

Abstract
Tracer studies are analyzed almost universally by multicompartmental models where the state variables are tracer amounts or activities in the different pools. The model parameters are rate constants, defined naturally by expressing fluxes as fractions of the source pools. We consider an alternative state space with tracer enrichments or specific activities as the state variables, with the rate constants redefined by expressing fluxes as fractions of the destination pools. Although the redefinition may seem unphysiological, the commonly computed fractional synthetic rate actually expresses synthetic flux as a fraction of the product mass (destination pool). We show that, for a variety of structures, provided the structure is linear and stationary, the model in the enrichment state space has fewer parameters than that in the activities state space, and is hence better both to study identifiability and to estimate parameters. The superiority of enrichment modeling is shown for structures where activity model unidentifiability is caused by multiple exit pathways; on the other hand, with a single exit pathway but with multiple untraced entry pathways, activity modeling is shown to be superior. With the present-day emphasis on mass isotopes, the tracer in human studies is often of a precursor, labeling most or all entry pathways. It is shown that for these tracer studies, models in the activities state space are always unidentifiable when there are multiple exit pathways, even if the enrichment in every pool is observed; on the other hand, the corresponding models in the enrichment state space have fewer parameters and are more often identifiable. Our results suggest that studies with labeled precursors are modeled best with enrichments.
Keywords: Enrichments, Estimation, Identifiability, Modeling, Rate constants
1. Introduction
Many biological systems are studied by introducing a tracer, typically as a bolus or as a primed constant infusion, and following the tracer appearance and disappearance in one or more chemical species. The data are typically tracer enrichment (abundance, atoms percent excess) or specific radioactivity, e.g., d3-leucine as tracer and data on d3-leucine enrichment in plasma leucine and in circulating apolipoproteins. Tracer kinetics are studied typically by linear, stationary models. Hearon (1963), and later Bright (1973), pointed out that, when pool masses are constant, state variables can be the total tracer amounts (expressed in mass units, activities, etc.) in the pools, or the tracer concentrations (expressed as enrichments, specific activities, etc.) in the pools. However, modeling has been performed almost universally in terms of activities (Berman and Schoenfeld, 1956; Shipley and Clark, 1972; Rescigno and Michels, 1973; DiStefano 3rd, 1983; Chapman and Godfrey, 1985; Cobelli et al., 1987, 2000; García-Meseguer et al., 2003), and for good reason: the coefficients in the differential equations for activities are rate constants that express mass fluxes as fractions of the source pools, a natural definition in the context of the common assumption of first-order kinetics. This is not the case with enrichment modeling, where some coefficients do not have the same natural physical interpretation.
We focused instead on the fact that in most human tracer studies, measurements are of tracer enrichments or specific activities (SA), and looked at tracer kinetics models in the state space of enrichments compared to models in the state space of activities. We present both activity and enrichment (or SA) formulations for tracer studies and show that, for certain commonly encountered model structures, enrichment modeling has fewer parameters, and hence is better suited with respect to identifiability and parameter estimation. We find that there is an advantage, especially where there is direct removal of material from multiple pools, to modeling enrichments and not activities.
Enrichment and activity modeling are first compared in four simple, illustrative structures: the simple situation of calculating the fractional synthetic rate (FSR) in a single pool, then a simple two-pool cascade structure with direct material removal from both pools and tracer introduced as an exogenous bolus into the first pool or endogenously via a precursor, and finally a two-pool exchange structure with multiple outflows. Enrichment modeling is shown to be superior in each example—it leads to simpler formulations and fewer parameters, and consequently to identifiability when the commonly used activity models are unidentifiable.
The two-pool structures are followed by general n-pool structures, first for exogenous tracer studies, and then for endogenous tracer studies, which generalize FSR modeling. Finally, a duality is proved between activity and enrichment models to explain why one approach is better for certain structures and the other for others.
2. Preliminaries and notation
2.1. Definitions
The words “system,” “structure,” and “model” are used synonymously in the literature on identifiability of pool models, as seen in the seminal paper of Bellman and Åström (1970) as well as in the major review by Cobelli and DiStefano 3rd (1980). We believe it is useful to distinguish among (1) a biological system, (2) a structure with pools and pathways used to represent the system, and (3) a mathematical model for tracer kinetics when a tracer is introduced into the system. Thus, a pool structure abstracts the system into a set of interconnected pools and is completely described by a diagram, with no equations; the model contains the mathematical relationships needed to describe the structure.
We consider multicompartmental structures, i.e., structures made up of a number of compartments or pools, the material within each of which is assumed to behave identically (homogeneous). Tracer activity refers to the amount of tracer, typically expressed in units of mass or of radioactivity. Activity modeling refers to modeling (writing differential and algebraic equations for) tracer activities in different structural pools. Enrichment is expressed as the amount of tracer divided by the total of tracer and tracee. We use enrichment modeling to refer to modeling enrichments or equivalent quantities—tracer abundance in the form of atoms percent excess or a fraction, tracer-to-tracee ratio where appropriate, specific radioactivity in a study with a radiolabel. Activity modeling refers to the usual formulation of differential equations for the tracer amount, quantity or activity. Following the definition of local identifiability by Bellman and Åström (1970) and later by Chapman and Godfrey (1985), and dropping the word “local” for brevity, a model is identifiable if error-free data lead to a unique solution (or a finite number of solutions) for all the parameters in the model equations; a model is unidentifiable if one or more parameters are unidentifiable, i.e., have an infinity of possible values consistent with error-free data.
We consider a biological system that can be abstracted by a linear, stationary structure of n pools. Linear means that mass fluxes are linearly proportional to (i.e., a constant multiplied by) pool masses so that linear differential equations can describe the changes with time of tracer quantities in different pools. Stationary means the biological system is in a steady state and pool masses are not changing with time so that the differential equations for tracer quantities have only constant coefficients. The quantity or mass (tracer+tracee) of the ith pool is Qi, and the quantity or activity of tracer qi (t), and the tracer enrichment or SA is yi (t) = qi (t)/Qi. Qi is assumed to be constant, either because the tracer is radioactive, and hence of negligible mass or, in case of a stable isotope, the tracer enters the system via synthetic pathways unaffected by the introduction of the isotope (Garlick et al., 1994; Ramakrishnan, 2006). Some systems with mass isotopes have been modeled by considering the amount of tracee to be constant (Cobelli et al., 1987), especially in glucose kinetics (Basu et al., 2003). The results of the present paper will apply to those systems provided Qi stands for the quantity or mass of tracee alone in the ith pool, and yi (t) stands for the tracer-to-tracee ratio. Qi may be unknown.
Tracer is introduced in one of two ways: as a bolus into one or more pools (e.g., if introduced into pool 1, q1(0) = q10, possibly unknown), or into a precursor structure with the tracer concentration of the immediate precursor known as a function of time, w(t). More generally, w(t) can be a vector in case of multiple immediate precursor pools; while we assume a scalar w(t) for simplicity of presentation, the results would hold for a vector w(t). The mass fluxes are Fij into pool i from pool j, with the additional understanding of Fi0 as the direct inflow or synthesis into pool i, F0j as the direct outflow or catabolism from pool j, and Fii as the total flux through the ith pool (equal to the sum of all the individual fluxes into the ith pool, as well as to the sum of all the fluxes out of the ith pool).
Rate constants are defined conventionally as fluxes divided by source pool masses:
| (1) |
For convenience, which will become apparent presently, we also define
| (2) |
The rate constant ki0 is termed the fractional synthetic rate (FSR) in protein turnover.
An alternative, seldom used (Hearon, 1963), definition for rate constants is as fluxes divided by the destination pool masses:
| (3) |
with the additional definition for the fractional catabolic rates (FCR):
| (4) |
It may be noted that kij expresses each flux as a fraction of its source pool mass so that the flux out of a pool, Fij, is kij times Qj, analogous to and consistent with first order reaction kinetics and mass diffusion models where the mass transport is proportional to the source mass. On the other hand, rij expresses the flux from j to i as a fraction of the destination pool mass and thus has no natural physical meaning. It is for this reason that modeling with k’s is nearly universal while modeling with r’s is virtually nonexistent (Rubinow and Winzer, 1971; Ramakrishnan et al., 1981, 1984; Anderson, 1983; Ramakrishnan, 1984).
The parameters kij and rij are strongly related. It is easily seen that
| (5) |
The total flux out of the ith pool (= kii Qi) must equal the total of all the fluxes from the ith pool to the other pools and to the outside (= kji Qi summed over j):
| (6) |
Also, the total flux into the ith pool (= rii Qi) must equal the total of all the fluxes into the ith pool from the other pools and from the outside (= rij Qi summed over j):
| (7) |
Since kii = rii, it follows that
| (8) |
Also, writing Eq. (7) in terms of the k-parameters, and Eq. (6) in terms of the r-parameters, yields two more relationships:
| (9) |
| (10) |
Data are typically measurements of enrichments. The measurements may be made in single structure pools. Often, however, if the measurement technique cannot separate material in structural pools that occupy the same physical space, the measurement is of the weighted mean enrichment in multiple structure pools. For instance, Demant et al. (1996) consider model structures for apolipoprotein B in which each measurement typically is of the enrichment in two or three structural pools. [If tracer concentration in some unit volume is measured, e.g., dpm/ml plasma, we assume that it can be converted to SA on dividing by tracee concentration in the same unit volume.] We define an index set Jm that points to the pools whose enrichment is zm(t). For instance, if z2 is the enrichment in pool 4, then J2 = {4} and z2 = y2; if z6 is the combined enrichment in pools 5, 7, 8, 10, then J6 = {5, 7, 8, 10} and . We also define the masses of these responses:
| (11) |
2.2. Two alternative models for the same structure
The differential equations for tracer kinetics in a pool structure can be written for q(t), the tracer activities in the pools, or for y(t), the tracer enrichments (or SA) in the pools. It is to be noted that there are two models for the same structure. The models are equivalent in that they describe the same biological processes and the same assumptions; a pictorial representation of the structure with pools and arrows would be the same for the enrichment and activity models. But the models are different in their state variables and model parameters so that the differential equations and the model solutions take different forms, which as we see below, can lead to one model being identifiable while the other is not. Each model describes a different state space, much as a change of variable in calculus.
We begin by noting that, by the assumptions of stationarity, linear relationships among the pool masses can be derived from flux balances for the ith pool:
| (12) |
for the ith pool. We note that Eq. (9) above follows from this equation, which is referred to as the Q-model or as the tracee model (Pont et al., 1998).
The activity model differential equations are written readily (Cobelli and DiStefano 3rd, 1980). The rate of change in tracer activity in the ith pool is given by
| (13) |
The first term on the right side is tracer entry from the precursor into the ith pool; the second term is tracer entry from the other pools into the ith pool; the last term is tracer leaving the ith pool, going to other pools or to the outside. The quantity Si is the synthetic flux into the ith pool from the precursor with enrichment w(t); Si equals Fi0 = ki0Qi if all flux into the ith pool is labeled. The parallel to the steady-state equation (12) is apparent, making clear once again why activity modeling is natural.
For the enrichment model, the rate of change in tracer enrichment in the ith pool is derived from Eq. (13) (Ramakrishnan et al., 1984) by a change of variable qj (t) = yj (t)Qj, using the relationships kij Qj = rij Qi from Eq. (5), and noting that, since the structure is stationary, Qi ’s are constant:
| (14) |
The quantity si is Si /Qi, the fractional synthetic flux into the ith pool with enrichment w(t), equaling ri0 if all flux into the i th pool is labeled.
The activities model is written readily in matrix-vector notation (Cobelli and DiStefano 3rd, 1980):
| (15) |
where the matrix K, vector S, and matrix C are given by
| (16) |
The activities model is termed the q-model.
The enrichment model in matrix-vector notation is as below:
| (17) |
where the matrix R, vector s, and matrix D are given by
| (18) |
The enrichment model is termed the y-model.
Either model can be derived from the other by noting that
| (19) |
The state spaces for q(t) and y(t) are differentiable vector spaces of n-tuples of functions of time, isomorphic to each other. Equation (19) defines the transformation between the two state spaces.
It follows from Eqs. (5), (16), and (18) (as shown in Anderson, 1983, Section 9) that
| (20) |
Often, each response is the enrichment in a single pool, obviating the need for index sets J: If the mth response is the enrichment in the j th pool,
| (21) |
The differential equation coefficients in a q-model (for activities) are k’s, rate constants in terms of source pool masses, while those in a y-model (for enrichments) are r ’s, rate constants in terms of destination pool masses. As noted above, a rate constant in terms of the source pool mass has a natural physical meaning, explaining why tracer kinetics models are almost always in terms of total activities, even though the data are generally of enrichments or specific activities.
3. Four simple illustrations of superiority of enrichment modeling
3.1. Modeling fractional synthetic rate
Consider the usual method of estimating an organ-specific protein synthetic rate constant or the fractional synthetic rate (FSR) of a particular protein (Zilversmit, 1960; Zak et al., 1979), modeled by a single pool, as shown in Fig. 1. The precursor is shown by a square, instead of the usual circle for a pool, to indicate that it is used as a forcing function known from precursor enrichment data, and that it is not necessarily a single pool. Note that, in this case, the parameter of interest itself is flux divided by the destination pool mass. The q-model is a single differential equation:
| (22) |
Fig. 1.

A simple one-pool structure for a product of interest, with the tracer entering by a synthetic pathway from a precursor whose enrichment, w(t), is known. The precursor is denoted by a square to indicate an arbitrary model structure for the precursor. The synthetic rate is S, the mass of the product pool is Q, the tracer activity or amount in the product pool is q(t), the tracer enrichment or specific activity in the product pool is y(t), and the fractional synthetic (or catabolic) rate is k.
There are three parameters, k, S, Q. One is eliminated easily since S = kQ:
| (23) |
However, it is not actually possible to estimate Q from the data. This is easily seen with the y-model for the enrichment:
| (24) |
A single parameter, k, is identifiable. This point is obscured by the formulation in the q-model.
This example is quite trivial as the q-model’s unidentifiability is manageable: Q can be set to an arbitrary value and k estimated from the enrichment data. The point to note is that the q-model unidentifiability is not apparent from Eq. (23). In the three examples that follow, setting a mass arbitrarily is not enough to make the k rate constants in the activity state space identifiable.
The generalized models for FSR are analyzed in Section 4.2 under Endogenous Tracer Studies.
3.2. A two-pool cascade with entry and removal from both pools
Consider the simple two-pool structure in Fig. 2, a great simplification of complex structures such as the delipidation cascade of very low density lipoproteins (VLDL) to intermediate density lipoproteins (IDL) (Packard et al., 2000; Barrett et al., 2006). Assume a known bolus tracer injection u into pool 1 at time zero, and enrichments in both pools observed. The y-model for enrichments involves two differential equations:
| (25) |
Fig. 2.

A two-pool cascade structure with precursor feeding both pools and material exit from both pools. Two experimental designs are considered in the text, one with a bolus tracer injection into pool 1, and the other with a labeled precursor at constant enrichment as in Fig. 1. With data available on enrichments in both pools, the activity model is unidentifiable, but the enrichment model is identifiable. Next to each arrow is a definition for the corresponding rate constant in the activity model (k’s) and in the enrichment model (r’s).
The y-model has four parameters—three rate constants (r11, r21, r22) and one mass (Q1). The differential equations (25) are easily solved:
| (26) |
It is readily seen that all four parameters can be estimated from the data: the two exponential rate constants are r11 and r22; the coefficient for y1(t) leads to Q1; the coefficients for y2(t), equal in magnitude, lead to r21.
The q-model for activities also involves two differential equations:
| (27) |
The activity model has five parameters, one more than the enrichment model—three rate constants (k11, k21, k22) and two masses (Q1, Q2). But Eqs. (26) for the enrichments, which are observed, contain only four parameters—two exponential rate constants and two coefficients. Therefore, the activity model is unidentifiable while the enrichment model is identifiable. And the unidentifiability of the activity model is not obvious.
Further, unlike in the first example with FSR, it is not apparent how to deal with the unidentifiability. From Eqs. (5), we know that k11 = r11, k22 = r22. Therefore, from the analytical solutions in Eqs. (26), three parameters (k11, k22, Q1) are identifiable, but what about k21 and Q2? How are they related to r21, which is identifiable, and to the other parameters?
With the help of the results from the enrichment model, we can investigate k21 and Q2, the two unidentifiable parameters of the activity model, and determine what values they can assume consistent with the data. From Eqs. (5), we know that
| (28) |
The mass ratio Q2/Q1 and k01, both unidentifiable, have a negative linear relationship involving r21, an identifiable enrichment model parameter, as shown in Fig. 3.
Fig. 3.
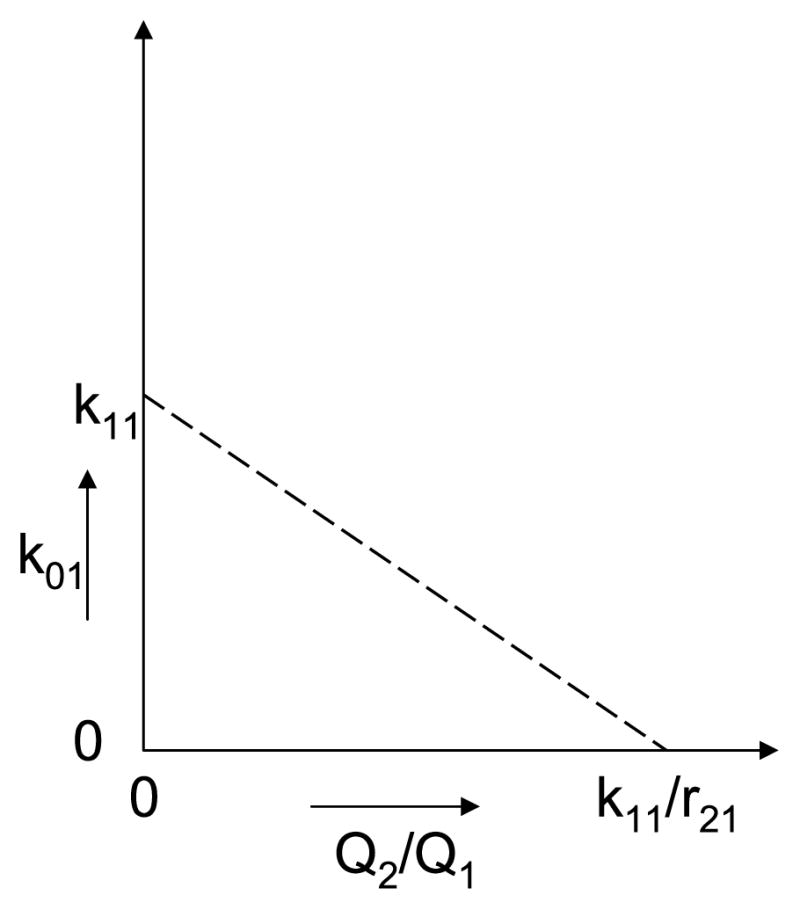
For the structure in Fig. 2, the dashed line shows how two unidentifiable parameters, the direct removal rate constant from pool 1 and the ratio of the two pool masses, can vary together. The removal rate constant, k01, can take any value between 0 and k11, while the mass ratio Q2/Q1 goes from a high of k11/r21 down to zero.
Thus, even if activity model parameters are of interest, we can first fit the data with enrichment modeling and estimate the identifiable Q1, r11, r21, and r22, three of which are activity model parameters as well, and then use Eqs. (5) to obtain a relationship between Q2/Q1 and k01, the direct removal rate constant, as in Fig. 3. The activity model, on the other hand, is unidentifiable, so some simplification (e.g., setting k01 = 0) is necessary even to fit the data. In contrast, no simplifying assumption is needed in the state space of enrichments.
3.3. Two-pool cascade with tracer entry from precursor
Consider again the two-pool structure in Fig. 2 but, instead of a bolus tracer injection into pool 1, tracer enters both pools from a precursor at constant enrichment, c, and enrichments in both pools are observed. Lipoprotein kinetics are typically studied by a primed constant infusion of a labeled amino acid so that the precursor enrichment may be assumed to be constant (Nagashima et al., 2005; Tremblay et al., 2006). The y-model for enrichments again involves two differential equations:
| (29) |
The y-model has three parameters—the rate constants r11, r21, r22. The differential equations (29) are easily solved:
| (30) |
The three rate constants (and, if needed, the precursor enrichment c) can be estimated by fitting the model to enrichment data from the two pools.
The q-model for activities also involves two differential equations:
| (31) |
The activity model has five parameters, two more than the enrichment model—three rate constants (k11, k21, k22) and two masses (Q1, Q2). We know from Eqs. (30) that only three parameters can be estimated from the data—three rate constants. Therefore, the activity model is unidentifiable while the enrichment model is identifiable.
Once again, it is not obvious how to deal with the unidentifiability of the activity model. From Eqs. (5), we know that k11 = r11, k22 = r22. Therefore, two parameters (k11, k22) are identifiable, but in order to estimate them, an identifiable model is needed; the enrichment model can be used for this purpose. We can analyze the other three using the results from the previous two examples. From the first example, with FSR, Q1 is unidentifiable but can be set to an arbitrary value. From the second example, the mass ratio Q2/Q1 and k01, both unidentifiable, have a negative linear relationship involving r21, an identifiable enrichment model parameter, as shown in Fig. 3. As in the previous example, the choice of state space determines the identifiability of the tracer kinetics model.
3.4. Two-pool exchange structure with removal from both pools
Consider the simple two-pool structure in Fig. 4. Assume a known bolus tracer injection u into pool 1 at time zero, and pool 1 enrichment observed. The y-model for enrichments involves two differential equations:
| (32) |
Fig. 4.

A simple two-pool exchange structure with tracee input into pool 1 alone but with removal from both pools. A bolus injection of tracer is made into pool 1, and the enrichment in pool 1 is observed. The activity model is unidentifiable, but the enrichment model is identifiable. Next to each arrow is a definition for the corresponding rate constant in the activity model (k’s) and in the enrichment model (r’s).
The y-model has four parameters—three rate constants (r11, r12, r22) and one mass (Q1). The solution is given by
| (33) |
It can be shown easily that the four parameters can be estimated from the two eigenvalues (λ1 and λ2) and the two exponential coefficients in y1(t). The y-model is identifiable.
The q-model for activities also involves two differential equations:
| (34) |
The activity model has five parameters, one more than the enrichment model—four rate constants (k11, k12, k21, k22) as opposed to three in the enrichment model, and one mass (Q1). We know from Eq. (33) for the enrichment in pool 1 that only four parameters can be estimated from the data—two exponential rate constants and two coefficients. Therefore, the activity model is unidentifiable.
As in the previous examples, the identifiable enrichment model can be used to study the unidentifiable activity model. From Eqs. (5), we know that k11 = r11, k22 = r22. Therefore, three parameters (k11, k22, Q1) are identifiable in the activity model. As for the other two, we know from Eqs. (5) that k12k21 = r12r21 = r12r22. This means that we can only estimate the product of the two exchange rate constants k12 and k21. Each has an upper bound: k12 ≤ k22; k21 ≤ k11. Since the product is fixed, each has a lower bound as well:
| (35) |
The relationship between k12 and k21 is displayed in Fig. 5, a rectangular hyperbola. The product of the two unidentifiable activity model parameters, k12 and k21, equals the product of two identifiable enrichment model parameters r12 and r22.
Fig. 5.

For the structure in Fig. 4, the curve, a rectangular hyperbola, shows how k12 and k21, two unidentifiable parameters in the activity model, vary together. Their product is fixed (equal to the product r12r22). The smallest and largest values possible for each are indicated on the axes.
4. Enrichment and activity modeling compared in multicompartmental structures
We next consider some general n-pool structures where analytical solutions are not available but the relative merits of working in the q-space versus the y-space can be determined. Exogenous tracer studies are followed by endogenous tracer studies and then by a duality.
4.1. Modeling exogenous tracer studies
We contrast q- and y-modeling with mammillary structures; catenary and other structures will be shown to yield similar results. A mammillary structure, seen in Fig. 6, has a central pool that exchanges material directly with each of the other pools with no direct material flux between any other pools; a catenary structure is one that can be visualized on a line with each pool exchanging material directly only with the pool immediately to the left or to the right (Hart 1955, 1965). Consider an n-pool mammillary structure with a bolus injection of tracer into the central pool and the tracer enrichment (or specific activity) in that pool observed. In this case, w(t) is zero. The q-model becomes:
| (36) |
Fig. 6.

An n-pool mammillary structure studied by a bolus tracer injection into the central pool 1, and tracer enrichment measured in the same pool. Three possibilities are shown for material entry and exit in the peripheral pools 2, …, i, …, n. Figure 6A has all entry and exit solely in the central pool. Figure 6B has possible exit from all the pools but entry solely into the central pool. Figure 6C has possible entry into all the pools but exit solely from the central pool.
Alternatively, the y-model is
| (37) |
The system matrices for the q-model and for the y-model, respectively, are
| (38) |
| (39) |
The matrices K and R have each been augmented by a column on the left to indicate pathways from the outside, and by a row at the top to indicate pathways to the outside. [This formulation extends the notation of Chapman and Godfrey (1985) who used an augmented row to account for fluxes to the outside.] Equations (5) provide relationships between K and R. With n pools, z(t) can be expressed by a sum of n exponentials, which means 2n parameters are identifiable.
We begin with the simplest flux configuration and proceed to more complex structures.
4.1.1. All tracee input and output in central pool
First, suppose that all tracee entry is into the central pool 1 (i.e., ki0 = ri0 = 0 for i > 1), and all removal is from that pool as well (i.e., k0i = r0i = 0 for i > 1), as shown in Fig. 6A. Applying Eq. (6) leads to kii = k1i for i > 1, while Eq. (7) leads to rii = ri1 for i > 1.
The system matrices for the q-model and for the y-model, respectively, are
| (40) |
| (41) |
For the q-model, there are 2n parameters—Q1, k11, and kii, ki1 for i > 1. For the y-model, as well, there are 2n parameters—y0, r11, and rii, r1i for i > 1. Thus, both models satisfy a necessary condition for the model to be identifiable. Cobelli et al. (1979) have shown that the q-model is identifiable; the y-model is identifiable from applying Eqs. (5):
| (42) |
4.1.2. All tracee input into central pool
We next consider a structure with outflows possible from all pools but entry only into the central pool, as shown in Fig. 6B. This means that while rii = ri1 for i > 1 as in the simpler case, kii = k0i + k1i ≥ k1i for i > 1. The system matrices for the q-model and for the y-model, respectively, are
| (43) |
| (44) |
The y-model is identical to the simpler case in Fig. 6A with all tracee output from the central pool because r0i ’s do not appear in the differential equations; not so for the q-model in which the presence of k0i ’s makes it impossible to eliminate the k1i ’s unlike in the simpler case. While the y-model still has only 2n parameters (y0, r11, and rii, r1i for i > 1), the q-model has 3n − 1 parameters—Q1, k11, and kii, k1i, ki1 for i > 1. Again, we note that kii = rii from Eqs. (5), but k1i = F1i /Qi, ki1 = Fi1/Q1, while r1i = F1i /Q1, rii = Fi1/Qi, and so the q-model has 2n − 2 unidentifiable parameters with the only constraints being k1i ki1 = r1i rii. Each k1i can assume a range of values ≤ kii with a corresponding value for ki1.
DiStefano 3rd (1983) has derived bounds for the q-model parameters, but the identifi-ability of the y-model when all tracee input is into the central pool appears to be a novel result here.
4.1.3. All tracee output from central pool
We next consider a structure with entry possible into all pools but outflow only from the central pool, as shown in Fig. 6C. The system matrices for the q-model and for the y-model, respectively, are
| (45) |
| (46) |
In this case, the q-model is identical to the simpler case in Fig. 6A with all tracee input into the central pool because ki0’s do not appear in the differential equations; not so for the y-model in which the presence of ri0’s makes it impossible to eliminate the ri1’s unlike in the simpler case. The q-model has only 2n parameters (Q1, k11, and kii, ki1 for i > 1), while the y-model has 3n − 1 parameters (y0, r11, and rii, r1i, ri1 for i > 1) with 2n − 2 unidentifiable parameters with the only constraints being kii ki1 = r1i ri1. So, q-modeling is to be preferred in this case.
4.1.4. Catenary structures
The results are similar with general catenary structures. We assume tracer injection and observation in one of the two terminal pools, termed pool 1 for convenience. The system matrices K and R are tridiagonal: nonzero elements of the system matrix are on the diagonal, superdiagonal and subdiagonal for a total of 3n − 2, the same as in the mammillary structure. When all tracee input and outflow are in pool 1, each diagonal element other than the first can be expressed in terms of other elements—in the q-model, equal to the negative sum of the other elements in its column (as output from each pool goes only to other pools and not to the outside); and, in the y-model, equal to the negative sum of the other elements in its row (as tracee input into each pool comes only from other pools):
| (47) |
This decreases the number of distinct nonzero elements in the system matrix to 2n − 1 with both the q-model and the y-model. Both models are identifiable.
When all tracee input is into pool 1 but outflow is from multiple pools, the system matrix for the y-model is the same as with the simpler configuration but not for the q-model. And when all tracee outflow is from pool 1 but input is into multiple pools, the system matrix for the q-model is the same as with the simpler configuration but not for the y-model. Thus, the results for catenary structures parallel those for mammillary structures.
4.1.5. General pool structures
Considering a more general mammillary or catenary structure, with tracee input as well as outflow in multiple pools, it can be seen that both the q-model and the y-model have more than 2n and up to 3n − 1 parameters because neither the kii ’s nor the rii ’s can all be eliminated; neither is superior.
The above results for mammillary and catenary structures can be extended to arbitrarily general structures as follows. If a pool has tracee outflow to the outside, it is not possible to use Eq. (6) to express an element in that column in K in terms of the others, and so there is one more unknown parameter in K. On the other hand, if a pool has tracee inflow from the outside, it is not possible to use Eq. (7) to express an element in that row in R in terms of the others, and so there is one more unknown parameter in R. Thus, for exogenous tracers, enrichment modeling is superior when there are multiple exit pathways while activity modeling is superior with multiple unlabeled entry pathways. The results are different with endogenous labeling as shown in the next section.
4.2. Modeling endogenous tracer studies
We now consider experiments where most or all entry pathways are labeled by the use of a labeled precursor. With an endogenous tracer, if all synthetic pathways are labeled, si = ri0 = ki0 for all i. The precursor enrichment w(t) can be constant in a primed constant infusion study; in general, w(t) is a time-varying function assumed to be known. We consider a general n-pool structure with arbitrary connectivity with the enrichment in every pool observed. This is a generalization of the structure shown in Fig. 2 and analyzed in Section 3.3, as well as of the one-pool structure in Fig. 1 analyzed in Section 3.1. The q-model is as follows:
| (48) |
In the system matrix above, the ki0 can be eliminated by applying Eqs. (9). The k0i do not appear in the model differential equations but, if any k0i is zero, the corresponding kii can be set to the sum of the other kji ’s in that column by applying Eqs. (6); if k0i is nonzero because of a clearance pathway out of pool i, the corresponding kii is an unknown parameter. The nQi ’s appear in the differential equations as well as in P to calculate the observed z(t). The number of unknown parameters to be estimated from the data is the number of nonzero off-diagonal elements (equal to ma, the number of pathways among the pools) in K plus the number of pools n, plus mc, the number of nonzero entries in the top row for clearance pathways, or ma + n + mc. This number is reduced if the Qi ’s are not of interest. At least one Qi can be set to an arbitrary value such as 1. If the matrix K can be partitioned into md disconnected blocks (i.e., no flux between blocks, i.e., i, j in different blocks implies kij = kj i = 0), md of the masses can be set arbitrarily. Thus, the number of unknown parameters is ma + n + mc − md. We note that, since each block must have at least one outflow element in the top row, mc ≥ md. If md > 1, the structure graph is not connected (Rescigno and Segre, 1964).
The y-model is as follows:
| (49) |
In the system matrix above, the ri0 can be eliminated as equal to . The removal rate constants r0i do not appear in the model differential equations. The number of unknown parameters to be estimated from the data is just the number of nonzero elements in R, which is ma + n.
Thus, the q-model has ma + n + mc − md parameters while the y-model has only ma + n. Since the information content is the same, the number of parameters that can be uniquely identified cannot exceed ma + n. If mc = md, then the activity model is identifiable if the enrichment model is; the structure in Fig. 1, analyzed in Section 3.1, is an example, where the activity model is identifiable except for Q. However, with multiple exit pathways, mc > md, and activity modeling results in an unidentifiable model, with more parameters than can be identified from the data. As an example, for the structure shown in Fig. 2 and analyzed in Section 3.3, n = 2, ma = 1, and mc = 2, so that, as shown in Section 3.3, the q-model with ma + mc + n = 5 parameters (k11, k21, k22, Q1, Q2), only one (md = 1) of which (Q1) can be set arbitrarily, is unidentifiable, while the y-model with only ma + n = 3 parameters (r11, r21, r22) is identifiable.
4.3. Duality in flux balances between modeling activities and enrichments
Pool model parameters are masses and rate constants. Flux balances around the pools provide relationships among the parameters, which can be used to decrease their number by expressing some parameters in terms of the others, as in Section 4.2 to analyze endogenous tracer studies. Here, we manipulate the flux balances for a general pool structure and show a duality between modeling activities and modeling enrichments.
The flux balances are simple to state: for each pool, the total of all the individual fluxes into that pool must equal the total flux out of that pool and, in turn, the total of all the individual fluxes from that pool.
With the matrix K for rate constants in modeling activities, using the relationships between Kij and kij in Eqs. (16), we can rewrite Eqs. (9) for the total of the individual fluxes into the ith pool in matrix-vector notation as follows:
| (50) |
where Q is the vector of pool masses; P is a diagonal matrix whose iith element is Qi, i.e., P = diag(Q); and f is the vector of outside entry rate constants (fi = ki0 = ri0).
Equation (6) for the total of the individual fluxes from the ith pool to the other pools and to the outside becomes:
| (51) |
where KT is the transpose of K; u is a vector whose every element is 1; and g is the vector of removal rate constants (gi = k0i = r0i).
Proceeding similarly with the matrix R for rate constants in modeling enrichments, using the relationships between Rij and rij in Eqs. (18), we can rewrite Eq. (7) for the total of the individual fluxes into the ith pool in matrix-vector notation as follows:
| (52) |
Equation (10) for the total of the individual fluxes from the ith pool to the other pools and to the outside becomes:
| (53) |
where RT is the transpose of R; and the other symbols are as explained for Eqs. (50) and (51).
Equations (50)–(51) and (52)–(53) are quite distinct. However, there is a structural similarity between Eqs. (50) and (53), and between (51) and (52).
Consider a dual of a structure, obtained by reversing every pathway. An entry from the outside to the ith pool becomes a path to the outside from the ith pool; a path to the outside becomes an entry in from the outside; a flux from pool j to pool i becomes a flux from pool i to pool j. Denoting the parameters of the dual structure by the prime symbol (′), Eqs. (50)–(51) become for the dual q-model:
| (54) |
But since, by definition:
| (55) |
we get, substituting these equalities into Eqs. (54) for the dual structure:
| (56) |
which are identical to Eqs. (52)–(53) for the original structure with R.
Likewise, substituting the equalities in (55) into Eqs. (52)–(53) for the dual y-model, we get
| (57) |
which are identical to Eqs. (50)–(51) for the original structure with K.
Thus, the flux balances for the dual q-model and for the original y-model are identical. Likewise, the flux balances are identical for the dual y-model and for the original q-model.
4.3.1. An illustration of duality
As an illustration, consider the three-pool structure in Fig. 7A. The flux balances for the activities model lead to:
| (58) |
Fig. 7.

An example of duality as defined here: each structure is obtained from the other by reversing all the pathways. The flux balances for an activities model are the same as those for the enrichment model of its dual, and vice versa.
Next, consider the dual structure in Fig. 7B; note that every path in this figure is the opposite of a corresponding path in Fig. 7A. The flux balances for the enrichment model leads to:
| (59) |
Equations (58) and (59) can each be obtained from the other by interchanging “r” and “k,” and reversing all subscripts (i.e., “ij” by “ji”). A similar duality can be shown between the flux balances for the enrichment model for Fig. 7A and the activities model for Fig. 7B.
This duality helps to explain the differences between Figs. 6B and 6C. We saw that enrichment modeling was superior for the structure in Fig. 6B, while activity modeling was superior for the structure in Fig. 6C. The two structures are duals of each other. This means that the flux equations for the activities model for Fig. 6B are identical to those for the enrichment model for Fig. 6C. Thus, since the activities model is unidentifiable for Fig. 6B, the enrichment model is similarly unidentifiable for Fig. 6C.
5. Discussion
5.1. Paradox of identifiable and unidentifiable models for same structure
It may appear paradoxical that a biological system, with a specific configuration of pools and pathways and a specific tracer injection/observation study design, can have an unidentifiable as well as an identifiable model. In each of the four examples in Section 3, the structure being modeled was the same, shown in Figs. 1, 2, and 4, but the activity model was unidentifiable while the enrichment model was identifiable. The reason is that the same structure can be modeled in two different state spaces—the space of activities as state variables or the space of enrichments as state variables. Each state space induces a distinct parameter space. The dimensionality of the two parameter spaces may be different, depending on the pathways among the structure pools and the study design (how the tracer is introduced, which enrichments are observed).
We have shown in Section 4.2 that, particularly with endogenous tracer studies, which are widely used, enrichment modeling is to be preferred because the dimensionality of its parameter space is smaller.
Another way to understand this is that following the definition of Cobelli and DiStefano 3rd (1980), the identifiability of a model is determined by just those parameters that appear in the differential and observation equations and initial conditions. Parameters that do not appear thus, and there may be many such, do not influence the identifiability of the model. Thus, in the first example, in Section 3.1, the enrichment model in Eq. (24) has just one parameter, the rate constant k. It is not that the pool mass Q and flux S are not system parameters, but they do not appear in the enrichment model and so their unidentifiability does not affect the enrichment model’s identifiability. On the other hand, the activity model, in Eq. (23), contains the pool mass Q as well and is, therefore, unidentifiable. Similarly, for either of the two examples in Fig. 2, analyzed in Sections 3.2 and 3.3, the enrichment model is identifiable though the direct removal rate constant r01 is unidentifiable; this is because r01 does not appear in the enrichment model given by Eqs. (25) or (29).
It should be noted here that what we propose is not reparameterization. Rather, the state space is transformed, in a manner analogous to change of variable in calculus, so the model is in a completely different state space, which in turn induces a different parameter space of possibly different dimensionality.
5.2. Limitations of enrichment modeling
The most important limitation of enrichment modeling is that it relies on the stationarity assumption to replace the conventional k parameters with the r parameters. In Eqs. (5), which express the relationships between the k and r parameters, kij equals rij multiplied by the ratio of two pool masses. In a stationary structure, the pool masses, and consequently their ratios, do not change with time and so the rij parameters are constant and enrichment modeling is useful. However, if the structure is nonstationary, the pool masses, as well as their ratios, may be changing with time, which means the rij parameters are changing with time even if the kij parameters are constant with time, which makes enrichment modeling using rij not useful. Linearity is also required but this assumption is likely to be satisfied in tracer studies: even if the tracee system is nonlinear, the differential equations for the tracer are linear.
Also, as shown in Sections 4.1.3 and 4.1.5, with exogenous tracers and multiple unlabeled inputs into the structure, activity modeling can have fewer parameters and may be the preferred approach. This is much less common with the increasing use of mass isotopes and the use of labeled precursors to achieve endogenous labeling, which means most if not all input pathways are labeled.
The obvious fact should also be noted that any parameters that are unidentifiable in the activity model remain unidentifiable with enrichment modeling. When the focus of interest is an unidentifiable k parameter, enrichment modeling can first fit the observed data and estimate the identifiable r parameters, and the numerical values used to construct useful relationships for the unidentifiable k parameters of interest. This approach was illustrated in Section 3.2 with Fig. 3 for the structure in Fig. 2, and in Section 3.4 with Fig. 5 for the structure in Fig. 4.
5.3. Relationship to earlier work in pool model identifiability
An important paper by DiStefano 3rd (1983) introduced the idea of quasi-identifiability. The main example of an unidentifiable model in that paper was a mammillary model with tracer input into the central pool and exit pathways from all the pools—the model shown here in Fig. 6B, except that DiStefano’s model is more general in not specifying tracee input, thus allowing for tracee input into multiple pools, not just in the central pool as in Fig. 6B. The author derived the transfer function, solved for the k parameters in terms of the system eigenvalues and transfer function coefficients in order to determine what combinations of the k parameters are identifiable, and constructed bounds on the others. The algebraic expressions are quite complicated. We have shown here that, when the modeling is done with enrichments, the elements of the matrix R are identifiable when all tracee input is into the central pool. The other parameters, the removal rate constants r0i and the mass ratios Qi /Q1 are indeed unidentifiable, but their bounds can be derived in a manner similar to what was done here for the structure in Fig. 2, as shown in Fig. 3. Neither DiStefano nor Cobelli and Toffolo (1984), who commented critically, noted that the structure could be analyzed in a much simpler fashion by enrichment modeling if all tracee could be assumed to enter the central pool.
DiStefano’s work on quasi-identifiability was followed by papers from his group on algorithms for the identifiable parameter combinations and parameter bounds of unidentifiable mammillary structures (Landaw et al., 1984) of the type shown in Fig. 6B here, and similarly for catenary structures (Chen et al., 1985; DiStefano 3rd et al., 1988), and later on the effects of measurement errors (Lindell et al., 1988) and fixing some rate constants (Vicini et al., 2000) on these parameter bounds. Chau (1985) considered more general bolus-introduction and observation situations in mammillary structures of the type in Fig. 6B. Cobelli and coworkers (Cobelli et al., 1984; Ferrannini et al., 1985; Gastaldelli et al., 1997) studied glucose kinetics and developed relationships among unidentifiable parameters in three-pool mammillary structures with all tracee input into the central pool. The examples given in the glucose papers can all be studied much more easily by enrichment modeling since the models are identifiable in the enrichment state space.
5.4. Utility in parameter estimation
Going beyond identifiability analysis, the knowledge that certain combinations of rate constants in an activity model are identifiable is not helpful when the aim is to estimate parameters for a given study, because a model has to be identifiable for an iterative estimation algorithm to work well. Vajda (1984), Cobelli and Toffolo (1987), and Vajda et al. (1989) suggested constructing “submodels,” typically obtained by setting some of the outflows (k0i) to zero so that the model is made identifiable. Parameter estimates of the identifiable submodels are used to construct bounds on the parameters of the original unidentifiable model. In contrast, with the state space transformation approach proposed here, the tracer enrichment data can be fitted by an identifiable enrichment model, and the resulting parameter estimates for the elements of R used in Eqs. (5) to calculate identifiable rate constants, and to develop bounds for the unidentifiable rate constants, in the activity model, as illustrated in Section 2 and in Figs. 3 and 5. This approach is not feasible in the activity state space, as seen in the many papers referenced above. It is to be noted that enrichment modeling is quite different from, say, fitting enrichment data by sums of exponentials.
5.5. Impact of pool mass measurements
If all pool masses are known through measurements, activity and enrichment models are equivalent: if one is identifiable, so is the other; if one is not, the other is not as well. In all four examples in Section 3, the activity model would be identifiable if all the pool masses were known. Even in such structures, it may be of interest to know which parameters are identifiable without the mass data, and which require mass measurements. We have considered this question elsewhere (Ramakrishnan and Ramakrishnan, 2008). Enrichment modeling can help answer the question, as in the examples considered here.
5.6. Prior use of enrichment modeling
Rubinow and Winzer (1971) described both activity and concentration models and used the equivalents of the rate constants rij defined here, noting that it “represents the rate of transport of material from the jth compartment to the ith compartment, per unit amount of material in the ith compartment. Such a quantity is not of particular physical or physiological interest, but it is mathematically convenient.” Bright (1973) allowed for the state equations to be in terms of activities or enrichments, with the corresponding equivalents of kij and rij defined here. Perl et al. (1975), while modeling indicator kinetics, mentioned that the analog with tracers would be specific activities. Hearon (1974) used the analog of the R matrix here to prove a result in open linear systems. Anderson (1983, Section 25) derived the y-model and used it to study catenary structures. Jacquez (1985a) worked out a number of examples with specific-activity modeling but using the k-rate constants and mass ratios. A review of the literature since Hearon’s (1963) early observation on the equivalence of activity and enrichment modeling turns up no other publication with enrichment modeling in tracer kinetics outside of our group at Columbia University (Ramakrishnan et al., 1981, 1984; Ramakrishnan, 1984; Arad et al., 1990; Berglund et al., 1998; Nagashima et al., 2005). The use of activity models has been so universal that even authors who have studied identifiability questions and made major contributions (Jacquez, 1985b; Berman et al., 1962; DiStefano 3rd, 1983; Chapman and Godfrey, 1985; Jacquez and Simon, 1993; Eisenfeld, 1996) have not looked at enrichment modeling as an alternative approach to the problem, including in a book devoted to identifiability (Walter, 1987) or in a journal volume concerned with the work of Bellman (Jacquez, 1985a).
5.7. Relationship to pharmacokinetics
A major distinction in pharmacokinetics is that, unlike in tracer kinetics, there is no tracee. Activity modeling is easily extended to pharmacokinetics since the quantity of a drug in a pool is analogous to the quantity of a tracer in a pool. Rate constants are defined simply as fractions of the amount of drug in the source pool, and Eq. (6) relates kii to kj i ; the equation can be derived, without recourse to any tracee, from a balance between the drug flux leaving the ith pool (= kii qi) and the total of all the drug fluxes from the ith pool to the other pools and to the outside (= kji qi summed over j). State equations are similar to Eqs. (15) except for S.
The analog of enrichment modeling in pharmacokinetics is to model drug concentrations, but the r-parameters are not useful. Since there is no tracee and consequently no tracee steady state, Eq. (7) relating rii to rij does not hold. Without this equation, there is no simplification and the matrix R will always have more parameters than the matrix K. Thus, Evans et al. (2004) modeled drug concentrations in cell studies with k-rate constants and volume ratios.
While it is risky to speculate on the development of ideas, it seems to us that one reason for researchers not pursuing enrichment modeling in tracer kinetics may be that pharmacokinetics was a major area of modeling. Early books on kinetics covered drugs as well as tracers (Jacquez, 1985b; Rescigno and Segre, 1966; Shipley and Clark, 1972). Models were written for the tracer; arrows in figures denoted tracer fluxes. Unlabeled tracee fluxes into the structure were not even shown since they did not appear in differential equations for the tracer (Brown and Godfrey, 1978; Cobelli and DiStefano 3rd, 1980; Chapman and Godfrey, 1985).
5.8. Nature of observations and choice of model
Anderson (1983, Section 9) remarked: “In the first and probably most common type of experiment, the concentration of tracer in one or more compartments is followed and sampled over time. Thus, it is preferable to have our basic tracer model in a form involving tracer concentrations rather than amounts.” So, tracer enrichments should be the natural choice as state variables in order to keep the modeling straightforward, with the minimum number of parameters needed to solve for the observed variables. The commonly used state variables are total tracer quantities. The differential equations involve pool masses in tracer entry expressions and also in calculating the observed enrichments from the total tracer quantities. As a consequence, total activity modeling involves more parameters, making the model unidentifiable and estimation more complex. By modeling enrichments directly, studying identifiability is facilitated.
The main reason for total activity modeling is that the rate constants have a natural physical meaning. But we have seen that the rate constants from enrichment modeling are related to those from activity modeling through mass ratios, as given in Eqs. (5). In particular, as shown there, fractional catabolic rates (FCR), fractional synthetic rates (FSR) and pool turnover rate constants, which are the rate constants of greatest biological relevance, are the same with either type of model:
Further, Eqs. (5) express the other k parameters in terms of the identifiable r parameters and mass ratios.
It may also be noted that, with the increasing use of precursor tracers, FSR’s are routinely estimated and reported in the protein literature; FSR is a rate constant expressing a synthetic or input flux as a fraction of the destination pool. Thus, rate constants as defined in enrichment models are in fact considered to have physical meaning.
5.9. Conclusion
A number of general linear, stationary structures were analyzed here. When there are multiple exit pathways, the q-model for total activities has many more parameters, whether the tracer is introduced as an exogenous bolus or by endogenous labeling through a precursor. The only situation in the linear, stationary setting where q-modeling has fewer parameters, and is the preferred approach, is with an exogenous tracer and multiple unlabeled tracee entry pathways. Tracer methodology in humans increasingly makes use of mass isotopes and highly sensitive mass spectrometry so that there are now hardly any radiotracer studies in humans. Mass isotopes are often introduced in a precursor—amino acids to study proteins, for example. The resulting structures are of the type described above under endogenous modeling, where most or all the entry pathways are labeled. It was seen that total activity modeling offers no benefit—enrichment modeling has fewer parameters and is to be preferred. SAAM, a popular modeling program, does only total activity modeling and finds the structure in Fig. 2 to be unidentifiable.
To conclude, when the data to be fitted are of enrichments, and especially when the activity model is unidentifiable for the chosen model structure, it may be helpful to write the model with enrichments as the state variables, defining rate constants as fluxes divided by the masses of destination pools. This unconventional definition facilitates modeling enrichment data from linear, stationary structures.
Acknowledgments
This work was supported by grants HL55638 from the National Heart, Lung, and Blood Institute. The authors would like to acknowledge discussions with Henry Ginsberg.
Abbreviations
- F
flux
- f
vector of rate constants for entry from outside
- FCR
fractional catabolic rate
- FSR
fractional synthetic rate
- g
vector of rate constants for exit to outside
- K,R
system matrix of rate constants
- k,r
rate constant
- P
diagonal matrix of pool masses
- Q
total mass or activity of tracer+tracee
- q
mass or activity of tracer
- q-model
model for tracer activities or amounts
- S
synthetic flux
- s
synthetic rate constant
- t
time
- u
a vector whose every element is 1
- w
precursor enrichment
- y
tracer enrichment
- y-model
model for tracer enrichments or specific activities
- z
observed tracer enrichment
References
- Anderson DH. Compartmental Modeling and Tracer Kinetics. Springer; Berlin: 1983. [Google Scholar]
- Arad Y, Ramakrishnan R, Ginsberg HN. Lovastatin therapy reduces low density lipoprotein apoB levels in subjects with combined hyperlipidemia by reducing the production of apoB-containing lipoproteins: implications for the pathophysiology of apoB production. J Lipid Res. 1990;31:567–582. [PubMed] [Google Scholar]
- Barrett PHR, Chan DC, Watts GF. Design and analysis of lipoprotein tracer kinetics studies in humans. J Lipid Res. 2006;47:1607–1619. doi: 10.1194/jlr.R600017-JLR200. [DOI] [PubMed] [Google Scholar]
- Basu R, Di Camillo B, Toffolo G, Basu A, Shah P, Vella A, Rizza R, Cobelli C. Use of a novel triple-tracer approach to assess postprandial glucose metabolism. Am J Physiol-Endocrinol Metab. 2003;284:E55–E69. doi: 10.1152/ajpendo.00190.2001. [DOI] [PubMed] [Google Scholar]
- Bellman R, Åström KJ. On structural identifiability. Math Biosci. 1970;7:329–339. [Google Scholar]
- Berglund L, Witztum JL, Galeano NF, Khouw AS, Ginsberg HN, Ramakrishnan R. Threefold effect of lovastatin treatment on low density lipoprotein metabolism in subjects with hyperlipidemia: increase in receptor activity, decrease in apoB production, and decrease in particle affinity for the receptor. Results from a novel triple-tracer approach. J Lipid Res. 1998;39:913–924. [PMC free article] [PubMed] [Google Scholar]
- Berman M, Schoenfeld R. Invariants in experimental data on linear kinetics and the formulation of models. J Appl Phys. 1956;27:1361–1370. [Google Scholar]
- Berman M, Weiss MF, Shahn E. Some formal approaches to the analysis of kinetic data in terms of linear compartmental systems. Biophys J. 1962;2:289–316. doi: 10.1016/s0006-3495(62)86856-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bright PB. Volumes of some compartment systems with sampling and loss from one compartment. Bull Math Biol. 1973;35:69–79. doi: 10.1007/BF02558795. [DOI] [PubMed] [Google Scholar]
- Brown RF, Godfrey KR. Problems of determinacy in compartmental modeling with application to bilirubin kinetics. Math Biosci. 1978;40:205–224. [Google Scholar]
- Chapman MJ, Godfrey KR. Some extensions to the exhaustive modelling approach to structural identifiability. Math Biosci. 1985;77:305–323. [Google Scholar]
- Chau NP. Parameter identification in n-compartment mammillary models. Math Biosci. 1985;74:199–218. [Google Scholar]
- Chen BC, Landaw EM, DiStefano JJ., 3rd Algorithms for the identifiable parameter combinations and parameter bounds of unidentifiable catenary compartmental models. Math Biosci. 1985;76:59–68. [Google Scholar]
- Cobelli C, DiStefano JJ., 3rd Parameter and structural identifiability concepts and ambiguities: a critical review and analysis. Am J Physiol-Endocrinol Metab. 1980;239:R7–R24. doi: 10.1152/ajpregu.1980.239.1.R7. [DOI] [PubMed] [Google Scholar]
- Cobelli C, Toffolo G. Identifiability from parameter bounds, structural and numerical aspects. Math Biosci. 1984;71:237–243. [Google Scholar]
- Cobelli C, Toffolo G. Theoretical aspects and practical strategies for the identification of unidentifiable compartmental systems. In: Walter E, editor. Identifiability of Parametric Models. Pergamon; Oxford: 1987. pp. 85–91. [Google Scholar]
- Cobelli C, Lepschy A, Jacur GR. Identifiability results on some constrained compartmental systems. Math Biosci. 1979;47:173–195. [Google Scholar]
- Cobelli C, Toffolo G, Ferrannini E. A model of glucose kinetics and their control by insulin, compartmental and noncompartmental approaches. Math Biosci. 1984;72:291–315. [Google Scholar]
- Cobelli C, Toffolo G, Bier DM, Nosadini R. Models to interpret kinetic data in stable isotope tracer studies. Am J Physiol-Endocrinol Metab. 1987;253:E551–E564. doi: 10.1152/ajpendo.1987.253.5.E551. [DOI] [PubMed] [Google Scholar]
- Cobelli C, Foster D, Toffolo G. Tracer kinetics in biomedical research: from data to model. Kluwer Academic; New York: 2000. [Google Scholar]
- Demant T, Packard CJ, Demmelmair H, Stewart P, Bedynek A, Bedford D, Seidel D, Shepherd J. Sensitive methods to study human apolipoprotein B metabolism using stable isotope-labeled amino acids Am. J Physiol-Endocrinol Metab. 1996;270(6):E1022–E1036. doi: 10.1152/ajpendo.1996.270.6.E1022. [DOI] [PubMed] [Google Scholar]
- DiStefano JJ., 3rd Complete parameter bounds and quasiidentifiability conditions for a class of unidentifiable linear systems. Math Biosci. 1983;65:51–68. [Google Scholar]
- DiStefano JJ, 3rd, Chen BC, Landaw EM. Pool size and mass flux bounds and quasiidentifiability relations for catenary models. Math Biosci. 1988;88:1–14. [Google Scholar]
- Eisenfeld J. Partial identification of underdetermined compartmental models: a method based on positive linear Lyapunov functions. Math Biosci. 1996;132:111–140. doi: 10.1016/0025-5564(95)00049-6. [DOI] [PubMed] [Google Scholar]
- Evans ND, Erlington RJ, Shelley M, Feeney GP, Chapman MJ, Godfrey KR, Smith PJ, Chappell MJ. A mathematical model for the in vitro kinetics of the anti-cancer agent topotecan. Math Biosci. 2004;189:185–217. doi: 10.1016/j.mbs.2004.01.007. [DOI] [PubMed] [Google Scholar]
- Ferrannini E, Smith JD, Cobelli C, Toffolo G, Pilo A, DeFronzo RA. Effect of insulin on the distribution and disposition of glucose in man. J Clin Investig. 1985;76:357–364. doi: 10.1172/JCI111969. [DOI] [PMC free article] [PubMed] [Google Scholar]
- García-Meseguer MJ, Vidal de Labra JA, García-Moreno M, García-Cánovas F, Havsteen BH, Varón R. Mean residence times in linear compartmental systems. Symbolic formulae for their direct evaluation. Bull Math Biol. 2003;65:279–308. doi: 10.1016/S0092-8240(02)00096-4. [DOI] [PubMed] [Google Scholar]
- Garlick PJ, Mcnurlan MA, Essen P, Wernerman J. Measurement of tissue protein-synthesis rates in-vivo—a critical analysis of contrasting methods. Am J Physiol-Endocrinol Metab. 1994;266(3):E287–E297. doi: 10.1152/ajpendo.1994.266.3.E287. [DOI] [PubMed] [Google Scholar]
- Gastaldelli A, Schwarz JM, Caveggion E, Traber ID, Traber DL, Rosenblatt J, Toffolo G, Cobelli C, Wolfe RR. Glucose kinetics in interstitial fluid can be predicted by compartmental modeling. Am J Physiol-Endocrinol Metab. 1997;272:E494–E505. doi: 10.1152/ajpendo.1997.272.3.E494. [DOI] [PubMed] [Google Scholar]
- Hart HE. Analysis of tracer experiments in non-conservative steady-state systems. Bull Math Biophys. 1955;17:87–94. [Google Scholar]
- Hart HE. Determination of equilibrium constants and maximum binding capacities in complex in vitro systems: I. The mammillary system. Bull Math Biophys. 1965;27:87–98. doi: 10.1007/BF02476471. [DOI] [PubMed] [Google Scholar]
- Hearon JZ. Theorems on linear systems. Ann N Y Acad Sci. 1963;108:36–68. doi: 10.1111/j.1749-6632.1963.tb13364.x. [DOI] [PubMed] [Google Scholar]
- Hearon JZ. A note on open linear systems. Bull Math Biol. 1974;36:97–99. [Google Scholar]
- Jacquez JA. Richard Bellman. Math Biosci. 1985a;77:1–4. [Google Scholar]
- Jacquez JA. Compartmental Analysis in Biology and Medicine. University of Michigan; Ann Arbor: 1985b. [Google Scholar]
- Jacquez JA, Simon CP. Qualitative theory of compartmental systems. SIAM Rev. 1993;35:43–79. doi: 10.1016/s0025-5564(02)00131-1. [DOI] [PubMed] [Google Scholar]
- Landaw EM, Chen BC, DiStefano JJ., 3rd An algorithm for the identifiable parameter combinations of the general mammillary compartmental model. Math Biosci. 1984;72:199–212. [Google Scholar]
- Lindell R, DiStefano JJ, 3rd, Landaw EM. Statistical variability of parameter bounds for n-pool unidentifiable mammillary and catenary models. Math Biosci. 1988;91:175–199. [Google Scholar]
- Nagashima K, Lopez C, Donovan D, Ngai C, Fontanez N, Bensadoun A, Fruchart-Najib J, Holleran S, Cohn JS, Ramakrishnan R, Ginsberg HN. Effects of the PPARgamma agonist pioglitazone on lipoprotein metabolism in patients with type 2 diabetes mellitus. J Clin Investig. 2005;115:1323–1332. doi: 10.1172/JCI23219. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Packard CJ, Demant T, Stewart JP, Bedford D, Caslake MJ, Schwertfeger G, Bedynek A, Shepherd J, Seidel D. Apolipoprotein B metabolism and the distribution of VLDL and LDL sub-fractions. J Lipid Res. 2000;41(2):305–317. [PubMed] [Google Scholar]
- Perl W, Lassen NA, Effros RM. Matrix proof of flow, volume and mean transit time theorems for regional and compartmental systems. Bull Math Biol. 1975;37:573–588. doi: 10.1007/BF02459526. [DOI] [PubMed] [Google Scholar]
- Pont F, Duvillard L, Verges B, Gambert P. Development of compartmental models in stable-isotope experiments—application to lipid metabolism Arterioscler. Thromb Vasc Biol. 1998;18(6):853–860. doi: 10.1161/01.atv.18.6.853. [DOI] [PubMed] [Google Scholar]
- Ramakrishnan R. An application of Berman’s work on pool-model invariants in analyzing indistinguishable models for whole-body cholesterol metabolism. Math Biosci. 1984;72:373–385. doi: 10.1016/0025-5564(84)90119-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ramakrishnan R. Studying apolipoprotein turnover with stable isotope tracers—correct analysis is by modeling enrichments. J Lipid Res. 2006;47:2738–2753. doi: 10.1194/jlr.M600302-JLR200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ramakrishnan R, Ramakrishnan JD. Utilizing mass measurements in tracer studies—a systematic approach to efficient modeling. Metab-Clin Exp. 2008;57:1078–1087. doi: 10.1016/j.metabol.2008.03.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ramakrishnan R, Dell RB, Goodman DS. On determining the extent of side-pool synthesis in a three-pool model for whole body cholesterol kinetics. J Lipid Res. 1981;22:1174–1180. [PMC free article] [PubMed] [Google Scholar]
- Ramakrishnan R, Leonard EF, Dell RB. A proof of the occupancy principle and the mean transit time theorem for compartmental models. Math Biosci. 1984;68:121–136. doi: 10.1016/0025-5564(84)90076-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rescigno A, Michels L. Compartment modeling from tracer experiments. Bull Math Biol. 1973;35:245–257. [Google Scholar]
- Rescigno A, Segre G. On some topological properties of the systems of compartments. Bull Math Biophys. 1964;26:31–38. doi: 10.1007/BF02476618. [DOI] [PubMed] [Google Scholar]
- Rescigno A, Segre G. Drug and Tracer Kinetics. Blaisdell; Waltham: 1966. [Google Scholar]
- Rubinow SI, Winzer A. Compartment analysis: an inverse problem. Math Biosci. 1971;11:203–247. [Google Scholar]
- Shipley RA, Clark RE. Tracer Methods for Vivo Kinetics—Theory and Applications. Academic Press; New York: 1972. [Google Scholar]
- Tremblay AJ, Lamarche B, Cohn JS, Hogue JC, Couture P. Effect of Ezetimibe on the in vivo kinetics of ApoB-48 and ApoB-100 in men with primary hypercholesterolemia. Arterioscler Thromb Vasc Biol. 2006;26(5):1101–1106. doi: 10.1161/01.ATV.0000216750.09611.ec. [DOI] [PubMed] [Google Scholar]
- Vajda S. Analysis of unique structural identifiability via submodels. Math Biosci. 1984;71:125–146. [Google Scholar]
- Vajda S, DiStefano JJ, 3rd, Godfrey KR, Fagarasan J. Parameter space boundaries for unidentifiable compartmental models. Math Biosci. 1989;97:27–60. doi: 10.1016/0025-5564(89)90042-4. [DOI] [PubMed] [Google Scholar]
- Vicini P, Su H, DiStefano JJ., 3rd Identifiability and interval identifiability of mammillary and catenary compartmental models with some known rate constants. Math Biosci. 2000;167:145–161. doi: 10.1016/s0025-5564(00)00035-3. [DOI] [PubMed] [Google Scholar]
- Walter E. Identifiability of Parametric Models. Pergamon; Oxford: 1987. [Google Scholar]
- Zak R, Martin AF, Blough R. Assessment of protein turnover by use of radioisotopic tracers. Physiol Rev. 1979;59:407–447. doi: 10.1152/physrev.1979.59.2.407. [DOI] [PubMed] [Google Scholar]
- Zilversmit DB. The design and analysis of isotope experiments. Am J Med. 1960;29:832–848. doi: 10.1016/0002-9343(60)90117-0. [DOI] [PubMed] [Google Scholar]