

Abstract
Signal to noise ratios in physical systems can be significantly degraded if the output of a system is highly variable. Biological processes for which highly stereotyped signal generation is a necessary feature appear to have reduced their signal variabilities by employing multiple processing steps. To better understand why this multi-step cascade structure might be desirable, we prove that the reliability of a signal generated by a multi-state system with no memory (i.e. a Markov chain) is maximal if and only if the system topology is such that the process steps irreversibly through each state, with transition rates chosen such that an equal fraction of the total signal is generated in each state. Furthermore, our result indicates that by increasing the number of states, it is possible to arbitrarily increase the reliability of the system. In a physical system, however, there is an energy cost associated with maintaining irreversible transitions, and this cost increases with the number of such transitions (i.e. the number of states). Thus an infinite length chain, which would be perfectly reliable, is infeasible. To model the effects of energy demands on the maximally reliable solution, we numerically optimize the topology under two distinct energy functions that penalize either irreversible transitions or incommunicability between states respectively. In both cases, the solutions are essentially irreversible linear chains, but with upper bounds on the number of states set by the amount of available energy. We therefore conclude that a physical system for which signal reliability is important should employ a linear architecture with the number of states (and thus the reliability) determined by the intrinsic energy constraints of the system.
1 Introduction
In many physical systems, a high degree of signal stereotypy is desirable. In the retina, for example, the total number of G proteins turned on during the lifetime of activated rhodopsin following a photon absorption event needs to have a low variability to ensure that the resulting neural signal is more or less the same from trial to trial [Rieke and Baylor, 1998]. If this were not the case, accurate vision in low light conditions would not be possible. Biology offers us a myriad of other examples where signal reproducibility or temporal reliability are necessary for proper function: muscle fiber contraction [Edmonds et al., 1995b], action potential generation and propagation [Kandel et al., 2000], neural computations underlying motor control [Olivier et al., 2007] or time estimation [Buhusi and Meck, 2005], ion channel and pump dynamics [Edmonds et al., 1995a], circadian rhythm generation [Reppert and Weaver, 2002], cell-signalling cascades [Locasale and Chakraborty, 2008], etc. In some cases it may be possible to reduce signal variability by making a system exceedingly fast, but in many cases a nonzero mean processing time is necessary. The mechanism involved in the inactivation of rhodopsin, for example, needs to have some latency in order for enough G proteins to accumulate to effect the neural signal. In this paper we address the question of how to design a physical system that has a low signal variability while maintaining some desired nonzero mean total signal (and thus a nonzero mean processing time).
A previous numerical study of the variability of the signal generated during the lifetime of activated rhodopsin found that a multistep inactivation procedure (with the individual steps proposed to be sequential phosphorylations) was required to account for the low variability observed experimentally [Hamer et al., 2003]. This theoretical prediction was borne out when knockouts of phosphorylation sites in the rhodopsin gene were seen to result in an increased variability [Doan et al., 2006]. These results led us to consider more generally whether a multi-step system is optimal in terms of the reliability of an accumulated signal. Specifically, we limit ourselves to consider memoryless systems where the future evolution of the system dynamics depends on the current configuration of the system but not simultaneously on the history of past configurations. If such a memoryless system has a finite or countable number of distinct configurations (states) with near instantaneous transition times between them, it can be modeled as a continuous time Markov chain. This class of models, though somewhat restricted, is sufficiently rich to adequately approximate a wide variety of physical systems, including the phosphorylation cascade employed in the inactivation of rhodopsin. By restricting ourselves to systems which can be modeled by Markov chains, our goal of identifying the system design that minimizes the variance of the total generated signal while maintaining some nonzero mean may be restated as the goal of determining the Markov chain network topology that meets these requirements given a set of state-specific signal accumulation rates.1 This is the primary focus of the present work.
The paper is organized as follows: in Sec. 2, we review basic continuous time Markov chain theory, introduce our notation, and review the necessary theory of the “hitting time”, or first passage time, between two states in a Markov network. We then define a random variable to represent the total signal generated during the path between the first and last states in the network and show that this is a simple generalization of the hitting time itself. The squared coefficient of variation of this variable (the CV2, or ratio of the variance to the square of the mean) will be our measure of the variability of the system modeled by the Markov chain. In Sec. 3, we present our main theoretical result regarding the maximally reliable network topology. Simply stated, we prove that a linear Markov chain with transition rates between pairs of adjacent states that are proportional to the state-specific signal accumulation rates is optimal in that it minimizes the CV2 of the total generated signal. In the special case that the state-specific signal accumulation rates are all equal to one, the total generated signal is the hitting time, and the optimally reliable solution is a linear chain with the same transition rate between all adjacent states (see Fig. 1b). As an intermediate step, we also prove a general bound regarding the signal reliability of an arbitrary Markov chain (Eq. 10) which we show to be saturated only for the optimal topology. In Sec. 4, we numerically study the deviations from the optimal solution when additional constraints are applied to the network topology. Specifically, we develop cost functions that are meant to represent the energy demands that a physical system might be expected to meet. As the available “energy” is reduced, the maximally reliable structure deviates further and further from the optimal (i.e. infinite energy) solution. If the cost function penalizes a quantity analogous to the Gibbs free energy difference between states, then the resulting solution is composed of two regimes: a directed component, which is essentially an irreversible linear subchain, followed by a diffusive component where the forward and backward transition rates between pairs of states along the chain become identical (Sec. 4.2). In the zero energy limit, the maximally reliable solution is purely diffusive, which is a topology that is amenable to analytic interpretation (Sec. 4.2.1). If, instead, the cost function penalizes all near-zero transition rates, then states are seen to merge until, at the minimum energy limit, the topology reduces to a simple 2-state system (Sec. 4.3). In Secs. 4.4 and 4.5, we present a brief analytic comparison of the solutions given by the two energy functions to show that, while they superficially seem quite different, they are in fact analogous. In both cases, the amount of available energy sets a maximum or effective maximum number of allowable states, and, within this state space, the maximally reliable Markov chain architecture is a linear chain with transition rates between each pair of adjacent states that are proportional to the state-specific signal accumulation rates. Finally, in Sec. 4.6, we argue that structure is necessary for reliability, and that randomly connected Markov chains do not confer improved reliability with increased numbers of states. From this we conclude that investing the energy resources needed to construct a linear Markov chain would be advantageous to a physical system.
Figure 1.

a. A schematic of a 6-state Markov chain. The circles and arrows represent the states and the transitions between states respectively. The thicknesses of the arrows correspond to the values of the transition rates or, equivalently, the relative probabilities of transition. Nonexistent arrows (e.g. between states 2 and 3) reflect transition rates of zero. b. A linear Markov chain with the same transition rate λ between all pairs of adjacent states in the chain (i.e. λi+1,i = λ). This topology uniquely saturates the bound on the CV2 of the hitting time t1N (Eq. 10).
2 Continuous time Markov chains
A Markov chain is a simple model of a stochastic dynamical system that is assumed to transition between a finite or countable number of states (see Fig. 1a). Furthermore, it is memoryless—the future is independent of the past given the present. This feature of the model is called the Markov property.
In this paper, we will consider homogeneous continuous time Markov chains. These are fully characterized by a static set of transition rates {λij : ∀i, ∀j ≠ i} that describe the dynamics of the network, where λij is the rate of transition from state j to state i. The dwell time in each state prior to a transition to a new state is given by an exponentially distributed random variable, which appropriately captures the Markovian nature of the system. Specifically, the dwell time in state j is given by an exponential distribution with time constant τj, where
| (1) |
the inverse of the sum of all of the transition rates away from state j. Once a transition away from state j occurs, the probability pj→i that the transition is to state i is given by the relative value of λij compared to the other rates of transitions leaving state j. Specifically,
| (2) |
It is convenient to construct an N × N transition rate matrix to describe a homogeneous continuous time Markov chain as follows:
| (3) |
where qj = −1/τj. Note that each column of A sums to zero and that all off-diagonal elements (the transition rates) are non-negative. The set of N × N matrices of this form corresponds to the full set of N-state Markov chains. For an introduction to the general theory of Markov chains, see, for example, [Norris, 2004].
2.1 Hitting times and total generated signals
In this paper we consider the reliability of the total signal generated during the time required for a Markovian system to arrive at state N given that it starts in state 1.2 This time is often referred to as the hitting time, which can be represented by the random variable t1N. The total generated signal, F1N, can subsequently be defined in terms of the hitting time and the state-specific signal accumulation rates. If the rate of signal accumulation in state i is given by the coefficient fi, and the current state at time t is denoted q(t), then we can define the total signal as
| (4) |
Note that in the case that fi = 1, ∀i, the total generated signal equals the hitting time. The statistics of these random variables are governed by the topology of the network, namely, the transition matrix A. Our goal is to identify the network topology that minimizes the variance of the total signal, and thus maximizes the reliability of the system, while holding the mean total signal constant.
Recall that the standard expression for the probability that a Markovian system that starts in state 1 is in state N at time t is given as
| (5) |
where e1 ≡ (1, 0, …, 0)T and eN ≡ (0, …, 0, 1)T (i.e. the first and Nth standard basis vectors respectively) [Norris, 2004]. If the Nth column of A is a zero vector so that transitions away from state N are disallowed making N a so-called collecting state of the system, then p(q(t) = N) is equivalent to the probability that the hitting time t1N is less than t. Assuming that this is true,3 then the time derivative of Eq. 5 is the probability density of the hitting time itself:
| (6) |
Note that state N must be collecting in order for this distribution to integrate to 1. Additionally, p(t1N ) is only well-defined if state N both is accessible from state 1 and is the only collecting state or collecting set of states accessible from state 1. We only consider topologies for which these three properties hold.
We can show that studying the statistics of the hitting time t1N is equivalent to studying the statistics of the the total generated signal F1N since the two random variables are simple transforms of each other. To determine the probability distribution of F1N, we can consider the signal accumulation rates to simply rescale time. The transition rate λij can be stated as the number of transitions to state i per unit of accumulated time when the system is in state j, and so the ratio λij/fj can similarly be stated as the number of transitions to state i per unit of accumulated signal when the system is in state j. Thus by dividing each column of A by the corresponding signal accumulation rate, we can define the matrix à with elements φij ≡ λij/fj. Then, the probability distribution of F1N is given, by analogy with the hitting time distribution (Eq. 6), as
| (7) |
Thus, for the remainder of the paper we focus solely on the reliability of a Markovian system as measured by the statistics of the hitting time rather than of the total generated signal (i.e. we consider fi = 1, ∀i). This can be done without loss of generality since the results we present regarding the reliability of the hitting time can be translated to an equivalent set of results regarding the reliability of the total generated signal by a simple column-wise rescaling of the transition rate matrices.
2.2 The CV2 as a measure of reliability
It is clear that given a Markov chain with a set of fixed relative transition rates, the reliability of the system should be independent of the absolute values of the rates (i.e. the scale) since a scaling of the rates would merely rescale time (e.g. change the units from seconds to minutes). Furthermore, the variance and the square of the mean of the hitting time t1N would be expected to vary in proportion to each other given a scaling of the transition rates, since again this is just a rescaling of time. This can be demonstrated by noting, from Eq. 3, that scaling the rates of a Markov chain by the same factor is equivalent to scaling A, since A is linear in the rates λij, and, from Eq. 6, that scaling A is equivalent to rescaling t1N and thus the statistics of t1N. Therefore, we use the squared coefficient of variation (CV2, or the dimensionless ratio of the variance to the square of the mean) to measure the reliability of a Markov chain, and seek to determine the network topology (i.e. with fixed relative rates, but not fixed absolute rates) which minimizes the CV2 and thus is maximally reliable.
3 Optimal reliability
Intuitively, it seems reasonable that an irreversible linear chain with the same transition rate between all pairs of adjacent states (i.e. λi+1,i = λ for all i and for some constant rate λ, and λij = 0 for j ≠ = i − 1; see Fig. 1b) may be optimal. For such a chain, the hitting time t1N equals the sum from 1 to M (where we define M ≡ N −1 for convenience) of the dwell times in each state of the chain ti,i+1. This gives the CV2 as
| (8) |
where we use the fact that the dwell times are independent random variables and so their means and variances simply add. Since the ti,i+1 are drawn from an exponential distribution with mean 1/λ and variance 1/λ2, the CV2 reduces further as
| (9) |
It is trivial to show via simple quadratic minimization that the constant-rate linear chain is optimal over all possible irreversible linear chains since its variance is minimal for a given mean, but the proof that no other branching, loopy, or reversible topologies exist that may have equal or lower variabilities as measured by the CV2 appears to be less obvious. The main mathematical result of this paper is that, in fact, no other topologies reach a CV2 of 1/M. Our proof, detailed in Sec. A.1, proceeds in two steps. First, we prove that the following bound holds for all N-state Markov chains:
| (10) |
Second, we show that our proposed constant-rate linear chain is the unique solution which saturates this bound.
Confirming the relevance of this theoretical result to natural systems, the best fit of a detailed kinetic model for rhodopsin inactivation to experimental data has exactly the constant-rate linear chain architecture although for the total generated signal rather than for the lifetime of the system (i.e. in each phosphorylation state, the rate of subsequent phosphorylation is proportional to the state-specific G protein activation rate, and so the mean fraction of the total signal accumulated in each state is constant) [Gibson et al., 2000, Hamer et al., 2003]. We postulate that studies of other biological systems for which temporal or total signal reliabilities are necessary features will uncover similar constant-rate linear topologies. Although not experimentally validated, previous theoretical work [Miller and Wang, 2006] has shown that a constant-rate linear chain could be implemented by the brain as a potential mechanism for measuring an interval of time. Specifically, if a set of strongly intra-connected populations of bistable integrate-and-fire neurons are weakly inter-connected in a series, then the total network works like a stochastic clock (i.e. in the presence of noise). By activating the first population through some external input, each subsequent population is activated in turn after some delay given by the strength of the connectivity between the populations. The time from the activation of the first population until the last is equivalent to the hitting time in a linear Markov chain with each population representing a state. Interestingly, in [Miller and Wang, 2006], the authors use this timing mechanism as a way to explain the well-known adherence to Weber’s Law seen in the behavioral data for interval timing [Gibbon, 1977, Buhusi and Meck, 2005], while our result indicates that this timing architecture is optimal without reference to the data.4
4 Numerical studies of energy constraints
Given the inverse relationship between the CV2 of the hitting time (or the total generated signal) and the number of states for a system with a linear, unidirectional topology, (Eq. 9) it would seem that such a system may be made arbitrarily reliable by increasing the number of states. Why, then, do physical systems not employ a massively large number of states to essentially eliminate trial to trial variability in signal generation? The inactivation of activated rhodopsin, for example, appears to be an eight [Doan et al., 2006] or nine [Hamer et al., 2003] state system. Why did nature not increase this number to hundreds of thousands of states? In the case of rhodopsin, one might speculate that the reduction in variability achieved with only eight or nine states is sufficient to render negligible the contribution that the variability in the number of G proteins generated by rhodopsin adds to the total noise in the visual system (i.e. it is small compared to other noise components such as photon shot-noise and intrinsic noise in the retinothalamocortical neural circuitry); more generally, for an arbitrary system, it is reasonable to hypothesize that a huge number of states is infeasible due to the cost incurred in maintaining such a large state-space. We will attempt to understand this cost by defining a measure of “energy” over the topology of the system.
The optimal solution given in the previous section consists entirely of irreversible transitions. We can analyze the energetics of such a topology by borrowing from Arrhenius kinetic theory and considering transitions between states in the Markov chain to be analogous to individual reactions in a chemical process. An irreversible reaction is associated with an infinite energy drop and thus our optimal topology is an energetic impossibility. Even if one deviates slightly from the optimal solution and sets the transitions to be nearly, but not perfectly, irreversible, then each step is associated with a large though finite energy drop. Thus, the total energy required to reset the system following its progression from the first to the final state would equal the sum of all of the energy drops between each pair of states. In this context it is apparent why a physical system could not maintain the optimal solution with a large number of states N since each additional state would add to the total energy drop across the length of the chain. At some point, the cost of adding an additional state would outweigh the benefit in terms of reduced variability, and thus the final topology would have a number of states that balances the counteracting goals of variability reduction and conservation of energy resources.
Specifically, in Arrhenius theory, energy differences are proportional to the negative logarithms of the reaction rates (i.e. ΔE ∝ −ln λ). In Secs. 4.2 and 4.3 below, we define two different energy functions, both of which are consistent with this proportionality concept, but apply it differently and have different interpretations. We then numerically optimize the transition rates of an N-state Markov chain to minimize the CV2 of the hitting time while holding the total energy Etot constant. This process is repeated for many values of Etot to understand the role that the energy constraints defined by the two different energy functions play in determining the minimally variable solution. As expected and shown in the results below, the CV2 of the optimal solution increases with decreasing Etot.
4.1 Numerical methods
Constrained optimization was performed using the optimization toolbox in MATLAB. Rather than minimize the CV2 of the hitting time directly, the variance was minimized while the mean was constrained to be 1, thus making the variance equal to the CV2. Expressions for the mean and the variance of the hitting time for arbitrary transition rate matrices are given using the known formula for the moments of the hitting time distribution ([Norris, 2004]; see Sec. A.2 for a derivation). In order to implicitly enforce the constraint that the rates must be positive, the rates λij were reparameterized in terms of θij, where θij ≡ − ln λij. The variance was then minimized over the new parameters rather than the rates themselves. The gradients of these functions with respect to θ were also utilized to speed the convergence of the optimization routine. The gradients of the mean, variance, and energy functions are given in Sec. A.3.
For each value of Etot, parameter optimization was repeated with multiple initial conditions to both discard locally optimal solutions and avoid numerically unstable parameter regimes. For the second energy function (Sec. 4.3), local optima were encountered, while none were observed in the parameter space of the first (Sec. 4.2).
4.2 Energy cost function I: constrain irreversibility of transitions
Our first approach at developing a reasonable energy cost function is predicated on the idea that if the values of the reciprocal rates between a single pair of states (e.g. λij and λji for states i and j) are unequal, then this asymmetry should be penalized, but that the penalty should not depend on the absolute values of the rates themselves. Thus if two states have equal rates between them (including zero rates), no penalty is incurred, but if the rates differ significantly, then large penalties are applied. In other words, perfectly reversible transitions are not penalized, while perfectly irreversible transitions are infinitely costly. From an energy standpoint, different rates between a pair of states can be thought of as resulting from a quantity analogous to the Gibbs free energy difference between the states. In chemical reactions, reactants and products have intrinsic energy values which are defined by their specific chemical makeups. The difference between the product and the reactant energies is the Gibbs free energy drop of a reaction. If this value is negative then the forward reaction rate exceeds the backward rate, and vice versa if the value is positive. By analogy then, we can consider each state in a Markov chain to be associated with an energy, and thus that the relative difference between the transition rates in a reciprocal rate pair is due to the energy drop between their corresponding states.5 For nonzero energy differences, one of the rates is fast because it is associated with a drop in energy, while the other is slow since energy must be invested to achieve the transition. On the other hand, if the energy difference is zero, then both rates are identical. This idea is schematized in Fig. 2a where the energy drop ΔEij between states i and j results in a faster rate λji than λij.
Figure 2.

a. A schematization of the energy associated with the transitions between states i and j for the energy cost function given in Eq. 13. The energies of each state are not equal, and so the transition rates differ (i.e. λji from state i to j is faster than λji from j to i). For this cost function, the height of the energy barrier in the schematic, which can be thought to represent the absolute values of λji and λji, does not contribute to Etot, which is only affected by the difference between the energies associated with each state |ΔEij|. b. The contribution to the total energy Etot for the pair of transition rates λji and λji under the first energy function (Eq. 13). For rates that are nearly identical (i.e. when the ratio λji/λji is close to one), |ΔEji| is near zero, but it increases logarithmically with the relative difference between the rates. c. Similar to a, but for the energy cost function given in Eq. 25. In this case, the transition rate λji from state i to j is faster, and thus associated with a lower energy barrier, than the rate λji from j to i. d. The contribution to the total energy Etot for the transition rate λji under the second energy function (Eq. 25). For large transition rates, Eij is near zero, but it increases logarithmically for near-zero rates. Note that the abscissae in b and d are plotted on a log scale.
Thus, the total energy of the system Etot can then be given as the sum of the energy drops between every pair of states:
| (11) |
where we exclude pairs that contain state N (i.e. since the outgoing rates for transitions away from state N do not affect the hitting time t1N and thus can always be set to equal the reciprocal incoming rates to state N, making those energy drops zero) and only count each rate pair once (because |ΔEij| = |ΔEji|). From Arrhenius kinetic theory, the Gibbs free energy difference is proportional to the logarithm of the ratio of the forward and backward reaction rates, and so we use the following definition for the energy drop (plotted in Fig. 2b for a single pair of reciprocal rates):
| (12) |
Therefore, the complete energy cost function is
| (13) |
Note that the individual magnitudes of the rates do not enter into the energy function, only the relative magnitudes between pairs of reciprocal rates.
The results of numerical optimization of the rates λij to minimize the CV2 of the hitting time t1N under the energy function defined in Eq. 13 are given in Fig. 3a. At large values of Etot, the optimized solution approaches the asymptotic CV2 limit of (i.e. the CV2 of the unconstrained or infinite energy, ideal linear chain; see Eq. 9). As the available energy is decreased, the CV2 consequently increases until, at Etot = 0, the CV2 reaches a maximal level of (the function ξ(M ) will be defined in Sec. 4.2.1 below).
Figure 3.

a. The minimum CV2 achieved by the numerical optimization procedure as a function of Etot for an 8-state Markov chain using the energy function defined in Eq. 13. At large energy values, the CV2 approaches the asymptotic infinite energy limit ( ), while at Etot = 0, the CV2 reaches its maximum value of (the function ξ(M) is given by Eq. 17). b. The transition rate values for the six nonzero pairs of rates between adjacent states along the linear chain (e.g. λ12 & λ21, λ23 & λ32, etc.). At large values of Etot the forward rates (solid lines) and the backward rates (dashed lines) approach the infinite energy limits of (for T ≡ 〈t1N〉) and zero respectively. As the energy is decreased, the rates smoothly deviate from these ideals until, at energy value E6, the rates λ67 & λ76 (in yellow) merge and remain merged for all lower energy values. Between E6 and E5, the rates again change smoothly until the rates λ56 & λ65 (in purple) merge. This pattern repeats itself until ultimately the first rate pair in the chain— λ12 & λ21 (in blue)—merges at Etot = 0. The zero energy solutions λ1,…, λ6 are given by Eq. 15. Inset. The final, unpaired rate in the chain (λ87) versus Etot. Its zero energy solution λM is also given by Eq. 15. As discussed in Sec. 4.2.1, this rate is proportional to M, whereas the zero energy solutions of the paired rates are proportional to i2, and so λM is considerably slower then, for example, λM−1. Note that the abscissae are plotted on a log scale and that the ordinate in b is plotted on a square-root scale for visual clarity.
Upon inspection, for large values of the total energy, the optimized transition rate matrix is seen, as presumed, to be essentially identical to the ideal, infinite energy solution. Specifically, the forward transition rates along the linear chain (i.e. the elements of the lower subdiagonal of transition rate matrix; see Eq. 3) are all essentially equal to each other, while the remaining rates are all essentially zero. Since the energy function does not penalize symmetric reciprocal rate pairs, the reciprocal rates between nonadjacent states in a linear chain (which are both zero and thus symmetric) would not contribute to the energy. Thus it would be expected that the optimal solutions found using this energy function would be linear chains, and indeed the minimization procedure does drive rates between nonadjacent states to exactly zero, or, more precisely, the numerical limit of the machine. The only deviations away from the ideal, infinite energy solution occur in the rates along the lower and upper sub-diagonals of the transition rate matrix (i.e. the forward and backward rates between adjacent states in the linear chain). As the available energy is decreased, these deviations become more pronounced until the lower and upper subdiagonals become equal to each other at Etot = 0. An analytical treatment of the structure of this zero energy solution is given in the subsection 4.2.1.
An inspection of the transition rate matrix at intermediate values of Etot reveals that as the minimum CV2 solution deviates between the infinite energy and the zero energy optima, the pairs of forward and backward transition rates between adjacent states become equal, and thus give no contribution to Etot, in sequence, starting from the last pair in the chain (λM−1,M & λM,M−1) at some relatively high energy value and ending with the first pair (λ12 & λ21) at Etot = 0. This sequential merging of rate pairs, from final pair to first pair, with a decrease in the available energy was a robust result over all network sizes tested. In Fig. 3b, for example, the results are shown for the optimization of an 8-state Markov chain. It is clear from the figure that the transition rates deviate smoothly from the infinite energy ideal as Etot is decreased until the final rate pair (in yellow) merges together at the energy level E6. At all lower energy values, these two rates remain identical and thus, given the definition of the energy function (Eq. 13), are noncontributory to Etot. After this first merging, the rates again deviate smoothly with decreasing Etot until the next rate pair (in purple) merges. This pattern repeats itself until, at Etot = 0, all rate pairs have merged. The value of the unpaired rate at the end of the chain (i.e. λ87 in this case) as a function of the available energy is shown in the figure inset. At intermediate values of Etot, the as-of-yet unmerged rate pairs (except for the first rate pair λ12 & λ21) are all identical to each other. That is, all of the forward rates in these unmerged rate pairs are equal as are all of the backward rates. For example, above E6 in Fig. 3b, the forward rates λ32, …, λ65 are equal as are the backward rates λ23, …, λ56. In other words, the green, brown, cyan, and purple traces lie exactly on top of each other. Only the yellow traces, corresponding to the rate pair which is actively merging in this energy range, and the blue traces, corresponding to the first rate pair, deviate from the other forward and backward rates. Between E5 and E6, the same unmerged rates continue to be equal except for λ56 & λ65 (in purple) which have begun to merge.6 Essentially, this means that the behavior of the system at intermediate values of Etot is insensitive to the current position along the chain anywhere within this set of states with unmerged rate pairs (i.e. the forward and backward rates are the same for all states in this set).
We can understand why rate pairs should merge by considering the energy function to be analogous to a prior distribution over a set of parameters in a machine-learning style parameter optimization (e.g. a maximum a posteriori fitting procedure). In this case, the parameters are the logarithms of the ratios of the pairs of rates and the prior distribution is the Laplace, which, in log-space, gives the L1-norm of the parameters (i.e. exactly the definition of the individual terms of Etot; see Eq. 13). As is well known from the machine-learning literature, a Laplace prior or, equivalently, an L1-norm regularizer, gives rise to a sparse representation where parameters on which the data are least dependent are driven to zero and thus ignored while those that capture important structural features of the data are spared and remain nonzero [Tibshirani, 1996]. In this analogy, Etot is similar to the standard deviation of the prior distribution (or the inverse of the Lagrange multiplier of the regularizer), in that, as it is decreased towards zero, it allows fewer and fewer nonzero log-rate ratios to persist. Ultimately, at Etot = 0, the prior distribution overwhelms optimization of the CV2, and all the pairs of rates are driven to be equal, thus making the log-rate ratios zero. This analogy might lead one to consider energy functions which correspond to other prior distributions (e.g. the Gaussian), but, unlike Eq. 13, functions based on other priors (e.g. a quadratic which would correspond to a Gaussian prior) do not result in a clear interpretation of what the energy means and thus they were not pursued in this work.
One interpretation of the solutions of the optimization procedure at different energy values shown in Fig. 3b is as follows. Before a rate pair merges, the corresponding transition can thought of as “directed” with the probability of a forward transition exceeding that of a backward transition. On the other hand, after a merger has taken place, the probabilities of going forward and backward become equal, and we term this behavior as “diffusive”. At high values of Etot, the solution is entirely directed, with the system marching from the first state to the final state in sequence. At Etot = 0, the solution is purely diffusive, with the system performing a random walk along the Markov chain. At intermediate energy values, both directed and diffusive regimes coexist. Interestingly, the directed regime always precedes the diffusive regime (i.e. the rate pairs towards the end of the chain merge at higher energy values than those towards the beginning of the chain). Recalling our analogy from the previous paragraph, the first parameters to be driven to zero using a Laplace prior are those which have the least impact in accurately capturing the data. Therefore, in our case, we expect that the first log-rate ratios driven to zero are those that have the least impact on minimizing the CV2 of the hitting time t1N. Thus, our numerical results indicate that at energy levels where a completely directed solution is not possible, it is better, in terms of variability reduction, to first take directed steps and then diffuse rather than diffuse and then take directed steps or mix the two regimes arbitrarily. We will present a brief interpretation as to why this structure is favored in Sec. 4.2.2 below. A schematic of an intermediate energy solution is shown in Fig. 4.
Figure 4.

A schematic of a nonzero, finite energy solution for a 7-state Markov chain optimized under the energy function given in Eq. 13. In this case, the first two transitions can be called directed since their forward rates exceed their backward rates. The forward rate λ21, for example, is determined by the height of the energy barrier between states 1 and 2 (i.e. it is proportional to e−Δ E1. This rate will be a larger value than the backward rate λ12 (proportional to e−ΔE1 − ΔE2). On the other hand, the rates between states towards the end of the chain are equal as represented by states that are at the same energy level. The decreasing energy barriers towards the end of the chain represent the empirical result that the rates increase down the length of the chain (see Fig. 3). The larger energy barrier for the final transition to state N represents the result that this rate is much slower than the other rates at the end of the chain. As shown in Sec. 4.2.1 for the Etot = 0 solution, the final rate is a linear function of M while the other rates grow quadratically (Eq. 15). Note that the energy level of state N is not represented since there is no reverse transition N → M to consider.
4.2.1 Zero energy or pure diffusion solution
If Etot is zero under the energy function given by Eq. 13, then all the pairs of rates λij and λji are forced to be equal. The rates corresponding to transitions between non-adjacent states in the linear chain (i.e. for |i − j| ≠ = 1), are driven to zero by the optimization of the CV2, while the adjacent state transition rates remain positive. It is possible to analytically solve for the rates in such a zero energy chain as well as find a semi-closed form expression for the CV2 of the hitting time t1N (see Sec. A.4 for details).
To simplify notation a bit, since transitions between adjacent states are equal and, between non-adjacent states, zero, we can consider only the rates λi for i ∈ {1,…, M} where λi = λi,i+1 = λi+1,i. Then the CV2 can be shown to be
| (14) |
where we have defined the vector x as , the matrix Z as Zij ≡ min (i,j)2, and, for notational convenience, T as 〈t1N〉. The λi that minimize this CV2 are
| (15) |
which, substituted back into Eq. 14, give the minimum CV2 as
| (16) |
where ξ(M) is calculated as
| (17) |
where Ψ(x) is the digamma function defined as the derivative of the logarithm of the gamma function (i.e. ) and γ is the Euler–Mascheroni constant. Although Ψ (x) has no simple closed-form expression, efficient algorithms exist for determining its values. For M = 1, ξ (1) = 1, and, as can be shown by asymptotic expansion of Ψ (x), ξ(M) grows logarithmically with M.
Compared to the CV2 versus number-of-states relationship at infinite energy (Eq. 9), in the zero energy setting, the CV2 scales inversely with log N (Eq. 16) rather than with N, and thus adding states gives logarithmically less advantage in terms of variability reduction. Furthermore, even to achieve this modest improvement with increasing N, the rates must scale with i2 (i.e. λi ∝ 4i2 − 1; see Eq. 15), and thus the rates towards the end of the chain need to be O(N2 ln N) while those near the start are only O(ln N). To summarize then, the zero energy setting has two disadvantages over the infinite energy case. First, for the optimal solution, the CV2 is inversely proportional to the logarithm of N rather than to N itself, and second, even to achieve this modest variability reduction, a dynamic range of transition rates proportional to N2 must be maintained.
4.2.2 The diffusive regime follows the directed regime
We can understand the numerical result that, at intermediate energy values, the diffusive regime always follows the directed regime by careful consideration of the structure of this solution. First, let us assume that for some value of Etot the directed regime consists of Mi directed transitions and that the remainder of the system consists of a purely diffusive tail with Mr transitions (where N = Mi + Mr + 1). Recalling that transitions to state N are unpaired, then there are actually Mi + 1 directed transitions for this intermediate energy solution: Mi in the directed regime and one at the end of the diffusive tail. However, the energy resources of the system are being devoted solely to maintain the Mi transitions composing the directed regime, since the energy function (Eq. 13) does not penalize perfectly reversible transitions or transitions leading to state N, such as the one at the end of the diffusive tail.
Now consider if the diffusive regime preceded the directed regime. Then, though there would still be Mi+1 directed transitions (one at the end of the diffusive regime leading into the directed regime and Mi in the directed regime), the energy resources would be apportioned in a new manner. The final transition of the directed regime, since it leads to state N, would not incur any penalty, while the final transition of the diffusive regime would incur a penalty since it now leads to the first state of the directed regime rather than to state N. In other words, the final transition of the diffusive regime is penalized as are the first Mi − 1 transitions of the directed regime. It is now possible to understand why our numerical optimizations always yield solutions with directed-first, diffusive-second architectures. If the transition rate at the end of the diffusive regime λMr (to use the notation introduced in Sec. 4.2.1 above) is greater than the transition rate at the end of the directed regime λ, then more energy would be required for the diffusive-first architecture, which would penalize λMr, than for the directed-first architecture, which does not. Numerically, λMr is always seen to be greater than λ, and the following simple analysis also supports this idea.
If we approximate the directed regime as consisting of Mi perfectly irreversible transitions with backward rates of exactly zero, then the directed and diffusive subchains can be considered independently and thus their variances can be added as
| (18) |
where we have multiplied the expressions for the CV2 of an ideal linear chain (Eq. 9) and a zero energy, purely diffusive chain (Eq. 16) by the squares of the mean processing times for each subchain (Ti and Tr) to get the variances. In order to find the relative rates between the directed and diffusive portions of the chain, we minimize Eq. 18 with respect to the subchain means subject to the constraint that the mean total time is T. This gives
| (19) |
and
| (20) |
The forward rate along the directed portion of the chain is thus
| (21) |
and the final rate along the diffusive portion (Eq. 15) is thus
| (22) |
Therefore, for the case of a perfectly irreversible directed regime, the final transition rate of the diffusive regime is always larger than the rate of the directed regime as long as Mr > 1. Although this result does not necessarily hold for real intermediate energy solutions (where the directed regime is not perfectly irreversible), this analysis seems to explain the numerical result that the directed-first architecture is optimal.
4.3 Energy cost function II: constrain incommunicability between states
Although the results from the previous section are revealing and provide insight into why a physical system might be limited in the number of directed steps it can maintain (as discussed in Sec. 4.4 below, the diffusive tail found at intermediate values of Etot in the previous section is essentially negligible in terms of variability reduction), it is unclear whether the energy cost function given in Eq. 13 is generally applicable to an arbitrary multi-state physical process. Therefore, as a test of the robustness of our results, we defined an additional cost function to determine the behavior of the optimal solution under a different set of constraints. As shown in Secs. 4.4 and 4.5 below, the results given by our second cost function, while superficially appearing to be quite different, are in fact analogous to the those given in the preceding section.
Our second energy cost function is predicated on the idea that there should be a large penalty for all near-zero rates, or, equivalently, that the maintenance of incommunicability between states should be costly. Although not as neatly tied to a physical energy as the first energy function (which is exactly analogous to the Gibbs free energy; see Sec. 4.2), a small rate of transition between two states can be thought of as resulting from a high “energy” barrier that is preventing the transition from occurring. Inversely, a large rate corresponds to a low energy barrier, and in the limit, one can think of two states with infinite transition rates between them as in fact the same state. This idea is schematized in Fig. 2c for the transitions between a pair of states i and j. The energy Eji can be thought of as the energy needed to permit the transition from i to j, and similarly for Eij. Given our intuition regarding the relationship between energies and rates, from the diagram one expects that the rate λji is faster than the rate λij, since Eji is less than Eij. The total energy in the system Etot can simply be defined as the sum of energies associated with each transition in the system:
| (23) |
The energies of the transitions originating in state N are excluded from the preceding sum since their associated transition rates do not effect the hitting time t1N (i.e. transitions away from state N are irrelevant).
To determine a reasonable expression for the individual transition energies, we choose a function such that, for near-zero transition rates, Eij → ∞, and, for large transition rates, Eij → 0, which corresponds to our intuition from the previous paragraph. The following definition for the transition energy, plotted in Fig. 2d, meets these two conditions:
| (24) |
Therefore, the sceond energy cost function is
| (25) |
Our results are insensitive to the exact definition of the function as long as the asymptotic behaviors at transition rates of zero and infinity are retained.
The results of numerical optimization of the rates λij to minimize the CV2 for a 5-state Markov chain are given in Fig. 5a. For large values of Etot, the optimal solution is represented in blue. This solution asymptotes to , which is the theoretical minimum for N = 5 (see Eq. 9). Thus the optimized transition rate matrix looks essentially identical to the ideal, infinite energy solution:
| (26) |
where T ≡ 〈t1N 〉. Since Etot is finite, transition rates of exactly zero are not possible, but, for large enough values of Etot, the rates given as zero in Eq. 26 are in fact optimized to near-zero values. Note that this is a different behavior than that seen in the previous section where reciprocal rates between nonadjacent states in the linear chain were optimized to exactly zero (or, at least, the machine limit) and only the forward and backward rates along the linear chain were affected by the amount of available energy. In this case, all of the rates in the matrix are affected by Etot and the degree which the rates given as zero in Eq. 26 deviate from true zero depends on the energy. Thus, while in the previous section the linear architecture is maintained at all value of Etot, optimization under the second energy function would be expected to corrupt the linear structure, and, indeed, as Etot is decreased, all of the near-zero rates, including those between nonadjacent states in the linear chain, deviate farther from zero. Concomitantly, the minimum CV2, as shown in Fig. 5a, is seen to rise as expected.
Figure 5.

a. The minimum achievable CV2 resulting from numerical optimization of the rates of a 5-state Markov chain as a function of Etot (given by Eq. 25). The blue trace corresponds to a solution close to the 5-state linear chain given by Eq. 26, which is the theoretical optimum. As Etot decreases, this solution deviates from the optimal linear chain and the CV2 increases from the theoretical limit ( ) until, at the intersection of the blue and green traces, the solution corresponding to a linear chain with four effective states (i.e. two of the five available states have merged; see Eq. 27) becomes optimal. This 4-state chain also deviates from its theoretical minimum with decreasing Etot until the linear chain with three effective states (Eq. 28), shown in cyan, becomes optimal. The minimum energy limit corresponds to a chain with two effective states (Eq. 29), and this solution is represented with the magenta dot. See the text for a fuller interpretation of these results, b–d. The optimal transition rates as they vary with Etot for Markov chains with five (b), four (c), and three (d) states. At large energy values, the rates along the lower subdiagonal of the transition rate matrix (i.e. the rates which compose the linear chain) are equal to , while all other rates are essentially zero (thus the upper and lower sets of curves in b–d). These are the optimal solutions. As Etot decreases, the rates deviate from their ideal values and the CV2 grows as in a. The dashed vertical red lines mark the energy values where the CV2 is equal for numerically optimized chains of different lengths. At E5→4, for example, the minimum achievable CV2 is the same for both the 5 and 4-state Markov chains. This is where the blue and green traces cross in a. It is clear from these crossing points that the linear structure of the shorter chain is essentially fully intact while that of the longer chain has started to degrade significantly. In d, the 3-state Markov chain is seen to converge to the 2-state solution (shown with the magenta dot) at Emin. One of the rates becomes while the others diverge to infinities (i.e. two of the three states merge).
The green trace in Fig. 5a corresponds to another stable solution of the optimization procedure, which, for large values of Etot, is not globally optimal. Inspection of the solution reveals the following transition rate matrix:
| (27) |
where, in the third column, ∞2 is an infinity of a different order than the other infinities in the column (e.g. 10100 versus 1050). This hierarchy of infinities is an artifact of the numerical optimization procedure, but the solution is nonetheless revealing. Essentially, states 3 and 4 are merged into a single state in this solution. Whenever the system is in state 3, it immediately transitions to state 4 because the infinity of the higher order (i.e. ∞2) dominates. From state 4, the system immediately transitions back to state 3, and thus states 3 and 4 are equivalent. There is a single outflow available from this combined state to state 5 with rate . Furthermore, there are two sources of input into states 3 and 4 both from state 2, but, since the states are combined, this is the same as a single source with a total rate also of . Finally, there is an irreversible transition from state 1 to 2 with rate . This then is exactly the optimal solution for 4-state Markov chain: for large values of Etot every forward rate is equal to , all other rates are near zero, and the CV2 asymptotes to the theoretical minimum of .
The solution to which the cyan trace corresponds can be interpreted similarly to that of the green trace, except that in this case states 2, 3 and 4 have all merged and thus the effective number of states is three, not four. For large Etot, the transition matrix approaches
| (28) |
which is the optimal solution for a 3-state Markov chain (i.e. the forward rates are , the others rates are zero, and the asymptotic CV2 is ).
The magenta dot represents the 2-state system where the first four states have all merged:
| (29) |
In this case, the constraints on the desired mean and on Etot cannot both be met for arbitrary values of the two variables. There is only one rate available to the optimization procedure in a 2-state system, and thus, for mean T, the transition rate must be . Therefore, Etot is not a free variable and is locked to ln (T + 1) by Eq. 25. This is another point of difference from the results in the preceding section where the constraint on the mean could still be satisfied when the energy was zero (i.e. when all reciprocal pairs of rates of were equal).
Analysis of the behavior of the solutions with greater than two states as the total energy is decreased is revealing. In all cases, as expected, the minimum values of the CV2 deviate from the infinite energy asymptotes, but, more interestingly, the curves cross. At the point when the blue and green traces cross in Fig. 5a, for example, the 4-state system becomes the globally optimal solution despite the fact that its theoretical minimum at infinite energies is higher than that of the 5-state system (i.e. ). This can be understood by considering how the available energy that constitutes a given value of Etot is divided up amongst the rates of the system. The largest penalties are being paid for the near-zero rates, and thus most of the available energy is apportioned to maintain them. As Etot is decreased, maintaining the near-zero rates becomes impossible, and so the network topology begins to deviate significantly from the infinite energy optimum with the CV2 growing accordingly. This deviation occurs at higher values of Etot for a 5-state system than for a 4-state system because there are more near-zero rates to maintain for a larger value of N.
Thus we can understand the tradeoff imposed on the system by the energy function given in Eq. 25. The inability to maintain a long irreversible linear chain at decreasing energy values drives the system to discard states and focus on maintaining a linear chain of a shorter length, rather than a branching or loopy chain with more states. Figs. 5b–d shows the degree to which the transition rates deviate from their optimal values for Markov chains of five, four, and three states. The energy thresholds below which a 4-state chain outperforms a 5-state chain and a 3-state chain outperforms a 4-state chain are indicated in the figures. It is clear that at these crossing points the linear structure of the shorter chain is essentially totally intact while that of the longer chain has been significantly degraded.
4.4 Comparison of energy functions I and II at finite nonminimal energies
The results of the optimizations under the two energy functions in the preceding sections are illuminating. From the theoretical development of the optimal linear Markov chain topology (see Sec. 3), we saw that the CV2 of the hitting time was equal to (Eq. 9), which suggests that a physical system can arbitrarily improve its temporal reliability by increasing the number of states. If, however, as in the second energy function (Eq. 25), a cost is incurred by a system for maintaining zero transition rates (which, functionally, results in incommunicability between states), then, given a finite amount of available energy, we see from Sec. 4.3 that there is some maximum number of states Nmax achievable by the system regardless of the total allowable size of the state space N. The CV2 is thus at best equal to where Mmax ≡ Nmax − 1 (i.e. assuming that the linear chain architecture with Nmax states is essentially fully intact; see Fig. 5).
Alternatively, as in the first energy function (Eq. 13), by employing a cost incurred for the inclusion of asymmetries between reciprocal pairs of transition rates in the system topology (i.e. irreversible transitions), then, as shown in Sec. 4.2, only a subset of the total number of transitions can be close to irreversible, while the rest must be fully reversible with equal forward and backward transition rates (see Fig. 3). Although in this case a larger N will always result in a lower CV2, a simple analysis reveals that an effective maximum number of states Neff can be defined which is much less than N itself. If, as in the analysis in Sec. 4.2.2, one assumes that the first Mi transitions form a perfect, irreversible linear chain and that the remainder of the system consists of Mr fully reversible transitions (where N = Mi + Mr + 1), then, by combining Eqs. 18, 19, and 20, the CV2 is given as
| (30) |
By comparing Eq. 30 with the CV2 equation for the ideal chain (Eq. 9), we can equate the denominators and thus define an effective number of states as
| (31) |
Since ξ(M) grows logarithmically, Neff ≈ Mi unless the magnitude of N is on the order of eMi or greater. Furthermore, since the available energy dictates what fraction of the N-state chain can be irreversible and thus the value of Mi, then, in the absence of a massive state space, the energy is the primary determining factor in setting the temporal variability while the value of N itself secondary.
From this it appears that the maximally reliable solutions at finite nonminimal energies under either energy constraint are in fact quite similar. If irreversibility is penalized, then, as long as N is limited enough such that ξ (Mr) ≪ Mi, the available energy sets the number of states to Neff (≈ Mi). If, rather, incommunicability is penalized, then, regardless of how large N is permitted to be, the available energy mandates that the number of states be limited to Nmax. Furthermore, in both cases, the solutions are essentially irreversible linear chains. The only difference between the two solutions—the diffusive tail at the end of the chain optimized under the first energy function—has minimal impact on the behavior of the system.7
Fig. 6a shows the relationship between the total allowable number of states N and the minimum achievable CV2 under the two energy cost functions where the available energies have been tuned such that Mmax and Mi are equal, finite, and nonzero. As is clear from the figure, although the variability does continue to decrease as N is increased past Mi for the solutions determined under the first energy function (in red), the difference compared to the variability resulting from the second energy function (in green) is minimal. The values of the CV2 as functions of N are shown for two different settings of Mmax and Mi, and although the domain of N stretches over several orders of magnitude in the figure, the primary determinants of the CV2 are the values of Mmax and Mi, not N, for both settings.
Figure 6.

a. The decrease in the CV2 as a function of the total allowable size of the state space N for maximally reliable solutions determined under the first (in red) and second (in green) energy functions where the energies have been tuned such that Mi = Mmax = 10 (solid lines) and Mi = Mmax = 20 (dashed lines). Over a large range of N, the solutions determined under the first energy function are seen to deviate little from those determined under the second despite their long diffusive tails. The CV2 in the infinite energy case ( ) is shown in blue as a reference. b. The CV2 as a function of N for the minimal energy solutions resulting from the first energy function ( ; in red) and the second energy function (1; in green). Unlike in a for nonminimal energies, these solutions differ quite significantly with N. However, if the range of transition rates is restricted, then the CV2 of the solution determined under the first energy function does not decrease to zero with increasing N but rather reaches a constant as in the cyan trace for a maximally restricted range where all the transition rates are equal (then ; see text for more details). The infinite energy solution is again shown for comparison. Note that the abscissae are plotted on a log scale.
4.5 Comparison of energy functions I and II at minimal energies
Although optimization at finite nonminimal energy values under the two cost functions results in similar solutions, at minimal energies, the solutions seem quite different. Recall from Sec. 4.2.1, that at Etot = 0 (the minimal energy value under the first energy function), the CV2 of the minimally variable solution is equal to and thus decreases towards zero with increasing N. Under the second energy function, however, the CV2 is always equal to 1 for all N at the minimal energy value (recall from Sec. 4.3 that, with mean hitting time T, the minimal energy value is ln(T + 1) at which point all of the states have merged leaving Nmax equal to 2). These different behaviors as functions of N are shown in Fig. 6b in red and green respectively. Although approaches zero much more slowly than the CV2 of the infinite energy solution ( ), it is still significant compared to the CV2 of the minimal energy solution under the second cost function (i.e. 1). However, as discussed in Sec. 4.2.1, to achieve a CV2 of , the transition rates near the end of the linear chain must be on the order of N2 times larger than the values of the rates near the beginning of the chain.
Maintaining such a large dynamic range of rates may be infeasible in the context of a specific system, and so it is reasonable to consider what the advantage is in terms of variability reduction of having such a large range of rates versus having a single nonzero rate (i.e. a constant rate λ for all reciprocal pairs of rates between adjacent states in the linear chain). By substituting a constant rate into Eq. 14 and simplifying, the following can be shown:
| (32) |
This rapidly gives a CV2 of with increasing N (as shown in cyan in Fig. 6b), and thus it is clear that only with an unrestricted range of rates can the variability be driven arbitrarily close to zero by adding states. If an unrestricted range is not feasible, then even at minimal energy values, the solutions given by the two energy cost functions are not qualitatively different. That is, both result in constant values of the CV2 that are independent of N (compare the green and cyan traces in Fig. 6b).
4.6 Reliability of random transition rate matrices
In all cases, under either energy function at any amount of available energy from the minimal possible value to infinity, the goal of the system is to reduce the temporal variability within the given energy constraints, and, as has been shown throughout this paper, this is achieved by choosing the maximally reliable network structure amongst the set of structures which meet the constraints. Thus, it is reasonable to consider the value of choosing an explicit structure rather than an arbitrary random connectivity between a set of states. In Fig. 7a we show the distribution of the CV2 as a function of N, calculated empirically from 2000 random transition matrices at each value of N, with transition rates λij drawn as independent identically distributed samples from an exponential distribution. As N increases, the distribution of the CV2 quickly converges to a delta function centered at one. This is the CV2 of a minimally reliable 2-state system. Numerical studies using other random rate distributions with support on the positive real line (e.g. the uniform, gamma, log-normal, etc.) produced similar results.
Figure 7.

a. The mean (in blue) and the ±1σ deviations (in green) of the CV2 as a function of N, determined empirically from 2000 random transition rate matrices at each value of N, with rates drawn as i.i.d. samples from an exponential distribution. For large N, the distribution of the CV2 is a delta function at 1. This indicates that random. N-state chains are performing identically to 2-state chains. b–d. The instantaneous (in blue) and mean (in green) transition rates to state N as the system transitions between the first N − 1 states of random (b) 10, (c) 100, and (d) 1000-state chains with transition rates drawn i.i.d. from an exponential distribution with mean 1. The correlation time of the instantaneous transition rate scales as 1/N, and so, for large N, the mean rate, which is also the mean of the distribution from which the transition rates are drawn, dominates.
While initially surprising, the convergence observed in Fig. 7a can be easily understood as a consequence of the averaging phenomenon illustrated in Figs. 7b–d. These figures show λ (t), the instantaneous transition rate to state N, for sample evolutions of random matrices with 10, 100, and 1000 states. If the state of the system at time t is given by q(t), then λ (t) equals λNq(t), the rate of transition from state q(t) to state N. As is clear from the figures, the correlation time of λ (t) goes to zero with increasing N (it can be shown to scale as 1/N), and so a law of large numbers averaging argument can be applied to replace λ (t) with its mean (i.e. λ̄, the mean of the distribution from which the transition rates are drawn). In particular, the time-rescaling theorem [Brown et al., 2002] establishes that the random variable u, defined as
| (33) |
is drawn from an exponential distribution with mean one. By the averaging argument, u reduces as follows:
| (34) |
Finally, since u is distributed exponentially with mean one, then t1N is distributed exponentially with mean 1/λ̄, and thus must have a CV2 of one (confirming the numerical results).
These results make clear the advantage of specific network structure over arbitrary connectivity. A CV2 of 1 is the same as the reliability of a 2-state, one-step process. That is, a random network structure, regardless of the size of N, is minimally reliable.
5 Summary
Many physical systems require reliability in signal generation or temporal processing. We have shown that, for systems which may be modeled reasonably well as Markov chains, an irreversible linear chain architecture with the same transition rate between all pairs of adjacent states (Fig. 1b) is uniquely optimal over the entire set of possible network structures in terms of minimizing the variability of the hitting time t1N (equivalently, the architecture that optimally minimizes the variability of the total generated signal F1N is a linear chain with transition rates between pairs of adjacent states that are proportional to the state-specific signal accumulation rates). This result suggests that a physical system could become perfectly reliable by increasing the length of the chain, and so we have attempted to understand why perfect reliability is not observed in natural systems by employing energy cost functions which, depending on the amount of available energy, reduce the possible set of network structures by some degree. Although the two functions are quite different, the optimal network structures resulting from maximizing the system reliability under the constraints of either function are in fact quite similar. In short, they are irreversible linear chains with a fixed maximum length.
We would predict to see that natural systems for which temporal or total signal reliabilities are necessary features would be composed of linear chains of finite length with the length determined by the specific constraint encountered by the system. This prediction has applications across many disciplines of biology. For example, it suggests both that the sequence of openings and closings in the assemblage of ion channels responsible for active membranes processes (i.e. action potentials), and the progression of a dynamical neural network through a set of intermediate attractor states during the cognitive task of estimating an interval of time, should be irreversible linear processes. Our analysis is also useful in the event that some system for which signal reliability is important is found to have a branching or loops structure. By setting the linear structure as the theoretical limit, deviations from this limit may offer insight into what other counteracting goals physical systems are attempting to meet.
Acknowledgments
S.E. would like to acknowledge the NIH Medical Scientist Training Program and the Columbia University MD-PhD Program for supporting this research. L.P. is supported by an NSF CAREER award, an Alfred P. Sloan Research Fellowship, and a McKnight Scholar award. We thank B. Bialek, S. Ganguli, L. Abbott, T. Toyoizumi, X. Pitkow, and other members of the Center for Theoretical Neuroscience at Columbia University for many helpful discussions.
Appendix
A.1 Proof of the optimality of the linear, constant-rate architecture
The primary theoretical result of this paper is that a linear Markov chain with the same transition rate between all pairs of adjacent states is optimally reliable in terms of having the lowest CV2 of the hitting time from state 1 to state N of any N-state Markov chain (see Fig. 1b). To establish this result, we prove the following two theorems.
Theorem 1 (General bound)
The following inequality holds for all Markov chains of size N and all pairs of states i and j:
| (35) |
where the is the squared coefficient of variation of tij, the hitting time from state i to j.
Theorem 2 (Existence and uniqueness)
The equality holds if and only if states i and j are the first and last states of an irreversible, N-state linear chain with the same forward transition rate between all pairs of adjacent states and with state j as a collecting state.
We employ an inductive argument to prove these theorems (i.e. by assuming that they hold for networks of size N − 1 and proving that they hold for networks of size N). It is trivial to establish the base case of N = 2. Since the random variables t12 and t21 are both exponentially distributed (i.e. with means 1/λ21 and 1/λ12 respectively), and since the CV2 for exponential distributions is known to be unity, Thm. 1 holds. Furthermore, both t12 and t21 satisfy the conditions for Thm. 2 (i.e. they are hitting times between the first and last states of linear chains with the same transition rates between all pairs of adjacent states), and both saturate the bound. As they are the only hitting times in a 2-state network, then Thm. 2 also holds for N = 2. This establishes a base case and allows us to employ an inductive argument to prove the general result (i.e. by assuming that Thms. 1 and 2 hold for networks of size N − 1 and proving that they hold for networks of size N).
The logic of the proof is illustrated in Fig. 8. We break up the hitting time tij into a sum of simpler, independent random variables whose means and variances can be easily determined and to which some variance inequalities and the induction principle can be applied. Specifically, tij can be decomposed into the following sum:
| (36) |
where ti+l is the total time the system spends in the start state i and during any loops back to state i, while tpath is the time required for the transit along the path through the network to state j after leaving state i for the final time. The important part of this decomposition is that tpath is a random variable over a reduced network of size N −1 (excluding state i), which will allow us to apply the inductive principle. Since ti+l and tpath are independent variables due to the Markov property, their means and variances simply add, and so we can write down the following expression for the of the hitting time tij:
| (37) |
Figure 8.

a. A sample path through an N-state Markov chain conditioned on the assumption that the system loops back to return to the start state i twice (R = 2). By conditioning the hitting time tij on such a path, proof-by-induction is possible since the time required for the final transit to state j refers, by definition, to a network of size N − 1 excluding state i. The wavy lines indicate unspecified paths requiring unspecified numbers of transitions, b. A schematic of how the hitting time tij conditioned on two loops (R = 2) is decomposed into a set of conditionally independent random variables according to Eqs. 36 and 38. The brown box represents the conditional hitting time tij|R, while the smaller boxes represent the proportion of the total time due to, in sequential order from left to right: wi,1, the dwell time in state i prior to loop 1; tloop,1, the subsequent time required to loop back to i; wit2, the dwell time in i prior to loop 2; tloop,2, the subsequent time required to loop back to i; wi, the dwell time in i prior to the final transit to j; and tpath, the time required for the final transit to j. Note that the blocks representing the loop times and the final transit time correspond in color to the analogous wavy lines in a.
To establish Thm. 1, this quantity must not be less than for any topology, and, to establish Thm. 2, it must equal only for a hitting time tij where i is the first state and j the final state of a constant-rate, irreversible linear chain of length N. To analyze Eq. 37 and thus establish these theorems, we need expressions for the means and variances of the total pre-final transit time ti+l and of the final transit time tpath.
A.1.1 The mean and variance of the pre-final transit time ti+l
The statistics of ti+l can be determined by first considering the conditional case where the number of return loops back to state i prior to hitting state j is assumed to be R. Then ti+l (the sum of the total dwell time in start state i plus the total loop time) conditioned on R can be further decomposed as follows:
| (38) |
where wi,r is the dwell time in state i at the beginning of the rth loop, tloop,r is the time required to return to state i for the rth loop, and wi is the dwell time in state i prior to the final transit to state j.8 The total hitting time tij conditioned on R loops is given as the sum of the right-hand side of Eq. 38 and tpath (see Fig. 8 for a schematic when R = 2).
The conditional pre-final transit time ti+l|R is simple to analyze since, due to the Markov principle, the random variables on the right-hand side of Eq. 38 are all conditionally independent given R. Thus, we can calculate the conditional mean and variance as
| (39) |
and
| (40) |
where we have used the notation that 〈f(x)〉p(x) and var(f (x))p(x) are defined, respectively, as the mean and variance of f(x) over the distribution p(x). In Eqs. 39 and 40, we are able to drop the r indices since we assume time homogeneity and thus that (1) the distribution over the dwell time in state i prior to loop r (wi,r) is the same for every loop r and the same as the distribution over the dwell time in i prior to the final transit to j (wi), and that (2) the distribution over the time required to loop back to i for the rth loop (tloop,r) has the same distribution for each loop. Furthermore, in Eq. 40, since the dwell time wi is an exponentially distributed random variable and thus has a variance equal to the square of its mean, we have substituted var(wi) with 〈wi〉2.
To construct expressions for the marginal mean and variance of the pre-final transit time (〈ti+l〉p(ti+l) and var(ti+l)p(ti+l)) from the conditional mean and variance (Eqs. 39 and 40), the following identities are useful:
| (41) |
and
| (42) |
Thus, for the marginal mean, we have
| (43) |
Similarly, for the marginal variance, we have
| (44) |
where we have used the fact that the mean dwell time 〈wi〉 and the mean loop time 〈tloop〉 are both independent of R, and, in the final step, the fact that the number of loops R is given by a shifted geometric distribution, and thus has a variance equal to 〈R〉(〈R〉 + 1).
By expanding the first term in Eq. 44, and then refactorizing and substituting in the expression for the mean (Eq. 43), we can rewrite the variance of ti+l as
| (45) |
A.1.2 The variance of the final transit time tpath in terms of hitting times
In order to get an expression for the variance of the time for the final transit tpath in terms of hitting times over reduced networks of size N − 1 (so that we can use induction), we apply the identity given in Eq. 42 to decompose the variance of tpath as
| (46) |
where state k is the first state visited by the system after state i at the beginning of the final transit from i to j. The random variable tpath was originally defined as the time required for the final transit to state j, and so, given a specific start state, tpath|k is thus the time required for the path from state k to state j, which is exactly the definition of the hitting time tkj. Substituting this equivalence into Eq. 46, we get the following:
| (47) |
where we have replaced the variance of the hitting time tkj with the product of the squares of the CV and the mean, an equivalent formulation.
A.1.3 Establishing Theorem 1
Returning to the of the hitting time tij (Eq. 37), we can replace var(ti+l) with the second term of Eq. 45 and var(tpath) with the second term of Eq. 47 (the first terms of Eqs. 45 and 47 are nonnegative) to state the following bound:
| (48) |
Next, we can employ the inductive step of the proof and assume that Thm. 1 is true for the reduced networks represented by tkj (recall that these subnetworks are of size N − 1 since the ith state is withheld by definition from tpath and thus tkj). This substitution yields the expression
| (49) |
We can also use the fact that the second moment of a random variable is not less than the square of its mean (i.e. 〈x2〉 ≥ 〈x〉2) to perform an additional inequality step:
| (50) |
Finally, recalling that the hitting time 〈tkj〉 is equivalent to 〈tpath〉 p(tpath|k), we can use the identity given in Eq. 41 to replace 〈tkj〉 p̂(k) and state the following final expression for the :
| (51) |
or
| (52) |
where, for notational simplicity, we have replaced 〈ti+l〉 and 〈tpath〉 with L and P respectively.
Our goal is to establish that the is not less than for all networks of size N. Since Eq. 52 is true for all networks, if the minimum value of the ratio on the right-hand side of the inequality is greater than or equal to , the theorem is proved. The network topology affects this ratio through the values of L and P, and so we minimize with respect to these variables ignoring whether or not the joint minimum of L and P corresponds to a realizable Markov chain (i.e. since the unconstrained minimum cannot be greater than any constrained minimum, if the inequality holds for the unconstrained minimum, it must hold for all network structures).
| (53) |
Note that the ratio in Eq. 53 is a Rayleigh quotient as a function of the vector (L, P)T and thus has known minimum solution (which we derive here for clarity) [Strang, 2003]. Eq. 53 gives rise to a Lagrangian minimization as
| (54) |
with Lagrange multiplier φ. Differentiating with respect to L and P, gives expressions for these variables in terms of φ as
| (55) |
and
| (56) |
Substituting these expressions back into Eq. 53 establishes the proof of the theorem:
| (57) |
A.1.4 Establishing Theorem 2
In order to prove that an irreversible linear chain with the same forward transition rate between all adjacent pairs of states is the unique topology which saturates the bound on the of the hitting time tij given by Thm. 1, we follow a similar inductive approach as in Sec. A.1.3. To derive the inequality expression for the given by in Eq. 52, three successive inequality steps were employed. For Eq. 52 to be an equality—a necessary condition for the bound in Thm. 1 to also be an equality—each of those steps must be lossless. If the steps are lossless only for the linear chain architecture, then the theorem is proved.
Consider the second inequality step (the inductive step) in Sec. A.1.3 which results in Eq. 49. Recall that the hitting times tkj represent subnetworks of size N − 1 starting in some set of states
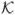 where every k ∈
is reachable by a single transition from state i. For Eq. 49 to be an equality, the
must be equal to
for all k ∈
. By assuming the inductive hypothesis that, for networks of size N −1, constant-rate linear chains are the only topologies which saturate the bound, then, for Eq. 49 to be an equality, all the states in set
must be start states of linear chains of length N − 1. This is clearly possible only if the set
consists of a single state k.
where every k ∈
is reachable by a single transition from state i. For Eq. 49 to be an equality, the
must be equal to
for all k ∈
. By assuming the inductive hypothesis that, for networks of size N −1, constant-rate linear chains are the only topologies which saturate the bound, then, for Eq. 49 to be an equality, all the states in set
must be start states of linear chains of length N − 1. This is clearly possible only if the set
consists of a single state k.
This constraint, that there is a single state k reachable by direct transition from state i and that this state is the start state of a constant-rate linear chain of length N − 1, forces the other two inequality steps in Sec. A.1.3 (Eqs. 48 and 50) to also be equalities. The mean number of loops 〈R〉 is zero since no loops are possible (i.e. after transitioning from state i to k the system follows an irreversible linear path to j which never returns to i), and so the first term of Eq. 45 is zero. Furthermore, the variance of 〈tkj〉 is zero since there is only one k ∈
, and so the first term of Eq. 47 is also zero. Thus the substitutions comprising the first inequality step (Eq. 48) are lossless. Similarly, since there is only one k ∈
, the second moment of 〈tkj〉 equals the square of its mean, which makes the substitution resulting in the final inequality (Eq. 50) also lossless.
Therefore, if and only if the network topology is such that state k is the only state reachable from state i and state k is the start state of a constant-rate linear chain of length N −1, then the following holds:
| (58) |
We can simplify this expression by noting (1) that R = 0 and so 〈ti+l〉 = 〈wi〉 = 1/λki where λki is the transition rate from state i to state k, (2) that there is only one k ∈
and so 〈tpath〉 = 〈tkj〉, and (3) that tkj represents a constant-rate linear chain of length N − 1 and so its mean hitting time will be the number of transitions divided by the constant transition rate (i.e.
for constant rate λ):
| (59) |
As in Sec. A.1.3, to determine the relative values of λki and λ that minimize the , we can define the following Lagrangian:
| (60) |
Differentiating by each variable and substituting out the Lagrange multiplier φ establishes the theorem:
| (61) |
| (62) |
All transition rates are equal and so the uniqueness proof is complete. An N-state Markov chain saturates the bound given in Thm. 1 if and only if it is an irreversible linear chain with the same forward transition rate between all pairs of adjacent states. Furthermore, the bound is only saturated for the hitting time from the first to the last state in the chain (Fig. 1b).
A.2 The moments of tij
For clarity, we give a derivation of the explicit formula for the nth moment of the hitting time tij from state i to j for the Markov chain given by the transition rate matrix Aj. The subscript j in Aj is used to denote the fact that the jth column of the matrix is a vector of all zeros (i.e. j is a collecting state). For the purposes of this derivation, we assume that the underlying transition rate matrix A, without the connections away from j removed, represents a Markov chain for which all states are reachable from all other states in a finite amount of time. In other words, A is assumed to be ergodic (although the resulting formulae still hold if this assumption is relaxed). Substituting t for tij to simplify notation and using the expression for the probability distribution of tij given in Eq. 6, we have
| (63) |
where we have used the fact that a matrix commutes with the exponentiation of itself.
In order to evaluate this integral, it is convenient to construct an identity matrix defined in terms of Aj and a pseudoinverse of Aj, PA. If the eigenvalue decomposition of Aj is RDL (with L = R−1), then PA ≡ RPDL where PD is a diagonal matrix composed of the inverse eigenvalues of Aj except for the jth entry which is left at zero (the jth eigenvalue of Aj is zero). In matrix notation, PD is given as
| (64) |
which gives PA as
| (65) |
where, in the final step, we have used the fact that the jth column of R (the jth right eigenvector of Aj) is ej (since the jth column of Aj is 0) and the fact that the jth row of L (the jth left eigenvector) is 1T ≡ (1, …, 1) (since the columns of Aj all sum to 0). Thus, Rej = ej and .9
To construct an appropriate identity matrix, we calculate the product of Aj and its pseudoinverse as
| (66) |
where we have used the fact that DPD is an identity matrix except for a zero in the jth diagonal entry (due to the non-inverted zero eigenvalue). Furthermore, it is trivial to show that for any positive integer n (since Ajej = 0), and so we have derived the following expression for the identity matrix:
| (67) |
Finally, this allows us to restate the transition rate matrix as
| (68) |
where again we have used the fact that ej is the eigenvector of Aj associated with the zero eigenvalue.
Substituting Eq. 68 and the eigenvalue decomposition of Aj into Eq. 63 gives
| (69) |
The off-diagonal elements of the integral portion of Eq. 69 are zero as is the jth diagonal element (i.e. the zero eigenvalue of Aj associated with eigenvector ej). The kth diagonal element of the integral for k ≠ j is given by
| (70) |
where ηk is the kth eigenvalue. These integrals are analytically tractable:
| (71) |
where we have used the fact that all of the eigenvalues of Aj except the jth are strictly negative, which is a result of the following argument. Since Aj is a properly structured transition rate matrix for a continuous time Markov chain, there exists a finite, positive dt such that I + Ajdt is a properly structured transition probability matrix for a discrete time Markov chain. We can rewrite this probability matrix as R (I + Ddt) L and use the Perron-Frobenius theorem, which states that the eigenvalues of transition probability matrices (i.e. the entries of I + Ddt) are all less than or equal to one [Poole, 2006]. Furthermore, since we assumed that the underlying Markov chain A is ergodic, the Perron-Frobenius theorem asserts that exactly one of the eigenvalues is equal to one. Thus, it is clear that one of the entries of D is equal to zero and the rest are negative.
Substituting the result from Eq. 71 back into Eq. 69, gives the final expression for the moments of the hitting time:
| (72) |
As an alternative to the preceding somewhat cumbersome algebra, it is also possible to use an intuitive argument to find the analytic expression for the first moment (mean) of the hitting time [Norris, 2004]. With the expression for the first moment known, the higher order moments can then be derived using Siegert’s recursion [Siegert, 1951, Karlin and Taylor, 1981].
A.3 The gradients of the mean, variance, and energy cost functions
From Sec. A.2, the expressions for the mean and variance of the hitting time t1N are given as
| (73) |
and
| (74) |
The definition of PA (Eq. 65) and the expression for the derivative of an inverse matrix (∂M−1 = −M−1 (∂M) M−1) give the following:
| (75) |
where we have defined ∂A as the derivative of AN with respect to the variable of interest, and have used the fact that eN and 1T are the right and left eigenvectors of AN associated with the zero eigenvalue and thus that both (∂A) eN and 1T∂A are zero. Therefore, the gradients of the mean and variance with respect to the optimization parameters θij (where θij ≡ − ln λij for transition rate λij) can be shown to be
| (76) |
and
| (77) |
where the element in the kth row and lth column of the differential matrix ∂Aij is given by
| (78) |
Energy cost function I (Sec. 4.2), given as
| (79) |
has a gradient of
| (80) |
while energy cost function II (Sec. 4.3), given as
| (81) |
has a gradient of
| (82) |
A.4 Derivation of pure diffusion solution
At Etot = 0 under the energy function given in Eq. 13, it is possible to analytically solve for the transition rates which minimize the CV2 of the hitting time. First, note that all pairs of reciprocal rates must be equal (since the energy is zero), and furthermore, that all pairs of rates between nonadjacent states are equal to zero. Thus, to simplify notation, we shall only consider the rates λi for i ∈ {1, …, M} where λi ≡ λi,i+1 = λi+1,i and M ≡ N − 1. This yields the following transition rate matrix:
| (83) |
From our general definitions of the moments of t1N for abitrary Markov chains (Eq. 72), we have, respectively,
| (84) |
and
| (85) |
where PA ≡ (AN + eN 1T)−1 − eN 1T (Eq. 65) as before. For the specific tridiagonal matrix AN given in Eq. 83, PA can be shown to be
| (86) |
from which, with a bit more manipulation, we can give expressions for the mean and variance as follows:
| (87) |
and
| (88) |
where we have defined the vectors x and z as and
zi ≡ i respectively, and the matrix Z as Zij ≡ min (i, j)2.
Finding x, and thus the rates λi, that minimizes the CV2 of t1N is equivalent to employing Lagrangian optimization to minimize the variance while holding the mean constant at 〈t1N 〉. This gives the following simple linear algebra problem:
| (89) |
where xmin is guaranteed to be the unique optimum since Z is positive definite (Sec. A.4.1) and the constraint is linear. Thus the solution can be found by setting the gradient to zero:
| (90) |
Note that we did not enforce that the elements of x (and thus the rates λi) be positive under this optimization. However, if the solution xmin has all positive entries, as will be shown, then this additional constraint can be ignored.
Some algebra reveals that Z−1 is a symmetric tridiagonal matrix with diagonal elements
| (91) |
and subdiagonal elements
| (92) |
Substituting this inverse into the expression for the minimum above (Eq. 90) yields, for i < M,
| (93) |
and, for i = M,
| (94) |
For positive values of α—corresponding to positive values of 〈t1N 〉—all of the elements of xmin are positive and thus this solution is reasonable. Therefore, the following rates minimize the processing time variability for a zero energy, purely diffusive system:
| (95) |
To determine α from 〈t1N 〉, we substitute the solution (Eq. 95) into the expression for the mean given by Eq. 87:
| (96) |
where we have defined and have taken advantage of the following series identity (which can easily be shown by induction):
| (97) |
Our introduced function, ξ(M), can be shown to have the following closed-form solution [Abramowitz and Stegun, 1964]:
| (98) |
where Ψ(x) is the digamma function defined as the derivative of the logarithm of the gamma function (i.e. ) and γ is the Euler–Mascheroni constant.
From Eq. 96 we see that
| (99) |
which can be substituted back into Eq. 95 to give the optimal rates in terms of 〈t1N 〉 rather than α:
| (100) |
It is now possible to find an expression for the CV2 in terms of M and 〈t1N 〉. From the derivation of Eq. 90, we have
| (101) |
which can be substituted into Eq. 88 to get
| (102) |
Finally, using the expressions for the mean and for α (Eqs. 87 and 99), we obtain the following result:
| (103) |
where we revert to a notation using the number of states N.
A.4.1 The matrix Zij ≡ min(i, j)2 is positive definite
The M × M matrix Z introduced in Sec. A.4, where Zij ≡ min (i, j)2, is positive definite. First, note the following identity:
| (104) |
which can be easily proven inductively. Now let us define a set of vectors for i = 1, …, M where vector consists of i−1 zeros followed by M −i+1 elements all having the value . For example,
| (105) |
| (106) |
and
| (107) |
From the identity given in Eq. 104, Z can be rewritten as the following sum of outer products:
| (108) |
Now consider xTZx for arbitrary nonzero x. We have
| (109) |
which must be nonnegative since it is a sum of squares. Furthermore, the vectors are linearly independent and, since there are M of them, they form a basis. Since the projection of an arbitrary nonzero vector on at least one basis vector must be nonzero, one of the terms in the sum in Eq. 109 must be positive. Thus we have
| (110) |
and so Z is positive definite.
Footnotes
As we show below, in the case that the state-specific signal accumulation rates are all unity, then the generated signal is the system processing time itself.
States 1 and N are arbitrary, albeit convenient, choices. The labels of the states can always be permuted without changing the underlying network topology.
Whether N truly is collecting or not does not affect the hitting time t1N since this random variable is independent of the behavior of the system after arrival at state N. Thus setting the Nth column of A to zero does not result in a loss of generality.
In animal and human behavioral data, the variance of a measured interval of time is proportional to the square of its mean (Weber’s Law). As discussed in Sec. 2.2, all timing mechanisms which can be modeled as Markov chains will have a constant CV2 (and will thus exhibit Weber’s Law), but our proof shows that a constant-rate linear mechanism is optimally reliable.
Note that an arbitrary Markov chain is not conservative (i.e. the path integral of the energy depends on the path), so, although for a pair of states i and j each state can be thought of as having an associated energy, these associated energies may change when i and j are paired with other states in the chain.
It is not clear why the first rate pair has its own unique behavior. Attempts to analytically solve for the rate values at finite, nonzero energies were unsuccessful, but these numerical results were robust. Similarly, we were unable to determine expressions for the merge-point energies.
Note that many more states may be in the diffusive tail than in the irreversible linear chain portion of the solution, but as long as ξ(Mr) ≪ Mi these states fail to remarkably change the reliability of the system.
Note that hitting time variables (e.g. tij) refer to specific start and end states (i and j, in this case), while tloop and tpath refer to specific end states (i and j respectively), but not specific start states.
Note that PA defined in this manner does not meet all of the conditions of the unique Moore-Penrose pseudoinverse [Penrose and Todd, 1955]. Though the equalities AjPAAj = Aj and PAAjPA = PA hold (as long as Aj is an appropriately structured transition rate matrix with j as the unique collecting state), the products PAAj and AjPA are not symmetric matrices (as they are for the Moore-Penrose pseudoinverse).
References
- Abramowitz M, Stegun I, editors. National Bureau of Standards Applied Mathematics Series. U.S. Government Printing Office; 1964. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables. [Google Scholar]
- Brown E, Barbieri R, Ventura V, Kass R, Frank L. The time-rescaling theorem and its application to neural spike train data analysis. Neural Computation. 2002;14:325–346. doi: 10.1162/08997660252741149. [DOI] [PubMed] [Google Scholar]
- Buhusi C, Meck W. Functional and neural mechanisms of interval timing. Nature Reviews Neuroscience. 2005;6:755–765. doi: 10.1038/nrn1764. [DOI] [PubMed] [Google Scholar]
- Doan T, Mendez A, Detwiler P, Chen J, Rieke F. Multiple phosphorylation sites confer reproducibility of the rod’s single-photon responses. Science. 2006;313:530–533. doi: 10.1126/science.1126612. [DOI] [PubMed] [Google Scholar]
- Edmonds B, Gibb A, Colquhoun D. Mechanisms of activation of glutamate receptors and the time course of excitatory synaptic currents. Annual Review of Physiology. 1995a;57:495–519. doi: 10.1146/annurev.ph.57.030195.002431. [DOI] [PubMed] [Google Scholar]
- Edmonds B, Gibb A, Colquhoun D. Mechanisms of activation of muscle nicotinic acetylcholine receptors and the time course of endplate currents. Annual Review of Physiology. 1995b;57:469–493. doi: 10.1146/annurev.ph.57.030195.002345. [DOI] [PubMed] [Google Scholar]
- Gibbon J. Scalar expectancy theory and Weber’s law in animal timing. Psychological Review. 1977;84:279–325. [Google Scholar]
- Gibson S, Parkes J, Liebman P. Phosphorylation modulates the affinity of light-activated rhodopsin for G protein and arrestin. Biochemistry. 2000;39:5738–5749. doi: 10.1021/bi991857f. [DOI] [PubMed] [Google Scholar]
- Hamer R, Nicholas S, Tranchina D, Liebman P, Lamb T. Multiple steps of phosphorylation of activated rhodopsin can account for the reproducibility of vertebrate rod single-photon responses. Journal of General Physiology. 2003;122(4):419–444. doi: 10.1085/jgp.200308832. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kandel E, Schwartz J, Jessell T, editors. Principles of Neural Science. 4 McGraw-Hill; New York: 2000. [Google Scholar]
- Karlin S, Taylor H. A First Course in Stochastic Processes. Academic Press; New York: 1981. [Google Scholar]
- Locasale JW, Chakraborty AK. Regulation of signal duration and the statistical dynamics of kinase activation by scaffold proteins. PLoS Comput Biol. 2008;4(6):e1000099. doi: 10.1371/journal.pcbi.1000099. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miller P, Wang X. Stability of discrete memory states to stochastic fluctuations in neuronal systems. Chaos. 2006;16:026109. doi: 10.1063/1.2208923. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Norris J. Markov Chains. Cambridge University Press; Cambridge, UK: 2004. [Google Scholar]
- Olivier E, Davare M, Andres M, Fadiga L. Precision grasping in humans: from motor control to cognition. Current Opinion in Neurobiology. 2007;17:644–648. doi: 10.1016/j.conb.2008.01.008. [DOI] [PubMed] [Google Scholar]
- Penrose R, Todd J. A generalized inverse for matrices. Mathematical Proceedings of the Cambridge Philosophical Society. 1955;51:406–413. [Google Scholar]
- Poole D. Linear algebra: A modern introduction. 2 Thomson Brooks/Cole; Belmont, CA: 2006. [Google Scholar]
- Reppert S, Weaver D. Coordination of circadian timing in mammals. Nature. 2002;418:935–941. doi: 10.1038/nature00965. [DOI] [PubMed] [Google Scholar]
- Rieke F, Baylor D. Origin of reproducibility in the responses of retinal rods to single photons. Biophys J. 1998;75:1836–1857. doi: 10.1016/S0006-3495(98)77625-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Siegert A. On the first passage time probability problem. Physical Review. 1951;81:617–623. [Google Scholar]
- Strang G. Introduction to linear algebra. 3 Wellesley-Cambridge; Wellesley, MA: 2003. [Google Scholar]
- Tibshirani R. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society, Series B. 1996;58:267–288. [Google Scholar]