

Abstract
We report on a user study evaluating Redirected Free Exploration with Distractors (RFED), a large-scale, real-walking, locomotion interface, by comparing it to Walking-in-Place (WIP) and Joystick (JS), two common locomotion interfaces. The between-subjects study compared navigation ability in RFED, WIP, and JS interfaces in VEs that are more than two times the dimensions of the tracked space. The interfaces were evaluated based on navigation and wayfinding metrics and results suggest that participants using RFED were significantly better at navigating and wayfinding through virtual mazes than participants using walking-in-place and joystick interfaces. Participants traveled shorter distances, made fewer wrong turns, pointed to hidden targets more accurately and more quickly, and were able to place and label targets on maps more accurately. Moreover, RFED participants were able to more accurately estimate VE size.
Index Terms: H.5.1 [Information Interfaces and Presentation]: Multimedia Information Systems—Artificial, augmented and virtual realities; I.3.6 [Computer Graphics]: Methodology and Techniques—Interaction techniques;; I.3.7 [Computer Graphics]: Three-Dimensional Graphics and Realism—Virtual Reality
1 Introduction
Navigation is the combination of wayfinding and locomotion and as such is both cognitive and physical. Wayfinding is building and maintaining a cognitive map and it is used to determine how to get from one location to another, while locomotion is moving, physically or virtually, between two locations [4]. In the real world people often locomote by walking. Walking is simple and natural, and enables people not only to move between locations, but also to develop cognitive maps, or mental representations, of environments.
People navigate every day in the real world without problem, however users navigating VEs often become disoriented and frustrated, and find it challenging to transfer spatial knowledge acquired in the VE to the real world [5, 7, 8, 17]. Navigation is important for VE applications where spatial understanding of the VE must transfer to the real world, such as exploring virtual cities, training ground troops, or visiting virtual models of houses.
Real-walking locomotion interfaces are believed to enable better user navigation, are more natural, and produce a higher sense of presence than other locomotion interfaces [25, 28]. In this paper we further develop the real-walking locomotion interface, Redirected Free Exploration with Distractors (RFED) which was first presented in [16]. RFED is for head-mounted display (HMD) users who are moving through VEs on foot, i.e., walking. Additionally, we demonstrate the effectiveness of RFED to enable free exploration in large scale VEs.
A common argument against redirection and distractors is a potential increase in cognitive load, disorientation, and simulator sickness. We demonstrate through a between-subjects user study that users perform significantly better on navigation and wayfinding metrics with RFED than with joystick and walking-in-place locomotion interfaces. RFED participants traveled shorter distances, made fewer wrong turns, pointed to hidden targets more accurately and more quickly, and were able to place and label targets on maps more accurately than both joystick and walking-in-place participants. No significant difference in either presence or simulator sickness was found between RFED, WIP, and JS.
2 Background
Previous research suggests that users navigate best in VEs with locomotion interfaces such as real-walking [23] that provide users with vestibular and proprioceptive feedback. Interfaces that stimulate both of these systems improve navigation performance and are less likely to cause simulator sickness than locomotion interfaces that do not stimulate both systems [2, 23]. VE locomotion interfaces such as walking-in-place, omni-directional treadmills, or bicycles [3, 9] require physical-input from the user, however they do not stimulate the vestibular and proprioceptive systems in the same way as really walking. In contrast, RFED users really walk, generating both vestibular and proprioceptive feedback.
Since user motion must be tracked, VEs using a real-walking locomotion interface have typically been restricted in size to the area of the tracked space. Current interfaces that enable real walking in larger-than-tracked-space VEs include redirected walking (RDW) [18, 19, 20], scaled-translational-gain [21, 31, 32], seven-league boots [10], and motion compression (MC) [13, 27]. Each of these interfaces transforms the VE or user motion by rotating the environment or scaling user motion.
When freely walking in the locomotion interfaces mentioned above, users may find themselves about to walk out of the tracked space, and possibly into a real wall. When a user nears the edge of the tracked space a reorientation technique (ROT) is used to prevent the user from leaving the tracked space [14, 15]. ROTs must be applied before the user leaves the tracked space. ROTs rotate the VE around the user's current location, returning the user's predicted path to the tracked space. The user must also reorient his body by physically turning so he can follow his desired path in the newly-rotated VE.
Redirected Free Exploration with Distractors (RFED) is a locomotion interface that combines transformation of the VE, based on the redirected walking (RDW) system [18], which uses redirection—imperceptibly rotating the VE model around the user—to remap areas of the VE to the tracked space, and distractors—visual objects and/or sounds in the VE— as a ROT [14, 15].
Transforming the VE by rotation has advantages over other transformations because when people turn their heads at normal angular velocities, the vestibular system dominates the visual system, thus enabling rotation of the VE visuals without the user noticing [6]. As demonstrated by [18], users can be imperceptibly redirected very little unless the redirection is performed while the user's head is turning, which desensitizes the visual system. Additionally, larger amounts of redirection can be imperceptibly accomplished during head turns [11, 18].
To elicit head-turns, RDW used prescribed paths through the VE that at predetermined locations required the user to physically turn her head and body. The principal aim of RFED is to remove this limitation and enable users to walk freely about in a VE.
Walking freely in VEs raises a new problem—how to ensure that the user avoids real-space obstacles. Our system uses distractors to guide users away from the tracker boundary. Additionally, we introduce a new technique, deterrents—objects in the virtual environment that people stay away from or do not to cross.
While VE transformations, distractors, and deterrents enable large-scale real-walking in VEs, the effect of the transformations on navigational ability is unknown. The study presented in the paper evaluates the effect of rotational transformations and distractions from distractors and deterrents on navigational ability.
3 Conditions
3.1 Redirected Free Exploration with Distractors (RFED)
The RFED algorithm presented here is designed based on the Improved Redirection with Distractors (IRD) algorithm presented in [16] and enables free-walking in large-scale VEs as follows:
Predict and Redirect: At each frame, predict the user's real-space future direction, vfuture and rotate the VE around the user such that vfuture is rotated toward c, the center of the tracked space. See Figure 1.
-
Distract: Introduce a distractor to:
Stop the user.
Force a head-turn, enabling large amounts of redirection.
Redirect the user's future direction toward the center of the tracked space.
Deter: If the user is at the boundary, introduce a deterrent, objects in the environment that people stay away from or do not cross, to guide the user away from the boundary.
Figure 1.
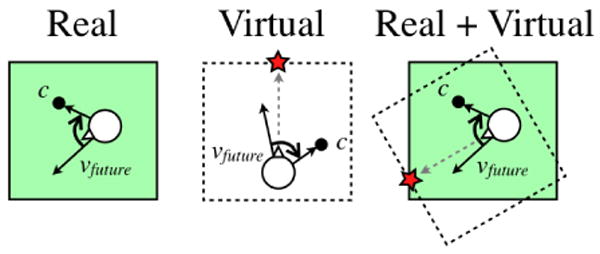
The shaded region represents the real tracked space and the dashed region represents the virtual space. c is in the center of the whole tracked space. We predict the user's future direction, vfuture and rotate the virtual space such that vfuture is toward the center of the tracked space, c.
Distractors are used to stop the user when they are near the boundary. We additionally use distractors when the user is away from the boundary to preemptively preemptively increase redirection and redirect the user toward the center of the lab. However, our overall desire is to minimize the number of distractors, since they impair the VE experience. To limit the number of distractions, one wants to redirect as quickly as possible to redirect the user away from the boundary. The two goals of our redirection implementation are to:
Minimize the total VE redirection used to redirect the user away from the boundary.
Maximize the instantaneous redirection to quickly redirect the user away from the boundary.
We minimize total redirection by rotating the VE in the direction of the smaller angle between vfuture and the vector between the user's current position and the center of the tracked space. vfuture is computed by extrapolation from recent path positions.
If there were no limits to the amount of imperceptible redirection that could occur in any frame, and users were always redirected toward the center of the tracked space, users would never reach a boundary and a distractor would never be introduced. However, there is a limit to the amount of instantaneous redirection that is imperceptible to the visual system.
Results from [11] tell us that the faster the user turns his head, the less aware he will be of VE rotation. Based on that result, we compute θVE, the amount of rotation that is added to each frame, as a function of ωhead, the user's head speed, and a predefined rotation constant, c.
| (1) |
Based on pilot experiments and results in [11], we chose c to be 0.10 when the VE is rotating in the same direction as ωhead and 0.05 when the VE rotates in the direction opposite of ωhead.
When redirection fails a distractor is used to prevent the user from leaving the tracked space. Our distractor was a hummingbird that flew back and forth in front of the user. See Figure 2 A. The distractor forces user head-turns, thus enabling large amounts of redirection to steer the user back toward the center of the tracked space.
Figure 2.
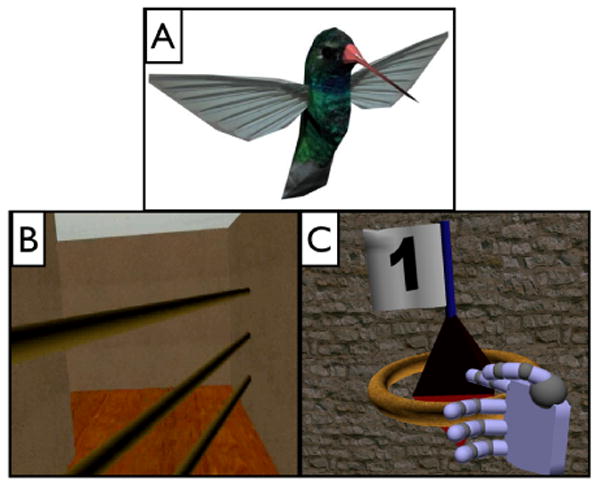
Screen shots of A: the hummingbird distractor, B: the horizontal bars used as deterrents, and C: the virtual avatar hand selecting a target.
If the user is very close to the tracker boundary, we deter the user from the boundary with a deterrent—an object in the environment that people are instructed to stay away from or not to cross. For this implementation, deterrents were 6.5m virtual horizontal bars that were aligned with the boundaries of the tracked space. Participants were never able to see all of the deterrent bars because the virtual models occluded much of the deterrent model. See Figure 2 B. The bars fade in as the user nears the boundary of the tracked space and fade out as the user walks away from the boundary. The virtual bars provided participants with a visual cue as to which direction to walk to stay in the real space. No participants complained about the bars.
3.2 Walking-In-Place (WIP)
Subjects in the WIP system condition locomoted by stepping in place. Advantages of WIP interfaces include: participants receive kinesthetic feedback from the in-place steps that move the viewpoint, and WIP interfaces can be implemented in small spaces. We used the GUD-WIP locomotion interface, because it closely simulates real-walking [30]. Subjects wore shin-guards equipped with Phase Space beacons and shin position was tracked with a PhaceSpace tracker. See Figure 3. As in [30], heading direction was determined by the participant's average-forward shin direction. Forward speed was a function of shin movement and stepping frequency.
Figure 3.

The GUD WIP locomotion interface set-up. Participants were kept in place with the cage make of PVC pipe. The same physical setup was also used in the JS condition.
3.3 Joystick (JS)
Participants in the JS condition controlled forward speed with a hand-held X-Box 360 controller. Deflection of the spring loaded JS controlled speed. The maximum speed of the participant in the joystick condition was chosen to be a moderate walking speed of 3 miles/hour. Subjects in the JS condition also used the PhaseSpace tracker to determine heading direction from shin positions. Pushing forward on the joystick translated the participant's viewpoint forward in the average direction of the participant's shins. Virtual movement was restricted to be only in the direction of the participants shins as calculated with the Phase Space beacons.
4 Methods
The evaluation of RFED compared to WIP and JS required participants to locomote through the virtual mazes shown in Figure 4. The mazes were 15.85m×15.85m, more than twice the dimension (four times the area) of the tracked space. Participants in the RFED condition were restricted to really walking in a space that was 6.5m×6.5m, while participants in the WIP and JS conditions were confined to 1.5m×1.5m area. See Figure 3.
Figure 4.
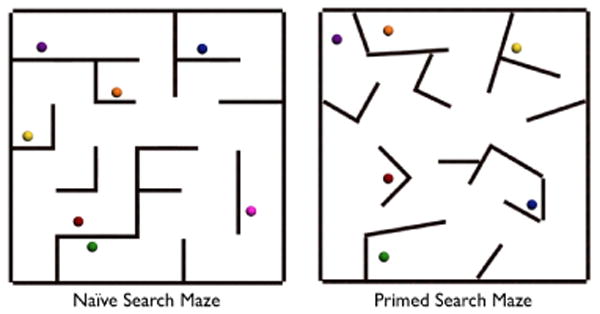
The 15.85m × 15.85m virtual mazes used in this study. Left: the maze used during the naive search with seven targets. Right: the maze used during the primed search with six targets. Participants started each maze in the bottom left corner.
Turning, which stimulates the kinesthetic senses, is believed to aid navigation [2, 23]. Thus, we eliminated turning as a possible confounding factor by requiring users in all conditions to turn, i.e., change heading direction, by physically turning their bodies.
We compared RFED to WIP and JS using navigation and wayfinding tasks: search for specified targets within the VE, point-to-targets that are not visible, and map completion.
Navigation
Search tasks, which are commonly used in VE locomotion studies [1], are used to evaluate navigational ability and VE training-transfer of spatial knowledge for locomotion interfaces [29, 33]. Search tasks include naïve searches, in which targets have not yet been seen, and primed searches, in which targets have previously been seen.
Participants performed both naïve and primed searches. Navigational performance was measured by the total distance participants traveled and the number of times participants revisited routes, i.e., returned to previously visited routes of the virtual mazes.
The distance participants travel is a measure of overall spatial knowledge accuracy [22]. Participants who travel shorter distances tend to have a better spatial understanding of the environment enabling them to walk directly to targets without unnecessarily retracing previous steps.
Wayfinding
Point-to-target techniques require participants to point to targets that they have previously seen, but that are currently out of view. Pointing tasks measure a user's ability to wayfind within VEs [2] by testing the user's mental model of target location in relation to the user's current location. Angular pointing errors with small magnitudes suggest that participants have a good understanding of the location of targets.
Map completion requires users to place and label targets on a paper map of the VE after exiting the VE. The map target locations should correspond to VE target locations. Map completion is often used as a wayfinding metric because maps are a familiar navigation metaphor [4]. Participants with a better mental model of the VE can more accurately place targets in correct locations and correctly label targets on the map.
4.1 Participants
Thirty-six participants, 25 men and 11 women, average age 26, participated in the IRB-approved experiment. Twelve participants were assigned to each condition (8 men and 4 women in both RFED and WIP, and 9 men and 3 women in JS).
4.2 Equipment
Each participant wore a stereo nVisor SX head-mounted display with 1280×1024 resolution in each eye and a diagonal FOV of 60°. The environment was rendered on a Pentium D dual-core 2.8GHz processor machine with an NVIDIA GeForce GTX 280 GPU with 4GB of RAM. The interface was implemented in our locally developed EVEIL intermediate level library that communicates with the Gamebryo® software game engine from Emergent Technologies. The Virtual Reality Peripheral Network (VRPN) was used for tracker communication. The system latency was 50 ± 5ms.
The tracked-space was 9m × 9m and head and hand tracked using a 3rdTech HiBall 3000.
The Walking-in-Place and Joystick systems used an eight-camera PhaseSpace Impulse optical motion capture system with the cameras placed in a circle around the user. The user wore shin guards with seven beacons attached to each shin. PhaseSpace tracked the forward-direction and stepping motion of each leg. The GUD-WIP interface and Joystick direction detection code ran on a PC with an Intel Core2 2.4GHz CPU, NVIDIA GeForce 8600 GTS GPU, and 3 GB RAM.
4.3 Experimental Design
The experimental design is very similar to the study presented in [16]. Participants locomoted through three virtual mazes: a training environment and two testing environments. See Figure 4. The virtual environments were 15.85m × 15.85m mazes with uniquely colored and numbered targets placed at specified locations. See Figure 2 C. All environments used the same textures on the walls and floors, and the same coloring and numbering of targets. The naïve search included seven targets and the primed search included six targets. The VE for the primed search is similar to the naïve search except that the walls are not all placed at 90° angles. This was done to make the experiment more challenging by removing feedback that enables users to determine cardinal directions from axis-aligned walls. The location of the targets changed between the naive and primed searches. All subjects completed the same trials in the same order to control for training effects, and were not given performance feedback during any part of the experiment. Subjects were randomly assigned to the RFED, WIP or JS condition, and completed all parts of the experiment, including training, in the assigned condition.
4.3.1 Training
Subjects received oral instructions before beginning each section of the experiment. The training environment was a directed maze with all walls placed at 90° angles. Subjects walked through the environment pressed a button on a hand-held tracked device to select each of the seven targets which were placed at eye-height and located along the path. Participants had to be within an arm's length to select a target. When a target was selected, a ring appeared around it and audio feedback was played to signify that the target had been found. See Figure 2 C.
After subjects completed the training maze, the head-mounted display was removed and participants were asked to complete a 8.5″ × 11″ paper map of the environment. The map representation of the environment was a 16cm × 16cm overhead view of the maze with the targets missing. Participants were given their starting location and maps were presented such that the initial starting direction was away from the user. By hand, subjects placed a dot at the location corresponding to each target and labeled each target with its corresponding number or color.
4.3.2 Part 1: Naïve Search
After training, participants were given oral instructions for Part 1, the naïve search. The maze and target locations for Part 1 can be seen in Figure 4. Participants were instructed to, in any order, find and remember the location of the seven targets within the maze. Participants were also reminded they would have to complete a map, just as in the training session. As soon as subjects found and selected all targets, the virtual environment faded to white and subjects were instructed to remove the head-mounted display. Subjects then completed a map in the same manner as in training.
4.3.3 Part 2: Primed Search
After completing the naïve search, subjects were given oral instructions for Part 2, the primed search. The maze and target locations for the primed search can be seen in Figure 4. Participants first followed a directed priming path that led to each of the six targets in a pre-specified order. After participants reached the end of the priming path the HMD faded to white, and the participants returned to the starting point in the VE. Participants in the RFED condition had to remove the HMD and physically walk to the starting location in the tracked-space. Participants using WIP or JS were asked if they wanted to remove the HMD, none did, and then they turned in place so they would be facing the starting forward direction in the virtual maze.
Participants were then asked to locomote, as directly as possible, to one of the targets. Once the participant reached and selected the specified target, they were instructed, via audio, to point, in turn, to each of the other targets. The instructions referenced targets by both color and number. After participants pointed to each other target, they were instructed to walk to another target where they repeated the pointing task. If a participant could not find a target within three minutes, arrows appeared on the floor directing the participant to the target. Arrows appeared in 2% of the trials and did not appear more frequently in any one condition. Once the participant reached the target, the experiment continued as before, with the participant pointing to all other targets.
Participants walked to the six targets in the order 3-5-4-1-2-6 and, from each, pointed to each of the other targets in numerical order. At the end of Part 2, subjects had pointed to each target five times, for a total of 30 pointing tasks per subject.
After completing the search and pointing tasks, subjects removed the HMD and completed a map just as in Part 1.
After the experiment, subjects completed a modified Slater-Usoh-Steed Presence Questionnaire [24] and a Simulator Sickness Questionnaire [12].
4.4 Results and Discussion
4.4.1 Part 1: Naïve Search
Navigation
Head-position data for all three conditions were filtered with a box filter to remove higher-frequency head-bob components of the signal. The filter width was three seconds. Participant travel distance was calculated from the filtered head pose data. Figure 5 shows the routes of the participant in each condition who's total distance is closest to the median total distance for that condition. Since participants were asked to find all the targets as directly as possible, our hypothesis is that participants who travel shorter distances have a better spatial understanding of the environment and of previously visited locations. We evaluated the null hypothesis that there was no difference in locomoted distances among locomotion interfaces, Figure 6. We used a Mixed Model ANOVA with locomotion interface as the between-subjects variable and distance traveled as the dependent variable and found a significant difference among locomotion interfaces, F(2,35)=4.688, p=0.016, r=0.353.
Figure 5.
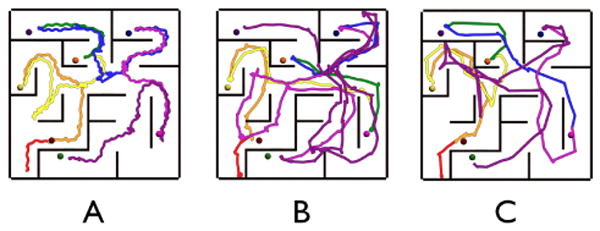
The virtual routes of three participants performing the naïve search, one using each of the three locomotion interfaces. The routes of the participant who traveled the median distance in each locomotion interface is displayed. A. RFED. B. WIP. C. JS.
Figure 6.
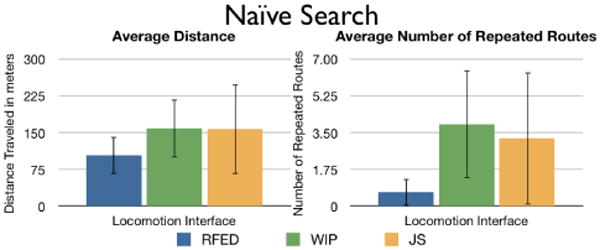
The average total distance traveled and the average number of repeated routes, by locomotion interface, when performing the naive search to find seven targets within the maze, with ±1 standard deviation error bars.
We performed Tukey pair-wise, post-hoc tests on the distance traveled data, and applied a Bonferroni correction since multiple Tukey tests were applied on the same data. Bonferroni corrections were applied to all further Tukey pair-wise tests. Participants using RFED traveled significantly shorter distances than participants using either WIP and JS, p=0.028 and p=0.037 respectively. No significant difference was found in locomoted distance between WIP and JS, p=0.992. These results suggest that participants using RFED had a better spatial understanding of the environment.
The number of times participants revisited routes was counted, where a repeated route was a route in the maze that a participant walked more than once. See Figure 6. We interpret repeated routes of the maze as indicating that participants were having a harder time building a mental model of the environment. We performed a Kruskal-Wallis test on the number of repeated routes and found a significant difference among locomotion interfaces for the number of times participants repeated routes of the maze when performing a naive search, H(2)=7.869, p=0.02. Pair-wise comparison post-hoc tests were performed. We found that participants using RFED revisited significantly fewer routes of the maze than participants using WIP, H(1)=-11.000, p=0.026. This suggests that, participants using RFED were not as lost, or had built a better mental model of the environment than participants using WIP. No significant difference was found comparing RFED to JS, or WIP to JS.
Wayfinding
We evaluated participants' ability to place and label each virtual target on a map of the VE. Targets were counted as correctly placed if they were within one meter (scaled) of the actual target and on the correct side of walls. Targets were counted as correctly labeled if they were both correctly-placed and were labeled with either the correct number or color. We performed two Mixed Model ANOVAs with locomotion interface as the between-subjects variable and percentage of correctly placed, and correctly-placed-and-labeled targets as the dependent variables. No significant difference was found among locomotion interfaces in user ability to place targets on maps. However, there was a trend that suggest a difference between interfaces on ability to correctly place and label targets after the naive search, F(2,30)=2.591, p=0.092, ω = −0.683, see Figure 7.
Figure 7.
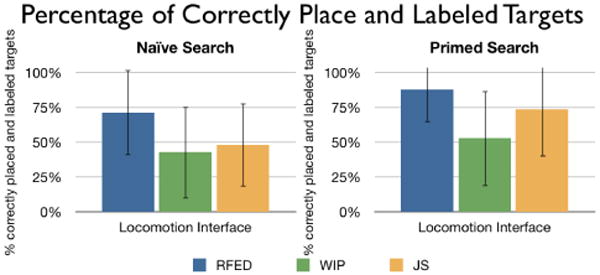
The average percentage of correctly placed and correctly labeled targets on paper maps after completing the naive and primed searches. ±1 standard deviation.
Conclusion
The naive search showed RFED participants traveled significantly shorter distances than both WIP and JS participants and revisited significantly fewer routes in the maze than participants using WIP. These results suggest that, when performing a naive search, participants using RFED had a better understanding of where they had already been within the VE and had a better spatial understanding of the VE than participants using either WIP or JS.
4.4.2 Part 2: Primed Search
Navigation
We calculated each participant's total travel-distance to find each of the six targets for the primed search, in the same way as the naïve search. The real and virtual routes from an RFED participant can be seen in Figure 8. While each participant travels the directed training path he builds a mental model of the environment. We assert that participants who build a better mental model during priming, i.e., while following the priming path, will locomote shorter distances between targets during the search and pointing portions of the task.
Figure 8.
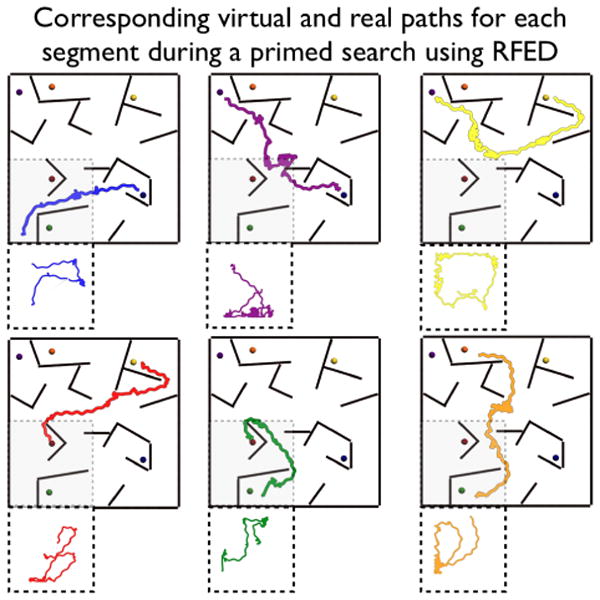
The virtual routes with corresponding real routes taken by a participant in the RFED condition during the primed search part of the experiment. Participants were really walking in one-quarter of the area of the VE. The large boxes are the virtual routes, and the small dashed line boxes are the corresponding real routes. Routes are displayed to scale.
We performed a MANOVA with locomotion interface as the between-subjects variable and distance traveled to each of the six targets as the within-subjects repeated measure. See Figure 9. We found a significant difference between locomotion interfaces on distance traveled, F(2,32)=7.150, p=0.003, r=0.427. Tukey post-hoc tests show that participants using RFED traveled significantly shorter distances than participants using WIP, p=0.002. No other significant results were found. This suggests that participants using RFED were better at navigating the VE than participants using WIP.
Figure 9.
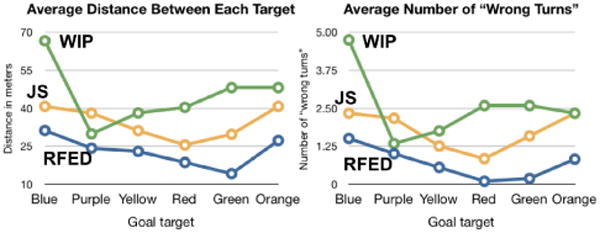
The average distance traveled between targets (in visited order) and the average number of “wrong turns”, by locomotion interface when performing the primed search for each of the six targets within the maze.
An additional path evaluation was performed by using a Kruskal-Wallis test on the total number of wrong turns taken by each participant during the primed search. A wrong turn occurs at an intersection when the participant does not take the shortest route to the current target goal. A significant difference was found between locomotion interfaces, H(2)=11.251, p=0.004. Pairwise comparisons, show that participants using RFED made significantly fewer wrong turns than those using either WIP, H(1)=-13.667, p=0.004, or JS, H(1)=-10.708, p=0.038. No significant difference was found between JS and WIP users, H(1)=2.958, p=1.00. These results suggest that participants in RFED had a better understanding of where they were going in the virtual maze and had a better mental model of the environment after having the same experience in the VE as participants in the WIP and JS interfaces.
Analysis of the routes taken to each individual target show significant difference between walking to target #1, the red target, and target #2 the green target, H(2)=6.505, p=0.039, and H(2)=8.881, p=0.012 respectively. Post-hoc tests reveal that participants using WIP made significantly more wrong turns when navigating to these two targets than participants using RFED, H(1)=-9.352, p=0.034, and H(1)=-11.727, p=0.01 respectively. It is interesting to note that during the priming portion of the task, participants visited target #1, the red target first, and visited target #2 the green target last. This may suggest that participants using WIP have problems in the beginning and end of the VE experience. Note: all subjects had to regularly stop and start locomoting to select the targets as they walked the directed path, and participants had to “walk” to get to target #1. Further evaluation of WIP interfaces should be explored, specifically looking at cognitive load at the beginning and end of a virtual experience. There was no significant difference for any of the individual routes between RFED and JS or WIP and JS.
Wayfinding
During the primed search, when subjects reached a target they then were asked to point to each of the other targets. See Figure 10. Small absolute angular pointing error suggests that participants have a better understanding of the location of targets. We ran a Mixed Model ANOVA with locomotion interface as the between-condition variable and absolute pointing error to each target as the repeated measure. There was a significant difference among locomotion interfaces for the absolute angular error when pointing to targets, F(2,28)=5.314, p=0.011, r= 0.399. Tukey pair-wise post-hoc tests reveal that participants using RFED had significantly smaller absolute pointing errors than both WIP and JS, p=0.021 and p=0.024 respectively. That is, participants using RFED had significantly better understanding of the location of targets in relation to their current location.There was no significant difference in absolute pointing error between WIP and JS, p=0.993.
Figure 10.
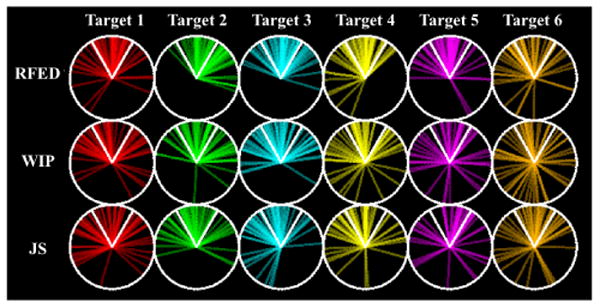
The pointing data for all participants to each of the six targets (columns) by each locomotion interface (row). The white lines denote ±30°.
In addition to evaluating point-to ability, we also analyzed how long participants took to point to each target. See Figure 11. We hypothesized that participants with a clearer mental model would be able to point more quickly to targets. The first pointing trial was also the first time participants pointed, thus we considered this as a training trial and removed it from the data. We ran a Mixed Model ANOVA with locomotion interface as the between-condition variable, and time to point to each target as the repeated measure and found a trend suggesting a difference in pointing time among locomotion interfaces, F(1,19)=2.992, p=0.074, r=0.369.
Figure 11.
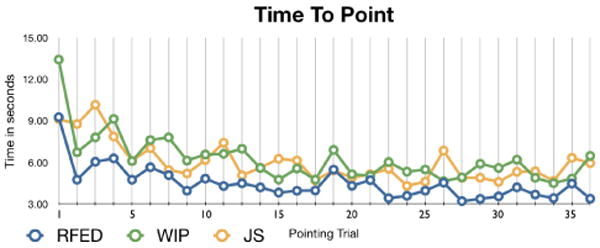
The average pointing time for each pointing trial by locomotion interface.
Further analysis of the first 14 trials, with the first trial removed, shows a significant difference among locomotion interfaces, F(2,23)=4.636, p=0.02, r=0.410. Tukey post-hoc tests show a significant difference between RFED and both WIP and JS, p=0.031 and p=0.050 respectively. This suggests that participants using RFED had a better mental model when pointing, compared to participants in WIP and JS, during the first half of the primed search. This result may imply that participants using RFED train faster than participants in either WIP or JS conditions, however further studies should evaluate interface training time.
We compared the difference in map completion ability using Mixed Model ANOVAs with locomotion interface as the between-subjects variable and percentage of correctly placed, and correctly-placed-and-labeled targets as the dependent variable, and found a significant difference among interfaces in participant ability to correctly place and label targets, F(2,30)=3.534, p=0.042, ω = −0.603. See Figure 7. Tukey pair-wise post-hoc tests revealed a significant difference between RFED and WIP in correctly placing and labeling targets on maps after completing the primed search part of the experiment, p=0.034. No other significant differences were found.
Conclusion
The primed search results suggest that participants using RFED navigate and wayfind significantly better than participants using WIP or JS. RFED participants travel shorter distances than participants using WIP, suggesting that RFED participants have a better spatial understanding of the environment and consequently walk more directly to targets. Participants using RFED make fewer wrong turns than either WIP and JS participants, providing additional evidence that RFED participants walk more directly to the goal targets, and hence are better at navigating the environment.
Participants in RFED were significantly better at wayfinding than participants in WIP or JS. RFED participants had significantly smaller absolute pointing errors than those using either WIP and JS. In addition to pointing to targets more accurately, participants using RFED are also better at placing and labeling the targets on maps than participants using WIP. This further suggests that participants in RFED develop a better mental model than WIP participants.
Finally, RFED participants point more quickly to targets in the beginning of the experiment than participants in both WIP and JS, suggesting that participants using RFED build mental models faster, however further studies should be run to verify this result. Overall, participants using RFED point to targets more accurately, complete maps with fewer mistakes, and are quicker at pointing to targets in the first half of the experiment.
4.4.3 Post Tests
After completing the final map, participants were asked to estimate the size of the VEs compared to the size of the tracker space they were currently in. See Table 1. Subjects were told that all three virtual environments were the same size and were given the dimensions of the tracked space. We found a significant difference between VE size predictions based on locomotion condition, F(2,31)=6.7165, p=0.006, r=0.742. Tukey pair-wise post-hoc tests reveal differences between RFED and both WIP (p=0.033) and JS (p=0.007). The results suggest that people have a better understanding of VE size when using RFED than with both WIP or JS.
Table 1.
The average VE size estimate and area underestimate by locomotion interface.
| Locomotion Interface | Dimension Estimate | Area Underestimate (%) |
|---|---|---|
| RFED | 15.0 m × 15.0 m | 10% |
| WIP | 10.5 m × 10.5 m | 56% |
| JS | 9.1 m × 9.1 m | 67% |
|
| ||
| Actual | 15.85 m × 15.85 m | 0% |
One possible confounding factor was that participants in the RFED condition saw virtual bars in the environment that represented the location of the bounds of the tracked space in the real lab. Based on the design of the maze, participants were not able to see more than 25% of the deterrent boundary at any given instant and usually saw less than 10% of the deterrent boundary. This “real world”-sized reference may have given people in the RFED condition an advantage in estimating the size of the VE. However, two participants in the RFED condition asked to walk around the room before making a guess as to the dimensions of the VE. No participants in JS or WIP asked to walk around the room. This suggests that two participants in the RFED condition realized that their physical walking steps could help measure the size of the VE. The two participants who asked to walk around the room were permitted to walk however neither estimated the lab size significantly better than other participants in the RFED condition.
Presence was evaluated using a modified Slater-Usoh-Steed presence questionnaire [24]. The number of “high” presence scores were counted, scores with a 5 or higher, and a Pearson's chi-square test was performed on the transformed data. No significant difference was found among locomotion interfaces and the number of “high” presence scores, χ2(12) = 14.143, p=0.292.
Participant simulator sickness scores were calculated using Kennedy's simulator sickness questionnaire [12]. A Pearson's chi-square test was performed on the results. No significant difference was found between locomotion interfaces and simulator sickness scores, χ2(40) = 42.800, p=0.337.
5 RFED Limitations
The current RFED implementation is limited by distractors appearing too frequently, a result of participants reaching the edge of the tracked space too often. In the current implementation, on average a distractor appears after the participant travels 5m ± 4m and remains visible for 8s ±2s. However, participants often travel longer distances than 5m before being stopped by a distractor. Once the participant stops, 2 or 3 distractors occasionally appear before the participant is redirected to the center of the tracked space and resumes walking.
The frequent occurrence of distractors is an obvious drawback of the current implementation. Improving the current redirection design and implementation, as well as determining how to encourage users to turn their heads, will reduce the occurrence of distractors and deterrents and the number of times participants reach the boundary of the tracked space.
Additionally, the implementation of RFED requires a large tracked area to enable redirection. With an average step length of 0.75m, in four steps a person can travel 3m, a typical tracking width. Although it is currently unknown as to how much redirection can be added at any instance, results from [11] suggest that, with head turns, the virtual scene can rotate 1.87°/sec and [26] suggests that people can be reoriented up to 30° when performing a 90° virtual rotation, i.e., the rotation could be 60° or 120°. From observation, if a person is walking straight and not turning their head, very little unobservable redirection can be added to the scene. Therefore, in a 3m×3m tracked space, the user may have to be stopped every 4 or 5 steps.
6 Conclusion
This study shows that RFED is significantly better than walking-in-place based on the same navigation metrics that were used in [16]. Researchers have shown that walking interfaces are significantly superior to joystick interfaces on many kinds of measures [33, 28]. Trends have been seen suggesting that real walking is superior to walking-in-place but no previous results have been able to show a statistically significant superiority. The study presented in this paper does that. We used a WIP system, GUD-WIP that is state-of-the-art [30]. We developed a real-walking system, RFED, that enabled free exploration of larger-than-tracked-space virtual environments. Pairwise comparisons showed that RFED was significantly superior to GUD-WIP and a JS interface on several navigation measures. Moreover, RFED was never significantly worse than either the JS and WIP interfaces on any measured metric in this study.
Further, we found no significant differences between our JS implementation and GUD-WIP. This was a surprising result, as we expected GUD-WIP to out-perform JS. We believe one reason for the lack of a significant differences stems from the challenges of stopping and starting in WIP systems, including GUD-WIP. The virtual mazes required many starts and stops to select and point to targets and WIP participants occasionally walked through targets when trying to stop in front of them. Additionally, when starting to walk, participants intentionally “walked” through targets in both JS and WIP interfaces instead of walking around them, while RFED participants did not walk through targets.
Although we found no navigational difference between WIP and JS, our results further support that real walking is critical for navigating VEs. Even though RFED continuously rotates the virtual world around the user and frequently stops the user with distractors, RFED participants were significantly better at navigating VEs than both WIP and JS participants. The physical difference between the systems is the stimulation of the proprioceptive system. There was no kinesthetic difference between interfaces since heading direction was controlled by physical heading direction. Although WIP stimulates the proprioceptive system, RFED more accurately stimulates the proprioceptive system because it is more similar to real-walking.
Our results support that accurate stimulation of the proprioceptive system is critical to navigation and even with rotation of the VE around the user and distractors, participants were able to navigate VEs significantly better than without accurate proprioceptive stimulation. Further development of RFED and RFED-like systems to improve usability will further aid VEs and the intended goal of free exploration of large spaces without user awareness of the enabling techniques.
Acknowledgments
Support for this work was provided by the Link Foundation. The authors would like to thank the EVE team, especially Jeremy Wendt for the use of his GUD-WIP system, and the anonymous reviewers for their thoughtful and helpful comments.
Contributor Information
Tabitha C. Peck, The University of North Carolina at Chapel Hill.
Henry Fuchs, The University of North Carolina at Chapel Hill.
Mary C. Whitton, The University of North Carolina at Chapel Hill.
References
- 1.Bowman DA. Principles for the Design of Performance-oriented Interaction Techniques. chapter 13. The Handbook of Virtual Environments. Lawrence Erlbaum Associates; Mahwah, NJ: 2002. pp. 277–300. [Google Scholar]
- 2.Chance S, Gaunet F, Beall A, Loomis J. Locomotion mode affects the updating of objects encountered during travel: The contribution of vestibular and proprioceptive inputs to path integration. Presence. 1998 April;7(2):168–178. [Google Scholar]
- 3.Darken RP, Cockayne WR, Carmein D. The omni-directional treadmill: a locomotion device for virtual worlds. UIST'97: Proceedings of the 10th annual ACM symposium on User interface software and technology; 1997. pp. 213–221. [Google Scholar]
- 4.Darken RP, Peterson B. Spatial Orientation, Wayfinding, and Representation. chapter 24. The Handbook of Virtual Environments. Lawrence Erlbaum Associates; Mahwah, NJ: 2002. pp. 493–518. [Google Scholar]
- 5.Darken RP, Sibert JL. Wayfinding strategies and behaviors in large virtual worlds. CHI'96: Proceedings of the SIGCHI conference on Human factors in computing systems; 1996. pp. 142–149. [Google Scholar]
- 6.Duh HBL, Parker DE, Phillips J, Furness TA. “Conflicting” motion cues at the frequency of crossover between the visual and vestibular self-motion systems evoke simulator sickness. Human Factors. 2004;46:142–153. doi: 10.1518/hfes.46.1.142.30384. [DOI] [PubMed] [Google Scholar]
- 7.Durlach NI, Mayor AS. Virtual reality: scientific and technological challenges. Washington, DC: National Academy Press; 1995. [Google Scholar]
- 8.Grant SC, Magee LE. Contributions of proprioception to navigation in virtual environments. Human Factors. 1998 Sept.40.3:489. doi: 10.1518/001872098779591296. [DOI] [PubMed] [Google Scholar]
- 9.Hollerbach JM. Locomotion Interfaces. chapter 11. The Handbook of Virtual Environments. Lawrence Erlbaum Associates; Mahwah, NJ: 2002. pp. 493–518. [Google Scholar]
- 10.Interrante V, Ries B, Anderson L. Seven league boots: A new metaphor for augmented locomotion through moderately large scale immersive virtual environments. IEEE 3D User Interfaces. 2007:167–170. [Google Scholar]
- 11.Jerald J, Peck T, Steinicke F, Whitton M. Sensitivity to scene motion for phases of head yaws. APGV'08: Proceedings of the 5th symposium on Applied perception in graphics and visualization; 2008. pp. 155–162. [Google Scholar]
- 12.Kennedy R, Lane N, Berbaum K, Lilenthal M. Simulator sickness questionnaire: An enhanced method for quantifying simulator sickness. The International Journal of Aviation Psychology. 1993:203–220. [Google Scholar]
- 13.Nitzsche N, Hanebeck UD, Schmidt G. Motion compression for telepresent walking in large target environments. Presence: Teleoper Virtual Environ. 2004;13(1):44–60. [Google Scholar]
- 14.Peck T, Whitton M, Fuchs H. Evaluation of reorientation techniques for walking in large virtual environments. Virtual Reality Conference, 2008 VR'08 IEEE; Mar, 2008. pp. 121–127. [Google Scholar]
- 15.Peck TC, Fuchs H, Whitton MC. Evaluation of reorientation techniques and distractors for walking in large virtual environments. IEEE Transactions on Visualization and Computer Graphics. 2009;15(3):383–394. doi: 10.1109/TVCG.2008.191. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Peck TC, Fuchs H, Whitton MC. Improved redirection with distractors: A large-scale-real-walking locomotion interface and its effect on navigation in virtual environments. IEEE Conference on Virtual Reality; 2010. pp. 35–38. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Psotka J. Immersive training systems: Virtual reality and education and training. Instructional Science. 1995;23:405–431. [Google Scholar]
- 18.Razzaque S. PhD dissertation. University of North Carolina at Chapel Hill, Department of Computer Science; 2005. Redirected Walking. [Google Scholar]
- 19.Razzaque S, Kohn Z, Whitton MC. Redirected walking. EUROGRAPHICS 2001 / Jonathan C Roberts Short Presentation The Eurographics Association. 2001 [Google Scholar]
- 20.Razzaque S, Swapp D, Slater M, Whitton MC, Steed A. Redirected walking in place. EGVE'02. 2002:123–130. [Google Scholar]
- 21.Robinett W, Holloway R. Implementations of flying, scaling and grabbing in virtual worlds. Interactive 3D graphics. 1992:189–192. [Google Scholar]
- 22.Ruddle RA. Engineering psychology and cognitive ergonomics. Vol. 6. Ashgate; 2001. Navigation: Am I really lost or virtually there; pp. 135–142. [Google Scholar]
- 23.Ruddle RA, Lessels S. The benefits of using a walking interface to navigate virtual environments. ACM Trans Comput-Hum Interact. 2009;16(1):1–18. [Google Scholar]
- 24.Slater M, Steed A. A virtual presence counter. Presence. 2000;9(5):413–434. [Google Scholar]
- 25.Slater M, Usoh M, Steed A. Taking steps: the influence of a walking technique on presence in virtual reality. ACM Trans Comput-Hum Interact. 1995;2(3):201–219. [Google Scholar]
- 26.Steinicke F, Bruder G, Hinrichs K, Jerald J, Frenz H, Lappe M. Real walking through virtual environments by redirection techniques. Journal of Virtual Reality and Broadcasting. 2009 Feb;6(2) [Google Scholar]
- 27.Su J. Motion compression for telepresence locomotion. Presence. 2007;16(4):385–398. [Google Scholar]
- 28.Usoh M, Arthur K, Whitton MC, Bastos R, Steed A, Slater M, Frederick J, Brooks P. Walking > walking-in-place > flying, in virtual environments. SIGGRAPH'99: Proceedings of the 26th annual conference on Computer graphics and interactive techniques; 1999. pp. 359–364. [Google Scholar]
- 29.Waller D, Hunt E, Knapp D. The transfer of spatial knowledge in virtual environment training. Presence. 1998 April;7(No. 2):129–143. [Google Scholar]
- 30.Wendt J, Whitton MC, Brooks F. GUD WIP: Gait-understanding-driven walking-in-place. IEEE Conference on Virtual Reality; 2010. pp. 51–58. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Williams B, Narasimham G, McNamara TP, Carr TH, Rieser JJ, Bodenheimer B. Updating orientation in large virtual environments using scaled translational gain. APGV'06: Proceedings of the 3rd symposium on Applied perception in graphics and visualization; 2006. pp. 21–28. [Google Scholar]
- 32.Williams B, Narasimham G, Rump B, McNamara TP, Carr TH, Rieser J, Bodenheimer B. Exploring large virtual environments with an hmd when physical space is limited. APGV'07: Proceedings of the 4th symposium on Applied perception in graphics and visualization; 2007. pp. 41–48. [Google Scholar]
- 33.Witmer BG, Bailey JH, Knerr BW, Parsons KC. Virtual spaces and real world places: transfer of route knowledge. Int J Hum-Comput Stud. 1996;45(4):413–428. [Google Scholar]