

Abstract
Two methods for point and interval estimation of relative risk for log-linear exposure-response relations in meta-analyses of published ordinal categorical exposure-response data have been proposed. The authors compared the results of a meta-analysis of published data using each of the 2 methods with the results that would be obtained if the primary data were available and investigated the circumstances under which the approximations required for valid use of each meta-analytic method break down. They then extended the methods to handle nonlinear exposure-response relations. In the present article, methods are illustrated using studies of the relation between alcohol consumption and colorectal and lung cancer risks from the ongoing Pooling Project of Prospective Studies of Diet and Cancer. In these examples, the differences between the results of a meta-analysis of summarized published data and the pooled analysis of the individual original data were small. However, incorrectly assuming no correlation between relative risk estimates for exposure categories from the same study gave biased confidence intervals for the trend and biased P values for the tests for nonlinearity and between-study heterogeneity when there was strong confounding by other model covariates. The authors illustrate the use of 2 publicly available user-friendly programs (Stata and SAS) to implement meta-analysis for dose-response data.
Keywords: cohort studies; data interpretation, statistical; dose-response relationship, drug; linear models; meta-analysis; meta-analysis as topic
Quantitative reviews of published epidemiologic studies of exposure-response relations typically include an assessment of the relation between exposure levels and risk of disease (1). The standard approach to trend estimation in meta-analysis of exposure-response relations when only published category-specific relative risks and their confidence intervals are available is to fit a weighted linear regression through the origin, in which the dependent variable is the estimated log relative risk, the independent variable is the exposure level to which the dependent variable corresponds, and the weights are the estimated inverse variances of the log relative risks. This method assumes that the log relative risks are independent. It has been shown that assuming zero correlation among a series of log relative risks estimated using a common referent group leads to a biased estimate for the variance of the trend (2). Therefore, Greenland and Longnecker (2) proposed a method (hereafter referred to as the GL method) to approximate these correlations and incorporate them into the estimation of the linear trend using generalized least-squares regression. More recently, Hamling et al. (3) developed an alternative to the GL method (hereafter referred to as the Hamling method) for reconstructing the cell counts of the original 2 × 2 tables of constituent studies in a meta-analysis, with the apparent advantage of being able to adjust for a loss of precision due to confounding. A third possibility involves application of the floating absolute risk (FAR) method of Easton et al. (4). Studies in which relative risks with floating standard errors or floating confidence intervals are reported have an advantage in that the variance of the reference exposure level equals the common covariance of the set of adjusted relative risks, obviating the need to apply a method to approximate this, as is usually required (4, 5).
Since the article by Greenland and Longnecker was published in 1992, it has been cited 262 times. Of these citations, 5 were in methodological articles in which other related issues such as publication bias (6), confidence bounds for the covariances (7), how to model nonlinear dose-response relations (8, 9), and how to assign dose values to each exposure level (1, 6, 10) were investigated. At the time that the present article was written, the article by Hamling et al. (3) had received 5 citations.
In the present article, we evaluate the accuracy of the approximation by Greenland and Longnecker and that of the approximation by Hamling et al. for the confidence interval of the linear trend for the relative risk compared with the exact estimate from pooled primary data. We show how to use these methods to obtain a pooled estimate of linear and nonlinear trends, the latter by applying the method of restricted cubic splines (11). We investigate situations in which failing to apply either the GL method or the Hamling method to account for within-study covariance of the exposure-level relative risks would be particularly misleading. In addition, we compare the assumptions made in the GL and Hamling methods and discuss the conditions under which each method may be more accurate. Finally, we present publicly available user-friendly programs for meta-analysis of dose-response data written in Stata (StataCorp LP, College Station, Texas) and SAS (SAS Institute, Inc., Cary, North Carolina).
MATERIALS AND METHODS
Review of the GL method for reconstructing covariances among a series of published relative risk estimates
Published dose-response data are typically reported as a series of dose-specific relative risks, with one category serving as the common referent group. We define Ak, the number of cases in exposure level k; Bk, the number of controls (for case-control data) in exposure level k; and Nk, the total number of subjects (for cumulative incidence data) or the total person-time (for incidence rate data) in exposure level k, where the subscript k ranges from 0 (referent) to K (the total number of nonreference exposure levels). In the present article, the term “relative risk” will be used as a generic term for the risk ratio (cumulative incidence data), rate ratio (incidence-rate data), and odds ratio (case–control data).
Three steps are required to estimate the covariances of a series of multivariate-adjusted log relative risks (RR1,RR2,…,RRK) for each study that will be included in the meta-analysis:
Solve for the effective numbers of cases and noncases at each exposure level, given the multivariate-adjusted log relative risks and the total numbers of cases and the total number of exposed at each level of exposure reported in each published article. An iterative algorithm for solving the system of nonlinear equations is given in Appendix 2 of the article by Greenland and Longnecker (2), although many other options exist for solving systems of nonlinear equations.
Approximate the correlations among the log relative risks as rkl = s0/(sksl)1/2, where s0 is the common covariance and sk and sl are the variances of the log relative risks. The formulas for the covariances and variances depend on the type of summarized data, as follows: s0 = (1/A0 + 1/B0) and sk = (1/Ak + 1/Bk + 1/A0 + 1/B0) for case-control data; s0 = (1/A0) and sk = (1/Ak + 1/A0) for incidence-rate data; and s0 = (1/A0 − 1/N0) and sk = (1/Ak − 1/Nk + 1/A0 − 1/N0) for cumulative incidence data.
Approximate the multivariate covariances between the adjusted log relative risks as ckl = rkl×(vkvl)1/2, where rkl represents the correlations estimated in the previous step and vk and vl are the variances of the adjusted log relative risks, defined as the length of the confidence interval on the log scale divided by the square of the (1 − α/2)-level standard normal deviate (use 1.96 for a 95% confidence interval) for all k ≠ l.
The formulas given in step 2 for the variances of the log relative risks for incidence rate and cumulative incidence data fix errors in 2 formulas given in the article by Greenland and Longnecker (2). The formulas are correct as originally given only if the exposure has 2 levels; otherwise, they overestimate the variance (2).
Review of the Hamling method for reconstructing covariances among a series of relative risks
Solve for the effective numbers of cases and noncases at each exposure level given the multivariate-adjusted log relative risks, the multivariate-adjusted variances (as defined as above in step 2), the crude prevalence of unexposed subjects, person-time, or controls (for cumulative incidence, incidence rate, and case-control data, respectively), and the overall ratio of noncases (or noncase person-time) to cases. An iterative algorithm for solving this system of nonlinear equations is given in Appendix A of the article by Hamling et al. (3), although many other options exist for solving systems of nonlinear equations.
Approximate the correlations among the log relative risks as rkl = s0/(sksl)1/2 as defined above for the GL method.
Approximate the multivariate covariances between the adjusted log relative risks as ckl = rkl×(vkvl)1/2 as defined above for the GL method. Because the Hamling method provides the effective counts that correspond approximately to the published multivariate relative risks and their confidence intervals, sk = vk and the covariances of the multivariate log relative risks are all equal to ckl = rkl×(vkvl)1/2 = s0/(sksl)1/2×(vkvl)1/2 = s0 for all k ≠ l.
Interestingly, if the relative risks were reported using the FAR method, the average covariance s0 would be directly available from the publication (variance of the log relative risk used as reference category), and thus neither the GL procedure and approximations nor the Hamling procedure and approximations described above would be needed (5).
Evaluation of the assumptions used in the GL and Hamling methods
An assumption of the GL method is that the correlation matrices of the unadjusted and adjusted relative risks are approximately equal. The GL method of approximating the correlations is valid when there is no confounding by other model covariates in the published results of each study included in the meta-analysis. When there is no confounding, the correlation matrix of the crude relative risks will equal that of the adjusted relative risks because no confounding implies no correlation between the exposure of interest and the other risk factors. When the crude analysis is valid, the covariances of the relative risks are inversely related to the number of cases in the referent group (A0) for all study designs. In a study with a small number of cases in the referent exposure level, the GL approximation will be more unstable because it is derived from an unstable estimate.
When the original data are available, as in the examples given here, we can check the validity of the GL assumptions by calculating the relative difference between crude relative risks (RRc) and adjusted relative risks (RRa) ((RRc − RRa)/RRc × 100), which gives us an overall estimate of the extent of confounding, and the absolute relative difference between any pair of correlations between crude and adjusted log relative risks (|rckl − rakl|/|rckl×100), which quantifies more exactly the accuracy of the GL approximation. The range and average of these 2 sets of values provide information about the conditions under which the GL approximations would be useful. The crude and adjusted relative risks are usually published in the literature, whereas the pairwise correlations between the crude and adjusted relative risks are rarely published.
The Hamling method accounts for confounding more explicitly when used to estimate the effective numbers of subjects. It reconstructs the 2 × (K + 1) table of pseudocounts that corresponds to adjusted relative risks and their confidence intervals. Given that adjustment usually increases the width of the confidence intervals, the estimated effective numbers of subjects are lower than the published (unadjusted) numbers of subjects. A practical advantage of the Hamling method compared with the GL method is that less information needs to be retrieved from the original publications; only the 2 × 2 tables that classify subjects according to dichotomized exposure (exposed/unexposed) and disease (cases/noncases) are necessary.
It is of interest to understand under what circumstances the correlations among log relative risks estimated by the GL method are not equal to the correlations estimated by the Hamling method, and, ultimately, under what circumstances the log relative risks estimated by the 2 methods become materially different. It is not possible to write down explicit closed-form expressions for the correlations given by these 2 procedures; hence, direct analysis of the functional relations is not possible. In the examples presented here, the estimated correlations are similar; however, this is not always the case. Because the Hamling method fixes the multivariate-adjusted variances of the log relative risks whereas the GL method preserves the original margins of the crude 2 × (K + 1) tables (essentially fixing the crude variance), when the adjustment factors are strongly associated with either the exposure, the outcome, or both, the 2 methods will give different results. In fact, it is noted by Greenland and Longnecker (2) that their method will generally be valid only when the adjustment factors are only weakly related to the exposure and outcome (2). To see this, consider the set of hypothetical data presented in Table 1 with the corresponding unadjusted and multivariate-adjusted relative risks and their variances.
Table 1.
Hypothetical Data From a Single Study in a Dose-Response Meta-Analysis
| Exposure Level | No. of Cases | No. of Controls | Total No. of Subjects | Unadjusted |
Multivariate-Adjusted |
||
| RR | Variance of Log RR | RR | Variance of Log RR | ||||
| 0 | 670 | 1,000 | 1,670 | 1 | Referent | 1 | Referent |
| 0.01 | 8,309 | 10,539 | 18,848 | 1.18 | 0.0025 | 1.17 | 0.11 |
| 0.40 | 149 | 176 | 325 | 1.26 | 0.0027 | 1.75 | 0.11 |
| Total | 9,128 | 11,715 | |||||
Abbreviation: RR, relative risk.
The GL and Hamling methods were used to reconstruct the adjusted 2 × (K + 1) tables of pseudocounts (Table 2), and straightforward calculations can be used to establish that the restrictions of each method are met. The estimated correlations between the log relative risks are 0.39 by the GL method and 0.87 by the Hamling method, giving covariances between the log relative risks for use in trend estimation of 0.10 and 0.04, respectively. For exposure levels of 0, 0.01, and 0.40, the Hamling method gives a relative risk for trend of 2.91 (95% confidence interval: 1.46, 5.82), and the GL method gives a relative risk for trend of 3.58 (95% confidence interval: 0.78, 16.50). This is an example in which the difference between the 2 methods is quite evident. Using the notation developed below, it can be seen that, in the case of 3 exposure levels,
and
where it is evident that the values of obtained from the 2 methods will increasingly diverge as increases, and the value of obtained from the 2 methods will increasingly diverge as |X1X2| increases.
Table 2.
Adjusted 2 × (K + 1) Pseudocounts for Hypothetical Data Reconstructed by Using the Greenland and Longnecker Method and the Hamling Method
| Method |
||||
| Exposure Level X | Greenland and Longnecker |
Hamling |
||
| No. of Cases | No. of Controls | No. of Cases | No. of Controls | |
| 0 | 670 | 1,000 | 16 | 28 |
| 0.01 | 8,282.6 | 10,565.4 | 120 | 180 |
| 0.40 | 175.4 | 149.6 | 120 | 120 |
| Total | 9,128 | 11,715 | 256 | 328 |
Estimation procedure for linear and nonlinear exposure-response relations and software
Once the covariances of the published multivariate-adjusted log relative risks for each exposure level relative to the referent are calculated as described above using either the GL method or the Hamling method, the pooled exposure-response relation and its variance can be estimated using standard fixed-effects and random-effects models for meta-analysis (12, 13). A principal reason why epidemiologists report exposure-response relations through relative risks corresponding to ranges of exposure levels is to avoid making an assumption of linearity of the exposure-response relation, even at the expense of a (sometimes substantial) loss of statistical power (14). Therefore, at the meta-analysis stage, it will be useful to model the relation in a flexible nonlinear manner and explicitly assess the evidence (or lack thereof) of nonlinearity, both graphically and through formal statistical testing procedures. When a log-linear exposure-response relation is established, the estimated linear trends can be pooled in the usual manner under the assumption of log-linearity of the exposure response association, using fixed and random-effects models for meta-analysis (1, 6).
Liu et al. (9) presented a method to fit a quadratic random-effects model for meta-analysis. Here, we develop a more flexible restricted cubic splines method that can be used to assess nonlinearity graphically and through a formal statistical hypothesis test (11, 15). Briefly, for each study s(s = 1,…,S) contributing to the analysis, there are Ks nonreferent log relative risks (k = 1,…,Ks) corresponding to Ks doses Xks(k = 1,…,Ks), which are typically taken at the midpoint of the range of each exposure group. A common q-knot restricted cubic spline transformation is applied to the vector of aggregated exposure data (including the midpoint of the reference category), X = (X01,…,XK11,…,X0S,…,XKSS)T, out of which is obtained a matrix of q − 1 spline transformations Z = (Z1,Z2,…,Zq − 1) (11). Then,
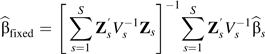 |
and
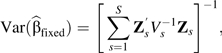 |
where for the fixed-effects model, , in which is the variance-covariance matrix for for study s, the variances are obtained from the published confidence intervals, and the covariances are reconstructed using either the GL method or the Hamling method. The procedures for calculating P values and predictions are derived using standard techniques available for simpler parametric models. For example, given that the log-linear dose-response model is nested within the restricted cubic spline model (Z1 = X), to obtain the P value for nonlinearity, we test the joint null hypothesis that the regression coefficients of the spline transformations Z2,…,Zq − 1 are all equal to zero.
The predicted relation between the relative risks and the exposure X modeled with spline transformations is given as , where Zref is a vector containing the values of the spline transformations corresponding to the chosen reference value. Based on asymptotic normality, the approximate pointwise 95% confidence interval of the predicted relative risks is then calculated as follows:
The methods described above have been implemented in publicly available macros we have written in Stata (located at http://nicolaorsini.altervista.org/stata/tutorial/g/glst.htm) and in SAS (located at http://www.hsph.harvard.edu/faculty/donna-spiegelman/software). Our SAS macro implements restricted cubic splines with 4 knots at the 5th, 35th, 65th, and 95th percentiles of the exposure data assuming the fixed-effects model. Because of the sparseness of data in most settings for estimating the variance-covariance matrix of the random effects that would involve the estimation of 6 parameters and an underpowered and difficult-to-interpret multivariate test for between-studies heterogeneity, we did not implement a nonlinear random-effects model in our current version of the software.
RESULTS
Alcohol and colorectal cancer
We first examined the relation between total alcohol intake and colorectal cancer risk in the 8 eligible prospective cohort studies participating in the Pooling Project of Prospective Studies of Diet and Cancer (16). A total of 3,646 cases and 2,511,424 person-years were included in the analysis. Because the raw data were available to us, each study provided 5 nonreferent dose levels with the same cutpoints, for a total of 40 (5 × 8 = 40) log relative risks. Ordinarily, the number of reference levels and the median dose corresponding to each level vary in the published data, and the methods considered here generalize directly to this data structure. Table 3 shows comparisons of the estimated slopes for the log-linear exposure-response relations and their 95% confidence intervals from the pooled primary data (2-stage meta-analysis of the individual data) with the slope estimated from the 2-stage meta-analysis of the published data, assuming nonzero correlations using the FAR, GL, and Hamling methods, as well as when incorrectly assuming zero correlations between the study-specific relative risks. Based on primary data, it appeared that the risk of colorectal cancer increased by 8% for every 12-g/day increase in total alcohol intake (95% confidence interval: 1.04, 1.12). In this example, no important differences were observed between the results obtained from the meta-analyses of the primary and published data when either nonzero or zero correlations among the estimated log relative risks were assumed. When using the heterogeneity test, we did not detect any significant differences among the study-specific slopes (P = 0.74), so the fixed-effects and random-effects models gave similar results. The average relative difference between the crude and adjusted relative risks was 11%, which indicated little evidence of confounding by the measured risk factors for colorectal cancer, and the average relative difference between crude and adjusted correlations among relative risks was 17%. There was borderline-significant nonlinearity detected (Figure 1A), with no effect of alcohol intake up to 20 g/day of intake, followed by a sharp increase in risk at the higher levels.
Table 3.
Estimates of Linear Trend in Colorectal Cancer RRs From Fixed-Effects and Random-Effects Meta-Analysis According to Alcohol Intakea
| Model and Method | Relative Riskb | 95% Confidence Interval | P for Trend | P for Nonlinearity | P for Heterogeneity |
| Fixed-effects model | |||||
| Primary data | |||||
| Age-adjusted | 1.09 | 1.06, 1.13 | <0.001 | 0.05 | 0.50 |
| Multivariatec | 1.08 | 1.04, 1.12 | <0.001 | 0.04 | 0.74 |
| Floating absolute risk | 1.08 | 1.05, 1.12 | <0.001 | 0.05 | 0.62 |
| Greenland and Longnecker | 1.08 | 1.05, 1.12 | <0.001 | 0.05 | 0.69 |
| Hamling | 1.08 | 1.05, 1.11 | <0.001 | 0.05 | 0.70 |
| Zero correlationd | 1.05 | 1.02, 1.08 | 0.003 | 0.02 | 0.45 |
| Random-effects model | |||||
| Primary data | |||||
| Age-adjusted | 1.09 | 1.06, 1.13 | <0.001 | ||
| Multivariatec | 1.08 | 1.04, 1.12 | <0.001 | ||
| Floating absolute risk | 1.08 | 1.05, 1.12 | <0.001 | ||
| Greenland and Longnecker | 1.08 | 1.05, 1.12 | <0.001 | ||
| Hamling | 1.08 | 1.05, 1.11 | <0.001 | ||
| Zero correlationd | 1.05 | 1.02, 1.08 | 0.003 |
Analyses were based on pooled primary and summarized published dose-response data (Ann Intern Med. 2004;140(8):603–613) and assumed either nonzero or zero covariances across relative risks within each study.
Relative risk for a 12-g/day increase in alcohol intake.
Adjusted for energy intake (kcal/day), multivitamin use, family history of colorectal cancer, current smoking, past smoking, red meat intake (quartiles), total milk intake (quartiles), and dietary folate intake (quintiles).
Covariances among log relative risks within each study were set to zero.
Figure 1.

Dose-response relations between alcohol intake and relative risks of A) colorectal cancer (P for nonlinearity = 0.05) and B) lung cancer (P for nonlinearity = 0.22). Data were modeled with fixed-effects restricted cubic spline models with 4 knots and using the Greenland and Longnecker method to estimate the covariances of multivariable-adjusted relative risks. Lines with long dashes represent the pointwise 95% confidence intervals for the fitted nonlinear trend (solid line). Lines with short dashes represent the linear trend.
Smoking, alcohol, and lung cancer
We next examined the 4 eligible prospective studies among men in which alcohol consumption was hypothesized to contribute to lung cancer risk (17). A total of 1,762 cases and 673,766 person-years were included in this analysis. Because the raw data were available to us, each study provided 4 nonreferent dose levels with the same cutpoints, for a total of 16 (4 × 4 = 16) log relative risks. The risk of lung cancer increased by 7% for every 12-g/day increase in total alcohol consumption (Table 4). No between-study heterogeneity in the log-linear slopes was detected (P = 0.11); hence, there was little difference between the relative risks for linear trend estimated from the fixed model and those estimated using the random-effects model. However, when incorrectly assuming no correlation between relative risks from the same study, falsely significant evidence for between-study heterogeneity was given. We found no material difference between the widths of the confidence intervals when comparing the meta-analysis of the primary data and the published data using the FAR, GL, or Hamling method. However, when we incorrectly assumed zero correlation, the trend test P value was considerably larger for both the fixed-effects model (P = 0.28) and the random-effects model (P = 0.58) meta-analyses of published data than it was when either the GL method or the Hamling method was used (P = 0.002 for the fixed-effects model with both the GL and Hamling methods and P = 0.04 and P = 0.03 for the random-effects model with the GL and Hamling methods, respectively). The average relative difference between the crude relative risk and the adjusted relative risk was 19%, which provided substantial evidence of confounding by the measured risk factors for lung cancer. The average relative difference between crude and adjusted correlations among relative risks was 2%. There was no evidence of a nonlinear association in the pooled multivariate analysis of the original raw data (Figure 1B). When we assumed zero correlation between relative risks from the same study, falsely significant evidence for between-study heterogeneity was indicated.
Table 4.
Estimates of Linear Trend in Lung Cancer Relative Risks From Fixed-Effects and Random-Effects Meta-Analysis According to Alcohol Intakea
| Model and Method | Relative Riskb | 95% Confidence Interval | P for Trend | P for Nonlinearity | P for Heterogeneity |
| Fixed-effects model | |||||
| Primary data | |||||
| Age-adjusted | 1.21 | 1.16, 1.26 | <0.0001 | 0.22 | <0.0001 |
| Multivariatec | 1.07 | 1.03, 1.12 | 0.001 | 0.17 | 0.11 |
| Floating absolute risk | 1.07 | 1.03, 1.12 | <0.001 | 0.19 | 0.11 |
| Greenland and Longnecker | 1.07 | 1.02, 1.12 | 0.002 | 0.22 | 0.11 |
| Hamling | 1.07 | 1.03, 1.12 | 0.002 | 0.17 | 0.10 |
| Zero correlationd | 1.03 | 0.98, 1.08 | 0.28 | 0.15 | 0.02 |
| Random-effects model | |||||
| Primary data | |||||
| Age-adjusted | 1.20 | 1.08, 1.34 | 0.0009 | ||
| Multivariatec | 1.07 | 1.01, 1.14 | 0.03 | ||
| Floating absolute risk | 1.07 | 1.01, 1.14 | 0.03 | ||
| Greenland and Longnecker | 1.07 | 1.00, 1.13 | 0.04 | ||
| Hamling | 1.07 | 1.01, 1.14 | 0.03 | ||
| Zero correlationd | 1.02 | 0.94, 1.11 | 0.58 |
Analyses were based on pooled primary and summarized published dose-response data (Am J Clin Nutr. 2005;82(3):657–667) and assumed either nonzero or zero covariances across relative risks within each study.
Relative risk for a 12-g/day increase in alcohol intake.
Adjusted for smoking status (never, past, or current), smoking duration for past and current smokers (years), number of cigarettes smoked daily for current smokers (continuous), educational level (less than high school graduate, high school graduate, or postsecondary education), body mass index (weight (kg)/height (m)2; <23, 23–<25, 25–<30, or ≥30), and energy intake (kcal/day).
Covariances among log relative risks within each study were set to zero.
We conducted an empirical comparison of the actual average covariances from the primary data with the average covariances estimated by the GL method and the Hamling method in the 4 studies available in the pooled analysis of alcohol in relation to lung cancer risk. Although the mean biases of the covariances estimated by the 2 methods were similar (about 1%), there was slightly more variation in the covariance biases by study when using the GL method than when using the Hamling method (−9%, 14%, −5%, and 3% vs. −8%, 12%, −4%, and 1%, respectively).
DISCUSSION
In the present study, we found that the differences between the results of meta-analyses of summarized published data using the FAR, GL, or Hamling method and a meta-analysis of individual original data were negligible, even when there was evidence of substantial confounding. In addition, we found that assuming zero correlations led to biased point estimates and confidence intervals for the trend, biased tests for nonlinearity, and biased tests for between-study heterogeneity when confounding of the estimated dose-specific relative risks was evident. This was especially evident in the second example (the relation between alcohol consumption and lung cancer), in which cigarette smoking was a strong confounder (17). The average relative difference between the crude and adjusted relative risks was twice that in the first example (in which there was little evidence for confounding).
There are several strengths of the present article. First, we provided the correct formulas for the variance of the relative risk in cohort studies for both incidence rate and cumulative incidence data, rectifying errors in the original publication (2). Second, we developed publicly available user-friendly programs for these methods in the environments of 2 statistical packages commonly used by epidemiologists and biostatisticians, and we demonstrated their use in the appendices (Web Appendix 1 and Web Appendix 2, available at http://aje.oxfordjournals.org/). Third, we compared results from the GL method with those from the Hamling method and assessed their validity against a meta-analysis of the pooled individual data when the need for these methods is obviated.
Some limitations should be mentioned. We did not consider other important issues, such as optimal choices of dose values for exposure levels, publication bias, and methodological bias (6, 10, 18).
In conclusion, we recommend using the Hamling method or the GL method whenever it is possible to retrieve the required information from the published articles to be included in the meta-analysis. It is particularly important to use one of these methods when the association of interest is strongly affected by confounding, in which case the standard inverse variance-weighted regression assuming zero correlations among log relative risks would lead to biased confidence intervals for the trends and invalid P values of the hypothesis tests of interest. In addition, we found that 2 meta-analyses of summarized published data using the GL and Hamling methods provided an estimated linear trend and a confidence interval close to the ones estimated by the pooled analysis of the original data. Because both methods make somewhat different assumptions that are unlikely to be exactly true in any given setting, it is not possible to globally recommend one method over the other. However, it is clear that one of these methods should be used in meta-analyses of dose-response whenever possible.
Supplementary Material
Acknowledgments
Author affiliations: Unit of Nutritional Epidemiology, Institute of Environmental Medicine, Karolinska Institutet, Stockholm, Sweden (Nicola Orsini, Alicja Wolk); Unit of Biostatistics, Institute of Environmental Medicine, Karolinska Institutet, Stockholm, Sweden (Nicola Orsini); Department of Epidemiology, Harvard School of Public Health, Boston, Massachusetts (Ruifeng Li, Polyna Khudyakov, Donna Spiegelman); and Department of Biostatistics, Harvard School of Public Health, Boston, Massachusetts (Polyna Khudyakov, Donna Spiegelman).
This work was supported by Karolinska Institutet awards, the Swedish Research Council/Longitudinal Studies, the Swedish Cancer Society, the Swedish Foundation for International Cooperation in Research and Higher Education, and the US National Institutes of Health (grants NIH P01 CA-055075 and NIH P30 CA-06516).
Conflict of interest: none declared.
Glossary
Abbreviations
- FAR
floating absolute risk
- RR
relative risk
References
- 1.Berlin JA, Longnecker MP, Greenland S. Meta-analysis of epidemiologic dose-response data. Epidemiology. 1993;4(3):218–228. doi: 10.1097/00001648-199305000-00005. [DOI] [PubMed] [Google Scholar]
- 2.Greenland S, Longnecker MP. Methods for trend estimation from summarized dose-response data, with applications to meta-analysis. Am J Epidemiol. 1992;135(11):1301–1309. doi: 10.1093/oxfordjournals.aje.a116237. [DOI] [PubMed] [Google Scholar]
- 3.Hamling J, Lee P, Weitkunat R, et al. Facilitating meta-analyses by deriving relative effect and precision estimates for alternative comparisons from a set of estimates presented by exposure level or disease category. Stat Med. 2008;27(7):954–970. doi: 10.1002/sim.3013. [DOI] [PubMed] [Google Scholar]
- 4.Easton DF, Peto J, Babiker AG. Floating absolute risk: an alternative to relative risk in survival and case-control analysis avoiding an arbitrary reference group. Stat Med. 1991;10(7):1025–1035. doi: 10.1002/sim.4780100703. [DOI] [PubMed] [Google Scholar]
- 5.Orsini N. From floated to conventional confidence intervals for the relative risks based on published dose-response data. Comput Methods Programs Biomed. 2010;98(1):90–93. doi: 10.1016/j.cmpb.2009.11.005. [DOI] [PubMed] [Google Scholar]
- 6.Shi JQ, Copas JB. Meta-analysis for trend estimation. Stat Med. 2004;23(1):3–19. doi: 10.1002/sim.1595. [DOI] [PubMed] [Google Scholar]
- 7.Berrington A, Cox DR. Generalized least squares for the synthesis of correlated information. Biostatistics. 2003;4(3):423–431. doi: 10.1093/biostatistics/4.3.423. [DOI] [PubMed] [Google Scholar]
- 8.Bagnardi V, Zambon A, Quatto P, et al. Flexible meta-regression functions for modeling aggregate dose-response data, with an application to alcohol and mortality. Am J Epidemiol. 2004;159(11):1077–1086. doi: 10.1093/aje/kwh142. [DOI] [PubMed] [Google Scholar]
- 9.Liu Q, Cook NR, Bergstrom A, et al. A two-stage hierarchical regression model for meta-analysis of epidemiologic nonlinear dose-response data. Comput Stat Data Anal. 2009;53(12):4157–4167. [Google Scholar]
- 10.Hartemink N, Boshuizen HC, Nagelkerke NJ, et al. Combining risk estimates from observational studies with different exposure cutpoints: a meta-analysis on body mass index and diabetes type 2. Am J Epidemiol. 2006;163(11):1042–1052. doi: 10.1093/aje/kwj141. [DOI] [PubMed] [Google Scholar]
- 11.Durrleman S, Simon R. Flexible regression models with cubic splines. Stat Med. 1989;8(5):551–561. doi: 10.1002/sim.4780080504. [DOI] [PubMed] [Google Scholar]
- 12.Dersimonian R, Laird N. Meta-analysis in clinical trials. Control Clin Trials. 1986;7(3):177–188. doi: 10.1016/0197-2456(86)90046-2. [DOI] [PubMed] [Google Scholar]
- 13.Stram DO. Meta-analysis of published data using a linear mixed-effects model. Biometrics. 1996;52(2):536–544. [PubMed] [Google Scholar]
- 14.Greenland S. Avoiding power loss associated with categorization and ordinal scores in dose-response and trend analysis. Epidemiology. 1995;6(4):450–454. doi: 10.1097/00001648-199507000-00025. [DOI] [PubMed] [Google Scholar]
- 15.Govindarajulu US, Spiegelman D, Thurston SW, et al. Comparing smoothing techniques in Cox models for exposure-response relationships. Stat Med. 2007;26(20):3735–3752. doi: 10.1002/sim.2848. [DOI] [PubMed] [Google Scholar]
- 16.Cho E, Smith-Warner SA, Ritz J, et al. Alcohol intake and colorectal cancer: a pooled analysis of 8 cohort studies. Ann Intern Med. 2004;140(8):603–613. doi: 10.7326/0003-4819-140-8-200404200-00007. [DOI] [PubMed] [Google Scholar]
- 17.Freudenheim JL, Ritz J, Smith-Warner SA, et al. Alcohol consumption and risk of lung cancer: a pooled analysis of cohort studies. Am J Clin Nutr. 2005;82(3):657–667. doi: 10.1093/ajcn.82.3.657. [DOI] [PubMed] [Google Scholar]
- 18.Greenland S. Multiple-bias modelling for analysis of observational data. J R Stat Soc Ser A Stat Soc. 2005;168(2):267–291. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.