

Abstract
Epistatic interactions between genes and individual mutations are major determinants of the evolutionary properties of genetic systems and have therefore been well documented, but few quantitative data exist on epistatic interactions between beneficial mutations, presumably because such mutations are so much rarer than deleterious ones. We explored epistasis for beneficial mutations by constructing genotypes with pairs of mutations that had been previously identified as beneficial to the ssDNA bacteriophage ID11 and by measuring the effects of these mutations alone and in combination. We constructed 18 of the 36 possible double mutants for the nine available beneficial mutations. We found that epistatic interactions between beneficial mutations were all antagonistic—the effects of the double mutations were less than the sums of the effects of their component single mutations. We found a number of cases of decompensatory interactions, an extreme form of antagonistic epistasis in which the second mutation is actually deleterious in the presence of the first. In the vast majority of cases, recombination uniting two beneficial mutations into the same genome would not be favored by selection, as the recombinant could not outcompete its constituent single mutations. In an attempt to understand these results, we developed a simple model in which the phenotypic effects of mutations are completely additive and epistatic interactions arise as a result of the form of the phenotype-to-fitness mapping. We found that a model with an intermediate phenotypic optimum and additive phenotypic effects provided a good explanation for our data and the observed patterns of epistatic interactions.
Author Summary
Epistasis, the extent to which the effects of a mutation depend on its genetic context, can have profound effects on the evolutionary process and strongly affects our understanding of the prevalence of sexual reproduction. It has been investigated in a diverse array of organisms but almost exclusively for deleterious mutations. Interactions between beneficial mutations can impede adaptation, and we therefore investigated epistasis between beneficial mutations by constructing 18 bacteriophage genomes, each with two mutations that had been previously identified as beneficial, and measuring their fitnesses. We found universal evidence for epistasis—every pair of mutations conferred fitness lower than that expected from the single mutations alone. In many cases, a beneficial mutation became deleterious when in combination with another, and in fact, only one pair out of 18 could be shown to confer significantly greater fitness than its constituent mutations alone. To explain these results, we developed a model of the relationship between phenotype and fitness that posits an intermediate phenotypic optimum and assumes no epistasis at the phenotypic level. This model fit our data well and showed that the patterns we observed could result because mutants have phenotypes that overshoot the optimum.
Introduction
The nature of epistatic interactions between loci or mutations is a major component of evolutionary theories. For example, epistasis is thought to have been important in the evolution of sexual reproduction [1], [2] and reproductive isolation between incipient species [3]–[6]. In models of adaptation and fitness landscapes, epistatic interactions are the primary determinant of the topology of landscape and thus the accessibility of high-fitness genotypes [7]–[11]. Previous empirical studies have provided much evidence for a variety of forms of epistasis. Compensatory mutations, whose beneficial effects depend on the presence of a deleterious mutation, provide direct evidence of the relevance of epistasis; numerous empirical examples have been described [12]–[17]. Experiments in microbial [18], [19] and viral systems [20]–[24] have provided abundant evidence for antagonistic epistasis, in which the total effect of multiple mutations is less than expected on the basis of their individual effects. Similarly, some of these same studies have provided evidence for synergistic epistasis [18], [22], [23], in which the combined effects of mutations are greater than expected. Some evidence suggests that the predominance of antagonistic epistasis is a feature of simpler genomes, whereas synergistic epistasis is more common in more complex genomes [25].
The majority of commonly cited effects of epistasis in evolution are the results of interactions between deleterious alleles, but interactions between beneficial alleles can significantly affect the rate of adaptation. Epistasis has been shown to constrain pathways of molecular adaptation severely [26]–[28]. One of the major advantages of sexual reproduction is the presumed benefit of recombining separate beneficial mutations or alleles into the same genome [2]. Discussions of microbial evolution are dominated by the phenomenon of clonal interference [29]–[37], in which, because of their asexual mode of reproduction, clonal organisms suffer a reduced rate of adaptation because individual beneficial mutations must compete for fixation rather than being combined into the same genome by recombination. These results rest on the assumption that mutations that are individually beneficial remain beneficial when combined. Furthermore, many models of adaptation rely on the assumption that the effects of beneficial mutations are additive [29], [30], [38]. Though these assumptions are widely used, their validity is largely undetermined.
To explore epistatic interactions between beneficial mutations, we constructed bacteriophage mutants with pairs of previously identified beneficial mutations by site-directed mutagenesis. We used nine beneficial mutations (which we designate A through I, in order of their appearance in the genome; Table 1) identified for the ssDNA microvirid bacteriophage ID11 [39]. This phage infects Escherichia coli strain C, and the nine mutations increased growth rate of the wild type at 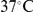 in liquid culture with excess hosts. We built 18 of the possible 36 pairs of these nine beneficial mutations (designated by two-letter combinations) and measured the fitnesses of the wild-type genotype, those of the single beneficial mutations, and the double mutants. A similar approach was used to study epistatic interactions between deleterious mutations and between beneficial mutations for the RNA virus vesicular stomatitis virus (VSV) [22], but we go beyond characterizing the patterns by constructing an explanatory model that posits that epistatic interactions arise at the level of the mapping from phenotypes to fitness and assessing the fit of our data to it.
in liquid culture with excess hosts. We built 18 of the possible 36 pairs of these nine beneficial mutations (designated by two-letter combinations) and measured the fitnesses of the wild-type genotype, those of the single beneficial mutations, and the double mutants. A similar approach was used to study epistatic interactions between deleterious mutations and between beneficial mutations for the RNA virus vesicular stomatitis virus (VSV) [22], but we go beyond characterizing the patterns by constructing an explanatory model that posits that epistatic interactions arise at the level of the mapping from phenotypes to fitness and assessing the fit of our data to it.
Table 1. Nine mutations beneficial to the ssDNA bacteriophage ID11.
| Label | Protein function | Protein name | Aa position |
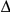 Aa Aa |
Nuc position |
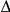 Nuc Nuc |
| A | DNA binding | J | 15 | A V V |
2520 | C T T |
| B | DNA binding | J | 20 | V L L |
2534 | G T T |
| C | coat | F | 3 | V F F |
2609 | G T T |
| D | coat | F | 314 | A V V |
3543 | C T T |
| E | coat | F | 322 | N S S |
3567 | A G G |
| F | coat | F | 355 | P S S |
3665 | C T T |
| G | coat | F | 416 | M I I |
3850 | G A A |
| H | coat | F | 419 | T A A |
3857 | A G G |
| I | coat | F | 421 | D G G |
3864 | A G G |
The nine beneficial mutations used in this study affect two different viral proteins: the DNA binding protein J and the major coat protein F. Positions are based on the published genome sequence of ID11 (GenBank accession # AY751298). Nuc, nucleotide; 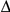 Nuc, nucleotide change.
Nuc, nucleotide change.
Results/Discussion
Antagonistic epistasis between beneficial mutations
For the 18 double mutants, the expected effect of incorporating both beneficial mutations into the genome under additivity (i.e., without epistasis) was greater than the observed effect (Figure 1). Because our fitness was measured as a growth rate (i.e., log fitness), the expectation under additivity was that the effect of the two mutations in combination would be the sum of the single-mutant effects on growth rate. We can measure the deviation from additivity by calculating
| (1) |
where 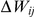 is the effect of the double mutant with mutations
is the effect of the double mutant with mutations  and
and 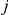 relative to the wild type, and
relative to the wild type, and 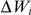 is the effect of single mutant
is the effect of single mutant  relative to the wild-type. An
relative to the wild-type. An  of 0 implies additivity;
of 0 implies additivity; 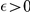 implies synergistic epistasis, and
implies synergistic epistasis, and 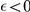 implies antagonistic epistasis [22]. The average deviation from additivity over the 18 double mutants was
implies antagonistic epistasis [22]. The average deviation from additivity over the 18 double mutants was 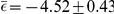 . We could easily reject additivity (
. We could easily reject additivity ( ,
, 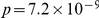 ). All deviations were less than zero (
). All deviations were less than zero (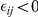 for all
for all  and
and 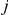 ), and the deviation of smallest magnitude,
), and the deviation of smallest magnitude, 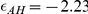 , was more than 5 standard errors less than zero. We therefore found no evidence of synergistic epistasis between beneficial mutations and could strongly reject additivity. Epistasis between beneficial mutations of ID11 was entirely antagonistic. Previous work with the RNA virus VSV looking at the effects of pairs of beneficial mutations also found evidence for a predominance of antagonistic epistasis and no significant cases of synergistic epistasis for beneficial mutations. This result confirmed the prediction by Martin et al. [40] based on a generalized version of Fisher's geometrical model [41] that values of
, was more than 5 standard errors less than zero. We therefore found no evidence of synergistic epistasis between beneficial mutations and could strongly reject additivity. Epistasis between beneficial mutations of ID11 was entirely antagonistic. Previous work with the RNA virus VSV looking at the effects of pairs of beneficial mutations also found evidence for a predominance of antagonistic epistasis and no significant cases of synergistic epistasis for beneficial mutations. This result confirmed the prediction by Martin et al. [40] based on a generalized version of Fisher's geometrical model [41] that values of  between pairs of beneficial mutations should be skewed toward negative values (see below for a full treatment of this model).
between pairs of beneficial mutations should be skewed toward negative values (see below for a full treatment of this model).
Figure 1. Universal antagonistic epistasis for beneficial mutations.

The fitness of double mutant ID11 phage expected on the basis of addition of the effects of the two mutations is plotted against the observed effects on the doubles mutants. Additive effects would fall on the diagonal, synergistic effects would fall above the diagonal, and antagonistic effects would fall below the diagonal. Effects are given in units of doublings per hour.
Decompensatory epistasis for beneficial mutations
Although, under antagonistic epistasis, the beneficial effect of a second mutation is reduced, that second mutation might still increase fitness to some lesser extent. We are also therefore interested in decompensatory epistasis [22], under which a beneficial mutation actually becomes deleterious in the presence of another beneficial mutation (analogous to compensatory mutations, which are beneficial only in the context of a deleterious mutation). Decompensatory epistasis is also a special case of sign epistasis [9] and would indicate that the set of beneficial mutations available for the wild-type genotype may be quite different from the set of beneficial mutations available after the first fixation event in adaptation. This situation would be consistent with, for example, the standard implementation of the mutational landscape model [42]–[45], which uses a random fitness landscape. After a mutation becomes fixed in the population, an entirely new set of beneficial mutations (if any) becomes available to the evolving population.
Figure 2 illustrates the cases in which the mean fitness conferred by the double mutation is less than the mean fitness conferred by one or both beneficial mutations on their own. To test for significance, we performed three different sets of tests of increasing stringency. For the first, we simply asked whether the fitness conferred by the double mutation was significantly less than the higher of the two fitnesses conferred by the single mutations of which it was composed. We called the situation in which it was conditional decompensatory epistasis, as it merely guaranteed that at least one of the two mutations was deleterious in the presence of the other and did not preclude the case where the double-mutant fitness lies between the two single-mutant fitnesses. Using a one-sided Welch two-sample t-test and a Bonferroni correction for 18 tests, we found six double mutants that showed evidence of conditional decompensatory epistasis with 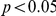 : BE, BG, BI, CE, DI, and EI. The second test was to determine whether the double mutant was less fit that the lower-fitness single mutant. We refer to the case in which it was as unconditionally decompensatory epistasis, as regardless of the order mutations might be added to the genome, the second was always deleterious. Using the same test as above, we found only two double mutants that were unconditionally decompensatory with
: BE, BG, BI, CE, DI, and EI. The second test was to determine whether the double mutant was less fit that the lower-fitness single mutant. We refer to the case in which it was as unconditionally decompensatory epistasis, as regardless of the order mutations might be added to the genome, the second was always deleterious. Using the same test as above, we found only two double mutants that were unconditionally decompensatory with 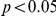 : CE and EI. Finally, our most stringent test was to ask whether the double mutant was less fit than the wild-type genotype. This situation would imply that the two mutations together constituted a deleterious mutation, i.e., a population in which both mutations became fixed would be worse off than one in which neither had. Using the same test as above, we found two double mutants that were significantly less fit than the wild type with
: CE and EI. Finally, our most stringent test was to ask whether the double mutant was less fit than the wild-type genotype. This situation would imply that the two mutations together constituted a deleterious mutation, i.e., a population in which both mutations became fixed would be worse off than one in which neither had. Using the same test as above, we found two double mutants that were significantly less fit than the wild type with 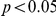 : CE and EI, the two unconditionally decompensatory doubles.
: CE and EI, the two unconditionally decompensatory doubles.
Figure 2. Evidence for decompensatory epistasis.

The grid shows the fitnesses of the wild type, single mutants, and double mutants. Empty cells represent the double mutants that were not constructed. Red indicates that the average fitness of the double mutant is lower than the average fitness conferred by its two constituent single mutations. Blue indicates that its fitness is higher than that of either single mutant, and purple indicates that it is between the fitnesses of the two single mutants. A “*” in a red box indicates the double mutation confers a fitness significantly lower than that conferred by one single mutation, and a “**” indicates that the double mutation confers a fitness significantly lower than that conferred by either of its single mutations. A “*” in a blue box indicates that the double mutation confers a fitness significantly higher than that conferred by either constituent single mutation.
The presence of decompensatory epistasis for beneficial mutations is consistent with a random fitness landscape, but clearly not all pairs of beneficial mutations show this pattern. In fact, at least one double mutant is significantly more fit than mutants bearing either of its constituent single mutations (see below). Nevertheless, in a number of cases, both beneficial mutations could not become fixed in the population because they could not outcompete one or both of the single mutations from which they were formed. A similar observation about beneficial mutations was made for VSV [22]. Under landscape models such as the block model [10], [11] or 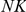 model [7], [8], the ruggedness of the landscape can be adjusted if the extent of epistatic interactions is changed from a smooth, additive landscape with no epistasis to a highly rugged, highly epistatic random landscape. We can clearly reject the nonepistatic model, but just as clearly, the random landscape is too extreme. Under a random-landscape model, the probability that a second mutation increases fitness (i.e., is not decompensatory) is the same as the probability that a random mutation is beneficial, which is generally assumed to be small. Our observation of nondecompensatory mutations is therefore inconsistent with this model.
model [7], [8], the ruggedness of the landscape can be adjusted if the extent of epistatic interactions is changed from a smooth, additive landscape with no epistasis to a highly rugged, highly epistatic random landscape. We can clearly reject the nonepistatic model, but just as clearly, the random landscape is too extreme. Under a random-landscape model, the probability that a second mutation increases fitness (i.e., is not decompensatory) is the same as the probability that a random mutation is beneficial, which is generally assumed to be small. Our observation of nondecompensatory mutations is therefore inconsistent with this model.
The advantage of sex
One of the major proposed advantages of sexual reproduction is that it facilitates recombination, which can increase the rate of adaptation by allowing beneficial mutations arising in different genomes to be combined in the same genome. This advantage is contigent on the assumption of a fitness increase for the recombinant over its composite single mutations. To test this assumption, we asked whether any of the 18 double mutants had significantly higher fitness than the higher of the fitnesses of mutants bearing the single mutations of which it was composed. Using a one-sided Welch two-sample t-test and Bonferroni correction for 18 tests, we found only a single double mutation that could outcompete its constituent single mutations: AG (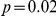 with Bonferroni correction). Even without the Bonferroni correction, only two doubles are significantly higher at the 5% significance level: AG (
with Bonferroni correction). Even without the Bonferroni correction, only two doubles are significantly higher at the 5% significance level: AG (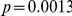 ) and AH (
) and AH (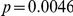 ). Therefore, recombination would not increase the rate of adaptation in this phage system.
). Therefore, recombination would not increase the rate of adaptation in this phage system.
This observation, together with the presence of decompensatory epistasis described above, indicates that the patterns predicted by clonal interference models [29], [30] may actually arise even in the presence of recombination. The assumption of the model is that, because of their asexual mode of reproduction, clonal organisms have a lower rate of adaptation because individual beneficial mutations must compete with one another for fixation rather than be combined into the same genome through recombination for simultaneous fixation. If combinations of beneficial mutations confer less fitness or not more fitness than the single mutations, however, even with recombination, the single mutations must compete for fixation because of a kind of epistatic interference or epistatic repulsion. Our results suggest that the types of theoretical results derived for asexuals have broader applicability even in sexual organisms, while at the same time calling into question the underlying impetus for the models, if similar results are found in other systems. In other words, in our phage, sexual reproduction would provide little or no increase in the rate of adaptation, because ultimately one of the single mutants will outcompete the other singles and any double mutants that could be produced by recombination.
Additivity of phenotypic effects
Clearly, our results and Figures 1 and 2 reveal significant epistatic interactions between the nine beneficial mutations in our data set. Recent theoretical and empirical work has suggested that mutations produce additive biochemical effects [26], [46], and bacteriophage growth is merely a somewhat complex biochemical reaction. If phenotypic (e.g., biochemical) effects are completely additive, epistatic interactions might still arise through nonlinearity in the mapping from phenotype to fitness [40]. In addition, work with the nine beneficial mutations we studied revealed a distinct upper bound on fitness effects for beneficial mutations [47]. Such an upper bound could arise naturally with an intermediate phenotypic optimum (i.e., stabilizing selection). To determine whether such a scenario might apply to the ID11 system, we developed a simple model of the phenotype-to-fitness mapping and fit it to our data. Our model is analogous in structure to the model of Martin et al. [40], who assumed a fitness landscape based on Fisher's geometrical model [41] in a multidimensional phenotype space, additivity of phenotypic effects of mutations, and a Gaussian fitness function to map phenotypes to fitness (see below for a comparison of the two models). DePristo et al. [46] also assumed additivity of phenotypes in their model. For our model, we assumed the phenotype-fitness relationship took the form of a gamma curve, with shape ( ), scale (
), scale (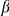 ), height (
), height (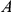 ), and shift (
), and shift (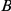 ) parameters. We also assumed that the mutations were all affecting a single underlying and unknown phenotype. Under the model, we assumed that the phenotype of the double mutant with single mutations
) parameters. We also assumed that the mutations were all affecting a single underlying and unknown phenotype. Under the model, we assumed that the phenotype of the double mutant with single mutations  and
and 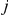 with phenotypes
with phenotypes 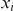 and
and 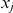 was given by
was given by 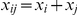 . We treated the phenotypes of the single mutations as missing data and imputed their values and estimated the values of the gamma parameters
. We treated the phenotypes of the single mutations as missing data and imputed their values and estimated the values of the gamma parameters  ,
, 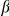 ,
, 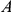 , and
, and 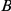 . For our nine single mutants and the 18 constructed double mutants, we found that the model provides a good fit to our data (Figure 3), with a coefficient of determination
. For our nine single mutants and the 18 constructed double mutants, we found that the model provides a good fit to our data (Figure 3), with a coefficient of determination 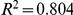 . We rejected a null model that assumed the fitnesses of the doubles and the singles to be independent draws from a normal probability distribution with
. We rejected a null model that assumed the fitnesses of the doubles and the singles to be independent draws from a normal probability distribution with 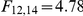 giving
giving 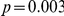 . The parameter estimates for the phenotype-to-fitness map were
. The parameter estimates for the phenotype-to-fitness map were 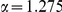 ,
, 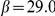 ,
, 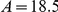 , and
, and 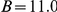 . This distribution is right skewed and suggested that our wild-type ID11 is close to the phenotypic optimum.
. This distribution is right skewed and suggested that our wild-type ID11 is close to the phenotypic optimum.
Figure 3. The phenotype-to-fitness map.

The plot shows the fit of our model for the phenotype-to-fitness map. The model assumes a gamma curve for the relationship between fitness and phenotype. Phenotypic effects were assumed to be additive and epistasis for fitness to arise through the shape of the curve. The variance of the normal error was estimated to be 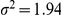 .
. 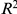 gives the coefficient of determination. The
gives the coefficient of determination. The 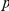 value is based on an
value is based on an 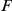 test comparing our model to a model assuming that single- and double-mutant fitnesses are independent of each other. For these data,
test comparing our model to a model assuming that single- and double-mutant fitnesses are independent of each other. For these data, 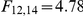 . We rescaled fitness by substracting
. We rescaled fitness by substracting 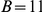 rather than the fitness of the wild type to avoid negative values.
rather than the fitness of the wild type to avoid negative values.
Our gamma model and the model of Martin et al. [40] make similar assumptions but differ in the number of phenotypic dimensions and the shape of the phenotype-fitness map. Martin et al. assume a Gaussian map. To compare the performance of the models, we produced predicted distributions of epistatic effects (Figure 4). The gamma model provided a 12 log-likelihood improvement over the model of Martin et al. but requires imputation of nine phenotypes and estimates of five parameters (four for the gamma and one for the error distribution). The model of Martin et al. has only two parameters, leaving a difference of 12 parameters. Therefore, when Akaike Information Criterion (AIC) scores were used to penalize for over-fit, the two models explained the data equally well (Figure 4). Both models predicted a pattern of negative epistatic effects, which was reflected in the data, but the model of Martin et al. predicted more extreme antagonistic epistasis than was observed. The lack of fit for this model is due primarily to this prediction of extreme negative epistasis. The pattern of epistasis predicted by the gamma model is consistent with the data, but this model is penalized for extra parameters.
Figure 4. Comparison between the gamma model (left) and the model of Martin et al. [40] (right).

The plots show the predicted distributions of the deviations from additivity (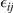 ; Equation 1) based on simulations under the two models. The observed values are plotted as triangles (Table 3). The gamma model fits the data better by approximately 12 log likelihoods but requires the estimation of 12 more parameters. The Akaike Information Criterion (AIC) scores of the two models are therefore similar, indicating that the two explain the data equally well.
; Equation 1) based on simulations under the two models. The observed values are plotted as triangles (Table 3). The gamma model fits the data better by approximately 12 log likelihoods but requires the estimation of 12 more parameters. The Akaike Information Criterion (AIC) scores of the two models are therefore similar, indicating that the two explain the data equally well.
The gamma model assumes that the phenotypic optimum is intermediate, and our fitted values suggested that five of the nine single mutants actually overshoot this optimum. Therefore, adding two of these effects together had an overall tendency to reduce fitness, except for those mutations conferring the smallest phenotypic effects, A, D, and H (Figure 3). Note that all cases in which the second mutation appeared to have increased fitness involved at least one of these three mutations (Figure 2). In addition, the strongest epistatic interactions (i.e., those involving the unconditionally decompensatory mutations) involved at least one of the mutations with the largest phenotypic effects, E and I (Figure 3). Therefore, the model did explain the major patterns in our data, and it also made a number of testable predictions. For example, we can predict which of the 18 unconstructed possible double mutants will have low or high fitness or predict the fitness of triple mutants and beyond. To test the predictive power of the model, we conducted a series of analyses, each of which involved the removal of one of the 18 double mutants from the data set. The model was fit to each reduced data set, then used to predict the removed value. The model generated accurate predictions for 17 of the 18 double mutants (Table 2), suggesting good predictive power. More interestingly, the model predicts that, if we can change the phenotypic optimum by, for example, changing the environment, we can entirely alter the patterns of epistasis. Increasing the distance of the wild type from the optimum might produce additive effects or even synergistic epistasis rather than the uniform antagonistic effects we observed. Intriguingly, recent work on the phage 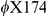 , a close relative of our phage ID11, showed that epistatic interactions between different amino-acid residues at two particular sites in the phage coat protein can change from antagonistic to synergistic depending on the environment in which fitness is measured [23]. Our simple model can evince such behavior in response to simple changes in the optimum.
, a close relative of our phage ID11, showed that epistatic interactions between different amino-acid residues at two particular sites in the phage coat protein can change from antagonistic to synergistic depending on the environment in which fitness is measured [23]. Our simple model can evince such behavior in response to simple changes in the optimum.
Table 2. The predictive power of the gamma model.
| Removed | Predicted | Observed |
|
|
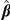
|
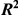
|
# SD |
| AB |
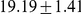
|
18.66 | 14 | 1.06 | 23 | 0.81 | 0.37 |
| AD |
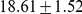
|
18.82 | 13 | 1.10 | 20 | 0.78 | 0.14 |
| AF |
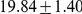
|
18.07 | 14 | 1.08 | 40 | 0.81 | 1.26 |
| AG |
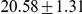
|
22.50 | 14 | 1.11 | 48 | 0.80 | 1.46 |
| AH |
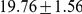
|
20.29 | 15 | 1.20 | 27 | 0.75 | 0.34 |
| BD |
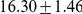
|
17.77 | 15 | 1.17 | 49 | 0.80 | 1.01 |
| BE |
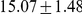
|
15.58 | 15 | 1.15 | 21 | 0.78 | 0.34 |
| BG |
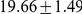
|
17.31 | 15 | 1.21 | 42 | 0.78 | 1.58 |
| BH |
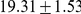
|
19.47 | 15 | 1.18 | 48 | 0.77 | 0.11 |
| BI |
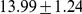
|
16.52 | 15 | 1.06 | 30 | 0.85 | 2.05 |
| CD |
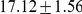
|
17.52 | 12 | 1.08 | 20 | 0.76 | 0.26 |
| CE |
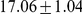
|
11.56 | 13 | 1.05 | 59 | 0.85 | 5.30* |
| CH |
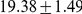
|
19.49 | 15 | 1.16 | 29 | 0.78 | 0.08 |
| DF |
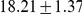
|
19.30 | 15 | 1.11 | 22 | 0.82 | 0.79 |
| DH |
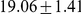
|
18.48 | 15 | 1.08 | 38 | 0.81 | 0.41 |
| DI |
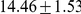
|
15.40 | 15 | 1.19 | 20 | 0.76 | 0.62 |
| EH |
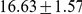
|
16.54 | 15 | 1.20 | 27 | 0.76 | 0.06 |
| EI |
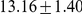
|
12.74 | 14 | 1.06 | 31 | 0.77 | 0.30 |
Each analysis consisted of removing one of the 18 double mutants, fitting the model to the remaining data, and predicting the fitness of the removed double mutant. For simplicity, we assumed the same shift (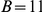 ) for each analysis. The last column gives the magnitude of the difference between the observed and predicted values as a number of standard deviations. A “*” indicates a significant difference at a 5% significance level from the model predictions with 15 degrees of freedom. A difference greater than 2.13 standard deviations is significant.
) for each analysis. The last column gives the magnitude of the difference between the observed and predicted values as a number of standard deviations. A “*” indicates a significant difference at a 5% significance level from the model predictions with 15 degrees of freedom. A difference greater than 2.13 standard deviations is significant.
Materials and Methods
Constructing the mutants and fitness assays
The isolation and initial characterization of the nine beneficial mutations of the microvirid bacteriophage ID11 [48] have been described in detail previously [39], [48]. These mutations confer an increased growth rate on the wild-type ID11. The isolates used were confirmed by full-genome sequencing to have the mutations of interest and no other mutations.
PCR-based construction of the double mutants was based on published techniques [23], [49]. Pairs were selected such that each mutation was found in multiple genotypes, and all combinations of large-, intermediate-, and small-effect mutations were included. To construct the double mutants, we added the second mutation into a sequence-confirmed isolate of the first. We PCR amplified the circular genome in two halves, in which the forward primer for one half and the reverse of the other had the mutation to be incorporated. The other primers were selected to result in an overlap of the resulting genome halves. These halves were cleaned with a Qiagen QIAquick PCR purification kit and combined in a PCR (no primers). This reaction was cleaned with the QIAquick kit and electroporated into E. coli. The resulting plaques were picked and plaque purified by replating. We then subjected the final isolate to full-genome sequencing to confirm the incorporation of the mutation and the lack of secondary mutations.
Fitness assays were performed as described previously [12]. We measured fitness as the 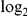 increase in the phage population per hour on E. coli strain C at
increase in the phage population per hour on E. coli strain C at 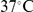 . Assays were performed in an orbital water bath shaking at 200 rpm. We measured each genotype at least five times (Table 3).
. Assays were performed in an orbital water bath shaking at 200 rpm. We measured each genotype at least five times (Table 3).
Table 3. Fitnesses and fitness effects of all genotypes tested.
| Genotype | Fitness |

|
|
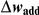
|
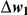
|
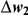
|
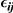
|
| ID11 |
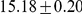
|
14 | - | - | - | - | - |
| A |
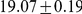
|
5 | 3.89 | - | - | - | - |
| B |
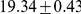
|
5 | 4.15 | - | - | - | - |
| C |
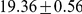
|
6 | 4.18 | - | - | - | - |
| D |
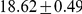
|
7 | 3.44 | - | - | - | - |
| E |
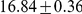
|
5 | 1.65 | - | - | - | - |
| F |
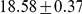
|
5 | 3.39 | - | - | - | - |
| G |
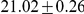
|
6 | 5.84 | - | - | - | - |
| H |
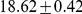
|
5 | 3.44 | - | - | - | - |
| I |
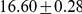
|
5 | 1.42 | - | - | - | - |
| AB |
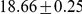
|
5 | 3.47 | 8.04 | −0.42 | −0.68 | −4.57 |
| AD |
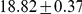
|
5 | 3.63 | 7.33 | −0.26 | 0.19 | −3.70 |
| AF |
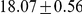
|
5 | 2.88 | 7.28 | −1.00 | −0.51 | −4.40 |
| AG |
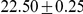
|
5 | 7.32 | 9.73 | 3.43 | 1.48 | −2.41 |
| AH |
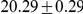
|
5 | 5.10 | 7.33 | 1.21 | 1.66 | −2.23 |
| BD |
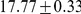
|
5 | 2.59 | 7.59 | −1.56 | −0.85 | −5.00 |
| BE |
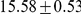
|
6 | 0.40 | 5.8 | −3.75 | −1.26 | −5.40 |
| BG |
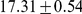
|
7 | 2.12 | 9.99 | −2.03 | −3.72 | −7.87 |
| BH |
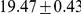
|
5 | 4.29 | 7.59 | 0.14 | 0.85 | −3.30 |
| BI |
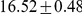
|
7 | 1.34 | 5.57 | −2.82 | −0.08 | −4.23 |
| CD |
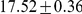
|
6 | 2.34 | 7.62 | −1.84 | −1.10 | −5.28 |
| CE |
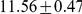
|
6 | −3.62 | 5.83 | −7.80 | −5.28 | −9.45 |
| CH |
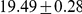
|
5 | 4.31 | 7.62 | 0.13 | 0.87 | −3.31 |
| DF |
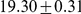
|
5 | 4.12 | 6.83 | 0.68 | 0.72 | −2.71 |
| DH |
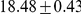
|
5 | 3.30 | 6.88 | −0.14 | −0.14 | −3.58 |
| DI |
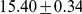
|
5 | 0.21 | 4.86 | −3.23 | −1.20 | −4.65 |
| EH |
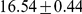
|
5 | 1.35 | 5.09 | −0.30 | −2.09 | −3.74 |
| EI |
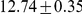
|
5 | −2.44 | 3.07 | −4.09 | −3.86 | −5.51 |
Fitnesses are given as the average plus or minus the standard error. The column labeled  gives the number of replicate assays for each genotype. The fitness effect relative to the wild type is designated by
gives the number of replicate assays for each genotype. The fitness effect relative to the wild type is designated by 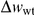 .
. 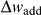 gives the fitness effect expected on the assumption that the effects of single mutations were additive,
gives the fitness effect expected on the assumption that the effects of single mutations were additive, 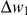 gives the effect of adding the first mutation in the genotype name into the background of the second, and
gives the effect of adding the first mutation in the genotype name into the background of the second, and 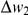 gives the effect of adding the second mutation in the genotype name into the background of the first.
gives the effect of adding the second mutation in the genotype name into the background of the first.
Testing for additivity of phenotypic effects
Let  be the fitness effect of mutation
be the fitness effect of mutation  and let
and let 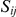 be the fitness effect of the double mutant with mutations
be the fitness effect of the double mutant with mutations  and
and 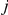 . We assumed the phenotype-to-fitness mapping followed a gamma curve given by
. We assumed the phenotype-to-fitness mapping followed a gamma curve given by
Note that this is not a probability density function. We view  as the shape parameter,
as the shape parameter, 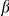 as the scale parameter,
as the scale parameter, 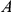 as the height parameter, and
as the height parameter, and 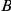 as the shift parameter. The phenotypic effect is denoted by
as the shift parameter. The phenotypic effect is denoted by  . Our model is then given by
. Our model is then given by 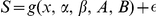 where
where  is normally distributed with mean zero and variance
is normally distributed with mean zero and variance 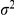 . Our data consisted of the fitness effects of single mutations,
. Our data consisted of the fitness effects of single mutations, 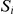 , and fitness effects of double mutants,
, and fitness effects of double mutants, 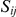 ; average effects are given by
; average effects are given by 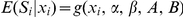 and additivity of phenotypic effects was modeled on the assumption that
and additivity of phenotypic effects was modeled on the assumption that 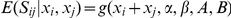 .
.
For model fitting, the estimate of the shift parameter 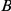 , denoted by
, denoted by 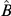 , was based on the fitness of the lowest-fitness genotype (see below). We treated
, was based on the fitness of the lowest-fitness genotype (see below). We treated  ,
, 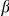 , and
, and 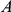 as parameters and the phenotypes
as parameters and the phenotypes 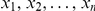 as missing data. We first imputed the phenotypes and estimated the parameters from nonlinear least squares regression. Let the array of phenotypes be
as missing data. We first imputed the phenotypes and estimated the parameters from nonlinear least squares regression. Let the array of phenotypes be 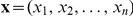 . We then minimize
. We then minimize
| (2) |
We denote the estimates and imputations by 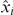 ,
, 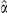 ,
, 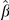 ,
, 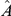 , and
, and 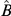 . Then the predicted fitness are
. Then the predicted fitness are 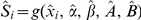 and
and 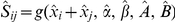 .
.
To assess model fit, we used a simple null model where 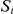 and
and 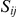 are draws from some probability distribution and vary about some mean
are draws from some probability distribution and vary about some mean 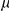 such that
such that 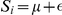 and
and 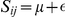 , where
, where  follows a normal distribution with mean zero and variance
follows a normal distribution with mean zero and variance 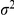 . Under this null model, the fitnesses of the single mutations and double mutations are completely independent of one another. We can therefore consider
. Under this null model, the fitnesses of the single mutations and double mutations are completely independent of one another. We can therefore consider 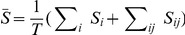 to be our estimate of
to be our estimate of 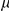 , where
, where 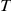 is the total number of mutants considered (doubles and singles). Then, the coefficient of determination is
is the total number of mutants considered (doubles and singles). Then, the coefficient of determination is
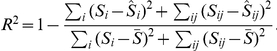 |
When 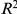 was close to 1, the model explained a large amount of the variation. For a formal test, we used an approach analogous to an
was close to 1, the model explained a large amount of the variation. For a formal test, we used an approach analogous to an 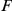 test. The sum of squared error is defined by
test. The sum of squared error is defined by
and the sum squared total is
The sum of squares model is then the difference 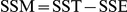 . The degrees of freedom for SST is
. The degrees of freedom for SST is 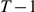 , and the degrees of freedom for SSE is
, and the degrees of freedom for SSE is 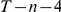 , where
, where  is the number of single mutants. The degrees of freedom for SSM is then
is the number of single mutants. The degrees of freedom for SSM is then 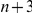 . Therefore the
. Therefore the 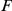 statistic would be
statistic would be
The standard 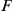 distribution may not hold because of the nonlinear nature of the model. All statistical analyses were done in R [50].
distribution may not hold because of the nonlinear nature of the model. All statistical analyses were done in R [50].
Fitting the model to our data
To analyze our data, we shifted all fitnesses, which are given in units of doublings per hour, by subtracting a fitness value of 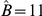 from each. This shifting allowed our model to address only fitnesses in the observed range without making predictions about the phenotype-fitness relationship for very low fitness values. Because of the simplicity of the model, it may not accurately describe the behavior far outside the range of our data. We could not shift by the wild-type fitness because two double mutants had fitnesses below that of the wild-type, which would have given negative fitness values. Therefore, we shifted by the largest integer value that was less than all observed fitnesses. The degrees of freedom for SSE becomes
from each. This shifting allowed our model to address only fitnesses in the observed range without making predictions about the phenotype-fitness relationship for very low fitness values. Because of the simplicity of the model, it may not accurately describe the behavior far outside the range of our data. We could not shift by the wild-type fitness because two double mutants had fitnesses below that of the wild-type, which would have given negative fitness values. Therefore, we shifted by the largest integer value that was less than all observed fitnesses. The degrees of freedom for SSE becomes  , and the degrees of freedom for SSM becomes
, and the degrees of freedom for SSM becomes 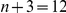 . Note that the scale of the phenotypes is arbitrary, as a change in the phenotype scale can be absorbed by a change in the gamma scale parameter.
. Note that the scale of the phenotypes is arbitrary, as a change in the phenotype scale can be absorbed by a change in the gamma scale parameter.
Minimization algorithm
The minimization problem given by equation (2) is an 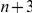 dimensional problem, where
dimensional problem, where  is the number of single mutations. We used the following algorithm to solve this problem.
is the number of single mutations. We used the following algorithm to solve this problem.
Begin with an initial guess for
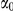 ,
, 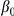 , and
, and 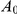 .
.For each fitness value
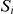 for the single mutants, solve for the two possible phenotypes
for the single mutants, solve for the two possible phenotypes 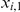 and
and 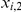 using
using 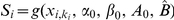 , where
, where 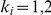 . The two possible phenotypes for each single mutant represent the points of equal fitness on either side of the peak in the hypothesized phenotype-fitness map.
. The two possible phenotypes for each single mutant represent the points of equal fitness on either side of the peak in the hypothesized phenotype-fitness map.- For each single mutation, a pair of possible phenotypes is denoted by the array
For each single mutant, choose one phenotype from each column to form a row of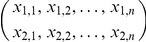
 phenotypes. Denote the set of all row vectors by
phenotypes. Denote the set of all row vectors by 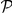 . Among all arrays of phenotypes in
. Among all arrays of phenotypes in 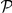 , choose the one that minimizes the fitness effects of the doubles.
, choose the one that minimizes the fitness effects of the doubles.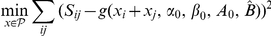
- Denote the phenotypes solved for in steps 2 and 3 by
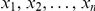 . Fix the phenotypic values and minimize
. Fix the phenotypic values and minimize
The solution can be used as input in step 1. The whole process can then be iterated until the solved values of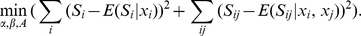
 ,
, 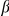 , and
, and 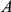 no longer change.
no longer change.
Model comparisons
To compare the gamma model to the model of Martin et al. [40], we simulated the expected distributions of the deviations from additivity (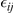 in our notation) under the two models. Parameter values were selected such that the two models yielded the same distributions for single beneficial mutations. For both models, we assumed the distribution of fitness effects followed the generalized Pareto distribution (GPD) with shape parameter
in our notation) under the two models. Parameter values were selected such that the two models yielded the same distributions for single beneficial mutations. For both models, we assumed the distribution of fitness effects followed the generalized Pareto distribution (GPD) with shape parameter 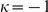 as estimated previously for the single mutations [47], [51]. The GPD with
as estimated previously for the single mutations [47], [51]. The GPD with 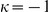 corresponds to a uniform distribution. We used the maximum observed fitness of the single mutations as our estimate for the upper bound and used the smallest observed fitness for a beneficial mutation as the lower bound.
corresponds to a uniform distribution. We used the maximum observed fitness of the single mutations as our estimate for the upper bound and used the smallest observed fitness for a beneficial mutation as the lower bound.
To simulate 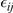 's under the gamma model, we chose nine fitness effects from the uniform distribution and mapped them to phenotypes using the inverse of the fitted gamma function. Each fitness value could be mapped to either side of the optimum; we selected the side at random. We assumed additivity of the phenotypes and generated the phenotypes of 18 double mutants. Double mutants were selected to match the pattern in our empirical data. Fitness was calculated for each on the basis of the gamma curve with normal error added from the estimated error. Deviations from addivity were calculated as described above. We generated 1,000 replicate data sets. This model requires imputation of nine phenotypes and estimation of four gamma parameters and the error parameter.
's under the gamma model, we chose nine fitness effects from the uniform distribution and mapped them to phenotypes using the inverse of the fitted gamma function. Each fitness value could be mapped to either side of the optimum; we selected the side at random. We assumed additivity of the phenotypes and generated the phenotypes of 18 double mutants. Double mutants were selected to match the pattern in our empirical data. Fitness was calculated for each on the basis of the gamma curve with normal error added from the estimated error. Deviations from addivity were calculated as described above. We generated 1,000 replicate data sets. This model requires imputation of nine phenotypes and estimation of four gamma parameters and the error parameter.
To simulate 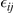 's under the model of Martin et al. [40], we noted that Fisher's geometrical model predicts a GPD distribution of beneficial fitness effects with
's under the model of Martin et al. [40], we noted that Fisher's geometrical model predicts a GPD distribution of beneficial fitness effects with 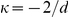 , where
, where 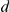 is the number of phenotypic dimensions [52]. Therefore, the number of dimensions for our data is
is the number of phenotypic dimensions [52]. Therefore, the number of dimensions for our data is 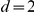 . We used the same upper and lower bounds on fitness as for the gamma model and a two-dimensional geometrical model with a Gaussian phenotype-fitness map. The wild type was assumed to be one phenotypic unit from the optimum. Given phenotype values
. We used the same upper and lower bounds on fitness as for the gamma model and a two-dimensional geometrical model with a Gaussian phenotype-fitness map. The wild type was assumed to be one phenotypic unit from the optimum. Given phenotype values  and
and 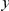 , the fitness function is
, the fitness function is
where 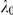 is the fitness of the wild type, and
is the fitness of the wild type, and 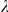 is the difference between the maximum fitness and the wild-type fitness. This form was selected to satisfy several constraints. We wanted
is the difference between the maximum fitness and the wild-type fitness. This form was selected to satisfy several constraints. We wanted 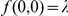 and, for simplicity,
and, for simplicity, 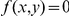 when
when 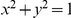 . The final constraint shifted the floor of the function to
. The final constraint shifted the floor of the function to 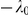 ; the location of this floor was not found to affect the results significantly. To generate our distribution of deviations from additivity, we simulated nine phenotypes at random within the circle defined by the fitness of the smallest-effect mutation, created 18 double mutants by vector addition, and mapped the single and double mutants to fitness to calculate the deviations from additivity. Double mutants were selected to match the pattern in our empirical data. We simulated 1,000 replicate data sets. This model requires the estimation of two parameters.
; the location of this floor was not found to affect the results significantly. To generate our distribution of deviations from additivity, we simulated nine phenotypes at random within the circle defined by the fitness of the smallest-effect mutation, created 18 double mutants by vector addition, and mapped the single and double mutants to fitness to calculate the deviations from additivity. Double mutants were selected to match the pattern in our empirical data. We simulated 1,000 replicate data sets. This model requires the estimation of two parameters.
To compare the fit of the two models, we calculated AIC scores for each model, where 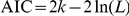 . The number of parameters for the gamma model is
. The number of parameters for the gamma model is  and
and  for the model of Martin et al. We approximated likelihoods (
for the model of Martin et al. We approximated likelihoods (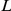 ) from the histogram densities.
) from the histogram densities.
Acknowledgments
The authors thank M. Wingerson for laboratory assistance and J. J. Bull for advice during the development and execution of this project.
Footnotes
The authors have declared that no competing interests exist.
This research was funded by Florida State University and the following grants: NIH R01 GM076040 and P20-RR016448 (http://www.nih.gov/). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.Otto SP, Feldman MW. Deleterious mutations, variable epistatic interactions, and the evolution of recombination. Theor Pop Biol. 1997;51:134–147. doi: 10.1006/tpbi.1997.1301. [DOI] [PubMed] [Google Scholar]
- 2.Otto SP. The evolutionary enigma of sex. Am Nat. 2009;174:S1–S14. doi: 10.1086/599084. [DOI] [PubMed] [Google Scholar]
- 3.Dobzhansky T. Studies on hybrid sterility. II. Localization of sterility factors in Drosophila pseudoobscura hybrids. Genetics. 1936;21:113–135. doi: 10.1093/genetics/21.2.113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Muller HJ. Reversibility in evolution considered from the standpoint of genetics. Biol Rev Cambridge Phil Soc. 1939;14:261–280. [Google Scholar]
- 5.Coyne JA, Orr HA. Speciation. Sunderland (MA): Sinauer Associates; 2004. [Google Scholar]
- 6.Orr HA. The population genetics of speciation: the evolution of hybrid incompatibilities. Genetics. 1995;139:1805–1813. doi: 10.1093/genetics/139.4.1805. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Kauffman S, Levin S. Towards a general theory of adaptive walks on rugged landscapes. J Theor Biol. 1987;128:11–45. doi: 10.1016/s0022-5193(87)80029-2. [DOI] [PubMed] [Google Scholar]
- 8.Kauffman SA. The origins of order. New York (NY): Oxford University Press; 1993. [Google Scholar]
- 9.Weinreich DM, Watson RA, Chao L. Sign epistasis and genetic constraint on evolutionary trajectories. Evolution. 2005;59:1165–1174. [PubMed] [Google Scholar]
- 10.Orr HA. The population genetics of adaptation on correlated fitness landscapes: the block model. Evolution. 2006;60:1113–1124. [PubMed] [Google Scholar]
- 11.Perelson AS, Macken CA. Protein evolution on partially correlated landscapes. Proc Natl Acad Sci U S A. 1995;92:9657–9661. doi: 10.1073/pnas.92.21.9657. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Rokyta D, Badgett MR, Molineux IJ, Bull JJ. Experimental genomic evolution: extensive compensation for loss of DNA ligase activity in a virus. Mol Biol Evol. 2002;19:230–238. doi: 10.1093/oxfordjournals.molbev.a004076. [DOI] [PubMed] [Google Scholar]
- 13.Bull JJ, Badgett MR, Rokyta D, Molineux IJ. Experimental evolution yields hundreds of mutations in a functional viral genome. J Mol Evol. 2003;57:241–248. doi: 10.1007/s00239-003-2470-1. [DOI] [PubMed] [Google Scholar]
- 14.Poon A, Chao L. The rate of compensatory mutation in the DNA bacteriophage φX174. Genetics. 2005;170:989–999. doi: 10.1534/genetics.104.039438. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Poon A, Davis BH, Chao L. The coupon collector and the suppressor mutation: estimating the number of compensatory mutations by maximum likelihood. Genetics. 2005;170:1323–1332. doi: 10.1534/genetics.104.037259. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Kulathinal RJ, Bettencourt BR, Hartl DL. Compensated deleterious mutations in insect genomes. Science. 2004;306:1553–1554. doi: 10.1126/science.1100522. [DOI] [PubMed] [Google Scholar]
- 17.Kondrashov AS, Sunyaev S, Kondrashov FA. Dobzhansky-Muller incompatibilities in protein evolution. Proc Natl Acad Sci U S A. 2002;99:14878–14883. doi: 10.1073/pnas.232565499. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Elena SF, Lenski RE. Test of synergistic interactions among deleterious mutations in bacte- ria. Nature. 1997;390:395–398. doi: 10.1038/37108. [DOI] [PubMed] [Google Scholar]
- 19.Trindade S, Sousa A, Xavier KB, Dionisio F, Ferreira MG, et al. Positive epistasis drives the acquisition of multidrug resistance. PLoS Genet. 2009;5:e1000578. doi: 10.1371/journal.pgen.1000578. doi: 10.1371/journal.pgen.1000578. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Bonhoeffer S, Chappey C, Parkin NT, Whitcomb JM, Petropoulos CJ. Evidence for positive epistasis in HIV-1. Science. 2004;306:1547–1550. doi: 10.1126/science.1101786. [DOI] [PubMed] [Google Scholar]
- 21.Burch CL, Chao L. Epistasis and its relationship to canalization in the RNA virus φ6. Genetics. 2004;167:559–567. doi: 10.1534/genetics.103.021196. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Sanjuán R, Moya A, Elena SF. The contribution of epistasis to the architecture of fitness in an RNA virus. Proc Natl Acad Sci U S A. 2004;101:15376–15379. doi: 10.1073/pnas.0404125101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Pepin KM, Wichman HA. Variable epistatic effects between mutations at host recognition sites in φX174 bacteriophage. Evolution. 2007;61:1710–1724. doi: 10.1111/j.1558-5646.2007.00143.x. [DOI] [PubMed] [Google Scholar]
- 24.Sanjuán R. Quantifying antagonistic epistasis in a multifunctional RNA secondary structure of the Rous sarcoma virus. J Gen Virol. 2006;87:1595–1602. doi: 10.1099/vir.0.81585-0. [DOI] [PubMed] [Google Scholar]
- 25.Sanjuán R, Elena SF. Epistasis correlates to genomic complexity. Proc Natl Acad Sci U S A. 2006;103:14402–14405. doi: 10.1073/pnas.0604543103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Lunzer M, Miller SP, Felsheim R, Dean AM. The biochemical architecture of an ancient adaptive landscape. Science. 2005;310:499–501. doi: 10.1126/science.1115649. [DOI] [PubMed] [Google Scholar]
- 27.Weinreich DM, Delaney NF, DePristo MA, Hartl DL. Darwinian evolution can follow only very few mutational paths to fitter proteins. Science. 2006;312:111–114. doi: 10.1126/science.1123539. [DOI] [PubMed] [Google Scholar]
- 28.Lozovsky ER, Chookajorn T, Brown KM, Imwong M, Shaw PJ, et al. Stepwise acquisition of pyrimethamine resistance in the malaria parasite. Proc Natl Acad Sci U S A. 2009;106:12025–12030. doi: 10.1073/pnas.0905922106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Gerrish PJ, Lenski RE. The fate of competing beneficial mutations in an asexual population. Genetica 102/ 1998;103:127–144. [PubMed] [Google Scholar]
- 30.Kim Y, Orr HA. Adaptation in sexuals vs. asexuals: clonal interference and the Fisher-Muller model. Genetics. 2005;171:1377–1386. doi: 10.1534/genetics.105.045252. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Park SC, Krug J. Clonal interference in large populations. Proc Natl Acad Sci U S A. 2007;104:18135–18140. doi: 10.1073/pnas.0705778104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Bollback JP, Huelsenbeck JP. Clonal interference is alleviated by high mutation rates in large populations. Mol Biol Evol. 2007;24:1397–1406. doi: 10.1093/molbev/msm056. [DOI] [PubMed] [Google Scholar]
- 33.Pepin KM, Wichman HA. Experimental evolution and genome sequencing reveal variation in levels of clonal interference in large populations of bacteriophage φX174. BMC Evol Biol. 2008;8:85. doi: 10.1186/1471-2148-8-85. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Kao KC, Sherlock G. Molecular characterization of clonal interference during adaptive evolution in asexual populations of Saccharomyces cerevisiae. Nat Genet. 2008;40:1499–1504. doi: 10.1038/ng.280. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Fogle CA, Nagle JL, Desai MM. Clonal interference, multiple mutations and adaptation in large asexual populations. Genetics. 2008;180:2163–2173. doi: 10.1534/genetics.108.090019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Wilke CO. The speed of adaptation in large asexual populations. Genetics. 2004;167:2045–2053. doi: 10.1534/genetics.104.027136. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Rouzine IM, Brunet É, Wilke CO. The traveling-wave approach to asexual evolution: Muller's ratchet and speed of adaptation. Theor Pop Biol. 2008;73:24–46. doi: 10.1016/j.tpb.2007.10.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Desai MM, Fisher DS. Beneficial mutation-selection balance and the effect of linkage on positive selection. Genetics. 2007;176:1759–1798. doi: 10.1534/genetics.106.067678. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Rokyta DR, Joyce P, Caudle SB, Wichman HA. An empirical test of the mutational landscape model of adaptation using a single-stranded DNA virus. Nat Genet. 2005;37:441–444. doi: 10.1038/ng1535. [DOI] [PubMed] [Google Scholar]
- 40.Martin G, Elena SF, Lenormand T. Distributions of epistasis in microbes fit predictions from a fitness landscape model. Nat Genet. 2007;39:555–560. doi: 10.1038/ng1998. [DOI] [PubMed] [Google Scholar]
- 41.Fisher RA. The genetical theory of natural selection. Oxford (UK): Oxford University Press; 1930. [Google Scholar]
- 42.Gillespie JH. Molecular evolution over the mutational landscape. Evolution. 1984;38:1116–1129. doi: 10.1111/j.1558-5646.1984.tb00380.x. [DOI] [PubMed] [Google Scholar]
- 43.Gillespie JH. The causes of molecular evolution. New York: Oxford University Press; 1991. [Google Scholar]
- 44.Orr HA. The population genetics of adaptation: the adaptation of DNA sequences. Evolution. 2002;56:1317–1330. doi: 10.1111/j.0014-3820.2002.tb01446.x. [DOI] [PubMed] [Google Scholar]
- 45.Rokyta DR, Beisel CJ, Joyce P. Properties of adaptive walks on uncorrelated landscapes under strong selection and weak mutation. J Theor Biol. 2006;243:114–120. doi: 10.1016/j.jtbi.2006.06.008. [DOI] [PubMed] [Google Scholar]
- 46.DePristo MA, Weinreich DM, Hartl DL. Missense meanderings in sequence space: a biophysical view of protein evolution. Nat Rev Genet. 2005;6:678–687. doi: 10.1038/nrg1672. [DOI] [PubMed] [Google Scholar]
- 47.Rokyta DR, Beisel CJ, Joyce P, Ferris MT, Burch CL, et al. Beneficial fitness effects are not exponential for two viruses. J Mol Evol. 2008;67:368–376. doi: 10.1007/s00239-008-9153-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Rokyta DR, Burch CL, Caudle SB, Wichman HA. Horizontal gene transfer and the evolution of microvirid coliphage genomes. J Bacteriol. 2006;188:1134–1142. doi: 10.1128/JB.188.3.1134-1142.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Pepin KM, Samuel MA, Wichman HA. Variable pleiotropic effects from mutations at the same locus hamper prediction of fitness from a fitness component. Genetics. 2006;172:2047–2056. doi: 10.1534/genetics.105.049817. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.R Development Core Team. R: A Language and Environment for Statistical Computing. 2006. R Foundation for Statistical Computing, Vienna (Austria). URL http://www.R-project.org.
- 51.Beisel CJ, Rokyta DR, Wichman HA, Joyce P. Testing the extreme value domain of attraction for distributions of beneficial fitness effects. Genetics. 2007;176:2441–2449. doi: 10.1534/genetics.106.068585. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Martin G, Lenormand T. The distribution of beneficial and fixed mutation fitness effects close to an optimum. Genetics. 2008;179:907–916. doi: 10.1534/genetics.108.087122. [DOI] [PMC free article] [PubMed] [Google Scholar]