

Abstract
How our perceptual experience of the world remains stable and continuous in the face of continuous rapid eye movements still remains a mystery. This review discusses some recent progress towards understanding the neural and psychophysical processes that accompany these eye movements. We firstly report recent evidence from imaging studies in humans showing that many brain regions are tuned in spatiotopic coordinates, but only for items that are actively attended. We then describe a series of experiments measuring the spatial and temporal phenomena that occur around the time of saccades, and discuss how these could be related to visual stability. Finally, we introduce the concept of the spatio-temporal receptive field to describe the local spatiotopicity exhibited by many neurons when the eyes move.
Keywords: vision, eye movements, spatiotopicity, remapping
1. Introduction
How a stable representation of the world is created from the output of mobile sensors is an old and venerable problem that has fascinated many scientists, including Descartes, Helmholtz, Mach and Sherrington, and indeed goes back to the eleventh century Persian scholar Abū ‘Alī al-Hasan ibn al-Hasan ibn al-Haytham (Latinized ‘Alhazen’): ‘For if the eye moves in front of visible objects while they are being contemplated, the form of every one of the objects facing the eye … will move on the eyes as the latter moves. But sight has become accustomed to the motion of the objects' forms on its surface when the objects are stationary, and therefore does not judge the objects to be in motion’ [1]. Although the problem of visual stability is far from solved, tantalizing progress has been made over the last few years.
2. Spatiotopicity
Because of the spatial selectivity of individual neurons, the response of primary visual cortex forms a map [2], similar in principle (except for magnification distortions) to that imaged on the retinae. This retinotopic representation, which changes completely each time the eyes move, forms the input for all further representations in the brain. So a major question is how this retinotopic map becomes transformed into the spatiotopic representation of world that we perceive, anchored in stable real-world coordinates. Electrophysiological studies have shown that neurons in specific areas of associative visual cortex, including V6 [3] and ventral intraparietal area (VIP) [4], show the spatiotopic selectivity that we would expect to exist, with spatial tuning in real-world coordinates, invariant of gaze. Indeed, even primary cortex V1 is modulated to some extent by gaze [5], particularly the peripheral representation [6]. What about humans?
(a). Psychophysical evidence for spatiotopicity in humans
If there exist in the brain neural mechanisms tuned in spatiotopic coordinates, then these mechanisms should respond to stimuli in particular positions in space, irrespective of retinal projection. Melcher & Morrone [7] used a summation technique to investigate the spatiotopicity of neural mechanisms tuned to motion. They took advantage of the long integration time for motion stimuli [8] and showed that observers can integrate motion signals that are individually below threshold (and hence not perceived when presented alone) across saccades. Two periods of coherent horizontal motion, each lasting 150 ms, were presented successively, separated by sufficient time to allow for a saccadic eye movement between them. On some blocks of trials, subjects saccaded across the stimulus between the two motion intervals, while on others they maintained fixation above or below the stimulus. As figure 1 shows, sensitivity was similar in the two conditions, twice that for a single motion stimulus, showing that the two motion signals were integrated across the saccade—but only when the two motion signals were in the same position in space, indicating that the brain must use a mechanism anchored to external rather than retinal coordinates. Not only was trans-saccadic integration possible, it occurred for longer durations than in fixation, 1.5 s as opposed to nearly 3 s. Importantly, the methodology excluded cognitive strategies or verbal coding as the motion signals presented before and after the saccade were each well below the conscious detection threshold: only by summating the two signals could motion be correctly discriminated. Interestingly, not all psychophysical studies show evidence for a spatiotopic representation of motion. For example, the motion aftereffect seems to be anchored mainly in retinotopic coordinates [9–11].
Figure 1.

Integration of motion signals across saccades. (a) Illustration of experimental setup. Subjects fixated above a field of dynamic random noise. When cued they saccaded to a target below this field. (b) Timeline of stimuli presentation. For two brief (150 ms) moments, a proportion of the dots moved coherently, both leftwards or rightwards. One motion signal was presented before the saccade, the other after. Subjects had to identify the direction of motion in two-alternative forced choice. (c) Coherence sensitivity (inverse of minimum coherence to support reliable direction discrimination) as a function of separation of the two pulses. The dashed line shows the sensitivity for just a single motion signal. Presenting two stimuli with brief separation, either in fixation or straddling saccades, doubles the sensitivity, implying total integration. The integration continues for longer when interspersed with a saccade than when presented during fixation (filled symbols indicate fixation and open symbols indicate saccade).
Other experiments have shown that many attributes, such as form [12] and position [13], are integrated over saccades. This contrasts sharply with older claims that information is not integrated across saccades [14,15]. We (and many others) suggest that the reason for this is that the information integrated from one fixation to the next is information about features—such as motion and form—not light elements or pixels. As other reviews in this issue point out [16–21], the process is not like ‘sticking postage stamps on a tailor's dummy’, integrating detailed ‘snapshots’ within a trans-saccadic buffer with an external metric. This would suggest that very early stages of analysis, such as V1, should not be spatiotopic, while higher centres responsible for motion and form (including middle temporal (MT) and medial superior temporal (MST) areas) might be spatiotopic. These areas would integrate motion signals or other elaborated information across saccades, not the detailed description of the individual dots that generated the motion signals.
Spatiotopicity has also been studied with vision aftereffects: after inspecting for some time a specific stimulus, such as a slanted grating, a vertical grating presented to the same position will appear to be slanted in the other direction (see [22]). Melcher [23] adapted this technique to study spatiotopicity. His subjects adapted to various stimuli, then made a large saccade before presenting the test stimulus either in the same (spatiotopic) position as the adaptor, or a different, control position. He observed partial spatiotopic adaptation for orientation, form and face perception, pointing to the existence of spatiotopically encoded neural mechanisms for these attributes. On the other hand, contrast aftereffects did not transfer across saccades at all, whether in the same spatial position or not. More recent experiments suggest that colour adaptation is spatiotopic [24]. Interestingly, the perception of event time is also subject to adaptation [25], and this adaptation has been shown to be almost entirely spatiotopic [9]. The clear implication is that low-level descriptive details of images such as local contrast are not integrated across saccades but high-level descriptions, such as orientation, form, time and colour are built up over saccades.
(b). Physiological evidence for spatiotopicity in humans
Functional magnetic resonance imaging has also indicated the existence of spatiotopic coding in human cortex, in lateral occipital area (LO) [26], an area involved in the analysis of objects, in VIP [27], a multi-sensory area and in MT+ [28]. We [29,30] have studied spatiotopicity of visual cortex by measuring blood oxygen level-dependent (BOLD) responses to random-dot motion stimuli presented to various positions while subjects maintained fixation at one of three different gaze directions (see inset to figure 2). In our first study [30], we reported that area MT, heavily involved in the perception of motion, showed a clear selectivity in external rather than retinal coordinates, whereas primary cortex V1 was retinotopically selective.
Figure 2.

BOLD response amplitudes for area MT for one hemisphere of an example subject as a function of the spatiotopic stimulus coordinates (0 is screen centre), during (a) passive fixation and (b) the high-load attentional task. The responses are colour-coded by fixation (red −8°, black 0°, blue +8°: fixation indicated by the dotted coloured lines). In the passive viewing the responses at all three fixations line up well, consistent with spatiotopic selectivity; with foveal attention they are clearly displaced in the direction of gaze, and become retinotopic. The inserts at right show by colour-code how the ‘spatiotopicity index’ of voxels in the region is dependent on attention. During passive fixation, most of MT is blue (spatiotopic), but when the subject performed the attention-demanding foveal task these voxels became strongly retinotopic (red/yellow code). The index was similar to that used by Gardner et al. [31]. It is the difference of the squared residuals differences in response amplitude for the three fixation conditions when they are in a spatiotopic alignment (residS) and retinotopic alignment (residR), normalized by the sum of the squared residuals 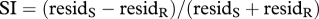 .The index is constrained between −1 (full spatiotopicity) and +1 (full retinotopicity).
.The index is constrained between −1 (full spatiotopicity) and +1 (full retinotopicity).
More recently, we repeated the experiment under two conditions: passive viewing (as before), where subjects simply maintained fixation (but were free to attend to the motion stimuli), and a dual-task attentive condition, where they performed a demanding detection task at the fovea [29]. Figure 2 shows preliminary data from one example subject. BOLD responses of motion area MT are plotted against the position of the stimulus (in screen coordinates) for three different fixation conditions. The responses at different fixations are strong for both the attention-to-fovea and passive-viewing conditions. However, there is an enormous difference in their spatial selectivity: in the passive-viewing condition the responses were similar for all fixations, tuned spatiotopically; but when attention was concentrated at the fovea, the responses become displaced in the direction of gaze, clearly retinotopic.
From responses like those of figure 2, we calculated a spatiotopicity index for each voxel (see figure 2 caption), which varies from –1 (blue in figure 2) for perfect spatiotopicity to +1 (yellow) for perfect retinotopicity. The insets show how the spatiotopicity of voxels in MT in the same subject are affected by attention. With passive fixation most of the region shows a clearly spatiotopic response. But performing the attention-demanding foveal task causes these same voxels to become retinotopic. This effect—spatiotopicity with passive viewing that becomes retinotopic when attention is confined to the fovea—occurred not only in area MT, but also areas MST, LO and V6. However, primary and secondary cortex, V3, V3a and VP showed mainly retinotopic responses in both conditions. Interestingly, the peripheral field of V1 also contained some spatiotopic voxels, consistent with Durand et al.'s report in behaving monkey [6]. This result is consistent both with a report by Gardner et al. [31], who claimed that visual cortex is retinotopic rather than spatiotopic, and with our previous report [30], claiming the opposite: in our study subjects were free to attend to the stimuli (and for one experiment were required to attend to the stimuli), while the subjects of Gardner et al. maintained attention at the fovea.
Attention is known to modulate BOLD responses in many areas, including V1 and associative cortex, particularly the dorsal pathway [32–36]. Directing attention to the fovea boosts the response to stimuli near the attended target, while suppressing that to irrelevant stimuli distant from the attended location. The effect of attention can even reshape and shift the receptive fields (RFs) of single cells in monkey's MT [37] and in human V1 [38]. Is attention also instrumental in building spatiotopic selectivity? Evidence shows that attention can be allocated in retinal and spatiotopic coordinates [39,40] and could be an important mechanism mediating spatiotopic coding [41,42]. This raises the fascinating possibility that attention is an integral part of spatiotopicity. As it is well known that there exists a close link between attention and eye movements, it is not unreasonable that the two should work together in the creation of spatial maps. There is much evidence that only attended objects are remapped (e.g. [43]), and several other chapters in this issue highlight the importance of attention in visual stability and remapping, particularly Wurtz et al. [44] and Mathôt & Theeuwes [45].
How may attention affect the spatial tuning of BOLD responses? One of the more successful models of attentional effects is the normalization model of Reynolds & Heeger [46], which predicts the reshaping and shift of RFs of single cells in monkey's MT [37]. However, attention away from the fovea, or towards the stimulus, is not in itself sufficient to generate spatiotopicity. To obtain spatiotopic tuning from a normalization model, a gaze signal must contribute to the normalization factor, together with attention. In other words, attention should bind with gaze direction to generate a new functional entity that is spatiotopic. Interestingly gain changes contingent on gaze position (termed ‘gain fields’ [47,48]) have been described in much of associative visual cortex. To date, no one has investigated whether gain field mechanisms are under attentional control, but it does not seem unreasonable that they should be.
The BOLD response of many areas of parietal, temporal (including MT) and frontal cortex [32–36,49], implicated in control of action, is clearly modulated by attention, even in the absence of visual stimuli [50,51]. Areas that are clearly implicated in eye movement control, like frontal eye field (FEF) and lateral intraparietal area (LIP) [52,53], are also very clearly involved with attention. And attention is anchored to motor programmes [54]: it is possible that the interaction between motor and attentional signals could yield a selectivity in external space.
Our results suggest that head-centred coding is more common in dorsal areas, which are implicated in action. Our studies on perceptual mislocalization have suggested that the action system seems to update spatial maps much later than the perceptual system [55,56]. Perhaps the updating of craniotopic maps takes time, but leads to more robust coding of information, explaining the resistance of the action system to saccadic mislocalization [57–59]. The perceptual system, on the other hand, may not always operate with a complete map anchored in external coordinates, and in some cases may be more efficient to operate on retinotopic coordinates.
3. Remapping of transient stimuli at the time of saccades
As the reviews in this issue make clear, visual stability is almost certainly a complex process involving many neural mechanisms. Spatiotopic maps are certainly involved, but it is unlikely that these are the sole mechanism implicated in keeping the world stable. These maps are unlikely to constitute detailed representations of the whole world, but probably only items of importance, those that attract attention: a form of saliency map. Furthermore, a map of this sort must take time to compute, probably too long for rapid online interaction with the world. Most researchers now agree that besides the existence of spatiotopicity, transient processes that occur around the time of saccades are important for stability. Psychophysical studies have described a myriad of robust and at times bizarre perceptual effects to brief peri-saccadic stimuli: some (but not all) stimuli are suppressed; stimuli are poorly localized, shifted in the direction of the saccade, and also compressed in space; and stimuli are delayed and compressed in time.
Some of these phenomena have obvious functional correlates. For example, the very specific suppression of low-frequency, luminance-modulated stimuli could serve to dampen motion perception [60–62]. The eyes move very quickly during saccades, up to 600° s−1, which smears-out much detail in the high- and mid-spatial frequency range, but the visual system can still resolve very low spatial frequencies associated with this large-field fast motion [63]. Under normal circumstances motion of this sort is most disturbing; but during saccades it is suppressed, reflected not only in raised thresholds, but also in that the motion itself is less salient, less disturbing [60,64]. There is good evidence from imaging studies for suppression at various levels of the visual system, during both saccades and blinks [65–67]. Suppression is also observed in many areas of the monkey’s visual system, particularly the motion areas MT and MST [68,69]. This suppression may reflect suppression in the superior colliculus, which responds to these low frequencies, feeds to area MT and is suppressed during saccades [70].
Suppression clearly plays an important role in reducing the sense of motion that the moving eyes would otherwise elicit. But suppression alone is not sufficient to account for stability and continuity of perception across saccades; even with the sense of motion damped, perception still has to link together images that are displaced on the retina. Another phenomenon, probably related to stability, is that stimuli briefly presented at the time of saccades are mislocalized. Matin et al. [71], Bischof & Kramer [72], Honda [73,74] and Mateeff [75] showed that stimuli presented within 50 ms of saccadic onset are not seen veridically, but mislocalized in the direction of the saccade. The explanation for these data was that they reveal the action of a corollary discharge signal that compensates for the change in eye position, a signal that does not follow the exact dynamics of the eye motion, but starts to act before the eyes actually move, producing the shift in perceived position of stimuli flashed briefly peri-saccadically.
However, as is often the case in neuroscience, the story is not so simple. Most early studies measured mislocalization of stimuli flashed to the same spatial position. However, more recent studies [76,77] showed that the magnitude—and indeed the sign—of mislocalization depend strongly on spatial position. Mislocalization is not always in the direction of the saccade—as ‘compensation’ theories would expect but, under most experimental conditions, towards the saccadic target. The net result is a strong peri-saccadic compression of the visual field, as shown in figure 3a: stimuli flashed to the left of the saccadic target (for a rightward saccade) are seen displaced rightwards, while stimuli flashed beyond it are displaced leftwards, in all cases towards the saccadic target. Indeed all stimuli flashed between −10° and +20°−30° of visual space are all seen near the saccadic target at +8°. This displacement clearly cannot result from the simple addition of a single ‘efference copy’ vector to the retinal eccentricity signal.
Figure 3.
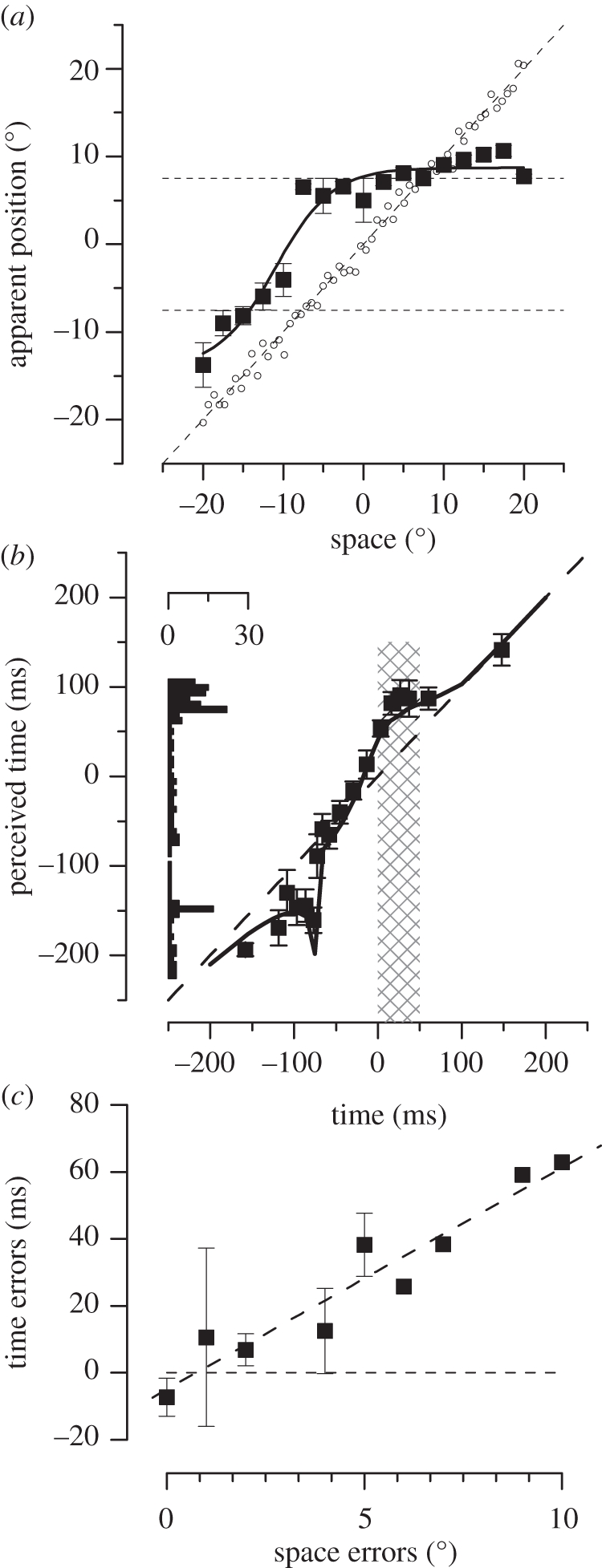
Spatial and temporal effects of saccades. (a) Perceived position of stimuli briefly flashed just before a saccadic eye movement. All stimuli are seen as displaced towards the saccadic target, resulting in a massive compression of space: all stimuli falling between −10 and +20° were seen at +7°. (b) Perceived time of stimuli presented around the time of saccades. Time perception is not veridical during saccades, but shows a similar compression towards saccadic landing. (c) Temporal against spatial mislocalization for experiments for trials in which subjects were required to localize objects in both space and in time. The errors correlate highly with each other (R2 = 0.92).
The compression is very real, causing multiple objects straddling the saccadic target to collapse down to a single bar. We displayed on the screen a variable number of vertical bars, ranging from zero to four, and asked subjects to report how many they saw. The square symbols of figure 4a show the number of bars reported as a function of time relative to saccadic onset, for the condition where there were actually four bars displayed. The data show clear evidence of compression, following a tight timecourse around saccadic onset. The bars were coloured and sharply defined, stimuli that were not suppressed. Indeed, no errors occurred when one bar was displayed (triangle symbols), nor were there false alarms when no bars were displayed (filled circles).
Figure 4.

Saccadic compression of space and time at the time. (a) A number of bars, varying randomly from zero to four, were presented at random positions around saccadic target, and the subject reported how many she saw. Open symbols refer to trials when there were four bars present, triangles to trials with one bar and filled circles to catch trials with none. Zero and one were reported correctly, but four bars were all compressed together as one when presented near saccadic onset. (b) Perceived duration as a function of presentation time, relative to saccadic onset. The stimulus pair were separated by 100 ms, but perceived as separated by 50 ms when presented near saccadic onset.
When the same experiments (localization or reporting bar number) were performed under conditions of ‘simulated saccades’ (by moving a mirror rapidly to mimic a saccade), the results were quite different [76]: very few errors were made in detecting bar number, and no compression was observed in localization. This, and the fact that the timecourses of peri-saccadic compression are so tight, suggests that they are driven by an extra-retinal signal, or corollary discharge, but that this is not simply an addition of a vector.
The phenomenon of saccadic compression has now been replicated in many laboratories, under various conditions, and shown to be robust [78–81]. Interestingly, compression does not work at the level of details, or ‘pixels’, but at the level of features. For example, squares are displaced towards the saccadic target, but they do not become thinner, changing to rectangles [82–84]. Also, information about features such as colour remains, even when different coloured bars are compressed to the same point in space [85]. This is reminiscent of the nature of trans-saccadic integration, which clearly operates at the level of features rather than fine detail.
4. Function of compression?
So what may be the function of peri-saccadic compression, and peri-saccadic displacement in general?—or what visual processes may it reflect? Most studies of saccadic mislocalization report the systematic errors, the systematic biases of localization. Recently, however, we [86] have shown that peri-saccadically vision is not only biased, but also very imprecise. In a two alternative forced choice procedure, subjects reported whether a bar flashed peri-saccadically appeared to the left or right of one flashed some time before the saccade. These data yield psychometric functions (best fit cumulate Gaussians) like those of figure 5, whose median (50% point) estimates the bias of the judgement, and width (s.d.) reflects the precision. During fixation, visual localization is both accurate and precise: but peri-saccadically, localization becomes inaccurate—with a systematic bias towards the saccadic target—and imprecise, reflected by the broad curve. The bias is consistent with the many other studies showing localization errors, with non-forced choice techniques such as naming. But this is the first study to show that the precision for localization is also affected, about 10 times worse during saccades than in fixation (figure 5a).
Figure 5.

Localization of visual and auditory stimuli, during fixation and saccades. (a) Subjects were required to report in forced choice which of two bars seems to be more rightward, one presented in fixation, the other peri-saccadically (open squares). Filled grey squares show the results when both were presented in fixation. During saccades the curve is displaced—reflecting a bias in judgements—and broader—reflecting a reduction in precision. (b) Results for localization of visual bars (open squares), auditory click (open circles) and audio-visual bar-clicks (filled triangles). The audio-visual results show both less bias and improved precision, suggesting that during saccades auditory signals are as reliable as visual signals.
As a further test of visual precision, we investigated how visual and auditory stimuli combined during saccades. Under normal conditions, when sight and sound are in conflict, vision wins: the so-called ventriloquist effect. The dominance of vision has been well explained by the popular Bayes-based model of optimal, reliability-based integration: as vision is the more reliable (precise) sense, it is given a much higher weight than audition when the two are combined [87]. However, when the reliability of vision is reduced by blurring the stimulus, audition can dominate. We measured localization of audio-visual stimuli presented at the time of the saccade, taking advantage of the fact that saccades have no effect on auditory localization, either accuracy or precision. The audio-visual results are shown by the triangular symbols of figure 5b: these stimuli are mislocalized in the direction of the saccades, but far less than the purely visual stimuli. The curves are also steeper, reflecting improved precision for the combined audio-visual signals, compared with either vision during saccades, or auditory localization.
These data clearly show that vision relaxes its precision for spatial localization at the time of saccades, to the point where visual localization is as poor as auditory localization. This would seem to be strongly linked to compression. If all stimuli presented over a wide range of positions are compressed to a single position, it follows that precision would be lost. But why should this occur, and how is it related to stability? As discussed above, and in other reviews of this issue, trans-saccadic integration of features seems to be important for stability. How does the system decide what is appropriate to integrate? One criterion for integration could be spatial coincidence (in external space) before and after the saccade. But if the corollary discharge signal is only a coarse signal, as many suspect, or the saccades themselves are slightly off target, the pre- and post-saccadic images will not line up exactly. So it makes sense to relax the reliability of the positional information of features (probably only salient features) at the time of saccades, allowing for integration of stimuli that may not coincide precisely after the saccade. There is evidence in this direction. Peri-saccadic mislocalization varies from individual to individual, and correlates strongly with eye velocity: individuals with faster saccadic velocities show more compression than do those with slower saccadic velocities [88]. The reason for the correlation is far from certain, but it known that it is not related to the faster retinal motion. It seems reasonable to assume that higher saccadic velocities are associated with lower reliability in localization, around the time of saccades, and hence the need of a stronger compression.
We are currently performing experiments to verify our hypothesis, measuring fusion and separation of stimuli presented before and after saccades. Note that this idea is similar to that of Deubel and colleagues (e.g. [89]), except they assume that the alignment is only for the saccadic landing point, while we make no such assumption and believe it affects all salient features in the visual field.
5. The effect of saccades on time
One of the more fascinating psychophysical discoveries of recent times is the demonstration that saccades not only cause a shift and compression of space, but also affect time perception in a very similar way. Like space, time becomes both displaced and compressed around the time of the saccades. As figure 4b shows, a pair of peri-saccadic stimuli, actually separated in time by 100 ms, appear to be separated by only 50 ms when presented near a saccade [90]. The compression follows a similar timecourse to that for spatial compression (the curve is broader only because the stimulus spans 100 ms). Not only are pairs of stimuli temporally compressed, single stimuli are severely mislocalized in time [91]. Figure 3b shows how apparent time (measured with auditory markers) becomes distorted around the time of saccades. Stimuli near saccadic onset were delayed by up to 50 ms, resulting in a gross distortion of the perceptual timeline. The curve flattens out considerably during the saccade, so all stimuli presented during that period are perceived at the same time, after the eye has landed in its new fixation. The histogram on the left shows the frequency of stimuli appearing at a particular time (assuming a uniform distribution in real time). The effect of the saccade is to accumulate stimuli towards the beginning of the new fixation.
The peri-saccadic change in timing is robust, and at certain critical times it can cause pairs of stimuli to appear to be inverted in time [90]. The inversion in time can be predicted quantitatively from the saccade-induced distortions [91]. At very particular times, about 70 ms before saccadic onset, the first of two stimuli is accelerated with respect to other times, causing it to ‘overtake’ the second and arrive in consciousness first.
Saccades affect both space and time, and do so in the same way. The timecourses of mislocalization (when corrected for stimulus duration) are very similar. Binda et al. [91] asked subjects to localize flashed stimuli in space, and also in time (compared with an auditory marker) in the same experiment. Figure 3c plots the temporal mislocalization against the spatial mislocalization. The two are very strongly correlated, explaining 92 per cent of the variance. It is clear that saccades affect not just time, but space–time.
6. Neurons with ‘shifting receptive fields’
Neurons in many visual areas show clear saccade-related changes to their RF properties. In some areas, such as areas V6 [3] and VIP [4] there exist neurons with spatiotopic RFs, tuned to external not retinal space, providing a plausible neural substrate for a stable spatiotopic map. But this behaviour seems to be the exception, rather than the rule. In a landmark paper [92], it was reported that RFs of many visual neurons in area LIP change at the time of saccades, shifting in the direction of the saccade (figure 6a,b). This result has proven robust, and has been replicated in many other visual areas including superior colliculus, FEFs, area V3 and even, to a less extent, in V1 (see review of Wurtz et al. [44]).
Figure 6.

Spatio-temporal transformation of RFs at the time of saccades. (a,b) Illustration of ‘classical’ RF during fixation (a, light blue) and displacement to ‘future’ RF just before saccades (b, pink). (c,d) Example responses of an FEF neuron to stimuli presented in the classical RF (light blue), future RF (pink) or an irrelevant position (grey), either during fixation (c) or just prior to the saccade (d). The responses to the future RF are delayed with respect to the classic RF. (e) Cartoon drawn from data of Wang et al. [99] reporting the response of an LIP neuron. All responses are aligned to the saccadic onset (bottom trace in black, illustrated in external space), and sorted by time from saccadic onset (shown in the ordinate). Irrespective of the time of stimulation, all spikes tend to arrive at the same time. (f) Spatio-temporal RF of the neuron (in retinal space), defined as the region of confusion in space–time that gives rise to the same spiking pattern. As the eye movement (illustrated by the icon above, in external coordinates) changes the retinal position, a transient flash delivered to the pink circle (future RF) before the saccade will be fused with a flash delivered to the light-blue circle (classical RF) after the saccade by a neuron with the oriented RF in space–time as illustrated by the colour-coded plot. This spatio-temporal RF is oriented in space–time along the trajectory of the retinal motion created by the saccade, and, therefore, effectively stabilizes transiently the image on the retina.
Other reviews (especially [44]) describe how the RFs of many neurons in many cortical areas shift before saccades are executed, so they respond to the region of space that will be brought into view by the saccade, but do this before the eyes actually move. This behaviour is particularly evident in areas LIP and FEF, but has been reported in many areas including superior colliculus, V3 and even V1 and V2 (e.g. [93–95]).
It is tempting to jump immediately to the conclusion that the shifting RFs reflect neural mechanisms that lead to spatiotopicity, shifting the retinal images around so they can slot into a spatiotopic map. There is only one problem with this reasoning: the shift is in the wrong direction to compensate for the eye movement. The shift in the RFs of LIP and other areas is in the same direction as the saccade, while compensation for saccade-induced image shifts needs to go in the opposite direction. If the head moves rightwards, to maintain fixation at a given point the eye must move leftwards. Similarly, if the eyes move 10° rightward, the compensation must be leftwards. Suppose a neuron in LIP has a ‘classical RF’ centred at location 0 (straight ahead). Spatiotopicity requires that this neuron maintains its selectivity to location 0 in external space after the movement has occurred. But the physiology suggests that just before the movement, the RF shifts to a location in the same direction of the saccade, +10° to the right. The eyes then move 10° rightwards, so the RF (in external space) is now at +20°, twice as distant from the spatiotopic location as would have occurred by the eye movement alone! The tuning of the cell presumably returns then to its ‘classical’ location (in retinal space), but it is far from clear why the anticipatory shift, that seems to exacerbate the problem, should occur at all.
Many modellers glide over the problem, either ignoring (or pretending to ignore) the fact that the sign is wrong for their model, or recognizing the conflict and concluding that these RFs do not create spatiotopicity, but serve other stability-related functions, such as comparing pre- and post-saccadic responses. For example, Mathôt & Theeuwes [45] believe that the ‘anticipatory RF shift allows neurons to take a ‘sneak peak’ at the location which will be brought into the RF’. Similarly, Wurtz et al. [44] suggest that ‘comparing the activity in the RF after the saccade to the activity in the future RF before the saccade is a potential mechanism that might underlie the perception of visual stability’. Similar ideas have been expressed by Nakamura & Colby [93], Kusunoki & Goldberg [96] and Melcher & Colby [42]. Heiser & Colby [97] have suggested a further role that updating activity in LIP could be used to generate accurate eye movements towards targets of interest.
We [91] believe that the key to the mystery is that saccades have profound psychophysical consequences not only for the perception of space but also for the perception of time, and the two cannot be considered independently. The temporal dynamics of remapping is also interesting, as shown in figure 6. Figure 6a,b schematize the concept of the ‘future RF’. Suppose that during normal fixation a neuron has a RF selective to a region directly below the fovea. In the moments just prior to the monkey making a saccade to the right, while the eyes are still fixating the red spot, the RF shifts rightward to what is termed the future RF. Typical responses of an example FEF cell to stimulation in these two regions are shown in figure 4c,d [98]: during normal fixation the cell responded only to stimuli in the ‘RF’ (blue), while peri-saccadically it responded best to the future RF (pink). But what is interesting is that the latencies of the responses are quite different, those of the future RF being much longer. Similar results can be seen in recordings in LIP [96] and other visual areas [93].
Figure 6e is a cartoon of a space–time plot of the response of an LIP neuron, drawn from data of Wang et al. [99]. In an experiment similar to that reported above, they recorded from an LIP neuron to stimuli delivered to the future RF at various times before, during and after the saccade. Note that after the saccade, the eye movement will have brought the retinal projection of the future RF back to the original classical RF, under the fovea. In this cartoon the responses are all aligned to the saccade, and ordered according to stimulus presentation relative to it. With this representation, the first spikes of the responses to all stimuli occur at the same time, implying that pre- and post-saccadic stimulation to this part of space causes a spike train that is effectively identical. A higher order cell (or a neurophysiologist) monitoring the response has no way of distinguishing whether a particular spike results from early pre-saccadic stimulation to the future RF or later post-saccadic stimulation of the classic RF. By definition, the region in space–time that elicits identical responses defines the RF of the cell, in space and in time. The RF at the time of the saccade of this hypothetical LIP cell is illustrated schematically in figure 6f. In retinal coordinates, it is oriented in space–time along the trajectory of the retinal projection of the saccadic target during the eye movement. All spikes from this spatio-temporal RF arrive at the same time, and are, therefore, indistinguishable. Objects falling within the spatio-temporal RF, either in the ‘future field’ (pink circle) or classical RF (light-blue circle) will be integrated, and coded as being in the same external location. The fact that the RF is aligned to the saccadic target trajectory effectively stabilizes the image, at least transiently. A similar argument has previously been developed for the mechanisms involved in the perception of spatial form of moving objects [100,101].
That is not to say that these neurons are spatiotopic: their RFs are not anchored in external space. At most they exhibit a form of local transient spatiotopicity, in space and in time achieved by delaying the future RF response. To achieve absolute spatiotopicity, the eye position signal must be combined in some way with the transient retinal position signalled by this cell. But perhaps local spatiotopicity is sufficient to offset the retinal motion and displacement caused by the saccade, providing an immediate compensation for the displacement, thereby allowing perception to proceed seamlessly. The oriented spatio-temporal RF will generate a signal of continuity between pre- and post-saccadic view of the same object, and integrate signals of the same object trans-saccadically, possibly over a longer time span compared with fixation. A true spatiotopic representation, invariant to eye and body position, may be constructed in other areas, by integrating successive corollary discharge vectors.
Interestingly, the spatio-temporal behaviour of the LIP neurons described by Wang et al. [99] closely resemble the psychophysical results for transient stimuli around the time of saccades (figure 3b, histogram at left). Stimuli presented just before and during the saccade are delayed relative to those presented later, similar to the neural discharges of LIP cells. The result is that stimuli presented over a wide range of times are localized in time to appear just after the saccade (histogram at left), just as stimuli presented at different times to the ‘future’ RF of LIP cells all cause spike trains that arrive at a similar time, after the saccade has been completed. Interestingly, the thick curves that fit the data are derived from a model based on units that transiently change their impulse-response function to become oriented in space–time, similar to the hypothetical spatio-temporal RF cartooned in figure 6.
7. Concluding remarks
While the problem of visual stability is far from solved, tantalizing progress has been made over the past few years. It is clear that there do exist spatiotopic representations in the human brain, and that the construction of these representations requires visual attention. It is also clear that many transient processes occur when the eyes move, in both space and in time, leading to a spatio-temporal tuning that could provide a quick transient local spatiotopicity for immediate interaction with the world. Exactly how all these different mechanisms interact to provide stability will be one of the main challenges for future research.
Acknowledgements
Supported by EEC framework 6 (MEMORY) and 7 (ERC: STANIB) and Italian Ministry of Universities and Research.
Footnotes
One contribution of 11 to a Theme Issue ‘Visual stability’.
References
- 1.Alhazen I. 1083. Book of optics. In The optics of Ibn al-Haytham (ed. Sabra A. I.). London, UK: Warburg Institute; (1989). [Google Scholar]
- 2.Morgan M. J. 2003. The space between your ears: how the brain represents visual space. London, UK: Weidenfeld & Nicolson [Google Scholar]
- 3.Galletti C., Battaglini P. P., Fattori P. 1993. Parietal neurons encoding spatial locations in craniotopic coordinates. Exptl. Brain Res. 96, 221–229 [DOI] [PubMed] [Google Scholar]
- 4.Duhamel J., Bremmer F., BenHamed S., Graf W. 1997. Spatial invariance of visual receptive fields in parietal cortex neurons. Nature 389, 845–848 10.1038/39865 (doi:10.1038/39865) [DOI] [PubMed] [Google Scholar]
- 5.Trotter Y., Celebrini S. 1999. Gaze direction controls response gain in primary visual-cortex neurons. Nature 398, 239–242 10.1038/18444 (doi:10.1038/18444) [DOI] [PubMed] [Google Scholar]
- 6.Durand J. B., Trotter Y., Celebrini S. 2010. Privileged processing of the straight ahead direction in primate area V1. Neuron 66, 126–137 10.1016/j.neuron.2010.03.014 (doi:10.1016/j.neuron.2010.03.014) [DOI] [PubMed] [Google Scholar]
- 7.Melcher D., Morrone M. C. 2003. Spatiotopic temporal integration of visual motion across saccadic eye movements. Nat. Neurosci. 6, 877–881 10.1038/nn1098 (doi:10.1038/nn1098) [DOI] [PubMed] [Google Scholar]
- 8.Burr D. C., Santoro L. 2001. Temporal integration of optic flow, measured by contrast thresholds and by coherence thresholds. Vis. Res. 41, 1891–1899 10.1016/S0042-6989(01)00072-4 (doi:10.1016/S0042-6989(01)00072-4) [DOI] [PubMed] [Google Scholar]
- 9.Burr D., Tozzi A., Morrone M. C. 2007. Neural mechanisms for timing visual events are spatially selective in real-world coordinates. Nat. Neurosci. 10, 423–425 10.1038/nn1874 (doi:10.1038/nn1874) [DOI] [PubMed] [Google Scholar]
- 10.Knapen T., Rolfs M., Cavanagh P. 2009. The reference frame of the motion aftereffect is retinotopic. J. Vis. 9, 16. 10.1167/9.5.16 (doi:10.1167/9.5.16) [DOI] [PubMed] [Google Scholar]
- 11.Wenderoth P., Wiese M. 2008. Retinotopic encoding of the direction aftereffect. Vis. Res. 48, 1949–1954 10.1016/j.visres.2008.06.013 (doi:10.1016/j.visres.2008.06.013) [DOI] [PubMed] [Google Scholar]
- 12.Hayhoe M., Lachter J., Feldman J. 1991. Integration of form across saccadic eye movements. Perception 20, 393–402 10.1068/p200393 (doi:10.1068/p200393) [DOI] [PubMed] [Google Scholar]
- 13.Prime S. L., Niemeier M., Crawford J. D. 2006. Transsaccadic integration of visual features in a line intersection task. Exp. Brain Res. 169, 532–548 10.1007/s00221-005-0164-1 (doi:10.1007/s00221-005-0164-1) [DOI] [PubMed] [Google Scholar]
- 14.Irwin D. E., Yantis S., Jonides J. 1983. Evidence against visual integration across saccadic eye movements. Percept. Psychophys. 34, 49–57 [DOI] [PubMed] [Google Scholar]
- 15.Jonides J., Irwin D. E., Yantis S. 1983. Failure to integrate information from successive fixations. Science 222, 188. 10.1126/science.6623072 (doi:10.1126/science.6623072) [DOI] [PubMed] [Google Scholar]
- 16.Medendorp W. P. 2011. Spatial constancy mechanisms in motor control. Phil. Trans. R. Soc. B 366, 476–491 10.1098/rstb.2010.0089 (doi:10.1098/rstb.2010.0089) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Hall N. J., Colby C. L. 2011. Remapping for visual stability. Phil. Trans. R. Soc. B 366, 528–539 10.1098/rstb.2010.0248 (doi:10.1098/rstb.2010.0248) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Prime S. L., Vesia M., Crawford J. D. 2011. Cortical mechanisms for trans-saccadic memory and integration of multiple object features. Phil. Trans. R. Soc. B 366, 540–553 10.1098/rstb.2010.0184 (doi:10.1098/rstb.2010.0184) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Hamker F. H., Zirnsak M., Ziesche A., Lappe M. 2011. Computational models of spatial updating in peri-saccadic perception. Phil. Trans. R. Soc. B 366, 554–571 10.1098/rstb.2010.0229 (doi:10.1098/rstb.2010.0229) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Zimmer M., Kovács G. 2011. Position specificity of adaptation-related face aftereffects. Phil. Trans. R. Soc. B 366, 586–595 10.1098/rstb.2010.0265 (doi:10.1098/rstb.2010.0265) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Tatler B. W., Land M. F. 2011. Vision and the representation of the surroundings in spatial memory. Phil. Trans. R. Soc. B 366, 596–610 10.1098/rstb.2010.0188 (doi:10.1098/rstb.2010.0188) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Thompson P., Burr D. 2009. Visual aftereffects. Curr. Biol. 19, R11–R14 10.1016/j.cub.2008.10.014 (doi:10.1016/j.cub.2008.10.014) [DOI] [PubMed] [Google Scholar]
- 23.Melcher D. 2005. Spatiotopic transfer of visual-form adaptation across saccadic eye movements. Curr. Biol. 15, 1745–1748 10.1016/j.cub.2005.08.044 (doi:10.1016/j.cub.2005.08.044) [DOI] [PubMed] [Google Scholar]
- 24.Wittenberg M., Bremmer F., Wachtler T. 2008. Perceptual evidence for saccadic updating of color stimuli. J. Vis. 8, 9. 10.1167/8.14.9 (doi:10.1167/8.14.9) [DOI] [PubMed] [Google Scholar]
- 25.Johnston A., Arnold D. H., Nishida S. 2006. Spatially localized distortions of event time. Curr. Biol. 16, 472–479 10.1016/j.cub.2006.01.032 (doi:10.1016/j.cub.2006.01.032) [DOI] [PubMed] [Google Scholar]
- 26.McKyton A., Zohary E. 2006. Beyond retinotopic mapping: the spatial representation of objects in the human lateral occipital complex. Cereb. Cortex 17, 1164–1172 10.1093/cercor/bhl027 (doi:10.1093/cercor/bhl027) [DOI] [PubMed] [Google Scholar]
- 27.Sereno M. I., Huang R. S. 2006. A human parietal face area contains aligned head-centered visual and tactile maps. Nat. Neurosci. 9, 1337–1343 10.1038/nn1777 (doi:10.1038/nn1777) [DOI] [PubMed] [Google Scholar]
- 28.Goossens J., Dukelow S. P., Menon R. S., Vilis T., van den Berg A. V. 2006. Representation of head-centric flow in the human motion complex. J. Neurosci. 26, 5616–5627 10.1523/JNEUROSCI.0730-06.2006 (doi:10.1523/JNEUROSCI.0730-06.2006) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Crespi S. A., Biagi L., Burr D. C., d'Avossa G., Tosetti M., Morrone M. C. 2009. Spatial attention modulates the spatiotopicity of human MT complex. Perception 38 (ECVP Abstract Supplement). [Google Scholar]
- 30.d'Avossa G., Tosetti M., Crespi S., Biagi L., Burr D. C., Morrone M. C. 2007. Spatiotopic selectivity of BOLD responses to visual motion in human area MT. Nat. Neurosci. 10, 249–255 10.1038/nn1824 (doi:10.1038/nn1824) [DOI] [PubMed] [Google Scholar]
- 31.Gardner J. L., Merriam E. P., Movshon J. A., Heeger D. J. 2008. Maps of visual space in human occipital cortex are retinotopic, not spatiotopic. J. Neurosci. 28, 3988–3999 10.1523/JNEUROSCI.5476-07.2008 (doi:10.1523/JNEUROSCI.5476-07.2008) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Brefczynski J. A., DeYoe E. A. 1999. A physiological correlate of the ‘spotlight' of visual attention. Nat. Neurosci. 2, 370–374 10.1038/7280 (doi:10.1038/7280) [DOI] [PubMed] [Google Scholar]
- 33.Corbetta M., Shulman G. L. 2002. Control of goal-directed and stimulus-driven attention in the brain. Nat. Rev. Neurosci. 3, 201–215 10.1038/nrn755 (doi:10.1038/nrn755) [DOI] [PubMed] [Google Scholar]
- 34.Gandhi S. P., Heeger D. J., Boynton G. M. 1999. Spatial attention affects brain activity in human primary visual cortex. Proc. Natl Acad. Sci. USA 96, 3314–3319 10.1073/pnas.96.6.3314 (doi:10.1073/pnas.96.6.3314) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Kastner S., De Weerd P., Desimone R., Ungerleider L. G. 1998. Mechanisms of directed attention in the human extrastriate cortex as revealed by functional MRI. Science 282, 108–111 10.1126/science.282.5386.108 (doi:10.1126/science.282.5386.108) [DOI] [PubMed] [Google Scholar]
- 36.Tootell R. B., Hadjikhani N., Hall E. K., Marrett S., Vanduffel W., Vaughan J. T., Dale A. M. 1998. The retinotopy of visual spatial attention. Neuron 21, 1409–1422 10.1016/S0896-6273(00)80659-5 (doi:10.1016/S0896-6273(00)80659-5) [DOI] [PubMed] [Google Scholar]
- 37.Womelsdorf T., Anton-Erxleben K., Pieper F., Treue S. 2006. Dynamic shifts of visual receptive fields in cortical area MT by spatial attention. Nat. Neurosci. 9, 1156–1160 10.1038/nn1748 (doi:10.1038/nn1748) [DOI] [PubMed] [Google Scholar]
- 38.Fischer J., Whitney D. 2009. Attention narrows position tuning of population responses in V1. Curr. Biol. 19, 1356–1361 10.1016/j.cub.2009.06.059 (doi:10.1016/j.cub.2009.06.059) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Golomb J. D., Chun M. M., Mazer J. A. 2008. The native coordinate system of spatial attention is retinotopic. J. Neurosci. 28, 10 654–10 662 10.1523/JNEUROSCI.2525-08.2008 (doi:10.1523/JNEUROSCI.2525-08.2008) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Sapir A., Hayes A., Henik A., Danziger S., Rafal R. 2004. Parietal lobe lesions disrupt saccadic remapping of inhibitory location tagging. J. Cogn. Neurosci. 16, 503–509 10.1162/089892904323057245 (doi:10.1162/089892904323057245) [DOI] [PubMed] [Google Scholar]
- 41.Cavanagh P., Hunt A. R., Afraz A., Rolfs M. 2010. Visual stability based on remapping of attention pointers. Trends Cogn. Sci. 14, 147–153 10.1016/j.tics.2010.01.007 (doi:10.1016/j.tics.2010.01.007) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Melcher D., Colby C. L. 2008. Trans-saccadic perception. Trends Cogn. Sci. 12, 466–473 10.1016/j.tics.2008.09.003 (doi:10.1016/j.tics.2008.09.003) [DOI] [PubMed] [Google Scholar]
- 43.Melcher D. 2009. Selective attention and the active remapping of object features in trans-saccadic perception. Vis. Res. 49, 1249–1255 10.1016/j.visres.2008.03.014 (doi:10.1016/j.visres.2008.03.014) [DOI] [PubMed] [Google Scholar]
- 44.Wurtz R. H., Joiner W. M., Berman R. A. 2011. Neuronal mechanisms for visual stability: progress and problems. Phil. Trans. R. Soc. B 366, 492–503 10.1098/rstb.2010.0186 (doi:10.1098/rstb.2010.0186) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Mathôt S., Theeuwes J. 2011. Visual attention and stability. Phil. Trans. R. Soc. B 366, 516–527 10.1098/rstb.2010.0187 (doi:10.1098/rstb.2010.0187) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Reynolds J. H., Heeger D. J. 2009. The normalization model of attention. Neuron 61, 168–185 10.1016/j.neuron.2009.01.002 (doi:10.1016/j.neuron.2009.01.002) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Andersen R. A., Essick G. K., Siegel R. M. 1985. Encoding of spatial location by posterior parietal neurons. Science 230, 456–458 10.1126/science.4048942 (doi:10.1126/science.4048942) [DOI] [PubMed] [Google Scholar]
- 48.Zipser D., Andersen R. A. 1988. A back-propagation programmed network that simulates response properties of a subset of posterior parietal neurons. Nature 331, 679–684 10.1038/331679a0 (doi:10.1038/331679a0) [DOI] [PubMed] [Google Scholar]
- 49.Rees G., Frith C. D., Lavie N. 1997. Modulating irrelevant motion perception by varying attentional load in an unrelated task. Science 278, 1616–1619 10.1126/science.278.5343.1616 (doi:10.1126/science.278.5343.1616) [DOI] [PubMed] [Google Scholar]
- 50.Kastner S., Pinsk M. A., De Weerd P., Desimone R., Ungerleider L. G. 1999. Increased activity in human visual cortex during directed attention in the absence of visual stimulation. Neuron 22, 751–761 10.1016/S0896-6273(00)80734-5 (doi:10.1016/S0896-6273(00)80734-5) [DOI] [PubMed] [Google Scholar]
- 51.Saygin A. P., Sereno M. I. 2008. Retinotopy and attention in human occipital, temporal, parietal, and frontal cortex. Cereb. Cortex 18, 2158–2168 10.1093/cercor/bhm242 (doi:10.1093/cercor/bhm242) [DOI] [PubMed] [Google Scholar]
- 52.Bisley J. W., Goldberg M. E. 2003. Neuronal activity in the lateral intraparietal area and spatial attention. Science 299, 81–86 10.1126/science.1077395 (doi:10.1126/science.1077395) [DOI] [PubMed] [Google Scholar]
- 53.Moore T., Armstrong K. M., Fallah M. 2003. Visuomotor origins of covert spatial attention. Neuron 40, 671–683 10.1016/S0896-6273(03)00716-5 (doi:10.1016/S0896-6273(03)00716-5) [DOI] [PubMed] [Google Scholar]
- 54.Rizzolatti G., Riggio L., Dascola I., Umilta C. 1987. Reorienting attention across the horizontal and vertical meridians: evidence in favor of a premotor theory of attention. Neuropsychologia 25, 31–40 [DOI] [PubMed] [Google Scholar]
- 55.Cohen Y. E., Andersen R. A. 2002. A common reference frame for movement plans in the posterior parietal cortex. Nat. Rev. Neurosci. 3, 553–562 10.1038/nrn873 (doi:10.1038/nrn873) [DOI] [PubMed] [Google Scholar]
- 56.Ma-Wyatt A., Morrone M. C., Ross J. 2002. A blinding flash increases saccadic compression. J. Vis. 2, 569. 10.1167/2.7.569 (doi:10.1167/2.7.569) [DOI] [Google Scholar]
- 57.Burr D. C., Morrone M. C., Ross J. 2001. Separate visual representations for perception and action revealed by saccadic eye movements. Curr. Biol. 11, 798–802 10.1016/S0960-9822(01)00183-X (doi:10.1016/S0960-9822(01)00183-X) [DOI] [PubMed] [Google Scholar]
- 58.Morrone M. C., Ma-Wyatt A., Ross J. 2005. Seeing and ballistic pointing at perisaccadic targets. J. Vis. 5, 741–754 10.1167/5.9.7 (doi:10.1167/5.9.7) [DOI] [PubMed] [Google Scholar]
- 59.Wurtz R. H. 2008. Neuronal mechanisms of visual stability. Vis. Res. 48, 2070–2089 10.1016/j.visres.2008.03.021 (doi:10.1016/j.visres.2008.03.021) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Burr D. C., Holt J., Johnstone J. R., Ross J. 1982. Selective depression of motion sensitivity during saccades. J. Physiol. 333, 1–15 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Burr D. C., Morrone M. C., Ross J. 1994. Selective suppression of the magnocellular visual pathway during saccadic eye movements. Nature 371, 511–513 10.1038/371511a0 (doi:10.1038/371511a0) [DOI] [PubMed] [Google Scholar]
- 62.Ross J., Burr D. C., Morrone M. C. 1996. Suppression of the magnocellular pathways during saccades. Behav. Brain Res. 80, 1–8 10.1016/0166-4328(96)00012-5 (doi:10.1016/0166-4328(96)00012-5) [DOI] [PubMed] [Google Scholar]
- 63.Burr D. C., Ross J. 1982. Contrast sensitivity at high velocities. Vis. Res. 23, 3567–3569 [DOI] [PubMed] [Google Scholar]
- 64.Allison R. S., Schumacher J., Sadr S., Herpers R. 2009. Apparent motion during saccadic suppression periods. Exp. Brain Res. 202, 155–169 10.1007/s00221-009-2120-y (doi:10.1007/s00221-009-2120-y) [DOI] [PubMed] [Google Scholar]
- 65.Bristow D., Haynes J. D., Sylvester R., Frith C. D., Rees G. 2005. Blinking suppresses the neural response to unchanging retinal stimulation. Curr. Biol. 15, 1296–1300 10.1016/j.cub.2005.06.025 (doi:10.1016/j.cub.2005.06.025) [DOI] [PubMed] [Google Scholar]
- 66.Burr D. 2005. Vision: in the blink of an eye. Curr. Biol. 15, R554–R556 10.1016/j.cub.2005.07.007 (doi:10.1016/j.cub.2005.07.007) [DOI] [PubMed] [Google Scholar]
- 67.Kleiser R., Seitz R. J., Krekelberg B. 2004. Neural correlates of saccadic suppression in humans. Curr. Biol. 14, 386–390 10.1016/j.cub.2004.02.036 (doi:10.1016/j.cub.2004.02.036) [DOI] [PubMed] [Google Scholar]
- 68.Bremmer F., Kubischik M., Hoffmann K. P., Krekelberg B. 2009. Neural dynamics of saccadic suppression. J. Neurosci. 29, 12 374–12 383 10.1523/JNEUROSCI.2908-09.2009 (doi:10.1523/JNEUROSCI.2908-09.2009) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Ibbotson M. R., Crowder N. A., Cloherty S. L., Price N. S., Mustari M. J. 2008. Saccadic modulation of neural responses: possible roles in saccadic suppression, enhancement, and time compression. J. Neurosci. 28, 10 952–10 960 10.1523/JNEUROSCI.3950-08.2008 (doi:10.1523/JNEUROSCI.3950-08.2008) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Richmond B. J., Wurtz R. H. 1980. Vision during saccadic eye movements. II. A corollary discharge to monkey superior colliculus. J. Neurophysiol. 43, 1156–1167 [DOI] [PubMed] [Google Scholar]
- 71.Matin L., Pearce D. G. 1965. Visual perception of direction for stimuli flashed during voluntary saccadic eye movmements. Science 148, 1485–1487 10.1126/science.148.3676.1485 (doi:10.1126/science.148.3676.1485) [DOI] [PubMed] [Google Scholar]
- 72.Bischof N., Kramer E. 1968. Untersuchungen und Überlegungen zur Richtungswahrnehmung bei wilkuerlichen sakkadischen Augenbewegungen. Psychol. Forsch. 32, 185–218 [DOI] [PubMed] [Google Scholar]
- 73.Honda H. 1989. Perceptual localization of visual stimuli flashed during saccades. Percept. Psychophys. 46, 162–174 [DOI] [PubMed] [Google Scholar]
- 74.Honda H. 1993. Saccade-contingent displacement of the apparent position of visual stimuli flashed on a dimly illuminated structured background. Vis. Res. 33, 709–716 10.1016/0042-6989(93)90190-8 (doi:10.1016/0042-6989(93)90190-8) [DOI] [PubMed] [Google Scholar]
- 75.Mateeff S. 1978. Saccadic eye movements and localization of visual stimuli. Percept. Psychophys. 24, 215–224 [DOI] [PubMed] [Google Scholar]
- 76.Morrone M. C., Ross J., Burr D. C. 1997. Apparent position of visual targets during real and simulated saccadic eye movements. J. Neurosci. 17, 7941–7953 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Ross J., Morrone M. C., Burr D. C. 1997. Compression of visual space before saccades. Nature 384, 598–601 10.1038/386598a0 (doi:10.1038/386598a0) [DOI] [PubMed] [Google Scholar]
- 78.Awater H., Burr D., Lappe M., Morrone M. C., Goldberg M. E. 2005. The effect of saccadic adaptation on the localization of visual targets. J. Neurophysiol. 93, 3605–3614 10.1152/jn.01013.2003 (doi:10.1152/jn.01013.2003) [DOI] [PubMed] [Google Scholar]
- 79.Awater H., Lappe M. 2004. Perception of visual space at the time of pro- and anti-saccades. J. Neurophysiol. 91, 2457–2464 10.1152/jn.00821.2003 (doi:10.1152/jn.00821.2003) [DOI] [PubMed] [Google Scholar]
- 80.Kaiser M., Lappe M. 2004. Perisaccadic mislocalization orthogonal to saccade direction. Neuron 41, 293–300 10.1016/S0896-6273(03)00849-3 (doi:10.1016/S0896-6273(03)00849-3) [DOI] [PubMed] [Google Scholar]
- 81.Lappe M., Awater H., Krekelberg B. 2000. Postsaccadic visual references generate presaccadic compression of space. Nature 403, 892–895 10.1038/35002588 (doi:10.1038/35002588) [DOI] [PubMed] [Google Scholar]
- 82.Matsumiya K., Uchikawa K. 2001. Apparent size of an object remains uncompressed during presaccadic compression of visual space. Vis. Res. 41, 3039–3050 10.1016/S0042-6989(01)00174-2 (doi:10.1016/S0042-6989(01)00174-2) [DOI] [PubMed] [Google Scholar]
- 83.Matsumiya K., Uchikawa K. 2003. The role of presaccadic compression of visual space in spatial remapping across saccadic eye movements. Vis. Res. 43, 1969–1981 10.1016/S0042-6989(03)00301-8 (doi:10.1016/S0042-6989(03)00301-8) [DOI] [PubMed] [Google Scholar]
- 84.Noritake A., Uttl B., Terao M., Nagai M., Watanabe J., Yagi A. 2009. Saccadic compression of rectangle and Kanizsa figures: now you see it, now you don't. PLoS ONE 4, e6383. 10.1371/journal.pone.0006383 (doi:10.1371/journal.pone.0006383) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.Lappe M., Kuhlmann S., Oerke B., Kaiser M. 2006. The fate of object features during perisaccadic mislocalization. J. Vis. 6, 1282–1293 10.1167/6.11.11 (doi:10.1167/6.11.11) [DOI] [PubMed] [Google Scholar]
- 86.Binda P., Bruno A., Burr D. C., Morrone M. C. 2007. Fusion of visual and auditory stimuli during saccades: a Bayesian explanation for perisaccadic distortions. J. Neurosci. 27, 8525–8532 10.1523/JNEUROSCI.0737-07.2007 (doi:10.1523/JNEUROSCI.0737-07.2007) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87.Alais D., Burr D. 2004. The ventriloquist effect results from near-optimal bimodal integration. Curr. Biol. 14, 257–262 10.1016/j.cub.2004.01.029 (doi:10.1016/j.cub.2004.01.029) [DOI] [PubMed] [Google Scholar]
- 88.Ostendorf F., Fischer C., Finke C., Ploner C. J. 2007. Perisaccadic compression correlates with saccadic peak velocity: differential association of eye movement dynamics with perceptual mislocalization patterns. J. Neurosci. 27, 7559–7563 10.1523/JNEUROSCI.2074-07.2007 (doi:10.1523/JNEUROSCI.2074-07.2007) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89.Deubel H., Schneider W. X., Bridgeman B. 2002. Transsaccadic memory of position and form. Prog. Brain Res. 140, 165–180 10.1016/S0079-6123(02)40049-0 (doi:10.1016/S0079-6123(02)40049-0) [DOI] [PubMed] [Google Scholar]
- 90.Morrone M. C., Ross J., Burr D. 2005. Saccadic eye movements cause compression of time as well as space. Nat. Neurosci. 8, 950–954 10.1038/nn1488 (doi:10.1038/nn1488) [DOI] [PubMed] [Google Scholar]
- 91.Binda P., Cicchini G. M., Burr D. C., Morrone M. C. 2009. Spatiotemporal distortions of visual perception at the time of saccades. J. Neurosci. 29, 13 147–13 157 10.1523/JNEUROSCI.3723-09.2009 (doi:10.1523/JNEUROSCI.3723-09.2009) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 92.Duhamel J. R., Colby C. L., Goldberg M. E. 1992. The updating of the representation of visual space in parietal cortex by intended eye movements. Science 255, 90–92 10.1126/science.1553535 (doi:10.1126/science.1553535) [DOI] [PubMed] [Google Scholar]
- 93.Nakamura K., Colby C. L. 2002. Updating of the visual representation in monkey striate and extrastriate cortex during saccades. Proc. Natl Acad. Sci. USA 99, 4026–4031 10.1073/pnas.052379899 (doi:10.1073/pnas.052379899) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 94.Tolias A. S., Moore T., Smirnakis S. M., Tehovnik E. J., Siapas A. G., Schiller P. H. 2001. Eye movements modulate visual receptive fields of V4 neurons. Neuron 29, 757–767 10.1016/S0896-6273(01)00250-1 (doi:10.1016/S0896-6273(01)00250-1) [DOI] [PubMed] [Google Scholar]
- 95.Walker M. F., Fitzgibbon J., Goldberg M. E. 1995. Neurons of the monkey superior colliculus predict the visual result of impending saccadic eye movements. J. Neurophysiol. 73, 1988–2003 [DOI] [PubMed] [Google Scholar]
- 96.Kusunoki M., Goldberg M. E. 2003. The time course of perisaccadic receptive field shifts in the lateral intraparietal area of the monkey. J. Neurophysiol. 89, 1519–1527 10.1152/jn.00519.2002 (doi:10.1152/jn.00519.2002) [DOI] [PubMed] [Google Scholar]
- 97.Heiser L. M., Colby C. L. 2006. Spatial updating in area LIP is independent of saccade direction. J. Neurophysiol. 95, 2751–2767 10.1152/jn.00054.2005 (doi:10.1152/jn.00054.2005) [DOI] [PubMed] [Google Scholar]
- 98.Sommer M. A., Wurtz R. H. 2008. Brain circuits for the internal monitoring of movements. Annu. Rev. Neurosci. 31, 317–338 10.1146/annurev.neuro.31.060407.125627 (doi:10.1146/annurev.neuro.31.060407.125627) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 99.Wang X., Zhang M., Goldberg M. E. 2008. Perisaccadic elongation of receptive fields in the lateral interparietal area (LIP). Soc. Neurosci. Abstr. 855, 17/FF23 [Google Scholar]
- 100.Burr D. C., Ross J. 1986. Visual processing of motion. Trends Neurosci. 9, 304–306 10.1016/0166-2236(86)90088-3 (doi:10.1016/0166-2236(86)90088-3) [DOI] [Google Scholar]
- 101.Burr D. C., Ross J., Morrone M. C. 1986. Seeing objects in motion. Proc. R. Soc. Lond. B 227, 249–265 10.1098/rspb.1986.0022 (doi:10.1098/rspb.1986.0022) [DOI] [PubMed] [Google Scholar]