

Abstract
Whenever a trial is conducted, there are three possible explanations for the results: a) findings are correct (truth), b) represents random variation (chance) or c) they are influenced by systematic error (bias). Random error is deviation from the ‘truth’ and happens due to play of chance (e.g. trials with small sample, etc.). Systematic distortion of the estimated intervention effect away from the ‘truth’ can also be caused by inadequacies in the design, conduct or analysis of a trial. Several studies have shown that bias can obscure up to 60% of the real effect of a healthcare intervention. A mounting body of empirical evidence shows that ‘biased results from poorly designed and reported trials can mislead decision making in healthcare at all levels’. Poorly conducted and reported RCTs seriously compromise the integrity of the research process especially when biased results receive false credibility. Therefore, critical appraisal of the quality of clinical research is central to informed decision-making in healthcare. Critical appraisal is the process of carefully and systematically examining research evidence to judge its trustworthiness, its value and relevance in a particular context. It allows clinicians to use research evidence reliably and efficiently. Critical appraisal is intended to enhance the healthcare professional's skill to determine whether the research evidence is true (free of bias) and relevant to their patients.
Keywords: Critical appraisal, randomized controlled trials, decision-making
INTRODUCTION
A five-year-old male child presents with dry and scaly skin on his cheeks and was brought to the pediatric out-patient clinic by his parents. After initial evaluation, the young patient was diagnosed with atopic dermatitis. During the initial consultation, a junior resident mentions that a topical formulation of tacrolimus, an immunosuppressant currently marketed for the prevention of rejection after solid organ transplant, is a potential therapeutic agent for atopic dermatitis. Nevertheless, the senior resident wants to know the evidence related to the safety and efficacy of topical tacrolimus in treating younger patients with atopic dermatitis. The junior resident enthusiastically performs an electronic search of the literature and finds a randomized controlled trial (RCT) conducted to determine the safety and efficacy of tacrolimus ointment in pediatric patients with moderate-to-severe atopic dermatitis.[1] The junior resident also mentions that since this is an RCT, it should be considered reliable as it stands at a higher level in the hierarchy of the evidence pyramid [Figure 1]. However, the question now arises that because the trial claims to be a RCT, are the results from this study reliable, and whether the results are applicable to the young patient in question here?
Figure 1.

Evidence pyramid showing the hierarchy of evidence.[13]
THE NEED FOR CRITICAL APPRAISAL
Whenever a trial is conducted, there are three possible explanations for the results: a) findings are correct (truth), b) represents random variation (chance) or c) they are influenced by systematic error (bias). Random error is deviation from the ‘truth’ and happens due to play of chance (e.g. trials with small sample, etc.). Systematic distortion of the estimated intervention effect away from the ‘truth’ can also be caused by inadequacies in the design, conduct or analysis of a trial. Several studies have shown that bias can obscure up to 60% of the real effect of a healthcare intervention. A mounting body of empirical evidence shows that ‘biased results from poorly designed and reported trials can mislead decision-making in healthcare at all levels’.[2] Poorly conducted and reported RCTs seriously compromise the integrity of the research process especially when biased results receive false credibility. Therefore, critical appraisal of the quality of clinical research is central to informed decision-making in healthcare.
Critical appraisal is the process of systematically examining research evidence to judge its trustworthiness, its value and relevance in a particular context. It allows clinicians to use research evidence reliably and efficiently.[3] Critical appraisal is intended to enhance the healthcare professional's skill to determine whether the research evidence is true (free of bias) and relevant to their patients. In this paper, we focus on the evaluation of an article (RCT) on a treatment intervention. The same framework would be applicable to preventive interventions as well.
Three essential questions need to be asked when dealing with an article on therapeutic intervention.[4]
Are the results valid? Do the findings of this study represent the truth? That is, do the results provide an unbiased estimate of the treatment effect, or have they been clouded by bias leading to false conclusions?
How precise are the results? If the results are unbiased, they need further examination in terms of precision. The precision would be better in larger studies compared with smaller studies.
Are the results applicable to my patient? What are the patient populations, disease and treatments (including comparators) under investigation? What are the benefits and risks associated with the treatment? Do the benefits outweigh the harms?
-
Are the results valid?
-
Did the study address a clearly focused issue?Is there a clearly stated aim and research question? Ideally, a well-designed RCT should follow the acronym of PICOTS, which stands for patient, intervention, control, outcome, timing and setting, to formulate the research question. Is there a sound and understandable explanation of the population being studied (inclusion and exclusion criteria)? Is there an overview of which interventions are being compared? Are the outcomes being measured clearly stated with a rationale as to why these outcomes were selected for the study?
-
Was the assignment of participants to treatments randomized?Randomization aims to balance the groups for known and unknown prognostic factors by allocating patients to two groups by chance alone. The aim is to minimize the probabilities of treatment differences attributed to chance and to maximize the attribution to treatment effects. Therefore, it is important that the intervention and control groups are similar in all aspects apart from receiving the treatment being tested. Otherwise, we cannot be sure that any difference in outcome at the end is not due to pre-existing disparity. If one group has a significantly different average age or social class make-up, this might be an explanation of why that group did better or worse. The best method to create two groups that are similar in all important respects is by deciding entirely by chance, into which group a patient will be assigned.[5] This is achieved by random assignment of patients to the groups. In true randomization, all patients have the same chance as each other of being placed into any of the groups.[4,5] Allocation concealment ensures that those assessing eligibility and assigning subjects to groups do not have knowledge of the allocation sequence. In order to ensure adequate allocation concealment, centralized computer randomization is ideal and is often used in multicenter RCTs. The successful randomization process will result in similar groups. It is important to note that randomization will not always produce groups balanced for known prognostic factors. A large sample size will potentially reduce the likelihood of placing individuals with better prognoses in one group.[4,6]
-
Were all the participants who entered the study properly accounted for at its conclusion? Description of dropouts and withdrawals: How do dropouts threaten validity?Participants in a RCT are considered lost to follow-up when their status or outcomes are not known at the end of the study. Dropouts might happen due to several natural reasons (e.g. participant relocation). It is assumed that such dropouts will not necessarily be a substantial number. However, when the dropout rate is large (e.g. >10%), it is a reason for concern. Often the reason that patients are lost to follow up relates to a systematic difference in their prognosis compared with patients who continue with a study until the end (e.g., patients lost to follow-up may have more adverse events or worse outcomes than those who continue). Therefore, the loss of many participants may threaten internal validity of the trial. Furthermore, if loss to follow-up and drop outs is different between two study groups, it may result in missing data that can disrupt the balance in groups created by randomization.The abovementioned questions should be adequate for screening purposes of the manuscript to help make a decision whether to continue assessing the article further. That is, if the answers to the first three questions are negative, it is not worth evaluating the findings, as the results from this study would not be considered reliable to be used in decision-making.
-
-
How precise are the results?
-
What are the results?The readers of the paper should be attentive as to whether authors of the study adequately describe the data collection that was employed in the study. These should be clearly described and justified. All outcome measures should be referenced and their validity reviewed. If data was self-reported by patients, it would need to be verified in some way for maximum credibility.Were the methods of analysis appropriate, clearly described and justified? Analysis should relate to the original aims and research questions. Choice of statistical analyses should be explained with a clear rationale. Any unconventional tests should be justified with references to validation studies.An important issue to consider in the analysis of a RCT is whether the analysis was performed according to the intention to treat (ITT) principle. According to this principle, all patients are analyzed in the same treatment arm regardless of whether they received the treatment or not. Intention to treat (ITT) analysis is important because it preserves the benefit of randomization. If certain patients in either arm dropped out, were non-compliant or had adverse events are not considered in the analysis, it is similar to allowing patients to select their treatment and the purpose of randomization is rendered futile.Alternatively, a ‘per-protocol’ or ‘on treatment’ analysis includes only patients who have sufficiently complied with the trial's protocol. Compliance covers exposure to treatment, availability of measurements and absence of major protocol violations and is necessary to measure the treatment-related harm (TRH) outcomes. Adhering to ITT analysis for assessment of TRH leads to biased estimates.[7,8] In summary, analysis of benefits associated with treatments should be performed using the ITT principle and associated risks according to per protocol.
-
What are the key findings?The findings should answer the primary research question(s). Each outcome measure should be analyzed and its results presented with comparisons between the groups. Other issues of analysis include the magnitude of the effect, which can be measured by relative and absolute risk differences, odds ratios and numbers needed to treat. The significance of any differences between the groups should be discussed, with p-values given to indicate statistical significance (< 0.05 being the common threshold for significance). The confidence intervals should be presented to demonstrate the degree of precision of the results. Was the sub-group analyses preplanned or derived post hoc (derived from a fishing expedition after data collection)? For example, in the RCT mentioned in the clinical scenario, tacrolimus in children aged 6 to 17 years suffering from atopic dermatitis had a statistically significant difference compared with vehicle group for the outcome of Physician's Global Evaluation of clinical response.[1] It is important to note that the study was adequately powered to address the primary question only. It would be incorrect if the investigators decided to address the issue of efficacy according to age groups (e.g. subgroup of 6 to 8 years old versus 9 to 17) or any other subgroups if it was not decided a priori. That is, subgroup analysis could be justified for hypothesis generation but not hypothesis testing. The validity of subgroup–treatment effects can only be tested by reproducing the results in future trials. Rarely are trials powered to detect subgroup effects. There is often a high false negative rate for tests of subgroup-treatment effect interaction when a true interaction exists.[9]The authors should include the descriptive analysis of the data (mean, median, standard deviation, frequencies etc.) and not just the results of statistical tests used. Most often, results are presented as dichotomous outcomes (yes or no). Consider a study in which 25% (0.25) of the control group died and 20% (0.20) of the treatment group died. The results can be expressed in many ways as shown in Table 1.[10]
-
Are the results applicable to my patient?How will the results help me work with my patients/clients? Can the results be applied to the local population of my practice and clients? How similar is the study sample to your own clients? Are there any key differences that you would need to consider for your own practice?In the case of our five-year-old with atopic dermatitis, even if the trial was performed flawlessly with positive results, if the population studied was not similar then the evidence is not applicable. An example of this would be if the study was performed in patients with severe atopic disease who had failed all other regimens but our patient was naïve to any therapy. If the population was a different age range or ethnicity, it could also impact relevance.Other important considerations are whether you have the necessary skills or resources to deliver the intervention. Were all the important outcomes considered? Has the research covered the most important outcomes for your patients? If key outcomes were overlooked, do you need further evidence before changing your practice? Are the benefits of the intervention worth the harms and the costs? If the study does not answer this question, you will need to use your own judgment, taking into account your patients, all the stakeholders, yourself and your colleagues.
-
Table 1.
Essential terminologies and their interpretations
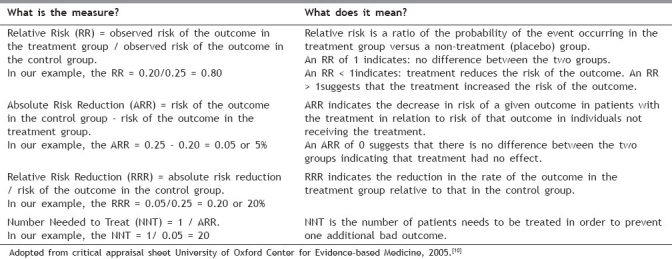
Absolute Risk Reduction (ARR) = risk of the outcome in the control group – risk of the outcome in the treatment group.
In our example, the ARR = 0.25 – 0.20 = 0.05 or 5%. Absolute Risk Reduction (ARR) indicates the decrease in risk of a given outcome in patients with the treatment in relation to risk of that outcome in individuals not receiving the treatment.
An ARR of ‘0’ suggests that there is no difference between the two groups indicating that treatment had no effect.
Relative Risk Reduction (RRR) = absolute risk reduction / risk of the outcome in the control group.
In our example, the RRR = 0.05/0.25 = 0.20 or 20%. Relative Risk Reduction (RRR) indicates the reduction in the rate of the outcome in the treatment group relative to that in the control group.
Number Needed to Treat (NNT) = 1 / ARR.
In our example, the NNT = 1/ 0.05 = 20. Number Needed to Treat (NNT) is the number of patients needs to be treated in order to prevent one additional bad outcome.
In conclusion, the reporting of RCT can be plagued with numerous quality control issues. Consolidated Standards of Reporting Trials group (CONSORT) has developed various initiatives to improve the issues arising from inadequate reporting of RCTs. The main products of CONSORT are the CONSORT statement[11] and CONSORT harms statement,[12] which are an evidence-based, minimum set of recommendations for reporting RCTs. These offer a standard way for authors to prepare reports of trial findings, facilitating their complete and transparent reporting and aiding their critical interpretation.[11] In essence there is a need to assess the quality of evidence; and, if adequate, establish the range of true treatment effect. Then, consider whether results are generalizable to the patient at hand, and whether the measured outcomes are relevant and important. Finally, carefully review the patient's risk of TRH and related treatment benefit – risk ratio.[6] We believe that methodologically assessing the strength of evidence and using it to guide treatment of each patient will certainly improve health outcomes.
Additional material
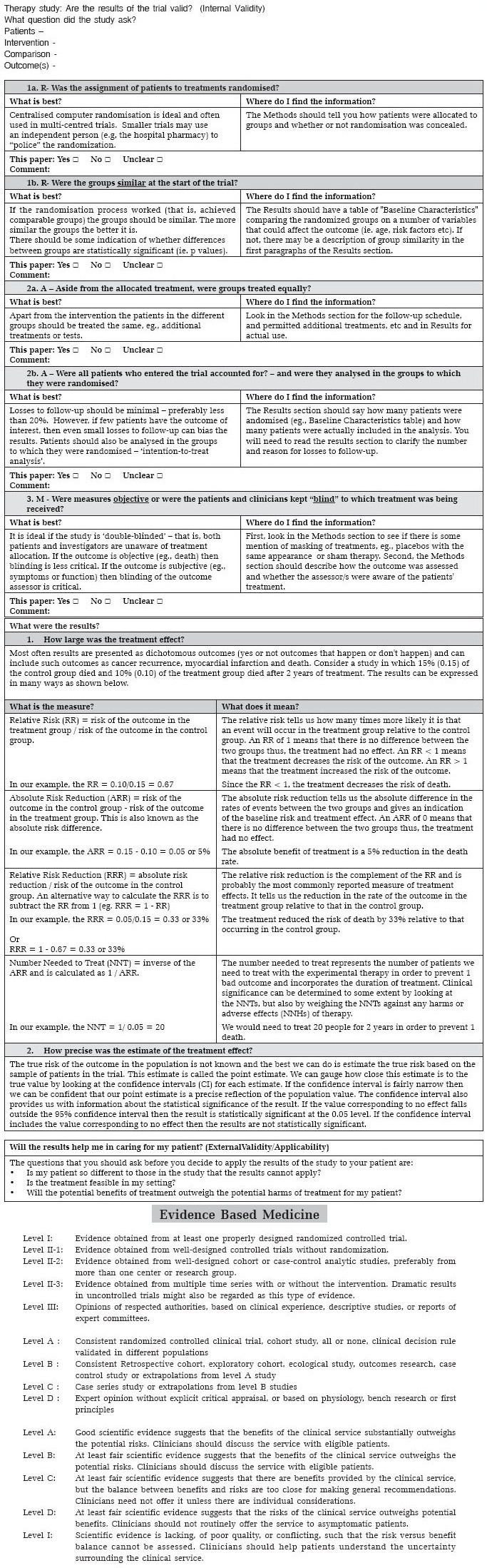
A critical appraisal worksheet (with permission from http://www.cebm.net/index.aspx?o=1157) is provided in the appendix section of the manuscript. We encourage the readers to assess the manuscript mentioned in the clinical scenario[1] and critically appraise it using the worksheet (see appendix).
Appendix.
ACKNOWLEDGEMENT
This paper was supported in part by the Fogarty International Center/USNIH: Grant # 1D43TW006793-01A2-AITRP.
Footnotes
Source of Support: Fogarty International Center/USNIH: Grant #1D43TW006793-01A2-AITRP.
Conflict of Interest: None declared.
REFERENCES
- 1.Boguniewicz M, Fiedler VC, Raimer S, Lawrence ID, Leung DY, Hanifin JM. A randomized, vehicle-controlled trial of tacrolimus ointment for treatment of atopic dermatitis in children. J Allergy Clin Immunol. 1998;102:637–44. doi: 10.1016/s0091-6749(98)70281-7. [DOI] [PubMed] [Google Scholar]
- 2.Moher D, Schulz KF, Altman D. CONSORT Group. The CONSORT Statement: Revised recommendations for improving the quality of reports of parallel-group randomized trials 2001. Explore (NY) 2005;1:40–5. doi: 10.1016/j.explore.2004.11.001. [DOI] [PubMed] [Google Scholar]
- 3.Burls A. What is critical appraisal? 2009 [Google Scholar]
- 4.Guyatt GH, Sackett DL, Cook DJ. Users’ guides to the medical literature.II. How to use an article about therapy or prevention. A. Are the results of the study valid? Evidence-Based Medicine Working Group. JAMA. 1993;270:2598–601. doi: 10.1001/jama.270.21.2598. [DOI] [PubMed] [Google Scholar]
- 5.Jüni P, Altman DG, Egger M. Systematic reviews in health care: Assessing the quality of controlled clinical trials. BMJ. 2001;323:42–6. doi: 10.1136/bmj.323.7303.42. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Guyatt GH, Sackett DL, Cook DJ. Users’ guides to the medical literature. II. How to use an article about therapy or prevention. B. What were the results and will they help me in caring for my patients? Evidence-Based Medicine Working Group. JAMA. 1994;271:59–63. doi: 10.1001/jama.271.1.59. [DOI] [PubMed] [Google Scholar]
- 7.Clinical trials, Shapiro SH. New York: Marcel Dekker; 1983. Armitage. Exclusions, losses to follow-up and withdrawals in clinical trials. [Google Scholar]
- 8.Gail MH. Eligibility exclusions, losses to follow-up, removal of randomized patients, and uncounted events in cancer clinical trials. Cancer Treat Rep. 1985;69:1107–13. [PubMed] [Google Scholar]
- 9.Rothwell PM. Treating individuals 2.Subgroup analysis in randomised controlled trials: importance, indications, and interpretation. Lancet. 2005;365:176–86. doi: 10.1016/S0140-6736(05)17709-5. [DOI] [PubMed] [Google Scholar]
- 10.Oxford, T.U.o. Critical appraisal sheet for RCT. 2009 [Google Scholar]
- 11.Egger M, Altman DG, Schulz KG. The CONSORT Statement: Explanation and Elaboration. Ann Intern Med. 2002;136:926–7. [Google Scholar]
- 12.Ioannidis JP, Evans SJ, Gøtzsche PC, O’Neill RT, Altman DG, Schulz K, et al. Better reporting of harms in randomized trials: an extension of the CONSORT statement. Ann Intern Med. 2004;141:781–8. doi: 10.7326/0003-4819-141-10-200411160-00009. [DOI] [PubMed] [Google Scholar]
- 13.Sackett DL. New York: Churchill Livingstone Inc; 2000. Evidence-based medicine.How to practice and teach EBM; p. 136. [Google Scholar]