

Abstract
There is growing evidence that personality traits are affected by many genes, all of which have very small effects. As an alternative to the largely-unsuccessful search for individual polymorphisms associated with personality traits, we identified large sets of potentially related single nucleotide polymorphisms (SNPs) and summed them to form molecular personality scales (MPSs) with from 4 to 2,497 SNPs. Scales were derived from two-thirds of a large (N = 3,972) sample of individuals from Sardinia who completed the Revised NEO Personality Inventory and were assessed in a genome-wide association scan. When MPSs were correlated with the phenotype in the remaining third of the sample, very small but significant associations were found for four of the five personality factors when the longest scales were examined. These data suggest that MPSs for Neuroticism, Openness to Experience, Agreeableness, and Conscientiousness (but not Extraversion) contain genetic information that can be refined in future studies, and the procedures described here should be applicable to other quantitative traits.
Keywords: Genome-wide association study, personality assessment, founder effect, Five-Factor Model
The Five-Factor Model (FFM; Digman, 1990) is a classification of personality traits into five broad dimensions or factors, usually called Neuroticism, Extraversion, Openness to Experience, Agreeableness, and Conscientiousness. The FFM structure subsumes most of the traits in natural language and in the systems developed by psychologists, and it appears to be universal, having been replicated in over 50 cultures (McCrae et al., 2005). A likely reason for the universality of the FFM is that the structure has its roots in genetic factors shared by all human beings (Yamagata et al., 2006). This article describes a new approach to uncovering the molecular genetic basis of personality traits; although the results are only a first step in that direction, the method and its rationale may be of value in moving forward in this challenging area.
The heritability of personality traits is well established from behavior genetic studies (Bouchard & Loehlin, 2001), and since 1996 (Benjamin et al., 1996; Lesch et al., 1996) there has been intense interest in discovering the relevant genes. The initial approach was to identify candidate genes known to be involved in neurotransmission and relate allele differences on these genes to assessed trait levels. Some of these findings have been widely publicized, and only readers familiar with the whole literature on the molecular genetics of personality—which is replete with null findings (e.g., Vandenbergh, Zonderman, Wang, Uhl, & Costa, 1997) —are aware that little, if anything, has been firmly established.
For example, one of most prominent candidate genes is the serotonin transporter (5-HTT), which re-uptakes serotonin from synapses and is the site of action of selective serotonin re-uptake inhibitors (SSRI antidepressants). Lesch and colleagues (1996) reported that a polymorphism in the promoter region of 5-HTT (5-HTTLPR) was associated with Neuroticism scores. They estimated that the polymorphism accounted for 3% to 4% of total variance and 7% to 9% of the heritable variance of anxiety-related personality traits in their sample of 505 individuals. Such relatively large effects should be easily replicated, yet several studies have failed find an association of 5-HTTLPR with Neuroticism-related traits. Meta-analyses of up to 60 samples (Munafò, Freimer et al., 2009; Schinka, Busch, & Robichaux-Keene, 2004; Sen, Burmeister, & Ghosh, 2004), and three large studies that included roughly 4,000 participants each (Munafò, Freimer et al., 2009; Terracciano et al., 2009; Willis-Owen et al., 2005), indicate that there is in fact no association between the 5-HTTLPR and Neuroticism related traits.
Unfortunately, similar failures to replicate have been observed for other candidate genes. The Val66Met variant of the brain-derived neurotrophic factor (BDNF), for example, appeared to be related to Neuroticism in an earlier report based on 441 subjects (Sen et al., 2003), but a recent meta-analysis (N = 15,251) found that Val66Met was unrelated to Neuroticism (Terracciano et al., 2010). Genes (such as APO-E4) and known to predispose individuals to illnesses (such as Alzheimer’s disease) that alter personality traits (Siegler et al., 1991), but we are not aware of any gene or SNP that is consistently related to a personality trait in healthy individuals across a range of samples. At present, the claim that personality traits have a genetic basis rests chiefly on behavior genetic studies.
This failure to find consistent effects might be due to several factors, including differences in the genetic bases of traits in different populations or the small size of the effects of any single gene. But it might also be due to the choice of the wrong candidates: There are thought to be about 25,000 genes in the human genome (Venter et al., 2001), and researchers are only beginning to understand how they function. Hypotheses tested so far may understandably have been incorrect.
Newer technology permits a different strategy: the genome-wide association (GWA) study. In this approach, a large number of single nucleotide polymorphisms (SNPs) densely distributed across the entire genome are used as markers. Each SNP is defined by variation in a single DNA base (A, C, T, or G) that occurs with a frequency generally higher than 1% in the population. SNPs that are located close together on the chromosome tend to co-segregate, forming what are called haplotype blocks, in which the SNPs are highly correlated (i.e., show linkage disequilibrium). Association studies take advantage of the high degree of linkage disequilibrium by testing only one or a few SNPs (tag SNPs) that are representative of the neighboring variants. By the same principle, a SNP that shows an association with the phenotype is not necessarily the mutation influencing the trait, but is more likely a neighboring marker in high linkage disequilibrium with the responsible gene. With the GWA approach, association analyses are performed simultaneously on hundreds of thousands of SNPs in search of those allelic variants which are related to high scores on a given trait. This approach does not require any hypotheses about which genes are related to the trait; it is a strictly empirical exploration in which the mechanisms of gene action are left to be inferred from future studies.
It is now possible to assess 500,000 or more SNPs for each individual, covering about 80% of the common variation via linkage disequilibrium (International HapMap Consortium, 2007). Although this increases the likelihood that the relevant genes will be assessed, it also means that the number of false positive associations with the phenotype will increase dramatically. GWAs are efficient and successful methods when some genes have relatively large effects that stand out from the distribution of random effects, as is the case with some diseases (Uda et al., 2008; Zhang et al., 2009). This is shown in Figure 1A, which illustrates the hypothetical distribution of observed associations of SNPs with the phenotype for a full GWA study.
Figure 1.
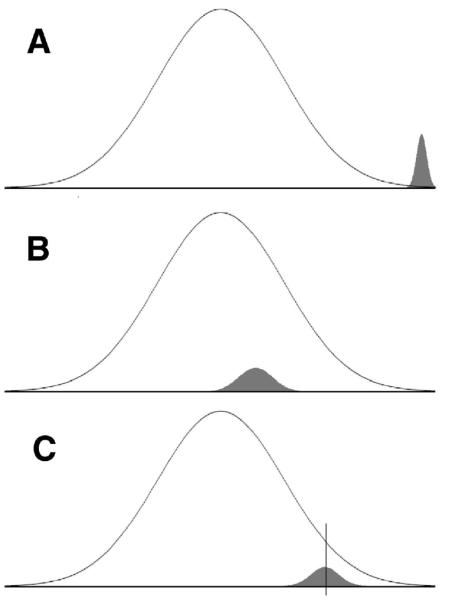
Schematic representation of three possible distributions of 499,000 random (open curve) and 1,000 real (shaded curve) associations between SNPs and a phenotype. The horizontal axis represents the magnitude of correlations between SNPs and the phenotype; the vertical axis represents frequency. (A) Scenario with large single SNP effects. (B) Scenario with very small effects. (C) Scenario with small effects; the vertical line represents a cutoff separating potentially real from random effects. (Curve graphic courtesy D. Elrod.)
But use of this method in the search for genes related to psychiatric disorders or psychological traits has yet to produce reliable results: Genes identified in one study have not been replicated in others (e.g., Plomin et al., 2002; Shifman et al., 2008; Terracciano et al., 2008). The most plausible explanation for this is that quantitative traits like intelligence, height, or Neuroticism result from the operation of many genes, each of which has a small effect. If they are very small, such effects would be almost impossible to separate from chance fluctuations, as illustrated Figure 1B.
In principle, this difficulty can be overcome by the use of extraordinarily large samples (see Wray, Goddard, & Visscher, 2007), because the effect of increasing the number of subjects is to reduce the standard error of observed correlations: The bell curve of random associations in Figure 1B is progressively squeezed until the true associations stand apart from error. This approach has been successful in identifying a few of the many genes associated with height (Sanna et al., 2008) and weight (Frayling et al., 2007), but requires the assessment of tens of thousands of individuals. Figure 1C is perhaps a more realistic representation of what may be obtained from samples of a few thousand cases.
Bonferroni correction is one way to reduce Type I errors, but at great cost. With 500,000 SNPs tested, a p level of 1 × 10−7 is required, and only very strong effects are likely to be considered significant. If quantitative traits are the result of many uniformly weak effects, Bonferroni correction is untenable. An alternative correction procedure, controlling the false discovery rate (Benjamini & Hochberg, 1995), is still likely to be too stringent for dealing with the vast numbers of tests conducted in a typical GWA.
The most common strategy for dealing with the problem of false positives is to choose a small number of SNPs with the largest associations with the phenotype and determine if they are significantly associated with the phenotype in a second, independent replication sample. In essence, this is a version of the candidate gene approach, in which the candidate SNPs are selected empirically rather than theoretically. Although it is undoubtedly true that real, replicable effects are more likely to be found among strong associations than among weak associations, it is also possible that many or most of the strongest observed effects are due to chance.
In this article we describe a strategy for identifying sets of SNPs that are collectively associated with personality traits, creating molecular personality scales (MPSs) from these sets, and providing tentative evidence of the scales’ validity. The idea of creating a scale from SNPs was used by Baum and colleagues (2007), who created an index of risk for bipolar disorder by summing 10 SNPs that had replicated associations across two samples. They showed that risk increased significantly with scores on this index (cf. Willer et al., 2009). Similarly, Butcher and colleagues (2005) created SNP sets by summing a small number of genes they had found to be related to intelligence, and Lango and colleagues (2008) assessed the combined risk for diabetes conferred by 18 SNPs. These studies, however, used small numbers of replicated SNPs, and the purpose of the composite scales was to estimate the cumulative impact of these SNPs on the phenotype. In the present study we create scales based on large numbers of SNPs and offer evidence of cross-validation of the scales as a whole; our MPSs are intended merely to provide statistical evidence that a collection of SNPs includes genetic information relevant to the phenotype. This represents a step back from the identification of individual SNPs or genes, but it is a strategic retreat necessitated by the difficulty of findings specific SNPs reliably related to personality traits. A similar approach was used successfully by the International Schizophrenia Consortium (Purcell et al., 2009) in a case-control study. Our analysis appears to be the first application of this approach to the study of personality traits.
The Nature and Potential Use of Molecular Scales
Before turning to the mechanics of our approach, it is useful to consider the nature and utility of the molecular scales we propose. Our approach identifies a large number of SNPs that are associated with the phenotype in derivation samples and sums them to estimate the additive genetic basis of the trait in each individual. This is a strictly empirical strategy, similar to that used to select items for scales of the Minnesota Multiphasic Personality Inventory (MMPI; Hathaway & McKinley, 1943) and the California Psychological Inventory (Gough, 1987). In principle, researchers need know nothing about why a given item (or SNP) is associated with the trait; they only require data showing that it is. Empirical scales are conceptually primitive, although they can be pragmatically useful.
How should molecular scales be evaluated? Internal consistency is not relevant, because the different genes marked by the SNPs in an MPS may be independent (i.e., uncorrelated) contributors to the phenotype. Further, the interpretation of internal consistency is complicated by the redundancy (linkage disequilibrium) among SNPs.1 Similarly, retest reliability is not an issue: DNA does not change, and the reproducibility of MPS scores is limited only by the technical accuracy of the assays, which is extremely high.
However, both convergent and discriminant validity are relevant to the evaluation of MPSs. Significant correlations with the phenotype in the hypothesized direction in an independent validation sample provide some degree of evidence for convergent validity, although past experience with the molecular genetics of personality suggests that such correlations are likely to be quite modest in magnitude. MPSs should also show discriminant validity: They should be unrelated, or more weakly related, to phenotypes other than the one for which they were developed.
It remains to be seen whether the approach presented here leads to the development of effective MPSs: sets of SNPs which in combination are strongly associated with the phenotype. But if so—and if they proved generalizable beyond the population in which they were developed—how might MPSs be used? First, they would provide objective measures of traits that would avoid many of the methodological problems of self-reports and informant ratings: MPS scores are not subject to self-presentational biases or halo effects.2 Second, an analysis of the genes associated with the chosen SNPs should give clues to the biological mechanisms underlying personality traits that could be useful in designing interventions (e.g., drugs to decrease Neuroticism or increase Conscientiousness).
Personality traits are not completely heritable, so no genetic analysis could ever provide a perfect measure of personality. However, successful MPSs—consisting of all and only SNPs truly associated with the trait—would raise ethical problems, because reasonably accurate personality assessment would require nothing more than a sample of DNA, which might easily be obtained without consent. Could an accused criminal’s genetic propensity to low Agreeableness be used as evidence against him or her? Perhaps fortunately, we are at present far from having to deal with such issues: For the foreseeable future, MPSs are likely to be only very weakly related to the phenotype.
Details of the Approach: Within-Sample Replication
Although small real effects cannot be distinguished from random effects on the basis of effect size, they may be detectable through an internal replication strategy. If the data summarized in Figure 1C were obtained from a second, independent sample, the distribution of results would be similar, but by chance a different set of SNPs would appear to the right of the vertical cutoff line. A comparison of the two independent distributions would help identify real SNPs. If the cutoff represents, for example, the top 4% of the distribution of 499,000 random effects but the top 50% of 1,000 real effects, then in either sample alone, one would expect to find .04 × 499,000 = 19, 960 false positive (“random”) SNPs and 500 true positive (“real”) SNPs above the cutoff; only 500/19,960 = 2.5% of the identified SNPs would be real. However, if one examined the set of SNPs above the cutoff in both samples, one would expect that .04 × .04 = .0016 = 0.16% of the 499,000 random SNPs—that is, 798 SNPs—would be found, whereas .5 × .5 = .25 = 25% of the 1,000 real SNPs—250 SNPs—would be identified. This replication approach thus yields a set of 1,048 replicated SNPs, of which 23.9% represent true genetic effects. Although the set of replicated SNPs is still chiefly error, and although it discards half the true positive SNPs in either sample, it is ten times richer in real genetic information than the sets from the two individual samples. If Figure 1C is realistic, identifying real SNPs will require a consideration of many SNPs beyond those with the largest effects.
Of course, the appropriate cutoff for identifying the optimal proportion of real effects is not known, so an exploratory approach must be used. At each of a series of cutoffs, the number of effects replicated across two samples can be examined and compared by chi-square to the number expected by chance. (This strategy of evaluating sets of SNPs resembles that of Moskvina and colleagues, 2009, who compared statistically the number of SNPs associated with a phenotype—schizophrenia or bipolar disorder—that were within genes versus outside genes.) Although Figure 1 assumes that all the real effects are positive, the coding of SNPs is arbitrary, so half the real effects are likely to be negative, and in practice SNPs must be considered beyond the cutoff at both tails of the distribution.
Creating and Validating Scales
The sets of replicated SNPs associated with each cutoff can be used to create MPSs. For each individual, each SNP is treated as an item, scored in terms of the number of coded alleles it has. For example, if the G allele for a certain SNP is associated with the trait, individuals receive a score of “2” if both of their alleles for the SNP are Gs; a “1” if exactly one is a G; and a “0” if neither is a G. If the SNP is positively related to the trait, the item is positively keyed; if it is negatively related, the item is reverse keyed. An MPS can be created at each of several cutoff levels, although each scale will include all the items from the shorter scales. These scales will, of course, be correlated with the phenotypic trait in the samples in which they were derived, if only by capitalizing upon chance. To validate the scales it is necessary to correlate the MPSs with the trait in a third, independent sample. These cross-validations provide a basis for selecting the optimal cutoff. The most direct way to implement this strategy is by obtaining genetic data from a large sample and dividing it into three subsamples, two for internal replication and the third for validation.
The logic of validating MPSs is crucially different from that of replicating individual SNPs used in candidate gene approaches. Even when a SNP is truly related to the phenotype in a population, in any given sample its association will also be influenced by chance. SNPs that are truly associated with the trait and strongly related to the phenotype in one sample may be weakly, or even inversely, related in another sample, as may have happened in a recent study of bipolar disorder (Kerner et al., 2009). It is only the average effect across many items, indexed by the full scale score (MPS), that can be expected to recur across samples. Thus, replicability is assessed by the significance of the correlation of the MPS with the phenotype, not by the associations of individual SNP items. In the present study, we will validate MPSs by correlating them with the phenotype in an independent replication sample. Cross-validated scales should contain true genetic information. Further, because only a small number of hypothesized convergent correlations are examined (25, in our case), corrections for multiple statistical tests are not needed.
The association analyses used to create MPSs in this study are limited to additive genetic effects. Dominance effects, in which one copy of a dominant allele is not distinguished from two copies, are harder to detect in this design, and epistatic effects, which depend on the joint contributions of two or more genes, cannot be detected at all. Further, because only linear associations are considered, this analysis also overlooks any heterozygous effects (in which the combination of two different alleles, say A and T, is more strongly associated with the trait than two copies of either, i.e., two As or two Ts). The MPSs calculated here reflect only the additive variance that is measured by narrow heritability. In the Sardinia sample, estimates of additive heritability ranged from .20 for Conscientiousness to .33 for Openness to Experience (Pilia et al., 2006). Thus, the upper limit of correlations between MPSs and self-reported traits range from .201/2 = .45 to .331/2 = .57.
At a more basic level, it must be recalled that this study is focused only on the presence or absence of particular sets of SNPs. It cannot address important issues such as Gene × Environment (G × E) interactions, or gene expression—which genes are actually functioning in an individual at any given point in the lifespan. Nevertheless, the identification of genetic material that distinguishes between high and low scorers on various personality traits would appear to be the first task in the complex enterprise of understanding the genetics of personality.
Method
Sample
DNA and self-reports of personality traits were obtained from individuals living in the Ogliastra province of Sardinia (Costa et al., 2007; Pilia et al., 2006; Terracciano et al., 2009). This is a founder population, in which most individuals are descended from a small group of common ancestors with minimal intermarriage with other groups, which leads to greater genetic homogeneity in such groups. (There is also substantial cultural homogeneity in this sample that may increase the relative importance of genetic influences.) Founder populations are desirable for genetic studies because they reduce the possibility of a kind of confound know as population stratification. If a sample contains two or more relatively distinct ethnic groups, associations between genes and traits can appear as an artifact of their association with the third variable of ethnicity. For example, if a sample includes both African- and Chinese Americans, genes that are more frequent among individuals of Chinese ancestry will be (spuriously) associated with behaviors more characteristic of Chinese Americans, such as the ability to use chopsticks (Hamer & Sirota, 2000). This association would not appear if the sample were more homogeneous and contained only Chinese Americans or only African Americans. In general, population homogeneity reduces such potential confounds.
There are two potential drawbacks to the use of a founder population: Restriction of range in the phenotype, and lack of generalizability of findings to other populations. In Sardinia there is some evidence of phenotypic homogeneity, seen in reduced variance of personality traits (Costa et al., 2007). However, this effect is small; in most respects, Sardianians resemble mainland Italians in the mean and range of their personality traits. With regard to generalizability, previous studies have replicated gene associations identified in Sardinia in other, diverse populations (Sanna et al., 2008; Tanaka et al., 2009; Willer et al., 2009).
A total of 6,148 participants enrolled in the SardiNIA project, of whom 5,669 had valid personality data. Detailed pedigrees were obtained to document kinship relations between all participants. A 10K genome scan was performed on 3,329 participants; however, most of the genetic information was obtained from a full 500K genome scan performed for an overlapping group of 1,412 participants. The final sample size, with complete genomic and personality data, consisted of 3,972 individuals (57% female), ranging in age from 14 to 93 years. These included 1,277 individuals who had had the full 500K scan. About 7% of the sample has a college degree, whereas 23% had a primary school education or less.
Genotyping and Selection of SNPs
The Affymetrix 10,000 SNP Mapping Array was used to genotype 3,329 participants, and the Affymetrix 500,000 SNP Mapping Array was used to genotype 1,412 participants selected to represent the largest families in the sample.3 The remaining 490,000 SNPs were imputed based on haplotype sharing of family members (Burdick, Chen, Abecasis, & Cheung 2006).
The genotyping approach used in the SardiNIA study takes advantage of the large number of multigenerational families in this sample. Related individuals, such as siblings and parents and their offspring, share long stretches of chromosome. If these shared stretches are genotyped with a high density array in only a few individuals, the information from these individuals can be propagated to their relatives (Chen & Abecasis 2007; Li, Willer, Sanna, & Abecasis, 2009). This within-family imputation method, based on “identical-by-descent” sharing and implemented by the MERLIN program (Chen & Abecasis, 2007), has allowed researchers to conduct full GWA scans in the SardiNIA sample that have been successfully combined with other GWA studies of physical and psychological traits, such as height and cigarette smoking (e.g., Sanna et al., 2008; Liu et al., 2010).
The organization of SNPs into haplotypes in the entire human population has been codified in a project called the HapMap (International HapMap Consortium, 2007). Using this as a guide, SNPs that are not directly assessed can be imputed with a high degree of accuracy (Marchini, Howie, Myers, McVean, & Donnelly, 2007). This imputation process is a standard part of GWA research (e.g., Li, Willer, Sanna, & Abecasis, 2009; Sanna et al., 2008). After the initial within-family imputation to 500,000 SNPs (Burdick, Chen, Abecasis, & Cheung 2006), data from the HapMap were used to correct and expand these imputations to 2.4 million SNPs (Li & Abecasis, 2006). Markers showing low imputation quality (r2 ≤ 0.3) were discarded from the analysis., leaving a potential pool of 2.2 million autosomal SNPs. Imputations are probabilistic, so that the number of alleles attributed to an individual may be fractional.
Many of the SNPs assessed or imputed are in high linkage disequilibrium, and thus highly redundant. To reduce the number of SNPs to those that provide quasi-independent tests, we performed the analyses on tag SNPs selected to be a representative subset of available SNPs. A convenient set of tag SNPs are those included in the Illumina platform. Of these, 340,105 matched the 2.2 million autosomal SNPs assessed or imputed in Sardinia. By restricting attention to these tag SNPs, we eliminated many of the closely related and thus redundant SNPs. Our results are also potentially replicable in studies using the Illumina platform.
Measures
Personality was assessed by the Italian version of the Revised NEO Personality Inventory (NEO-PI-R; Costa & McCrae, 1992; Terracciano, 2003). The NEO-PI-R is a 240-item inventory that measures 30 specific traits, or facets, six of which are combined to form each of the five 48-item domains scales. Items use a 5-point Likert response format, from strongly disagree to strongly agree, and scales are roughly balanced to control the effects of acquiescence. Evidence on the reliability and validity of the instrument is summarized in the Manual (Costa & McCrae, 1992). For this analysis, we correlated SNPs with continuous domain scores, thus using all available information on the phenotype.
Education was coded from none (1) to college graduate (5).
Analyses
Creating random subsamples by assignment of individuals to three groups would not yield maximally independent subsamples, because members of the same family in this highly related sample could be found in different subsamples. Consequently, all related individuals were grouped into families, and the families randomly assigned to Subsamples One (n = 1,339), Two (n = 1,340) or Three (n = 1,339). In essence, this randomization tests whether results can be generalized across families in Sardinia.
Linear associations (correlations) between SNPs and phenotypes were estimated by methods that make use of family information (Chen & Abecasis, 2007) and control for age, age-squared, and sex. Within Subsamples One and Two, SNPs were ordered in decreasing magnitude of signal strength (effect size) for each of the five factors, without regard to the direction of the association. Within each subsample, we identified sets of SNPs from the top down, that is, beginning with the largest effect size for each personality factor. Our first set (for each of the five factors) consisted of the 850 SNPs with the largest effect size; this is approximately 0.25% of the total of 340,105 SNPs. The second set consisted of the 1,700 SNPs (0.5% of the total) with largest effect sizes (that is, the first set plus the next 850 SNPs in descending order). Additional cutoffs were used to identify cumulative sets of 3,400 (1%); 8,500 (2.5%); 17,000 (5%); 34,000 (10%); 68,000 (20%); and 170,000 SNPs (50%) in each subsample. The two larger sets were used only for preliminary analyses; no attempt was made to create scales from them.4
At each cutoff, we compared the SNPs identified in Subsample One with those in Subsample Two. If the same SNP appeared in both sets, and if it was associated in the same direction with the phenotype, we considered it an internal replication and used it as an item in an MPS. This might, however, occur by chance. For example, the probability that the same SNP would appear in the top 10% of two independent samples purely by chance is .1 × .1 = .01. Thus, at the 10% cutoff level, we would expect to find .01× 340,105 ≈ 3,400 SNPs appear in both sets, and of these, half would be in the same direction. Thus, the expected number of SNPs in a MPS scale at the 10% cutoff level is 1,700. Chi-square tests can be used to determine if the observed number of replications exceeds the expected number. However, SNPs are not necessarily independent, so chi-square tests and their associated probabilities are distorted to an unknown degree. Additional evidence of an association—one that is not affected by the non-independence of SNPs—is provided by correlations of the MPSs with the phenotype in Subsample Three.
Replication in independent samples is so important for establishing the molecular genetic basis of personality traits that it is worthwhile to attempt it in subsets of Subsample Three itself. For that purpose, we examine correlations of each significant MPS with its phenotype within subgroups defined by age and gender. If significant overall effects are replicated in these subgroups (despite the lower sample sizes and consequent loss of statistical power), it will strengthen the evidence that the effect is real. If effects are seen only in certain subgroups (such as women or older persons), it will serve as a caution to future researchers to consider these variables as possible moderators of the MPS/trait relationship.
Results
Following traditional methods for the analysis of GWA data, we first examined the distribution of p-values in the full sample. There were thousands of effects significant at p < .05—in fact, about 5% of SNPs showed so large a correlation. This is precisely what would be expected if only a very small proportion of the SNPs are truly related to the phenotype. However, both Bonferroni correction and the more liberal false discovery rate analyses suggested that not a single SNP was statistically significant; there were no clear outliers from the random distribution of effects. Clearly, Figure 1A is not the correct model for personality factors in this population.
Table 1 presents results of replication across Subsamples One and Two. The first data cell, for example, indicates that only one replicated SNP was found for analyses of Neuroticism at the 0.025% cutoff—a number that would be expected purely by chance. However, chi-square analyses appear to provide evidence for the presence of genetic influences on all five personality factors when more inclusive cutoff points are used. Chi-square tests are only meaningful for cutoffs of 1% and greater; in 26 of these 30 comparisons (87%), more SNPs were observed to replicate than would be expected by chance. Across all five factors, chi-square values tended to increase and peak at the 50% cutoff, suggesting that the genetics of personality traits is characterized by an extraordinarily large number of very small effects. Effects for Extraversion were considerably smaller than for the other factors.
Table 1.
Observed Number of Replicated SNPs Across Subsamples One and Two.
| Cutoff in Each Subsample |
|||||||||
|---|---|---|---|---|---|---|---|---|---|
| Factor | 0.25% | 0.5% | 1% | 2.5% | 5% | 10% | 20% | 50% | |
| Expected | 1 | 4 | 17 | 106 | 425 | 1,700 | 6,801 | 42,498 | |
| Neuroticism | 1 | 7 | 27 | 154 | 566 | 2,149 | 7,810 | 45,409 | |
| χ 2 | 5.9* | 21.4*** | 46.9*** | 119.3*** | 152.7*** | 227.8*** | |||
| Extraversion | 2 | 10 | 15 | 107 | 481 | 1,788 | 7,048 | 43,330 | |
| χ 2 | 0.2 | 0.0 | 7.4** | 4.6* | 9.1** | 18.6*** | |||
| Openness | 0 | 4 | 14 | 112 | 508 | 1,992 | 7,577 | 44,617 | |
| χ 2 | 0.5 | 0.3 | 16.3*** | 50.5*** | 90.3*** | 120.7*** | |||
| Agreeableness | 4 | 13 | 36 | 188 | 720 | 2,497 | 8,954 | 49,219 | |
| χ 2 | 21.2*** | 62.8*** | 205.2*** | 375.8*** | 695.3*** | 1214.5*** | |||
| Conscientiousness | 4 | 12 | 34 | 144 | 540 | 2,035 | 7,743 | 45,408 | |
| χ 2 | 17.0*** | 13.4*** | 31.2*** | 66.4*** | 133.1*** | 227.6*** | |||
Note. Chi-square is not calculated for the first two cutoffs because the expected value is less than 5.
p< .05
p< .01
p< .001.
At each cutoff level from 0.5% to 10%, replicated SNPs were combined into an MPS after reverse-keying those negatively related to the phenotype. Correlations of these scales with the domain scale in derivation Subsamples One and Two ranged from .158 to .291 at the 0.5% cutoff and from .525 to .626 at the 10% cutoff, with monotonic increases for the intervening cutoffs. However, these correlations certainly capitalize greatly on chance. Cross-validation is essential, and it is provided by correlations in Subsample Three, given in Table 2. These are partial correlations, controlling for age, age-squared, and sex. No significant effects were seen for Extraversion, which had shown the smallest effects in Table 1, and significance was reached for Neuroticism only at the highest cutoff. However, Openness, Agreeableness, and Conscientiousness showed significant findings at several levels.
Table 2.
Partial Correlations of Molecular Personality Scales with NEO-PI-R Domains as a Replication in Subsample Three, Controlling for Age, Age-squared, and Sex.
| Cutoff in Each Subsample |
||||||
|---|---|---|---|---|---|---|
| Factor | 0.5% | 1% | 2.5% | 5% | 10% | Difference |
| Neuroticism | .023 | .029 | .054b | .016 | .063*c, e | .079**c, d |
| k | 7 | 27 | 154 | 566 | 2,149 | 1,583 |
| Extraversion | .009 | .018 | .007 | .013 | .009 | .006 |
| k | 10 | 15 | 107 | 481 | 1,788 | 1,308 |
| Openness | .007 | −.006 | .019b | .095***b, e | .125***a, d | .123***a, d |
| k | 4 | 14 | 112 | 508 | 1,992 | 1,484 |
| Agreeableness | .074**c, f | .069*c, f | .060*c, f | .057*b, f | .080**a, f | .086**a, f |
| k | 13 | 36 | 188 | 720 | 2,497 | 1,785 |
| Conscientiousness | .004 | .021 | .083**a, d | .112***a, d | .095**a, d | .077**c, f |
| k | 12 | 34 | 144 | 540 | 2,035 | 1,495 |
Note. N = 1,319. k = number of SNPs (items) in molecular personality scale. Difference = (10% MPS – 5% MPS).
p < .05
p < .01
p < .001, one-tailed.
Significant in both males and females.
Significant in males only.
Significant in females only.
Significant in both older and younger.
Significant in younger only.
Significant in older only.
The strongest effects are found for the 5% and 10% cutoffs, where scales of about 500 or about 2,000 SNPs are created. At these two levels, correlations for the longer MPSs are not appreciably larger than those for the shorter MPSs. Is anything gained by adding 1,500 more SNPs to the 500-item MPSs? To answer that question, we created Difference scales by subtracting the 5% MPS from the 10% MPS for each factor (leaving Difference MPSs with about 1,500 SNPs), and calculating partial correlations of these Difference scales with the phenotype. As shown in the last column of Table 2, these correlations were significant for Neuroticism, Openness, Agreeableness, and Conscientiousness, suggesting that it is indeed worthwhile to examine at least as many as 2,000 SNPs. Although SNPs in the Difference scales would not be considered candidates for replication in traditional approaches, they are collectively associated with the phenotype. Note that the 5% MPSs and Difference MPSs are non-overlapping; thus, two distinct sets of SNPs are significantly associated with personality traits in the independent Subsample Three.
We repeated analyses separately for subgroups including 595 men and 724 women (controlling for age and age-squared) and for 667 participants over age 40 and 652 participants age 40 or younger (controlling for sex) in Subsample Three. Results are indicated by table footnotes, which show that, despite the smaller sample sizes, most effects are replicated in at least one subgroup. For Agreeableness, effects are consistently found in the older participants, but never in the younger, as if the genes associated with these scales function only in later life. Effects are strongest for Openness and Conscientiousness, which, at the 10% level, are significant in all four subgroups.
Openness is known to be modestly associated with intelligence in most samples (McCrae & Costa, 1997), and it might be argued that the relatively strong correlations are due to SNPs associated with intelligence. Intelligence was not measured in the Sardinia sample, but education, which is strongly correlated with it, was. However, partial correlations controlling for education had little effect on the correlations between MPSs and Openness in Table 2. For example, the partial correlation of the 10% MPS declined only slightly, from .125, p < .001, to .105, p < .001, when education was controlled.
To assess the discriminant validity of the MPS scales, we correlated each of the 10% MPS scales with all five NEO-PI-R domains. Of the 20 non-predicted correlations (e.g., MPS Conscientiousness with NEO-PI-R Neuroticism), 16 were non-significant, and (except in the case of Extraversion), all discriminant correlations were smaller than the relevant convergent correlations shown in Table 2.5
Lists of the SNPs included in each of the MPS scales are available from the corresponding author (PTC).
Discussion
When the SardiNIA project was begun, it was hoped that a genome-wide scan in that founder population would reveal a new set of genes for personality traits by identifying SNPs whose associations with traits were well beyond chance. It was soon clear that single SNPs do not explain large amounts of variance, and with a sample of a few thousand subjects it is difficult to distinguish small but real effects from chance findings. The data clearly indicate that personality traits are the result of very large numbers of genes, each of which has a very small effect (cf. Purcell et al., 2009).
In this study, therefore, we sought to identify sets of SNPs that were collectively related to traits. An internal replication strategy provided evidence that the number of replicable SNP associations exceeded chance (Table 1). Correlations of the MPSs formed from these sets with the phenotype in an independent subsample provided consistent evidence that some truly associated SNPs had been identified and that real genetic information was contained in the scales we created. Given the repeated failures to replicate trait/phenotype associations for candidate genes, this is arguably some of the best molecular evidence to date for the genetic basis of personality.
For four of the factors, scales composed of approximately the top 500 items were significant predictors, as were Difference scales composed of the next 1,500 items. In contrast to standard approaches that examine only a handful of the strongest effects (e.g., Terracciano et al., 2008), the present study suggests that valid genetic variance is to be found deep into the distribution of effect sizes. 2,000 SNPs is a small fraction of the 340,000 we examined—only about one-half of one percent—but it is orders of magnitude larger than the number usually considered.
The correlations in Table 2 are small, but not unexpectedly so (cf. Arden, Harlaar, & Plomin, 2007). A comparison of the expected and observed numbers of SNPs in Table 1 shows that most of the SNPs used in these scales are the result of chance, and contribute only noise to the associations with the phenotype in independent samples. Further, the maximal possible correlation is limited by the additive heritability of the traits. In view of this, the results in Table 2 appear to be strong evidence that SNPs—and thus genes—truly associated with the phenotypes are to be found among the item pools, at least for Neuroticism, Openness, Agreeableness, and Conscientiousness.
In this study we examined only five personality factors. However, the same strategy might profitably be applied to many other quantitative trait variables, including more specific personality traits or facets, such as anxiety, assertiveness, or achievement striving; cognitive traits including memory, decision speed, and general intelligence; and dimensional measures of personality pathology (Costa & Widiger, 2002), depression, and other forms of psychopathology.
Other Genetic Analyses
One limitation of the present study is that analyses were restricted to the search for additive genetic effects in 22 pairs of chromosomes. An obvious extension is to consider SNPs on the X chromosome as well as the few on the Y chromosomes and in mitochondrial DNA, which are not routinely genotyped or imputed.
It is likely that the effects of many personality-related genes are modified by other genes—a phenomenon known as epistasis. Without theoretical guidance, the search for epistatic effects is extraordinarily difficult, because the number of combinations of SNPs, two or more at a time, soon becomes astronomical. One possibility would be to examine interactions between pairs of SNPs defining MPSs. At the 5% cutoff level, this would entail some 250,000 statistical tests.
Psychologists have been particularly excited about the possibility that genetic effects are moderated by experience (e.g., Caspi et al., 2003). In principle, it would be possible to examine such G × E effects for all the SNPs assessed here, provided measures of the relevant environments were available. In practice, we do not know which of the myriad of situational variables is relevant, and even if we did, much larger sample sizes would probably be needed to provide the statistical power to detect interaction effects (Flint & Munafò, 2008). Soberingly, recent large-scale studies (Surtees, Wainwright, Willis-Owen, Lubin, Day, & Flint, 2009) and meta-analyses (Munafò, Durrant, Lewis, & Flint, 2009) have failed to replicate earlier reports of G × E effects. The need for alternative approaches—such as MPSs—seems clear.
From Scales to Genes
The strategy of creating scales based on empirical associations with a criterion is well known to psychologists and psychiatrists because it was used in the development of the MMPI (Hathaway & McKinley, 1943). In an era when the self-reports of psychiatric patients were regarded with great suspicion, MMPI scales seemed to offer a way to circumvent defensive distortions: Whatever the items ostensibly concerned, they were chosen solely because they distinguished a group of patients from controls. Yet over time the item content was analyzed rationally (Wiggins, 1966), and the clinical scales themselves were related to theoretically-grounded personality constructs (McCrae, 1991). Similarly, MPSs can be used simply as empirically-based SNP scales, but they can also be scrutinized as a guide to genes likely to affect personality traits.
As measures of personality, our MPSs perform poorly. No one would recommend assessing personality with scales whose validity coefficients are less than .10. This does not, however, mean that they are useless. In fact, the MPSs created here should be valuable in understanding and stimulating research on the genetics of personality. For example, the present results confirm what has been a growing suspicion: that genetic effects on personality are due to the influence of a very large number of genes. They suggest that this may be particularly true for Neuroticism and Extraversion, classical dimensions of temperament that have analogues in many other species (Gosling, 2001). Has evolution accumulated an exceptionally large array of genes that influence these two basic traits?
As another example, consider the question of the replicability of findings across population groups. The general failure of the candidate genes approach might be interpreted to mean that early studies reported false positive effects. But another possibility is that different genes may be responsible for personality traits in different groups. The present study suggests that the same genes are relevant to traits in different groups of families in Sardinia, but it is not clear whether they would also be relevant in Asia or the US. Correlating MPSs developed in Sardinia with personality scores in other populations could answer the question of generalizability quickly and efficiently.
Studies that attempt to identify individual SNPs associated with traits typically focus on genes related to the SNP and discuss the mechanisms by which they might influence the phenotype. That strategy is less promising when examining MPSs with as many as 2,000 items. Many of the SNPs included in these MPSs were surely selected by chance, although we do not know which ones. Replication in other samples could weed out many chance findings, though it would also discard some real SNPs that happened to show weak associations in the replication sample. Applying this successive replication approach to large pools—2,000 SNPs instead of 500 or 10—may most effectively balance the pursuit of true positives and avoidance of false negatives. Indeed, even longer MPSs than those examined here might prove useful as a starting point, especially for Neuroticism and Extraversion.
A recent study of pancreatic cancer (Jones et al., 2008) suggested that there are numerous alterations of individual genes, but that the disease process might be understood in terms of disturbances to a relatively small number of cellular signaling pathways affected by these genes. In the same way, future research may make sense of the large sets of SNPs identified here in terms of common pathways of gene expression that shape the personality phenotype.
In many respects, the pools of SNPs we have identified are comparable to low-grade ore. For precious metals like platinum, even with relatively rich deposits, it may be necessary to process tons of ore to extract a single ounce of metal. The SNPs in our MPSs can be considered rich deposits of genetic information, but they will still require extensive processing, perhaps using techniques not yet devised, to yield the genetics of personality.
Acknowledgments
This research was supported entirely by the Intramural Research Program, NIH, National Institute on Aging. Robert R. McCrae and Paul T. Costa, Jr., receive royalties from the Revised NEO Personality Inventory. We thank Jason Thayer and Nicholas Patriciu for assistance in analyses, as well as our collaborators in the SardiNIA project.
Footnotes
We calculated rough estimates of split-half internal consistency reliability for the five longest MPSs in the cross-validation sample by correlating the 5% MPSs with the Difference MPSs (see text for a description of these scales) for each factor. These Spearman-Brown corrected reliabilities ranged from .69 to .89.
This assertion is based on the assumption that MPSs are created using criteria that are themselves unbiased. Otherwise, if response biases that affect a criterion are themselves heritable, SNPs related to the bias might be selected as part of the scale. Future research should use multiple methods of measurement to define criteria as free from bias as possible. In any case, successful MPS scales created using volunteer samples would presumably be far less affected by bias than self-reports obtained in highly evaluative situations, such as forensic assessment.
After controlling for age, age-squared, and sex, there were no significant differences between the individuals directly assessed with the 500K assay and the remainder of the sample on any of the five NEO-PI-R domains or the largest MPSs.
It is useful to give some idea of the magnitude of the associations of these SNPs with the traits. Because the great majority of SNPs are presumably unrelated to the phenotype, the distribution of the observed associations is essentially random. That means that 5% of the SNPs (2.5% at each tail, if direction is considered) will have nominal p-values of .05 or better, corresponding to correlations (with sample sizes ≈ 1,400) of about r ≥ .05. This is therefore the approximate magnitude of the 17,000 SNPs at our 5% cutoff level. By the same logic, the 850 SNPs at the highest cutoff value (0.25%) have associations corresponding to correlations of r ≥ .08, and the 34,000 at the lowest cutoff value used to create MPSs (10%) show associations of about r ≥ .04. These are small values, but recall that the MPSs consist only of SNPs found at this magnitude in both of two independent subsamples.
We also conducted supplementary analyses to test a simplified method of creating MPSs. We combined the two derivation subsamples and selected SNPs with the highest signal strength in the combined sample (N = 2,679). To parallel the MPSs in Table 2, each of these new MPSs had the same number of SNPs as those in Table 2. The original and new MPSs were expected to show considerable overlap, because an item is unlikely to be among the strongest signals in the combined derivation subsample unless it is relatively high in both. In fact, correlations between the two MPSs for a given factor ranged from r = .32 at the 0.25% level to r = .89 at the 10% level, and both showed similar results when applied in Subsample Three. One difference was that none of the new MPSs for Neuroticism was significantly related to the phenotype in Subsample Three.
References
- Abecasis GR, Cherny SS, Cookson WO, Cardon LR. Merlin--rapid analysis of dense genetic maps using sparse gene flow trees. Nature Genetics. 2002;30:97–101. doi: 10.1038/ng786. [DOI] [PubMed] [Google Scholar]
- Arden R, Harlaar N, Plomin R. Sex differences in childhood associations between DNA markers and general cognitive ability. Journal of Individual Differences. 2007;28:161–164. [Google Scholar]
- Baum AE, Akula N, Cabanero M, Cardona I, Corona W, Klemens B, et al. A genome-wide association study implicates diacylglycerol kinase eta (DGKH) and several other genes in the eitiology of bipolar disorder. Molecular Psychiatry. 2007:1–11. doi: 10.1038/sj.mp.4002012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Benjamin J, Li L, Patterson C, Greenberg BD, Murphy DL, Hamer DH. Population and familial association between the D4 dopamine receptor gene and measures of novelty seeking. Nature Genetics. 1996;12:81–84. doi: 10.1038/ng0196-81. [DOI] [PubMed] [Google Scholar]
- Benjamini Y, Hochberg Y. Controlling the False Discovery Rate: A practical and powerful approach to multiple testing. Journal of the Royal Statistical Society, Series B. 1995;57:289–300. [Google Scholar]
- Bouchard TJ, Loehlin JC. Genes, evolution, and personality. Behavior Genetics. 2001;31:243–273. doi: 10.1023/a:1012294324713. [DOI] [PubMed] [Google Scholar]
- Butcher LM, Meaburn E, Jo K, Sham PC, Schalkwyk LC, Craig IW, et al. SNPs, microarrays and pooled DNA: Identification of four loci associated with mile mental impairment in a sample of 6000 children. Human Molecular Genetics. 2005;14:1315–1325. doi: 10.1093/hmg/ddi142. [DOI] [PubMed] [Google Scholar]
- Burdick JT, Chen WM, Abecasis GR, Cheung VG. In silico method for inferring genotypes in pedigrees. Nature Genetics. 2006;38:1002–1004. doi: 10.1038/ng1863. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Caspi A, Sugden K, Moffitt TE, Taylor A, Craig IW, Harrington H, et al. Influence of life stress on depression: Moderation by a polymorphism in the 5-HTT gene. Science. 2003;301:386–389. doi: 10.1126/science.1083968. [DOI] [PubMed] [Google Scholar]
- Chen W-M, Abecasis GR. Family based association tests for genome-wide association scans. American Journal of Human Genetics. 2007;81:913–926. doi: 10.1086/521580. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Costa PT, Jr., McCrae RR. Revised NEO Personality Inventory (NEO-PI-R) and NEO Five-Factor Inventory (NEO-FFI) professional manual. Psychological Assessment Resources; Odessa, FL: 1992. [Google Scholar]
- Costa PT, Jr., Terracciano A, Uda M, Vacca L, Mameli C, Pilia G, et al. Personality traits in Sardinia: Testing founder population effects on trait means and variances. Behavior Genetics. 2007;37:376–387. doi: 10.1007/s10519-006-9103-6. [DOI] [PubMed] [Google Scholar]
- Costa PT Jr., Widiger TA, editors. Personality disorders and the Five-Factor Model of personality. 2nd ed. American Psychological Association; Washington, DC: 2002. [Google Scholar]
- Digman JM. Personality structure: Emergence of the Five-Factor Model. Annual Review of Psychology. 1990;41:417–440. [Google Scholar]
- Flint J, Munafò MF. Forum: Interactions between gene and environment. Current Opinion in Psychiatry. 2008;21:315–317. doi: 10.1097/YCO.0b013e328306a791. [DOI] [PubMed] [Google Scholar]
- Frayling TM, Timpson JJ, Weedon MN, Zeggini E, Freathy RM, Lindgren CM, et al. A common variant in the FTO gene is associated with body mass index and predisposes to childhood and adult obesity. Science. 2007;316:889–894. doi: 10.1126/science.1141634. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gosling SD. From mice to men: What can we learn about personality from animal research? Psychological Bulletin. 2001;127:45–86. doi: 10.1037/0033-2909.127.1.45. [DOI] [PubMed] [Google Scholar]
- Gough HG. California Psychological Inventory administrator’s guide. Consulting Psychologists Press; Palo Alto, CA: 1987. [Google Scholar]
- Hathaway SR, McKinley JC. The Minnesota Multiphasic Personality Inventory. rev. ed. University of Minnesota Press; Minneapolis: 1943. [DOI] [PubMed] [Google Scholar]
- Hamer D, Sirota L. Beware the chopsticks gene. Molecular Psychiatry. 2000;5:11–13. doi: 10.1038/sj.mp.4000662. [DOI] [PubMed] [Google Scholar]
- International HapMap Consortium A second generation human haplotype map of over 3.1 million SNPs. Nature. 2007;449:851–861. doi: 10.1038/nature06258. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu JZ, Tozzi F, Waterworth DM, Pillai SG, Muglia P, Middleton L, et al. Meta-analysis and imputation refines the association of 15q25 with smoking quantity. Nature Genetics. 2010;42:436–440. doi: 10.1038/ng.572. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jones S, Zhang X, Williams Parsons D, Lin JC-H, Leary RJ, Angenendt P, et al. Core signaling pathways in human pancreatic cancers revealed by global genomic analyses. Science. 2008;321:1801–1806. doi: 10.1126/science.1164368. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kerner B, Jasinska AJ, DeYoung J, Almonte M, Choi OW, Freimer NB. Polymorphisms in the GRIA1 gene region in psychotic bipolar disorder. American Journal of Medical Genetics, B: Neuropsychiatric Genetics. 2009;150B:24–32. doi: 10.1002/ajmg.b.30780. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lango H, Palmer CN, Morris AD, Zeggini E, Hattersley AT, McCarthy MI, et al. Assessing the combined impact of 18 common genetic variants of modest effect sizes on type 2 diabetes risk. Diabetes. 2008;57:3129–3135. doi: 10.2337/db08-0504. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lesch KP, Bengel D, Heils A, Sabol SZ, Greenberg BD, Petri S, et al. Association of anxiety-related traits with a polymorphism in the serotonin transporter gene regulatory region. Science. 1996;274:1527–1529. doi: 10.1126/science.274.5292.1527. [DOI] [PubMed] [Google Scholar]
- Li Y, Abecasis GR. Mach 1.0: Rapid haplotype reconstruction and missing genotype inference. American Journal of Human Genetics. 2006;S79:2290. [Google Scholar]
- Li Y, Willer C, Sanna S, Abecasis G. Genotype imputation. Annual Review of Genomics and Human Genetics. 2009;10:387–406. doi: 10.1146/annurev.genom.9.081307.164242. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marchini J, Howie B, Myers S, McVean G, Donnelly P. A new multipoint method for genome-wide association studies by imputation of genotypes. Nature Genetics. 2007;39:906–913. doi: 10.1038/ng2088. [DOI] [PubMed] [Google Scholar]
- McCrae RR. The Five-Factor Model and its assessment in clinical settings. Journal of Personality Assessment. 1991;57:399–414. doi: 10.1207/s15327752jpa5703_2. [DOI] [PubMed] [Google Scholar]
- McCrae RR, Costa PT., Jr. Conceptions and correlates of Openness to Experience. In: Hogan R, Johnson JA, Briggs SR, editors. Handbook of personality psychology. Academic Press; Orlando, FL: 1997. pp. 825–847. [Google Scholar]
- McCrae RR, Terracciano A, 78 Members of the Personality Profiles of Cultures Project Universal features of personality traits from the observer’s perspective: Data from 50 cultures. Journal of Personality and Social Psychology. 2005;88:547–561. doi: 10.1037/0022-3514.88.3.547. [DOI] [PubMed] [Google Scholar]
- Moskvina V, Craddock N, Holmans P, Nikolov I, Pahwa JS, Green E, et al. Gene-wide analyses of genome-wide association data sets: Evidence for multiple common risk alleles for schizophrenia and bipolar disorder and for overlap in genetic risk. Molecular Psychiatry. 2009;14:252–260. doi: 10.1038/mp.2008.133. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Munafò MR, Durrant C, Lewis G, Flint J. Gene x Environment interactions at the serotonin transporter locus. Biological Psychiatry. 2009;65:211–219. doi: 10.1016/j.biopsych.2008.06.009. [DOI] [PubMed] [Google Scholar]
- Munafò MR, Freimer NB, Ng W, Ophoff R, Veijola J, Miettunen J, et al. 5-HTTLPR genotype and anxiety-related personality traits: A meta-analysis and new data. American Journal of Medical Genetics, B: Neropsychiatric Genetics. 2009;150B:271–281. doi: 10.1002/ajmg.b.30808. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pilia G, Chen W-M, Scuteri A, Orrú M, Albai G, Deo M, et al. Heritability of cardiovascular and personality traits in 6,148 Sardinians. PLoS Genetics. 2006;2:1207–1223. doi: 10.1371/journal.pgen.0020132. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Plomin R, Hill L, Craig IW, McGuffin P, Prurcell S, Sham P, et al. A genome-wide scan of 1842 DNA markers for allelic associations with general cognitive ability: A five-stage design using DNA pooling and extreme selected groups. Behavior Genetics. 2002;31:497–509. doi: 10.1023/a:1013385125887. [DOI] [PubMed] [Google Scholar]
- Purcell SM, Wray NR, Stone JL, Visscher PM, O’Donovan MC, Sullivan PF, et al. Common polygenic variation contributes to risk of schizophrenia and bipolar disorder. Nature. 2009;460:748–752. doi: 10.1038/nature08185. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sanna S, Jackson AU, Nagaraja R, Willer CJ, Chen WM, Bonnycastle LL, et al. Common variants in the GDF5-UQCC region are associated with variation in human height. Nature Genetics. 2008;40:198–203. doi: 10.1038/ng.74. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schinka JA, Busch RM, Robichaux-Keene N. A meta-analysis of the association between the seretonin transporter gene polymorphism (5HTTLPR) and anxiety-related personality traits. Molecular Psychiatry. 2004;9:197–202. doi: 10.1038/sj.mp.4001405. [DOI] [PubMed] [Google Scholar]
- Sen S, Burmeister M, Ghosh D. Meta-analysis of the association between a serotonin transporter promoter polymorphism (5-HTTLPR) and anxiety-related personality traits. American Journal of Medical Genetics, B: Neropsychiatric Genetics. 2004;127:85–89. doi: 10.1002/ajmg.b.20158. [DOI] [PubMed] [Google Scholar]
- Sen S, Nesse RM, Stoltenberg SF, Li S, Gleiberman L, Chakravarti A, et al. A BDNF coding variant is associated with the NEO Personality Inventory domain Neuroticism, a risk factor for depression. Neuropsychopharmacology. 2003;28:397–401. doi: 10.1038/sj.npp.1300053. [DOI] [PubMed] [Google Scholar]
- Shifman S, Bhomra A, Smiley S, Wray NR, James MR, Martin NG, et al. A whole genome association study of neuroticism using DNA pooling. Molecular Psychiatry. 2008 doi: 10.1038/sj.mp.4002048. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Siegler IC, Welsh KA, Dawson DV, Fillenbaum GG, Earl NL, Kaplan EB, et al. Ratings of personality change in patients being evaluated for memory disorders. Alzheimer Disease and Associated Disorders. 1991;5:240–250. doi: 10.1097/00002093-199100540-00003. [DOI] [PubMed] [Google Scholar]
- Surtees P, Wainwright N, Willis-Owen S, Luben R, Day N, Flint J. Social adversity, the serotonin transporter (5-HTTLPR) polymorphism and major depressive disorder. Biological Psychiatry. 2009;59:224–229. doi: 10.1016/j.biopsych.2005.07.014. [DOI] [PubMed] [Google Scholar]
- Tanaka A, Scheet P, Giusti B, Bandinelli S, Piras MG, Usala G, et al. Genome-wide association study of vitamin B6, vitamin B12, folate, and homocysteine blood concenrtrations. American Journal of Human Genetics. 2009;84:477–482. doi: 10.1016/j.ajhg.2009.02.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Terracciano A. The Italian version of the NEO-PI-R: Conceptual and empirical support for the use of targeted rotation. Personality and Individual Differences. 2003;35:1859–1872. doi: 10.1016/S0191-8869(03)00035-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Terracciano A, Balaci L, Thayer J, Scally M, Kokinos S, Ferrucci L, et al. Variants of the serotonin transporter gene and NEO-PI-R Neuroticism: No association in the BLSA and SardiNIA samples. American Journal of Medical Genetics, B: Neuropsychiatric Genetics. 2009;150B:1070–1077. doi: 10.1002/ajmg.b.30932. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Terracciano A, Sanna S, Uda M, Deiana B, Usala G, Busonero F, et al. Genome-wide association scan for five major dimensions of personality. Molecular Psychiatry. 2008 doi: 10.1038/mp.2008.113. doi: 10.1038/mp.2008.1113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Terracciano A, Tanaka T, Sutin AR, Deiana B, Balaci L, Sanna S, et al. BDNF Val66Met is associated with Introversion and interacts with 5-HTTLPR to influence Neuroticism. Neuropsychopharmacology. 2010;35:1083–1089. doi: 10.1038/npp.2009.213. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Uda M, Galanello R, Sanna S, Lettre G, Sankaran VG, Chen W, et al. Genome-wide association study shows BCL11A associated with persistent fetal hemoglobin and amelioration of the phenotype of I2-thalassemia. Proceedings of the National Academy of Sciences. 2008;105:1620–1625. doi: 10.1073/pnas.0711566105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vandenbergh DJ, Zonderman AB, Wang J, Uhl GR, Costa PT., Jr. No association between Novelty Seeking and dopamine D4 receptor (D4DR) exon III seven repeat alleles in Baltimore Longitudinal Study of Aging participants. Molecular Psychiatry. 1997;2:417–419. doi: 10.1038/sj.mp.4000309. [DOI] [PubMed] [Google Scholar]
- Venter JC, Adams MD, Myers EW, Li PW, Mural RJ, Sutton GG, et al. The sequence of the human genome. Science. 2001;291:1304–1351. doi: 10.1126/science.1058040. [DOI] [PubMed] [Google Scholar]
- Wiggins JS. Substantive dimensions of self-report in the MMPI item pool. Psychological Monographs. 1966;80(No. 22) doi: 10.1037/h0093901. Whole No. 630. [DOI] [PubMed] [Google Scholar]
- Willer CJ, Speliotes EK, Loos RJF, Li S, Lindgren CM, Heid IM, et al. Six new loci associated with body mass index highlight a neuronal influence on body weight regulation. Nature Genetics. 2009;41:25–34. doi: 10.1038/ng.287. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Willis-Owen SA, Turri MG, Munafò MR, Surtees PG, Wainwright NW, Brixey RD, et al. The serotonin transporter length polymorphism, neuroticism, and depression: a comprehensive assessment of association. Biological Psychiatry. 2005;58:451–456. doi: 10.1016/j.biopsych.2005.04.050. [DOI] [PubMed] [Google Scholar]
- Wray NR, Goddard ME, Visscher PM. Prediction of individual genetic risk to disease from genome-wide association studies. Genome Research. 2007;17:1520–1528. doi: 10.1101/gr.6665407. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yamagata S, Suzuki A, Ando J, Ono Y, Kijima N, Yoshimura K, et al. Is the genetic structure of human personality universal? A cross-cultural twin study from North America, Europe, and Asia. Journal of Personality and Social Psychology. 2006;90:987–998. doi: 10.1037/0022-3514.90.6.987. [DOI] [PubMed] [Google Scholar]
- Zhang X-J, Huang W, Yang S, Sun L-D, Zhang F-Y, Zhu Q-X, et al. Psoriasis genome-wide association study identifies susceptibility variants within LCE gene cluster at 1q21. Nature Genetics. 2009;41:205–210. doi: 10.1038/ng.310. [DOI] [PubMed] [Google Scholar]