

Abstract
In this paper we extract the topology of the semantic space in its encyclopedic acception, measuring the semantic flow between the different entries of the largest modern encyclopedia, Wikipedia, and thus creating a directed complex network of semantic flows. Notably at the percolation threshold the semantic space is characterised by scale-free behaviour at different levels of complexity and this relates the semantic space to a wide range of biological, social and linguistics phenomena. In particular we find that the cluster size distribution, representing the size of different semantic areas, is scale-free. Moreover the topology of the resulting semantic space is scale-free in the connectivity distribution and displays small-world properties. However its statistical properties do not allow a classical interpretation via a generative model based on a simple multiplicative process. After giving a detailed description and interpretation of the topological properties of the semantic space, we introduce a stochastic model of content-based network, based on a copy and mutation algorithm and on the Heaps' law, that is able to capture the main statistical properties of the analysed semantic space, including the Zipf's law for the word frequency distribution.
Introduction
The meaning of a word can be defined as an indefinite set of interpretants, which are other words that circumscribe the semantic content of the word they represent [1]. In the same way each interpretant has a set of interpretants representing it and so on. Hence the indefinite chain of meaning assumes a rhizomatic shape that can be represented and analysed via the modern techniques of network theory [2].
The semantic or conceptual space (SS hereafter) has already been investigated by different approaches. A common understanding within these approaches is that the SS is made up of words or concepts that are connected by certain relationships. Depending on the nature of these relationships different semantic webs have already been considered. In the psycholinguistics approach the SS is often extracted via free word association game and a network is constructed where two words are connected if they appear to be consecutive in a free word association experiment [3], [4]. Other semantic webs are generated through linguistics approaches [5]. Among others an interesting one is based on the dictionary, where the relationships between words are set to be of synonymy, antonymy, belonging to the same category or class, etc. [6], [7]. In all the mentioned cases a scale-free topology and small-world properties for the SS are found, suggesting an intrinsic self-organising nature of the SS [6]. However it has been argued that networks derived by dictionaries and representing the so called dictionary semantics, characterised by scale-free distribution for the connectivity with exponents smaller than -2, reflect the properties of language use more than the properties of the SS [8], [9].
In contrast to the dictionary representation of the SS, it has been suggested that the meaning of a sign, where a sign can be a word, a concept, etc. can be recovered within an encyclopedic model, where every sign is specified by a set of other signs that interpret it [10]. “This notion of interpretants is fertile because it shows how semiotic processes, via continuous movements that refer a sign to other signs or sign chains, circumscribe the meanings in an asymptotic way. They never touch them, and make them accessible via other cultural units […]. In this way an open system of connections between different signs is created that takes the shape of a rhizome [11]” [10].
Hence, in its encyclopedic semantics acception, the SS can be interpreted as a metapopulation system where each page of an encyclopedia is a population of interpretants/words characterising some meanings. Then the structure of SS assumes a dynamical connotation, typical of population dynamics, where the different concepts are born and grow in time, exchanging and inheriting attributes from other concepts (it is interesting to notice how Deleuze and Guattari foresaw the very essence of the semantic machine not as a machine producing meaning, but as a machine producing its own structure [12]).
In this work we attempt to extract the SS in its encyclopedic semantics acception. Following the semiotics rationale described above, we consider each page of an encyclopedia as a population of interpretants and we measure the correlations between each pair of pages of that encyclopedia in terms of directional semantic flows. In particular we analyse a whole dump of Wikipedia. Wikipedia is not only the largest encyclopedia existing nowadays, but it is an open encyclopedia with its pages always growing in size and number, thus it represents well the idea of encyclopedic semantics expressed above. The resulting network is a directed network of semantic flows between the different concepts that are present in an encyclopedia and thus portrays a snapshot of the dynamics of meaning in that representation of the SS.
The concept of information flow, as it is used in this context, is introduced in [13] to indicate the correlations between populations whose elements are defined by abstract attributes. Those populations can be social, biological or, as in this case, made of words. We choose the use of the term “information flow”, instead of distance between probability distributions or correlations, because in those systems correlations are often caused by migration or inheritance of a part of a population to another one. Thus the very term of information flow, that can be ethnical, genetical or, as in this case, semantic, gives an idea of such a dynamical process, where to a movement of elements from a population to another one, it corresponds to a flow of information in the attribute space where those elements are defined.
The dataset
We consider the articles of a complete snapshot of English Wikipedia dated June 2008 [14], consisting of 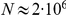 entries. To process our dataset first of all we get rid of redirection pages. Then, in order to analyse the semantic content of the encyclopedia, we process the text, cleaning it of punctuation and of the so called structural words like articles, pronouns, common adverbs, etc. [15], [16]. In fact those words are very frequent in each page and often don't contribute to its semantic characterisation. After that we lemmatise the text, transforming the different words in their singular form or in their infinite form if they are verbs [17]. The resulting set of lemmas defines the interpretants or attribute space where the different pages are defined and each Wikipedia page comes out to be defined by its lemmas frequency distribution and by its size.
entries. To process our dataset first of all we get rid of redirection pages. Then, in order to analyse the semantic content of the encyclopedia, we process the text, cleaning it of punctuation and of the so called structural words like articles, pronouns, common adverbs, etc. [15], [16]. In fact those words are very frequent in each page and often don't contribute to its semantic characterisation. After that we lemmatise the text, transforming the different words in their singular form or in their infinite form if they are verbs [17]. The resulting set of lemmas defines the interpretants or attribute space where the different pages are defined and each Wikipedia page comes out to be defined by its lemmas frequency distribution and by its size.
In order to compute the directional semantic flow between the pages we use the method introduced in [13]. This method is very general and allows the extraction of a directed information flow network from a set of populations whose elements are defined by an  -dimensional symbolic attribute vector. It is based on the Jensen-Shannon divergence [18] and within an information theory approach it is able to measure the amount of information flow within a set of populations of different sizes, defined in a symbolic attribute space. Moreover, using concepts derived from geographical segregation, the methodology in [13] is able to infer the directionality of the information flow. More details are given in the Materials and Methods section.
-dimensional symbolic attribute vector. It is based on the Jensen-Shannon divergence [18] and within an information theory approach it is able to measure the amount of information flow within a set of populations of different sizes, defined in a symbolic attribute space. Moreover, using concepts derived from geographical segregation, the methodology in [13] is able to infer the directionality of the information flow. More details are given in the Materials and Methods section.
The resulting network representing the SS, as we show below, displays scale invariant structures and small world properties, revealing a hierarchical SS, where the semantic clusters are strongly connected and communication between different areas of knowledge is fast.
Results
Topology of the Semantic Space
To build the network the directional semantic flow is measured between all the entry pairs. Then the entry pairs are ordered by the increasing values of their semantic distance, and a network of entries is defined considering two pages as linked when their semantic distance is smaller than a given threshold.
By increasing the value of the threshold we obtain a growing network where the first links to form are the strongest in a semantic sense. As the threshold is increased further, very well connected clusters form, each cluster representing different semantic areas. A significative threshold to analyse the network representing the SS is the percolation threshold (PT hereafter), when a giant cluster forms and a phase transition happens [2], [19].
The SS network reaches its PT at approximately 362000 pages, when the two main clusters merge to form a giant cluster of 57800 pages. At the PT the network has 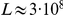 links with an average degree
links with an average degree 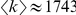 . The very large average degree means that the clusters are very densely connected. The network is composed by 44500 disconnected clusters showing scale invariant cluster size distribution,
. The very large average degree means that the clusters are very densely connected. The network is composed by 44500 disconnected clusters showing scale invariant cluster size distribution, 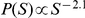 , with a fat tail (Fig. 1).
, with a fat tail (Fig. 1).
Figure 1. Cluster size distribution of the semantic space.

Cluster size distribution 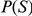 of the semantic network at the percolation threshold. In the inset we show the cumulative distribution
of the semantic network at the percolation threshold. In the inset we show the cumulative distribution 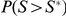 .
.
The scale-free cluster size distribution is the first important property we find for the SS. It has been shown that in a random growing network at the PT the cluster size distribution decays faster than a power law, 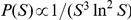 [2], [20]. Then it can be argued that the scale-free behaviour we find for the cluster size distribution is not an effect of a random growing network at percolation, but a peculiar property of the SS.
[2], [20]. Then it can be argued that the scale-free behaviour we find for the cluster size distribution is not an effect of a random growing network at percolation, but a peculiar property of the SS.
As a matter of fact at this threshold almost each cluster represents a well defined semantic area. Hence the scale-free distribution implies a hierarchy between the semantic areas and gives us a picture of the structure of the SS.
The largest clusters, representing the greater body of the SS, are composed of large taxonomies, such as geographical places, biological species, etc… The largest cluster is made of 38500 pages and consists of geographical places of USA, such as villages, cities, rivers, etc… The second largest cluster is made of 19300 pages and consists of taxonomies of living species as animal, plants, insects, bacteria, etc…The third largest cluster is mainly made of Romanian geographical entries, the fourth by French cities and villages and so on. In each of these clusters the pages are very simple and have a structure very similar to each other. A typical example of these kinds of pages is the Canarium Zeylanicum page, that is in the second largest cluster: “Canarium Zeylanicum is a species of flowering plant in the frankincense family, Burseraceae, that is endemic to Sri Lanka.”. The content word lemmas of this page are: “Canarium Zeylanicum specie flower plant frankincense family Burseraceae endemic Sri Lanka”. This page easily connects with all pages containing “specie flower plant endemic Sri Lanka”, hence forming a taxonomy with other pages as the Mastixia Nimali page: “Mastixia Nimali is a species of plant in the Cornaceae family. It is endemic to Sri Lanka.”. It is interesting to notice how the passage from a taxonomic page to another resides in the mutation of a few rare words.
Then clusters are found at all scales of magnitude, consisting of any semantic area one can possibly think of and generally the greater is the complexity of the page, the smaller is the cluster which it belongs to. There are clusters of football players, small clusters of different kind of bicycles, ethnicity clusters, language family clusters, singers, technology, religions, etc…
The out-degree and in-degree distribution of the network at the PT are scale-free with a very slow decay, characterised by exponents: 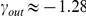 and
and 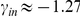 (see Fig. 2). The distributions are scale invariant until very large scales where a sharp cut-off appears, revealing that the SS is characterised by structures at all the scales. The giant component of the network has a directed diameter
(see Fig. 2). The distributions are scale invariant until very large scales where a sharp cut-off appears, revealing that the SS is characterised by structures at all the scales. The giant component of the network has a directed diameter 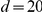 that is of the order of the logarithm of the cluster size. Moreover its average clustering coefficient is
that is of the order of the logarithm of the cluster size. Moreover its average clustering coefficient is 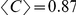 , that is larger than the clustering coefficient of a random network of the same size,
, that is larger than the clustering coefficient of a random network of the same size, 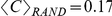 , revealing local small-world properties of the SS [21].
, revealing local small-world properties of the SS [21].
Figure 2. Connectivity distribution of the semantic space.

Out-degree distribution 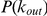 (left panel) and in-degree distribution
(left panel) and in-degree distribution 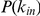 (right panel) of the semantic network at the percolation threshold. In the insets the corresponding cumulative degree distributions
(right panel) of the semantic network at the percolation threshold. In the insets the corresponding cumulative degree distributions 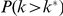 are displayed.
are displayed.
If the description at the cluster level represents the main body of the SS, the minimum spanning tree (hereafter MST) represents its backbone. The MST of a weighted network is an acyclic graph that has all the vertices of the network and that minimises the sum of the distances between the pages [22]. It represents the skeleton of the network and in a sense it represents how semantic information best flows throughout the SS.
We compute the undirected MST of the complete network of Wikipedia via the Prim's algorithm [23]. The degree distribution of the MST is scale free with exponent -2.4 and a fat tail (see Fig. 3). Again the scale-free behaviour of the degree distribution tells us about the hierarchical structure of the MST of the SS. If we glimpse at Fig. 4, where a small portion of the MST centred on the Wikipedia entry nature is shown, we can have a rough idea of how this hierarchy organises itself. A very general concept, such as “nature”, hasn't got a lot of connections, but it is an important bridge for the semantic flow between less complex concepts. Those less complex concepts are in general more connected and eventually form taxonomies, which are hubs in the MST.
Figure 3. Connectivity distribution of the minimum spanning tree of the semantic space.

Degree distribution 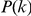 for the undirected minimum spanning tree for the whole network representing the semantic space. In the insets the cumulative degree distribution
for the undirected minimum spanning tree for the whole network representing the semantic space. In the insets the cumulative degree distribution 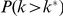 is displayed.
is displayed.
Figure 4. A portion of the minimum spanning tree of the semantic space.

A portion of the undirected minimum spanning tree of the network representing the semantic space in the neighbourhood of the entry nature until its third neighbour. The nodes represent different Wikipedia entries, while the edges represent a semantic flow between the different entries. The color partition is based on the nodes modularity classes. Figure realised with the opensource software Gephi [24].
From what has been said we can draw a general picture of the SS, as a space whose body is mainly composed of simple concepts that are densely clustered in taxonomies or classifications. Then, at higher levels, more complex concepts form, creating smaller semantic clusters. This hierarchy goes further, in a scale-free fashion, until the more general and elaborated concepts emerge and those create an architecture of semantic flow channels that spans through the whole SS.
The values of the exponents of the degree distributions are too large to be explained by standard growing network models based on preferential attachment [25]. For the character of the system and its statistical properties, the emerging topology of the SS is more likely to be represented by a new class of models of stochastic content-based networks of the type presented in [26]–[28], with the difference that in the case of Wikipedia the correlations generated by the zipfean distribution of content words [16] play an important role on the topology of the system as it is explained below. This observation relates the topology of the SS to a wider range of biological phenomenology [28].
The model
The complexity of the system we are considering is large, since it relates the phenomenology of different topics page writing to the topology of the macroscopic system of the SS.
Here we present a descriptive model that is able to catch the properties of the SS at three different levels of complexity. In particular it is able to reproduce the scale-free cluster size distribution, the exponents for the out and in-degree distribution and the Zipf's law for the word frequency distribution [29]. It is a growing stochastic model of content-based network generated by a copy and mutation algorithm. This is intended on one hand to create a multiplicative process a la Simon [30], to reproduce the scale-free cluster distribution and on the other hand to create, via mutation, very well connected taxonomic clusters to reproduce the very low exponent of the degree distribution. In the overall process a Heaps'-like law [31] for the text growth is imposed to produce correlations between pages and to allow a phase transition and this finally generates the Zipf's law for the word frequency distribution (see the Materials and Methods section for more details about the Heaps'-like law).
We give the details of the model in the Materials and Methods section, while here we just give its general description. Each page in the model is considered to be a collection of words. Those words can be new, extracted from a potentially infinite vocabulary, or old, picked up randomly from already written pages. The balance between new and old words is set to respect the Heaps'-like law between text size and vocabulary size. Each page is generated with an invariant part, whose size is random, that is a fixed portion of the page that doesn't change when the page mutates.
The model starts with a few pages of random words. Then, at each time step, we generate a new page of words, that, as explained above, are in part new words and in part words picked up randomly from already written pages, keeping the balance between text size and vocabulary size via the Heaps'-like law. Then, at each time step, we generate 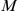 new pages by copying
new pages by copying 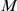 old pages, keeping unchanged their invariant part and mutating their variant part with some old or new words, always considering the balance between text size and vocabulary size via the Heaps'-like law.
old pages, keeping unchanged their invariant part and mutating their variant part with some old or new words, always considering the balance between text size and vocabulary size via the Heaps'-like law.
The generation of new pages in the model is intended to mimic the appearance of new pages in the encyclopedia, that are formed partially by a new vocabulary and partially by words that are inherited by already existing pages. Beside, the generation of pages via the mutation mechanism allows to generate the different growing taxonomies and in this way to mimic the phenomenology observed in the real encyclopedia, where different pages belonging to the same taxonomy differ only by a few rare words.
In Fig. 5 we show that with an opportune choice of the parameters this model can generate a system with the desired properties.
Figure 5. The stochastic model representing the semantic space.

Results for the simulation of the stochastic model representing the semantic space. This is a simulation of a toy-model for an encyclopedia of 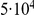 pages with size
pages with size 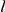 log-normally distributed, with first moment
log-normally distributed, with first moment 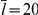 and second moment
and second moment 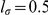 . The parameter of the model are
. The parameter of the model are 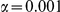 ,
, 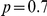 and
and 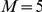 . In the top panels the out-degree distribution
. In the top panels the out-degree distribution 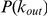 (left panel) and the in-degree distribution
(left panel) and the in-degree distribution 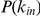 (right panel) of the semantic network at the percolation threshold are shown. The corresponding cumulative distributions
(right panel) of the semantic network at the percolation threshold are shown. The corresponding cumulative distributions 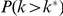 are displayed in the insets. In the bottom left panel we show the cluster size distribution
are displayed in the insets. In the bottom left panel we show the cluster size distribution 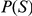 at the percolation threshold, the relative cumulative distribution
at the percolation threshold, the relative cumulative distribution 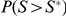 is displayed in the inset. In the right bottom panel we show the frequency-rank distribution
is displayed in the inset. In the right bottom panel we show the frequency-rank distribution 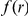 for the words in the model.
for the words in the model.
Discussion
Nowadays understanding the topology of the SS and the dynamics of meaning is a fundamental issue in many fields of knowledge and technology [32]. We can think about its value for understanding the dynamics of language and its evolution [33]–[35], or its relevance in psycholinguistics and psychology [36]. Also, apart for being one of the main research topics in semiotics, linguistics and philosophy [10], it has recently been a hot topic in artificial intelligence and robotics [37]. Moreover there is an active effort in the information systems community to develop semantic-based web research tools [38].
The results of this research shed light upon the topology of the SS, represented as an encyclopedic semantics. The empirical research is unique in two fundamental aspects: the first one is the content analysis of a whole snapshot of Wikipedia, the second one is that this analysis is directional.
The empirical analysis reveals interesting properties of the SS. On one hand we can observe that the SS cluster size distribution is scale-free. This observation relates the SS to a wide range of scale-free phenomena [25]. On the other hand we find a peculiar behaviour of the degree distribution. The latter observation relates the SS to a recently observed class of molecular biology phenomena, such as protein networks and more in general of genomic interaction networks [26], [28] and draws a bridge between phenomena whose underlying mechanism is a language, words for the SS and the DNA alphabet for the genomic networks.
Models of content-based network are powerful tools and recently they have attracted the attention of the scientific community especially for their relation to the so called hidden variable graphs [39], [40]. The presented stochastic model is descriptive and wants to individuate a few simple mechanisms that are able to reproduce some interesting statistical behaviours of the SS. In particular it is able to capture the statistical properties of Wikipedia at three levels of complexity. At microscopic level it can reproduce the Zip's law for the word frequency distribution, at mesoscopic level it generates the scale-free distribution for the semantic cluster size and finally at macroscopic level it can reproduce the exponents of the out and in-degree distribution. Interestingly enough we find again that the description of the SS at the model level resembles mechanisms of DNA evolution, where the process involved is of copy and mutation.
It is straightforward to relate the presented analysis with previous works on Wikipedia based on the analysis of the network of hyperlinks connecting the Wikipedia different entries [41]. In particular one of the questions arising from those works is if the Wikipedia hyperlink network has any relation to the underlying semantic network. Some attempts to answer this question are exposed in [32], where a positive correlation is found between hyperlinked pages and their semantic content. In the light of this research we can say that the topology of the SS is drastically different from the ones obtained by the hyperlinks analysis. In the latter case the exponents of the degree distribution are smaller than -2 and linear preferential attachment is recovered [41], [42], revealing a dynamics based on popularity. However this should not be a surprise since the network of hyperlinks is superimposed to the SS of the encyclopedia, so that it does not reflect the topology of the SS, but the structures locally imposed by the writers of the different entries.
We also notice that the topological properties of the SS are different from the ones obtained for dictionary semantics [6], [8]. The topological properties of dictionary networks, characterised by scale-free distribution with exponents smaller than -2, seem to be based again on a popularity mechanism and to reflect properties of language use more than the properties of the SS [9]. In contrast we find that the architecture of SS is scale invariant, hierarchical, it has small-world properties, but it is not associated to a rich get richer mechanism for the degree distribution.
In fact the SS structure is keen to be interpreted as an emerging property of a content-based network, where the Zipf's distribution of the content words is a key feature for the resulting topology.
Materials and Methods
A measure for the directional semantic flow
Given two pages characterised by their lemmas frequency distributions 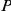 and
and 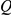 and by their size
and by their size 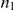 and
and 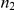 , we define their distance
, we define their distance 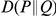 as:
as:
| (1) |
where 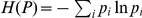 is the Shannon entropy measured in nats and
is the Shannon entropy measured in nats and 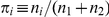 are the weights.
are the weights.
If 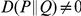 , the two pages have one or more words in common. Let's call
, the two pages have one or more words in common. Let's call 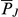 the frequency distribution of those common words for the first page, normalised to 1 and
the frequency distribution of those common words for the first page, normalised to 1 and 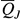 the frequency distribution of those common words for the second page, normalised to 1. Moreover let's call
the frequency distribution of those common words for the second page, normalised to 1. Moreover let's call 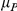 the fraction between the number of common words in the first page and the total number of words in the first page and
the fraction between the number of common words in the first page and the total number of words in the first page and 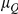 the fraction between the number of common words in the second page and the total number of words in the second page. Then we can define a directionality index as:
the fraction between the number of common words in the second page and the total number of words in the second page. Then we can define a directionality index as:
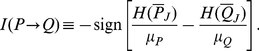 |
(2) |
If 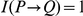 we can infer a direction of the semantic flow from the first page to the second one. Otherwise, if
we can infer a direction of the semantic flow from the first page to the second one. Otherwise, if 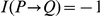 , we can infer a semantic flow from the second page to the first one.
, we can infer a semantic flow from the second page to the first one.
A detailed description of Eq.1 and Eq.2 is given in [13].
The Heaps'-like law
Written human language displays a fascinating puzzle of empirical regularities. Among them, the Heaps' law states that the vocabulary 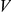 of a written text is a function of its size
of a written text is a function of its size 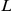 ,
, 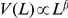 , with
, with 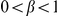 . The Heaps' law is strictly related to the Zipf's law for the word frequency distribution. The Heaps' law has been analytically and algorithmically derived from the Zipf's law [43], [44]. In [45] there is a derivation of the Zipf's law from the Heaps' law, even if it is not straightforward.
. The Heaps' law is strictly related to the Zipf's law for the word frequency distribution. The Heaps' law has been analytically and algorithmically derived from the Zipf's law [43], [44]. In [45] there is a derivation of the Zipf's law from the Heaps' law, even if it is not straightforward.
In network theory a written text can be represented by a network whose vertices are the words and two vertices are linked if they are adjacent in the text [46], [47]. A convenient way to model a growing text in network theory is to assume that at each time step  a new word and a fraction of old words
a new word and a fraction of old words 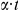 is introduced in text, possibly preserving the eulerianity of the system [48]. Hence in this representation the discrete time
is introduced in text, possibly preserving the eulerianity of the system [48]. Hence in this representation the discrete time  represents the size of the vocabulary. At each time step
represents the size of the vocabulary. At each time step 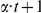 words are introduced in the text and the size
words are introduced in the text and the size 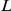 of the text is a function of the vocabulary size:
of the text is a function of the vocabulary size: 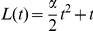 .
.
| (3) |
The model
a- When we generate a new page we first extract its size 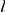 from a log-normal distribution, with first moment
from a log-normal distribution, with first moment 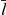 and second moment
and second moment 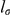 . Then we fill the page with some new words from a potentially infinite vocabulary and some old words picked at random from the already written pages. To establish the balance between new and old words we assume a variation of the Heaps' law, frequently used in network theory [2], that states that the growth of the length
. Then we fill the page with some new words from a potentially infinite vocabulary and some old words picked at random from the already written pages. To establish the balance between new and old words we assume a variation of the Heaps' law, frequently used in network theory [2], that states that the growth of the length 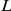 of a written text is a quadratic function of the size of the vocabulary
of a written text is a quadratic function of the size of the vocabulary  ,
, 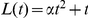 . Then we assign to the page a random number
. Then we assign to the page a random number  , so that
, so that 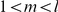 , representing the size of the invariant part of the page.
, representing the size of the invariant part of the page.
b-When we mutate a page we keep unchanged the first 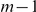 words of the page, that is the page invariant part. For the last
words of the page, that is the page invariant part. For the last 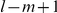 words of the page, each word is changed with probability
words of the page, each word is changed with probability 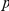 and it is kept unchanged with probability
and it is kept unchanged with probability 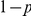 , where
, where 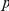 is a random number between 0 and 1. When we change a word we substitute it with an old or a new word considering the balance between vocabulary and text size as in point a.
is a random number between 0 and 1. When we change a word we substitute it with an old or a new word considering the balance between vocabulary and text size as in point a.
We start the model with a few pages of random words. Then at each time-step:
we generate a new page as explained at point a.
We create
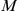 new pages copying
new pages copying 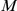 old pages picked up randomly from the old pages and mutating them as explained at point b.
old pages picked up randomly from the old pages and mutating them as explained at point b.
The important parameters of the model are 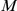 and
and  .
. 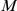 regulates the exponent of the cluster size distribution that goes, increasing the value of
regulates the exponent of the cluster size distribution that goes, increasing the value of 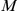 , from
, from 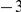 to
to 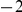 . Moreover, increasing
. Moreover, increasing 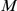 , more connected clusters form and this increases the exponent of the degree distribution from
, more connected clusters form and this increases the exponent of the degree distribution from 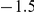 to
to  . The coefficient
. The coefficient  regulates the amount of correlations between the different semantic clusters and this gives the possibility to tune the point of percolation of the system.
regulates the amount of correlations between the different semantic clusters and this gives the possibility to tune the point of percolation of the system.
Acknowledgments
The authors are grateful to Konstantin Klemm, Marco Patriarca and José Ramasco for the useful comments and discussions on the subject and to Chris Bate for his last proof-reading. The IGraph package was used for some of the analysis of this research [49].
Footnotes
Competing Interests: The authors have declared that no competing interests exist.
Funding: Supported by Ministerio de Ciencia e Innovacion and Fondo Europeo de Desarrollo Regional through project FISICOS (FIS2007-60327). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.Derrida J. Minuit, Paris; 1972. Margins of Philosophy. [Google Scholar]
- 2.Dorogovtsev SN, Mendes JFF. Oxford: Oxford University Press; 2003. Evolution of Networks: From Biological Nets to the Internet and WWW. [Google Scholar]
- 3.Steyvers M, Tenenbaum JB. The Large-Scale Structure of Semantic Networks: Statistical Analyses and a Model of Semantic Growth. Cognitive Science. 2005;29:41–78. doi: 10.1207/s15516709cog2901_3. [DOI] [PubMed] [Google Scholar]
- 4.Borge-Holthoefer J, Arenas A. Categorizing words through semantic memory navigation. Eur Phys J B. 2010;74:265–270. [Google Scholar]
- 5.Montemurro M, Zanette D. Towards the quantification of the semantic information encoded in written language. Adv in Complex Syst. 2010;13:135–153. [Google Scholar]
- 6.Sigman M, Cecchi G. Global organization of the Wordnet lexicon. Proc Natl Acad Sci USA. 2002;99:1742–1747. doi: 10.1073/pnas.022341799. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Samsonovic AV, Ascoli GA. Principal Semantic Components of Language and the Measurement of Meaning. PLoS ONE. 2010;5:e10921. doi: 10.1371/journal.pone.0010921. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.de Jesus Holanda A, Torres Pisa I, Kinouchi O, Souto Martinez A, Seron Ruiz EE. Thesaurus as a complex network. Physica A. 2004;344:530–536. [Google Scholar]
- 9.Violi P. Milano: Bompiani; 1997. Meaning and experience. [Google Scholar]
- 10.Eco U. Torino: Biblioteca Einaudi; 1984. Semiotics and the Philosophy of Language. [Google Scholar]
- 11.Deleuze G, Guattari F. Paris: Minuit; 1976. Rhizome. [Google Scholar]
- 12.Deleuze G, Guattari F. New York: Continuum; 2004. A Thousand Plateaus: Capitalism and Schizophrenia.95 [Google Scholar]
- 13.Masucci AP, Kalampokis A, Eguíluz VM, Hernández-García E. arXiv: Phys Rev E, in press; 2010. Extracting directed information flow networks: an application to genetics and semantics.1009.4797. [DOI] [PubMed] [Google Scholar]
- 14.Wikipedia: Database download website. Available: http://en.wikipedia.org/wiki/Wikipedia:Database_download. Accessed 2011 Feb 2.
- 15.Hopper PJ, Traugott EC. Cambridge: Cambridge University Press; 1993. Grammaticalization. [Google Scholar]
- 16.Ferrer i Cancho R, Solé RV. Two regimes in the frequency of words and the origin of complex lexicons: Zipf's law revisited. Journal of Quantitative Linguistics. 2001;8:165–173. [Google Scholar]
- 17.Unitex website. Available: http://www-igm.univ-mlv.fr/~unitex/index.php?page=5. Accessed 2011 Feb 2.
- 18.Lin J. Divergence Measures Based on the Shannon Entropy. IEEE Transactions On Information Theory. 1991;37:145–151. [Google Scholar]
- 19.Stauffer D, Aharony A. London 2nd Ed: CRC; 1994. Introduction to Percolation Theory. [Google Scholar]
- 20.Kim J, Krapivsky PL, Kahng B, Redner S. Infinite-order percolation and giant fluctuations in a protein interaction network, Phys Rev E. 2002;66:055101(R). doi: 10.1103/PhysRevE.66.055101. [DOI] [PubMed] [Google Scholar]
- 21.Watts DJ, Strogatz SH. Collective dynamics of ‘small-world’ networks. Nature. 1998;393:440–442. doi: 10.1038/30918. [DOI] [PubMed] [Google Scholar]
- 22.Macdonald PJ, Almaas E, Barabasi AL. Minimum spanning trees of weighted scale-free networks. Europhys Lett. 2005;72:308–314. [Google Scholar]
- 23.Prim RC. Shortest connection networks and some generalizations. Bell System Technical Journal. 1957;37:1389–1401. [Google Scholar]
- 24.Bastian M, Heymann S, Jacomy M. International AAAI Conference on Weblogs and Social Media; 2009. Gephi: an open source software for exploring and manipulating networks. pp. 361–362. [Google Scholar]
- 25.Albert R, Barabási AL. Statistical mechanics of complex networks. Rev Mod Phys. 2002;74:47–98. [Google Scholar]
- 26.Balcan D, Kabakçoğ lu A, Mungan M, Erzan A. The Information Coded in the Yeast Response Elements Accounts for Most of the Topological Properties of Its Transcriptional Regulation Network. PLoS ONE. 2007;2:e501. doi: 10.1371/journal.pone.0000501. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Mungan M, Kabakc A, Balcan D, Erzan A. Analytical solution of a stochastic content-based network model. J Phys A. 2005;38:9599–9620. [Google Scholar]
- 28.Bergmann S, Ihmels J, Barkai N. Similarities and Differences in Genome-Wide Expression Data of Six Organisms. PLoS Biol. 2004;2:e9. doi: 10.1371/journal.pbio.0020009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Zipf GK. Hafner, New York, reprint; 1972. Human behaviour and the principle of least effort: An introduction to human ecology. [Google Scholar]
- 30.Simon HA. On a class of skew distribution functions. Biometrika. 1955;42:425–440. [Google Scholar]
- 31.Heaps HS. New York: Academic Press; 1978. Information Retrieval: Computational and Theoretical Aspects. [Google Scholar]
- 32.Menczer F. Growing and navigating the small world Web by local content. Proc Natl Acad Sci USA. 2002;99:14014–14019. doi: 10.1073/pnas.212348399. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Skyrms B. Signals: Evolution, Learning & Information, Oxford University Press; 2010. [Google Scholar]
- 34.Lieberman E, Michel JB, Jackson J, Tang T, Nowak MA. Quantifying the evolutionary dynamics of language. Nature. 2007;449:713–716. doi: 10.1038/nature06137. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Tecumseh Fitch W. Linguistics: an invisible hand. Nature. 2007;449:665–667. doi: 10.1038/449665a. [DOI] [PubMed] [Google Scholar]
- 36.Gleason J, Bernstein N. New York: Psycholinguistics, Harcourt Brace; 1998. [Google Scholar]
- 37.Baronchelli A, Gong T, Puglisi A, Loreto V. Modeling the emergence of universality in color naming patterns. Proc Natl Acad Sci USA. 2010;107:2403–2407. doi: 10.1073/pnas.0908533107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Bizer C, Lehmann J, Kobilarov G, Auer S, Becker C, Cyganiak R, Hellmann S. DBpedia – A Crystallization Point for the Web of Data. Web Semantics: Science, Services and Agents on the World Wide Web. 2009;7:154–165. [Google Scholar]
- 39.Ramasco JJ, Mungan M. Inversion method for content-based networks. Phys Rev E. 2008;77:036122. doi: 10.1103/PhysRevE.77.036122. [DOI] [PubMed] [Google Scholar]
- 40.Sinatra R, Condorelli D, Latora V. Networks of Motifs from Sequences of Symbols. Phys Rev Lett. 2010;105:178702. doi: 10.1103/PhysRevLett.105.178702. [DOI] [PubMed] [Google Scholar]
- 41.Muchnik L, Itzhack R, Solomon S, Louzoun Y. Self-emergence of knowledge trees: Extraction of the Wikipedia hierarchies. Phys Rev E. 2007;76:016106. doi: 10.1103/PhysRevE.76.016106. [DOI] [PubMed] [Google Scholar]
- 42.Capocci A, Servedio VDP, Colaiori F, Buriol LS, Donato D, Leonardi S, Caldarelli G. Preferential attachment in the growth of social networks: The internet encyclopedia Wikipedia. Phys Rev E. 2006;74:036116. doi: 10.1103/PhysRevE.74.036116. [DOI] [PubMed] [Google Scholar]
- 43.van Leijenhorst DC, van der Weide TP. A formal derivation of Heap's Law. Information Sciences. 2005;170:263–272. [Google Scholar]
- 44.Serrano MA, Flammini A, Menczer F. Modeling Statistical Properties of Written Text. PLoS ONE. 2009;4:e5372. doi: 10.1371/journal.pone.0005372. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Zanette D, Montemurro M. Dynamics of Text Generation with Realistic Zipf's Distribution. Journal of Quantitative Linguistics. 2005;12:29–40. [Google Scholar]
- 46.Dorogovtsev SN, Mendes JFF. Language as an evolving word web. Proc Roy Soc London B. 2001;268:2603–2606. doi: 10.1098/rspb.2001.1824. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Masucci AP, Rodgers GJ. Network properties of written human language. Phys Rev E. 2006;74:026102. doi: 10.1103/PhysRevE.74.026102. [DOI] [PubMed] [Google Scholar]
- 48.Masucci AP, Rodgers GJ. Multi-directed Eulerian growing networks. Physica A. 2007;386:557–563. [Google Scholar]
- 49.Csárdi G, Nepusz T. InterJournal Complex Systems; 2006. The igraph software package for complex network research.1695 [Google Scholar]