

Abstract
Successful attempts to predict judges' votes shed light into how legal decisions are made and, ultimately, into the behavior and evolution of the judiciary. Here, we investigate to what extent it is possible to make predictions of a justice's vote based on the other justices' votes in the same case. For our predictions, we use models and methods that have been developed to uncover hidden associations between actors in complex social networks. We show that these methods are more accurate at predicting justice's votes than forecasts made by legal experts and by algorithms that take into consideration the content of the cases. We argue that, within our framework, high predictability is a quantitative proxy for stable justice (and case) blocks, which probably reflect stable a priori attitudes toward the law. We find that U.S. Supreme Court justice votes are more predictable than one would expect from an ideal court composed of perfectly independent justices. Deviations from ideal behavior are most apparent in divided 5–4 decisions, where justice blocks seem to be most stable. Moreover, we find evidence that justice predictability decreased during the 50-year period spanning from the Warren Court to the Rehnquist Court, and that aggregate court predictability has been significantly lower during Democratic presidencies. More broadly, our results show that it is possible to use methods developed for the analysis of complex social networks to quantitatively investigate historical questions related to political decision-making.
Introduction
Could we replace a justice of the U.S. Supreme Court by an algorithm that does not know anything about the law or the case at hand, but has access to the remaining justices' votes and to the voting record of the court? Surely, the algorithm would not be able to hear the case or write an opinion, but would it be able to mimic the vote of the missing judge? Here, we investigate these questions and discuss the implications for quantifying deviations from “ideal” judicial behavior and for getting quantitative insights into the dynamics and historical evolution of the judiciary.
Questions of justice predictability have deep implications from at least two perspectives: the perspective of decision theory and the perspective of legal studies and political science. From a decision–theory perspective, Supreme Court decisions are singular because, in some ways, they are expected to be quasi–ideal. Indeed, justices are expected to make rational decisions with almost perfect information, that is, as perfect as one may possibly expect in any complex real–world decision–making situation. Additionally, the decision of one justice may be expected not to affect the decisions of the others, that is, the decisions may be expected to be non–strategic in a game–theoretic sense [1]. Despite all of this, unanimous decisions are not the norm; and even when decisions of the Court are unanimous, legal experts have difficulties in predicting, not only that the vote will be unanimous, but even the “sign” of the Court's decision–in a study of the 2002 term of the Supreme Court, experts incorrectly predicted the global outcome of as many as 34.7% of the Court's unanimous decisions [2]. Even more puzzling, although consistent with empirical evidence from real decision–making processes, are recent observations that extraneous factors (such as the position of a case within a session) affect judges' decisions because of psychological biases [3], [4].
From the perspective of legal studies and political science, on the other hand, scholars have argued that, by trying to predict the behavior of judges, one can get insights into how legal decisions are truly made [2], [5], [6]. This argument usually appears in the framework of the “debate” between legalism and attitudinalism (or, more broadly, legal realism), which argue, respectively, for purely legal versus personal attitude explanations to justices' decisions [7]. Within this debate, successful predictions based on variables describing the case under consideration (such as the issue area of the case or the ideological direction of the lower court ruling) lend evidence to one theory or the other.
Here we take an approach that is complementary to these vote–forecasting efforts. Specifically, we investigate whether and to what extent it is possible to make predictions of a justice's vote based on the other justices' votes in the same case (and the track record of the court), independently of case content. To make our predictions, we use methods that have been developed to analyze complex social networks [8], [9] and complex affiliation networks [10], [11], and that are able to uncover hidden associations between social actors (in this case, justices) [12]. We show that our approach is more accurate at predicting justice's votes than forecasts made by legal experts and by algorithms that take into consideration the content of the cases [2], [5].
Moreover, we argue that a justice's predictability relative to her predictability in an equivalent “ideal court” provides a quantitative proxy for stable voting blocks (groups of justices that vote consistently the same way in groups of cases) [13]–[16], which ultimately reflect stable a priori attitudes towards the law. We find that Supreme Court justices are significantly more predictable than one would expect from “ideally independent” justices in “ideal courts” [17]. Deviations from ideal behavior are most prominent in divided 5–4 decisions, where justice blocks seem to be most stable. We find evidence that different justices have significantly different relative predictabilities (which suggests that some justices are more stably associated to certain justice–case blocks than others) and that justice relative predictability has decreased during the 50–year period spanning from the Warren Court to the Rehnquist Court. We also find that courts, as a whole, have been significantly less predictable during Democratic presidencies.
Court idealizations
In an “omniscient Court” [17], justices are perfectly rational and free of preferences or attitudes, and have access to complete information about the case at hand. Given these legalist idealizations, all justices must reach the same conclusion and all cases must result in unanimous decisions [17]. Of course, the omniscient Court model is trivially refuted by the empirical observation that not all cases result in unanimous decisions. Therefore, one must relax some of the assumptions to account for justice variability.
Still within the legalist idealization, one may assume that the information available to justices is not perfect and/or that there is some other source of uncertainty. In such an “ideal Court”, each justice evaluates, still free of ideology and independently of other justices, the merits of a case taking into account, to the best of her abilities and knowledge, law and precedent. Cases, on the other hand, all raise rigorously new issues, so previous decisions cannot “easily” determine by themselves the outcome of the present case. Without this assumption that each new case is intrinsically hard, one might think, for example, of a situation where all cases are identical and each justice votes the same every time, even in an “ideal Court.” The assumption of intrinsic difficulty of the cases seems relatively weak given that: (i) the Supreme Court is mostly an appellate court, with ultimate and discretionary appellate jurisdiction over state and federal courts; (ii) even legal experts have difficulties predicting court decisions [2].
Under these assumptions, the ruling on a case can be modeled as a binomial process where each justice has the same probability 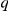 of agreeing with the petitioner, so that “easy cases” (those with
of agreeing with the petitioner, so that “easy cases” (those with 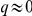 or
or 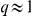 ) result in unanimous decisions, whereas “hard cases” (
) result in unanimous decisions, whereas “hard cases” (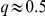 ) generally result in divided votes. The defining characteristic of an ideal court is that justices' votes are uncorrelated, that is, the fact that two justices agree (or disagree) on one case carries no information about their potential agreement on another case.
) generally result in divided votes. The defining characteristic of an ideal court is that justices' votes are uncorrelated, that is, the fact that two justices agree (or disagree) on one case carries no information about their potential agreement on another case.
Because of the lack of correlations, the best possible algorithm to predict the vote of a justice in an ideal court, given the vote of the other eight, is the majority rule (one could in general do better than the majority by estimating, from previous cases, the distribution of 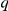 values; in practice, this requires more than 150 cases and is impractical) [18]: if the majority of the eight justices agreed with the petitioner, predict agreement; if the majority disagreed, predict disagreement; in case of a tie, toss a coin.
values; in practice, this requires more than 150 cases and is impractical) [18]: if the majority of the eight justices agreed with the petitioner, predict agreement; if the majority disagreed, predict disagreement; in case of a tie, toss a coin.
If the court is less than ideal and some of its justices cast votes with a consistent bias, the decisions of individual justices become more predictable because, given the vote of eight justices on a case, one can use the track record of the court to classify the case into a certain “block”; then the track record of the ninth justice enables one to assess what is her most likely decision for cases in that block. In other words, bias introduces correlations between justices' voting patterns, which in turn result in increased predictability.
From this perspective, the predictability of a justice with respect to her predictability in an equivalent ideal court provides a quantitative proxy for stable justice correlations, which ultimately reflect a priori attitudes towards the law.
Stochastic block models for vote prediction
To assess to what extent votes of individual Supreme Court justices are predictable due to stable correlations, we use methods that have been developed to analyze complex social networks. In particular, we adapt a method that is able to uncover unobserved associations between actors (in this case, justices) in complex networks [12]. The method relies on the assumption that justices and cases can be grouped into “blocks,” which carry relevant information about justices' voting patterns [13]–[16]. Unlike previous analyses of coalition formation in the Supreme Court [16], we do not assume a priori which blocks are the most relevant or even that there is a single or a few relevant block structures. Rather, we assume that all blocks of justices and cases are possible in principle, and use a Bayesian approach to correctly average over them.
Consider the voting record 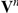 of a court up to case
of a court up to case  . The voting record can be represented as a matrix whose elements are
. The voting record can be represented as a matrix whose elements are 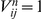 if justice
if justice  (with
(with 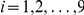 ) voted in favor of the petitioner in case
) voted in favor of the petitioner in case 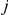 (with
(with 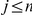 ), and
), and 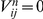 otherwise. We want to predict the vote of a justice in case
otherwise. We want to predict the vote of a justice in case  (without loss of generality we set this justice to be number 1), given the complete voting record of the court up to case
(without loss of generality we set this justice to be number 1), given the complete voting record of the court up to case  and the votes of the other eight justices in case
and the votes of the other eight justices in case  . We denote this available information (or observation)
. We denote this available information (or observation) 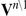 , which is the same as
, which is the same as 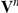 except that the vote of justice 1 in case
except that the vote of justice 1 in case  ,
, 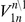 , is not defined.
, is not defined.
Let's assume that there is a potentially infinite collection 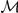 of generative models that could plausibly explain the voting record of the court (that is, that could generate observation
of generative models that could plausibly explain the voting record of the court (that is, that could generate observation 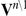 ). Then, our expectation for the probability of justice 1 voting in favor of the petitioner in case
). Then, our expectation for the probability of justice 1 voting in favor of the petitioner in case  is
is
| (1) |
where 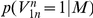 is the probability that
is the probability that 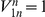 in a voting history generated with model
in a voting history generated with model 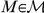 , and
, and 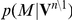 is the plausibility of model
is the plausibility of model 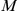 given our observation. Using Bayes theorem, we can rewrite Eq. (1) as
given our observation. Using Bayes theorem, we can rewrite Eq. (1) as
| (2) |
where 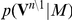 is the probability that model
is the probability that model 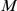 gives rise to
gives rise to 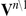 among all possible voting histories, and
among all possible voting histories, and 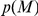 is the a priori probability that model
is the a priori probability that model 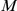 is the one that actually gave rise to
is the one that actually gave rise to 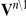 .
.
The key to good predictions is to identify sets of models that are general, empirically grounded, and analytically or computationally tractable. We focus on the family 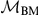 of stochastic block models [12], [19], [20]. In a stochastic block model, justices and cases are partitioned into blocks and the probability that a justice votes in favor of the petitioner in a case depends only on the blocks to which the justice and the case belong (see Methods and Ref. [12]).
of stochastic block models [12], [19], [20]. In a stochastic block model, justices and cases are partitioned into blocks and the probability that a justice votes in favor of the petitioner in a case depends only on the blocks to which the justice and the case belong (see Methods and Ref. [12]).
Under these conditions, the probability that justice 1 votes in favor of the petitioner in case  is:
is:
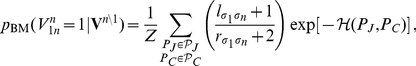 |
(3) |
where the sum is over all possible partitions of the justices and cases into blocks (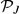 and
and 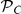 , respectively),
, respectively), 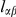 is the number of votes favorable to the petitioner from justices in block
is the number of votes favorable to the petitioner from justices in block  to cases in block
to cases in block 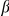 ,
, 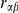 is the maximum number of such votes (that is, the number of pairs justice–case such that the justice is in
is the maximum number of such votes (that is, the number of pairs justice–case such that the justice is in  and the case is in
and the case is in 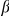 ),
), 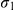 is the block of justice 1 (in partition
is the block of justice 1 (in partition 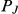 ), and
), and 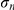 is the block of case
is the block of case  (in partition
(in partition 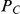 ).
).
The weighting function 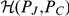 depends on the partitions only
depends on the partitions only
| (4) |
Because of the formal analogy of Eq. (3) with a thermal average in statistical physics, one can estimate 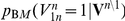 using Metropolis sampling [12], [21].
using Metropolis sampling [12], [21].
Results
We study the first 150 cases of each of the courts from the first Warren Court (1953) to the last Rehnquist Court (1994–2004). We use the data in the original Supreme Court Database compiled by Spaeth and coworkers [22]. We restrict our analysis to “simple cases” defined as those that verify: (i) all nine justices either voted with the majority or dissented (cases with regular or special concurrence, nonparticipation, or other voting behaviors are excluded); and (ii) were formally decided with full opinions, that is, were granted oral argument and resulted in a signed opinion. For cases dealing with multiple issues, we consider only the main issue, as defined in the database. We restrict ourselves to the first 150 cases of each court because few courts have seen more than 150 simple cases, so results become very noisy after that.
Justice predictability is higher in real courts than in ideal courts
As discussed above, justice votes in ideal courts are uncorrelated, so the fact that two justices agree or disagree on one case carries no information about their potential agreement on another case. In such a scenario, the stochastic block model cannot possibly extract any useful information from past votes, and we can expect it to be at most as accurate as the majority rule. Conversely, in real courts the majority rule is as accurate as in ideal courts because, for this heuristic, the only relevant piece of information is how many justices voted with the majority (for example, in a 6–3 vote, the majority rule will always correctly predict six votes, and incorrectly predict the other three); since the stochastic block model does exploit the block–structure of the voting record, we expect it to be at least as accurate as the majority rule in real courts.
Therefore, a “predictability gap” between the majority rule and the stochastic block model in ideal courts would reflect the inability of the latter to capture the little information available in ideal courts; a predictability gap in real courts would reflect the existence of a stable block–structure in the voting record.
To investigate these situations, we artificially generate ideal courts. Given a real court, we generate its corresponding ideal court by randomly reshuffling, within each case, the votes of the justices (Fig. 1). By doing that, each case ends up with the same number of favorable votes as the real case (and, therefore, the same decision), but correlations between justices across cases are eliminated.
Figure 1. Court idealization.

Each row represents the votes of the nine justices in a case (dark, agreement with the petitioner; bright, disagreement with the petitioner). We obtain the ideal court (right) from the real court (left) by randomly reshuffling, within each case, the votes of the justices so that the number of agreements and disagreements is preserved.
For these artificially–generated ideal courts, we find that both the majority rule and the stochastic block model algorithms correctly predict 71% of individual justices votes (Fig. 2A; see Methods for the precise definition of predictability). The absence of predictability gap in ideal courts indicates that, lacking any consistent voting patterns, the stochastic block model is able to capture the maximum possible amount of information.
Figure 2. Average predictability of U.S. Supreme Court votes as a function of the case number (first decision of the court, second decision of the court, and so on; see Methods for the definition of predictability).

Lines represent the moving average (with a window of 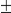 5 cases) of the average over courts for: (A–C) Ideal courts; (D–F) Real courts. (A, D) Predictability considering all decisions; (B, E) excluding unanimous and 8–1 decisions; (C, F) considering only 5–4 decisions.
5 cases) of the average over courts for: (A–C) Ideal courts; (D–F) Real courts. (A, D) Predictability considering all decisions; (B, E) excluding unanimous and 8–1 decisions; (C, F) considering only 5–4 decisions.
For real courts, on the other hand, the block model algorithm correctly predicts 83% of the individual justices' decisions (Fig. 2D), and is therefore consistently more accurate than the majority rule. Although direct comparison with previous forecasting attempts is not straightforward, it is remarkable that our algorithm based on hidden associations between justices is more accurate at predicting justice votes than forecasts made by legal experts as well as those made by algorithms that take into consideration the content of the cases [2], [5]. Indeed, while we correctly predict 83% of the votes, legal experts correctly predicted 67.9% and content–based algorithms correctly predicted 66.7% [2], [5].
Additionally, one needs to consider that the real extent of the correlations between justices' voting patterns is obscured by two facts. First, for unanimous votes, which constitute a significant fraction of all Supreme Court decisions, both the majority rule and the stochastic block model correctly predict all of the votes. Second, for 8–1 votes both algorithms predict eight votes correctly and one incorrectly. In either case there is no predictability gap.
Since we are interested in non–trivial voting correlations and to eliminate the effect of these somewhat pathologic situations, we turn to what we call “divided votes,” that is, votes in which the minority comprises at least two justices (Figs. 2C–D). In ideal courts, divided votes are necessarily more difficult to predict than regular votes: both algorithms accurately predict 53% of the decisions. In real courts, however, the predictability gap widens and the stochastic block model algorithm correctly predicts 73% of the votes.
The widening of the predictability gap becomes even more apparent if we limit our analysis to the cases that are, in principle, most difficult, namely those resulting in a 5–4 vote (Figs. 2E–F). Remarkably, while the majority rule only predicts 28% of these votes correctly, the stochastic block model makes the right prediction in 77% of the cases. This result may appear as a trivial consequence of a single ideological left–right divide in the Supreme Court–that is not the case. Indeed, the most common 5–justice coalition accounts for less than 50% of the 5–4 decisions of the court [16]; our predictions are more accurate thanks to the Bayesian approach that we use to average over all possible justice coalitions and case types.
Besides providing further quantitative evidence for the observation that justices' votes are not immune to the their personal preferences [23]–[25] and are not independent [17], our approach enables us to quantitatively investigate historical questions about the behaviors of individual justices and courts.
Relative predictability
The predictability gap in real courts highlights the existence of consistent and stable voting correlations between justices, which our algorithm identifies as justice and case blocks. As we have shown, these correlations become more apparent as one considers closer votes. Based on these observations, we define the relative predictability of a set of votes as the ratio between the predictability of the votes using the stochastic block model, and the predictability of hypothetical ideal votes in equivalent ideal courts using the stochastic block model (Methods). A relative predictability of one indicates no deviations from ideal behavior, whereas larger values indicate stable associations between justices.
As discussed above, unanimous decisions and 8–1 votes carry no information about stable associations between justices and, consequently, result in relative predictabilities of 1. Therefore, in the rest of our analysis we consider only divided votes (although all the results reported hold if one considers all the votes instead).
Justice predictability has decreased over time
Virtually any new nomination to the Supreme Court comes with accusations of judicial bias and/or judicial activism from the opposition party. This raises, among others, the question of whether different justices have different predictabilities and, if so, whether Democrat–nominated justices are more or less predictable than Republican–nominated justices.
We find evidence that not all justices are equally predictable (Fig. 3A). Golberg, the least predictable justice in the period considered is only 2% more predictable than he would have been had he voted ideally in an ideal court (although one needs to consider his short tenure at the Supreme Court). Marshall, on the other extreme, is 64% more predictable than he would have been had he voted ideally in ideal courts. Most justices have relative predictabilities between 1.2 and 1.5 (Fig. 3B). Of note, our measure of predictability may not correlate with expectations based on the liberal or conservative attitudes of the justices. For example, justice Stevens, who is generally regarded as a liberal and was the easiest justice to predict by experts in Refs. [2], [5], is relatively unpredictable to the stochastic block model. This means that, liberal or not, for most of his career he did not vote consistently with the same other justices.
Figure 3. Relative predictability of individual U.S. Supreme Court justices.

(A) Each line indicates the average relative predictability (that is, predictability according to the block model algorithm in the real court over the predictability in an equivalent ideal court) of a justice over their tenure, which is indicated by the length of the line. Red lines correspond to Republican–nominated justices and blue lines to Democrat–nominated justices. The background color indicates the party of the president. (B) Histogram of relative predictabilities. Bar colors indicate the fraction of Republican–nominated (red) and Democrat–nominated (blue) justices within each bin. (C) Relative predictability as a function of the nomination date of the judge. Relative predictability has significantly decreased during the period considered (p = 0.026, Spearman's rank correlation), as indicated by the dashed line (which is only shown as a guide to the eye).
We do not find any evidence that Democrat–nominated or Republican–nominated justices are more predictable; in fact, both the most and the least predictable justices were nominated by Democratic presidents (Fig. 3B). Interestingly, however, we do find that justice predictability significantly decreased during the period studied (p = 0.026, Fig. 3C). This global trend seems to be shared by Republican–nominated and Democrat–nominated justices, but is more significant for the former (p = 0.026) than for the latter (p = 0.063).
Court predictability is lower during Democratic presidencies
Finally, we investigate the evolution of the relative court predictability, defined as the average relative predictability of the votes of each individual justice for each of the first 150 cases handled by the court (Methods).
As for justices, we find that courts have relative predictabilities significantly different from each other (Fig. 4A). The most predictable courts are over 60% more predictable than their ideal equivalents, whereas the least predictable court (the last Warren court) is only 7% more predictable than its ideal counterpart. Also similar to what happens with individual justices, we find no statistical evidence that courts with more Democrat–nominated justices are more or less predictable than those with more Republican–nominated justices.
Figure 4. Relative court predictability.

(A) The height of each bar indicates the average predictability of a court and its width the time span of the court. The color of the bar indicates the makeup of the court, with dark blue corresponding to a court with many Democrat–nominated justices, and dark red to a court with many Republican–nominated justices. (B) Cumulative distribution functions of the relative court predictability for courts that operated mostly under Democratic presidencies (blue) and Republican presidencies (red). The dashed lines indicate the means of the respective distributions.
In terms of its historical evolution, we find that courts have been significantly less predictable during Democratic presidencies than during Republican presidencies (p = 0.002; Fig. 4B). In fact, the largest predictability drop occurs between the 6th and 8th Warren Courts, coinciding with President Kennedy's election and subsequent assassination.
Discussion
Predicting justice behavior is a way to test hypotheses about how justices make decisions, so that studying such predictions sheds light in important problems in decision theory and in legal studies and political science. Here we have studied to what extent can one predict the vote of a justice from the votes of other justices in the same case (and the track record of the court). Our approach thus focuses in the stable correlations between justice behaviors, which, we argue, reflect consistent attitudes towards the law.
Our approach complements previous attempts to predict justice behavior from the characteristics of cases alone. In this regard, our predictions turn out to be more accurate than forecasts made by legal experts and by algorithms that take into consideration the content of the cases. We surmise that two main factors explain the success of the approach. First, contrary to heuristic approaches, the Bayesian formalism that we use to account for the information encoded in previous Court decisions is the correct probabilistic treatment of the data for inference of future votes. Second, the block model is more realistic than one–dimensional (liberal–conservative) models often assumed in analysis of the judiciary [16], [23], [24], which are inspired by classic studies of voting patterns in Congress [26] (where the one–dimensional approximation is likely to be more appropriate and is easier to justify). For example, the block model can account for a justice voting with certain justices on issues of federalism, and with others in issues related to civil rights.
We have found that justices are significantly more predictable than one would expect from an ideal situation in which justice decisions are uncorrelated. These deviations become more evident for more evenly divided cases; even in 5–4 decisions, which might be expected to be the hardest to predict, our algorithm is able to correctly predict 77% of the individual justices' votes.
Perhaps more importantly, our approach enables us to quantitatively investigate a number of questions related to the historical evolution of the Supreme Court. In particular, we find that justices that were appointed towards the end of the period considered were, in general, less predictable than those that were appointed at the beginning. In addition, we observe that courts operating during Democratic presidencies have been consistently and significantly less predictable than those operating during Republican presidencies.
Providing explanations and contrasting theories for these empirical observations is beyond the scope of this work. In this regard, it is important to note that justice attitudes are only revealed by their votes on cases, so although we focus on justice correlations it is impossible to separate those from correlations between cases. That means, in particular, that predictability may reflect factors that are exogenous to the court, such as the makeup of the cases on which the court has to rule. For example, a court may be less predictable if it has to rule on less politically–charged cases (so justice attitudes play a smaller role), or if it has to rule on very disparate cases (where there is little information from case to case).
In any case, we believe that our approach and our findings open the door for testing such theories in a quantitative manner. More broadly, we believe that out empirical findings illustrate the sort of patterns that quantitative analysis of historical data can help to uncover, and also illustrate how quantitative analysis can help formulate new questions and hypothesis for historical inquiry [27], [28].
Methods
Outline of the reliability calculations
Formally, a block model 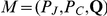 is completely determined by the partitions
is completely determined by the partitions 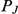 and
and 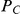 of justices and cases into blocks, and a matrix
of justices and cases into blocks, and a matrix 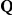 whose elements
whose elements 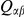 represent the probability that a justice in block
represent the probability that a justice in block  votes in favor of the petitioner in a case in block
votes in favor of the petitioner in a case in block 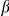 . Therefore, Eq. (2) can be rewritten as
. Therefore, Eq. (2) can be rewritten as
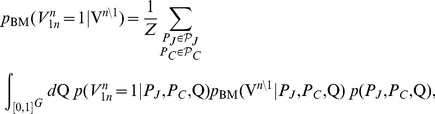 |
(5) |
where 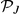 (respectively
(respectively 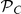 ) is the space of all possible partitions of the justices (cases) into blocks,
) is the space of all possible partitions of the justices (cases) into blocks, 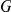 is the number of distinct block pairs, and
is the number of distinct block pairs, and 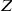 is a normalizing constant.
is a normalizing constant.
Within the family of stochastic block models, one can evaluate the likelihood of each model 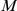 because the probability of justice
because the probability of justice  voting in favor of the petitioner in case
voting in favor of the petitioner in case 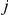 depends only on the blocks to which they belong. We have that [20]
depends only on the blocks to which they belong. We have that [20]
| (6) |
where 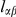 is the number of votes favorable to the petitioner in
is the number of votes favorable to the petitioner in 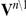 between justices in block
between justices in block  and cases in block
and cases in block 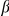 , and
, and 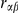 is the maximum number of such votes (that is, the number of pairs justice–case such that the justice is in
is the maximum number of such votes (that is, the number of pairs justice–case such that the justice is in  and the case is in
and the case is in 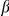 ). Note that we exclude element
). Note that we exclude element 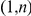 when computing
when computing 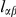 and
and 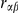 .
.
Using that 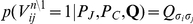 (where
(where 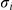 is the block of justice
is the block of justice  in partition
in partition 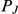 and
and 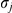 is the block of case
is the block of case 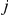 in partition
in partition 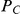 ) and assuming no prior knowledge about the models (that is,
) and assuming no prior knowledge about the models (that is, 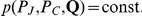 ), one can use Eqs. (5) and (6) to obtain Eq. (3).
), one can use Eqs. (5) and (6) to obtain Eq. (3).
Predictability definitions
Let 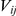 be the vote of justice
be the vote of justice  in case
in case 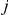 (
(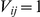 if justice
if justice  agreed with the petitioner in case
agreed with the petitioner in case 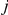 , and 0 otherwise), and
, and 0 otherwise), and 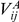 the prediction of algorithm
the prediction of algorithm 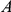 for that vote. The predictability of a set of
for that vote. The predictability of a set of 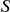 of decisions is
of decisions is
| (7) |
where 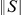 is the number of decisions in the set.
is the number of decisions in the set.
In particular, the predictability 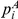 of justice
of justice  is defined as the fraction (over the whole career of the justice) of correctly predicted votes for that justice:
is defined as the fraction (over the whole career of the justice) of correctly predicted votes for that justice:
| (8) |
where 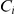 is the set of cases in which
is the set of cases in which  participated.
participated.
Similarly, the predictability 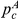 of a court is
of a court is
| (9) |
where 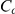 is the set of cases heard by court
is the set of cases heard by court  .
.
We define the relative predictability 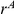 of an algorithm
of an algorithm 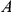 as the ratio between the predictability of the real rulings over the same predictability in an equivalent ideal court (obtained as described in Fig. 1):
as the ratio between the predictability of the real rulings over the same predictability in an equivalent ideal court (obtained as described in Fig. 1):
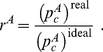 |
(10) |
Acknowledgments
We thank L.A.N. Amaral, A. Fernández, and J.M. Mateo for helpful comments and suggestions.
Footnotes
Competing Interests: The authors have declared that no competing interests exist.
Funding: This work was supported by Spanish Ministerio de Ciencia e Innovación (MICINN) Grant FIS2010-18639, James S. McDonnell Foundation Research Award, European Union Grant PIRG-GA-2010-277166 (to R.G.), and European Union Grant PIRG-GA-2010-268342 (to M.S.-P.). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.Camerer CF. Behavioral game theory: Predicting human behavior in strategic situations. In: Camerer CF, Loewenstein G, Rabin M, editors. Advances in Behavioral Economics. Princeton: Princeton University Press; 2004. pp. 374–392. [Google Scholar]
- 2.Ruger TW, Kim PT, Martin AD, Quinn KM. The Supreme Court forecasting project: Legal and political science approaches to predicting Supreme Court decisionmaking. Columbia Law Rev. 2004;104:1150–1209. [Google Scholar]
- 3.Danziger S, Levav J, Avnaim–Pesso L. Extraneous factors in judicial decisions. Proc Natl Acad Sci U S A. 2011;108:6889–6892. doi: 10.1073/pnas.1018033108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Guthrie C, Rachlinski JJ, Wistrich AJ. Blinking on the bench: How judges decide cases. Cornell Law Review. 2007;93:1–44. [Google Scholar]
- 5.Martin AD, Quinn KM, Ruger TW, Kim PT. Competing approaches to predicting supreme court decision making. Perspectives on Politics. 2004;2:761–767. [Google Scholar]
- 6.Schauer F. Prediction and particularity. B U L Rev. 1998;78:773–789. [Google Scholar]
- 7.Posner RA. How judges think. Cambridge: Harvard University Press; 2010. 400 [Google Scholar]
- 8.Amaral LAN, Ottino JM. Complex networks: Augmenting the framework for the study of complex systems. Eur Phys J B. 2004;38:147–162. [Google Scholar]
- 9.Borgatti SP, Mehra A, Brass DJ, Labianca G. Network analysis in the social sciences. Science. 2009;323:892–895. doi: 10.1126/science.1165821. [DOI] [PubMed] [Google Scholar]
- 10.Scott J. Social Network Analysis: A Handbook. London: SAGE Publications Ltd; 2000. 240 [Google Scholar]
- 11.Guimerà R, Sales–Pardo M, Amaral L. Module identification in bipartite and directed net–works. Phys Rev E. 2007;76:036102. doi: 10.1103/PhysRevE.76.036102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Guimerà R, Sales–Pardo M. Missing and spurious interactions and the reconstruction of complex networks. Proc Natl Acad Sci U S A. 2009;106:22073–22078. doi: 10.1073/pnas.0908366106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Porter MA, Mucha PJ, Newman MEJ, Warmbrand CM. A network analysis of committees in the U.S. House of Representatives. Proc Natl Acad Sci U S A. 2005;102:7057–7062. doi: 10.1073/pnas.0500191102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Porter MA, Mucha PJ, Newman M, Friend A. Community structure in the United States House of Representatives. Physica A. 2007;386:414–438. [Google Scholar]
- 15.Mucha PJ, Richardson T, Macon K, Porter MA, Onnela JP. Community structure in time–dependent, multiscale, and multiplex networks. Science. 2010;328:876–878. doi: 10.1126/science.1184819. [DOI] [PubMed] [Google Scholar]
- 16.Brams SJ, Camilo G, Franz AD. Coalition formation on the U.S. Supreme Court: 1969–2009. 2011. Available: http://ssrncom/abstract=1815164. Accessed 2011 Oct 18.
- 17.Sirovich L. A pattern analysis of the second Rehnquist U.S. Supreme Court. Proc Natl Acad Sci USA. 2003;100:7432–7437. doi: 10.1073/pnas.1132164100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Moreira AA, Mathur A, Diermeier D, Amaral LAN. Efficient system–wide coordination in noisy environments. Proc Natl Acad Sci USA. 2004;101:12083–12090. doi: 10.1073/pnas.0400672101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.White HC, Boorman SA, Breiger RL. Social structure from multiple networks. i. blockmodels of roles and positions. Am J Sociol. 1976;81:730–780. [Google Scholar]
- 20.Holland PW, Laskey KB, Leinhardt S. Stochastic blockmodels: First steps. Soc Networks. 1983;5:109–137. [Google Scholar]
- 21.Metropolis N, Rosenbluth AW, Rosenbluth MN, Teller AH, Teller E. Equation of state calculations by fast computing machines. The Journal of Chemical Physics. 1953;21:1087–1092. [Google Scholar]
- 22.The Supreme Court Database. Available: http://scdb.wustl.edu/data.php. Accessed 2011 Oct 18.
- 23.Segal JA, Cover AD. Ideological values and the votes of the U.S. Supreme Court justices. Am Polit Sci Rev. 1989;83:557–565. [Google Scholar]
- 24.Segal JA, Epstein L, Cameron CM, Spaeth HJ. Ideological values and the votes of U.S. Suprime Court justices revisited. J Politics. 1995;57:812–823. [Google Scholar]
- 25.Epstein L, Knight J. The choices justices make. Washington: CQ Press; 1998. 186 [Google Scholar]
- 26.Poole KT, Rosenthal H. A spatial model for legislative roll call analysis. Am J Polit Sci. 1985;29:357–384. [Google Scholar]
- 27.Turchin P. Arise ‘cliodynamics’. Nature. 2008;454:34–35. doi: 10.1038/454034a. [DOI] [PubMed] [Google Scholar]
- 28.Krakauer D, J G, Pomeranz K. An inquiry into history, big history, and metahistory. Clio–dynamics. 2011;2:1–5. [Google Scholar]