

Abstract
Background
The bacterial nucleoid contains several hundred kinds of nucleoid-associated proteins (NAPs), which play critical roles in genome functions such as transcription and replication. Several NAPs, such as Hu and H-NS in Escherichia coli, have so far been identified.
Methodology/Principal Findings
Log- and stationary-phase cells of E. coli, Pseudomonas aeruginosa, Bacillus subtilis, and Staphylococcus aureus were lysed in spermidine solutions. Nucleoids were collected by sucrose gradient centrifugation, and their protein constituents analyzed by liquid chromatography-mass spectrometry/mass spectrometry (LC-MS/MS). Over 200 proteins were identified in each species. Envelope and soluble protein fractions were also identified. By using these data sets, we obtained lists of contaminant-subtracted proteins enriched in the nucleoid fractions (csNAP lists). The lists do not cover all of the NAPs, but included Hu regardless of the growth phases and species. In addition, the csNAP lists of each species suggested that the bacterial nucleoid is equipped with the species-specific set of global regulators, oxidation-reduction enzymes, and fatty acid synthases. This implies bacteria individually developed nucleoid associated proteins toward obtaining similar characteristics.
Conclusions/Significance
Ours is the first study to reveal hundreds of NAPs in the bacterial nucleoid, and the obtained data set enabled us to overview some important features of the nucleoid. Several implications obtained from the present proteomic study may make it a landmark for the future functional and evolutionary study of the bacterial nucleoid.
Introduction
The genomes of all living organisms are packed in cells with proteins involved in various cellular processes such as transcription and replication. Most bacteria have circular genomes of various sizes (Staphylococcus aureus: 1 mm; Bacillus subtilis: 1.4 mm: Escherichia coli: 1.6 mm; Pseudomonas aeruginosa: 2.1 mm; per genome [estimated according to a base pair size of 0.34 nm]), which are packed into cells of a few micrometers in the form of a “nucleoid” [1], [2].
Over 300 protein species are expected to be associated with the nucleoids isolated from E. coli and B. subtilis, although most of them have yet to be identified [3]–[6]. In the case of E. coli, several proteins have been identified as major nucleoid-associated proteins (NAPs): heat-unstable nucleoid protein (HU), integration host factor (IHF) (Hu paralogue), histone-like nucleoid structuring protein (H-NS), factor for inversion stimulation (Fis), host factor for RNA phage Qβ replication (Hfq), suppressor of T4 td mutant phenotype A (StpA) (H-NS homologue), and DNA-binding protein from starved cells (Dps) [7], [8]. These proteins occupy wide portions of genomic DNA [9], [10] and are involved in a series of genome functions, such as transcription (Hu, IHF, H-NS, StpA, and Fis) [11]–[15], translation (Hu, HNS, StpA, and Hfq) [16]–[19], replication (HU, IHF, Fis, and Dps) [20]–[23], DNA protection (Dps) [24], [25], and DNA packing (Hu, H-NS, Fis, and Dps) [26]–[30].
These NAPs are not quantitatively static throughout growth [31]. Hu and Fis are abundant in the log phase but decrease toward the stationary phase. Conversely, IHF and Dps are induced toward the stationary phase and become the major components. Under anaerobic conditions, DNA-binding protein in anaerobic conditions (DAN) becomes the most abundant NAP [32]. In addition, comparative genomic analysis revealed that these E. coli NAPs are not commonly conserved in the bacterial kingdom [33], [34] (see Table 1). Fis, H-NS, and StpA are present only in the Gammaproteobacteria. About half of all bacteria lack Hfq. Chlamydia and some of the Proteobacteria, Actinobacteria, and Firmicutes lack Dps. Even the most broadly conserved NAP, Hu or its homologue IHF, is absent in Leptospira interrogans and Corynebacterium diphtheriae. Thus, the features of the major NAPs of E. coli suggest the necessity of a comparative study of NAPs to gain insight into the general/specific characteristics of the bacterial nucleoid.
Table 1. Major NAPs Identified in This Study.
| hupA | hupB | ihfA | ihfB | hns | stpA | fis | hfq | dps | |||
| log phase | E. coli | Protein amount* | 55,000 | 10,000 | 20,000 | 25,000 | 60,000 | 57,000 | 7,500 | ||
| E. coli | Nucleoid fraction+ | 47.63 | 3.3 | 0.35 | - | 1.45 | 3.89 | 0.36 | 0.84 | 0.46 | |
| Envelop fraction+ | - | - | - | - | - | - | 0.36 | - | 0.21 | ||
| Top fraction+ | - | - | - | - | 0.56 | - | - | 0.84 | 0.46 | ||
| P. aeruginosa | Nucleoid fraction+ | 0.42 | 1.09 | - | - | × | × | 0.34 | 1.09 | - | |
| Envelop fraction+ | - | - | - | - | × | × | - | - | - | ||
| Top fraction+ | - | - | - | - | × | × | - | - | - | ||
| B. subtilis | Nucleoid fraction+ | - | 0.98 | × | × | × | × | × | × | - | |
| Envelop fraction+ | - | - | × | × | × | × | × | × | - | ||
| Top fraction+ | - | - | × | × | × | × | × | × | - | ||
| S. aureus | Nucleoid fraction+ | - | 0.42 | × | × | × | × | × | × | - | |
| Envelop fraction+ | - | - | × | × | × | × | × | × | - | ||
| Top fraction+ | - | - | × | × | × | × | × | × | - | ||
| stationary phase | E. coli | Protein amount* | 15,000 | 28,000 | 6,500 | 9,000 | 0 | 17,500 | 160,000 | ||
| E. coli | Nucleoid fraction+ | 0.42 | - | 0.35 | 0.89 | 0.96 | 0.25 | - | - | 0.46 | |
| Envelop fraction+ | - | - | - | - | - | - | - | - | 0.21 | ||
| Top fraction+ | - | - | - | - | - | - | - | - | 0.76 | ||
| S. aureus | Nucleoid fraction+ | - | 1.85 | × | × | × | × | × | × | - | |
| Envelop fraction+ | - | - | × | × | × | × | × | × | - | ||
| Top fraction+ | - | - | × | × | × | × | × | × | - | ||
*The amount of molecules were determined according to Azam et al, 1999 (molecules/cell).
+emPAI values.
- Not detected; × Absence of gene.
The biochemical methods for purifying the cell membrane and cell wall fractions have been established [35], [36], and the total proteins in such purified fractions have been identified by mass spectrometry techniques (reviewed in [37]). However, difficulty in isolating nucleoids remains. The isolated nucleoid under physiological salt conditions always includes contaminants derived from the cell membrane, cell wall, and cytosol [4], [5], [38]–[43]. Treatment with high salt and/or RNase can disassociate the contaminated proteins, but the number of proteins identified in this manner was limited [44]–[46].
In this study, we identified the proteins in the isolated spermidine nucleoids of E. coli, P. aeruginosa, B. subtilis, and S. aureus by liquid chromatography-mass spectrometry/mass spectrometry (LC-MS/MS). Nucleoids isolated in a spermidine solution with mild ionic strength retain the most proteins directly/indirectly bound to the genomic DNA [5], [39]. The comparison of proteins detected in the nucleoid and envelope and soluble fractions suggested some characteristics of the bacterial nucleoid. We discuss several implications yielded by the obtained NAP data sets regarding the possible functional and evolutionary aspects of the bacterial nucleoid.
Results
Identification of NAPs in E. coli
We isolated spermidine nucleoids from E. coli cells grown in aerobic conditions (see Figure S1 for growth curves and sampling points). DNA content was monitored for each sucrose gradient fraction (Figure1A, 1B, 1D and 1E), and the one with the highest DNA content was further analyzed as the nucleoid fraction. In the case of the log phase, multiple peaks were sometimes observed, probably owing to the viscous characteristics of the nucleoid (Figure 1A-1B). It might be because of the heterogeneous density of nucleoids: e.g. existence of the stationary-phase type nucleoid (Figure 1E). However, analysis by SDS-PAGE showed that the protein signal patterns of fractions 1 and 2 were indistinguishable (Figure 1C). The upper fraction (fraction 1) was analyzed by LC-MS/MS. We also analyzed proteins in the envelope and top fractions, as described in the Materials and Methods section (Figure 1C and 1F). The numbers of the identified proteins and peptides are summarized in Figure 2A to 2C. The full list of identified proteins with the number of corresponding peptides is provided in the supplementary tables (Table S1, S2, and S3).
Figure 1. E. coli nucleoid isolation.

Isolation of spermidine nucleoids in the log (A to C) and stationary (D to F) phases. (A) (D) The lysed cells were fractionated by sucrose-gradient centrifugation with a 10%-to-60% sucrose gradient. (B) (E) The relative DNA amount in the sucrose gradient detected by DAPI fluorescence. (C) (F) SDS-PAGE of the whole-cell lysates, the top fraction of the sucrose gradient, the nucleoid fractions, and the envelope fraction. The gels were stained with Coomassie Brilliant Blue (CBB). The pattern of the envelope in the log phase was similar to that reported by Lai et al [89].
Figure 2. Statistical information for the identified proteins.

(A, B) Relation between the number of peptide species, the total number of peptides, and the number of identified protein species in the nucleoid (circle), envelope (square), and top (triangle) fractions of E. coli (pink), P. aeruginosa (orange), B. subtilis (green), and S. aureus (blue) in the log (blank) and stationary (filled) phases (C) Number of identified protein species in each fraction csNAP represents contaminant-subtracted NAP. (D) The estimated coverage rates in each fraction. Constant, Linear, and SCL indicate the models representing the amounts of individual proteins in the fractions. The rates gaining over 0.80 are colored red, from 0.60 to 0.79, black, and less than 0.60, grey.
The number of the detected peptides was correlated with the number of identified proteins (Figure 2B). This implied that the identified protein sets with lower numbers of peptides were not sufficient to cover all the proteins in the given fractions. By using in silico simulation, we estimated the coverage rates, which represent the extent of the identified proteins out of the total proteins in the fractions (Figure 2D, see Materials and Methods). Here, we applied 3 different models representing the amounts of individual proteins in the factions (Figure S2). The constant model represents the uniform distribution of protein amounts, and the linear model represents the linear decrease of the distribution. The simplified canonical law (SCL) model has been reported to be consistent with the relative expression of proteins in prokaryotic cells [47]. In the case of the nucleoid fractions of the log phase, the coverage rates of the identified protein species according to these models were estimated as 0.63 to 0.93, and the rates of protein amounts covered by the identified proteins as 0.88 to 0.96. In the case of the stationary phase, the rates of the species and amounts were 0.82 to 0.94 and 0.92 to 0.97, respectively. Thus, it can be expected that over 60% of the protein species that occupy at least 80% of the protein amounts out of the total proteins in the nucleoid fractions were identified in E. coli. The rates of the envelope and top fractions were 0.43 to 0.96 for the protein species, and 0.71 to 0.98 for the protein amounts. These data suggest that we successfully identified at least 70% of protein amounts although there may remain various unidentified protein species in each fraction. In Table S4, we summarized the potential number of protein species in each fraction and the numbers of the peptides required for identifying all of them. The number of peptides required to identify all the proteins in each fraction were estimated based on the SCL model (Table S4).
Major NAPs were identified in the nucleoid fractions (Table 1). Hu was detected in the nucleoid fraction in both the log and stationary phases, consistent with the Western blot analysis against Hu (Figure 3). In the nucleoid fraction of the log phase, Hu (hupA and hupB), IHF (ihfA), HNS (hns), StpA (stpA), Fis (fis), Hfq (hfq), and Dps (dps) were identified. In the stationary phase, Hu (hupA), IHF (ihfA and ihfB), HNS (hns), StpA (stpA), and Dps (dps) were identified. Their emPAI values, which roughly represent the amount of proteins detected by MS [48], were correlated with the intracellular amount of all of these proteins other than Fis and Hfq (Table 1).
Figure 3. Western blots against Hu.
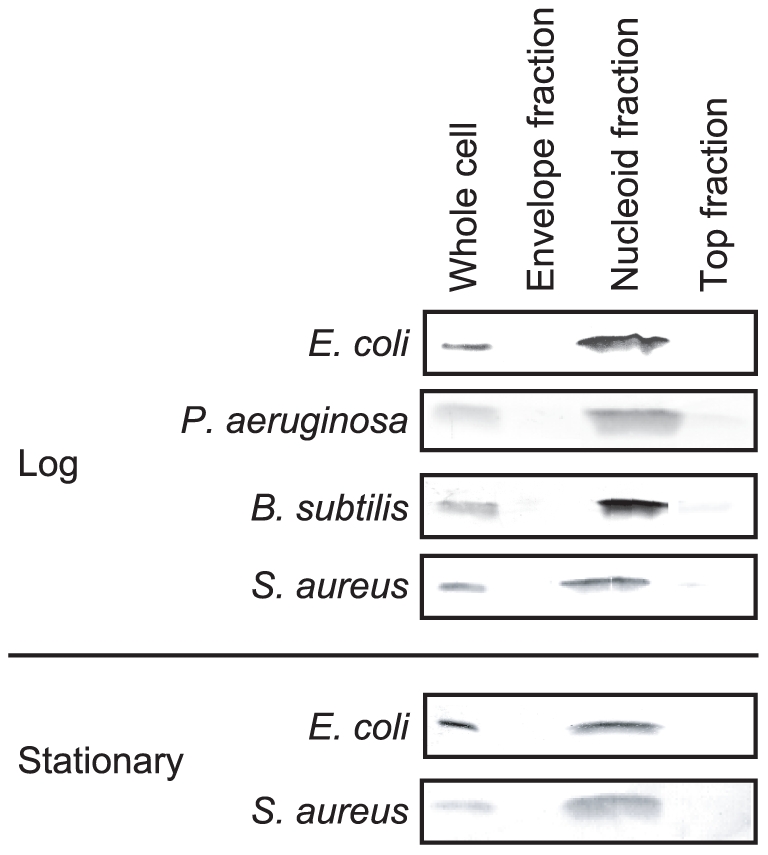
Five micrograms of proteins from the whole-cell lysates, the nucleoid fractions, the envelope fractions, and the top fractions were separated by SDS-PAGE, and Hu was detected by Western blotting. ‘Log’ and ‘Stationary’ represent the log phase and stationary phase, respectively.
In addition to the major NAPs, various DNA and RNA binding proteins were identified in the nucleoid fractions (Table 2). Twenty-six transcription factors were identified in the log phase, and three in the stationary phase. RNA polymerases and ribosomal proteins, which have been identified in spermidine nucleoids [5], were also identified in both phases. Other proteins related to translation (tsf, infC etc.), replication (seqA, topA etc.), and DNA repair (mutS, uvrA etc.) were also included. Non-DNA binding proteins should be included in the isolated nucleoids. For example, it is known that transcription elongation factors Rho (rho) and NusA (nusA) interact with RNA polymerase, and, indeed, our list included them.
Table 2. DNA and RNA Binding Proteins Identified in the Nucleoid Fractions (except major NAPs).
| Category | Phase | Species | Genes |
| Transcription factors | log phase | E. coli | arcA *, ascG, chbR *, crl *, crp *, cspE *, fruR *, fur *, idnR *, lacI *, lldR *, lrp *, malT *, osmE *, ompR *, phoU *, pspB *, purR *, putA *, rtcR *, srlR *, ybaD, yciT *, ydeW, ydfH *, yheO * |
| P. aeruginosa | crp, fabG, yebK, yhbY | ||
| B. subtilis | degA, gabR, gntR, kdgR, rsfA, spo0J, xylR, ybbB, ydiP, yhdQ, yplP | ||
| S. aureus | codY, fabG, graR, rex, rot, sarA, sarH1, sarR, spxA, srrA, vraR | ||
| stationary phase | E. coli | osmE *, lysR *, putA * | |
| S. aureus | ahrC, codY, fabG, graR, mgrA, nreC, pyrR, rocA, saeR, sarA, sarR, sarH1, sarV, sarZ, srrA, tcaR, vraR, vicR | ||
| Proteins involved in transcription, translation, replication, and DNA repair | log phase | E. coli | deaD, fusA, treA, hrpA, hsdS, infB, infC, insB, insI, mfd, mutS, nusA, nusG, parC *, pcnB, pnp, polA *, rdgC, rhlB, rho, rimM, rlmB, rmuC, rnb, rne, rpoA *, rpoB *, rpoC *, rpoD *, rusA, seqA *, srmB, topA *, tsf, tufB, unvrA *, xthA, yejK, ygjF |
| P. aeruginosa | efp, fusA, gyrA, gyrB, infB, infC, mutS, nusG, parC, parE, pnp, rdgC, recA, rhlB, rho, rne, rpoA, rpoB, rpoC, rpoD, ssb, topA, tsf, tufA, uvrA, yejK | ||
| B. subtilis | fusA, gidB, gyrA, gyrB, ihfB, ihfC, mutL, mutS, nusA, pnpA, polA, polC, rpoA, rpoB, rpoC, sigF, smc, tsf, tuf, uvrA, uvrC, ydbR, yhaM, yhcR, yirY, yqfR, yqjW | ||
| S. aureus | fus, efp, tsf, tufA, end4, ermA, infA, nusG, pnpA, recA, rnc, rnh3, rpoA, rpoB, rpoC, rpoE, uvrC, xerD | ||
| stationary phase | E. coli | hrpA, rdgC, rpoA *, rpoB *, rpoC *, rpoD *, rpoZ *, rusA, ruvA, topA *, tsf, tufB, uvrA *, yejK | |
| S. aureus | lig, dnaN, fus, efp, tsf, tufA, gyrB, hsdR, infA, infB, infC, mfd, nusG, parC, parE, pnpA, rnc, rnj1, rnj2, rpoA, rpoB, rpoC, rpoE, gidB, ruvA, ssb, topA, Y1885 |
Underlined genes represent the proteins selected as contaminant-subtracted NAPs (csNAPs).
*Genes reported as DNA-binding proteins in EcoSal [1].
The nucleoid fractions were enriched in the envelope and cytosolic proteins (Figure 4, Table S2, and Table S3). When the proteins in the nucleoid fractions were sorted by emPAI value, 18 out of the top 40 proteins were envelope and cytosolic proteins in the log phase (Figure 4A). These include F0F1-ATPase (coded by atpA, atpD, etc.), porins (ompA, ompC, etc.), flagellin (fliC, etc.), a chaperone (groEL), and metabolic enzymes (tnaA, nuoC, etc.). In the stationary phase, 31 out of the 40 proteins were envelope or cytosolic proteins including F0F1-ATPase, porins, flagellin, a chaperone, and metabolic enzymes (Figure 4B). Most of these proteins were also identified in the envelope and/or top fractions with high emPAI values, suggesting that these proteins in the nucleoid fractions are contaminated largely owing to the difficulty of nucleoid isolation (see Discussion).
Figure 4. Proteins identified in the nucleoid fractions of E. coli.

The listed proteins were the top 40 proteins sorted by the emPAI values. The colors of the letters indicate the categories of the proteins (red: major NAPs; green: transcription factors; dark blue: DNA/RNA binding proteins involved in transcription, translation, replication, and DNA repair; light blue: ribosomal proteins; black: cytosolic-type proteins; and orange: envelope-type proteins). The major NAPs, transcription factors, and DNA/RNA binding proteins were classified according to EcoSal [1] and their annotations by KEGG [86]. The ribosomal proteins were based on gene annotations. The residual proteins were classified into cytosolic-type and envelope-type proteins according to the prediction of their intracellular localization. The localizations of E. coli proteins were predicted by EchoLOCATION [90]. Those of P. aeruginosa, B. subtilis, and S. aureus were predicted by PSORTb [91]. Underlined genes were reported as DNA binding proteins in EcoSal. pep_num represents the number of peptides detected from each protein.
NAPs in P. aeruginosa, B. subtilis, and S. aureus
We investigated the NAPs of P. aeruginosa, B. subtilis, and S. aureus. P. aeruginosa is Gram-negative and, like E. coli, belongs to the Gammaproteobacteria. B. subtilis and S. aureus are both Gram-positive and belong to the Firmicutes/Bacillales. The number of major E. coli NAP genes varies depending on the species (Table 1). P. aeruginosa possesses hupA, hupB, ihfA, ihfB, fis, hfq, and dps, but not hns and stpA (but possesses mvaT and mvaU as functional counterparts of hns and stpA [49]). B. subtilis possesses only hupB (annotated as hbs), its homologues, yonN, and dps. S. aureus possesses hupB (hu) and dps (mrgA) but lacks fis, hns, stpA, and hfq.
Proteins in the spermidine-nucleoid fractions, as well as in the envelope and top fractions, were isolated (Figure 5) and identified by LC-MS/MS (Figure 2, Figure S3, Tables S1 and S5, S6, S7, S8). Over 200 proteins were identified in each nucleoid fraction. The coverage rates of the proteins in the nucleoid fractions were 0.60 to 0.92 as protein species and 0.73 to 0.96 as protein amounts (Figure 2D), suggesting that major part, but not all, of the nucleoid proteins were identified (Table S4). Hu was exclusively detected in the nucleoid fractions of all species tested. This was consistent with the Western blots against Hu (Figure 3). In the case of P. aeruginosa, Hu (hupA and hupB), Fis (fis), and Hfq (hfq) were detected in the nucleoid fraction, but IHF (ihfA and ihfB), Dps (dps), MvaT (mvaT), and MvaU (mvaU) were not. In the case of B. subtilis and S. aureus, HU (hbs, yonN, and hu) was identified, but Dps (dps and mrgA) was not. DNA and RNA binding proteins other than ribosomal proteins are listed in Table 2. In all species tested, as in E. coli, many ribosomal proteins, envelope proteins, and cytosolic proteins were identified in the nucleoid fractions (Table S1 and Table S5, S6, S7, S8).
Figure 5. Proteins in the nucleoid, top, and envelope fractions of S. aureus, P. aeruginosa, and B. subtilis.

SDS-PAGE analysis of the whole-cell lysates, envelope fractions, nucleoid fractions, and top fractions of the sucrose gradient assay. The gels were stained with CBB.
Data analysis: contaminant-subtracted NAPs (csNAPs)
The isolated nucleoids contained various envelope and cytosolic proteins. This was the expected result, as described in the Introduction section. To deduce reasonable considerations in the Discussion section, we here define “contaminant-subtracted NAPs (csNAPs)” as follows:
csNAPs = “Proteins detected only in the nucleoid fraction” + “Proteins calculated to be relatively abundant in the nucleoid fraction.”
-
-
Proteins detected only in the nucleoid fraction”: Proteins detected only in the nucleoid fraction in a given condition.
-
-
Proteins calculated to be relatively abundant in the nucleoid fraction”: The number of peptides detected by LC-MS/MS is a good benchmark to investigate the fraction in which the target protein is dominantly present. If the number of peptides of a certain protein identified in the nucleoid fraction is larger than that of the other fractions, the protein is thought to be abundant in the nucleoid [50]. For instance, in the log phase of E. coli, 7 Fis peptides were detected in the nucleoid fraction, and 2 in the envelope fractions, suggesting that Fis was more abundant in the nucleoid fraction. Here, we need to pay attention to the total number of peptides detected by the LC-MS/MS because more peptides should be detected if more sample is loaded for the LC-MS/MS [51]. In the case of the log phase of E. coli, 7148 peptides from 401 proteins were detected in the nucleoid fraction, and 13657 peptides from 334 proteins in the envelope fraction (Figure 2). Therefore, the relative abundances of Fis peptides in the log phase of E. coli were 9.8×10−4 (7/7148) and 1.5×10−4 (2/13657) in the nucleoid fraction and the top fraction, respectively, and the ratio was 6.7 (9.8×10−4/1.5×10−4). We arbitrarily selected proteins with a ratio higher than 3 as csNAPs.
According to the above-mentioned criterion, 164, 66, 98, and 92 proteins were selected as csNAPs from the log phases of E. coli, P. aeruginosa, B. subtilis, and S. aureus, respectively (Figure 2, Figure 6, 7, 8, and Table S9, S10, S11, S12). From the stationary phase, 76 and 141 proteins were selected from E. coli and S. aureus, respectively (Figure 2, Figure 6, 7, 8, and Table S13-S14).
Figure 6. csNAPs of E. coli.

The listed proteins were the top 30 csNAPs sorted by the emPAI values. (A) log phase and (B) stationary phase. The meanings of the colors, letters, and underlines are the same as those for Figure 4. The proteins with a yellow background are the oxidation-reduction enzymes. DBS and RBS represent the number of DNA-binding sites and RNA-binding sites per amino acid predicted by BindN [88], respectively. Values over 10 indicate high possibilities to bind to DNA and/or RNA (see materials and methods).
Figure 7. csNAPs of P. aeruginosa and B. subtilis.

The listed proteins were the top 30 csNAPs sorted by the emPAI values. (A) log phase of P. aeruginosa and (B) log phase of B. subtilis. The meanings of the colors, letters, and underlines are the same as those for Figure 4. The proteins with a yellow background are the oxidation-reduction enzymes. DBS and RBS represent the number of DNA-binding sites and RNA-binding sites as described in Figure 6.
Figure 8. csNAPs of S. aureus.

The listed proteins were the top 30 csNAPs sorted by the emPAI values. (A) log phase and (B) stationary phase. The meanings of the colors, letters, and underlines are the same as those for Figure 4. The proteins with a yellow background are the oxidation-reduction enzymes. DBS and RBS represent the number of DNA-binding sites and RNA-binding sites as described in Figure 6.
Various major envelope and cytosolic proteins were excluded in this operation. For instance, in the log phase of E. coli, all the porins (ompA, ompC, ompF, ompN, ompT, and ompX), most of the flagellar components (fliC, fliF, fliL, and fliM in both phases, but not fliO in the log phase), and many of the F0F1-ATPase subunits (atpA, atpD, atpE, atpF, and atpG in both phases, but not atpB and atpH in the log phase), chaperones (groEL, groES, tig, etc.), and metabolic enzymes (tnaA, nuoC, etc.) were excluded.
In contrast, the major NAPs, such as Hu (hupA and hupB), IHF (himA and himB), Fis (fis), and StpA (stpA), were judged to be csNAPs. H-NS (hns) and Hfq (hfq) were not included in the csNAPs in the log phase because they were also detected with high peptide numbers in the envelope and/or top fraction.
Discussion
The csNAPs were selected as those proteins that were relatively abundant in the nucleoid fraction as compared with in the envelope and top fractions. It should be noted that the list of csNAPs is an incomplete one. Indeed, various proteins known to be included in the nucleoid (eg, ribosomal proteins, RNA polymerases, and some major NAPs such as HNS and Hfq) were eliminated from the csNAPs list. Nevertheless, it is reasonable to expect that the proteins selected as csNAPs are indeed involved in the functions of the bacterial nucleoid. Below, we discuss the csNAPs to gain insight into some of the characteristics of the bacterial nucleoid.
Characteristics of csNAPs
When csNAPs of E. coli in the log phase are sorted according to the emPAI values that roughly represent the amount of proteins in the mixture [48], various DNA and/or RNA binding proteins, such as Hu (hupA, hupB) and StpA (stpA), are included in the top 10 E. coli csNAPs (Figure 6A). These proteins are global transcription/translation regulators that facilitate the response to various environmental changes [12]–[14]. In addition, other global regulators, such as CspE (cspE) [52], Lrp (lrp) [53], Fis (fis), and IHF (ihfA), were ranked in the top 20 E. coli csNAPs. In the stationary phase, global regulators including HNS (hns), IHF (ihfA, ihfB), Hu (hupA), and StpA (stpA) were involved in the top 20 (Figure 6B). Global regulators were also abundant in the csNAPs of P. aeruginosa (Figure 7A): The top 20 csNAPs of this bacterium included 5 global regulators, Hu (hupA, hupB), Hfq (hfq), Fis (fis), and HexR (hexR) [54], [55]. Thus, the csNAPs in the Gammaproteobacteira comprise a plentiful amount of global regulators. Other than Hu, such global regulator genes are not genetically conserved in B. subtilis and S. aureus (Firmicutes/Bacillales). Recently, staphylococcal accessory regulator A (SarA) and its homologues in S. aureus were proposed as global regulators [56]. Our csNAP list of S. aureus contains SarA (sarA) and its homologues SarR (sarR) and SarH1 (sarH) in both the log and stationary phases (Figure 8). In addition, the stationary-phase csNAPs include SarV (SA2062) and SarZ (SA2174).
Many functionally unknown proteins (y-genes) were also included with high emPAI values in the lists, especially in the B. subtilis list (Figure 7B). The prediction of DNA/RNA binding abilities showed that several y-genes had strong potential to bind DNA and/or RNA (Figure 7B, Figure S4, and Materials and Methods). There were 10 y-genes in the top 30 csNAPs of B. subtilis, and all of them encoded predicted DNA-binding (yflI, yneK, and ydhF) or RNA-binding (yneK, ylbF, and ydhF) proteins. It is possible that these genes encode novel global regulators.
An additional feature of csNAPs is the abundance of enzymes required for stress responses. For instance, in the log phase of S. aureus, the top 30 csNAPs included 3 reductase-like superoxide dismutases, sodA), alkyl hydroperoxide reductase (ahpC), and thioredoxine reductase (trxA), which have been reported to play important roles in coping with oxidative stress-responsive elements [57], [58]. In all the species, the various enzymes involved in the oxidative stress responses were selected as csNAPs. A NAP having such property has been found in the nucleoid of the plant plastid. Sulfite reductase (SiR), the enzyme that catalyzes the reduction of sulfite to sulfide in the sulfur assimilation pathway (see review in [59]), has been identified as a DNA-binding protein of the plastid nucleoid [60]. Recently, it has been proposed that SiR is also involved in oxidative stress resistance [61]. Although the present study only suggested the possibility of association/interaction of these enzymes with the nucleoid, it is possible that the bacterial genomic DNA is, in general, protected by these enzymes from reactive oxygen species, which we term the ‘armor hypothesis’ (see also Future Perspective in Discussion).
Constitutive csNAPs through growth phases
The csNAPs in the log- and stationary-phase lists were different (Figure 9). In the list for E. coli, 4.3% of the csNAPs (10 out of 230 csNAPs [164 csNAPs in the log phase + 76 csNAPs in the stationary phase – 10 csNAPs present in both the log and stationary phases]) including Hu (hupA), StpA (stpA), and IHF (ihfA) were common between the log and stationary phases. In S. aureus, 15.9% of the csNAPs (32 out of 201 [92 in the log phase + 141 in the stationary phase – 32 present in both the log and stationary phases]) were common csNAPs throughout growth. One of the reasons for such a limited number of constitutive csNAPs could be the incomplete coverage of the proteins. Estimation of the real numbers of csNAPs on the basis of the coverage rates showed that the number of E. coli csNAPs may be 88 to 225 in the log phase and 62 to 85 in the stationary phase, while those of S. aureus may be 92 to 130 in the log phase and 127 to 169 in the stationary phase (Table S15). If all of the additional csNAPs overlap between the log and stationary phases, 34.8% of the csNAPs will be common in E. coli (80 out of 230 [225 in the log phase + 85 in the stationary phase – 80 present in both phases]). Accordingly, 45.3% of S. aureus csNAPs might be common (91 out of 201). Although it is unlikely that all the additional csNAPs overlapped, these data suggest that additional common csNAPs are constitutively present on the nucleoid.
Figure 9. Common csNAPs between the log and stationary phases.

(A) Classification of csNAPs Common csNAPs are csNAPs common to the log and stationary phases. Localization difference indicates the proteins which were not classified as csNAPs in either the log or the stationary phase but were detected in the envelope, and/or top fractions in the other phase. Expression difference represents the proteins which were classified as csNAPs in either the log or the stationary phase but not detected in any fractions in the other phase. (B) Common csNAPs between the log and stationary phases in E. coli and S. aureus.
Even considering the unidentified csNAPs, over 50% of csNAPs were expected not to be common. One reason would be the on/off of their expression. In E. coli and S. aureus, 66.5% (153 out of 230) and 36.3% (73 out of 201) csNAPs, respectively, exhibited log- or stationary-phase specific expression. Another reason seems to be the growth-dependent changes in localization of the csNAPs. For instance, E. coli HNS was detected both in the nucleoid and top fractions in the log phase (thereby not selected as a csNAP), but only in the nucleoid fraction in the stationary phase. S. aureus superoxide dismutase (SodA) appeared in the nucleoid fraction only in the log phase and was detected in all the fractions in the stationary phase. The percentage of csNAPs that exhibited such growth-dependent changes was 28.7% (66 out of 230) in E. coli and 47.8% (96 out of 201) in S. aureus.
Little is known about how NAPs change in the process of growing. It should be noted that the growth-dependent structural change of the nucleoid is induced in E. coli, but not in S. aureus [28], [33], [34], [62]. The increase in the amount of Dps and the decrease in Fis cause nucleoid condensation in the stationary phase in E. coli. On the other hand, the Dps orthologue, MrgA, is hardly expressed throughout the normal growth of S. aureus, and its nucleoid does not alter its apparent structure toward the stationary phase. The number of constitutive csNAPs that we could detect was smaller in E. coli than in S. aureus. This might imply the correlation between such structural change and the exchange of the NAP constituents.
Even under such growth-dependent changes, several global regulators and oxidation-reduction enzymes were constitutively present. In E. coli, Hu (hupA), IHF (ihfA), and StpA (stpA) were listed as global regulators, and nitrate reductase (narY) was listed as an oxidation-reduction enzyme. In S. aureus, the global regulators Hu (hu), SarA (sarA), SarR (sarR), and SarH (sarH) and the oxidation-reduction enzyme SodM (sodM) was constitutively present as csNAPs. These results suggest that global regulators and oxidation-reduction enzymes have important roles in the nucleoid regardless of their growths.
csNAPs shared by E. coli, P. aeruginosa, B. subtilis, and S. aureus
Comparison of csNAPs among species showed that Hu-β (coded by hupB in E. coli, hupB in P. aeruginosa, hbs in B. subtilis, and hu in S. aureus) was common to the 4 species. E. coli and P. aeruginosa share 5 additional csNAPs, whereas B. subtilis and S. aureus share 2 additional csNAPs (Figure 10). This low number of common csNAPs seems due both to ‘gene-level difference (the lack of the orthologous genes)' and to ‘protein-level difference (expression or localization difference).’ E. coli and P. aeruginosa, for example, did not share 33.9% of the csNAPs genes as orthologues (76 out of 224 [164 E. coli csNAPs + 66 P. aeruginosa csNAPs – 6 common csNAPs between these species]). Among the residual 148 csNAPs, whose genes are present in both species, 66.2% (98 out of 148) csNAPs were not detected in either E. coli or P. aeruginosa. While 30.4% (45 out of 148) of the csNAPs were detected in both species, they were not selected as csNAPs in either. B. subtilis and S. aureus showed a similar pattern. Although the degree of ‘gene-level difference’ increased in the distantly related species (41.8% to 66.9%), the ‘protein-level difference’ could still explain approximately half of the cross-species difference of the csNAPs (Figure 10A). As discussed in the previous section, it is possible that additional common csNAPs remain undetected (Table S15). However, the amount of those additional csNAPs in the cell should be small. Accordingly, the main csNAPs seem to differ among the species, suggesting that as each species evolved, it developed its own proteins associated with the nucleoid.
Figure 10. Common csNAPs in E. coli, P. aeruginosa, B. subtilis, and S. aureus.

(A) Classification of csNAPs. Common csNAPs represent csNAPs common to 2 species. Localization difference means the proteins that were not classified as csNAPs in either 2 species but were detected in the envelope and/or top fractions in the other species. Expression difference indicates the proteins that were classified as csNAPs in either species but were not detected in any fractions in the other species. Gene lacking represents the proteins that were csNAPs in either species but for which the corresponding genes were not present in the other species' genomes. (B) csNAPs common to 2 species in the log phase. Underlined genes were ranked in the top 30 emPAI values in both compared species.
When the common csNAPs were sorted by emPAI values, Hu (hupA, hupB, hbs, hu), Fis (fis), and FabD (fabD) were included in the top 30 in certain pairs of species (Figure 10B). Hu gained high emPAI values in all the species. Given that it is crucial in various species [63]–[65], Hu should play a critical role in the bacterial kingdom. The abundance of Fis in E. coli and P. aeruginosa implies its importance in Gammaproteobacteria. It is interesting that FabD, also known as malonyl CoA-acyl carrier protein transacylase, was abundantly present in E. coli and S. aureus. In both species, fabG, which encodes 3-oxoacyl-[acyl-carrier-protein] reductase (FabG) and forms an operon with fabD [66], was also common. These genes are involved in fatty acid biosynthesis [67]. Between P. aeruginosa and S. aureus, FabZ, which is (3R)-hydroxymyristoyl-[acyl-carrier-protein] dehydratase and also involved in fatty acid synthesis, was a common csNAP. The prediction of their localization and DNA/RNA binding ability showed that these proteins are cytoplasmic proteins with less potential to bind DNA and RNA (Figure 6A and 6E). It might be possible that fatty acid synthesis occurs near the genomic DNA in those bacteria.
NAPs not listed in the csNAPs: contaminant or genuine NAP?
Many proteins that have been reported to exist in the nucleoid were not included in the list of csNAPs. The involvement of the real NAPs in the top fraction might be due to disassociation from the NAPs during the purification procedure or might reflect their dynamic association with or disassociation from the nucleoid. Indeed, Hfq was reported to exist in both the cytoplasm and the nucleoid [68]. It might also be possible that high expression levels of NAPs lead to their higher accumulation in the cytoplasm owing to their saturation in the nucleoid.
Regarding the cell envelopes, the outer membranes of Gram-negative bacteria are resistant to nonionic detergents such as Brij-58 that was used in this study [5], [36]. It is likely that the outer membrane proteins detected in E. coli and P. aeruginosa, such as flagellin and porins, were contaminated owing to the insufficient solubilization of the outer membrane. The cell walls of Gram-positive bacteria are relatively thicker than those of Gram-negative bacteria. In particular, S. aureus possesses a thick cell wall that is resistant to lysozyme [69]. We used lysostaphin [70] to disrupt the cell wall, but it is possible that the cell wall fragments remained, in which case, cell-surface proteins such as immunodominant antigen A (coded by isaA) [71] and protein A (coded by spa) [72] in S. aureus would be the contaminants.
The inner membranes of E. coli are readily solubilized by Brij-58 [36], and indeed various inner membrane proteins, such as TonB [73], TolR [74], TatAB [75], and SecG [76], were detected only in the envelope fraction (Table S1). Nevertheless, some inner membrane proteins, such as the methyl-accepting chemotaxis proteins Tar and Tsr [77] were included in our nucleoid fractions (but not selected as csNAPs). These proteins may play some role in the nucleoid characteristics that require, for instance, interaction with the membrane. Similarly, Portalier and Worcel previously reported that several inner membrane proteins remained in the E. coli nucleoid even after treatment with sarkosyl and 1M NaCl [5]. In the present study, cytosolic portions of F0F1-ATPase (F1 β [atpD] and F1 γ [atpG]) were detected in the nucleoid and envelope fractions with high emPAI values under all the conditions tested. These remained in the nucleoid even after high salt treatment [45].
Recently, cell envelope-attached proteins, such as MreB, have been reported to interact with RNA polymerases and elongation factor EF-Tu [78], [79]. In B. subtilis, these proteins were indeed detected in both the nucleoid and envelope fractions. In E. coli, MreB (mreB) itself was not detected in the nucleoid fractions, but RpoZ (rpoZ), which is also a cytoskeleton protein and interacts with MreB [80], was detected in both the nucleoid and the envelop fractions. Thus, cytoskeleton proteins are also possible candidates for the linker of the nucleoid and cell envelope.
Future Perspectives
Through the analyses of csNAPs in this study, we showed that global regulators, oxidation-reduction enzymes, and fatty acid synthases were enriched in the nucleoids. The distinct evolutionary origins of those proteins imply that bacteria have individually developed nucleoid-associated proteins in order to obtain similar characteristics.
While it was reasonable that various global regulators were in the nucleoid, it was surprising that oxidation-reduction enzymes and fatty acid synthase were enriched in the nucleoid because they have been believed to work in the cytosol and/or the envelope. The enrichment of oxidation-reduction enzymes facilitates our proposal of a new hypothesis - the armor hypothesis, which postulates the proteins in the nucleoid defuse the oxidative stress elements that challenge genomic DNA.
The presence of csNAPs involved in fatty acid synthesis implies certain relationships between the cellular membrane and the nucleoid. Phospholipids have been reported to regulate DNA replication via direct interaction with the replication initiator protein DnaA [81]–[83]. On the contrary, mutations in the replication machinery proteins such as DnaA, SeqA (negative modulator of initiation of replication), and Dam (DNA adenine methyltransferase) change the phospholipid constituents [84], [85], suggesting the presence of a bidirectional regulatory system to maintain the genomic DNA and cellular membrane. Fatty acid synthases in the nucleoid might also be involved in such a crosstalk system.
Although the current study only suggested the presence of the oxidation-reduction enzymes and fatty acid synthasesfattyf in the nucleoid, it would be fascinating in future studies to focus on nucleoid characteristics such as the ‘armor hypothesis’ and ‘nucleoid-membrane crosstalk.’
Materials and Methods
Bacterial strains and growth conditions
Glycerol stocks of E. coli K-12 W3110, P. aeruginosa PAO1, and B. subtilis 168 were inoculated in LB medium and cultured at 37°C with constant shaking (180 rpm; Bioshaker BR-15, TAITEC) for 18 h. Twenty-five microliters of the saturated culture was inoculated in 25 or 50 mL of fresh LB medium and cultured at 37°C with constant shaking (180 rpm) until the OD600 reached 0.7 (log phase) (Figure S1). The cell density was determined by measuring absorbance at 600 nm. Glycerol stocks of S. aureus N315 were inoculated in Brain Heart Infusion (BHI) medium (Difco, Detroit, MI, USA) and cultured at 37°C with constant shaking (180 rpm) for 18 h. Two hundred fifty microliters of the saturated culture was inoculated in 25 mL of fresh BHI and cultured at 37°C, with constant shaking, to an appropriate cell density (OD600 = 0.7). The cultures in the stationary phases were collected 12 to 14 h after the inoculations, and cells collected from 2 mL culture were used for the subsequent studies.
Isolation of nucleoids
Cultures (25 mL for E. coli, P. aeruginosa, and S. aureus and 50 mL for B. subtilis) were centrifuged at 8000 g for 10 min at 4°C. Cell pellets were suspended in 0.5 mL ice-cold Buffer A (10 mM Tris-HCl [pH 8.2], 100 mM NaCl, and 20% sucrose) followed by the addition of 0.1 mL ice-cold Buffer B (100 mM Tris-HCl [pH 8.2], 50 mM EDTA, 0.6 mg/mL lysozyme [plus 100 µg/mL lysostaphin in the case of S. aureus]). The mixtures were incubated for the appropriate time at the appropriate temperature according to previous reports (E. coli [4] and B. subtilis [3]) or the preliminary experiments to understand the minimum requirements for the incubation conditions: in detail, 1 to 3 min on ice for the log phase of E. coli, 5 min at room temperature (RT) for the stationary phase of E. coli, 5 min on ice for the log phase of P. aeruginosa, 15 min on ice for the log phase of B. subtilis, and 15 min at RT for the log and stationary phases of S. aureus). Then, 0.5 mL ice-cold Buffer C (10 mM Tris-HCl [pH 8.2], 10 mM EDTA, 10 mM spermidine, 1% Brij-58, and 0.4% deoxycholate) was added, and the mixtures were incubated for the appropriate time (3–5 min at RT for the log phase of E. coli, 15 min at RT for the stationary phase of E. coli, 10 min at RT for P. aeruginosa, 20 min at RT for B. subtilis, and 30 min at RT for the log and stationary phases of S. aureus). The lysed cell suspensions were loaded onto linear sucrose density gradients containing 10 mM Tris-HCl (pH 8.2) and 100 mM NaCl (10%–60% for E. coli, P. aeruginosa, and B. subtilis, and 10%–30% for S. aureus) and centrifuged at 10,000 rpm with a Beckmann SW 40 Ti rotor (20 min for E. coli, 50 min for P. aeruginosa and S. aureus, and 40 min for B. subtilis). The DNA concentration in each fraction was quantified by DAPI fluorescence signals [4].
Preparation of envelope fractions
Cellular envelopes were purified according to Zimmerman's method with several modifications [4]. The cultures (25 mL for E. coli, P. aeruginosa, and S. aureus and 50 mL for B. subtilis) were centrifuged at 8000 g for 10 min. Cell pellets were suspended in 0.5 mL ice-cold Buffer A followed by the addition of 0.1 mL ice-cold Buffer B (plus lysostaphin [25 µg/mL final concentration] in the case of S. aureus). The mixtures were incubated for the appropriate time (2 min at RT for E. coli and P. aeruginosa and 5 min at RT for B. subtilis and S. aureus). After adding PMSF (1 mM final concentration), the solutions were sonicated in ice water until they became clear. The debris was removed by centrifugation at 1200 g for 20 min at 4°C. The supernatants were collected, and 5 µg RNase, 10 U DNase, and MgCl2 (40 mM final) added. After 60-min incubation at 37°C, the envelope fractions were collected as pellets by centrifugation at 20,000 g for 60 min at 4°C.
LC-MS/MS
Each lane of the Coomassie Brilliant Blue (CBB)-stained SDS-PAGE gels (8.5×6 cm) was cut into 10 sequential slices. Proteins in each gel slice were destained in 50% acetonitrile/50 mM ammonium bicarbonate (ABB), deoxidized by 10 mM DTT in 100 mM ABB, and alkylated by 55 mM iodoacetamide in 100 mM ABB. After being washed in 100 mM ABB and then 50% acetonitrile and 50 mM ABB, the gel slices were dried thoroughly in a MicroVac (Tomy Digital Biology, Tokyo, Japan). The proteins were then digested with 15 ng/µL trypsin (Trypsin Gold; [Promega, Madison, WI, USA]) in 50 mM ABB for 8 to 12 h at 37°C. Tryptic peptides were extracted by sonication in 50% acetonitrile/0.1% trifluoroacetic acid (TFA), and the supernatants collected. Again, the peptides were extracted by sonication in 75% acetonitrile/0.1% TFA and collected as supernatants. The samples were dried using the MicroVac and suspended in 2% acetonitrile/0.1% TFA. After being filtered by C-TIP (AMR Technology, Albany, NY, USA), the samples were analyzed by LC-MS/MS.
Reverse-phase nano-LC-MS/MS was performed using a Paradigm MS4 system (Michrom BioResources, Auburn, CA, USA) coupled to an LXQ (Thermo Scientific). The digested peptides were separated on an HPLC column (0.1×150 mm, 3 µm Magic C18AQ; Michrom BioResource) using a linear gradient of 6.4% to 41.6% acetonitrile in 0.1% formic acid for 20 min at a flow rate of 500 nL/min and detected by the ion trap in the 450–1800 m/z range following the supplier's recommendations. Mass spectra were acquired in the positive-ion mode with automated data-dependent MS/MS on the 3 most intense ions from the precursor MS scans.
Protein identification was performed using a Mascot Server (Matrix Science). Protein identifications were obtained by processing the experimental data against the SwissProt bacteria subset database (Release 57.4, June 16, 2009). The search parameters were as follows: trypsin was used as the cutting enzyme, mass tolerance for the monoisotopic peptide window was set to ±2 Da, the MS/MS tolerance window was set to ±1 Da, and 1 missed cleavage was allowed. Cysteine carbamidomethyl modification and oxidized methionine were chosen as the variable modifications. The criteria of positive identification were set as follows: identification of at least 2 peptides with more than 7 amino acids, and a significant threshold of P<0.05.
Estimation of coverage rates
The coverage rates of proteins identified in each fraction were calculated by in silico simulation. We first created hypothetical protein sets (X-axis in Figure S2 B–D) and estimated the expected number of proteins identified by random sampling with a given number of the peptides (Y-axis in Figure S2 B–D). These plots make it possible to expect the actual number of the protein in the cognate samples. In detail, the steps of the procedure were as follows:
Step 1: Creation of hypothetical protein sets
We randomly collected 1 to 1500 protein sequences without overlaps from the genomic database of E. coli, P. aeruginosa, B. subtilis, or S. aureus [86]. The relative protein amounts (Pr) in the hypothetical protein sets were given as follows: here we applied 3 different models: the constant model, the linear model, and the simplified canonical law (SCL) model (Figure S2A).
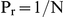 constant model
constant model
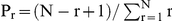 linear model
linear model
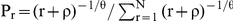 SCL model,
SCL model,
where r is the rank of individual protein species sorted by their amounts, N is the number of the collected protein species (1–1500 in this study), and ρ and θ are the parameters to determine the individual protein amounts. In the constant model, the amounts of individual proteins were equal. In the linear model, the protein amounts linearly decreased. SCL was reported to fit well with the expression pattern in prokaryotic cells [47]. ρ and θ were set as 5.17 and 0.58, respectively, because Ramsden and Vohradsky showed that E. coli followed these values [47]. The ranks of the individual proteins were randomly determined. The number of the least protein was set as 1. Each of the collected protein sequences was replicated for the times according to the above statistical models. The summation of the number of replicated proteins was defined as the total amount of proteins. (We symbolize this value as M in the following steps.)
Step 2: Creation of theoretical peptide sets
The theoretical peptide sets that were theoretically produced by the digestion of trypsin were created from the hypothetical protein sets. Since the lengths of our detected peptides were between 6 and 45, we discarded the peptides with lengths out of this range.
Step 3: Estimation of the expected number of proteins identified in the hypothetical protein sets
Random sampling of the peptides from the theoretical peptide set was performed. Here, the number of the sampling cycles was set as the number of the experimentally identified peptides (eg, the log phase of the E. coli nucleoid as 7148). Then, the number of the selected protein species was counted (we counted only the proteins that were hit by more than 2 peptides according to our criteria for the protein identification). The amount of the selected proteins was set according to the number of the individual protein sequences determined in Step 1.
Step 4: Repetition of Steps 1 to 3 for calculation of the averages
We repeated Step 1 to 3 5 times and calculated the averages of the number of protein species (Ne) and the amount of proteins (Me). Examples of the plots of N, M, Ne, and Me are shown in Figure S2 B to F.
Step 5: Estimation of the coverage rates
The coverage rates of protein species (RN) and amounts (RM) were calculated as follows:
where Nes is the number of protein species identified in the real sample and Ns is the value of N when Ne gains Nes. Mes and Ms are the values of Me and M, respectively, when Ne gains Nes. Examples of the RN and RM values are shown in Figure S2 G and H.
The number of peptides required for identifying all the potential proteins in the sample was estimated based on the above criterion of SCL model. We fixed the number of proteins in Step 1, and increased the numbers of peptides (with 1,000 intervals) to achieve the coverage rate of 1. The average of 5 trials is shown in Table S4. The above analyses were performed wholly by means of the Perl script.
Comparative genomic analyses
The orthologue relationships were determined by best-best hit analyses using the FASTA package [87] on a desk-top computer. The pairs of proteins that showed a ‘best-best’ relation and a gain of less than 0.0001 of e-values were determined to be orthologous pairs. Total protein sequences identified in E. coli W3110, P. aeruginosa PAO1, B. subtilis 168, and S. aureus N315 were downloaded from KEGG on June 1, 2009 [86] and used for the best-best hit analyses.
The prediction of DNA/RNA binding abilities
The DNA/RNA binding sites of the csNAPs were predicted by BindN [88]. The criterion for the search is ‘the predicted DNA/RNA binding residues with expected specificity equal to 90%.' We estimated the percentages of DNA/RNA binding residues in a protein and set 10% as the proteins having high DNA/RNA binding ability. This criterion was based on the following observations (Figure S4): The investigation of the number of DNA/RNA binding sites of Hu, IHF, HNS, StpA, Fis, and Hfq and of ribosomal proteins in E. coli showed that over 10% of the residues in each protein were predicted to be DNA/RNA binding sites. The distribution of the rates of the DNA/RNA binding sites of the csNAPs showed that 2 normal distributions appeared whose peaks were around 7.5% and 14% and that the gulf of the 2 distributions was around 10%. In contrast, the distribution of the protein detected only in the envelope and/or top fractions showed that only 1 normal distribution appeared whose peak was around 7.5%. These results support the notion that proteins whose predicted DNA/RNA binding sites are over 10% have high potential to bind to DNA/RNA.
The number of potential csNAPs
The number of potential csNAPs (Np) was estimated based on the coverage rates of proteins and the number of subtracted proteins in the selection of csNAPs. Np was calculated as follows:
where Nn is the number of proteins identified in the nucleoid fractions, Nne is the number of ‘overlapped proteins’ between the nucleoid and envelope fractions (‘overlapped proteins’ represent the proteins subtracted in the process of the csNAPs selection), and Nnt is the number of ‘overlapped proteins’ between the nucleoid and top fractions. Nnet is the number of ‘overlapped proteins’ in all 3 fractions. Rn, Re and Rt represent the coverage rates of proteins in the nucleoid, envelope, and top fractions, respectively. The highest number of Np was obtained when Rn was the lowest and Re and Rt were the highest. The minimum Np was obtained vice versa.
Supporting Information
Sampling points of bacterial cells. The log phase cultures were collected at OD600 = 0.7, and the stationary phase cultures were collected 12 to 14 h after inoculation (arrows).
(TIF)
The estimation of the coverage rates of the proteins in the samples. (A) The probability distribution of protein amounts according to 3 different models: constant model (blue line), linear model (red line), and SCL model (green line). (B, C, D) The number of protein species expected to be identified in the hypothetical protein set with the constant model (B), the linear model (C), and the SCL model (D). The x axis represents the number of protein species in the hypothetical protein set, and the y axis, the expected number of protein species detected in the hypothetical protein sets. (E, F) The protein amounts expected to be identified in the hypothetical protein set with the SCL model (E), and the linear model (F). The x axis represents the number of protein species, and the y axis, the protein amounts expected to be identified. The solid line indicates the total amounts of proteins in hypothetical protein sets. (G, H) The coverage rates of protein species (G) and amounts (H) estimated with the SCL model. The x axis represents the number of protein species identified, and the y axis, the coverage rates of protein species (G) and protein amounts (H), respectively. The pink circle, square, and triangle indicate the points corresponding to the experimental results.
(EPS)
Nucleoid isolation of S. aureus , P. aeruginosa, and B. subtilis . The nucleoid isolations of the log phases of S. aureus (A, B), the stationary phase of S. aureus (C, D), the log phase of P. aeruginosa (E, F), and the log phase of B. subtilis (G, H). The spermidine nucleoids were fractionated by sucrose-gradient centrifugation with a 10%-to-30% (60%) gradient (A, C, E, G). The fractions containing genomic DNA were identified by DAPI fluorescence (B, D, F, H).
(TIF)
The distribution of the percentages of DNA/RNA binding sites in proteins. (A) The number of DNA/RNA binding sites in Hu, IHF, Fis, HNS, StpA, and Hfq in E. coli. Percent (%) represents the percentage of DNA (or RNA) binding amino acid in each protein. (B) The distributions of the percentages of the DNA/RNA binding sites of the csNAPs and the proteins that appeared only in the envelope and/or top fractions (env_top_specific) in E. coli.
(TIF)
Full list of the proteins identified in this study.
(XLS)
Proteins identified in the nucleoid fraction of the log phase of E. coli .
(XLS)
Proteins identified in the nucleoid fraction of the stationary phase of E. coli .
(XLS)
Number of peptides required to cover all the potential proteins in samples.
(XLS)
Proteins identified in the nucleoid fraction of the log phase of P. aeruginosa .
(XLS)
Proteins identified in the nucleoid fraction of the log phase of B. subtilis .
(XLS)
Proteins identified in the nucleoid fraction of the log phase of S. aureus .
(XLS)
Proteins identified in the nucleoid fraction of the stationary phase of S. aureus .
(XLS)
csNAPs of E. coli in the log phase.
(XLS)
csNAPs of E. coli in the stationary phase.
(XLS)
csNAPs of P. aeruginosa in the log phase.
(XLS)
csNAPs of B. subtilis in the log phase.
(XLS)
csNAPs of S. aureus in the log phase.
(XLS)
csNAPs of S. aureus in the stationary phase.
(XLS)
Potential number of csNAPs.
(XLS)
Acknowledgments
We thank Dr. Kunio Takeyasu for his valuable suggestions and for providing us with Hu antibody. The LC-MS/MS analyses were supported by the “Nanotechnology Network Project" of the Ministry of Education, Culture, Sports, Science and Technology (MEXT) of Japan. In particular, Dr. Taro Takemura of the National Institute for Material Sciences kindly helped us with handling the LC-MS/MS devices. We also thank Dr. Flaminia for her helpful proof reading.
Footnotes
Competing Interests: The authors have declared that no competing interests exist.
Funding: This work was supported by a grant provided by The Ichiro Kanehara Foundation (to K.M), by a Grant-in-Aid for Young Scientists of the Japan Society for the Promotion of Science (to R.L.O), and by a Collaborative Research (B) grant from the National Institute of Genetics, Japan (to R.L.O). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.Ishihama A. EcoSal—Escherichia coli and Salmonella: Cellular and Molecular Biology. In: Böck A, Curtiss R III, Kaper JB, Karp PD, Neidhardt FC, Nyström T, Slauch JM, Squires CL, Ussery D, editors. The nucleoid: an Overview. Washington, DC: ASM Press; 2009. [Google Scholar]
- 2.Robinow C, Kellenberger E. The bacterial nucleoid revisited. Microbiol Rev. 1994;58:211–232. doi: 10.1128/mr.58.2.211-232.1994. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Guillen N, Le Hegaret F, Fleury AM, Hirschbein L. Folded chromosomes of vegetative Bacillus subtilis: composition and properties. Nucleic Acids Res. 1978;5:475–489. doi: 10.1093/nar/5.2.475. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Murphy LD, Zimmerman SB. Isolation and characterization of spermidine nucleoids from Escherichia coli. J Struct Biol. 1997;119:321–335. doi: 10.1006/jsbi.1997.3883. [DOI] [PubMed] [Google Scholar]
- 5.Portalier R, Worcel A. Association of the folded chromosome with the cell envelope of E. coli: characterization of the proteins at the DNA-membrane attachment site. Cell. 1976;8:245–255. doi: 10.1016/0092-8674(76)90008-8. [DOI] [PubMed] [Google Scholar]
- 6.Yamazaki T, Yahagi S, Nakamura K, Yamane K. Depletion of Bacillus subtilis histone-like protein, HBsu, causes defective protein translocation and induces upregulation of small cytoplasmic RNA. Biochem Biophys Res Commun. 1999;258:211–214. doi: 10.1006/bbrc.1999.0615. [DOI] [PubMed] [Google Scholar]
- 7.Azam TA, Ishihama A. Twelve species of the nucleoid-associated protein from Escherichia coli. Sequence recognition specificity and DNA binding affinity. J Biol Chem. 1999;274:33105–33113. doi: 10.1074/jbc.274.46.33105. [DOI] [PubMed] [Google Scholar]
- 8.Drlica K, Rouviere-Yaniv J. Histonelike proteins of bacteria. Microbiol Rev. 1987;51:301–319. doi: 10.1128/mr.51.3.301-319.1987. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Grainger DC, Hurd D, Goldberg MD, Busby SJ. Association of nucleoid proteins with coding and non-coding segments of the Escherichia coli genome. Nucleic Acids Res. 2006;34:4642–4652. doi: 10.1093/nar/gkl542. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Oshima T, Ishikawa S, Kurokawa K, Aiba H, Ogasawara N. Escherichia coli histone-like protein H-NS preferentially binds to horizontally acquired DNA in association with RNA polymerase. DNA Res. 2006;13:141–153. doi: 10.1093/dnares/dsl009. [DOI] [PubMed] [Google Scholar]
- 11.Altuvia S, Almiron M, Huisman G, Kolter R, Storz G. The dps promoter is activated by OxyR during growth and by IHF and sigma S in stationary phase. Mol Microbiol. 1994;13:265–272. doi: 10.1111/j.1365-2958.1994.tb00421.x. [DOI] [PubMed] [Google Scholar]
- 12.Lucchini S, McDermott P, Thompson A, Hinton JC. The H-NS-like protein StpA represses the RpoS (sigma(38)) regulon during exponential growth of Salmonella Typhimurium. Mol Microbiol. 2009 doi: 10.1111/j.1365-2958.2009.06929.x. [DOI] [PubMed] [Google Scholar]
- 14.Oberto J, Nabti S, Jooste V, Mignot H, Rouviere-Yaniv J. The HU regulon is composed of genes responding to anaerobiosis, acid stress, high osmolarity and SOS induction. PLoS ONE. 2009;4:e4367. doi: 10.1371/journal.pone.0004367. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Weinstein-Fischer D, Elgrably-Weiss M, Altuvia S. Escherichia coli response to hydrogen peroxide: a role for DNA supercoiling, topoisomerase I and Fis. Mol Microbiol. 2000;35:1413–1420. doi: 10.1046/j.1365-2958.2000.01805.x. [DOI] [PubMed] [Google Scholar]
- 16.Aronsson H, Jarvis P. A simple method for isolating import-competent Arabidopsis chloroplasts. FEBS Lett. 2002;529:215–220. doi: 10.1016/s0014-5793(02)03342-2. [DOI] [PubMed] [Google Scholar]
- 17.Balandina A, Claret L, Hengge-Aronis R, Rouviere-Yaniv J. The Escherichia coli histone-like protein HU regulates rpoS translation. Mol Microbiol. 2001;39:1069–1079. doi: 10.1046/j.1365-2958.2001.02305.x. [DOI] [PubMed] [Google Scholar]
- 18.Brescia CC, Kaw MK, Sledjeski DD. The DNA binding protein H-NS binds to and alters the stability of RNA in vitro and in vivo. J Mol Biol. 2004;339:505–514. doi: 10.1016/j.jmb.2004.03.067. [DOI] [PubMed] [Google Scholar]
- 19.Mayer O, Waldsich C, Grossberger R, Schroeder R. Folding of the td pre-RNA with the help of the RNA chaperone StpA. Biochem Soc Trans. 2002;30:1175–1180. doi: 10.1042/bst0301175. [DOI] [PubMed] [Google Scholar]
- 20.Chodavarapu S, Gomez R, Vicente M, Kaguni JM. Escherichia coli Dps interacts with DnaA protein to impede initiation: a model of adaptive mutation. Mol Microbiol. 2008;67:1331–1346. doi: 10.1111/j.1365-2958.2008.06127.x. [DOI] [PubMed] [Google Scholar]
- 21.Filutowicz M, Ross W, Wild J, Gourse RL. Involvement of Fis protein in replication of the Escherichia coli chromosome. J Bacteriol. 1992;174:398–407. doi: 10.1128/jb.174.2.398-407.1992. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Hwang DS, Kornberg A. Opening of the replication origin of Escherichia coli by DnaA protein with protein HU or IHF. J Biol Chem. 1992;267:23083–23086. [PubMed] [Google Scholar]
- 23.Polaczek P. Bending of the origin of replication of E. coli by binding of IHF at a specific site. New Biol. 1990;2:265–271. [PubMed] [Google Scholar]
- 24.Almiron M, Link AJ, Furlong D, Kolter R. A novel DNA-binding protein with regulatory and protective roles in starved Escherichia coli. Genes Dev. 1992;6:2646–2654. doi: 10.1101/gad.6.12b.2646. [DOI] [PubMed] [Google Scholar]
- 25.Nair S, Finkel SE. Dps protects cells against multiple stresses during stationary phase. J Bacteriol. 2004;186:4192–4198. doi: 10.1128/JB.186.13.4192-4198.2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Dame RT, Noom MC, Wuite GJ. Bacterial chromatin organization by H-NS protein unravelled using dual DNA manipulation. Nature. 2006;444:387–390. doi: 10.1038/nature05283. [DOI] [PubMed] [Google Scholar]
- 27.Grant RA, Filman DJ, Finkel SE, Kolter R, Hogle JM. The crystal structure of Dps, a ferritin homolog that binds and protects DNA. Nat Struct Biol. 1998;5:294–303. doi: 10.1038/nsb0498-294. [DOI] [PubMed] [Google Scholar]
- 28.Ohniwa RL, Morikawa K, Kim J, Ohta T, Ishihama A, et al. Dynamic state of DNA topology is essential for genome condensation in bacteria. Embo J. 2006;25:5591–5602. doi: 10.1038/sj.emboj.7601414. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Rouviere-Yaniv J, Yaniv M, Germond JE. E. coli DNA binding protein HU forms nucleosomelike structure with circular double-stranded DNA. Cell. 1979;17:265–274. doi: 10.1016/0092-8674(79)90152-1. [DOI] [PubMed] [Google Scholar]
- 30.Swinger KK, Lemberg KM, Zhang Y, Rice PA. Flexible DNA bending in HU-DNA cocrystal structures. Embo J. 2003;22:3749–3760. doi: 10.1093/emboj/cdg351. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Talukder AA, Iwata A, Nishimura A, Ueda S, Ishihama A. Growth phase-dependent variation in protein composition of the Escherichia coli nucleoid. J Bacteriol. 1999;181:6361–6370. doi: 10.1128/jb.181.20.6361-6370.1999. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Teramoto J, Yoshimura SH, Takeyasu K, Ishihama A. A novel nucleoid protein of Escherichia coli induced under anaerobiotic growth conditions. Nucleic Acids Res. 2010;38:3605–3618. doi: 10.1093/nar/gkq077. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Kim J, Yoshimura SH, Hizume K, Ohniwa RL, Ishihama A, et al. Fundamental structural units of the Escherichia coli nucleoid revealed by atomic force microscopy. Nucleic Acids Res. 2004;32:1982–1992. doi: 10.1093/nar/gkh512. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Takeyasu K, Kim J, Ohniwa RL, Kobori T, Inose Y, et al. Genome architecture studied by nanoscale imaging: analyses among bacterial phyla and their implication to eukaryotic genome folding. Cytogenet Genome Res. 2004;107:38–48. doi: 10.1159/000079570. [DOI] [PubMed] [Google Scholar]
- 35.Osborn MJ, Gander JE, Parisi E, Carson J. Mechanism of assembly of the outer membrane of Salmonella typhimurium. Isolation and characterization of cytoplasmic and outer membrane. J Biol Chem. 1972;247:3962–3972. [PubMed] [Google Scholar]
- 36.Schnaitman CA. Protein composition of the cell wall and cytoplasmic membrane of Escherichia coli. J Bacteriol. 1970;104:890–901. doi: 10.1128/jb.104.2.890-901.1970. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Weiner JH, Li L. Proteome of the Escherichia coli envelope and technological challenges in membrane proteome analysis. Biochim Biophys Acta. 2008;1778:1698–1713. doi: 10.1016/j.bbamem.2007.07.020. [DOI] [PubMed] [Google Scholar]
- 38.Cunha S, Odijk T, Suleymanoglu E, Woldringh CL. Isolation of the Escherichia coli nucleoid. Biochimie. 2001;83:149–154. doi: 10.1016/s0300-9084(01)01245-7. [DOI] [PubMed] [Google Scholar]
- 39.Kornberg T, Lockwood A, Worcel A. Replication of the Escherichia coli chromosome with a soluble enzyme system. Proc Natl Acad Sci U S A. 1974;71:3189–3193. doi: 10.1073/pnas.71.8.3189. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Materman EC, Van Gool AP. Nucleoid release from Escherichia coli cells. J Bacteriol. 1978;133:878–883. doi: 10.1128/jb.133.2.878-883.1978. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Pettijohn DE, Clarkson K, Kossman CR, Stonington OG. Synthesis of ribosomal RNA on a protein-DNA complex isolated from bacteria: a comparison of ribosomal RNA synthesis in vitro and in vivo. J Mol Biol. 1970;52:281–300. doi: 10.1016/0022-2836(70)90031-8. [DOI] [PubMed] [Google Scholar]
- 42.Pettijohn DE, Stonington OG, Kossman CR. Chain termination of ribosomal RNA synthesis in vitro. Nature. 1970;228:235–239. doi: 10.1038/228235a0. [DOI] [PubMed] [Google Scholar]
- 43.Stonington OG, Pettijohn DE. The folded genome of Escherichia coli isolated in a protein-DNA-RNA complex. Proc Natl Acad Sci U S A. 1971;68:6–9. doi: 10.1073/pnas.68.1.6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Murphy LD, Zimmerman SB. Condensation and cohesion of lambda DNA in cell extracts and other media: implications for the structure and function of DNA in prokaryotes. Biophys Chem. 1995;57:71–92. doi: 10.1016/0301-4622(95)00047-2. [DOI] [PubMed] [Google Scholar]
- 45.Zimmerman SB. Cooperative transitions of isolated Escherichia coli nucleoids: implications for the nucleoid as a cellular phase. J Struct Biol. 2006;153:160–175. doi: 10.1016/j.jsb.2005.10.011. [DOI] [PubMed] [Google Scholar]
- 46.Alberts BM, Amodio FJ, Jenkins M, Gutmann ED, Ferris FL. Studies with DNA-cellulose chromatography. I. DNA-binding proteins from Escherichia coli. Cold Spring Harb Symp Quant Biol. 1968;33:289–305. doi: 10.1101/sqb.1968.033.01.033. [DOI] [PubMed] [Google Scholar]
- 47.Ramsden JJ, Vohradsky J. Zipf-like behavior in procaryotic protein expression. Physical Review E. 1998;58:7777–7780. [Google Scholar]
- 48.Ishihama Y, Oda Y, Tabata T, Sato T, Nagasu T, et al. Exponentially modified protein abundance index (emPAI) for estimation of absolute protein amount in proteomics by the number of sequenced peptides per protein. Mol Cell Proteomics. 2005;4:1265–1272. doi: 10.1074/mcp.M500061-MCP200. [DOI] [PubMed] [Google Scholar]
- 49.Vallet-Gely I, Donovan KE, Fang R, Joung JK, Dove SL. Repression of phase-variable cup gene expression by H-NS-like proteins in Pseudomonas aeruginosa. Proc Natl Acad Sci U S A. 2005;102:11082–11087. doi: 10.1073/pnas.0502663102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Washburn MP, Wolters D, Yates JR., 3rd Large-scale analysis of the yeast proteome by multidimensional protein identification technology. Nat Biotechnol. 2001;19:242–247. doi: 10.1038/85686. [DOI] [PubMed] [Google Scholar]
- 51.Liu H, Sadygov RG, Yates JR., 3rd A model for random sampling and estimation of relative protein abundance in shotgun proteomics. Anal Chem. 2004;76:4193–4201. doi: 10.1021/ac0498563. [DOI] [PubMed] [Google Scholar]
- 52.Phadtare S, Tadigotla V, Shin WH, Sengupta A, Severinov K. Analysis of Escherichia coli global gene expression profiles in response to overexpression and deletion of CspC and CspE. J Bacteriol. 2006;188:2521–2527. doi: 10.1128/JB.188.7.2521-2527.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Tani TH, Khodursky A, Blumenthal RM, Brown PO, Matthews RG. Adaptation to famine: a family of stationary-phase genes revealed by microarray analysis. Proc Natl Acad Sci U S A. 2002;99:13471–13476. doi: 10.1073/pnas.212510999. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.del Castillo T, Duque E, Ramos JL. A set of activators and repressors control peripheral glucose pathways in Pseudomonas putida to yield a common central intermediate. J Bacteriol. 2008;190:2331–2339. doi: 10.1128/JB.01726-07. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Kim J, Jeon CO, Park W. Dual regulation of zwf-1 by both 2-keto-3-deoxy-6-phosphogluconate and oxidative stress in Pseudomonas putida. Microbiology. 2008;154:3905–3916. doi: 10.1099/mic.0.2008/020362-0. [DOI] [PubMed] [Google Scholar]
- 56.Fujimoto DF, Higginbotham RH, Sterba KM, Maleki SJ, Segall AM, et al. Staphylococcus aureus SarA is a regulatory protein responsive to redox and pH that can support bacteriophage lambda integrase-mediated excision/recombination. Mol Microbiol. 2009;74:1445–1458. doi: 10.1111/j.1365-2958.2009.06942.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Karavolos MH, Horsburgh MJ, Ingham E, Foster SJ. Role and regulation of the superoxide dismutases of Staphylococcus aureus. Microbiology. 2003;149:2749–2758. doi: 10.1099/mic.0.26353-0. [DOI] [PubMed] [Google Scholar]
- 58.Vlamis-Gardikas A. The multiple functions of the thiol-based electron flow pathways of Escherichia coli: Eternal concepts revisited. Biochim Biophys Acta. 2008;1780:1170–1200. doi: 10.1016/j.bbagen.2008.03.013. [DOI] [PubMed] [Google Scholar]
- 59.Mendoza-Cozatl D, Loza-Tavera H, Hernandez-Navarro A, Moreno-Sanchez R. Sulfur assimilation and glutathione metabolism under cadmium stress in yeast, protists and plants. FEMS Microbiol Rev. 2005;29:653–671. doi: 10.1016/j.femsre.2004.09.004. [DOI] [PubMed] [Google Scholar]
- 60.Sekine K, Fujiwara M, Nakayama M, Takao T, Hase T, et al. DNA binding and partial nucleoid localization of the chloroplast stromal enzyme ferredoxin:sulfite reductase. FEBS J. 2007;274:2054–2069. doi: 10.1111/j.1742-4658.2007.05748.x. [DOI] [PubMed] [Google Scholar]
- 61.Nakamura M, Kuramata M, Kasugai I, Abe M, Youssefian S. Increased thiol biosynthesis of transgenic poplar expressing a wheat O-acetylserine(thiol) lyase enhances resistance to hydrogen sulfide and sulfur dioxide toxicity. Plant Cell Rep. 2009;28:313–323. doi: 10.1007/s00299-008-0635-5. [DOI] [PubMed] [Google Scholar]
- 62.Morikawa K, Ohniwa RL, Kim J, Maruyama A, Ohta T, et al. Bacterial nucleoid dynamics: oxidative stress response in Staphylococcus aureus. Genes Cells. 2006;11:409–423. doi: 10.1111/j.1365-2443.2006.00949.x. [DOI] [PubMed] [Google Scholar]
- 63.Chaudhuri RR, Allen AG, Owen PJ, Shalom G, Stone K, et al. Comprehensive identification of essential Staphylococcus aureus genes using Transposon-Mediated Differential Hybridisation (TMDH). BMC Genomics. 2009;10:291. doi: 10.1186/1471-2164-10-291. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Kano Y, Imamoto F. Requirement of integration host factor (IHF) for growth of Escherichia coli deficient in HU protein. Gene. 1990;89:133–137. doi: 10.1016/0378-1119(90)90216-e. [DOI] [PubMed] [Google Scholar]
- 65.Kobayashi K, Ehrlich SD, Albertini A, Amati G, Andersen KK, et al. Essential Bacillus subtilis genes. Proc Natl Acad Sci U S A. 2003;100:4678–4683. doi: 10.1073/pnas.0730515100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Podkovyrov SM, Larson TJ. Identification of promoter and stringent regulation of transcription of the fabH, fabD and fabG genes encoding fatty acid biosynthetic enzymes of Escherichia coli. Nucleic Acids Res. 1996;24:1747–1752. doi: 10.1093/nar/24.9.1747. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Fujita Y, Matsuoka H, Hirooka K. Regulation of fatty acid metabolism in bacteria. Mol Microbiol. 2007;66:829–839. doi: 10.1111/j.1365-2958.2007.05947.x. [DOI] [PubMed] [Google Scholar]
- 68.Kajitani M, Kato A, Wada A, Inokuchi Y, Ishihama A. Regulation of the Escherichia coli hfq gene encoding the host factor for phage Q beta. J Bacteriol. 1994;176:531–534. doi: 10.1128/jb.176.2.531-534.1994. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Wooley RE, Blue JL. In-vitro effect of edta-tris-lysozyme solutions on selected pathogenic bacteria. J Med Microbiol. 1975;8:189–194. doi: 10.1099/00222615-8-1-189. [DOI] [PubMed] [Google Scholar]
- 70.Schindler CA, Schuhardt VT. Lysostaphin: A New Bacteriolytic Agent for the Staphylococcus. Proc Natl Acad Sci U S A. 1964;51:414–421. doi: 10.1073/pnas.51.3.414. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Sakata N, Terakubo S, Mukai T. Subcellular location of the soluble lytic transglycosylase homologue in Staphylococcus aureus. Curr Microbiol. 2005;50:47–51. doi: 10.1007/s00284-004-4381-9. [DOI] [PubMed] [Google Scholar]
- 72.Forsgren A, Sjoquist J. "Protein A" from S. aureus. I. Pseudo-immune reaction with human gamma-globulin. J Immunol. 1966;97:822–827. [PubMed] [Google Scholar]
- 73.Letain TE, Postle K. TonB protein appears to transduce energy by shuttling between the cytoplasmic membrane and the outer membrane in Escherichia coli. Mol Microbiol. 1997;24:271–283. doi: 10.1046/j.1365-2958.1997.3331703.x. [DOI] [PubMed] [Google Scholar]
- 74.Cascales E, Lloubes R, Sturgis JN. The TolQ-TolR proteins energize TolA and share homologies with the flagellar motor proteins MotA-MotB. Mol Microbiol. 2001;42:795–807. doi: 10.1046/j.1365-2958.2001.02673.x. [DOI] [PubMed] [Google Scholar]
- 75.Weiner JH, Bilous PT, Shaw GM, Lubitz SP, Frost L, et al. A novel and ubiquitous system for membrane targeting and secretion of cofactor-containing proteins. Cell. 1998;93:93–101. doi: 10.1016/s0092-8674(00)81149-6. [DOI] [PubMed] [Google Scholar]
- 76.Hanada M, Nishiyama K, Tokuda H. SecG plays a critical role in protein translocation in the absence of the proton motive force as well as at low temperature. FEBS Lett. 1996;381:25–28. doi: 10.1016/0014-5793(96)00066-x. [DOI] [PubMed] [Google Scholar]
- 77.Hazelbauer GL, Falke JJ, Parkinson JS. Bacterial chemoreceptors: high-performance signaling in networked arrays. Trends Biochem Sci. 2008;33:9–19. doi: 10.1016/j.tibs.2007.09.014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Defeu Soufo HJ, Reimold C, Linne U, Knust T, Gescher J, et al. Bacterial translation elongation factor EF-Tu interacts and colocalizes with actin-like MreB protein. Proc Natl Acad Sci U S A. 2010;107:3163–3168. doi: 10.1073/pnas.0911979107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Kruse T, Blagoev B, Lobner-Olesen A, Wachi M, Sasaki K, et al. Actin homolog MreB and RNA polymerase interact and are both required for chromosome segregation in Escherichia coli. Genes Dev. 2006;20:113–124. doi: 10.1101/gad.366606. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.van den Ent F, Johnson CM, Persons L, de Boer P, Lowe J. Bacterial actin MreB assembles in complex with cell shape protein RodZ. Embo J. 2010;29:1081–1090. doi: 10.1038/emboj.2010.9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 81.Yung BY, Kornberg A. Membrane attachment activates dnaA protein, the initiation protein of chromosome replication in Escherichia coli. Proc Natl Acad Sci U S A. 1988;85:7202–7205. doi: 10.1073/pnas.85.19.7202. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Ichihashi N, Kurokawa K, Matsuo M, Kaito C, Sekimizu K. Inhibitory effects of basic or neutral phospholipid on acidic phospholipid-mediated dissociation of adenine nucleotide bound to DnaA protein, the initiator of chromosomal DNA replication. J Biol Chem. 2003;278:28778–28786. doi: 10.1074/jbc.M212202200. [DOI] [PubMed] [Google Scholar]
- 83.Sekimizu K, Kornberg A. Cardiolipin activation of dnaA protein, the initiation protein of replication in Escherichia coli. J Biol Chem. 1988;263:7131–7135. [PubMed] [Google Scholar]
- 84.Suzuki E, Kondo T, Makise M, Mima S, Sakamoto K, et al. Alteration in the contents of unsaturated fatty acids in dnaA mutants of Escherichia coli. Mol Microbiol. 1998;28:95–102. doi: 10.1046/j.1365-2958.1998.00777.x. [DOI] [PubMed] [Google Scholar]
- 85.Daghfous D, Chatti A, Marzouk B, Landoulsi A. Phospholipid changes in seqA and dam mutants of Escherichia coli. C R Biol. 2006;329:271–276. doi: 10.1016/j.crvi.2006.02.002. [DOI] [PubMed] [Google Scholar]
- 86.Kanehisa M, Goto S. KEGG: kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 2000;28:27–30. doi: 10.1093/nar/28.1.27. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87.Pearson WR, Lipman DJ. Improved tools for biological sequence comparison. Proc Natl Acad Sci U S A. 1988;85:2444–2448. doi: 10.1073/pnas.85.8.2444. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88.Wang L, Brown SJ. BindN: a web-based tool for efficient prediction of DNA and RNA binding sites in amino acid sequences. Nucleic Acids Res. 2006;34:W243–248. doi: 10.1093/nar/gkl298. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89.Lai EM, Nair U, Phadke ND, Maddock JR. Proteomic screening and identification of differentially distributed membrane proteins in Escherichia coli. Mol Microbiol. 2004;52:1029–1044. doi: 10.1111/j.1365-2958.2004.04040.x. [DOI] [PubMed] [Google Scholar]
- 90.Horler RS, Butcher A, Papangelopoulos N, Ashton PD, Thomas GH. EchoLOCATION: an in silico analysis of the subcellular locations of Escherichia coli proteins and comparison with experimentally derived locations. Bioinformatics. 2009;25:163–166. doi: 10.1093/bioinformatics/btn596. [DOI] [PubMed] [Google Scholar]
- 91.Yu NY, Wagner JR, Laird MR, Melli G, Rey S, et al. PSORTb 3.0: improved protein subcellular localization prediction with refined localization subcategories and predictive capabilities for all prokaryotes. Bioinformatics. 2010;26:1608–1615. doi: 10.1093/bioinformatics/btq249. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Sampling points of bacterial cells. The log phase cultures were collected at OD600 = 0.7, and the stationary phase cultures were collected 12 to 14 h after inoculation (arrows).
(TIF)
The estimation of the coverage rates of the proteins in the samples. (A) The probability distribution of protein amounts according to 3 different models: constant model (blue line), linear model (red line), and SCL model (green line). (B, C, D) The number of protein species expected to be identified in the hypothetical protein set with the constant model (B), the linear model (C), and the SCL model (D). The x axis represents the number of protein species in the hypothetical protein set, and the y axis, the expected number of protein species detected in the hypothetical protein sets. (E, F) The protein amounts expected to be identified in the hypothetical protein set with the SCL model (E), and the linear model (F). The x axis represents the number of protein species, and the y axis, the protein amounts expected to be identified. The solid line indicates the total amounts of proteins in hypothetical protein sets. (G, H) The coverage rates of protein species (G) and amounts (H) estimated with the SCL model. The x axis represents the number of protein species identified, and the y axis, the coverage rates of protein species (G) and protein amounts (H), respectively. The pink circle, square, and triangle indicate the points corresponding to the experimental results.
(EPS)
Nucleoid isolation of S. aureus , P. aeruginosa, and B. subtilis . The nucleoid isolations of the log phases of S. aureus (A, B), the stationary phase of S. aureus (C, D), the log phase of P. aeruginosa (E, F), and the log phase of B. subtilis (G, H). The spermidine nucleoids were fractionated by sucrose-gradient centrifugation with a 10%-to-30% (60%) gradient (A, C, E, G). The fractions containing genomic DNA were identified by DAPI fluorescence (B, D, F, H).
(TIF)
The distribution of the percentages of DNA/RNA binding sites in proteins. (A) The number of DNA/RNA binding sites in Hu, IHF, Fis, HNS, StpA, and Hfq in E. coli. Percent (%) represents the percentage of DNA (or RNA) binding amino acid in each protein. (B) The distributions of the percentages of the DNA/RNA binding sites of the csNAPs and the proteins that appeared only in the envelope and/or top fractions (env_top_specific) in E. coli.
(TIF)
Full list of the proteins identified in this study.
(XLS)
Proteins identified in the nucleoid fraction of the log phase of E. coli .
(XLS)
Proteins identified in the nucleoid fraction of the stationary phase of E. coli .
(XLS)
Number of peptides required to cover all the potential proteins in samples.
(XLS)
Proteins identified in the nucleoid fraction of the log phase of P. aeruginosa .
(XLS)
Proteins identified in the nucleoid fraction of the log phase of B. subtilis .
(XLS)
Proteins identified in the nucleoid fraction of the log phase of S. aureus .
(XLS)
Proteins identified in the nucleoid fraction of the stationary phase of S. aureus .
(XLS)
csNAPs of E. coli in the log phase.
(XLS)
csNAPs of E. coli in the stationary phase.
(XLS)
csNAPs of P. aeruginosa in the log phase.
(XLS)
csNAPs of B. subtilis in the log phase.
(XLS)
csNAPs of S. aureus in the log phase.
(XLS)
csNAPs of S. aureus in the stationary phase.
(XLS)
Potential number of csNAPs.
(XLS)