Goal and Source paths in prepositional phrases (into/out of the cave), Greek commonly encodes path information in verbs (beno `enter'/vjeno `exit'; Papafragou et al., 2002), Turkish expresses path information in case marking (Kornfilt, 1997). Despite such typological differences, if the Source-Goal asymmetry in Experiments 1b and 2b is an in-built feature of spatial encoding, it should broadly characterize production and comprehension data across different languages. Evidence supporting this prediction comes from a recent study which used a set of schematic Source and Goal paths similar to those used in Experiment 2b to elicit motion descriptions from children who were native speakers of either English or Greek (Johanson, Selimis & Papafragou, 2009). The study confirmed that Source expressions were more likely to be omitted compared to Goal expressions in the speech of young children from both language groups. An extension of this study confirmed the asymmetry in (adult) speakers of 11 different languages (Johanson & Papafragou, in prep.; see also Lakusta, Yoshida, Landau & Smith, 2006). Closer inspection of these data will be required to test whether specific morphosyntactic devices might affect the extent of the Source and Goal asymmetry cross-linguistically: for instance, one might hypothesize that speakers of a language like English which encodes Manner of motion information in verbs and Path information in prepositional phrases might drop Source information more frequently than speakers of a language like Greek where Path information is often encoded in the main verb. Nevertheless, at present, this specific prediction does not seem to be borne out (Johanson et al., 2009).
Second, the Source-Goal facts from Experiment 2b are consistent with the expectation that, across languages, there should be a smaller inventory of dedicated Source expressions compared to Goal ones – and by extension, children acquiring their native tongue should use Source expressions to refer to a wider set of spatial scenes and relations compared to Goal expressions. Preliminary positive evidence for this hypothesis emerges in the cross-linguistic inventory of Johanson and Papafragou (in prep.), where separation expressions (e.g., away from) are used for a wider array of scenes compared to joining expressions (e.g., to; cf. also Bowerman, 1985; Bowerman et al., 1995; Johanson et al., 2009; Zheng & Regier, 2007). It remains to be seen whether this loss of specificity in the Source domain exhibits interesting cross-linguistic similarities. For instance, on the basis of the data in Experiment 2b, one might expect that the degree of specificity of linguistic TO and FROM paths might interact with the type of relation, with Containment configurations being more likely to elicit more specialized encoding compared to Support configurations. A first inspection of the cross-linguistic corpus of Johanson and Papafragou lends some support to this hypothesis: cross-linguistically, removal from container (out of) is more likely to be marked with a dedicated expression compared to removal from surface (off of), even if the corresponding Goal relations (into, onto) are consistently differentiated from each other in the language.
Third, the present linguistic data, especially those from Experiment 2b, are consistent with the proposal that the acquisition of a word for motion into a spatial configuration should precede and assist the process of learning a word for motion out of that configuration – but not vice versa (Regier, 1997). More direct tests of this claim, even though limited, have generally yielded confirmatory evidence: for instance, production data from Greek suggest that `enter' (beno) is acquired before `exit' (vjeno; Katis & Selimis, in press).
Some questions remain open about the nature and scope of the linguistic Source-Goal asymmetry. We know that this asymmetry extends beyond motion to events such as change of possession (give/get) and change of state (change/turn from X to Y), for which spatial language is also employed (Lakusta & Landau, 2005; cf. Gruber, 1965; Jackendoff, 1983). It is an interesting question whether the asymmetries in the generalization of spatial predicates observed in Experiment 2b hold across these other domains too, and whether memory for the corresponding non-linguistic events is also Goal-oriented.
Perhaps most importantly, the present results raise questions concerning the origin of the linguistic Source- Goal pattern. There is evidence that the non-linguistic preference for motion endpoints may only be present for intentional actions. For instance, the Goal bias in memory disappears for events with inanimate agents (e.g., a tissue falling off magazine onto a book; Lakusta, Wessel & Landau, 2006; Lakusta & Carey, 2008), or in the presence of intentional cues that make Goals less salient (Lakusta & Landau, 2007; Landau, 2009; Lakusta, 2005). Similarly, infants do not confer privileged status to motion endpoints when motion events have an inanimate/non-intentional agent (Lakusta & Carey, 2008), even though infants encode the Goal of an (animate) agent's reach, point and gaze (Woodward, 1998, 2003; Woodward & Guajardo, 2002) and even extend Goal reasoning to self-propelled, rationally behaving inanimate objects (Luo & Baillargeon, 2005; Csibra, Bíró, Koós & Gergely, 2003). Since the present stimuli involved either animate agents (Experiment 1) or a self-propelled inanimate object (soccer ball; Experiment 2), it is natural to ask whether results would change if one introduced inanimate, non-self-propelled agents (e.g., a leaf, a piece of leather). On the basis of the evidence just reviewed, it seems likely that the Goal advantage in memory would decrease or disappear. It is less clear how the absence of intentionality might affect the linguistic results in this paper. If there is a strict homology between spatial language and memory, the Source-Goal discrepancy observed in language production and comprehension should also diminish for inanimate events. Alternatively, if the non-linguistic bias motivates but does not completely determine the linguistic data, Sources and Goals in language might still be treated differently for inanimate events, even though in memory both components would be equally salient. Further research is required to adjudicate between these two possibilities and assess the implications for the nature of the relationship between linguistic and non-linguistic motion paths.
Acknowledgments
I wish to thank Solveig Bosse, Margaret Cahill, CarolAnn Edie, Kendra Goodwin, Carlyn Friedberg, Megan Johanson, Brooke Leiman, Sarah Lorch, Seth Rider Marshall, Erica Miao, Taraneh Mojaverian and Amy Ritter for their help in putting together and conducting the studies, as well as the staff, parents and children at the Early Learning Center and Educare. This research was partially supported by grant R01HD055498 (awarded to Anna Papafragou and John Trueswell) from the Eunice Kennedy Shriver National Institute of Child Health and Human Development.
Footnotes
The terms `endpoint' and `goal' (and `origin' and `source') will be used interchangeably for present purposes (see also Lakusta et al., 2007).
Since the stimuli and procedure for adults and children were not identical, performance of the two age groups is not directly compared in this and the following studies.
Notice that the non-linguistic task does not preclude linguistic encoding, at least from adults (there is evidence that young children are unlikely to use language strategically in memory tasks; see Hitch, Halliday, Schaafstal & Heffernan, 1991, and Palmer, 2000). To ensure that the adult responses truly reflected a non-linguistic Source-Goal asymmetry, a shadowing condition was run with a separate group of 26 adults. In this condition, participants had to count aloud starting with the number 33 as they viewed the events and had to keep counting with no interruptions until the memory phase began. Overall, this secondary task resulted in low memory accuracy. Participants were therefore split into a group of low-performers (n=12), each with 50% or fewer correct responses on the total number of filler and test trials (group mean of 39%), and a group of high-performers (n=14), each with more than 50% correct responses (group mean of 66%). In the first group, there was no difference between Source and Goal trials (t(11)=−1.33, p=.2, n.s.; Ms = .30 vs. MG = .23). But in the second group, there was a significant difference between Source and Goal trials in the predicted direction (t(13)=−2.5, p=.02; Ms = .48 vs. MG = .67). Furthermore, in this group, performance on the Goal trials was different from chance (t(13)=3.5, p=.003) but on Source trials it was not (t(13)=−.23, p=.8, n.s.). To the extent that participants could do this dual task, then, the Source-Goal asymmetry in memory was preserved even when linguistic encoding was unavailable.
A more specific analysis was also conducted looking at the frequency with which adults mentioned the specific objects that were targeted in the memory task. For this analysis, mention of the flower but not the tree in the event of Fig.1 would count as a Goal/Source path. The analysis confirmed that Source paths were less likely to be mentioned than Goal paths (M = .50 vs. .78 respectively, matched-pairs t(15) = −4.76, p = .0003).
Support for the first possibility comes from an additional analysis of the adult data of Exp.1a. Depending on the Spatial Relation they instantiated, test events in that study were classified into five categories: Cover (a snake crawls under/from under a chair; a baby crawls under/from under a desk); Support (a bug flies onto/off of a window; a bird flies onto/off the top of a trash can; a fairy flies onto/off of a flower); Containment (a man tiptoes into/from inside a room; a man skates into/out of a cave); Direction (a car drives to/from a church; a dolphin swims towards/away from two flags in a pool; a couple dances to/away from a gazebo); and Occlusion (a man on crutches hops behind/from behind a fence; a mouse jumps behind/from behind a bush). The question was whether memory accuracy in the test items differed depending on the kind of Spatial Relation (independently of the Source-Goal distinction). Results showed that Spatial Relation did have a significant effect on memory accuracy (F(4, 12) = 8.96, p = .0014). Closer inspection revealed that Containment elicited a significantly higher accuracy rate (M = .75) compared to Occlusion (M = .25), Cover (M = .50) and Support (M = .48; all p's < .05), but not Proximity (M = .60; p=.20, n.s.). These findings support the presence of a potential advantage of Containment in the non-linguistic representation of spatial events.
The present linguistic tasks focused on whether (a) the specificity of encoding of Source vs. Goal objects differs in verbal descriptions, and (b) the specificity of encoding Source vs. Goal relations differs in the comprehension of new linguistic terms. Additional ways of testing how the Source-Goal asymmetry impacts language could ask whether (c) the specificity of encoding Source vs. Goal objects differs in interpreting new spatial terms, and (d) the specificity of encoding Goal vs. Source relations differs during production of verbal descriptions. The possibility in (c) cannot be evaluated directly due to lack of relevant developmental data, but it seems plausible that the specificity of Goal objects is more important for spatial vocabulary than the specificity of Source objects. Relevant evidence comes from Talmy, who reports that, in Atsugewi, Ground and Path information is often encoded by verb suffixes (e.g., - cis `into a fire', -ićt `into a liquid'); in this language, there are many more Goal-marked than Source-marked verbs (Talmy, p.c.; see also Talmy, 2000). The possibility in (d) is discussed in more detail at a later point in the General Discussion, when evidence is presented in support of the fact that Goal relations are expressed in a more precise manner than Source relations.
References
- Arnold J. The effect of thematic roles on pronoun use and frequency of reference continuation. Discourse Processes. 2001;31:137–162. [Google Scholar]
- Arsenijevič B. VP semantics as a temporal structure. In: Salzmann M, Vicente L, editors. 1st Syntax AiO Meeting; Leiden: Leiden Papers in Linguistics; 2005. pp. 17–42. [Google Scholar]
- Bowerman M. Learning how to structure space for language: A cross-linguistic perspective. In: Bloom P, Peterson M, Nadel L, Garrett M, editors. Language and Space. MIT Press; Cambridge, MA: 1996. pp. 385–436. [Google Scholar]
- Bowerman M, de León L, Choi S. Verbs, particles, and spatial semantics: Learning to talk about spatial actions in typologically different languages. In: Clark EV, editor. Twenty-Seventh Annual Child Language Research Forum; Stanford, CA: Center for the Study of Language and Information; 1995. pp. 101–110. [Google Scholar]
- Casasola M, Cohen LB. Infant categorization of containment, support, and tight-fit spatial relationships. Developmental Science. 2002;5:247–264. [Google Scholar]
- Casasola M, Cohen LB, Chiarello E. Six-month-old infants' categorization of containment spatial relations. Child Development. 2003;74:1–15. doi: 10.1111/1467-8624.00562. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Clark H. Space, time, semantics and the child. In: Moore TE, editor. Cognitive development and the acquisition of language. Academic Press; New York: 1973. pp. 27–63. [Google Scholar]
- Crawford LE, Regier T, Huttenlocher J. Linguistic and non-linguistic spatial categorization. Cognition. 2000;75:209–235. doi: 10.1016/s0010-0277(00)00064-0. [DOI] [PubMed] [Google Scholar]
- Csibra G, Bíró S, Koós O, Gergely G. One-year-old infants use teleological representations of actions productively. Cognitive Science. 2003;27:111–133. [Google Scholar]
- Filip H. Prefixes and the delimitation of events. Journal of Slavic Linguistics. 2003;11:55–101. [Google Scholar]
- Fisher C, Hall DG, Rakowitz S, Gleitman L. When it is better to receive than to give: syntactic and conceptual constraints on vocabulary growth. In: Gleitman L, Landau B, editors. Acquisition of the Lexicon. MIT Press; Cambridge, MA: 1994. pp. 333–375. [Google Scholar]
- Freeman NH, Sinha CG, Stedmon JA. The allative bias in three-year-olds is almost proof against task naturalness. Journal of Child Language. 1980;8:283–296. doi: 10.1017/s0305000900003196. [DOI] [PubMed] [Google Scholar]
- Gehrke B. Online Proceedings from ESSLI Workshop “Formal Semantics and Cross-Linguistic Data'. Radboud Universit; Nijmegen: 2005. The prepositional aspect of Slavic prefixes and the goal-source asymmetry. [Google Scholar]
- Gennari S, Sloman S, Malt B, Fitch T. Motion events in language and cognition. Cognition. 2002;83:49–79. doi: 10.1016/s0010-0277(01)00166-4. [DOI] [PubMed] [Google Scholar]
- Hayward WG, Tarr MJ. Spatial language and spatial representation. Cognition. 1995;55:39–84. doi: 10.1016/0010-0277(94)00643-y. [DOI] [PubMed] [Google Scholar]
- Hitch GJ, Halliday MS, Schaafstal AM, Heffernan TM. Speech, `inner speech', and the development of short-term memory: Effects of picture-labeling on recall. Journal of Experimental Child Psychology. 1991;51:220–234. doi: 10.1016/0022-0965(91)90033-o. [DOI] [PubMed] [Google Scholar]
- Ikegami Y. `Source' vs. `goal': A case of linguistic dissymmetry. In: Dirven R, Radden G, editors. Concepts of case. Narr; Tübingen: 1987. pp. 122–146. [Google Scholar]
- Jackendoff R. Semantics and cognition. MIT Press; Cambridge, MA: 1983. [Google Scholar]
- Jackendoff R. Semantic structures. MIT Press; Cambridge, MA: 1990. [Google Scholar]
- Johanson M, Papafragou A. Ms., University of Delaware; Cross-linguistic structure of motion expressions. in prep. [Google Scholar]
- Johanson M, Selimis S, Papafragou A. Cross-linguistic biases in the semantics and acquisition of spatial language. 33rd Annual Boston University Conference on Language Development; Somerville, MA: Cascadilla Press; 2009. [Google Scholar]
- Johnston JR, Slobin D. The development of locative expressions in English, Italian, Serbo-Croatian and Turkish. Journal of Child Language. 1978;6:529–545. doi: 10.1017/s030500090000252x. [DOI] [PubMed] [Google Scholar]
- Katis D, Selimis S. The development of metaphoric motion: Evidence from Greek children's narratives. 31st Annual Meeting of the Berkeley Linguistic Society; Berkeley, CA: BLS; in press. [Google Scholar]
- Kornfilt J. Turkish. Routledge; London and New York: 1997. [Google Scholar]
- Lakusta L. Ph.D. thesis. Johns Hopkins University; 2005. Source and goal asymmetry in non-linguistic motion event representations. [Google Scholar]
- Lakusta L, Carey S. Ms., Harvard University; 2008. Pre-linguistic encoding of source and goal paths. [Google Scholar]
- Lakusta L, Landau B. Poster presented at the Society for Research in Language Development. Boston, MA: Apr, 2007. Goal bias in language and in non-linguistic motion event representations. [Google Scholar]
- Lakusta L, Landau B. Starting at the end: The importance of goals in spatial language. Cognition. 2005;96:1–33. doi: 10.1016/j.cognition.2004.03.009. [DOI] [PubMed] [Google Scholar]
- Lakusta L, Yoshida H, Landau B, Smith L. Cross-linguistic evidence for a goal/source asymmetry: The case of Japanese. International Conference on Infant Studies; Kyoto, Japan. Jun, 2006. [Google Scholar]
- Lakusta L, Wessel A, Landau B. Goal bias in non-linguistic motion event representations: The role of intentionality. Vision Science Society Annual Meeting; Sarasota. May, 2006. [Google Scholar]
- Lakusta L, Wagner L, O'Hearn K, Landau B. Conceptual foundations of spatial language: Evidence for a goal bias in infants. Language Learning and Development. 2007;3:179–197. [Google Scholar]
- Landau B. Spatial language, spatial cognition: Origins, development, and interaction. 33rd Annual Boston University Conference on Language Development; Somerville, MA: Cascadilla Press; 2009. [Google Scholar]
- Landau B, Jackendoff R. “What” and “where” in spatial language and spatial cognition. Behavioral and Brain Sciences. 1993;16:217–255. [Google Scholar]
- Landau B, Stecker D. Objects and places: Geometric and syntactic representations in early lexical learning. Cognitive Development. 1990;5:287–312. [Google Scholar]
- Landau B, Zukowski A. Objects, motions and paths: Spatial language in children with Williams syndrome. Developmental Neuropsychology. 2003;23:107–139. doi: 10.1080/87565641.2003.9651889. [DOI] [PubMed] [Google Scholar]
- Li P, Dunham Y, Carey S. Of substance: The nature of language effects on entity construal. Cognitive Psychology. 2009;58:487–524. doi: 10.1016/j.cogpsych.2008.12.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luo Y, Baillargeon R. Can a self-propelled box have a goal? Psychological reasoning in 5-month-old infants. Psychological Science. 2005;16:601–608. doi: 10.1111/j.1467-9280.2005.01582.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Malt B, Sloman S, Gennari S, Shi M, Wang Y. Knowing versus naming: Similarity and the linguistic categorization of artifacts. Journal of Memory and Language. 1999;40:230–262. [Google Scholar]
- Mandler JM, Johnson NS. Some of the thousand words a picture is worth. Journal of Experimental Psychology: Human Learning & Memory. 1976;2:529–540. [PubMed] [Google Scholar]
- Markovskaya E. Goal-source asymmetry and Russian spatial prefixes. In: Svenonius P, editor. Nordlyd: TromsØ Working Papers in Linguistics. Vol. 33. CASTL; TromsØ: 2006. pp. 200–219. Special issue on Adpositions. [Google Scholar]
- Miller G, Johnson-Laird P. Language and perception. Harvard University Press; Cambridge, MA: 1976. [Google Scholar]
- Naigles L, Terrazas P. Motion-verb generalizations in English and Spanish: Influences of language and syntax. Psychological Science. 1998;9:363–369. [Google Scholar]
- Nam S. Paper presented at the Workshop on Event Structures in Linguistic Form and Interpretation. Leipzig: 2004. Goal and source: Asymmetry in their Syntax and Semantics. [Google Scholar]
- Palmer S. Working memory: A developmental study of phonological recoding. Memory. 2000;8:179–193. doi: 10.1080/096582100387597. [DOI] [PubMed] [Google Scholar]
- Papafragou A, Selimis S. Event categorization and language: The case of motion events. 2007a Submitted. [Google Scholar]
- Papafragou A, Selimis S. Lexical and structural biases in the acquisition of motion verbs cross-linguistically. 2007b Submitted. [Google Scholar]
- Papafragou A, Massey C, Gleitman L. Shake, rattle, `n' roll: the representation of motion in language and cognition. Cognition. 2002;84:189–219. doi: 10.1016/s0010-0277(02)00046-x. [DOI] [PubMed] [Google Scholar]
- Pruden SM, Hirsh-Pasek K, Maguire M, Meyers M, Golinkoff RM. Foundations of verb learning: Infants form categories of path and manner in motion events. 28th Annual Boston University Conference on Language Development; Somerville, MA: Cascadilla Press; 2004. pp. 461–472. [Google Scholar]
- Pulverman R, Sootsman J, Golinkoff RM, Hirsh-Pasek K. Infants' non-linguistic processing of motion events: One-year-old English speakers are interested in manner and path. Stanford Child Language Research Forum; Stanford: Center for the Study of Language and Information; 2003. [Google Scholar]
- Quinn PC. On the infant's prelinguistic conceptions of spatial relations. In: Plumert JM, Spencer JP, editors. The emerging spatial mind. Oxford University Press; New York: 2007. pp. 117–141. [Google Scholar]
- Regier T. The human semantic potential: Spatial language and constrained connectionism. MIT Press; Cambridge, MA: 1996. [Google Scholar]
- Regier T. Constraints on the learning of spatial terms: A computational investigation. In: Goldstone R, Schyns P, Medin D, editors. Psychology of Learning and Motivation. Mechanisms of Perceptual Learning. Vol. 36. Academic Press; San Diego: 1997. pp. 171–271. [Google Scholar]
- Regier T, Carlson L. Grounding spatial language in perception: An empirical and computational investigation. Journal of Experimental Psychology: General. 2001;130:273–298. doi: 10.1037//0096-3445.130.2.273. [DOI] [PubMed] [Google Scholar]
- Regier T, Zheng M. Attention to endpoints: A cross-linguistic constraint on spatial meaning. Cognitive Science. 2007;31:705–719. doi: 10.1080/15326900701399954. [DOI] [PubMed] [Google Scholar]
- Skordos D, Papafragou A. Extracting paths and manners: Linguistic and conceptual biases in the acquisition of spatial language. Talk to be delivered at the 34th Annual Boston University Conference on Language Development; Boston. Nov, 2009. pp. 7–9. [Google Scholar]
- Stefanowitsch A, Rohlde A. The goal bias in the encoding of motion events. In: Radden G, Panther K-U, editors. Studies in linguistic motivation. Mouton de Gruyter; Berlin & New York: 2004. [Google Scholar]
- Talmy L. Lexicalization patterns: Semantic structure in lexical forms. In: Shopen T, editor. Language typology and syntactic description. Cambridge University Press; New York: 1985. pp. 57–149. [Google Scholar]
- Talmy L. Toward a Cognitive Semantics. 2 vols. MIT Press; Cambridge, MA: 2000. [Google Scholar]
- Woodward AL. Infants selectively encode the goal object of an actor's reach. Cognition. 1998;69:1–34. doi: 10.1016/s0010-0277(98)00058-4. [DOI] [PubMed] [Google Scholar]
- Woodward AL. Infants' developing understanding of the link between looker and object. Developmental Science. 2003;6:297–311. [Google Scholar]
- Woodward AL, Guajardo JJ. Infants' understanding of the point gesture as an object-directed action. Cognitive Development. 2002;17:1061–1084. [Google Scholar]
- Zheng M, Goldin-Meadow S. Thought before language: How deaf and hearing children express motion events across cultures. Cognition. 2002;85:145–175. doi: 10.1016/s0010-0277(02)00105-1. [DOI] [PubMed] [Google Scholar]