

Summary
We present a natural generalization of the Buckley-James-type estimator for traditional survival data to right-censored length-biased data under the accelerated failure time model. Length-biased data are often encountered in prevalent cohort studies and cancer screening trials. Informative right censoring induced by length-biased sampling creates additional challenges in modeling the effects of risk factors on the unbiased failure times for the target population. In this paper, we evaluate covariate effects on the failure times of the target population under the accelerated failure time model given the observed length-biased data. We construct a Buckley-James-type estimating equation, develop an iterative computing algorithm, and establish the asymptotic properties of the estimators. We assess the finite-sample properties of the proposed estimators against the estimators obtained from the existing methods. Data from a prevalent cohort study of patients with dementia are used to illustrate the proposed methodology.
Keywords: Accelerated failure time model, Buckley-James estimator, Estimating equation, Length-biased sampling, Prevalent cohort
1. Introduction
When studying the natural history of cancer, a prevalent sampling design that draws samples from individuals with a condition or disease (e.g. diagnosed with breast cancer) at the time of enrollment is generally more efficient and practical than an incident sampling design. The individuals are then followed over time to monitor endpoints such as disease progression or death. Under this design, individuals with shorter survival times are selectively excluded, while those with longer survival times are more likely to be included in the follow-up cohort. Length-biased data arise when the probability of a subject being selected from the target population is proportional to the time from the initiation event to the failure event (Zelen and Feinleib, 1969; Vardi, 1989; Zelen, 2004). These data are often encountered in epidemiologic studies, cancer screening trials, and marketing and economics studies (Nowell and Stanley, 1991; De Una-Alvarez et al., 2003).
In the Canadian Study of Health and Aging (CSHA), about ten thousand individuals age 65 and over were screened for dementia, and then were followed for their time to death. Length-biased sampling occurred here because the “observed” time intervals from the onset of dementia to death tended to be longer among those individuals in the study cohort identified to have dementia than among the general population. This occurred because individuals who had not survived to the examination time for the CSHA were excluded from the study. It is well known that statistical inference depends on the sampling scheme in which the data are obtained. An approach ignoring biased sampling could result in an overall underestimation of the deleterious effect of dementia on life expectancy and, in the presence of right censoring, lead to a biased inference of covariate effects on the failure times.
There is substantial literature on the analysis of length-biased data with diverse applications; however, a considerable methodological gap still exists. Prior work has mainly focused on nonparametric estimation for the population distribution (Wang et al., 1986; Turnbull, 1976; Lagakos et al., 1988; Tsai et al., 1987; Wang, 1991; Wang et al., 1993; Vardi, 1982, 1989; Gill et al., 1988; Asgharian et al., 2002; Asgharian and Wolfson, 2005). A limited amount of work has considered regression analysis for modeling the association between risk factors and population failure times, which is of practical interest in many applications. One prominent challenge in modeling right-censored length-biased failure times is the potential dependence between the failure times and the right censoring times, measured from the initiating event(e.g., onset of disease) to the failure event (e.g., death). Such informative censoring induced by the sampling scheme has often been avoided by prohibiting right censoring (Vardi, 1982, 1985; Wang, 1996) or by ignoring it. Another challenge is that the regression model structure assumed for the target population data is often changed for the observed length-biased data.
As an important alternative to Cox’s proportional hazards model, the accelerated failure time (AFT) model has been used for traditional survival data under independent right censoring. The AFT model has appealed to investigators because the logarithm of the failure time can be linearly related to the covariates of interest so that the interpretation of coefficients is straightforward. Large sample properties and methods of inference have been extensively investigated over the last twenty years for traditional survival data (Prentice, 1978; Buckley and James, 1979; Miller and Halpern, 1982; Ritov, 1990; Tsiatis, 1990; Lai and Ying, 1991a; Ying, 1993; Lin and Ying, 1995; Jin et al., 2003). However, little of this work has explicitly considered right-censored length-biased data. Lai and Ying (1991b) proposed a rank-based estimating equation to estimate regression coefficients for left-truncated and right-censored data under the AFT model. Lai and Ying (1994) and Gross and Lai (1996) considered M-estimators for regression analysis in the presence of left truncation and right censoring. These estimating methods, originally proposed for general left-truncated data, do not incorporate any truncation information and are consequently less efficient for length-biased data. More recently, Shen et al. (2009) proposed estimating equation approaches to estimate regression parameters under the transformation model as well as the AFT model. Although the closed form of the solution from the inverse weighted estimating equation under the AFT model is easy to calculate, there are also limitations. First, one has to either assume that the censoring distribution is independent of covariates or explicitly model and fit the covariate dependence of the censoring variable. Second, the proposed estimating equation approach may not be efficient, because the information from the covariates for censored individuals is not adequately utilized in the estimating equation. When length-biased failure times are not subject to right censoring, Chen (2010) and Mandel and Ritov (2010) proved the invariant property of the covariate effects in the AFT model under length-biased sampling and provided the estimating methods. When length-biased failure times are subject to right censoring, the invariant property does not hold in general and the aforementioned methods cannot be easily extended to accommodate the dependent censoring.
In this paper, we propose a Buckley-James-type estimator for the regression coefficients under the AFT model in order to study the covariate effects on failure times in the target population given the observed length-biased data. The remainder of our paper is organized as follows. In Section 2, we introduce the notation and the model. In Section 3, we construct a Buckley-James-type estimating equation and develop an iterative algorithm to obtain the root of the estimating equation. We assess the empirical performance of the proposed estimators and compare them with the estimators from the inverse weighted estimating equation and from the rank-based estimating equation approach in a simulation study in Section 4, and describe an application of our methodology to a real data example in Section 5. A discussion is provided in Section 6. The Appendix details the proofs.
2. Notation and Accelerated Failure Time Model
Let T̃ denote the unbiased time from initiation to failure in the targeted population. In the observed dataset, let T denote the length-biased failure time measured from initiation (T̃ > A), A denote the time from initiation to recruitment (also referred to as truncation variable), V denote the time from recruitment to failure (also referred to as residual survival time), C denote the residual censoring time measured from recruitment, X denote the p-vector of covariates. We make the standard assumption that the residual censoring time C is independent of (A, V) conditional on X, with covariate-specific survival function denoted by Sc(.|x). The major sampling constraint is that the value of T is observed only when T̃ > A, which subsequently induces dependent censoring because cov(T, A+C|X) = cov(A+V, A+ C|X) = var(A|X) + cov(V, A|X) > 0 except for in the trivial cases. For a random sample of size n, the data consist of (yi, ai, δi, xi), i = 1, ···, n, where yi = min{ti, ai+ci} represents the observed time, δi indicates the type of event for which δi=1 if failure occurs before censoring, and xi is the corresponding p-vector of covariates.
The AFT model takes the log-linear form to relate failure time and the corresponding covariates (Kalbeisch and Prentice, 2002; Cox and Oakes, 1984),
| (1) |
where β0 is a P × 1 vector of parameters and ε has an unknown density function q(.) with mean zero.
Without right censoring and biased sampling, the classical least-squares principle is a natural approach to estimate β and yields the estimating equation
| (2) |
In the presence of right censoring, Buckley and James (1979) modified equation (2) by replacing the residual time of a censored observation, , with its estimated conditional expectation
where Ŝβ(.) is the Kaplan-Meier estimator of the residual survival function based on the transformed data (εi(β), δi, i = 1, ···, n). After replacing the censored data by their conditional expectations, we have following estimating equation for β:
The Buckley-James estimator is the root of U(β) = 0, and its asymptotic properties have been rigorously studied (Ritov, 1990; Lai and Ying, 1994; Jin et al., 2006) for application to traditional right-censored data.
3. Buckley-James-type estimator for right-censored length-biased data
Recall that the unbiased time-to-event data are not directly observed. Instead, the biased samples and their corresponding covariates are observed. Under the stationarity assumption for disease incidence, the joint density of (A, T) given X = x is (Wang, 1999)
and the conditional distribution of A given T = t and X is uniform (0, t). Therefore, the marginal density of T given X is
| (3) |
Under the AFT model (1), the covariate-specific density function of unbiased failure time T̃ and the corresponding length-biased density function can be expressed by
where μ(x) = ∫ tf (t|x)dt = ∫ q(log y−xTβ0)dy. Define T̃0 = T̃ exp(−xTβ0), T0 = T exp(−xTβ0) and μ = ∫ q(log t)dt. Then the density functions of T̃0 and T0 are f0(t) = q(log t)/t and g0(t) = q(log t)/μ, respectively. Define and assume that τ < ∞. Note that τ is also the upper bound for the support of T̃0.
Without right censoring, we can prove that the expectation of log T0/T0 is zero,
because the mean of ε is zero. Accordingly, an unbiased estimating equation for β follows:
| (4) |
In the presence of right censoring, let A0 = Aexp(−XTβ0), V0 = V exp(−XTβ0), C0 = C exp(−XTβ0), and Y0 = min{A0 + V0, A0 + C0}. Because of right censoring, the value of log T0/T0 with δ = 0 cannot be observed, but can be approximated naturally by its conditional expectation given the observed information. Given the joint distribution of (T0, A0), fT0,A0 (t0, a0) = f0(t0)/μ, t0 > a0, we have
where .
Using the same principle as for traditional right-censored survival data, we modify the estimating equation for length-biased data without censoring in (4) by incorporating the component for right-censored data as follows:
With the unknown distribution F0, we need the following iterative procedure to solve for β. Note that the transformed data vectors,
denoted by (ai0, vi0, ci0, yi0, xi) are independent and identically distributed data vectors for i = 1, ···, n. Using the EM algorithm proposed in Vardi (1989), one can estimate the nonparameteric maximum likelihood estimator of the distribution of length-biased failure time T0 from the likelihood
where . With the estimated distribution Ĝ0(t; β) for G0(t), we can then derive an estimator of the unbiased distribution F0(t) (Asgharian et al., 2002),
The Buckley-James-type estimator β̂BJ is the root of U(β) = 0, where
It is difficult to solve for β directly from U(β), especially when β is multi-dimensional, because U(β) is neither continuous nor monotone in β. Using a computational algorithm similar to that in Buckley and James (1979), we can obtain the root of the equation through an iterative procedure. We first fix an initial value β̂(0) and transform the observed data yi to . We then obtain the maximum likelihood estimate of the unbiased survival function, F̂0 (u; β̂(0)) given the transformed data. We can find the root of the modified equation using the estimated distribution of F0:
The iterative procedures continue until prespecified convergence criteria meet.
For traditional right-censored data, Jin et al. (2006) found that if the initial estimator β̂0 is consistent and asymptotically normally distributed, the Buckley-James estimator at the mth step, β̂(m), should be consistent and asymptotically normally distributed for any m ≥ 1. For length-biased right-censored data, the estimating equation in the mth step, U(β, β̂(m−1)), does not have a closed-form solution. Instead, the coefficient vector β at the mth step is obtained through one-step Newton-Raphson approximation,
| (5) |
When the residual censoring variable is independent of covariates, a consistent and asymptotically normal initial estimator, β̂(0), can be obtained from the inverse weighted estimating equation (IWEE) of Shen et al. (2009), which has a closed form expression
| (6) |
where Ŝc(.) is the Kaplan-Meier estimator for the censoring survival function. We can prove that, for any fixed m, β̂(m) is consistent and asymptotically normally distributed given a consistent and asymptotically normal initial estimator. Theorem 1 summarizes these asymptotic properties. The regularity assumptions for a rigorous justification of the results are listed in the Appendix.
Theorem 1
If the regularity assumptions 1–6 listed in the appendix are satisfied and a consistent and asymptotically normal initial estimator is chosen, then β̂(m) is a consistent estimator of β0. Moreover, converges weakly to a normal distribution with mean zero and variance-covariance matrix Vm.
See the Appendix for the detailed proof. Since the explicit form of the asymptotic variance of β̂(m) involves the complex linear operators and two unknown density functions, it is difficult to directly obtain a consistent variance estimator for β̂(m). Alternatively, the bootstrap procedure can be used to estimate the asymptotic variance of β̂(m). When the residual censoring time is dependent on the covariates, the estimator obtained from the IWEE may not be consistent. By contrast, the estimator obtained from the following estimating method for general left-truncated data (Lai and Ying, 1991b) remains consistent,
| (7) |
where x̃i is the covariate vector except for the constant one and β̃ denotes the corresponding vector of regression parameters except for the intercept. Once the estimator is obtained by solving (7), the intercept can be estimated by the weighted average
where and Ŝc̃0 is the Kaplan-Meier estimator for the survival function of the transformed censoring C exp (−X̃T β̃). We refer to this estimating method as the left-truncation (LT) method. The weak convergence of the Buckley-James-type estimator with the initial consistent estimator from the LT method can be derived, similarly to that the Buckley-James-type estimator with the initial consistent estimator from the IWEE method. In the simulation study, we use the estimator from the LT method as the initial value for obtaining the Buckley-James estimator in the presence of covariate-depending censoring.
4. Simulation
4.1 Design and Data Generation
We conducted simulations to evaluate the performance of the proposed estimate and compare it with the performance of two existing methods: IWEE method given by (6) and LT method by (7) for general left-truncated data. We first generated independent pairs of (Ai, T̃i), then kept the pairs conditioning on Ai < T̃i. Here, A was distributed uniformly on (0, ω) and ω was larger than the upper bound of T̃ to ensure the stationarity assumption. We considered an AFT model with two covariates,
where X1 is a binary covariate with P(X1 = 1) = 0.5, X2 is a continuous covariate with a uniform(0,1) distribution, and ε has a mean zero normal distribution with standard deviation of 0.3. We set α0 = 1, α1 = 0.5, and α2 = 1. Each study comprised 500 replications, and the bootstrap procedure used 200 re-samplings in each replication. A cohort size of 100 or 200 was used.
The censoring variables measured from the examination time, Ci, were independently generated from uniform distributions with two censoring percentages: 20% and 35%. The censoring indicator was obtained by δi = I(ti ≤ ci + ai). Aside from the scenarios in which right censoring was assumed to be independent of covariates, we also studied scenarios in which the censoring times were dependent on the covariates. Specifically, we generated censoring times either from a mixed distribution C ~ X1Uniform(ν1)+(1−X1)Uniform(ν2), or from a Cox regression model λc(t) = ν3t exp(X1 +X2). Here ν1, ν2, and ν2 are parameters to control the degree of censoring. In this setting, the estimators obtained from IWEE given by (6) may not be consistent, but the estimators obtained from LT method in equation (7) remain to be consistent. We thus use the estimator from the LT method as the initial value for obtaining the Buckley-James estimator.
4.2 Simulation Results
Table 1 lists the average of the estimators, empirical standard errors (ESE) and bootstrap standard error (BSE) of the proposed approach, the IWEE method given by (6) and the LT method by (7) under independent censoring. When the censoring percentage was low (e.g. 20%) all three types of estimators achieved good accuracy: the empirical biases were less than 1%. In the presence of moderate censoring (35%), the Buckley-James-type estimators and LT estimators were virtually unbiased, with empirical percentage biases smaller than 2%, and the biases of estimators from the IWEE method were slightly larger but still comparable. For all scenarios, the Buckley-James-type approach exhibited the best precision among three types of estimators, with empirical standard errors 1%-13% smaller than those from the IWEE approach, and 5%–26% smaller than those from the LT approach. With a sample size of 100 and 35% censoring, the empirical standard error of α̂2 from the Buckley-James-type approach was 13% smaller than that from the IWEE, and 26% smaller than that from the LT method.
Table 1.
Simulation Study. Comparison of three estimating procedures: Buckley-James-type estimator, IWEE estimator and ULT Estimator
| Cohort | C% | Buckley-James-type Estimator | IWEE Estimator | ULT Estimator | |||||
|---|---|---|---|---|---|---|---|---|---|
| size | (α̂0, α̂1, α̂2) | (α̂0, α̂1, α̂2) | (α̂0, α̂1, α̂2) | ||||||
| Mean | ESE | BSE | CP of 95%CI | Mean | ESE | Mean | ESE | ||
| 100 | 0% | (1.001,.494,.997) | (.087,.068,.121) | (.085,.068,.115) | (.940,.960,.930) | (1.007,.495,.996) | (.091,.069,.128) | (.999,.500,1.005) | (.092,.081,.139) |
| 20% | (1.003,.500,.999) | (.093,.066,.119) | (.090,.071,.120) | (.952,.954,.942) | (1.008,.497,.991) | (.094,.069,.127) | (1.000,.501,1.002) | (.102,.085,.151) | |
| 35% | (1.004,.499,.999) | (.097,.070,.126) | (.093,.076,.127) | (.954,.946,.936) | (1.019,.483,.966) | (.101,.080,.145) | (1.005,.499, .980) | (.113,.090,.171) | |
| 200 | 0% | (1.003,.498,.999) | (.062,.047,.086) | (.060,.048,.083) | (.942,.948,.940) | (1.002,.498,1.000) | (.067,.049,.092) | (1.000,.501,1.002) | (.065,.055,.099) |
| 20% | (1.001,.499,.999) | (.062,.049,.085) | (.073,.050,.086) | (.936,.923,.942) | (1.005,.499, .992) | (.067,.052,.090) | (.998,.503,1.003) | (.070,.058,.104) | |
| 35% | (1.002,.501,.998) | (.064,.051,.089) | (.065,.054,.094) | (.958,.932,.944) | (1.015,.486, .968) | (.072,.058,.101) | (.993,.502, .999) | (.076,.063,.110) | |
To evaluate the robustness of Buckley-James-type estimators, we simulated censoring times from a mixed distribution depending on covariates, as specified in Section 4.1. The results were presented in Table 2. Again, the Buckley-James-type estimates outperformed the other two types of estimates with smaller bias and standard error. As expected, the IWEE approach yielded biased estimates for covariate effects compared with Buckley-James-type and LT estimates, especially when the censoring percentage increased. For Buckley-James type and LT estimates, their empirical biases of estimates were smaller than 1%. When censoring was dependent on covariates, the standard errors of Buckley-James-type estimators were appreciably (1%–15%) smaller than those from the IWEE estimators, and substantially (6%–25%) smaller than the LT estimators. We also performed additional simulation to evaluate how sensitive the Buckley-James-type estimator to the consistent initial estimator, β̂(0) (by using the IWEE estimator as the initial estimator when the censoring distribution depends on covariates). The results not presented here due to limited space suggest that the Buckley-James-type estimator is robust with respect to the initial estimator.
Table 2.
Simulation Study. Comparison of three estimating procedures when censoring depends on covariates: Buckley-James-type estimator, IWEE estimator and ULT Estimator
| Cohort | C% | Buckley-James-type Estimator | IWEE Estimator | ULT Estimator | |||||
|---|---|---|---|---|---|---|---|---|---|
| size | (α̂0, α̂1, α̂2) | (α̂0, α̂1, α̂2) | (α̂0, α̂1, α̂2) | ||||||
| Mean | ESE | BSE | CP of 95%CI | Mean | ESE | Mean | ESE | ||
| C: X1Uniform(τ1) + (1 − X1)Uniform(τ2) | |||||||||
| 100 | 20% | (1.008,.497,.994) | (.091,.070,.128) | (.095,.071,.120) | (.930,.942,.956) | (1.021,.476, .998) | (.097,.075,.136) | (1.007,.501, .993) | (.104,.084,.154) |
| 35% | (1.007,.497,.995) | (.099,.074,.135) | (.103,.079,.138) | (.942,.950,.930) | (1.030,.445, .991) | (.106,.084,.158) | (1.019,.499, .968) | (.120,.090,.181) | |
| 200 | 20% | (1.005,.497,.998) | (.063,.050,.091) | (.065,.049,.088) | (.944,.938,.946) | (1.015,.476,1.000) | (.068,.053,.098) | (1.005,.498,1.000) | (.071,.060,.106) |
| 35% | (1.004,.497,.999) | (.073,.052,.096) | (.069,.054,.094) | (.934,.954,.954) | (1.025,.441,1.005) | (.076,.061,.116) | (1.004,.498, .999) | (.078,.063,.117) | |
| C: λc(t) = ν3t exp(X1 + X2) | |||||||||
| 100 | 20% | (1.005,.501,.995) | (.095,.070,.120) | (.091,.072,.121) | (.944,.934,.944) | (.991,.513, .999) | (.098,.073,.130) | (.997,.504, .999) | (.104,.087,.149) |
| 35% | (1.006,.502,.992) | (.109,.082,.133) | (.110,.087,.137) | (.946,.956,.924) | (.977,.526,1.002) | (.108,.083,.144) | (.994,.502,1.000) | (.119,.096,.168) | |
| 200 | 20% | (1.002,.502,.997) | (.067,.053,.086) | (.066,.051,.088) | (.938,.942,.958) | (.987,.514,1.003) | (.072,.054,.092) | (.994,.503,1.001) | (.074,.060,.106) |
| 35% | (1.003,.501,.996) | (.072,.056,.094) | (.069,.055,.091) | (.934,.940,.946) | (.970,.527,1.009) | (.080,.061,.103) | (.990,.502,1.000) | (.085,.067,.116) | |
The bootstrap procedure can accurately capture the variability of the proposed estimators and the bootstrap confidence intervals have proper coverage probabilities close to the nominal level of 0.95, as shown in Tables 1–2. As suggested by one reviewer, we have also conducted some simulation studies to explore whether the efficiency can be improved by multiple iterations. The simulation results (for brevity the results are not presented) suggest that the estimators with a small number of iterations (such as the three-step estimator) may be sufficient to achieve adequate precision for the proposed estimators.
5. Data Application
In an epidemiologic study to evaluate the survival of patients with dementia, more than 10,000 Canadians age 65 or older were screened for dementia in the first stage of the Canadian Study of Health and Aging in 1991. The individuals identified as having dementia were classified into one of three diagnostic categories: (1) probable Alzheimer’s disease, (2) possible Alzheimer’s disease, and (3) vascular dementia; their dates of dementia onset were retrieved from their medical records. At the second stage of the CSHA, individuals with confirmed dementia were followed prospectively until 1996, and their dates of death or censoring were ascertained. Details of the design and analysis of the study were described by Wolfson et al. (2001). We applied the proposed method to CSHA data to assess the effect of different diagnostic categories of dementia on survival.
The data we analyzed included 818 individuals with dementia, 393 with probable Alzheimer’s disease, 252 with possible Alzheimer’s disease, and 173 with vascular dementia. For each individual, the date of disease onset, date of entry into the study, date of death or right censoring, and death indicator were collected.
We first examined the stationarity assumption for the cohort. The formal test of stationarity assumption given by Addona and Wolfson (2006) yields a two-sided p-value of 0.33, which suggests that the stationarity assumption is reasonable. We next assessed the applicability of the AFT model. The AFT model assumes that a covariate has a multiplicative effect on the survival time quantiles of the baseline group. For the dementia study, the survival distributions of three subgroups are compared under the AFT model. Therefore, the Q-Q plot can be used to check the AFT assumption, where the survival time quantiles of one subgroup were plotted against the survival time quantiles of another subgroup (baseline group). In the Q-Q plots shown in Figure 1, the distribution functions were estimated nonparametrically by the EM algorithm proposed by Vardi (1989). The Q-Q plots approximate well to a straight line from the original, indicating that the AFT model provides a reasonable regression structure for modeling survival times among individuals with three types of dementia. We applied the AFT model of E (log Y) = α0 + α1X1 + α2X2 to the observed survival time Y’s, where X1 and X2 indicate whether the individual had probable Alzheimer’s disease and possible Alzheimer’s disease, respectively. The estimated coefficients from the Buckley-James-type equation for length-biased data, including their bootstrap standard errors, are listed in Table 3. The estimators were comparable with those obtained from the IWEE and LT approaches. Inferences from the three estimating methods adjusting for length-biased sampling agreed well. There were no significant differences in long-term survival among three subtypes of dementia.
Figure 1.

QQ plots for survival time from onset of dementia to death (days)
Table 3.
Analysis results of dementia data
| Method | Buckley-James-type estimator with length-biased | Naive Buckley-James estimator | ||
|---|---|---|---|---|
| Parameter | Est. | SE | Est. | SE |
| α0 | 7.102 | 0.075 | 7.648 | 0.056 |
| α1 | 0.073 | 0.132 | 0.115 | 0.064 |
| α2 | 0.187 | 0.123 | 0.200 | 0.075 |
Est., parameter estimate; SE, bootstrap standard error of the parameter estimator.
For comparison, we also provided the estimated covariate coefficients in Table 4 under the AFT model ignoring the length-biased sampling in the data (referred to as “Naive Buckley-James estimator”). The naive estimators resulted in a median survival duration of 5.74 years (95% CI: 5.14–6.41) for vascular dementia, 6.44 years (95% CI: 6.00–6.91) for probable Alzheimer’s disease, and 7.01 years (95% CI: 6.39–7.71) for possible Alzheimer’s disease. Adjusting for length bias the estimators resulted in a median survival duration of 3.33 years (95% CI: 2.87–3.86) for vascular dementia, 3.58 years (95% CI: 2.84–4.51) for probable Alzheimer’s disease, and 4.01 years (95% CI: 3.35–4.80) for possible Alzheimer’s disease. The substantial differences between the median survival times when using different estimation methods indicate that the use of an approach that ignores length-biased sampling will lead to a severe underestimation of the deleterious effects of dementia.
6. Concluding Remarks
The semiparametric AFT regression model has the advantage of simple interpretation for the covariate effects on time-to-event data. It is thus appealing to generalize the Buckley-James-type estimator under the AFT model for traditional survival data to length-biased right-censored data. The Buckley-James iterative algorithm is adapted to obtain the consistent root of the proposed estimating equation given a consistent estimator as the initial value. In our simulation studies, we have always found the proposed Buckley-James-type estimators to be more efficient than the two existing estimators (IWEE and LT) for analyzing length-biased data. Because the estimator from the IWEE relies only on uncensored failure times, information for the covariates of the censored times are not properly utilized in the estimating equation. In contrast, the proposed method effectively utilizes the censored observations with their conditional expectations in the estimating equations. Another advantage of the proposed method is that the estimation procedure is robust to the assumption that the censoring distribution is independent to covariates. While the rank-based method proposed for left-truncated right censoring data is also robust to the independent assumption between the censoring distribution and covariates (Lai and Ying, 1991b), the method is less efficient without utilizing the information of length-biased sampling (i.e. stationarity assumption).
The asymptotic properties of the proposed estimator hold when a consistent estimator is used as initial value in the iterations. Clearly, the two existing estimation approaches (IWEE and LT) under the AFT model can provide the initial consistent estimator for the Buckley-James-type estimators under different censoring mechanisms. Our additional empirical studies also suggest that the Buckley-James-type estimator is quite robust, even if the initial value is not a consistent estimator of β.
The implementation of the Buckley-James approach is much more challenge for length biased right-censored data than for traditional right-censored data. There is a fundamental difference in estimating the nonparametric survival distribution in the absence and presence of length bias. Unlike the approach for conventional survival data that the nonparametric maximum likelihood estimator jumps only at the observed failure time points with a closed form, the nonparametric maximum likelihood estimator based on length-bias data jumps at all the observed failure and censored time points without a closed-form expression.
For general left-truncated and right-censored data, the intercept in the AFT model or the mean of the residual is generally not estimable, especially when the censoring has support that is shorter than that of the event times. The length-biased data however, have some unique features and require different conditions compared to the setting with general left-truncated right-censored data. As established in Theorem 1 and its Corollary 2 of Asgharian et al. (2002), the mean of the target failure time (T̃0), μ can be consistently estimated by with convergency under some mild sufficient conditions. This fact, combined with the property that τ can be consistently estimated by τ̂ = max1, ···,n{yi0} and its convergence rate is higher than n−1/2, ensures that the intercept in the AFT model can be estimated consistently under the assumptions listed in the Appendix. Some details are provided in the Web Supplementary Materials.
Supplementary Material
Acknowledgments
We thank Professor David Zucker, the Associate Editor, and the two referees for their constructive comments that improved the paper greatly. This work was supported by the U.S. National Institutes of Health. The authors are grateful to Professor M. Asgharian and investigators from the Canadian Study of Health and Aging for providing us with the dementia data. The data reported in the example were collected as part of the CHSA. The core study was funded by the Seniors’ Independence Research Program, through the National Health Research and Development Program of Health Canada (Project no.6606-3954-MC(S)). Additional funding was provided by P_zer Canada Incorporated through the Medical Research Council/Pharmaceutical Manufacturers Association of Canada Health Activity Program, NHRDP Project 6603-1417-302(R), Bayer Incorporated, and the British Columbia Health Research Foundation Projects 38 (93-2) and 34 (96-1). The study was coordinated through the University of Ottawa and the Division of Aging and Seniors, Health Canada.
Appendix Proof of Theorem 1
For notation simplicity, we assume covariate-independent censoring and use the estimator obtained from IWEE given by (6) as the initial value to show the weak convergence of β̂(1). However, the arguments here can be readily extended to the case of covariate-dependent censoring and initial estimator from the LT method. We assume the following regularity conditions:
Assumption 1
X is bounded and the n × p matrix  = (X1, X2, ···, Xn)T is of full rank.
= (X1, X2, ···, Xn)T is of full rank.
Assumption 2
P(V < C) > 0.
Assumption 3
G0(.) is a continuous and differentiable distribution function over (0, τ) and τ < ∞.
Assumption 4
, where Sc0 is the survival function of C0
Assumption 5
There exists a τ0 > 0 such that F0(y) = 0, ∀y < τ0.
Assumption 6
.
Assumption 1 is to ensure the non-singularity of matrix . Assumptions 2 to 5 are to ensure uniform consistency and weak convergence of the estimator F̂0 for all 0 < t ≤ τ and the properties of μ̂ (Asgharian et al., 2002; Asgharian and Wolfson, 2005). Assumption 6 is sufficient to ensure that various expectations are finite.
Proof of Theorem 1
Note that it suffices to show the asymptotic properties of β̂(m) for m = 1. By equation (5), we have
| (A.1) |
We show in the Web Supplementary Materials that the difference between the estimating equation with the true value β0 and the estimating equation with the consistent estimate β̂(0) is asymptotically linear in β̂(0),
where B is a matrix defined in the Web supplementary materials. This linear approximation, together with equation (A.1), implies that
where Ip is an identity matrix. It follows that β̂(1) and thus β̂(m) are consistent for each fixed m. Note that the estimating equation with the true parameter requires estimating the unknown survival function, and its independent and identically distributed representations could be derived by the asymptotic properties of Vardi’s estimator,
where ,
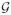 and
and  are linear operators defined by
are linear operators defined by
and g*(x) and f*(x) are the conditional density functions of G*(x) and F*(x), respectively. This representation, together with the asymptotic independent and identically distributed representation of the estimator β̂(0), implies that converges in distribution to a zero-mean normal distribution.
Footnotes
Web Appendices referenced in Section 6 and in the Appendix are available under the Paper Information link at the Biometrics website http://www.biometrics.tibs.org.
References
- Addona V, Wolfson DB. A formal test for the stationarity of the incidence rate using data from a prevalent cohort study with follow-up. Lifetime Data Anal. 2006;12:267–274. doi: 10.1007/s10985-006-9012-2. [DOI] [PubMed] [Google Scholar]
- Asgharian M, M’Lan CE, Wolfson DB. Length-biased sampling with right censoring: An unconditional approach. J Am Statist Assoc. 2002;97:201–209. [Google Scholar]
- Asgharian M, Wolfson DB. Asymptotic behavior of the unconditional NPMLE of the length-biased survivor function from right censored prevalent cohort data. Ann Statist. 2005;33:2109–2131. [Google Scholar]
- Buckley J, James I. Linear regression with censored data. Biometrika. 1979;66:429–436. [Google Scholar]
- Chen YQ. Semiparametric regression in size-biased sampling. Biometrics. 2010;66:149–158. doi: 10.1111/j.1541-0420.2009.01260.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cox DR, Oakes D. Analysis of Survival Data. Boca Raton, FL: Chapman and Hall/CRC Press; 1984. [Google Scholar]
- De Una-Alvarez J, Otero-Giraldez MS, Alvarez-Llorente G. Estimation under length-bias and right-censoring: An application to unemployment duration analysis for married women. J Appl Statist. 2003;30:283–291. [Google Scholar]
- Gill RD, Vardi Y, Wellner JA. Large-sample theory of empirical distributions in biased sampling models. Ann Statist. 1988;16:1069–1112. [Google Scholar]
- Gross ST, Lai TL. Nonparametric estimation and regression analysis with left-truncated and right-censored data. J Amer Statist Assoc. 1996;91:1166–1180. [Google Scholar]
- Jin Z, Lin D, Wei L, Ying Z. Rank-based inference for the accelerated failure time models. Biometrika. 2003;90:341–353. [Google Scholar]
- Jin Z, Lin DY, Ying Z. On least-squares regression with censored data. Biometrika. 2006;93:147–161. [Google Scholar]
- Kalbeisch JD, Prentice RL. The Statistical Analysis of Failure Time Data. John Wiley and Sons; New Jersey: 2002. [Google Scholar]
- Lagakos SW, Barraj LM, De Gruttola V. Nonparametric analysis of truncated survival data, with applications to aids. Biometrika. 1988;75:515–523. [Google Scholar]
- Lai TL, Ying Z. Large sample theory of a modified Buckley-James estimator for regression analysis with censored data. Ann Statist. 1991a;19:1370–1402. [Google Scholar]
- Lai TL, Ying Z. Rank regression methods for left-truncated and right-censored data. Ann Statist. 1991b;19:531–556. [Google Scholar]
- Lai TL, Ying Z. A missing information principle and M-Estimators in regression analysis with censored and truncated data. Ann Statist. 1994;22:1222–1255. [Google Scholar]
- Lin DY, Ying Z. Semiparametric inference for the accelerated life model with time-dependent covariates. J Statist Plan and Inference. 1995;44:47–63. [Google Scholar]
- Mandel M, Ritov Y. The accelerated failure time model under biased sampling. Bimetrics. 2010 doi: 10.1111/j.1541-0420.2009.01366_1.x. in press. [DOI] [PubMed] [Google Scholar]
- Miller RG, Halpern J. Regression with censored data. Biometrika. 1982;69:521–531. [Google Scholar]
- Nowell C, Stanley LR. Length-biased sampling in mall intercept surveys. J Market Res. 1991;28:475–479. [Google Scholar]
- Prentice RL. Linear rank tests with right censored data. Biometrika. 1978;65:167–179. [Google Scholar]
- Ritov Y. Estimation in a linear regression model with censored data. Ann Statist. 1990;18:303–328. [Google Scholar]
- Shen Y, Ning J, Qin J. Analyzing length-biased data with semiparametric transformation and accelerated failure time models. J Am Statist Assoc. 2009;104:1192–1202. doi: 10.1198/jasa.2009.tm08614. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tsai WY, Jewell NP, Wang MC. A note on the product-limit estimator under right censoring and left truncation. Biometrika. 1987;74:883–886. [Google Scholar]
- Tsiatis AA. Estimating regression parameters using linear rank tests for censored data. Ann Statist. 1990;18:354–372. [Google Scholar]
- Turnbull BW. The empirical distribution function with arbitrarily grouped, censored and truncated data. J R Statist Soc B. 1976;38:290–295. [Google Scholar]
- Vardi Y. Nonparametric estimation in the presence of length bias. Ann Statist. 1982;10:616–620. [Google Scholar]
- Vardi Y. Empirical distributions in selection bias models. Ann Statist. 1985;13:178–203. [Google Scholar]
- Vardi Y. Multiplicative censoring, renewal processes, deconvolution and decreasing density: Nonparametric estimation. Biometrika. 1989;76:751–761. [Google Scholar]
- Wang MC. Nonparametric estimation from cross-sectional survival data. J Am Statist Assoc. 1991;86:130–143. [Google Scholar]
- Wang MC. Hazards regression analysis for length-biased data. Biometrika. 1996;83:343–354. [Google Scholar]
- Wang MC. Gap time bias in incident and prevalent cohorts. Stat Sin. 1999;9:999–1010. [Google Scholar]
- Wang MC, Brookmeyer R, Jewell NP. Statistical models for prevalent cohort data. Biometrics. 1993;49:1–11. [PubMed] [Google Scholar]
- Wang MC, Jewell NP, Tsai WY. Asymptotic properties of the product limit estimate under random truncation. Ann Statist. 1986;14:1597–1605. [Google Scholar]
- Wolfson C, Wolfson DB, Asgharian M, M’Lan CE, Ostbye T, Rockwood K, Hogan DB the Clinical Progression of Dementia Study Group. A reevaluation of the duration of survival after the onset of dementia. New Engl J Med. 2001;344:1111–1116. doi: 10.1056/NEJM200104123441501. [DOI] [PubMed] [Google Scholar]
- Ying Z. A large sample study of rank estimation for censored regression data. Ann Statist. 1993;21:76–99. [Google Scholar]
- Zelen M. Forward and backward recurrence times and length biased sampling: Age specific models. Lifetime Data Anal. 2004;10:325–334. doi: 10.1007/s10985-004-4770-1. [DOI] [PubMed] [Google Scholar]
- Zelen M, Feinleib M. On the theory of screening for chronic diseases. Biometrika. 1969;56:601–614. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.