

Abstract
Peptide recognition domains (PRDs) are ubiquitous protein domains which mediate large numbers of protein interactions in the cell. How these PRDs are able to recognize peptide sequences in a rapid and specific manner is incompletely understood. We explore the peptide binding process of PDZ domains, a large PRD family, from an equilibrium perspective using an all-atom Monte Carlo (MC) approach. Our focus is two different PDZ domains representing two major PDZ classes, I and II. For both domains, a binding free energy surface with a strong bias toward the native bound state is found. Moreover, both domains exhibit a binding process in which the peptides are mostly either bound at the PDZ binding pocket or else interact little with the domain surface. Consistent with this, various binding observables show a temperature dependence well described by a simple two-state model. We also find important differences in the details between the two domains. While both domains exhibit well-defined binding free energy barriers, the class I barrier is significantly weaker than the one for class II. To probe this issue further, we apply our method to a PDZ domain with dual specificity for class I and II peptides, and find an analogous difference in their binding free energy barriers. Lastly, we perform a large number of fixed-temperature MC kinetics trajectories under binding conditions. These trajectories reveal significantly slower binding dynamics for the class II domain relative to class I. Our combined results are consistent with a binding mechanism in which the peptide C terminal residue binds in an initial, rate-limiting step.
Author Summary
The complex biological processes occurring in living organisms are enabled by numerous networks of interacting proteins. It is therefore of great interest to understand the physical interplay between proteins and, in particular, how this process gives rise to highly specific network connectivities. For a long time, the dominant molecular view of protein-protein interactions was the docking of more or less static folded structures, with specificity obtained from a complementarity in shape and charge distributions. Lately it has been realized that many of the links in protein networks are mediated by interactions between folded domains, on the one hand, and disordered polypeptide segments, on the other. We use an all-atom Monte Carlo based approach which attempts to capture this domain-peptide binding process in full and apply it to representative members of a common domain family. This allows us to examine and compare detailed aspects of the binding free energy landscapes which underlie specificity and affinity. Being able to model domain-peptide binding in a physically sound, yet computationally tractable way is essential for identifying molecular binding mechanisms and opens up possibilities for modifying interaction networks in a controlled way.
Introduction
Protein-protein interactions control numerous processes in the cell. Recently, it has been realized that a significant fraction of these interactions are mediated by the binding of flexible polypeptide segments to folded domains [1]–[3]. This realization is in part due to the discovery of many so-called peptide recognition domains (PRDs), which function specifically by recognizing sets of short peptide sequences [4], [5]. PRDs often interact with their ligand peptides in a reversible, transient manner, making them particularly well suited to mediate interactions in signaling and regulatory processes, which require fast response to initiated or ceased stimuli. A fundamental understanding of the detailed dynamics and binding free energy landscapes of these PRD-peptide interactions will therefore eventually be necessary in order to understand the finely tuned specificities and affinities which underpin many protein interaction networks. Achieving such an understanding may also be of practical importance, as it can be a starting point towards altering signaling networks in a controlled way [6], [7] or designing small molecules to inhibit domain-peptide binding [8], [9].
Modeling peptide binding in atomistic detail is a challenge. One reason for this is the inherent flexibility of a disordered peptide chain which necessitates a statistical mechanical approach. At the same time it is a major modeling opportunity because of the relatively small molecular interface and few amino acids involved, making the peptide binding process computationally accessible. Several docking methods designed specifically for peptide binding have been developed [10]–[16], which aim to predict the correct peptide binding pose on a protein surface. Most of these methods require some prior knowledge of the peptide binding site, although true blind docking has also been attempted [17], [18]. Other in silico methods seek to provide binding predictions for whole PRD families, including SH2 [19], SH3 [20], [21], and PDZ [22] domains. These methods rely on structural models of domain-peptide complexes using an available experimental peptide-bound configuration as a template. Most PRD families, however, display significant diversity in how peptides interact with domains, which fundamentally limits this approach. In a recent effort to alleviate this problem, King et al [15] combined peptide docking and subsequent structure-based binding prediction using the Rosetta scoring function. Molecular Dynamics simulations of domain-peptide bound states have also been carried out, emphasizing the importance of dynamics and flexibility for understanding the molecular basis of peptide binding [23]–[25].
Our aim here is to go beyond docking and investigate the binding process from an equilibrium perspective. To this end, we use a recently developed Monte Carlo-based procedure for protein-peptide binding [26] and apply it to three different PDZ domains and their target peptide sequences. The approach combines a global conformational search of the peptide chain, as well as limited protein backbone flexibility around the native state, with an effective energy function inspired by protein folding studies [27]–[29]. Rather than relying on large numbers of docking attempts, we perform fewer but long simulations such that each run exhibits multiple binding and unbinding events, thereby providing an equilibrium picture of the binding process. In particular, this allows us to investigate and compare features of the global binding free energy landscape as determined by the interaction between the protein surface and the amino acid sequence of the peptide.
The PDZ domain is an archetypical PRD existing in large numbers in many genomes [30]–[32]. It distinguishes itself from other PRDs in that it typically binds sequence motifs at the extreme C terminal end of proteins. The architecture is mostly conserved across the domain family with a typical core structure consisting of two  -helices and six
-helices and six 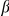 -strands. The PDZ fold includes a binding pocket between the second
-strands. The PDZ fold includes a binding pocket between the second  -helix (
-helix (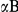 ) and second
) and second 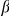 -strand (
-strand (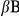 ) such that a ligand peptide can augment the
) such that a ligand peptide can augment the 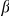 -strand upon binding and pack its sidechains against the
-strand upon binding and pack its sidechains against the  -helix. In addition, the peptide C terminus forms hydrogen bonds with the backbone amides of a highly conserved loop on the PDZ domain. Like many other PRD families, PDZ domains have been divided into different classes depending on which peptide sequences they preferentially bind. The most established division of PDZ domains is into classes I, II, and III, corresponding to the sequence patterns Ser/Thr-X-
-helix. In addition, the peptide C terminus forms hydrogen bonds with the backbone amides of a highly conserved loop on the PDZ domain. Like many other PRD families, PDZ domains have been divided into different classes depending on which peptide sequences they preferentially bind. The most established division of PDZ domains is into classes I, II, and III, corresponding to the sequence patterns Ser/Thr-X-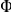 -COOH,
-COOH, 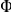 -X-
-X-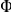 -COOH, and Asp/Glu-X-
-COOH, and Asp/Glu-X-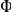 -COOH, respectively, where
-COOH, respectively, where 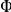 is any hydrophobic amino acid, X is any amino acid, and COOH is the C terminus [32]. It can be pointed out that more fine-grained classifications are also possible [33]. We focus here on comparing the binding behavior of class I and II domains, which represent the majority of known PDZ domains [30], [32].
is any hydrophobic amino acid, X is any amino acid, and COOH is the C terminus [32]. It can be pointed out that more fine-grained classifications are also possible [33]. We focus here on comparing the binding behavior of class I and II domains, which represent the majority of known PDZ domains [30], [32].
An important aspect of any binding study is the ability to capture binding to free molecules, i.e., to structures determined in the absence of a ligand. This is important not the least for PDZ domains, for which only 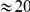 domain-peptide complexes have been solved experimentally so far [32], compared to the almost 200 free PDZ domain structures in the Protein Data Bank (PDB) [34]. We therefore start out by testing our computational procedure using two different structural forms of the domains, free and peptide-bound. Thereafter, we describe the conformational transitions of the peptides and the binding free energy landscapes for the domains. Finally, we perform a large number of Monte Carlo based kinetic simulations to obtain a deeper microscopic picture of the peptide binding process.
domain-peptide complexes have been solved experimentally so far [32], compared to the almost 200 free PDZ domain structures in the Protein Data Bank (PDB) [34]. We therefore start out by testing our computational procedure using two different structural forms of the domains, free and peptide-bound. Thereafter, we describe the conformational transitions of the peptides and the binding free energy landscapes for the domains. Finally, we perform a large number of Monte Carlo based kinetic simulations to obtain a deeper microscopic picture of the peptide binding process.
Results/Discussion
Selected Protein Domains
As class I and class II representatives we chose the 3rd PDZ domain of PSD-95 and the 6th PDZ domain of GRIP1, respectively. These are typical class I and II PDZ domains in the sense that all known binding peptides fall within their respective ideal class motifs [30], [35]. Free and peptide-bound X-ray structures have been determined for both domains [36], [37], and for PSD-95 the binding thermodynamics [38] as well as kinetics [39], [40] have been particularly well characterized. The ligands present in the two peptide-bound structures were derived from the C termini of the proteins CRIPT (PSD-95) [36] and human Liprin- (GRIP1) [37]. We consider here the binding of these two ligands to both the bound (b) and free (f) structural forms and denote the systems by PSD95-Ib, PSD95-If, GRIP1-IIb, and GRIP1-IIf, respectively. In addition to these class I and II domains, we include in this study the PDZ domain of PICK1 which is one of the few known PDZ domains with dual class I and II specificity. The structure of PICK1 PDZ has been determined with class II peptides [41], [42]. We consider binding of ligands taken from protein kinase
(GRIP1) [37]. We consider here the binding of these two ligands to both the bound (b) and free (f) structural forms and denote the systems by PSD95-Ib, PSD95-If, GRIP1-IIb, and GRIP1-IIf, respectively. In addition to these class I and II domains, we include in this study the PDZ domain of PICK1 which is one of the few known PDZ domains with dual class I and II specificity. The structure of PICK1 PDZ has been determined with class II peptides [41], [42]. We consider binding of ligands taken from protein kinase 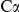 (
(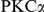 , class I) and AMPA receptor subunit GluR2 (GluR2, class II), which are known binders to PICK1 [43], [44], and denote the systems with PICK1-Ib and PICK1-IIb, respectively. The PDZ domains and peptide amino acid sequences under study are summarized in Table 1.
, class I) and AMPA receptor subunit GluR2 (GluR2, class II), which are known binders to PICK1 [43], [44], and denote the systems with PICK1-Ib and PICK1-IIb, respectively. The PDZ domains and peptide amino acid sequences under study are summarized in Table 1.
Table 1. PDZ domains and peptide sequences studied.
| Abbreviation | PDB ID | Exp | Peptide sequence | Peptide name |
| PSD95-Ib/PSD95-If | 1BE9/1BFE | X-ray | KQTSV | CRIPT |
| GRIP1-IIb/GRIP1-IIf | 1N7F/1N7E | X-ray | ATVRTYSC | Liprin-
|
| PICK1-Ib | –- | –- | LQSAV |
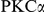
|
| PICK1-IIb | 2PKU | NMR | ESVKI | GluR2 |
Simulation Procedure and Minimum-Energy Conformations
To simulate the domain-peptide binding process, we use the MC based approach developed in Ref. [26]. This simulation procedure is general in that it can in principle be applied to any protein-peptide pair as long as a protein structure is available. Briefly, it works in the following way. A relaxed protein domain structure is centered in a cubic box and joined by a peptide in a random conformation away from the protein surface. The peptide is entirely free to search conformational space, restricted only by periodic boundary conditions on the box. The protein, on the other hand, is kept close to its native structure using constraints on the 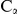 -atoms, which allow limited backbone and in principle full sidechain flexibility. We combine this simple procedure with an implicit-solvent all-atom energy function based on effective hydrogen bond, electrostatic, and hydrophobic forces [26]. Here we improve the model by including a context-dependent desolvation effect for backbone atoms groups (see Methods). We find, in particular, that including such a context-dependence improves the challenging case of simulating peptide binding to free domain structures. Energies E and temperatures T are given in dimensionless model units.
-atoms, which allow limited backbone and in principle full sidechain flexibility. We combine this simple procedure with an implicit-solvent all-atom energy function based on effective hydrogen bond, electrostatic, and hydrophobic forces [26]. Here we improve the model by including a context-dependent desolvation effect for backbone atoms groups (see Methods). We find, in particular, that including such a context-dependence improves the challenging case of simulating peptide binding to free domain structures. Energies E and temperatures T are given in dimensionless model units.
The thermodynamic behavior of our systems is obtained using Simulated Tempering (ST) [45]–[47], an expanded ensemble MC method in which T is treated as a dynamical parameter. The method is convenient both for finding global minimum-energy states and studying equilibrium behavior. For each PSD-95 and GRIP1 structure-peptide pair, we performed 5 independent ST runs. An example trajectory is shown in Figure S1 in Supporting Information. In addition, fixed-T MC simulations close to the midpoint, 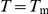 , i.e., where bound and unbound populations are equal, were also performed to provide additional statistics for free energy surface calculations. 10 independent fixed-T runs were performed for each structure-peptide pair in Table 1. Additional details on the computational model and simulation procedure are provided in Methods.
, i.e., where bound and unbound populations are equal, were also performed to provide additional statistics for free energy surface calculations. 10 independent fixed-T runs were performed for each structure-peptide pair in Table 1. Additional details on the computational model and simulation procedure are provided in Methods.
A challenging test for our computational model, used also in guiding the development of our all-atom energy function, is the prediction of bound peptide conformations. Figure 1 shows the model conformations found with the lowest total energy, E, across all ST and fixed-T MC runs for each system, superimposed on the corresponding experimental structures. All 6 min-E conformations are bound at the PDZ peptide binding pocket and many of the finer atom-level details match the experimental structures. Of special interest is to compare the two sets of results obtained for the ligand-bound and ligand-free PSD-95 and GRIP1 PDZ domain structures. One of the most pronounced differences is due to the different sidechain orientations at P(–2) between GRIP1-IIb and GRIP1-IIf docked peptides, such that the Tyr sidechain is pointing either out (GRIP1-IIf) or into (GRIP1-IIb) the peptide binding pocket (residue positions on PDZ binding peptides are typically numbered P(0) for the C terminus residue, P(–1) for the immediately preceding residue, and so on). This difference in orientation is likely related to a small shift in the 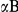 helix between the ligand-free and ligand-bound structures of the GRIP1 domain [37], such that the binding pocket is slightly wider in the bound structure.
helix between the ligand-free and ligand-bound structures of the GRIP1 domain [37], such that the binding pocket is slightly wider in the bound structure.
Figure 1. Minimum-energy peptide conformations found across all simulations for (A) PSD95-Ib, (B) PSD95-If, (C) GRIP1-IIb, (D) GRIP1-IIf, (E) PICK1-Ib, and (F) PICK1-IIb.

Nitrogen and carbon are shown in dark blue, oxygen in red, sulfur in yellow, and hydrogen in white. Experimentally determined domain-peptide complexes with PDB IDs (A, B) 1BE9, (B, C) 1N7F, and (D, E) 2PKU are shown in uniform light blue. The corresponding 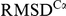 values between model and experimental peptide conformations are 0.9, 1.1, 1.7, 1.7, 2.4, and 2.3 Å, respectively (see Equation 1).
values between model and experimental peptide conformations are 0.9, 1.1, 1.7, 1.7, 2.4, and 2.3 Å, respectively (see Equation 1).
Free vs Peptide-Bound Domain Structures
Having seen that the lowest-E states represent more or less correctly bound ligands, we turn to the equilibrium behavior of the domain-peptide interaction. Figure 2 shows the T dependence of inter-chain hydrogen bond and hydrophobic interactions for PSD95-If/b and GRIP1-IIf/b. Some general trends are immediately seen. At high Ts, only limited interactions between peptides and domains occur, consistent with a process dominated by entropic effects. As T is lowered, peptides and domains associate increasingly, making both favorable hydrogen bonds and hydrophobic interactions. While all binding curves are smooth, the precise behavior is seen to depend on which domain structure type is used. Particularly, we find that the free domain structures (PSD95-If and GRIP1-IIf) bind their ligands somewhat weaker than their respective bound structures (PSD95-Ib and GRIP1-IIb).
Figure 2. Equilibrium peptide binding curves.

Thermodynamic averages of inter-chain hydrogen bond (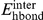 ) and hydrophobicity (
) and hydrophobicity (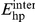 ) energies as a function of temperature, T, normalized by the number of peptide amino acids,
) energies as a function of temperature, T, normalized by the number of peptide amino acids, 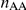 (we note that the expression for the hydrophobicity energy,
(we note that the expression for the hydrophobicity energy, 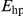 , equation 4 in Ref. [26], contains an overall sign error which we correct here; in all calculations,
, equation 4 in Ref. [26], contains an overall sign error which we correct here; in all calculations, 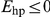 , and consequently
, and consequently 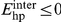 , as it should be). Solid lines are fits to a simple model assuming only two states, bound (B) and unbound (U), in which the temperature dependence of an observable X has the functional form
, as it should be). Solid lines are fits to a simple model assuming only two states, bound (B) and unbound (U), in which the temperature dependence of an observable X has the functional form 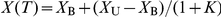 , where
, where 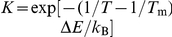 ,
, 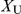 and
and 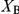 are observable baseline values,
are observable baseline values, 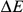 is the energy difference between U and B, and
is the energy difference between U and B, and 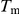 is the midpoint temperature. All statistical errors in this and other plots are jackknife estimates indicating
is the midpoint temperature. All statistical errors in this and other plots are jackknife estimates indicating 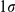 errors.
errors.
To investigate this difference quantitatively, we fit the binding curves in Figure 2 to a simple two-state expression with 4 free parameters. The fits are good for all binding curves and the fitted parameters are given in Tables 2 and 3. Of particular interest are the parameters 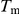 , the midpoint temperature representing equal populations of the two states, and
, the midpoint temperature representing equal populations of the two states, and 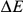 , the energy difference which controls the sharpness of the transition. The midpoints obtained are
, the energy difference which controls the sharpness of the transition. The midpoints obtained are 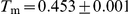 and
and 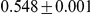 for PSD95-Ib and GRIP1-IIb, respectively. The corresponding
for PSD95-Ib and GRIP1-IIb, respectively. The corresponding 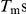 for PSD95-If and GRIP1-IIf are roughly 4% lower. We also find differences in
for PSD95-If and GRIP1-IIf are roughly 4% lower. We also find differences in 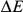 , as well as in the other 2 fit parameters, but the statistical errors for these parameters are larger (see Table 2 and 3). One statistically significant difference is a slightly sharper binding transition for PSD95-If compared to PSD95-Ib. This can also be seen as a relatively higher peak in the specific heat capacity curve (
, as well as in the other 2 fit parameters, but the statistical errors for these parameters are larger (see Table 2 and 3). One statistically significant difference is a slightly sharper binding transition for PSD95-If compared to PSD95-Ib. This can also be seen as a relatively higher peak in the specific heat capacity curve (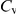 ) for PSD95-If, as shown in Figure 3. However, all
) for PSD95-If, as shown in Figure 3. However, all 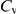 curves exhibit single peak behavior and the T-values at the
curves exhibit single peak behavior and the T-values at the 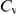 peaks correspond well to the
peaks correspond well to the 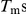 found from the fits in Figure 2. Hence, while we find differences in the binding behavior for bound and free domain structures, binding as an overall two-state process with a single transition appears to be a robust feature.
found from the fits in Figure 2. Hence, while we find differences in the binding behavior for bound and free domain structures, binding as an overall two-state process with a single transition appears to be a robust feature.
Table 2. Parameter values for two-state fits to ligand binding curves for PSD95-Ib and PSD95-If.
| Parameter | PSD95-Ib/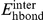
|
PSD95-Ib/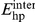
|
PSD95-If/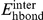
|
PSD95-If/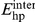
|
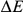
|
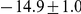
|
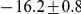
|
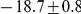
|
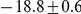
|
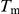
|
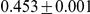
|
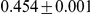
|
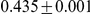
|
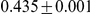
|
|
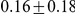
|
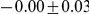
|
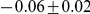
|
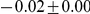
|
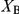
|
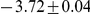
|
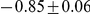
|
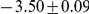
|
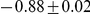
|
Table 3. Parameter values for two-state fits to ligand binding curves for GRIP1-IIb and GRIP1-IIf.
| Parameter | GRIP1-IIb/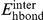
|
GRIP1-IIb/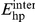
|
GRIP1-IIf/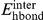
|
GRIP1-IIf/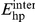
|
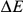
|
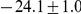
|
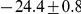
|
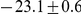
|
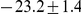
|
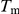
|
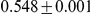
|
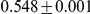
|
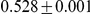
|
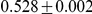
|
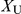
|
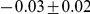
|
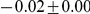
|
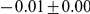
|
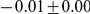
|
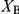
|
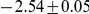
|
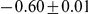
|
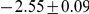
|
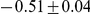
|
Figure 3. Specific heat capacity as a function of temperature.

The specific heat is calculated using 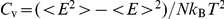 , where N is the total number of amino acids, E is the total energy, and
, where N is the total number of amino acids, E is the total energy, and 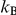 is the Boltzmann constant (taken to be 1 in this work).
is the Boltzmann constant (taken to be 1 in this work).
The variations in binding behavior between bound and free structures obtained in our simulations reflect structural differences between liganded and unliganded PDZ domain forms. Some of these differences are likely preserved by our native state constraints. Previous simulation results indicate that overall receptor flexibility and dynamics can play a major role in PDZ peptide binding and selectivity [7], [25], [48], [49]. Interestingly, structural differences in the binding pocket between bound and free form is significant for the GRIP1 domain [37] while quite negligible for PSD-95 [36]. Our results thus indicate that even subtle structural differences can impact binding significantly. Regardless of these differences between bound and free form our model predicts that the GRIP1 domain binds its peptide more strongly than PSD-95, with 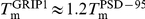 (see Figure 2). Meaningful quantitative binding affinities cannot be directly obtained, however, because T is not matched to physical units. Experimentally, the dissociation constant of the PSD-95/CRIPT interaction has been measured to
(see Figure 2). Meaningful quantitative binding affinities cannot be directly obtained, however, because T is not matched to physical units. Experimentally, the dissociation constant of the PSD-95/CRIPT interaction has been measured to 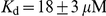 at 298 Kelvin, using isothermal titration calorimetry [38]. The binding affinity of the GRIP1 domain for the Liprin-
at 298 Kelvin, using isothermal titration calorimetry [38]. The binding affinity of the GRIP1 domain for the Liprin- peptide has to our knowledge not yet been determined.
peptide has to our knowledge not yet been determined.
Binding vs Folding
The binding curves in Figure 2 report on the overall character of the binding transition but do not provide any structural details, such as where on the protein surface binding preferentially occurs or how the peptide chain dynamics is influenced by binding. In defining a bound state, we use the root-mean-square-deviation between the atom coordinates of a model peptide conformation, 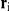 , and those of the experimental (native) peptide structure,
, and those of the experimental (native) peptide structure, 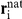 , i.e.,
, i.e.,
| (1) |
where the sum goes over n peptide atoms, either all non-H or only 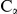 -atoms (indicated by superscripts ALL and
-atoms (indicated by superscripts ALL and 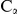 , respectively). An advantage of the RMSD measure is that a small value indicates that binding has occurred both at the right surface area and with a native-like internal conformation. Any peptide with
, respectively). An advantage of the RMSD measure is that a small value indicates that binding has occurred both at the right surface area and with a native-like internal conformation. Any peptide with 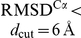 is considered correctly bound in the PDZ binding pocket. The choice of
is considered correctly bound in the PDZ binding pocket. The choice of 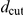 will be discussed later. In order to delineate the internal conformational dynamics of the peptide chain from its binding, we calculate also
will be discussed later. In order to delineate the internal conformational dynamics of the peptide chain from its binding, we calculate also 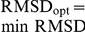 , where the minimization is over all rigid body translations and rotations of the peptide conformation. Hence,
, where the minimization is over all rigid body translations and rotations of the peptide conformation. Hence, 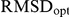 is the measure typically used in the analysis of folding trajectories and its notation is chosen merely to distinguish it from the “non-optimized” RMSD measure in Equation 1. A small
is the measure typically used in the analysis of folding trajectories and its notation is chosen merely to distinguish it from the “non-optimized” RMSD measure in Equation 1. A small 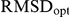 means that the peptide is native-like regardless of whether it is bound or not.
means that the peptide is native-like regardless of whether it is bound or not.
For both the PSD-95 and GRIP1 domain-peptide pairs, the probability that the peptides occupy the bound state, 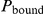 , increases sharply as T is lowered (see Figure 4). It is notable that for PSD95-Ib, at the lowest T simulated,
, increases sharply as T is lowered (see Figure 4). It is notable that for PSD95-Ib, at the lowest T simulated, 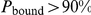 , indicating a very low probability for the peptide to bind parts of the domain surface other than the PDZ binding pocket.
, indicating a very low probability for the peptide to bind parts of the domain surface other than the PDZ binding pocket. 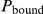 values for PSD95-If, GRIP1-IIb, and GRIP1-IIf are lower but the PDZ binding pocket is the dominating binding site in these cases, too, and
values for PSD95-If, GRIP1-IIb, and GRIP1-IIf are lower but the PDZ binding pocket is the dominating binding site in these cases, too, and 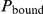 will likely increase further at still lower Ts. Consistent with our results in Figure 2, Figure 4 shows a higher peptide binding propensity for liganded (PSD95-Ib and GRIP1-IIb) compared to the unliganded structures (PSD95-If and GRIP1-IIf). These shifts are smaller than the differences between the two PDZ domains, as noted above.
will likely increase further at still lower Ts. Consistent with our results in Figure 2, Figure 4 shows a higher peptide binding propensity for liganded (PSD95-Ib and GRIP1-IIb) compared to the unliganded structures (PSD95-If and GRIP1-IIf). These shifts are smaller than the differences between the two PDZ domains, as noted above.
Figure 4. Domain-peptide binding as a minimal example of coupled folding and binding.

The probability for a peptide chain to occupy the PDZ peptide binding pocket, 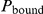 , increases with decreasing temperature, T. The solid curves are obtained with
, increases with decreasing temperature, T. The solid curves are obtained with 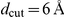 . Dotted curves indicate
. Dotted curves indicate 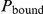 values obtained with
values obtained with 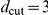 and
and 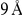 , respectively, for PSD95-Ib and GRIP1-IIb. Peptide binding is mirrored by an increasing internal similarity with the corresponding native peptide structures, as manifested by a decrease in
, respectively, for PSD95-Ib and GRIP1-IIb. Peptide binding is mirrored by an increasing internal similarity with the corresponding native peptide structures, as manifested by a decrease in 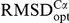 . No such decrease in
. No such decrease in 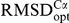 is seen for isolated peptides.
is seen for isolated peptides.
When the peptides associate with the protein surfaces they not only bind to the peptide binding pocket, they also undergo internal conformational transitions such that they more closely resemble the native peptide structures. This is clear from the lower panel of Figure 4, which shows that 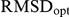 decreases with temperature T. Hence, the peptide-binding process also leads to increasingly native-like peptide conformations. By contrast, the peptide chains by themselves show little tendency to form any specific structure, at least over the temperatures studied, as indicated by a relative constant
decreases with temperature T. Hence, the peptide-binding process also leads to increasingly native-like peptide conformations. By contrast, the peptide chains by themselves show little tendency to form any specific structure, at least over the temperatures studied, as indicated by a relative constant 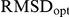 for isolated chains (see Figure 4). Moreover, the chain compactness is similarly only weakly dependent on T for both peptide sequences (see Figure S2 in Supporting Information). In this sense, our peptides are intrinsically disordered and their interaction with the PDZ domains can be seen as a minimal example of coupled folding and binding. Direct observation of such coupled folding-binding behavior in atomistic simulations has been seen previously mainly for
for isolated chains (see Figure 4). Moreover, the chain compactness is similarly only weakly dependent on T for both peptide sequences (see Figure S2 in Supporting Information). In this sense, our peptides are intrinsically disordered and their interaction with the PDZ domains can be seen as a minimal example of coupled folding and binding. Direct observation of such coupled folding-binding behavior in atomistic simulations has been seen previously mainly for  -helical peptides [50]–[54].
-helical peptides [50]–[54].
It must be pointed out that despite the indicated “folding,” significant structural heterogeneity remains in the bound state. This diversity represents the conformational entropy of the bound state and is important to take into account since it can significantly contribute to ligand binding [55]–[57]. In fact, in defining the bound state, our aim was to choose 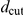 large enough to comprise most of this diversity, but not too large such that incorrectly bound peptide conformations are included. To explore this tradeoff, we show in Figure 4
large enough to comprise most of this diversity, but not too large such that incorrectly bound peptide conformations are included. To explore this tradeoff, we show in Figure 4
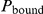 curves obtained also with
curves obtained also with 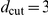 and
and 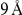 for PSD95-Ib and GRIP1-IIb. Increasing
for PSD95-Ib and GRIP1-IIb. Increasing 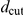 to 9 Å from 6 Å has a relatively small impact on the
to 9 Å from 6 Å has a relatively small impact on the 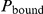 curves. Most of the structural diversity is therefore included with
curves. Most of the structural diversity is therefore included with 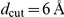 . At the other end, to see that
. At the other end, to see that 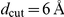 is not too large, we superimposed representative sets of peptide conformations with
is not too large, we superimposed representative sets of peptide conformations with 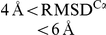 . This ensemble is naturally diverse but do not include conformations that can be considered misdocked (see Figure S3 in Supporting Information). Finally, we find it instructive to construct reference structures by rotating the experimental peptide structures by a half turn, such that the
. This ensemble is naturally diverse but do not include conformations that can be considered misdocked (see Figure S3 in Supporting Information). Finally, we find it instructive to construct reference structures by rotating the experimental peptide structures by a half turn, such that the 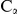 atoms of the first and last peptide amino acids exchange positions. These “flipped” peptides have
atoms of the first and last peptide amino acids exchange positions. These “flipped” peptides have 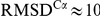 and
and 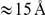 for the CRIPT (PSD-95) and Liprin-
for the CRIPT (PSD-95) and Liprin- (GRIP1) peptides, respectively. Hence, peptide conformations of this nature would not contribute positively towards
(GRIP1) peptides, respectively. Hence, peptide conformations of this nature would not contribute positively towards 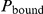 in our definition of the bound state (and are not observed in our simulations).
in our definition of the bound state (and are not observed in our simulations).
Binding Free Energy Surfaces
We turn now to the binding free energy landscapes of our PDZ domains, i.e., the free energy as a function of a set of order parameters indicating the progress of binding. For this purpose we use, in addition to the total energy E, two standard [58], [59] structural order parameters, 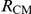 and Q, defined as the distance between the centers-of-mass (CM) of model and experimental peptide conformations and the fraction of inter-chain native contacts, respectively.
and Q, defined as the distance between the centers-of-mass (CM) of model and experimental peptide conformations and the fraction of inter-chain native contacts, respectively. 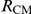 and Q are complementary in that each provide different perspective on the peptide binding process. The binding free energy surfaces for PSD95-Ib and GRIP1-IIb show bound and unbound states well separated with a single barrier (the transition state, TS) at
and Q are complementary in that each provide different perspective on the peptide binding process. The binding free energy surfaces for PSD95-Ib and GRIP1-IIb show bound and unbound states well separated with a single barrier (the transition state, TS) at 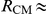 4–6 Å and
4–6 Å and 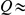 0.1–0.2 (see Figure 5). The binding landscapes do not exhibit any competing deep local minima representing misdocked conformations and therefore constitute almost ideal “binding funnels” [60]. This is reassuring in terms of the validity of the model and indicates that nonspecific binding between PDZ domain and peptide chains may be very limited.
0.1–0.2 (see Figure 5). The binding landscapes do not exhibit any competing deep local minima representing misdocked conformations and therefore constitute almost ideal “binding funnels” [60]. This is reassuring in terms of the validity of the model and indicates that nonspecific binding between PDZ domain and peptide chains may be very limited.
Figure 5. Peptide binding free energy surfaces for PSD95-Ib, GRIP1-IIb, PICK1-Ib, and PICK1-IIb, at .

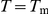 . Free energies are calculated using
. Free energies are calculated using 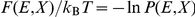 , where
, where 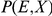 is the joint probability distribution in total energy, E, and
is the joint probability distribution in total energy, E, and 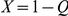 or
or 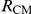 . The one-dimensional free energy profiles are obtained from the corresponding marginal distributions. PSD95-Ib and GRIP1-IIb free energies were calculated directly from fixed-T MC simulations at the respective
. The one-dimensional free energy profiles are obtained from the corresponding marginal distributions. PSD95-Ib and GRIP1-IIb free energies were calculated directly from fixed-T MC simulations at the respective 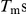 . PICK1-Ib and PICK1-IIb simulations were performed at
. PICK1-Ib and PICK1-IIb simulations were performed at 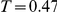 and
and 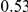 , respectively. Free energies at the midpoints (
, respectively. Free energies at the midpoints (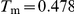 for PICK1-Ib and
for PICK1-Ib and 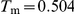 for PICK1-IIb, determined from the
for PICK1-IIb, determined from the 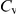 maxima) were obtained using single-histogram reweighting [64].
maxima) were obtained using single-histogram reweighting [64].
The one-dimensional free energy profiles in 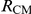 , Q and E reveal a more distinct free energy barrier between the bound and unbound states for GRIP1-IIb compared to PSD95-Ib, indicating a more cooperative binding process for the class II domain (see Figure 5). In the E parameter, a small barrier separates bound and unbound states for GRIP1-IIb while such a barrier is mostly absent for PSD95-Ib. In the structural parameters, Q and
, Q and E reveal a more distinct free energy barrier between the bound and unbound states for GRIP1-IIb compared to PSD95-Ib, indicating a more cooperative binding process for the class II domain (see Figure 5). In the E parameter, a small barrier separates bound and unbound states for GRIP1-IIb while such a barrier is mostly absent for PSD95-Ib. In the structural parameters, Q and 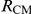 , the barriers are overall much higher but the trend remains. This can be seen, for example, in the free energy difference between the transition state and the native, bound state,
, the barriers are overall much higher but the trend remains. This can be seen, for example, in the free energy difference between the transition state and the native, bound state, 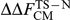 , in the
, in the 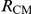 parameter. From Figure 5, we find that
parameter. From Figure 5, we find that 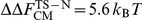 and
and 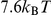 for PSD95-Ib and GRIP1-IIb, respectively. One could easily suspect that the relatively higher barrier for GRIP1-IIb is due to its longer peptide. This is however not the case. We re-made our simulations for GRIP1-IIb with a truncated, 5-amino acid version of Liprin-
for PSD95-Ib and GRIP1-IIb, respectively. One could easily suspect that the relatively higher barrier for GRIP1-IIb is due to its longer peptide. This is however not the case. We re-made our simulations for GRIP1-IIb with a truncated, 5-amino acid version of Liprin- and found that
and found that 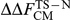 in fact increases slightly to
in fact increases slightly to 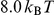 . Hence, the difference between the PSD-95 and GRIP1 systems is likely mainly related to differences in the amino acid sequences. The bound state for GRIP1-IIb is characterized by a single, deep minimum at
. Hence, the difference between the PSD-95 and GRIP1 systems is likely mainly related to differences in the amino acid sequences. The bound state for GRIP1-IIb is characterized by a single, deep minimum at 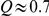 , i.e., with most of the native contacts formed. The PSD-95 domain, by contrast, exhibit a significantly wider distribution of Q-values in the bound state. In addition to a deep
, i.e., with most of the native contacts formed. The PSD-95 domain, by contrast, exhibit a significantly wider distribution of Q-values in the bound state. In addition to a deep 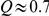 minimum, a second weaker minimum exists at
minimum, a second weaker minimum exists at 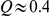 . Visual inspection of the
. Visual inspection of the 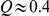 minimum reveals peptide conformations in which the C terminal Val of CRIPT is tethered to the PDZ binding pocket, kept in place mainly through hydrophobic interactions involving the Val and hydrogen bonding between the peptide C terminus and the PDZ carboxylate binding loop, leaving a floppy N terminal region. Such flexible, yet bound conformations are mostly absent for GRIP1-IIb. Instead, its peptide typically binds through both the Cys and Tyr sidechains at P(0) and P(–2). From the perspective of our model, we find that additional hydrophobic contacts provided by P(–2) in class II domain-peptide binding give a more rigidly bound peptide ensemble, which in turn produces a higher free energy barrier for binding and a more cooperative binding process.
minimum reveals peptide conformations in which the C terminal Val of CRIPT is tethered to the PDZ binding pocket, kept in place mainly through hydrophobic interactions involving the Val and hydrogen bonding between the peptide C terminus and the PDZ carboxylate binding loop, leaving a floppy N terminal region. Such flexible, yet bound conformations are mostly absent for GRIP1-IIb. Instead, its peptide typically binds through both the Cys and Tyr sidechains at P(0) and P(–2). From the perspective of our model, we find that additional hydrophobic contacts provided by P(–2) in class II domain-peptide binding give a more rigidly bound peptide ensemble, which in turn produces a higher free energy barrier for binding and a more cooperative binding process.
A question that arises in comparing features of the free energy surfaces of PSD95-Ib and GRIP1-IIb is to what extent they can be controlled by the peptide sequence. In this regard, promiscuous PDZ domains which bind both class I and II peptides are of particular interest. We therefore apply our method to one such domain, the PDZ domain of PICK1, and simulate the binding of both a class I (PICK1-Ib) and a class II (PICK1-IIb) peptide, as displayed in Table 1. Despite that the two peptide sequences bind the same domain structure, their free energy surfaces are quite different (see Figure 5C and D). Specifically, the PICK1-Ib landscape exhibits striking similarities with PSD95-Ib, particularly with regard to a broad Q-distribution of the bound state. PICK1-IIb, on the other hand, has a binding free energy landscape similar to GRIP1-IIb, with a single well-defined native basin of attraction. The binding free energy barriers for PICK1-Ib and PICK1-IIb are 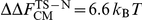 and
and 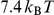 , respectively, such that the class II peptide again shows a relatively stronger binding cooperativity.
, respectively, such that the class II peptide again shows a relatively stronger binding cooperativity.
It is interesting to compare our results for PICK1-Ib and PICK1-IIb with those of Madsen et al.
[44]. Using an assay based on fluorescence polarization, they found that the PICK1 PDZ domain showed a higher affinity for a class II than a class I peptide (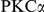 ). This is in qualitative agreement with our results, as we find a higher
). This is in qualitative agreement with our results, as we find a higher 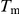 for PICK1-IIb over PICK1-Ib (see Figure 5 legend), although their class II ligand was not the same as ours. Madsen et al. also obtained docked peptide structures using homology modeling and found
for PICK1-IIb over PICK1-Ib (see Figure 5 legend), although their class II ligand was not the same as ours. Madsen et al. also obtained docked peptide structures using homology modeling and found 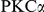 to be unusually displaced from
to be unusually displaced from 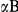 at the N terminal end, somewhat reminiscent our
at the N terminal end, somewhat reminiscent our 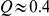 local free energy minimum. However, for typical
local free energy minimum. However, for typical 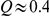 peptides in our simulations the N terminal ends have become almost entirely displaced from the
peptides in our simulations the N terminal ends have become almost entirely displaced from the  -helix. One might think that this structural diversity is exaggerated by our model because, after all, PDZ specificity is in part obtained from interactions with P(–2). We therefore tested the PICK1 mutation Ala87Leu, which was introduced by Madsen et al. and meant to fill out the hydrophobic pocket normally occupied by the P(–2) residue. The mutation was indeed found to essentially eliminate binding to both the class I and II peptides in their assay [44]. We find in our simulations that the Ala87Leu mutation drastically reduces
-helix. One might think that this structural diversity is exaggerated by our model because, after all, PDZ specificity is in part obtained from interactions with P(–2). We therefore tested the PICK1 mutation Ala87Leu, which was introduced by Madsen et al. and meant to fill out the hydrophobic pocket normally occupied by the P(–2) residue. The mutation was indeed found to essentially eliminate binding to both the class I and II peptides in their assay [44]. We find in our simulations that the Ala87Leu mutation drastically reduces 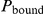 from roughly 0.5 at
from roughly 0.5 at 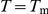 in wild-type PICK1 to
in wild-type PICK1 to 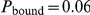 and 0.09 for the class I and II peptides, respectively. Hence, interactions involving P(–2) are still crucial for proper binding in our model despite the
and 0.09 for the class I and II peptides, respectively. Hence, interactions involving P(–2) are still crucial for proper binding in our model despite the 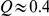 local minimum. In this context, it is interesting to note that experimental PDZ domain-peptide complexes were recently obtained in which the interaction occurs mainly through the P(0) position, such that the peptides bind roughly perpendicular to the domain surface [61].
local minimum. In this context, it is interesting to note that experimental PDZ domain-peptide complexes were recently obtained in which the interaction occurs mainly through the P(0) position, such that the peptides bind roughly perpendicular to the domain surface [61].
Monte Carlo Binding Kinetics
Above we have shown that, in our model, peptide binding can be seen roughly as a two-state process in which a single free energy barrier separates the bound and unbound states. How is this free energy barrier crossed during binding? To address this question and further investigate the mechanism underlying peptide binding we perform a large number of fixed-temperature simulations where the peptide chains are, as previously, initiated in random positions and conformations. In contrast to above, the MC “kinetics” simulations are performed using only small-step updates for the peptide chain; global, unphysical pivot moves are excluded (see Methods). A fraction of rigid body translation and rotation MC moves for the peptide chain is included. There are two processes for the peptide chain in these simulations, a search on the protein surface for the peptide-binding pocket and, subsequently, a conformational search for the correctly bound structure. Because of the inclusion of rigid body moves, we assume a dynamics in which the search process across the protein surface is fast. Relaxation towards equilibrium is therefore limited by a conformational reorganization of the peptide and protein chains during binding, which is the process we are primarily interested in.
We find that the relaxation behavior for both PSD95-Ib and GRIP1-IIb systems is consistent with a single-exponential curve, as can be seen in Figure 6. This indicates a single rate-limiting step in the peptide binding process, or, in other words, the free energy barrier is crossed without significantly populating an intermediate state. Only a handful kinetic experiments of PDZ domain-peptide binding have been performed so far but one such study has presented results for the PSD-95 system analyzed here. Using stopped-flow fluorescence spectroscopy, Jemth et al.
[39] observed single-exponential binding traces for the PSD-95 PDZ domain and a dansylated CRIPT peptide. Our results are therefore consistent with these observations. However, it must be pointed out that the MC-based simulations performed here should not be seen as mimicking kinetic experiments, as chain diffusion effects are not rigorously taken into account. A more realistic comparison is likely achieved by focusing on relative kinetic effects between peptide binding systems. In this respect, we observe a significant difference in relaxation times  between PSD95-Ib and GRIP1-IIb, such that
between PSD95-Ib and GRIP1-IIb, such that 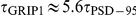 , a prediction which may be tested experimentally. This difference in relaxation rate between the two domains is consistent with the larger free energy barrier seen for GRIP1-IIb over PSD95-Ib.
, a prediction which may be tested experimentally. This difference in relaxation rate between the two domains is consistent with the larger free energy barrier seen for GRIP1-IIb over PSD95-Ib.
Figure 6. Binding relaxation curves for PSD95-Ib and GRIP1-IIb.

Peptide chains are initiated in random conformations and positions away from the domain surface and thereafter evolved using fixed-T, small-step MC dynamics at 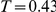 and
and 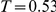 for PSD95-Ib and GRIP1-IIb, respectively. The chosen Ts are slightly below the respective
for PSD95-Ib and GRIP1-IIb, respectively. The chosen Ts are slightly below the respective 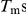 . Averages are obtained from 200 independent runs. Solid lines are fits to a single-exponential curve,
. Averages are obtained from 200 independent runs. Solid lines are fits to a single-exponential curve, 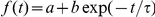 , where T is the number of MC steps, and a, b and
, where T is the number of MC steps, and a, b and  are fit parameters.
are fit parameters.
Conclusions
We have developed a MC based procedure for exploring peptide binding processes and employed it to two typical PDZ class I and II domains and a dual class I–II domain. In combining the equilibrium and small-step, fixed-temperature kinetic simulation results, a picture emerges for the binding process in which there are overall similarities but also differences in the details. In all cases, binding is coupled to folding, and can be characterized as an overall two-state process with a free energy surface funneled towards the peptide bound state. Binding to the PSD-95 PDZ domain involves a lower free energy barrier than the GRIP1 PDZ domain, leading to significantly faster binding kinetics, at least for the peptide sequences studied. What is the origin of this difference? The shape of the near-native free energy surface for the GRIP1 PDZ domain indicates a relatively coherent ensemble of bound peptide conformations, stabilized by hydrophobic interactions with P(0) and P(–2). As a class I domain, the PSD-95 domain lacks strong hydrophobic interactions at P(–2) leading to a more conformationally diverse bound state, spanning a wider range of 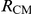 and Q values. In particular, we find a weak free energy minimum corresponding to peptides bound to the PDZ binding pocket mainly through the P(0) position, with a flexible N terminal tail. The population of such conformations are significantly smaller for the GRIP1 PDZ domain. Our results are therefore consistent with a binding mechanism in which the rate-limiting step is the initial binding of P(0) at the PDZ peptide binding pocket. This interpretation is also supported by recent experimental PDZ domain-peptide structures, including GRASP [61] and X11 [62], where peptides are attached in a “perpendicular” mode. To what extent these results apply to other class I and II PDZ domains remains to be seen. However, the fact that an analogous behavior is found for the dual class I–II PICK1 domain indicates that it may have some generality.
and Q values. In particular, we find a weak free energy minimum corresponding to peptides bound to the PDZ binding pocket mainly through the P(0) position, with a flexible N terminal tail. The population of such conformations are significantly smaller for the GRIP1 PDZ domain. Our results are therefore consistent with a binding mechanism in which the rate-limiting step is the initial binding of P(0) at the PDZ peptide binding pocket. This interpretation is also supported by recent experimental PDZ domain-peptide structures, including GRASP [61] and X11 [62], where peptides are attached in a “perpendicular” mode. To what extent these results apply to other class I and II PDZ domains remains to be seen. However, the fact that an analogous behavior is found for the dual class I–II PICK1 domain indicates that it may have some generality.
Methods
All-Atom Computational Model
All simulations are performed using essentially the model described in [26], with a small improvement described in the following. Our original starting point was a model developed for peptide folding [27], [28] which combines an all-atom protein representation with an effective energy function based mainly on hydrogen bonding, hydrophobicity, and electrostatic attractions. This model was then adapted for peptide binding [26], where, in particular, we added a context dependence to the energy function such that electrostatic attractions between partial charges buried in the protein were made effectively stronger than those solvent exposed. This was accomplished by using a parameter, 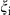 , indicating the “degree of buriedness” for any atom i. In this work, we add a context-dependent term describing desolvation effects on backbone atom groups,
, indicating the “degree of buriedness” for any atom i. In this work, we add a context-dependent term describing desolvation effects on backbone atom groups,
| (2) |
in which the sum goes over all backbone NH and CO groups i. For “unsatisfied” NH and CO groups, i.e., those not participating in any intra- or inter-chain hydrogen bond, 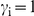 , and for all others,
, and for all others, 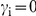 . The quantity
. The quantity 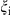 is calculated at a point,
is calculated at a point, 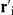 , which for a NH group is located 2.0 Å from the H atom in the NH direction, and for a CO group, 2.0 Å from the O atom in the CO direction.
, which for a NH group is located 2.0 Å from the H atom in the NH direction, and for a CO group, 2.0 Å from the O atom in the CO direction. 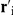 is thus found approximately in the space occupied by a potential solvent molecule hydrogen bonded to i.
is thus found approximately in the space occupied by a potential solvent molecule hydrogen bonded to i. 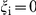 indicates that this space is available to a solvent molecule while
indicates that this space is available to a solvent molecule while 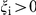 indicates it is instead occupied by other protein atoms. Hence, “unsatisfied” NH and CO groups with
indicates it is instead occupied by other protein atoms. Hence, “unsatisfied” NH and CO groups with 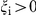 (i.e. also unlikely to participate in solvent hydrogen bonding) are energetically penalized. The term therefore acts as a desolvation effect for backbone atoms. The strength chosen is
(i.e. also unlikely to participate in solvent hydrogen bonding) are energetically penalized. The term therefore acts as a desolvation effect for backbone atoms. The strength chosen is 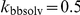 . Including this energy term yields a crucially improved performance over the previous model [26], most notably for peptide binding to free domain structures. Specifically, the PSD95-If domain-peptide pair exhibited almost no propensity for correct binding previously [26] while including
. Including this energy term yields a crucially improved performance over the previous model [26], most notably for peptide binding to free domain structures. Specifically, the PSD95-If domain-peptide pair exhibited almost no propensity for correct binding previously [26] while including 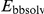 yields reliable binding as detailed in this work.
yields reliable binding as detailed in this work.
Monte Carlo Simulations
To obtain equilibrium conformational ensembles of our domain-peptide systems we used Simulated Tempering (ST). [45]–[47], in which conformational updates are alternated with updates in the temperature T. Initially, a set of discrete temperatures are selected. Changes between these discrete temperatures during simulations are then treated as ordinary MC updates. 8 different temperatures in suitable ranges are used for all domain-peptide systems. For updates in conformational space, we use a few different move types. For the protein domain, which is constrained close to its native structure, we use sidechain rotations, in which a single 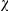 -angle is turned, and semi-local backbone moves, in which 8 consecutive
-angle is turned, and semi-local backbone moves, in which 8 consecutive 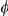 - and
- and 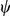 -angles are turned in a coordinated way [63]. For the peptide chain, 3 additional moves are used: a pivot move which turns a single
-angles are turned in a coordinated way [63]. For the peptide chain, 3 additional moves are used: a pivot move which turns a single 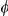 - or
- or 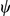 -angle, and rigid body translation (
-angle, and rigid body translation (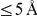 ) and rotation (
) and rotation (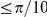 ) moves. An effective peptide concentration is set by the box side L. For computational reasons, we use a small box such that
) moves. An effective peptide concentration is set by the box side L. For computational reasons, we use a small box such that 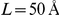 , corresponding to an effective concentration of
, corresponding to an effective concentration of 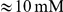 .
.
We performed the following peptide binding simulations. For PSD95-Ib, PSD95-If, GRIP1-IIb, and GRIP1-IIf, 5 ST runs were performed with at least 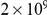 elementary MC steps. These runs were used to find the T dependence of various observables including the specific heat curves. 10 fixed-T MC runs at
elementary MC steps. These runs were used to find the T dependence of various observables including the specific heat curves. 10 fixed-T MC runs at 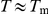 were performed for all of the 6 domain structure-peptide pairs in Table 1, each with 2 or
were performed for all of the 6 domain structure-peptide pairs in Table 1, each with 2 or 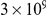 steps. These simulations were used for free energy surfaces calculations. The MC kinetic simulations differs from the equilibrium runs in the following ways. First, the global, unphysical pivot move was turned off, such that only small-step chain moves were allowed. Second, the translation step size was decreased from 5 Å to 1 Å. 200 independent binding runs were performed for PSD95-Ib and GRIP1-IIb consisting of
steps. These simulations were used for free energy surfaces calculations. The MC kinetic simulations differs from the equilibrium runs in the following ways. First, the global, unphysical pivot move was turned off, such that only small-step chain moves were allowed. Second, the translation step size was decreased from 5 Å to 1 Å. 200 independent binding runs were performed for PSD95-Ib and GRIP1-IIb consisting of 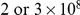 elementary MC steps.
elementary MC steps.
Order Parameters
The progress of binding is quantified using the two order parameters Q, the fraction of native inter-chain contacts, and 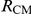 , the distance between model and native peptide centers-of-mass (CM). To calculate Q, we determined initially a set of inter-chain amino acid contacts for each experimental domain-peptide structure. Two amino acids are considered in contact if any two non-H atoms, one from each amino acid, have a distance
, the distance between model and native peptide centers-of-mass (CM). To calculate Q, we determined initially a set of inter-chain amino acid contacts for each experimental domain-peptide structure. Two amino acids are considered in contact if any two non-H atoms, one from each amino acid, have a distance 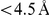 . This yields sets of 28, 30, and 23 inter-chain native contacts for the domain-peptide structures 1BE9 (PSD-95), 1N7F (GRIP1), and 2PKU (PICK1), respectively. For PICK1-Ib, in the absence of an experimental ligand-bound structure for the
. This yields sets of 28, 30, and 23 inter-chain native contacts for the domain-peptide structures 1BE9 (PSD-95), 1N7F (GRIP1), and 2PKU (PICK1), respectively. For PICK1-Ib, in the absence of an experimental ligand-bound structure for the 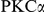 peptide, we use our minimum-energy conformation (see Figure 1F), which yields a set of 23 native contacts. In calculating Q for a peptide conformation, the fraction of native contacts formed is determined by applying the same contact definition. The CM distance is determined using
peptide, we use our minimum-energy conformation (see Figure 1F), which yields a set of 23 native contacts. In calculating Q for a peptide conformation, the fraction of native contacts formed is determined by applying the same contact definition. The CM distance is determined using 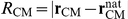 , where
, where 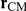 and
and 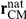 are the CMs of the model and native peptide conformations, respectively, calculated over the
are the CMs of the model and native peptide conformations, respectively, calculated over the 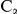 atoms of the last 4 amino acids.
atoms of the last 4 amino acids.
Supporting Information
Example of a simulation trajectory. One of the 5 Simulated Tempering runs performed for PSD95-If. The index k represents different temperatures chosen according to 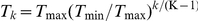 , where
, where 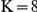 is the number of temperatures,
is the number of temperatures, 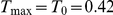 , and
, and 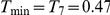 . Changes in k are performed as ordinary MC updates. The figure shows, as functions of the number of MC steps,
. Changes in k are performed as ordinary MC updates. The figure shows, as functions of the number of MC steps, 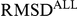 , the total energy E, and the temperature index k.
, the total energy E, and the temperature index k.
(TIFF)
Conformational behavior of isolated peptide chains. The radius of gyration, 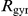 , as a function of the temperature, T, for two different peptide sequences in isolation.
, as a function of the temperature, T, for two different peptide sequences in isolation. 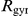 is calculated over all peptide
is calculated over all peptide 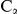 atoms. The relative variation in
atoms. The relative variation in 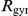 is around 2–3% for both sequences over the Ts studied.
is around 2–3% for both sequences over the Ts studied.
(TIFF)
Structural diversity of bound peptide conformations. Superposition of a set of model peptide conformations (dark blue) with 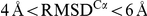 for PSD95-Ib (left) and GRIP1-IIb (right). The corresponding experimental domain-peptide complexes are shown in light blue (domain) and green (peptide).
for PSD95-Ib (left) and GRIP1-IIb (right). The corresponding experimental domain-peptide complexes are shown in light blue (domain) and green (peptide).
(TIFF)
Footnotes
The authors have declared that no competing interests exist.
This work is in part supported by the Swedish Research Council. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.Dyson HJ, Wright PE. Intrinsically unstructured proteins and their functions. Nat Rev Mol Cell Biol. 2005;6:197–208. doi: 10.1038/nrm1589. [DOI] [PubMed] [Google Scholar]
- 2.Radivojac P, Iakoucheva LM, Oldfield CJ, Obradovic Z, Uversky VN, et al. Intrinsic disorder and functional proteomics. Biophys J. 2007;92:1439–1456. doi: 10.1529/biophysj.106.094045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Petsalaki E, Russell RB. Peptide-mediated interactions in biological systems: new discoveries and applications. Curr Opin Biotechnol. 2008;19:344–350. doi: 10.1016/j.copbio.2008.06.004. [DOI] [PubMed] [Google Scholar]
- 4.Pawson T, Nash P. Assembly of cell regulatory systems through protein interaction domains. Science. 2003;300:445–452. doi: 10.1126/science.1083653. [DOI] [PubMed] [Google Scholar]
- 5.Bhattacharyya RP, Remenyi A, Yeh BJ, Lim WA. Domains, motifs, and scaffolds: the role of modular interactions in the evolution and wiring of cell signaling circuits. Annu Rev Biochem. 2006;75:655–680. doi: 10.1146/annurev.biochem.75.103004.142710. [DOI] [PubMed] [Google Scholar]
- 6.Russell RB, Aloy P. Targeting and tinkering with interaction networks. Nat Chem Biol. 2008;4:666–673. doi: 10.1038/nchembio.119. [DOI] [PubMed] [Google Scholar]
- 7.Smock RG, Gierasch LM. Sending signals dynamically. Science. 2009;324:198–203. doi: 10.1126/science.1169377. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Neduva V, Russell RB. Peptides mediating interaction networks: new leads at last. Curr Opin Biotechnol. 2006;17:465–471. doi: 10.1016/j.copbio.2006.08.002. [DOI] [PubMed] [Google Scholar]
- 9.Rubinstein M, Niv MY. Peptidic modulators of protein-protein interactions: progress and challenges in computational design. Biopolymers. 2009;91:505–513. doi: 10.1002/bip.21164. [DOI] [PubMed] [Google Scholar]
- 10.Desmet J, Wilson IA, Joniau M, De Maeyer M, Lasters I. Computation of the binding of fully flexible peptides to proteins with flexible side chains. FASEB J. 1997;11:164–172. doi: 10.1096/fasebj.11.2.9039959. [DOI] [PubMed] [Google Scholar]
- 11.Liu Z, Dominy BN, Shakhnovich EI. Structural mining: self-consistent design on flexible protein-peptide docking and transferable binding affinity potential. J Am Chem Soc. 2004;126:8515–8528. doi: 10.1021/ja032018q. [DOI] [PubMed] [Google Scholar]
- 12.Tong JC, Tan TW, Ranganathan S. Modeling the structure of bound peptide ligands to major histocompatibility complex. Protein Sci. 2004;13:2523–2532. doi: 10.1110/ps.04631204. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Niv MY, Weinstein H. A flexible docking procedure for the exploration of peptide binding selectivity to known structures and homology models of PDZ domains. J Am Chem Soc. 2005;127:14072–14079. doi: 10.1021/ja054195s. [DOI] [PubMed] [Google Scholar]
- 14.Raveh B, London N, Schueler-Furman O. Sub-angstrom modeling of complexes between flexible peptides and globular proteins. Proteins. 2010;78:2029–2040. doi: 10.1002/prot.22716. [DOI] [PubMed] [Google Scholar]
- 15.King CA, Bradley P. Structure-based prediction of protein-peptide specificity in Rosetta. Proteins. 2010;78:3437–3449. doi: 10.1002/prot.22851. [DOI] [PubMed] [Google Scholar]
- 16.Kaufmann K, Shen N, Mizoue L, Meiler J. A physical model for PDZdomain/peptide interactions. J Mol Model. 2011;17:315–324. doi: 10.1007/s00894-010-0725-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Hetnyi C, van der Spoel D. Efficient docking of peptides to proteins without prior knowledge of the binding site. Protein Sci. 2002;11:1729–1737. doi: 10.1110/ps.0202302. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Petsalaki E, Stark A, García-Urdiales E, Russell RB. Accurate prediction of peptide binding sites on protein surfaces. PLoS Comput Biol. 2009;5:e1000335. doi: 10.1371/journal.pcbi.1000335. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Wunderlich Z, Mirny LA. Using genome-wide measurements for computational prediction of SH2-peptide interactions. Nucleic Acids Res. 2009;37:4629–4641. doi: 10.1093/nar/gkp394. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Fernandez-Ballester G, Beltrao P, Gonzalez JM, Song YH, Wilmanns M, et al. Structure-based prediction of the Saccharomyces cerevisiae SH3-ligand interactions. J Mol Biol. 2009;388:902–916. doi: 10.1016/j.jmb.2009.03.038. [DOI] [PubMed] [Google Scholar]
- 21.Hou T, Xu Z, Zhang W, McLaughlin WA, Case DA, et al. Characterization of domain-peptide interaction interface: a generic structure-based model to decipher the binding specificity of SH3 domains. Mol Cell Proteomics. 2009;8:639–649. doi: 10.1074/mcp.M800450-MCP200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Chen JR, Chang BH, Allen JE, Stiffler MA, MacBeath G. Predicting PDZ domain-peptide interactions from primary sequences. Nat Biotechnol. 2008;26:1041–1045. doi: 10.1038/nbt.1489. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Zacharias M, Springer S. Conformational flexibility of the MHC class I alpha1-alpha2 domain in peptide bound and free states: a molecular dynamics simulation study. Biophys J. 2004;87:2203–2214. doi: 10.1529/biophysj.104.044743. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Basdevant N, Weinstein H, Ceruso M. Thermodynamic basis for promiscuity and selectivity in protein-protein interactions: PDZ domains, a case study. J Am Chem Soc. 2006;128:12766–12777. doi: 10.1021/ja060830y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Dhulesia A, Gsponer J, Vendruscolo M. Mapping of two networks of residues that exhibit structural and dynamical changes upon binding in a PDZ domain protein. J Am Chem Soc. 2008;130:8931–8939. doi: 10.1021/ja0752080. [DOI] [PubMed] [Google Scholar]
- 26.Staneva I, Wallin S. All-atom Monte Carlo approach to protein-peptide binding. J Mol Biol. 2009;393:1118–1128. doi: 10.1016/j.jmb.2009.08.063. [DOI] [PubMed] [Google Scholar]
- 27.Irbäck A, Samuelsson B, Sjunnesson F, Wallin S. Thermodynamics of alphaand beta-structure formation in proteins. Biophys J. 2003;85:1466–1473. doi: 10.1016/S0006-3495(03)74579-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Irbäck A, Mohanty S. PROFASI: A Monte Carlo simulation package for protein folding and aggregation. J Comput Chem. 2006;27:1548–1555. doi: 10.1002/jcc.20452. [DOI] [PubMed] [Google Scholar]
- 29.Mitternacht S, Mohanty S, Irbäck A. An effective all-atom potential for proteins. PMC Biophys. 2009;2:2. doi: 10.1186/1757-5036-2-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Sheng M, Sala C. PDZ domains and the organization of supramolecular complexes. Annu Rev Neurosci. 2001;24:1–29. doi: 10.1146/annurev.neuro.24.1.1. [DOI] [PubMed] [Google Scholar]
- 31.Spaller MR. Act globally, think locally: systems biology addresses the PDZ domain. ACS Chem Biol. 2006;1:207–210. doi: 10.1021/cb600191y. [DOI] [PubMed] [Google Scholar]
- 32.Lee HJ, Zheng JJ. PDZ domains and their binding partners: structure, specificity, and modification. Cell Commun Signal. 2010;8:8. doi: 10.1186/1478-811X-8-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Tonikian R, Zhang Y, Sazinsky SL, Currell B, Yeh JH, et al. A specificity map for the PDZ domain family. PLoS Biol. 2008;6:e239. doi: 10.1371/journal.pbio.0060239. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Berman HM, Westbrook J, Feng Z, Gilliland G, Bhat TN, et al. The Protein Data Bank. Nucleic Acids Res. 2000;28:235–242. doi: 10.1093/nar/28.1.235. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Beuming T, Skrabanek L, Niv MY, Mukherjee P, Weinstein H. PDZBase: a protein-protein interaction database for PDZ-domains. Bioinformatics. 2005;21:827–828. doi: 10.1093/bioinformatics/bti098. [DOI] [PubMed] [Google Scholar]
- 36.Doyle DA, Lee A, Lewis J, Kim E, Sheng M, et al. Crystal structures of a complexed and peptide-free membrane protein-binding domain: molecular basis of peptide recognition by PDZ. Cell. 1996;85:1067–1076. doi: 10.1016/s0092-8674(00)81307-0. [DOI] [PubMed] [Google Scholar]
- 37.Im YJ, Park SH, Rho SH, Lee JH, Kang GB, et al. Crystal structure of GRIP1 PDZ6-peptide complex reveals the structural basis for class II PDZ target recognition and PDZ domain-mediated multimerization. J Biol Chem. 2003;278:8501–8507. doi: 10.1074/jbc.M212263200. [DOI] [PubMed] [Google Scholar]
- 38.Saro D, Li T, Rupasinghe C, Paredes A, Caspers N, et al. A thermodynamic ligand binding study of the third PDZ domain (PDZ3) from the mammalian neuronal protein PSD-95. Biochemistry. 2007;46:6340–6352. doi: 10.1021/bi062088k. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Gianni S, Engström Å, Larsson M, Calosci N, Malatesta F, et al. The kinetics of PDZ domain-ligand interactions and implications for the binding mechanism. J Biol Chem. 2005;280:34805–34812. doi: 10.1074/jbc.M506017200. [DOI] [PubMed] [Google Scholar]
- 40.Chi CN, Bach A, Engström Å, Wang H, Strømgaard K, et al. A sequential binding mechanism in a PDZ domain. Biochemistry. 2009;48:7089–7097. doi: 10.1021/bi900559k. [DOI] [PubMed] [Google Scholar]
- 41.Pan L, Wu H, Shen C, Shi Y, Jin W, et al. Clustering and synaptic targeting of PICK1 requires direct interaction between the PDZ domain and lipid membranes. EMBO J. 2007;26:4576–4587. doi: 10.1038/sj.emboj.7601860. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Elkins JM, Papagrigoriou E, Berridge G, Yang X, Phillips C, et al. Structure of PICK1 and other PDZ domains obtained with the help of self-binding C-terminal extensions. Protein Sci. 2007;16:683–694. doi: 10.1110/ps.062657507. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Dev KK, Nakanishi S, Henley JM. The PDZ domain of PICK1 differentially accepts protein kinase C-alpha and GluR2 as interacting ligands. J Biol Chem. 2004;279:41393–41397. doi: 10.1074/jbc.M404499200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Madsen KL, Beuming T, Niv MY, Chang CW, Dev KK, et al. Molecular determinants for the complex binding specificity of the PDZ domain in PICK1. J Biol Chem. 2005;280:20539–20548. doi: 10.1074/jbc.M500577200. [DOI] [PubMed] [Google Scholar]
- 45.Marinari E, Parisi G. Simulated tempering: a new Monte Carlo scheme. Europhys Lett. 1992;19:451–458. [Google Scholar]
- 46.Lyubartsev AP, Martsinovski AA, Shevkunov SV, Vorontsov-Velyaminov PN. New approach to Monte Carlo calculation of the free energy: Method of expanded ensembles. J Chem Phys. 1992;96:1776–1783. [Google Scholar]
- 47.Irbäck A, Potthast F. Studies of an off-lattice model for protein folding: sequence dependence and improved sampling at finite temperature. J Chem Phys. 1995;103:10298–10305. [Google Scholar]
- 48.Gerek ZN, Keskin O, Ozkan SB. Identification of specificity and promiscuity of PDZ domain interactions through their dynamic behavior. Proteins. 2009;77:796–811. doi: 10.1002/prot.22492. [DOI] [PubMed] [Google Scholar]
- 49.Kong Y, Karplus M. Signaling pathways of PDZ2 domain: a molecular dynamics interaction correlation analysis. Proteins. 2009;74:145–154. doi: 10.1002/prot.22139. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Chen H, Luo R. Binding induced folding in p53–MDM2 complex. J Am Chem Soc. 2007;129:2930–2937. doi: 10.1021/ja0678774. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Chen J. Intrinsically disordered p53 extreme C-terminus binds to S100B(ββ) through “fly-casting”. J Am Chem Soc. 2009;131:2088–2089. doi: 10.1021/ja809547p. [DOI] [PubMed] [Google Scholar]
- 52.Higo J, Nishimura Y, Nakamura H. A free-energy landscape for coupled folding and binding of an intrinsically disordered protein in explicit solvent from detailed all-atom computations. J Am Chem Soc. 2011 doi: 10.1021/ja110338e. In Press. [DOI] [PubMed] [Google Scholar]
- 53.Huang Y, Liu Z. Anchoring intrinsically disordered proteins to multiple targets: Lessons from N-terminus of the p53 protein. Int J Mol Sci. 2011;12:1410–1430. doi: 10.3390/ijms12021410. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Wang J, Wang Y, Chu X, Hagen SJ, Han W, et al. Multi-scaled explorations of binding-induced folding of intrinsically disordered protein inhibitor IA3 to its target enzyme. PLoS Comput Biol. 2011;7:e1001118. doi: 10.1371/journal.pcbi.1001118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Forman-Kay JD. The ‘dynamics’ in the thermodynamics of binding. Nat Struct Biol. 1999;6:1086–1087. doi: 10.1038/70008. [DOI] [PubMed] [Google Scholar]
- 56.Chang CE, Chen W, Gilson MK. Ligand configurational entropy and protein binding. Proc Natl Acad Sci USA. 2007;104:1534–1539. doi: 10.1073/pnas.0610494104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Killian BJ, Kravitz JY, Somani S, Dasgupta P, Pang YP, et al. Configurational entropy in protein-peptide binding: computational study of Tsg101 ubiquitin E2 variant domain with an HIV-derived PTAP nonapeptide. J Mol Biol. 2009;389:315–335. doi: 10.1016/j.jmb.2009.04.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Levy Y, Cho SS, Onuchic JN, Wolynes PG. A survey of flexible protein binding mechanisms and their transition states using native topology based energy landscapes. J Mol Biol. 2005;346:1121–1145. doi: 10.1016/j.jmb.2004.12.021. [DOI] [PubMed] [Google Scholar]
- 59.Huang Y, Liu Z. Kinetic advantage of intrinsically disordered proteins in coupled folding-binding process: a critical assessment of the “fly-casting” mechanism. J Mol Biol. 2009;393:1143–1159. doi: 10.1016/j.jmb.2009.09.010. [DOI] [PubMed] [Google Scholar]
- 60.Tsai CJ, Kumar S, Ma B, Nussinov R. Folding funnels, binding funnels, and protein function. Protein Sci. 1999;8:1181–1190. doi: 10.1110/ps.8.6.1181. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Elkins JM, Gileadi C, Shrestha L, Phillips C, Wang J, et al. Unusual binding interactions in PDZ domain crystal structures help explain binding mechanisms. Protein Sci. 2010;19:731–741. doi: 10.1002/pro.349. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Long JF, Feng W, Wang R, Chan LN, Ip FCF, et al. Autoinhibition of X11/Mint scaffold proteins revealed by the closed conformation of the PDZ tandem. Nat Struct Mol Biol. 2005;12:722–728. doi: 10.1038/nsmb958. [DOI] [PubMed] [Google Scholar]
- 63.Favrin G, Irbäck A, Sjunnesson F. Monte Carlo update for chain molecules: biased Gaussian steps in torsional space. J Chem Phys. 2001;114:8154–8158. [Google Scholar]
- 64.Ferrenberg AM, Swendsen RH. New Monte Carlo technique for studying phase transitions. Phys Rev Lett. 1989;61:2635–2638. doi: 10.1103/PhysRevLett.61.2635. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Example of a simulation trajectory. One of the 5 Simulated Tempering runs performed for PSD95-If. The index k represents different temperatures chosen according to , where is the number of temperatures, , and . Changes in k are performed as ordinary MC updates. The figure shows, as functions of the number of MC steps, , the total energy E, and the temperature index k.
(TIFF)
Conformational behavior of isolated peptide chains. The radius of gyration, , as a function of the temperature, T, for two different peptide sequences in isolation. is calculated over all peptide atoms. The relative variation in is around 2–3% for both sequences over the Ts studied.
(TIFF)
Structural diversity of bound peptide conformations. Superposition of a set of model peptide conformations (dark blue) with for PSD95-Ib (left) and GRIP1-IIb (right). The corresponding experimental domain-peptide complexes are shown in light blue (domain) and green (peptide).
(TIFF)