

Summary
We extend the standard multivariate mixed model by incorporating a smooth time effect and relaxing distributional assumptions. We propose a semiparametric Bayesian approach to multivariate longitudinal data using a mixture of Polya trees prior distribution. Usually, the distribution of random effects in a longitudinal data model is assumed to be Gaussian. However, the normality assumption may be suspect, particularly if the estimated longitudinal trajectory parameters exhibit multimodality and skewness. In this paper we propose a mixture of Polya trees prior density to address the limitations of the parametric random effects distribution. We illustrate the methodology by analyzing data from a recent HIV-AIDS study.
Keywords: Conditional predictive ordinate, Longitudinal data, Mixture of Polya trees, Penalized spline
1 Introduction
Longitudinal data analysis, in which repeated measurements are taken on subjects at various time points, plays an important role in applied statistics, especially in biomedical research involving clinical trials. Rather than considering a single outcome, it is common nowadays to measure multiple outcomes on a subject to characterize an effect of interest, thus resulting in multivariate longitudinal data. Although statistical methods and estimation techniques are well developed for univariate longitudinal data (Grizzle & Allen, 1969; Khatri, 1966; Pothoff & Roy, 1964; Laird & Ware, 1982; Kleinman & Ibrahim, 1998; Shah et al., 1997; Zhang et al., 1998; Zeger & Diggle, 1994; Diggle et al., 2002), relatively little attention has been concentrated on longitudinal data of a multivariate response. Reinsel (1984) considered a multivariate random intercept covariance structure for balanced data. However, balanced data are quite unlikely in a longitudinal setting. Shah et al. (1997) developed a multivariate longitudinal model for unbalanced data with inference carried out via the EM algorithm. They assumed multivariate longitudinal data with Gaussian random effects and allowed for missing observations. They considered two responses (log CD4 count, log CD8 count) in their example; each was modelled linearly, and so the subject-specific random effect was 4-dimensional. Roy & Lin (2002) also developed a multivariate model for longitudinal data that allows for missing observations, assuming a latent variable approach. Recently, Fieuws & Verbeke (2006) developed a pairwise approach in which all possible bivariate models are fitted.
In this paper we take a Bayesian approach to multivariate longitudinal data. Our method generalizes existing methods on several issues. Most of the mixed models above provide a flexible likelihood framework to model continuous correlated outcomes parametrically. However, in practice the parametric assumption on the covariate effects may not always be appropriate; in our example CD4 and CD8 counts vary in a complicated manner over time (see Figure 1). To model longitudinal data of this kind, Zhang et al. (1998) and Zeger & Diggle (1994) considered semiparametric mixed models. In this paper we extend their semiparametric approach to the multivariate setting. We specify fixed covariate effects, but develop a smooth function of time to model the overall mean population effect, and account for the within-subject correlations using random effects. The unknown function is modelled using a linear combination of B-spline basis terms (de Boor, 1978), where the coefficients are modelled using a pairwise shrinkage prior distribution. In multivariate longitudinal data, random effects are usually assumed to have a normal distribution, and it may well happen that this distributions does not correctly fit the data at hand. This is particularly true if the data are multimodal, skewed, have outliers, or consist of diverse populations. Specifically, in our application we consider data on two widely used markers in HIV-AIDS studies: CD4 and CD8 counts. These data are collected from a new AIDS clinical trial (ACTG 398). It is well known that these markers usually have a high amount of between-subject variability (Figure 1). Thus, the normal distribution may not effectively model this extra heterogeneity in the samples. Also, observations from each patient's profile may not have the same distribution. For example, in a clinical study some patients may drop out of the study before the study ends. The longitudinal observations of the patients who left the study may not have the same distribution as those who completed the study (Brown & Ibrahim, 2003). Based on these observations, it is desirable to take the random effects from a sufficiently large class to capture such possibilities. Thus, we consider a model for multivariate random effects which generalizes the parametric normal distributional assumption to include a class of distributions that allows for features such as skewness and multimodality as well as generalizes the parametric models.
Figure 1.

Trajectories of log(CD4) and log(CD8) for 10 randomly selected subjects, ACTG 398 data.
One can use a simple extension of the existing model that employs a finite mixture of normal distributions for random effects. However, determining the number of mixands can be problematic; identifiability issues also arise. In contrast, continuous mixtures alleviate these problems, with nonparametric specification of the mixing distribution being most attractive. Thus, in this paper we assume a multivariate mixture of Polya trees (MPT) prior distribution for q-dimensional random effects. Univariate Polya tree and MPT models have been recently developed (Lavine, 1992, 1994; Walker & Mallick, 1997, 1999; Berger & Guglielmi, 2001; Hanson & Johnson, 2002; Hanson, 2006), but relatively little has been done for the multivariate case. We model the random effects distribution for our multivariate longitudinal data as a mixture of absolutely continuous finite Polya trees in ℝq centred at the family of mean-zero q-variate Gaussian distributions. This new framework allows the incorporation of the existing prior information based on the parametric model. This robust generalization has the potential to capture departures from a normal distribution, while having a good performance if the actual distribution is normal. One of the major advantages of using Polya tree prior distributions is that, in contrast to Dirichlet process prior distributions, they can place probability one on the set of absolutely continuous distributions. We perform the analysis within a Bayesian framework, thus providing a coherent means of inference and allowing for easy computation by standard Markov chain Monte Carlo (MCMC) techniques (Gelfand & Smith,1990).
The paper is organized as follows. In the next section we develop a model for multivariate longitudinal data. In Section 3 we develop the Bayesian analysis of the parametric model. We relax the normality assumption with multivariate MPT and Polya tree prior distributions in Section 4. In Section 5 we describe and analyze a clinical trial data set, ACTG 398; Section 6 draws conclusions.
2 Multivariate mixed model
Here we introduce our notation for the form of the multivariate longitudinal model. Let the sample in a longitudinal study consists of K characteristics and m subjects, with the ith subject having ni measurements over time. Let yijk denote the measurement of the ith subject at time tij for characteristic k, i = 1, 2, …, m; k = 1, 2, …, K; j = 1, 2, …, ni. Then the semiparametric mixed model for outcome yijk is given by
| (1) |
where βk is the pk × 1 vector of regression coefficients associated with covariates xijk (pk × 1), and fk(t) is a twice-differentiable smooth function of time for characteristic k. Thus, we allow each characteristic to have a unique nonparametric population mean function in time. The γik are independent qk × 1 vectors of random effects associated with covariates zijk (qk × 1), and the eijk are independent measurement errors.
Let yik = (yi1k, yi2k, …, yinik)⊤. Then we define the following notation:
| (2) |
We write t0 for the vector of the r ordered distinct time points of {tij}. Nik is the incidence matrix for the ith subject and kth characteristic connecting ti = (ti1, …, tini) to t0 such that the (j, h)th element of Nik is 1 if and 0 otherwise for j = 1, 2, …, ni, h = 1, 2, …, r. Finally, , the subject-specific design matrix Xik contains the ni rows , and Zik contains the ni rows .
We assume that , where γij ∈ ℝqj, . For initial model development, γi is assumed to have a Nq(0, D) distribution, where D is a symmetric positive definite matrix. The normality assumption for γi will be relaxed in Section 4, where we will assume a nonparametric distribution for γi. The measurement error eik is assumed to be distributed as N(0, Rik), where . We also assume independence between γi and eik.
3 Smoothing spline and priors
Let be the set of parameters for model (2), where we generically write for any matrices v1, …, vn. We assume conditionally conjugate, independent prior distributions that lead to simpler updating schemes in the Markov chain sampling methodology. In particular,
We model each of the K flexible nonparametric time effects in (2) as a linear decomposition of basis terms. Suppose that . Let us suppress the notation k for the moment. Then f is modlled as
Here {b1, …, bL} are B-spline basis functions of degree 2 with equidistant knots, and ϕ = (ϕ1, …, ϕL)⊤ are the associated coefficients. To ensure that the function is flexible, yet smooth, we follow the methodology of Lang & Brezger (2004) and place a first order random walk prior distribution on the coefficients, so that
Here the random walk variance τ2 can be interpreted as a smoothing parameter. Thus the resulting conditional prior density for ϕ satisfies
with a banded penalty matrix
Now let us generalize the above prior density for fk(t). Write the vector of function evaluations as the product fk = Bkϕk, where Bk is an L × r design matrix. Then the prior density on the penalized spline coefficients can be cast into a general form as follows:
For the variance parameter we assume an inverse gamma distribution, i.e., . This prior structure is a Bayesian interpretation of the work of Eilers & Marx (1996), who constructed a difference penalty from the random walk prior and took a penalized maximum likelihood approach.
Because the marginal and joint posterior distributions are analytically intractable, an MCMC sampling scheme is used to produce iterates from the joint posterior distribution, from which the full spectrum of inference can be constructed. Full details of the evaluation of conditional posterior distributions are provided in the Appendix.
4 Nonparametric random effects distribution
We consider a MPT prior distribution for the distribution G on the γis in order to relax distributional assumptions. Many authors have investigated nonparametric distributions for random effects. Kleinman & Ibrahim (1998) considered a univariate linear mixed effects model where the random effects γ1, …, γm ∈ ℝq arise from a probability measure G assigned a Dirichlet process prior distribution. Zhang & Davidian (2001) considered modelling the random effects distribution in a standard linear mixed model as the square of a polynomial of order K multiplied by a bivariate Gaussian density. Song, Davidian & Tsiatis (2002) extended this approach to the joint modelling of survival and longitudinal data. and modelled a bivariate random effects distribution for CD4 counts in this manner. More recently, Ghidey, Lesaffre & Eilers (2004) considered modelling a bivariate random effects distribution using a mixture of bivariate Gaussian densities with fixed locations.
Lavine (1992) introduced MPT models and noted that random partitions smooth out partitioning effects seen in simple Polya tree models. Berger & Guglielmi (2001) considered a univariate MPT model with a fixed partition to test whether data arise from a parametric family versus a nonparametric alternative. The marginal model is fitted using an importance sampling distribution derived from the parametric family. Hanson & Johnson (2002) considered a median regression model with a univariate MPT prior distribution on the error density centred at a scaled family of Gaussian distributions.
Paddock (1999) and Paddock et al. (2003) considered multivariate Polya trees centred at a multivariate uniform distribution. They randomly jittered the partition, smoothing out the partition effects in a manner similar to an MPT. Hanson (2006) proposed a class of multivariate MPT prior distributions that generalized the multivariate Gaussian family. In either approach, the Polya tree is fully specified up to a finite level J and suffers from an explosion of parameters when the dimension q climbs past 2 or 3. For a q-dimensional MPT prior distribution, the number of 2q-dimensional Dirichlet vectors needed to define the model is . For example, for a finite 4-dimensional tree with J = 5 levels, 69 905 16-dimensional Dirichlet vectors are required, along with the 10 parameters in D. For this reason, we instead develop associated marginal models which have only the parameters in the covariance matrix D.
A random probability measure G given a Polya tree prior distribution is defined by a class of partitions
and a class of Dirichlet distribution parameters 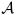 . We consider one method to extend the “canonical” partitions of described in Lavine (1992) to multiple dimensions.
. We consider one method to extend the “canonical” partitions of described in Lavine (1992) to multiple dimensions.
The space ℝq is partitioned at level j by sets B0(j; k1, …, kq) where kl = 1, …, 2j, l = 1, …, q. Define
| (3) |
Let denote the class of partitions at level j, . The transformed partitions are obtained from (3) through
| (4) |
Clearly, if y ∼ Nq(0, D), then Pr(y ∈ BD(j; k1, …, kq)) = 2−qj.
Let Sj = {1, …, 2j−1}q. Define vectors of conditional probabilities Cj;s = (C(j; k1, …, kq) : kl = 2sl − 1, 2sl; l = 1, …, q), where s = (s1, …, sq)⊤ ∈ Sj, by
| (5) |
For example, C2;(1,2) = (C(2; 1, 3), C(2; 1, 4), C(2; 2, 3), C(2; 2, 4))⊤. These are the conditional probabilities of, respectively, sets BD(2; 1, 3), BD(2; 1, 4), BD(2; 2, 3), BD(2; 2, 4) given BD(1; 1, 2). The G-measure of a set in
given 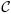 = {Cj,s : j = 1, …, J; s ∈ Sj} is defined to be
= {Cj,s : j = 1, …, J; s ∈ Sj} is defined to be
| (6) |
where ⌈·⌉ is the ceiling function. On sets at level J, we assume that G follows a Nq(0, D) distribution given D. That is, for A ⊂ BD(J, k1, …, kq), G(A)∣G(BD(J, k1, …, kq)) = 2qJ ΦD(A)G{BD(J, k1, …, kq)}.
Denote the prior Polya tree (PT) model on the measure G, given by (4)-(6), as G ∼ PTq(α, ρ, ΦD) and further assume the hyperprior D−1 ∼ Wishart(η0, Ση). The random effects model is then
| (7) |
It is easy to verify, given D, for y∣G ∼ G, G ∼ PTq(c, ρ, ΦD), that E(y) = 0, cov(y) = D, and Pr(y ∈ A) = ∫A ϕD (x) dx, where ϕD(·) is the probability density function (pdf) of a Nq(0, D) vector. The precision α determines how “close” the random probability measure G is to the centering ΦD, with larger values giving G ≈ ΦD (Hanson, 2006).
Given a vector y ∈ ℝq, we need to know which set k = (k1, …, kq)⊤ in at level j, BD(j; k1, …, kq), contains it. This is given by
The kth index of kD(j − 1,w) is recursively given by the ceiling of one half of the kth index of kD(j, w).
Define nD(j, s; γ1:t) to be the 2q-dimensional vector {# in BD(j; k1, …, kq)} where each kl, l = 1, …, q, ranges over the two values 2sl − 1 and 2sl. Then the full conditional distribution for Cj,s is given by
Let y ∈ ℝq. Given and D, the pdf of G is given by
where p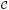 (k1, …, kq) = G{BD(J; k1, …, kq)}, which is obtained from (6).
(k1, …, kq) = G{BD(J; k1, …, kq)}, which is obtained from (6).
Given γ1:i and D, the expected value of the pdf of G is given by
| (8) |
Through (8), the marginal pdf of γ1, …, γm is thus given by
When the vectors are evenly distributed among sets BD(j∣k1,…, kq) on each level j, qD(γ1:m; α) = 1 and the parametric density is obtained. We exploit this fact in the construction of Metropolis-Hastings proposal distributions for sampling D given the remaining parameters as well as sampling the γ1, …, γm.
Assuming the model (7), the full conditional distribution for D given and γ1, …, γm is
By experimenting with various types of Metropolis-Hastings proposal distributions, we have found a Metropolis-Hastings step centred at the current value D−1 updates D−1 fairly well when the estimated random effects are not highly “non-normal.” Updating D−1 proceeds by sampling D*−1 ∼ Wishart(df, D−1/df) and accepting the proposal D*−1 with probability
The random effects γ1, …, γm are also updated via Metropolis-Hastings steps by generating , where Ri = diag(Ri1, …, RiK) and Zi = diag(Zi1, …, ZiK) (see Appendix), and accepting the proposal with probability
where is the set γ1:m with replacing γi. When a prior density p(α) is placed on α, the full conditional distribution is given by p(α∣;γ1:m, D) ∝ p(α)qD(γ1:m; α). Updates proceed via Metropolis-Hastings steps as before.
To our knowledge, the random effects model we present is the only direct generalization of the Gaussian model considered in the literature. Under Dirichlet process mixing, a Gaussian model is obtained in the limit as the precision goes to zero, but this is at the boundary of the parameter space. A formal Bayes factor can be computed (see, for example, Basu & Chib, 2003), but the models are not formally nested in the sense that one can test H0 : θ = θ0 where θ0 is an interior point of Θ. Thus, to compare the different models, we follow Geisser & Eddy (1979), who introduced a predictive criterion termed the log pseudo marginal likelihood (LPML). The conditional predictive ordinate (CPO) for the (ijk)th observation is
where y(−ijk) denotes the rest of the data after deleting the (ijk)th observation. The expectation is taken with respect to the posterior distribution of the model parameter given the cross-validated data y(−ijk). Gelfand & Dey (1994) suggested a particularly simple method to obtain estimates of CPO statistics from MCMC output, which we adapt to the situation at hand.
A useful aggregate measure of predictive model performance is the sum of the log CPO statistics: . The model with the larger LPML value is the better-fitting model from a predictive standpoint. One can compute a pseudo-Bayes factor for comparing model 2 to model 1, defined as PBF21 = exp(LPML2−LPML1). Kadane & Lazar (2004) noted that predictive measures, such as the pseudo-Bayes factor, attempt to find “which models give the best predictions of future observations generated from the same process as the original data”.
5 Data Analysis
We illustrate our method using data from a large clinical trial on HIV-AIDS, ACTG 398. All regimens included the following ART drugs: abacavir, a nucleoside reverse transcriptase inhibitor (NRTI); adefovir dipivoxil, another NTRI; efavirenz, a non-NRTI (NNRTI); and amprenavir, a protease inhibitor (PI). In addition, three of the four arms included a second PI: saquinavir, indinavir, or nelfinavir, respectively, whereas the fourth arm received a matched placebo. Thus, three of the treatment arms were similar in that they contained a second PI drug, while the fourth arm had a single PI drug and a matched PI placebo. The results of the primary analysis were reported by Hammer et al. (2002). Based on these results, we combined the three dual PI arms together, versus the single PI arm. Thus, we take two treatment arms in our analysis. The primary objective of the study was to compare the proportion of subjects who had virologic failure after 24 weeks on study between the double-PI arms and the single-PI arm. The subjects in the trial were either NNRTI naive, i.e., they had not previously received drugs from the NNRTI class, or NNRTI experienced, i.e., they had previously received NNRTIs as part of their treatment. NNRTI naive subjects have a better virologic response in the trial. We are interested in analyzing the markers, CD4 and CD8 cell counts of the subjects on the study. These markers were measured at r = 47 distinct time points starting from the 0th week to a maximum 56th week. However, not all subjects have responses at each time point. We discarded patients with two or fewer (ni ≤ 2) observations and thus our analysis consisted of m = 454 patients with a total of observations. The covariates we included in this analysis are: treatment (second PI versus placebo), NNRTI experience, and baseline log10 viral load. We assumed 10 equally-spaced knots between and , so the number of quadratic B-spline basis functions is 11.
We fitted the following bivariate model:
| (9) |
for i = 1, …, 454; j = 1, …, ni, and k = 1, 2. Again, yijk is the response of the kth marker for the ith subject at the jth time point tij (in weeks), k = 1 denotes the log(CD4) count and k = 2 denotes the log(CD8) count. The covariates are fixed for each subject i across the ni time points: xij11 = xij21 = log10 baseline HIV RNA, xij12 = xij22 = treatment arm (1=double-PI and 0=single-PI placebo), and xij13 = xij23 = NNRT experience (1=experienced and 0=naive). The γ0ik and γ1ik are subject i's random effects corresponding to each marker. The longitudinal model can be interpreted as follows. The smooth trajectory fk(t) is an overall mean response for marker k that anticipates a time-dependent population response, for example a dip following by a levelling off after a subject was initially enrolled in the trial. The ith subject's “intercept” term γ0ik allows for a global subject deviation in population mean response and the “slope” γ1ik can be interpreted as the subject-specific difference from the overall population rate of change of the marker at any time t.
More complex subject-specific trajectories are easily modelled in the existing framework. For example, each trajectory could be modelled with a second nonpenalized spline on top of the population trend fk(t). However given the very limited number of measurements taken on each subject, this would amount to gross overfitting of these data. For example, Brown, Ibrahim & DeGruttola (2005) considered this sort of framework with a normal prior distribution on the subject-specific spline coefficients; their fitted mean trajectories tracked the data quite well, even with measurements totalling as few as ni = 4.
Prior values were fixed as follows: α = 5, 10, ∞; the μks were zero vectors; Σk = 10−6I4 (precision matrices for β1 and β2); (precision matrix for Wishart prior); η0 = 4; ν01 = ν02 = δ01 = δ02 = a1 = b1 = a2 = b2 = 0.001. The matrix Ση was chosen to centre D−1 at precision values obtained by Shah, Laird & Schoenfeld (1997) for a different, but similar, data set on (log(CD4), log(CD8)) counts using a Gaussian model. The degrees of freedom (df), df = 3 worked well for α = 10, df = 6 worked for α = 5. However, obtaining reasonable mixing was difficult for α = 1.
Table 1 gives the posterior means and standard deviations (in parentheses) of model parameters along with the LPML values. Predictively, the MPT model with α = 5 is a better model than either α = 10 or the parametric model (α = ∞). The LPML from fitting the model without the splines, but rather an overall population line and with Gaussian random effects is −2024. The LPML assuming a spline rather than a simple linear function in time was −1933, indicating vastly increased predictive utility. The baseline HIV-RNA is a significant covariate for both CD4 and CD8, since the 95% credible intervals do not contain zero across models. However, none of the other covariates are significant in any of the models. These results are similar across the various MPT and the normal models; however, there is a general decreasing trend in both estimated effects and standard deviations as α decreases from ∞ to small values. The estimates of treatment effect are negative for both markers, suggesting a decrease in marker count over the the study period. However, the NNRTI experience was estimated to be negative for CD4 count and positive for CD8 count, although not significant. Hammer et al. (2002) found that, at 48 weeks, there was no significant difference in mean changes in CD4 cell counts relative to baseline in combined double-PI arms versus single-PI placebo, in line with our retaining the hypothesis H0 : β12 = 0.
Table 1.
Posterior means (standard deviations) of regression effects and LPML values for models (9) and (7), ACTG 398 data. α is the mixture of Polya trees (MPT) and Polya tree (PT) prior distribution precision; higher α values indicate a more parametric model.
|
α ∼ Γ(5, 1) PT |
α = 5 MPT |
α =10 MPT |
α = ∞ Parametric |
|
|---|---|---|---|---|
| LPML | −1901 | −1924 | −1930 | −1933 |
| β11 | −0.294 (0.040) | −0.399 (0.0489) | −0.439 (0.0488) | −0.490 (0.0493) |
| β12 | −0.068 (0.062) | −0.0608 (0.0706) | −0.0246 (0.0744) | −0.00619 (0.0788) |
| β13 | −0.147 (0.054) | −0.125 (0.0679) | −0.136 (0.0710) | −0.145 (0.0743) |
| β21 | −0.064 (0.030) | −0.102 (0.0315) | −0.121 (0.0324) | −0.140 (0.0318) |
| β22 | −0.032 (0.043) | −0.0196 (0.0470) | 0.0029 (0.0489) | 0.00915 (0.0507) |
| β23 | 0.036 (0.043) | 0.0323 (0.0461) | 0.0325 (0.0468) | 0.0330 (0.0480) |
As α falls from α = ∞ (parametric model) to α = 10 to α = 5, the overall predictive performance of the model increases according to the LPML measure. For α = 1, reasonable MCMC mixing did not occur even after 100 000 iterations. We instead fitted a simple Polya tree model with D−1 fixed at the posterior mean under the α = 10 model, assigned a prior distribution on α as α ∼ gamma(5, 1). The MCMC mixed very well for this simple PT model. The resulting posterior mean and standard deviation for α were 0.176 and 0.147, a marked shift towards much smaller values than under the prior, and indicating highly “non-normal” random effects. The LPML for the simple PT model increased by about 22, yielding a pseudo Bayes factor of e22 ≈ 109 in favor of the simple PT model with a prior distribution on α. The estimated regression coefficients under this simple Polya tree model are also given in Table 1. Under the MPT model, the correlation between the intercepts is estimated to be 0.61, the correlation between the slopes 0.86. But the correlation between intercept and slope is 0.10 for log(CD4) and −0.13 for log(CD8). Thus, there is a high degree of similarity between CD4 and CD8 counts within a subject over time.
Figure 2 shows the kernel-smoothed estimated posterior densities for the random effects along with the posterior estimates of the m = 454 values from fitting the PT model with α ∼ gamma(5, 1). It is clear from these graphs that the PT ably models the non-normal, skewed characteristics of these densities. Figure 3 shows the estimated mean trajectories for two patients, along with 95% credible intervals; the solid circles represent the observed log CD4 and CD8 counts. The solid line is the parametric model with spline mean, and the dashed line is the simple PT model with spline mean and α ∼ Gamma(5, 1). The trajectories are not wildly different, but some differences are noticeable, especially for the CD8 counts. Differences in predictive (CD4, CD8) counts for subjects not in the study are bound to show more dissimilarities, if interest is rather in predictive inference.
Figure 2.

Estimated marginal densities (lines) and posterior mean random effects (dots) from simple Polya tree model with α ∼ gamma(5, 1), ACTG 398 data. Top panels are intercept (left) and slope (right) for log(CD4), bottom panels are for log(CD8).
Figure 3.

Raw data (dots) and estimated trajectories for two subjects, ACTG 398 data. Solid lines are parametric (α → ∞) model and dashed lines are simple Polya tree model. Columns are subjects and the top panel is log(CD4), bottom log(CD8).
6 Conclusion
Normality of random effects is a routine assumption for linear mixed models, but may be unrealistic. In this paper, we have proposed an approach based on a nonparametric Bayesian method for multivariate longitudinal data, where the random effects are assumed to have a flexible MPT prior distribution that generalizes the standard Gaussian assumption. The model with an MPT prior distribution is shown to outperform the usual Gaussian random effects model. We have found in general that an MPT outperforms a PT with a fixed covariance matrix estimated from either an MPT model or the parametric model, with the same fixed value of α.
Though our model was built from the features of the data at hand, it has general application to situations where multiple responses are measured over time. As pointed out, our model can have more general subject-specific curves such as splines, but due to data limitations, we instead considered a more parsimonious model.
Acknowledgments
The authors thank the editor, associate editor, and referees for their valuable suggestions. Dr. Hanson's research was supported in part by USA NIH grant 2-R01-CA95955-05.
Appendix: Conditional Distributions Under the Gaussian Model
Define matrices Xi = diag(Xi1 …, XiK), Zi = diag(Zi1 …, ZiK), Ni = diag(Ni1 …, NiK), Ri = diag(Ri1, …, RiK), and the vectors , , . Define , , and .
The full conditional distributions under the parametric normal model are:
References
- Basu S, Chib S. Marginal likelihood and Bayes factors for Dirichlet process mixture models. J Amer Statist Assoc. 2003;98:224–235. [Google Scholar]
- Berger JO, Guglielmi A. Bayesian testing of a parametric model versus nonparametric alternatives. J Amer Statist Assoc. 2001;96:174–184. [Google Scholar]
- Brown ER, Ibrahim JG. A Bayesian semiparametric joint hierarchical model for longitudinal and survival data. Biometrics. 2003;59:221–228. doi: 10.1111/1541-0420.00028. [DOI] [PubMed] [Google Scholar]
- Brown ER, Ibrahim JG, DeGruttola V. A flexible B-spline model for multiple longitudinal biomarkers and survival. Biometrics. 2005;61:64–73. doi: 10.1111/j.0006-341X.2005.030929.x. [DOI] [PubMed] [Google Scholar]
- de Boor C. A Practical Guide to Splines. New York: Springer-Verlag; 1978. [Google Scholar]
- Diggle P, Heagerty P, Liang K, Zeger S. Analysis of Longitudinal Data. Oxford: Oxford University Press; 2002. [Google Scholar]
- Eilers PHC, Marx BD. Flexible smoothing with B-splines and penalties. Statist Sci. 1996;11:89–121. [Google Scholar]
- Fieuws S, Verbeke G. Pairwise fitting of mixed models for the joint modeling of multivariate longitudinal profiles. Biometrics. 2006;62:424–431. doi: 10.1111/j.1541-0420.2006.00507.x. [DOI] [PubMed] [Google Scholar]
- Geisser I, Eddy W. A predictive approach to model selection. J Amer Statist Assoc. 1979;74:153–160. [Google Scholar]
- Gelfand AE, Dey D. Bayesian model choice: asymptotic and exact calculations. J Roy Statist Soc Ser B. 1994;56:501–514. [Google Scholar]
- Gelfand AE, Smith AFM. Sampling based approaches to calculating marginal densities. J Amer Statist Assoc. 1990;85:398–409. [Google Scholar]
- Ghidey W, Lesaffre P, Eilers PHC. P-spline smoothing of the random effects distribution in a linear mixed model. Biometrics. 2004;60:945–953. doi: 10.1111/j.0006-341X.2004.00250.x. [DOI] [PubMed] [Google Scholar]
- Grizzle JE, Allen DM. Analysis of growth and dose-response curves. Biometrics. 1969;25:357–381. [PubMed] [Google Scholar]
- Hanson TE. Inference for mixtures of finite Polya trees models. J Amer Statist Assoc. 2006;101:1548–1565. [Google Scholar]
- Hanson T, Johnson W. Modeling regression error with a mixture of Polya trees. J Amer Statist Assoc. 2002;97:1020–1033. [Google Scholar]
- Hammer SM, Vaida F, Bennett KK, et al. Dual vs single protease inhibitor therapy following antiretroviral treatment failure. J Amer Med Assoc. 2002;288:169–180. doi: 10.1001/jama.288.2.169. [DOI] [PubMed] [Google Scholar]
- Kadane JB, Lazar NA. Methods and criteria for model selection. J Amer Statist Assoc. 2004;99:279–290. [Google Scholar]
- Khatri CG. A Note on a MANOVA model applied to problems in growth curve. Ann Inst Statist Math. 1966;8:75–86. [Google Scholar]
- Kleinman K, Ibrahim JG. A semi-parametric Bayesian approach to the random effects model. Biometrics. 1998;54:921–938. [PubMed] [Google Scholar]
- Laird NM, Ware JH. Random effects model for longitudinal data. Biometrics. 1982;38:963–974. [PubMed] [Google Scholar]
- Lang S, Brezger A. Bayesian P-Splines. J Comput Graph Statist. 2004;13:183–212. [Google Scholar]
- Lavine M. Some aspects of Polya tree distributions for statistical modelling. Ann Statist. 1992;20:1222–1235. [Google Scholar]
- Lavine M. More aspects of Polya tree distributions for statistical modelling. Ann Statist. 1994;22:1161–1176. [Google Scholar]
- O'Brien PC. Procedures for comparing samples with multiple endpoints. Biometrics. 1984;40:1079–1087. [PubMed] [Google Scholar]
- Paddock SM. Unpublished Doctoral Thesis. Duke University; 1999. Randomized Polya Trees: Bayesian Nonparametrics for Multivariate Data Analysis. [Google Scholar]
- Paddock S, Ruggeri F, Lavine M, West M. Randomised Polya Tree Models for Nonparametric Bayesian Inference. Statist Sinica. 2003;13:413–460. [Google Scholar]
- Potthoff R, Roy SN. A genaralized multivaraite analysis of variance model useful especially for growth curve problems. Biometrika. 1964;51:313–326. [Google Scholar]
- Reinsel G. Estimation and prediction in a multivariate random effects generalized linear model. J Amer Statist Assoc. 1984;79:406–414. [Google Scholar]
- Roy J, Lin X. Analysis of multivariate longitudinal outcomes with nonignorable dropouts and missing covariates: changes in methadone treatment practices. J Amer Statist Assoc. 2002;97:40–52. [Google Scholar]
- Shah A, Laird N, Schoenfeld D. A random-effects model for multiple characteristics with possibly missing data. J Amer Statist Assoc. 1997;92:775–779. [Google Scholar]
- Song X, Davidian M, Tsiatis AA. A semiparametric likelihood approach to joint modeling of longitudinal and time-to-event data. Biometrics. 2002;58:742–753. doi: 10.1111/j.0006-341x.2002.00742.x. [DOI] [PubMed] [Google Scholar]
- Walker SG, Mallick BK. Hierarchical generalized linear models and frailty models with Bayesian nonparametric mixing. J Roy Statist Soc Ser B. 1997;59:845–860. [Google Scholar]
- Walker SG, Mallick BK. Semiparametric accelerated life time model. Biometrics. 1999;55:477–483. doi: 10.1111/j.0006-341x.1999.00477.x. [DOI] [PubMed] [Google Scholar]
- Zeger SL, Diggle P. Semiparametric models for longitudinal data with application to CD4 cell numbers in HIV seroconverters. Biometrics. 1994;50:689–699. [PubMed] [Google Scholar]
- Zhang D, Lin X, Raz J, Sowers MF. Semiparametric stochastic mixed models for longitudinal data. J Amer Statist Assoc. 1998;93:710–719. [Google Scholar]
- Zhang D, Davidian M. Linear mixed models with flexible distributions of random effects for longitudinal data. Biometrics. 2001;57:795–802. doi: 10.1111/j.0006-341x.2001.00795.x. [DOI] [PubMed] [Google Scholar]