

Abstract
This study investigated the perception of elliptical speech (Miller & Nicely, 1955) in an adult cochlear implant patient. A group of 20 adult listeners with normal hearing were used for comparison. Two experiments were conducted using sets of meaningful and anomalous English sentences. Two versions of each set of sentences were constructed: One set contained correct place of articulation cues; the other was transformed into elliptical speech using a procedure in which different places of articulation were all converted to alveolar place of articulation. The patient, “Mr. S,” completed a same-different discrimination task and a sentence transcription task. The listeners with normal hearing completed both tasks under masking noise and low-pass filtering. In the same-different task, under both conditions of signal degradation, listeners with normal hearing labeled a sentence with intact place of articulation cues and its elliptical version as the same. Mr. S also showed the same pattern. These findings support the claim by Miller and Nicely (1955) that under conditions of signal degradation, ellipsis can no longer be detected. In the sentence transcription task, however, subjects with normal hearing showed better transcription performance for sentences with intact place of articulation cues than for elliptical speech sentences, which was unexpected given the findings from the sentence discrimination experiment. Mr. S also showed the same pattern of performance. These new findings on the perception of elliptical speech suggest that cochlear implant users perceive speech and recognize spoken words using broad phonetic categories.
Introduction
What does speech sound like to an individual with a cochlear implant (CI)? This is a difficult question to answer. We know that cochlear implant users often do not perform well on open-set tests of word recognition, in which the listener hears an isolated word and has to identify it from a large number of words in his or her lexicon. Many of the perceptual confusions shown by CI users are confusions of place of articulation in consonants. However, despite this apparent problem with place of articulation, a large number of CI users do very well in everyday conversations. How can these two conflicting observations be reconciled?
In their well-known study of perceptual confusions in speech perception, Miller and Nicely (1955) examined the patterns of errors for consonants under a wide range of low-pass filtering and masking conditions. They found that place of articulation was a common confusion under both kinds of signal degradation. Miller and Nicely explained the patterns of errors by proposing that consonants that could be confused with each other under conditions of signal degradation could be thought of as representing the same perceptual equivalence class. For example, if [p t k] can be confused with each other under some conditions of signal degradation, then one could argue that these sounds form a common equivalence class. Miller and Nicely suggested that a single member of each perceptual equivalence class could be chosen as a exemplar of that class, (such as [t], out of the class [p t k]). If speech were produced when a specific instance or token of a sound was replaced by any other individual member of its equivalence class, it would sound quite strange and distorted in the clear. Miller and Nicely called this type of degradation “elliptical speech” because of the ellipsis (or “leaving out”) of place of articulation information after the substitution.
To be more specific, if elliptical speech sentences were produced so that every [p t k] was simply replaced by a [t], the utterances would sound very odd in the clear because of the presence of conflicting phonetic cues. However, as Miller and Nicely (1955) predicted, if elliptical speech is played back under the same masking or filtering conditions, the ellipsis should be undetectable because the members of the equivalence class were found to be perceptually equivalent under those exact degradation conditions. Miller and Nicely reported that this was the case, although they never presented the results of a formal experiment to demonstrate this interesting perceptual phenomenon (see Miller, 1956). The theoretical rationale underlying their predictions and the methodology for creating elliptical speech may be useful in learning more about how CI users use degraded and partial acoustic-phonetic information to perceive speech and understand spoken language under a wide range of listening conditions.
In a recent study from our laboratory, Quillet, Wright, and Pisoni (1998) noted possible parallels in perception between the performance of listeners with normal hearing under conditions of signal degradation and that of CI users. Just as listeners with normal hearing show systematic confusions among different places of articulation under conditions of signal degradation, CI users also display systematic perceptual confusions among places of articulation. Quillet et al. (1998) suggested that it might be possible to use elliptical speech as a tool to investigate CI users' perception of speech and to understand how many of these listeners often do so well even with highly impoverished input signals. If elliptical speech is undetectable as a degraded signal for listeners with normal hearing under masking or filtering conditions, then perhaps it will also be undetectable as elliptical speech for CI users. This finding would provide support for the hypothesis that CI users use broader perceptual equivalence classes for place of articulation in speech perception than listeners with normal hearing. The use of broad phonetic categories in speech perception would also help us explain how many patients are able to perceive speech with a cochlear implant despite the highly impoverished and degraded nature of the speech signal presented to their auditory system.
Using a same-different discrimination task, Quillet and colleagues (1998) attempted to replicate the findings of Miller and Nicely (1955) that ellipsis of place of articulation in consonants under conditions of signal degradation is undetectable as ellipsis and is perceived as the original pattern before the transformation. Listeners with normal hearing were presented with pairs of meaningful sentences and were asked to judge whether the two sentences were the same or different. The two sentences in each pair were either lexically the same or lexically different. Three conditions were examined. In the first condition, both sentences in a pair had intact place of articulation cues. In the second condition, both sentences in a pair were transformed into elliptical speech. In the third condition, one sentence in a pair had intact place of articulation cues and the other had been converted into elliptical speech.
The critical case in this experiment was the last condition in which the two sentences were lexically identical, but one sentence had intact place of articulation cues while the other was an elliptical speech version of the same sentence. Quillet and colleagues (1998) predicted that listeners with normal hearing would label these two sentences as different when they were presented in the clear, that is, without masking noise or degradation. If Miller and Nicely's (1955) elliptical speech phenomenon is robust and can be replicated, then listeners with normal hearing should label this pair of sentences as the same when presented under degraded conditions. Quillet and colleagues did find this pattern of results. In the clear, listeners identified the majority of the sentence pairs as different. Under signal degradation using random-bit-flip noise, their listeners identified a majority of the sentence pairs as the same, indicating that the ellipsis of place of articulation was no longer detected by the listeners. Listeners with normal hearing perceived the words in the degraded conditions using broad phonetic categories.
In order to investigate whether CI users also perceive speech using broad phonetic categories, we used a same-different task that was similar to the one described above. Pairs of sentences were presented to “Mr. S,” an adult with a cochlear implant who is postlingually and profoundly deaf, who was then asked to judge whether the two sentences were the same or different. The two sentences in each pair were either lexically the same or lexically different. In one condition, both sentences in a pair had intact place of articulation cues. In the second condition, both sentences in a pair were transformed into elliptical speech. In the third condition, one sentence had intact place of articulation cues while the other was elliptical speech. The critical test case was the third condition. We predicted that Mr. S would label these two sentences as the same. If our patient labels the two sentences in this condition as the same, then this response pattern suggests that consonants with the same manner and voicing features but different places of articulation form a broad perceptual equivalence class, that is, they are treated as functionally the same for purposes of word recognition and lexical access. These results would provide support for the proposal that CI users perceive speech as a sequence of familiar words and do not normally detect fine phonetic differences among words unless explicitly required to do so in a particular experimental task.
Up to this point, our discussion has centered on what speech might sound like to a patient with a cochlear implant, and thus what obstacles might have to be overcome to achieve word recognition. We are also interested in why some CI users manage to do quite well in everyday conversations despite the highly degraded speech input they receive through their implants. One explanation of their good performance under these conditions is the observation that powerful sequential constraints operate on the sound patterns of words in language (Shipman & Zue, 1982; Zue & Huttenlocher, 1983). As Zue and Huttenlocher (1983) pointed out, the sound patterns of words are constrained not only by the inventory of sounds in a particular language, but also by the allowable combinations of those sound units (i.e., by the phonotactic constraints of a given language). Shipman and Zue (1982) discovered that an analysis of English, which distinguishes only between consonants and vowels, could prime a 20,000-word lexicon down to less than 1%, given just the consonant-vowel (CV) pattern of a specific word. Since these strong constraints on sound patterns do exist in language, a broad phonetic classification may serve to define the “cohort”—the set of possible candidate words having the same global sound pattern.
Using computational analyses, Shipman and Zue (1982) found that these candidate sets may actually be quite small. They reported that the average size of these equivalence classes for a 20,000-word lexicon was approximately 2, and the maximum size was close to 2000 (Zue & Huttenlocher, 1983). Thus, even if a listener fails to correctly perceive the precise place of articulation, he or she can still recognize the intended word correctly using broad equivalence classes if only the sequence of consonants and vowels in the pattern can be recognized. This is an impressive finding that suggests that broad phonetic categories may provide reliable support for word recognition and lexical access under degraded listening conditions or under conditions where only partial acoustic-phonetic information is available.
Does coarse coding of the speech signal provide a set of cues that is rich and sufficient enough to allow listeners with normal hearing to recognize words and understand what is being said in an utterance? In order to answer this question, Quillet and colleagues (1998) carried out a second experiment that used a transcription task. Listeners with normal hearing were asked to transcribe three “key” words from each sentence. The sentences had either intact place of articulation cues or were transformed into elliptical speech. All of the sentences were presented in the clear or in white noise at 0 dB, -5 dB, and -10 dB SPL signal-to-noise ratio. Quillet and colleagues (1998) predicted that though speech with intact place of articulation cues should show decreased intelligibility scores under conditions of masking or low-pass filtering, elliptical speech should display the reverse pattern. In other words, sentences transformed into elliptical speech should show increases in intelligibility as distortion of the signal increases.
As expected, Quillet and colleagues (1998) found that speech containing intact place of articulation cues did show decreases in transcription accuracy under conditions of signal degradation, whereas the elliptical speech showed improvements in transcription accuracy from the 0 dB level to the −5 dB level before dropping off at the −10 dB level. The authors interpreted these findings as support for the proposal that listeners with normal hearing use broad phonetic categories to identify words in sentences under degraded listening conditions. Thus, listeners with normal hearing use different perceptual strategies to recognize words under different listening conditions depending on the nature of the signal degradation.
In order to explore whether CI users use coarse coding strategies and broad phonetic categories in speech perception, we carried out a second experiment using elliptical speech. Sentences were presented to Mr. S one at a time and he was asked to transcribe three of the five keywords in each sentence. Half of the sentences were produced using elliptical speech and half were intact-sentences. We predicted that Mr. S would display the same transcription performance on sentences with intact place of articulation cues as he would on sentences produced with elliptical speech. If our patient did show similar transcription performance in both cases, this pattern would indicate that coarse coding was an efficient perceptual strategy for word recognition in spoken sentences.
Experiment 1: Same-Different Task
Experiment 1 used a same-different discrimination task. Listeners heard pairs of sentences and categorized each pair as same or different. They were told to label the pair of sentences as same if the two sentences they heard were word-for-word and sound-for-sound identical, or different if any of the words or any of the speech sounds differed between the two sentences. Listeners with normal hearing have been found to label normal and elliptical versions of lexically identical sentences as the same under conditions of signal degradation. Because there are parallels in confusions in place of articulation between listeners with normal hearing under conditions of signal degradation and CI users, we predicted that Mr. S would also label the normal and elliptical versions of the same sentence as the same.
Stimulus Materials
Normal sentences
The stimulus materials consisted of 96 Harvard Psychoacoustic Sentences (IEEE, 1969) taken from lists 1–10 of Egan (1948). These are meaningful English sentences containing five keywords with declarative or imperative structure.
Anomalous sentences
Anomalous sentences were also used in this experiment to block top-down semantic processing. Ninety-six anomalous sentences were created specifically for this experiment by substituting random words of the same lexical category (noun, verb, etc.) into lists 11–20 of the Harvard Psychoacoustic Sentences (IEEE, 1969). The inserted words were selected from lists 21–70 of the Harvard Psychoacoustic Sentences (IEEE, 1969).
Elliptical speech
Several new sets of elliptical sentences were created through a process of featural substitution similar to that employed by Miller and Nicely (1955). The stops, fricatives, and nasal consonants in each of the five keywords in each sentence were replaced with a new consonant that preserved the same manner and voicing features of the original consonant but changed the place feature to an alveolar place of articulation. Liquids |r l| and glides |y w| were excluded from the substitution process. Several examples are given in (1) below, with the keywords underlined.
-
(1)
-
A wisp of cloud hung in the blue air.—Original
A wist of tloud hund in the dlue air.—Elliptical
-
Glue the sheet to the dark blue background.—Original
Dlue the seet to the dart dlue datdround.—Elliptical
-
This method of replacing consonants with alveolar consonants follows Miller and Nicely's (1955) original procedure of creating elliptical speech and differs from the methods used by Quillet and colleagues (1998). Following the suggestions of Miller (1956), they replaced consonants with consonants randomly selected from within the same equivalence class sharing manner and voicing features. An example from Miller (1956) is shown in (2), in which it can be seen that the replacement consonants do not all have the same alveolar place of articulation:
-
(2)
-
Two plus three should equal five.—Original
Pooh kluss free soub eatwell size.—Elliptical
-
In the present study, half of the utterances were spoken by a male speaker and the other half by a female speaker. Both talkers practiced saying all of the test sentences several times before the recording session began. An attempt was made to use the same intonation pattern in both versions of an utterance. Sentences were recorded using a head-mounted Shure microphone (Model SM98A®) and a Sony® DAT recorder (Model TCD-D8®). The audio recordings were then segmented into individual utterances and downsampled to 22,050 Hz using Cool Edit Pro LE.
Signal Degradation
Low-pass filtering
For the listeners with normal hearing, a new set of stimuli was created from the original recordings. Low-pass filtering was applied to the signal using MATLAB®. Specifically, the signal-processing tool Colea® was used (Loizou, 1998). Colea's filter tool was used to apply a 10th order low-pass Butterworth® filter with a cutoff of 1000 Hz. This procedure was applied to each of the sentences individually. After filtering, each sentence was saved as a separate file. Thus, the filtering was done off-line before presenting the stimuli to the listeners.
Noise-masking
Using Colea®, Gaussian noise was applied to each sentence to create another set of stimuli. Noise was added at a −5 dB SPL signal-to-noise ratio (SNR). Each noise-masked sentence was saved as a separate file for use during presentation of the stimuli to the listeners.
Listeners
Our adult CI patient, Mr. S, was 36 years old at the time of testing. He had been profoundly deaf with an unknown etiology for 20 months before receiving his cochlear implant at age 32. Mr. S had served as a listener in prior studies in our laboratory and is considered to be an excellent cochlear implant user (see also Goh, Pisoni, Kirk, & Remez, 2001; Herman & Clopper, 1999).
Nine listeners with normal hearing were assigned to the low-pass filtered condition, and another 9 were assigned to the noise-masked condition. All of the listeners with normal hearing were enrolled in an undergraduate introductory psychology course and received course credit for their participation in this experiment. Listeners ranged in age from 18 to 22 years old. None of the listeners reported any speech or hearing disorders at the time of testing. All listeners were native speakers of American English.
Procedures
Mr. S heard the test stimuli over a Harman/Kardon® loudspeaker (Model HK 195®). He was given four preexperiment trials in which he could adjust the volume of the loudspeaker to a comfortable listening level. The experiment was controlled by a Visual Basic program running on a Windows® operating system, which also recorded subject responses. The experiment was self-paced. Each pair of sentences was presented only once, with a 500-ms interval between the two sentences in each pair. Responses were entered into the computer by using a mouse to click on a dialog box labeled same or different on the CRT monitor. Mr. S was presented with four blocks of 24 trials each. He heard a block of normal sentences spoken by the male speaker, then a block of normal sentences spoken by the female speaker, then a block of anomalous sentences spoken by the male speaker, and finally a block of anomalous sentences spoken by the female speaker. Half of the sentences were elliptical speech and half were the original sentences containing intact place of articulation cues.
The listeners with normal hearing followed the same procedure as Mr. S except they heard the stimuli through Beyerdynamic® headphones (Model DT 100®) at a comfortable listening level of about 70 dB SPL. There was a 1-second interval between the two sentences in each pair. The 192 pairs of sentences were presented in a random order. For the listeners with normal hearing, half of the sentence pairs were presented under signal degradation and half were presented in the clear. The signal degradation was either low-pass filtering for one group of listeners or masking noise for the other group. The type of signal degradation used was a between-subjects variable.
All listeners received eight types of sentence pairs, as shown in Table I. In this report, sentences with the original intact place of articulation are referred to by I; elliptical sentences are referred to by E. Sentence pairs that are lexically identical are marked with two lowercase i's. Pairs of sentences that are lexically different are marked with a lowercase i and a lowercase j.
Table I. The Different Types of Sentence Pairs Used in the Same-Different Discrimination Task.
| Place of Articulation Cues: | Different Sentences | Same Sentences |
|---|---|---|
| Both Intact: | IiIj | IiIi |
| Both Elliptical: | EiEj | EiEi |
| One Intact, One Elliptical: | IiEj | IiEi |
| EiIj | EiIi |
Results: Listeners with Normal Hearing
Normal sentences
A summary of the same responses to the normal sentences from the listeners with normal hearing under low-pass filtering is shown in Figure 1. The different sentence pairings are listed along the abscissa (i.e., IiIj and EiEj). The percent of same responses is shown on the ordinate. Sentences presented in the clear are shown by the open bars, and sentences presented under low-pass filtering are shown by the dark bars.
Figure 1.
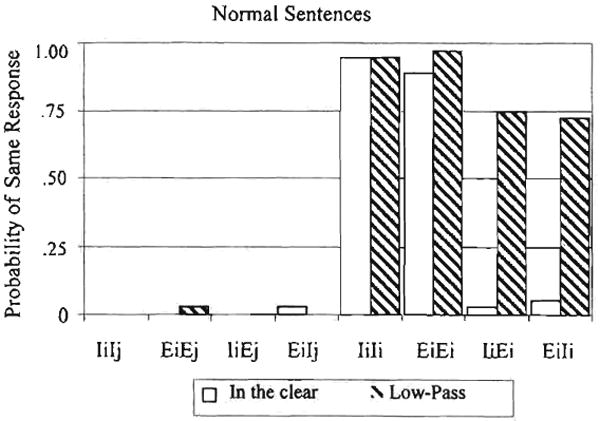
Results from the same-different task for listeners with normal hearing.
A 2 × 2 × 4 analysis of variance (ANOVA) was carried out on the same responses. The first factor was meaningfulness—normal vs. anomalous sentences. (Normal and anomalous sentences were both included in the analysis, although they are shown separately in Figures 1 and 3—for convenience so they may be examined separately.) The second factor was degradation, in the clear vs. low-pass filtering. The third factor was the type of sentence pair. This factor is shown in the four different cells in Table I.
Figure 3.

Results from the same-different task for listeners with normal hearing.
We were specifically interested in whether there would be a statistical difference in the same responses for sentences heard in the clear and sentences heard under low-pass filtering when one sentence was intact and the other sentence elliptical. We grouped together the IiIj and EiEj sentences (both are intact or both are elliptical), the IiEj and EiIj sentences (two lexically different sentences, one intact and one elliptical), the IiIi and EiEi (the same sentence repeated, both intact or both elliptical), and finally the critical test cases of IiEi and EiIi (the same sentence repeated, one intact and one elliptical).
We found a main effect of sentence meaningfulness. Responses to normal sentences were significantly higher than responses to anomalous sentences, F(1,8) = 7.2, p < .05. We also found a main effect of signal degradation. Responses to sentences presented in the clear were significantly higher than the responses to sentences presented under low-pass filtering, F(1,8) = 105.09, p < .001. The main effect of type of sentence pair was also significant F(3,24) = 408.6, p < .001.
The ANOVA also revealed a significant two-way interaction between signal degradation and type of sentence pair. Signal degradation within the first level (IiIj and EiEj) showed no difference. Listeners had little difficulty judging these pairs as different. A post hoc test of simple effects showed that signal degradation within the second level (IiEj and EiIj) was also not significant. Thus, when the listeners with normal hearing heard two different sentences, they were able to correctly discriminate the differences and respond different regardless of whether the two sentences were both intact or both elliptical, or one sentence was intact and one was elliptical. Moreover, there was no difference in performance in the clear compared to the filtered conditions for any of these sentence pairs.
Tests of simple effects also showed that signal degradation within the third level (IiIi and EiEi) was not significant. In these two cases (IiIi and EiEi), the same sentence was heard twice. Thus, the listeners correctly labeled the two sentences as the same, and there was no statistical difference when these sentences were presented in the clear or when they were presented under filtering.
The post hoc tests showed that signal degradation within the fourth level (IiEi and EiIi) was highly significant, F(1,8) = 217.4, p < .001. These two sentence pairs are the critical conditions for testing the prediction that ellipsis will be undetectable under degraded listening conditions. In these conditions, two lexically identical sentences were presented, but one sentence was intact while the other was elliptical. In both cases, the listeners labeled the pairs as same a very low percentage of time when the sentences were presented in the clear, but they judged them as same in a majority of cases when the sentences were presented under low-pass filtering.
This pattern of results for the critical pairs of sentences, in which a sentence with intact place of articulation and its elliptical version are labeled different when heard in the clear but are labeled the same when heard under low-pass filtering, replicates and confirms the earlier informal observations of Miller and Nicely (1955) that ellipsis of place of articulation will be undetectable under signal degradation. The findings with listeners with normal hearing in this study also replicate the earlier results reported by Quillet and colleagues (1998) using synthetic speech.
We turn next to the results obtained under masking noise. A summary of the findings for the same responses is shown in Figure 2. This data parallels the findings shown in Figure 1. A 2 × 2 × 4 ANOVA of the responses revealed main effects of meaningfulness, F(1,8) = 14.29, p < .01; degradation, F(1,8) = 217.35, p < .001; and type of sentence pair, F(3,24) = 2418.99, p < .001.
Figure 2.
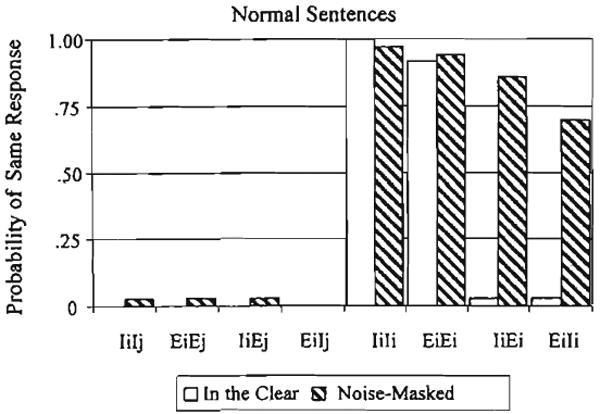
Results from the same-different task for listeners with normal hearing.
The ANOVA also revealed an interaction between signal degradation and type of sentence pair. Post hoc tests showed that the effects of signal degradation within the first level (IiIj and EiEj) and second level (IiEj and EiIj) were not significant. When the two sentences in a pair were lexically different (IiIj, EiEj, IiEj, and EiIj), a very low percentage of the pairs were labeled same. No differences were observed when these signals were presented in the clear or when they were presented in masking noise.
Post hoc tests also showed that the effect of signal degradation within the third level (IiIi and EiEi) was not significant. In these two cases (IiIi and EiEi), the same sentence was heard twice. Once again, listeners correctly labeled the two sentences as the same a high number of times. No statistical difference was found when these signals were presented in the clear or when they were presented in masking noise.
As expected, the post hoc tests showed that signal degradation within the fourth level (IiEi and EiIi) was significant, F(1,8) = 345.6, p < .001. For these critical pairs of stimuli, listeners labeled the two sentences as the same a very low percentage of the time when they were presented in the clear. However, when the sentences were presented in noise, listeners tended to label the two sentences as the same on a majority of trials. Thus, the same pattern of ellipsis was observed in listeners with normal hearing under both low-pass filtering and noise masking.
Anomalous sentences
A summary of the main results for the participants with normal hearing listening to pairs of anomalous sentences presented under low-pass filtering is shown in Figure 3. The results under noise-masking conditions are shown in Figure 4. Both sets of results are very similar to the findings for the normal sentences shown in Figures 1 and 2. Pairs of sentences that were lexically different were labeled as the same on a very low percentage of trials. No statistical differences were found in performance between pairs of sentences presented in the clear and pairs presented under signal degradation. Pairs of stimuli in which the same sentence was presented twice tended to be labeled as the same for the majority of cases. Again, there was no statistical difference in performance between the sentences presented in the clear and those presented under signal degradation. Pairs in which one sentence was intact and the other elliptical were labeled as different on a high percentage of the trials when heard in the clear. However, under low-pass filtering (see Figure 3) or noise masking (see Figure 4), listeners labeled these pairs of sentences as the some on a high percentage of trials. In short, the same pattern was observed for both normal sentences and anomalous sentences across all three presentation formats.
Figure 4.
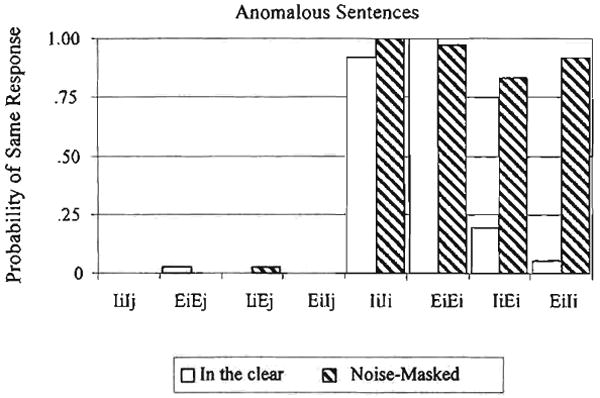
Results from the same-different task for listeners with normal hearing.
The findings shown in Figures 1–4 for listeners with normal hearing confirm the earlier observations of Miller and Nicely (1955) that ellipsis of place of articulation is very difficult to discriminate under degraded listening conditions such as low-pass filtering and masking. The results of the present study also replicate the more recent findings of Quillet and colleagues (1998) using a same-different discrimination task. Having demonstrated that we can obtain elliptical speech effects in listeners with normal hearing under both low-pass filtering and noise-masking conditions, we turn now to the results from our CI patient, Mr. S.
Results: Mr. S
Normal sentences
A summary of the discrimination responses from Mr. S after listening to pairs of normal sentences is shown in Figure 5. Again, the type of sentence pair is shown along the abscissa and the percentage of sentence pairs labeled as the same is shown on the ordinate.
Figure 5.
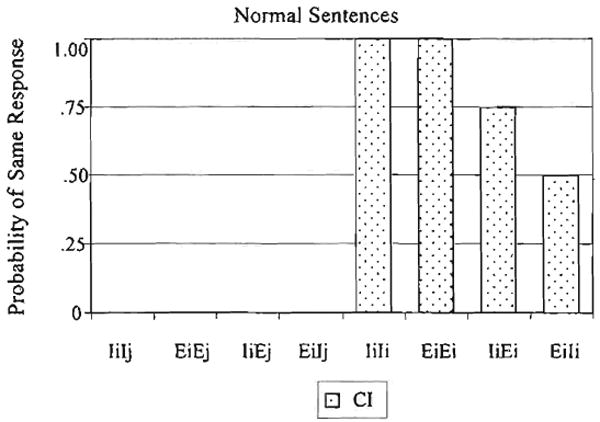
Results from the same-different task for Mr. S.
Figure 5 shows that Mr. S did not label any of the pairs consisting of two different sentences as the same (i.e., pairs including IiIj, EiEj, IiEj, and EiIj). However, he labeled 100% of the pairs consisting of the identical sentence heard twice as the same (IiIi and EiEi). Thus, he demonstrated the same pattern of performance as the listeners with normal hearing on these pairs of sentences. The critical cases for assessing the effects of elliptical speech are the two conditions labeled IiEi and EiIi. In both of these conditions, pairs of lexically identical sentences were presented, but one sentence was intact and the other was elliptical. On the trials in which the sentence with intact place of articulation was presented first (IiEi), Mr. S labeled the two sentences as same on 75% of the trials. On the trials in which the sentence with elliptical speech was presented first, Mr. S labeled the two sentences as the same on 50% of the trials. Thus, overall, he tends to label intact and elliptical speech versions of sentences as the same, although there is an order effect. This pattern parallels the findings obtained for listeners with normal hearing presented with the same sentences under degraded conditions.
Anomalous sentences
A summary of the responses from Mr. S after listening to pairs of anomalous sentences is shown in Figure 6. The same pattern of results found for normal sentences was also obtained for anomalous sentences. Mr. S consistently labeled pairs of sentences that were lexically different (IiIj, EiEj, IiEj, and EiIj) as different on 100% of the trials and he consistently labeled pairs of sentences that were lexically identical (IiIi and EiEi) as the same on 100% of the trials. And once again, he tended to label a sentence with intact place of articulation cues and its elliptical counterpart (IiEi and EiIi) as the same on a majority of trials, again paralleling the performance observed with listeners with normal hearing under degraded conditions.
Figure 6.
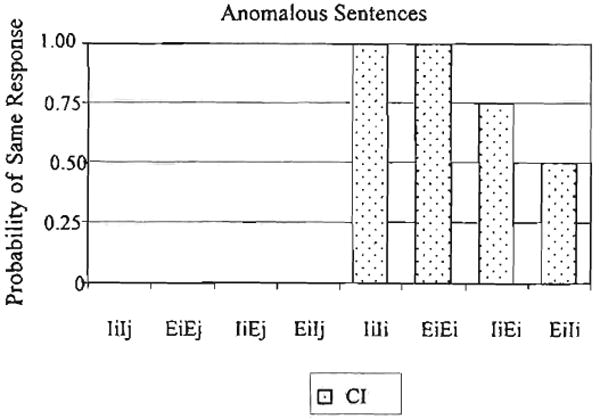
Results from the same-different task for Mr. S.
The results from Mr. S shown in Figures 5 and 6 support our original predictions that a postlingually deafened adult with a cochlear implant would show similar perceptual behavior to listeners with normal hearing under degraded conditions. In particular, Mr. S was unable to detect the presence of elliptical speech on a majority of the trials in which a sentence with intact place of articulation was paired with an elliptical speech version of the same sentence. This pattern of performance suggests that, even though CI users can recognize spoken words and understand sentences, these patients might not be able to discriminate phonetic contrasts such as place of articulation in consonants.
Discussion
When pairs of sentences were presented in the clear, listeners with normal hearing could easily discriminate stimuli that had intact place of articulation cues from elliptical speech versions of the same sentences. However, under conditions of signal degradation, the information about place of articulation was degraded and became less reliable, and listeners with normal hearing tended to label the intact and elliptical versions of the same sentence as the same. Mr. S also judged the intact and elliptical versions of the same sentence as the same, suggesting that he perceives speech and recognizes spoken words in sentences using broad phonetic categories. However, he does not detect fine phonetic differences among words in sentences.
Informal questioning of our listeners after the experiment was completed provided some insights into the processes used to recognize speech under these conditions. At the end of the experiment, Mr. S did not mention any conscious awareness of the ellipsis in the stimulus materials. A posttest questionnaire administered to the listeners with normal hearing, on the other hand, revealed that all of them were explicitly aware of the elliptical speech. These listeners described what they heard as words “slurred,” the t's in words were pronounced incorrectly, some of the letters in each word were transposed, the s and t were used interchangeably, there was a “speech impediment” or the talker sounded as if he or she had a lisp, or the speech sounded “like Latin or German.” Thus, the listeners with normal hearing had some conscious explicit awareness of the ellipsis in the stimulus materials whereas Mr. S did not report any of these changes after testing was completed.
The overall pattern of same-different discrimination responses obtained from listeners with normal hearing under degraded conditions and from Mr. S was similar despite small differences in procedure. Signal degradations for both listeners with normal hearing and users of cochlear implants seem to encourage the use of coarse coding strategies in which place of articulation differences are no longer perceptually salient. The listeners with normal hearing and Mr. S responded to the intact version and the elliptical version of a sentence as the same in these conditions. Under both masking and filtering conditions, listeners with normal hearing and Mr. S both gave responses that demonstrate the use of broad equivalence classes in recognizing spoken words in sentences when only partial stimulus information is present in the speech signal.
The data collected in this experiment required listeners to make an explicit same-different discrimination response to pairs of sentences presented on each trial. In the next experiment, listeners transcribed the sentence, a process that requires recognizing words in context from information in the speech signal. No mention was made about attention to fine phonetic differences in the signals.
Experiment 2: Transcription of Keywords
Our second experiment employed a transcription task. Listeners heard a sentence and were asked to transcribe three of the five keywords from each sentence. For each of these keywords, a blank line was substituted in a text version of the sentence that was presented on a specially prepared paper response sheet. In Experiment 1, we found that sentences with intact place of articulation cues were judged to be perceptually equivalent to sentences containing elliptical speech cues. In this experiment, we predicted that under conditions of signal degradation our listeners with normal hearing and Mr. S would transcribe words from elliptical sentences at the same level of accuracy as they would from sentences containing intact place of articulation cues.
Stimulus Materials
The stimulus materials were constructed the same way for Experiment 2 as they were for Experiment 1. For Mr. S, however, separate sets of sentences were used in the two experiments, so that none of the sentences were repeated more than once. Mr. S was presented with 96 sentences: half were normal sentences and half were anomalous sentences. Half of the sentences in each set were pronounced with intact place of articulation cues and half were transformed using elliptical speech. Half of the sentences were spoken by a male and half were spoken by a female.
The listeners with normal hearing in this experiment were presented with 192 sentences. These were the same set of sentences used in Experiment 1. Different listeners with normal hearing participated in the two experiments.
Signal Degradation
For the listeners with normal hearing, a third of the sentences were presented in the clear, a third under low-pass filtering at 1000 Hz, and a third under noise masking of −5 dB SPL SNR. Low-pass filtering and noise masking were both applied to the signal using Colea® (Loizou, 1998), as in Experiment 1.
Subjects
Mr. S, who participated in Experiment 1, also served as our postlingually deafened adult patient with a cochlear implant in Experiment 2.
Nine listeners with normal hearing participated in this experiment. All subjects were enrolled in an undergraduate psychology course and received course credit for their participation. The listeners ranged in age from 18 to 22 years. None reported any history of speech or hearing disorders at the time of testing. All were native speakers of American English. None of the listeners in this experiment had participated in Experiment 1.
Procedures
As in Experiment 1, Mr. S was presented with the sentences over a loudspeaker, at a self-selected comfortable level of loudness. Sentences were played back one at a time in random order. He could listen to each sentence up to five times, after which he had to provide a response. After hearing each sentence, he could select either “listen again” or “next trial.” The experiment was self-paced. The current trial number was displayed on the computer monitor. Mr. S wrote his responses on a printed paper response sheet. The response sheet consisted of a list of all of the sentences written out. Each sentence contained three blank lines replacing the three keywords that were to be transcribed. Thus, subjects had access to the sentential context of the keywords in each sentence. Listeners with normal hearing followed the same procedures, except that they were presented with the sentences over headphones at a comfortable listening level of around 70 dB SPL and four different random orders were used for the subjects with normal hearing.
Scoring of the sentence transcriptions was done using a strict criterion of whether the word written down by the subject matched the intended word exactly. In the elliptical speech sentences, the scoring was done on the basis of whether the original English word (i.e., prior to conversion to elliptical speech) was written down, not on the basis of whether the elliptical version that was actually heard was written as an English word or transcribed in an approximation to phonetic transcription. For example, suppose the target word was dark and the elliptical version that was heard in the sentence was dart. If the subject wrote dart, this would be scored as incorrect; however, if the subject wrote dark, the response would be scored as correct.
Results: Listeners with Normal Hearing
A 2 × 3 × 2 ANOVA was conducted on the percentage of keywords correctly transcribed. The three factors were place of articulation (intact vs. elliptical speech), signal degradation (in-the-clear vs. low-pass filtered vs. noise-masked), and meaningfulness (normal vs. anomalous). Main effects of place of articulation, F(1,8) = 193.356, p < .001; signal degradation, F(2,16) = 148.87, p < .001; and meaningfulness, F(1,8) = 359.80, p < .001, were observed. A significant three-way interaction was also found among these variables, F(2,16) = 10.033, p < .01. In order to probe the results further, the data were split along one of the factors. The normal sentences were examined separately from the anomalous sentences.
Normal sentences
A summary of the keyword transcription performance of the normal sentences by the listeners with normal hearing is shown in Figure 7. In this figure, the signal degradations are shown along the abscissa. Percent correct transcription of the keywords is shown on the ordinate. Transcription performance for intact sentences is shown by the open bars; transcription performance for elliptical sentences is shown by the dark bars. This graph shows the average performance for all nine listeners with normal hearing.
Figure 7.
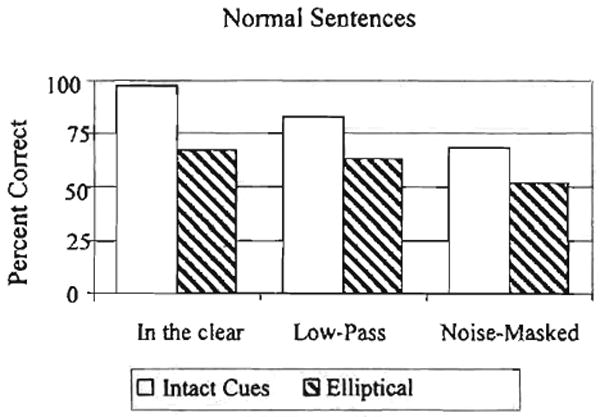
Results from the transcription task for the listeners with normal hearing.
A 2 × 3 × 2 ANOVA on the normal sentences revealed a main effect of place of articulation, F(1,8) = 102.75, p < .001. Keywords in the intact sentences were transcribed better than the keywords in the elliptical sentences. The main effect of signal degradation was also significant, F(2,16) = 48.14, p < .001. There was no interaction between these two factors. As expected, transcription performance was lower for elliptical speech presented in the clear than for speech containing intact place of articulation cues.
However, under both low-pass filtering and noise masking, transcription performance was also lower for elliptical sentences than for intact sentences. This pattern of the results failed to support our original prediction that transcription of keywords from intact and elliptical sentences would be equivalent under degraded listening conditions. We expected to find similar transcription performance for both sets of sentences because they were identified as the same in the discrimination task in Experiment 1. In Experiment 1, however, trials with one intact and one elliptical sentence showed a lower percentage labeled same in the IiEi and EiIi conditions than in the IiIi and EiEi conditions, even though they were significantly different from each other for clear vs. degraded presentation.
Although much of the place information may have been attenuated by the signal degradation manipulations, it is possible there were still some phonetic cues available because of the redundancy in natural speech. It is possible that the weak phonetic cues remaining in the signal after low-pass filtering or noise masking were responsible for the lower percentage of trials labeled same in the same-different task in the IiEi and EiIi conditions. If there was information about place of articulation in the signal, these cues may have helped to improve transcription performance for the sentences with intact place of articulation.
The present findings showing poorer transcription performance for elliptical speech under signal degradation failed to replicate the earlier results of Quillet and colleagues (1998), who found an increase in transcription performance of elliptical speech from noise masking of 0 dB SPL SNR to noise masking of −5 dB SPL SNR. However, Quillet and colleagues used synthetic speech, which has much less redundancy than the natural speech used in the present study Thus, the redundant natural speech cues present in these sentences may have actually survived the signal degradation more robustly than the synthetic speech, thus providing conflicting phonetic information by retaining weak cues to alveolar place of articulation, even under degraded conditions.
Anomalous sentences
A summary of the keyword transcriptions for the anomalous sentences for the listeners with normal hearing is shown in Figure 8. Again, the signal degradations are shown along the abscissa and the percent correct transcription of keywords is shown on the ordinate.
Figure 8.
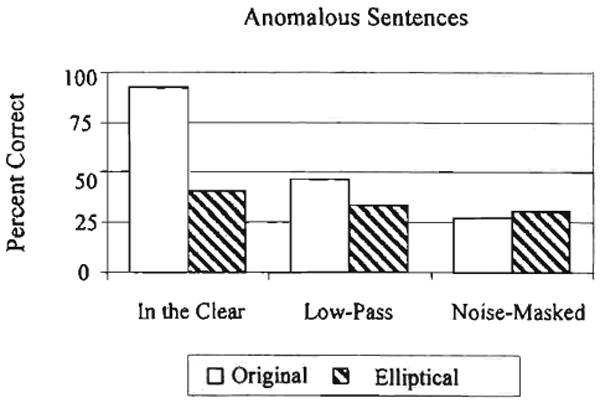
Results from the transcription task for the listeners with normal hearing.
A 2 × 3 × 2 ANOVA on the anomalous sentences revealed a main effect of place of articulation, F(1,8) = 345.83, p < .001. A main effect of signal degradation was also found, F(2,16) = 133.45, p < .001. The two-way interaction between these two factors was significant, F(2,16) = 63.83, p < .001. For sentences presented in the clear or under low-pass filtering, tests of simple effects indicated that the transcription of keywords from sentences with intact place of articulation cues was significantly better than the transcription of keywords from sentences containing elliptical speech (clear: t[8] = 16.06, p < .001; low-pass filtered: t[8] = 4.0, p < .01). Under noise masking, however, transcription of keywords from sentences with intact place of articulation cues was not significantly different from the elliptical sentences.
When presented in the clear, transcription of keywords from elliptical sentences was much lower than from intact sentences. This finding was expected. The elliptical anomalous sentences are both semantically anomalous and have incorrect cues to place of articulation, making them extremely difficult to parse. Under low-pass filtering, the transcription of elliptical sentences was still lower than intact sentences. This result also failed to support our prediction that transcription performance for intact and elliptical sentences would be equivalent under degraded conditions. Under masking noise the transcription performance for both intact and elliptical sentences was extremely low, around 25%–30% correct. In this case, the transcription performance for elliptical speech was slightly higher than for intact speech, but both scores were so low that this finding may simply be due to a floor effect.
Our prediction that intact speech and elliptical speech would show equivalent transcription performance under degraded conditions was not supported by these findings. Although most of the phonetic cues to place of articulation were attenuated by the signal degradation, some weak cues to place of articulation may still have been present in these sentences. Such cues, although weak, may have generated other perceptual confusions for listeners in the elliptical speech condition, thus lowering transcription performance. Moreover, because each sentence in the transcription task could be heard up to five times by listeners, the repetition may have helped to reinforce whatever weak phonetic cues to place of articulation were still present in the signal after degradation. Regardless of the reason, transcribing keywords from anomalous sentences, either with or without ellipsis of place of articulation under conditions of signal degradation, was a very difficult task for these listeners with normal hearing.
In summary, the results obtained for the listeners with normal hearing on the keyword transcription task failed to replicate the earlier findings of Quillet and colleagues (1998), who found improvement in transcription performance for elliptical speech under degraded conditions. It may be that the natural speech used here, with all of the rich phonetic redundancy, provided weak cues to place of articulation, despite the signal degradation manipulations. If the cues to alveolar place of articulation were perceived correctly in some of the sentences, this would have resulted in lowered keyword transcription performance overall.
Results: Mr. S
Normal sentences
The results of Mr. S's transcription performance for the normal sentences are shown in Figure 9. The percentage of keywords correctly transcribed is shown on the ordinate. Sentences with intact place of articulation cues are shown by the open bar and sentences containing elliptical speech cues are shown by the dark bar.
Figure 9.
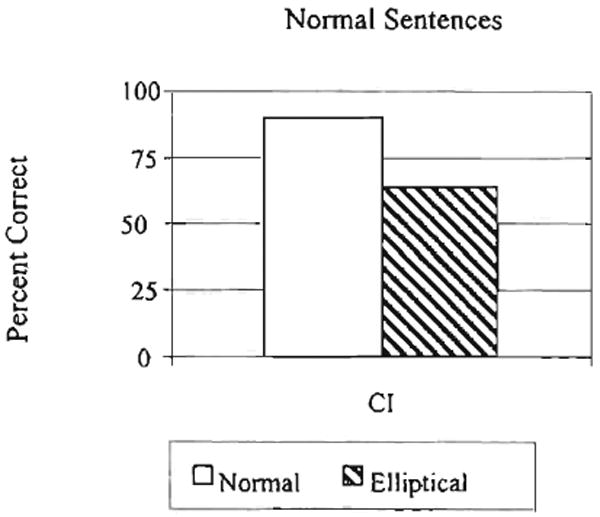
Results from the transcription task tor Mr. S.
As shown in Figure 9, Mr. S transcribed keywords from intact sentences with high levels of accuracy. This demonstrates that he is able to perform an open-set sentence transcription task; however, his transcription performance for the elliptical speech was somewhat lower. This pattern also did not match our original predictions. We expected that Mr. S's transcription performance would be similar for these two conditions because speech with intact place of articulation cues and elliptical speech were labeled as the same in a majority of trials in Experiment 1. Mr. S, however, labeled only 75% of IiEi sentence pairs in the same-different task as the same and only 50% of the EiIi sentence pairs in the same-different task as the same. Thus, despite the presumed loss of detailed phonetic information about place of articulation due to the cochlear implant, some phonetic cues that provide information about place of articulation still seem to be present. If this information is available, then cues to the alveolar place of articulation in the elliptical sentences may have provided Mr. S with conflicting phonetic information, thus lowering his overall transcription scores relative to our predictions.
Anomalous sentences
The results of Mr. S's transcription performance for the anomalous sentences are shown in Figure 10. Overall, Mr. S showed lower performance for the anomalous sentences compared to the normal sentences shown in Figure 9. This result was expected because the anomalous sentences are more difficult to parse than normal sentences. But again, the keywords in the elliptical anomalous sentences were transcribed more poorly than the keywords in the intact anomalous sentences. This was surprising given the discrimination results obtained in Experiment 1. It should be emphasized here that transcribing words from anomalous sentences, in which the words have ellipsis of place of articulation, is an extremely difficult task, as evidenced by the extremely low keyword transcription scores obtained by Mr. S in this condition. He did not do well on these sentences compared to his performance on the intact meaningful sentences shown in Figure 9.
Figure 10.
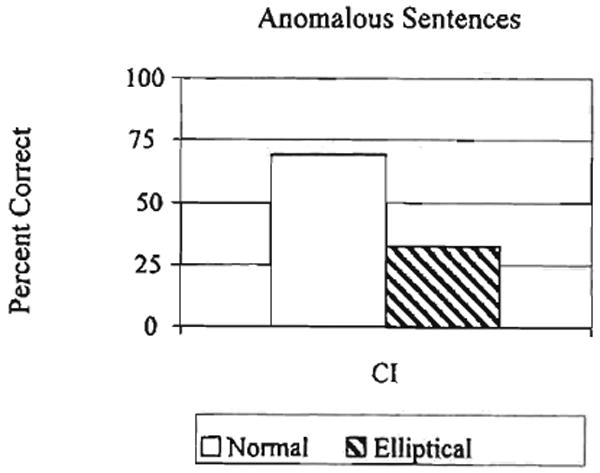
Results from the transcription task for Mr. S.
Mr. S's performance on the transcription task with the anomalous sentences was not consistent with the predictions based on his sentence discrimination scores from the same-different task in Experiment 1. Although he did extremely well in transcribing keywords in normal, intact sentences, his transcription performance for elliptical sentences was much poorer than we predicted based on his sentence discrimination scores. The poorer performance for elliptical sentences was also observed for the anomalous sentences, suggesting that Mr. S may have been relying on different sources of information to recognize words in each of these different conditions.
Discussion
The listeners with normal hearing and our CI patient, Mr. S, showed consistent use of lexical knowledge in the keyword transcription task. Several of the examples below, taken from the transcriptions of listeners with normal hearing, show the effects of top-down knowledge on processing anomalous sentences. The intended utterance is shown first and the transcription response is shown second. The keywords, which were left blank on the response sheets and which subjects wrote in by hand, are reproduced in italics in these examples. As shown here in (3), higher-level lexical and semantic context clearly play a more substantial role in controlling the transcription process and the final responses than the phonological regularities in the speech signal.
-
(3)
Anomalous Sentences
-
Stimulus: A winding dinner lasts fine with pockets.
Response: A wine dinner lasts fine with pasta.
-
Stimulus: These dice bend in a hot desk.
Response: These guys are in a hot bath.
-
Stimulus: Steam was twisted on the front of his dry grace.
Response: Skin was plastered on the front of his dry grapes.
-
Stimulus: Metal can sew the most dull switch.
Response: Mother can sew the most dull slips.
-
These examples of the contribution of top-down lexical and semantic knowledge are similar to the transcription responses observed with synthetic speech described by Pisoni (1982). For example, Pisoni reports the anomalous input “The bright guide knew the glass” and the wrong response “The bright guy threw the glass” In the examples from studies on the perception of synthetic speech, just as in the examples in the present experiment with degraded speech, responses to sentences that are difficult to perceive frequently show a strong tendency and bias toward generating meaningful responses, even if such a response leads to a complete reanalysis and reinterpretation of the sound structure of the words in the sentence. In the responses shown above, the response patterns of the listeners with normal hearing do not show only a simple place of articulation substitution. Rather, their final responses are errors in the sequence of manners of articulation.
In several cases, we found that Mr. S used a set of perceptual strategies that was somewhat different from the listeners with normal hearing. He made more sophisticated guesses based on lower-level phonological regularities in the speech signal, combined with top-down guidance and constraints. Listeners with normal hearing tended to use considerably more top-down lexical processing and sentence context, and did not necessarily exploit phonological regularities as well as Mr. S. For example, Mr. S tended to substitute words with sounds that have similar voicing and manner features to the word that he heard. These responses share a sequence of manners of articulation and of voicing values with the original utterance. Consider the following examples from Mr. S's transcriptions of anomalous sentences:
-
(4)
Anomalous Sentences
-
Stimulus: They could scoot although they were cold.
Mr. S's Response: They could scoop although they were cold.
-
Stimulus: Green ice can be used to slip a slab.
Mr. S's Response: Clean ice can be used to slip a sled.
-
Stimulus: Grass is the best weight of the wall.
Mr. S's Response: Brass is the best weight of the wall.
-
All of these examples show errors in the perception of place of articulation, but the general phonological shape of the original intended word is correctly perceived and, most important, the sequence of manners of articulation (e.g., fricative, liquid, vowel, stop) are correctly perceived. This difference in the nature of the error patterns between Mr. S and the listeners with normal hearing was probably the result of our patient's long-term experience and familiarity listening to highly degraded speech through his cochlear implant. If Mr. S must constantly guess at place of articulation given the general prosodic form of words and the sequence of manners of articulation and if he is aware that place of articulation distinctions are not as perceptible to him and are not reliable cues to word recognition, as they were before the onset of his hearing loss, it is very likely he would develop more sophisticated perceptual strategies for coarse coding the input speech signals than listeners with normal hearing would during the course of a one-hour experiment. On the other hand, the listeners with normal hearing have had little, if any, experience listening to speech signals as severely degraded as the ones presented in this study or the ones transmitted via a cochlear implant to a patient with hearing loss. The Listeners with normal hearing were exposed to these kinds of speech signals for only a short period of time and they received no feedback in any of these experiments. The patterns of errors observed here reveal important differences in the perceptual strategies used by listeners with normal hearing when faced with degraded or impoverished speech signals and those used by patients with hearing loss who have had extensive experience dealing with partial and/or unreliable acoustic-phonetic information in speech signals before and after receiving their cochlear implant.
General Discussion
Despite difficulties in perceiving fine phonetic contrasts, such as place of articulation in consonants, many CI users are able to comprehend fluent speech. What does the speech sound like for implant recipients? How do CI users manage to comprehend spoken language despite receiving degraded input? The results of these two experiments on the perception of elliptical speech provide some new insights into the underlying perceptual processes and suggest some possibilities for intervention and oral (re)habilitation for adult patients in the weeks and months immediately after implantation.
The first experiment used a same-different discrimination task with pairs of sentences that either had intact place of articulation cues or were transformed into elliptical speech. The results replicated the informal observations of Miller and Nicely (1955). They suggested speech that is impoverished with respect to place of articulation may not be perceived as deficient under degraded Listening conditions (e.g., noise-masking, low-pass filtering) because these conditions “reinstate” or “reproduce” the original conditions that produced the degradation. We found that listeners with hearing loss were able to discriminate the intact version of a sentence from an elliptical version in the clear, but they displayed a perceptual bias for labeling an intact and an elliptical version as the same when the two sentences were degraded by noise masking or low-pass filtering. Mr. S, a profoundly deaf cochlear implant user, also labeled the intact version and the elliptical version of the same sentence as the same. This pattern of results indicates that low-pass filtering, noise masking, or use of a cochlear implant all create impoverished or degraded speech and encourage the use of more efficient coarse coding strategies in which categories of sounds that bear phonetic resemblances to each other are all identified as functionally the same. Perceptual equivalence classes consisting of phonemes with the same manner of articulation and the same voicing, but different places of articulation, were clearly evident in the listeners' performance on this task.
The second experiment used a keyword transcription task with sentences that either had intact place of articulation cues or were transformed into elliptical speech. The sentences were presented in the clear, under low-pass filtering, or noise masking. The results failed to support our original predictions that keyword transcription performance for speech with intact place of articulation and elliptical speech would be perceived as equivalent under degraded presentation conditions. Both Mr. S and the normal hearing listeners under degradation showed poorer transcription performance for elliptical speech compared to speech with intact place of articulation. The results from the transcription task did not support the predictions of Miller and Nicely (1955) and failed to replicate the earlier findings of Quillet and colleagues (1998). It is possible that despite the signal degradation manipulations, some weak cues to place of articulation were still present in these sentences due to the rich redundancy of natural speech signals. If place of articulation cues were present in these sentences, they could be responsible for slightly lower percentage of trials labeled as the same in comparing the IiEi and EiIi results to the IiIi and EiEi results in the final experiment.
Although failing to meet the prediction of similar performance for speech with intact place of articulation and elliptical speech, Mr. S did show high transcription performance for the normal sentences compared to anomalous sentences, despite the impoverished input from his implant. The earlier observations of Shipman and Zue (1982) and Zue and Huttenlocher (1983) about the presence of strong sound-sequencing constraints in English and their role in spoken word recognition are consistent with Mr. S's performance in these two tasks. Mr. S is clearly able to make extremely good use of the minimal speech cues available to him in order to reduce the search space and to permit lexical selection to take place even with the highly impoverished input signal he receives from his cochlear implant.
Cochlear implant users who were postlingually deafened seem to code speech sounds more coarsely than listeners with normal hearing and, in turn, make use of broader perceptual equivalence classes consisting of consonants with the same manner of articulation and voicing but different places of articulation. It seems reasonable to suppose that the more successful CI users are able to use broader phonetic categories in speech more efficiently by showing greater selectivity to the potential lexical candidates within a larger search space. As noted earlier, Mr. S displayed sophisticated guessing strategies based on the overall phonological shape of a word. In order to explore these perceptual strategies further, it might be useful to study less successful CI users and examine how they encode speech using both sentence and word recognition tasks. We would also like to carry out more detailed error analyses of the transcription performance of these patients to examine the specific confusions they make in recognizing words in meaningful as well as anomalous sentences. If listeners can be matched based on how coarsely coded their input is (using the same-different task with elliptical speech), we would expect the more successful CI users to show greater phonological regularities and less variance in their errors in these transcription tasks. Less successful CI users, although they may display the same degree of coarse coding as more successful users, might show more variability in their error patterns. It is also possible that less successful CI users might not be using the phonological shape of words to prune the lexicon down to a smaller set of lexical candidates that are consistent with the sentence context.
If the more successful CI users make better use of the phonological regularities and phonological shape of words, these strategies might have some direct implications for oral (re)habilitation strategies immediately following implantation. It may be useful to encourage CI users to become more aware of the phonotactic structures of English so they can exploit this source of knowledge about spoken words to help narrow the search space in lexical retrieval. It may also be beneficial to increase awareness of the new perceptual equivalence classes that arise through the use of a cochlear implant, which may lead to the development and use of more sophisticated guessing strategies such as those displayed by Mr. S in these tasks. The use of elliptical speech perception tests may lead not only to a better understanding of which speech sounds are discriminable after implantation and which are not, but the use of these new types of stimulus materials may also help us create better methods of developing awareness of difficult phonological contrasts for CI users. This, in turn, may help them deal with speech in more efficient and optimal ways as they gain more experience with their implant and the nature of how it transforms the speech signal.
Acknowledgments
This work was supported by NTH Training Grant T32DC00012 and NTH Research Grant R01DC00111 to Indiana University from the National Institute on Deafness and Other Communication Disorders (NTDCD) at the National Institutes of Health (NTH). We would like to acknowledge the help of Mr. S, who graciously volunteered his time as a subject in this experiment. We would also like to acknowledge the help of Michael S. Vitevitch, Ph.D., who served as the male speaker in the creation of the stimuli used in this experiment. Thanks also to Corey Yoquelet for assistance with transcription and scoring of results in Experiment 2. We are grateful to Lorin Lachs, Ph.D., for help with the statistical analysis and to Miranda Cleary, Ph.D., for editorial assistance.
References
- Egan JP. Articulation testing methods. Laryngoscope. 1948;58:955–991. doi: 10.1288/00005537-194809000-00002. [DOI] [PubMed] [Google Scholar]
- Goh WD, Pisoni DB, Kirk KJ, Remez RE. Audio-visual perception of sinewave speech in an adult cochlear implant user: A case study. Ear & Hearing. 2001;22:412–419. doi: 10.1097/00003446-200110000-00005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Herman R, Clopper C. Research on Spoken Language Processing Progress Report No 23. Bloomington, IN: Speech Research Laboratory, Indiana University; 1999. Perception and production of intonational contrasts in an adult cochlear implant user; pp. 301–321. [Google Scholar]
- IEEE. IEEE recommended practice for speech quality measurements (IEEE Report No 297) 1969. [Google Scholar]
- Loizou P. Colea: A MATLAB software tool for speech analysis. Dallas, TX: Author; 1998. [Google Scholar]
- Miller GA. The perception of speech. In: Halle MA, editor. For Roman fakobson. The Hague: Mouton; 1956. pp. 938–1062. [Google Scholar]
- Miller GA, Nicely PE. An analysis of perceptual confusions among some English consonants. Journal of the Acoustical Society of America. 1955;27:338–352. [Google Scholar]
- Pisoni DB. Perception of speech: The human listener as a cognitive interface. Speech Technology. 1982;1(2):10–23. [Google Scholar]
- Quillet C, Wright R, Pisoni DB. Research on Spoken Language Processing Progress Report No 22. Bloomington, IN: Speech Research Laboratory, Indiana University; 1998. Perception of “place-degraded speech” by normal-hearing listeners: Some preliminary findings; pp. 354–375. [Google Scholar]
- Shipman DW, Zue VW. Properties of large lexicons: Implications for advanced isolated word recognition systems. ICASSP 82 Proceedings, May 3, 4, 5, 1982, Palais des Congrès, Paris, France: IEEE International Conference on Acoustics, Speech and Signal Processing; New York: The Institute; 1982. pp. 546–549. [Google Scholar]
- Zue VW, Huttenlocher DP. Computer recognition of isolated words from large vocabularies. ICASSP 83: Proceedings, April 14,15, and 16, 1983, Sheraton-Boston Hotel, Boston, Massachusetts, IEEE International Conference on Acoustics, Speech, and Signal Processing; New York: The Institute; 1983. pp. 121–125. [Google Scholar]