

Abstract
This acoustic study examines sound (vowel) change in apparent time across three successive generations of 123 adult female speakers ranging in age from 20 to 65 years old, representing three regional varieties of American English, typical of western North Carolina, central Ohio and southeastern Wisconsin. A set of acoustic measures characterized the dynamic nature of formant trajectories, the amount of spectral change over the course of vowel duration and the position of the spectral centroid. The study found a set of systematic changes to /I, ε, æ/ including positional changes in the acoustic space (mostly lowering of the vowels) and significant variation in formant dynamics (increased monophthongization). This common sound change is evident in both emphatic (articulated clearly) and nonemphatic (casual) productions and occurs regardless of dialect-specific vowel dispersions in the vowel space. The cross-generational and cross-dialectal patterns of variation found here support an earlier report by Jacewicz, Fox, and Salmons (2011) which found this recent development in these three dialect regions in isolated citation-form words. While confirming the new North American Shift in different styles of production, the study underscores the importance of addressing the stress-related variation in vowel production in a careful and valid assessment of sound change.
1. Introduction
This paper is a sociophonetic investigation of an ongoing vowel change in American English. The specific sound change examined is an anticlockwise parallel rotation of /I, e, æ/ along with systematic variation in dynamic characteristics of these vowels identified as the North American Shift (Jacewicz et al., 2011). The study is conducted in three narrowly defined dialect regions in the United States: western North Carolina, central Ohio and southeastern Wisconsin. Based on the classification in the Atlas of North American English (Labov, Ash, & Boberg, 2006), these varieties represent respectively the American South (specifically Inland South), the Midland, and the North (specifically Inland North). Although strong features of all three dialects are clearly present in their respective vowel systems produced by long-term residents selected for the study, the new common development is evident in each regional variety. As it will be shown, the parallel-shift-like vowel rotation includes both gradual lowering of /I, ε, æ/ across three successive age groups and increased “monophthongization,” that is, reduction of dynamic spectral changes, in these vowels. The study examines this variation in both emphatic and nonemphatic vowels produced in a sentential context.
1.1. Regional variation in American English vowel systems
Vowel systems in English spoken in the United States vary across dialect regions in terms of their dispersion, occurrence of chain shifts and other dialect-specific vowel changes. These patterns have been well-studied for decades, from brief studies on particular regions (such as Wise, 1933 on Southern English), broader regional surveys (Kurath & McDavid, 1961, on the east coast or Allen, 1976, on the Upper Midwest), down to more recent works such as Clopper, Pisoni, and de Jong (2005), Labov, Yaeger, and Steiner (1972), Labov et al. (2006) or Thomas (2001). In this study, the focus is on three diverse regional varieties spoken in the South, in the Midland and in the North whose vowels do not differ solely on the basis of their positions in the acoustic vowel space. Namely, in addition to positional variations, systematic differences in these regional varieties were also found in vowel durations and in the amount of spectral change over the course of the vowels (Fox & Jacewicz, 2009; Jacewicz, Fox, & Salmons, 2007; Jacewicz et al., 2011). In this paper, we will observe how these acoustic vowel characteristics differ cross-generationally, indicating that sound change involves not only a change in the position of a vowel in the acoustic space but also spectral dynamics.
The Southern speakers in the present study come from the Appalachian area of western North Carolina, which is identified as a center of the most advanced features of the Southern vowel system (Labov et al., 2006). The dialects of the South are defined by the operation of the Southern Shift. The Southern Shift is a complex chain shift, manifested somewhat differently in different parts of the South, which spans several states spreading from Virginia, North and South Carolina, and Georgia westward through parts of Texas, Oklahoma, southern Missouri and Kentucky. Generally, the triggering event of the Southern Shift (Stage 1) is the deletion of the offglide in /ɑI/ and its monophthongization, so the vowel is pronounced basically as [ɑ] (Labov et al., 2006, pp. 125, 244). Stage 2 is the centralization and lowering of /e/ and fronting and raising of /ε/, the so-called reversal of the front/back locations of /e/ and /ε/. Stage 3 is a parallel lowering of /i/ and fronting and raising of /I/ which results in another reversal of the front/back locations of /i/ and /I/. Dialects of the American South are particularly known for the “Southern drawl,” which includes a pattern of “breaking,” widely discussed since Sledd (1966). This feature can be informally described as the realization of a vowel as heavily diphthongized or even triphthongized; this can give an auditory impression as consisting of a sequence of two vowels connected by the glide [j]. For example, the word bed may be pronounced in the South as [bεːEid].
The Midland region is regarded by some dialectologists as a broad transitional region between the North and the South (but see Preston, 2003). Within that view, Midland vowel systems have been argued to be influenced to some extent by the vowel characteristics of these two dialects. An ongoing set of changes in central Ohio, the area from which the present speakers were recruited, involve the Low Back Merger (i.e., loss of contrast between /ɑ, ɔ/) or near-merger of those vowels (Labov et al., 2006; Thomas, 2001), back vowel fronting and some raising of /æ/ before nasals (Labov et al., 2006); backing of /æ/ has also been reported by Thomas (1989, 2001). Finally, most recent reports point to the operation of a form of the Canadian shift (Clarke, Elms, & Youssef, 1995) in the Columbus area (e.g., Durian, Dodsworth, & Schumacher, 2010).
The Northern dialect of Inland North selected for this study is undergoing a set of specific vowel changes attributed to the Northern Cities Shift. The triggering event for the shift is the raising and fronting of /æ/. This movement is regarded as initiating a series of follow-on vowel rotations: lowering of /ɔ/, fronting of /ɑ/, lowering and backing of /ε/, backing of /Λ/, and some centralization and backing of /I/. The exact order of the stages in this chain shift is subject to inter-speaker and regional variation, but the general pattern is viewed as a clockwise rotation (see Gordon, 2001). The defining characteristic of the Northern Cities Shift is a raised /æ/ which includes Northern breaking, that is, a heavily diphthongized variant of /æ/, often consisting of a sequence [εːæ]. Most of these features are present in the production of the current speakers selected from the southeastern Wisconsin area.
In addition to the dialect-specific positional changes, vowels in these three regions differ in their durations: North Carolina vowels are the longest, followed by Ohio and Wisconsin, respectively (Fox & Jacewicz, 2009; Jacewicz et al., 2007). Another difference is in their spectral dynamics. On average, North Carolina vowels have the greatest amount of spectral change followed by Ohio and Wisconsin, respectively. However, this general pattern has notable variations as a function of individual vowels (Fox & Jacewicz, 2009; Jacewicz et al., 2011). Finally, differences in speech tempo exist between the varieties in North Carolina and Wisconsin, the former having slower articulation rate than the latter (Jacewicz, Fox, O'Neill, & Salmons, 2009; Jacewicz, Fox, & Wei, 2010). These differences may account for at least some dialect-related variation in vowel duration, although modeling of this relation is needed in order to draw firmer conclusions.
1.2. Variation in vowel emphasis in relation to sound change
In sociophonetic investigations of sound change, we are faced with a not-so-trivial problem of stress-related variations in vowel characteristics. In particular, we can expect unstressed (or casual) vowels to be more centralized in the vowel space relative to their stressed (or hyperarticulated) counterparts because of their less extreme formant values (e.g. Agwuele, Sussman, & Lindblom, 2008; Johnson, Flemming, & Wright, 1993; Lindblom, Agwuele, Sussman, & Cortes, 2007; Moon & Lindblom, 1989; Picheny, Durlach, & Braida, 1986). Thus, in some cases, claims about sound change in progress may be, in fact, related to the centralizing (or fronting) effects due to the variation in stress. To rule out this possibility, care needs to be taken so as to properly control for stress in selecting the testing materials or analyzing spontaneous speech data. This variation is particularly important in examining formant dynamics which are greatly affected by emphasis-related changes in the course of a vowel's duration (Fox & Jacewicz, 2009).
To minimize the effects of prosodic and contextual variation on formant measurements, citation-form vowels produced in isolated words or vowels in stressed positions such as in the phrase Say ___ again are typically used in collecting data in laboratory conditions. Yet, this approach may compromise some aspects of spontaneous productions (such as those obtained in a typical sociolinguistic interview, especially those often labeled “casual speech”) which are believed to provide more realistic and more representative speech samples for exploration of social variables (e.g., Labov, 1994, pp. 156–157). The present study seeks to minimize this problem by using as testing materials a set of sentences in which the main sentence stress is varied systematically. It is expected that the general vowel space along with the amount of formant movement in selected vowels will be considerably reduced when the experimental token is produced in a casual manner (yielding a nonemphatic vowel) as opposed to a hyperarticulated token in which formant movement is proportionally expanded. This approach allows us to assess sound change in a more controlled way, by examining cross-generational data in both nonemphatic and emphatic productions.
The cross-generational and cross-dialectal patterns of variation reported in Jacewicz et al. (2011) were found in isolated citation-form hVd-words representing the most formal style of production. Furthermore, the robust set of changes in /I, ε, æ/ became evident when comparing vowel variants of three generations (in apparent time) termed grandparents (66–91 years old), parents (35–50) and children (8–12). The present paper tracks the sound change over apparent time intervals not included in the above study and examines productions of two age groups immediately preceding and immediately following the “parents:” adults in their 20s (21–33 years old) and those in their late 50s (51–65 years old). The first aim of the paper is to verify the chain-like shift and the increased monophthongization of /I, ε, æ/ in different styles of productions, including both casual and hyperarticulated forms that occur in a sentence context. The second aim is to better understand the nature of this sound change by examining the change in the vowels produced over several decades in apparent time.
2. Methods
2.1. Participants
One hundred twenty three adult female speakers participated in the study. Each speaker was born, raised and has spent most of her life in one of three narrowly defined geographic regions in the United States: western North Carolina (Jackson and Haywood counties southwest of Asheville in the Appalachian region), central Ohio (Columbus and adjacent areas) and southeastern Wisconsin (the area between Madison, Milwaukee and Green Bay). They fall into three age groups: A1 (youngest adults: 21–33 years), A2 (young adults: 37–49 years) and A3 (older adults: 51–65 years). In each region, there were 9 speakers in A1 and 16 in each A2 and A3 group, for a total of 41 speakers per region. The mean ages for each group are summarized in Table 1. The smaller number of speakers in A1 group was due to limited availability of subjects within the time frame of the project. The speech material was recorded in years 2006–2008. None of the speakers reported any speech disorders and none were wearing corrective devices such as dental braces or dentures. All participants were paid for their participation. An initial screening by research staff was administered prior to data collection to ensure that each speaker represented the variety of American English typical of her dialect region. The participants were comparable in terms of education and socioeconomic status as determined by a background questionnaire administered at the time of testing. All speakers were linguistically untrained and were recruited through posted materials.
Table 1.
Mean (s.d.) age (in years) for each age group classified as: Al—youngest adults (age range 21–33 years), A2—young adults (age range 37–49 years), A3—older adults (age range 51–65 years).
| Dialect region | Al mean (s.d) | A2 mean (s.d) | A3 mean (s.d) |
|---|---|---|---|
| NC | 26.7 (4.1) | 44.1 (4.4) | 56.9 (3.5) |
| OH | 25.1 (4.0) | 41.3 (3.7) | 58.1 (5.9) |
| WI | 23.2 (3.1) | 42.0 (4.7) | 58.9 (4.1) |
2.2. Speech materials
Three American English vowels /I, ε, æ/ were selected for the study. They were contained in the phonetic context [bVdz] so that the monosyllabic target words were: bids, beds, bads. The target word occurred in a sentential frame designed to elicit variable emphasis of the target vowel. This was done by systematically manipulating main sentence stress using contrastive stress patterns in a two-sentence frame as in the following examples for the word bids:
BOB thinks the fall bids are low. No! TED thinks the fall bids are low.
Ted KNOWS the fall bids are low. No! Ted THINKS the fall bids are low.
Ted thinks the SPRING bids are low. No! Ted thinks the FALL bids are low.
Ted thinks the fall SALES are low. No! Ted thinks the fall BIDS are low.
Ted thinks the fall bids are HIGH. No! Ted thinks the fall bids are LOW.
Similar sets of sentences were constructed for the words beds and bads. In these sentences, the proximity of the target word to the word-bearing main sentence stress affected the degree of vowel emphasis. In order to select two levels of vowel emphasis, the highest and the lowest, all five sentence pairs were initially produced by each speaker and analyzed. On the basis of acoustic analysis including vowel duration and formant frequency changes in the course of vowel's duration, the following two-sentence pairs were found to produce the most consistent pattern across all speakers in all three regions:
Emphatic vowel (in a target word carrying main sentence stress in a second sentence):
Ted thinks the fall SALES are low. No! Ted thinks the fall BIDS are low.
Nonemphatic vowel (the main sentence stress falls on the last word in a sentence):
Ted thinks the fall bids are HIGH. No! Ted thinks the fall bids are LOW.
These sentence pairs, producing the highest and the lowest levels of emphasis, were selected for further analyses in this paper and the remaining sentences were excluded. During the analyses, it was discovered that some speakers produced slight hesitations and pauses while reading the first sentence in a pair. Since fluency was essential to our study of formant dynamics, we decided to analyze only the second sentence in each sentence pair and exclude the first sentence. In this way, we were assured that a better control of fluency in production was executed for all speakers in the study. The final sample included in the analyses consisted of 2214 vowel tokens (3 vowels×2 emphasis positions×3 repetitions×123 speakers) which were contained in the target words in the following sentences:
Emphatic vowel
Ted thinks the fall BIDS are low.
Rob said the tall BEDS are warm.
Mike thinks the small BADS are worse.
Nonemphatic vowel
Ted thinks the fall bids are LOW.
Rob said the tall beds are WARM.
Mike thinks the small bads are WORSE.
We wish to point out that, in this paper, we use the term “emphatic” rather than “stressed” and “nonemphatic” rather than “unstressed” to underscore that we do not claim that linguistic stress is the only source of vowel enhancement. That is, dynamic changes in a vowel of the type examined in the present study can be found in a variety of speaking situations. Although we use contrastive stress to elicit emphatic and nonemphatic vowel variants (in a manner similar to Lindblom et al., 2007), such vowel exemplars can also be found as a function of prosodic structure, a particular speaking style (such as speaking clearly or casually) or emotional intent.
2.3. Procedure
Speakers were recorded at the university facilities in three locations: Western Carolina University in Cullowhee, NC; The Ohio State University in Columbus, OH; and University of Wisconsin-Madison, WI. The same equipment setup was used and the same experimental protocol was followed at each of the three locations. Each participant was seated and was facing a computer monitor. She spoke to a head-mounted Shure SM10A dynamic microphone positioned at a distance of about 1.5 inches from her lips. Recordings were controlled by a custom program in Matlab, which displayed the sentence pairs to be read by the subject and a set of control buttons for the experimenter.
The sentence pairs were presented in random order. The word bearing the main sentence stress was written in capital letters as in the examples above but the target word did not appear in bold face. The speaker was instructed to read the mini-dialog as naturally as possible and to emphasize the capitalized word “by putting more stress on it than on any other word in a sentence.” A short practice set was recorded prior to the experiment to familiarize the speaker with the experimental procedure. During this practice, the experimenter adjusted recording levels, answered questions and ensured that the speaker understood the task and was able to vary the main sentence stress while reading the practice sentences. After the practice, the participant read the set of experimental sentences. After reading each sentence pair, the experimenter either accepted and saved the production or re-recorded the utterance in case of any mispronunciations, hesitations, pauses or inaccurate stress placement. The participant could repeat the sentence pair as many times as needed and could take a break at any time during the recording session. Speech samples were recorded and digitized at a 44.1-kHz sampling rate directly onto a hard disc drive. Each speaker filled out a background questionnaire at the end of the session that included questions about her basic demographics such as place of birth, age, height, place of residence and travel history, education, occupation or occurrence of speech and hearing disorders.
2.4. Acoustic measurements
Acoustic measurements included vowel duration and the frequencies of F1 and F2 measured at multiple time points in the course of a vowel. From these measurements, two acoustic parameters were further derived: trajectory length (a measure of formant movement) and spectral centroid (a measure of overall vowel position in the acoustic space). Prior to acoustic analysis, all tokens were digitally filtered and downsampled to 11.025 kHz.
2.4.1. Vowel duration
Measurements of vowel duration served as input to subsequent analysis of formant frequency change. Vowel onsets and offsets were located by hand. These locations (landmarks) were determined primarily on the basis of a waveform (using the waveform editing software Adobe Audition 1.0) and were verified with the spectrographic display (in TF32, Milenkovic, 2003). Vowel onset was measured from onset of periodicity (at a zero crossing) following the release burst of the stop (if present). The vowel offset was defined as that point when the amplitude dropped significantly (to near zero). The locations of vowel onset and offset were entered by hand in a spreadsheet and were then used as input to a custom program written in Matlab which computed all duration values (other duration values such as sentence duration, target word duration, duration of the stop closure preceding the vowel and duration of the word-final fricative segment were of interest to other subprojects of this study). The program was also used as a check of all segmentation decisions which were displayed as vertical marks superimposed over a display of the waveform (for vowel duration measurements, the program displayed two different views: a view that included the entire word token and an expanded view that concentrated on the vowel portion only). The segmentation marks were subsequently examined by two different experimenters who ran the same Matlab program. If it was determined that some of the landmarks needed adjustments, the acoustic locations were hand corrected and the program was run repeatedly to recheck the corrected segmentation marks and to compute the new duration values.
2.4.2. Formant frequencies
A separate Matlab program was written to analyze frequencies of F1 and F2 at five equidistant temporal locations corresponding to the 20–35–50–65–80%-points in the vowel. The central part of the vowel (spanning the 20–80%-temporal points) is affected less by immediate effects of consonant environment than are the transitional portions closer to vowel onset and offset. This part of the vowel was selected as representing the vowel “target” in the present study. The frequencies of F1 and F2 were measured by centering a 25-ms Hanning window at each temporal location. F1 and F2 values were based on 14-pole LPC analysis and were extracted automatically. These values were displayed along with the FFT and LPC spectra (at each temporal location), a corresponding waveform and a wideband spectrogram of the entire vowel. The first experimenter hand corrected any dubious formant values displayed by the Matlab program. The entire set of formant measurements were later re-checked by two different experimenters using a separate Matlab program which displayed formant frequency marks and, as needed, verified using smoothed FFT spectra and formant tracks displayed in wideband spectrograms (using the program TF32). Any errors in formant estimation in LPC analysis were hand corrected and the same Matlab program was used again as a final check by a third experimenter.
2.4.3. Trajectory length
Formant trajectory length (TL) represents a measure of formant movement in F1 by F2 plane and is an indication of the amount of formant change over the course of a vowel's production. The general assumption is that a larger TL corresponds to a greater magnitude of formant movement. Given the sampling of formant trajectories at five equidistant locations, we first calculated the length for each of four separate vowel sections, i.e. 20–35%, 35–50%, 50–65% and 65–80%, where the length of one vowel section (VSL) is
The formant TL was then defined as a sum of trajectories of four vowel sections:
The TL measure provides an estimate of the amount of spectral change which may differentiate dialectal variants of the same vowel category. This measure, although still only an estimate of the actual amount of spectral change, uses a denser sampling than the estimate sampled at two temporal points located closer to vowel onset and offset termed vector length (cf., Ferguson & Kewley-Port, 2002; Hillenbrand, Getty, Clark, & Wheeler, 1995). Vector length was found to severely underrepresent formant trajectory change in comparison with TL (Fox & Jacewicz, 2009). Although the TL measure needs further refinements – since it fails to account for the direction of formant movement, for example – its use in the present study is advantageous to characterize the amount of formant change as a function of emphatic stress (see Fox & Jacewicz (2009) for further discussion).
2.4.4. Spectral centroid
Variation in vowel emphasis produces changes to both the magnitude of formant movement and the relative position of the vowel in the acoustic space. Formant dynamics (including the amount of spectral change and spectral rate of change) can also be affected systematically by speaker dialect (Fox & Jacewicz, 2009). It is expected that, in addition to any spectral changes, vowel chain shifts must include positional vowel changes as a function of speaker generation in order to advance the shift. Spectral centroid, a characterization of overall vowel position in the acoustic space, is used in this study to characterize the positional change of the vowel. The F1 centroid is an unweighted mean of all five F1 frequencies measured in the course of vowel's duration:
Similarly, the F2 centroid is the equivalent mean of F2:
The unweighted centroid includes information about vowel-inherent spectral change in locating the vowel's position in the F1×F2 space. In this respect, it differs from a single-measurement point, typically taken at the vowel midpoint or “steady-state,” which is a common approach to represent the vowel's location in the acoustic space. The advantage of using the centroid rather than a single-measurement point is that it takes into account spectral contributions further away from the vowel's center. We decided to use an unweighted rather than weighted centroid based on our experimentation with both types. Assigning different weights to different measurement points symmetrically did not result in a substantial change in centroid location.
2.5. Results and discussion
2.5.1. Variation in vowel duration
Table 2 provides mean durations of emphatic and nonemphatic vowels across dialects and age groups. A within-subject ANOVA was used to assess differences in vowel duration as a function of the within-subject factors vowel and emphasis level and the between-subject factors dialect and age group. In this and subsequent analyses, in addition to the significance values, a measure of the effect size – partial eta squared (η2) – is also reported. The value of η2 can range from 0.0 to 1.0 and it should be considered a measure of the proportion of variance explained by a dependent variable when controlling for other factors. The α level for determining statistical significance was 0.05. Where applicable, separate repeated-measures ANOVAs making pairwise comparisons were used in post-hoc analyses.
Table 2.
Mean durations of individual vowels (in ms) (s.d.) in emphatic and nonemphatic positions across age groups (Al—youngest adults, A2—young adults, A3—older adults). NC—North Carolina, OH—Ohio, WI—Wisconsin.
| Age group | Vowel | NC emphatic | NC nonemphatic | OH emphatic | OH nonemphatic | WI emphatic | WI nonemphatic |
|---|---|---|---|---|---|---|---|
| A1 | /I/ | 230 (46) | 148 (48) | 195 (44) | 110 (29) | 134 (32) | 90 (15) |
| /ε/ | 278 (50) | 149 (47) | 215 (46) | 120 (28) | 148 (26) | 105 (20) | |
| /æ/ | 310 (43) | 198 (43) | 284 (50) | 189 (40) | 234 (43) | 161 (25) | |
| A2 | /I/ | 229 (56) | 145 (33) | 173 (36) | 115 (33) | 165 (41) | 107 (24) |
| /ε/ | 259 (57) | 164 (37) | 189 (30) | 129 (30) | 182 (37) | 123 (24) | |
| /æ/ | 297 (58) | 224 (45) | 273 (32) | 181 (41) | 271 (51) | 187 (33) | |
| A3 | /I/ | 226 (51) | 158 (41) | 185 (58) | 127 (40) | 150 (28) | 114 (37) |
| /ε/ | 254 (57) | 166 (41) | 216 (60) | 130 (39) | 181 (32) | 121 (30) | |
| /æ/ | 297 (59) | 227 (56) | 300 (65) | 201 (46) | 277 (50) | 200 (36) |
Three main effects were significant. The main effect of vowel was particularly strong ([F(2, 228)=1410, p<0.001, η2=0.925]) and subsequent post-hoc analyses revealed that the durations of all three vowels differed significantly from one another (M=156 ms for /i/, 174 ms for /ε/ and 239 ms for /æ/). There was also a strong effect of emphasis ([F(1, 114)=560.4, p<0.001, η2=0.831]); as might be expected, emphatic vowels (M=227 ms) were substantially longer than nonemphatic vowels (M=152 ms). The main effect of dialect ([F(2, 114)=27.4, p<0.001, η2=0.325]) was significant and subsequent post-hoc tests revealed that vowel durations in the three dialects all differed significantly from one another. The North Carolina (NC) vowels were the longest (M=219 ms), followed by Ohio (OH) (MM=185 ms) and Wisconsin (WI) vowels (M=164 ms), respectively. The main effect of age group was not significant, indicating no changes in vowel duration as a function of age, at least for the 21–65 years-old adults studied here. Dialectal differences also appeared in two significant interactions. The interaction between vowel and dialect ([F(4, 228)=19.52, p<0.001, η2=0.255]) arose from the fact that differences among durations of all three vowels in NC were smaller than those in either OH or WI. The second interaction, dialect by emphasis position ([F(2, 114)=6.94, p<0.001, η2=0.108]), was due to a smaller difference between emphatic and nonemphatic variants in WI, most likely because WI vowels were the shortest among all three dialects. Overall, the durations of the vowels in the nonemphatic positions were reduced to 68% of the durations of emphatic vowels. There was no significant difference in this ratio as a function of vowel, dialect or age group (determined by a separate ANOVA not described here).
Summarizing these results, we find that, in each dialect, vowel duration increases progressively with vowel openness, showing that this intrinsic property of vowels (e.g., Peterson & Lehiste, 1960) remains unaffected by factors such as phonetic context, regional variation or speaker age. Emphatic stress is also a strong source of predictable changes in duration: Without exception, emphatic vowels were longer than nonemphatic vowels. The effects of dialect were also strong for the three regional varieties studied here. The Southern (North Carolina) vowels were the longest, the Northern (Wisconsin) were the shortest, and the vowels from the Midland region in central Ohio fell in between. These temporal differences may be related to regional differences in speech tempo (Jacewicz et al., 2010) and/or prosody although this relation needs to be explored in future work.
2.5.2. Formant dynamics
The panels in Fig. 1 show vowel plots across three age groups (A3, A2, A1) for the NC speakers. The data points indicate mean F1 and F2 values measured at five equidistant temporal locations corresponding to the 20–35–50–65–80%-point in the vowel. The general direction of frequency change is indicated by arrows. Overall, we observe substantial variation in formant dynamics across all three individual vowels. Emphatic vowels occupy a more peripheral position and show more formant movement relative to their nonemphatic conterparts. Based on visual inspection, the amount of spectral change seems to be greatest for /i/ and smallest for /æ/. The trajectory shapes, particularly in the productions of A3 and A2 groups, indicate a type of formant movement typical of the “Southern drawl” or Southern breaking. With each successively younger generation, the vowels seem to descend in the acoustic space and exhibit less formant movement (especially in F2) becoming progressively less diphthongized.
Fig. 1.
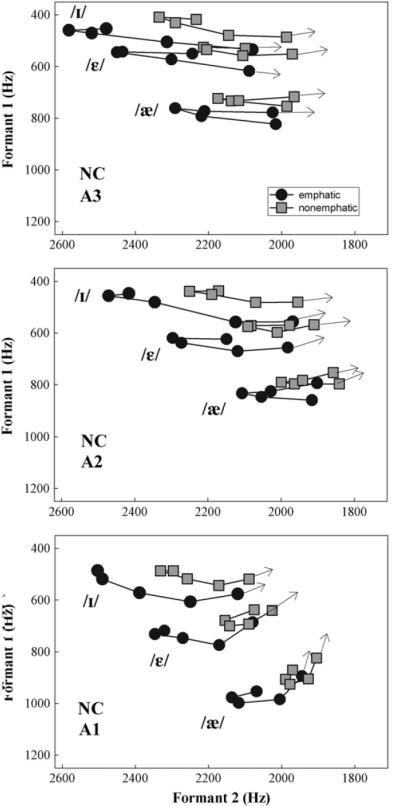
Mean relative positions of western North Carolina vowels /I, ε, æ/ in the F1/F2 plane and their formant movement measured at five equidistant time points (20–35–50–65–80%) in the vowel. Shown are emphatic and nonemphatic variants produced in the [bVdz] context by three groups of female speakers, representing youngest (A1), young (A2) and older adults (A3). Arrows are located at the 80%-point and indicate the direction of formant movement.
Fig. 2 displays plots for the OH speakers. We can observe that, in general, OH vowels are less fronted than NC vowels and are also comparatively lower in the acoustic space. They show a different pattern of formant dynamics in that the spectral change is not as much in F2 as we found in NC but the trajectories are more spread along F1 dimension. Similar cross-generational changes can be detected, however: The vowels descend in the acoustic space with each younger age group and the amount of formant movement is progressively reduced.
Fig. 2.
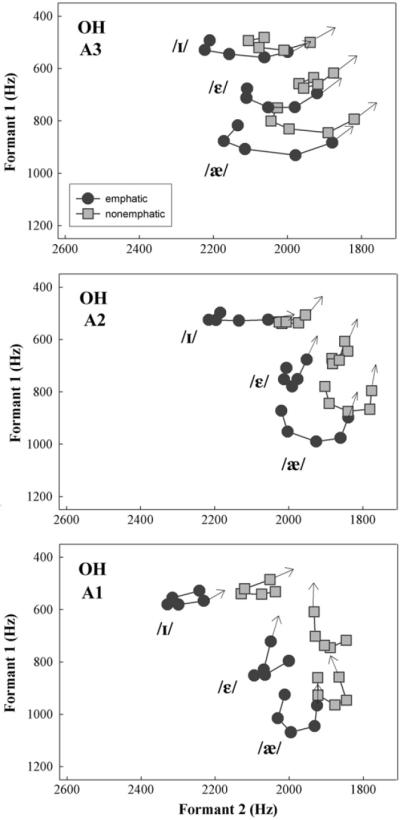
Mean relative positions of central Ohio vowels /I, ε, æ/ in the F1/F2 plane and their formant movement.
Wisconsin vowels show yet another pattern of vowel dispersion and formant movement as displayed in Fig. 3. Older speakers (A3 and A2) have the characteristic mark of Northern Cities Shift, i.e., the raised and fronted /æ/, particularly in its early portion before vowel midpoint. The vowel exhibits extended spectral change (the Northern breaking), by far the greatest of all three vowels. The raised onset and the Northern breaking are still present in young adults (A1) despite considerable lowering and backing of the vowel. Both /æ/ and /ε/ are close to one another to the extent that the formant values of the nonemphatic /æ/ overlap with emphatic /ε/. It seems that, in the latter case, it is the different pattern of formant dynamics that differentiates the two vowels given their spectral overlap and small duration differences (see Table 2). One can also observe that WI /I/ and /ε/ are more centralized in comparison with both NC and OH variants. A further inspection of the plots points to similar cross-generational trend as in the two other dialects, i.e., the lowering in the vowel space and reduction of formant movement.
Fig. 3.

Mean relative positions of southeastern Wisconsin vowels /I, ε, æ/ in the F1/F2 plane and their formant movement.
2.5.3. Variation in TL
The cross-dialectal and cross-generational variation in the amount of spectral change in the vowels displayed in Figs. 1–3 was assessed using the TL measure (see Section 2.4.3). Fig. 4 summarizes the obtained mean TL values for each vowel across dialects and age groups as a function of vowel emphasis. As can be seen, TLs of emphatic vowels (left panels) are substantially longer than nonemphatic vowels (right panels). Additional TL differences can also be found as a function of dialect (the NC vowels have the longest TLs), individual vowels and age group.
Fig. 4.

Trajectory length (TL), i.e., sum of the trajectory lengths of four vowel sections measured between 20% and 80% time points. Shown are means (s.e.) for the vowels /I, ε, æ/ in each dialect as a function of vowel emphasis and age group (A1, A2, A3).
A within-subject ANOVA with vowel and emphasis level as within-subject factors and dialect and age group as between-subject factors was used to assess these differences. There was a significant main effect of emphasis ([F(1, 114)=253.6, p<0.001, η2=0.690]) showing that emphatic vowels had significantly longer TLs than nonemphatic vowels (M=496 and 348 Hz, respectively). The main effect of vowel was also significant ([F(2, 228)=32.18, p<0.001, η2=0.220], M=404 Hz for /I/, 389 Hz for /ε/ and 472 Hz for /æ/). Subsequent post-hoc analyses revealed significant differences between /ε/−/æ/ and /I/–/æ/; however, the TLs for /I/ and /ε/ did not differ significantly from one another. There was a significant main effect of dialect ([F(2, 114)=30.61, p<0.001, η2=0.349]) and post-hoc analyses showed that all three TL pairwise comparisons were significant. NC vowels had the longest TLs (M=516 Hz) followed by WI (M=396 Hz) and OH (M=353 Hz). The main effect of age group was significant ([F(2, 114)=11.09, p<0.001, η2=0.163]). Post-hoc analyses revealed that TLs of the oldest speakers (A3, M=477 Hz) were significantly longer compared to either A2 (M=408 Hz) or A1 (M=380 Hz) but the latter two groups did not differ significantly from one another.
Two significant interactions involving dialect are of interest. An interaction between dialect and vowel ([F(4, 228)=24.22, p<0.001, η2=0.298]) arose from the fact that NC TLs showed a a different pattern compared to either OH or WI. Namely, for OH and WI, the TLs for /I/ and /ε/ were shorter than for /æ/ and did not differ significantly from one another whereas in NC, the TLs for /I/ were the longest and no significant difference was found between /ε/ and /æ/. These dialectal differences can be well observed in Fig. 4 and in the plots in Figs. 1–3. The second significant interaction was between dialect and emphasis ([F(2, 114)=8.42, p<0.001, η2=0.129]). This interaction showed that the difference between TLs of emphatic and nonemphatic vowels was greater in NC than in either OH or WI.
The results for the TL measure help us better understand the variation in formant dynamics for individual vowels displayed in Figs. 1–3. In particular, the strong effects of emphasis are well manifested in greater amount of formant movement for emphatic variants compared to nonemphatic. The two between-subject factors, dialect and age group, also contribute significantly to this variation. On average, NC vowels have more spectral change compared to either WI or OH, which is related to their dialect-specific production known as Southern breaking. WI /I/ and /ε/ have very little formant movement; however, the amount of spectral change is great in /æ/, reflecting the Northern breaking. OH vowels are most “monophthongal,” showing relatively little formant movement. In all three dialects, the vowels of the oldest speakers (A3) have the greatest amount of spectral change which is progressively reduced in the two younger groups. The major reduction takes place between A3 and A2; the difference between A2 and A1 is proportionally smaller and fails to reach statistical significance.
In this paper, we inquire into the nature of the spectral change for emphatic vowels, which are comparable to citation-form vowels, and nonemphatic ones which are more like the casually produced unstressed vowels that are abundant in spontaneous speech. Because the statistical results did not yield significant interactions with age group, we assumed that generational changes in formant movement are similar regardless of the degree of emphasis of the vowel. Subsequent separate ANOVAs conducted on emphatic and nonemphatic variants confirmed our assumptions, yielding essentially the same pattern of results. Thus, whether emphatic or nonemphatic variants are considered, the effects of vowel, dialect and age group remain the same. This indicates that formant dynamics provide a reliable framework to define the cross-generational vowel change. We will return to this point below.
2.5.4. Positional changes in spectral centroid
The traditional view of sound (vowel) change is that it involves changes in the relative positions of vowels in the acoustic space, commonly referred to as vowel movements or rotations (e.g., Labov, 1991, 1994). Following this tradition, we will now observe how the dialect-specific positions of the spectral centroids of emphatic and nonemphatic vowels change across the three generations and whether the direction of this change corresponds to the general pattern of the North American Shift (Jacewicz et al., 2011).
The upper panels in Fig. 5 show cross-generational plots for the vowel /I/ in each dialect redrawn from Figs. 1–3 and include both emphatic and nonemphatic variants. The corresponding lower panels show the average positions of spectral centroids of F1 and F2 of each vowel variant (see Section 2.4.4). The lines connecting the centroids of emphatic (filled symbols) and nonemphatic (open symbols) variants of /I/ produced by the same age group represent a linear distance between these two. As can be seen, the speakers of each dialect successfully produced emphatic (or hyperarticulated) variants in the predicted direction. That is, in each regional variety, the hyperarticulated variants are more fronted and generally slightly lower than the nonemphatic ones. This predicted variation between the spectral centroids for emphatic and nonemphatic variants should overlap for all three age groups unless there are cross-generational differences present. However, we can observe that the positions of the centroids change across age groups, suggesting a possibility that this additional variation is linked to sound change in progress.
Fig. 5.

Mean relative positions of the emphatic and nonemphatic variants of /I/ in the F1/F2 plane in each dialect and their formant movement across three age groups redrawn from Figs. 1–3 (upper panels). Mean spectral centroids (s.e.) of the same emphatic (filled symbols) and nonemphatic (open symbols) variants are shown in the corresponding lower panels.
To assess the significance of the cross-generational variation related to sound change, we used one-way ANOVAs conducted separately for each vowel, each dimension (F1: corresponding to lowering/raising; F2: corresponding to fronting/backing), each emphasis level and each dialect. Age group was the only between-subject factor. Following the significance of the main effect of age group, Scheffé's multiple comparisons were used as post-hoc tests. The use of separate ANOVAs for each F1 and F2 dimension (with age group as the between-subject factor) and for each emphasis level assures that any significant effect of F1 and F2 is attributable to a diachronic shift (i.e., sound change) and is not confounded by speaking style that may produce vowel-specific undershoot/overshoot effects (e.g., Lindblom, 1961; Moon & Lindblom, 1989).
Consider now the lower panels in Fig. 5 which display the positional changes in the spectral centroids of the vowel /I/. The statistical results for NC /I/ indicated significant lowering of the vowel for nonemphatic variants ([F(2, 38)=4.4, p=0.019, η2=0.188]) and a near significant effect for the emphatic (p=0.054). In both cases, however, the significant (or near significant) lowering of the vowel was found for comparisons involving A3 and A1 groups (p=0.020 for nonemphatic, p=0.059 for emphatic) and not A2. There was no significant lowering of the vowel in OH and WI, which is evident in the considerable overlap of cross-generational variants, particularly in OH. However, some fronting was present in emphatic variants in WI ([F(2, 38)=4.37, p=0.020, η2=0.187]) due to the significant increase in F2 in A1 compared to A2 and A3. Similar pattern was also obtained in OH although the fronting in emphatic variants did not reach significance (p=0.052).
The lower panels in Fig. 6 show the spectral centroid locations for the vowel /ε/. ANOVA results indicated lowering of the vowel across generations in all three dialects. In NC, significant lowering was found for both emphatic ([F(2, 38)=17.99, p<0.001, η2=0.486]) and nonemphatic variants ([F(2, 38) = 12.8, p<0.001, η2=0.403]). All pairwise age group comparisons were significant for the emphatic variants; for the nonemphatic, only the difference between A3 and A2 was not significant. There was also a significant backing of the NC vowel in emphatic positions ([F(2, 38)=3.65, p 0.036, η2=0.161]), which took place between A3 and A2 however, the F2 change was too small to reach significance in nonemphatic positions for these two groups.
Fig. 6.

Mean relative positions, formant movement and corresponding centroids of the variants of /ε/ in the F1/F2 plane.
In OH, significant lowering of /ε/ was found only for emphatic variants ([F(2, 38)=5.98, p=0.006, η2=0.239]). In particular, the difference in F1 between A3 and A2 was small and not significant but there was a significant difference in F1 between A1 and both A2 and A3. Spectral centroid changes in F2 were not significant for OH, as one could infer from Fig. 6. In WI, we found significant lowering of the vowel ([F(2, 38)=6.32, p=0.004, η2=0.250]) in nonemphatic (significant difference in F1 was found only between A3 and A2 groups). The effect was near significance in emphatic positions (p=0.050). Interestingly, the vowel in young adults (A1) appears to be raising rather than lowering although no further conclusions as to the direction of sound change can be formulated at present due to the small and not significant differences between F1 values of A1 and any other age group. Spectral centroid changes in F2 were not significant for WI variants.
The final set of plots is for the vowel /æ/ in Fig. 7. Referring to the lower panels, we observe that the vowel is lowering with each successive generation in all three dialects. This trend was significant for NC (emphatic: [F(2, 38)=29.18, p<0.001, η2=0.606], nonemphatic: [F(2, 38)=23.58, p<0.001, η2=0.554]; all pairwise comparisons were significant), for OH (emphatic: [F(2, 38)=9.5, p<0.001, η2=0.339], nonemphatic: [F(2, 38) 22.09, p=<0.001, η2=0.544]; significant lowering was between A3 and A1 for emphatic and between A3 and A1 and A2 and A1 for nonemphatic) as well as for WI (emphatic: F(2, 38)=5.82, p=0.006, η2=0.235], nonemphatic: [F(2, 38)=3.42, p=0.043, η2=0.153]; significant lowering between A3 and A1 for was both emphatic and nonemphatic). In addition to the lowering, NC and OH /æ/ show backing which took place between A3 and A2, in both emphatic and nonemphatic variants (for NC: emphatic ([F(2, 38) 4.98, p 0.012, η2=0.208]), nonemphatic [F(2, 38) 5.96, p=0.006, η2=0.239]; for OH: emphatic [F(2, 38)=3.37, p=0.045, η2=0.154), nonemphatic [F(2, 37)=3.35, p=0.046, η2=0.153]). There was no further significant backing in young adults (A1). No significant backing was found in WI variants of /æ/.
Fig. 7.

Mean relative positions, formant movement and corresponding centroids of the variants of /æ/ in the F1/F2 plane.
To summarize these results, we find a set of parallel positional changes (for each level of emphasis) which pertain primarily to the lowering of the three vowels across the three age groups. This ongoing sound change is common to all three dialects despite notable differences in their dispersion in the acoustic space. The vowel /I/ shows more variability, however, because it was least affected by positional changes and significant lowering was found only for young adults (A1) in NC (relative to A3); no significant lowering took place in either OH or WI. The lowering of /ε/ was consistent across all three dialects although there was a dialect-specific variation in its size. One could speculate that this variation reflects the difference in the rate of sound change across the three age groups although such a strong claim may be premature based on the way the current data were analyzed. Statistical modeling such as fixed-mixed effects analyses with age as a continuous variable could provide more details about this relationship. This possibility will be explored in our future work using an even wider range of speaker ages. Besides lowering of the vowel, we also find some backing of /ε/ in NC. Finally, lowering of /æ/ is well manifested in all three dialects. The effect is particularly strong in NC and OH (considering the high η2 values) and involves all three generations in NC and the two younger age groups in OH. The vowel is also backing in NC and OH, beginning with A2 group. No such backing was found in WI although the vowel is clearly lowering, consistent with the two other dialects.
3. Conclusions
This study investigated vowel change across three successive age groups of adult female speakers, who represented three diverse regional varieties of American English. Within each dialect region, a common set of systematic changes to /I, ε, æ/ was found which included both positional vowel changes (mostly lowering of the vowels in the acoustic space) and significant variation in their formant dynamics (increased monophthongization). The cross-generational and cross-dialectal patterns of variation reported here support an earlier report by Jacewicz et al. (2011) which found this recent development in isolated citation-form words. The major finding of the present study is that, in the speech of the current adults whose ages range from 20 to 65 years old, the vowels /I, ε, æ/ are undergoing a sound change which is evident in both emphatic (articulated clearly) and nonemphatic (casual) productions. This common sound change occurs regardless of dialect-specific vowel dispersion patterns in the acoustic space.
This study verified the occurrence of the chain-like shift and the increased monophthongization of /I, ε, æ/ in different styles of productions. This finding provides evidence that citation-form words, although generally valued less in sociolinguistic investigations in comparison with linguistic forms obtained in a typical sociolinguistic interview, allow a useful and valid assessment of vowel change. Consider the three types of productions in Fig. 8,i.e., citation-form, emphatic and nonemphatic vowels for A2 group. Citation-form vowels were produced in hVd-words as reported in Jacewicz et al. (2011). Formant values for A2 group used here were taken from Appendix B in that paper. Both the emphatic and nonemphatic vowel variants for this age group come from the present study. As can be seen, citation-form vowels are generally more fronted (and even more hyperarticulated) than the emphatic variants. However, their relative positions correspond to what one would predict on the basis of more extreme productions coming from the same vocal tracts. This indicates that variation in vowel emphasis supplies predictable information about positional changes (mostly in F2) which ought to be taken into consideration in examination and adequate assessment of sound change.
Fig. 8.

Mean relative positions of /I, ε, æ/ in the F1/F2 plane in the productions of A2 speakers. (Redrawn from Figs. 1–3) and the corresponding citation-form variants plotted from the formant values listed in Jacewicz et al. (2011).
The results of this study help us better understand the nature of this recent sound change in American English. The centroid analysis indicates that it is a positional change (although more variability was found in /I/ compared to either /ε/ or /æ/). However, the analysis of formant movement (TL) also brought to light that dynamic vowel characteristics may be an important component of this sound change. In general, these three vowels lose their “gliding” parts with each younger generation of speakers. Whether listeners are sensitive to these cross-generational variations will be determined in our future work. Although it is still premature to speculate what motivates this new development in the regional vowel systems of American English, it is informative to point out that similar developments involving these vowels have been reported in other English-speaking countries including the Canadian shift in parts of Canada (e.g., Boberg, 2005; Clarke et al., 1995) and a shift in southeastern England (Torgersen & Kerswill, 2004; Trudgill, 2004). However, these studies report only positional vowel changes and we lack information about possible variation in formant dynamics.
At present, the set of basic acoustic vowel characteristics reported here provides evidence not only about cross-generational sound change but about regional distinctiveness of vowels in American English. Regional varieties differ in terms of vowel duration, dispersion in the acoustic space and the amount of vowel-inherent spectral change. These differences are still strong despite the fact that at least some of the widely known chain shifts like the Southern Shift or the Northern Cities Shift may not be active in younger speakers as in the regions examined in this paper. Future generations yet to be born will inform research about potential loss or maintenance of these dialect-specific variations.
Acknowledgments
This work was supported by the research grant R01 DC006871 from the National Institute of Deafness and Other Communication Disorders, National Institutes of Health. We thank the following for help with data collection and analysis: Mahnaz Ahmadi, Kristin Hatcher, Sarah Hines, Anne Hoffmann, Yolanda Holt, Janaye Houghton, Katherine Lamoreau, Ting-fen Lin, Samantha Lyle, Jeff Murray, Kristi Poole, Leigh Smitley, Dilara Tepeli, Lisa Wackler and Laura Winder. We also thank two anonymous reviewers for their helpful comments on an earlier version of this paper.
Footnotes
Q1 Uncited reference Mencken (1937).
References
- Agwuele A, Sussman HM, Lindblom B. The effect of speaking rate on consonant vowel coarticulation. Phonetica. 2008;65:194–209. doi: 10.1159/000192792. [DOI] [PubMed] [Google Scholar]
- Allen H. Pronunciation. Vol. 3. University of Minnesota Press; Minneapolis: 1976. The linguistic atlas of the Upper Midwest. [Google Scholar]
- Boberg C. The Canadian shift in Montreal. Language Variation and Change. 2005;17:133–154. [Google Scholar]
- Clarke S, Elms F, Youssef A. The third dialect of English: Some Canadian evidence. Language Variation and Change. 1995;7:209–228. [Google Scholar]
- Clopper CG, Pisoni D, de Jong K. Acoustic characteristics of the vowel systems of six regional varieties of American English. Journal of the Acoustical Society of America. 2005;118:1661–1676. doi: 10.1121/1.2000774. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Durian D, Dodsworth R, Schumacher J. Convergence in blue-collar Columbus, Ohio, African American and white vowel systems? In: Yaeger-Dror M, Thomas E, editors. AAE speakers and their participation in local sound changes: A comparative study. Vol. 94. Publication of the American Dialect Society; Duke University Press; Durham: 2010. pp. 161–190. [Google Scholar]
- Ferguson SH, Kewley-Port D. Vowel intelligibility in clear and conversational speech for normal-hearing and hearing-impaired listeners. Journal of the Acoustical Society of America. 2002;112:259–271. doi: 10.1121/1.1482078. [DOI] [PubMed] [Google Scholar]
- Fox RA, Jacewicz E. Cross-dialectal variation in formant dynamics of American English vowels. Journal of the Acoustical Society of America. 2009;126:2603–2618. doi: 10.1121/1.3212921. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gordon MJ. Small-town values and big-city vowels: A study of the Northern Cities Shift in Michigan. Vol. 84. Publication of the American Dialect Society; Duke University Press; Durham: 2001. [Google Scholar]
- Hillenbrand JM, Getty LA, Clark MJ, Wheeler K. Acoustic characteristics of American English vowels. Journal of the Acoustical Society of America. 1995;97:3099–3111. doi: 10.1121/1.411872. [DOI] [PubMed] [Google Scholar]
- Jacewicz E, Fox RA, O'Neill K, Salmons J. Articulation rate across dialect, age, and gender. Language Variation and Change. 2009;21:233–256. doi: 10.1017/S0954394509990093. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jacewicz E, Fox RA, Salmons J. Vowel duration in three American English dialects. American Speech. 2007;82:367–385. doi: 10.1215/00031283-2007-024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jacewicz E, Fox RA, Salmons J. Cross-generational vowel change in American English. Language Variation and Change. 2011;23:45–86. doi: 10.1017/S0954394510000219. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jacewicz E, Fox RA, Wei L. Between-speaker and within-speaker variation in speech tempo of American English. Journal of the Acoustical Society of America. 2010;128:839–850. doi: 10.1121/1.3459842. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Johnson K, Flemming E, Wright R. The hyperspace effect: Phonetic targets are hyperarticulated. Language. 1993;69:505–528. [Google Scholar]
- Kurath H, McDavid RI., Jr. The pronunciation of English in the Atlantic states. University of Michigan Press; Ann Arbor: 1961. [Google Scholar]
- Labov W. The three dialects of English. In: Eckert P, editor. New ways of analyzing sound change. Academic Press; New York: 1991. pp. 1–44. [Google Scholar]
- Labov W. Internal factors. Vol. I. Basil Blackwell; Oxford: 1994. Principles of linguistic change. [Google Scholar]
- Labov W, Ash S, Boberg C. Atlas of North American English: Phonetics, phonology, and sound change. Mouton de Gruyter; Berlin: 2006. [Google Scholar]
- Labov W, Yaeger M, Steiner R. A quantitative study of sound change in progress. U.S. Regional Survey; Philadelphia: 1972. [Google Scholar]
- Lindblom B. Spectrographic study of vowel reduction. Journal of the Acoustical Society of America. 1961;35:1773–1781. [Google Scholar]
- Lindblom B, Agwuele A, Sussman HM, Cortes EE. The effect of emphatic stress on consonant vowel coarticulation. Journal of the Acoustical Society of America. 2007;121:3802–3813. doi: 10.1121/1.2730622. [DOI] [PubMed] [Google Scholar]
- Mencken HL. The American language: An inquiry into the development of English in the United States. Alfred Knopf; New York: 1937. [Google Scholar]
- Milenkovic P. TF32 software program. University of Wisconsin; Madison: 2003. [Google Scholar]
- Moon S-Y, Lindblom B. Interaction between duration, context, and speaking style in English stressed vowels. Journal of the Acoustical Society of America. 1989;96:40–55. [Google Scholar]
- Peterson GE, Lehiste I. Duration of syllable nuclei in English. Journal of the Acoustical Society of America. 1960;32:693–703. [Google Scholar]
- Picheny MA, Durlach NI, Braida LD. Speaking clearly for the hard of hearing, II: Acoustic characteristics of clear and conversational speech. Journal of Speech & Hearing Research. 1986;29:434–446. doi: 10.1044/jshr.2904.434. [DOI] [PubMed] [Google Scholar]
- Preston DR. Where are the dialects of American English at anyhow? American Speech. 2003;78:235–254. [Google Scholar]
- Sledd JH. Breaking, umlaut and the Southern drawl. Language. 1966;42:18–41. [Google Scholar]
- Thomas ER. Vowel changes in Columbus, Ohio. Journal of English Linguistics. 1989;22:205–215. [Google Scholar]
- Thomas ER. An acoustic analysis of vowel variation in New World English. Duke University Press; Durham, NC: 2001. [Google Scholar]
- Torgersen E, Kerswill P. Internal and external motivation in phonetic change: Dialect levelling outcomes for an English vowel shift. Journal of Sociolinguistics. 2004;8:23–53. [Google Scholar]
- Trudgill P. New-dialect formation: The inevitability of colonial Englishes. Edinburgh University Press; Edinburgh: 2004. [Google Scholar]
- Wise CM. Southern American dialect. American Speech. 1933;8:37–43. [Google Scholar]