

Abstract
We demonstrate the mathematical equivalence of two commonly used forms of firing-rate model equations for neural networks. In addition, we show that what is commonly interpreted as the firing rate in one form of model may be better interpreted as a low-pass-filtered firing rate, and we point out a conductance-based firing rate model.
Keywords: Firing rate, voltage, models
At least since the pioneering work of Wilson and Cowan (1972), it has been common to study neural circuit behavior using rate equations – equations that specify neural activities simply in terms of their rates of firing action potentials, as opposed to spiking models, in which the actual emissions of action potentials or “spikes” are modeled. Rate models can be derived as approximations to spiking models in a variety of ways (e.g. Aviel and Gerstner 2006, Ermentrout 1994, La Camera et al. 2004, Mattia and Del Giudice 2002, Ostojic and Brunel 2011, Shriki et al. 2003, Wilson and Cowan 1972; reviewed in Ermentrout and Terman 2010, Chapter 11; Gerstner and Kistler 2002, Chapter 6; Dayan and Abbott 2001, Chapter 7)).
Two forms of rate model most commonly used to model neural circuits are the following, which we will refer to as the v-equation and r-equation respectively:
| (1) |
| (2) |
Here, v and r are each vectors representing neural activity, with each element representing the activity of one neuron in the modeled circuit. v is commonly thought of as representing voltage, while r is commonly thought of as representing firing rate (probability of spiking per unit time). f(x) is a nonlinear input-output function that acts element-by-element on the elements of x, i.e. it has ith element (f(x))i = f(xi) for some nonlinear function of one variable f. f typically takes such forms as an exponential, a power law, or a sigmoid function, and f(vi) is typically regarded as a static nonlinearity converting the voltage of the ith cell vi to the cell’s instantaneous firing rate. W is the matrix of synaptic weights between the neurons in the modeled circuit. Ĩ and I are the vectors of external inputs to the neurons in the v or r networks, respectively, which may be time dependent. In the Appendix, we illustrate a simple heuristic “derivation” of the v-equation, starting from the biophysical equation for the voltages v. Along the way, we also point to a conductance-based version of the rate equation.
When developing a rate model of a network, it can be unclear which form of equation to use or whether or not it makes a difference. Here we demonstrate that the choice between Eqs. 1 and 2 makes no difference: the two models are mathematically equivalent, and so will display the same set of behaviors. It has been noted previously (Beer 2006) that, when I is constant and W is invertible, then the two equations are equivalent under the relationship v = Wr + I, Ĩ = I. We generalize this result to demonstrate the equivalence of the two equations when W is not invertible and inputs may be time dependent.
The v-equation is defined when we specify the input across time, Ĩ (t), and the initial condition v(0); we will call the combination of these and Eq. 1 a v-model. The r-equation is defined when we specify I(t) and r(0); we will call the combination of these and Eq. 2 an r-model. We will show that any v-model can be mapped to an r-model and any r-model can be mapped to a v-model such that the solutions to Eqs. 1–2 satisfy v = Wr + I.
As we will see, the inputs in equivalent models are related by , or . That is, I is a low-pass filtered version of Ĩ. Note that there is an equivalence class of I, parametrized by I(0), that all correspond to the same Ĩ under this equivalence. We assume that the equivalence class has been specified, i.e. Ĩ has been specified (if I has been specified, Ĩ can be found as ). Then a v-model is defined by specifying v(0), while an r-model is defined by specifying the set {r(0), I(0)}. If W is D × D, then v(0) is D-dimensional, while {r(0), I(0)} is 2D-dimensional, so we can guess that the map from r to v takes a D-dimensional space of r-models to a single v-model, and conversely the map from v to r takes a single v-model back to a D-dimensional space of r-models, and we will show that this is true.
We first show that if r evolves according to the r-equation, then Wr + I evolves according to the v-equation. Setting v = Wr + I, we find:
| (3) |
| (4) |
| (5) |
Therefore, if v evolves according to the v-equation and r evolves according to the r-equation and v(0) = Wr(0) + I(0), then – since the v-equation propagates Wr + I forward in time − v = Wr + I at all times t > 0. We will thus have established the desired equivalence if we can solve v(0) = Wr(0) + I(0) for any v-model, specified by v(0), or for any r-model, specified by {r(0), I(0)}.
Note that, as expected, a D-dimensional space of r-models converges on the same v-model. Since {r(0), I(0)} forms a 2D-dimensional space, which is constrained by the D-dimensional equation v(0) = Wr(0)+I(0), the D-dimensional subspace of r-models {r(0), I(0)} that satisfy this equation all converge on the same v-model.
To go from an r-model to a v-model is straightforward: we simply set v(0) = Wr(0) + I(0).
To go from a v-model to an r-model, we first define some useful notation:1
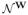 is the nullspace of W, i.e. the subspace of all vectors that W maps to zero. PN is the projection operator into
.
is the nullspace of W, i.e. the subspace of all vectors that W maps to zero. PN is the projection operator into
.is the subspace perpendicular to
. This is the subspace spanned by the rows of W. PN⊥ is the projection operator into
.ℛW is the range of W, i.e. the subspace of vectors that can be written Wx for some x. This is the subspace spanned by the columns of W. PR is the projection operator into ℛW.
is the subspace perpendicular to ℛW, also called the left nullspace. PR⊥ is the projection operator into .
For any vector x, we define xN ≡ PN x, xN⊥ ≡ PN⊥x, xR ≡ PRx, xR⊥ ≡ PR⊥x. We rely on the fact that x = xN + xN⊥ = xR + xR⊥.
Given a v-model, the equation v(0) = Wr(0)+I(0) has a solution if and only if v(0)−I(0) ∈ ℛW, which is true if and only if vR⊥ (0) − IR⊥ (0) = 0,2 so we must choose
| (9) |
Letting DR be the dimension of ℛW and DN the dimension of
the fundamental theorem of linear algebra states that DR + DN = D. So IR⊥ (0) has dimension DN. This leaves unspecified IR(0), which has dimension DR.
To solve for rN⊥ (0), we note that the equation v = Wr + I can equivalently be written v = WrN⊥ + I (because WrN = 0, so Wr = WrN⊥). That is, knowledge of v only specifies rN⊥. We define W−1 to be the Moore-Penrose pseudo-inverse of W. This is the matrix that gives the 1-to-1 mapping of ℛW into that inverts the 1–1 mapping of to ℛW induced by W, and that maps all vectors in to zero.3 The pseudoinverse has the property that W−1W = PN⊥ while WW−1 = PR. Then we can solve for rN⊥ (0) as
| (10) |
This is a DR-dimensional equation for the 2DR-dimensional set of unknowns {rN⊥ (0), IR(0)}, so it determines DR of these parameters and leaves DR free. For example, it could be solved by freely choosing IR(0) and then setting rN⊥ (0) = W−1(vR(0) − IR(0)), or by freely choosing rN⊥ (0) and then setting IR(0) = vR(0) − WrN⊥ (0).
Equations 10 and 9 together ensure the equality v(0) = Wr(0) + I(0). Applying W to both sides of Eq. 10 yields vR(0) = WrN⊥ (0)+IR(0) = Wr(0)+IR(0). This states that the equality hold within the range of W; orthogonal to the range of W, we have PR⊥ Wr = 0 and vR⊥ (0) = IR⊥ (0). Together these yield v(0) = Wr(0) + I(0).
Finally, we can freely choose rN (0), which has no effect on the equation v(0) = Wr(0) + I(0). rN (0) has DN dimensions, so we have freely chosen DR + DN = D dimensions in finding an r-model that is equivalent to the v-model. That is, we have found a D-dimensional subspace of such r-models, those that satisfy v(0) = Wr(0) + I(0).
To summarize, we have established the equivalence between r-models and v-models. For each fixed choice of W, τ, and Ĩ(t), an r-model is specified by {r(0), I(0)} and Eq. 2, while a v-model is specified by v(0) and Eq. 1. The equivalence is established by setting v(0) = Wr(0) + I(0), which yields a D-dimensional subspace of equivalent r-models for a given v-model. Under this equivalence, v obeys Eq. 1, r obeys Eq. 2, and the two are related at all times by v = Wr+ I, with . To go from an r-model to its equivalent v-model, we simply set v(0) = Wr(0)+I(0). To go from a v-model to one of its equivalent r-models, we set IR⊥ (0) = vR ⊥ (0); freely choose rN (0); and freely choose {rN⊥ (0), IR(0)} from the DR-dimensional subspace of such choices that satisfy rN⊥ (0) = W−1(vR(0) − IR(0)), where W−1 is the pseudoinverse of W.
Finally, note that Eq. 2 can be written . That is, if we regard v as a voltage and f(v) as a firing rate, as suggested by the “derivation” in the Appendix, then r is a low-pass-filtered version of the firing rate, just as I is a low-pass-filtered version of the input Ĩ.
Acknowledgments
Supported by R01-EY11001 from the National Eye Institute and by the Gatsby Charitable Foundation through the Gatsby Initiative in Brain Circuitry at Columbia University.
Appendix
As an example of an unsophisticated and heuristic derivation of these equations (more sophisticated derivations can be found in the references in the main text), the v-equation can be “derived” as follows: we start with the equation for the membrane voltage of the ith neuron:
| (11) |
where Ci is the capacitance of the ith neuron and gij is the jth conductance onto the neuron, with reversal potential Eij. We assume that the gij’s are composed of an intrinsic conductance, , with reversal potential ; extrinsic input with reversal potential ; and within-network synaptic conductances, with g̃ij representing input from neuron j with reversal potential Ẽij. Dividing by Σk gik and defining τi(t) = Ci/Σk gik gives
| (12) |
We now make a number of further simplifying assumptions. We assume that g̃ij is proportional to the firing rate rj of neuron j, with proportionality constant W̃ij ≥ 0: g̃ij = W̃ijrj. This ignores synaptic time courses, among other things. We assume that rj is given by the static nonlinearity rj = f(vj) (e.g., see Hansel and van Vreeswijk 2002, Miller and Troyer 2002, Priebe et al. 2004 for such a relationship between firing rate and voltage averaged over a few 10’s of milliseconds). We assume synapses are either excitatory with reversal potential EE or inhibitory with reversal potential EI, and linearly transform the units of voltage so that EE = 1 and EI = −1. We define Wij = W̃ijEj: this is now a synaptic weight that is positive for excitatory synapses and negative for inhibitory synapses. We define and define . This yields the “conductance-based rate equation”:
| (13) |
with τi(t) = Ci/ (gi + Σk |Wik|f(vk)).
Finally, we assume that the total conductance, represented by the denominator in the last term of Eq. 13, can be taken to be constant, e.g. if is much larger than synaptic and external conductances, or if inputs tend to be “push-pull”, with withdrawal of some inputs compensating for addition of others. We absorb the constant denominator into the definitions of Ĩi and Wij, and note that this also implies that τi is constant, to arrive finally at the v-equation:
| (14) |
Footnotes
Note: if W is normal, the eigenvectors are orthogonal, so the nullspace is precisely the space orthogonal to the range: PN = PR⊥ and PN⊥ = PR. However, if W is nonnormal, then vectors orthogonal to the nullspace can be mapped into the nullspace; the range always has the dimension of the full space minus the dimension of the nullspace, but it need not be orthogonal to the nullspace.
| (6) |
| (7) |
| (8) |
If the singular value decomposition of a matrix M is M = USV†, where S is the diagonal matrix of singular values and U and V are unitary matrices, then its pseudoinverse is M−1 = VS̃U† where S̃ is the pseudoinverse of S, obtained by inverting all nonzero singular values in S.
References
- Aviel Y, Gerstner W. From spiking neurons to rate models: a cascade model as an approximation to spiking neuron models with refractoriness. Phys Rev E. 2006;73:051908. doi: 10.1103/PhysRevE.73.051908. [DOI] [PubMed] [Google Scholar]
- Beer RD. Parameter space structure of continuous-time recurrent neural networks. Neural Comput. 2006;18:3009–3051. doi: 10.1162/neco.2006.18.12.3009. [DOI] [PubMed] [Google Scholar]
- Dayan P, Abbott LF. Theoretical Neuroscience. MIT Press; Cambridge, MA: 2001. [Google Scholar]
- Ermentrout B. Reduction of conductance based models with slow synapses to neural nets. Neural Comput. 1994;6:679–695. [Google Scholar]
- Ermentrout GB, Terman DH. Mathematical Foundations of Neuroscience. Springer; New York: 2010. [Google Scholar]
- Gerstner W, Kistler W. Spiking Neuron Models. Cambridge University Press; Cambridge, UK: 2002. [Google Scholar]
- Hansel D, van Vreeswijk C. How noise contributes to contrast invariance of orientation tuning in cat visual cortex. J Neurosci. 2002;22:5118–5128. doi: 10.1523/JNEUROSCI.22-12-05118.2002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- La Camera G, Rauch A, Luscher HR, Senn W, Fusi S. Minimal models of adapted neuronal response to in vivo-like input currents. Neural Comput. 2004;16:2101–2124. doi: 10.1162/0899766041732468. [DOI] [PubMed] [Google Scholar]
- Mattia M, Del Giudice P. Population dynamics of interacting spiking neurons. Phys Rev E. 2002;66:051917. doi: 10.1103/PhysRevE.66.051917. [DOI] [PubMed] [Google Scholar]
- Miller KD, Troyer TW. Neural noise can explain expansive, power-law nonlinearities in neural response functions. J Neurophysiol. 2002;87:653–659. doi: 10.1152/jn.00425.2001. [DOI] [PubMed] [Google Scholar]
- Ostojic S, Brunel N. From spiking neuron models to linear-nonlinear models. PLoS Comput Biol. 2011;7:e1001056. doi: 10.1371/journal.pcbi.1001056. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Priebe N, Mechler F, Carandini M, Ferster D. The contribution of spike threshold to the dichotomy of cortical simple and complex cells. Nat Neurosci. 2004;7(10):1113–22. doi: 10.1038/nn1310. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shriki O, Hansel D, Sompolinsky H. Rate models for conductance-based cortical neuronal networks. Neural Comput. 2003;15:1809–1841. doi: 10.1162/08997660360675053. [DOI] [PubMed] [Google Scholar]
- Wilson HR, Cowan JD. Excitatory and inhibitory interactions in localized populations of model neurons. Biol Cybern. 1972;12:1–24. doi: 10.1016/S0006-3495(72)86068-5. [DOI] [PMC free article] [PubMed] [Google Scholar]