

Abstract
A set of necessary conditions for the choice of diffusion gradient vectors to make the linear equations nonsingular for the estimation of the diffusion matrix are given in a coordinate free manner. The conditions assert that the initial step in the design of a DTI experiment with six or more acquisitions must be to select six valid diffusion gradients first and then add new ones.
Keywords: Diffusion tensor imaging, Linear algebra
1. Introduction
One way of estimating the diffusion matrix from DTI experiments is to solve a set of linear equations. The number of the measurements and thus the number of the equations is generally chosen to be over determined to alleviate the effects of noise. First pointed out by Papadakis et al. [1] and later used by different researchers [2-4] the linear algebraic technique can be described as follows. To estimate d = [d1, d2, d3, d4, d5, d6]T, six entries of the diffusion matrix corresponding to
one has to solve one of the following equations depending on the number of acquisitions denoted by :
| (1) |
| (2) |
The scalar factor b is , where γ is the gyromagnetic ratio, δ is the length of and Δ is the time between the rectangular diffusion gradient pulses in the pulsed gradient spin echo (PGSE) experiment. The result of the experiment is kept in a vector , where is the measurement corresponding to the ith diffusion gradient and S0 is the reference image. Define a nonlinear function w that maps the diffusion gradient vector gi = [gix giy giz] in , to a vector in
then Vg is the matrix
| (3) |
If the number of acquisitions is equal to six, d (thus D) is estimated by using Eq. (1), otherwise if the number of acquisitions is larger than six, , the expression of Eq. (2) is used. It is a standard fact from linear algebra [5] that in either case Vg must be full rank for the equations to have a unique solution. When , Vg is a (6 × 6) square matrix and the rank condition is equivalent to the invertibility of Vg. In the case the rank condition guarantees the invertibility of the Gram matrix .
Note that in Eq. (3) there is no restriction on the norm of gradient vectors, they might or might not be unit vectors.
2. Necessary conditions for gradient vectors
By definition (Eq. (3)) Vg is a matrix. The previous section shows that in the case the Gram matrix of Eq. (2) will be invertible if and only if Vg has a 6 × 6 submatrix which is invertible. This problem is equivalent to first choosing six gradient vectors g = {g1, … ,g6} such that the corresponding matrix Vg will be full rank. There has to be six gradient vectors guaranteeing the rank condition on Vg regardless of the number of aquisitions, .
It is stated without proof in [1,6-11] that for the equations to have a unique solution “the only requirement is that the six gradient vectors not all lie in the same plane and no two gradient vectors are collinear.”1 The statement is in fact only a necessary condition and is not complete. To see this note that neither any pair of the six gradient vectors given below are pointing to the same direction nor all six of them belong to the same two dimensional subspace and yet when Vg is calculated by Eq. (3)
| (4) |
its determinant |Vg| = 0, i.e., Vg is not full rank.
As a preliminary to the problem in take a look at the problem in . The gradients and the corresponding matrix Vg are
A straightforward calculation shows that the determinant of Vg is given by the product of the determinants of the pairs of gradient direction vectors:
| (5) |
The necessary and sufficient condition for nonsingularity in is clear:
Vg is nonsingular if and only if no pair of gradient vectors are pointing to the same direction.
In , there is unfortunately no clear formula like Eq. (5) to describe the determinant of Vg that relates it to the diffusion gradients. The formula for the determinant can be obtained by direct calculation. For this remember that the number of three element subsets of
denote rth of these subsets with ordered elements i.e., i < j < k. Denote the complement of Γr by {l,m,n} = {1, … ,6}/{i,j,k}. Define
then the determinant is
It follows immediately from the formula that “a necessary condition for nonsingularity is that there exists at least one triplet of linearly independent gradient vectors.” Otherwise α(Γr) = 0 for all r ∈ {1, … ,20} which implies Det(Vg) = 0. This is equivalent to say that not all six gradient vectors belong to the same two-dimensional subspace. This condition will be absorbed in (NC3) described below.
It is clear from the definition of Vg that if there exists such that for i ≠ j, gi = agj then w(gi) = a2w(gj) and Vg will be singular. The first necessary condition for the nonsingularity of Vg is therefore:
(NC1) No two gradient vectors should point to the same direction.
Without loss of generality let g4,g5,g6 be linearly dependent without violating (NC1). This implies that there exists a1, a2 ≠ 0 such that g6 = a1g4 + a2g5.
A direct calculation shows
| (6) |
One of the conditions this equation brings up is that g1,g2,g3 should be linearly independent: (see Fig. 1)
Fig. 1.
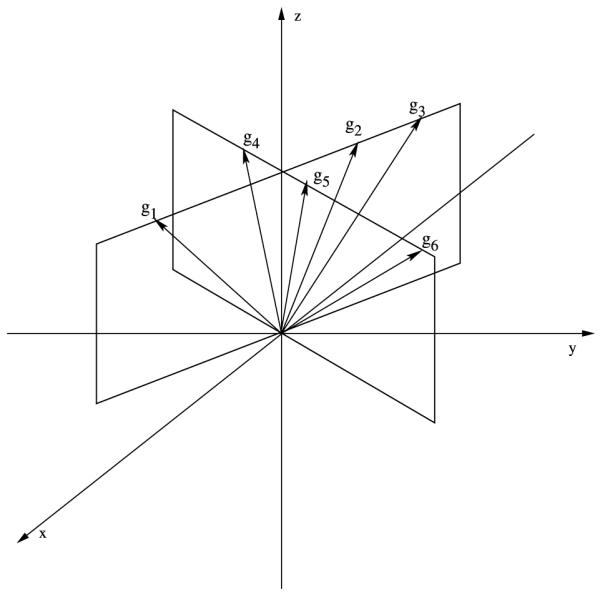
An example violating (NC2), g1,g2,g3 are linearly dependent as well as g4,g5,g6.
(NC2) If there is a triplet of vectors belonging to a two dimensional subspace that conform to (NC1), the remaining triplet should be linearly independent.
In addition Eq. (6) indicates that none of the vectors g1,g2,g3 should belong to the two-dimensional subspace spanned by g4,g5. To investigate this assume that four of the gradient vectors belong to the same two-dimensional subspace and are (NC1), say g3,g4,g5,g6. This means that there exists a11,a12,a21,a22 ≠ 0 such that Det[aij] ≠ 0 with g5 = a11g3 + a12g4 and g6 = a21g3 + a22g4. A straightforward calculation shows that
The rows of Vg corresponding to those directions are linearly dependent. Therefore:
(NC3) No four gradient vectors should belong to the same two dimensional subspace.
Notice that all of the conditions above are described in a coordinate free manner, since being an element of a subspace and linear independence are in fact properties that are independent of coordinate frame. This important fact provides the possibility of constructing different valid gradient sets starting from one set by means of nonsingular linear transformations.
It is crucial to note that the conditions are only necessary and are not necessary and sufficient.
3. Conclusion
In any DTI experiment where the diffusion matrix is to be estimated completely (i.e., all six elements), the initial step must be to choose six diffusion gradients that will make the corresponding Vg invertible. This skeleton gradients guarantee that the addition of more diffusion gradients or more acquisitions to the experiment will be safe. The earlier condition given in [6] that requires not all of the gradients to be in the same subspace, is not complete. Interested reader is encouraged to do the calculations for the following set of gradients with unit norm to see that although the number of acquisitions is larger than six and that not all of the gradients are in the same two-dimensional subspace, still the system of linear equations Eq. (2) does not posses a unique solution:
| (7) |
Moreover, there is no six element subset of these gradients which makes the corresponding square Vg invertible.
Acknowledgments
This study was supported, in part, by the Washington University Small Animal Imaging Resource, a National Cancer Institute funded Small Animal Imaging Resource Program facility (R24-CA83060) and NIH grant number N01NS92319. Special thanks to JMR reviewers for their valuable comments, Tom Conturo, Heinz Schättler for reviewing the manuscript and Nikolaos “Çekiç” Tsekos for his support.
Footnotes
The term collinear is ambiguous. In a point space two points or the tips of two vectors are always collinear. It is clear to say no two vectors point to the same direction or belong to the same one dimensional subspace. Similarly, instead of the term coplanar, it is precise to say the vectors belong to a two dimensional subspace.
References
- [1].Papadakis NA, Xing D, Huang CL-H, Hall LD, Carpenter TA. A comparative study of acquisition schemes for diffusion tensor imaging using MRI. J. Magn. Reson. 1999;137:67–82. doi: 10.1006/jmre.1998.1673. [DOI] [PubMed] [Google Scholar]
- [2].Hassan K, Parker DL, Alexander AL. Comparison of gradient encoding schemes for diffusion-tensor MRI. J. Magn. Reson. Imag. 2001;13:769–780. doi: 10.1002/jmri.1107. [DOI] [PubMed] [Google Scholar]
- [3].Skare S, Hedehus M, Moseley ME, Li T-Q. Condition number as a measure of noise performance of diffusion tensor data acquisition schemes with MRI. J. Magn. Reson. 2000;147:340–352. doi: 10.1006/jmre.2000.2209. [DOI] [PubMed] [Google Scholar]
- [4].Batchelor P, Atkinson D, Hill D, Calamante F, Connelly A. Anisotropic noise propagation in diffusion tensor MRI sampling schemes. Magn. Reson. Med. 2003;49:1143–1151. doi: 10.1002/mrm.10491. [DOI] [PubMed] [Google Scholar]
- [5].Luenberger DG. Optimization by Vector Space Methods. Wiley; New York: 1969. [Google Scholar]
- [6].Basser PJ, Matiello J, LeBihan D. Estimation of the effective self-diffusion tensor from the NMR spin echo. J. Magn. Reson. Ser. A. 1994;103:247–254. doi: 10.1006/jmrb.1994.1037. [DOI] [PubMed] [Google Scholar]
- [7].Basser PJ, Pierpaoli C. Microstructural and physiological features of tissues elucidated by quantitative-diffusion-tensor MRI. J. Magn. Reson. Ser. B. 1996;111:209–219. doi: 10.1006/jmrb.1996.0086. [DOI] [PubMed] [Google Scholar]
- [8].Papadakis NA, Murrils CD, Hall LD, Huang CL-H, Carpenter TA. Minimal gradient encoding for robust estimation of diffusion anisotropy. Magn. Resonan. Imag. 2000;18:671–679. doi: 10.1016/s0730-725x(00)00151-x. [DOI] [PubMed] [Google Scholar]
- [9].Westin C-F, Maier SE, Mamata H, Nabavi A, Jolesz FA, Kikinis R. Processing and visualization for diffusion tensor MRI. Med. Image Anal. 2002;6:93–108. doi: 10.1016/s1361-8415(02)00053-1. [DOI] [PubMed] [Google Scholar]
- [10].Ito R, Mori S, Melhem ER. Diffusion tensor brain imaging and tractography. Neuroimag. Clin. North Am. 2002;12(1):1–19. doi: 10.1016/s1052-5149(03)00067-4. [DOI] [PubMed] [Google Scholar]
- [11].Basser PJ, Pierpaoli C. A simplified method to measure the diffusion tensor from seven MR images. Magn. Reson. Med. 1998;39:928–934. doi: 10.1002/mrm.1910390610. [DOI] [PubMed] [Google Scholar]