

Abstract
We describe recent advances in the empirical analysis of insurance markets. This new research proposes ways to estimate individual demand for insurance and the relationship between prices and insurer costs in the presence of adverse and advantageous selection. We discuss how these models permit the measurement of welfare distortions arising from asymmetric information and the welfare consequences of potential government policy responses. We also discuss some challenges in modeling imperfect competition between insurers and outline a series of open research questions.
Keywords: asymmetric information, adverse selection
1. INTRODUCTION
Since the seminal theoretical work of Arrow (1963), Akerlof (1970), and Rothschild & Stiglitz (1976), economists have been acutely aware of the potential for market failures arising from asymmetric information in private insurance markets. The possibility that competitive forces may not push toward efficiency in a large and important class of markets creates interesting and difficult economic and policy issues. It also poses a challenge for empirical research: to identify and quantify the effects of asymmetric information and trace out its implications for welfare, competition, and government policy.
From relatively modest beginnings, research in this direction has advanced rapidly over the past decade, beginning with theoretically motivated attempts to test whether asymmetric information actually exists in particular insurance markets and, if so, in what form. This work owes much to the efforts of Chiappori & Salanié (2000, 2003), who described a set of positive correlation tests for asymmetric information. The basic idea is to compare claims rates for consumers who self-selected into different insurance contracts (e.g., see Puelz & Snow 1994, Cawley & Philipson 1999, Cardon & Hendel 2001, Finkelstein & Poterba 2004, Cohen 2005, Finkelstein & McGarry 2006). A finding that consumers who selected more insurance coverage have higher claim rates, conditional on all information available to insurers, suggests asymmetric information: Either consumers had prior information about their exposure risk (adverse selection) or purchasers of greater coverage took less care (moral hazard).1
Although tests for asymmetric information provide valuable descriptive information about the workings of an insurance market, they have some important limitations. Notably, without a clearly specified model of consumer preferences, they are relatively uninformative about market efficiency or about the welfare impact of potential market interventions (Einav et al. 2007). This has motivated recent work to move beyond testing for asymmetric information by building empirical models that incorporate theoretically grounded specifications of consumer preferences. These models can be used to quantify the welfare distortions arising from asymmetric information and the potential impact of government policies such as mandates, pricing restrictions, and taxes. This more structured approach takes its cues from descriptive findings in the testing literature, in particular by seeking to incorporate rich heterogeneity in consumer preferences as well as the heterogeneity in risk emphasized in classic theoretical contributions.
We describe this recent generation of models in Section 4, after setting out the standard theory of insurance in Section 2 and briefly reviewing the testing literature on comparative claims analysis in Section 3. We focus on two alternative approaches, both of which combine models predicting consumer choice and subsequent claims behavior. The first type of model builds directly on the underlying theory of expected utility and attempts to map insurance demand back to specific parameters describing individual risk exposure, risk preferences, bequest motives, liquidity, and so forth. The second type of model sticks closer to traditional discrete choice analysis by directly specifying consumers’ value for particular insurance contracts as a function of consumer and contract characteristics. This higher-level approach requires a weaker set of assumptions about exactly why and how consumers derive value from insurance, but it limits the researcher’s ability to recover certain parameters, such as the distribution of consumer risk aversion, that may be of intrinsic interest or could allow for more radical extrapolation from the observed data.
This difference notwithstanding, both empirical approaches provide an econometric framework for evaluating market efficiency and examining the welfare consequences of certain types of government policy. We elaborate on this point in Section 5, describing an empirical approach to welfare analysis and discussing some recent attempts to apply it in the context of health insurance and annuity markets. A surprisingly common finding of this research is that even in those markets in which there appears to be substantial evidence of adverse selection, the welfare costs from misallocation appear to be relatively limited. We offer one potential explanation, which is that current work has considered only a limited type of distortions: those arising from the mispricing of existing contracts, rather than inefficiencies from certain types of coverage not being offered at all. The latter type of analysis appears to raise new challenges of both a conceptual and applied nature, and we consider it an important direction for further work.
The research we describe has focused on insurance demand and contracting under asymmetric information, with less attention to the nature of insurer competition or to other sources of market frictions. We devote the final section of the review to these issues, focusing on promising areas for future research. Chief among these are empirical analyses of imperfect competition that take up the incentives of insurers in terms of pricing, plan design, and information acquisition in the underwriting process. We also discuss a variety of market frictions that seem particularly relevant for welfare and policy analyses. These include competitive underwriting and lemon dropping, trade-offs between static and dynamic efficiency in insurance markets, and models of consumer behavior that incorporate search frictions or deviations from expected utility maximization.
A central theme of this review, and in our view a particularly attractive feature of the research we describe, is the close connection between the underlying theory of asymmetric information and the empirical modeling. Both the initial questions posed by the testing literature and the more recent approaches we discuss have been strongly motivated and guided by the seminal theoretical works on asymmetric information in insurance. At the same time, the findings from recent empirical work—in particular the quantitative importance of multidimensional heterogeneity in preferences as well as risk type—have suggested the importance of refinements both to the empirical modeling and to the theory. Insurance markets provide a natural environment for testing, applying, and refining information economics. This is in part because the contracting problems are often relatively structured and also because the underwriting and claims process generates comprehensive individual-level data. Most of the empirical papers we describe take advantage of both these features.2
We should emphasize at the outset that this article is not a comprehensive literature review. We focus on a subset of questions that have motivated recent research and a subset of contributions that illustrate particular empirical strategies. Our own papers get probably more attention than they deserve. We only touch on, and do not do justice to, a number of important issues, including moral hazard in insurance utilization, dynamic aspects of insurance provision such as experience rating, and many issues relating to imperfect competition that come up in the final section.
2. THEORY OF INSURANCE
2.1. The Canonical Insurance Model
We start by describing our basic model of insurance coverage and consumer choice that we use throughout the review. Suppose that a consumer can be described by a vector of characteristics ζ that embodies risk characteristics, preferences, income, and so forth. Below, it is useful to separate these characteristics into those that are readily observable, denoted x, and those that are not, denoted ν. Similarly, we describe an insurance contract by a vector of coverage characteristics φ and a price or premium p.
A consumer’s value for insurance and the insurer’s cost of coverage are determined by events during the coverage period. Let A denote the actions available to the consumer during the coverage period and S the set of possible outcomes. For example, a ∈ A might represent the level of care in driving and s ∈ S whether the consumer has an accident. More generally, filing a claim might be part of the outcome so that consumer’s behavior would encompass both the level of care and the decision to file a claim conditional on an accident.
To formulate this in a general way, we allow the probability of a given outcome to depend on both the consumer’s behavior and her risk characteristics. Let π (s|a, ζ) denote the probability of outcome s. The consumer’s utility depends on what happens and her coverage; we let u(s, a, ζ, φ, p) denote the consumer’s realized utility.
With this notation, and adopting a standard expected utility framework,3 the consumer’s valuation of a contract (φ, p) is
| (1) |
It is useful to let a* (ζ, φ, p) denote the consumer’s optimal behavior given coverage (φ, p) and π*(·|φ, p, ζ) = π (·|a* (ζ, φ, p), ζ) the resulting vector of outcome probabilities.
Most of the work we discuss below, and therefore the subsequent discussion in the rest of the review, imposes the assumption that the premium enters separably in the consumer’s contract valuation. In the textbook case of expected utility over wealth, this separability assumption is equivalent to a constant absolute risk aversion (CARA) assumption. Although in principle one could work with any other form of risk preferences, the separable case is attractive for two related reasons. First, it implies that changes in the premium do not affect consumer behavior a* or the outcome probabilities π*. Second, it makes for a natural choice of social welfare function that is invariant to transfers and redistribution. We return to this later in the review.
We now can describe insurer costs. During the coverage period, the insurer makes payments depending on the outcome s and the coverage φ. Let τ (s, φ) denote these insurer payments. The expected cost of coverage to the insurer is
| (2) |
where we have imposed the premium separability assumption mentioned above. The cost formula highlights an essential feature of selection markets, namely that unit costs depend on the composition of consumers (i.e., enrollee characteristics ζ) rather than just the quantity of consumers.4
Finally we introduce consumer choice by considering a set of insurance contracts J, with each contract described by a pair (φj, pj). A consumer with characteristics ζ finds contract j ∈ J optimal if and only if
| (3) |
This brings us to the usual starting point for a discrete choice demand model. One point to emphasize is that although we have derived expressions for costs and contract valuation from an underlying model of coverage, knowledge of the primitives π, u, S, and A is actually not required to resolve many questions of interest. To describe consumer demand for a given set of products, characterize consumer and producer surplus, or analyze optimal pricing, knowledge of v and c is sufficient. Of course, we may still be interested in the primitive parameters in order to understand exactly why consumers value insurance: due to risk preferences, risk exposure, or other factors. A related point pertains to insurer costs. The cost function c expresses costs as a function of consumer and contract characteristics; the more primitive model provides a way to understand, for instance, whether costs are driven primarily by intrinsic risks or by behavior that can be influenced by incentives.
2.2. Selection Effects and Moral Hazard
To establish a common vocabulary, we briefly define adverse selection and moral hazard in the context of the above model. Adverse selection in insurance markets is commonly used as shorthand for a situation in which high-risk individuals self-select into more generous coverage. This is the phenomenon captured in the classic models of Akerlof (1970) and Rothschild & Stiglitz (1976). For empirical work, however, patterns of risk selection often are less straightforward. Market outcomes may not lead to clear sorting, as in the case in which some low-risk individuals are also highly risk averse. Consumers may face varying types of risks: For instance, some individuals may have a small chance of a large loss as opposed to a larger chance of modest loss. And insurers offering plans with different types of coverage may not have identical views on the desirability of different consumers.
It is useful therefore to have a definition of adverse selection that applies in settings beyond those in which individuals are ordered by a single-dimensional risk characteristic. One such definition views a contract as adversely selected if it attracts a relatively unfavorable set of customers. To formalize this, consider a set of consumers I selecting from the same set of contracts J. Let I(j) denote the set of consumers who choose contract j. Contract j is adversely selected by population I if
| (4) |
It is advantageously selected if the reverse inequality holds. In other words, contract j is adversely selected if the expected cost of insuring j’s enrollees under contract j is greater than the expected cost of insuring the population I under contract j.5
Although this review focuses mainly on selection, let us briefly discuss moral hazard. The basic problem of moral hazard is that insured consumers do not internalize all the costs associated with risky behavior or utilization of covered services; i.e., optimal behavior (in Equation 1) is chosen without regard for the insurer’s cost of making the claims payments τ (s, φ). As consumer behavior may vary with the terms of coverage φ, the difference in costs associated with two alternative contracts φ and φ′ can be quite subtle. The contracts may not only specify different contingent payments, they may also result in different outcomes (i.e., by changing a* and hence π*). One example is a health insurance plan with large copayments or a restrictive network that induces different utilization than a straight indemnity plan.
3. TESTING FOR ASYMMETRIC INFORMATION
Recent empirical advances in insurance markets began with the development of so-called reduced-form tests for the existence of asymmetric information. The idea of these tests is to compare claim rates for groups of individuals who have self-selected into different insurance contracts, typically more and less generous policies. To implement the test, we assume the researcher has access to some outcome variable y, such as the number of accidents by insured drivers or the mortality rate of annuity purchasers.
Given data on individuals who had the option to choose either contract j or some alternative contract k (perhaps no insurance at all), we can ask whether
| (5) |
i.e. whether the expected outcome of consumers who chose contract j is greater than for consumers who chose k. Generally, both sides of the inequality can be directly estimated from the data. A positive finding provides evidence of sorting, with riskier types self-selecting into contract j, or incentive effects, with individuals behaving differently under the two contracts.6
Chiappori & Salanié (2000) emphasize that this approach requires some refinement because it does not clearly differentiate, as economic theories do, between individual characteristics that are observable and those that are not. They propose to test whether inequality 5 holds conditional on characteristics x that are observed by insurers. That is, they propose to test whether
| (6) |
Now, a positive finding can be interpreted as evidence of asymmetric information: Enrollees in contract j have worse outcomes than enrollees in k for reasons that cannot be ascribed to observable characteristics.7
Note that the set of conditioning variables is essential to the interpretation. For instance, in many insurance markets, certain characteristics can be observed but are not used in pricing due to regulation or insurer decisions (e.g., race and gender, or in markets with community rating, essentially all x’s). If the goal is to identify a true asymmetry of information between firms and consumers, one should presumably condition on these variables. But from a theoretical perspective, there is not much difference between a risk characteristic that firms cannot observe and one they can observe but must ignore. So one may be interested in a version of inequality 6 that does not condition on variables that insurers observe but do not price (Finkelstein & Poterba 2006). A related, and important, point is that what is observable to insurers is often endogenous because of the ability to conduct more or less scrutiny in underwriting.
The last point may help to explain the sometimes surprising results that have been obtained in implementing comparative claims tests. Results have been mixed, with some papers finding no evidence of asymmetric information in particular markets (e.g., Cawley & Philipson 1999, Chiappori & Salanié 2000, Cardon & Hendel 2001) and others finding evidence of asymmetric information in particular markets (e.g., Finkelstein & Poterba 2004, Cohen 2005, He 2009; for more detailed literature reviews, see Chiappori & Salanié 2003, Cutler et al. 2008). In comparing these studies, and others in the same vein, a recurring theme is the extent to which measurable risk is priced in the underwriting process. For example, prices of auto and life insurance policies are highly tailored to reflect risk, whereas there is little risk adjusting of prices in the U.K. annuity market.
The comparative claims tests do not distinguish between risk-based selection (a contract having riskier enrollees) and moral hazard (a contract inducing riskier behavior). To see why, consider the decomposition
| (7) |
The first term is the effect of risk-based selection—the difference in expected outcomes between j and k enrollees under contract j. The second term is the effect of changing coverage for a fixed population (in this case, those selecting k). We note that the order of the decomposition can matter if there is heterogeneity in the response to coverage.
For certain insurance products (e.g., annuities), it may be reasonable to assume that changes in coverage do not induce large behavioral effects. In other cases in which there may be some concern, it still may be possible to isolate certain outcomes that are relatively immune to incentives. For instance, researchers have focused on auto accidents that involve two or more drivers so as to avoid discretionary decisions about filing a claim on a single-car accident. More generally, and particularly for products such as health insurance, incentives for covered consumers are harder to ignore. There may be no easy way to separately isolate selection from incentive effects unless one has experimental or quasi-experimental variation that moves consumers across contracts without directly affecting their behavior.8 Cardon & Hendel (2001) is one of the first studies that entertained such variation. Assuming that the employment relationship is exogenous to employer-provided benefits, Cardon & Hendel used the variation in the health insurance options offered by different employers to separate selection from moral hazard.
A further point about testing for asymmetric information is that even with a clear set of conditioning variables and no moral hazard effects, differences in comparative claims rates can be challenging to interpret. Consider a finding that there is no difference between purchasers and nonpurchasers of insurance. This could suggest that private information about risk is not a factor in consumer choices or that sorting based on private information about risk is offset by some other dimension of unobserved heterogeneity, such as differences in risk aversion.9 Finkelstein & McGarry (2006) provide a striking example of offsetting self-selection in the market for long-term care insurance. By exploiting auxiliary survey data, they show that individuals possess private information about their likelihood of using long-term care but that lower-risk individuals are also more risk averse so that on average they are equally likely to buy insurance as higher-risk individuals. Fang et al. (2008) similarly document multiple dimensions of private information in the U.S. Medigap market. Their findings suggest that differences in cognition, rather than in risk aversion, may be an important dimension of heterogeneity affecting consumer choices and ultimately leading to advantageous selection of Medigap coverage.
These latter papers illustrate an important practical point: Differences among purchasers of insurance go well beyond the differences in risk assumed in textbook models. This observation has a variety of implications. For instance, in textbook models of insurance market failure, a full-insurance mandate is often welfare enhancing. But this conclusion easily can be reversed in a model in which consumers differ in preferences as well as risk exposure. An attractive feature of the models in the next section is that they allow the data to dictate which dimensions of consumer heterogeneity are important and can be used to illustrate how different types of heterogeneity affect welfare or policy assessments.
4. EMPIRICAL MODELS OF INSURANCE DEMAND
We now turn to more recent work that seeks to estimate empirical versions of the insurance contracting model described in Section 2. This more recent work builds on, and complements, the insights obtained in the testing literature, particularly regarding the rich nature of consumer heterogeneity and the value of combining choice data with ex post claims behavior. That being said, there are several reasons to go beyond testing toward more structured empirical models.
One primary motivation, and a standard one for demand analysis, is to use estimates of demand and costs to analyze market efficiency and the effects of market interventions. Without strong additional assumptions, a finding from the testing literature of asymmetric information is insufficient for even qualitative statements about the efficiency costs of asymmetric information (Einav et al. 2007). At the very least, welfare analysis requires a model of consumer preferences and the effect of consumer choices on insurer costs. Moreover, the interdependence of demand (self-selection) and costs, and the possibility that consumers have private information relevant for insurer costs, calls for a joint model of consumer demand and insurer cost. In the same way that claims differentials are taken as evidence of private information in the testing literature, ex post cost realizations can be used to proxy for information consumers might have had in self-selecting.
A second motivation for modeling consumer demand is to understand in more detail what determines the willingness to pay for insurance in a given population. For instance, one may like to know whether individuals differ mainly in their underlying risk, in their behavioral response to coverage, or simply in their tastes for being insured. Optimal policy and contract design may be quite different depending on the answer to this question. Related to this, and a motivation that is perhaps most distinct from more traditional demand analysis, is the desire to estimate aspects of consumer preferences (e.g., risk aversion) that might be generalized to other contexts. Information from relatively simple choices under uncertainty (e.g., the choice of deductible in auto or homeowner insurance) can be useful in this regard.
In considering applications that pursue these objectives, we find it useful to distinguish two classes of empirical models. The first approach builds directly on the model of expected utility described in Section 2, with the goal of recovering consumers’ realized utility over wealth. The second approach follows more closely traditional discrete choice demand analysis, attempting only to recover the distribution of consumer contract valuations v (as opposed to the realized utility u) over different insurance products or product characteristics. Both approaches also lead to estimates of claims rates and how they covary with consumer preferences. Moreover, both approaches recover the essential information to analyze consumer surplus or explore the implications of many policy interventions. The first class of models imposes stronger assumptions in its reliance on the underlying theory, but also allows for more ambitious extrapolation using theory as a guide, and provides the ability to estimate parameters, such as those governing risk aversion, that may be of inherent interest. We discuss the trade-offs further below.
4.1. Modeling Realized Utility
We begin by describing empirical models that build directly on the framework described in Section 2 to estimate a realized utility function ui for each consumer. We illustrate this approach using the work of Cohen & Einav (2007). Cohen & Einav attempt to estimate the distribution of risk aversion using coverage choices made by customers of an Israeli automobile insurance company. Individuals in their data faced a choice between two alternative deductible levels with different attached premiums. Each individual i chose between a high-deductible contract with price and (per-claim) deductible of pi,HD and di,HD, respectively, and a low-deductible contract (pi,LD, di,LD).
Cohen & Einav assume that claims arrive according to a Poisson process that is not affected by the choice of deductible—i.e., there is no incentive effect on driving or claims behavior from a change in coverage. Combining this with an assumption of CARA utility over wealth,10 we can write the expected utility from a contract φ = (p,d) over a short time period t as follows:
| (8) |
Here εi is the individual’s Poisson risk rate, wi is his wealth, and ui(x) = −exp(−ψi x), with ψi denoting the coefficient of absolute risk aversion. With CARA preferences, the consumer’s wealth does not affect his insurance choices, so the relevant consumer characteristics (ζ in our notation of Section 2) are the predictable risk ε and risk aversion ψ. The main object of empirical interest is the joint distribution G(ε, ψ) in the sample.
Cohen & Einav show that this model leads to a simple approximation of the optimal deductible choice. The low-deductible contract is preferred to the high-deductible contract if and only if
| (9) |
Naturally higher risk aversion and higher risk both make greater coverage (a lower deductible) more attractive. So one can envision choice behavior by thinking of individuals as distributed in (ε, ψ) space, and the space divided so that individuals with relatively high levels of ψ (risk aversion) and/or ε (risk) prefer the low deductible. [Cohen & Einav (2007), figure 2, provide exactly this graphical presentation.]
An essential feature for identification and estimation, and especially to separate whether willingness to pay is driven by ψ or ε, is the ability to use claims data (or, more generally, outcome data). Intuitively, the ex post information about claims provides a proxy for the private information about risk (ε) that consumers might have had at the time of purchase. In the setting of Cohen & Einav, employing the claims data requires a modeling assumption about the possible information possessed by consumers at the time of purchase. They assume that consumers know exactly their individual-specific Poisson claim rate and combine this with the convenient assumption that individual Poisson parameters and coefficients of absolute risk aversion are jointly log-normally distributed in the population. These assumptions allow them to map from claims realizations back to the marginal distribution of Poisson parameters and, from there, to use the choice data to recover the marginal distribution of the coefficient of absolute risk aversion and its correlation with risk.
The joint distribution of risk and risk preference reported by Cohen & Einav has some interesting features. They find that individuals appear on average to exhibit a relatively high degree of risk aversion in making their deductible choices, although there is also a high degree of dispersion. They also find a positive correlation between risk and risk aversion, so that risk preferences tend to reinforce the tendency of high-risk individuals to purchase more coverage.
Finally, the model generates estimates of the incremental cost (to the insurer) associated with selling individual i a low-deductible contract. Specifically,
| (10) |
so the cost differential depends on the claims rate εi, but not on the risk aversion parameter ψi.
Cohen & Einav do not pursue the welfare implications of their model, but this is the impetus for the related paper by Einav et al. (2010b). Einav et al. apply a similar empirical strategy to estimate the joint distribution of risk type and consumer preferences in the U.K. annuity market. In their case, the relevant preference variation is not in risk aversion, but in the preference for wealth after death (perhaps because of a bequest motive). They find that, all else equal, consumers who have higher mortality rates (and are therefore associated with lower costs to the annuity provider) have a stronger preference for wealth after death. In this context, the preference for wealth after death reinforces the demand of high-mortality individuals for annuities with a guaranteed minimum payout, increasing the extent of adverse selection along this contract dimension. We discuss their use of these estimates for welfare analysis in Section 5.
Cohen & Einav (2007) and Einav et al. (2010b) help illustrate the complementarity between tests for asymmetric information and more complete models of insurance demand and claims. Cohen & Einav build on earlier work by Cohen (2005), who uses a comparison of claims rates to identify a strong element of adverse selection in the underlying data. Similarly, Einav et al. (2010b) are motivated by earlier work of Finkelstein & Poterba (2004, 2006), who find evidence of adverse selection using claims data from the U.K. annuity market. In both cases, the reduced-form comparative claims tests provide robust empirical findings for the existence of adverse selection without the need to invoke assumptions on the form of the utility function or the exact information structure. The more tightly specified models impose these assumptions but then can provide quantitative evidence on the relative contribution of risk and preferences in determining choices. And as we emphasize below, they provide a quantitative framework for welfare and policy analysis.
An earlier and pioneering paper in this general line of research is Cardon & Hendel’s (2001) study of health insurance demand, which we mention in Section 3. Cardon & Hendel’s analysis allows not just for private information about risk (selection) but also for discretionary utilization (moral hazard). [A similar demand model has been used subsequently by Bajari et al. (2006).] They assume consumers have homogenous risk preferences but allow them to differ in underlying risk and in their tastes for different health plans. In contrast to the above papers, however, they find little evidence that private information about risk drives consumer choices. Although their primary objective was to test for adverse selection, the model they develop is also well-suited to welfare analysis or counter-factual exercises.
4.2. Modeling Valuation of Insurance Contracts
The applications above began with a primitive model of how consumers derive value from insurance. For many questions of interest, particularly those related to pricing or to welfare analysis of contracts similar to those observed in the data, a useful alternative is to begin directly with a model of contract valuation v.
The idea can be illustrated using the Cohen & Einav example. Their model gives rise to a specific functional form for v, with parameters that can be interpreted as risk and risk aversion. However, if they were solely interested in the value of having the lower deductible, and the relationship between this value and a consumer’s risk, a natural way to proceed could have been to specify vi as a flexible function of price and deductible, e.g., v(pi,LD,di,LD,θi) = f(di,LD, di,HD; θi) − (pi,LD − pi,HD), and to use the variation in prices or in deductibles to estimate the distribution of the random coefficient θi, interacting θi with the realized claims to obtain a model for costs.
Roughly speaking, this is the approach taken by Bundorf et al. (2008) to analyze pricing and welfare in health insurance. Bundorf et al. use data from a health insurance intermediary to analyze the welfare implications associated with offering employees choice between HMO and PPO coverages. Because the data come from an intermediary, the authors take advantage of the fact that the same underlying health insurance plans are offered to employees at different firms with substantial cross-firm price variation (and some modest variations in coverage terms). The goal of the paper is to estimate demand and claims behavior to assess the welfare consequences of alternative pricing policies and the degree to which risk adjustment improves allocative efficiency. Like the papers described above, the authors find that accounting for consumer heterogeneity in both risk and preferences is important.
Bundorf et al. model consumer i’s valuation of contract j by
| (11) |
where the α’s are coefficients to be estimated, individual observed characteristics are given by the vector of demographics zi and a risk score ri, and individual unobserved characteristics are given by unobserved risk type εi and an independently and identically distributed logit error term for each plan ωij. The unobserved risk type εi can be thought of as the ex ante information an employee has regarding his subsequent health utilization (in addition to the predictable portion given by ri), whereas the unobserved plan preference ωij can be thought of as a preference characteristic that is orthogonal to underlying risk.
This demand model closely resembles familiar models of discrete choice. Without the two middle terms—ziαz,j + f(ri + εi; αr,j)—it reduces to a standard multinomial logit demand model. The additional terms essentially add a plan fixed effect with random coefficients. Here, the random coefficients vary with individual demographics (zi) and risk score (ri), as well as with an unobserved component (εi). Unlike the typical random coefficient formulation, however, here the unobserved component is not free but is restricted by its correlation with an outcome variable, insurer costs.11 The model captures selection by the additional specification that the expected cost to the insurer from covering consumer i with plan j is given by
| (12) |
with the same εi entering both the plan choice equation and the insurer’s cost.
The availability of an observed risk score, which is assigned to each household by the intermediary based on demographics and drug prescriptions, and the assumption that an unobservable individual risk type enters the model in the same way as the observed risk score help identify the model. Loosely, the coefficients bj and αr,j are identified by having rj as a shifter, thus leaving any residual correlation between choices and subsequent costs to identify the importance of risk unobservables εi.
There are several related papers that model consumer valuations over different health plans. Carlin & Town (2007) and Lustig (2008) pursue approaches that are similar in spirit to Bundorf et al., although tailored in various ways to their specific data and application. A variant of this approach models contract valuations in product space rather than characteristic space. For instance, Einav et al. (2010a) use data from a single large employer to estimate demand over health insurance options. Rather than modeling contract valuation as a function of plan and individual characteristics, they simply trace out the distribution of willingness to pay for incremental health coverage, and the average cost of covering consumers with each level of willingness to pay, using the observed price variation in their data. Relative to modeling contract valuation over characteristic space, their approach imposes even less structure although it further narrows the types of welfare questions that can be answered (as we discuss in more detail in Section 5).
It is also informative to contrast the contract valuation modeling approach taken by papers like Bundorf et al.’s with the more complete models in papers such as Cohen & Einav’s. The former captures the fact that different plans are more or less attractive to higher risks through the interaction of risk scores and plan fixed effects (by letting αr,j vary with j). Presumably, a more complete model would provide more guidance as to how plan characteristics (φj) interact with risk, but for the purpose of Bundorf et al.—estimating the welfare consequences of alternative pricing regimes—approximating the contract valuation by interacting plan fixed effects and risk is sufficient.
More generally, the trade-off between these two broad approaches is a familiar one. The more primitive approach involves an extra layer of modeling assumptions, including the underlying distribution of risk type, the ex ante information set of the consumer, a model of moral hazard, and an underlying decision-theoretic framework.12 In return, it provides additional guidance about the appropriate functional form for contract valuation and allows for a broader set of counterfactual predictions: for instance, predictions about choices over insurance products that are simply not observed in the data (e.g., a cap on coverage in the Cohen & Einav application). Moreover, certain estimated parameters, such as the coefficient of risk aversion, may be of independent interest.
5. WELFARE COST OF ASYMMETRIC INFORMATION
The models of insurance contracting described in the previous section provide a useful framework for analyzing welfare distortions. As is well understood, asymmetric information can generate at least two barriers to efficient insurance arrangements. The first is moral hazard during the coverage period. To provide incentives for precaution and utilization, insured individuals may need to bear some risk, and resources may be required to monitor behavior.13 The second is self-selection in the choice of insurance coverage. If individuals are privately informed about their risk, market prices are unlikely to incorporate the relevant information necessary to achieve allocative efficiency.
Recent work has used the modeling approaches described above to make progress on quantifying these types of welfare losses, focusing on the problem of self-selection. Some of this work has also examined the welfare consequences of potential government interventions aimed at ameliorating the welfare losses due to self-selection. We start this section by more precisely defining what we mean by welfare and highlighting the well-known inefficiencies associated with competitive provision of insurance when consumers have private information about their risk. We then discuss recent approaches to quantifying the inefficiency of observed prices as well as the welfare implications of alternative government interventions.
The results from this recent literature are in some ways surprising, in that in several settings researchers have not found large inefficiencies attributable to asymmetric information. As we discuss below, this may in part result from the research focus on consumers choosing among a limited set of coverage options offered in the market, rather than on whether changes in the characteristics of offered insurance could significantly enhance efficiency. This is a potentially critical omission and likely biases downward—perhaps by a substantial margin—the existing estimates of the welfare cost of adverse selection.
5.1. Measuring Welfare
We start by using our theoretical framework to construct a welfare metric that can be used to compare alternative allocations. To do this, we again focus on the case in which each consumer’s value for insurance is quasi-linear in the premium.14 Then we can write the value of an individual with characteristics ζ who obtains coverage φ at a price of p as
| (13) |
If we further normalize the value from having no coverage to be zero, ṽ(φ, ζ) is the monetary value of coverage φ. Letting c(φ, ζ) denote the cost of providing coverage φ for a consumer with characteristics ζ (Equation 2), the net surplus created by the coverage is ṽ(φ, ζ) − c(φ, ζ).
To move from individual to market welfare, suppose that we have a population of consumers and that each consumer obtains coverage φ = φ(ζ) according to her characteristics ζ. We refer to φ(·) as a coverage allocation, that is, a function that maps individuals into contracts. Of course, the nature of the coverage allocation is likely to depend on the set of contracts offered, the degree of price competition among insurers, market regulation, and so forth, but we can put that aside for the purpose of defining welfare.
We say that a coverage allocation φ generates (per-person) surplus equal to
| (14) |
where G is the distribution of consumer characteristics in the market.
At least conceptually, the information needed to compute W(φ) can be obtained directly from the empirical models described above. These models provide empirical analogs of ṽ and c, along with estimates of how consumer characteristics are distributed in the population (G)—precisely the inputs for calculating welfare. In practice, one serious constraint is that a limited set of coverage options is likely to be observed in the data so that obtaining reliable estimates of ṽ and c may be possible only for a fairly narrow class of coverage terms [i.e., φ(ζ) ∈ Φ, and Φ is a “small” set]. At least partially for this reason, the papers we describe below primarily consider welfare analyses that leave fixed the set of coverage options Φ and simply ask how different pricing regimes affect efficiency, rather than address the welfare effects of changes in the underlying set of coverage options.
5.2. Efficient and Competitive Allocations
Most welfare analyses are concerned with the efficiency of alternative coverage allocations—observed allocations, or the allocations that would result from different modes of competition or market interventions—relative to some efficient or constrained efficient benchmark.
Given a set Φ of feasible coverage options, the efficient coverage for an individual with characteristics ζ solves
| (15) |
We can then define the efficiency cost of an allocation φ (·) relative to the set of coverage options Φ as
| (16) |
In describing efficient arrangements, two types of constraints may be relevant. First, the set of feasible contracts Φ may impose certain limitations. If the insurance company cannot observe certain types of precautionary behavior, or the circumstances that led to certain types of claims, efficient contracting may be hampered by moral hazard. Historical, legal, and regulatory factors can also limit the set of feasible contracts. Second, h(Φ, ζ) provides a perfect information benchmark for efficiency (subject to any constraints on the set of feasible contracts Φ) in the sense that individuals are assigned coverage based on all relevant characteristics ζ. By comparing surplus (welfare) in the observed allocation φ with that in the perfect information benchmark, Equation 16 provides a metric of the welfare loss associated with private information.
Of course, the observed allocation φ may also reflect distortions other than imperfect information, such as market power, frictions in consumer search, or various transaction costs. A second natural benchmark for applied research is therefore to compare utility in the perfect information benchmark to the allocation that would result from perfect competition between insurers when individuals have private information. With asymmetric information, competitive and efficient allocations generally do not coincide. As with the case of efficient allocations, estimates of consumer demand and insurer costs are exactly what is required to solve for the types of competitive equilibria described by Akerlof (1970), Rothschild & Stiglitz (1976), Miyazaki (1977), and Wilson (1977).
A practical difficulty for empirical research is that, except in relatively restrictive settings, solving for competitive equilibria, or even assuring that one exists, may be difficult. The case of insurers competing in price to offer a single (exogenously fixed) type of coverage φ permits a straightforward, but still interesting, analysis. In this case, at a market price p consumers with ṽ(φ, ζ) ≥ p will purchase coverage, and the average cost of covering these consumers will be AC(p) = 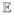 [c(φ, ζ)|ṽ(φ, ζ)≥ p]. Competitive equilibrium will occur at a point at which firms make zero profit, so that pc = AC(pc).
[c(φ, ζ)|ṽ(φ, ζ)≥ p]. Competitive equilibrium will occur at a point at which firms make zero profit, so that pc = AC(pc).
In the textbook case of adverse selection, the most costly consumers are also most eager to buy coverage, so the cost of covering the marginal purchaser at p, equal to MC(p) = [c(φ, ζ)|ṽ(φ, ζ) = p], is strictly below the average cost. As a result, competitive equilibrium is inefficient. At the competitive price pc, there is a set of consumers who do not purchase coverage but for whom their value ṽ(φ, ζ) exceeds their cost of coverage c(φ,ζ). Einav et al. (2010a) provide a graphical analysis of this case that highlights the close connection to standard supply and demand analysis. They observe that competitive equilibrium occurs at the intersection of the demand and average cost curve, whereas the efficient allocation occurs at the intersection of the demand and marginal cost curves, so that the inefficiency is captured by a familiar deadweight loss triangle.
The single-contract case also provides a useful starting point for thinking about the type of pricing necessary to implement efficient allocations. Suppose, for instance, that individuals vary in their risk ε and risk aversion ψ, both of which affect willingness to pay. The full-information efficient allocation will assign coverage to an individual with characteristics (ε, ψ) if and only if ṽ(ε, ψ) ≥ c(ε). If prices are to induce efficient self-selection, a single price p may not suffice. All individuals with the same ṽ(ε, ψ) will make the same purchase decision, but it may be inefficient to cover those with high ε, and therefore high c(ε).
This highlights another implication of richer consumer heterogeneity. In the Akerlof setting in which consumers are differentiated in a single risk dimension, setting p = MC(p) can lead to efficient self-selection if it separates individuals who are efficiently covered from those who are not. With richer heterogeneity, we may still be interested in the degree of efficiency that can be realized with a uniform price, but we may also want to understand how the potential for efficient coverage depends on the information available to set prices; Bundorf et al. (2008) explore this set of issues. A related point applies to competitive pricing. If insurers can observe information about individual risk ε and price it, the welfare loss associated with competitive pricing is sometimes reduced (although in general the welfare effects are ambiguous—see Levin 2001).
5.3. Distortions in the Pricing of Offered Contracts
We now turn to assessing the allocative inefficiency associated with general pricing regimes. To see the mechanics, consider a fixed set of coverage options, say φ and φ′ (e.g., a higher or lower deductible, or a PPO or an HMO health insurance plan) and a pricing regime such that an individual with characteristics ζ faces prices p(φ, ζ) and p(φ′, ζ) (that may partly reflect his characteristics). Recall that the empirical models above provide estimates of consumer utility ṽ(φ, ζ), insurer costs c(φ, ζ), and the distribution of consumer types G(ζ). Under the candidate pricing regime, a consumer with characteristics ζ will select coverage φ if and only if
| (17) |
Therefore, by combining choice behavior with the welfare formula in Equation 16 above, one can use the model to map directly from a pricing regime to the resulting coverage allocation to welfare.15
Cutler & Reber (1998), Carlin & Town (2007), Bundorf et al. (2008), and Einav et al. (2010a) all follow this approach to analyze the efficiency of alternative allocations in employer-sponsored health insurance.16 Einav et al. (2010a) focus on the difference between competitive and efficient allocations. Specifically, they consider a case in which employees are assigned to a default level of coverage, and incremental coverage is priced competitively—i.e., according to the average cost of covering the individuals who select it. Because their estimates imply that incremental coverage is adversely selected, the resulting allocation exhibits fewer individuals opting for high coverage than if incremental coverage was priced to maximize efficiency. Interestingly, they find that the magnitude of the welfare loss resulting from competitive allocation is quite small, in both absolute and relative terms.17
The setting in Bundorf et al. (2008) is a bit different because the health plans in their data are more richly differentiated: Employees in their data choose between PPO and HMO plans rather than more or less coverage. They estimate that the lowest cost plan in their data (an integrated HMO) achieves most of its savings for predictably high-cost consumers. These cost savings, however, cannot be passed on in a targeted way without risk-adjusting prices, something employers are not barred from doing. Motivated by this, Bundorf et al. investigate how much efficiency can be achieved by setting prices conditional on varying amounts of information and how this compares to standard types of contribution policies used by employers. They find that, relative to any sort of feasible pricing policy, the losses from observed contribution policies are in fact relatively small.
These papers are first cuts at addressing efficiency issues in insurance markets, but they illustrate how these types of questions might be addressed with the modeling approaches we describe above. The link with the testing approach also bears mention. In the settings we describe, a descriptive analysis reveals patterns in insurer costs that suggest the potential for large welfare distortions and guide the welfare questions being asked. The more complete model allows for precision and quantification—in these applications yielding the perhaps surprising finding of limited inefficiencies. The interplay between the model and the descriptive analysis of the data, however, is central.
5.4. Distortions in the Set of Contracts Offered
The papers above take a relatively narrow (albeit practical) approach to measuring inefficiency by focusing on how market prices or various pricing interventions efficiently sort consumers into a fixed set of coverage options. A potentially more significant source of inefficiency is that certain types of coverage are not offered because of concerns about extremely adverse take-up. Government regulations mandating specific components of coverage (such as coverage for mental health or in vitro fertilization) are arguably a response to such problems.
Estimating the potential welfare gains from the introduction of coverage options not observed in the data poses a series of additional challenges. One difficulty is that although contract valuation demand models can allow for some extrapolation in predicting consumer value for coverage options close to those observed in the data, these models are not well-suited for assessing the value of wholly new types of coverage. A more primitive model that specifies exactly how consumers derive value from insurance in principle can be used for more dramatic extrapolation, but of course one may be concerned about how much relevant information is really contained in the data. In practice, even papers with “rich-enough” demand models (e.g., Einav et al. 2010b) have shied away from analyzing the welfare effects of novel coverage options, although Lustig (2008) is a notable exception.
A further challenge for welfare analysis of nonoffered contracts stems from modeling competition between insurers. Although analyzing price competition over a fixed set of coverage offerings, or analyzing competition in prices and coverage in a setting in which insurers have symmetric information to consumers, appears to be a relatively manageable problem, characterizing equilibria for a general model of competition in which consumers have multiple dimensions of private information is another matter. Here it is likely that empirical work would be aided by more theoretical progress.
An alternative approach to examining welfare losses from nonoffered contracts is to identify cases in which adverse selection has caused a previously available coverage option to disappear. Cutler & Reber (1998), for instance, describe the case of an adverse selection “death spiral,” in which a particularly generous health insurance plan was initially propped up by subsidized pricing and subsequently disappeared when the cross-subsidization was removed. Pauly et al. (2004) describe a similar demise of a generous employer-sponsored plan but argue against a death-spiral interpretation. We view this as a potentially promising approach to quantifying the welfare cost on this important margin, but of course it can only be used if the policy was offered at some point in time.
The lamppost problem of empirical work gravitating to markets for which there are data and dimensions of coverage along which there is observed variation may be one reason that existing papers have found relatively small welfare losses. We are not aware, for instance, of any empirical work that looks at the welfare cost of complete market failures of the type described by Akerlof (1970).18 A few recent papers, including Hosseini (2008), Brown & Finkelstein (2008a), and Mahoney (2009), have used calibration exercises to investigate insurance markets that are virtually nonexistent (U.S. annuities, long-term care insurance, and high-deductible health insurance, respectively). The approach in these papers is quite complementary to the models in Section 4 in the sense that the calibrated models require assumptions about the population distributions of specific utility parameters, e.g., characterizing risk aversion. Demand analysis for insurance products in principle can provide useful input, although with natural caveats about making heroic extrapolations from the models we describe above.
5.5. Welfare Consequences of Government Policy
Adverse selection provides a textbook economic rationale for government intervention in insurance markets. Such intervention is ubiquitous, occurring through coverage mandates, restrictions on pricing and underwriting, tax subsidies to private insurance purchases, prudential regulation of insurers, or in many cases direct government involvement as an insurance provider. A natural question for empirical work, therefore, is to explore the welfare consequences of these types of policies and to try to identify settings in which government policies might or might not be beneficial.19 Because the set of questions one might ask is large, we limit ourselves to a few policies that have received some empirical attention.
5.5.1. Mandates
The empirical analysis of the welfare consequences of mandatory insurance provides an interesting example of the interaction between advances in empirical modeling and the original underlying theory. Mandatory social insurance is the canonical solution to the problem of adverse selection in insurance markets (Akerlof 1970). Yet, as emphasized by Feldstein (2005) and others, mandates are not necessarily welfare improving when individuals differ in their preferences. Instead, they may involve a trade-off between reducing the allocative inefficiency produced by adverse selection and increasing allocative inefficiency by eliminating self-selection. In light of this, evidence of preference heterogeneity (Finkelstein & McGarry 2006, Cohen & Einav 2007, Fang et al. 2008) has important implications for welfare analyses of mandates. For example, Einav et al. (2010b) find that mandates have ambiguous welfare consequences in an annuity market with risk and preference heterogeneity.
5.5.2. Restrictions on pricing characteristics
Another common government intervention in insurance markets is to restrict insurers’ ability to price on the basis of observable characteristics such as gender, age, or other predictors of risks, partially as a way to circumvent adverse selection, to shield consumers from reclassification risk, or to redistribute. In addition, firms often appear to forego voluntarily the use of readily observable characteristics that are correlated with expected claims, such as gender in the case of long-term care insurance (Brown & Finkelstein 2008b) or geographic location in the case of annuities (Finkelstein & Poterba 2006).20 Several papers have evaluated the potential welfare consequences of such restrictions. Bundorf et al. (2008) and Einav et al. (2010a), described above, examine the efficiency and competitive consequences of characteristics-based pricing of health plans. There are also a number of studies of the empirical effects of community rating, which suggest the potential for interesting welfare analyses (e.g., see Buchmueller & Dinardo 2002, Simon 2005).
5.5.3. Taxes and subsidies
Empirical insights regarding the nature of consumer heterogeneity are also relevant for tax policy in insurance markets. In classic models of adverse selection, a government subsidy can efficiently mitigate the inefficiently low level of insurance coverage provided in a competitive market. But this conclusion can be reversed if consumer heterogeneity creates the opposite type of advantageous selection, in which case taxation rather than subsidies may be warranted (de Meza & Webb 2001). Einav et al. (2010a) provide an illustrative calculation of tax policy to induce efficient outcomes, noting that the theoretical ambiguity created by the possibility of advantageous selection creates an opportunity for new empirical analyses of optimal tax policy toward insurance.
6. COMPETITION AND MARKET FRICTIONS
Relative to the research described above, there has been much less progress on empirical models of insurance market competition, or on empirical models of insurance contracting that incorporate realistic market frictions. One challenge is to develop an appropriate conceptual framework. Even in stylized models of insurance markets with asymmetric information, characterizing competitive equilibrium can be challenging, and the challenge is compounded if one wants to allow for realistic consumer heterogeneity and market imperfections. Moreover, many of the microlevel data sets used in recent work come from a single insurer or from firms that offer a menu of insurance plans to their employees. Ideally one would like somewhat broader data to analyze market competition.
Despite these difficulties, we view competition and frictions in insurance markets as an exciting direction for research. Health insurance markets, for example, exhibit high concentration, and some distinguished economists have argued that insurers tend to compete along dimensions such as risk selection that are highly inefficient.21 Increased access to consumer information, particularly genetic and other health information, also raises novel questions about competition in markets for life insurance, annuities, and other insurance products. A more sophisticated view of competition also seems essential for analyzing the types of welfare and policy questions discussed in the previous section, particularly if one hopes to account for strategic behavior by insurers, or dynamic inefficiencies. Concerns about these factors frequently motivate public policy and insurance market regulation.
Given this motivation, we use the next two subsections to briefly surface some promising questions for future research. We start by discussing plan design and pricing under imperfect competition and then highlight a few types of market imperfections for which there seems to be promise for bringing together theory and data.
6.1. Pricing and Plan Design
Empirical demand models provide a natural starting point for analyzing the incentives of imperfectly competitive insurers to set coverage options and prices. To illustrate, it is useful to start with the case of a monopoly provider of insurance. Suppose the provider offers a single contract, described by its coverage characteristics φ and premium p.
Normalizing consumer value from no coverage to zero, and assuming quasi-linearity in the premium, a consumer with characteristics ζ will purchase the contract if ṽ (φ, ζ) ≥ p. So the share of consumers who purchase will be
| (18) |
and the insurer’s expected costs are
| (19) |
The firm’s problem is to choose contract terms to maximize expected profit:
| (20) |
Fixing the coverage φ, the effect of a small increase in price is
| (21) |
The first term represents the additional revenue Q(p) from existing customers. The second term captures the lost profit on marginal consumers who now choose not to purchase.
Relative to the standard monopoly problem, the identity of the marginal consumer plays a key role. If riskier consumers tend to have higher values for coverage (as in a standard adverse selection setting), marginal consumers will be relatively attractive compared with the average consumer, so there is in some sense an extra incentive to keep prices low. In general, however, a firm’s marginal consumers could be more or less desirable than the firm’s average customer, or the average customer in the market.
A similar analysis can be used to describe incentives for plan design, with the added subtlety that changes in coverage may affect utilization as well as selection. For instance, if φ denotes the fraction of losses that the insurer will reimburse, we can write the effect of increasing plan generosity as
| (22) |
Offering more generous coverage therefore has three effects: It is likely to increase demand, it may alter the composition of purchasers (to the extent that marginal purchasers with ṽ = p are different than the existing customer base with ṽ ≥ p), and it is likely to increase costs for the covered population—potentially by inducing behavioral changes as well as mechanically. So the optimal choice of coverage level may involve a consideration of both selection and incentive effects on profit margins, as well as the usual market share considerations.22
From an applied perspective, the types of demand models described in Section 4 provide exactly the primitives needed to fill in Equations 21 and 22 and examine provider incentives to adjust premiums and coverage options. Moreover, at least in principle, the same approach can be taken to look at the benefits of offering various menus of contracts, with the added complication that one must consider substitution across contracts as premiums or coverage levels are adjusted. Although we are unaware of empirical papers that attempt even the basic type of pricing analysis for insurance providers, Einav et al. (2008) develop and apply a related approach to study pricing of credit contracts.
A still more ambitious agenda is to extend the single-firm model above to characterize Bertrand-Nash equilibrium outcomes with oligopolistic firms. This raises both conceptual and computational challenges. Conceptually, there is little reason to believe that even a game in which firms compete in prices alone will have the convexity properties typically invoked to assure existence or to justify an analysis based on first-order conditions for optimal pricing. Moreover, even if an equilibrium does exist and even if it can be characterized in terms of first-order conditions, solving numerically for the equilibrium may be challenging. A recent paper by Lustig (2008) makes a first attempt on this agenda, analyzing imperfect competition in the market for Medicare HMOs (Medicare Part C).23
6.2. Other Aspects of Competition
The discussion above emphasizes how one might study incentives for imperfectly competitive pricing and plan design without specific assumptions about the source of market power or market frictions. Many interesting issues in insurance markets revolve around particular types of market frictions and how they interact with competition.
6.2.1. Underwriting and risk selection
A common concern in insurance markets, and particularly in health insurance, is that insurers have an incentive to engage in risk selection or so-called lemon dropping, and this incentive may be heightened by competition. This possibility raises two issues from a welfare perspective. First, costly efforts by an insurer to identify and avoid large risks may simply serve to shift costs onto other insurers (this is the rent-seeking aspect of competition). Second, to the extent that all insurers invest to avoid bad risks, an unregulated market may lead to less cross-subsidization in the risk pool than would be optimal from a social perspective (this is the so-called Hirshleifer effect, after Hirshleifer 1971). We are unaware of concerted empirical efforts to assess the extent of risk selection or its welfare impacts, but the types of cost and demand models we describe could be applied fruitfully in this direction.
6.2.2. Dynamic insurance provision
The models described above take a static view of the insurance problem, but in practice individual risk evolves over time. An obvious example is the cost of providing life or health insurance, which increases with age and the onset of chronic health conditions. This evolution can create a tension between efficient short-term contracting and the provision of dynamic insurance. Static efficiency may require that consumers face prices that are actuarially fair, but the resulting price adjustment over time creates a dynamic risk of being reclassified to steeper premiums, or perhaps even dropped from coverage if there are further inefficiencies in the market. Regulatory efforts to ensure insurance portability or guaranteed renewability attempt to combat the lack of dynamic insurance created by competitive markets with short-term contracting, but we are not aware of attempts to analyze these policies from a welfare perspective. Extending welfare and policy analysis to examine the implications of short-term contracting, or partial long-term commitments (Hendel & Lizzeri 2003), or quantifying inherent trade-offs between static and dynamic efficiency would be an interesting direction for future research.
6.2.3. Consumer search and switching costs
Many insurance products are purchased infrequently and can be complex to evaluate. In light of this, one expects that insurance market competition may be limited by the partial information of consumers and their hesitancy to switch away from a familiar product. The highly customized nature of insurance premiums (and sometimes other contract terms) exacerbates this effect, making price comparison and reliance on consumer reviews more difficult. One indication of this is the price dispersion commonly observed even in insurance markets for which firms appear to be offering similar, or even identical, coverage. Another indication is the very low price elasticities of demand often reported in studies of employer-sponsored health insurance, suggesting that consumers switch only reluctantly among plans. With appropriate modifications, the demand models described above provide a potentially promising framework for addressing these issues and their welfare consequences. One wonders, for instance, whether the amount of consumer search or consumer interest in plan switching is systematically related to risk, and whether this might affect competition. Another interesting set of questions concerns the changes in consumer demand and competition spurred by increased access to information on the Internet (Brown & Goolsbee 2002).
6.2.4. Alternative models of consumer behavior
Finally, and perhaps less directly related to competition, are concerns about the behavior and sophistication of consumers. The standard model of insurance assumes that risk preferences are well-captured by the expected utility model, and empirical implementations tend to assume that individuals formulate their probability assessments according to objective risk probabilities. Both assumptions can be challenged. Cutler & Zeckhauser (2004), for instance, argue that certain puzzles about the provision of insurance are hard to explain without alternative models of consumer decision making, such as those involving loss aversion, misapprehension of probabilities, or simply confusion.24 In principle the modeling approaches described above could be adapted to these alternative theories, with potentially new implications for insurer incentives and the role of competition. Of course, welfare analysis becomes increasingly subtle as one moves away from the conventional model and allows for the possibility of consumer mistakes.
7. CONCLUSIONS
For many years empirical methods lagged well behind the frontier of theoretical work on asymmetric information. Now the gap is closing. We describe above some recent advances in building and estimating empirical models of insurance. Already these models have yielded insights into the subtle nature of consumer heterogeneity and the possibility that certain kinds of welfare losses from asymmetric information, at least in some insurance markets, may be modest.
Many interesting questions remain, however. In addition to the above-mentioned topical questions, the applications described above have focused on a relatively narrow set of insurance markets—health insurance, auto insurance, life insurance, and annuities—leaving others to be explored. Largely untouched, for instance, is an important set of insurance products for which public provision or regulation has a strong presence. These include disability insurance, unemployment insurance, and worker’s compensation. As adverse selection is a standard economic rationale for intervention in these markets, it is unfortunate that we lack convincing evidence on whether selection would exist in the private market, not to mention its welfare consequences and the welfare effects of government intervention. Of course, such work is made challenging by the current existence of the large public programs, but nonetheless these are important and interesting issues to try to examine.
Acknowledgments
We thank Tim Bresnahan, Phil Haile, and Igal Hendel for helpful comments. We gratefully acknowledge research support from the National Institute of Aging (Einav and Finkelstein, R01 AG032449), the National Science Foundation (Einav, SES-0643037; and Levin, SES-0349278), and the Stanford Institute for Economic Policy Research (Einav and Levin).
Footnotes
Consumers with more coverage may also be more likely to file a claim for any given loss, a phenomenon sometimes called ex post moral hazard.
Of course, researchers sometimes have access to individual-level choice data in more standard product markets, but the value is sometimes less pronounced. It may be reasonable to assume, for instance, that consumers shopping for cereal in a grocery store aisle share the same choice set. But in insurance markets, contract terms and prices are often highly customized, and this can complicate inference if individual choice sets are not observed. For example, if one observed high-risk individuals having more limited coverage, it would be hard to know if this was caused by demand (high-risk individuals choosing less coverage) or supply (high-risk individuals being offered less coverage). This type of concern therefore puts at a particular premium individual-level data in which researchers can observe the individual-specific choice set.
Expected utility strikes us as the natural starting point for modeling, but the empirical approaches we describe could employ alternative models of choice under uncertainty such as those with probability weighting or loss aversion with respect to a reference point. We view this as an interesting avenue for future work.
Equation 2 denotes the expected costs to the insurer in terms of claims paid. The insurer may also have administrative costs per enrollee or per claim, which could be easily modeled, although reliable data on such costs may be more difficult to obtain.
This definition views adverse selection as a market outcome and hence dependent on the set of contracts offered and their prices. By this definition, a contract offering intermediate coverage could be adversely selected if the competing contracts offered little coverage, but the adverse selection might disappear if there was a government mandate to offer at least the intermediate level. Moreover, if costs are minimized by matching consumers with specific contracts—as might be the case if different consumers respond to different contract incentives—one could have a market in which every insurer views its selection as advantageous (or adverse, for that matter).
Variants of this idea have been around for many years. For instance, Glied (2000) and Cutler & Zeckhauser (2000) summarize attempts to identify risk-based sorting in health insurance choice, where yi is typically not an outcome but a particular individual characteristic thought to be associated with higher claims, such as age or chronic illness. The test is cleanest if all consumers choosing between j and k faced the same prices. If they faced different prices, it is necessary to control for price so as not to confuse self-selection across contracts with different risks having different incentives in their choice of contract.
Chiappori & Salanié (2000) emphasize that a main issue in implementing the conditional inequality test is to control flexibly for observed characteristics—for instance, they suggest that a linear (or probit) regression of y on a linear index of x’s and a contract dummy may not be sufficiently flexible. Dionne et al. (2001) suggest that a failure to account flexibly for observable characteristics can lead to spurious results; they ask whether this might be the case for the particular specification adopted by Puelz & Snow (1994).
This is really just the familiar econometric problem of selection and treatment. In health insurance, the Rand Health Experiment is a gold standard in its use of random assignment to different coverages, but one can also hope for naturally occurring variation. Exogenous variation in premiums (as in Einav et al. 2010a) provides one possibility so long as premiums per se do not affect behavior. The use of panel data is another alternative and is explored by Abbring et al. (2003a,b). The same problem of separating selection and moral hazard arises in other contracting settings, and there has been some recent progress, particularly in credit markets (Adams et al. 2009, Karlan & Zinman 2009).
The idea that differences in risk-seeking attitudes could lead some individuals to purchase insurance while taking few risks, and that this could offset standard adverse selection effects, dates back at least to Hemenway (1990).
The baseline model of Cohen & Einav (2007) is of quadratic utility, which carries certain computational advantages. But in order to be consistent with the price separability we use throughout this review, we illustrate the same ideas in the context of CARA utility.
Bundorf et al. (2008) do not observe individual-level outcomes (costs). Rather, they observe costs at the employer level and aggregate their model predictions about outcomes to the aggregation level provided by the data.
The underlying decision-theoretic framework, in particular, is often a questionable assumption, with prominent researchers arguing for some form of mistakes in coverage choices (Heiss et al. 2007, Abaluck & Gruber 2009).
We would put the type of copayments and utilization reviews that are typical in health insurance into this category. It is also common to see insurance restricted so as not to create perverse incentives. For example, insurance companies typically do not allow homeowners to insure their home for more than its market value even if the consumer feels that this is unlikely to fully compensate for a loss.
As shown below, the quasi-linear assumption leads conveniently to a welfare analysis based on total surplus. For certain policy debates related to insurance, however, distributional effects are likely to be of first-order importance. In these cases, it may be desirable to incorporate income effects or adopt a social welfare function that prioritizes distributional objectives. The empirical framework we describe also can be applied to these settings (e.g., see Einav et al. 2010b).
Our quasi-linearity assumption renders the level of prices unimportant, making it natural to focus on the incremental price of different coverage options.
Einav et al. (2010b) analyze the welfare cost of asymmetric information in a different setting, the U.K. annuity market. They also report a relatively small efficiency loss relative to an efficient assignment of consumers to the offered types of annuity.
Specifically, Einav et al. (2010a) estimate this welfare cost to be less than 10 dollars per employee per year and to be only approximately one-fifth of the social cost required to achieve the efficient allocation through a government price subsidy.
There is some work looking at insurance market failures, notably for catastrophic risks, such as terrorism, hurricanes on the Gulf Coast, and earthquakes in California. Failures in these markets, however, appear to have been caused by institutional failures not directly related to the type of asymmetric information we discuss above. We are also not aware of attempts to measure any welfare impacts in these markets.
Siegelman (2004) provides an interesting, and critical, discussion of how concerns about adverse selection have shaped legal jurisprudence as well as public policy.
Finkelstein & Poterba (2006) discuss a variety of potential explanations—including perhaps most promisingly the threat of regulation—for this ostensibly puzzling behavior.
To quote Krugman (2009) on health insurance, “the truth is that the notion of beneficial competition in the insurance industry is all wrong in the first place: insurers mainly compete by engaging in ‘risk selection’—that is, the most successful companies are those that do the best job of denying coverage to those who need it most.”
Although we largely emphasize selection effects above, there is a fairly substantial literature, particularly in health insurance, that attempts to measure the sensitivity of utilization to consumer prices or plan features such as copayment levels (for one recent example, see lo Sasso et al. 2009).
Lustig (2008) characterizes the available plans by their premium and their generosity index and uses variation in market structure (number of firms) across geographical markets in the United States to estimate demand. Lacking cost data, he uses the first-order conditions for optimal pricing as moments in the estimation to back out the implied adverse selection. With estimates in hand, he then runs counterfactual simulations in which he allows plans to reset their equilibrium premiums and generosity index given various information structures.
See also Barseghyan et al. (2008) and Abaluck & Gruber (2009) who test (and reject) whether individuals appear to behave as rational expected utility maximizers. Of course, such tests are really joint tests of the behavioral model and all the other assumptions needed to identify the model.
DISCLOSURE STATEMENT
The authors are not aware of any affiliations, memberships, funding, or financial holdings that might be perceived as affecting the objectivity of this review.
Contributor Information
Liran Einav, Email: leinav@stanford.edu.
Amy Finkelstein, Email: afink@mit.edu.
Jonathan Levin, Email: jdlevin@stanford.edu.
LITERATURE CITED
- Abaluck J, Gruber J. Choice inconsistencies among the elderly: evidence from plan choice in the Medicare part D program. NBER Work Pap. 2009:14759. doi: 10.1257/aer.101.4.1180. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Abbring JH, Chiappori PA, Heckman JJ, Pinquet J. Adverse selection and moral hazard in insurance: Can dynamic data help to distinguish? J Eur Econ Assoc. 2003a;1:512–21. [Google Scholar]
- Abbring JH, Chiappori PA, Pinquet J. Moral hazard and dynamic insurance data. J Eur Econ Assoc. 2003b;1:767–820. [Google Scholar]
- Adams W, Einav L, Levin J. Liquidity constraints and imperfect information in subprime lending. Am Econ Rev. 2009;99:49–84. [Google Scholar]
- Akerlof G. The market for “lemons”: quality uncertainty and the market mechanism. Q J Econ. 1970;84:488–500. [Google Scholar]
- Arrow K. Uncertainty and the welfare economics of medical care. Am Econ Rev. 1963;53:941–73. [Google Scholar]
- Bajari P, Hong H, Khwaja A. Moral hazard, adverse selection and health expenditures: a semiparametric analysis. NBER Work Pap. 2006:12445. [Google Scholar]
- Barseghyan L, Prince JT, Teitelbaum JC. Work Pap. Cornell Univ; 2008. Are risk preferences stable across contexts? Evidence from insurance data. [Google Scholar]
- Brown J, Finkelstein A. The interaction of public and private insurance: Medicaid and the long-term insurance market. Am Econ Rev. 2008a;98:1083–102. [Google Scholar]
- Brown J, Finkelstein A. Why is the market for long-term care insurance so small? J Public Econ. 2008b;91:1967–91. [Google Scholar]
- Brown J, Goolsbee A. Does the internet make markets more competitive? Evidence from the life insurance industry. J Polit Econ. 2002;110:481–507. [Google Scholar]
- Buchmueller T, Dinardo J. Did community rating induce an adverse selection death spiral? Evidence from New York, Pennsylvania and Connecticut. Am Econ Rev. 2002;92:280–94. [Google Scholar]
- Bundorf KM, Levin J, Mahoney N. Pricing and welfare in health plan choice. NBER Work Pap. 2008:14153. doi: 10.1257/aer.102.7.3214. [DOI] [PubMed] [Google Scholar]
- Cardon JH, Hendel I. Asymmetric information in health insurance: evidence from the national medical expenditure survey. Rand J Econ. 2001;32:408–27. [PubMed] [Google Scholar]
- Carlin C, Town RJ. Work Pap. Univ. Minn; 2007. Adverse selection, welfare and optimal pricing of employer-sponsored health plans. [Google Scholar]
- Cawley J, Philipson T. An empirical examination of information barriers to trade in insurance. Am Econ Rev. 1999;89:827–46. [Google Scholar]
- Chiappori PA, Salanié B. Testing for asymmetric information in insurance markets. J Polit Econ. 2000;108:56–78. [Google Scholar]
- Chiappori PA, Salanié B. Testing contract theory: a survey of some recent work. In: Dewatripont M, Hansen L, Turnovsky S, editors. Advances in Economics and Econometrics. Vol. 1. Cambridge: Cambridge Univ. Press; 2003. pp. 115–49. [Google Scholar]
- Cohen A. Asymmetric information and learning: evidence from the automobile insurance market. Rev Econ Stat. 2005;87:197–207. [Google Scholar]
- Cohen A, Einav L. Estimating risk preferences from deductible choice. Am Econ Rev. 2007;97:745–88. [Google Scholar]
- Cutler DM, Finkelstein A, McKarry K. Preference heterogeneity in insurance markets: explaining a puzzle. Am Econ Rev. 2008;98:157–62. doi: 10.1257/aer.98.2.157. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cutler DM, Reber S. Paying for health insurance: the trade-off between competition and adverse selection. Q J Econ. 1998;113:433–66. [Google Scholar]
- Cutler DM, Zeckhauser RJ. The anatomy of health insurance. In: Culyer AJ, Newhouse JP, editors. Handbook of Health Economics. Amsterdam: North Holland; 2000. pp. 563–643. [Google Scholar]
- Cutler DM, Zeckhauser RJ. Extending the theory to meet the practice of insurance. In: Herring R, Litan RE, editors. Brookings-Wharton Papers on Financial Services: 2004. Washington, DC: Brookings Inst; 2004. pp. 1–53. [Google Scholar]
- de Meza D, Webb DC. Advantageous selection in insurance markets. Rand J Econ. 2001;32:249–62. [Google Scholar]
- Dionne G, Gouriéroux C, Vanasse C. Testing for evidence of adverse selection in the automobile insurance market: a comment. J Polit Econ. 2001;109:444–53. [Google Scholar]
- Einav L, Finkelstein A, Cullen MR. Estimating welfare in insurance markets using variation in prices. Q J Econ. 2010a;125 doi: 10.1162/qjec.2010.125.3.877. In press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Einav L, Finkelstein A, Schrimpf P. The welfare cost of asymmetric information: evidence from the U.K. annuity market. NBER Work Pap. 2007:13228. doi: 10.3982/ECTA7245. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Einav L, Finkelstein A, Schrimpf P. Optimal mandates and the welfare cost of asymmetric information: evidence from the U.K. annuity market. Econometrica. 2010b doi: 10.3982/ECTA7245. In press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Einav L, Jenkins M, Levin J. Work Pap. Stanford Univ; 2008. Contract pricing in consumer credit markets. [Google Scholar]
- Fang H, Keane MP, Silverman D. Sources of advantageous selection: evidence from the Medigap insurance market. J Polit Econ. 2008;116:303–50. [Google Scholar]
- Feldstein M. Rethinking social insurance. NBER Work Pap. 2005:11250. [Google Scholar]
- Finkelstein A, McGarry K. Multiple dimensions of private information: evidence from the long-term care insurance market. Am Econ Rev. 2006;96:938–58. [PubMed] [Google Scholar]
- Finkelstein A, Poterba J. Adverse selection in insurance markets: policyholder evidence from the U.K. annuity market. J Polit Econ. 2004;112:183–208. [Google Scholar]
- Finkelstein A, Poterba J. Testing for adverse selection with unused “observables”. NBER Work Pap. 2006:12112. [Google Scholar]
- Glied S. Managed Care. In: Culyer AJ, Newhouse JP, editors. Handbook of Health Economics. Amsterdam: North Holland; 2000. pp. 707–53. [Google Scholar]
- He D. The life insurance market: asymmetric information revisited. J Public Econ. 2009;93:1090–97. [Google Scholar]
- Heiss F, McFadden D, Winter J. Mind the gap! Consumer perceptions and choice of Medicare part D prescription drug plans. NBER Work Pap. 2007:13627. [Google Scholar]
- Hemenway D. Propitious selection. Q J Econ. 1990;105:1063–69. [Google Scholar]
- Hendel I, Lizzeri A. The role of commitment in dynamic contracts: evidence from life insurance. Q J Econ. 2003;118:299–327. [Google Scholar]
- Hirshleifer J. The private and social value of information and the reward to inventive activity. Am Econ Rev. 1971;61:561–74. [Google Scholar]
- Hosseini R. Work Pap. Arizona State Univ; 2008. Adverse selection in the annuity market and the role for Social Security. [Google Scholar]
- Karlan D, Zinman J. Observing unobservables: identifying information asymmetries with a consumer credit field experiment. Econometrica. 2009;77:1993–2008. [Google Scholar]
- Krugman P. Competition, redefined. 2009 http://krugman.blogs.nytimes.com/2009/06/22/competition-redefined/
- Levin J. Information and the market for lemons. Rand J Econ. 2001;32:657–66. [Google Scholar]
- lo Sasso AT, Helmchen LA, Kaestner R. The effects of consumer-directed health plans on health care spending. NBER Work Pap. 2009:15106. [Google Scholar]
- Lustig J. Work Pap. Boston Univ; 2008. The welfare effects of adverse selection in privatized Medicare. [Google Scholar]
- Mahoney N. Work Pap. Stanford Univ; 2009. Bankruptcy, unpaid care, and health insurance coverage. [Google Scholar]
- Miyazaki H. The rat race and internal labor markets. Bell J Econ. 1977;8:394–418. [Google Scholar]
- Pauly MV, Mitchell O, Zeng Y. Death spiral or euthanasia? The demise of generous group health insurance coverage. NBER Work Pap. 2004:10464. doi: 10.5034/inquiryjrnl_44.4.412. [DOI] [PubMed] [Google Scholar]
- Puelz R, Snow A. Evidence on adverse selection: equilibrium signaling and cross-subsidization in the insurance market. J Polit Econ. 1994;102:236–57. [Google Scholar]
- Rothschild M, Stiglitz JE. Equilibrium in competitive insurance markets: an essay on the economics of imperfect information. Q J Econ. 1976;90:630–49. [Google Scholar]
- Siegelman P. Adverse selection in insurance markets: an exaggerated threat. Yale Law J. 2004;113:1223–81. [Google Scholar]
- Simon K. Adverse selection in health insurance markets? Evidence from state small-group health insurance reforms. J Public Econ. 2005;89:1865–77. [Google Scholar]
- Wilson C. A model of insurance markets with incomplete information. J Econ Theory. 1977;16:167–207. [Google Scholar]