

Abstract
3D surfaces are important geometric models for many objects of interest in image analysis and Computational Anatomy. In this paper, we describe a Bayesian inference scheme for estimating a template surface from a set of observed surface data. In order to achieve this, we use the geodesic shooting approach to construct a statistical model for the generation and the observations of random surfaces. We develop a mode approximation EM algorithm to infer the maximum a posteriori estimation of initial momentum μ, which determines the template surface. Experimental results of caudate, thalamus, and hippocampus data are presented.
1. Introduction
3D surfaces are important geometric models for many objects of interest in image analysis and Computational Anatomy. For example, they are often used to represent the shape of 3D objects, the surface of human faces, and the boundaries of brain structures or of other human organs. Most data analysis methods in this domain are template-centered, and a proper estimation of a template plays an important role to obtain high quality results. This paper is devoted to the description of statistically supported template estimation method which is adapted to surface data sets.
Our approach will be to build a generative statistical shape model in which the template is a parameter. We will then estimate it using maximum likelihood. This model relies on the very natural setting for which an observed surface is a noisy version of a random deformation of the template. This is the most generic and most basic approach of the deformable template paradigm, even if we add a small refinement by including a prior distribution on the template, based on what we will call a hypertemplate. Even with this global scheme which is fairly simple, we will see that implementing it in the context of surfaces will constitute a significant theoretical and numerical challenge.
At the exception of the recent work of [1], this approach significantly differs from what has been mostly proposed in the literature, in which most of the methods compute templates as averages over specific common parametrizations of the surfaces (using, for example, the sphere as a parameter space [2]). Parametric representations, however, are limited by the fact that, because they are defined a priori and independently for each object, they cannot be assumed to suitably align important features in a given data set of surfaces (i.e., give similar coordinates to similar features in the surfaces). This usually results in oversmoothed template surfaces (which is the equivalent of getting blurry template images in the case of image averaging). In [1], a similar diffeomorphic transformation model is used, but, as we will see, our Bayesian construction will provide a well-specified template whereas [1] needs to rely to topologically unconstrained approximations to end up with a manageable template.
In addition to the references above, there have been several publications addressing the issue of shape averaging over a dataset, although most of them work with 3D volume data or landmark points set. In several cases, the average is based on metric properties of the space of shapes [3–7], and the template is computed as an intrinsic average, minimizing the sum of square distances to each element of the set (Fréchet mean). Such methods have been implemented in the context of diffeomorphic deformation models (which are also models of interest in the present paper) for landmark matching [8], for 3D average digital atlas construction [9], and to quantify variability in heart geometry [10]. Other definitions of the average, adapted to situations in which the data is corrupted by noise, have been proposed [11–13], based on variational approaches (but not relying on a generative statistical model).
Our approach to build a generative statistical shape model is reminiscent of the construction developed in [14] for linear models of deformations, and in [15] for large diffeomorphic deformations in 3D volume image averaging. Adapting these ideas to surfaces will however require new algorithms and numerical developments.
In order to present our model, we need to first provide some background materials and notation, describing in particular the geodesic shooting equations that we will use to generate deformed surfaces. We will then introduce a random statistical model describing the generation and the observations of random surfaces. We then develop a Mode Approximation EM algorithm for surface averaging, to estimate the template from observations. In the optimization part, we derive and implement a new variational scheme, which is also applicable to surface matching, providing an alternative approach to the one originally proposed in [16, 17]. Finally, we present and discuss experimental results on caudate, thalamus, and hippocampus data.
2. EPDiff for Surface Evolution
We will base our random shape model on the so-called EPDiff equation, which describes the evolution of deformable structures (like images, surfaces, or landmarks) under the action of groups of diffeomorphisms. It is a geodesic equation for a Riemannian metric on diffeomorphisms, and describes a momentum conservation law in the associated Hamiltonian system. The reader interested by the theory behind this equation can refer to [18–20], but most of this background will not be needed for the present paper, in which we will only use the specific form of the equations for surface evolution. The term EPDiff comes from its determination as an Euler-Poincaré equation in the group of diffeomorphisms, as introduced in [21]. One of its main interests here is that it provides a numerically stable, easily described, Hamiltonian evolution over diffeomorphisms, which will constitute an ideal support for our shape models.
The EPDiff equations describe the combined time evolution of a diffeomorphism, denoted ϕ(t, ·) and of what can be interpreted as a momentum, denoted p(t, ·). The initial conditions are always ϕ(0, x) = x for ϕ, and some initial value, p 0, for p. This initial momentum will be a key component of the statistical model that will be built later on.
Let us start with the simplest form of the equation, which assumes that p 0 is a vector-valued function over ℝd, that is, p 0 : ℝd → ℝd. It involves a smoothing kernel, K, defined on ℝ3 × ℝ3, a typical choice being
| (1) |
Letting ∇1 K denote the gradient of K with respect to its first variable, the corresponding EPDiff equation is
| (2) |
Here, the notation a · b refers to the usual dot product between vectors in ℝ3. If K is smooth enough, this system has solutions for arbitrary large t, and the mapping x ↦ ϕ(t, x) is a diffeomorphism at all times.
The interesting fact about these equations is that they can have singular variants that are described in a similar way and have the same existence properties. The simplest way to relate the variants to the previous equation is to replace the Lebesgue's measure in the integrals by another, possibly singular, measure. For example, taking a surface S 0 in ℝ3, we can use the volume form on S 0 as a reference measure and obtain the equations (in which p 0 and p(t, ·) need only to be defined on S 0)
| (3) |
where d ω S0 is the volume form on S 0. Note that the first equation is defined for x ∈ ℝ3, but it suffices to use it for x ∈ S 0 to obtain an equation for the evolving surface
| (4) |
We can write a discrete form of the equations by replacing d y by a sum of Dirac measures (at points x 1,…, x L in ℝ3), which gives, letting a l(t) = p(t, x l),
| (5) |
Similarly to (3), the first equation is valid for all x ∈ ℝ3, but it suffices to solve it for x = x l, l = 1,…, L to obtain the evolution of the point set
| (6) |
Also, (5) can be seen as a discretization of (3) in which x 1,…, x L are the vertices of a triangulation of S 0, and a l(t) = p(t, x l)δ σ S0(x l), where δ σ S0(x l) is the area of a surface element around x l.
The evolution of point sets is the most important from a practical point of view, since it is an ODE that can be easily implemented. Assuming a radial kernel K(x, y) = γ(||x−y||2) like in (1), and denoting γ kl = γ(||x k−x l||2), and γ kl′ = γ′(||x k−x l||2), (5) can be rewritten as
| (7) |
Once the initial position of the vertices, x(0) = (x 1(0),…, x L(0)), and the initial momentum, a(0) = (a 1(0),…, a L(0)), are provided, the evolution of the point set is uniquely determined.
3. Generative Model for Surface Observation
3.1. Random Triangulated Surfaces
If a triangulated template surface T with vertices x (T) is given, and we solve, until time t = 1, (5) initialized with x(0) = x (T) and a random initial momentum a(0) = α, the displaced vertices provide a random perturbation of the initial surface that will be denoted by T α. This is stated in the following definition.
Definition 1 —
Let T be a triangulated surface with vertices x (T) = (x 1 (T),…, x L (T)). Let α ∈ (ℝ3)L be a collection of L vectors in ℝ3. Let (x(t), a(t)) be the solution of (5) with initial condition x(0) = x (T) and a(0) = α. One defines T α to be the triangulated surface with vertices x (Tα) = x(1) and the same topology as T.
By letting α be random, we build T α as a random deformation of T. This will form the “ideal”, unobserved, surface, of which only a noisy version is observable (the noise process will be described in the next section).
Following [15], we will use a Bayesian formulation in which T is itself represented as a random deformation T 0,μ : = (T 0)μ, where T 0 is a fixed surface that we will call the hypertemplate, and μ is a prior initial momentum shooting from T 0 to T (same notation as in Definition 1). One of the main interests of using a hypertemplate is to fix the topology of T so that it belongs, by construction, to the same class of objects as T 0.
So, if N surfaces are observed, we need to model the probability distribution of the prior momentum, μ (starting at T 0), which specifies T = T 0,μ and of N deformation momenta α (1),…, α (N) which specify the surfaces T α(1),…, T α(N). We now provide a statistical model for the joint probability distribution of μ, α (1),…, α (N).
We first introduce some notation. Letting K be the kernel introduced in the previous section to define the geodesic shooting equations, we let ΓT be the 3L by 3L matrix formed with the 3 by 3 blocks K(x k (T), x l (T))I d ℝ3. We define, for a triangulated surface T with L vertices x (T), and α ∈ ℝ3L,
| (8) |
We define the joint distribution of μ, α (1),…, α (N) on ℝ3L × (ℝ3L)N by
| (9) |
where λ is a fixed parameter regulating the weight on the hypertemplate.
There is a technical difficulty here, which is that one must make sure that this probability can be normalized (Z exists), which requires that the exponential is integrable. That this is true is not straightforward, and we have not been able to find a proof that works with any choice of the kernel K. One way to deal with this is to introduce a constant A μ (which can be chosen arbitrarily large so that it does not interfere with the algorithms that will follow), and add to the model the constraint that ||μ||T0 is smaller than A μ. Under such an assumption, one obtains (after integrating out the α's)
| (10) |
This is finite, since, for any given μ, the transformation x (T0) → x (T0,μ) is the restriction of a diffeomorphism to the vertices of T 0 (as seen from (5)). This implies that ΓT0,μ is nonsingular, and its determinant is bounded away from 0 when μ is restricted to a compact space.
In fact, the choice A μ = ∞ can be proved to be acceptable for a large class of kernels. Those are kernels for which the smallest eigenvalue of ΓT decreases at a speed which is at most polynomial in the minimal distance, h T, between the vertices. A list of kernels satisfying this property can be found in [22]. For such kernels, we find that (L being fixed) log det ΓT = O(log h T). Just sketching the argument here, one can prove, using elementary properties of dynamical systems, that h T = O(exp (−C||μ||T0,μ) for some constant C, so that the log determinant in (9) is linear in ||μ||T0,μ and Z is well defined, even with A T0,μ = ∞. For very smooth kernels, including the Gaussian, bounds on the smallest eigenvalue of ΓT are much worse (with a decay which is exponential in (−1/h T 2)), and the previous argument does not work. Since the bounds in [22] hold uniformly with respect to the number of points, a polynomial bound may still be valid for a fixed L, although we were unable to discover it.
Notice that, conditionally to the template, the momenta α are independent and follow a Gaussian distribution with inverse covariance matrix given by ΓT. An example of simulated random deformations obtained using such a model is provided in Figure 1.
Figure 1.

Random deformation of a template caudate surface (left). The six surfaces following the template are independent realization of the model described in (9).
3.2. Observation and Noise
The second part of our generative model is to describe the observation process, which takes an ideal surface T α generated according to the model above, and returns the noisy observable.
Modeling such a noise process is a tricky issue. Obvious choices (like adding noise to the vertices of T α) do not work because one cannot assume that the observed surfaces are discretized consistently with the template. In this paper, we will work around this issue by assimilating the observation of a surface that of a singular Gaussian process.
For this, we consider that surfaces in ℝ3 are not observable directly, but only via their action on test functions, that we will call sensors. We define a sensor to be a smooth vector field w over ℝ3 (typically with small support). Given an oriented surface S, define
| (11) |
where N S is the normal to S. The real number, (S, w) is the measurement of S through the sensor w.
Now, modeling noisy surfaces will result in assuming that, given any w, the measurement (S, w) is a random variable. We will assume that it is Gaussian, and more generally, that, given m sensors, w 1,…, w m, the random vector ((S, w j), j = 1,…, m) is Gaussian.
S, via its action on sensors, is therefore modeled as a Gaussian random field. Given an ideal surface T α, we will assume that its mean is given by
| (12) |
and the process is thereafter uniquely characterized by its covariance operator
| (13) |
We will assume that this covariance is associated to a symmetric operator L obs so that
| (14) |
(The apparently redundant parameter σ 2, which could have been included in L obs, appears here because it can be easily estimated by the algorithm, with the operator L obs remaining constant.)
To finalize our model, it remains to describe how S is discretized, that is, to make explicit a finite family of sensors through which S is measured. Let (z j, j ∈ J) form a regular grid of points in Ω. Let γ s be a radial basis function (a Gaussian, e.g.,) and define, for j ∈ J and d = 1,2, 3
| (15) |
where e d is the dth vector of the standard basis of ℝ3 (this therefore specifies 3|J| sensors). The resulting observed variables are
| (16) |
where N S (d) = N S · e d is the dth coordinate of N S. These variables are, by assumption, jointly Gaussian, with means m j,d = (T α, w j,d) and covariance matrix
| (17) |
Assuming that L obs is translation invariant, the resulting expression is a function of z i − z i′ that we will denote
| (18) |
Let R obs = (r ij (obs)) be the inverse matrix of the one with coefficients (γ obs(z j − z j′), j, j′ ∈ J). The log likelihood of the process will include error terms taking the form
| (19) |
Replacing y j,d by its expression in (16), we have
| (20) |
Let us analyze the first term. We have
| (21) |
with the notation
| (22) |
Treating the other terms similarly, we can rewrite the error term in the form
| (23) |
and we will abbreviate this (introducing a notation for the right-hand side) as ℰ obs = (1/σ 2)||S−T α||obs 2. Thus, we can write
| (24) |
We have the following important proposition.
Proposition 1 —
Assume that γ s is taken equal to the Green function of L obs. Then, when the grid J becomes finer and K obs is given by (22), one has
(25)
See the appendix for a proof of this proposition (which requires some background on the theory of Hilbert spaces with a reproducing kernel) and possible extensions. For practical purposes, we will use γ obs instead of K obs in ||·||obs, therefore assuming that the sensors are chosen according to the proposition. It is interesting to notice that the resulting norm in this case is precisely the norm that has been introduced in [16] to compare surfaces, when they are considered as elements of a reproducing kernel Hilbert space of currents. We refer to [16] for details on the mathematical construction.
In the rest of the paper, we develop a parametric procedure to estimate the template T from the observation of i.i.d. surfaces S (1), S (2),…, S (N) generated as described above. This includes in particular N hidden deformation momenta α (1), α (2),…, α (N), such that the complete distribution of observed and unobserved variables is
| (26) |
where we have written for short T = T 0,μ.
We now discuss the estimation of the parameter μ, and of the associated template T 0,μ, which is the main purpose of this paper. This will be implemented with a mode approximation of the EM algorithm, as described in the next section.
4. Algorithms for Surface Template Estimation
4.1. Mode Approximation EM
Let Θ = (α (1), α (2),…, α (N)) be the hidden part of the process, representing the collection of initial momenta, and let S = (S (1), S (2),…, S (N)) be the collection of observed surfaces. The complete distribution for the process, including the prior is given by (26).
The EM algorithm is an iterative method that updates a current estimation of μ using the following two E- and M-steps.
E-step: determine the conditional expectation .
M-step: maximize this expression with respect to and replace the current estimation of μ by the obtained maximizer.
The conditional expectation can be expanded as
| (27) |
Considering the highly nonlinear relation between α (n) and the deformed surface T α(n), an explicit computation in (27) is impossible. We will therefore rely on the classic mode approximation in the EM which replaces the conditional distribution by a Dirac measure taken at the conditional mode, yielding
| (28) |
where
| (29) |
This results in a maximum a posteriori procedure that maximizes alternatively in μ and in the α (n)'s. Like in [15], we will refer to it as a mode approximation to the EM (MAEM) rather than a MAP algorithm, in order to strengthen the fact that it is an approximation of the maximum a posteriori procedure relying on the likelihood of the observed data only. As illustrated in [14], the MAEM can be biased (leading to inexact estimation of the template, even with a very large number of samples), especially when the noise is important, but it is obviously more feasible than the exact EM. Notice that the MAEM method is a special form of EM algorithm, and as such optimizes a lower bound of the log likelihood of the observed data.
We summarize the two steps of the ith iteration of the MAEM in our case. Suppose μ and the α (n)'s are the current variables to be updated. Then the next iteration is as follows.
MAE step: with μ (and therefore T) fixed, find, for n = 1,…, N, to minimize
| (30) |
and replace α (n) by .
M step: with α (n) fixed, update μ with the minimizer of
| (31) |
We now discuss how each of these steps can be implemented.
4.2. MAE Step
Our goal in this section is to optimize (30). We work with fixed n and drop it from the notation to simplify the expressions. The objective function is
| (32) |
This problem is equivalent to the surface matching algorithm considered in [16], with a slightly different formulation since [16] optimize an energy with respect to a time-dependent momentum instead of just the initial momentum (i.e., they solved simultaneously the geodesic estimation and the matching problems). These two formulations are equivalent when using continuous time (they produce the same minima), but they yield different results when discretized. In our setting, formulating the problem as in (32) is natural, and focuses on the modeled random variable, α.
We need to compute the variation of E with respect to α. This computation will be useful for the M-step also. We first discuss the discretization of the error term, which follows [16]. Let S be a triangulated surfaces, with vertices x (S) = (x 1 (S),…, x L (S)) and faces F (S) = (f 1 (S),…, f M (S)). Each face is represented by an ordered triple of vertices: f = (x 1 f, x 2 f, x 3 f), and we define the face centers and area-weighted normals by
| (33) |
Then a discrete approximation of ||S−S′||obs 2 is
| (34) |
where S is considered as fixed and U is therefore considered as a function of the vertices, x (S′), of S′.
With this notation, we can write
| (35) |
We want to compute the gradient of E and for this, apply the chain rule to the transformations α → T α → U(x (Tα)), yielding
| (36) |
where A* is the transpose matrix of A.
The gradient of U with respect to x (S′) has been computed in [16], and is given as follows. We denote by F l (S) the set of faces (triangles) that contain a vertex x l in a triangulated surface S. For f ∈ F l (S), we let e l(f) denote the edge opposed to x l in f, positively oriented in f. With S′ = T α, we have
| (37) |
where a g = 1 if g ∈ F (S′) and a(g) = −1 if g ∈ F (S).
Now let us derive the variation of x (Tα) with respect to the initial momentum, α. We know that x (Tα) = x(1), where x and a evolve according to the system (7)
| (38) |
with x(0) = x (T) and a(0) = α (and γ kl, γ kl′ are short for γ(||x k−x l||2) and γ′(||x k−x l||2)). Now an infinitesimal variation α → α + δ α in the initial condition induces infinitesimal variations a + δ a and x + δ x over time, and the pair (δ x, δ a) obeys the following differential system, that can be obtained from a formal differentiation of (7):
| (39) |
| (40) |
with γ kl′′ = γ′′(||x k−x l||2).
One can rewrite it in the matrix form:
| (41) |
where with
| (42) |
Solving this system with initial condition δ x(0) = 0 and δ a(0) = δ α provides what we have denoted
| (43) |
One does not need to compute all the coefficients of the matrix d x (Tα)/d α using this equation in order to apply the transpose in (36). This is fortunate because this would constitute a computationally demanding effort given that this matrix is 3L by 3L with L large. The right hand side of (36) can be in fact computed directly using a single dynamical system, given by
| (44) |
where J(t) is defined in (39). If (44) is solved from time t = 1 to time t = 0 with η x(1) = ∂x U and η α(1) = 0, then
| (45) |
This is a simple consequence of the theory of linear differential systems (a proof is provided in the Appendix for completeness). Note that the matrix J(t) depends on the solution of (7) computed with initial conditions x(0) = x (T) and a(0) = α. To emphasize this dependency, we will denote it J(t) = J (T,α)(t) in the following.
Given this, we see that a variation α → α + δ α induces a first-order variation δ E of the energy given by
| (46) |
where the T-dot product is 〈δ α , α〉T = δ α · (ΓT α) and ΓT is the matrix formed with 3 by 3 blocs γ kl I d ℝ3.
We choose to operate the gradient descent with respect to this dot product and therefore choose a variation proportional to δ α = −(2α + ΓT −1 η α(0)). So, the algorithm to compute an optimal α is the following.
Algorithm 1 (MAE Step for Surface Template Estimation) —
This algorithm has to be applied N times (for all α k, k = 1,…, N) in the MAE step.
Remark 1 —
The matrix ΓT being typically very badly conditioned, we numerically compute ΓT −1 η α after adding a small positive number to the diagonal of ΓT. The inversion itself is computed using conjugate gradient.
4.3. M Step
There are many similarities between the M-step and the E-step variational problems, so that we will be able to only sketch the detail of the computation here. We need to minimize
| (47) |
with
| (48) |
Let us consider the variation of each term in the sum (fixing n, that we temporarily drop from the notation). Since
| (49) |
we can write
| (50) |
The function U being defined as before, we see that the derivative of the second term is given by applying the chain rule again, this time in the form
| (51) |
Like in the previous section, the transpose of the differential applied to the gradient of U can be computed by solving a dynamical system backward in time. In fact, it is the same system as with the variation in α, namely,
| (52) |
still initialized with η x(1) = ∂x(Tα) U and η α(1) = 0, but the relevant result now is η x(0). The gradient of is then
| (53) |
Once this is computed, the next step is to compute (reintroducing n in the notation)
| (54) |
This follows a similar procedure, using (44), with T 0 instead of T and μ instead of α. This requires solving
| (55) |
initialized with and η μ(1) = 0. The variation of associated to an infinitesimal variation of μ is then
| (56) |
We summarize the M step in the following algorithm.
Algorithm 2 (M-Step Algorithm for Surface Template Estimation) —
- (1)
For n = 1,…, N:
- (2)
Solve system (55) backward in time withand η μ(1) = 0.
(58) - (3)
Replace μ by μ − ϵ(μ + ΓT0 −1 η μ(0)/λ), ϵ being optimized with a line search.
4.4. Surface Template Estimation Algorithm
We finally summarize the surface template estimation algorithm:
Algorithm 3 (Surface Template Estimation) —
Having the hypertemplate T 0 and observed surfaces S (1),…, S (N), the goal is to estimate the template T. Let T, μ, α (1),…, α (N) denote the current estimation with initial guess T = T 0, μ = 0, α (n) = 0. Then, in the next iteration, update with the following steps:
With T fixed, apply Algorithm 1 to update each α (n), n = 1,…, N.
With α (n)'s fixed, apply Algorithm 2 to obtain a new value for μ.
Solve (7) initialized with the hypertemplate T 0 and the newly obtained μ to update the estimated template, T.
5. Result and Discussion
We applied the algorithm to surface data of human brain's caudate, thalamus, and hippocampus. All data are courtesy of Center for Imaging Science at Johns Hopkins University. Each surface has around 5–10 thousand triangle cells. We randomly chose one as the hypertemplate and the others as observed surfaces. In these experiments, we set λ = 1.0 and σ 2 = 1.0.
Figures 2 and 3 are the template estimation result for caudate and thalamus, respectively.
Figure 2.

Estimating the surface template from 9 caudate data. (a)–(i) observed surfaces. (j) is the hypertemplate. (k) is the result.
Figure 3.

Estimating the surface template from 9 thalamus data. (a)–(i) observed surfaces. (j) is the hypertemplate. (k) is the result.
We also applied the algorithm to 101 hippocampus surface data in the BIRN Project (Biomedical Informatics Research Network). In Figure 4, Panels (a)–(h) are 8 examples of the 101 observations. Panel (i) is the hypertemplate and Panel (j) is the estimated template.
Figure 4.

Estimating the surface template from 101 data. (a)–(h) are 8 examples out of 101 observed surfaces. (i) is the hypertemplate. (j) is the result.
The result is visually satisfying in the sense that the estimated template is found to agree with a qualitative representation of the population. For example, in the caudate experiment, the estimated template has an obviously narrower upper tip than the hypertemplate. This captures the population characteristic since most observed data have narrower upper tips. Notice that the obtained template does not look smoother than the rest of the population, as would typically yield template estimation methods that average over fixed parametrizations.
Figure 5 shows how the energy in (31) changes with the iteration in the caudate experiment. This confirms the effectiveness and convergence of the algorithm. One can see the energy drops quickly in the first twenty iterations, then gradually slows down. After the 35th iteration, the energy changes little and the estimated template remains stable.
Figure 5.

Energy change with the iteration.
In our model, the hypertemplate can be provided by an atlas obtained from other studies, although we here simply choose one of the surfaces in the population. Actually, as Figure 6 shows, different choices for the hypertemplate yield very similar results.
Figure 6.
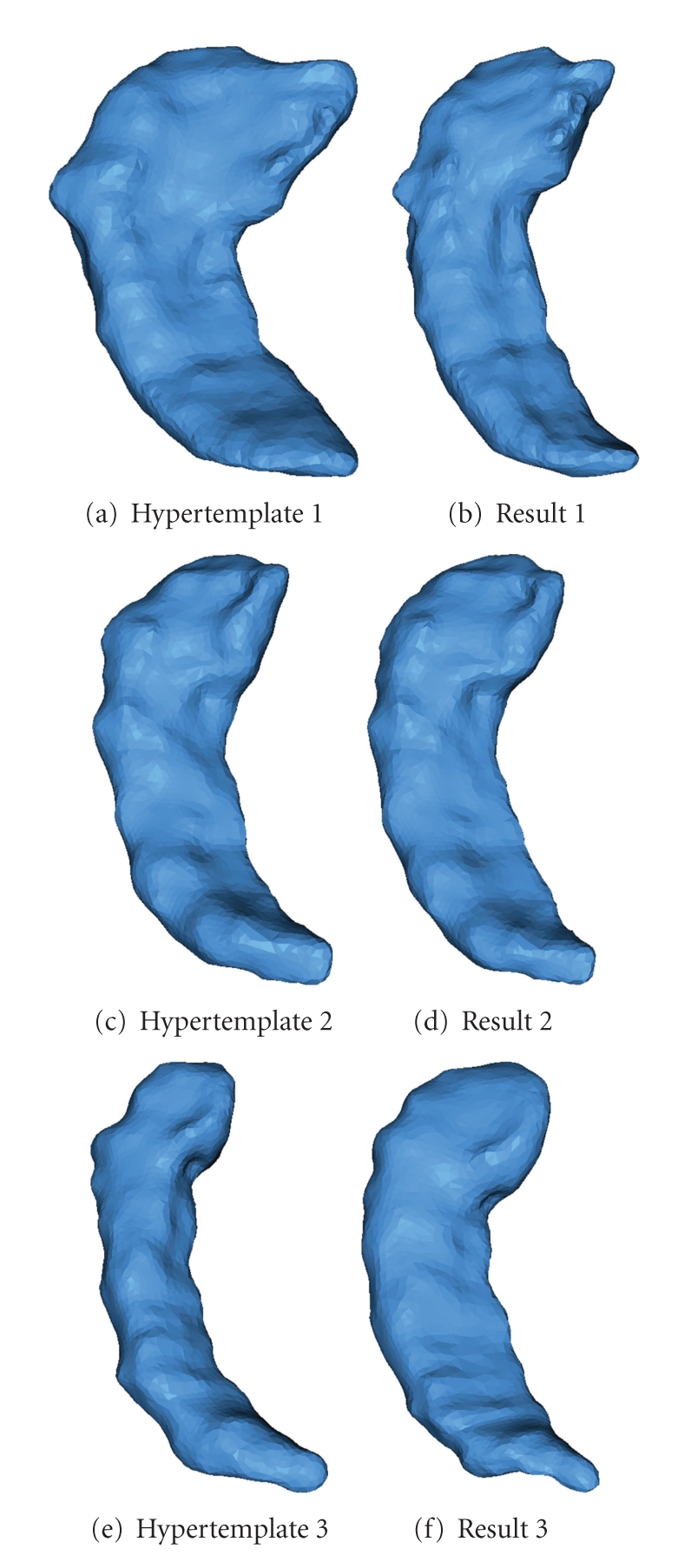
For the same observed population, we choose different surfaces as hypertemplate. The results only have minor differences.
6. Conclusion
In this paper, we have presented a Bayesian approach for surface template estimation. We have built, for this purpose, a generative statistical model for surfaces: the construction first applies a random initial momentum to the template surface, then assumes an observation process using test functions and noise. The template is assumed to be generated as a random deformation of a hypertemplate, completing the Bayesian model. We used a mode approximation EM scheme to estimate the surface template, and introduced for this purpose a novel surface matching algorithm optimizing with respect to the initial momentum. The procedure has been tested with caudate, thalamus, and hippocampus surface data, showing its effectiveness and convergence, and also experimentally proved to be robust to variations in the choice of the hypertemplate.
Acknowledgments
This paper is partially supported by R01-MH056584, R01-EB000975, R01-MH60883, P50-MH071616, P01-AG003991, P01-AG0262761, P41-RR015241, R24-RR021382, and NSF DMS-0456253.
Appendices
A. Proof of Proposition 1
Let us assume that L obs γ s = δ 0, that is, γ s is the Green Kernel of the operator L obs. This assumption implies, in particular, that γ s = γ obs. Given a smooth function f, denote
| (A.1) |
Define the vector space
| (A.2) |
Introduce the RKHS V with scalar product given by
| (A.3) |
Then f J can be identified to the orthogonal projection of f on V j, because r (obs) is the inverse of the Gram matrix (matrix of dot products) of (γ obs(·−z j), j ∈ J), which are the generators of V J, and
| (A.4) |
by assumption.
Now, let J m be a sequence of progressively finer grids with resolution ϵ m tending to 0 when m tends to infinity. We prove that ||f Jm−f||V → 0, for which it suffices to prove that ⋃V Jm is dense in V. This is equivalent to the fact that no nonzero g in V can be orthogonal to all the V Jm's. But g orthogonal to V Jm is only possible when, for all j ∈ J m,
| (A.5) |
Since the z j′s form an arbitrarily fine grid in V and functions in V are continuous, this implies g = 0.
So, f J → f in V, which implies, for example, pointwise convergence as soon as V is embedded in the set of continuous functions (that is, if γ obs is continuous). This directly implies Proposition 1 in the case γ s = γ obs, by taking f(x) = γ obs(x − y) for a given y.
Extensions of this result is when γ s is obtained by applying some linear operator, say A, to γ obs. One then has
| (A.6) |
and passing to the limit in the sum (for which one needs γ s ∈ V and A continuous on V), one gets .
B. Transposing Linear Differential Equations
We here justify the procedure described in Section 4, and prove the following fact: consider the solution, z(t) ∈ ℝp, of the ordinary differential equation
| (B.1) |
where J is a time-dependent operator (a p by p matrix). Then, for any u ∈ ℝp, we have
| (B.2) |
where η is the solution of the differential equation
| (B.3) |
with η(1) = u.
Let us prove this result. First remark that since z is the solution of a linear equation, it depends linearly on the initial condition, z(0). More precisely, let M(s, t) be the p by p matrix such that
| (B.4) |
and M(s, s) = I d ℝp. Then z(t) = M(0, t)z(0), and, obviously, η(0) = M(0,1)*u. Using the identity M(t, s)M(s, t) = I d ℝp, we obtain
| (B.5) |
so that ∂s M(s, t) = −M(s, t)J(s). Computing the transposed equation yields and taking t = 1
| (B.6) |
Thus, if η(s) = M(s,1)*u, we have η(1) = u and ∂s η = −J(s)*η as announced.
References
- 1.Durrleman S, Pennec X, Trouvé A, Ayache N. A forward modelto build unbiased atlases from curves and surfaces. In: Proceedings of the International Workshop on the Mathematical Foundations of Computational Anatomy (MFCA ’08); September 2008; New York, NY, USA. [Google Scholar]
- 2.Shen L, Farid H, McPeek MA. Modeling three-dimensional morphological structures using spherical harmonics. Evolution. 2008;63(4):1003–1016. doi: 10.1111/j.1558-5646.2008.00557.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Guimond A, Meunier J, Thirion J-P. Average brain models: a convergence study. Computer Vision and Image Understanding. 2000;77(2):192–210. [Google Scholar]
- 4.Mio W, Srivastava A, Joshi S. On shape of plane elastic curves. International Journal of Computer Vision. 2007;73(3):307–324. [Google Scholar]
- 5.Fletcher PT, Joshi S, Lu C, Pizer SM. Principal geodesic analysis for the study of nonlinear statistics of shape. IEEE Transactions on Medical Imaging. 2004;23(8):995–1005. doi: 10.1109/TMI.2004.831793. [DOI] [PubMed] [Google Scholar]
- 6.Le H, Kume A. The Fréchet mean shape and the shape of the means. Advances in Applied Probability. 2000;32(1):101–113. [Google Scholar]
- 7.Pennec X. Intrinsic statistics on riemannian manifolds: basic tools for geometric measurements. Journal of Mathematical Imaging and Vision. 2006;25(1):127–154. [Google Scholar]
- 8.Vaillant M, Miller MI, Younes L, Trouvé A. Statistics on diffeomorphisms via tangent space representations. NeuroImage. 2004;23(1):S161–S169. doi: 10.1016/j.neuroimage.2004.07.023. [DOI] [PubMed] [Google Scholar]
- 9.Beg MF, Khan A. Computation of average atlas using lddmmand geodesic shooting. In: Proceedings of the IEEE International Symposium on Biomedical Imaging; April 2006; Arlington, Va, USA. [Google Scholar]
- 10.Helm PA, Younes L, Beg MF, et al. Evidence of structural remodeling in the dyssynchronous failing heart. Circulation Research. 2006;98(1):125–132. doi: 10.1161/01.RES.0000199396.30688.eb. [DOI] [PubMed] [Google Scholar]
- 11.Joshi S, Davis B, Jomier M, Gerig G. Unbiased diffeomorphic atlas construction for computational anatomy. NeuroImage. 2004;23(supplement 1):S151–S160. doi: 10.1016/j.neuroimage.2004.07.068. [DOI] [PubMed] [Google Scholar]
- 12.Avants B, Gee J. Symmetric geodesic shape averaging and shape interpolation. In: Proceedings of the Computer Vision and Mathematical Methods in Medical and Biomedical Image Analysis, Workshops CVAMIA and MMBIA, vol. 3117; 2004; pp. 99–110. [Google Scholar]
- 13.Avants B, Gee JC. Geodesic estimation for large deformation anatomical shape averaging and interpolation. NeuroImage. 2004;23(supplement 1):S139–S150. doi: 10.1016/j.neuroimage.2004.07.010. [DOI] [PubMed] [Google Scholar]
- 14.Allassonnière S, Amit Y, Trouvé A. Towards a coherent statistical framework for dense deformable template estimation. Journal of the Royal Statistical Society. Series B. 2007;69(1):3–29. [Google Scholar]
- 15.Ma J, Miller MI, Trouvé A, Younes L. Bayesian template estimation in computational anatomy. NeuroImage. 2008;42(1):252–261. doi: 10.1016/j.neuroimage.2008.03.056. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Vaillant M, Glaunès J. Surface matching via currents. In: Proceedings of the 19th International Conference on Information Processing in Medical Imaging (IPMI ’05), vol. 3565; July 2005; Glenwood Springs, Colo, USA. [Google Scholar]
- 17.Beg MF, Miller MI, Trouvé A, Younes L. Computing large deformation metric mappings via geodesic flows of diffeomorphisms. International Journal of Computer Vision. 2005;61(2):139–157. [Google Scholar]
- 18.Arnol’d VI, Arnold VI, Vogtmann K, Weinstein A. Mathematical Methods of Classical Mechanics. Berlin, Germany: Springer; 1989. [Google Scholar]
- 19.Marsden JE, Ratiu TS. Introduction to Mechanics and Symmetry. Berlin, Germany: Springer; 1999. [Google Scholar]
- 20.Younes L. Shapes and Diffeomorphisms. Berlin, Germany: Springer; 2010. [Google Scholar]
- 21.Holm DD, Marsden JE, Ratiu TS. The Euler-Poincaré equations and semidirect products with applications to continuum theories. Advances in Mathematics. 1998;137(1):1–81. [Google Scholar]
- 22.Schaback R. Error estimates and condition numbers for radial basis function interpolation. Advances in Computational Mathematics. 1995;3(1):251–264. [Google Scholar]