

Abstract
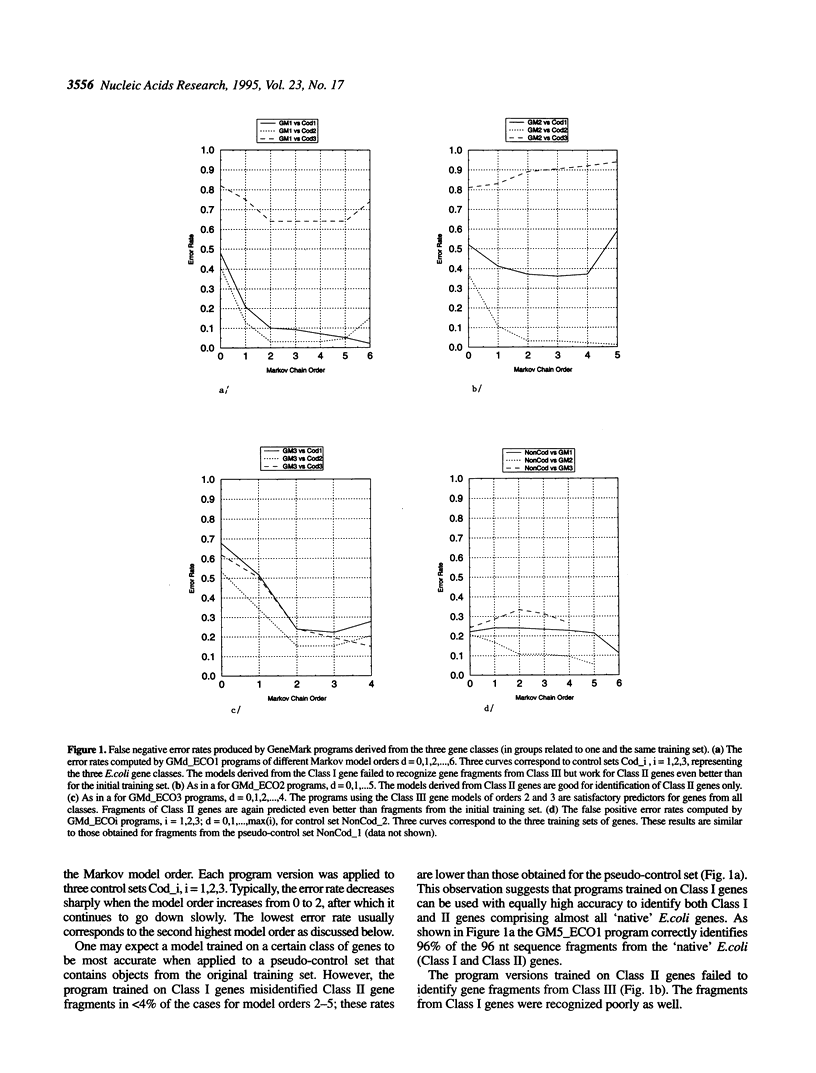
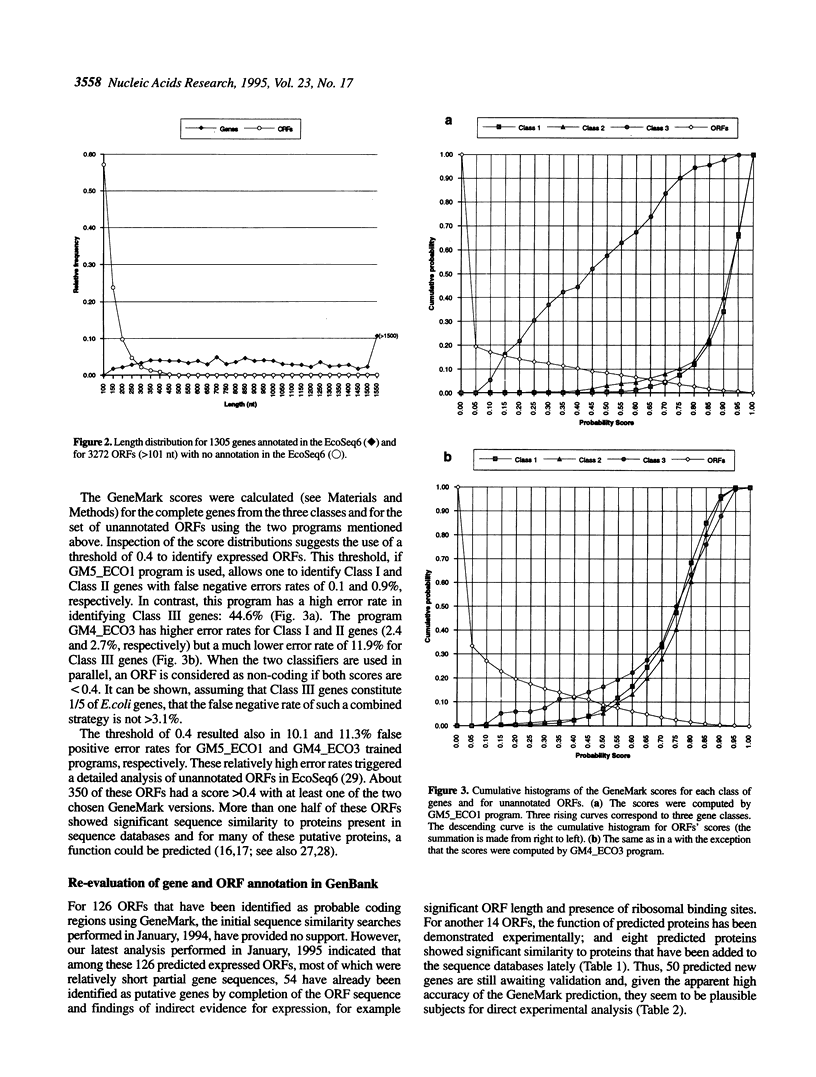
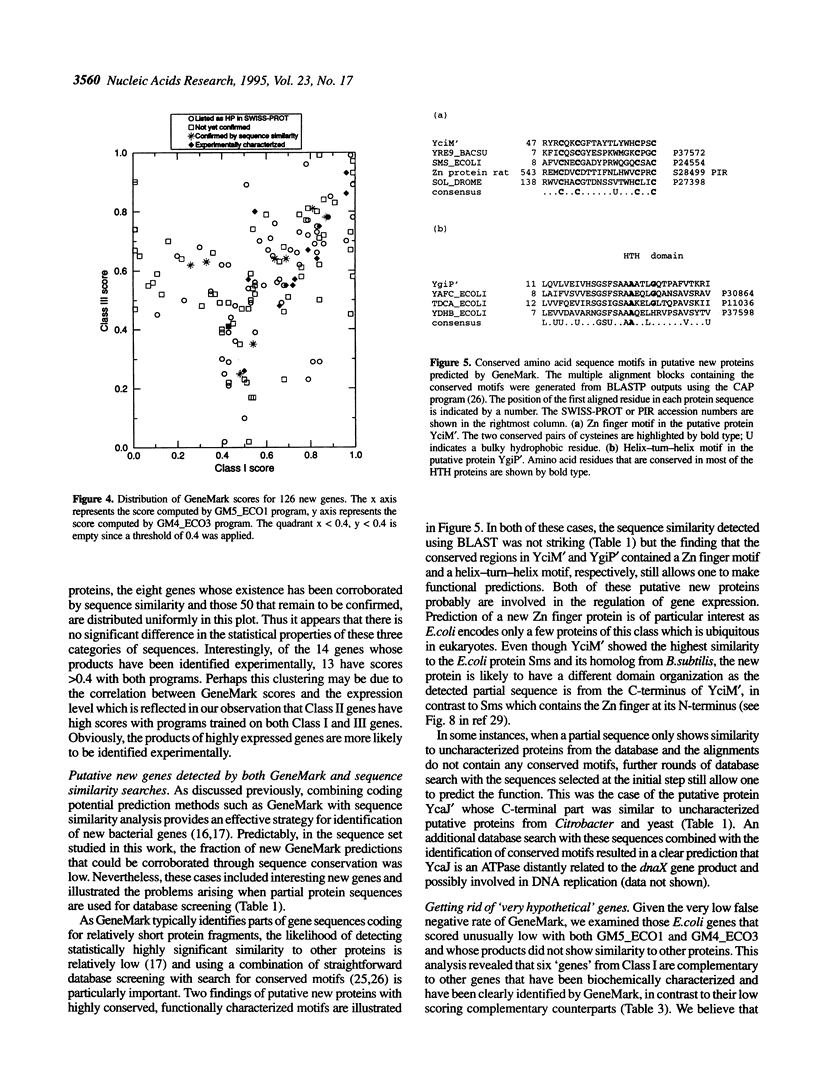
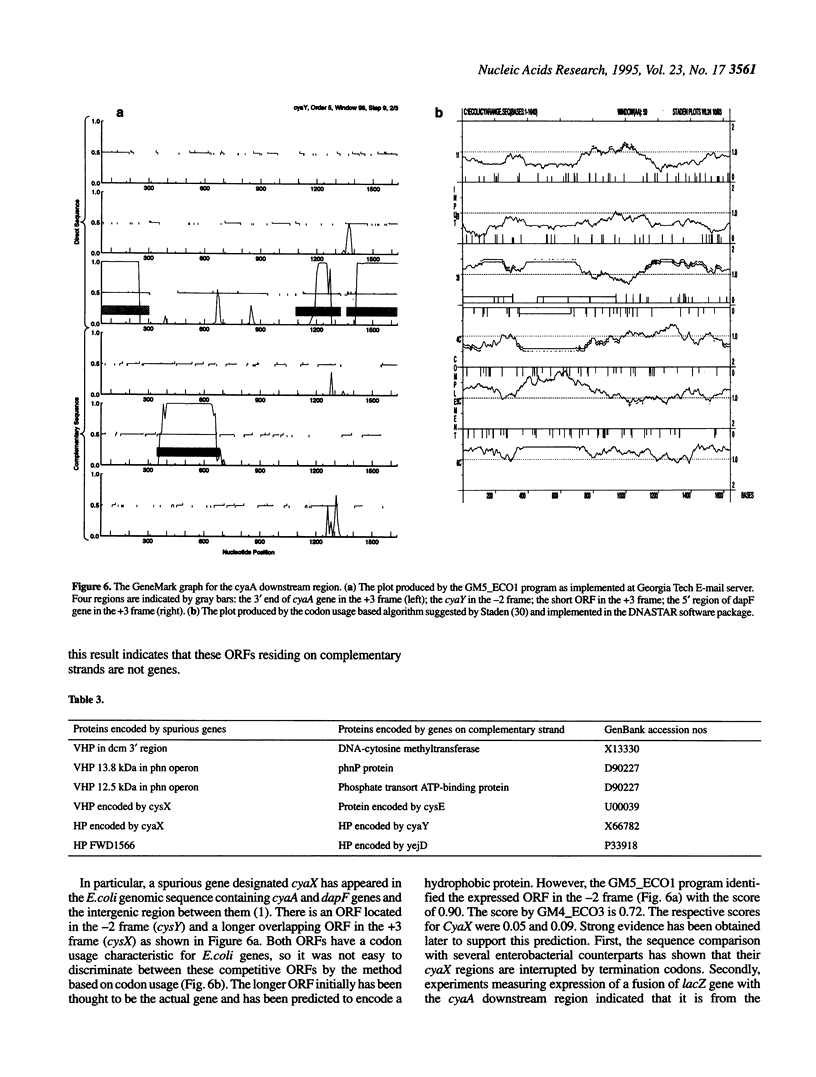
We further investigated the statistical features of the three classes of Escherichia coli genes that have been previously delineated by factorial correspondence analysis and dynamic clustering methods. A phased Markov model for a nucleotide sequence of each gene class was developed and employed for gene prediction using the GeneMark program. The protein-coding region prediction accuracy was determined for class-specific Markov models of different orders when the programs implementing these models were applied to gene sequences from the same or other classes. It is shown that at least two training sets and two program versions derived for different classes of E. coli genes are necessary in order to achieve a high accuracy of coding region prediction for uncharacterized sequences. Some annotated E. coli genes from Class I and Class III are shown to be spurious, whereas many open reading frames (ORFs) that have not been annotated in GenBank as genes are predicted to encode proteins. The amino acid sequences of the putative products of these ORFs initially did not show similarity to already known proteins. However, conserved regions have been identified in several of them by screening the latest entries in protein sequence databases and applying methods for motif search, while some other of these new genes have been identified in independent experiments.
Full text
PDF





Selected References
These references are in PubMed. This may not be the complete list of references from this article.
- Altschul S. F., Boguski M. S., Gish W., Wootton J. C. Issues in searching molecular sequence databases. Nat Genet. 1994 Feb;6(2):119–129. doi: 10.1038/ng0294-119. [DOI] [PubMed] [Google Scholar]
- Blattner F. R., Burland V., Plunkett G., 3rd, Sofia H. J., Daniels D. L. Analysis of the Escherichia coli genome. IV. DNA sequence of the region from 89.2 to 92.8 minutes. Nucleic Acids Res. 1993 Nov 25;21(23):5408–5417. doi: 10.1093/nar/21.23.5408. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Borodovsky M., Koonin E. V., Rudd K. E. New genes in old sequence: a strategy for finding genes in the bacterial genome. Trends Biochem Sci. 1994 Aug;19(8):309–313. doi: 10.1016/0968-0004(94)90067-1. [DOI] [PubMed] [Google Scholar]
- Borodovsky M., Rudd K. E., Koonin E. V. Intrinsic and extrinsic approaches for detecting genes in a bacterial genome. Nucleic Acids Res. 1994 Nov 11;22(22):4756–4767. doi: 10.1093/nar/22.22.4756. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Burland V., Plunkett G., 3rd, Daniels D. L., Blattner F. R. DNA sequence and analysis of 136 kilobases of the Escherichia coli genome: organizational symmetry around the origin of replication. Genomics. 1993 Jun;16(3):551–561. doi: 10.1006/geno.1993.1230. [DOI] [PubMed] [Google Scholar]
- Daniels D. L., Plunkett G., 3rd, Burland V., Blattner F. R. Analysis of the Escherichia coli genome: DNA sequence of the region from 84.5 to 86.5 minutes. Science. 1992 Aug 7;257(5071):771–778. doi: 10.1126/science.1379743. [DOI] [PubMed] [Google Scholar]
- Delorme M. O., Hénaut A. Merging of distance matrices and classification by dynamic clustering. Comput Appl Biosci. 1988 Nov;4(4):453–458. doi: 10.1093/bioinformatics/4.4.453. [DOI] [PubMed] [Google Scholar]
- Fickett J. W., Tung C. S. Assessment of protein coding measures. Nucleic Acids Res. 1992 Dec 25;20(24):6441–6450. doi: 10.1093/nar/20.24.6441. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gouy M., Gautier C. Codon usage in bacteria: correlation with gene expressivity. Nucleic Acids Res. 1982 Nov 25;10(22):7055–7074. doi: 10.1093/nar/10.22.7055. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grantham R., Gautier C., Gouy M., Jacobzone M., Mercier R. Codon catalog usage is a genome strategy modulated for gene expressivity. Nucleic Acids Res. 1981 Jan 10;9(1):r43–r74. doi: 10.1093/nar/9.1.213-b. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ikemura T. Codon usage and tRNA content in unicellular and multicellular organisms. Mol Biol Evol. 1985 Jan;2(1):13–34. doi: 10.1093/oxfordjournals.molbev.a040335. [DOI] [PubMed] [Google Scholar]
- Kleffe J., Borodovsky M. First and second moment of counts of words in random texts generated by Markov chains. Comput Appl Biosci. 1992 Oct;8(5):433–441. doi: 10.1093/bioinformatics/8.5.433. [DOI] [PubMed] [Google Scholar]
- Krogh A., Mian I. S., Haussler D. A hidden Markov model that finds genes in E. coli DNA. Nucleic Acids Res. 1994 Nov 11;22(22):4768–4778. doi: 10.1093/nar/22.22.4768. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Médigue C., Rouxel T., Vigier P., Hénaut A., Danchin A. Evidence for horizontal gene transfer in Escherichia coli speciation. J Mol Biol. 1991 Dec 20;222(4):851–856. doi: 10.1016/0022-2836(91)90575-q. [DOI] [PubMed] [Google Scholar]
- Neuwald A. F., Berg D. E., Stauffer G. V. Mutational analysis of the Escherichia coli serB promoter region reveals transcriptional linkage to a downstream gene. Gene. 1992 Oct 12;120(1):1–9. doi: 10.1016/0378-1119(92)90002-7. [DOI] [PubMed] [Google Scholar]
- Plunkett G., 3rd, Burland V., Daniels D. L., Blattner F. R. Analysis of the Escherichia coli genome. III. DNA sequence of the region from 87.2 to 89.2 minutes. Nucleic Acids Res. 1993 Jul 25;21(15):3391–3398. doi: 10.1093/nar/21.15.3391. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robison K., Gilbert W., Church G. M. Large scale bacterial gene discovery by similarity search. Nat Genet. 1994 Jun;7(2):205–214. doi: 10.1038/ng0694-205. [DOI] [PubMed] [Google Scholar]
- Savakis C., Doelz R. Contamination of cDNA sequences in databases. Science. 1993 Mar 19;259(5102):1677–1678. doi: 10.1126/science.8456288. [DOI] [PubMed] [Google Scholar]
- Sharp P. M., Li W. H. The codon Adaptation Index--a measure of directional synonymous codon usage bias, and its potential applications. Nucleic Acids Res. 1987 Feb 11;15(3):1281–1295. doi: 10.1093/nar/15.3.1281. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Staden R. Measurements of the effects that coding for a protein has on a DNA sequence and their use for finding genes. Nucleic Acids Res. 1984 Jan 11;12(1 Pt 2):551–567. doi: 10.1093/nar/12.1part2.551. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tatusov R. L., Koonin E. V. A simple tool to search for sequence motifs that are conserved in BLAST outputs. Comput Appl Biosci. 1994 Jul;10(4):457–459. doi: 10.1093/bioinformatics/10.4.457. [DOI] [PubMed] [Google Scholar]
- Tavaré S., Song B. Codon preference and primary sequence structure in protein-coding regions. Bull Math Biol. 1989;51(1):95–115. doi: 10.1007/BF02458838. [DOI] [PubMed] [Google Scholar]