

Abstract
Objectives
Previous studies have confirmed that current steering can increase the number of discriminable pitches available to many CI users; however, the ability to perceive additional pitches has not been linked to improved speech perception. The primary goals of this study were to determine (1) whether adult CI users can achieve higher levels of spectral-cue transmission with a speech processing strategy that implements current steering (Fidelity120) than with a predecessor strategy (HiRes) and, if so, (2) whether the magnitude of improvement can be predicted from individual differences in place-pitch sensitivity. A secondary goal was to determine whether Fidelity120 supports higher levels of speech recognition in noise than HiRes.
Design
A within-subjects repeated measures design evaluated speech perception performance with Fidelity120 relative to HiRes in 10 adult CI users. Subjects used the novel strategy (either HiRes or Fidelity120) for 8 weeks during the main study; a subset of five subjects used Fidelity120 for 3 additional months following the main study. Speech perception was assessed for the spectral cues related to vowel F1 frequency (Vow F1), vowel F2 frequency (Vow F2) and consonant place of articulation (Con PLC); overall transmitted information for vowels (Vow STIM) and consonants (Con STIM); and sentence recognition in noise. Place-pitch sensitivity was measured for electrode pairs in the apical, middle and basal regions of the implanted array using a psychophysical pitch-ranking task.
Results
With one exception, there was no effect of strategy (HiRes vs. Fidelity120) on the speech measures tested, either during the main study (n=10) or after extended use of Fidelity120 (n=5). The exception was a small but significant advantage for HiRes over Fidelity120 for the Con STIM measure during the main study. Examination of individual subjects' data revealed that 3 of 10 subjects demonstrated improved perception of one or more spectral cues with Fidelity120 relative to HiRes after 8 weeks or longer experience with Fidelity120. Another 3 subjects exhibited initial decrements in spectral cue perception with Fidelity120 at the 8 week time point; however, evidence from one subject suggested that such decrements may resolve with additional experience. Place-pitch thresholds were inversely related to improvements in Vow F2 perception with Fidelity120 relative to HiRes. However, no relationship was observed between place-pitch thresholds and the other spectral measures (Vow F1 or Con PLC).
Conclusions
Findings suggest that Fidelity120 supports small improvements in the perception of spectral speech cues in some Advanced Bionics CI users; however, many users show no clear benefit. Benefits are more likely to occur for vowel spectral cues (related to F1 and F2 frequency) than for consonant spectral cues (related to place of articulation). There was an inconsistent relationship between place-pitch sensitivity and improvements in spectral cue perception with Fidelity120 relative to HiRes. This may partly reflect the small number of sites at which place-pitch thresholds were measured. Contrary to some previous reports, there was no clear evidence that Fidelity120 supports improved sentence recognition in noise.
Introduction
One of the key limitations of cochlear implant systems is a lack of spectral detail in the electrically-transmitted stimulus. This stems from a number of factors including irregular survival of auditory nerve fibers, current spread in the cochlea and the limited number of stimulating electrodes along the implanted array. Recently, limitations related to electrode spacing have led to an interest in “virtual channels” as a means of increasing the number of intracochlear stimulation sites (Wilson et al., 2005). The concept underlying virtual channels is that stimulation of two electrodes, either simultaneously or sequentially with a brief temporal offset, can generate pitch percepts intermediate to those corresponding to the physical electrodes. In the case of simultaneous stimulation, currents from the two electrodes sum directly in the cochlear fluids, resulting in a current field that peaks at an intermediate location along the longitudinal dimension of the cochlea (Bonham and Litvak, 2008; Saoji et al., 2009). By weighting the relative amplitudes of the two currents, the peak of the combined current field can be “steered” to arbitrary locations between the electrode contacts. Hence, simultaneous dual-electrode stimulation is often referred to as “current steering.”
Psychophysical studies have shown that most CI users can detect one or more intermediate pitches between adjacent physical electrodes when tested with current-steered stimuli (Donaldson et al., 2005; Koch et al., 2007; Firszt et al., 2007). In the largest study to date, Firszt et al. (2007) evaluated place-pitch sensitivity in 106 subjects with an Advanced Bionics CI. About two-thirds of the subjects could discriminate adjacent physical electrodes in the apical, medial and basal regions of the electrode array. For this sub-group of subjects, current steering produced an average of 5 intermediate pitches per physical electrode pair.
It is generally expected that virtual channels will support improved perception of the spectral cues in speech, at least among CI users with good place-pitch sensitivity. However, this possibility is called into question by studies that measured speech recognition as a function of the number of spectral channels transmitted through the CI system (Fishman et al.,1997; Fu et al., 1998; Faulkner et al., 2001; Friesen et al., 2001). These studies have shown that CI users' performance asymptotes at a maximum of 6–10 channels, depending on the speech materials tested and whether speech stimuli were presented in quiet or noise. Since traditional speech processing strategies provide more than 10 channels of spectral information, these findings suggest that the addition of virtual channels may have no benefit. However, in the studies cited above, there was no attempt to optimize spectral resolution in frequency regions that may be important for speech perception. Thus, it remains possible that the use of virtual channels could lead to improved perception of spectral speech cues by providing better spatial resolution in key frequency regions. Virtual channels might also be expected to support improvements in speech-in-noise perception, since additional spectral channels are needed to maintain a constant level of speech recognition as signal-to-noise ratio decreases (Fu et al, 1998; Friesen et al., 2001; Shannon et al., 2004).
Current steering has been implemented recently in the Fidelity120 speech processing strategy (Advanced Bionics, 2006). Fidelity120 groups 16 intracochlear electrodes into 15 adjacent pairs and uses weighted stimulation to generate 7 virtual channels per pair. This allows it to make use of 120 possible stimulation sites along the length of the electrode array as compared to 16 stimulation sites in the predecessor HiResolution (HiRes) strategy. The Advanced Bionics clinical trial of Fidelity120 used a within-subjects design to compare CI users' speech recognition performance with the HiRes and Fidelity120 strategies. Subjects were tested with HiRes at baseline, tested with Fidelity120 after 3 months take-home experience, and re-tested with HiRes immediately thereafter. A report describing outcomes for the first 34 subjects who completed the trial showed small improvements in group performance for CNC words, HINT sentences in quiet, and HINT sentences in noise (+ 8 dB SNR) for Fidelity120 as compared to HiRes (Boston Scientific, 2007). Presentation levels were not specified. Individual data were provided only for the HINT sentences in noise test. Fifteen of 33 subjects showed performance gains of 10 percentage points or greater with Fidelity120 relative to HiRes. Each of these subjects had overall performance in the poor to moderate range. Four other subjects showed decrements in performance of 10 percentage points or more with Fidelity120 and the remaining 14 subjects showed less than a 10 percentage point difference in performance between the two strategies. No benefit for Fidelity120 was observed among the 10 highest-performing subjects; however, ceiling effects may have influenced outcomes for six of these subjects. One limitation of the clinical trial was that pulse rate may have co-varied with strategy for some subjects. Pulse rate is approximately halved when the paired stimulation version of the HiRes strategy (HiRes-P) is converted to Fidelity120; such a change in pulse rate does not occur for the alternative, sequential stimulation option (HiRes-S). This variable was not tracked (Osberger, personal communication). Since pulse rate has a significant influence on speech recognition performance in some individuals (Loizou et al., 2000; Kiefer et al., 2000; Vandali et al., 2000; Verschuur, 2005; Plant et al., 2007), changes in pulse rate could have confounded the results for some subjects.
Studies by Brendel et al. (2008), Firszt et al. (2009) and Nogueira et al. (2009) have also compared speech recognition performance with the HiRes and Fidelity120 strategies. Brendel et al. (2008) tested 11 subjects using sentences presented in quiet, in background noise (+ 10 dB SNR) and in the presence of a single competing talker (+10 dB SNR). Presentation levels were not specified. Improvements were reported for Fidelity120 relative to HiRes for the single competing talker condition. However, the experimental design did not allow the effects of strategy to be separated from possible effects of using different processors across strategies. Thus, it is not clear whether improvements stemmed from the Fidelity120 strategy, the associated Harmony processor, or both. Firszt et al. (2009) tested 8 subjects using monosyllabic words (presented at 60 dB SPL), sentences in quiet (presented at 50 or 60 dB SPL), and several sentence-in-noise tests (with target speech presented at 60 or 65 dB SPL). They reported small but significant gains in performance with Fidelity120 over HiRes for monosyllabic words and for two of three sentence-in-noise tests. However, for some measures, subjects were tested only once with the HiRes strategy. Thus, it is possible that improvements with Fidelity120 were due to learning effects rather than differences in strategy. In addition, two subjects were tested in the paired-stimulation option, resulting in a lower stimulation rate with Fidelity120 than with HiRes (Firszt, personal communication). Nogueira et al. (2009) compared performance with HiRes and a research version of Fidelity120 known as SpecRes, in 9 subjects. For sentences presented in steady-state noise at +10 dB SNR, 4 subjects achieved higher scores with SpecRes, 2 achieved higher scores with HiRes and 3 had similar scores (< 10% difference) across strategies. For sentences presented with a single competing talker, 2 subjects achieved higher scores with SpecRes, 1 achieved a higher score with HiRes and 6 performed similarly (< 10% difference in scores) across strategies. Presentation levels were not specified for the speech stimuli in this study.
Despite the methodological limitations that exist in some cases, the above studies indicate that some users of the Advanced Bionics CI are able to achieve improved speech perception with the Fidelity120 strategy as compared to the HiRes strategy. However, none of these studies attempted to understand the differences in benefit observed across individual listeners. It is generally expected that Fidelity120 will support improved perception of spectral cues in those listeners who are able to distinguish intermediate pitches with current-steered stimuli. However, this expectation has not been directly tested.
Accordingly, the primary goal of this study was to determine whether CI listeners who can perceive intermediate pitches between adjacent physical electrodes demonstrate improved perception of spectral cues in vowels and consonants when using the Fidelity120 strategy as compared to the HiRes strategy. To this end, a within-subjects, repeated measures design was used to assess vowel and consonant identification with each strategy. Place-pitch sensitivity was measured using a psychophysical pitch-ranking task similar to one that we and others have used previously (Donaldson et al., 2005; Firszt et al., 2007). It was hypothesized that improvements in spectral cue transmission with Fidelity120 relative to HiRes would be predicted by place-pitch sensitivity, i.e., subjects with better place-pitch sensitivity would show larger improvements with Fidelity120. A secondary goal was to determine if subjects could achieve improved speech recognition in noise with Fidelity120 relative to HiRes when pulse rate and other map parameters were held constant across the two strategies.
Subjects and Methods
Subjects
Subjects were 10 adults who had used an Advanced Bionics CI for at least 6 months, and had used the HiRes or Fidelity120 speech processing strategy for at least 3 months prior to entering the study. They were recruited from the University of South Florida (USF) CI Center and other CI centers in the greater Tampa Bay area. Subjects were paid for their participation. In addition, subjects who completed the main part of the study (time points A0 – A2, see below) were given a choice of one of the following incentives provided by Advanced Bionics Corporation: (1) a $200 product credit, or (2) the option to purchase a Harmony speech processor at a discounted price. Study procedures were approved by the USF Institutional Review Board and informed consent was obtained from each subject prior to testing.
Table 1 shows relevant subject information. As indicated in the table, subjects were 5 males and 5 females with an average age of 60.9 years (range 19–84 years). The mean duration of bilateral severe-to-profound hearing loss was 27.5 years (range 7–41 years), and the mean duration of CI use was 3 years (range 0.75 to 6 years). In daily life, four subjects used a unilateral CI, two subjects used bilateral CIs and four subjects used a unilateral CI with a contralateral hearing aid. All subjects were native speakers of American English. Nine subjects were postlingually deafened; the remaining subject (CI-26) was peri-lingually deafened but demonstrated good spoken and written language skills and was a successful college student. Two subjects (CI-6 and CI-30) entered the study using Fidelity120 as their clinical strategy; the remaining 8 subjects entered the study using HiRes.
Table 1.
Description of subjects.
| Subj | M/F | Age | Dur of HL (yrs) | CI use (yrs) | Etiology | Sent. in quiet (%) | Contra ear | Strategy-1 |
|---|---|---|---|---|---|---|---|---|
| CI-6 | F | 61 | 18 | 3 | Meniere's/autoimmune | 91.3 | CI | Fidelity120 |
| CI-17 | M | 50 | 40 | 0.75 | Hereditary, progressive | 100 | HA | HiRes |
| CI-22 | M | 77 | 7 | 4 | Autoimmune | 98.5 | CI | HiRes |
| CI-23 | F | 56 | 25 | 4 | Unknown | 100 | HA | HiRes |
| CI-24 | F | 84 | 24 | 3 | Unknown | 95.3 | - | HiRes |
| CI-25 | F | 76 | 41 | 6 | Unknown | 90.3 | - | HiRes |
| CI-26 | F | 19 | 16 | 2 | Waardenburg syndrome | 43.3 | - | HiRes |
| CI-27 | M | 62 | 37 | 1 | Noise-induced HL | 88.3 | HA | HiRes |
| CI-28 | M | 56 | 33 | 5 | Acoustic trauma | 90.8 | - | HiRes |
| CI-30 | M | 68 | 34 | 0.75 | Unknown | 96.8 | HA | Fidelity120 |
|
| ||||||||
| mean | 60.9 | 27.5 | 3.0 | 89.4 | ||||
| s.d. | 18.2 | 11.4 | 1.8 | 16.8 | ||||
Subjects who normally used a contralateral hearing aid agreed to wear their CI alone for a minimum of 8 hours per day during the course of the study; all speech perception measures were obtained with the CI alone. Individual procedures were established for each of the bilateral CI users (CI-6 and CI-22). CI-6 wore both implants during the course of the study, and changes in speech processing strategies were implemented on both CIs. She was tested with each ear separately at the first two test sessions (A0 and A1 time points). However, due to a testing error during the third session (B1 time point), data collection from the right ear was discontinued. Only data for the left CI is reported here. The other bilateral CI user, CI-22, used a Nucleus-24 CI in the contralateral ear. This subject was tested while wearing only the study implant, and was asked to wear that implant alone at least 8 hours per day over the course of the study. On average, however, he used the study CI alone for only 5 hours per day because he relied on bilateral stimulation to converse in difficult listening situations.
Study design
An A0A1B1A2 within-subject experimental design was followed, with 2–3 hours of testing performed at each of the four time points. As described below, a fifth time point (B2) was completed by some subjects. “Strategy-1” (the subject's clinical strategy) was evaluated at time points A1 and A2; “strategy-2” (the novel strategy) was evaluated at time points B1 and B2. The main portion of the study (time points A0 through A2) incorporated 8 weeks of take-home experience with strategy-2. This duration of experience was chosen as a compromise between what we considered to be an ideal period of experience (12 weeks or longer, as used in the Advanced Bionics clinical trial) and a total study duration that would be palatable to potential subjects. The fifth time point (B2) was added to determine whether 3 months' additional experience with strategy-2 would lead to further changes in performance. Five of the 10 subjects agreed to complete this optional phase of the study: CI-17, CI-23, CI-26, CI-27 and CI-28. All five of these subjects began the study using the HiRes strategy; thus, they received 3 months additional experience with Fidelity120 and were retested with Fidelity120 at the B2 time point. The activities performed at each time point are summarized in Table 2.
Table 2.
Summary of activities conducted at each time point in the study.
| Time point | Activities |
|---|---|
| A0: week 1 (baseline) |
|
| A1: week 3 (strategy-1) |
|
| B1: week 11 (strategy-2) |
|
| A2: week 13 (strategy-1) |
|
| B2: week 25 (strategy-2) |
|
Pitch ranking
Pitch ranking was tested using the Bionic Ear Data Collection System (BEDCS; Advanced Bionics, 2003), which permitted direct stimulation of the implanted electrodes through a serial-port interface and dedicated speech processor. Adjacent electrodes in the apical, middle and basal regions of the implanted array (electrodes 2–3, 7–8 and 12–13, respectively) were tested. Electrodes in each pair were stimulated simultaneously using current amplitudes that varied in their relative weights. Following the convention used in previous reports (e.g., Donaldson et al. 2005; Firszt et al., 2007), the proportion of current directed to the more basal electrode in the pair was denoted as α. α = 0 refers to the single electrode condition where all current was directed to the apical electrode in the pair; α = 1 refers to the single-electrode condition where all current is directed to the basal electrode in the pair; and 0 < α < 1 refers to the dual-electrode stimulus where α is the proportion of current directed to the basal electrode and 1- α is the proportion of current directed to the apical electrode.
Stimuli were 200-ms trains of 1000 pps, 32.2 μs/ph, cathodic-first biphasic pulses presented in monopolar mode. Current levels producing loudness percepts of MEDIUM, MEDIUM LOUD, and LOUD were determined for the α=0 and α =1 stimuli, and proportional current levels for α = 0.75, 0.5 and 0.25 were computed using linear interpolation. During the pitch-ranking task, stimuli were presented at an average current level corresponding to MEDIUM LOUD, and were roved from trial to trial over ±20% of the range of current amplitudes spanning the MEDIUM and LOUD loudness levels. Level roving was intended to compensate for possible loudness differences between the single- and dual-electrode stimuli, since dual-electrode stimuli may require slightly higher current levels to generate equivalent loudness levels (Donaldson et al., 2005).
A 2AFC fixed-level procedure was used to construct a psychometric function of place-pitch sensitivity versus α for each electrode pair (apical, middle, basal), following procedures we have used previously (Donaldson et al., 2005). Four values of α (1, 0.75, 0.5, 0.25) were tested. Two stimuli were presented on each trial: α=0 (the reference stimulus) and α=1, 0.75, 0.5 or 0.25 (the comparison stimulus). The subject was instructed to pick the sound with the higher pitch; the response was counted correct if the stimulus with the larger value of α was selected. No correct-answer feedback was given. Test blocks consisted of 10 trials for each value of α (40 trials per block) presented in easy-to-hard order (α=1 decreasing to α=0.25). Five blocks were completed for each pair of electrodes; thus, the final percent-correct score for each value of α was based on 50 pitch judgments. For each electrode pair, percent-correct scores were converted to d' values using a table (Hacker and Ratcliff, 1979) and a psychometric function (d' versus α) was constructed. The value of α producing performance of d'=1.16 (equivalent to 79.4% correct) was estimated using linear interpolation between points on the function. This value was taken to be the place-pitch threshold.
Sound field thresholds
Sound field thresholds were obtained at three time points during the study to assess audibility and to ensure that audibility was similar for the HiRes and Fidelity120 strategies. Thresholds were determined for pulsed warble tones at octave frequencies from 500 to 4000 Hz using a Modified Hughson-Westlake procedure (Carhart and Jerger, 1959).
Mapping and volume control settings
Prior to the first test session, each subject was asked whether their current clinical map was judged to be satisfactory. All subjects expressed satisfaction with their clinical maps, thus, no basic remapping was performed. Seven of 10 subjects had all 16 intracochlear electrodes activated in their clinical maps; two subjects had 1 of 16 electrodes deactivated (CI-26: el. 16; CI-30: el.4) and the remaining subject had 2 of 16 electrodes deactivated (CI-6L: els. 8, 16).
At the A0 time point the subject's clinical map (strategy-1) was loaded onto a Harmony BTE processor. Six subjects used their own Harmony processor; the remaining four subjects used one of four new loaner processors provided by Advanced Bionics Corporation. The processor was fitted with a new microphone (T-mic) and, if necessary, the following adjustments were made to the initial map: First, if the input dynamic range (IDR) was set to a value less than 60 dB, it was increased to 60 dB. Second, if the subject's sound field thresholds were higher than 35 dB HL at 1000, 2000 or 4000 Hz, then the threshold current levels specified for individual electrodes (T-levels) were increased. This increase was limited to 25% of maximum stimulation levels (M-levels) so that the degree of compression in the amplitude mapping function would not change dramatically from that used clinically. Finally, two subjects' maps (CI-27, CI-28) were changed from the paired stimulation option (HiRes-P) to the sequential option (HiRes-S). As described earlier, this change was necessary in order to maintain a constant stimulation rate across strategies. No further changes were made to subjects' maps (other than changing strategies) during the remainder of the study.
Pulse rate varies inversely with pulse duration in the HiRes and Fidelity120 strategies. Most subjects in the present study used a relatively narrow pulse duration (16–21 μs/ph), resulting in pulse rates of 1500–1900 pps/channel. However, four subjects (CI-23, CI-24, CI-28, CI-30) used longer pulse durations (31–66 us/ph), resulting in pulse rates of 500–1000 pps/channel.
Subjects were instructed to adjust the volume control on their speech processor as needed to ensure comfortable loudness and clarity of speech signals in daily use. In addition, they were encouraged to adjust the volume control setting during the initial practice testing completed prior to each speech test. Once this setting was selected, it was unchanged for the remainder of testing for a given speech stimulus on a given test date.
Equipment for speech testing
Speech testing was conducted in a double-walled sound room that met ANSI standards for ambient noise levels (ANSI S3.1-1996). Vowel and consonant stimuli were stored on a personal computer, played out through a sound card (Lynx One), amplified (Crown D75) and presented to the subject through a high-quality loudspeaker (Spendor S3/5 se). Sentence stimuli were stored on an audio compact disc (CD), played out from a CD player (TEAC CD-P1250) through a 2-channel audiometer (InterAcoustics AC-40) and amplifier (Crown D45), and presented to the subject through the loudspeaker. Speech levels were calibrated using the A-weighting scale of a Type 2 sound level meter.
Vowel and consonant identification
A standard phoneme identification task was used to obtain vowel and consonant confusion data, using custom scripts written for the EPrime version 1.1 software (Psychology Software Tools, Inc., 2002) running on a personal computer. Stimuli were presented at a level of 65 dB SPL. The subject was seated approximately 1 meter in front of the loudspeaker (0° azimuth) in front of a computer monitor. After each stimulus presentation, the subject used a computer mouse to select his or her response from a list of phonemes displayed on the monitor.
Vowel stimuli were taken from the /hVd/ database of Hillenbrand et al. (1995). The eleven stimuli were the words “had, hod, head, hayed, heard, hid, heed, hoed, hood, hud, and who'd.” Subjects were familiarized with the task using a practice block of 22 stimuli consisting of 2 presentations of each word spoken by different male talkers. Standard blocks consisted of 6 presentations of each word spoken by 6 different male talkers for a total of 66 presentations per block. Ordering of stimuli within the practice and standard blocks was randomized.
Consonant stimuli were taken from the database of Shannon et al. (1999). Nineteen consonants, /p, t, k, b, d, g, t , f, s,
, f, s,  , v, z, ð, m, n, r, l, w, and j/, were tested using the /iCi/ vowel context; this context is more challenging for CI users than the commonly used /
, v, z, ð, m, n, r, l, w, and j/, were tested using the /iCi/ vowel context; this context is more challenging for CI users than the commonly used / C
C / context (Donaldson and Kreft, 2006). Practice blocks consisted of 2 tokens of each consonant spoken by 2 different male talkers, for a total of 38 presentations. Standard test blocks consisted of 3 tokens of each consonant spoken by 3 different male talkers for a total of 57 presentations per block. As was the case for vowels, the ordering of stimuli was randomized within the practice and standard blocks.
/ context (Donaldson and Kreft, 2006). Practice blocks consisted of 2 tokens of each consonant spoken by 2 different male talkers, for a total of 38 presentations. Standard test blocks consisted of 3 tokens of each consonant spoken by 3 different male talkers for a total of 57 presentations per block. As was the case for vowels, the ordering of stimuli was randomized within the practice and standard blocks.
For both vowel and consonant stimuli, a minimum of 5 standard blocks were collected and an overall percent correct score was computed for each block. If scores for the initial 5 blocks had a range greater than 10%, additional blocks were collected up to a maximum of 7 blocks, and the 5 blocks yielding the highest scores were used for data analysis. The five blocks to be analyzed were merged into a single matrix and submitted to information transmission analysis (Miller and Nicely, 1955). Measures of percent transmitted information (%TI) were computed for overall identification of vowel stimuli (Vow STIM) and consonant stimuli (Con STIM). Similar measures (%TI) were computed for the spectrally-based features of vowel F1 frequency (Vow F1), vowel F2 frequency (Vow F2) and consonant place-of-articulation (Con PLC) using the feature categories shown in Table 3.
Table 3.
Feature categories used for the vowel and consonant transmission analyses.
| Category # | Vow F1 | Vow F2 | Con PLC |
|---|---|---|---|
| 1 | /  , i, u / (high) , i, u / (high) |
/  , o, , o,  , u / (back) , u / (back) |
/ p, b, f, v, m, w / (front) |
| 2 | / ε, e, o,  / (mid) / (mid) |
/ æ, ε, e, I, i / (front) | /t, d, s, ð, t , n, l / (mid) , n, l / (mid) |
| 3 | / æ,  / (low) / (low) |
/ k, g,  , r, j / (back) , r, j / (back) |
BKB Sentences in Noise
The Bamford-Kowal-Bench Sentences In Noise (BKB-SIN) test (Etymōtic Research) was used to determine the signal-to-noise ratio (SNR) at which subjects recognized 50% of key words in sentences (SNR-50 value). This test consists of BKB Sentences (Bench et al., 1979) spoken by a male talker and recorded in the presence of four-talker babble. Within each list, the level of the target sentences is held constant and the level of background babble increases from +21 dB SNR to 0 dB SNR in 3 dB steps. Target sentences were presented at a level of 60 dB HL (75 dB SPL). This level is similar to the average MCL (58.1 dB HL) reported for 21 CI users listening to a narrative passage read by a male talker (Donaldson et al., 2009). At each time point (A1, B1, A2 and B2), two lists of sentences (32 sentences total) were presented to the subject after administration of a practice list. SNR-50 values from the four lists were then averaged to produce a single SNR-50 estimate.
BKB Sentences in Quiet
The BKB Sentences were also administered at the initial test session without background noise, to provide an overall index of subjects' sentence recognition ability under optimal listening conditions. Two lists of BKB Sentences (32 sentences, total) were presented at 60 dB HL (75 dB SPL) and scored for key words correct. Subjects' scores on these sentences are included in Table 1.
Results
Place Pitch Sensitivity
Figure 1 shows psychometric functions constructed from the pitch-ranking data of two subjects, CI-17 and CI-26. CI-17 achieved one of the highest scores on the BKB Sentences in quiet, whereas CI-26 achieved the lowest score on that measure. Each function describes d' as a function of α, with the dashed line representing the threshold criterion of d' = 1.16. The functions are generally well behaved, with performance increasing or remaining relatively constant with increasing values of α. For CI-17 (top row of graphs) estimated thresholds were α = 0.13 for the apical and basal electrode pairs (left and right panels, respectively) and α = 0.23 for the middle pair (center panel). By extrapolation, it may be inferred that CI-17 could perceive approximately 7 intermediate pitches between electrodes comprising the apical and basal electrode pairs and approximately 3 intermediate pitches between electrodes comprising the middle pair (Firszt et al., 2007). CI-26 demonstrated poorer place-pitch sensitivity. For the middle electrode pair, threshold was estimated to be α = 0.58, suggesting that CI-26 could perceive only 1 intermediate pitch. The place-pitch threshold was even larger for the apical electrode pair (α = 0.85), indicating that she could barely distinguish the pitches of the two physical electrodes. For the basal electrode pair, CI-26 was unable to distinguish the two physical electrodes on the basis of pitch, as indicated by the α value of “ > 1”.
Figure 1.

Example psychometric functions for place-pitch discrimination for two subjects (CI-17 and CI-26), for apical, middle and basal electrode pairs. Each function shows discrimination performance (d') as a function of the proportion (α) of current delivered to the more basal electrode of the pair. The dashed line in each panel indicates the performance level (d'=1.16) corresponding to place-pitch threshold.
Table 4 shows the place-pitch thresholds for all 10 subjects. Overall, place-pitch sensitivity was best for the middle electrode pair. For this pair, every subject was able to discriminate the two physical electrodes and 8 of 10 subjects had place-pitch thresholds smaller than α = 0.5, corresponding to 1 or more intermediate pitch between the physical electrodes. Thresholds were poorer for the apical and basal pairs. Two subjects (CI-25 and CI-26), were unable to discriminate the adjacent physical electrodes for one or the other of these pairs. A third subject (CI-6), was unable to discriminate the physical electrodes for either pair, despite having excellent place-pitch discrimination for the middle pair (α = 0.15). Notably, only 4 of the 10 subjects (CI-17, CI-23, CI-24 and CI28) had place-pitch thresholds smaller than α = 0.5 for all three electrode pairs.
Table 4.
Place-pitch discrimination thresholds for individual subjects. A value of “>1” indicates that the subject was not able to discriminate between the two physical electrodes in the pair. These values were excluded from computations of the mean and standard error.
| Subj | apical | middle | basal |
|---|---|---|---|
| CI-6L | >1 | 0.15 | >1 |
| CI-17 | 0.16 | 0.30 | 0.16 |
| CI-22 | 0.43 | 0.21 | 0.96 |
| CI-23 | 0.49 | 0.22 | 0.44 |
| CI-24 | 0.30 | 0.14 | 0.44 |
| CI-25 | >1 | 0.78 | 0.96 |
| CI-26 | 0.85 | 0.58 | >1 |
| CI-27 | 0.36 | 0.28 | 0.80 |
| CI-28 | 0.23 | 0.45 | 0.35 |
| CI-30 | 0.69 | 0.32 | 0.09 |
|
| |||
| mean* | 0.44 | 0.34 | 0.53 |
| s.e.* | 0.08 | 0.07 | 0.12 |
excludes values > 1
Vowel and consonant identification
Figure 2 shows the percentage of transmitted information (%TI) conveyed to each subject for vowels (Vow STIM) and the two vowel spectral features (Vow F1 and Vow F2). Figure 3 shows comparable data for consonants (CON STIM) and the consonant place-of-articulation feature (Con PLC). Here, and in later tables and figures, the following abbreviations are used: HR = HiRes strategy (data from main study), Fid = Fidelity120 strategy (data from main study), and Fid3M = Fidelity120 data from the B2 time point (after 3 months' additional use). In each panel of these figures, the 8 subjects who entered the study using HiRes are shown in the left subplot and the 2 subjects who entered the study using Fidelity120 are shown in the right subplot. Within each group, subjects are arranged in increasing order of performance for vowel transmitted information (%TI Vow STIM) at the A1 time point. Note that for subjects in the left subplot of each panel, the A1 data were obtained with the HiRes strategy, whereas for subjects in the right subplot, the A1 data were obtained with the Fidelity120 strategy.
Figure 2.

Percent transmitted information (%TI) for the Vow STIM, Vow F1 and Vow F2 measures, by subject and time point. The left panel shows data for subjects who entered the study using HiRes; the right panel shows data for subjects who entered the study using Fidelity120. Within each panel, subjects are shown in increasing order of initial (A1) performance on the Vow Stim measure.
Figure 3.

Percent transmitted information (%TI) for the Con STIM and Con PLC measures, by subject and time point. Subjects are arranged as in Figure 2.
There was considerable individual variability in performance for each measure. For example, performance on the Vow STIM measure ranged from 35%TI to 85%TI, and performance on the Con STIM measure ranged from 42%TI to 77%TI. Transmission of Vow F1 and Vow F2 information was considerably better than transmission of Con PLC information, consistent with previous reports (McKay and McDermott, 1993; Donaldson and Allen, 2003).
A comparison of mean performance at the A1 and A2 time points revealed small but significant improvements at the A2 time point for the Vow F1 and Con STIM measures, suggesting possible learning effects (paired t-tests, Vow F1: t=−2.43, df=9, p=0.04; Con STIM: t = −2.61, df = 9, p = 0.03). In addition, several individual subjects showed possible learning effects for other measures. These learning effects could reflect task learning or, alternatively, could reflect perceptual learning that occurred when using the novel strategy. For example, when the novel strategy was Fidelity120, experience with virtual channels could have led to a generalized improvement in spectral cue perception that was reflected in subsequent testing with HiRes. To compensate for such learning effects, %TI values from the B1 and A2 time points were used to compare the HiRes and Fidelity120 strategies. By comparing performance at these two time points, strategy-1 (typically HiRes) was given the benefit of any possible learning that occurred between the B1 and A2 time points. This results in a maximally stringent test of improvement with strategy-2 (typically Fidelity120).
Figure 4 plots the mean comparison data for all 10 subjects (HR and Fid conditions) and Figure 5 plots the mean comparison data for the subset of 5 subjects who completed the B2 time point (HR, Fid and Fid3M conditions). The mean %TI scores shown in Fig. 4 (representing all 10 subjects) indicate that strategy (HiRes vs. Fidelity120) had little effect on average performance for any of the vowel or consonant measures. Statistical evaluation confirmed this observation for 4 of 5 measures (paired t-tests [df=9], Vow STIM: t=0.75, p=−0.47; Vow F1: t=−6.54, p=0.53; Vow F2: t=−0.04, p=0.97; Con PLC: t=−0.06, t=0.95). For Con STIM, HiRes produced significantly higher average scores than Fidelity120 (paired t-test, t =2.29, df=9, p=0.048). However, the absolute difference in mean performance was only 2.7 percentage points (63.1 %TI for HiRes vs. 60.4% %TI for Fid120).
Figure 4.
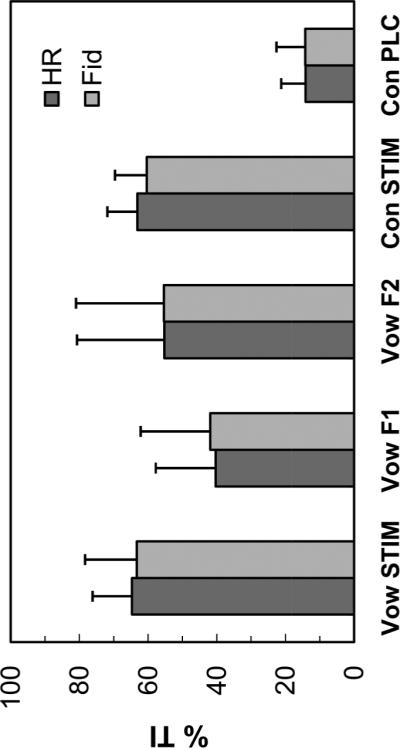
Mean %TI data for five vowel and consonant measures, for the HiRes and Fidelitiy120 strategies. The data represent 10 subjects who completed the main study (HR and Fid conditions).
Figure 5.

Mean %TI data for five vowel and consonant measures, for the HR, Fid and Fid3M conditions. The data represent 5 subjects who used Fidelity120 for an additional 3 months following the main study (Fid3M condition).
The data in Fig. 5, representing 5 subjects who completed the B2 time point, indicate a trend toward higher performance for Fid3M as compared to HiRes (or Fid) for the three vowel measures and Con PLC. One-way repeated measures analyses of variance (ANOVAs) indicated that differences were clearly not significant for Vow F1, Vow F2, Con STIM or Con PLC (Vow F1: F[2,8]=2.52, p=0.14; Vow F2: F[2,8]=2.84, p=0.12; Con STIM: F[2,8]=2.29, p=0.16; Con PLC: F[2,8]=0.80, p=0.48). Differences approached (but did not reach) significance for the Vow STIM measure (F[2,8]=3.82; p=0.07), with mean performance for the Fid3M condition being approximately 6 percentage points higher than performance for either the HiRes or Fid condition (71.6 %TI for Fid3M vs. 65.5 %TI for HiRes and 65.0 %TI for Fid).
In Figure 6, individual subjects' Fid and Fid3M data are expressed relative to their performance with HiRes. Positive values represent better performance with Fidelity120 relative to HiRes; negative values represent better performance with HiRes relative to Fidelity120. Dashed lines are shown at values of +10 %TI and −10 %TI in order to highlight those instances in which performance differed by ten percentage points or more across strategies. The choice of ten percentage points was intended to reflect a change that may be meaningful from a clinical perspective.
Figure 6.

Change in performance with Fidelity120 relative to HiRes, for each of five vowel and consonant measures. Comparisons reflect data obtained with Fidelity120 during the main study (Fid condition) or after 3 months of additional experience (Fid3M condition).
As illustrated in Fig. 6, there were relatively few instances where performance differed by more than 10 percentage points across strategies. None of the 10 subjects showed performance differences of this magnitude for the Vow STIM measure. Three subjects showed differences exceeding 10 percentage points for the Vow F1 measure, with two instances favoring Fidelity120 (CI-26 and CI27) and one instance favoring HiRes (CI-28). For the two subjects whose performance was higher with Fidelity120, gains were apparent only at the Fid3M time point. One of these subjects (CI-26) showed a sizable gain of 27.3 percentage points, representing more than a four-fold improvement in performance relative to HiRes (34.9 %TI for Fid3M vs. 7.3 %TI for HiRes). Recall that this subject was peri-lingually deafened and demonstrated poor sentence recognition in quiet. For the subject who exhibited decrements in performance with Fidelity120 relative to HiRes (CI-28), the deficit was greatest at the 8-week time point (Fid) and partially resolved with additional use of the Fidelity120 strategy (Fid3M). This suggests possible acclimatization over time. For the Vow F2 measure, two subjects (CI-17 and CI-27) showed clear gains with Fidelity120 relative to HiRes while two others (CI-25, CI-22) showed clear deficits. CI-17's gain with Fidelity120 was robust (~20 percentage points), and was evident after only 8 weeks' use of the new strategy (Fid condition). In constrast, CI-27's gain (~18 percentage points) was apparent only after a longer period of use (Fid 3M condition). Neither of the subjects who showed early deficits with Fidelity120 participated in the final phase of the study; thus, it is not known whether their deficits would have resolved with additional use of that strategy. Strategy had neglible effects on the Con STIM measure for all subjects except one. That subject (CI-28) showed a deficit of 11 percentage points with Fidelity120 during the main study (Fid); however, the deficit was reduced to 7.1 percentage points at the Fid3M time point. Recall that CI-28 showed a similar pattern of performance for the Vow F1 measure. Overall, this subject appears to have had difficulty with the change to Fidelity120, but to have been adjusting slowly to the new stimulation patterns over time. Only one subject (CI-17) showed changes related to strategy for the Con PLC measure. He showed a gain of 12.3 percentage points with Fidelty120 relative to HiRes during the main study (Fid); however, this gain was reduced to 8.3 percentage points at the later (Fid3M) time point.
The data in Fig. 6 may also be summarized on a subject-by-subject basis, as follows: Only 3 of 10 subjects showed improvements of ten percentage points or more with Fidelity120 relative to HiRes on one or more phoneme measures. Subject CI-26 demonstrated a gain for one measure (Vow F1); subjects CI-17 and CI-27 demonstrated gains for two measures (Vow F2 and Con PLC for CI-17; Vow F1 and Vow F2 for CI-27). An equal number of subjects (3 of 10) showed decrements of ten percentage points or more with Fidelity120 as compared to HiRes. CI-25 and CI-22 exhibited decrements on the Vow F2 measure. These subjects did not complete the final phase of Fidelity120 testing, so it is not known whether their early deficits with Fidelity120 would have resolved over time. CI-28 showed early deficits with Fidelity120 on the Vow F1 and Con STIM measures; however, as noted above, his performance improved at the Fid3M time point, suggesting possible acclimatization over time.
Sentence recognition in noise
Individual subjects' BKB-SIN scores measured at the A1, B1 and A2 time points are plotted in Figure 7. Scores are expressed as the SNR (in dB) producing 50% correct key word recognition (SNR-50), with lower values representing better performance. Similar to earlier figures, subjects who began the study using HiRes are shown in the left panel, and subjects who began the study using Fidelity120 are shown in the right panel. Visual inspection of the data in Fig. 7 reveals that five subjects (CI-23, CI-27, CI-17, CI-30 and CI-6L) showed little or no change in SNR-50 scores with Fidelity120 as compared to HiRes. Four other subjects (CI-28, CI-22, CI-24 and CI-25) showed a consistent difference across strategies, with HiRes always supporting better performance than Fidelity120. One subject (peri-lingually deafened subject CI-26) had very poor SNR-50 scores (~19 dB SNR) with both strategies during the main part of the study, but showed an improvement of more than 3 dB SNR after using Fidelity120 for an extended period of time. This result is reminiscent of the improvements shown by several poorer-performing subjects in the Advanced Bionics clinical trial.
Figure 7.

BKB-SIN scores (SNR-50 values) by subject and time point. Smaller SNR-50 values correspond to better speech recognition in noise. Subjects are ordered as in Figure 2.
To evaluate the effect of strategy, the same conservative comparison (A2 vs. B2 time points) was used as described previously for the vowel and consonant measures. Mean BKB-SIN scores are shown in Figure 8. Bars on the left side of Fig. 8 represent mean data for all 10 subjects for the HR and Fid conditions. These data reflect a 2.2 dB advantage for the HiRes strategy (12.0 dB SNR) over the Fidelity120 strategy (14.2 dB SNR). This difference approached but did not reach statistical significance (paired t-test, t =−1.93, p=0.08). Bars on the right side of Fig. 8 show mean data for the subset of 5 subjects who used Fidelity120 for 3 months following the main study (Fid3M condition). These subjects show a 2.1 dB mean advantage for HiRes during the main part of the study, similar to that shown by the larger group of subjects. However, a repeated measures ANOVA indicated that differences were not significantly different across the HiRes, Fid and Fid3M conditions (F[2,8]=1.67, p=0.25). Overall, the data shown in Figs. 7 and 8 indicate that strategy has no long-term effect on speech-in-noise performance for most subjects. However, a small proportion of subjects (e.g., CI-28) may perform better with HiRes even after extended experience with Fidelity120, and a small proportion of subjects (e.g., CI-26) may achieve small, long-term benefits with Fidelity120.
Figure 8.

Mean BKB-SIN scores (SNR-50 values) for the HiRes and Fidelity120 strategies. Data are shown for all 10 subjects (left) and for the subset of 5 subjects who used Fidelity120 for an additional 3 months following the main study (right). Smaller SNR-50 values correspond to better speech recognition in noise.
Relationship to place-pitch sensitivity
To evaluate our hypothesis that subjects with smaller place-pitch thresholds would demonstrate larger improvements in the perception of spectral speech cues with Fidelity120, place-pitch thresholds were compared to changes in performance for the Vow F1, Vow F2 and Con PLC measures using correlations. Fidelity120 data were limited to those obtained during the main study (Fid condition) due to the small number of subjects who completed Fid3M testing. Changes in %TI for a given measure were correlated with place-pitch thresholds for electrode pairs having the closest frequency correspondence based on the frequency-to-electrode map used in the HiRes and Fidelity120 strategies. For Vow F1, place-pitch thresholds for the apical electrode pair were used (electrodes 2–3, center frequencies 455–540 Hz). For Vow F2 and Con PLC, average place-pitch thresholds for the middle and basal electrode pairs were used (electrodes 7–8 and 12–13, center frequencies 1076–1278 Hz and 2544–3022 Hz, respectively). Data points were excluded for those comparisons where one or more of the relevant place-pitch thresholds could not be measured (α >1).
Correlations between place-pitch thresholds and subjects' change in performance with Fidelity120 relative to HiRes were not significant for the Vow F1 or Con PLC measures (Vow F1: Pearson r =0.27, n=8, p=0.26; Con PLC: Pearson r=−0.17, n=8, p=0.34). However, a significant correlation was observed between place-pitch thresholds and performance on the Vow F2 measure (Pearson r = −0.73, n=8, p=0.04). As shown in Figure 9, Fidelity120 tended to produce better performance than HiRes when place pitch thresholds were smaller than α= 0.3 and HiRes tended to produce better performance than Fidelity120 when place pitch thresholds were larger than α= 0.3. This finding suggests that Fidelity120 can support improved perception of vowel F2 information only when subjects can detect several intermediate pitches between adjacent electrodes. It should be noted that the correlation shown in Fig. 9 depends relatively strongly on the data point representing CI-25 (lower right corner of the graph). With this data point eliminated, the correlation is no longer significant (r=−.53, n=7, p=0.22). Thus, we view the relationship between place-pitch sensitivity and improvement on the Vow F2 measure as being only weakly significant.
Figure 9.

Change in transmitted information (%TI) for Vow F2 (Fidelity120 vs. HiRes), plotted as a function of place-pitch threshold (a). Fidelity120 data are those from the main study (Fid condition). Individual data points were excluded when place-pitch thresholds > 1.
Discussion
To our knowledge, this study is the first to evaluate the potential benefit of Fidelity120 for the perception of spectral cues in vowels and consonants. Findings indicate that a relatively small proportion of subjects can be expected to show gains with Fidelity120 in comparison to HiRes after 2 to 5 months' experience. Three of 10 subjects in the present study achieved gains of 10 percentage points or more for at least one spectral feature (Vow F1, Vow F2 or Con PLC). Notably, these subjects represented varied speech recognition abilities. The subject who demonstrated the largest gain was a peri-lingually-deafened individual with relatively poor overall speech recognition ability. The other two subjects were postlingually-deafened individuals with higher levels of sentence recognition.
It is not clear from our data what duration of experience is needed for previous users of the HiRes strategy to attain asymptotic levels of spectral-cue perception with Fidelity120. Several subjects showed gains between the 8 week time point (Fid) and the final 3-month time point (Fid3M). This suggests that relatively long periods of adjustment may be needed for subjects to realize the potential benefits of Fidelity120, perhaps reflecting qualitative differences in the nature of spectral cues provided by the two strategies. Spectral cues are necessarily coded as across-channel cues with HiRes. Due to the implementation of current steering, some spectral cues will be coded as within-channel cues with Fidelity120. Subjects who have access to both types of cues, by virtue of good place-pitch sensitivity, may require a relatively long period of acclimatization to make use of the newly available within-channel cues.
Given the above supposition, it might be expected that age would influence subjects' ability to make use of the novel electrical stimulation patterns provided by Fidelity120. Among the nine postlingually deafened subjects in our sample, there was a trend for elderly subjects (ages > 75 years) to achieve less benefit than their younger counterparts (ages 50–68 years) for the Vow F2 measure (Pearson r = −0.62, p=0.8); however, there was no evidence of an age effect for any of the other speech measures that we tested.
We hypothesized that place-pitch thresholds would predict improvements in subjects' perception of spectral speech cues with the Fidelity120 strategy relative to the HiRes strategy. This prediction was only partially supported. There was a weakly significant, inverse relationship between place-pitch thresholds and improvement for the Vow F2 feature; however, there was no clear relationship between place-pitch thresholds and gains in performance for the Vow F1 and Cons PLC features. Several factors could potentially have contributed to our failure to find a consistent relationship between these measures:
First, there were clear differences in the perceptual requirements of the pitch-ranking and speech perception tasks. Place-pitch sensitivity was measured using a simple pulse train stimulus having a relatively long duration. In order to detect a difference between two stimuli, subjects needed only to detect a change in the excitation patterns of those stimuli, for example, by monitoring the apical or basal edge of the pattern. Such a change was presumably associated with a pitch or quality difference between the stimuli. In contrast, the perception of spectral cues in speech required the subject to detect and interpret differences in one or more acoustic features of a spectrally-complex stimulus. In some cases, such as vowel formant frequency, spectral cues are relatively long in duration and relatively static in frequency, similar to the stimuli used in the pitch-ranking task. However, speech energy falling into higher and lower frequency bands may obscure the excitation pattern related to a given formant. As a result, the perception of spectral cues related to formant frequency may be more difficult for a CI user than a simple pitch ranking task. This notion is supported by comparisons of formant discrimination thresholds for isolated formants and formants in CVC context in normal hearing listeners. Specifically, Kewley-Port (1995) found that second formant discrimination thresholds were up to twice as large in CVC context as in isolation. A related factor is that some of the other spectral cues that code vowel and consonant identity (e.g., formant transitions) are brief in duration and dynamic in nature. The ability to perceive and interpret such cues likely involves perceptual abilities different from those accessed by a simple pitch-ranking task.
Second, the perception of spectral speech cues may depend on the consistency of place-pitch sensitivity across a wide range of cochlear locations. In the present study, place-pitch sensitivity was estimated for only three pairs of adjacent electrodes, corresponding to frequency ranges of 455–540 Hz (apical), 1076–1278 Hz (mid) and 2544–3022 Hz (basal), respectively, in the speech processor map. For a given speech measure, we selected the most appropriate place-pitch thresholds for comparison, based on the frequency range of the measure in question; however, only one (Vow F1) or two (Vow F2, Con PLC) estimates were available. Given the relatively wide frequency ranges associated with these cues, undersampling of place-pitch thresholds may have influenced our results. This possibility could be investigated in future studies by examining place-pitch sensitivity for all pairs of implanted electrodes. It would be particularly interesting to measure the variability of place-pitch sensitivity across the implanted array since consistent place-pitch sensitivity may be important for the perception of spectrally-based cues in speech.
Previous studies have compared performance between the HiRes and Fidelity120 strategies on various sentence in noise tasks (Boston Scientific, 2007; Brendel et al., 2008; Firszt et al., 2009). However, in most cases, the data reported were subject to potential confounds as described in the Introduction. In the present study, BKB-SIN data failed to show a benefit of Fidelity120 over HiRes. Thus, as yet, there appears to be no clear evidence that Fidelity120 supports higher levels of sentence recognition in noise than HiRes. The key evidence that spectral resolution is important for speech perception in noise by CI users stems from the “number-of-channels” studies cited earlier. In these studies, CI users and NH listeners required more channels of spectral information to achieve asymptotic performance when speech was presented in noise as compared to quiet. However, the maximum number of channels that were useful to CI users was generally 10 or fewer. This degree of spectral resolution is considerably less than that provided by either the HiRes or Fidelity120 strategy. Our BKB-SIN data suggest that CI users cannot readily make use of the added spectral detail provided by Fidelity120 when listening in high levels of background noise. This is generally consistent with the findings of previous number-of-channels studies. However, it should be noted that subjects' daily use of the Fidelity120 processor may not have included much listening practice in levels of background noise (multi-talker babble) similar to those encountered during BKB-SIN testing. Thus, it is possible that subjects did not have the experience necessary to take advantage of enhanced spectral information in the test situation. If experience is indeed important in this regard, then subjects' performance with Fidelity120 may improve with targeted practice or auditory training using speech-in-noise tasks (e.g., Sweetow and Henderson Sabes, 2007). Such training could also lead to improved performance with the HiRes strategy.
An important limitation of the present study is that only subjects who began the study with Fidelity120 agreed to complete the final (B2) phase of the study. As a result, we were able to evaluate the effect of three months' additional experience with Fidelity120, but could not perform a similar evaluation with HiRes. Some subjects may have shown better performance with HiRes had they received additional experience with that strategy.
Conclusions
Fidelity120 supports improvements in the perception of vowel and consonant spectral cues, relative to HiRes, in some users of the Advanced Bionics CI. However, the proportion of users who demonstrate such benefit is relatively small. Only 3 of 10 subjects in the present study showed clear evidence of improved performance with Fidelity120 for one or more spectral features. Among these subjects, improvement was more common for vowel spectral cues than for consonant spectral cues.
Some experienced users of the HiRes device may demonstrate poorer spectral cue perception with Fidelity120 than with HiRes. Three subjects in the present study exhibited clear decrements in spectral cue perception with Fidelity120 after 8 weeks' take-home use. Data from one subject suggested that such decrements may be lessened or reversed as longer periods of experience are accumulated.
Some CI users require an extensive period of experience with Fidelity120 to achieve maximal gains in spectral cue perception. The present findings suggest that 5 months of experience, or more, may be needed.
Individual subjects' gains in spectral cue perception with Fidelity120 relative to HiRes are not strongly predicted by measures of place-pitch sensitivity measured in the apical, middle and basal regions of the electrode array. In the present study, improvement in the Vow F2 measure was inversely related to place-pitch sensitivity; however, other speech measures were not. Our failure to observe stronger relationships between these measures may reflect (1) differences in the simple-versus-complex nature of the stimuli used in the two tasks, and/or (2) limited sampling of place-pitch sensitivity across the electrode array in the present study.
Fidelity120 does not appear to support improvements in the recognition of speech in noise, relative to HiRes, at least given the durations of experience provided in this study.
Acknowledgements
This study was supported in part by NIH/NIDCD grant R01-DC006699. Advanced Bionics Corporation provided loaner speech processors for use during the study and cochlear implant microphones that were used during the study and kept by the subjects at the end of the study. They also provided subject incentives in the form of product credits and discount product pricing as described in the text. James Hillenbrand and Robert Shannon provided the vowel and consonant stimuli, respectively. Ben Russell assisted with data collection, and Jean Krause took part in helpful discussions during the course of the study. Leo Litvak provided technical consultation. He is employed by Advanced Bionics Corporation and was involved in the development of the Fidelity120 strategy. The authors are grateful to the research subjects who participated in this work and to Mario Svirsky and three anonymous reviewers who provided valuable comments on an earlier version of this paper.
Footnotes
This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Advanced Bionics . Bionic Ear Data Collection System, Version 1.16 Users Manual. 2003. [Google Scholar]
- Advanced Bionics . HiRes with Fidelity ™ 120 sound processing Implementing active current steering for increased spectral resolution in CII Bionic Ear and HiRes 90K users. Valencia, California: 2006. [Google Scholar]
- Bench J, Kowal A, Bamford J. The BKB (Bamford-Kowal-Bench) sentence lists for partially-hearing children. Br. J. Audiol. 1979;13:108–112. doi: 10.3109/03005367909078884. [DOI] [PubMed] [Google Scholar]
- Bonham BH, Litvak LM. Current focusing and steering: modeling, physiology, and psychophysics. Hear. Res. 2008;242:141–153. doi: 10.1016/j.heares.2008.03.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boston Scientific . HiRes with Fidelity 120™ Clinical Results. Advanced Bionics Corporation; Valencia, California: Feb, 2007. 2007. [Google Scholar]
- Brendel M, Buechner A, Krueger B, Frohne-Buechner C, Lenarz T. Evaluation of the Harmony soundprocessor in combination with the speech coding strategy HiRes 120. Otol. .Neurotol. 2008;29:199–202. doi: 10.1097/mao.0b013e31816335c6. [DOI] [PubMed] [Google Scholar]
- Carhart R, Jerger JF. Preferred method for clinical determination of pure-tone thresholds. J. Speech Hear. Res. 1959;24:330–345. [Google Scholar]
- Donaldson GS, Allen SL. Effects of presentation level on phoneme and sentence recognition in quiet by cochlear implant listeners. Ear Hear. 2003;24:392–405. doi: 10.1097/01.AUD.0000090340.09847.39. [DOI] [PubMed] [Google Scholar]
- Donaldson GS, Chisolm TH, Blasco GP, Shinnick LJ, Ketter K, Krause JC. BKB-SIN and ANL predict perceived communication ability in cochlear implant users. Ear Hear. 2009;30:401–410. doi: 10.1097/AUD.0b013e3181a16379. [DOI] [PubMed] [Google Scholar]
- Donaldson GS, Kreft HA. Effects of vowel context on the recognition of initial and medial consonants by cochlear implant users. Ear Hear. 2006;27:658–677. doi: 10.1097/01.aud.0000240543.31567.54. [DOI] [PubMed] [Google Scholar]
- Donaldson GS, Kreft HA, Litvak L. Place-pitch discrimination of single-versus dual-electrode stimuli by cochlear implant users. J. Acoust. Soc. Am. 2005;118:623–626. doi: 10.1121/1.1937362. [DOI] [PubMed] [Google Scholar]
- Faulkner Al, Rosen D, Wilkinson L. Effects of the number of channels and speech-to-noise ratio on rate of connected discourse tracking through a simulated cochlear implant speech processor. Ear Hear. 2001;22:431–438. doi: 10.1097/00003446-200110000-00007. [DOI] [PubMed] [Google Scholar]
- Firszt JB, Holden LK, Reeder RM, Skinner MW. Speech recognition in cochlear implant recipients: Comparison of standard HiRes and HiRes 120 sound processing. Otol. Neurotol. 2009;39:146–152. doi: 10.1097/MAO.0b013e3181924ff8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Firszt JB, Koch DB, Downing M, Litvak L. Current steering creates additional pitch percepts in adult cochlear implant recipients. Otol. Neurotol. 2007;28:629–636. doi: 10.1097/01.mao.0000281803.36574.bc. [DOI] [PubMed] [Google Scholar]
- Fishman KE, Shannon Rl. V., Slattery WH. Speech recognition as a function of the number of electrodes used in the SPEAK cochlear implant speech processor. J. Speech Hear. Res. 1997;40:1201–1215. doi: 10.1044/jslhr.4005.1201. [DOI] [PubMed] [Google Scholar]
- Friesen LM, Shannon RV, Baskent D, Wang X. Speech recognition in noise as a function of the number of spectral channels: Comparison of acoustic hearing and cochlear implants. J. Acoust. Soc. Am. 2001;110:1150–1163. doi: 10.1121/1.1381538. [DOI] [PubMed] [Google Scholar]
- Fu Q-J, Shannon RV, Wang X. Effects of noise and spectral resolution on vowel and consonant recognition: Acoustic and electric hearing. J. Acoust. Soc. Am. 1998;104:3586–3596. doi: 10.1121/1.423941. [DOI] [PubMed] [Google Scholar]
- Hacker MJ, Ratcliff R. A revised table of d' for M-alternative forced choice. Percept. Psychophys. 1979;26:168–170. [Google Scholar]
- Hillenbrand J, Getty LA, Clark MJ, Wheeler K. Acoustic characteristics of American English vowels. J. Acoust. Soc. Am. 1995;97:3099–3111. doi: 10.1121/1.411872. [DOI] [PubMed] [Google Scholar]
- Kewley-Port D. Thresholds for formant-frequency discrimination of vowels in consonantal context. J. Acoust. Soc. Am. 1995;97:3139–3146. doi: 10.1121/1.413106. [DOI] [PubMed] [Google Scholar]
- Kiefer J, von Ilberg C, Hubner-Egner J, Rupprecht V, Knecht R. Optimized speech understanding with the Continuous Interleaved Sampling speech coding strategy in patients with cochlear implants: effect of various in stimulation rate and number of channels. Annals Otol. Rhinol. Laryngol. 2000;109:1009–1020. doi: 10.1177/000348940010901105. [DOI] [PubMed] [Google Scholar]
- Koch DB, Downing M, Osberger MJ, Litvak L. Using current steering to increase spectral resolution in CII and HiREs 90K users. Ear Hear. 2007;28:38S–41S. doi: 10.1097/AUD.0b013e31803150de. [DOI] [PubMed] [Google Scholar]
- Loizou PC, Poroy O, Dorman MF. The effect of parametric variations of cochlear implant processors on speech understanidng. J. Acoust. Soc. Am. 2000;108:790–808. doi: 10.1121/1.429612. [DOI] [PubMed] [Google Scholar]
- McKay CM, McDermott HJ. Perceptual performance of subjects with cochlear implants using the Spectral Maxima Sound Processor (SMSP) and the Mini Speech Processor (MSP) Ear Hear. 1993;14:350–367. doi: 10.1097/00003446-199310000-00006. [DOI] [PubMed] [Google Scholar]
- Miller GA, Nicely PE. An analysis of perceptual confusions among some English consonants. J. Acoust. Soc. Am. 1955;27:338–352. [Google Scholar]
- Nogeira W, Litvak L, Edler B, Ostermann J, Buchner A. Signal processing strategies for cochlear implants using current steering. EURASIP J. Adv. Sig. Proc. 2009;2009:1–20. [Google Scholar]
- Russell BA, Donaldson G. Pitch-ranking of electric and acoustic stimuli by CI users. Proc. Mtgs. Acoustics. 2010;9:1–7. [Google Scholar]
- Saoji AA, Litvak LM, Hughes ML. Excitation of simultaneous and sequential dual-electrode stimulation in cochlear implant recipients. Ear Hear. 2009;30:559–567. doi: 10.1097/AUD.0b013e3181ab2b6f. [DOI] [PubMed] [Google Scholar]
- Shannon RV, Jensvold A, Padilla M, Robert ME, Wand X. Consonant recordings for speech testing. J. Acoust. Soc. Am. 1999;106:L71–L74. doi: 10.1121/1.428150. [DOI] [PubMed] [Google Scholar]
- Shannon RV, Fu Q-J, Galvin JJ. The number of spectral channels required for speech recognition depends on the difficulty of the listening situation. Acta Otolaryngol. Suppl. 204. 2004;552:50–54. doi: 10.1080/03655230410017562. [DOI] [PubMed] [Google Scholar]
- Sweetow RW, Henderson Sabes J. The need for and development of an adaptive listening and communication enhancement (LACE) program. J. Am. Acad. Audiol. 2006;17:538–558. doi: 10.3766/jaaa.17.8.2. [DOI] [PubMed] [Google Scholar]
- Vandali AE, Whitford LA, Plant KL, Clark GM. Speech perception as a function of electrical stimulation rate using the Nucleus 24 cochlear implant system. Ear Hear. 2000;21:608–624. doi: 10.1097/00003446-200012000-00008. [DOI] [PubMed] [Google Scholar]
- Verschuur CA. Effect of stimulation rate on speech perception in adult users of the Med-El CIS speech processing strategy. Int. J. Audiol. 2005;44:58–63. doi: 10.1080/14992020400022488. [DOI] [PubMed] [Google Scholar]
- Wilson BS, Schatzer R, Lopez-Poveda EA, Sun X, Lawson DT, Wolford RD. Two new directions in speech processor design for cochlear implants. Ear Hear. 2005;26:73S–81S. doi: 10.1097/00003446-200508001-00009. [DOI] [PubMed] [Google Scholar]