

Abstract
Although reinforcement learning (RL) theories have been influential in characterizing the mechanisms for reward-guided choice in the brain, the predominant temporal difference (TD) algorithm cannot explain many flexible or goal-directed actions that have been demonstrated behaviorally. We investigate such actions by contrasting an RL algorithm that is model based, in that it relies on learning a map or model of the task and planning within it, to traditional model-free TD learning. To distinguish these approaches in humans, we used functional magnetic resonance imaging in a continuous spatial navigation task, in which frequent changes to the layout of the maze forced subjects continually to relearn their favored routes, thereby exposing the RL mechanisms used. We sought evidence for the neural substrates of such mechanisms by comparing choice behavior and blood oxygen level-dependent (BOLD) signals to decision variables extracted from simulations of either algorithm. Both choices and value-related BOLD signals in striatum, although most often associated with TD learning, were better explained by the model-based theory. Furthermore, predecessor quantities for the model-based value computation were correlated with BOLD signals in the medial temporal lobe and frontal cortex. These results point to a significant extension of both the computational and anatomical substrates for RL in the brain.
Introduction
Using past experience to guide future decisions is critical for survival, but a long-standing question is how the brain represents this experience. A predominant theory is temporal difference (TD) reinforcement learning (RL), which learns from reinforcement the future reward value expected after an action (Sutton, 1988; Sutton and Barto, 1998). Much evidence links such learning to spiking and blood oxygen level-dependent (BOLD) signals in the nigrostriatal dopamine system (Houk et al., 1994; Schultz et al., 1997; Berns et al., 2001; O'Doherty et al., 2002; Pagnoni et al., 2002).
However, such mechanisms, which rely on repeating successful actions (Thorndike, 1911), cannot explain flexible or novel action planning seen in tasks such as latent learning or reinforcer devaluation (Tolman, 1948; Balleine and Dickinson, 1998). There are many suggestions of such sophistication across species (Maguire et al., 1998; Hampton et al., 2006; Pan et al., 2007), notably lesion results in rodent conditioning (Balleine et al., 2008) and navigation (Packard and McGaugh, 1996), suggesting that it might coexist in the brain with simpler reinforcement mechanisms. Such behaviors are envisioned to arise from considering the future consequences of an action, drawing on a learned cognitive map or model of the environment (Thistlethwaite, 1951; Gallistel and Cramer, 1996). One candidate computational formalization of these processes is model-based RL (Doya, 1999; Daw et al., 2005; Johnson et al., 2007), which constructs the values of possible action trajectories indirectly by simulating a learned model of the environment. This planning process contrasts with model-free TD algorithms, which learn future values directly.
However, although there has been much work quantitatively investigating TD characterizations of learning (O'Doherty et al., 2003, 2006; Lee et al., 2004; Seymour et al., 2004), much less research has analogously investigated the neural and computational substrates for model-based learning and planning. One promising domain for such an investigation is spatial navigation, which sparked early cognitive map work (Tolman, 1948) and in which a distinction has been made between deliberate “place” learning and habitual “response” behaviors (Blodgett and McCutchan, 1947) that may parallel the model-based versus TD distinction.
We thus used functional magnetic resonance imaging (fMRI) to investigate the neural substrates for model-based learning and planning in humans navigating a virtual maze for money. This task had two key features that we expected would encourage a model-based strategy: first, the basic structure of a spatial model is known a priori and need not have been learned during the task; second, ongoing reconfiguration of the maze promoted continuous learning and on-line planning of new routes (Daw et al., 2005). These dynamic reconfigurations also generated discrepancies between hypothesized model-based and model-free update mechanisms, allowing us to distinguish these strategies over many trials and verify our hypothesis that behavior and value-related BOLD signals were driven by model-based rather than TD mechanisms. Having done so, we used this computational characterization of the learning to begin to map the network supporting model-based values, much as has been done for TD, by seeking neural correlates of learning about the more elementary quantities from which model-based values are constructed.
Materials and Methods
Participants
Eighteen healthy, right-handed adults (10 females), 18–36 years of age, performed the task for payment while undergoing functional magnetic resonance imaging. All participants gave informed consent, and the study was approved by the New York University Committee on Activities Involving Human Subjects.
Task
Subjects navigated a virtual 4 × 4 grid of rooms (designated as states s ∈ 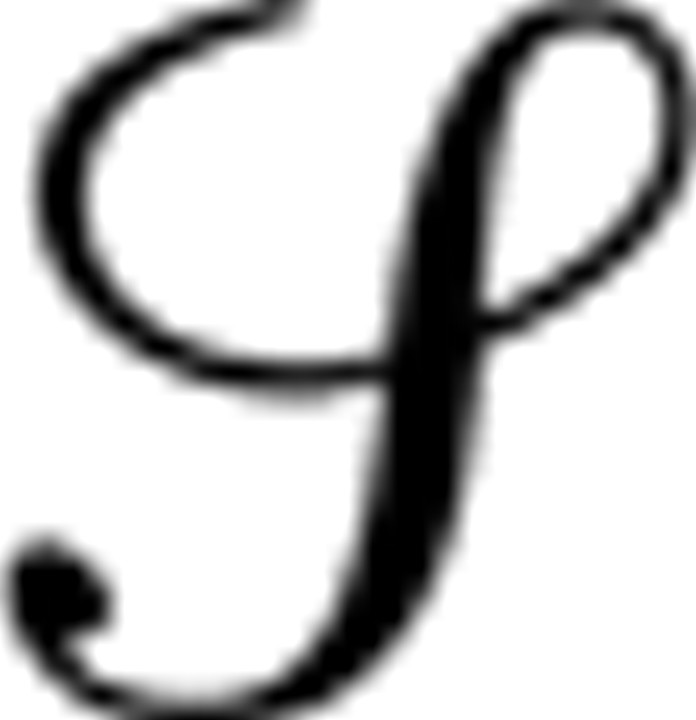 ) by making choices between the available rooms adjoining the current location (Fig. 1A). Subjects continuously viewed rendered images of a three-dimensional representation of these rooms with a first-person perspective from their current position. The display included boundary cues and distal direction cues so that subjects could identify their position within the grid, as well as any rooms ahead of them (within a 100° viewing angle). Each of the 24 pairs of adjoining rooms was connected by a one-way door, which at any time was available for use in exactly one direction between the rooms.
) by making choices between the available rooms adjoining the current location (Fig. 1A). Subjects continuously viewed rendered images of a three-dimensional representation of these rooms with a first-person perspective from their current position. The display included boundary cues and distal direction cues so that subjects could identify their position within the grid, as well as any rooms ahead of them (within a 100° viewing angle). Each of the 24 pairs of adjoining rooms was connected by a one-way door, which at any time was available for use in exactly one direction between the rooms.
Figure 1.

Task flow and example state. A, Subjects were cued to choose a direction by pressing a key. If the subject did not respond within 2 s, she lost a turn and was again presented with the same choice (no movement). Otherwise, an animation was shown moving to the room in the selected direction (or to a random room for randomly occurring jumps); this movement lasted 1.5–2 s, jittered uniformly. Then, the next room was presented, including the available transitions from that room and any received reward. Finally, after 0.5 s, the subject was cued to make the next decision. Only the doors in the current room were visible to the subject. B, A possible abstract layout of the task, where each square represents a room, and each arrow represents an available door direction the subject may choose from. The circles represent reward locations, where the subject would gain the indicated reward value each time the room was visited. At each step, each one-way door could flip direction independently with probability .
At each room, subjects chose between the available doors by pressing one of three keys with their right hand so as either to move forward or to turn 90° and move through the left or right door. It was not possible to backtrack (i.e., to exit a room via the door from which it was entered). We denote the cardinal directions of movement (N, E, S, W) as actions a ∈ 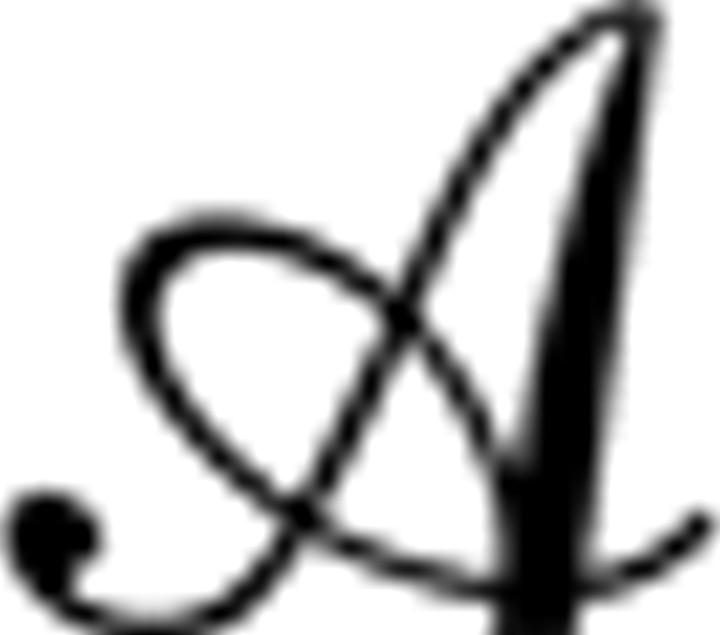 , where (because of one-way doors and the no-backtracking rule) on each particular trial, only a subset A ⊂ of one to three directions can be selected. Once an acceptable choice was made, subjects viewed an animation moving to the selected adjoining room. To encourage planning of new routes, with a 10% probability at each step, but no more often than every four steps, a “jump” occurred in which a new room was selected at random from all 16, and instead of arriving in their chosen room, subjects viewed an animation rising above the maze and dropping into the new location.
, where (because of one-way doors and the no-backtracking rule) on each particular trial, only a subset A ⊂ of one to three directions can be selected. Once an acceptable choice was made, subjects viewed an animation moving to the selected adjoining room. To encourage planning of new routes, with a 10% probability at each step, but no more often than every four steps, a “jump” occurred in which a new room was selected at random from all 16, and instead of arriving in their chosen room, subjects viewed an animation rising above the maze and dropping into the new location.
Four rooms were designated as reward rooms, each with a corresponding fixed reward value of 2 or 3 units, such that each time a reward room was visited the stated reward was received. The locations and values of these rooms were instructed to the subjects and also represented in the visual display by flags above the rooms, visible from a distance. At the end of the study, subjects were paid proportional to final reward count (at $0.04 per unit).
The critical dynamic element of the task, designed to drive learning, was ongoing, random reconfiguration of the available transitions between adjoining rooms (Fig. 1B). After each decision step, the doors between rooms could reverse their direction; this would happen independently at each door with probability . This change process was additionally subject to the constraint that each room would always have at least one available exit. Only the state of the doors leading to or from the current room was visible on any particular trial (represented with colored signs at each door, with those visible in other, distant rooms colored gray), so subjects did not know when changes in the doors occurred until they encountered them.
Subjects were fully instructed on the dynamics of the task, including specific instruction of the independence of the random processes associated with jumps and doors (supplemental Fig. 1, available at www.jneurosci.org as supplemental material). Before scanning, subjects trained and practiced the task for 10 min on a different layout than would be used for the main experiment (reward locations and door directions). After entering the MRI, they performed 25 trials to familiarize them with the scanner interface and reward locations, and then performed 1000 decision steps during functional image acquisition, with breaks every 250 steps.
Behavioral
We analyzed the sequences of subjects' choices (at) by comparing them step by step to those predicted by different learning algorithms modeled as having encountered the same state (st), action (at), reward (rt), and jump (jt) sequence up to each step. In particular, we compared different algorithms for evaluating actions, each formalized as a method for estimating an action value function (Q : × → ℝ) based on earlier observations (e.g., of rewards received and available doors). The action value function maps each potential action at time t to a predicted value sum of expected future rewards (r) for each available option, discounted for delay according to the free discount parameter γ as follows:
 |
where each algorithm specifies a particular method for estimating this expectation. For each algorithm, we assumed a softmax decision rule to produce a probability of a choice (p) given the predicted values of all the available choices as follows:
 |
where β is a free “temperature” parameter controlling the degree of randomness in action selection.
For each algorithm, we estimated the set of free parameters (θ, including γ and β), separately for each subject so as to minimize the negative log-likelihood of all observed choices (i.e., the sum over the log of Eq. 2, for the action chosen on each of n trials) as follows:
 |
To compare the quality of model fit correcting for the number of free parameters optimized, we estimated Bayes factors (Kass and Raftery, 1995), the ratio of the model evidences (i.e., the probabilities of the models given the data). To approximate the model evidence, we computed the Bayesian information criterion (BIC) (Schwarz, 1978) as follows:
 |
where l(θ̂) is the negative log-likelihood of data at the maximum-likelihood parameters, θ̂; m is the number of free parameters optimized; and n is the number of observations or (nontrivial) choices the subject made (note that BIC, as we define it, is ½ the standard definition, to put it in the same scale as likelihood and evidence measures; all statistical tests are corrected appropriately). As a standardized measure of model fit, we also report ρ2, a pseudo-r2 statistic which is analogous to a measure of variance accounted for and is computed as (Camerer and Ho, 1999; Daw et al., 2006). Also, allowing that the algorithm used might differ across subjects in the population as a random effect, we report statistical tests on the Bayes factors across subjects, along with the “exceedance probability” or posterior probability that one algorithm is the most common of a set across the population (Stephan et al., 2009), as computed using the spm_BMS function in SPM8.
To generate regressors reflecting predicted quantities from the models for fMRI analysis (below), we simulated the models for all subjects using a single set of parameters taken as the median of the best-fitting parameters over the individuals. The group median can be viewed as an estimator for the group-level parameters in a random-effects model of the population (Holmes and Friston, 1998). We took this approach because we have repeatedly observed, in this and other data sets (Daw et al., 2006; Gläscher et al., 2010), that neural regressors generated using separate maximum-likelihood estimates of the parameters produce poorer fMRI results (i.e., noisier neural effect size estimates and diminished sensitivity). This is likely because parameters are not always well identified at the individual level, and variability in the point estimates effectively results in noisy rescaling of regressors between subjects, which in turn suppresses population level significance in fMRI (for additional discussion, see Daw, 2011).
To compare subjects' performance in terms of payoffs earned, we determined two reference point payoffs for each subject: expected random payoff and maximum possible payoff. Expected random payoff was determined simply by calculating the expected state occupancy under a uniform random policy, and weighting the rewards by the expected occupancy of their location (note that this is slightly different than uniform occupancy because of the heterogeneous connectivity: more central rooms are more likely to be visited). The maximum possible payoff for a subject was defined as the largest payoff possible over all possible choice sequences for the particular sequence of door configurations that subject encountered. Note that actually taking advantage of such a policy would require the subject to be omniscient or “psychic” about all current and future unobservable door changes. Because perfect play using only the available information is computationally intractable because of the partially observable nature of the task, we neither determined nor compared this value, but it is guaranteed to be somewhere between the best average play from any of our formalized algorithms and psychic play.
The timing of the task was such that the choices were first allowed to be entered 500 ms after all the information relevant to that choice was presented (Fig. 1A). As such, the task was not well suited for analyzing reaction times (RTs), since subjects were presumably able to preplan their responses and time them to the appropriate moment. To examine reaction time effects given these limitations, we discarded all trials with reaction times <50 ms and analyzed the remainder using the same regressors as with fMRI (see below, Model-based analysis) as explanatory variables in linear regressions in which the dependent variable was taken as the log reaction time. Regression coefficients were computed per subject, and then tested across subjects to assess their significance as random effects (Holmes and Friston, 1998).
Algorithms
Although the task was simple to understand, an optimal solution is computationally intractable. This design allowed for a wide range of possible (suboptimal) strategies that could be used. Thus, in analyzing the behavioral data, we are faced with (and did explore) a wide variety of algorithms using different representations and learning methods based on both TD and planning processes.
The main questions of the study concern valuation by model-based planning. Such a strategy is categorically distinguished from more common “model-free” approaches to RL by two key features: the use of a model representing the environment, and on-line evaluation based on recently learned changes to this model. For specificity and efficiency, for the bulk of the analyses we report, we used a canonical model-based algorithm (value iteration) that exhibits these features. It is canonical in the sense of being derived directly from a formal definition of the decision problem (Sutton and Barto, 1998); it is also, in the particular details and approximations of this derivation, the best-fitting algorithm we discovered from the model-based class. To verify that behavior and BOLD signals are best explained by an approach of this sort, we compare its predictions to a canonical model-free algorithm (Q learning), which was also the best-fitting representative of that class we discovered. We additionally compare both algorithms (see supplemental material, available at www.jneurosci.org) to reduced or extended variants that isolate particular distinguishing features of the model-based and model-free approaches. However, these best-fitting models, by virtue of being derived from decision-theoretic definitions, are also computationally complex. Accordingly, we do not suggest that these algorithms are direct process-level accounts of the steps of computation, but rather that they are representative of the overall form of the relationships between experience, representation, and choices or BOLD activity. Additionally, as discussed further below, the quantities that these algorithms define also help us to examine some process-level questions.
In the following descriptions, we take as data the experience of each subject over steps, t: visited states, st ∈ ; rewards, rt ∈ ℕ; available actions, At ⊂ ; choices, at ∈ ; and jumps, jt ∈ {0, 1}. Each state–action pair (s, a) ∈ × represents one side of a particular door within the maze, where only valid doors are considered. We use the fixed transition function T : × → such that T(s, a) = s′ if behind the door (s, a) is the room s′ (regardless of whether it is currently open), along with the reward map R : → {0, 2, 3} to represent the fixed reward locations. We also use the symbol At to indicate the set of available outgoing doors from the room st at time t. For clarity, we thus have the following invariants:
 |
Planning.
Rather than estimating action values directly, a model-based approach learns a “model” of the structure of the task—here the current configuration of the maze—and computes action values by searching across possible future trajectories, accumulating the rewards in expectation according to the definition of these values (Eq. 1).
To learn the model, our implementation represents the subject's estimate of the direction of each one-way door as a probability of it being open, pt(s, a), which is updated when a door is observed, and also decayed at each step by a free factor η, to capture subjects' knowledge of the chance that doors may have changed since last observed, as well as any other processes by which observed door knowledge plays a declining role in valuation (e.g., forgetting or search pruning). The two sides of each door may be learned independently, even though this may create a model inconsistent with the one-way dynamics. The probabilities are initialized to 0.5 and updated at each step in which a set of open doors At is observed in room st, according to the following:
 |
The other part of the task model—the reward value for each room, R(s)—is assumed to be known. We believe this assumption to be innocuous, since this information was fixed, instructed, and signaled in the visual display.
Using the learned maze configuration, we compute state–action values based on a tree search planning process terminating at reward states. For computational efficiency (e.g., in fitting free parameters to choice data), we implemented this planning process using value iteration, which simply unrolls a breadth-first search tree over the states from leaves (horizon 1 values) to roots (end horizon values). Specifically, at each step, in room st, initialize all Q(s, a) ← 0 and, for all (s, a) pairs in parallel, repeatedly perform the following:
 |
We took Qplan(st, a) to be the value resulting after 16 iterations of this update.
Here, the sum takes an expectation over possible sets of open doors A′ in state s′ according to the current beliefs about the probability of each door being open individually, the no-backtracking constraint [here, that the door T(s′, a′) = s, from which s′ is entered, must be closed], and the constraint that at least one door must be open as follows:
 |
The algorithm thus has three free parameters: η, γ, β.
Although this algorithm is derived directly from the definition of action value from Equation 1, it does incorporate a number of simplifications or approximations, all of which accorded well with the data. First, we terminate each search path at reward. In terms of the definition of the decision variable, this is equivalent to treating the reward states as terminal in an episodic view of the problem (Sutton and Barto, 1998). Similarly, we terminate each search path if no reward has been found along it by a depth of 16. This is an innocuous assumption since the value of a reward converges to zero as its distance increases, given γ < 1 or η > 0. Sixteen steps is above the maximum distance between any two points in the maze and was well beyond the point at which relevant fit quantities changed meaningfully given the data (see supplemental Fig. 3, available at www.jneurosci.org as supplemental material). In terms of the model, the evaluation of the expectation treats the model as frozen throughout the iteration process (i.e., it does not take into account the effect of potential future observations and updates on the model as a full Bayesian/partially observable Markov decision process approach would do). Finally, and closely related to this, it approximates the expectation over maze configurations as a factored tree of states, by treating the probability of a particular door set being open as independent between states within each iteration and, for each state, also independent between each iteration of the value update. These last assumptions allowed the algorithm to execute in reasonable time.
Finally, at the process level, there are many different approaches to evaluating the multistep value expectation from Equation 1. For instance, it seems most plausible that subjects search forward from the current state (or perhaps backward from a goal state), rather than from all states in parallel as in value iteration. However, for the current state, the total value and also the intermediate values (nth horizon partial sums of each step) from value iteration correspond to those that would be computed at each step by a breadth-first search. Other search processes, such as depth first, visit the states in different order, and perhaps (e.g., because of stochastic pruning or early termination) only visit a subset of them on any particular trial. However, since a very wide family of such approaches can be viewed as different ways of evaluating the expectation defined by Equation 1, their end values should coincide either exactly or (particularly in the average over trials) approximately with those we compute here. For instance, the end values we compute correspond, in the average, to those that would be computed if discounting is eliminated but paths are instead terminated stochastically with probability γ; or to values accumulated over a trajectory where door traversals are not weighted according to pt but instead sampled with this probability (for related models, see Sutton and Pinette, 1985; Suri and Schultz, 2001; Smith et al., 2004).
TD.
We use a model-free Q-learning algorithm (Watkins, 1989), augmented with eligibility traces. Such an algorithm maintains a representation of the state–action value function Q directly and updates it locally after experience with particular state–action pairs and rewards. The inclusion of eligibility traces, for λ > 0, allows the algorithm to update the values for states and actions other than the pair most recently observed, but only backward along the recently encountered trajectory. In this implementation (unlike that of Watkins), eligibility traces are truncated on “jump” events but not for exploratory actions.
The model has five free parameters: Q0, α, γ, λ, β. Specifically, each door within the maze, (s, a), is associated with a value, Qt(s, a), all initially set to Q0. Each also has an associated trace et(s, a), all initially 0. At each step, if door at is chosen in room st, arriving in room st+1 (either via a jump, jt = 1, or not, jt = 0) with reward rt+1 = R(st+1), the variables are updated according to the following:
 |
QTD(s, a) is simply the learned value function Qt(s, a).
Imaging
Functional imaging was performed on a 3T Siemens Allegra head-only scanner with a custom head coil (NM-011; Nova Medical) located at the Center for Brain Imaging at New York University. Thirty-three contiguous oblique-axial echo-planar images (3 × 3 × 3 mm voxels) were obtained each 2000 ms repetition time (TR), oriented 23° off the anterior commissure–posterior commissure axis so as to improve functional sensitivity in orbital frontal areas (Deichmann et al., 2003). Slices were positioned to obtain full coverage from the base of the orbitofrontal cortex and medial temporal lobes ventrally; coverage extended dorsally/caudally into the superior parietal lobule and above the dorsal anterior cingulate cortex but omitted some occipital and parietal regions, and in a few cases, some posterior-superior frontal regions. A high-resolution T1-weighted anatomical image (magnetization-prepared rapid-acquisition gradient echo sequence, 1 × 1 × 1 mm) was also acquired for each subject.
Images were preprocessed and analyzed using the SPM5 software (Wellcome Department of Cognitive Neurology, London, UK), and final results were corrected for multiple comparisons using SPM8 (Wellcome Trust Centre for Neuroimaging, London, UK). Functional images were realigned for head motion, coregistered between runs and to the structural image, spatially normalized to Montreal Neurological Institute coordinates (SPM5 “segment and normalize”), and finally resampled to 2 × 2 × 2 mm voxels and smoothed with an 8 mm full width at half-maximum Gaussian kernel. Because of the short TR, interleaved acquisition, and fast events, we did not additionally resample temporally to correct for slice timing.
Neural models were analyzed using general linear models to obtain single-subject β images. Regressors were convolved with the canonical hemodynamic response function in SPM5. To control for nuisance effects, all designs included the following: the six rigid-body motion parameters that were inferred by realignment; four event regressors covering times in which the subject was viewing animations of left turns, right turns, forward movement, and jump movement, respectively; and a “no-choice” impulse event regressor at the time of choices in which the choice set size was one.
Separate coefficients were computed for each regressor for each of the four runs, and contrasts were computed by adding up these coefficients. Contrast values were then brought to the group level using one- or paired-sample t tests for random effects. Unless otherwise noted, we produced whole-brain effect maps using a p < 0.001 uncorrected threshold, and then assessed significance correcting for whole-brain multiple comparisons using topological cluster-size false discovery rate (FDR), p < 0.05, as implemented in SPM8. [Note that cluster-level FDR is distinct from voxelwise FDR, which has recently been argued to be invalid (Chumbley and Friston, 2009).] Accordingly, reported peak t values are uncorrected, and significance is in relation to the containing cluster. SPMs have been displayed graphically by including all uncorrected activations, with clusters that did not reach significance, where assessed, depicted in a lighter, translucent color.
Model-based analysis
Each general linear model (GLM) included an event regressor containing an impulse at each choice (response) time, along with some number of parametric regressors on these events, depending on the particular computational algorithm being analyzed. These regressors were mean-corrected separately within choice and no-choice trials (according to the corresponding nuisance regressor), but, except where stated, when multiple parametric regressors were entered in a design, these were not orthogonalized against one another. Parametric regressors were derived from the sequence of predicted values or other latent variables produced by each algorithm, according to the learning algorithm exposed to the subject's actual experience up to the current trial. Because we were interested in many different, often highly correlated, properties of the neural signals, such as different deconstructions of the value signal, we ran separate GLMs to ask different questions, primarily focusing on distinct brain regions.
In order initially and qualitatively to identify basic activation patterns related to the predictions of either algorithm separately (which are correlated), the first two analyses entered the predicted Q(s, a) values for the current state and chosen action (from Eqs. 9 and 7) as parametric regressors, with GLM1 containing only QTD and GLM2 only Qplan. (We refer to these as the “chosen values.”) To identify peak value-responsive voxels in an unbiased manner, and to directly compare the fit of these regressors, GLM3 contained both of these values as separate regressors, and a contrast summing the coefficients from both was used on the second level. Confining the analysis to an anatomically defined striatal region of interest (ROI) (Maldjian et al., 2003)—which was of specific interest because it is often associated with TD (O'Doherty et al., 2006; Lohrenz et al., 2007)—we found all peak (locally maximally responsive) value voxels from GLM3 in caudate and putamen that exceeded a p < 0.001 uncorrected threshold and defined these as our voxels of interest (VOIs). To then compare between these two predictions with an independent test, the orthogonal contrast,a taking the difference between the planning and TD coefficients, was used on these VOIs.
In order further to decompose and explore differences between the predicted value signals of the algorithms, we performed additional analyses using a series representing the chosen values Q(s, a), as they would be computed either by the TD or planning algorithms. Both algorithms can be viewed as representing cues as exponentially decaying sums of terms, either of expected rewards (for planning), or of prediction errors previously encountered at a state (for TD). Since the GLM is additive, we can use separate regressors to express the BOLD signal by their weighted sum, and estimate the relative weights.
For planning, the state–action values are explicitly computed as a sum of exponentially discounted expected rewards expected at each future step (from Eq. 1) as follows:
 |
Here, the expectation is as in Equation 7 and simply unrolls the independent reward terms from that computation. When making predictions from a forward breadth-first search, this is exactly how the values are computed: by considering reward at the next step, then potential rewards at the subsequent step, and so on. [Other types of search (e.g., depth first) do not visit the states in the same order, but insofar as they compute the same end values they may still be decomposed this way.]
For the TD algorithm, the rewards expected at individual states are never explicitly represented, but instead values are produced (i.e., learned through the action of the learning rule) by accumulating them over time with each prediction error update, weighted by the learning rate. That is, we can unroll the effects of the iterated updates in Equation 9 in a form similar to Equation 1, expressing the learned value at a particular time as the exponentially weighted sum of previous prediction errors. For λ = 0, this sum is over the prediction errors encountered on previous state–action pair choices as follows:
 |
where u→(st, at) is the sequence of times at which that action was chosen in that state before time t, so that u0(st, at) = t, u1(st, at) is the time of the first such preceding visit, and so on. When λ > 0 (as in our behavioral fits), a state–action is updated not only after visits to it, but also by prediction errors subsequently encountered at other states, weighted by the decaying eligibility trace. We can modify Equation 11 to account for this effect by taking the terms δ in the sum to be themselves accumulated series of single-step prediction errors encountered subsequently to the state visit as follows:
 |
Here, k ranges up until whichever is first: ui(st, at) + k = t − 1 (the present) or jui(st, at)+k+1 = 1 (the first subsequent jump) at which point eligibility is cleared.
For both algorithms, if the BOLD signal is representing the corresponding value, it should reflect the sum of all these terms, with the appropriate coefficients: the sums essentially unroll the computation or learning of the values as predicted by either algorithm. To investigate these predictions, we created two more designs that decompose the two chosen values using the first two terms of either sum. (Since the weights are exponentially decaying, the earliest terms should dominate.) GLM4 included parametric regressors for δu1(st,at) and δu2(st,at) from the TD algorithm, and GLM5 included E[R(st+1)] and E[R(st+2)] from planning (referred to as δ1, δ2, r1, and r2, respectively). For comparison, we also inferred what the expected coefficients from this analysis would be based on the Q coefficients from GLM1 and GLM2 and the (behaviorally fit) values of γ and α. These two GLMs were initially applied only to the identified VOIs. This analysis is similar to a number of techniques used to analyze neural data in terms of value subcomponents (Bayer and Glimcher, 2005; Montague et al., 2006; Samejima and Doya, 2008).
We additionally used GLM5 to seek areas better correlated with only the expected next reward r1, viewed here as an intermediate quantity in the value computation as opposed to a portion of the full value. (As noted, r1 is indeed the first partial sum computed during a breadth-first search; for another approach like depth-first, it might be viewed as the expectation over trials of the value of the first state visited.) We thus sought activity related specifically to r1 rather than the cumulative future reward Q ≈ r1 + γr2, using the contrast . (Note that this contrast equates the length of the two contrast vectors to avoid confounding the test of the direction of the neural effect.)
Next, in looking for effects related to the iterative computation of future values, we first considered the total number of choices available from the current state, n0. This information is clearly relevant for any decision-making system that considers all the options, and in particular, an algorithm that searches forward through possible routes will have this many starting points. We then considered the next-step expectation of this quantity: the expected number of total choices in all reachable rooms given the model of the doors specified by the best-fitting planning algorithm, using the behaviorally fit value for η and the subject's observations up to the current point as follows:
 |
where the conditional expectation is the same as in Equation 7. Although the normative planning algorithm as we actually implement it examines all state–action–state pairs regardless of how likely it is that a door exists, a more realistic process-level search implementation would likely “prune” or examine the most likely transitions, thus requiring expected computation proportional to n1. We constructed GLM6 with a regressor for n0 and a regressor for n1 orthogonalized against the n0 regressor.b We also included a regressor of no interest containing reaction time for each trial, against which the other two regressors were orthogonalized. We then identified all voxels significantly responsive to n0 (p < 0.05 cluster-size FDR on p < 0.001) and used this as a mask to identify regions responsive to n1 using p < 0.001 and assessing significance with small-volume familywise error (FWE) correction. Unfortunately, because of our slice prescription, three subjects ended up with reduced coverage of superior frontal regions, resulting in these areas being masked out of our analysis because of missing data. Thus, to study the extent of activity identified in premotor regions, these 3 subjects were left out, and the GLM6 analysis repeated using the remaining 15 subjects.
Finally, to investigate whether obtained results were specifically related to model-based planning processes, we studied how neural effects covaried with the degree to which the planning or TD models fit their data (measured by the per-subject log-likelihood of the choice data under either model, or the difference between the two). In particular, we selected the per-subject β values from the peaks of the relevant contrast and correlated these with the log-likelihood measures from the per-subject behavioral fits, assessing one-tailed significance for the correlation coefficient. Since the contrasts used to define the peak voxels are main effects over all subjects, and since, furthermore, they are extrema of contrasts unrelated to the likelihood measures, the resulting correlations will be unbiased and not subject to corrections for the whole-brain multiple comparisons involved in seeking the peak voxel.
Results
Behavioral
On average over 1000 steps, subjects earned $23.78 ± $1.91 (mean ± 1 SD). These earnings exceeded what would have been expected under chance performance by 12.5 ± 8.8% on average, which was significantly different from zero across subjects (t = 6.82) and numerically greater than zero for 16 of 18 subjects individually. Although it is computationally intractable to define the earnings of an optimal decision maker in this task, an upper bound on this quantity is the earnings of a psychic subject who was fully informed about the maze state at each step, and behaved optimally according to this knowledge. On average, earnings were 10.4 ± 5.4% worse than this benchmark. Together, these results suggest that subjects were reasonably successful at harvesting rewards.
Learning models
We attempted to characterize subjects' learning—that is, how their choices depended on previous feedback—by fitting two alternative algorithms to explain their trial-by-trial choices. These exemplify two representational strategies for reinforcement learning: a model-based planning approach, which learns a representation of the maze layout and evaluates actions using it, and a model-free TD approach that learns estimates of the values of actions directly and locally. These approaches have been argued to formalize a long-standing distinction in psychology between response-based approaches and more cognitive, map-based or goal-directed approaches (Doya, 1999; Dickinson and Balleine, 2002; Valentin et al., 2007; Gläscher et al., 2010). We hypothesized that the task would favor a model-based strategy instead of the model-free strategy quantified in many previous fMRI studies of decision making (Daw et al., 2005), allowing us to examine the neural implementation of such learning. In this task, the ongoing maze reconfigurations play a similar role to an outcome revaluation manipulation (Balleine and Dickinson, 1998), allowing the strategies to be distinguished by their distinct predictions about how behavior should adjust after observed changes. In particular, although the strategies are related in that they are pursuing the same ends, they make different trial-by-trial predictions about choices because they draw on past experience to evaluate options using different strategies and representations. Notably, the TD approach updates the predicted values of actions only locally after they are encountered (via a so-called bootstrapping process in which value estimates are updated based on adjacent ones), whereas a model-based approach incorporates all learned information into a map of the environment resulting in a global update of the derived action value estimates. This delay in the propagation of learning in a TD model predicts that choices should sometimes not respect recently learned information (Daw et al., 2005).
We fit each subject's trial-by-trial choice behavior individually with each model and assessed the relative goodness of fit. Aggregating the data likelihoods across subjects (which is equivalent to assuming that all subjects used the same one of the models), the group's behavior was best explained by planning (BIC 3098), and worse by TD (BIC 3397; random was 4085).
We may instead consider that the identity of the best-fitting model might have varied from subject to subject and characterize the tendencies of the population by the summary statistics on their individual fits, analogous to a random-effect analysis in fMRI (Stephan et al., 2009). Thus, the average Bayes factor (the difference in BIC scores or approximate log odds in favor of one model vs another) was 16.61 in favor of model-based planning over TD. This was significantly different from zero across subjects (t(17) = 4.92; p = 0.0001), indicating that a subject drawn randomly from the population will, on average, exhibit behavior better fit by model-based RL compared with TD. An alternative way to characterize the predominance of the strategies in the population is to fit the entire behavioral dataset with a mixture model in which each subject exhibits exactly one of the candidate algorithms, the identity of which is treated as a random variable [BMS (Stephan et al., 2009)]. In such a fit, it was overwhelmingly likely that planning was the more common strategy (expected frequency, E[p(plan)] = 0.947; exceedance probability, P[p(plan) > p(TD)] > 0.999). These results suggest that subjects' learning about choices in this task was, at the population level, predominantly driven by model-based spatial planning. The comparison of the model-based and TD approaches suggests that values are determined prospectively by planning rather than by local bootstrap-based learning.
We may also break down the contributions of individual subjects to these groupwise results. Primarily, both of the learning models fit significantly better than chance for each subject (likelihood ratio tests; for TD, all χ52 ≥ 13.32, p < 0.031; for planning, all χ32 ≥ 12.02, p < 0.008). Comparing BIC scores for each individual, planning was favored over TD for 17 of 18 subjects. These results further indicate that, although there is some evidence of individual variability among the subjects, the predominant strategy appears to be model-based RL (Fig. 2).
Figure 2.

Behavioral model likelihood comparison. Negative log-likelihood evidence values under BIC. Shown are per-subject log Bayes factors comparing planning against TD.
We additionally compared each algorithm to a reduced or augmented version, to isolate the necessity of the kind of learning each posited. In particular, we tested “dead-reckoning” variants of the planning algorithm that did not involve on-line learning of the map of doors but instead evaluated actions only on the basis of the distance to reward, essentially relying only on the known spatial structure and reward locations. The full planning model explained choices better than these variants, supporting the interpretation that subjects plan using a learned transition map. Even so, dead reckoning models still fit the choices better than TD, providing additional evidence that even simple planning processes dominate TD learning in this task. In fact, the dead reckoning fit was not improved by incorporating TD learning such that the fixed distanced-weighted values were updated based on experience using TD. For full details on these analyses and comparisons with other variants in each model class, see supplemental Results, supplemental Figures 2 and 3, and supplemental Table S1 (available at www.jneurosci.org as supplemental material).
Reaction times
We reasoned that, if subjects were planning trajectories by forward search, as our results suggest, then this might be reflected in their reaction times as well as their choices. In particular, we hypothesized that subjects' reaction times would be longer on steps when the search was more extensive. This would predict longer reaction times not only in rooms in which they were facing more open doors (a quantity we called n0) (see Materials and Methods), but that they would also be longer for searches in which they expected that more doors would be open in subsequent rooms, a measure unique to a forward planning model. We defined this quantity, n1, in expectation at each step according to the learned beliefs of the model about the maze.
One complication in assessing this hypothesis is that subjects were allowed to enter a decision one-half second after they first entered a room and observed the doors available there. This pause allowed subjects to decide and prepare their responses during this time, making reaction times a poor measure of planning. Accordingly, there were a high proportion of extremely fast responses: reaction times averaged 278 ± 251 ms, with 36.1% of responses <150 ms and 11.8% <50 ms. To focus on the subset of trials in which reaction time might reflect differential amounts of planning, we eliminated the fastest reaction times (those <50 ms) from analysis.
For the remaining subset of trials, we found weak but significant effects of the search complexity (t(17) = 4.50, p = 0.0003 for n0; t(17) = 2.49, p = 0.023 for n1) on log reaction time, such that more complex choices resulted in longer reaction times.
Imaging
Given that the behavioral analysis indicated that the predominant learning strategy among our candidates was model-based planning, we next exploited this model to interrogate related neural signals. Our overall strategy, based on previous work on TD learning, was to use simulations of the fit algorithm to define trial-by-trial time series of relevant variables such as predicted action values, to seek and tease apart neural correlates of these otherwise subjective quantities (O'Doherty et al., 2007). For this, we used on the model-based algorithm (and, for initial analyses, also the TD one) along with the medians of the parameters that best fit the individual subjects' choices (Table 1; supplemental Table S1, available at www.jneurosci.org as supplemental material). The median was used because in our experience (Daw et al., 2006; Gläscher et al., 2010; Daw, 2011), unregularized maximum-likelihood parameter estimates from individuals tend to be too noisy to obtain reliable neural results. Since what distinguishes planning from model-free RL is that it constructs action values from more elementary information on-line at choice time rather than simply retrieving previously learned aggregate values as in TD, our primary questions concerned dissecting these computations. As a first step, we sought neural correlates of aggregate chosen values; we did this both for values predicted by planning and for those predicted by TD to verify our hypothesis that in this task neural value signals, like choices, were predominantly better explained by planning. To maximize power, we compared the algorithms on the basis of BOLD signal in value-responsive voxels selected in an unbiased manner. After similarly confirming that planning predominates in striatal value signals over the population, we proceeded to tease apart these activations and the computations that we hypothesized would give rise to them by examining neural correlates of the components of model-based value construction. In particular, model-based predictions of aggregate future value are based on two quantities: predicted single-step rewards and predicted future states (based on knowledge of state transitions). We thus sought neural correlates related to both of these hypothesized representations. Finally, to verify the extent to which our results related specifically to planning processes as opposed to valuation more generally, we studied whether individual variation in the strength of our neural effects covaried, across subjects, with the extent to which planning versus TD explained their choice behavior.
Table 1.
Distribution of subjects' individual maximum likelihoods and parameter estimates
| Plan | TD | Random | |
|---|---|---|---|
| β | 4.081, 11.78, 17.14 | 3.405, 5.315, 6.841 | |
| γ | 0.461, 0.816, 0.861 | 0.550, 0.861, 0.936 | |
| h | 0.058, 0.142, 0.516 | ||
| Q0 | 1.260, 2.883, 6.774 | ||
| α | 0.319, 0.408, 0.579 | ||
| λ | 0.565, 0.756, 0.915 | ||
| NLL | 131.1, 156.3, 195.8 | 152.7, 171.3, 207.5 | 214.7, 224.5, 237.0 |
| BIC | 139.6, 165.0, 204.5 | 167.1, 185.6, 222.0 | 214.7, 224.5, 237.0 |
| ρ2 | 0.141, 0.279, 0.391 | 0.130, 0.226, 0.321 | (0) |
Quartiles (medians in bold) of best-fitting parameters for the two algorithms used to produce regressors for imaging analysis, along with negative log likelihood (NLL), BIC estimated evidence, and pseudo-r2 measures of individual fit quality.
Unless otherwise stated, all t statistics are uncorrected and refer to peak voxels of clusters that have been deemed significant at p < 0.05 by cluster-size FDR correction.
Correlates of value
Following much previous work on RL, we began by generating the sequence of values, Q, that each algorithm would predict at each step of the task on the basis of previous experience (Tanaka et al., 2004; O'Doherty et al., 2006; Seymour et al., 2007; Wittmann et al., 2008). We first asked where the BOLD signal significantly correlated with the sequences of values for the chosen actions (chosen values), for TD and planning considered separately. For plan-predicted values within striatum, we found that clusters in bilateral posterior ventrolateral putamen/claustrum and bilateral dorsolateral prefrontal cortex extending ventrally into orbitofrontal regions correlated significantly (peaks: [−32, −8, −6] t(17) = 6.60, [28, −2, −10] t(17) = 4.72, [−48, 38, 18] t(17) = 6.79, [52, 40, 8] t(17) = 5.34). We also found a weaker correlation in the bilateral ventral caudate that did not survive cluster-level correction for multiple comparisons (peaks: [−24, 16, −8] t(17) = 4.97, [12, 14, −10] t(17) = 4.53, NS). Using the TD-based values, we found only one significant cluster in striatum (left ventrolateral putamen peak: [−30, −8, −6] t(17) = 5.34). The ventral and dorsomedial regions of striatum have commonly been identified with general reward and value expectations (Delgado et al., 2000; Knutson et al., 2001; O'Doherty, 2004; Tricomi et al., 2004; Samejima et al., 2005), although the posterior putamen regions have been less commonly implicated (Delgado et al., 2003; O'Doherty et al., 2004). Outside of striatum, we found that distinct regions of bilateral inferior frontal, postcentral, and insular cortex showed significant correlations with these values as well, again apparently more robustly to the planning values (Fig. 3). However, cortical correlates of chosen value are found in ventral prefrontal areas (Knutson et al., 2005; Hampton and O'Doherty, 2007; Kable and Glimcher, 2007; Chib et al., 2009; Gläscher et al., 2009; Wunderlich et al., 2009) more often than other areas (Breiter et al., 2001; Plassmann et al., 2007; Hare et al., 2008). On a targeted investigation of ventromedial prefrontal cortex (vmPFC), we found that there was a correlation with planning values in this region that did not meet our reporting threshold for uncorrected significance (peak: [−6, 40, 8] t(17) = 3.03; p = 0.003, uncorrected), whereas correlates with TD values here were much weaker (p > 0.01).
Figure 3.

Value-responsive areas. A, B, T statistic map of group response size to planned (A) and TD-based (B) value predictions from separate models (shown at p < 0.001, uncorrected; significant p < 0.05 FDR clusters highlighted).
As expected given the findings that the behavior showed evidence predominantly for only a single sort of (model-based) learning, as well as the correlation between the two sets of values, the two maps show a good deal of similarity, although overall the planning responses are slightly stronger. This suggests, consistent with the choice analysis, that neural signals aligned with model-based valuation. However, a difference in thresholded statistical maps does not itself demonstrate a statistically significant difference [“the imager's fallacy” (Henson, 2005)]; thus, we next sought to confirm statistically the superiority of planning.
TD versus model-based value
Since the algorithms made similar predictions for many situations, and thus the chosen value regressors themselves were substantially correlated between algorithms (r = 0.791; for related correlations, see supplemental Fig. 3, available at www.jneurosci.org as supplemental material), we wanted to maximize power for comparing them by minimizing multiple comparisons. To this end, we targeted our direct comparison by first identifying a small number of VOIs in an anatomically constrained striatal ROI that showed value-selective activations. We identified these voxels in a manner that did not bias the subsequent test for differences between the two chosen value regressors, by using a summed contrast over both of them. Based on other studies, we focused on the caudate and putamen as regions relevant for value computations (see Materials and Methods for more information on voxel selection). The four selected VOIs were [−32, −8, −6] (left ventrolateral putamen), [28, −6, −12] (right ventrolateral putamen/pallidus border), [−20, 16, −6] (left anterior ventromedial putamen), and [20, 18, −10] (right anterior ventromedial putamen) (Fig. 4). We then asked whether these voxels were significantly more correlated with planning or TD-based chosen values using the orthogonal (difference) contrast between both regressors in the same GLM. Each of these voxels showed a significantly stronger response to the planning predictions (p < 0.03, FDR corrected for the four comparisons). These findings provide evidence that neural correlates of value in striatum are not strictly bound to a TD-based value computation and may instead be informed by a model of the environment. This sharply contrasts with the common interpretation of the mesolimbic dopamine system as implementing TD learning (Lee et al., 2004; Seymour et al., 2004; O'Doherty et al., 2006).
Figure 4.

Identification of value-related voxels of interest. T statistic map of group response size to either planned or TD-based value predictions (summed contrast, shown at p < 0.001, uncorrected; significance not assessed). The most responsive peak voxels of this map anatomically within striatum were identified for additional analysis.
We also repeated these neural analyses using a version of TD augmented with dead-reckoning planning values for initialization. That the results were mostly the same (see supplemental Results, supplemental Figs. 4, 5, available at www.jneurosci.org as supplemental material) further suggests that value signals in ventral striatum reflect those generated from a learned cognitive map rather than from TD learning.
Decomposition of value responses
Having established that neural correlates of value prediction, like choices, were well explained by model-based values, we sought to dissect the computation of these values into the components from which, according to the theory, they are computed. We first attempted to tease apart the striatal BOLD response by separately investigating the effects of component quantities that should be combined together in the value computation, and in so doing to visualize the features of the response that gave rise to the previous finding (that value is better explained by model-based planning than TD). In particular, the values from both algorithms amount to weighted sums over a series of quantities (see Materials and Methods). TD updates values by accumulating prediction errors, resulting in a net learned value that at each step corresponds to the weighted sum over errors received after previous experiences with an action. Model-based planning produces a value at each step by a (time-discount weighted) sum over rewards predicted by the model at each time step into the future. We therefore may use the additivity of the GLM to seek to explain the net BOLD signal as a weighted sum of either sequence of subquantities. Thus, we unrolled the first two steps of each of these computations and entered them as separate regressors: Qplan = r1 + γr2 + …, QTD = α(δ1 + (1 − α)δ2 + …). (The early terms should dominate since in both algorithms the weights decline exponentially as the series progresses.)
We extracted the sizes of these effects in our voxels of interest (Fig. 5). As can be seen in the figure, the pattern of BOLD activation in all the voxels, in terms of the subcomponents of the value, more closely follows the pattern predicted by model-based planning than by TD, with the directions and relative sizes of effects consistently in line with the predictions. Having selected these voxels for having a large correlation with the chosen value Q (over both algorithms symmetrically), we of course bias the statistical test for correlations with components of the value computation of both algorithms to be positive as well. Thus, as expected, we found all the correlations with r1 were significantly positive (p < 0.035, all tests FDR corrected for the four voxels but uncorrected for multiple comparisons in VOI selection), as well as one of the paired r2 correlations (p = 0.02). However, only one of the δ1 correlations was significant (p = 0.033), whereas none of the paired δ2 correlations was (p > 0.1), despite the bias toward a positive finding expected from the selection of the voxels.
Figure 5.

Striatal BOLD responses to partial value components. Responses (mean effect sizes, arbitrary units) to key components of the value predictions as predicted by the two algorithms in the previously identified VOIs. Also shown are the predicted responses from the overall value fit assuming exponential discounting and updating. Note that significances, as indicated by *p < 0.05 and **p < 0.01, are biased by voxel selection.
One-step reward
We next sought neural reflections for the components of the world model elsewhere in the brain, to begin to map the broader network supporting the computation. In particular, these analyses use subcomponents of the normatively defined model-based values to examine aspects of their process-level computations. In the theory, model-based values are computed at choice time by summing expected rewards over candidate trajectories. Specifically, model-based planning predicts action values by combining information from two representations: a map of where rewards are located, and a map of transitions between states (here, doors). We thus hypothesized that we should be able to find neural correlates related to both representations. To seek a representation of rewards, we considered the value r1 discussed above, which has a clear interpretation: it is the expected immediate reward to be received in the next room. This is the first relevant value that a planning process would need to “look up” when searching forward paths, where the expectation over future states can either reflect the average over paths considered first on different trials (as in depth first search) or be explicitly computed in the brain on each particular trial (as in breadth-first search, where the expectation r1 is the first intermediate partial sum in computing a full action value).
The present analysis thus seeks activity related to the next reward separately, rather than as portion of a net signal related to the chosen value Q, as in the previous section. Of course, r1 and Q are strongly correlated, as the former is the first term in the sum defining the latter. To distinguish these possibilities and find activity related specifically to elemental rewards rather than aggregate future values, we searched for regions in which the correlation with r1 was significantly greater than the correlation with the summed value, here approximated by the sum of both of the first two terms in the series r1 + γr2 ≈ Qplan (Fig. 6). This contrast revealed a pair of regions containing significant clusters: left superior frontal cortex (peak: [−18, 46, 46] t(17) = 5.58) and right parahippocampal gyrus (peak: [18, −6, −20] t(17) = 4.64; left: [−34, −14, −18] t(17) = 4.66, NS). Such activity might either represent associations of place with reward, as perhaps in the case of the medial temporal lobe (MTL) activations, or reflect the incorporation of these one-step rewards into planning computations (Foster et al., 2000; Hasselmo, 2005; Zilli and Hasselmo, 2008). Also, in addition to their spatial associations, areas in MTL have been implicated more generally in drawing on memory to project future events (Buckner and Carroll, 2007; Hasselmo, 2009).
Figure 6.

Responses to predicted next-step rewards beyond chosen values. T statistic map of responsive regions to choices that are expected to lead to a reward room (r1), greater than the first two terms of the value equation (r1 + γr2; shown at p < 0.001, uncorrected; significant p < 0.05 FDR clusters highlighted).
Transitions and planning
Next, we sought neural evidence for a representation of the other aspect of the hypothesized world model, the maze transition structure. We did so indirectly, by using hypothesized effects of search complexity on activity related to choice difficulty in a manner analogous to the analysis of reaction times discussed above. In most accounts of decisions, choice difficulty increases with the size of the choice set (here, the number of doors in the current room). However, if actions are evaluated on-line via some kind of realistic forward-planning process, then choice difficulty should also depend on the complexity of the subsequent search (e.g., the number of choices expected to be available in subsequent rooms). (Here again, the expectation, computed from door probabilities in our full model, is meant to reflect the average search-related activity over trials in which different numbers of branches may be actually examined in a pruning search.) We thus looked throughout the brain for regions that correlated with the number of currently available choices, n0, and tested whether these also depended on the number of choices expected to be available in the next room, in expectation over potential choices at the first step, n1 (see Materials and Methods). Since reaction time was also previously shown to be correlated with these same quantities, to rule it out as a confound in neural activity it was included as a nuisance regressor in this analysis, and the variables of interest were orthogonalized against it.
Within the mask of regions significantly correlated with n0 (totaling 10,880 mm3; 1360 voxels for positive), we found three relevant regions that also correlated positively with n1 (Fig. 7) (whereas t statistics are still uncorrected, reported peak voxels are all significant, p < 0.05, corrected, voxelwise for FWE over multiple comparisons within the n0 mask): bilateral precentral cortex (peaks: [−38, 4, 30] t(17) = 4.80, [42, 8, 28] t(17) = 4.86), anterior insula (peaks: [−34, 24, 0] t(17) = 6.86, [38, 22, 6] t(17) = 5.79), and also medial cingulate/supplementary motor area (SMA) in the subset of 15 subjects with coverage in that region (peaks: [−12, 14, 50] t(14) = 5.14, [0, 18, 48] t(14) = 5.48). This indicates that these regions may be participating in a search-based planning process. We performed the same analysis looking for regions negatively correlated with both search difficulty regressors (mask, 34,656 mm3; 4332 voxels for negative) and found medial prefrontal cortex (peak: [−2, 46, 0] t(17) = 4.93) and bilateral amygdala/hippocampus (peaks: [−18, −8, −20] t(17) = 5.06, [22, −4, −18] t(17) = 5.44). This region of medial PFC is often associated with future value (although the trend toward this correlation did not reach significance in the present study). Nonetheless, BOLD correlations with value cannot explain the present activation, because n1 has a slight positive correlation with action value, and therefore a value confound would predict a positive correlation with n1 in BOLD. Instead, we speculate that activity negatively correlated with search difficulty there may relate to assessing the costs of the search process [e.g., for the purpose of deciding whether it is worthwhile to complete the computation (Daw et al., 2005; Rushworth and Behrens, 2008; M. Keramati, personal communication)]. In particular, both this activity and the value responses observed in vmPFC in other studies may reflect a top-down assessment for strategy selection based on expected cost, benefit, as well as the uncertainty associated with each approach (Dickinson, 1985; Barraclough et al., 2004; Lee et al., 2004).
Figure 7.

Response to both one-step predicted and immediate choice count. Masked T statistic map of responses to expected next-step choice set size within regions responsive to current choice set size (all n0 significant p < 0.05 FDR cluster size; n1 shown at p < 0.001, uncorrected; two-tailed).
Together, these results suggest that using model-based planning to project rewards on the basis of a remembered “map” of a maze uses a broad temporal and frontal network, areas broadly associated with memory and control.
Individual differences
Finally, to investigate whether our neural effects were specifically related to planning, or instead to valuation more generally (e.g., in a way that might be common or generic to TD and planning strategies) or even incidentally (e.g., unrelated to choice), we tested whether individual differences in fit quality between the two algorithms to choice behavior covaried across individuals with the strength of the neural responses found in each of these analyses (Hampton et al., 2008). In this way, since subjects varied in the extent to which their behavior was explained by either strategy, we made use of this variability to investigate the relationship of the behavior with the neural signaling. In each case, we select the β contrast values from each individual from the identified group peak voxel, and correlate these with either the log likelihoods of the fits to the two algorithms to choices (such that larger, less negative numbers indicate better fits), or the Bayes factor from choices (i.e., the difference between them so that larger numbers indicate better fits of planning than TD to choices). Of the striatal VOIs responsive to value, the strength of the unbiased value effect and the difference in the right lateral voxel (i.e., the Qplan + QTD contrast) covaried significantly with the individual subject planning likelihoods [r(16) = 0.498; p = 0.018], and both this and the contrast comparing value predictions (Qplan > QTD) correlated with the analogous Bayes factor between the two in the right medial voxel [r(16) = 0.552 and r(16) = 0.537; p < 0.011], but none with the TD likelihoods (p > 0.05). This indicated that the value-related neural effects are also stronger in subjects whose behavior is better explained by planning, consistent with the identification of this activity with planning. Similar results were also seen for the correlates we associate with the representations of the world model. Specifically, we found that the parahippocampal responses to expected next-step reward covaried significantly with the Bayes factor [r(16) = 0.520 for right, r(16) = 0.728 for left; both p < 0.014], and also that the search complexity responses in the SMA covaried with choice likelihoods under planning [for the full set of subjects, r(16) = 0.504, p = 0.016; r(13) = 0.510, p = 0.026 for the reduced set] but not with the likelihoods under TD (p > 0.05). All of these findings support the inference that these signals are related to the decision-making behaviors studied and are consistent with this activity supporting planning. However, although the lack of a similar relationship with model-free valuations might be interpreted as supporting the specificity of these signals to model-based planning, negative results must be interpreted with caution. For instance, to the extent the task design was successful in precluding the use of TD, it may not elicit meaningful individual differences in the fit of the TD model.
Discussion
Computational theories have driven rapid progress quantifying neural signals in the mesostriatal system, primarily in terms of model-free RL (Bar-Gad et al., 2003; O'Doherty et al., 2004; Tricomi et al., 2004; Bayer and Glimcher, 2005; Morris et al., 2006; Schönberg et al., 2007; Hikosaka et al., 2008; Bromberg-Martin and Hikosaka, 2009). Yet it has long been argued that the brain also uses more sophisticated and categorically distinct mechanisms such as cognitive maps (Tolman, 1948; Thistlethwaite, 1951). We extended the theory-driven fMRI approach to model-based planning by leveraging a quantitative characterization of its decision variables to investigate their neural substrates (Daw et al., 2005; Johnson et al., 2007). Having first verified that choices, RTs, and striatal BOLD responses suggest a forward planning mode of valuation in this task—in contrast to broadly successful TD models and their theoretical applicability even to complex spatial tasks (Sutton, 1988; Foster et al., 2000; Stone et al., 2008)—we aimed to map the network implementing such planning by seeking correlates of the theorized construction of these values from reward and state predictions.
To distinguish learning strategies, we elicited ongoing learning via continuous maze reconfiguration. This echoes the logic of the demonstrations by Tolman (1948) that rats could plan novel routes after maze changes, and of place responses, wherein rats approach previously rewarded locations from novel starting points (Packard and McGaugh, 1996). Rather than such a one-shot challenge (Valentin et al., 2007; Gläscher et al., 2010), we examined how subjects adjust their behavior after many small changes to the maze. This approach separates the valuation strategies partially (producing correlated predictions) but consistently over many trials, and is better suited to test accounts of trial-by-trial learning. We use a normative value iteration algorithm rather than a process-level account to define the quantities of interest, but these quantities should (and mostly do, according to an analysis of the covariation of regressors derived from different model variants) (supplemental Fig. 3, available at www.jneurosci.org as supplemental material) represent the model-based class more generally. Indeed, some aspects of our results (e.g., effects of search complexity and superior fits for reward-terminated searches) seem to resonate with a process-level tree search model, potentially one involving selective pruning. Nevertheless, more detailed studies will be required to investigate these fine algorithmic distinctions.
Although we adopt a spatial framing, our questions are more akin to previous studies of RL than to other work on navigation. For instance, our focus on behavioral adjustment precludes studying optimal or repeated routes; whereas Yoshida and Ishii (2006) used well learned behavior in a similar task to study how subjects resolved uncertainty about their location, we used visual cues to minimize locational uncertainty while investigating learning. Also, although the distinction in spatial research between planned navigation to a place and executing a learned response resonates with the algorithmic distinction studied here, much navigational work focuses on another aspect: allocentric versus egocentric representations (Maguire et al., 1999; Hartley et al., 2003; Burgess, 2006; Iglói et al., 2009). Therefore, although our logic parallels attempts to differentiate two navigational strategies (Doeller et al., 2008), since we do not manipulate location cues or viewpoints, our data only speak to the reference frame distinction insomuch as it coincides [plausibly but not unproblematically (Gallistel and Cramer, 1996; Iglói et al., 2010; Weniger et al., 2010)] with the distinction between model-based and model-free learning.
In other areas of learning, a distinction is drawn between one network for habitual, overtrained responses associated with striatum [especially dorsolateral (Knowlton et al., 1996; Packard and Knowlton, 2002)], and another, separate or competing, associated with MTL and PFC for planning “goal-directed” responses (Packard and McGaugh, 1996; Burgess et al., 2002; Poldrack and Packard, 2003; Doeller et al., 2008). fMRI studies have shown that value-related BOLD responses in PFC reflect knowledge about higher-order task contingencies, consistent with involvement in model-based reasoning, although not specifically its characteristic use in RL for sequential planning (Hampton et al., 2006, 2008). In the current task, in which behavior suggested valuations were primarily model-based, we found that the same was true even of responses in ventral striatum. These areas have also, in previous studies, been associated with the habit system and TD. Although we cannot directly test this interpretation since we did not detect neural or behavioral evidence for TD in our data, our results together with those others suggest that the two putative systems may be partly overlapping or convergent, with striatum potentially acting as a common value target and locus of action selection (Samejima et al., 2005). This may relate to unit recordings suggesting model-based knowledge in the dopaminergic afferents of striatum (Bromberg-Martin and Hikosaka, 2009) and also lesion work in rodents implicating striatum in both place and goal-directed responding, albeit a different, dorsomedial, part (Devan and White, 1999; Yin and Knowlton, 2004; Balleine et al., 2007).
Although our striatal results suggest that the substrates of model-based value are more convergent with the purported TD system than might have been suspected, our remaining results, locating antecedents of these values in MTL and frontal cortex, appear more specific to model-based planning. First, effects of anticipated choice set size both on RTs and on BOLD responses offer direct evidence for forward lookahead at choice time. The regions implicated here were primarily more posterior than might have been expected on the basis of work on prefrontal involvement in decision making (Hampton et al., 2006; Kennerley et al., 2006; Pan et al., 2007), neuroeconomics (McClure et al., 2004; Mushiake et al., 2006), or memory (Poldrack et al., 2001; Poldrack and Packard, 2003): in particular, the contrast revealed posterior frontal regions along the motor cortex. In fact, these areas and SMA in particular have been associated with movement sequencing in other motor tasks (Tanji and Shima, 1994; Lee and Quessy, 2003; Hoshi and Tanji, 2004). The effect in SMA was stronger for subjects whose behavior was better fit by model-based planning (but not so for TD), further indicating that this activity is related to the computations we hypothesize.
Meanwhile, although in other tasks BOLD activity in vmPFC is often found to correlate with expected value (Plassmann et al., 2007; Hare et al., 2008; Chib et al., 2009; Wunderlich et al., 2009), such a correlation did not reach significance in our study. Although this may be attributable to technical limitations (Deichmann et al., 2003), this difference might also relate to the spatial or sequential framing of this task shifting activity to other areas, such as MTL. Although our study does not directly address this possibility, correlations with the next-step reward value in anterior MTL (hippocampus and hippocampal gyrus) are consistent with many other findings indicating that these areas may subserve cognitive maps or spatial associations (O'Keefe, 1990; Maguire et al., 1998; Burgess et al., 2002; Johnson et al., 2007).
Although we have interpreted value correlates in ventral striatum as similar to those seen in studies of putatively model-free RL, in those studies striatal BOLD is more commonly seen to covary with reward prediction error (Pagnoni et al., 2002; McClure et al., 2003; Yacubian et al., 2006; Hampton and O'Doherty, 2007) rather than value (but see Delgado et al., 2000; Tanaka et al., 2004; Kable and Glimcher, 2007; Tom et al., 2007; on unit physiology: Arkadir et al., 2004; Samejima et al., 2005; Kim et al., 2009). Here, we found less robust correlations with a TD prediction error in striatum (analyses not shown); however, the two variables are highly related, and our task was not aimed at distinguishing them (Hare et al., 2008). Notwithstanding that, another possibility is that our task recruits a distinct but anatomically overlapping model-based choice process, which would not be expected to use a TD error signal since model-based valuation constructs values by forward lookahead rather than error-driven learning. This interpretation by no means contradicts the substantial evidence for TD prediction error signals in other tasks.
Overall, we demonstrate dynamic, parametric correlates in various brain areas for a number of previously unstudied decision-related variables, such as one-step reward predictions and search complexities. Should these correlates prove generalizable to future studies, they present a new possibility for investigating specific hypotheses about the details of human valuation, for example using BOLD activity in SMA to track a search process. The model-based approach to understanding the details of value prediction by examining its neural correlates in striatum and vmPFC has had considerable success (Hampton et al., 2006, 2008), and, with these tools, it could be extended to new computational questions and brain areas to elucidate further the details of human decision making. Similarly, our demonstration that we can identify these behavioral and neural signatures for model-based, as opposed to more commonly identified model-free, valuation in humans lays the groundwork for future studies of how these two approaches trade off or are controlled. Such information would be relevant to a number of problems of self-control hypothesized to relate to the compulsive nature of model-free habits, including overeating and drug abuse (Ainslie, 2001; Loewenstein and O'Donoghue, 2004; Everitt and Robbins, 2005).
Footnotes
This work was supported by National Institute of Mental Health Grant R01 MH087882 as part of the National Science Foundation–National Institutes of Health Collaborative Research in Computational Neuroscience Program and by a Scholar Award from The McKnight Foundation. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institute of Mental Health or the National Institutes of Health.
a Because there is correlation between TD and planning predictions, these two contrasts are not perfectly orthogonal in the space of the (temporally whitened) design matrix (Kriegeskorte et al., 2009). In fact, they are slightly anticorrelated (r = −0.142). This equates to a bias toward finding a more negative difference (i.e., TD coefficients being larger, when having first selected on their sum being large and positive); we neglect this bias since it works against the results reported here.
b Again, to be sure that these tests are independent, we need to consider whether these are truly orthogonal contrasts given temporal autocorrelation. Postwhitening, we find that they are very slightly anticorrelated (r = −0.034), so since we are only looking for where their signs agree, thiscan only make the test more conservative
References
- Ainslie G. Cambridge, UK: Cambridge UP; 2001. Breakdown of will. [Google Scholar]
- Arkadir D, Morris G, Vaadia E, Bergman H. Independent coding of movement direction and reward prediction by single pallidal neurons. J Neurosci. 2004;24:10047–10056. doi: 10.1523/JNEUROSCI.2583-04.2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Balleine BW, Dickinson A. Goal-directed instrumental action: contingency and incentive learning and their cortical substrates. Neuropharmacology. 1998;37:407–419. doi: 10.1016/s0028-3908(98)00033-1. [DOI] [PubMed] [Google Scholar]
- Balleine BW, Delgado MR, Hikosaka O. The role of the dorsal striatum in reward and decision-making. J Neurosci. 2007;27:8161–8165. doi: 10.1523/JNEUROSCI.1554-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Balleine BW, Daw ND, O'Doherty JP. Multiple forms of value learning and the function of dopamine. In: Glimcher PW, Camerer CF, Fehr E, Poldrack RA, editors. Neuroeconomics: decision making and the brain, Chap 24. London: Academic; 2008. pp. 367–387. [Google Scholar]
- Bar-Gad I, Morris G, Bergman H. Information processing, dimensionality reduction and reinforcement learning in the basal ganglia. Prog Neurobiol. 2003;71:439–473. doi: 10.1016/j.pneurobio.2003.12.001. [DOI] [PubMed] [Google Scholar]
- Barraclough DJ, Conroy ML, Lee D. Prefrontal cortex and decision making in a mixed-strategy game. Nat Neurosci. 2004;7:404–410. doi: 10.1038/nn1209. [DOI] [PubMed] [Google Scholar]
- Bayer HM, Glimcher PW. Midbrain dopamine neurons encode a quantitative reward prediction error signal. Neuron. 2005;47:129–141. doi: 10.1016/j.neuron.2005.05.020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Berns GS, McClure SM, Pagnoni G, Montague PR. Predictability modulates human brain response to reward. J Neurosci. 2001;21:2793–2798. doi: 10.1523/JNEUROSCI.21-08-02793.2001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blodgett HC, McCutchan K. Place versus response learning in the simple T-maze. J Exp Psychol. 1947;37:412–422. doi: 10.1037/h0059305. [DOI] [PubMed] [Google Scholar]
- Breiter HC, Aharon I, Kahneman D, Dale A, Shizgal P. Functional imaging of neural responses to expectancy and experience of monetary gains and losses. Neuron. 2001;30:619–639. doi: 10.1016/s0896-6273(01)00303-8. [DOI] [PubMed] [Google Scholar]
- Bromberg-Martin ES, Hikosaka O. Midbrain dopamine neurons signal preference for advance information about upcoming rewards. Neuron. 2009;63:119–126. doi: 10.1016/j.neuron.2009.06.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Buckner RL, Carroll DC. Self-projection and the brain. Trends Cogn Sci. 2007;11:49–57. doi: 10.1016/j.tics.2006.11.004. [DOI] [PubMed] [Google Scholar]
- Burgess N. Spatial memory: how egocentric and allocentric combine. Trends Cogn Sci. 2006;10:551–557. doi: 10.1016/j.tics.2006.10.005. [DOI] [PubMed] [Google Scholar]
- Burgess N, Maguire EA, O'Keefe J. The human hippocampus and spatial and episodic memory. Neuron. 2002;35:625–641. doi: 10.1016/s0896-6273(02)00830-9. [DOI] [PubMed] [Google Scholar]
- Camerer C, Ho TH. Experience-weighted attraction learning in normal form games. Econometrica. 1999;67:827–874. [Google Scholar]
- Chib VS, Rangel A, Shimojo S, O'Doherty JP. Evidence for a common representation of decision values for dissimilar goods in human ventromedial prefrontal cortex. J Neurosci. 2009;29:12315–12320. doi: 10.1523/JNEUROSCI.2575-09.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chumbley JR, Friston KJ. False discovery rate revisited: FDR and topological inference using Gaussian random fields. Neuroimage. 2009;44:62–70. doi: 10.1016/j.neuroimage.2008.05.021. [DOI] [PubMed] [Google Scholar]
- Daw ND. Trial-by-trial data analysis using computational models. In: Phelps EA, Robbins TW, Delgado M, editors. Affect, learning and decision making, attention and performance XXIII. Oxford: Oxford UP; 2011. [Google Scholar]
- Daw ND, Niv Y, Dayan P. Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control. Nat Neurosci. 2005;8:1704–1711. doi: 10.1038/nn1560. [DOI] [PubMed] [Google Scholar]
- Daw ND, O'Doherty JP, Dayan P, Seymour B, Dolan RJ. Cortical substrates for exploratory decisions in humans. Nature. 2006;441:876–879. doi: 10.1038/nature04766. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deichmann R, Gottfried JA, Hutton C, Turner R. Optimized EPI for fMRI studies of the orbitofrontal cortex. Neuroimage. 2003;19:430–441. doi: 10.1016/s1053-8119(03)00073-9. [DOI] [PubMed] [Google Scholar]
- Delgado MR, Nystrom LE, Fissell C, Noll DC, Fiez JA. Tracking the hemodynamic responses to reward and punishment in the striatum. J Neurophysiol. 2000;84:3072–3077. doi: 10.1152/jn.2000.84.6.3072. [DOI] [PubMed] [Google Scholar]
- Delgado MR, Locke HM, Stenger VA, Fiez JA. Dorsal striatum responses to reward and punishment: effects of valence and magnitude manipulations. Cogn Affect Behav Neurosci. 2003;3:27–38. doi: 10.3758/cabn.3.1.27. [DOI] [PubMed] [Google Scholar]
- Devan BD, White NM. Parallel information processing in the dorsal striatum: relation to hippocampal function. J Neurosci. 1999;19:2789–2798. doi: 10.1523/JNEUROSCI.19-07-02789.1999. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dickinson A. Actions and habits: the development of behavioural autonomy. Philos Trans R Soc Lond B Biol Sci. 1985;308:67–78. [Google Scholar]
- Dickinson A, Balleine B. New York: Wiley; 2002. The role of learning in the operation of motivational systems. [Google Scholar]
- Doeller CF, King JA, Burgess N. Parallel striatal and hippocampal systems for landmarks and boundaries in spatial memory. Proc Natl Acad Sci U S A. 2008;105:5915–5920. doi: 10.1073/pnas.0801489105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Doya K. What are the computations of the cerebellum, the basal ganglia and the cerebral cortex? Neural Netw. 1999;12:961–974. doi: 10.1016/s0893-6080(99)00046-5. [DOI] [PubMed] [Google Scholar]
- Everitt BJ, Robbins TW. Neural systems of reinforcement for drug addiction: from actions to habits to compulsion. Nat Neurosci. 2005;8:1481–1489. doi: 10.1038/nn1579. [DOI] [PubMed] [Google Scholar]
- Foster DJ, Morris RG, Dayan P. A model of hippocampally dependent navigation, using the temporal difference learning rule. Hippocampus. 2000;10:1–16. doi: 10.1002/(SICI)1098-1063(2000)10:1<1::AID-HIPO1>3.0.CO;2-1. [DOI] [PubMed] [Google Scholar]
- Gallistel CR, Cramer AE. Computations on metric maps in mammals: getting oriented and choosing a multi-destination route. J Exp Biol. 1996;199:211–217. doi: 10.1242/jeb.199.1.211. [DOI] [PubMed] [Google Scholar]
- Gläscher J, Hampton AN, O'Doherty JP. Determining a role for ventromedial prefrontal cortex in encoding action-based value signals during reward-related decision making. Cereb Cortex. 2009;19:483–495. doi: 10.1093/cercor/bhn098. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gläscher J, Daw N, Dayan P, O'Doherty JP. States versus rewards: dissociable neural prediction error signals underlying model-based and model-free reinforcement learning. Neuron. 2010;66:585–595. doi: 10.1016/j.neuron.2010.04.016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hampton AN, O'Doherty JP. Decoding the neural substrates of reward-related decision making with functional MRI. Proc Natl Acad Sci U S A. 2007;104:1377–1382. doi: 10.1073/pnas.0606297104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hampton AN, Bossaerts P, O'Doherty JP. The role of the ventromedial prefrontal cortex in abstract state-based inference during decision making in humans. J Neurosci. 2006;26:8360–8367. doi: 10.1523/JNEUROSCI.1010-06.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hampton AN, Bossaerts P, O'Doherty JP. Neural correlates of mentalizing-related computations during strategic interactions in humans. Proc Natl Acad Sci U S A. 2008;105:6741–6746. doi: 10.1073/pnas.0711099105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hare TA, O'Doherty J, Camerer CF, Schultz W, Rangel A. Dissociating the role of the orbitofrontal cortex and the striatum in the computation of goal values and prediction errors. J Neurosci. 2008;28:5623–5630. doi: 10.1523/JNEUROSCI.1309-08.2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hartley T, Maguire EA, Spiers HJ, Burgess N. The well-worn route and the path less traveled: distinct neural bases of route following and wayfinding in humans. Neuron. 2003;37:877–888. doi: 10.1016/s0896-6273(03)00095-3. [DOI] [PubMed] [Google Scholar]
- Hasselmo ME. A model of prefrontal cortical mechanisms for goal-directed behavior. J Cogn Neurosci. 2005;17:1115–1129. doi: 10.1162/0898929054475190. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hasselmo ME. A model of episodic memory: mental time travel along encoded trajectories using grid cells. Neurobiol Learn Mem. 2009;92:559–573. doi: 10.1016/j.nlm.2009.07.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Henson R. What can functional neuroimaging tell the experimental psychologist? Q J Exp Psychol A. 2005;58:193–233. doi: 10.1080/02724980443000502. [DOI] [PubMed] [Google Scholar]
- Hikosaka O, Bromberg-Martin E, Hong S, Matsumoto M. New insights on the subcortical representation of reward. Curr Opin Neurobiol. 2008;18:203–208. doi: 10.1016/j.conb.2008.07.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Holmes AP, Friston KJ. Generalisability, random effects and population inference. Paper presented at 4th International Conference on Functional Mapping of the Human Brain; June; Montreal, Quebec. 1998. [Google Scholar]
- Hoshi E, Tanji J. Differential roles of neuronal activity in the supplementary and presupplementary motor areas: from information retrieval to motor planning and execution. J Neurophysiol. 2004;92:3482–3499. doi: 10.1152/jn.00547.2004. [DOI] [PubMed] [Google Scholar]
- Houk JC, Adams JL, Barto AG. A model of how the basal ganglia generate and use neural signals that predict reinforcement. In: Houk JC, Davis JL, Beiser DG, editors. Models of information processing in the basal ganglia. Cambridge, MA: MIT; 1994. pp. 249–270. [Google Scholar]
- Iglói K, Zaoui M, Berthoz A, Rondi-Reig L. Sequential egocentric strategy is acquired as early as allocentric strategy: parallel acquisition of these two navigation strategies. Hippocampus. 2009;19:1199–1211. doi: 10.1002/hipo.20595. [DOI] [PubMed] [Google Scholar]
- Iglói K, Doeller CF, Berthoz A, Rondi-Reig L, Burgess N. Lateralized human hippocampal activity predicts navigation based on sequence or place memory. Proc Natl Acad Sci U S A. 2010;107:14466–14471. doi: 10.1073/pnas.1004243107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Johnson A, van der Meer MA, Redish AD. Integrating hippocampus and striatum in decision-making. Curr Opin Neurobiol. 2007;17:692–697. doi: 10.1016/j.conb.2008.01.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kable JW, Glimcher PW. The neural correlates of subjective value during intertemporal choice. Nat Neurosci. 2007;10:1625–1633. doi: 10.1038/nn2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kass RE, Raftery AE. Bayes factors. J Am Stat Assoc. 1995;90:773–795. [Google Scholar]
- Kennerley SW, Walton ME, Behrens TE, Buckley MJ, Rushworth MF. Optimal decision making and the anterior cingulate cortex. Nat Neurosci. 2006;9:940–947. doi: 10.1038/nn1724. [DOI] [PubMed] [Google Scholar]
- Kim H, Sul JH, Huh N, Lee D, Jung MW. Role of striatum in updating values of chosen actions. J Neurosci. 2009;29:14701–14712. doi: 10.1523/JNEUROSCI.2728-09.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Knowlton BJ, Mangels JA, Squire LR. A neostriatal habit learning system in humans. Science. 1996;273:1399–1402. doi: 10.1126/science.273.5280.1399. [DOI] [PubMed] [Google Scholar]
- Knutson B, Fong GW, Adams CM, Varner JL, Hommer D. Dissociation of reward anticipation and outcome with event-related fMRI. Neuroreport. 2001;12:3683–3687. doi: 10.1097/00001756-200112040-00016. [DOI] [PubMed] [Google Scholar]
- Knutson B, Taylor J, Kaufman M, Peterson R, Glover G. Distributed neural representation of expected value. J Neurosci. 2005;25:4806–4812. doi: 10.1523/JNEUROSCI.0642-05.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kriegeskorte N, Simmons WK, Bellgowan PS, Baker CI. Circular analysis in systems neuroscience: the dangers of double dipping. Nat Neurosci. 2009;12:535–540. doi: 10.1038/nn.2303. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee D, Quessy S. Activity in the supplementary motor area related to learning and performance during a sequential visuomotor task. J Neurophysiol. 2003;89:1039–1056. doi: 10.1152/jn.00638.2002. [DOI] [PubMed] [Google Scholar]
- Lee D, Conroy ML, McGreevy BP, Barraclough DJ. Reinforcement learning and decision making in monkeys during a competitive game. Brain Res Cogn Brain Res. 2004;22:45–58. doi: 10.1016/j.cogbrainres.2004.07.007. [DOI] [PubMed] [Google Scholar]
- Loewenstein G, O'Donoghue T. Ithaca, NY: Center for Analytic Economics, Cornell University; 2004. Animal spirits: affective and deliberative processes in economic behavior. Working Papers 04-14. [Google Scholar]
- Lohrenz T, McCabe K, Camerer CF, Montague PR. Neural signature of fictive learning signals in a sequential investment task. Proc Natl Acad Sci U S A. 2007;104:9493–9498. doi: 10.1073/pnas.0608842104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maguire EA, Burgess N, Donnett JG, Frackowiak RS, Frith CD, O'Keefe J. Knowing where and getting there: a human navigation network. Science. 1998;280:921–924. doi: 10.1126/science.280.5365.921. [DOI] [PubMed] [Google Scholar]
- Maguire EA, Burgess N, O'Keefe J. Human spatial navigation: cognitive maps, sexual dimorphism, and neural substrates. Curr Opin Neurobiol. 1999;9:171–177. doi: 10.1016/s0959-4388(99)80023-3. [DOI] [PubMed] [Google Scholar]
- Maldjian JA, Laurienti PJ, Kraft RA, Burdette JH. An automated method for neuroanatomic and cytoarchitectonic atlas-based interrogation of fMRI data sets. Neuroimage. 2003;19:1233–1239. doi: 10.1016/s1053-8119(03)00169-1. [DOI] [PubMed] [Google Scholar]
- McClure SM, Berns GS, Montague PR. Temporal prediction errors in a passive learning task activate human striatum. Neuron. 2003;38:339–346. doi: 10.1016/s0896-6273(03)00154-5. [DOI] [PubMed] [Google Scholar]
- McClure SM, Laibson DI, Loewenstein G, Cohen JD. Separate neural systems value immediate and delayed monetary rewards. Science. 2004;306:503–507. doi: 10.1126/science.1100907. [DOI] [PubMed] [Google Scholar]
- Montague PR, King-Casas B, Cohen JD. Imaging valuation models in human choice. Annu Rev Neurosci. 2006;29:417–448. doi: 10.1146/annurev.neuro.29.051605.112903. [DOI] [PubMed] [Google Scholar]
- Morris G, Nevet A, Arkadir D, Vaadia E, Bergman H. Midbrain dopamine neurons encode decisions for future action. Nat Neurosci. 2006;9:1057–1063. doi: 10.1038/nn1743. [DOI] [PubMed] [Google Scholar]
- Mushiake H, Saito N, Sakamoto K, Itoyama Y, Tanji J. Activity in the lateral prefrontal cortex reflects multiple steps of future events in action plans. Neuron. 2006;50:631–641. doi: 10.1016/j.neuron.2006.03.045. [DOI] [PubMed] [Google Scholar]
- O'Doherty JP. Reward representations and reward-related learning in the human brain: insights from neuroimaging. Curr Opin Neurobiol. 2004;14:769–776. doi: 10.1016/j.conb.2004.10.016. [DOI] [PubMed] [Google Scholar]
- O'Doherty JP, Deichmann R, Critchley HD, Dolan RJ. Neural responses during anticipation of a primary taste reward. Neuron. 2002;33:815–826. doi: 10.1016/s0896-6273(02)00603-7. [DOI] [PubMed] [Google Scholar]
- O'Doherty JP, Dayan P, Friston K, Critchley H, Dolan RJ. Temporal difference models and reward-related learning in the human brain. Neuron. 2003;38:329–337. doi: 10.1016/s0896-6273(03)00169-7. [DOI] [PubMed] [Google Scholar]
- O'Doherty JP, Dayan P, Schultz J, Deichmann R, Friston K, Dolan RJ. Dissociable roles of ventral and dorsal striatum in instrumental conditioning. Science. 2004;304:452–454. doi: 10.1126/science.1094285. [DOI] [PubMed] [Google Scholar]
- O'Doherty JP, Buchanan TW, Seymour B, Dolan RJ. Predictive neural coding of reward preference involves dissociable responses in human ventral midbrain and ventral striatum. Neuron. 2006;49:157–166. doi: 10.1016/j.neuron.2005.11.014. [DOI] [PubMed] [Google Scholar]
- O'Doherty JP, Hampton A, Kim H. Model-based fMRI and its application to reward learning and decision making. Ann N Y Acad Sci. 2007;1104:35–53. doi: 10.1196/annals.1390.022. [DOI] [PubMed] [Google Scholar]
- O'Keefe J. A computational theory of the hippocampal cognitive map. Prog Brain Res. 1990;83:301–312. doi: 10.1016/s0079-6123(08)61258-3. [DOI] [PubMed] [Google Scholar]
- Packard MG, Knowlton BJ. Learning and memory functions of the basal ganglia. Annu Rev Neurosci. 2002;25:563–593. doi: 10.1146/annurev.neuro.25.112701.142937. [DOI] [PubMed] [Google Scholar]
- Packard MG, McGaugh JL. Inactivation of hippocampus or caudate nucleus with lidocaine differentially affects expression of place and response learning. Neurobiol Learn Mem. 1996;65:65–72. doi: 10.1006/nlme.1996.0007. [DOI] [PubMed] [Google Scholar]
- Pagnoni G, Zink CF, Montague PR, Berns GS. Activity in human ventral striatum locked to errors of reward prediction. Nat Neurosci. 2002;5:97–98. doi: 10.1038/nn802. [DOI] [PubMed] [Google Scholar]
- Pan X, Sawa K, Sakagami M. Model-based reward prediction in the primate prefrontal cortex. Neurosci Res. 2007;58:S229–S229. [Google Scholar]
- Plassmann H, O'Doherty J, Rangel A. Orbitofrontal cortex encodes willingness to pay in everyday economic transactions. J Neurosci. 2007;27:9984–9988. doi: 10.1523/JNEUROSCI.2131-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Poldrack RA, Packard MG. Competition among multiple memory systems: converging evidence from animal and human brain studies. Neuropsychologia. 2003;41:245–251. doi: 10.1016/s0028-3932(02)00157-4. [DOI] [PubMed] [Google Scholar]
- Poldrack RA, Clark J, Paré-Blagoev EJ, Shohamy D, Creso Moyano J, Myers C, Gluck MA. Interactive memory systems in the human brain. Nature. 2001;414:546–550. doi: 10.1038/35107080. [DOI] [PubMed] [Google Scholar]
- Rushworth MF, Behrens TE. Choice, uncertainty and value in prefrontal and cingulate cortex. Nat Neurosci. 2008;11:389–397. doi: 10.1038/nn2066. [DOI] [PubMed] [Google Scholar]
- Samejima K, Doya K. Estimating internal variables of a decision maker's brain: a model-based approach for neuroscience. In: Ishikawa M, Doya K, Miyamoto H, Yamakawa T, editors. Neural information processing. Berlin: Springer; 2008. pp. 596–603. [Google Scholar]
- Samejima K, Ueda Y, Doya K, Kimura M. Representation of action-specific reward values in the striatum. Science. 2005;310:1337–1340. doi: 10.1126/science.1115270. [DOI] [PubMed] [Google Scholar]
- Schönberg T, Daw ND, Joel D, O'Doherty JP. Reinforcement learning signals in the human striatum distinguish learners from nonlearners during reward-based decision making. J Neurosci. 2007;27:12860–12867. doi: 10.1523/JNEUROSCI.2496-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schultz W, Dayan P, Montague PR. A neural substrate of prediction and reward. Science. 1997;275:1593–1599. doi: 10.1126/science.275.5306.1593. [DOI] [PubMed] [Google Scholar]
- Schwarz G. Estimating the dimension of a model. Ann Stat. 1978;6:461–464. [Google Scholar]
- Seymour B, O'Doherty JP, Dayan P, Koltzenburg M, Jones AK, Dolan RJ, Friston KJ, Frackowiak RS. Temporal difference models describe higher-order learning in humans. Nature. 2004;429:664–667. doi: 10.1038/nature02581. [DOI] [PubMed] [Google Scholar]
- Seymour B, Daw N, Dayan P, Singer T, Dolan R. Differential encoding of losses and gains in the human striatum. J Neurosci. 2007;27:4826–4831. doi: 10.1523/JNEUROSCI.0400-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith A, Li M, Becker S, Kapur S. A model of antipsychotic action in conditioned avoidance: a computational approach. Neuropsychopharmacology. 2004;29:1040–1049. doi: 10.1038/sj.npp.1300414. [DOI] [PubMed] [Google Scholar]
- Stephan KE, Penny WD, Daunizeau J, Moran RJ, Friston KJ. Bayesian model selection for group studies. Neuroimage. 2009;46:1004–1017. doi: 10.1016/j.neuroimage.2009.03.025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stone EE, Skubic M, Keller JM. Adaptive temporal difference learning of spatial memory in the water maze task. Paper presented at 7th IEEE International Conference on Development and Learning; August; Monterrey, CA. 2008. [Google Scholar]
- Suri RE, Schultz W. Temporal difference model reproduces anticipatory neural activity. Neural Comput. 2001;13:841–862. doi: 10.1162/089976601300014376. [DOI] [PubMed] [Google Scholar]
- Sutton RS. Learning to predict by the methods of temporal differences. Mach Learn. 1988;3:9–44. [Google Scholar]
- Sutton RS, Barto AG. Cambridge, MA: MIT; 1998. Reinforcement learning. [Google Scholar]
- Sutton RS, Pinette B. The learning of world models by connectionist networks. Paper presented at Seventh Annual Conference of the Cognitive Science Society; August; Irvine, CA. 1985. [Google Scholar]
- Tanaka SC, Doya K, Okada G, Ueda K, Okamoto Y, Yamawaki S. Prediction of immediate and future rewards differentially recruits cortico-basal ganglia loops. Nat Neurosci. 2004;7:887–893. doi: 10.1038/nn1279. [DOI] [PubMed] [Google Scholar]
- Tanji J, Shima K. Role for supplementary motor area cells in planning several movements ahead. Nature. 1994;371:413–416. doi: 10.1038/371413a0. [DOI] [PubMed] [Google Scholar]
- Thistlethwaite D. A critical review of latent learning and related experiments. Psychol Bull. 1951;48:97–129. doi: 10.1037/h0055171. [DOI] [PubMed] [Google Scholar]
- Thorndike EL. New York: Macmillan; 1911. Animal intelligence: an experimental study of the associative processes in animals; pp. 29–58. [Google Scholar]
- Tolman EC. Cognitive maps in rats and men. Psychol Rev. 1948;55:189–208. doi: 10.1037/h0061626. [DOI] [PubMed] [Google Scholar]
- Tom SM, Fox CR, Trepel C, Poldrack RA. The neural basis of loss aversion in decision-making under risk. Science. 2007;315:515–518. doi: 10.1126/science.1134239. [DOI] [PubMed] [Google Scholar]
- Tricomi EM, Delgado MR, Fiez JA. Modulation of caudate activity by action contingency. Neuron. 2004;41:281–292. doi: 10.1016/s0896-6273(03)00848-1. [DOI] [PubMed] [Google Scholar]
- Valentin VV, Dickinson A, O'Doherty JP. Determining the neural substrates of goal-directed learning in the human brain. J Neurosci. 2007;27:4019–4026. doi: 10.1523/JNEUROSCI.0564-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Watkins CJCH. Cambridge University; 1989. Learning from delayed rewards. PhD dissertation. [Google Scholar]
- Weniger G, Siemerkus J, Schmidt-Samoa C, Mehlitz M, Baudewig J, Dechent P, Irle E. The human parahippocampal cortex subserves egocentric spatial learning during navigation in a virtual maze. Neurobiol Learn Mem. 2010;93:46–55. doi: 10.1016/j.nlm.2009.08.003. [DOI] [PubMed] [Google Scholar]
- Wittmann BC, Daw ND, Seymour B, Dolan RJ. Striatal activity underlies novelty-based choice in humans. Neuron. 2008;58:967–973. doi: 10.1016/j.neuron.2008.04.027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wunderlich K, Rangel A, O'Doherty JP. Neural computations underlying action-based decision making in the human brain. Proc Natl Acad Sci U S A. 2009;106:17199–17204. doi: 10.1073/pnas.0901077106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yacubian J, Gläscher J, Schroeder K, Sommer T, Braus DF, Büchel C. Dissociable systems for gain- and loss-related value predictions and errors of prediction in the human brain. J Neurosci. 2006;26:9530–9537. doi: 10.1523/JNEUROSCI.2915-06.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yin HH, Knowlton BJ. Contributions of striatal subregions to place and response learning. Learn Mem. 2004;11:459–463. doi: 10.1101/lm.81004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yoshida W, Ishii S. Resolution of uncertainty in prefrontal cortex. Neuron. 2006;50:781–789. doi: 10.1016/j.neuron.2006.05.006. [DOI] [PubMed] [Google Scholar]
- Zilli EA, Hasselmo ME. Modeling the role of working memory and episodic memory in behavioral tasks. Hippocampus. 2008;18:193–209. doi: 10.1002/hipo.20382. [DOI] [PMC free article] [PubMed] [Google Scholar]