

Abstract
Objections to Darwinian evolution are often based on the time required to carry out the necessary mutations. Seemingly, exponential numbers of mutations are needed. We show that such estimates ignore the effects of natural selection, and that the numbers of necessary mutations are thereby reduced to about K log L, rather than KL, where L is the length of the genomic “word,” and K is the number of possible “letters” that can occupy any position in the word. The required theory makes contact with the theory of radix-exchange sorting in theoretical computer science, and the asymptotic analysis of certain sums that occur there.
Keywords: mutations, natural selection, geometric distribution
The 2009 “Year of Darwin” has seen many welcome tributes to this great scientist, and reaffirmations of the validity of his theory of evolution by natural selection, though this validity is not universally accepted. One of the main objections that have been raised holds that there has not been enough time for all of the species complexity that we see to have evolved by random mutations. Our purpose here is to analyze this process, and our conclusion is that when one takes account of the role of natural selection in a reasonable way, there has been ample time for the evolution that we observe to have taken place.
The Calculations
Biological evolution is such a complex process that any attempt to describe it precisely in a way similar to the description of the dynamic processes in physics by mathematical methods is impossible. This fact does not mean, however, that arbitrary models of biological evolution are allowed. Any allowable model has to reflect the main features of evolution. Our main aims, discussed below, are to indicate why an evolutionary model often used to “discredit” Darwin, leading to the “not enough time” claim, is inappropriate, and to find the mathematical properties of a more appropriate model.
Before doing so we take up some other points. Evolution as a Darwinian-Mendelian process takes place via a succession of gene replacement processes, whereby a new “superior” gene arises by mutation in the population and, by natural selection, steadily replaces the current gene. (We use here the word “gene” rather than the more technically accurate “allele”.) It has recently been estimated (1) that a newborn human carries some de novo 100–200 base mutations. Only about five of these can be expected, on average, to arise in parts of the genome coding for genes or in regulatory regions. In a population admitting a million births in any year, we may expect something on the order of five million such de novo mutations, or about 250 per gene in a genome containing 20,000 genes. There is then little problem about a supply of new mutations in any gene. However only a small proportion of these can be expected to be favorable. We formalize these considerations in the calculations below.
We now turn to the inappropriate evolutionary model referred to above concerning the fixation of these genes in the population. The incorrect argument runs along the following lines: Consider the replacement processes needed in order to change each of the resident genes at L loci in a more primitive genome into those of a more favorable, or advanced, gene. Suppose that at each such gene locus, the argument runs, the proportion of gene types (alleles) at that gene locus that are more favored than the primitive type is K-1. The probability that at all L loci a more favored gene type is obtained in one round of evolutionary “trials” is K-L, a vanishingly small amount. When trials are carried out sequentially over time, an exponentially large number of trials (of order KL) would be needed in order to carry out the complete transformation, and from this some have concluded that the evolution-by-mutation paradigm doesn’t work because of lack of time.
But this argument in effect assumes an “in series” rather than a more correct “in parallel” evolutionary process. If a superior gene for (say) eye function has become fixed in a population, it is not thrown out when a superior gene for (say) liver function becomes fixed. Evolution is an “in parallel” process, with beneficial mutations at one gene locus being retained after they become fixed in a population while beneficial mutations at other loci become fixed. In fact this statement is essentially the principle of natural selection.
The paradigm used in the incorrect argument is often formalized as follows: Suppose that we are trying to find a specific unknown word of L letters, each of the letters having been chosen from an alphabet of K letters. We want to find the word by means of a sequence of rounds of guessing letters. A single round consists in guessing all of the letters of the word by choosing, for each letter, a randomly chosen letter from the alphabet. If the correct word is not found, a new sequence is guessed, and the procedure is continued until the correct sequence is found. Under this paradigm the mean number of rounds of guessing until the correct sequence is found is indeed KL.
But a more appropriate model is the following: After guessing each of the letters, we are told which (if any) of the guessed letters are correct, and then those letters are retained. The second round of guessing is applied only for the incorrect letters that remain after this first round, and so forth. This procedure mimics the “in parallel” evolutionary process. The question concerns the statistics of the number of rounds needed to guess all of the letters of the word successfully. Our main result is
Theorem 1.
The mean number of rounds that are necessary to guess all of the letters of an L letter word, the letters coming from an alphabet of K letters, is
[1] with β(L) being the periodic function of log L that is given by Eq. 7 below. The function β(L) oscillates within a range which for K≥2, is never larger than .000002 about the first two terms on the right-hand side of Eq. 7.

For example, if we are using a K = 40 letter alphabet, and a word of length 20,000 letters, then the number of possible words is about 1034,040, but our theorem shows that a mean of only about
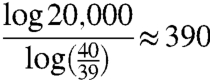 |
rounds of guessing will be needed, where each round consists of one pass through the entire as-yet-unguessed word.
The central feature of this result lies in the logarithmic terms in the above expression. Even if L is very large, log L is (for values of L arising in practice in any genome) in practice manageable. The inappropriate arguments referred to above lead to the value 1034,040, and arise because of the incorrect “in series” rather than the correct “in parallel” implicit assumption about the nature of genetic evolution.
We have chosen the numerical values in this example to reflect the biological evolutionary process. The value 20,000 represents the number of gene loci in the genome at which replacement processes are to take place. The value K = 40 is arrived at by using the value 250 found above for the number of de novo mutations per gene locus per year and a rough estimate that only one mutation in 10,000 is selectively favored over the resident gene type. In practice further modifications are needed to the calculations since, because of stochastic events, only a proportion of selectively favored new mutations become fixed in a population.
However, the force of our result does not depend on the numerical values that one assigns to K and L. The fact is that with the parallel model, i.e., taking account of natural selection, the number of rounds of mutations that are needed to change the complete genome to its desirable form are only about K log L, instead of the hugely exponential KL which would result from the serial model.
The Analysis
The probability that the first letter of the word will be correctly guessed in at most r rounds of guessing is
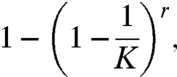 |
so the probability that all L letters of the given word will be guessed correctly in 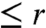 rounds is
rounds is
 |
Thus the mean number of rounds that will be needed to guess all of the letters of the word is
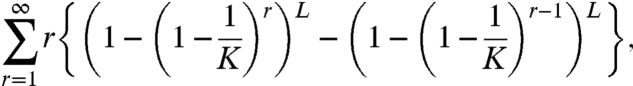 |
which is simply the mean of the maximum of L independently and identically distributed (iid) geometric random variables.
This infinite sum can be transformed into a finite sum because
 |
Consequently the mean number of rounds needed to guess all L letters is
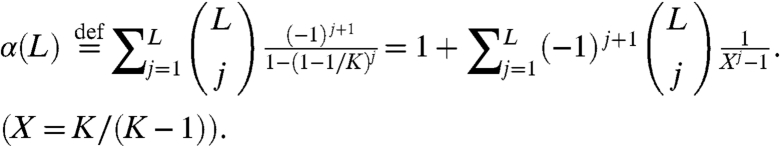 |
[2] |
The appearance of this latter sum in the current context is somewhat surprising. It is one which is well known to theoretical computer scientists, and it arises there in connection with radix-exchange sorting.
To find the asymptotic behavior of this sum, we note that the behavior of the following sum is known, and can be found in Exercise 50 of section 5.2.2 of (2):
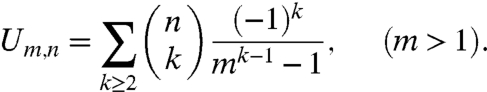 |
[3] |
The result in (2), due to N.G. deBruijn, is that
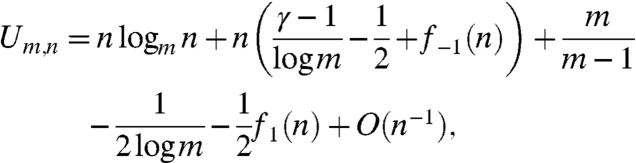 |
[4] |
where γ = .57721.. is Euler’s constant and
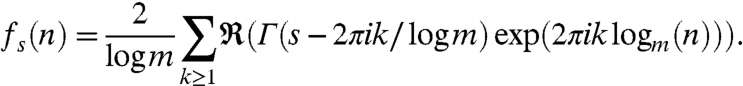 |
These fs(n)’s are bounded functions, and in fact, they are evidently periodic of period 1 in log m(n).
To relate our sum to Knuth’s, we have
We note in passing that our argument shows that the mean of L iid geometric random variables is, quite generally, simply related to the quantities Um,n, which had previously been encountered in connection with radix-exchange sorting, and whose (notoriously difficult) asymptotic behavior had been found as a result of that connection.
After doing the subtraction we obtain
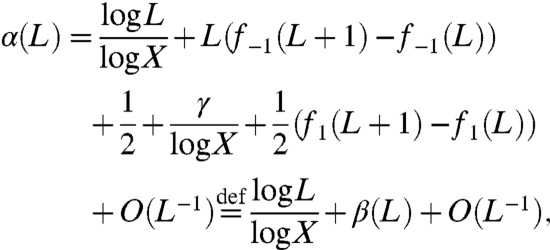 |
[5] |
where again X = K/(K - 1), and we have written
 |
[6] |
But we have
 |
whereas
Therefore for β(L) in Eq. 5 we can take
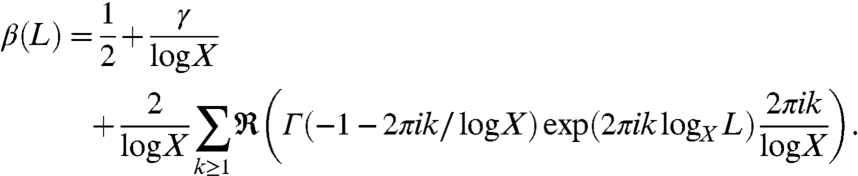 |
[7] |
Therefore the mean number of rounds that are necessary to guess all of the letters of an L letter word, the letters coming from an alphabet of K letters, is given exactly by Eq. 2, and is asymptotically
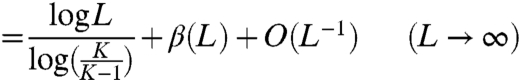 |
[8] |
with β(L) being the periodic function of period 1 in log XL that is given by Eq. 7 and X = K/(K - 1). If terms of order L-1 and the small constant 0.000002 mentioned in the statement of the theorem are ignored, Eq. 8 becomes simply
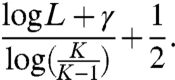 |
[9] |
We conclude with a comment on the oscillatory behavior of this mean, as revealed by the exact expression in Eq. 7. In probability theory the asymptotic behavior of a maximum of several iid random variables is often found by “sandwiching” the discrete random variable between two continuous random variables whose asymptotic behavior is known. In the case of geometric random variables the appropriate continuous random variables to be used for this purpose have negative exponential distributions. This sandwiching procedure has been used frequently and leads to the expression (9), but does not lead to the more precise oscillatory behavior exhibited in the expression Eq. 7.
Footnotes
The authors declare no conflict of interest.
This article is a PNAS Direct Submission.
References
- 1.Yali Xue, et al. Human Y chromosome base-substitution mutation rate measured by direct sequencing in a deep-rooting pedigree. Curr Biol. 2009 Sep 15;19:1453–1457. doi: 10.1016/j.cub.2009.07.032. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Knuth DE. Sorting and Searching. Vol 3. Reading MA: Addison-Wesley; 1973. The art of computer programming. [Google Scholar]