

Abstract
Many motile eukaryotic cells determine their direction by measuring external chemical gradients through the binding of ligands to membrane bound receptors. This process is limited by fluctuations arising from the binding process and from the diffusion of the ligand molecules. Here, we apply estimation-theoretic methods to determine the physical limits of gradient sensing for cells that are non-circular and for cells that have an internal bias. Specifically, we derive theoretical expressions for the accuracy of gradient sensing in elliptical cells. This accuracy for highly elliptical cells can significantly deviate from the gradient sensing limits derived for circular cells. Furthermore, we find that a cell cannot improve its sensing of the gradient steepness and direction simultaneously by elongating its cell body. Finally, we derive a lower bound on the accuracy of gradient sensing for cells that possess an internal bias and compare our analytical results with recent experimental findings.
I. INTRODUCTION
The response in biological systems to external stimuli is often limited by the inherent stochasticity of these stimuli. For example, the accuracy of human (and other vertebrate) vision at low light intensities approaches a fundamental limit set by statistical fluctuations of the number of absorbed photons [1, 2]. Another example includes the embryo patterning along the anterior-posterior axis of the fly Drosophila melanogaster which is primarily determined by concentration profiles of certain morphogens [3]. The accuracy of the resulting pattern is limited by the noise levels in these profiles. A final example is provided by chemotaxis, the directed movement of cells up or down a chemical gradient. In both prokaryotic chemotaxis, where cells measure and compare concentration signals over time [4, 5], and in eukaryotic chemotaxis, where cells measure concentration differences in space [6, 7], the precision of gradient sensing is limited by the stochastic binding of diffusing chemical molecules (ligands) to specific chemoreceptors on the cell membrane.
In this paper, we will apply techniques from estimation theory, which attempts to estimate the values of parameters based on measured data that contain a random component [8], to eukaryotic gradient sensing. Even though our approach and results are applicable in a general way, we will focus mainly on the social amoeba Dictyostelium discoideum, a well-characterized model system [9, 10]. Specific G-protein coupled receptors on the Dictyostelium cell membrane bind and detect the chemoattractants in the surrounding medium. This results in an asymmetric distribution of ligand-occupied receptors, which further activates multiple second-messenger pathways inside the cell and drive the extension of pseudopods preferentially in the direction of the chemoattractant gradient. Due to fluctuations in the ligand binding to chemoreceptors, the receptor signal is inherently noisy, as demonstrated by recent single-molecule imaging experiment [11]. Surprisingly, Dictyostelium cells exhibit extremely high sensitivity to gradients, as they have been observed to be able to detect a 1 – 2% difference in chemical concentration across the cell length [12, 13]. The difference in receptor occupancy between the front and back halves of a cell in these shallow gradients can be calculated to be 10–30. This raises a puzzle about eukaryotic chemotaxis: how can cells reliably acquire the gradient information from such a noisy receptor signal?
In 1977, Berg and Purcell analyzed bacterial chemotaxis and demonstrated that the limit of uncertainty of concentration sensing is set by the diffusion of ligand particles [14]. Their seminal work has been extended by many others [15–19]. The results of Berg and Purcell, however, do not completely carry over to eukaryotic cells, which employ a spatial sensing mechanism. In this mechanism, and in contrast to prokaryotic chemotaxis, cells use the spatial asymmetry (including the gradient steepness and direction) to direct their motion. A number of studies have been carried out to reveal the limits to spatial gradient sensing, but are either only applicable to idealized mechanisms that ignore the receptor kinetics [18], adopt heuristic signaling models [20, 21] or use a simplified geometry [22]. We recently addressed this problem for circular cells using a general statistical mechanical approach, where we view the surface receptors as a (possibly coupled) spin chain and treat the chemical gradient as a perturbation field [23]. By calculating the system’s partition function, we were able to derive the gradient sensing limits for either independent receptors or receptors exhibiting cooperativity. Furthermore, using information theoretical concepts and comparing theoretical results with experiments of chemotaxing Dictyostelium cells, we have shown that for shallow gradients and low background concentrations, the accuracy of gradient sensing is upper-bounded by fluctuations at the receptor level [13, 24].
In this paper, we will first revisit the spatial gradient sensing problem for circular cell shapes using purely estimation-theoretic methods (Section II). This will be the foundation for our extension to the elliptical cell shapes in the next section (Section III). Finally, we will examine how a possible intracellular bias can affect the perceived gradient and compare our results with recent experimental data (Section IV).
II. GRADIENT SENSING FOR A CIRCULAR CELL
We revisit the gradient sensing problem which we have examined in our previous paper using the method of maximum likelihood estimate (MLE) [8, 19, 23]. Consider a circular cell with diameter L placed in a chemoattractant gradient and assume that there are N receptors uniformly distributed on the cell perimeter. The angular coordinates of these receptors are denoted by ϕn for n = 1, …, N, which satisfy the uniform distribution P(ϕn) = 1/(2π). We further assume that the gradient field takes an exponential profile as has recently been realized in experiments [13, 25]. Then the local concentration at the n-th receptor can be expressed as , where C0 is the ambient (mean) concentration, defines the gradient steepness that quantifies the percentage concentration change across the cell length L, and φ denotes the gradient direction. Each receptor switches independently between two states, either empty (0) or occupied (1), with transition rates determined by the local concentration and the relevant chemical kinetics. Therefore, these receptors in a single snapshot constitute a series of independent Bernoulli random variables, represented by
| (1) |
for n = 1, …, N. For simple ligand-receptor kinetics, the occupancy probability of the nth receptor is Pn = Cn/(Cn + Kd), where Kd = k−/k+ is the dissociation constant. The probability mass distribution for Eq. (1) can be expressed as:
| (2) |
where Θ ≡ {p, φ} represents the parameters to estimate. Therefore, the likelihood function for a sample of N independent receptors is given by
| (3) |
and the log-likelihood function is
| (4) |
Here, we introduce the transformation Θα = (α1, α2)T ≡ (p cos φ, p sin φ)T and define (z1, z2) ≡ (Σn xn cos ϕn, Σn xn sin ϕn) which measures the spatial asymmetry in the receptor occupancy. Then, we have , and for shallow gradients the log-likelihood function becomes
| (5) |
The method of maximum likelihood estimates the unknown parameters by finding a value of Θα that maximizes
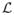 (Θα|x1, …, xN), i.e.,
(Θα|x1, …, xN), i.e.,
| (6) |
where the subscript “mle” denotes the maximum likelihood estimator. Since the logarithm is a continuous strictly increasing function over the range of the likelihood, the values which maximize the likelihood will also maximize its logarithm. Thus, the MLE can be found from ∂α1 ln
= 0 and ∂α2 ln
= 0, with the following solution
| (7) |
This solution is indeed the maximum of the likelihood function since it is the only turning point in Θα and the second derivative is strictly less than zero. By the properties of MLE, both α̂1 and α̂2 are asymptotically unbiased and normal as the sample size N goes to infinity, i.e., and , where “ ” denotes convergence in distribution. The asymptotic variances and can be derived from the inverse of the Fisher information matrix [8, 19]. This matrix has to be diagonal here as α1 and α2 are independent of each other. Thus, we have
| (8) |
where <> represents the expectation and the proof of the second equality can be found in [8]. This equality holds because ln
is twice differentiable with respect to α1 and α2. From the relation α̂1,2 = z1,2/μ, we can see that < z1,2 >= μα1,2 and that the asymptotic variances of z1 and z2 are equal:
| (9) |
In addition, one can check that the covariance is Cov[z1, z2] = 0, as reflected in the affine form of the log-likelihood: ln
= α1z1/2 + α2z2/2 + …. Thus, for small p, the joint probability density of z1 and z2 is [23, 25]:
| (10) |
As the one-to-one transformation of Θ̂α,mle, the MLE of Θ = (p, φ)T is given by
| (11) |
If we introduce the complex random variable Z ≡ z1+iz2, then Z follows the complex Gaussian distribution, and in the polar coordinates Z = μp̂exp(iφ̂). Eq. (10) suggests that we can define a signal-to-noise (SNR) ratio
| (12) |
Again, by the properties of MLE, both p̂ and φ̂ tend to be unbiased and normal in the large N limit, i.e., and . It has been found numerically that the asymptotic normality becomes excellent when the SNR is larger than 9 [25, 26]. Similarly, the asymptotic variances and can be computed from the inverse of the Fisher information matrix with respect to Θ = (p, φ). The matrix is still diagonal due to the orthogonality of p and φ. Thus, we have
| (13) |
| (14) |
or equivalently
| (15) |
The above results are identical to the ones we have recently derived in [23]. According to the Cramér-Rao inequality, the variances and represent the minimal uncertainties of gradient measurements from an instantaneous sampling of the receptor states [8].
If the cell in question integrates receptor signals over some time interval
 , then averaging over multiple measurements should obviously reduce the errors of gradient sensing. However, the error-reduction via temporal averaging is limited by the expected time it takes to perform an independent measurement. As shown in [17, 27], the time to make a single measurement is roughly twice the receptor correlation time τ. Hence, the number of independent measurements a cell can make within
is about
/(2τ). The correlation time can be decomposed as τ = τrec + τdiff, where τrec = 1/(k− + C0k+) is the time-scale of receptor-ligand reaction and τdiff ≅ N/(2πDLKd) describes the diffusion noise correlation time [15, 17, 20, 21, 23]. Let η ≡ τdiff/τrec, then the measurement is said to be reaction-limited if η ≪ 1 and diffusion-limited if η ≫ 1 [28]. Combining the above arguments, we find that integrating signals over
yields better gradient estimate,
, then averaging over multiple measurements should obviously reduce the errors of gradient sensing. However, the error-reduction via temporal averaging is limited by the expected time it takes to perform an independent measurement. As shown in [17, 27], the time to make a single measurement is roughly twice the receptor correlation time τ. Hence, the number of independent measurements a cell can make within
is about
/(2τ). The correlation time can be decomposed as τ = τrec + τdiff, where τrec = 1/(k− + C0k+) is the time-scale of receptor-ligand reaction and τdiff ≅ N/(2πDLKd) describes the diffusion noise correlation time [15, 17, 20, 21, 23]. Let η ≡ τdiff/τrec, then the measurement is said to be reaction-limited if η ≪ 1 and diffusion-limited if η ≫ 1 [28]. Combining the above arguments, we find that integrating signals over
yields better gradient estimate,
| (16) |
We can derive similar results for the direction inference, since . For typical eukaryotic cells, it has been estimated [17, 28] that η ≪ 1, which implies that .
An implicit assumption in the above derivation as well as in our previous paper [23] is that a cell can tell the location of each individual receptor. This is reflected in (z1, z2) ≡ (Σn xn cos ϕn, Σn xn sin ϕn) which keeps track of every individual receptor and its spatial position. Since the density of receptors on the cell surface can be high, one may argue that the cell cannot distinguish between receptors that are very close to each other. We can, however, easily relax this assumption by taking advantage of the Central Limit Theorem (CLT). To see this, we divide the cell surface into M small sensory sectors such that receptors in the same sector are responding to an almost identical chemical concentration. Therefore, receptors in the same sector can be regarded as independent and identically distributed (Bernoulli) random variables, and the state of each sector is represented by its receptor occupancy number which follows the binomial distribution. One can think of M as a quantity that reflects to what extent the cell can spatially distinguish its receptors. Of course, we want to ensure that the number of receptors in each sector Ns = N/M is large enough for the application of CLT. Here, we will choose M = 1000 and N = 40, 000, leading to Ns = 40. Now the local concentration at the mth sector with angular position ϑm = 2πm/M is given by for m = 1, …, M. Using the CLT, the number of occupied receptors in the mth sector in a single snapshot, ym, is approximately ym = NsCm/(Cm + Kd) + ηm (m = 1, …, M), where the Gaussian random component ηm satisfies 〈ηm〉 = 0 and 〈ηmηn〉 = δmnNsCmKd/(Cm + Kd)2 ≈ δmnNsC0Kd/(C0 + Kd)2 [20, 21, 28]. For small gradients, we can expand ym around p:
| (17) |
We can see that the sector states, denoted by Y = {y1, y2, …, yM}T, constitute a vector of independent Gaussian random variables with space-dependent means but approximately identical variance . Hereafter, the superscript symbol T means transpose. Eq. (17) suggest that one can view Y = {y1, y2, …, yM}T as observations of a sinusoidal signal corrupted by some white Gaussian noise. The likelihood function of Y conditional on Θ reads,
| (18) |
where
| (19) |
To maximize P(Y|Θ) is equivalent to minimize J(Y|Θ) which can be converted to a quadratic function by the one-to-one transformation Θα = (α1, α2)T = (p cos φ, p sin φ)T:
| (20) |
with
We can apply the formula of ordinary least squares (OLS) estimate to find the MLE solution that minimizes the quadratic objective function J(Y|Θα) and hence maximizes the likelihood function P(Y|Θα):
| (21) |
For large M, we have , and . Thus,
where in the last line we have noticed that z1 = Σn xn cos ϕn ≃ Σm ym cos ϑm and z2 = Σn xn sin ϕn ≃ Σm ym sin ϑm for sufficiently large M. By inverse mapping, we recover the MLE of Θ given in Eq. (11). According to the asymptotic properties, , with the Fisher information matrix:
| (22) |
Then, we recover our main MLE results:
| (23) |
| (24) |
III. GRADIENT SENSING FOR AN ELLIPTICAL CELL
Motile eukaryotic cells can become polarized and exhibit elongated shapes, which may affect the capacity of gradient sensing. In this section, we analyze a chemotactic cell with an elliptical geometry (Fig. 1). The ellipse can be described in parametric form (X(ω), Y(ω)) = (a cos ω, b sin ω), where a is the semi-major axis, b is semi-minor axis (thus b ≤ a) and 0 ≤ ω ≤ 2π. With ϑ = 0 measured from the major axis, the ellipse can also be described in polar coordinates by
FIG. 1.

Schematic representation of our model: an elliptical cell, covered with receptors, is placed in an exponential gradient. The angle between the direction of the gradient and the major axis of the elliptical cell is denoted by φ. The forward and backward rates k± control the transition between the bound and unbound states for the receptors.
| (25) |
where is the eccentricity of the ellipse and measures how much the geometry deviates from being circular. Obviously, ω and ϑ are related through
| (26) |
| (27) |
As before, we distribute the receptors uniformly along the cell circumference and divide the cell’s circumference into M sectors with identical arc lengths (containing Ns = N/M receptors). In the exponential gradient, the local concentration at the mth sector with polar angle ϑm and radius rm is
| (28) |
where φ is the gradient direction measured from the major axis and p ≡ 2a|∇→C|/C0 is the gradient steepness that quantifies the percentage concentration change across the major axis 2a. Here, we have used that
| (29) |
As before, the receptor occupancy number is ym = NsCm/(Cm + Kd) + ηm, for m = 1, …, M. For shallow gradients, we can expand ym to leading order in p:
| (30) |
where the random component ηm is approximately normal: 〈ηm〉 = 0 and . Thus, the likelihood function of Y = {y1, y2, …, yM}T is , where
| (31) |
with Θα = (α1, α2)T = (p cos φ, p sin φ)T and
| (32) |
Thus, the MLE of Θα is
| (33) |
Due to symmetry, one can directly find that
| (34) |
| (35) |
| (36) |
For convenience, we define the following two functions which we will evaluate later on:
| (37) |
| (38) |
Then, the MLE of Θα is given by
| (39) |
The expectations and variances of α̃1,2 are
One can also check that their covariance Cov[α̃1, α̃2] = 0.
Next, we evaluate Λ1,2(ε). Each sector has an arc length equal to
 /M, where
= 4aE(ε) is the circumference of the ellipse and
is the complete elliptic integral of the second kind. The arc length of the ellipse between ϑ = 0 and ϑ = ϑ(ω0) is given by
. Then,
. For sufficiently large M, we can approximate:
/M, where
= 4aE(ε) is the circumference of the ellipse and
is the complete elliptic integral of the second kind. The arc length of the ellipse between ϑ = 0 and ϑ = ϑ(ω0) is given by
. Then,
. For sufficiently large M, we can approximate:
| (40) |
where g(·) represents a general integrable function. Therefore, we have
| (41) |
where is the complete elliptic integral of the first kind. Similarly, one can find
| (42) |
Since Λ1,2(ε = 0) = 1/2, we have , consistent with Eq. (8). Therefore, α̃1,2 → α̂1,2 as the cell shape tends to be circular. In the other extreme, we have limε → 1 Λ1(ε) = 2/3 and limε → 1 Λ2(ε) = 0.
The MLE of Θ = (p, φ)T can be found directly,
| (43) |
where the last line is due to the asymptotic normality of MLE: as the sample size increases, the distribution of the MLE tends to the Gaussian distribution with mean Θ and covariance matrix equal to the inverse of the Fisher information matrix,
| (44) |
where
| (45) |
| (46) |
| (47) |
Again, one can use Eq. (40) to calculate the above three functions. Here, we will skip all the intermediate technical steps and will only present the final results:
| (48) |
| (49) |
where
It is easy to check that and , consistent with our results for the circular cell (Eqns. 13, 14). Also, we find that the covariance of p̃ and φ̃ can be written as Cov[p̃, φ̃] = A0(ε) sin(2φ), which vanishes at φ = 0, ±π, ±π/2. For the special case φ = 0, Eq. (48) reduces to . As b → 0 such that ε → 1, the ellipse becomes a one-dimensional segment of length 2a, which can measure the gradient steepness with an accuracy .
To determine how the eccentricity affects the accuracy of gradient estimates and to compare with our results for the circular cell, we fix the area of the elliptical cell, i.e., let be constant. We also keep the gradient profile identical by fixing p0 ≡ |∇→C|/C0. Then, the gradient is proportional to the major axis: p = 2ap0 = p(a). These assumptions allow us to define the following ratios as a measure how the eccentricity will change the gradient sensing limits:
| (50) |
| (51) |
with Λ1(ε) and Λ2(ε) given by Eq. (41) and Eq. (42).
In Fig. 2 we have plotted, as solid and dashed lines, these ratios for different values of φ (the gradient direction measured from the major axis). In the same figure, we have also plotted as symbols the results of our Monte-Carlo simulations. In these simulations, the ellipse of a given eccentricity ε was divided into M = 1000 sectors with equal arc lengths. Each sector contained Ns = 40 receptors and the receptor occupancy number for each sector, ym, was assigned a Gaussian random variable with mean NsCm/(Cm + Kd) and variance NsCmKd/(Cm+Kd)2. After plugging these random numbers into Eq. (39) and Eq. (43) for 104 realizations, we computed the numerical values for the sample variances of p̃ and φ̃. As shown in the figure, the agreement between our analytical and numerical results is excellent.
FIG. 2.

Δp and Δφ as a function of the eccentricity ε for different values of φ (lines: analytical expressions; symbols: Monte-Carlo simulations).
In the case where the gradient direction points along the major axis of the elliptical cell (φ = 0 and Fig. 2A), we see that Δp is a decreasing function of the eccentricity ε. This can be intuitively understood by realizing that for an elongated cell pointing in the gradient direction, the difference in concentration, and thus the difference in occupied receptors between the back and front sectors becomes large. Therefore, the more elongated the cell is along the gradient direction, the more accurately the cell is able to measure the gradient steepness. In contrast, Δφ increases with ε such that more elongated cells are less accurate in estimating the gradient direction than circular cells. When the external gradient is parallel to the cell’s minor axis (φ = ±π/2 and Fig. 2C), we have exactly the opposite: Δp increases with ε while Δφ decreases with ε. Finally, for the intermediate case φ = ±π/4 (Fig. 2B), we have Δp = Δφ and they both increase with ε. Depending on the gradient angle φ, the ratios can be even non-monotonic with ε; for example, Δp at φ = π/6 will first decrease and then increase with ε (data not shown).
It is noteworthy that gradient sensing generally fails in the line segment limit (ε → 1), except for the special cases of steepness sensing at φ = 0, ±π and direction sensing at φ = ±π/2. As a vector, the concentration gradient can be decomposed into two orthogonal components, one along the major axis of the cell pmajor = p cos φ and the other along the minor axis pminor = p sin φ. When sensing the gradient magnitude (steepness), the line-segment cell is only able to detect the magnitude of pmajor. But there is unlimited uncertainty in the other component pminor (except for vanishing pminor at φ = 0 or ±π). This explains why Δp always diverges as ε → 1 except for φ = 0 and ±π. Similar arguments hold for directional sensing: a line-segment cell can only tell the direction of the gradient component perpendicular to itself (i.e., pminor) but has unlimited uncertainty about pmajor which disappears only for φ = ±π/2.
Our analytical and numerical results reveal that, for every gradient direction φ, a cell cannot improve the gradient steepness and direction estimates simultaneously by elongating its cell body. It is difficult to connect this result to the experimental measurements of the accuracy of chemotaxis. This is mostly done in the form of the chemotactic index (CI), defined as the distance traveled by the cell in the direction of the gradient divided by the total distance traveled. Clearly, the CI is a function of both the accuracy in gradient steepness and gradient direction. To determine the relative importance of these two parameters would require a precise knowledge of the gradient sensing and cell motility process, both of which are currently absent.
Even in the absence of such precise knowledge, however, we can conclude that elongated cell shapes can strongly affect the cell’s accuracy of gradient sensing. In experiments, the cell shape varies depending on the precise conditions. Chemotactic neutrophils, for example, are found to have eccentricities up to 0.8 [29, 30]. For these values, we find that the variances of estimating gradient steepness and direction in the elliptical cells differ by a factor of 2 compared to the ones in circular cells. Furthermore, Dictyostelium cells can have much higher eccentricities (ε ≈ 0.95) [31]. Such highly elliptical geometries are expected to have even more significant effects on the accuracy of gradient sensing. Thus, the sensing limits derived using a circular geometry are a good approximation only for cells that are not significantly elongated.
IV. DIRECTIONAL SENSING IN THE PRESENCE OF AN INTRACELLULAR BIAS
A large number of experiments have revealed that an external cue can induce spatial localization of several signaling proteins along the plasma membrane during eukaryotic directional sensing [7, 10, 32]. The membrane localization of these signaling molecules enables a cell to polarize and migrate toward the external chemical source. Samadani et. al. have quantitatively monitored the spatial and temporal localization of one of the key signaling component fused to GFP [33]. Their data provides evidence for inherent asymmetries in the intracellular signaling network of cells prior to stimulation. The magnitude of this asymmetry was found to vary significantly from cell to cell. This naturally raises the question: what is the accuracy of directional sensing in the presence of such an intracellular bias?
To address this question, we can use a nonuniform prior distribution P(φ) to represent this internal bias and apply the maximum a posteriori (MAP) estimation. Specifically, we assume that the prior distribution follows the circular normal (CN) distribution in directional statistics, P(φ) = exp[κε cos(φ − φε)]/(2πI0(κε)), where φε denotes the bias direction, κε controls the magnitude of the bias, and I0(·) is the modified Bessel function of order zero. We have plotted the CN distribution in Fig. 3A for various values of κε.
FIG. 3.

A: The circular normal distribution for different values of κε. B: The lower bound on the variance in gradient sensing as a function of the direction of the bias φε (relative to the gradient direction) for different values of the strength of the bias κε. Parameter values are N = 40, 000 and C0 = Kd, resulting in a SNR of κ = 12.5.
The MAP estimate of φ is
| (52) |
with γ ≡ 2κε/p. This expression is similar to the maximal polarization angle derived from the geometric model in [33]. In the limit κε → 0, the prior distribution becomes uniform and the MAP estimate recovers the MLE of the gradient direction, i.e., φ̂map → φ̂. In the other extreme that κε → ∞, the prior distribution becomes a delta function and φ̂map → φε. Let z̃1 ≡ z1 + γ cos φε and z̃2 ≡ z2 + γ sin φε. Then, by Eq. (10), they are independent and both normal: z̃1 ~
 (α1 + γ cos φε, σ2) and z̃2 ~
(α2 + γ sin φε, σ2). If we define Z̃ = z̃1 + iz̃2, then Z̃ follows the complex Gaussian distribution and its phase variable is just the MAP estimator, i.e., φ̂map = arctan(z̃2/z̃1). As demonstrated in [25, 26], the phase of a complex Gaussian random variable has a distribution symmetric about the expected value of the phase. In our case, this implies that the MAP estimator φ̂map is symmetrically distributed about its mean
(α1 + γ cos φε, σ2) and z̃2 ~
(α2 + γ sin φε, σ2). If we define Z̃ = z̃1 + iz̃2, then Z̃ follows the complex Gaussian distribution and its phase variable is just the MAP estimator, i.e., φ̂map = arctan(z̃2/z̃1). As demonstrated in [25, 26], the phase of a complex Gaussian random variable has a distribution symmetric about the expected value of the phase. In our case, this implies that the MAP estimator φ̂map is symmetrically distributed about its mean
| (53) |
One can see that the value of 〈φ̂map〉 is largely determined by the ratio γ/(μp) = 2κε/(μp2) = κε/κ, where κ is the signal-to-noise ratio defined in Eq. (12).
In statistics, the bias function of an estimator is the difference between this estimator’s expected value and the true value of the parameter being estimated. In our case, the bias function of the MAP estimator is
| (54) |
Obviously, φ̂map is a biased estimator of φ due to bias in P(φ). The squared estimation error of φ̂map is
| (55) |
According to the Cramér-Rao inequality for biased estimators [34] the first term is bounded by
| (56) |
where the Fisher information has been calculated before, . Therefore,
| (57) |
In Fig. 3B we have plotted the lower bound of σφ,map as a function of the direction of the bias φε for different values of the bias strength κε. As expected, directional sensing is most accurate when the intracellular bias direction coincides with the extracellular gradient direction (φε = φ) and becomes less accurate it differs significantly from the gradient direction. This is consistent with the experimental findings in [33] which showed that the GFP polarization is strongest at φε = φ and weaker at φε = φ± π. Of course, we have chosen a fixed value for the parameter κε, corresponding to a single cell. To deal with a population averaged as in typical experiments, one would have to assign a probability distribution to κε (arising from cell individuality). This quenched randomness is expected to enlarge the cell-to-cell variability of directional sensing response, as observed in [33].
V. SUMMARY
In this paper we have used various concepts and techniques in estimation theory to investigate the physical limits of eukaryotic gradient sensing. We have derived explicit formulas for the variances of estimating both the gradient direction and steepness for an elliptical cell. Our theoretical and numerical results suggest that a cell cannot improve its sensing of both the gradient steepness and direction at the same time by simply elongating itself. We also show that highly eccentric cell shapes can significantly change the gradient sensing limits, which may be relevant in experimental observations for chemotactic eukaryotes like neutrophils and Dictyostelium. Finally, we examined how an intracellular bias may distort the cell’s perception of external stimuli. As expected, the accuracy of gradient detection increases when the internal bias aligned with the external gradient but decreases when the direction of the internal bias is significantly different from the external gradient direction. Our approach is general and in principle can be extended to cases including non-uniformly distributed receptors or more complicated cell shapes.
Acknowledgments
We thank W.F. Loomis and M. Skoge for valuable discussions. This work was supported by NIH Grant P01 GM078586.
References
- 1.Barlow HB. Proc R Soc Lond B Biol Sci. 1981;212:1. doi: 10.1098/rspb.1981.0022. [DOI] [PubMed] [Google Scholar]
- 2.Rieke F, Baylor DA. Biophys J. 1998;75:1836. doi: 10.1016/S0006-3495(98)77625-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Houchmandzadeh B, Wieschaus E, Leibler S. Nature. 2002;415:798. doi: 10.1038/415798a. [DOI] [PubMed] [Google Scholar]
- 4.Bray D, Levin MD, Morton-Firth CJ. Nature. 1998;393:85. doi: 10.1038/30018. [DOI] [PubMed] [Google Scholar]
- 5.Sourjik V, Berg HC. Proc Natl Acad Sci U S A. 2002;99:123. doi: 10.1073/pnas.011589998. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Parent CA, Devreotes PN. Science. 1999;284:765. doi: 10.1126/science.284.5415.765. [DOI] [PubMed] [Google Scholar]
- 7.Haastert PJV, Devreotes PN. Nat Rev Mol Cell Biol. 2004;5:626. doi: 10.1038/nrm1435. [DOI] [PubMed] [Google Scholar]
- 8.Kay S. Fundamentals of Statistical Signal Processing: Estimation Theory. Prentice Hall; Upper Saddle River: 1993. [Google Scholar]
- 9.Janetopoulos C, Firtel RA. FEBS Lett. 2008;582:2075. doi: 10.1016/j.febslet.2008.04.035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Rappel WJ, Loomis WF. Wiley Interdiscip Rev Syst Biol Med. 2009;1:141. doi: 10.1002/wsbm.28. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Ueda M, Sako Y, Tanaka T, Devreotes PN, Yanagida T. Science. 2001;294:864. doi: 10.1126/science.1063951. [DOI] [PubMed] [Google Scholar]
- 12.Song L, Nadkarni SM, Bödeker HU, Beta C, Bae A, Franck C, Rappel WJ, Loomis WF, Bodenschatz E. Eur J Cell Biol. 2006;85:981. doi: 10.1016/j.ejcb.2006.01.012. [DOI] [PubMed] [Google Scholar]
- 13.Fuller D, Chen W, Adler M, Groisman A, Levine H, Rappel WJ, Loomis WF. PNAS. 2010;107:9656. doi: 10.1073/pnas.0911178107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Berg HC, Purcell EM. Biophysical Journal. 1977;20:193. doi: 10.1016/S0006-3495(77)85544-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Bialek W, Setayeshgar S. PNAS. 2005;102:10040. doi: 10.1073/pnas.0504321102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Bialek W, Setayeshgar S. Phys Rev Lett. 2008;100:258101. doi: 10.1103/PhysRevLett.100.258101. [DOI] [PubMed] [Google Scholar]
- 17.Wang K, Rappel WJ, Kerr R, Levine H. Phys Rev E. 2007;75:061905. doi: 10.1103/PhysRevE.75.061905. [DOI] [PubMed] [Google Scholar]
- 18.Endres RG, Wingreen NS. PNAS. 2008;105:15749. doi: 10.1073/pnas.0804688105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Endres RG, Wingreen NS. Phys Rev Lett. 2009;103:158101. doi: 10.1103/PhysRevLett.103.158101. [DOI] [PubMed] [Google Scholar]
- 20.Rappel WJ, Levine H. PNAS. 2008;105:19270. doi: 10.1073/pnas.0804702105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Rappel WJ, Levine H. Phys Rev Lett. 2008;100:228101. doi: 10.1103/PhysRevLett.100.228101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Endres RG, Wingreen NS. Prog Biophys Mol Biol. 2009;100:33. doi: 10.1016/j.pbiomolbio.2009.06.002. [DOI] [PubMed] [Google Scholar]
- 23.Hu B, Chen W, Rappel WJ, Levine H. Phys Rev Lett. 2010;105:048104. doi: 10.1103/PhysRevLett.105.048104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Hu B, Chen W, Levine H, Rappel WJ. Submitted. [Google Scholar]
- 25.Hu B, Fuller D, Loomis WF, Levine H, Rappel WJ. Phys Rev E. 2010;81:031906. doi: 10.1103/PhysRevE.81.031906. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Gudbjartsson H, Patz S. Magn Reson Med. 1995;34:910. doi: 10.1002/mrm.1910340618. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.van Haastert PJ, Postma M. Biophys J. 2007;93:1787. doi: 10.1529/biophysj.107.104356. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Lauffenburger DA, Linderman JL. Receptors. Oxford University Press; New York: 1996. [Google Scholar]
- 29.Onsum MD, Wong K, Herzmark P, Bourne HR, Arkin AP. Phys Biol. 2006;3:190. doi: 10.1088/1478-3975/3/3/004. [DOI] [PubMed] [Google Scholar]
- 30.Nishio M, Watanabe K, Sasaki J, Taya C, Takasuga S, Iizuka R, Balla T, Yamazaki M, Watanabe H, Itoh R, et al. Nat Cell Biol. 2007;9:36. doi: 10.1038/ncb1515. [DOI] [PubMed] [Google Scholar]
- 31.Skoge Monica. personal communication.
- 32.Ridley AJ, Schwartz MA, Burridge K, Firtel RA, Ginsberg MH, Borisy G, Parsons JT, Horwitz AR. Science. 2003;302:1704. doi: 10.1126/science.1092053. [DOI] [PubMed] [Google Scholar]
- 33.Samadani A, Mettetal J, Oudenaarden A. PNAS. 2006;103:11549. doi: 10.1073/pnas.0601909103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Dayan P, Abbott L. Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems. The MIT Press; Boston: 2001. [Google Scholar]