

Abstract
Semiparametric additive partial linear models, containing both linear and nonlinear additive components, are more flexible compared to linear models, and they are more efficient compared to general nonparametric regression models because they reduce the problem known as “curse of dimensionality”. In this paper, we propose a new estimation approach for these models, in which we use polynomial splines to approximate the additive nonparametric components and we derive the asymptotic normality for the resulting estimators of the parameters. We also develop a variable selection procedure to identify significant linear components using the smoothly clipped absolute deviation penalty (SCAD), and we show that the SCAD-based estimators of non-zero linear components have an oracle property. Simulations are performed to examine the performance of our approach as compared to several other variable selection methods such as the Bayesian Information Criterion and Least Absolute Shrinkage and Selection Operator (LASSO). The proposed approach is also applied to real data from a nutritional epidemiology study, in which we explore the relationship between plasma beta-carotene levels and personal characteristics (e.g., age, gender, body mass index (BMI), etc.) as well as dietary factors (e.g., alcohol consumption, smoking status, intake of cholesterol, etc.).
Key words and phrases: BIC, LASSO, penalized likelihood, regression spline, SCAD
1 Introduction
Additive partial linear models (APLMs) are a generalization of multiple linear regression models, and can be regarded as a special case of generalized additive nonparametric regression models (Hastie and Tibshirani, 1990) as well. APLMs allow an easier interpretation of the effect of each variable and are preferable to completely nonparametric additive models, because APLMs combine both parametric and nonparametric components when it is believed that the response variable depends on some variables in a linear way but is nonlinearly related to the remaining independent variables.
Estimation and inference for APLMs have been well studied in literature (Stone, 1985; Opsomer and Ruppert, 1997), with backfitting algorithm generally used for estimation. Opsomer and Ruppert (1999) studied the asymptotics of the kernel-based backfitting estimators. Liang et al. (2008) suggested that a kernel-based estimation procedure is available for APLMs without an undersmoothing requirement, and applied APLMs to study the relationship between environmental chemical exposures and semen quality. When there are multiple nonparametric terms, it is both useful and required that estimation and inference methods be efficient and computationally easily implemented. Additionally, this implementation should be able to be achieved in a commonly used computational environment like R. Kernel-based procedures (Opsomer and Ruppert, 1999; Liang et al. 2008) are intuitively attractive and theoretically justifiable, but computationally inexpedient; Spline-based procedures (Li, 2000) are computationally expedient, but theoretically unreliable. Challenged by these demands and the drawbacks in the existing literature, we propose approximating the nonparametric components by using polynomial splines. With the models becoming linear, the resulting estimators for the linear components are therefore easily calculated, and of most importance still asymptotically normal.
Motivated by a dataset from a nutritional epidemiology project (see the details in Section 4), we study variable selection for APLMs. To the best of our knowledge, no variable selection procedures are available for APLMs. Best subset selection is commonly used to select significant variables in regression models. It examines all possible candidate subsets and selects the final subset by some criterion such as the Akaike information criterion (AIC) (Akaike, 1973) and the Bayesian information criterion (BIC) (Schwarz, 1978), which combine statistical measures of fit with penalties for increasing complexity (number of predictors). However, the best subset selection has two fundamental limitations. First, it is computationally infeasible to do subset selection when the number of predictors is large. Second, it is extremely variable because of its inherent discreteness (Breiman, 1996; Fan and Li, 2001). Stepwise selection is often used to reduce the number of candidate subsets. However, it still suffers from the high variability. Instead, Tibshirani (1996) proposed a regression method using L1 penalty, the LASSO, that is similar to ridge regression but can shrink some coefficients to 0, and thus implement variable selection. Fan and Li (2001) proposed a very general variable selection framework by using a smoothly clipped absolute deviation (SCAD) penalty. The choice of the SCAD penalty function encompasses the usually used variable selection approaches as special cases (see Section 2.2 for details). Most importantly the SCAD-based approach holds appealing statistical properties, as Fan and Li (2001) demonstrated. This approach has become popular and been widely studied in literature by, for instance, Fan and Li (2002) for Cox models, Li and Liang (2008) for semiparametric models, and Liang and Li (2009) for partially linear models with measurement errors. Xie and Huang (2009) and Ni, Zhang, and Zhang (2009) studied the variable selection for partially linear models with a divergent number of linear covariates, and established the selection consistency and asymptotic normality. The former used polynomial splines and the latter used the smoothing spline to approximate the nonparametric function. Since partially linear models have only one nonparametric component, they are not as flexible as APLM. In contrast to that in partially linear models, estimation or variable selection is much more difficult in APLM. Ravikumar et al. (2008, 2009) investigated high-dimensional nonparametric sparse additive models (SpAM), developed a new class of algorithms for estimation and discussed asymptotic properties of their estimators. SpAM are more general but lack of the simplicity property of APLM, which are more appropriate when some covariates are not continuous.
In this paper we will develop a SCAD-based variable selection procedure for APLMs combining the spline approximation. This combination overcomes a potential problem of how to define the objective function if a backfitting algorithm is used. Furthermore, employing spline approximation can still make our variable selection procedure have the oracle property, which is the best theoretical performance any procedure pursues.
The rest of the article is organized as follows. Section 2 introduces the estimation and SCAD-based variable selection procedures for APLMs, and presents the theoretical results. Numerical comparisons and simulation studies are given in Section 3. Section 4 examines in detail the nutritional data to illustrate the procedure. Section 5 concludes the article with a discussion. All technical details are given in the Appendix.
2 Estimation and Variable Selection Procedure
Suppose that {(X1, Z1, Y1), …, (Xn, Zn, Yn)} is an iid random sample of size n from an APLM
| (1) |
where X = (X1, … , Xd)T and Z = (Z1, … , ZK)T are the linear and nonparametric components, g1, … , gK are unknown smooth functions, β = (β1, …, βd) is a vector of unknown parameters, and the model error ε has the conditional mean zero and finite variance σ2 given (X, Z). To ensure identifiability of the nonparametric functions, we assume that E{gk(Zk)} = 0 for k = 1, …, K.
2.1 Spline Approximation
Let g0 = g01 (z1) + ⋯ + g0K (zK) and β0 be the true additive function and the true parameter values. For simplicity, we assume that the covariate Zk is distributed on a compact interval [ak, bk], k = 1, …, K, and without loss of generality, we take all intervals [ak, bk] = [0, 1], k = 1, …, K. Under some smoothness assumptions, g0ks can be well approximated by spline functions. Let Sn be the space of polynomial splines on [0, 1] of degree ϱ ≥ 1. We introduce a knot sequence with Jn interior knots
where Jn increases when sample size n increases, with the precise order given in Condition (C4). Then Sn consists of functions ξ satisfying
ξ is a polynomial of degree ϱ on each of the subintervals Ij = [tj, tj+1), j = 0, …, Jn − 1, IJn = [tJn, 1];
for ϱ ≥ 2, ξ is ϱ − 1 continuously differentiable on [0, 1].
Equally spaced knots are used in this article for simplicity of proof. However other regular knot sequences can also be used, with similar asymptotic results. Let h = 1/ (Jn + 1) be the distance between neighboring knots.
We will consider the additive spline estimates ĝ of g0 based on the independent random sample (Xi, Zi, Yi), i = 1, …, n. Let Gn be the collection of functions g with the additive form g (z) = g1 (z1)+⋯+gK (zK), where each component function gk ∈ Sn and .
We would like to find a function g ∈ Gn and a value of β that minimize the following sum of squared residuals function
| (2) |
For the k-th covariate zk, let bj,k (zk) be the B-spline basis functions of degree ϱ. For any g ∈ Gn, one can write
| (3) |
where b (z) = {bj,k (zk), j = −ϱ,…, Jn, k = 1,…, K}T, and the spline coefficient vector γ = {γj,k, j = −ϱ, …, Jn, k = 1,…, K}T. Thus the minimization problem in (2) is equivalent to find a value of β and γ to minimize
| (4) |
We denote the minimizer as β̂ and γ̂ = {γ̂j,k, j = −ϱ,…, Jn, k = 1, …, K}T. Then the spline estimator of g0 is ĝ = γ̂Tb(z), and the centered spline estimator of the component gk is
for k = 1, …, K. The above estimation approach can be easily implemented with existing linear models in any statistics software.
For simplicity of notation, write T = (X, Z). Let m0 (T) = g0 (Z) + XT β0, Γ (z) = E(X|Z = z), X̃ = X − Γ (Z), and Q⊗2 = QQT for any matrix or vector Q. The next theorem shows that the estimators β̂ of β0 is root-n consistent and asymptotically normal although the convergence rate of the estimators of the nonparametric component g0 is slower than root-n (Lemma A.4). Its proof is given in the Appendix.
Theorem 1
Under the conditions (C1)-(C5) given in Appendix, converges to N (0, D−1 ΣD−1) in distribution where D = E(X̃⊗2) and Σ = E(ε2X̃⊗2). Furthermore, if ε and (X, Z) are independent, , where σ2 = E (ε2).
2.2 SCAD-penalty variable selection procedure
Penalized likelihood has been widely used for non- and semi-parametric models to trade off model complexity and estimation accuracy. A comprehensive survey of these fields was given by Ruppert et al. (2003). The penalized objective function we used is defined as
| (5) |
where pλj (·) is a penalty function with a tuning parameter λj, which may be chosen by a data-driven method. See Liang and Li (2009) for a detailed discussion of the choice of the tuning parameter. Minimizing ℒP (β, γ) with respect to β results in a penalized least squares estimator β̂. It is worth noting that the penalty functions and the tuning parameters are not necessarily the same for all coefficients. For instance, we want to keep important variables in the final model, and therefore should not penalize their coefficients.
The penalized sum of squared residuals function (5) provides a general framework of variable selection for APLMs. Taking the penalty function to be the L0-penalty (also called the entropy penalty in the literature), namely, , where I {·} is an indicator function, we may extend the traditional variable selection criteria, including the AIC (Akaike, 1973), BIC (Schwarz, 1978), and RIC (Foster and George, 1994), for the APLM:
| (6) |
as equals the size of the selected model. Specifically, the AIC, BIC, and RIC correspond to , and respectively. Note that Bridge regression (Frank and Friedman, 1993) is equivalent to the Lq-penalty pλ(|βj|) = q−1λ|βj|q; the LASSO (Tibshirani, 1996; Zou, 2006) corresponds to the L1-penalty, and SCAD corresponds to the following smoothly clipped absolute deviation penalty function
where a = 3.7. As demonstrated in Fan and Li (2001), SCAD is an improvement of LASSO in terms of modeling bias, and of bridge regression with q < 1 in terms of stability. It also has an oracle property.
We now present the sampling property of the resulting penalized least squares estimate. Let be the true value of β. Without loss of generality, assume that β10 consists of all nonzero components of β0, and β20 = 0. Let s denote the length of β10. Write , , , and . Denote X1 as the vector comprised by the first s elements of X. We have the following theorem, whose proof is given in the Appendix.
Theorem 2
Suppose that an = O(n−1/2), bn → 0, and the regularity conditions (C1)-(C5) in the Appendix hold. Then (I) With probability approaching one, there exists a local minimizer β̂ of ℒP (β,γ) such that ∥β̂ − β∥ = OP(n−1/2). (II) Furthermore, if λj → 0, n1/2λj → ∞, and
| (7) |
then, with probability approaching one, the root-n consistent estimator β̂ in (I) satisfies (a) β̂2 = 0, and (b) β̂1 has an asymptotic normal distribution
where Σs = var (εX̃1).
Theorem 2 indicates that the SCAD-penalty variable selection procedure can effectively identify the significant components, with the associated estimators holding the oracle property.
3 Simulation studies
In this section, the finite sample performance of the proposed procedure is investigated by Monte Carlo simulations. We numerically compare estimation accuracy and complexity of models selected by SCAD, LASSO and BIC. We use the local quadratic approximation algorithm of Fan and Li (2001) to implement the SCAD and LASSO procedures, and select the tuning parameter by generalized cross-validation (GCV) in both simulation studies and the real data example in Section 4.
Let g1(z) = 5 sin (4πz) and g2(z) = 100{exp(−3.25z) − 4 exp(−6.5z) + 3 exp(−9.75z)}. We simulate 100 data sets consisting of n = 60, 100, and 200 observations from the model
where β = (3, 1.5, 0, 0, 2, 0, 0, 0)T, σ = 1, 3, 5, and the components of X and ε are standard normal. X and ε are independent. The correlation between xi and xj is ρ|i−j| with ρ = 0.5. We consider three cases: (i) g(Z) = g1(Z1); (ii) g(Z) = g2(Z2); and (iii) g(Z) = g1(Z1) + g2(Z2). Z1 and Z2 are independent uniformly distributed on [0, 1]; i.e., in the first two cases, there is only one nonparametric component, while in the third case there are two nonparametric components.
Cubic B-splines are used to approximate the nonparametric functions as described in Section 2.1. To determine the number of knots in the approximation, we examined several (say M) models, with the number of knots from 2 to 12 for each nonparametric component. In other words, M = 11 in both Case (i) and Case (ii), and M = 112 = 121 in Case (iii). In each case, the M linear prediction models are taken into account, and the model with the smallest median of relative model error when compared to the full model, which includes all covariates, is taken to be the final selected model.
Simulation results are presented in Tables 1-3, in which the columns labeled with “C” give the average number of the five zero coefficients correctly set to 0, the columns labeled with “I” give the average number of the three nonzero coefficients incorrectly set to 0, and the columns labeled “MRME” give the average of the median of relative model errors, which is defined as the ratio of model error comparing the selected model to the full model. The rows with “SCAD” and “LASSO” stand respectively for the penalized least squares with the SCAD penalty and the LASSO penalty. “BIC” stands for the best subset selection using the selection criterion BIC. The row “Oracle” stands for the oracle estimates computed by using the true model Y = β1X1 + β2X2 + β5X5 + g(Z) + σε. The oracle estimates always set the 5 zero coefficients correctly to zero and do not set any of the 3 nonzero coefficients to zero.
Table 1.
Simulation Results for Case (i)
| n | method | σ = 1 | σ = 3 | σ = 5 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| C | I | MRME | C | I | MRME | C | I | MRME | ||
| 60 | scad | 4.49 | 0 | 0.852 | 4.39 | 0.12 | 0.899 | 4.29 | 0.61 | 0.903 |
| lasso | 3.38 | 0 | 0.882 | 3.49 | 0.02 | 0.75 | 3.41 | 0.31 | 0.723 | |
| bic | 4.66 | 0 | 0.869 | 4.76 | 0.14 | 0.948 | 4.57 | 0.86 | 0.969 | |
| oracle | 5 | 0 | 0.662 | 5 | 0 | 0.68 | 5 | 0 | 0.635 | |
| 100 | scad | 4.45 | 0 | 0.838 | 4.44 | 0.03 | 0.87 | 4.35 | 0.32 | 0.947 |
| lasso | 3.31 | 0 | 0.906 | 3.53 | 0 | 0.775 | 3.4 | 0.09 | 0.768 | |
| bic | 4.84 | 0 | 0.876 | 4.8 | 0.03 | 0.88 | 4.77 | 0.6 | 1.036 | |
| oracle | 5 | 0 | 0.717 | 5 | 0 | 0.704 | 5 | 0 | 0.706 | |
| 200 | scad | 4.4 | 0 | 0.798 | 4.37 | 0 | 0.818 | 4.38 | 0.03 | 0.788 |
| lasso | 3.27 | 0 | 0.884 | 3.37 | 0 | 0.829 | 3.37 | 0 | 0.797 | |
| bic | 4.91 | 0 | 0.803 | 4.88 | 0 | 0.916 | 4.9 | 0.06 | 0.772 | |
| oracle | 5 | 0 | 0.723 | 5 | 0 | 0.668 | 5 | 0 | 0.693 | |
Table 3.
Simulation Results for Case (iii)
| n | method | σ = 1 | σ = 3 | σ = 5 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| C | I | MRME | C | I | MRME | C | I | MRME | ||
| 60 | scad | 4.43 | 0 | 0.924 | 4.39 | 0.28 | 1.045 | 4.37 | 0.74 | 1.01 |
| lasso | 3.52 | 0 | 1.072 | 3.68 | 0.1 | 0.922 | 3.67 | 0.26 | 0.783 | |
| bic | 4.32 | 0 | 0.939 | 4.42 | 0.31 | 1.077 | 4.43 | 0.87 | 1.012 | |
| oracle | 5 | 0 | 0.802 | 5 | 0 | 0.802 | 5 | 0 | 0.752 | |
| 100 | scad | 4.41 | 0 | 0.926 | 4.49 | 0.02 | 0.957 | 4.28 | 0.35 | 1.052 |
| lasso | 3.58 | 0 | 1.028 | 3.58 | 0 | 0.964 | 3.56 | 0.09 | 0.883 | |
| bic | 4.6 | 0 | 0.939 | 4.77 | 0.05 | 0.977 | 4.66 | 0.65 | 1.112 | |
| oracle | 5 | 0 | 0.8 | 5 | 0 | 0.782 | 5 | 0 | 0.784 | |
| 200 | scad | 4.44 | 0 | 0.881 | 4.45 | 0 | 0.953 | 4.45 | 0.06 | 0.973 |
| lasso | 3.42 | 0 | 1.022 | 3.48 | 0 | 0.995 | 3.41 | 0.01 | 0.891 | |
| bic | 4.84 | 0 | 0.9 | 4.79 | 0 | 0.988 | 4.86 | 0.11 | 1.021 | |
| oracle | 5 | 0 | 0.821 | 5 | 0 | 0.806 | 5 | 0 | 0.797 | |
The results for SCAD, BIC, and LASSO of correctly and incorrectly selected covariates show a similar pattern as those obtained by Fan and Li (2001) for linear models. In all three cases, BIC performs the best to correctly set coefficients to 0, followed by SCAD and LASSO. However, BIC has the highest average number of coefficients erroneously set to 0, followed by SCAD and LASSO. This indicates that BIC is the most aggressive method in terms of excluding variables, while LASSO is the most conservative and tends to include more variables.
As for the MRME, SCAD performs the best when the sample size is large or the error variance is small , while LASSO performs the best when the sample size is small or the error variance is large. The performance of BIC is worse than, although sometimes close to, SCAD for most of the time.
Overall, SCAD and BIC have the best performances in our simulations. Compared to BIC, SCAD has the higher prediction accuracy by slightly increasing the model complexity. In other words, SCAD selects more variables to reduce the prediction error. Furthermore, SCAD is much more computationally efficient than the best subset selection method using BIC, because the latter examines all the subset combinations and the number of all combinations is exponentially proportional to the total number of variables.
4 A Nutritional Study
It is well known that there is a direct relationship between beta-carotene and cancers such as lung, colon, breast, and prostate cancer (Fairfield and Fletcher, 2002). Some observational epidemiological studies have shown that beta carotene can not only effectively prevent cancer because beta carotene has powerful antioxidant properties, but can also help clean the body of free radicals that can cause cancer. Sufficient beta carotene supply can also strengthen the body’s autoimmune system, making it more effective in fighting degenerative diseases such as cancer. Clinicians and nutritionists are therefore interested in the relationship between serum concentrations of beta-carotene and other factors such as age, smoking status, alcohol consumption, and dietary intake because this information may be potentially useful in clinical decision-making and individualization of therapy. For example, Nierenberg et al. (1989) found that dietary carotene and female were positively related to beta-carotene levels, while cigarette smoking and body mass index (BMI) were negatively related to beta-carotene levels. Age was not associated with beta-carotene levels to a statistically significant extent. Faure et al. (2006) recently found that beta-carotene concentration depends on gender, age, smoking status, dietary intake, and location of residence. Examination of this relationship therefore shows diverse results so far, and there is insufficient evidence to draw a convincing conclusion regarding the relationship between beta-carotene and these factors.
A closer investigation of the methods used in these publications indicates that the investigators usually used either a simple analysis of variance(ANOVA) method or linear models to explore the relationship between beta-carotene and other factors, then expressed the factors that influence the beta-carotene concentration. As data sets from nutritional observational studies or clinical trials are far too complicated to comprehend with a linear model or simple statistical methods, using advanced statistical techniques is necessary in order to appropriately model the relationship. We examine a dataset from a nutritional epidemiology study in which we are interested in the relationships between the plasma beta-carotene levels and personal characteristics, including AGE, GENDER, BMI, and other factors: CALORIES (number of calories consumed per day), FAT (grams of fat consumed per day), FIBER (grams of fiber consumed per day), ALCOHOL (number of alcoholic drinks consumed per week), CHOL (cholesterol consumed mg per day), BETADIET (dietary beta-carotene consumed mcg per day), SMOKE2 (smoking status [1=former smoker, 0=never smoked], and SMOKE3 (smoking status [1=current smoker, 0=never smoked]). There was one extremely high leverage point in alcohol consumption that was deleted prior to any analysis. See Nierenberg et al. (1989) for a detailed description of the data. A general linear model was used to fit this dataset and the results are presented in the left panel of Table 4. These results indicate that only BMI, FIBER, GENDER, and SMOKE3 are statistically significant, while the other five variables (AGE, CALORIES, FAT, ALCOHOL, and CHOL) are not significant. However, a closer study shows that the relationship between the logarithm of beta-carotene levels and AGE and CHOL may be nonlinear. We therefore fitted the same dataset using the R function gam and found that the beta-carotene level seems to be linearly related to BMI, CALORIES, FAT, FIBER, ALCOHOL and BETADIET, but nonlinearly related to AGE and CHOL. Figure 1 shows the patterns of AGE and CHOL, which indicates a positive correlation before 45 years old or after 65 years old, and a slightly negative correlation between 45 and 65. Interestingly, we obtain a concave curve of the pattern of CHOL.
Table 4.
Results for the nutritional study. Left panel: Estimated values, associated standard error, and P-value by using the ordinary least squares. Right panel: Estimates, associated standard errors of the coefficients using the APLM with the proposed variable selection procedures.
| LS | APLM | ||||||
|---|---|---|---|---|---|---|---|
| Est. | s.e | z value | Pr(> |z|) | SCAD (s.e.) | LASSO (s.e.) | BIC (s.e.) | |
| BMI | -0.976 | 0.202 | -4.829 | < 10−4 | -0.947(0.189) | -0.948(0.173) | -1.001(0.188) |
| CALORIES | 0 | 0 | -0.457 | 0.648 | 0(0) | 0(0) | 0(0) |
| FAT | -0.002 | 0.003 | -0.711 | 0.477 | 0(0) | -0.001(0.001) | 0(0) |
| FIBER | 0.027 | 0.012 | 2.352 | 0.019 | 0.021(0.007) | 0.019(0.007) | 0.025(0.008) |
| BETADIET | 0.137 | 0.073 | 1.889 | 0.06 | 0.046(0.027) | 0.101(0.051) | 0(0) |
| GENDER | 0.277 | 0.135 | 2.06 | 0.04 | 0.194(0.088) | 0.201(0.096) | 0(0) |
| ALCOHOL | 0.043 | 0.048 | 0.901 | 0.368 | 0(0) | 0(0) | 0(0) |
| SMOKE2 | -0.068 | 0.091 | -0.742 | 0.458 | 0(0) | 0(0) | 0(0) |
| SMOKE3 | -0.286 | 0.13 | -2.191 | 0.029 | -0.245(0.097) | -0.224(0.096) | -0.293(0.117) |
| AGE | 0.005 | 0.003 | 1.724 | 0.086 | |||
| CHOL | -0.015 | 0.114 | -0.133 | 0.894 | |||
Figure 1.
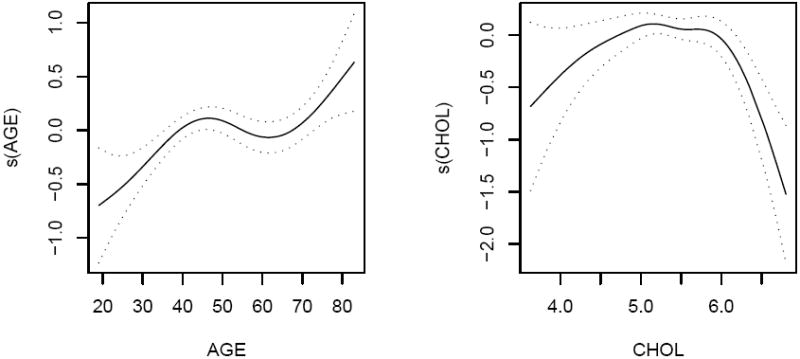
The patterns of AGE and CHOL with ±s.e. using the R function, gam, for the dataset from a nutritional study.
In this section, we use an APLM and the proposed procedures to study the relationship between beta-carotene and other factors, i.e., beta-carotene concentration linearly depends on covariates BMI, CALORIES, FAT, FIBER, ALCOHOL, BETADIET, GENDER and SMOKE2/3 but is nonlinearly related to the remaining covariates AGE and CHOL. We attempt to identify which linear covariates should be included in our final model and appropriately fit the nonlinear unknown functions, which can objectively reflect their impact on beta-carotene level and avoid misleading conclusions. To this end, we use the following model to fit the nutritional dataset, and then apply SCAD, LASSO and BIC procedures for variable selection.
To determine the number of knots in the cubic B-splines approximation of the nonparametric components AGE and CHOL, we examine the number of knots from 2 to 9 for each component and choose the number which makes the model has the smallest relative mean squared error when compared to the full model. As a result, for the nonparametric component AGE, 2 and 5 knots are chose in SCAD and LASSO respectively. For the nonparametric component CHOL, 2 knots are used in both SCAD and LASSO. The tuning parameters selected by GCV are 0.035 and 0.015 for SCAD and LASSO respectively.
The estimated coefficients and their standard errors are listed in the right panel of Table 4. SCAD confirms that BMI, FIBER, BETADIET, GENDER, and SMOKE3 are significant, while LASSO also identifies FAT as being significant. But BIC indicates that only BMI, FIBER, and SMOKE3 are significant. The standard errors of these non-zero coefficients based on the APLM are consistently smaller than the corresponding ones based on the linear fitting. The estimated values using different methods under the APLM setting are similar, but there are differences in magnitude. The estimated curves of the two nonparametric components, AGE and CHOL, are similar to those in Figure 1, and therefore are not shown here. It is worthwhile to mention that the effects of AGE and CHOL are not only significant, but also should not be described by linear functions.
5 Discussion
We proposed a very effective routine by using a regression spline technique, then used an advanced variable selection procedure to identify which linear predictors should be included in our model fitting. There are three principal advantages of our method over the published ones: (i) it avoids any iterative algorithms and computational challenges; (ii) the estimators of the linear components, which are of primary interest, are still asymptotically normal; and (iii) the variable selection procedure holds the oracle property. Combining the idea here and that of Liang and Li (2009), we believe a similar procedure can be developed for partially linear additive models with error-prone linear covariates. The approach is possibly extended to generalized additive partial linear models and the situation with longitudinal data (Lin and Carroll, 2001). However, these extensions are by no means straightforward, and require further efforts.
It would appear possible, at least in principle, to extend our methods to cases in which the numbers of linear components and nonparametric components are diverging. An alternative is a combination of the methods of Xie and Huang (2009) and Ravikumar et al. (2009). One main challenge is how to establish asymptotic properties of the methods and to give theoretical justifications. A detailed investigation of these issues needs a lot of efforts and is certainly worthwhile, but is beyond the scope of this article.
An important question commonly raised among nutritionists is whether available scientific data support an important role of beta-carotene in the prevention of pathologic conditions such as cancer. The research process leads to the demonstration of a causal relationship between nutritional factors and beta-carotene. In this paper, we have proposed the use of an APLM to describe such a relationship because the APLM model can parsimoniously reflect the influence of covariates in linear or nonlinear forms. It is believed that APLMs and the proposed approach can be used in the study of datasets from other biomedical research.
Table 2.
Simulation Results for Case (ii)
| n | method | σ = 1 | σ = 3 | σ = 5 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| C | I | MRME | C | I | MRME | C | I | MRME | ||
| 60 | scad | 4.44 | 0 | 0.774 | 4.48 | 0.14 | 0.937 | 4.32 | 0.69 | 1.028 |
| lasso | 3.28 | 0 | 1.017 | 3.41 | 0.02 | 1.003 | 3.47 | 0.35 | 0.889 | |
| bic | 4.6 | 0 | 0.792 | 4.74 | 0.19 | 0.983 | 4.58 | 0.88 | 1.058 | |
| oracle | 5 | 0 | 0.673 | 5 | 0 | 0.674 | 5 | 0 | 0.662 | |
| 100 | scad | 4.49 | 0 | 0.784 | 4.46 | 0.03 | 0.874 | 4.47 | 0.38 | 1.017 |
| lasso | 3.58 | 0 | 1.044 | 3.5 | 0 | 0.996 | 3.58 | 0.11 | 0.963 | |
| bic | 4.85 | 0 | 0.784 | 4.76 | 0.03 | 0.907 | 4.78 | 0.61 | 1.041 | |
| oracle | 5 | 0 | 0.747 | 5 | 0 | 0.655 | 5 | 0 | 0.681 | |
| 200 | scad | 4.4 | 0 | 0.768 | 4.31 | 0 | 0.805 | 4.31 | 0.03 | 0.87 |
| lasso | 3.29 | 0 | 1.006 | 3.38 | 0 | 0.983 | 3.36 | 0 | 0.91 | |
| bic | 4.89 | 0 | 0.767 | 4.89 | 0.01 | 0.839 | 4.84 | 0.08 | 0.954 | |
| oracle | 5 | 0 | 0.716 | 5 | 0 | 0.644 | 5 | 0 | 0.677 | |
Acknowledgments
Liu’s Research was supported by Merck Quantitative Sciences Fellowship Program. Wang’s Research was supported by NSF grant DMS-0905730. Liang’s research was supported by NIH/NIAID grant AI59773 and NSF grant DMS-0806097. The authors are grateful to an associated editor and two referees for valuable comments and suggestions that lead to a much better improvement of the paper.
Appendix
Throughout the article, let ||·|| be the Euclidean norm for vectors. For any matrix A, denote its L2 norm as . Let be the supremum norm of a function φ on [0,1].
Following Stone (1985) and Huang (2003), for any measurable functions φ1, φ2 on [0, 1]K, define the empirical inner product and the corresponding norm as
Let f(z) be the joint density of Z. If φ1 and φ2 are L2-integrable, define the theoretical inner product as
with the corresponding induced norm . Let and be the empirical and theoretical norm of a univariate function φ on [0, 1], defined by
where fk is the density of Zk for k = 1, …, K. Define the following centered version spline basis
| (A.1) |
with the standardized version given for any k = 1, …, K,
| (A.2) |
Notice that finding the (γ, β) that minimizes (4) is mathematically equivalent to finding the (γ, β) that minimizes
where B (z) = {Bj,k (zk), j = −ϱ + 1, …, Jn, k = 1, …, K}T. Then the spline estimator of g0 is ĝ(z) = γ̂TB (z) and the centered spline estimators of each component function are
In practice, basis {bj,k, j = −ϱ + 1, …, Jn, k = 1, …, K}T is used for data-analytic implementation, and the mathematically equivalent expression (A.2) is convenient for asymptotic analysis.
A.1 Assumptions
The following are some conditions necessary to obtain Theorems 1 and 2. Let r be a positive integer, and ν ∈ (0, 1] be such that p = r + ν > 1.5. Let ℋ be the collection of functions g on [0, 1] whose r-th derivative, g(r) exists and satisfies the Lipschitz condition of order ν:
where and below C is a generic positive constant.
-
(C1)
Each component function g0k ∈ ℋ, k = 1, …, K.
-
(C2)
The distribution of Z is absolutely continuous and its density f is bounded away from zero and infinity on [0, 1]K.
-
(C3)The random vector X satisfies that for any vector ω ∈ Rd
where c is a positive constant. -
(C4)
The number of interior knots Jn satisfies: n1/(2p) ≪ Jn ≪ n1/3. For example, if p = 2, we can take Jn ~ n1/4 log n.
-
(C5)
The projection function Γ (z) has an additive form, i.e., Γ (z) = Γ1(z1) + … + ΓK(zK), where Γk ∈ ℋ, E[Γk(Zk)] = 0 and E[Γk(Zk)]2 < ∞, k = 1, …, K.
A.2 Technical Lemmas
According to the result of de Boor (2001, page 149), for any function η ∈ ℋ and n ≥ 1, there exists a function η̃ ∈ Sn such that ||η̃ − η||∞ ≤ Chp. Recall that B(z) = {Bj,k(zk), j = −ϱ + 1, …, Jn, k = 1, …, K}T. For g0 satisfying (C1), we can find γ̃ = {γ̃j,k, j = −ϱ + 1, …, Jn, k = 1, …, K}T and an additive spline function g̃ = γ̃TB (z) ∈ Gn, such that
| (A.3) |
In the following, let
| (A.4) |
Denote m0i ≡ m0(Ti) = g0(Zi) + XiTβ0, and
| (A.5) |
Lemma A.1
Under Conditions (C1)-(C4),
where A = E (X⊗2) and Σ1 = E (ε2X⊗2).
Proof
Let . Note that β̃ minimizes , so, δ̂minimizes
By expansion, one has
where Observe that
By (A.3) and Condition (C3), the absolute value of the second term on the right-hand side of the above equation is
Thus,
and the convexity lemma of Pollard (1991) implies that
It follows that
Denote
| (A.6) |
The following lemma indicates that the Hessian matrix Vn is bounded, which will be used in Lemma A.3.
Lemma A.2
Under Conditions (C1)-(C4), for the random matrix Vn defined in (A.6), there exists a positive constant C such that
Proof
We first derive the lower and upper bound of the eigenvalue of matrix Vn. For any vectors ω1 = {ωj,k, j = −ϱ + 1, …, Jn, k = 1, …, K} ∈ R(Jn+ϱ)K and ω2 ∈ Rd, let , then one has
Lemma 1 of Stone (1985) provides a constant c > 0 such that
According to Theorem 5.4.2 of DeVore and Lorentz (1993), Condition (C2) and the definition of Bj,k in (A.2), there exist constants C′k > c′k > 0 such that for any k = 1, …, K
Thus there exist constants C0 > c0 > 0 such that
By Lemma A.8 in Wang and Yang (2007), we have
| (A.7) |
It is clear to see that
Therefore,
Next,
and according to Condition (C3), Then Thus
| (A.8) |
Let λmax (Vn) and λmin (Vn) be the maximum and minimum eigenvalues of Vn. Algebra and (A.8) show that and
In the following, denote and
| (A.9) |
Lemma A.3
Under Conditions (C1)-(C4),
Proof
Note that
where θ̄ is between θ̂ and θ̃. So
Next write
where
Observing that
and
we have By Condition (C4), equation (A.3) and Lemma A.1,
Therefore, Similarly, one has
Thus For the second order derivative, one has
According to Lemma A.2, . Thus
Lemma A.4
Under (C1)-(C4), ∥ĝ − g0∥2 = OP{(Jn/n)1/2}, ∥ĝ − g0∥n = OP{(Jn/n)1/2}, and ∥ĝk − g0k∥2k = OP{(Jn/n)1/2} and ∥ĝk − g0k∥nk = OP{(Jn/n)1/2}, for k = 1, …, K.
Proof
According to Lemmas A.2 and A.3, is equal to , thus ∥ĝ − g̃∥2 = OP{Jn1/2(hp + n−1/2)} and
By Lemma 1 of Stone (1985), ∥ĝk − g0k∥2k = OP {Jn1/2 (hp + n−1/2)}, 1 ≤ k ≤ K. Equation (A.7) then implies that ∥ĝ − g̃∥n = OP {Jn1/2 (hp + n1/2)}. Then
Similar to (A.7),
thus ∥ĝk − g0k∥nk = OP {Jn1/2 (hp + n−1/2)}, for any k = 1, …, K. The desired result follows by Condition (C4).
Lemma A.5
Under Conditions (C1)-(C4), one has
| (A.10) |
| (A.11) |
Proof
We first show (A.11). Let s (z, g) = g(z)x̃. Note that
By Lemma A.2 of Huang (1999), the logarithm of the ε-bracketing number of the class of functions
is c {(Jn + ϱ) log (δ/ε) + log (δ−1)}, so the corresponding entropy integral
According to Lemma 7 of Stone (1986) and Lemma A.4,
Lemma 3.4.2 of van der Vaar and Wellner (1996) implies that, for rn = (n/Jn)1/2,
By Condition (C4), O (n−1/2Jn) = o (1). Thus, one has
By the definition of X̃, for any measurable function φ, E {φ (Z) X̃} = 0. Hence (A.11) holds. Similarly, (A.10) follows from Lemma 3.4.2 of van der Vaar and Wellner (1996) and Lemma A.3.
Lemma A.6
Under the conditions of Theorem 2, with probability tending to 1, for any given β1 satisfying that ∥β1 − β10∥ = Op(n−1/2) and any constant C,
Proof
To prove that the minimum is attained at β2 = 0, it suffices to show that with probability tending to 1, as n → ∞, for any β1 satisfying ∥β1 − β10∥ = OP(n−1/2), and ∥β2∥ ≤ Cn−1/2, ∂ℒP(β)/∂βj and βj have the same signs for βj ∈ (−Cn−1/2, Cn−1/2), for j = s + 1, … , d. It follows by the similar arguments as given in the proof of Theorem 1 that,
where Ωj (Yi, Ti) is the jth element of −εiX̃i and Rj is the jth column of E(X̃⊗2). Note that ∥β − β0∥ = OP(n−1/2) by the assumption. Thus, n−1 ℓ′j(β) is of the order OP (n−1/2). Therefore, for any zero βj and j = s + 1, … , d,
Because and , the sign of the derivative is completely determined by that of βj. Thus the desired result is obtained.
A.3 Proof of Theorem 1
According to Condition (C5), the projection function Г (z) = Г1(z1) + … + ГK(zK), where the theoretically centered function Гk ∈ ℋ. By the result of de Boor (2001, page 149), there exists an empirically centered function Г̃k ∈ Sn, such that ║Г̃k − Гk║∞ = OP (hp), = k = 1, …, K. Denote Г̃ (z) = Г̃1(z1) + … + Г̃ K(zK) and clearly Г̃ ∈ Gn. Define a class of functions
| (A.12) |
For any υ ∈ Rd, let m̂ (x, z) = ĝ(z) + xTβ̂ and m̂ υ = m̂ (x, z) + υT{x − Г̃(z), then m̂υ = {ĝ(z) − υTГ̃(z)} + (β̂ + υ)Tx ∈ ℳn. Note that m̂υ minimizes the function for all m ∈ ℳn when υ = 0, thus . Denote
| (A.13) |
and X̃i = Xi − Г (Zi), then
| (A.14) |
Note that
We can rewrite the second term in (A.14) as
By Lemma A.5, one has
| (A.15) |
Combining (A.14), (A.15) and Condition (C4), one has
Thus the desired distribution of β̂ follows.
A.4 Proof of Theorem 2
Let τn = n−1/2 + an. It suffices to show that for any given ζ > 0, there exists a large constant C such that
| (A.16) |
Denote
and , where s is the number of components of β10. Note that pλn (0) = 0 and pλn (|β|) ≥ 0 for all β. Thus,
Let m̂0i = γ̂TB(Zi) + XiTβ0. For Dn,1, note that
A mimic of the proof for Theorem 1 indicates that
| (A.17) |
where the orders of the first term and the second term are OP (n1/2τn) and OP (nτn2), respectively. For Dn,2, by the Taylor expansion and the Cauchy-Schwartz inequality, n−1Dn,2 is bounded by
As wn → 0, both the first and second terms on the right-hand side of (A.17) dominate Dn,2, by making C sufficiently large. Hence (A.16) holds for a sufficiently large C.
We now prove part (II). From Lemma A.6, it follows that β̂2 = 0. Let , , and . Then, β̂1* minimizes
| (A.18) |
Denote ℓnl (β*1) the first term in (A.18), then
| (A.19) |
Using the arguments similar to the proofs for (A.15) and (A.17) yields
Using the Convexity Lemma (Pollard, 1991) and combining (A.18), one has
Hence the asymptotic normality is derived.
Contributor Information
Xiang Liu, Department of Biostatistics and Computational Biology, University of Rochester Medical Center, Rochester, NY 14642, U.S.A. xliu@bst.rochester.edu.
Li Wang, Department of Statistics, University of Georgia, Athens, GA 30602, U.S.A. lilywang@uga.edu.
Hua Liang, Department of Biostatistics and Computational Biology, University of Rochester Medical Center, Rochester, NY 14642, U.S.A hliang@bst.rochester.edu.
References
- Akaike H. Maximum likelihood identification of gaussian autoregressive moving average models. Biometrika. 1973;60:255–265. [Google Scholar]
- Breiman L. Heuristics of instability and stabilization in model selection. Ann Statist. 1996;24:2350–2383. [Google Scholar]
- de Boor C. A Practical Guide to Splines. New York: Springer-Verlag; 2001. [Google Scholar]
- DeVore RA, Lorentz GG. Constructive Approximation: Polynomials and Splines Approximation. Berlin: Springer-Verlag; 1993. [Google Scholar]
- Fairfield KM, Fletcher RH. Vitamins for chronic disease prevention in adults. J Am Med Assoc. 2002;287:3116–3226. doi: 10.1001/jama.287.23.3116. [DOI] [PubMed] [Google Scholar]
- Fan J, Li RZ. Variable selection via nonconcave penalized likelihood and its oracle properties. J Amer Statist Assoc. 2001;96:1348–1360. [Google Scholar]
- Fan J, Li RZ. Variable selection for Cox’s proportional hazards model and frailty model. Ann Statist. 2002;30:74–99. [Google Scholar]
- Faure H, Preziosi P, Roussel A-M, Bertrais S, Galan P, Hercberg S, Favie A. Factors influencing blood concentration of retinol, α-tocopherol, vitamin C, and β-carotene in the French participants of the SU.VI.MAX trial. European Journal of Clinical Nutrition. 2006;60:706–717. doi: 10.1038/sj.ejcn.1602372. [DOI] [PubMed] [Google Scholar]
- Foster DP, George EI. The risk inflation criterion for multiple regression. Ann Statist. 1994;22:1947–1975. [Google Scholar]
- Frank IE, Friedman JH. A statistical view of some chemometrics regression tools. Technometrics. 1993;35:109–148. [Google Scholar]
- Hastie T, Tibshirani R. Generalized Additive Models. London: Chapman and Hall; 1990. [DOI] [PubMed] [Google Scholar]
- Huang J. Efficient estimation of the partly linear additive Cox model. Ann Statist. 1999;27:1536–1563. [Google Scholar]
- Huang JZ. Local asymptotics for polynomial spline regression. Ann Statist. 2003;31:1600–1635. [Google Scholar]
- Li Q. Efficient estimation of additive partially linear models. Int Econometric Rev. 2000;41:1073–1092. [Google Scholar]
- Li RZ, Liang H. Variable selection in semiparametric regression modeling. Ann Statist. 2008;36:261–286. doi: 10.1214/009053607000000604. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liang H, Li RZ. Variable selection for partially linear models with measurement errors. J Amer Statist Assoc. 2009;104:234–248. doi: 10.1198/jasa.2009.0127. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liang H, Thurston S, Ruppert D, Apanasovich T, Hauser R. Additive partial linear models with measurement errors. Biometrika. 2008;95:667–678. doi: 10.1093/biomet/asn024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin XH, Carroll RJ. Semiparametric regression for clustered data using generalized estimating equations. J Amer Statist Assoc. 2001;96:1045–1056. [Google Scholar]
- Ni H, Zhang HH, Zhang D. Automatic model selection for partially linear models. J Multivariate Anal. 2009;100:2100–2111. doi: 10.1016/j.jmva.2009.06.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nierenberg DW, Stukel TA, Baron JA, Dain BJ, Greenberg ER. Determinants of plasma levels of beta-carotene and retinol. Am J Epidemiology. 1989;130:511–521. doi: 10.1093/oxfordjournals.aje.a115365. [DOI] [PubMed] [Google Scholar]
- Opsomer JD, Ruppert D. Fitting a bivariate additive model by local polynomial regression. Ann Statist. 1997;25:186–211. [Google Scholar]
- Opsomer JD, Ruppert D. A root-n consistent backfitting estimator for semiparametric additive modeling. J Comput Graph Statist. 1999;8:715–732. [Google Scholar]
- Pollard D. Asymptotics for least absolute deviation regression estimators. Econometric Theory. 1991;7:186–199. [Google Scholar]
- Ravikumar P, Liu H, Lafferty H, Wasserman L. Spam: Sparse additive models. Advances in Neural Information Processing System. 2008;20:1202–1208. [Google Scholar]
- Ravikumar P, Lafferty H, Liu H, Wasserman L. Sparse additive models. J R Stat Soc Ser B. 2009;71:1009–1030. [Google Scholar]
- Ruppert D, Wand M, Carroll R. Semiparametric Regression. New York: Cambridge University Press; 2003. [Google Scholar]
- Schwarz G. Estimating the dimension of a model. Ann Statist. 1978;6:461–464. [Google Scholar]
- Stone CJ. Additive regression and other nonparametric models. Ann Statist. 1985;13:689–705. [Google Scholar]
- Stone CJ. The dimensionality reduction principle for generalized additive models. Ann Statist. 1986;14:590–606. [Google Scholar]
- Tibshirani R. Regression shrinkage and selection via the LASSO. J R Stat Soc Ser B. 1996;58:267–288. [Google Scholar]
- van der Vaart AW, Wellner JA. Weak Convergence and Empirical Processes. New York: Springer-Verlag; 1996. [Google Scholar]
- Wang L, Yang L. Spline-backfitted kernel smoothing of nonlinear additive autoregression model. Ann Statist. 2007;35:2474–2503. [Google Scholar]
- Xie H, Huang J. SCAD-penalized regression in high-dimensional partially linear models. Ann Statist. 2009;37:673–696. [Google Scholar]
- Zou H. The adaptive lasso and its oracle properties. J Amer Statist Assoc. 2006;101:1418–1429. [Google Scholar]