

Abstract
Objectives
A common complaint of many older adults is difficulty communicating in situations where they must focus on one talker in the presence of other people speaking. In listening environments containing multiple talkers, age-related changes may be caused by increased sensitivity to energetic masking, increased susceptibility to informational masking (e.g., confusion between the target voice and masking voices), and/or cognitive deficits. The purpose of the present study was to tease out these contributions to the difficulties that older adults experience in speech-on-speech masking situations.
Design
Groups of younger, normal-hearing individuals and older adults with varying degrees of hearing sensitivity (n = 12 per group) participated in a study of sentence recognition in the presence of four types of maskers: a two-talker masker consisting of voices of the same sex as the target voice, a two-talker masker of voices of the opposite sex as the target, a signal-envelope-modulated noise derived from the two-talker complex, and a speech-shaped steady noise. Subjects also completed a voice discrimination task to determine the extent to which they were able to incidentally learn to tell apart the target voice from the same-sex masking voices and to examine whether this ability influenced speech-on-speech masking.
Results
Results showed that older adults had significantly poorer performance in the presence of all four types of maskers, with the largest absolute difference for the same-sex masking condition. When the data were analyzed in terms of relative group differences (i.e., adjusting for absolute performance) the greatest effect was found for the opposite-sex masker. Degree of hearing loss was significantly related to performance in several listening conditions. Some older subjects demonstrated a reduced ability to discriminate between the masking and target voices; performance on this task was not related to speech recognition ability.
Conclusions
The overall pattern of results suggests that although amount of informational masking does not seem to differ between older and younger listeners, older adults (particularly those with hearing loss) evidence a deficit in the ability to selectively attend to a target voice, even when the masking voices are from talkers of the opposite sex. Possible explanations for these findings include problems understanding speech in the presence of a masker with temporal and spectral fluctuations and/or age-related changes in cognitive function.
The primary auditory complaint of many older people is difficulty understanding speech in noisy situations. Numerous studies have documented this age-related decline in the ability to comprehend speech in the presence of a masker (e.g., Dubno, Dirks, & Shaefer, 1987; Plomp & Mimpen 1979). This research has demonstrated that older adults with presbycusis generally have greater difficulty understanding masked speech than do young, normal-hearing individuals. Although a portion of this problem is because of the filtering and distortion inherent in the aging cochlea (which leads to presbycusis), some data suggest that age-related changes in central auditory and/or cognitive functioning also influence speech understanding, as performance of older adults with relatively normal pure-tone thresholds is often less than optimal (e.g., Divenyi & Haupt, 1997; Helfer & Wilber, 1990; Tun, O’Kane, & Wingfield, 2002).
One type of interference that seems to be particularly detrimental to older listeners (at least as reported by these individuals) is that produced by competing talkers. In theory, a masker consisting of a small number of voices should produce less masking than a steady state noise as listeners can take advantage of brief fluctuations in the masker to reduce its efficiency (e.g., Festen & Plomp, 1990). However, the peripheral hearing loss that accompanies aging limits this advantage (e.g., Bronkhorst & Plomp, 1992; Carhart & Tillman, 1970; Hygge, Ronnberg, Larsby, & Arlinger, 1992; Moore, Glasberg, & Vickers, 1995; Peters, Moore, & Baer, 1998; Takahashi & Bacon, 1992). Age-related changes other than auditory threshold elevation also may contribute to a decreased ability to take advantage of spectral and/or temporal fluctuations in a masker (Dubno, Horwitz, & Ahlstrom, 2002, 2003; George, Festen, & Houtgast, 2006; Peters, et al., 1998; Stuart & Phillips, 1996).
Even though speech maskers have spectral and temporal fluctuations that can reduce their masking efficiency, there are instances where they actually are more detrimental than steady state interference. For example, Carhart, Tillman, and Greetis, (1969) documented situations where not only did the fluctuations in competing speech fail to produce release from masking, but the speech maskers actually caused more masking than noise. This occurs because competing speech has the potential to cause two types of masking: energetic and informational. Energetic masking is the traditional view of masking, in which the internal representation of the target is “covered up” by energy in the masker. With informational masking, the target speech is represented neurally at a peripheral level, and perhaps more centrally as well, but it is difficult to pull out or differentiate the target voice from the masker. Although steady state noise produces only energetic masking, under many circumstances competing speech leads to both energetic and informational masking (e.g., Arbogast, Mason, & Kidd, 2002; Brungart, 2001; Brungart, Simpson, Ericson, & Scott, 2001; Carhart, et al., 1969; Freyman, Balakrishnan, & Helfer, 2001; Freyman, Helfer, McCall, & Clifton, 1999). Informational masking often is a factor when there is confusion about which of two or more talkers is the “target” (that is, the one the listener is trying to understand). In general, informational masking is most likely to occur when the target and masker are similar to one another (e.g., when both a speech target and a speech masker are recorded from talkers of the same sex). A number of studies have demonstrated that both energetic and, in particular, informational masking can be reduced by spatially separating the target from the masker (e.g., Brungart & Simpson, 2002; Freyman, Balakrishnan, & Helfer, 2004; Freyman, et al., 1999, 2001; Freyman, Helfer, & Balakrishnan, 2005; Hawley, Litovsky, & Colburn, 1999) although the mechanisms leading to spatial separation advantage seem to differ between the two types of masking. Specifically, even when the head shadow and binaural interaction effects that lead to reductions in energetic masking are obscured by reflections, a spatial separation advantage still can be obtained when the competing sound produces informational masking (e.g., Brungart, Simpson, & Freyman, 2005; Freyman, et al., 1999; Kidd, Mason, Brughera, & Hartmann, 2005; Rakerd, Aaronson, & Hartmann, 2006).
Few studies have directly examined informational masking of speech in individuals with impaired hearing. Arbogast, et al. (2005) found less informational masking in a group of listeners with hearing loss varying in age from 21 years to 79 years, as compared to age-matched normal-hearing participants. They proposed that this result could be explained by the fact that the subjects with hearing loss needed to listen at such high signal-to-noise ratios that the masker and target speech were easy to differentiate (i.e., simply listening for the louder target message reduced informational masking). Alternatively, Arbogast, et al. also suggested that there may be an inverse relationship between the amount of energetic masking and the amount of informational masking, as has been shown in tonal informational masking tasks (e.g., Kidd, Mason, Brughera, & Chiu, 2003; Neff & Green, 1987; Oh & Lutfi, 1998). The results of Hornsby, Ricketts, and Johnson (2006) indicated that normal-hearing and hearing-impaired listeners yield similar amounts of increased masking when performance with a speech masker is compared to that obtained with speech-modulated noise. Group differences in their task could be attributed to either spectral variations between these two types of competition and/or degree of informational masking.
Only one study has directly examined energetic versus informational masking in speech recognition by older adults. Li, Daneman, Qi, and Schneider (2004) measured older adults’ ability to understand nonsense sentences recited by a female in the presence of a two-talker masker consisting of other female voices. Results of this study suggest equivalent amounts of informational masking in their older (age 63 to 75 years) and younger subjects as performance differences between the two participant groups could be explained by simply adjusting the S-N ratio by 2.7 dB for both speech and noise maskers. However, they temper this argument with the suggestion that it might be easier for older adults to ignore nonsense sentences (which were used as both target and masker in this study) than sentences with semantic information.
A number of studies have demonstrated that even for young, normal-hearing listeners, speech maskers that are meaningful produce more informational masking than those that cannot be understood (e.g., Freyman, et al., 2001). Because older adults rely more than younger adults do on top-down/cognitive processing in difficult listening situations (e.g., Pichora-Fuller, Schneider, & Daneman, 1995), the issue of the effect of understandability of the masker may be an especially important one to address in older individuals. Tun, et al. (2002) found that a semantically-meaningful distractor interfered with older adults’ memory to a greater extent than did word strings or a distractor spoken in a foreign language, although the type of distractor did not influence memory in their younger participants. Regression analyses of their results suggested that hearing, cognitive skills (visual executive functioning and processing speed), and age all contributed to subjects’ performance. This suggests that meaningful maskers may be especially detrimental for older adults.
Higher-level abilities undoubtedly play an important role when trying to understand one talker in the presence of competing speech. A number of age-related cognitive changes have the potential to adversely affect older adults’ ability to resolve such complex listening situations. A reduction in working memory capacity could limit older individuals’ ability to hold pieces of information for later processing (e.g., Zurif, Swinney, Prather, Wingfield, & Brownell, 1995). This type of information storage might be required to accurately decode a message in which parts are missing or distorted. Age-related change in executive function (e.g., Baddeley, 1996), which is responsible for allocating attentional resources, also is a likely contributor to problems understanding one person while inhibiting messages from other talkers (Tun, et al., 2002). In fact, there is ample evidence that aging brings about a reduced ability to ignore irrelevant information (e.g., Hasher & Zachs, 1988; Kausler, 1982; Wright & Elias, 1979) and/or difficulty discriminating relevant from irrelevant information (e.g., Plude & Hoyer, 1985).
The focus of the research presented in this paper is to better understand the degree to which (and why) older adults experience problems understanding speech in situations with more than one talker. This work is motivated by the large body of anecdotal and empirical evidence demonstrating that older adults, particularly those with hearing loss, have problems understanding speech that is masked by either noise or by other speech. Our aim is to better understand the relative contributions of energetic masking, informational masking, and higher-level cognitive capabilities (e.g., the ability to ignore a masker) to this deficit. To this end, we used a task in which the same subjects attended to a female talker reciting sentences in the presence of three types of maskers: a male two-talker (MTT) masker, a female two-talker (FTT) masker, and a wideband signal-envelope-modulated (SEM) noise. These data were compared to performance in the presence of a steady state speech-shaped noise. It was anticipated that our older subjects (who had high-frequency pure-tone thresholds ranging from normal to moderately elevated) would experience more difficulty than our younger subjects for all of these maskers. Of particular interest was comparison of group performance patterns. If relative group differences in speech recognition were greater for the three fluctuating maskers than for the steady state noise, it would suggest that the primary root of the problem in older listeners is a reduction in the ability to benefit from temporal gaps. If, however, age-related decline in selective attention was influencing performance, we would anticipate between-group performance differences to be larger for the (understandable) FTT and MTT maskers than for the noise maskers. If older adults experience greater susceptibility to informational masking, we would expect to see the largest group differences in situations where the target and masker are most confusable (i.e., in the presence of the FTT masker). Finally, this study also examined the influence of subjects’ ability to learn and differentiate the target voice from the masking voice, which could have an impact on how well listeners can understand one voice in the presence of other voices.
Materials and Methods
Subjects
Two groups of listeners (N = 12 per group) participated in this study. Each subject learned English as his or her first language. The younger subject group (11 women, 1 man) consisted of college-aged (mean age = 22.67 years) individuals with normal pure-tone thresholds (ANSI, 2004). Participants in the older group (9 women, 3 men) ranged in age from 61 to 81 years (mean age = 71.50 years). Pure-tone thresholds in the older subjects varied from normal hearing to moderate high-frequency hearing loss. A composite audiogram for the older subject group is shown in Figure 1. To participate in this study each subject was required to have an interaurally symmetric audiogram (thresholds within 15 dB between ears at each audiometric frequency) and bilaterally normal tympanograms. Each subject also was required to correctly identify at least 95% of the key words in a set of sentences presented in quiet at 65 dB SPL. None of the subjects in this study had participated in previous listening experiments using the same stimuli.
Fig. 1.
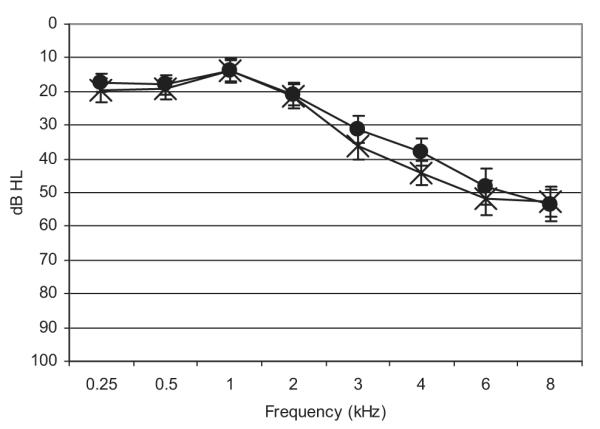
Composite audiogram from the older subjects. Error bars represent the standard error.
Stimuli
The target stimuli for this study consisted of a set of topic-based sentences used in previous speech-on-speech masking research (Helfer & Freyman, 2005). Each of these syntactically-simple sentences was related to one of 12 topics. Sentences had 3 one- or two-syllable key words used for scoring (a sample sentence in the food category is “The cherries in the bowl are sweet”). These sentences were originally video recorded from a female talker with no discernable regional dialect (see Helfer & Freyman, 2005 for details of the recording process). The stimuli were routed from the analog output of a video recorder (Sylvania VKC 242) to the sound card of a computer and were saved onto a computer hard drive. Using the CoolEditPro software package (Syntrillium Software, Phoenix, AZ) individual sentences were excised and saved in separate files. The sentences were then equated for rms (root-mean-squared) amplitude. The present study used only the audio portion of these stimuli.
Two other female talkers and two male talkers were recorded reciting a set of 40 neutral (i.e., unrelated to any of the topics) sentences for use as maskers. A two-talker masker was chosen for this study because it has the potential to produce a large amount of informational masking (e.g., Brungart, et al., 2001; Freyman, et al., 2004; Hall, Grose, Buss, & Dev, 2002; Yost, Dye, & Sheft, 1996). Each talker’s voice was recorded via a Shure Microflex MX100 microphone routed to a PreSonus Tubepre Pream-plifier, then to a Tascam DA-P1 Digital Audio Recorder. The masking sentences from each talker were downloaded to a computer hard drive where they were edited into individual sentence files. The individual sentence files for each talker were equated for rms amplitude and then were combined into a single file in which the sentences were concatenated to eliminate pauses. The combined sentence files from each of the two female masking talkers were then mixed (offset in time so that the two masking voices were reciting different sentences at any given moment), as were the sentences from the two male talkers, to produce 58-sec continuous streams of FTT and MTT maskers. The third masker (single-channel SEM noise) was produced by extracting the envelope of the FTT complex by full-wave rectifying and low-pass filtering the masker at 20 Hz with a three-pole Butterworth filter with a frequency-rejection slope of 12 dB/octave. The SEM noise was created by multiplying white noise with the extracted envelope. A Fast-Fourier Transform of this noise shows a flat spectrum with a 3 dB-down point at 7990 Hz. The fourth masker was a speech-shaped noise modeled after female speech (Byrne, et al., 1994). This masker (hereafter referred to as SSN) was created by spectrally shaping a sample of Gaussian noise with the appropriate filter characteristics. Spectral analysis of this noise showed a spectrum similar to that of our FTT masker, with the exception of a prominence in the region of the fundamental frequency in the actual speech masker that was not apparent in the noise spectrum. The SSN masker was used in a task that determined the extent to which subjects benefited from sentence topic (see below).
Each female masking talker also was recorded reciting 20 of the target sentences. These stimuli were used for the voice discrimination task described below.
Procedures
Subjects participated in two test sessions of approximately 1 to 1.5 hours in length. Testing took place in a double-walled IAC audiometric sound chamber. Calibration was performed before each test session using a sound-level meter placed in the position of the listener’s head. Target and masking stimuli were calibrated using a steady state speech-shaped noise having the same rms amplitude as the target sentences.
Speech recognition
Each subject contributed data for all combinations of the following factors: 3 maskers (FTT, MTT, and SEM noise) × 4 S-N ratios (−8, −4, 0, +4 dB) × 2 spatial conditions (F-F, or front-front, and F-RF, or front right-front). In the F-F condition, both target and masker were played from a Radio Shack Minimus 7 loudspeaker located directly in front of the subject at a height of 43 in from the floor and a distance of 48 in from the subject’s head. In the F-RF condition, the target was played from the front loudspeaker while the masker was presented from both the front loudspeaker and from a loudspeaker located 60° to the right of the subject, at the same distance and height as the front loudspeaker. In the F-RF condition the masker was presented with a 4-msec time lead favoring the right loudspeaker. Because of the precedence effect, listeners localized the masker well toward the right. This spatial arrangement leads to perceived spatial separation with minimal release from energetic masking in an anechoic chamber (e.g., Freyman, et al., 1999) as well as in the sound booth used in the present study (Helfer & Freyman, 2005). Hence, the potentially confounding effects of age- or hearing-loss-related reduction of spatial release from energetic masking were minimized by this paradigm.
The target sentences were played at a level of 65 dB SPL and the masker intensity was adjusted to produce the specified S-N ratio. Stimuli were played from a computer sound card, attenuated (TDT PA4), mixed (TDT SM3), routed to a headphone buffer (TDT HB5), amplified (TOA P75D), and then sent to the appropriate loudspeaker(s). Twenty sentences (with three scoring words per sentence) were presented in each of these 24 conditions. Condition order was randomized across subjects, as was assignment of sentences to condition.
Subjects participated in a brief practice session before each visit. The purpose of this practice session was to familiarize the participants with the task and to ascertain that each subject was able to meet the screening criterion of 95% accurate keyword recognition in quiet. During the practice session sentences were played in quiet and in the presence of the three types of maskers. At this time an informal check also was made to assure that all subjects localized the masker to the right during F-RF presentation.
On each trial the topic of the sentence was presented via text on a laptop computer screen immediately before and during stimulus presentation. The masker started approximately 1 sec before the target sentence, with masker and target ending simultaneously. Subjects responded by verbally repeating the target sentence and their responses were scored by a researcher using customized software.
One concern we had was the previously-reported finding that older adults rely on semantic information (such as the use of sentence topic) in adverse listening conditions to a greater extent than do younger listeners (e.g., Pichora-Fuller, et al., 1995). To identify any such confound in the present data, subjects repeated a set of 24 sentences in SSN at −8 dB S-N ratio in the F-F condition both with and without topic supplied. Half of the subjects heard this sentence list with topic on the first visit and without topic on the second visit; this order was reversed for the remaining subjects. In addition to allowing us to determine the extent to which subjects used knowledge of the sentence topic to aid in speech recognition, these data also let us compare performance in fluctuating maskers to that obtained in a steady state noise masker.
Voice discrimination
At the end of the second session each subject completed a task to determine whether they could differentiate the target talker’s voice from those of the female masking talkers. On a given trial subjects listened to the target talker and each of the female masking talkers reciting the same sentence sequentially. Using a 3-alternative forced choice paradigm with no feedback, participants indicated which interval they believed contained the target talker’s voice by clicking on a box on the screen of a laptop computer. Subjects heard 20 sets of sentences presented at a level of 65 dB SPL via the front loudspeaker.
Results
Speech Recognition
Percent-correct performance on the various measures (as well as means for age and degree of hearing loss) can be found in Table 1. Results for the speech recognition task are plotted in Figure 2. It can be observed that performance by the older listeners was poorer than that of the younger subjects for each listening condition, but to varying degrees. It is also clear (by comparing symbols between left and right panels of this figure) that spatially separating the target message from the same-sex FTT masker (i.e., the F-RF condition) improved performance substantially for both groups of participants, but did not affect performance when the masker was fluctuating noise or voices from the opposite sex.
TABLE 1.
Means and standard error (SE) values for demographic variables and test measures
| Younger Mean (SE) |
Older Mean (SE) |
|
|---|---|---|
| Age | 22.67 (1.09) | 71.50 (1.84) |
| HFPTA | 4.38 (.64) | 32.71 (3.36) |
| FTT F-F −8 S:N | 27.22 (3.38) | 8.33 (1.30) |
| FTT F-RF −8 S:N | 71.53 (1.83) | 31.11 (3.07) |
| MTT F-F −8 S:N | 86.11 (1.26) | 57.92 (2.28) |
| MTT F-RF −8 S:N | 88.75 (0.88) | 58.61 (3.03) |
| SEM F-F −8 S:N | 66.81 (2.10) | 54.72 (1.43) |
| SEM F-RF −8 S:N | 61.25 (1.71) | 49.86 (1.62) |
| FTT F-F −4 S:N | 70.97 (1.82) | 30.97 (2.68) |
| FTT F-RF −4 S:N | 88.33 (1.03) | 59.58 (2.85) |
| MTT F-F −4 S:N | 94.58 (0.57) | 79.58 (2.35) |
| MTT F-RF −4 S:N | 95.00 (0.53) | 83.19 (1.85) |
| SEM F-F −4 S:N | 85.00 (0.88) | 74.31 (1.57) |
| SEM F-RF −4 S:N | 79.58 (1.78) | 64.44 (1.84) |
| FTT F-F 0 S:N | 93.06 (0.63) | 73.06 (2.00) |
| FTT F-RF 0 S:N | 97.92 (0.28) | 86.39 (1.59) |
| MTT F-F 0 S:N | 97.92 (0.36) | 89.31 (1.77) |
| MTT F-RF 0 S:N | 98.61 (0.20) | 92.08 (1.13) |
| SEM F-F 0 S:N | 91.94 (1.34) | 89.58 (0.88) |
| SEM F-RF 0 S:N | 91.53 (1.15) | 83.89 (1.07) |
| FTT F-F +4 S:N | 98.47 (0.24) | 93.33 (1.40) |
| FTT F-RF +4 S:N | 98.19 (0.19) | 95.14 (0.77) |
| MTT F-F +4 S:N | 99.03 (0.19) | 95.28 (1.04) |
| MTT F-RF +4 S:N | 99.17 (0.22) | 95.69 (0.56) |
| SEM F-F +4 S:N | 95.83 (0.48) | 93.89 (0.58) |
| SEM F-RF +4 S:N | 94.58 (0.89) | 92.22 (0.62) |
| SSN F-F −8 S:N topic | 57.75 (3.97) | 33.91 (4.53) |
| SSN F-F −8 S:N no topic | 45.07 (3.83) | 23.61 (2.95) |
| Voice | 91.67 (7.45) | 75.42 (5.69) |
All values are in percent-correct except age (in years) and HFPTA (in dB HL). See text for a description of spatial conditions (F-F and F-RF). Voice refers to performance on the voice discrimination task.
HFPTA, average of better-ear pure-tone thresholds at 2, 3, 4, and 6 kHz; MTT, male two-talker masker; FTT, female two-talker masker; SEM, single-channel envelope-modulated noise; SSN, steady-state speech-shaped noise.
Fig. 2.

Performance of the older (upper panels) and younger (lower panels) subjects on the speech-on-speech masking task. F-F (left panels) represents scores obtained in spatially-coincident conditions; F-RF (right panels) are scores obtained with the target presented from the front loudspeaker and the masker presented from both the front and right loudspeakers with a 4-msec time delay favoring the right. MTT is a male two-talker masking complex; FTT is a female two-talker complex; SEM is single-channel signal-envelope modulated noise; SSN is a steady state speech-shaped noise. Error bars represent the standard error.
Data from each subject were converted to rationalized arcsine units (rau) before analysis to equalize error variance across the widely-ranging percent-correct scores (Studebaker, 1985). A repeated-measures Analysis of Variance (ANOVA) was completed with masker (FTT versus MTT versus SEM noise), spatial condition (F-F versus F-RF), and S-N ratio as within-subjects factors and subject group as a between-subjects factor. Significant main effects were found for all four factors (masker: F(2, 21) = 140.046, p < 0.001; spatial: F(1, 22) = 32.585, p < 0.001; S-N ratio: F(3, 20) = 331.884, p < 0.001; group: F(1,22) = 29.054, p < 0.001). The interaction between masker and group also was significant (F(2, 21) = 12.082, p < 0.001) as was the S-N × group interaction (F(3,20) = 11.552, p < 0.001) although the interaction between spatial condition and group was not significant (F(1,22) = 0.136, p = 0.716). The only higher-level interaction involving subject group that reached significance was the three-way interaction of masker × S-N × group (F(6, 17) = 8.497, p < 0.001). Results of this analysis confirmed that speech perception differences between groups varied with the type and amount of masking.
To further explore this pattern of results, additional analysis was completed comparing the size of the group differences in performance across the various conditions. As using a simple percent-correct difference would be confounded by the large absolute performance disparities between groups, we calculated relative difference scores. Data obtained at −8 dB S-N ratio and −4 dB S-N ratio were used in this analysis to minimize ceiling effects noted in the data collected at the other two S-N ratios. For each group, scores (in rau) from each subject were averaged across these two S-N ratios. The averaged group scores were used to derive relative group differences using the following formula (adapted from Sumby & Pollack, 1954):
The relative group differences are shown in Figure 3. It can be observed that relative group differences for the MTT masker are larger than those obtained for the other maskers, and relative group differences are smallest for the SEM noise. Hence, in relative terms, the largest difference between subject groups was obtained for a masker that had semantic content but was not necessarily confusable with the target voice. It should be noted, however, that the amount of relative benefit does depend on the precise point on the psychometric function that is used to derive benefit values.
Fig. 3.

Relative difference in group performance among the various listening conditions (see text for derivation of relative difference). The displayed relative difference indices were derived by averaging relative benefit (in rau) obtained at −8 and −4 dB S-N ratios for the MTT, FTT, and SEM maskers. The relative benefit value shown for the SSN noise was derived from −8 dB S-N ratio data only. MTT is a male two-talker masking complex; FTT is a female two-talker complex; SEM is single-channel signal-envelope modulated noise; and SSN is a steady state speech-shaped noise. F-F represents scores obtained in spatially-coincident conditions; F-RF are scores obtained with the target presented from the front loudspeaker and the masker presented from both the front and right loudspeakers with a 4-msec time delay favoring the right.
Our working assumption is that the F-F condition can produce both informational and energetic masking, whereas informational masking is released in the F-RF configuration as the subject no longer confuses the target with the masking voice(s). Neither group’s data showed evidence of informational masking from the MTT masker, as indicated by the lack of advantage from spatially separating the MTT masker from the target voice. As anticipated, there also was little benefit from spatially separating the SEM noise, a finding that replicates previous work showing similar performance for F-RF and F-F presentation modes in single-channel SEM noise (Freyman, et al., 1999). Both groups of subjects showed substantial spatial release from masking for the FTT masker. The amount of spatial separation advantage was approximately equal between the two groups. Hence, the present data suggest that our older subjects did not experience increased susceptibility to informational masking.
Scores obtained in steady state noise (measured only in the F-F condition at −8 dB S-N ratio) were significantly poorer for older than for younger listeners (F(1,22) = 13.968, p = 0.001 with topic supplied, F(1,22) = 21.590, p < 0.001 without topic). To examine the effect of temporal fluctuations in the masker, the difference in scores obtained in the SEM noise (at −8 dB S-N ratio in the F-F condition) and those found with the SSN masker (when topic was supplied) was compared across groups. Although the mean difference score for the older subject group was higher than that of the young subject group (20.81 percentage points versus 9.51 percentage points), this comparison (with the data transformed into rau) failed to reach statistical significance (F(1,22) = 3.251, p = 0.085).
The average amount of benefit from supplying topic (the difference between scores for no-topic versus topic trials in the presence of the SSN masker) was similar between groups (younger subjects: 11.23 percentage points, older subjects: 10.30 percentage points). This difference (analyzed using the rationalized-arcsine-transformed data) was not statistically significant (F(1,22) = 0.099, p = 0.755), suggesting that older and younger listeners were able to use topic to the same extent for speech recognition in the presence of steady state noise.
Voice Discrimination
All but two of the younger subjects performed with 100% accuracy on the voice discrimination task, with a group average of 91.67% correct. Several of the older adults had difficulty with this task, with a group mean of 75.42% correct. ANOVA on the voice discrimination data (in rau) revealed that this group difference was statistically significant (F(1,22) = 5.691, p = 0.026).
Correlations Among Measures
To examine connections between age, hearing loss, and test performance, Pearson r correlations were calculated for data (in rau) from the older subjects. To minimize possible ceiling effects, scores obtained in the most advantageous S-N ratio (+4 dB) were not used for this analysis. Data from the remaining three S-N ratios were averaged for each subject to yield six speech recognition scores (F-F and F-RF for each of the three maskers). An averaged metric of spatial separation advantage for the FTT masker (the difference between F-RF and F-F averaged across these three S-N ratios) also was computed for this analysis. The correlation matrix is shown in Table 2.
TABLE 2.
Pearson r correlations for the rationalized-arcsine-transformed data from older subjects
| Age | Voice | HFPTA | MTT F-F | MTT F-RF | FTT F-F | FTT F-RF | SEM F-F | SEM F-RF | Sepadftt | SSN F-F | Topben | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Age | — | −0.542 | −0.105 | −0.156 | −0.301 | −0.266 | −0.390 | −0.252 | −0.314 | −0.217 | −0.486 | −0.259 |
| Voice | — | 0.126 | −0.101 | 0.031 | 0.013 | 0.011 | 0.017 | 0.032 | 0.001 | −0.009 | −0.170 | |
| HFPTA | — | −0.764** | −0.574 | −0.365 | −0.602* | −0.645* | 0.070 | −0.379 | −0.424 | −0.120 | ||
| MTT F-F | — | 0.851** | 0.771** | 0.690* | 0.811** | 0.471 | 0.096 | 0.725** | 0.496 | |||
| MTT F-RF | — | 0.719** | 0.885** | 0.763** | 0.644* | 0.382 | 0.654* | 0.459 | ||||
| FTT F-F | — | 0.597* | 0.577* | 0.569 | −0.236 | 0.706* | 0.754** | |||||
| FTT F-RF | — | 0.613* | 0.377 | 0.638* | 0.645* | 0.466 | ||||||
| SEM F-F | — | 0.542 | 0.189 | 0.328 | 0.124 | |||||||
| SEM F-RF | — | −0.089 | 0.296 | 0.305 | ||||||||
| SepadFTT | — | 0.103 | −0.159 | |||||||||
| SSN F-F | — | 0.780** | ||||||||||
| Topben | — |
Voice is performance on the voice discrimination task. SSN F-F represents performance at −8 dB in the presence of steady-state noise with topic provided. Topben is the amount of benefit from topic (no topic-topic) in this same masker.
Significant beyond the 0.01 level;
Significant beyond the 0.05 level.
HFPTA, average of better-ear pure-tone thresholds at 2, 3, 4, and 6 kHz; MTT F-F and MTT F-RF, performance in the presence of the male two-talker masker for F-F and F-RF spatial conditions, respectively; FTT F-F and FTT F-RF, performance in the presence of the female two-talker masker for F-F and F-RF spatial conditions, respectively; SEM F-F and SEM F-RF, performance in the presence of single-channel signal-envelope-modulated noise for F-F and F-RF spatial conditions, respectively. Each of these values was calculated by averaging the rau-transformed data across −8, −4, and 0 dB S-N ratios. Sepadftt is the amount of spatial separation advantage (F-RF-FF) averaged across these three S-N ratios.
Among the current study’s older subjects, degree of high-frequency loss was negatively correlated with performance in the F-F condition for both the MTT masker and for the SEM noise, as well as in the F-RF condition for the FTT masker. Speech recognition ability was not significantly related to age within this study’s group of older subjects. Scores obtained in the F-F condition for the FTT masker were correlated with the amount of topic benefit. Performance with the steady state SSN masker was significantly associated with that obtained in the presence of both the FTT and MTT maskers, but not with scores found using the SEM noise. Amount of benefit from spatially separating the target speech from the masker was not significantly correlated with age or with degree of high-frequency hearing loss. Performance on the voice discrimination task was not significantly associated with subject age, high-frequency thresholds, or speech recognition performance. Taken as a whole, the correlation results suggest that degree of hearing loss does limit the speech recognition of older listeners. However, the impact of high-frequency hearing loss differs depending on the masker and the spatial configuration. Degree of high-frequency hearing loss was not associated with speech recognition ability in the most difficult listening condition (in the presence of the FTT masker in the F-F spatial configuration), suggesting that other factors (such as use of sentence topic) take on more importance in such situations. Moreover, scores on the voice discrimination task did not explain variance either in performance on our speech recognition task or benefit from spatial separation.
Discussion
Results of the present study objectify the often-cited complaint by older adults (especially those with high-frequency hearing loss) of difficulty in adverse listening conditions. The present data further suggest that the degree of age-related deficit is strongly influenced by the nature of the masking stimulus. Both groups of subjects experienced the greatest difficulty when the masker consisted of voices of the same sex as the target voice. However, in relative terms, the difference in performance between the younger and older listeners in this study was most substantial for a masker containing voices of the opposite sex from the target talker. Group differences were larger for either of these speech maskers than for SEM noise derived from the female masking complex or for scores obtained in a steady state noise.
The finding that the largest relative group difference was obtained for the different-sex MTT masker was somewhat surprising. Theories of age-related changes in inhibition posit that age differences should become larger as similarity between target and masker increases (e.g., Lustig & Hasher, 2001), which the present results support in terms of absolute differences but not in terms of relative differences. Moreover, the MTT masker was unlikely to produce substantial amounts of informational masking. Informational masking in speech recognition is currently conceptualized as arising from confusion between the target and masking voices and/or un-certainty regarding the target (e.g., Brungart, 2001; Freyman, et al., 1999). When there is little confusion regarding which speech signal is the target, informational masking is presumably minimized. Additional evidence that the MTT masker did not produce informational masking is found in the lack of a spatial separation advantage (i.e., there was no difference in speech recognition performance for this masker presented in the F-F versus in the F-RF spatial condition). Therefore, it is highly probable that our MTT masker produced little or no informational masking.
It is interesting to note that a similar pattern of results was reported recently by Humes, Lee, and Coughlin (2006). In their study, speech recognition differences between older and younger listeners (using a selective attention task with a single competing voice and monaural presentation of target and masker) were significant for opposite-gender stimuli but not when the target and masker were from same-sex talkers. Several other studies also have found that, although young normally-hearing listeners experience minimal problems when the masker is from the opposite sex as the target, older adults experience considerable difficulty on such tasks (Divenyi, Stark, & Haupt, 2005; Peters, et al., 1998; Tun & Wingfield, 1999; Wiley, et al., 1998). The picture that arises from this pattern of results is that situations where the target and masker are spoken by people of the same sex tend to be difficult for all listeners, but older adults experience a substantially greater deficit than younger listeners when the masking talkers are of the opposite sex.
The fact that older adults were at a greater disadvantage than younger adults when the masker was from opposite-sex talkers could be explained by an age-related reduction in the ability to ignore irrelevant stimuli containing semantic content. Therefore, one possible interpretation of the present results is a decrease in the ability to allocate attention and/or deselect information in a to-be-ignored masking stimulus, a finding that has been noted in numerous previous studies. For example, the data of Tun, et al. (2002) support the notion that although younger adults encode information from a masking speech signal more deeply than do older listeners, they are better able to suppress this information. The connection between performance in the presence of the FTT masker and the ability to benefit from sentence topic also can be taken as evidence of the importance of cognitive mediation in this type of task—subjects who were able to use sentence topic to a greater extent were better able to understand the target speech in the cognitively-demanding FTT conditions.
An alternative explanation for the results obtained in this study lies in the dynamic acoustic differences between the speech maskers and the SEM noise. Although the SEM noise retains the wideband temporal characteristics of the speech masker, it does not have the spectral fluctuations of speech. The performance patterns obtained here could be caused by an age- and/or hearing-loss-related decline in the ability to take advantage of the spectral fluctuations in the MTT and FTT maskers. Indeed, past research suggests that impaired frequency resolution concomitant with cochlear hearing loss can lead to a reduction in the use of spectral dips in a masker (e.g., Peters, et al., 1998). It should be noted that the two explanations (cognitive and spectral fluctuations) are not mutually exclusive, as both of these factors could simultaneously contribute to group differences in speech recognition. Additional research will be required to determine whether either (or both) of these explanations is accurate.
The present study’s results confirm that aging does not bring about an increased susceptibility to informational masking. When the target and masker are localized to different places in space, informational masking should not play a role in performance, as there is no longer confusion regarding which voice should receive greater attentional resources. As older and younger listeners in this study experienced very similar amounts of benefit from spatially separating the target from the FTT masker, the present results indicate that older and younger adults experience comparable susceptibility to informational masking. Moreover, the only condition that produced informational masking (F-F for the FTT masker) yielded only a modest relative group difference. The lack of an aging effect on susceptibility to informational masking is in agreement with the results of Li, et al. (2004) who also showed no apparent influence of senescence.
The high-frequency hearing loss experienced by many of our older subjects undoubtedly influenced the results. Several of the correlations between speech recognition in the presence fluctuating maskers and amount of high-frequency hearing loss were significant. As in many studies that compare the performance of young, normal-hearing listeners to that of older subjects with hearing loss, conclusions cannot be drawn regarding whether reduced speech recognition performance was caused by aging itself or by the peripheral hearing loss that accompanies aging. At first glance, it seems that our older subjects’ peripheral hearing loss was not restricting their use of temporal fluctuations in the maskers, as the difference in scores obtained in steady state noise versus SEM noise was actually greater for older participants than for younger subjects. This finding is at odds with that reported in numerous other studies (e.g., Bronkhorst & Plomp, 1992; Carhart & Tillman, 1970; Dubno, et al., 2003; Hygge, et al., 1992; Moore, et al., 1995; Peters, et al., 1998; Takahashi & Bacon, 1992). It is likely that this happened because of differences in the spectra between the steady state noise (which had a spectrum modeled after the long-term average of speech) and the SEM noise (which had a flat spectrum) used in the present study. Because the steady state noise had less high-frequency energy and these two maskers were equated for rms amplitude, the steady state noise had a greater amount of low-frequency energy than the SEM masker. Therefore, it is probable that our older subjects’ increased susceptibility to energetic masking was the primary reason why they had a larger performance differential for these two maskers, as compared to our young, normally-hearing listeners. However, the finding that relative group differences were smallest for the SEM noise suggests that increased susceptibility to temporal fluctuations cannot account entirely for the older adults’ difficulty in the presence of speech maskers.
The study described in this paper used a precedence effect task to achieve spatial separation of the target and masker. A question that must be addressed is whether age- or hearing-loss-related changes influenced our subjects’ ability to exploit the precedence effect, as past research suggests that certain aspects of the precedence effect may be impacted negatively by aging. Specifically, performance on tasks that measure the effect of an echo on localization judgments (e.g., Cranford, Andres, Piatz, & Reissig, 1993; Cranford, Boose, & Moore, 1990; Cranford & Romereim, 1992) seems to be influenced by age, whereas studies examining echo thresholds (e.g., Roberts, Besing, & Koehnke, 2002; Schneider, Pichora-Fuller, Kowalchuk, & Lamb, 1994) show only weak effects of senescence. The present data suggest little evidence of a decline in the precedence effect in our older subjects. All participants were able to localize the masker to the right upon F-RF presentation. Moreover, the spatial × group interaction in the ANOVA was nonsignificant, suggesting that older adults received as much benefit from spatially separating the target from masker as did younger adults. The present study was not designed to examine the precedence effect, but our data suggest that older adults retain the functional ability to exploit the precedence effect to obtain separation of signals, at least in this simple one-reflection paradigm.
A proportion of the older participants in the present study evidenced poorer incidental learning of and/or memory for voice characteristics. Performance on this voice discrimination task was significantly poorer in the older subject group, but was not associated with degree of high-frequency hearing loss. The present results agree with previous studies demonstrating age-related decrease in the encoding of voice characteristics (Naveh-Benjamin & Craik, 1996; Pilotti & Beyer, 2002; Sommers, 1999; Yonan & Sommers, 2000). Previous studies have used a resource-allocation model to explain age-related differences in perceptual encoding: as age-related hearing loss increases, additional resources must be expended for the understanding of speech, leaving fewer resources available for the encoding of indexical information (e.g., Pilotti, Beyer, & Yasunami, 2001; Schneider & Pichora-Fuller, 2000). As voice discrimination performance in the present study was not systematically related to high-frequency hearing loss, results suggest that an age-related factor other than peripheral hearing loss leads to reduced encoding of perceptual features, replicating a similar finding from Pilotti and Beyer (2002).
Performance on the voice discrimination task was not systematically related to speech recognition ability. Intuitively, proficiency in discriminating between a target voice and masking voices should be important in speech-on-speech masking tasks. It is possible that subjects did not need to use indexical information in the present task, as even in the F-F condition other cues (e.g., the delayed onset of the target relative to the maskers, other timing differences between target and maskers) could be used to segregate the speech signals. It is probable that indexical information would be more important in tasks that offer no other cues that allow the listener to segregate the target from the masker.
Summary
In summary, the present study’s results indicate that older adults (especially those with hearing loss) experience difficulty when the masker is speech, regardless of whether or not the masker produces informational masking. These individuals seem to be at a particular disadvantage (compared to younger adults) when the target speech and masking speech are from talkers differing in gender: when the target and masker are spatially coincident and are spoken by talkers of the same sex, all listeners (regardless of age) had difficulty but when the target and masker were from people of different sexes, older listeners demonstrated substantially greater problems with speech recognition as compared to younger subjects. Differences in speech recognition performance between older and younger listeners were largest at more adverse S-N ratios, suggesting that, in real-life communication, older adults may be at particular disadvantage when the message of interest is spoken softly or by a talker some distance away. Age-related hearing loss seems to play an important role in the ability to cope in speech-on-speech masking situations but cannot explain entirely the pattern of results. Reduction in selective attention, specifically in the ability to ignore a competing message and/or to allocate attention, could be limiting older adults’ performance on this task, as could a deficit in older listeners’ ability to use intervals of reduced masking caused by spectral fluctuations found in a speech masker. Finally, the current data suggest that some older listeners are less able to incidentally encode voice characteristics, although the impact of this deficit on speech perception remains undetermined.
Acknowledgment
We would like to thank Nate Whitmal, Ackland Jones, Beth Ann Jacques, and Sugata Bhattacharjee for their work on this project.
This research was supported by NIDCD 01625.
References
- ANSI . Specifications for audiometers, ANSI 3.6–2004. American National Standards Institute; New York, NY: 2004. [Google Scholar]
- Arbogast TL, Mason CR, Kidd GK., Jr. The effect of spatial separation on informational and energetic masking of speech. Journal of the Acoustical Society of America. 2002;112:2086–2098. doi: 10.1121/1.1510141. [DOI] [PubMed] [Google Scholar]
- Arbogast TL, Mason CR, Kidd GK., Jr. The effect of spatial separation on informational masking of speech in normal-hearing and hearing-impaired listeners. Journal of the Acoustical Society of America. 2005;117:2169–2180. doi: 10.1121/1.1861598. [DOI] [PubMed] [Google Scholar]
- Baddeley AD. Exploring the central executive. Quarterly Journal of Experimental Psychology: Human Perception and Performance. 1996;49a:5–28. [Google Scholar]
- Bronkhorst AW, Plomp R. Effect of multiple speech-like maskers on binaural speech recognition in normal and impaired hearing. Journal of the Acoustical Society of America. 1992;92:3132–3139. doi: 10.1121/1.404209. [DOI] [PubMed] [Google Scholar]
- Brungart D, Simpson B. The effects of spatial separation in distance on the informational and energetic masking of a nearby speech signal. Journal of the Acoustical Society of America. 2002;112:664–676. doi: 10.1121/1.1490592. [DOI] [PubMed] [Google Scholar]
- Brungart D, Simpson B, Freyman RL. Precedence-based speech segregation in a virtual auditory environment. Journal of the Acoustical Society of America. 2005;118:3241–3251. doi: 10.1121/1.2082557. [DOI] [PubMed] [Google Scholar]
- Brungart DS. Informational and energetic masking effects in the perception of two simultaneous talkers. Journal of the Acoustical Society of America. 2001;109:1101–1109. doi: 10.1121/1.1345696. [DOI] [PubMed] [Google Scholar]
- Brungart DS, Simpson BD, Ericson MA, Scott KR. Informational and energetic masking effects in the perception of multiple simultaneous talkers. Journal of the Acoustical Society of America. 2001;110:2527–2538. doi: 10.1121/1.1408946. [DOI] [PubMed] [Google Scholar]
- Byrne D, Dillon H, Tran K, Arlinger S, Wilbraham K, Cox R, et al. An international comparison of long-term average speech spectra. Journal of the Acoustical Society of America. 1994;96:2108–2120. [Google Scholar]
- Carhart R, Tillman TW. Interaction of competing speech signals with hearing loss. Archives of Otolaryngology. 1970;91:273–279. doi: 10.1001/archotol.1970.00770040379010. [DOI] [PubMed] [Google Scholar]
- Carhart R, Tillman T, Greetis R. Perceptual masking in multiple sound backgrounds. Journal of the Acoustical Society of America. 1969;45:694–703. doi: 10.1121/1.1911445. [DOI] [PubMed] [Google Scholar]
- Cranford JL, Andres MA, Piatz KK, Reissig KL. Influences of age and hearing loss on the precedence effect in sound localization. Journal of Speech and Hearing Research. 1993;36:437–441. doi: 10.1044/jshr.3602.437. [DOI] [PubMed] [Google Scholar]
- Cranford JL, Boose M, Moore CA. Effects of aging on the precedence effect in sound localization. Journal of Speech and Hearing Research. 1990;33:654–659. doi: 10.1044/jshr.3304.654. [DOI] [PubMed] [Google Scholar]
- Cranford JL, Romereim B. Precedence effect and speech understanding in elderly listeners. Journal of the American Academy of Audiology. 1992;3:405–409. [PubMed] [Google Scholar]
- Divenyi PL, Haupt KM. Audiologic correlates of speech understanding deficits in elderly listeners with mild-to-moderate hearing loss. I. Age and lateral asymmetry effects. Ear and Hearing. 1997;18:42–61. doi: 10.1097/00003446-199702000-00005. [DOI] [PubMed] [Google Scholar]
- Divenyi PL, Stark PB, Haupt KM. Decline of speech understanding and auditory thresholds in the elderly. Journal of the Acoustical Society of America. 2005;118:1089–1100. doi: 10.1121/1.1953207. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dubno JR, Dirks DD, Schaefer AB. Effects of hearing loss on utilization of short-duration spectral cues in stop consonant recognition. Journal of the Acoustical Society of America. 1987;81:1940–1947. doi: 10.1121/1.394758. [DOI] [PubMed] [Google Scholar]
- Dubno JR, Horwitz AR, Ahlstrom JB. Recovery from prior stimulation: masking of speech by interrupted noise for younger and older adults with normal hearing. Journal of the Acoustical Society of America. 2002;113:2084–2094. doi: 10.1121/1.1555611. [DOI] [PubMed] [Google Scholar]
- Dubno JR, Horwitz AR, Ahlstrom JB. Benefit from modulated maskers for speech recognition by younger and older adults with normal hearing. Journal of the Acoustical Society of America. 2003;111:2897–2907. doi: 10.1121/1.1480421. [DOI] [PubMed] [Google Scholar]
- Festen JM, Plomp R. Effects of fluctuating noise and interfering speech on the speech-reception threshold for impaired and normal hearing. Journal of the Acoustical Society of America. 1990;87:1725–1736. doi: 10.1121/1.400247. [DOI] [PubMed] [Google Scholar]
- Freyman RL, Balakrishnan U, Helfer KS. Spatial release from informational masking in speech recognition. Journal of the Acoustical Society of America. 2001;109:2112–2122. doi: 10.1121/1.1354984. [DOI] [PubMed] [Google Scholar]
- Freyman RL, Balakrishnan U, Helfer KS. Effect of number of masking talkers and auditory priming on informational masking in speech recognition. Journal of the Acoustical Society of America. 2004;115:2246–2256. doi: 10.1121/1.1689343. [DOI] [PubMed] [Google Scholar]
- Freyman RL, Helfer KS, Balakrishnan U. Spatial and spectral factors in release from informational masking in speech recognition. Acta Acustica United with Acustica. 2005;91:537–545. [Google Scholar]
- Freyman RL, Helfer KS, McCall DD, Clifton RK. The role of perceived spatial separation on the unmasking of speech. Journal of the Acoustical Society of America. 1999;106:3578–3588. doi: 10.1121/1.428211. [DOI] [PubMed] [Google Scholar]
- George ELJ, Festen JM, Houtgast T. Factors affecting masking release for speech in modulated noise for normal-hearing and hearing-impaired listeners. Journal of the Acoustical Society of America. 2006;120:2295–2311. doi: 10.1121/1.2266530. [DOI] [PubMed] [Google Scholar]
- Hall JW, Grose JH, Buss E, Dev MB. Spondee recognition in a two-talker masker and a speech-shaped noise masker in adults and children. Ear and Hearing. 2002;23:159–165. doi: 10.1097/00003446-200204000-00008. [DOI] [PubMed] [Google Scholar]
- Hasher L, Zacks RT. Working memory, comprehension, and aging: a review and a new view. Psychology of Learning and Motivation. 1988;22:193–225. [Google Scholar]
- Hawley ML, Litovsky RY, Colburn HS. Intelligibility and localization of speech signals in multi-source environment. Journal of the Acoustical Society of America. 1999;105:3436–3448. doi: 10.1121/1.424670. [DOI] [PubMed] [Google Scholar]
- Helfer KS, Freyman RL. The role of visual speech cues in reducing energetic and informational masking. Journal of the Acoustical Society of America. 2005;117:842–849. doi: 10.1121/1.1836832. [DOI] [PubMed] [Google Scholar]
- Helfer KS, Wilber LA. Hearing loss, age, and speech perception in reverberation and noise. Journal of Speech and Hearing Research. 1990;33:149–155. doi: 10.1044/jshr.3301.149. [DOI] [PubMed] [Google Scholar]
- Hornsby BWY, Ricketts TA, Johnson EE. The effects of speech and speechlike maskers on unaided and aided speech recognition in persons with hearing loss. Journal of the American Academy of Audiology. 2006;17:432–447. doi: 10.3766/jaaa.17.6.5. [DOI] [PubMed] [Google Scholar]
- Humes LE, Lee JH, Coughlin MP. Auditory measures of selective and divided attention in young and older adults using single-talker competition. Journal of the Acoustical Society of America. 2006;120:2926–2937. doi: 10.1121/1.2354070. [DOI] [PubMed] [Google Scholar]
- Hygge S, Ronnberg J, Larsby B, Arlinger S. Normal-hearing and hearing-impaired subjects’ ability to just follow conversation in competing speech, reversed speech, and noise backgrounds. Journal of Speech and Hearing Research. 1992;35:208–215. doi: 10.1044/jshr.3501.208. [DOI] [PubMed] [Google Scholar]
- Kausler DH. Experimental psychology and human aging. Wiley; New York: 1982. [Google Scholar]
- Kidd G, Jr., Mason CR, Brughera A, Chiu C-YP. Discriminating harmonicity. Journal of the Acoustical Society of America. 2003;114:967–977. doi: 10.1121/1.1587734. [DOI] [PubMed] [Google Scholar]
- Kidd G, Jr., Mason CR, Brughera A, Hartmann WM. The role of reverberation in release from masking due to spatial separation of sources for speech identification. Acta Acustica United With Acustica. 2005;91:526–536. [Google Scholar]
- Li L, Daneman M, Qi JG, Schneider BA. Does the information content of an irrelevant source differentially affect spoken word recognition in younger and older adults? Journal of Experimental Psychology: Human Perception and Performance. 2004;30:1077–1091. doi: 10.1037/0096-1523.30.6.1077. [DOI] [PubMed] [Google Scholar]
- Lustig C, Hasher L. Interference. In: Maddox GL, editor. The encyclopedia of aging. 3rd ed vol. 1. Springer; New York: 2001. pp. 553–555. [Google Scholar]
- Moore BCJ, Glasberg BR, Vickers DA. Simulation of the effects of loudness recruitment on the intelligibility of speech in noise. British Journal of Audiology. 1995;29:131–143. doi: 10.3109/03005369509086590. [DOI] [PubMed] [Google Scholar]
- Naveh-Benjamin M, Craik FIM. Effects of perceptual and conceptual processing on memory for words and voices: different patterns for young and old. Quarterly Journal of Experimental Psychology. 1996;49A:780–796. doi: 10.1080/713755640. [DOI] [PubMed] [Google Scholar]
- Neff DL, Green DM. Masking produced by spectral uncertainty with multi-component maskers. Perception and Psychophysics. 1987;41:409–415. doi: 10.3758/bf03203033. [DOI] [PubMed] [Google Scholar]
- Oh E, Lutfi RA. Nonmonotonicity of informational masking. Journal of the Acoustical Society of America. 1998;104:3489–3499. doi: 10.1121/1.423932. [DOI] [PubMed] [Google Scholar]
- Peters RW, Moore BCJ, Baer T. Speech reception thresholds in noise with and without spectral and temporal dips for hearing-impaired and normally hearing people. Journal of the Acoustical Society of America. 1998;103:577–587. doi: 10.1121/1.421128. [DOI] [PubMed] [Google Scholar]
- Pichora-Fuller MK, Schneider BA, Daneman M. How young and old adults listen to and remember speech in noise. Journal of the Acoustical Society of America. 1995;97:593–608. doi: 10.1121/1.412282. [DOI] [PubMed] [Google Scholar]
- Pilotti M, Beyer T. Perceptual and lexical components of auditory repetition priming in young and older adults. Memory and Cognition. 2002;30:226–236. doi: 10.3758/bf03195283. [DOI] [PubMed] [Google Scholar]
- Pilotti M, Beyer T, Yasunami M. Encoding tasks and the processing of perceptual information in young and older adults. Journal of Gerontology: Psychological Sciences. 2001;56B:P119–P128. doi: 10.1093/geronb/56.2.p119. [DOI] [PubMed] [Google Scholar]
- Plomp R, Mimpen AM. Speech-reception threshold for sentences as a function of age and noise level. Journal of the Acoustical Society of America. 1979;66:1333–1342. doi: 10.1121/1.383554. [DOI] [PubMed] [Google Scholar]
- Plude DJ, Hoyer WJ. Attention and performance: Identifying and localizing age deficits. In: Charness N, editor. Aging and performance. Wiley; New York: 1985. [Google Scholar]
- Rakerd B, Aaronson NL, Hartmann WM. Release from speech-on-speech masking by adding a delayed masker at a different location. Journal of the Acoustical Society of America. 2006;119:1597–1605. doi: 10.1121/1.2161438. [DOI] [PubMed] [Google Scholar]
- Roberts RA, Besing J, Koehnke J. Effects of hearing loss on echo thresholds. Ear and Hearing. 2002;23:349–357. doi: 10.1097/00003446-200208000-00010. [DOI] [PubMed] [Google Scholar]
- Schneider BA, Pichora-Fuller MK. Implications of perceptual deterioration for cognitive aging research. In: Craik FIM, Salthouse TA, editors. The handbook of aging and cognition. 2nd ed Lawrence Erlbaum; Mahwah, NJ: 2000. pp. 155–219. [Google Scholar]
- Schneider BA, Pichora-Fuller MK, Kowalchuk D, Lamb M. Gap detection and the precedence effect in young and old adults. Journal of the Acoustical Society of America. 1994;95:980–991. doi: 10.1121/1.408403. [DOI] [PubMed] [Google Scholar]
- Sommers MS. Perceptual specificity and implicit auditory priming in older and younger adults. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1999;25:1236–1255. doi: 10.1037//0278-7393.25.5.1236. [DOI] [PubMed] [Google Scholar]
- Stuart A, Phillips DP. Word recognition in continuous and interrupted broadband noise by young normal-hearing, older normal-hearing, and presbyacusic listeners. Ear and Hearing. 1996;17:478–489. doi: 10.1097/00003446-199612000-00004. [DOI] [PubMed] [Google Scholar]
- Studebaker GA. A “rationalized” arcsine transform. Journal of Speech and Hearing Research. 1985;28:455–462. doi: 10.1044/jshr.2803.455. [DOI] [PubMed] [Google Scholar]
- Sumby WH, Pollack I. Visual contribution to speech intelligibility in noise. Journal of the Acoustical Society of America. 1954;26:212–215. [Google Scholar]
- Takahashi GA, Bacon SP. Modulation detection, modulation masking, and speech understanding in noise in the elderly. Journal of Speech and Hearing Research. 1992;35:1410–1421. doi: 10.1044/jshr.3506.1410. [DOI] [PubMed] [Google Scholar]
- Tun PA, O’Kane G, Wingfield A. Distraction by competing speech in young and older listeners. Psychology and Aging. 2002;17:453–467. doi: 10.1037//0882-7974.17.3.453. [DOI] [PubMed] [Google Scholar]
- Tun PA, Wingfield A. One voice too many: adult age differences in language processing with different types of distracting sounds. Journal of Gerontology. 1999;54B:P317–P327. doi: 10.1093/geronb/54b.5.p317. [DOI] [PubMed] [Google Scholar]
- Wiley TL, Cruickshanks KJ, Nondahl DM, Tweed TS, Klein R, Klein BE. Aging and word recognition in competing message. Journal of the American Academy of Audiology. 1998;9:191–198. [PubMed] [Google Scholar]
- Wright LL, Elias JW. Age differences in the effects of perceptual noise. Journal of Gerontology. 1979;34:704–708. doi: 10.1093/geronj/34.5.704. [DOI] [PubMed] [Google Scholar]
- Yonan CA, Sommers MS. The effects of talker familiarity on spoken word identification in younger and older listeners. Psychology and Aging. 2000;15:88–99. doi: 10.1037//0882-7974.15.1.88. [DOI] [PubMed] [Google Scholar]
- Yost WA, Dye RH, Sheft S. A simulated cocktail party with up to three sound sources. Perception and Psychophysics. 1996;58:1026–1036. doi: 10.3758/bf03206830. [DOI] [PubMed] [Google Scholar]
- Zurif EB, Swinney D, Prather P, Wingfield A, Brownell H. The allocation of memory resources during sentence comprehension: evidence from the elderly. Journal of Psycholinguistic Research. 1995;24:165–182. doi: 10.1007/BF02145354. [DOI] [PubMed] [Google Scholar]