

Abstract
We consider the recent history functional linear models, relating a longitudinal response to a longitudinal predictor where the predictor process only in a sliding window into the recent past has an effect on the response value at the current time. We propose an estimation procedure for recent history functional linear models that is geared towards sparse longitudinal data, where the observation times across subjects are irregular and total number of measurements per subject is small. The proposed estimation procedure builds upon recent developments in literature for estimation of functional linear models with sparse data and utilizes connections between the recent history functional linear models and varying coefficient models. We establish uniform consistency of the proposed estimators, propose prediction of the response trajectories and derive their asymptotic distribution leading to asymptotic point-wise confidence bands. We include a real data application and simulation studies to demonstrate the efficacy of the proposed methodology.
Keywords: Basis expansion, B-splines, Functional data analysis, Local least squares, Smoothing, Sparse design
1. Introduction
We address estimation in regression modeling of sparse longitudinal data. Sparse designs where the repeated measurements taken on each subject are irregular and the number of repetitions per subject is small, is encountered commonly in applications. An example is the longitudinal primary biliary liver cirrhosis data collected by the Mayo Clinic (see Appendix D of Fleming and Harrington, 1991). Due to missed visits the data is sparse and highly irregular where each patient visited the clinic at different times. We consider estimation in regression models where the sparse longitudinal predictor process only from the recent past has an effect on the sparse response trajectory.
Consider the commonly used functional linear model to relate a response trajectory to a predictor trajectory
| (1) |
first introduced by Ramsay and Dalzell (1991). For excellent reviews of functional data analysis, see Ramsay and Silverman (2002; 2005), Rice (2004) and Müller (2005). In (1), X(s) is the random predictor process, Y(t) is the random response process, and ε(t) is the mean zero error process with covariance function Γε(t, t′), t, t′ ∈ [0, T]. When the predictor and response processes are observed over the same time interval, i.e. Ωt = [0, T], the entire predictor trajectory is assumed to affect the current value of the response process at time t in the functional linear model. This assumption may not be feasible in many applications and variations of the functional linear model have been considered corresponding to different choices of the support Ωt. A more suitable choice of Ωt for predictions was proposed by Malfait and Ramsay (2003) for their recently proposed historical functional linear model, where only the past of the predictor process is involved in predicting the current response. Another special case which had wide applications over the past fifteen years is the varying coefficient model (Cleveland et al., 1992; Hastie and Tibshirani, 1993) with point-wise support where only the current value of the predictor process is assumed to have an effect on the current value of the response process.
An intermediate model considered in this paper between the functional linear model with global support and the varying coefficient model with point-wise support is the recent history functional linear model of Kim et al. (2009)
| (2) |
where the two dimensional regression function β(s, t) of the functional linear model is approximated by the product form of one dimensional functions. In (2), the predictor process from the recent past in a sliding window is assumed to affect the current response value, i.e. Ωt = [t−δ1, t−δ2] for 0 < δ2 < δ1 < T. The two delay parameters help define the sliding window support where δ2 denotes the delay for the predictor process to start affecting the response, and δ1 is the delay beyond which the predictor process has no effect. Other regression models have also been proposed with a sliding window support such as the generalized varying coefficient model of Şentürk and Müller (2008) and the functional varying coefficient model of Şentürk and Müller (2010), where authors argue that the sliding support is useful in many applications where the response is affected by recent trends in the predictor process. Kim et al. (2009) consider the regression of river flow on rainfall as a motivating example where the river flow level would depend on the recent rainfall but not current rainfall or rainfall from distant past.
Kim et al. (2009) propose an estimation procedure for the recent history functional linear model for densely recorded functional data. In this paper, we propose a new estimation procedure for the recent history functional linear model specifically tailored for sparse longitudinal data. Sparsity is a real challenge in modeling longitudinal data, since nonparametric methods cannot feasibly explain a single trajectory for sparse designs. In addition, while standard semiparametric estimation approaches to longitudinal data have been studied extensively for irregular designs, they are not particularly designed to address sparsity issues and can yield inconsistent results for sparse noise contaminated longitudinal data.
Most recently there have been a number of proposals in the literature to broaden the reach of functional data analysis in general and functional linear models in specific, to include sparsely observed longitudinal data. Shi et al. (1996) proposed fixed and random effects which are linear combinations of B-splines, James et al. (2000) proposed an estimation method based on reduced rank mixed-effect model emphasizing the sparse data case among others. Yao et al. (2005a) proposed an estimation procedure for the functional linear model with Ωt = [0, T], which is applicable to sparse longitudinal data based on functional principal component analysis. The main idea is that information across all the subjects can still be pooled effectively even for sparse data in the estimation of mean functions and covariance surfaces of the random processes, which are needed for functional principle components analysis.
The challenge of estimation based on sparse longitudinal data is intensified when one considers sliding window supports for the regression function such as the support [t − δ1, t − δ2] of the recent history functional linear model. That is even if the entire observed process is not very sparse, observations in the sliding window can easily get sparse fast as the window size decreases. We address this challenge by drawing connections between the proposed recent history functional linear model and the varying coefficient model and basing the estimation algorithm mainly on the estimation of auto-and cross-covariances following the proposals of Yao et al. (2005a). More specifically, note that for a set of K predetermined basis functions φk(s), the recent history functional linear model in (2) reduces to a multiple varying coefficient model with K induced predictors ∫Ωt X(s)φk(s)ds. The unknown varying coefficient functions bk(t) are then targeted based on a set of covariance representations which can be estimated efficiently based on sparse longitudinal data, pooling information across subjects.
The paper is organized as follows. In Section 2, we introduce the recent history functional linear model. The proposed estimation method is outlined and uniform consistency of the proposed estimators are established in Section 3. The prediction of the response trajectories is also proposed in Section 3 utilizing Gaussian assumptions, where asymptotic distributions are derived leading to point-wise asymptotic confidence bands. In Section 4, we discuss numerical issues in implementation along with the choice of model parameters. We study the finite sample properties of the proposed estimators through simulations given in Section 5. We apply the proposed method to a primary biliary liver cirrhosis longitudinal data in Section 6, to study the dynamic relationship between serum albumin concentration and prothrombin time. Concluding remarks are given in Section 7 and technical details are assembled in an Appendix.
2. Data and model
Taking a functional approach we view the observed longitudinal data as noise contaminated realizations of a random process that produces smooth trajectories. We will reflect sparsity in the following representation through random number of repeated measurements per each subject at random time points. Let (Xi, Yi), i = 1, …, n, be the pairs of square integrable predictor and response trajectories, which are realizations of the smooth random processes (X, Y), defined on a finite and closed interval,
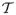 = [0, T]. The smooth random processes have unknown smooth mean functions μX(t) = EX(t) and μY(t) = EY(t), and auto-covariance functions GX(s, t) = cov{X(s), X(t)} and GY(s, t) = cov{Y(s), Y(t)}. Throughout this paper, s and t refer to time indices defined on
. The observed trajectories of the ith subject, Xij = X(Tij) + εij, Yij = Y(Tij) + eij, j = 1, …, Ni are noise contaminated realizations of the random processes X and Y measured at i.i.d. random time points, Tij. Here, εij and eij denote the additive i.i.d. zero mean finite variance measurement errors of the predictor and the response trajectories, respectively. The number of random time points per subject, Ni, are i.i.d. realizations of the random variable N where P(N > 1) > 0.
= [0, T]. The smooth random processes have unknown smooth mean functions μX(t) = EX(t) and μY(t) = EY(t), and auto-covariance functions GX(s, t) = cov{X(s), X(t)} and GY(s, t) = cov{Y(s), Y(t)}. Throughout this paper, s and t refer to time indices defined on
. The observed trajectories of the ith subject, Xij = X(Tij) + εij, Yij = Y(Tij) + eij, j = 1, …, Ni are noise contaminated realizations of the random processes X and Y measured at i.i.d. random time points, Tij. Here, εij and eij denote the additive i.i.d. zero mean finite variance measurement errors of the predictor and the response trajectories, respectively. The number of random time points per subject, Ni, are i.i.d. realizations of the random variable N where P(N > 1) > 0.
Under mild conditions, auto-covariance functions defined above have orthogonal expansions in terms of eigenfunctions ψm(·) and ϕp(·) with nonincreasing eigenvalues γm and ηp,
| (3) |
Then, based on Karhunen-Loéve expansion (Ash and Gardner, 1975), the observations Xij and Yij can be represented as
| (4) |
where ζim and ξik denote the mean zero functional principal component scores with the second moments equal to the corresponding eigenvalues γm and ηp for and .
Let Δt denote the interval, [t − δ1, t − δ2], where 0 < δ2 < δ1 < T, t ∈ [δ1, T], and let Δ denote the interval [0, δ1 − δ2]. Note that the first lag δ1 is the time point beyond which the predictor function does not have an effect on the response function and the second lag δ2 allows a delay for the predictor function to start having an effect on the response function. The recent history functional linear model where , can be given as
| (5) |
for K predetermined basis functions φk(t) defined on Δ. In (5) X̃k(t) = ∫Δt X(s)φk(s − t + δ1)ds, k = 1, …, K, are the induced covariates and bk(t), k = 1, …, K, are the unknown time varying coefficient functions of interest. Defining X̃(t) = [X̃1(t), …, X̃K(t)]T and b(t) = [b1(t), …, bK(t)]T, the model in (5) can be rewritten in vector form as E{Y(t)|X(s), s ∈ Δt} = α(t) + bT(t)X̃(t).
In (5), K controls the resolution of the fit and should be chosen based on the data. Depending on the specific features of the regression function, various basis functions such as Fourier, truncated power, eigen and B-spline basis can be used in (5). Because of their fast computation and good properties, we will use B-spline basis in the following calculations. For more discussions on the B-spline basis, see Fan and Gijbels (1996) and Ramsay and Silverman (2005).
3. Estimation and asymptotic properties
3.1. Proposed estimation algorithm
In the proposed estimation procedure, we utilize connections of the proposed model to varying coefficient models. There are three main estimation methods for varying coefficient models proposed in the literature: local polynomial smoothing (Wu et al., 1998; Hoover et al., 1998; Fan and Zhang, 2000; 2008; Kauermann and Tut, 1999), polynomial spline (Huang et al., 2002; 2004; Huang and Shen, 2004) and smoothing spline (Hastie and Tib-shirani, 1993; Hoover et al., 1998; Chiang et al., 2001).
Note that the previously proposed methods cannot be directly employed here, since the induced covariates, X̃k(t)’s in (5) cannot be estimated well for sparse designs due to the difficulty in numerically approximating the integral in their definition. In fact, the induced covariates may not be well approximated not only in sparse designs but also in longitudinal data in general, since the integration involved is over a narrow window into the past, where there may not be enough points. We propose to base the estimation on the covariance structure to address this difficulty, which will be shown to adjust for measurement error in predictors as well.
Let X̃ik(t) denote observation of the kth covariate in (5) for the ith subject taken at time point t, i.e., X̃ik(t) = ∫Δt Xi(s)φk(s)ds, and X̃i(t) = [X̃i1(t), …, X̃iK(t)]T. The proposed estimation rests on the following equality that follows from (5)
| (6) |
where θ(t) is the K × 1 vector with the kth element equal to cov{X̃k(t), Y(t)}, ν(t) is the K × K matrix with the (k, ℓ)th element equal to cov{X̃k(t), X̃ℓ(t)} and b(t) is the K × 1 vector of K varying coefficient functions. The elements νkℓ(t) and θk(t) can be given in terms of auto- and cross-covariance functions of the predictor and response processes as
| (7) |
and
| (8) |
where GXY(s, t) = cov{X(s), Y(t)}. The estimation of the components given in (7) and (8) begins with estimation of the mean functions, μX(t) and μY(t), via locally smoothing the aggregated data (Tij, Xij) and (Tij, Yij), i = 1, …, n, j = 1, …, Ni. For the estimation of the auto- and cross-covariance functions, we apply two-dimensional local linear smoothing to the raw auto-and cross-covariances defined as GX,i(Tij, Tij′) = {Xij − μ̂X(Tij)}{Xij′ − μ̂X(Tij′)}, GXY,i(Tij, Tij′) = {Xij− μ̂X(Tij)}{Yij′ − μ̂Y(Tij′)}, i = 1, …, n, j, j′ = 1, …, Ni, respectively. To obtain smooth estimates, the raw covariances are fed into a two dimensional local smoothing algorithm where special care needs to be taken in estimating the auto-covariance surface. Since the only terms in the raw auto-covaraince matrix that are perturbed by the additive measurement error on the predictors are along the diagonal, we remove the diagonal before the application of two dimensional smoothing, following (Yao et al., 2005a). Explicit forms of mean and covariance function estimators are given in Appendix C. The smoothing parameters used in the one and two dimensional smoothing procedures for the estimation of the mean functions and covariance surfaces respectively, can be chosen with respect to one-curve-leave-out cross-validation (Rice and Silverman, 1991). For computational efficiency we utilize generalized cross-validation (Liu and Müller, 2008) in simulation studies and data analysis. Plugging the covariance function estimators into equations (7) and (8), and performing numerical integrations, we can obtain the estimators of θ(t) and ν(t), μ̂(t) and ν̂(t), respectively. Then the estimator for varying coefficient vector, b(t), is defined as
leading to the final estimator for the regression surface .
There are two major advantages of the proposed estimation procedure. The first advantage is that, since it depends on estimation of the mean functions and covariance surfaces which are estimated from the entire data, it enables us to surmount the sparsity of the design by pooling information. The second is that it naturally adjusts for measurement error in the predictor process by considering the covariance structure and removing the diagonal terms before smoothing. In addition note that we can get estimates of the covariance surfaces on a fine set of grid points through smoothing, which allows precise numerical integration approximations in the estimation of θ(t) and ν(t).
For a given number of components, K, uniform consistency of the proposed estimator is established by the below Theorem.
Theorem 1
Under Assumptions (A.1)–(A.5) given in Appendix A,
Here, hX is the bandwidth used in obtaining the smooth auto-covariance surface of the predictor process and, h1 and h2 are used in obtaining the cross-covariance surface between the response and predictor processes. The set of bandwidths depend on n and are all required to converge to 0 as n → ∞, for further details see Appendix A.
3.2. Prediction of response trajectories
We will establish the prediction of a new response trajectory, Y*, based on the sparse predictor trajectory X*. In what follows, let us define , where ψm(s) are the eigen-functions of the auto-covariance of the predictor process defined in (3). From the functional representation of the predictor trajectory given in (4), the predicted response trajectory can be given as
| (9) |
where is the mth functional principal component score of the predictor function X*. For estimation of (9), μY(t) can be estimated from aggregated data as described above and estimators of the eigenfunctions, ψm(t), can be obtained from the eigen-decomposition of the estimated auto-covariance surface. Details on these estimation procedures are given in Appendix C. For estimation of in sparse designs, we invoke Gaussian assumptions following Yao et al. (2005b).
Let us define the collection of N* error contaminated observations from the predictor trajectory as , where is the ℓth measurement observed at time point . We assume that ( ), for ℓ = 1, …, N*, are jointly Gaussian. Further define and . Under the Gaussian assumption, the best linear predictor for given X′*, N* and T* is obtained by
| (10) |
where with IN* denoting the N* × N* identity matrix and denoting the variance of the measurement error on the predictor process. Defining and to be the estimators of and respectively, the estimator of can be given as
where the (i, j)th element of Σ̂X′* is defined as where is the estimator of the measurement error variance and δij = 1 for i = j and δij = 0 otherwise. Explicit form of is deferred to Appendix C. Hence the predicted response trajectory is obtained by
| (11) |
where . The number M of eigenfunctions used in the decomposition of the predictor auto-covariance surface, given in (11) can be selected by leave-one-curve-out cross validation, generalized cross validation (GCV), or the Akiake information criterion (AIC). For more details on the selection of M, see Yao et al. (2005a). A consistency result of the predicted trajectory for the target trajectory is established in Theorem 2.
Theorem 2
Under (A1)–(A5), (B1)–(B3) of Appendix A, given T* and N*, for all t ∈ [δ1, T], the predicted trajectories satisfy
Note that, the number M of eigenfunctions used in the eigen-decomposistion of the predictor process is a function of n and tends to infinity as n → ∞.
3.3. Asymptotic confidence bands for the predicted response trajectories
In this section, we construct point-wise asymptotic confidence intervals for the predicted response trajectory, . For M ≥ 1, let us define , where is as defined in (10). Note that . Defining the M × N* matrix , covariance matrix of ζ̃*M can be given in terms of H as . Observing that , we have cov(ζ̃*M − ζ*M|T*, N*) = cov(ζ̃*M|T*, N*) + cov(ζ*M|T*, N*) − 2cov(ζ̃*M, ζ*M|T*, N*) = cov(ζ*M|T*, N*) − cov(ζ̃*M|T*, N*) ≡ ΩM, where ΩM = D − HΣX′* HT with D = diag{γ1, …, γM}. Hence, under the Gaussian assumption, conditioning on T* and N*, ζ̃*M − ζ*M is distributed as N(0, ΩM).
Let and , where D̂ = diag{γ̂1, …, γ̂M } and . Defining P̂(t) = {P̂1(t), …, P̂M(t)}T, Theorem 3 gives the asymptotic distribution of the predicted response trajectory .
Theorem 3
Under (A1)–(A5), (B1)–(B3), and (C1) of Appendix A, given N* and T*, for all t ∈ [δ1, T ] and x ∈ ℝ,
| (12) |
where ωM(t, t) = PT(t)ΩM P(t), ω̂M(t, t) = P̂T(t)Ω̂M P̂(t) and Φ denotes the Gaussian cdf.
From Theorem 3, it follows that ignoring the bias from the truncation in at M eigen-components, the (1 − α)100(%) asymptotic pointwise confidence interval for E{Y*(t)|X*(s), s ∈ Δt} is
4. Numerical issues in implementation and parameter selection
An important issue in the implementation of the proposed estimation algorithm is the inversion of the matrix ν̂(t) in equation (6). To obtain stable estimators for β, penalized solutions have been studied in literature (Cardot et al., 2003) minimizing the penalized least squares
where Q is a K × K matrix that determines the type of penalty used. Here, λ is a tuning parameter that controls the amount of regularization and should be chosen from data balancing the stability and validity of the resulting estimator. The penalized estimator is then given by b̂λ(t) = {ν̂(t) + λQ}−1μ̂(t). A common choice of Q is the K × K identity matrix, which leads to the ridge solution, b̂λ(t) = {ν̂(t) + λI}−1μ̂(t). Another common choice of penalty used is on the degree of smoothness of the penalized solution where Q is chosen such that its (i, j)th element is equal to with denoting the mth derivative of the kth predetermined basis function. In the following applications, we use the ridge solution.
Hence, the proposed estimation procedure for the recent history functional linear model, includes three sets of parameters with different roles: K, λ, and (δ1, δ2). The number of predetermined basis functions used, K, controls the resolution of the fit; the tuning parameter, λ, controls the stability of the estimates; and the window, (δ1, δ2), determines the model used via controlling the predictor window affecting the response. An important observation in the current estimation set-up is that the proposed estimation procedure is not sensitive to the choice of K provided that there are enough number of basis functions used in the estimation, since the penalized solution employed via λ prevents over-fitting. Instead the choice of the tuning parameter λ is a more important choice controlling the stability of the estimates. This fact has been pointed out before in similar functional estimation problems, see Cardot et al. (2003) for further details. We run multiple simulation studies comparing the estimated regression surfaces obtained with different choices of K and λ to confirm this observation, where the results are summarized in Section 5.2. Based on the above argument, following Cardot et al. (2003), we fix K at a value that guarantees good precision and concentrate on the choice of λ and (δ1, δ2). For example, K is fixed at 10 in both the simulation studies and the data example that follow, to include 10 B-spline basis functions of order 4 with 6 interior equi-distance knots in the window Δ, which prove to provide good precision.
For the selection of λ and (δ1, δ2), consider the following two criteria. Define the normalized prediction error (NPE) as
where Ŷij is the predicted value for the jth measurement on the ith response trajectory obtained using λ and (δ1, δ2), is the number of observations from the ith subject obtained in the interval, [δ1, T ], and . Note that NPE measures the relative absolute prediction error which will also be used in evaluating the finite sample performance of the proposed estimates in the simulations given in Section 5. We also define leave-one-curve-out cross validation squared prediction error as
where is the fitted response function value of the ith subject at time point Tij obtained from the data excluding the ith subject. Note that in both criteria, NPE and the cross validation score, the fitted response values are obtained via the prediction methods proposed in Section 3.2.
We propose to estimate λ and (δ1, δ2) in a hierarchical manner, where first λ is chosen for a set of (δ1, δ2) values using NPE and finally the set of (δ1, δ2) values are compared to yield the final choice of (δ1, δ2) with minimum cross validation score. This hierarchical approach has the advantage that the computationally faster NPE criterion is used within the inside loop of choosing λ and that the relatively more refined cross validation score is utilized for the selection of (δ1, δ2), which is similar to model selection in an outer loop. More specifically, the algorithm can be outlined as follows. Let Λ and D be the predetermined sets of λ and (δ1, δ2) values considered. For a fixed (δ1, δ2)0 ∈ D, NPE values are calculated for all λ ∈ Λ. The λ that gives the smallest NPE value is selected as the optimal λ for the given (δ1, δ2)0 and is thus used for calculating the cross validation score for (δ1, δ2)0. Repeating the above steps for all (δ1, δ2) ∈ D, the optimal (δ1, δ2) is selected to be the one with the minimum cross validation score.
5. Simulation studies
In this section, we investigate the finite sample properties of the proposed estimators through two simulation studies. In the first simulation, we study efficiency of the NPE criterion for selecting the tuning parameter λ for a fixed (δ1, δ2) choice, along with the finite sample performance of the proposed estimator based on the selected λ from the algorithm. In the second simulation, we evaluate the performance of the cross validation method for choosing (δ1, δ2) with varying sample size. The following simulation results are reported based on 500 Monte Carlo runs. Bandwidths used in the smoothing of the mean and covariance functions are chosen by generalized cross-validation.
5.1. Data generation
For n subjects, the number of measurements made on the ith predictor and response processes, Ni, are randomly selected from 3, 4, and 5. The design points, Ti1, …, TiNi are randomly selected from the uniform distribution between 0 and 50. At a given time point t, the predictor function is evaluated around the mean function t + sin(t) using two principal components, and for t ∈ [0, 50]. The corresponding two eigen component scores, ζ1 and ζ2, are independently sampled from the Gaussian distributions with mean 0 and the variances, ρ1 = 4 and ρ2 = 1, respectively. Hence, the predictor process at time t is generated via . In addition, i.i.d. measurement error, ε, simulated from the Gaussian distribution with mean 0 and variance , is added to the predictor observations in accordance with (4). The regression function is generated based on the same basis functions used for the predictor process via, , s ∈ Δt, where c11 = 2, c12 = 2, c21 = 1, and c22 = 2. The true window combination, (δ1, δ2), is set at (20, 0). The error function, ε(t), is also generated using the same basis functions as the predictor process with eigen-component scores independently sampled from the Gaussian distributions with mean 0 and variance 0.025, 0.004, respectively. The response function, Y(t) is generated by the equation, ∫Δt β(s, t)X(s)ds+ε(t) using the numerical integration procedure. To obtain a noisy version of the response function, we add i.i.d measurement error, e, generated from the Gaussian distribution with mean 0 and variance 0.025.
5.2. Simulation results
To evaluate the performance of the λ selection criterion, NPE, let us define relative square deviation (RSD) at time t as
The RSD measures the relative size of the squared difference between the estimated and true regression functions at time t. The RSD integrated over the entire support, t ∈ [δ1, T], will be called integrated RSD, denoted IRSD.
Before reporting on results from the two simulation set-ups, we present the true and estimated regression functions with different λ and K choices to demonstrate the relative importance of λ over K in the estimation procedure discussed in Section 4. The true and estimated regression functions are plotted in Figure 1 from three Monte-Carlo simulation runs at n = 200 with (K, λ) equal to (5, 7.4) (Figure 1b, for the NPE minimizer (λ = 7.4)), (5, 1) (Figure 1c) and (10, 7.4) (Figure 1d), respectively. While the difference between the estimators plotted in Figures 1b and 1d is small corresponding to doubling of the K choice, the estimator given in Figure 1c at the wrong λ value of 1 cannot recover the true regression function with IRSD= 298. This confirms that the choice of λ plays a more important role in the proposed estimation algorithm than the choice of K.
Figure 1.

(a) The true regression function defined on Δ = [0, 20]. The estimated regression function with (K, λ) equal to (5, 7.4) (plot b, estimated IRSD= 0.3632), (5, 1) (plot c, estimated IRSD= 298) and (10, 7.4) (plot d, estimated IRSD= 0.3274).
The estimated regression function β̂(s, t) with the tuning parameter λ equal to the minimizer of IRSD can be thought of as the “optimal estimate”, since information on the true regression function is utilized in the comparison. Hence, this estimate can only be obtained in a simulation setting where the true regression function is known. We compare this choice of λ with the minimizer of NPE, which is the only estimate that can be obtained from the data in reality. The performance of the two estimators are compared in Figure 2 in terms of IRSD, where boxplots of estimated IRSD values are given for the optimal and proposed estimates at n = 200 and 500 from 500 Monte-Carlo simulation runs. In the displayed boxplots, 22 and 12 outliers are removed for n = 200 and n = 500, respectively.
Figure 2.

Boxplots of the estimated IRSD values of the proposed and optimal estimators for n = 200 (a) and n = 500 (b). (c) Boxplot of NPE values of the proposed estimators for n = 200 and n = 500.
Figure 2 suggests that the estimator with the λ choice selected via NPE and the one with the optimal choice of λ, both improve with increasing sample size. For the proposed estimators with λ chosen by NPE, the median estimated IRSD is 0.2937 at n = 200 and is 0.20670 at n = 500, which implies that the estimated regression surface is close to the true one. We also give in Figure 2 the boxplots of NPE values of the proposed estimator with λ chosen by NPE. The median NPE value at n = 200 is 0.3196 and the median NPE drops to 0.2928 for n = 500.
The performance of leave-one-curve-out cross validation score for the selection of δ is studied through the second simulation. For the computational efficiency, we use 10 fold cross validation. The true value of (δ1, δ2), is set to be (20, 0), where 6 candidate (δ1, δ2) pairs are considered at (30, 0), (30, 5), (20, 0), (20, 5), and (10, 5). The correct (δ1, δ2) choice ratio out of 500 Monte Carlo runs are 0.8929 and 0.9214 for n = 200 and 500, respectively. There seems to be improvement with increasing sample size.
6. Data analysis
To demonstrate the proposed method, we include an application to the longitudinal primary biliary liver cirrhosis data collected between January 1974 and May 1984 by the Mayo Clinic. In the study design, patients were scheduled to visit the clinic at six months, one year and annually thereafter post diagnosis, where certain blood characteristics were recorded. However, due to missed visits, the data is sparse and highly irregular where each patient visited the clinic at different times. We explore the dynamic relationship between serum albumin level in mg/dl (predictor) and prothrombin time in seconds (response). Both variables are used as an indicator of the liver function, where a decrease in serum albumin levels and elevated prothrombin times are typically associated with malfunctioning of the liver (Murtaugh et al., 1994). We include 201 female patients in the analysis where predictor and response measurements before 2500 days are considered. The number of observations per subject ranges from 1 to 9, with a median of 5 measurements. Individual trajectories of the serum albumin level and prothrombin time overlaying their respective estimated mean functions are given in Figure 3. The generalized cross-validation choice of smoothing bandwidths used in estimation of the prothrombin time and serum albumin level mean functions are 1100 and 1250, respectively. Generalized cross-validation choice for smoothing bandwidths of auto- and cross-covariance surfaces are (400, 400) and (550, 550), respectively. The estimated mean functions indicate opposite patterns as expected, where there is a decreasing trend for the predictor process and an increasing trend for the response.
Figure 3.

(a) Individual predictor trajectories (dashed) overlaying the estimated cross-sectional mean of the predictor process (solid). (b) Individual response trajectories (dashed) overlaying the cross-sectional mean of the response process (solid).
We next fit the proposed recent history functional linear model to the data with K = 10 B-spline functions. Among the five candidate (δ1, δ2) choices considered, [1000, 0], [500, 0], [700, 200], [1000, 200], and [1000, 500], the minimizer of cross-validation error was [1000, 0], and the NPE choice of λ was 6502. To save on computational time, we report results from 10 fold cross validation.
The estimated regression surface is displayed in Figure 4 viewed from two different angles. Most of the estimated regression surface is negative stressing the general opposing trends also observed in literature between serum albumin levels and prothrombin time. For a given time point, the albumin concentration has the strongest effect in magnitude on prothrombin time with a delay of about 500 days where the affect decays as the lag increases. Note also that the observed negative effect of the past albumin concentration levels on the current prothrombin time seems to get more pronounced towards the later stages of the study and hence the disease.
Figure 4.

The estimated regression surface defined on [t − 1000, t] × [1000, 2500] in the longitudinal primary biliary liver cirrhosis data obtained by λ = 6502 and K = 10.
Predicted response trajectories for four randomly selected subjects obtained from the proposals of Section 3.2 and 3.3 and the corresponding 95% asymptotic confidence bands are given in Figure 5. We also include for comparison predicted trajectories obtained from the functional linear model proposed by Yao et al. (2005a). The predicted trajectories seem to be quite close to those from a functional linear model fit which uses the entire predictor trajectory including observations from future and distant past measurement times in the predictions as well. Hence, we conclude that the recent history functional linear model which models the effects of the predictor process from the recent past of 1000 days till the present time, provide a reasonable model for the data in terms of prediction. Given its ease in interpretation due to its restricted regression support when compared with the full functional linear model, the proposed model merges as a viable alternative for the analysis of the current data set.
Figure 5.

Predicted trajectories for 4 randomly selected subjects. In each plot, circles denote the original response observations, the solid line is the response trajectory predicted via the proposed method, the dashed line is the predicted trajectory using the functional linear fit of Yao et al. (2005a), and the dotted lines represent the 95% asymptotic confidence bands.
7. Discussion
We proposed an estimation algorithm for the recent history functional linear models which are useful in applications. The sliding window support of the recent history functional linear model strikes a useful balance between the global support of the functional linear models and the point wise support of the varying coefficient models. The assumption that only the predictor process from the recent past has an effect on the response rather than the future predictor values or only the current predictor value, is useful in many applications where changes in the response process can be explained using recent trends of the predictor process. In addition the product form assumed for the regression surface uses only one dimensional smooth functions considerably easing and speeding estimation.
Our proposal is geared towards sparse longitudinal data where the estimation procedure proposed also accommodates measurement error in variables. Sparsity and measurement error are both commonly encountered in longitudinal designs. We provide asymptotic properties of our estimators that enable the estimation of the predicted response trajectories and that lead to asymptotic confidence bands. Choice of model parameters is also addressed, where favorable properties of the proposed estimators are demonstrated in simulations and data applications.
Acknowledgments
We are extremely grateful to an anonymous referee and the Editor for helpful remarks that improved the paper. Kim’s research is supported by NIDA, NIH grants R21 DA024260 as a research assistant. Li’s research is supported by NIDA, NIH grants P50 DA10075. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIDA or the NIH.
Appendix A. Assumptions
We present the assumptions in three groups, assumptions (A) are needed for all three Theorems, assumptions (B) are needed for the consistency and asymptotic normality of the predicted response trajectories given in Theorems 2 and 3 respectively, and assumption (C1) is only used in Theorem 3.
The data (Tij, Xij) and (Tij, Yij), i = 1, …, n, j = 1, …, Ni, are assumed to be the i.i.d. samples from the joint densities, g1(t, x) and g2(t, y). Assume also that the observation times Tij are i.i.d. with marginal densities
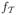 (t). Let T1 and T2 be two different time points, and X1 (respectively Y1) and X2 (respectively Y2) be the repeated measurements of X (respectively Y) made on the same subject at times T1 and T2. The predictor (and response) measurements made on the same subject at different times are allowed to be dependent. Assume (Tij, Til, Xij, Xil), 1 ≤ j ≠ l ≤ Ni, is identically distributed as (T1, T2, X1, X2) with joint density function gXX(t1, t2, x1, x2) and analogously for (Tij, Til, Yij, Yil) with identical joint density function gY Y (t1, t2, y1, y2). The following regularity conditions are assumed on
(t), g1(t, x), g2(t, y), gXX(t1, t2, x1, x2) and gYY(t1, t2, y1, y2). Let p1, p2 be integers with 0 ≤ p1 + p2 ≤ 4.
(t). Let T1 and T2 be two different time points, and X1 (respectively Y1) and X2 (respectively Y2) be the repeated measurements of X (respectively Y) made on the same subject at times T1 and T2. The predictor (and response) measurements made on the same subject at different times are allowed to be dependent. Assume (Tij, Til, Xij, Xil), 1 ≤ j ≠ l ≤ Ni, is identically distributed as (T1, T2, X1, X2) with joint density function gXX(t1, t2, x1, x2) and analogously for (Tij, Til, Yij, Yil) with identical joint density function gY Y (t1, t2, y1, y2). The following regularity conditions are assumed on
(t), g1(t, x), g2(t, y), gXX(t1, t2, x1, x2) and gYY(t1, t2, y1, y2). Let p1, p2 be integers with 0 ≤ p1 + p2 ≤ 4.
-
(A1)
The derivative (dp/dtp)
(t) exists and is continuous on [0, T] with
(t) > 0 on [0, T], (dp/dtp)g1(t, x) and (dp/dtp)g2(t, y) exist and are continuous on [0, T] × ℝ, and {dp/(dtp1dtp2)}gXX(t1, t2, x1, x2) and {dp/(dtp1dtp2)}gYY(t1, t2, x1, x2) exist and are continuous on [0, T]2×ℝ2 for p1 + p2 = p, 0 ≤ p1, p2 ≤ p. -
(A2)
The number of measurements Ni made for the ith subject is a random variable such that , where N is a positive discrete random variable with P(N > 1) > 0. The observation times and measurements are assumed to be independent of the number of observations for any subset Ji ∈ {1,…, Ni} and for all i = 1, …, n, i.e. {Tij, Xij, Yij: j ∈ Ji} is independent of Ni.
Let K1(·) and K2(·, ·) be the nonnegative univariate and bivariate kernel functions for smoothing the mean functions μX and μY, and auto-covariance surface, GX, and cross-covariance surface, GXY. Assume that K1 and K2 are densities with zero means and finite variances on a compact support.
-
(A3)
The Fourier transformations of K1(u) and K2(u, v), defined by κ1(t) = ∫e−iutK1(u)du and κ2(t, s) = ∫e−(iut+ivs)K2(u, v)dudv are required to absolutely integrable, i.e. ∫|κ1(t)|dt < ∞ and ∫∫|κ2(t, s)|dtds < ∞.
Let hX and hY be the bandwidths used for estimating μX and μY, respectively. Also let hG be the bandwidth used for estimating GX, and let (h1, h2) be bandwidths used in the estimation of GXY.
-
(A4)
As n → ∞, the following are assumed about the bandwidths.
-
(A4.1)
hX → 0, hY → 0, , and .
-
(A4.2)
hG → 0, , and .
-
(A4.3)
Without loss of generality, h1/h2 → 1, and .
-
(A5)
Assume that the fourth moments of Y and X are finite.
-
(B1)
The number of eigenfunctions used in (11), M = M(n), is an integer valued sequence that depends on sample size n and satisfies the rate conditions given in assumption (B5) of Yao et al. (2005a).
-
(B2)
The number and locations of measurements for a given subject does not change as the sample size n → ∞.
-
(B3)
For all 1 ≤ i ≤ n, m ≥ 1 and 1 ≤ ℓ ≤ Ni, the functional principal component scores ζim and the measurement errors εiℓ in (4) are jointly Gaussian.
-
(C1)
There exists a continuous positive definite function ω(s, t) such that ωM(s, t) → ω(s, t), as M → ∞.
Appendix B. Proofs
Proof of Theorem 1
Uniform consistency of ĜX(s, t) is given in Theorem 1 of Yao et al. (2005b) and that of ĜXY(s, t) is given in Lemma A.1 of Yao et al. (2005a). Consistency of ν̂kl(t) and μ̂k(t) for νkl and θk(t) follow from uniform consistency of ĜX(s, t) and ĜXY(s, t). This implies consistency of b̂(t) for b(t), and hence that of β̂(s, t).
Proof of Theorem 2
For fixed M, define , where ζ̂m is as defined in (10) and Pm(t) = ∫Δt β(s, t)ψm(s)ds. Then, it follows that
The convergence of Q2 to 0 as n → ∞ follows from Lemma A.3 in Yao et al. (2005a). Note that, for Q1,
Uniform consistency of μ̂Y(t) for μY(t) follows from Theorem 1 in Yao et al. (2005b), and consistency of for follows from Theorem 3 in Yao et al. (2005b). From uniform consistency of β̂(s, t) established in Theorem 1 of Section 3.1 and that of ψ̂k(t) shown in Yao et al. (2005a), uniform consistency of P̂m(t) follows. Combining these results, we have
and by Slutsky’s Theorem, Theorem 2 follows.
Proof of Theorem 3
Under the Gaussian assumption, for any fixed M ≥ 1, we have . In proof of Theorem 2, it is shown that . Observing that , we have . Under assumption (C1), letting M → ∞ leads to . From the Karhunen-Loéve Theorem, . Therefore, . From the convergence of ψ̂(t), , γ̂m and P̂m for ψ(t), , γm and P̃m, we can deduce as n → ∞. Under the assumption (C1), it follows that limM→∞ limn→∞ ω̂M(t, t) = ω(t, t) in probability. Applying Slutsky’s theorem, (12) follows.
Appendix C. Estimation procedures
In this section, we provide explicit forms for the local polynomial smoothing procedures used in estimating the mean functions and covariance surfaces. Eigendecompositions for the estimated covariance surfaces and explicit form of the measurement error variance estimator are also provided.
The estimator of mean function for the predictor process, μ̂X(t), can be obtained by local linear regression via minimizing
with respect to η0, η1, which leads to μ̂X(t) = η̂0. Estimation of μY(t) follows similarly.
For estimation of the cross-covariance surface GXY, the two dimensional local linear smoother is fitted to the raw covariances by minimizing
| (C.1) |
with respect to η = (η0, η1, η2), yielding ĜXY(s, t) = η̂0. Estimation of the auto-covariance surface of the predictor process can be obtained similarly where the diagonal elements of the raw auto covariance matrix are not included in the smoothing as described in Section 3.1. Hence the second sum in (C.1) is taken over 1 ≤ j ≠ ℓ ≤ Ni, excluding the diagonal terms.
In order to obtain the estimator for the measurement error variance , we first estimate the diagonal elements of the auto-covariance surface GX(t, t) excluding the diagonal raw covariances contaminated with error, by applying a local linear smoother along the diagonal and local quadratic smoother along the direction perpendicular to the diagonal. The resulting estimators of the diagonal elements are denoted by G̃X(t). This estimator is then compared to a linear smoother fit only to the diagonal raw covariance terms {Tij, GX,i(Tij, Tij)}, estimating . This estimator is denoted by V̂(t). We estimate the error variance by these two estimators, yielding
where
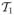 = [T/4, 3T/4]. Here, the integration is taken over the middle half of
in order to remove the boundary effect of the local polynomial smoother.
= [T/4, 3T/4]. Here, the integration is taken over the middle half of
in order to remove the boundary effect of the local polynomial smoother.
The eigenfunctions and eigenvalues of the estimated auto-covariance surface, ĜX(s, t), for the predictor process are the solutions, ψ̂k and γ̂k, of the eigenequation given by
where and ∫[0,T] ψ̂m(t)ψ̂k(t)dt = 0 for m ≠ k. For numerical solutions, discretization of the smoothed covariance function can be used following Rice and Silverman (1991).
References
- Ash RB, Gardner MF. Topics in Stochastic Processes. Academic Press; New York: 1975. [Google Scholar]
- Cardot H, Ferraty F, Sarda P. Spline estimators for the functional linear model. Statistica Sinica. 2003;13:571–592. [Google Scholar]
- Chiang CT, Rice JA, Wu CO. Smoothing spline estimation for varying coefficient models with repeatedly measured dependent variables. Journal of the American Statistical Association. 2001;96:605–619. [Google Scholar]
- Cleveland WS, Grosse E, Shyu WM. Local regression models. Statistical Models in S. 1991:309–376. [Google Scholar]
- Fan J, Gijbels I. Local Polynomial Modeling and Its Applications. Chapman and Hall; London: 1996. [Google Scholar]
- Fan J, Zhang W. Two-step estimation of functional linear models with applications to longitudinal data. Journal of the Royal Statistical Society Series B (Methodological) 2000;62:303–322. [Google Scholar]
- Fan J, Zhang W. Statistical methods with varying coefficient models. Statistics and Its Interface. 2008;1:179–195. doi: 10.4310/sii.2008.v1.n1.a15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fleming T, Harrington D. Counting Processes and Survival Analysis. Wiley; New York: 1991. [Google Scholar]
- Hastie T, Tibshirani R. Varying coefficient models. Journal of the Royal Statistical Society Series B (Methodological) 1993;55:757–796. [Google Scholar]
- Hoover D, Rice J, Wu C, Yang L. Nonparametric smoothing estimates of the time-varying coefficient models with longitudinal data. Biometrika. 1998;85:809–822. [Google Scholar]
- Huang J, Shen H. Functional coefficient regression models for nonlinear time series: a polynomial spline approach. Scandinavian Journal of Statistics. 2004;31:515–534. [Google Scholar]
- Huang JZ, Wu CO, Zhou L. Varying-coefficient models and basis function approximations for the analysis of repeated measurements. Biometrika. 2002;89:111–128. [Google Scholar]
- Huang JZ, Wu CO, Zhou L. Polynomial spline estimation and inference for varying coefficient models with longitudinal data. Statistica Sinica. 2004;14:763–788. [Google Scholar]
- James G, Hastie TJ, Sugar CA. Principal component models for sparse functional data. Biometrika. 2000;87:587–602. [Google Scholar]
- Kauermann G, Tutz G. On model diagnostics using varying coefficient models. Biometrika. 1999;86:119–128. [Google Scholar]
- Kim K, Şentürk D, Li R. Technical report. The Pennsylvania State University; 2009. The recent history functional linear models. [Google Scholar]
- Liu B, Müller HG. Functional data analysis for sparse auction data. Wiley and Sons Inc; 2008. pp. 269–290. [Google Scholar]
- Malfait N, Ramsay JO. The historical functional linear model. Canadian Journal of Statistics. 2003;31:115–128. [Google Scholar]
- Müller HG. Functional modelling and classification of longitudinal data. Scandinavian Journal of Statistics. 2005;32:223–240. [Google Scholar]
- Murtaugh P, Dickson E, Van Dam G, Malinchoc M, Grambsch P, Langworthy A, Gips C. Primary biliary cirrhosis: prediction of short-term survival based on repeated patient visits. Hepatology. 1994;20:126–134. doi: 10.1016/0270-9139(94)90144-9. [DOI] [PubMed] [Google Scholar]
- Ramsay J, Silverman B. Functional Data Analysis. Springer-Verlag; New York: 2002. [Google Scholar]
- Ramsay J, Silverman B. Functional Data Analysis. Springer-Verlag; New York: 2005. [Google Scholar]
- Rice J. Functional and longitudinal data analysis: Perspectives on smoothing. Statistica Sinica. 2004;14:631–647. [Google Scholar]
- Rice J, Silverman B. Estimating the mean and covariance structure nonparametrically when data are curves. Journal of the Royal Statistical Society Series B (Methodological) 1991;53:233–243. [Google Scholar]
- Şentürk D, Müller HG. Generalized varying coefficient models for longitudinal data. Biometrika. 2008;95:653–666. [Google Scholar]
- Şentürk D, Müller HG. Functional varying coefficient models for longitudinal data. Journal of the American Statistical Association. 2010 in-press. [Google Scholar]
- Shi M, Weiss RE, Taylor JMG. An analysis of paediatric CD4 counts for acquired immune deficiency syndrome using flexible random curves. Applied Statistics, Journal of the Royal Statistical Society Series C. 1996;45:151–163. [Google Scholar]
- Wu CO, Chiang CT, Hoover D. Asymptotic confidence regions for kernel smoothing of a varying coefficient model with longitudinal data. Journal of the American Statistical Association. 1998;93:1388–1389. [Google Scholar]
- Yao F, Müller HG, Wang JL. Functional data analysis for sparse longitudinal data. Journal of the American Statistical Association. 2005a;100:577–591. [Google Scholar]
- Yao F, Müller HG, Wang JL. Functional linear regression analysis for longitudinal data. Annals of Statistics. 2005b;33:2873–2903. [Google Scholar]