

Abstract
Two eyetracking experiments examined the real-time production of verb arguments and adjuncts in healthy and agrammatic aphasic speakers. Verb argument structure has been suggested to play an important role during grammatical encoding (Bock & Levelt, 1994) and in speech deficits of agrammatic aphasic speakers (Thompson, 2003). However, little is known about how adjuncts are processed during sentence production. The present experiments measured eye movements while speakers were producing sentences with a goal argument (e.g., the mother is applying lotion to the baby) and a beneficiary adjunct phrase (e.g., the mother is choosing lotion for the baby) using a set of computer-displayed written words. Results showed that the sentence production system experiences greater processing cost for producing adjuncts than verb arguments and this distinction is preserved even after brain-damage. In Experiment 1, healthy young speakers showed greater gaze durations and gaze shifts for adjuncts as compared to arguments. The same patterns were found in agrammatic and older speakers in Experiment 2. Interestingly, the three groups of speakers showed different time courses for encoding adjuncts: young speakers showed greater processing cost for adjuncts during speech, consistent with incremental production (Kempen & Hoenkamp, 1987). Older speakers showed this difference both before speech onset and during speech, while aphasic speakers appeared to preplan adjuncts before speech onset. These findings suggest that the degree of incrementality may be affected by speakers’ linguistic capacity.
Keywords: Adjuncts, Verb arguments, Agrammatism, Sentence production, Eyetracking
INTRODUCTION
The goal of a theory of sentence production is to explain how speakers use linguistic knowledge in the production of utterances (Bock, 1995). It has been suggested that grammatical encoding of a sentence is mediated by a verb’s argument structure information (e.g., Bock & Levelt, 1994). Verb argument structure has also been implicated in the speech deficits of individuals with agrammatic aphasia (Thompson, 2003). However, little is known about how elements that are not specified by a verb (i.e., adjuncts) are processed in normal and agrammatic sentence production. The purpose of the present research was to examine how and when knowledge of verb arguments and adjuncts is used during real-time sentence production in healthy and agrammatic speakers, using two “eyetracking while speaking” experiments. We begin by introducing the sentence production model proposed by Bock and Levelt (1994).
Processes of sentence production
Producing a sentence involves at least three levels of processing prior to articulation: message encoding, grammatical encoding, and phonological encoding. First, a speaker encodes a nonlinguistic message to convey in the form of “who did what to whom”. Next, the message is transformed into a linguistic structure via grammatical encoding. During grammatical encoding, lexical entries with syntactic and semantic information (lemmas) are selected from the speaker’s mental lexicon and their thematic-to-grammatical roles (e.g., agent-to-subject) are assigned, generating the syntactic structure of the sentence. Finally, the sound forms of the selected lemmas are specified during phonological encoding and then assembled into the linearly ordered structure of the sentence. These phonological specifications of each word are then fed into the articulatory system.
Two important properties underlie the process of sentence production. First, it’s been suggested that language production is at least to some extent incremental (Bock & Levelt, 1994; Kempen & Hoenkamp, 1987; Levelt, 1989). Speakers often begin speaking without planning the whole utterance; rather, they start articulating the first planned part of the utterance while planning the next part of the utterance. In a staged model of language production, incremental production implies that earlier levels need not complete their work on an utterance before the next level begins, resulting in parallel operations between processes (Bock & Levelt, 1994). For example, grammatical encoding can begin based on a partially encoded message. Likewise, phonological encoding of the utterance can begin before whole grammatical encoding is completed. Incremental production has been suggested as a mechanism that supports fast and fluent speech by making efficient use of processing resources available for sentence production (Ferreira & Slevc, 2007; Kempen & Hoenkamp, 1987). By producing the first available part of the utterance, a speaker does not need to hold linguistic information in the memory buffer, initiating speech faster and allowing resources to be available for simultaneous planning and speaking during speech.
Another important property of the Bock and Levelt (1994) model is that grammatical encoding is theorised to be lexically driven: when a lemma is selected, the lemma’s semantic and syntactic properties are also retrieved, guiding subsequent processes of grammatical encoding. In this context, a verb lemma plays a significant role because the verb specifies the number of arguments in an event, their thematic roles (e.g., agent, patient) and the categorical and positional information of the arguments (subcategorisation frame). Such information is called the “argument structure” of the verb, and as the lemma of a verb is accessed, its argument structure information also becomes available to the speaker. For example, as shown in (1a), in English the transitive verb fix requires two arguments, i.e., an agent (an initiator of the action) and a theme (an entity that is acted upon). Both arguments are realised as noun phrases (NPs), one preceeding and one following the verb. On the other hand, the dative verb put requires three arguments, i.e., an agent NP, a theme NP, and a goal prepositional phrase (PP, the direction of the action), as shown in (1b):
-
(1)

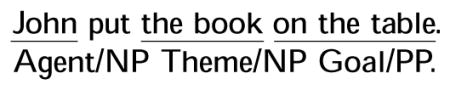
Verb arguments and adjuncts in normal sentence processing
A large body of literature has demonstrated that argument structure information stored with the verb is made immediately available during sentence processing (e.g., Ahrens, 2003; Boland, Tanenhaus, & Garnsey, 1990; Boland, Tanenhaus, Garnsey, & Carlson, 1995; Shapiro, Brookins, Gordon, & Nagel, 1991; Shapiro & Levine, 1990; Shapiro, Nagel, & Levine, 1993; Shapiro, Zurif, & Grimshaw, 1987). For example, Shapiro et al. (1991), Shapiro and Levine (1990), Shapiro, Nagel, et al. (1993), and Shapiro et al. (1987), in a series of cross-modal lexical decision (CMLD) studies, found that normal listeners show exhaustive activation of a verb’s arguments upon hearing the verb. In these studies, participants made lexical decisions to visually presented letter strings while they listened to sentences. When lexical decisions were required in the vicinity of verbs with more complex argument structure (e.g., dative verbs such as “send”), participants’ reaction times slowed down more so than when lexical decisions were required after verbs with simpler argument structures (e.g., transitive verbs such as “fix”), suggesting that upon encountering a verb in the sentence, the participants automatically activated its arguments (but see Schmauder, 1991, that did not replicate Shapiro and colleagues’ findings, using a set of on-line measures).
Another line of evidence suggesting the importance of verb argument information during sentence processing comes from studies which examined comprehension of arguments and adjunct phrases. Different from arguments, an adjunct phrase is not specified by its head. Therefore, its thematic information is not assigned by the verb (Grimshaw, 1990). Structurally, within X-bar theory, arguments are attached inside the verb phrase, while adjuncts are located outside the verb phrase (Jackendoff, 1977). Because adjuncts are not specified by a verb, they can occur with any type of verb as in (2), and omitting the adjunct phrase does not render a sentence ungrammatical.
-
(2)
John slept in the room.
John fixed the table in the room.
John put the book on the table in the room.
Whether and how the human parser differentiates arguments from adjuncts during on-line interpretation of sentences has been one of the central questions in sentence comprehension research. Many studies with normal listeners have found that the human parser uses verb argument structure information actively from the moment the verb is encountered, differentiating arguments from adjuncts (Boland, 2005; Boland & Blodgett, 2006; Kennison, 1999, 2002; Liversedge, Pickering, Branigan, & Van Gompel, 1998; Schütze & Gibson, 1999; and others). In English sentences, in which a verb often precedes objects and other words, individuals use the verb information to anticipate upcoming structure, even before the sentence is completed. That is, accessing a verb activates the argument information stored with the verb, allowing the parser to predict how many arguments should follow (Boland, 2005). In self-paced reading studies, this distinction results in shorter reading times for argument phrases, as compared to adjunct phrases (e.g., Clifton, Speer, & Abney, 1991; Kennison, 1999; Liversedge et al., 1998; Schütze & Gibson, 1999). Eyetracking studies similarly show longer fixation times to adjunct phrases than to argument phrases during both the initial reading pass and the second reading pass, suggesting that the verb information is used from the earliest stage of sentence parsing (e.g., Boland & Blodgett, 2006; Kennison, 1999, 2002). Compared to comprehension research, however, how the human sentence production system processes adjuncts, as compared to arguments, has received little attention. It remains an open question whether or not the production system differentiates adjuncts from verb arguments and, if so, how the difference is realised during sentence production.
Arguments and adjuncts in agrammatism
Verbs and their arguments have significant ramifications for language deficits in agrammatic aphasic speakers. Patients with agrammatic aphasia, which are often seen in the context of Broca’s aphasia, show greater impairment in producing verbs and sentences with more complex argument structure (e.g., De Bleser & Kauchke, 2003 in German; Kim & Thompson, 2000; Luzzatti et al., 2002 in Italian; Thompson, 2003; Thompson, Dickey, Cho, Lee, & Griffin, 2007 in English; Thompson, Lange, Sheneider, & Shapiro, 1997; and others). For example, Kim and Thompson (2000) found that a group of English-speaking agrammatic patients showed greater impairments in naming verbs with three arguments (dative verbs) as compared to verbs with two arguments (transitive verbs) when other relevant variables such as frequency and length were controlled. A similar deficit was observed in sentence production: agrammatic speakers show greater difficulty producing sentences with more arguments as compared to those with fewer arguments (Thompson et al., 1997).
Although these deficits have been attributed to impairments at the level of grammatical encoding, their nature remains unclear and some findings suggest that the lexical representation of verb argument structure may be preserved in agrammatism (Bastiaanse & van Zonneveld, 2004; Kim & Thompson, 2000; Shapiro, Gordon, Hack, & Killackey, 1993; Shapiro & Levine, 1990). Such patients show little difficulty comprehending verbs with different types of argument structure (Bastiaanse & van Zonneveld, 2004; Kim & Thompson, 2000). In addition, they show normal activation of verb arguments in CMLD studies (Shapiro, Gordon, et al., 1993; Shapiro & Levine, 1990): they automatically activate the argument structure of verbs as do normal speakers. However, it is unclear if their ability to use the lexical representation of verbs during sentence production is also preserved.
Only a few studies have examined the production of arguments and adjuncts in neurologically impaired speakers, and some findings suggest that arguments are better preserved than adjuncts. Canseco-Gonzalez, Shapiro, Zurif, and Baker (1990) trained a severe Broca’s aphasic patient in an artificial language. The patient had significantly more difficulty learning symbols that depicted “verbs” embedded in “sentences” where the third referent was an adjunct rather than an argument. In another study, Shapiro, McNamara, Zurif, Lanzoni, and Cermak (1992) reported that a group of amnesic patients showed greater difficulty repeating sentences with adjuncts than those with arguments only. On the other hand, Byng and Black (1989) found that three fluent and three nonfluent aphasic patients produced adjunct phrases such as locatives and temporal adjuncts successfully even when they failed to produce necessary arguments in a story-telling context.
The present study
The goal of the present research was to examine real-time production of verb arguments and adjuncts in healthy and agrammatic aphasic speakers in sentences. Experiment 1 examined if and how the normal sentence production system processes adjuncts differently from verb arguments by testing a group of healthy young speakers. Two questions were addressed within the framework of the lexically driven incremental production model (Bock & Levelt, 1994): does producing an adjunct involve greater processing costs than producing verb arguments, as shown in comprehension studies? And if the language production system differentiates adjuncts from arguments, at which point during sentence production will greater processing cost show up? In other words, do speakers plan adjuncts incrementally (Ferreira, 2000) or do they plan adjuncts before speech begins?
Experiment 2 examined the real-time production of verb arguments and adjuncts in agrammatic aphasic patients and age-matched older control speakers. We asked whether or not agrammatic speakers experience greater difficulty for adjuncts than for arguments in a constrained sentence production task, and if so, at which point during sentence production do agrammatic speakers show increased difficulty for adjuncts. Given that incremental production is driven by efficiency of speech production, it is possible that aphasic and older speakers use different planning strategies as compared to young speakers. Both experiments were approved by the Institutional Review Board at Northwestern University.
We used an “eyetracking while speaking” paradigm in both experiments. Monitoring eye movements during speech has proven to provide temporal indices for utterance planning (see Meyer, 2004, for review). Studies examining production of multiple objects in a fixed order (e.g., the clock and the chair) have found that the coordination between gaze and speech is very regular: speakers look at each object in the order of mention and just once before naming them (Griffin, 2001; Meyer, Sleiderink, & Levelt, 1998; van der Meulen, 2003). During this “name-related gaze”, speakers lexically encode each object, retrieving its lemma and phonological form (e.g., Griffin, 2001; Meyer et al., 1998; Meyer & van der Meulen, 2000). This lexical encoding occurs highly incrementally, that is, at the articulation onset of the first noun, speakers usually gaze at the second object.
On the other hand, when speakers produce utterances without a predefined structure, they show early inspection of the visual scene (apprehension phase) preceding sentence formulation and execution. Studies suggest that by apprehending the scene, speakers extract a coarse understanding of the event, building some “rudiments” of the utterance to be produced (Bock, Irwin, & Davidson, 2003; Griffin & Bock, 2000; van der Meulen, 2003); however, the exact nature of processes that occur during the apprehension phase is unclear. Then incremental sentence formulation and articulation follow: speakers look at each object in the order of mention right before articulating them to prepare the object’s name, even after scanning the objects during early inspection. In addition, Griffin and Mouzon (2004) report that speakers tend to decide the structure of their utterance as they speak. They found that when speakers have difficulty deciding the order of arguments (theme and goal), they show increased gaze shifts between the two objects in a picture description task, but these increased shifts appeared during speech rather than during the apprehension stage.
Recently, eyetracking methodology has been used to examine both sentence comprehension and production in aphasic patients and has proved to be a suitable methodology, which does not involve a secondary task such as a lexical decision (see Thompson & Choy, 2009, for comprehension; Thompson et al., 2007, for production). Based on previous studies, it was reasoned that monitoring eye movements during production of arguments and adjuncts would reveal differential processing routines and costs associated with them in both normal and aphasic speakers.
METHODS
Experiment 1
Experiment 1 examined on-line production of argument and adjunct phrases in healthy young speakers by tracking participants’ eye movements as they produced simple active sentences. Based on Bock and Levelt (1994) as well as the aforementioned results of comprehension studies, we predicted that adjuncts would engender greater processing costs than verb arguments during sentence production. In addition, it was predicted that if speakers produce utterances incrementally, evidence of increased processing cost associated with adjuncts would be seen during, rather than before, speech onset.
Participants
Thirteen undergraduate students at Northwestern University (eight females, five males; age range from 19 to 22 years old) participated in the study for partial course credit. All were native monolingual speakers of English and had normal or corrected-to-normal vision and reported normal hearing. None reported any history of psychiatric, developmental speech-language, or neurological disorders. The participants provided informed consent prior to the experiment.
Linguistic stimuli
Ten nonalternating dative verbs (e.g., donate) and 10 transitive verbs (e.g., choose) were selected for use in the argument and adjunct conditions, respectively. The dative verbs were selected from Ferreira (1996) and Levine (1993). The transitive verbs were selected from Boland (2005), Levine (1993), and Thompson et al. (2007). All verbs were equated in terms of log frequency per million, i.e., 1.74 vs. 1.84 for dative and transitive verbs, respectively; t(18) = 1.17, p = .25 (CELEX, Baayen, Pieenbrock, & van Rij, 1993). However, we could not match for length, because nonalternating dative verbs are often longer (e.g., donate) than transitive verbs (e.g., fix) in English (i.e., mean number of syllables 2.2 vs. 1.5 for the dative vs. the transitive verbs, respectively); t(18) = 2.69, p < .05. We included only nonalternating dative verbs to constrain participants to produce prepositional objective structures in the argument condition. Alternating dative verbs (e.g., give) allow both a prepositional dative (i.e., the man is giving an apple to the woman) and a double object structure (i.e., the man is giving the woman an apple). Previous eyetracking studies show that speakers gaze at objects in the order of mentioning them (e.g., Griffin & Mouzon, 2004). Thus, we excluded alternating verbs to eliminate any confounding effects in eye movement data analysis. While all verbs were regular verbs in the argument condition, two out of 10 verbs (hold, choose) were irregular in the adjunct condition. Each verb was repeated twice, resulting in a total of 20 items each for the argument and adjunct conditions. A complete list of verbs used is provided in Appendix A.
APPENDIX A.
List of verb stimuli
| Verbs (n = 10) | Log frequency | Number of syllables |
|---|---|---|
| Adjunct condition | ||
| select | 1.63 | 2 |
| lift | 1.94 | 1 |
| move | 2.63 | 1 |
| choose | 2.25 | 1 |
| hold | 2.66 | 1 |
| boil | 1.63 | 1 |
| wrap | 1.54 | 1 |
| repair | 1.08 | 2 |
| copy | 1.20 | 2 |
| examine | 1.89 | 3 |
| Mean | 1.85 | 1.5 |
| Argument condition | ||
| suggest | 2.35 | 2 |
| carry | 2.49 | 2 |
| deliver | 1.66 | 3 |
| apply | 2.07 | 2 |
| present | 1.99 | 2 |
| supply | 1.70 | 2 |
| donate | 0.60 | 2 |
| submit | 1.38 | 2 |
| display | 1.58 | 2 |
| recommend | 1.63 | 3 |
| Mean | 1.75 | 2.2 |
A set of 60 nouns, 40 animate, and 20 inanimate, was also prepared and combined with the verbs to make 40 NP V NP PP structures, 20 for each condition as shown in (2) (see Appendix B for the list of target sentences).
APPENDIX B.
List of target sentences
| Argument condition (n = 20) |
| The mother is applying the lotion to the baby. |
| The assistant is submitting the article to the manager. |
| The bellboy is carrying the box to the actor. |
| The chef is supplying the pasta to the patron. |
| The clerk is delivering the computer to the president. |
| The designer is displaying the dress to the queen. |
| The editor is recommending the book to the publisher. |
| The host is suggesting the chicken to the guest. |
| The lawyer is presenting the picture to the judge. |
| The man is delivering the sofa to the customer. |
| The minister is donating the gift to the orphan. |
| The agent is recommending the building to the client. |
| The nanny is supplying the milk to the toddler. |
| The nun is donating the toy to the child. |
| The nurse is applying the ointment to the patient. |
| The servant is carrying the package to the king. |
| The tailor is displaying the tuxedo to the mayor. |
| The teacher is suggesting the novel to the student. |
| The waiter is presenting the wine to the actress. |
| The woman is submitting the letter to the boss. |
| Adjunct condition (n = 20) |
| The mother is choosing the lotion for the baby. |
| The assistant is copying the article for the manager. |
| The bellboy is lifting the box for the actor. |
| The chef is boiling the pasta for the patron. |
| The clerk is moving the computer for the president. |
| The designer is repairing the dress for the queen. |
| The editor is examining the book for the publisher. |
| The host is selecting chicken for the guest. |
| The lawyer is holding the picture for the judge. |
| The man is moving the sofa for the customer. |
| The minister is wrapping the gift for the orphan. |
| The agent is examining the building for the client. |
| The nanny is boiling the milk for the toddler. |
| The nun is wrapping the toy for the child. |
| The nurse is choosing the ointment for the patient. |
| The servant is lifting the package for the king. |
| The tailor is repairing the tuxedo for the mayor. |
| The teacher is selecting a novel for the student. |
| The waiter is holding the wine for the actress. |
| The woman is copying the letter for the boss. |
-
(2)
The mother is applying the lotion to the baby. (Argument condition).
The mother is choosing the lotion for the baby. (Adjunct condition).
For each sentence, two animate and one inanimate noun were used (e.g., mother, lotion, baby). The role relationship between the two animate nouns was constrained, so that only one noun (e.g., mother) was more likely the agent of the action (e.g., applying the lotion) compared to the other (e.g., baby). The same nouns were used for the two conditions, making the same third noun (N3) (e.g., baby) a goal argument when the verb was a dative verb in the argument condition (2a) and a beneficiary adjunct when the verb was transitive in the adjunct condition (2b). By using the same nouns in the two conditions, we excluded any influence from factors that have been known to affect object naming difficulty, such as frequency, length, and name agreement. These factors affect not only naming latencies of objects, but also gaze durations in object naming tasks (Griffin, 2001; Meyer et al., 1998) and in word reading tasks (Rayner & Sereno, 1994).
The mean frequency of the nouns was matched across participant roles, i.e., agent (mean = 1.60), theme (mean = 1.56), and N3 (mean = 1.58), F(2, 57) = 0.16, p > .10, one-way ANOVA. The mean length of the nouns (number of syllables) was also equated across participant roles, i.e., agent (mean = 1.85), theme (mean = 1.85), and N3 (mean = 1.85), F(2, 57) = 0.00, p = 1.00, one-way ANOVA. Nouns that can be either a noun or a verb (e.g., cook) and ones that have more than one meaning (e.g., fan) were excluded, as these factors could affect word-retrieval difficulty.
To prevent participants from strategic use of one sentence structure, 20 intransitive filler sentences were prepared (e.g., the little mouse is jumping). Word stimuli used in the filler condition did not overlap with any of the words used in the two experimental conditions.
Visual stimuli
Sixty visual panels were created using the written word stimuli. On the left side of the panel, the verb was written, whereas on the right side, three nouns were displayed. A set of sample stimulus panels is provided in Figure 1. The verbs were presented in the present progressive form (e.g., is applying) to provide consistency across Experiments 1 and 2 and to reduce aphasic speakers’ verb inflection difficulty in Experiment 2. In addition, using the progressive form eliminated any possible linguistic and processing differences between regular and irregular verbs. The nouns and verbs were displayed in 32-font letter size. The positions of the three nouns were varied from trial to trial to avoid any visual bias due to repeated position. For filler items, instead of three nouns, one noun and one adjective were written on the right side of the panel.
Figure 1.

A sample set of visual stimuli, for the argument condition (a) and adjunct condition (b).
While most previous eyetracking studies in sentence production have used picture stimuli, written stimuli were used in the present study in order to eliminate any differences in imageability between the conditions, given that a beneficiary adjunct can be more difficult to portray than a goal argument. Prior to the experiment, the stimulus panels were normed by a group of undergraduate students at Northwestern University (n = 7) for their reliability to elicit the target structures. The panels elicited at least 80% production of target structures (i.e., the form of NP V NP PP for experimental items and the form of adjective noun verb for filler items). The stimulus panels were divided into two experimental sets, with 30 items in each set (i.e., 10 argument, 10 adjunct, and 10 filler items). The order of item presentation was randomised within each set. The order of the sets presented to the participants was also counterbalanced across participants.
Apparatus
Two computers were used for the experiment. The stimuli were presented on a 15-inch Macintosh computer, using Superlab 2.0 (Cedrus), and a Dell computer was used for recording eye and speech data. For recording of participants’ eye movements, a remote video-based pupil and corneal reflection system, Applied Science Laboratories model 504 remote eye-tracking camera was used. The remote camera was placed in front of the stimulus presentation computer and controlled by Eye-link system software. This system interconnected the two computers used for stimulus display and eye data recording. The remote camera sampled eye positions at the temporal resolution of 6 ms into saccades, fixations, and blinks. A fixation was defined by a speaker’s fixating one position for 100 ms, thus consisting of 16.6 consecutive samples.
Procedures
After obtaining informed consent, participants were seated in front of the stimulus display computer monitor, located approximately 24 inches from participants’ eyes. For head stabilisation, participants rested their chins on a University of Huston College of Optometry chinrest during the experiment. The position and height of the chinrest were adjusted for each participant, and cotton pads were placed beneath their chin to reduce any discomfort. None of the participants reported discomfort or interference with speaking from using the chinrest.
The eyetracking system was calibrated to each participant’s eyes at the beginning of the experimental session. The participants were first asked to click an image of a gopher, which popped out of nine different holes on the screen. Each calibration point was saved. Participants were then asked to look at one of nine numbers on the monitor as directed by an experimenter to ensure and adjust the saved calibration points. Additional calibrations were done following every 15 trials during the experiment.
After initial calibration, task instructions were presented over a loudspeaker. The instructions were recorded by a female native speaker of English. The participants were asked to make a sentence “using the verb and all the nouns presented on the screen”. Prior to each trial, participants also heard the target verb via instruction (e.g., “The next verb is apply. Make a sentence using ‘is applying”’). Each trial began with a blank white screen, which appeared for 1500 ms. This was replaced by a black fixation cross which appeared on the screen for 200 ms. A beep lasting 100 ms followed. At the onset of the beep, the fixation cross was replaced with the stimulus panel. Participants proceeded through the trials at their own pace by clicking a mouse or pressing the spacebar on the keyboard to advance to the next trial. They were told to rest when needed between trials.
A set of six practice trials preceded the experiment, including two items each for the argument, the adjunct, and the filler conditions. During both practice and experimental tasks, no feedback on the structure of sentences was provided. While participants were doing the task, their speech was recorded through a microphone placed in front of the participant using Praat software, and their eye movements were recorded. The recording of speech and eye data was controlled by the experimenter. The entire experimental session, from obtaining consent to completing the eyetracking task, lasted approximately 40 minutes.
Data analysis
Scoring
A total of 520 trials (40 trials × 13 participants) were scored and analysed. The participants’ recorded speech was transcribed by the experimenter verbatim, including all self-corrections and interjections (e.g., “uh”, “I guess”) and were checked for reliability by two reliability scorers who were blind to the purpose of the study.
The following sentences were scored as “correct (target)” responses: grammatical sentences which included all the nouns and the verb provided in the correct NP V NP PP order, disfluencies, and self-corrections within a word (e.g., the nanny is boil, boiling the milk for the toddler) and addition of NP modifiers (e.g., a bottle of wine instead of the wine).
Incorrect (nontarget) responses included role reversal errors (e.g., the president is moving the computer for the clerk for the clerk is moving the computer for the president), production of a possessive NP (e.g., the man is moving the president’s computer), use of a conjoined NP (e.g., the president and the man are moving the computer), and use of an embedded sentence (e.g., The president is asking the man to move his computer).
Speech data
Speech onsets of each content word were measured using NU aligner software (Chun, unpublished, NU Linguistics Labs, Northwestern University, Evanston, IL, USA.). These served as onset times for syntactic constituents (NP, VP, or PP), in line with other eyetracking studies of production (Griffin & Bock, 2000; Thompson et al., 2007). Within-word self-corrections and disfluencies were measured from the onset of the first-attempted content word. For example, in the case of “boil, boiling”, the onset of the verb (V) was measured from the onset of the first “boil”. For both argument and adjunct conditions, four constituents were measured, i.e., the subject noun (N1, agent), the verb (V), the object noun (N2, theme), and the indirect object noun or an adjunct noun (N3), as exemplified in (3). The N3 was the critical constituent in this study, as it served as a goal argument in the argument condition, but as a beneficiary adjunct in the adjunct condition. All the onset times measured by NU aligner were hand-checked for reliability by the experimenter and two additional persons:
-
(3)
Eye movement data
Eye movement data were computed using Eyenal 6.0 analysis software. Eye movements were recorded continuously throughout the experiment, but only fixations which occurred between the start and end of a trial were analysed. The start of each trial was marked by the onset of the picture stimulus, and the end of the trial was marked by the participant’s clicking on the mouse to advance to the next trial. To define areas of interests for the analysis of eye movement data, four squares were drawn surrounding the position of each word (agent, verb, theme, and N3), with approximately two degrees of visual angle. Fixations which fell inside those boxes were counted as fixations to the word covered by the box.
A participant had to fixate on the same position on the screen for 100 ms for it to count as a fixation. Temporally adjacent fixations in the same area of interest (i.e., on the same word), before the eye moved outside of the square were summed to compute a gaze. The onset and duration of these gazes were then aligned with the five speech regions, including “pre-N1”, “N1–V”, “V–N2”, “N2–N3”, and “N3-post” regions. The speech region “pre-N1” included the time between stimulus onset and articulation of the first noun. The region “N1–V” included the time after the articulation onset of N1 until the onset of the verb. The region “V–N2” included the time between the onset of the verb and the onset of N2. The region “N2–N3” included the time between the onset of N2 and the onset of N3. Following previous eyetracking studies in production, we assumed that eye movements during these speech regions would reveal on-line processes for message encoding, grammatical, and lexical encoding. Additionally, unlike previous studies, we included the region “N3-post”, which reflects the time from the onset of N3 to the end of the trial. Given that the critical word N3 appeared at the end of the target sentences, we reasoned that any increased end-of-speech processing cost related to adjuncts (e.g., self-monitoring of the constructed utterance) might appear in the eye movements during this region.
Once the gazes were aligned with respect to the speech regions, gaze durations to each word and gaze shifts between words within each speech region were computed. The number of gaze shifts was measured by counting the instances of a speaker shifting his or her gaze from one word to another word (e.g., from the verb to N3) and vice versa (e.g., from N3 to verb). Two eye movement measures were of our interest; i.e., gaze durations to N3 and the number of gaze shifts between the verb and N3. We measured gaze durations to N3 based on previous findings of comprehension studies, in which readers showed longer looking time to adjunct phrases as compared to argument phrases even when the same lexical items were used. It was reasoned that if the adjunct N3 indeed requires increased processing cost, speakers would show increased looking time to the adjunct as compared to argument N3. The number of gaze shifts between the verb and N3 was chosen because we specifically manipulated the relation between N3 and the verb between the two conditions. If adjuncts are more difficult to produce due to their weaker association with the verb as compared to arguments, as lexically mediated language production models predict, the difficulty should be reflected in increased gaze shifts between the N3 and the verb.
Results
Here we report the data for production accuracy, speech onset latency, and eye movement measures. All statistical analyses were done based on both participant and item means.
Production accuracy
The young participants produced target sentences equally well in both argument and adjunct conditions. The mean proportion of target sentences was 90% (SD = 4%) and 85% (SD = 4%) for the argument and adjunct conditions, respectively, t1(12) = 1.11; t2(19) = 0.88, ps > .10. The errors mainly consisted of grammatically acceptable nontarget sentences, such as sentences with an embedded clause (e.g., the nanny is boiling milk to give to the toddler for the target the nanny is boiling milk for the toddler) or a possessive object NP (e.g., the nanny is boiling the toddler’s milk).
Speech onset data
Analysis of the speech onset latency (the time from the onset of stimulus to the onset of N1) did not reveal any significant differences between conditions. The young participants spent only numerically longer times before they started talking in the adjunct condition (M = 2235 ms, SE = 61 ms) as compared to the argument condition (M = 2,172 ms, SE = 51 ms), t1(12) = 0.96; t2(19) = 0.74, ps > .10. We also compared the onset of N3 between the conditions, i.e., the time the participants spent to begin articulating N3 after the onset of N2. The participants spent only numerically longer times producing the adjunct N3 (M = 845 ms, SE = 30 ms) as compared to the argument N3 (M = 783 ms, SE = 35 ms), t1(12) = 1.32; t2(19) = 0.85, ps > .10.
Eye movement data
In general, after early inspection of the stimulus panel, participants gazed at each word in the order of mentioning them, prior to articulating each word in both the argument and adjunct conditions. Figure 2 shows the mean gaze durations (in ms) to N3 for each condition, by each speech region. Although participants in general showed longer gaze durations to adjunct N3s as compared to argument N3s, the difference was most noticeable during the N3-post region. The young participants showed longer gaze durations to N3 when it was an adjunct (M = 436 ms, SE = 28 ms) as compared to when it was an argument (M = 340 ms, SE = 25 ms) during this region. A set of paired t tests revealed that this difference was significant by items and approached significance by participants in the N3-post region, t1(12) = 2.12, p = .05; t2(19) = 2.12, p < .05. Gaze durations to arguments vs. adjuncts were not significantly different in any other speech regions, all ps > .10.
Figure 2.

Mean gaze durations (with standard errors) to N3 by speech regions in young participants, Experiment 1 (*p1 = .05, p2 < .05).
Figure 3 shows the mean number of gaze shifts between the verb and N3 by each speech region for each condition. A series of paired t tests were conducted for each region. The participants shifted their gazes between the verb and N3 more frequently in the adjunct condition than in the argument condition before articulating the verb, i.e., in the N1 = V region, t1(12) = 2.07, p = .05; t2(19) = 2.14, p < .05. Also, the difference was reliable by items during the N3-post region, t1(12) = 1.47, p > .06; t2(19) = 2.50, p < .05. However, there was no reliable difference between the argument and adjunct conditions in the other speech regions, ps > .10.
Figure 3.

Mean number of gaze shifts (with standard errors) between the verb and N3 by speech region in young speakers (*p1 = .05, p2 < .05).
Because we did not counterbalance the number of positions in which each word appeared between the argument and adjunct conditions, we tested if any of these differences were attributable to the interaction between the position of the nouns and verb type. For each of the two eye movement measures, participant-means were computed for the items which appeared at the top, left-bottom, and right-bottom positions of the panels, respectively. Then, these values were entered into 2 (condition) × 3 (position) mixed ANOVAs. This procedure was repeated for each of the speech regions in which significant differences were found. For both gaze durations to N3 and the gaze shifts between the verb and N3, we did not find any significant interaction between the position of the nouns and the conditions for any of the regions reported above, all Fs < 2.0, ps > .10.
We also compared gaze durations to the other words, including N1, V, and N2 as well as gaze shifts between other words (V–N1, V–N2, N1–N3, N2–N3, all three nouns, and all four words). None of these comparisons revealed significant differences between the argument and adjunct conditions, all ps > .06, paired t tests. Notably, although the dative verbs in the argument condition were longer (2.2 syllables) than the transitive verbs in the adjunct condition (1.5 syllables), participants’ gaze durations to the verb were not reliably different.
Summary
Experiment 1 examined if and how the normal language production system differentiates adjuncts from verb arguments. Two questions were asked: does producing adjuncts require increased processing cost than producing arguments, as shown in comprehension studies? If so, when do speakers most actively process adjuncts? With regard to the first question, our young participants did not show any noticeable differences between the argument and adjunct conditions in the production accuracy, speech onset latency, and time to produce N3. This is not surprising, given that the target sentence structures were relatively simple and the same lexical items were used between the conditions, except for the use of different verbs. However, the participants’ eye movement data showed differential processing costs associated with adjuncts as compared to arguments. Although the same nouns were used in both conditions, when the verb required N3 to be an adjunct rather than an argument, the participants showed increased gaze durations to N3 (Figure 2) and more frequent gaze shifts between the verb and N3 (Figure 3).
Concerning the time course of adjunct production, our young participants’ eye movement data suggest that adjuncts are processed most actively during speech in that all meaningful differences between arguments and adjuncts appeared during speech, rather than before speech onset. The increased gaze duration for adjunct N3s reached significance during the N3-post region (Figure 2). Participants also looked between the verb and N3 more frequently prior to the production of the verb and during the N3-post region in the adjunct condition than in the argument condition (Figure 3). Even though our task encouraged speakers to use the verb information to decide which noun to use as a subject before speech onset, the fact that differences reached significance only during speech suggests that young participants planned the sentences incrementally. Based on the findings from Experiment 1, we examined if this distinction between argument and adjunct production would also be found in agrammatic and age-matched control speakers in Experiment 2.
Experiment 2
The purpose of Experiment 2 was to examine both off-line and on-line production of adjuncts and arguments in agrammatic aphasic speakers and age-matched controls. We asked whether agrammatic aphasic and age-matched speakers would show greater difficulty producing adjuncts than arguments. Based on previous evidence showing intact representation of verb argument information in patients with agrammatic aphasia as well as the findings from our young normal speakers in Experiment 1, we predicted that both participant groups would show greater difficulty with adjuncts than arguments. In addition, we asked whether the time course of adjunct production in agrammatic speakers is different from normal speakers. If aphasic and age-matched speakers encode adjuncts incrementally, the greater processing cost for adjuncts would appear during speech as in young participants from Experiment 1. The same experimental design was used, as in Experiment 1, with some procedural modifications necessary for studying aphasic participants.
Participants
Nine individuals with nonfluent agrammatic aphasia and 13 age-matched controls participated in this experiment. The aphasic participants (one female, eight males; mean age (SD) = 54 (11), ranged from 35 to 56 years old; mean years of education (SD) = 16 (2.7), ranged from 12 to 21 years; postonset of stroke: 0.5–16 years) were recruited from the Aphasia and Neurolinguistics Research Laboratory at Northwestern University. All patients were monolingual speakers of English, except for one participant, A2, who was a bilingual speaker of Spanish and English. Although A2’s first language was Spanish, he began using English as his primary language at the age of four and preserved a greater competency in English than in Spanish poststroke. All suffered a left hemisphere stroke, without a history of language disorders or neurological disorders prior to their stroke. Age-matched English-speaking control participants were recruited from the Chicago community (two females, seven males; mean age (SD) = 60 (7), ranged from 48 to 73 years old; mean years of education (SD) = 15 (2.5), ranged from 12 to 20 years). They were matched with the aphasic participants in terms of their age and education level, t(20) = 1.56, p > .10 for age; t(20) = 1.03, p > .10 for years of education. None of the control participants reported history of language, learning, or neurological disorders prior to the participation in the experiment. Both aphasic and control participants showed normal or corrected-to-normal vision and hearing. From all participants, informed consent was obtained prior to the experiment.
The diagnosis of agrammatic aphasia was made based on performance on the western aphasia battery (Kertesz, 1982), the Northwestern Assessment of Verbs and Sentences (NAVS, Thompson, experimental version, Northwestern University, Evanston, IL, USA.), and neurolinguists’ judgement of spontaneous speech and narrative speech samples (Cinderella story). The aphasic participants’ language testing data are provided in Table 1. WAB aphasia quotients (AQs) ranged from 69.2 to 82.4. The NAVS results showed preserved verb comprehension, while verb production was compromised. At the sentence level, the participants’ argument structure production was reduced, showing more difficulty with sentences containing verbs with complex argument structure (i.e., three argument (dative) verbs) relative to sentences containing verbs with simpler argument structure (i.e., one (intransitive) and two argument (transitive) verbs). In addition, the patients were able to read single words. Their spontaneous speech was marked by reduced syntactic complexity and impaired production of grammatical morphology.
TABLE 1.
Aphasic participants’ language testing data
| Language testing | A1 | A2 | A3 | A4 | A5 | A6 | A7 | A8 | A9 | Mean |
|---|---|---|---|---|---|---|---|---|---|---|
| WAB | ||||||||||
| AQ | 79.3 | 82.4 | 78.5 | 74.5 | 74.4 | 81.9 | 87.6 | 69.2 | 71.2 | 77.7 |
| Fluency | 6.0 | 5.0 | 4.0 | 4.0 | 4.0 | 6.0 | 4.0 | 5.0 | 4.0 | 4.7 |
| Comprehension | 7.8 | 9.8 | 9.9 | 9.0 | 8.6 | 9.2 | 10.0 | 7.4 | 8.7 | 8.9 |
| Repetition | 8.3 | 10.0 | 6.4 | 9.6 | 7.2 | 6.8 | 9.7 | 6.3 | 7.6 | 8.0 |
| Naming | 8.6 | 9.3 | 9.5 | 6.7 | 8.4 | 10.0 | 9.1 | 7.9 | 7.3 | 8.5 |
| NAVS | ||||||||||
| Verb naming | 86 | 91 | 91 | 85 | 76 | 38 | 88 | 56 | 85 | 76 |
| Verb comprehension | 100 | 100 | 100 | 97 | 100 | 100 | 100 | 100 | 100 | 100 |
| Sentence production | ||||||||||
| Intransitive (one-place) verbs | 100 | 100 | 100 | 100 | 100 | 88 | 100 | 100 | 88 | 97 |
| Transitive (two-place) verbs | 97 | 95 | 100 | 100 | 100 | 79 | 100 | 96 | 100 | 97 |
| Dative (three-place) verbs | 97 | 88 | 89 | 89 | 83 | 78 | 94 | 44 | 72 | 81 |
Stimuli
The same sets of linguistic and visual stimuli from Experiment 1 were used.
Apparatus
The same apparatus was used as in Experiment 1, except that a 17-inch Dell computer and Superlab 4.0 (Cedrus) were used for presentation of the stimuli.
Procedures
Familiarisation of nouns and verbs
Prior to the experimental task, the aphasic participants were familiarised with the nouns and verbs off-line to ensure that their comprehension of the words and ability to read them aloud were intact. For familiarisation of the verbs, a written-word-to-picture-matching task was used. The patient was presented with three different action pictures, with a target verb written at the bottom of the page. The patient was first asked to read the verb aloud and then point to the picture which described the action. Forty action pictures were collected from the internet (www.clipart.com) and the database of the Northwestern Aphasia and Neurolinguistics Research Laboratory. All action pictures for both transitive and dative verbs included only an agent and a theme in order to minimise visual bias between the two verb types, except for the four dative verbs which could not be portrayed without a goal (suggest, deliver, donate, and submit). In addition, the agents and themes (and goals) in the familiarisation pictures (e.g., a man selecting cookies) differed from the nouns paired with the target verbs in experimental trials (e.g., the teacher is selecting a novel for the student).
For the noun stimuli, an auditory-to-written word matching task was used. The patient was presented with three written nouns at a time; the experimenter read aloud one of the words and the patient was asked to point to and read aloud the matching word. To prevent any repetition effects, the words were grouped differently from the way they were grouped in the experimental task and the order of presentation was randomised across patients.
For both the noun and verb familiarisation tasks, aphasic patients’ performance was scored for both comprehension (pointing to a target picture or word) and reading ability (whether the patient could read the word aloud). If the patient read 75% of the phonemes of the words correctly, it was scored as correct. When the patients were incorrect, they were provided with feedback. The patients showed a mean of 99% correct for reading verbs and 96% for comprehension of verbs. Mean scores for the nouns were 100% for both comprehension and reading.
Eyetracking task
Both aphasic and age-matched control participants underwent the same procedures as young participants in Experiment 1. The only difference was that aphasic participants were provided with three offline practice items prior to the eyetracking session, to ensure that they understood the task. The entire experimental session, from obtaining consent to completing the eyetracking task, lasted approximately 40 minutes for the control participants and 90 minutes for the aphasic participants.
Data Analysis
For the age-matched and aphasic data sets, a total of 10 trials were discarded from each, due to experimental errors. This resulted in a loss of 1.9% and 2.7% of the data, respectively, making a total of 510 analysable trials for the age-matched and 350 trials for the aphasic participants.
Scoring
The same scoring procedures used in Experiment 1 were used in Experiment 2. When the participant made more than one attempt, only the first attempt was scored and analysed. If the speaker produced at least a subject NP and a verb, the utterance was considered as an attempt. For aphasic participants, substitution of incorrect prepositions (e.g., the mother is applying lotion of the baby) was accepted because the purpose of the study was not to examine morphology. In addition, if 50% of the phonemes in the target word were produced correctly, the response was coded as correct. Also, the patients sometimes substituted experimental nouns with semantically related nouns (e.g., infant for child). These semantic paraphasias were scored as “incorrect”, given that written stimuli were used in the experiment. Other responses such as sentences begun with a theme, unintelligible responses, and “I don’t know” responses were all considered incorrect.
Speech data
Once the responses were coded, onsets of each noun and verb were measured using NU aligner software (Chun, unpublished), and reliability was checked as described in Experiment 1. All age-matched control participants’ speech data were measured this way. For the aphasic group, six patients’ data were measured using the software; however, three patients’ data were hand-timed because of their frequent production of interjections, self-corrections, and phonological errors.
Eye movement data
The same methods of eye data analyses from Experiment 1 were used.
Results
Production accuracy
Figure 4 shows production accuracies for both aphasic and age-matched speakers. A set of 2 (group) × 2 (condition) mixed ANOVAs was conducted. There was a main effect of group, suggesting aphasic participants in general produced fewer correct responses than age-matched controls, F1(1, 20) = 6.77, p < .05; F2(1, 38) = 21.85, p < .001. Posthoc t tests indicated that this group difference was significant both by participants and items in the argument condition, t1(20) = 2.68, p < .05; t2 (38) = 30.87, p < .001, but only by items in the adjunct condition, t1(20) = 16. 90, p = .07; t2(38) = 30.87, p < .001. However, crucially, there was no main effect of condition: both groups of speakers produced similar proportions of target sentences between the conditions, F1(1, 20) = 0.14, F2(1, 38) = 1.10, ps > .10. Aphasic participants produced 63% correct responses in both conditions. Age-matched controls produced 85% vs. 75% correct responses in the argument and adjunct conditions, respectively. Furthermore, the interaction between group and condition was not reliable, F1(1, 20) = 0.04, F2(1, 38) = 0.32, ps > .10.
Figure 4.

Production accuracies in age-matched and aphasic participants, Experiment 2.
Error analysis
Table 2 summarises error types produced by aphasic participants. There was no noticeable difference in error types between the argument and adjunct conditions. In both conditions, aphasic participants produced a variety of errors, including sentences with missing word(s) and word order errors. Sentences with missing words included those in which the N2 (theme) were omitted (e.g., the mother is choosing/applying the baby), sentences with omitted N3 (e.g., the mother is choosing/applying lotion) and sentences where both N2 and N3 were omitted (e.g., the mother is choosing). For most of the word omission errors, aphasic participants made self-corrections or additional attempts. Another noticeable error type was word order errors. Aphasic participants switched the order of N2 (theme) and N3 (e.g., the mother is choosing/applying the baby of the lotion) in both the adjunct and argument conditions. They also produced sentences with reversed N1 (agent) and N3 such as “the baby is choosing the lotion for the mother”, for “the mother is choosing the lotion for the baby”. It should be noted again that some of these word order errors did not necessarily result in “unacceptable” sentences in English. Rather, they were considered “non-target” structures in our study for the purpose of eye data analysis. Other errors included sentences with semantic and severe phonological errors, sentences with multiple different errors, and “I don’t know” responses.
TABLE 2.
Summary of error types in aphasic participants, Experiment 2
| Error types | Adjunct condition | Argument condition |
|---|---|---|
| Missing words | ||
| Missing N2 | 4 (6%) | 7 (10%) |
| Missing N3 | 5 (8%) | 1 (2%) |
| Missing N2 and N3 | 5 (8%) | 8 (13%) |
| Word order | ||
| Misordered N2 and N3 | 9 (14%) | 10 (16%) |
| Misordered N1 and N3 | 14 (22%) | 18 (28%) |
| Others | 27 (42%) | 20 (31%) |
| Total errors | 64 (100%) | 64 (100%) |
Unlike aphasic participants, the age-matched control participants’ errors were mainly nontarget but grammatical structures, similar to those produced by the young participants in Experiment 1. They included sentences with embedded clauses (e.g., the nanny is boiling milk to give it to the toddler), possessive NPs (e.g., the mother is choosing the baby’s lotion, mainly for the adjunct condition), and others. Due to the range of error types in aphasic and age-matched controls as well as due to difficulty mapping eye movements to speech regions for erred responses, we did not analyse the on-line data for incorrect responses. Therefore, speech onset latencies and eye movement data presented below are based on correct responses only.
Speech onset data
Figure 5 shows the speech onset latency data for both age-matched and aphasic participants. A set of 2 (group) × 2 (condition) mixed ANOVAs revealed a main effect of group, F1(1, 20) = 21.07; F2(1, 38) = 127.64, ps < .001. Aphasic speakers showed significantly longer, speech onset latencies than age-matched controls in both the argument, t1(20) = 4.02, p < .01; t2(38) = 9.13, p < .001, and adjunct conditions, t1(20) = 5.54; t2(38) = 7.20, ps < .001. However, neither group showed a condition effect: both groups spent numerically longer time to start talking in the adjunct condition compared to the argument condition, F1(1, 20) = 2.62; F2(1, 38) = 1.51, ps > .10. Age-matched controls showed means of and 2,792 (SE = 74) and 2,716 (SE = 78) ms for the adjunct and argument condition, respectively. The means for the aphasic participants were 8,028 (SE = 730) and 7,715 (SE = 463) ms for the argument and adjunct condition, respectively. The interaction between the condition and group was not significant, F1(1, 20) = 2.57, F2(1, 38) = 1.08, ps > .10.
Figure 5.

Speech onset latencies (with standard errors) in age-matched and aphasic participants, correct responses, Experiment 2.
In addition, the speech onset times of N3 after N2 were measured. A set of 2 (condition) × 2 (group) ANOVAs indicated a main effect of group, F1(1, 20) = 52.38, F2(1, 38) = 436.32, ps < .001, indicating that aphasics in general took significantly longer time to produce N3 as compared to age-matched controls. Importantly, there was no main effect of condition, F1(1, 20) = 1.57, F2(1, 38) = 0.04, ps > .10. Age-matched controls showed means of 929 (SE = 29) and 977 (SE = 34) ms for adjunct and argument condition, respectively. Aphasic participants spent 2,571 (SE = 227) and 2,486 (SE = 181) ms for adjunct and argument condition, respectively.
Eye movement data
As in young participants in Experiment 1, both aphasic and age-matched control participants gazed at each noun prior to articulating them in the order of mention in both the argument and adjunct conditions, following the apprehension phase. Figure 6 shows the mean gaze durations to N3 by speech region for age-matched (top figure) and aphasic participants (bottom figure). These data indicated that, in general, both age-matched and aphasic participants showed longer gaze durations to adjunct N3s than to argument N3s. Interestingly, however, the two groups showed statistically different patterns across speech regions. A set of paired t tests was used for each speech region within each group. Age-matched controls showed significantly longer gaze durations to adjunct N3s as compared to argument N3s in the pre-N1 region, t1(12) = 2.62, p < .05; t2(19) = 4.45, p < .001, as well as in the N3-post region, t1(12) = 3.82, p < .01; t2(19) = 4.62, p < .001. However, aphasic participants showed this difference in the pre-N1 region only, t1(8) = 2.26, p = .05; t2(19) = 3.33, p < .01. The patients did not show significant differences during speech.
Figure 6.

Mean gaze durations to N3 (with standard errors) by speech region in age-matched (top) and aphasic participants (bottom), Experiment 2 (**p1 < .05, p2 < .001; *p1 = .05, p2 < .01).
Figure 7 shows the mean number of gaze shifts between the verb and N3 by each speech region in the two participant groups (top figure age-matched controls; bottom figure aphasic speakers). For age-matched controls, although they showed numerically more frequent gaze shifts in the adjunct condition than in the argument condition, particularly in the N1–V and N3-post regions, these differences were not significant in any of the speech regions, ps > .06, paired t tests. On the other hand, aphasic participants showed more frequent gaze shifts before speech onset (i.e., pre-N1 region) between the verb and N3 in the adjunct condition than in the argument condition, t1(8) = 2.22, t2(19) = 2.03, ps = .05.
Figure 7.

Mean number of gaze shifts (with standard errors) by speech region in age-matched (top) and aphasic participants (bottom), Experiment 2 (*p1 and p2 = .05).
As in Experiment 1, we examined if any of these differences would be attributed to the interaction between the position of the nouns on the stimulus panels and verb types. The same analysis procedure was followed as in Experiment 1. For both aphasic and control groups, there was no interaction between the position of the nouns and the conditions, suggesting the differences reported above were not affected by the position in which the nouns appeared on the stimulus panels, all Fs < 2.0, ps > .06. Posthoc analysis was also done to examine if any other measures, including gaze durations to N1, verb, and N2, and other types of gaze shifts, showed significant differences. Both groups showed no reliable differences in gaze durations and gaze shifts for other words, all ps > .06, paired t tests.
Summary
Results from Experiment 2 showed that our aphasic participants as well as age-matched controls did not show significant differences in production accuracies and speech onset latencies between the argument and adjunct conditions, replicating the findings from Experiment 1 with young normal speakers. However, although some measures were only marginally significant (p = .05), the eye movement data revealed greater processing cost in the adjunct condition compared to the argument condition for both participant groups. Both groups showed greater gaze durations to adjuncts N3 than argument N3 (see Figure 6), as did young participants in Experiment 1. In addition, the aphasic group showed a greater number of gaze shifts between the verb and N3 in the adjunct condition, compared to the argument condition (Figure 7).
Interestingly, the two groups showed these differences at different time points. Age-matched controls showed greater gaze durations to N3 during both early and later stages of sentence production, i.e., in the pre-N1 region as well as in the N3-post region. On the other hand, the aphasic participants showed longer gaze durations to adjunct N3s as compared to argument N3s mostly during the pre-N1 region. This effect was not seen in later stages of sentence production. The parallel pattern was seen in the gaze shift data: aphasic speakers shifted their gazes between the verb and adjunct N3 more frequently than the verb and argument N3 before they started articulating the subject.
GENERAL DISCUSSION
This study examined how the linguistic distinction between verb arguments and adjuncts is realised during on-line sentence production. In two eyetracking experiments, young healthy speakers (Experiment 1) and older healthy and agrammatic aphasic speakers (Experiment 2) showed increased processing cost for adjuncts as compared to arguments. However, this difference showed up at different time points of sentence production in each group. In this section, we discuss how these findings shed light on our understanding of normal and agrammatic sentence production.
The first issue pertains to whether or not the human sentence production system experiences greater processing cost in producing adjunct phrases. Results of the present experiments suggest that when a linguistic context (verb, in our case) sets up an element as an adjunct, as opposed to an argument, it results in increased processing cost during on-line sentence production. Even when there were no differences in the number of target utterances produced between the conditions, all three participant groups showed longer gaze durations to adjunct N3 than to argument N3. Furthermore, our young and aphasic participants showed increased gaze shifts between the verb and N3 when the N3 was an adjunct compared to when it was an argument. Lack of meaningful differences in the gaze durations and shifts for the other words (e.g., agent, theme) further suggests that the differences mentioned above are specific to the verb argument = adjunct distinction, which was apparent only at N3. This finding is not only consistent with the findings from previous comprehension studies (e.g., Boland, 2005; Boland & Blodgett, 2006; Kennison, 1999, 2002; Liversedge et al., 1998; Schütze & Gibson, 1999), it also extends the argument status effects to sentence production. Furthermore, these results are in line with the lexically driven models of sentence production in that verb argument information plays a critical role during the grammatical encoding process (Bock & Levelt, 1994).
The argument status effects found in agrammatic participants also enhance our understanding of agrammatic aphasia. While agrammatic speakers performed less well than young and older healthy speakers in general, their eye movement data revealed greater difficulty associated with producing adjuncts as compared to arguments. This is consistent with previous studies in which neurologically impaired patients showed greater impairments with adjuncts than with verb arguments (Canseco-Gonzalez et al., 1990; Shapiro et al., 1992). However, this finding is inconsistent with those of Byng and Black (1989), in which aphasic patients produced adjunct phrases (e.g., locative and temporal phrases) successfully even when they failed to produce obligatory arguments in narrative speech. This inconsistency may be attributed to the different types of adjunct phrases examined (locative/temporal vs. beneficiary phrases) as well as the tasks that were used across studies (narrative speech vs. constrained sentence production task).
In terms of the nature of agrammatic deficits, the argument status effects shown in our patients’ eye movement data support that their knowledge of verb argument structure information is preserved (Lee & Thompson, 2004; Shapiro, Gordon, et al., 1993; Shapiro & Levine, 1990). Beyond previous findings, our results also suggest that patients can utilise verb argument information to differentially process arguments and adjuncts during real-time sentence production. For example, although Shapiro, Gordon, et al. (1993) and Shapiro and Levine (1990) found that Broca’s aphasic patients may have preserved ability to automatically activate argument entries of verbs upon hearing the verb, their studies did not address whether or not they are able to “use” that information to perform a linguistic task.
The second important finding of the present study is the three groups showed different time courses for producing adjuncts. None of the participant groups showed reliable differences in the speech onset times of N3 and gaze durations during the N2–N3 region, in which lexical encoding of N3 occurs prior to its articulation. This indicates that the argument/adjunct status of N3 did not affect difficulty in preparing their phonological forms, when the same lexical items were used. However, detailed analysis of gaze duration to N3 and gaze shifts between the verb and N3 across all speech regions revealed that each speaker group showed the increased processing demands for adjuncts at different time points during sentence production. This finding is significant because it suggests that the degree of incrementality (interleaved planning and speaking) may be affected by speakers’ linguistic capacity.
In Experiment 1, in line with incremental sentence production, our young healthy participants encoded adjuncts during speech, rather than prior to speech onset (Ferreira, 2000; Griffin & Bock, 2000; Kempen & Hoenkamp, 1987; Levelt, 1989). Although our task required at least some processing of the N3 before speech onset because two animate word candidates were provided for the subject, a reliable difference between the argument and adjunct conditions did not appear during the early inspection of the stimuli. Instead, after they began articulating the subject, i.e., N1–V region, the young speakers looked back and forth between the verb and N3 more frequently when the N3 was an adjunct than when it was a goal argument. These increased gaze shifts may reflect difficulty associated with deciding predicate structure of the sentence in the face of inconsistency between the verb’s argument structure and the number of words to be produced. When the transitive verb allows only one internal argument to follow (theme), speakers experience greater difficulty deciding what to mention next, compared to when the dative verb specifies the number and order of the arguments (theme and goal). Interestingly, in doing so, speakers looked at the verb and N3 back and forth, rather than between N2 and N3, suggesting that the processing of adjunct occurs in relation to the verb and that the verb information is used most actively during speech. This is consistent with previous findings suggesting that speakers plan postsubject elements (e.g., deciding the order of internal arguments) of the sentence after speech onset (e.g., Griffin, 2001; Lawler & Griffin, 2003).
In addition, our young speakers showed increased gaze durations to adjunct N3 and more frequent gaze shifts between the verb and adjunct N3 during the N3-post region. These findings suggest that speakers self-monitored their speech more carefully when producing sentences with an adjunct, as compared to when producing sentences in which all words are arguments. This difference is not likely due to planning of the utterance, given that before articulating N3, speakers would have finished most planning of the utterance (Griffin, 2001; Meyer et al., 1998). Rather, it appears that speakers spent more time ensuring that the constructed utterance was correct or not from the production of N3 until they advanced to the next trial, focusing on the relation of the adjunct N3 to the sentential head verb.
In Experiment 2, our older speakers showed longer gaze durations for adjunct N3s during the N3-post region, as did the young speakers in Experiment 1, suggesting increased self-monitoring of their production of adjuncts. Importantly, unlike young speakers, the older speakers showed significantly longer gaze durations to adjunct N3s than to argument N3s during the apprehension phase, i.e., pre-N1 region. For aphasic speakers, increased processing cost for adjuncts was noticeable mainly before speech onset, manifested by both gaze durations to N3 and gaze shifts between the verb and N3.
These patterns suggest that our older and aphasic speakers planned adjuncts prior to speech onset, unlike young speakers, using the verb information actively from the earliest stage of sentence planning.
These findings from Experiment 2 are difficult to account for within the incremental language production models which posit that the unit of utterance planning is word-by-word, as these studies suggest that any of the verb (or predicate) information is not used during the initial sentence planning (e.g., Griffin, 2001; Schriefers, Teruel, & Meinshausen, 1998). Both the gaze shift and duration data revealed patterns that do not suggest an incremental model. If our older and aphasic speakers did not use the verb information to plan their utterance in advance, we should not see increased on-line processing cost in the adjunct condition during the apprehension phase. Rather, these data are more consistent with studies suggesting that speakers plan utterances at larger units such as a clause (e.g., Garrett, 1975; Meyer, 1996) or at least some verb information is used before speech onset (e.g., Lindsley, 1975). Based on the present findings, it is difficult to tell whether the early planning of adjuncts includes only message encoding or structural encoding as well. It may be the case that our older and aphasic speakers used only the conceptual-thematic information of the verb to encode the event structure of the utterance, i.e., figuring out the thematic role that the adjunct N3 plays in the event in relation to the action of the verb. Alternatively, speakers might have encoded the structural configuration of the utterance as well, by building a hierarchical representation of the predicate structure in which the words will be inserted incrementally during lexical encoding. Further research is needed to delineate if and how differential verb information is used during on-line sentence planning. Also, given the novelty of the eyetracking methodology in studies of sentence production and the potential differences between the previous eyetracking studies that used picture stimuli and our study that used word stimuli, further studies are necessary to better understand the link between eye movement patterns and the processes of sentence production.
Then the question is raised: what mechanisms do underlie the different time courses observed across the speaker groups? We account for the findings based on the interaction between incremental production and the speakers’ linguistic capacities. One benefit of incremental language production lies in that by beginning the sentence with the first available part of the sentence, speakers do not have to hold information in the memory buffer, thus making fast speech possible (DeSmedt, 1990; Kempen & Hoenkamp, 1987). However, the downside of minimal planning is that speakers need to work on multiple processes simultaneously during speech in a timely manner to maintain speed and fluency of speaking. The simultaneous processing of multiple levels can pose greater difficulty to some speakers than planning ahead, by increasing a risk of facing unexpected difficulty during speech (DeSmedt, 1990). For example, when preparation of the next increment is not completed, while the current increment is articulated, the speaker may experience unexpected pauses or hesitations during speech. In other cases, starting off the sentence with the first conceptually prominent element such as a theme might pose greater difficulty to speakers whose grammatical encoding (e.g., passive production) is impaired. Thus, speakers with decreased linguistic capacities might have to decide how to allocate processing demands during the time course of sentence production. In our case, it appears that aphasic and older speakers allocated increased demands for adjuncts at an earlier stage of sentence production as compared to young speakers, thus reducing upcoming difficulty during speech (see Griffin & Spieler, 2006 for the opposite pattern of trade-off between fluencies and amount of planning in young vs. older speakers).
This discussion of speakers’ linguistic capacity in the degree of incremental production leads to two open questions. First, the nature of the mental machinery that is responsible for our participants’ use of different time courses for planning adjuncts is unclear. Compared to comprehension research, less attention has been paid to the relation between processing capacities and sentence production processes. Some evidence suggests that verbal working memory or semantic short-term memory is closely related to production, including sentence length in written sentence production (Kellogg, 2004), syntactic planning (Hartsuiker & Barkhuysen, 2006), and the production of complex NPs such as “brown long hair” (Martin & Freedman, 2001). Ferreira and Pashler (2002) showed that lemma and lexeme selection processes are also affected by central processing resources, while phoneme selection occurs in a modular, cognitively independent fashion. At the moment, we can only attribute the differences between our young and older speakers to general decreases in cognitive capacities due to ageing and the differences between our older and aphasic speakers, possibly to aphasic speakers’ impaired linguistic capacities. Understanding more precisely the nature of the mental machinery and its relation to the mechanisms of sentence production should be subject to further research.
The second question is whether or not the unit of planning used by our agrammatic speakers is under strategic control or intrinsic to their production system (Griffin & Spieler, 2006). In other words, for agrammatic speakers to successfully produce a sentence, does their sentence production system inevitably require a certain amount of planning such as encoding verb argument structure prior to speech onset? Ferreira and Swets (2002) found that under time pressure, normal speakers show more incremental patterns as compared to when there is no production deadline, suggesting that incremental production is under strategic control. However, this flexibility in incrementality might require a certain amount of linguistic capacity available, and brain-damage might alter mechanisms underlying sentence production, resulting in qualitatively different production operations. Elucidating this question will broaden our understanding of the nature of the agrammatic production system as well as mechanisms underlying language production in general.
This study has several limitations that need to be addressed in future studies. We familiarised aphasic participants with the target nouns and verbs as singletons prior to the eyetracking sentence production task to ensure that their single word comprehension and oral reading was sufficient to perform the experimental task. However, our young and older speakers did not undergo the same procedure. It is unlikely that this confounded our results, because the same nouns were used between the conditions and both dative and transitive verbs were familiarised. However, it is possible that having seen the words prior to the task might have affected the way aphasic participants approached the task, unlike young and older speakers. Thus, future research should confirm if agrammatic aphasic speakers show the same sentence planning strategies without familiarisation of the individual words.
Another limitation is that we could not analyse aphasic participants’ eye movement data for erred responses; thus what happens when aphasics fail to produce target sentences is unknown. Do aphasic speakers still show evidence of normal real-time distinctions between arguments and adjuncts, even when they fail to produce the target sentences? Do patients use different planning routines when they produce erred utterances? Previous eyetracking studies, using a visual-word paradigm during auditory comprehension, suggest that even when aphasics fail to comprehend sentences, their eye movements show evidence of preserved syntactic representation, including gap-filling and resolution of binding dependencies (Dickey, Choy, & Thompson, 2007; Thompson & Choy, 2009). However, much work is needed to understand what kinds of different real-time processes aphasic patients rely on for failed production as compared to correct production. Eyetracking methodology has a potential to provide a useful means to understand the link between planning patterns and success of sentence production in impaired speakers.
Lastly, the current study does not address the question as to whether differential processing costs associated with arguments vs. adjuncts are solely attributable to their linguistic status or are due to nonsyntactic sentence-level factors such as construction frequency, plausibility, and predictability (e.g., are adjuncts more difficult because they cooccur with particular verbs less frequently?). It may be that argument and adjunct constructions are different in various nonsyntactic aspects and processing of the two constructions is tightly weaved with those factors. However, pinning down which factor is most likely to account for the differential processing routines for arguments and adjuncts is beyond the scope of this study. Nonetheless, our findings do provide empirical evidence that arguments and adjuncts are categorically distinctive in the human sentence production system.
In conclusion, the current study provided a set of novel findings elucidating how normal and impaired language production systems use the knowledge of verb arguments and adjuncts during real-time sentence production. Consistent with previous comprehension studies and lexically driven models of sentence production (Bock & Levelt, 1994), we found that the human sentence production system experiences increased processing cost for producing adjuncts compared to arguments. Furthermore, this distinction is preserved even after brain-damage in agrammatic aphasic speakers. Critically, at which stage of sentence planning the increased processing cost of adjuncts occurred was different for young, older, and aphasic participants, suggesting an interaction between incremental production and speakers’ linguistic capacities. While young speakers processed adjuncts during speech, consistent with incremental production, older and aphasic speakers showed differences beginning at early stages of sentence production.
Acknowledgments
The authors want to thank Dr. Michael W. Dickey, Kyla Garibaldi, Keli Rulf and other members of the Aphasia & Neurolinguistics Research Laboratory for their comments and help with this study. We also thank the audience at CUNY 2008 on Human Sentence Processing and the fifth international language production workshop for their feedback. Special thanks go to the aphasic patients who participated in the study. This research was supported by the NIH R01-DC01948 (C.K. Thompson).
References
- Ahrens K. Verbal integration: The interaction of participant roles and sentential argument structure. Journal of Psycholinguistic Research. 2003;32:497–516. doi: 10.1023/a:1025452814385. [DOI] [PubMed] [Google Scholar]
- Baayen RH, Pieenbrock R, van Rij H. The CELEX lexical database (release1) Philadelphia, PA: Linguistic Data Consortium, University of Pennsylvania; 1993. [Google Scholar]
- Bastiaanse R, van Zonneveld R. Broca’s aphasia, verbs and the mental lexicon. Brain and the Language. 2004;90:198–202. doi: 10.1016/S0093-934X(03)00432-2. [DOI] [PubMed] [Google Scholar]
- Bock JK. Sentence production: From mind to mouth. In: Miller JL, Eimas PD, editors. Handbook of perception and cognition: Vol. 1. Speech, language, and communication. Orlando, FL: Academic Press; 1995. pp. 181–216. [Google Scholar]
- Bock K, Irwin DE, Davidson DJ. Minding the clock. Journal of Memory and Language. 2003;48:653–685. [Google Scholar]
- Bock JK, Levelt WJM. Language production: Grammatical encoding. In: Gernsbacher MA, editor. Handbook of psycholinguistics. San Diego, CA: Academic press; 1994. pp. 945–984. [Google Scholar]
- Boland JE. Visual arguments. Cognition. 2005;95:237–274. doi: 10.1016/j.cognition.2004.01.008. [DOI] [PubMed] [Google Scholar]
- Boland JE, Blodgett A. Argument status and PP-attachment. Journal of Psycholinguistic Research. 2006;35:385–403. doi: 10.1007/s10936-006-9021-z. [DOI] [PubMed] [Google Scholar]
- Boland JE, Tanenhaus MK, Garnsey SM. Evidence for the immediate use of verb control information in sentence processing. Journal of Memory and Language. 1990;29:413–432. [Google Scholar]
- Boland JE, Tanenhaus MK, Garnsey SM, Carlson GN. Verb argument structure in parsing and interpretation: Evidence from wh-questions. Journal of Memory and Language. 1995;34:774–806. [Google Scholar]
- Byng S, Black M. Some aspects of sentence production in aphasia. Aphasiology. 1989;3:241–263. [Google Scholar]
- Canseco-Gonzalez E, Shapiro LP, Zurif EB, Baker E. Predicate-argument structure as a link between linguistic and nonlinguistic representations. Brain and Language. 1990;39:391–404. doi: 10.1016/0093-934x(90)90147-9. [DOI] [PubMed] [Google Scholar]
- Clifton C, Jr, Speer S, Abney S. Parsing arguments: Phrase structure and argument structure determinants of initial parsing decisions. Journal of Memory and Language. 1991;30:251–271. [Google Scholar]
- De Bleser R, Kauchke C. Acquisition and loss of nouns and verbs: Parallel or divergent patterns? Journal of Neurolinguistics. 2003;16(2–3):213–229. [Google Scholar]
- DeSmedt KJJ. Unpublished doctoral dissertation. Nijmegen Institute for Cognition Research and Information Technology; The Netherlands: 1990. Incremental sentence generation: A computer model of grammatical encoding. [Google Scholar]
- Dickey MW, Choy J, Thompson CK. Real-time comprehension of wh-movement in aphasia: Evidence from eyetracking while listening. Brain and Language. 2007;100:1–22. doi: 10.1016/j.bandl.2006.06.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferreira F. Syntax in language production: An approach using tree-adjoining grammars. In: Wheeldon L, editor. Aspects of language production. Philadelphia, PA: Psychology Press; 2000. pp. 291–330. [Google Scholar]
- Ferreira VS. Is it better to give than to donate? Syntactic flexibility in language production. Journal of Memory and Language. 1996;35:724–755. [Google Scholar]
- Ferreira VS, Pashler H. Central bottleneck influences on the processing stages of word production. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2002;28:1187–1199. [PMC free article] [PubMed] [Google Scholar]
- Ferreira VS, Slevc RL. Grammatical encoding. In: Gaskell G, editor. Oxford handbook of psycholinguistics. Oxford: Oxford University Press; 2007. pp. 453–469. [Google Scholar]
- Ferreira F, Swets B. How incremental is language production? Evidence from the production of utterances requiring the computation of arithmetic sums. Journal of Memory and Language. 2002;46:57–84. [Google Scholar]
- Garrett MF. The analysis of sentence production. In: Bower GH, editor. The psychology of learning and motivation. Vol. 9. New York: Academic Press; 1975. [Google Scholar]
- Griffin ZM. Gaze durations during speech reflect word selection and phonological encoding. Cognition. 2001;82:B1–B14. doi: 10.1016/s0010-0277(01)00138-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Griffin ZM, Bock K. What the eyes say about speaking. Psychological Science. 2000;11:274–279. doi: 10.1111/1467-9280.00255. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Griffin ZM, Mouzon SS. Can speakers order a sentence’s arguments while saying it?. Poster presented at the 17th Annual CUNY Sentence Processing Conference; College Park, MD. 2004. [Google Scholar]
- Griffin ZM, Spieler DH. Observing the what and when of language production for different age groups by monitoring speakers’ eye movements. Brain and Language. 2006;99:272–288. doi: 10.1016/j.bandl.2005.08.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grimshaw J. Argument structure. Cambridge, MA: The MIT press; 1990. [Google Scholar]
- Hartsuiker RJ, Barkhuysen PN. Language production and working memory: The case of subject-verb agreement. Language and Cognitive Processes. 2006;21:181–204. [Google Scholar]
- Jackendoff R. X-bar syntax. Cambridge, MA: MIT Press; 1977. [Google Scholar]
- Kellogg RT. Working memory components in written sentence generation. American Journal of Psychology. 2004;117:341–361. [PubMed] [Google Scholar]
- Kempen G, Hoenkamp E. An incremental procedural grammar for sentence formulation. Cognitive Science. 1987;11:201–258. [Google Scholar]
- Kennison SM. Processing agentive “by”-phrases in complex event and nonevent nominals. Linguistic Inquiry. 1999;30:502–508. [Google Scholar]
- Kennison SM. Comprehending noun phrase arguments and adjuncts. Journal of Psycholinguistic Research. 2002;31:65–81. doi: 10.1023/a:1014328321363. [DOI] [PubMed] [Google Scholar]
- Kertesz A. Western Aphasia Battery. New York: Grune & Stratton; 1982. [Google Scholar]
- Kim M, Thompson CK. Patterns of comprehension and production of nouns and verbs in agrammatism: Implications for lexical organization. Brain and Language. 2000;74:1–25. doi: 10.1006/brln.2000.2315. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lawler EN, Griffin ZM. Gaze anticipates speech in sentence-construction task. Poster presented at the 15th Annual Convention of the American Psychological Society; Atlanta, GA. 2003. [Google Scholar]
- Lee M, Thompson CK. Agrammatic aphasic production and comprehension of unaccusative verbs in sentence contexts. Journal of Neurolinguistics. 2004;17:315–330. doi: 10.1016/S0911-6044(03)00062-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Levelt WJM. Speaking: From intention to articulation. Cambridge, MA: MIT press; 1989. [Google Scholar]
- Levine B. English verb classes and alternations. Chicago, IL: University of Chicago Press; 1993. [Google Scholar]
- Lindsley JR. Producing simple utterances: How far ahead do we plan? Cognitive Psychology. 1975;7:1–19. [Google Scholar]
- Liversedge S, Pickering M, Branigan H, Van Gompel R. Processing arguments and adjuncts in isolation and context: The case of by-phrase ambiguities in passives. Journal of Experimental Psychology: Learning, Memory and Cognition. 1998;24:461–475. [Google Scholar]
- Luzzatti C, Raggi R, Zonca G, Pistarini C, Contardi A, Pinna GD. Verb-noun double dissociation in aphasic lexical impairments: The role of word frequency and imageability. Brain and Language. 2002;81(1–3):432–444. doi: 10.1006/brln.2001.2536. [DOI] [PubMed] [Google Scholar]
- Martin RC, Freedman ML. Short-term retention of lexical-semantic representations: Implications for speech production. Memory. 2001;9:261–280. doi: 10.1080/09658210143000173. [DOI] [PubMed] [Google Scholar]
- Meyer A. Lexical access in phrase and sentence production: Results from picture-word interference experiments. Journal of Memory and Language. 1996;35:477–496. [Google Scholar]
- Meyer AS. The use of eye tracking in studies of sentence generation. In: Henderson JM, Ferreira F, editors. The interface of language, vision, and action: Eye movements and the visual world. New York: Psychology Press; 2004. pp. 191–212. [Google Scholar]
- Meyer AS, Sleiderink AM, Levelt WJM. Viewing and naming objects: Eye movements during noun phrase production. Cognition. 1998;66:B25–B33. doi: 10.1016/s0010-0277(98)00009-2. [DOI] [PubMed] [Google Scholar]
- Meyer AS, van der Meulen FF. Phonological priming effects on speech onset latencies and viewing times in object naming. Psycholinguistic Bulletin & Review. 2000;7:314–319. doi: 10.3758/bf03212987. [DOI] [PubMed] [Google Scholar]
- Rayner K, Sereno SC. Eye movements in reading. In: Gernsbacher MA, editor. Handbook of psycholinguistics. San Diego, CA: Academic Press; 1994. pp. 945–984. [Google Scholar]
- Schmauder RA. Argument structure frames: A lexical complexity metric? Journal of Experimental Psychology: Learning, Memory, and Cognition. 1991;17:49–65. doi: 10.1037//0278-7393.17.1.49. [DOI] [PubMed] [Google Scholar]
- Schriefers H, Teruel E, Meinshausen M. Producing simple sentences: Results from picture-word interference experiments. Journal of Memory and Language. 1998;39:609–632. [Google Scholar]
- Schütze CT, Gibson E. Argumenthood and English prepositional phrase attachment. Journal of Memory and Language. 1999;40:409–431. [Google Scholar]
- Shapiro LP, Brookins B, Gordon B, Nagel N. Verb effects during sentence processing. Journal of Experimental Psychology. 1991;17:983–996. doi: 10.1037//0278-7393.17.5.983. [DOI] [PubMed] [Google Scholar]
- Shapiro LP, Gordon B, Hack N, Killackey J. Verb-argument structure processing in complex sentences in Borca’s and Wernike’s aphasia. Brain and Language. 1993;45:423–447. doi: 10.1006/brln.1993.1053. [DOI] [PubMed] [Google Scholar]
- Shapiro LP, Levine BA. Verb processing during sentence comprehension in aphasia. Brain and Language. 1990;38:21–47. doi: 10.1016/0093-934x(90)90100-u. [DOI] [PubMed] [Google Scholar]
- Shapiro LP, McNamara P, Zurif E, Lanzoni S, Cermak L. Processing complexity and sentence memory: Evidence from amnesia. Brain and Language. 1992;42:431–453. doi: 10.1016/0093-934x(92)90078-s. [DOI] [PubMed] [Google Scholar]
- Shapiro LP, Nagel HL, Levine BA. Preferences for a verb’s complements and their use in sentence processing. Journal of Memory and Language. 1993;32:96–114. [Google Scholar]
- Shapiro LP, Zurif E, Grimshaw J. Sentence processing and the mental representation of verbs. Cognition. 1987;27:219–246. doi: 10.1016/s0010-0277(87)80010-0. [DOI] [PubMed] [Google Scholar]
- Thompson CK. Unaccusative verb production in agrammatic aphasia: The argument structure complexity hypothesis. Journal of Neurolinguistics. 2003;16:151–167. doi: 10.1016/S0911-6044(02)00014-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thompson CK, Choy J. Pronominal resolution and gap filling in agrammatic aphasia: Evidence from eye movements. Journal of Psycholinguistic Research. 2009;38:255–283. doi: 10.1007/s10936-009-9105-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thompson CK, Dickey MW, Cho S, Lee J, Griffin ZM. Verb argument structure encoding during sentence production in agrammatic aphasic speakers: An eye-tracking study. Brain and Language. 2007;103:24–26. [Google Scholar]
- Thompson CK, Lange KL, Sheneider SL, Shapiro LP. Agrammatic and non-brain damaged subjects’ verb and verb argument structure production. Aphasiology. 1997;11:473–470. [Google Scholar]
- van der Meulen FF. Coordination of eye gaze and speech in sentence production. In: Härtel H, Tappe H, editors. Mediating between concepts and grammar. Berlin: Morton de Gruyter; 2003. [Google Scholar]