

Abstract
Objective
To create a consistent time series to understand coverage trends by harmonizing 20 years of insurance coverage estimates from the Current Population Survey (CPS) that are an available public resource.
Data Source
1990–2009 CPS Annual Social and Economic Supplement data.
Study Design
CPS data are enhanced to account for methodological and conceptual changes in health insurance measurement and population control totals.
Principal Findings
The enhancements to the CPS result in an approximately 1 percent reduction in uninsurance rates. Reductions vary over time and by age group. Changes over the last two decades differ slightly using the two data sources. For example, the enhanced data show a greater erosion of private coverage.
Conclusion
The enhanced data provide the most consistent measure of health insurance coverage over the past two decades.
Keywords: Health insurance coverage, Current Population Survey, coverage trends, uninsurance
In order to appropriately evaluate state and national health reform efforts, researchers need to have a firm understanding of the historical developments concerning the rates of uninsurance and the rates of public and private coverage. This paper reports on an enhanced time series that corrects the Annual Social and Economic Supplement to the Current Population Survey (CPS) microdata for many of the changes that have occurred over the past 20 years.
The CPS is the only data source that provides historical annual national and state-level estimates of the number of people of all ages in the United States without health insurance. Further, it provides details on the type of coverage that people with insurance have. The CPS will likely provide similar data into the foreseeable future. As a result of the strengths of the CPS, it is the most frequently used source of insurance estimates by national and state-level health policy analysts (Blewett et al. 2004).
There are many other valuable sources for health insurance estimation, including the Medical Expenditure Panel Survey (MEPS), the National Health Interview Survey (NHIS), the Survey of Income and Program Participation (SIPP), and beginning in Fall 2009, the American Community Survey (ACS). A rich literature exists on the differences between these surveys and the pros and cons of each (Swartz 1986; Lewis, Ellwood, and Czajka 1998; Congressional Budget Office 2003; Davern et al. 2009b; State Health Access Data Assistance Center [SHADAC] 2009;). The analysis presented here is agnostic to which survey provides the most accurate estimate of coverage at any given point in time. Here, we use the CPS because it offers a relatively consistent measure over two decades on which we can improve.
In this analysis, we are also agnostic about whether the CPS is capturing the true rate of uninsurance. There is substantial evidence that the CPS undercounts Medicaid coverage (Klerman et al. 2009; Davern et al. 2009a;); however, this issue is not unique to the CPS (Call et al. 2008). There is also substantial debate regarding whether the CPS captures an all-year measure of uninsurance or is closer to a point-in-time estimate (Swartz 1986; Lewis, Ellwood, and Czajka 1998; Congressional Budget Office 2003; Klerman et al. 2009;). This paper does not tackle these issues; rather, it highlights the unique ability of the CPS to provide a consistent trend controlling for known measurement, processing, and adjustment errors.
Our enhanced data series makes changes to the individual records of the CPS to adjust for known consistency problems, discussed in detail below. By making changes to the individual-level microdata, it allows for the greatest utility to health policy analysts because they will be able to consistently run their specific analysis using our enhanced microdata series. Our enhanced data make changes both to the individual-level variables measuring health insurance coverage as well as to the person-level weights. Tabulated estimates using these data (i.e., predefined tables) are available from the SHADAC Data Center and the individual-level microdata are available through Integrated Public Use Microdata Series (IPUMS) CPS through the University of Minnesota's Population Center. Here, we present a summary of the results using these enhanced data examining rates of coverage over the past two decades and compare them with those available from the nonenhanced CPS.
BACKGROUND
The monthly CPS is primarily a labor force survey conducted by the Census Bureau for the Bureau of Labor Statistics. The Annual Social and Economic Supplement to the CPS is added to the monthly core in February through April, with most of the interviews being conducted in March. In 1980, questions about health insurance coverage were introduced. Since the introduction of the original minimal set of questions, many issues have been identified, and changes have been made. The Census Bureau should be lauded for maintaining a balance between improving the measure over time, yet providing tools for the analyst to create a consistent time series from 1988 to 2009. Here, we outline the aspects of which are still amenable to improvements and/or can be harmonized over time. We conclude by summarizing emergent trends using this enhanced data and compare conclusions that would be drawn using the enhanced data with the nonenhanced data.
METHODS
Each of the CPS enhancements is outlined below. All years refer to the CPS year, which is the year after the calendar year for which the health insurance estimate corresponds. The enhancements are conducted on CPS data from 1990 to 2009. Although most of the enhancements could be extended to 1988 and 1989, these years were not smoothed to decennial population estimates as described in more detail below, and as such are not presented here. Estimates of the portion of the U.S. population that is uninsured, publicly insured, and privately insured are presented by year using both the enhanced and the nonenhanced data. Individuals are allowed to report both public and private coverage, resulting in totals of more than 100 percent. Separate estimates are produced for children 0–17 and adults 18–64. All analysis was performed in StataSE 10 (StataCorp 2007) in order to correct for the complex survey design of the CPS (Davern et al. 2006). Any differences cited are significant at p<.05.
Health Insurance Coverage
The most notable change in the series of questions about health insurance coverage was the introduction of a verification question in 2000. Previously, the uninsured were defined using the residual approach. From 2000 onward, individuals who did not respond to any type of coverage were asked to verify whether they were in fact uninsured. This change resulted in 8 percent of the uninsured becoming classified as insured (Davern et al. 2003). Research into the characteristics of these cases indicated that the cases converted to have coverage appeared to be appropriate and the verification itself was seen as a more valid measure of coverage (Rajan, Zuckerman, and Brennan 2000; Nelson and Mills 2001;). Because including the verification yields a more valid measure of coverage, we wanted to “verify” earlier years of the CPS data that did not include the verification item. Of note, this is an improvement over the current recommendation to undo the impact of the verification in later years. We used a hotdeck imputation methodology to impute verification responses in 1990–1999 for those cases that were characterized as uninsured. CPS data from 2000 to 2001 were used as donors in the imputation. The selection of variables and imputation itself were performed separately for individuals under 15 years old and those 15 and older. Included in the imputation for the younger cohort were sex, citizenship, race, poverty level, highest educational level in household, and a state categorization described below. All of these variables were included in the imputation for the older cohort as well as if the individual was the respondent, age, health status, and if someone in the family was working. States were categorized into three groups dependent on the portion of cases that got picked up by the verification question in 2000 and 2001.
In 1998, the Census Bureau, in consultation with the Bureau of Indian Affairs, changed the way in which individuals with only Indian Health Services (IHS) were classified. A question about IHS was introduced in 1996. In 1996 and 1997, those with IHS and no other type of coverage were considered insured. After that time, the same individuals would be considered uninsured (SHADAC 2005). To correct for the change, those cases who have this and no other coverage in 1996 and 1997 are switched to be considered uninsured in the enhanced data.
In 2001, the CPS began asking children who did not have Medicaid whether they had coverage through the State Children's Health Insurance Program (SCHIP). The first year that this question was introduced, those cases who said yes to SCHIP were mistakenly coded as having private health insurance coverage instead of public coverage. The error was corrected in subsequent years (SHADAC 2009). Although this impacted few cases, those indicating that they have SCHIP are coded as having public coverage and if there is no other type of private coverage reported; they are no longer included in private coverage in the enhanced data. In 2008, the SCHIP question was asked of all children, regardless of what they reported their Medicaid coverage. In aggregate estimates of public coverage, this change has no impact and does not need to be accounted for in the enhanced time series.
In August 2006 and March of 2007, the Census Bureau made changes to the way in which health insurance is edited in the 2005 and 2006 CPS. These changes resulted in fewer people being considered uninsured. It was revealed that the previous edit mistakenly left health insurance missing for individuals in a household when a respondent reported that it should actually be assigned to everyone. The miscoded missing values were then imputed, resulting in some cases where an individual would be imputed to be uninsured when they should actually have been coded as insured, as reported initially by the respondent (Lee and Stern 2007). The edit was fixed with the release of the 2007 CPS. The 2005 and the 2006 were fixed retrospectively and rereleased in March 2007. The Census Bureau decided not to retrospectively fix the edit in the years before 2005 (Lee and Stern 2007). They did, however, release an indicator variable that approximates the edit in impacted years, 1997–2004. These fixes are reflected in both the estimates that the Census produces from the CPS and the enhanced time series.
Weights
Approximately 10 percent of cases do not answer any of the Annual Social and Economic Supplement. Davern et al. (2007) uncovered a systematic bias introduced in the way in which those cases were imputed. In order to correct for this bias, we removed those cases from the file and reweighted the remaining cases back to the population totals before removing those individuals, as Davern et al. (2007) recommended.
In order to correct for disjointed counts resulting from the introduction of new decennial estimates, we averaged the growth between the decades to occur linearly across years. In the CPS data released by the Census, we have correct counts for 1990 and 1993. 1991 and 1992 were fit for linear growth between these two time periods by age, race, and ethnicity. We also have correct counts for 2000; thus, 1993 and 2000 were used as bookends to determine linear growth by the same demographic characteristics for the years between 1994 and 1999.
RESULTS
The enhancements made to the CPS differentially impact the uninsurance rate. Overall, the imputation of the verification question decreases uninsurance estimates in 1990–1999 at a rate similar to that observed by Davern et al. (2003), the IHS change increases uninsurance rates slightly in 1996 and 1997, and the SCHIP edit has no impact on the uninsurance rate. While the household edit indicator decreases the uninsurance rate, this is reflected in both the enhanced and the nonenhanced CPS and thus has no differential impact. The reweighting of the data to exclude those cases that had the full supplement imputation decreased the uninsurance rate in all years and the smoothing to decennial control totals differentially impacted subpopulations.
In aggregate, the enhancements result in approximately a 1 percentage point gain in the portion of the population counted as having health insurance coverage. This varies somewhat over time and by age. Coverage gains are slightly higher for adults than for children (an average of 1.2 percentage point gain for adults compared with 1.0 percentage point for children averaged across years).
Figure 1 presents the rate of private coverage for adults and children in the United States over the last two decades using the enhanced and the nonenhanced data. Children have consistently had lower rates of private coverage than adults. For both adults and children, we see relatively parallel decreases over the past decade using both data sources. However, with the enhanced data, we see larger decreases in coverage than that which is observed using the nonenhanced data. For children, there is an 11.2 percentage point decrease in private coverage from 1989 to 2008 using the enhanced data compared with a 9.6 percentage point decrease using the nonenhanced data.
Figure 1.
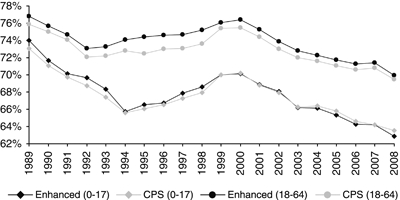
Private Health Insurance Coverage 1989–2008, United States
Source: CPS and Enhanced CPS, 2009–1990
Figure 2 depicts rates of public coverage by age over the last two decades. Consistently, rates of public coverage have been higher for children than for adults. While the estimates of public coverage are relatively close using the two data sources, larger gains in coverage over this time period are seen for children using the enhanced data (a 14.0 percentage point increase compared with a 13.7 percentage point increase). The opposite is observed for adults: a 3.1 percentage point gain with the enhanced data compared with a 3.4 percentage point gain with the nonenhanced data.
Figure 2.
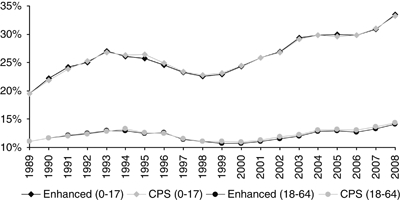
Public Health Insurance Coverage 1989–2008, United States
Source: CPS and Enhanced CPS, 2009–1990
Figure 3 depicts rates of uninsurance for children and adults over the same time period. Using the enhanced data, we see smaller decreases in the uninsurance rate over the past two decades than using the nonenhanced data (3.2 percentage points compared with 3.7 percentage points). For adults, we see larger increases in the uninsurance rate with the enhanced data (4.3 percentage point more uninsured compared with 3.8 percentage point more).
Figure 3.
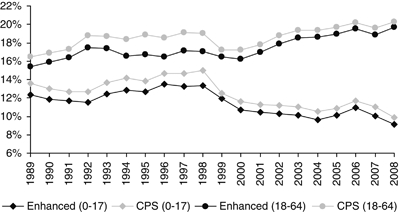
Uninsurance Rate 1989–2008, United States
Source: CPS and Enhanced CPS, 2009–1990
DISCUSSION
We present consistent estimates of health insurance coverage over the past two decades using the most consistent source of health insurance estimates available: the enhanced CPS. Compared with the nonenhanced CPS, slightly different conclusions about coverage trends are reported. For example, the erosion of private coverage over this time period is greater than that which would be concluded using the nonenhanced data, particularly for children. While this erosion has been somewhat offset for children by gains in public coverage, the offsets are not as great with the enhanced data. In addition to the empirical differences observed using the enhanced data, using these data is recommended because it reflects changes that cannot be attributable to measurement error.
When 2010 decennial census estimates are released, the smoothing of weights over the past decade will need to be done in a manner similar to that done in the 1990s. Without knowledge about possible discrepancies between the projected population totals based on the 2000 Census and those totals that will be obtained in the 2010 Census, we cannot predict the direction or magnitude of this additional enhancement. The infrastructure is in place to continue the enhancements described here as subsequent years of the CPS are available. Further, as future improvements are made to the CPS, they will be readily incorporated into the enhanced data presented here to extend the utility of the data for years to come.
CONCLUSION
We have presented the most comprehensive harmonization of health insurance estimates available from the CPS or from any data source. We believe that these improvements will be useful for health policy analysts. As has been done in the past, we are hopeful that the Census Bureau will continue to provide tools to researchers to make intentional decisions on how best to track changes over time. The need for continuous improvement of data measuring health insurance coverage exists (Blewett and Davern 2006); as these changes are made, it will be important to continue the harmonization of this important time series.
Acknowledgments
Joint Acknowledgment/Disclosure Statement: This work was completed under a contract to the U.S. Census Bureau (YA1323-08-CN-0057). The work was also funded in part by the Robert Wood Johnson Foundation through their support of the State Health Access Data Assistance Center (grant 52362). The authors would like to thank the Census Technical Advisory Group for their input on the enhanced data, specifically John Czajka. The authors would also like to thank Charles Nelson from the Census Bureau; Michel Boudreaux, Michele Burlew, Peter Graven, and Joanna Turner from SHADAC; and Amy Godecker from the Minneapolis Department of Health and Family Support. This paper does not necessarily reflect that opinion of NORC at the University of Chicago.
Disclosures: None.
Disclaimers: None.
SUPPORTING INFORMATION
Additional supporting information may be found in the online version of this article:
Appendix SA1: Author Matrix.
Please note: Wiley-Blackwell is not responsible for the content or functionality of any supporting materials supplied by the authors. Any queries (other than missing material) should be directed to the corresponding author for the article.
REFERENCES
- Blewett LA, Davern M. Meeting the Need for State-Level Estimates of Health Insurance Coverage: Use of State and Federal Survey Data. Health Service Research. 2006;41(3, Part 1):946–75. doi: 10.1111/j.1475-6773.2006.00543.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blewett LA, Good MB, Call KT, Davern M. Monitoring the Uninsured: A State Policy Perspective. Journal of Health Politics, Policy and Law. 2004;29(1):107–45. doi: 10.1215/03616878-29-1-107. [DOI] [PubMed] [Google Scholar]
- Call KT, Davidson G, Davern M, Nyman R. Medicaid Undercount and Bias to Estimates of Uninsurance: New Estimates and Existing Evidence. Health Service Research. 2008;43(3):901–14. doi: 10.1111/j.1475-6773.2007.00808.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Congressional Budget Office. How Many People Lack Health Insurance and for How Long?” Economic and Budget Issue Brief. Washington, DC: Congressional Budget Office; 2003. [Google Scholar]
- Davern M, Beebe TJ, Blewett LA, Call KT. Review: Recent Changes to the Current Population Survey: Sample Expansion, Health Insurance Verification, and State Health Insurance Coverage Estimates. Public Opinion Quarterly. 2003;67:603–26. [Google Scholar]
- Davern M, Jones A, Jr., Lepkowski J, Davidson G, Blewett LA. Unstable Inferences? An Examination of Complex Survey Sample Design Adjustments Using the Current Population Survey for Health Services Research. Inquiry. 2006;43(3):283–97. doi: 10.5034/inquiryjrnl_43.3.283. [DOI] [PubMed] [Google Scholar]
- Davern M, Klerman JA, Ziegenfuss J, Lynch V, Greenberg G. A Partially Corrected Estimate of Medicaid Enrollment and Uninsurance: Results from an Imputational Model Developed Off Linked Survey and Administrative Data. Journal of Economic and Social Measurement. 2009a;34(4):219–40. [Google Scholar]
- Davern M, Quinn BC, Kenney GM, Blewett LA. The American Community Survey and Health Insurance Coverage Estimates: Possibilities and Challenges for Health Policy Researchers. Health Service Research. 2009b;44(2, Part 1):593–605. doi: 10.1111/j.1475-6773.2008.00921.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Davern M, Rodin H, Blewett LA, Call KT. Are the Current Population Survey Uninsurance Estimates Too High? An Examination of the Imputation Process. Health Service Research. 2007;42(5):2038–55. doi: 10.1111/j.1475-6773.2007.00703.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Klerman JA, Davern M, Call KT, Lynch V, Ringel J. Understanding the Current Population Survey's Insurance Estimates and the Medicaid ‘Undercount’. Health Affairs. 2009;28(6):w991–1001. doi: 10.1377/hlthaff.28.6.w991. [DOI] [PubMed] [Google Scholar]
- Lee CH, Stern S. Health Insurance Estimates from the U.S. Census Bureau: Background for a New Historical Series. Washington, DC: U.S. Census Bureau, U.S. Poverty and Health Statistics Branch, Housing and Household Economic Statistics Division; 2007. [Google Scholar]
- Lewis K, Ellwood M, Czajka J. Counting the Uninsured: A Review of the Literature. Washington, DC: The Urban Institute; 1998. [Google Scholar]
- Nelson C, Mills R. The March CPS Health Insurance Question and Its Effects on Estimates of the Uninsured. Washington, DC: U.S. Census Bureau, U.S. Housing and Household Economic Statistics Division; 2001. [Google Scholar]
- Rajan S, Zuckerman S, Brennan N. Confirming Insurance Coverage in a Telephone Survey: Evidence from the National Survey of America's Families. Inquiry. 2000;37(3):317–27. [PubMed] [Google Scholar]
- State Health Access Data Assistance Center (SHADAC) Reclassifying Health Insurance Coverage for the Indian Health Service in the Current Population Survey: Impact on State Uninsurance Estimates. Minneapolis, MN: State Health Access Data Assistance Center; 2005. [Google Scholar]
- State Health Access Data Assistance Center (SHADAC) Historical Changes in Current Population Survey: Health Insurance Coverage Item for Survey Years 1988 Through 2008. Minneaspolis, MN: State Health Access Data Assistance Center; 2009. [Google Scholar]
- StataCorp. Stata Statistical Software: Release 10 (Release Software) College Station, TX: StataCorp LP; 2007. [Google Scholar]
- Swartz K. Interpreting the Estimates from Four National Surveys of the Number of People without Health Insurance. Journal of Economic and Social Measurement. 1986;14(3):233–42. [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.