

Abstract
SM is a patient with complete bilateral amygdala lesions who fails to fixate the eyes in faces and is consequently impaired in recognizing fear (Adolphs et al., 2005). Here we first replicated earlier findings in SM of reduced gaze to the eyes when seen in whole faces. Examination of the time course of fixations revealed that SM's reduced eye contact is particular pronounced in the first fixation to the face, and less abnormal in subsequent fixations. In a second set of experiments, we used a gaze-contingent presentation of faces with real time eye tracking, wherein only a small region of the face is made visible at the center of gaze. In essence, viewers explore the face by moving a small searchlight over the face with their gaze. Under such viewing conditions, SM's fixations to eye region of faces became entirely normalized. We suggest that this effect arises from the absence of bottom-up effects due to the facial features, allowing gaze location to be driven entirely by top-down control. Together with SM's failure to fixate the eyes in whole faces primarily at the very first saccade, the findings suggest that the saliency of the eyes normally attract our gaze in an amygdala-dependent manner. Impaired eye gaze is also a prominent feature of several psychiatric illnesses in which the amygdala has been hypothesized to be dysfunctional, and our findings and experimental manipulation may hold promise for interventions in such populations, including autism and fragile × syndrome.
Keywords: Eye tracking, Gaze-contingent, Autism, Bottom-up, Intervention, Eye contact
A person's eyes are normally the single feature within a face that we look at most frequently (Yarbus, 1967). It would make sense to pay attention to the eyes, because they convey a large amount of information, such as a person's emotional or mental state, the focus of their attention, and their social intentions (Emery, 2000). Moreover, looking someone in the eyes serves a dual purpose. Not only does it allow for the receipt of socioemotional information from the other person, but also it allows for the simultaneous transmission of such information back to them. This reciprocal nature of information sharing via eye contact is a fundamental process in human social interaction that arises early in development. Therefore, it is perhaps not surprising that many developmental disorders exhibit prominently abnormal levels of eye contact (e.g., autism spectrum disorders (Klin, Jones, Schultz, Volkmar, & Cohen, 2002; Pelphrey et al., 2002), fragile × syndrome (Farzin, Rivera, & Hessl, 2009), Williams Syndrome (Riby & Hancock, 2008)). Regardless of whether such abnormal eye contact is only correlated with or actually causative of abnormal social behavior, from a clinical perspective, it is of great importance to identify and understand the neural underpinnings of eye contact.
One brain region known to be involved in eye contact is the amygdala. Evidence for the amygdala's sensitivity to the eyes in a face comes from a variety of approaches, neuroimaging (Kawashima et al., 1999; Morris, deBonis, & Dolan, 2002; Whalen et al., 2004) and lesion studies (Adolphs et al., 2005; Spezio, Huang, Castelli, & Adolphs, 2007). While originally thought to be necessary for processing emotional information particularly for fear expressions (Adolphs, Tranel, Damasio, & Damasio, 1994; Adolphs et al., 1999), a more recent study has demonstrated that the amygdala serves a broader role in face processing. We previously found that a patient with complete bilateral amygdala damage (patient SM, who is also the subject of the current paper) failed to fixate the eyes in all faces, whether expressing fear or not (Adolphs et al., 2005). Her particularly poor performance for identifying fear could then be explained by the fact that facial expressions of fear contain a large amount of information in the eyes (Smith, Cottrell, Gosselin, & Schyns, 2005). Remarkably, when SM was instructed to fixate the eye region, her ability to identify fear became normal, suggesting that the amygdala is not necessary for processing fear-related information from the eyes, but, more generally, required for spontaneously attending to the socially or emotionally salient information in a face.
A more recent neuroimaging study in healthy control subjects further supports this revised role of the amygdala in spontaneously directing fixations to the eye region in faces (Gamer & Buchel, 2009). In that study, it was found that the amygdala was activated when participants fixated the mouth, but subsequently made fixations towards the eyes, of fearful faces. That is, it was not the fixations onto fearful eyes as such that were driving the amygdala, but the other way around. This finding is in line with an emerging literature arguing that the amygdala responds to ambiguity or unpredictability in the environment, and then helps program saccades in order to attempt to resolve the ambiguity (Whalen, 2007; Adolphs, 2010). The amygdala may be more instrumental than sensory in function.
Yet this emerging picture of amygdala function leaves a key open question: what tells the amygdala that there is something ambiguous to resolve in the first place? Is it catching sight of the eyes in a face in peripheral vision? Or is it any knowledge that there are eyes to be discovered? That is, does the amygdala come into play in stimulus-driven ambiguity, or even for more abstract knowledge? We investigated this question by comparing SM's fixations onto eyes in faces when faces were visible vs. when they were obscured except at the center of gaze.
Using a battery of experimental tasks and manipulations, we first replicate initial findings that SM displays reduced levels of fixation to the eye region of faces. We then show that this reduction is most pronounced on the first fixation to the face, wherein she demonstrates no bias towards the eye region, but does so on subsequent fixations. In a second experiment, we use gaze-contingent eye tracking to only show a small region of a face stimulus at the participant's center of gaze in real time (Fig. 1), providing the impression that one is moving a searchlight over a hidden face with ones eyes. This manipulation essentially eliminates all bottom-up competition between facial features and forces viewers to seek out face information in a more deliberate manner. Here, SM's pattern of fixations to the face became entirely normalized, suggesting that when viewing complete faces, SM has difficulty determining which features are relevant and need to be resolved, despite her normal top-down interest in these regions.
Fig. 1.
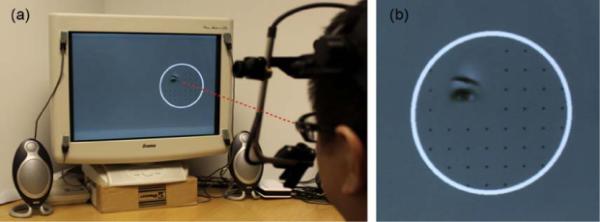
Example of experimental setup and stimuli for the gaze-contingent task. (a) The participant sees only a small aperture of the face that is centered at the direction of gaze. This aperture moves around on the face in real time as the participant's eyes move. (b) Close-up of the stimuli seen in (a). A circle outlined the area of the screen where the face could be revealed in a gaze-contingent manner. The evenly spaced grid of small dots was included after pilot testing found that it was difficult for pilot subjects to make a saccade to an empty area of the screen.
1. Materials and methods
1.1. Subjects
SM is a 43-year old woman with complete bilateral lesions of the amygdala who has been previously described in detail (Buchanan, Tranel, & Adolphs, 2009). SM makes abnormally few fixations onto the eye region of faces, resulting in impairments in emotion recognition (Adolphs et al., 2005). An additional 5 healthy participants were recruited from the Los Angeles area, matched on gender, age, and race (5 females; mean age = 43 years; range = 40–46 years; all Caucasian). One additional participant was tested, but performance on one of the tasks was below chance, and so was subsequently removed from the analyses. The study was approved by Caltech's Institutional Review Board, and written informed consent was obtained from all participants.
1.2. Stimuli
Stimuli consisted of 50 grayscale face images of the same size (25 male, 25 female), normalized for mean luminance, front-facing, and smiling with direct eye contact. Faces were spatially aligned for mouth and eyes using the Align Tools OSX toolbox (Dr. Fred Gosselin, University of Montreal, http://www.mapageweb.umontreal.ca/gosselif/align tools OSX/), and then cropped in an oval shape. Images were presented on a CRT monitor (800 × 600 resolution, 85 Hz refresh rate) approximately 76 cm away from participants, resulting in each face subtending approximately 11.8 (width)° × 16.5° (height) of visual angle.
1.3. Eye tracking
Eye tracking was carried out using a video-based head-mounted Eyelink II system (SR Research Ltd., Mississauga, Ontario, Canada), which determines fixation location by detecting both the pupil and corneal reflection. Before beginning each experiment, a 9-point calibration covering the entire screen was run, followed by validation. The experiment was only started if mean error across all 9 points was less than 1.5°, though the error was typically well below this threshold (error across all participants = 0.40°, SD = 0.12; range = 0.19–0.74°; excluding 2 missing data points from SM). Furthermore, across each experiment in which calibration error was available for SM, the error was not different between SM and controls (all t < 0.72, all p > 0.50, Crawford's modified t-test). Periodic drift correction (at least 1 every 8 or 10 trials, depending on the specific experiment) was implemented throughout each experiment. Stimuli were presented using Matlab (Mathworks Inc., Natick, MA, USA; version R2007a, 7.4.0.287), the Psychophysics Toolbox (version 3.0.8; Brainard, 1997; Pelli, 1997), and the Eyelink Toolbox (version 2; Cornelissen, Peters, & Palmer, 2002), and eye-tracking data were acquired at 250 Hz.
1.4. Task
1.4.1. Experiment 1
Experiment 1 consisted of 3 separate tasks. For the first two tasks, participants viewed faces either passively or while performing a 1-back gender matching task, which they practiced briefly prior to the eye-tracking experiment with a different set of faces. Each trial began with a fixation cross on one side of the screen, wherein the participant was required to fixate within 2° of the cross for 100 ms in order to begin the trial. If 5 s elapsed and the 100 ms fixation was not detected, a drift correction was automatically implemented, after which the trial was restarted and the fixation cross would reappear. Following the detection of a fixation on the cross, the face stimulus would appear on the opposite side of the screen, and remained there for 1.5 s, followed by a 0.5 s inter-trial interval consisting of a completely gray screen. The side of stimulus presentation was randomized across trials. A third passive viewing task consisted of a similar design as the first two tasks, but the fixation cross was located either above the face or below the face, such that the location of the fixation cross on any trial was never spatially coincident with the location of the face stimulus on any trial. Each of the 3 tasks consisted of 50 trials.
1.4.2. Experiment 2
Experiment 2 consisted of 2 separate tasks. In the first task, as in Experiment 1, participants performed a 1-back gender matching task, with the fixation cross located on either side of the screen and face stimulus appearing on the side opposite of the fixation cross. Face stimuli stayed on the screen for 5.0 s, followed by 1.5 s of feedback (“correct” or “wrong”), and a 0.5 s inter-trial interval. In this first baseline phase of the experiment, participants completed 30 trials in which the whole face was shown.
In the second, gaze-contingent phase of the experiment, participants completed 80 trials that showed only a small area of the face (Gaussian transparency mask with full-width half-maximum of 3° of visual angle) centered on their fixation location (see Fig. 1). Each of these gaze-contingent trials began with the fixation cross appearing on one side of the screen, and following a 100 msec fixation, the appearance of a circle outlining the location of the face. Within this circle was a fixed grid of small dots (3-pixel diameter, spaced 2.2° apart), randomly positioned with respect to the underlying hidden face. The dots were included to aid participants to initiate saccades to initially empty regions of the screen. Participants were free to move their eyes over the hidden face for the duration of the hidden face stimulus presentation (5 s), revealing underlying features wherever they fixated (the dots disappeared in an identical gaze-contingent manner; Fig. 1). After testing, all subjects reported that they had no trouble looking at the parts of the face they intended to.
1.4.3. Analysis
Data were analyzed using in-house software written in Matlab. Fixations were defined with the default settings of Eyelink II (by identifying saccades using a velocity threshold of 30°/s, an acceleration threshold of 8000°/s2, and a distance threshold of more than 0.1°), and provided coordinates (x,y) and duration for each fixation. For display purposes, heatmap images were smoothed with a 27-pixel (2°) FWHM Gaussian filter, which roughly corresponds to the foveal area. Unless stated otherwise, statistical analyses were conducted on non-smoothed data using predefined ROIs of the eyes and face (Fig. 2). Furthermore, we used a version of an independent samples t-test when comparing SM to control participants that has been modified to be suitable for single subject analyses (Crawford & Howell, 1998).
Fig. 2.
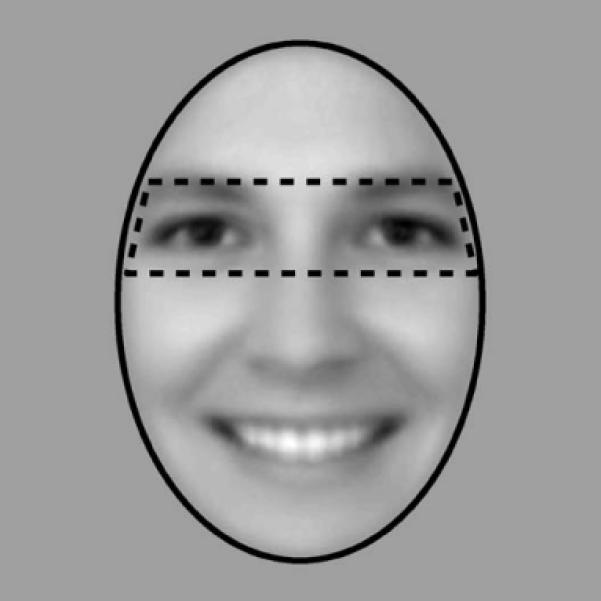
Eye and face regions of interest (ROIs) are shown, overlaid on the mean face image. The eye ROI covered 22% of the area of the entire face, and so fixations to the eye region would be expected 22% of the time by chance alone.
2. Results
2.1. Experiment 1
In terms of basic measures of eye movements (i.e., mean saccade amplitude, mean peak velocity, mean saccade distance, and mean saccade duration; mean number of saccades, fixations, and blinks; mean fixation duration; mean first fixation latency), SM generally did not differ from controls (most p > 0.10, modified t-tests, uncorrected for multiple comparisons). One exception is that during passive viewing of faces, SM had a shorter mean fixation duration (SM = 208.9 ms (±55.6); controls = 296.6 ms (±22.2); t(4) = −3.60, p = 0.023) and, relatedly, a trend towards more saccades (p = 0.06) and more fixations (p = 0.08), though these findings do not survive correction for multiple comparisons.
Fig. 3 shows fixation heatmaps for control participants and SM, for both the 1-back gender matching task and the passive viewing task separately. For the controls, and also for SM, the pattern of fixations were highly similar across the two different tasks, suggesting that the specific task requirements had little effect on the pattern of fixation. Therefore, for all subsequent analyses, unless stated otherwise, data from these two tasks were pooled. Subtraction of the heatmaps for SM and control participants revealed that SM spends less time looking at the eye region of the face, and more time looking at regions of the face below the eyes. This reduced eye fixation was confirmed statistically using an ROI analysis (Fig. 2). SM fixated the eyes only 26% (±7) of the time, very similar to what would be expected by chance (22%) given the area of the eye region, while the mean of controls was 64% (±13) (t(4) = −2.53, p = 0.032, 1-tailed). This group difference was particularly pronounced on the first fixation to the face (Figs. 4 and 5), where SM only looked at the eyes on 15% of trials (SD = ± 4% across tasks), compared to 74% (±12) for control participants (t(4) = −4.51, p = 0.005, 1-tailed). There was no group difference in any other subsequent individual fixations (fixations 2–4, all p > 0.10), owing, in part, to increased fixations to the eyes by SM and, in part, due to reduced fixations to the eyes by controls (Fig. 5). However, when summed across all these subsequent fixations, there was still a trend for SM to make fewer fixations to the eye region than controls (mean SM = 29% (±3); mean controls = 56% (±5); t(4) = −1.78, p = 0.075, 1-tailed).
Fig. 3.
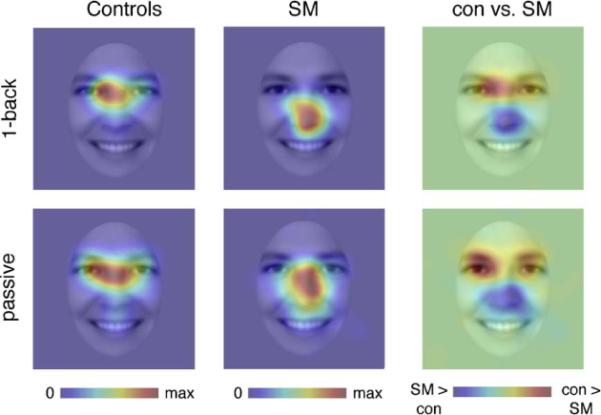
Fixation heat maps showing locations of face fixations for patient SM and control participants for both the 1-back gender task and passive viewing task. Fixations were smoothed with a 27-pixel FWHM Gaussian filter, corresponding to a 2° visual angle. Each heatmap is displayed in arbitrary units, but corresponds to fixation duration/smoothed area. Heatmaps are displayed on the mean of all face images. Each individual heatmap is scaled from zero fixations (blue) to the point of maximal fixation (red). The group difference heatmap shows areas SM fixated more than controls (blue), and vice versa (red), with green meaning there was no difference between groups. Please refer to ROI analyses (see Results) for statistical analyses. (For interpretation of the references to color in this figure legend, the reader is referred to the web version of the article.)
Fig. 4.
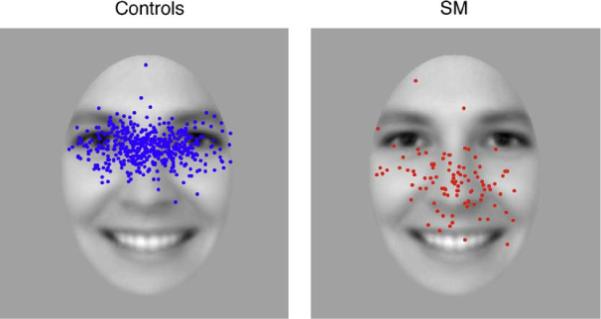
Locations of first face fixations for control participants and SM for both the 1-back gender task and the passive viewing task combined. Each dot represents a single fixation (control fixations, n = 500; SM fixations, n = 100).
Fig. 5.
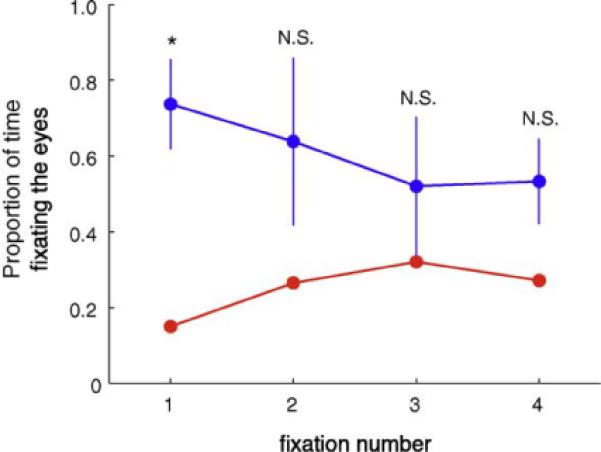
Proportion of time fixating the eye region across fixation number. SM (red) had fewer initial fixations to the eyes, but more so on subsequent fixations (control participants = blue). Errorbars reflect the standard deviation. *p = 0.005, N.S. = not significant. (For interpretation of the references to color in this figure legend, the reader is referred to the web version of the article.)
One potential explanation for why SM fixated the center of the face could be that the fixation cross on subsequent trials was roughly coincident with this location. Therefore, we repeated the passive viewing task, but with the fixation cross presented either above or below a centrally presented face, resulting in completely non-overlapping locations for the fixation cross and image. To concisely represent the location of first fixations for individual participants, we first smoothed the fixations and collapsed the data across the x-axis of the image, so that only a one-dimensional vector corresponding to the vertical location of fixations remains (Fig. 6). Regardless of the initial location of the fixation cross (either to the side of the face or above the face), SM consistently fixated regions of the face more towards the bottom of the face, compared to control participants (side: t(4) = 6.48, p = 0.001, 1-tailed; above: t(4) = 7.97, p = 0.0007, 1-tailed). This suggests that her lack of eye fixation cannot be accounted for by the location of the fixation cross.
Fig. 6.
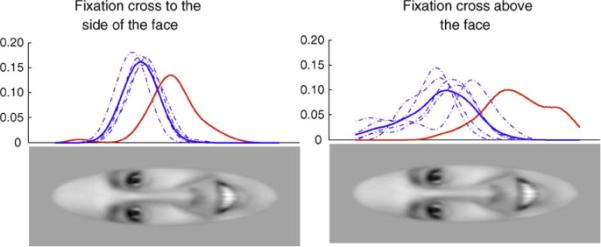
Fixation cross location does not account for SM's reduced fixation to the eyes. Even when the fixation cross was positioned above the face, SM (red) still bypassed the eyes to look at the lower regions of the face. The scale is in arbitrary units, but reflects the relative proportion of time fixating each particular area of the face, collapsed across the width of the face. The solid blue line represents the mean of controls, and the dotted blue lines represent individual subjects. (For interpretation of the references to color in this figure legend, the reader is referred to the web version of the article.)
2.2. Experiment 2
As expected, behavioral performance on the 1-back gender matching task was better in the baseline condition compared to the gaze-contingent condition. Specifically, SM was more accurate and had faster reaction times (RT) in the baseline condition compared to the gaze-contingent condition (Accuracy: 93.3% vs. 80.0%; RT: 1.62 vs. 2.43 s, t(102) = −4.59, p < 0.0001, 1-tailed). Comparison subjects showed the same pattern of performance as SM (Accuracy: 94.7% vs. 89.8%; t(4) = 4.61, p = 0.005; RT: 1.35 vs. 1.82 s; t(4) = −3.59, p = 0.011, both 1-tailed, paired t-test). There was no group difference in performance during baseline viewing (accuracy: t(4) = −0.67, p = 0.54; RT: t(4) = 1.03, p = 0.36, 2-tailed), but there was during windowed viewing (accuracy: t(4) = −3.28, p = 0.03; RT: t(4) = 2.54, p = 0.064, trend; 2-tailed), along with a significant interaction for accuracy (t(4) = 3.22, p = 0.032, 2-tailed) but not reaction time (p(4) = −1.03, p = 0.36, 2-tailed).
In terms of the basic measures of eye movements listed earlier, SM did not differ from controls in any way (all p > 0.15, modified t-tests, uncorrected for multiple comparisons). Furthermore, there were few differences in these basic parameters between baseline and gaze-contingent viewing in control participants (most p > .10, paired t-tests, 2-tailed, uncorrected for multiple comparisons). One measure that did differ across tasks was the latency to make the first fixation, with longer latencies in the gaze-contingent task (baseline = 0.246 s (±0.06), gaze-contingent = 0.348 s (±0.08), t(4) = −4.41, p = 0.012), along with a trend towards longer mean fixation durations (baseline = 0.299 s (±0.06), gaze-contingent = 0.398 s (±0.09), t(4) = −2.38, p = 0.08). Given the relative lack of visual stimulus in non-fixated areas during the gaze-contingent task, it makes sense that participants would take longer to break fixation and initiate saccades in this task, relative to baseline viewing when the whole face is visible at all times.
SM's spontaneous fixations to the eye region of faces increased dramatically under the gaze-contingent viewing condition (Fig. 7). In terms of first fixations, SM only looked at the eyes initially in 15% of the trials in the baseline task, but this increased to 60% during the gaze-contingent task (Fig. 7a). The opposite effect was found in the control group, who initially fixated the eyes more often in the baseline (78% (±15%)) compared to the gaze-contingent task (60% (±11%); t(4) = 3.52, p = 0.024, paired t-test). This difference between SM and controls during the baseline task was significant (t(4) = −4.04, p = 0.008, 1-tailed), replicating findings from experiment 1. There was no difference between groups during the gaze-contingent viewing (t(4) = −0.015, p = 0.99, 2-tailed). The group by task interaction was significant (t(4) = 5.20, p = 0.007, 2-tailed). Furthermore, the percent of first fixations to the eye region by SM during the gaze-contingent task was statistically indistinguishable from that of controls during the baseline task (t(4) = −1.13, p = 0.16).
Fig. 7.
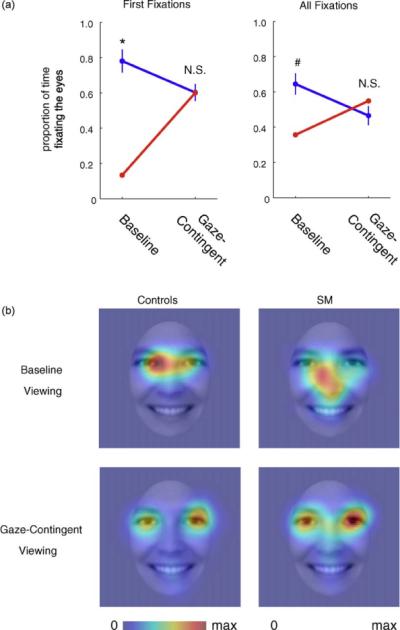
Gaze-contingent viewing of faces normalizes eye fixations in SM. (a) Line plots of the proportion of time fixating the eyes vs. non-eyes of the face for first fixations (left) and all fixations (right) during the baseline and gaze-contingent tasks. SM is shown in red, and comparison subjects are shown in blue. *p = 0.008, #p = 0.06 (trend). (b) Heatmaps across all fixations for SM and control participants during the baseline task and gaze-contingent task. The scale represents normalized fixation duration for each group separately, from no fixation to maximum fixation duration. Heatmaps are smoothed with a 27-pixel (2°) FWHM Gaussian filter.
When analyzing data across all fixations, SM spent only 36% of fixation time on the eyes when viewing whole faces in the baseline condition (compared to 64% (±13%) for control subjects), but this increased to 55% during the gaze-contingent viewing condition (t(108) = −3.75, p = 0.0003, 2-tailed; Fig. 7a and b). No such effect was seen in the control group, whose mean gaze to the eyes instead decreased somewhat under the gaze-contingent presentation (baseline = 64%, gaze-contingent = 47% (±12%); t(4) = 2.28, p = 0.08, paired t-test). There was a trend for SM to look less at the eye region than controls during the baseline task, consistent with findings from experiment 1 (t(4) = −1.96, p = 0.061), but there was no difference between SM's and controls mean eye fixations in the gaze-contingent task (t(4) = 0.63, p = 0.56). The group by task interaction was not significant when examining all fixations (t(4) = 1.93, p = 0.13). Furthermore, the amount of time SM fixated the eye region during the gaze-contingent task was statistically indistinguishable from the amount that controls fixated the eye region during the baseline task (t(4) = −0.65, p = 0.55).
3. Discussion
We found that a patient with bilateral amygdala lesions, SM, failed spontaneously to fixate the eye region of faces (Fig. 3), replicating previous studies on this same patient (Adolphs et al., 2005; Spezio et al., 2007). We further showed that the abnormality is particularly apparent in the first fixation to the face, where SM rarely (only 15% of the time) looks at the eyes (Figs. 4 and 5). These results could not be explained by the location of the fixation cross. Even when the fixation cross was positioned just above the face (and so close to the eyes), SM still did not look at the eyes on her initial fixation (Fig. 6). We did, however, find that SM's pattern of abnormal gaze to the eyes was normalized by only allowing her to see the area of the face that she specifically fixated (i.e., during the gaze-contingent viewing task), a task manipulation that essentially removed all bottom-up visual competition.
Together, these findings are consistent with a role for the amygdala in guiding fixations (particularly initial fixations) to the most socially salient parts of the face, as has been previously suggested (Adolphs & Spezio, 2006; Gamer & Buchel, 2009). There is no evidence to suggest that SM is averse to fixating the eyes, as she will willingly look at them if instructed to do so (Adolphs et al., 2005), does so with a higher probability on subsequent fixations on the face, and automatically does so in the gaze-contingent viewing task without any explicit instruction. This latter finding suggests that SM's top-down interest in the eyes of faces remains intact. Finally, SM's failure to fixate the eyes in whole faces does not appear to depend on her initial fixation location or the eccentricity of the eyes, since positioning the fixation cross above the face in such a way that SM would have to saccade right over the eyes did not increase the probability she would fixate the eyes.
Previous studies of SM have all consistently found that she fails to automatically fixate the eyes in the face, but the region of the face SM fixated most differs depending on the nature of the stimuli. When viewing static images, her fixations tend to be focused around the center of the face, although when conversing with a live person, SM looks mostly at the mouth region (Spezio et al., 2007), even when the person is not speaking (and so the lips are not moving). The above hypothesis about the role of the amygdala is consistent with both findings, but cannot explain why they should differ. One possibility is that the expectation of speech (and the consequent audiovisual synchrony during speech) makes the mouth more salient, even at times when the lips are not moving. The lack of expectation of speech from a static image might remove this bias towards the mouth, resulting in the center of the face being fixated the most.
Our interpretation of the effects of the gaze-contingent condition in SM is that top-down knowledge that the eyes are important, and allocation of visual attention and gaze on the basis of such deliberate control, are independent of the amygdala. That bottom-up, feature-based attention rather than top-down control depend on the amygdala is perhaps not too surprising. More puzzling is how SM has acquired such top-down knowledge about the importance of the eyes in the first place, especially in light of the fact that her amygdala lesion is developmental. Evidently, brain structures other than the amygdala mediate the knowledge that eyes are important.
From an interventional perspective, the gaze-contingent manipulation might be an effective method to train individuals to look at the eyes in faces. There are several particularly advantageous features of the current technique–it works without the need for explicit directions related to eye contact, it is largely automated, and the effect is immediate and robust. The task could also be tailored to encourage eye contact during more socially relevant behaviors, such as emotion discrimination or facial identity recognition. However, a major future question will be to determine whether the manipulation, after time, carries over to viewing whole faces and to social gaze in real life. Furthermore, it remains also to be seen how effective the method is in individuals with other disorders (such as autism spectrum disorders or fragile × syndrome), where the mechanism(s) underlying reduced eye contact may be different from that of SM (Neumann, Spezio, Piven, & Adolphs, 2006).
Acknowledgements
We thank Dr. Fred Gosselin for generously providing software used to spatially align the stimuli, Brian Cheng for assistance with data collection, and Dirk Neumann for helpful advice and discussions. Supported by NIMH and the Simons Foundation.
Footnotes
A publishers' error resulted in this article appearing in the wrong issue. The article is reprinted here for the reader's convenience and for the continuity of the special issue. For citation purposes, please use the original publication details; Neuropsychologia, 48(12), 2010, pp. 3392–3398.
References
- Adolphs R. What does the amygdala contribute to social cognition? Annals of the New York Academy of Sciences. 2010;1191:42–61. doi: 10.1111/j.1749-6632.2010.05445.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Adolphs R, Gosselin F, Buchanan TW, Tranel D, Schyns P, Damasio AR. A mechanism for impaired fear recognition after amygdala damage. Nature. 2005;433:68–72. doi: 10.1038/nature03086. [DOI] [PubMed] [Google Scholar]
- Adolphs R, Spezio M. Role of the amygdala in processing visual social stimuli. Progress in Brain Research. 2006;156:363–378. doi: 10.1016/S0079-6123(06)56020-0. [DOI] [PubMed] [Google Scholar]
- Adolphs R, Tranel D, Damasio H, Damasio A. Impaired recognition of emotion in facial expressions following bilateral damage to the human amygdala. Nature. 1994;372:669–672. doi: 10.1038/372669a0. [DOI] [PubMed] [Google Scholar]
- Adolphs R, Tranel D, Hamann S, Young AW, Calder AJ, Phelps EA, et al. Recognition of facial emotion in nine individuals with bilateral amygdala damage. Neuropsychologia. 1999;37:1111–1117. doi: 10.1016/s0028-3932(99)00039-1. [DOI] [PubMed] [Google Scholar]
- Brainard DH. The Psychophysics Toolbox. Spatial Vision. 1997;10:433–436. [PubMed] [Google Scholar]
- Buchanan TW, Tranel D, Adolphs R. In: The human amygdala in social function. The human amygdala. Whalen PW, Phelps L, editors. Oxford UP; New York: 2009. pp. 289–320. [Google Scholar]
- Cornelissen FW, Peters E, Palmer J. The Eyelink Toolbox: Eye tracking with MATLAB and the Psychophysics Toolbox. Behavior Research Methods Instruments & Computers. 2002;34:613–617. doi: 10.3758/bf03195489. [DOI] [PubMed] [Google Scholar]
- Crawford JR, Howell DC. Comparing an individual's test score against norms derived from small samples. The Clinical Neuropsychologist. 1998;12:482–486. [Google Scholar]
- Emery NJ. The eyes have it: The neuroethology, function and evolution of social gaze. Neuroscience and Biobehavioral Reviews. 2000;24:581–604. doi: 10.1016/s0149-7634(00)00025-7. [DOI] [PubMed] [Google Scholar]
- Farzin F, Rivera SM, Hessl D. Brief report: Visual processing of faces in individuals with fragile × syndrome: An eye tracking study. Journal of Autism and Developmental Disorders. 2009;39:946–952. doi: 10.1007/s10803-009-0744-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gamer M, Buchel C. Amygdala activation predicts gaze toward fearful eyes. Journal Of Neuroscience. 2009;29:9123–9126. doi: 10.1523/JNEUROSCI.1883-09.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kawashima R, Sugiura M, Kato T, Nakamura A, Hatano K, Ito K, et al. The human amygdala plays an important role in gaze monitoring. A PET study. Brain. 1999;122:779–783. doi: 10.1093/brain/122.4.779. [DOI] [PubMed] [Google Scholar]
- Klin A, Jones W, Schultz R, Volkmar F, Cohen D. Visual fixation patterns during viewing of naturalistic social situations as predictors of social competence in individuals with autism. Archives of General Psychiatry. 2002;59:809–816. doi: 10.1001/archpsyc.59.9.809. [DOI] [PubMed] [Google Scholar]
- Morris JS, deBonis M, Dolan RJ. Human amygdala responses to fearful eyes. Neuroimage. 2002;17:214–222. doi: 10.1006/nimg.2002.1220. [DOI] [PubMed] [Google Scholar]
- Neumann D, Spezio ML, Piven J, Adolphs R. Looking you in the month: abnormal gaze in autism resulting from impaired top-down modulation of visual attention. Social Cognitive and Affective Neurosciences. 2006;1:194–202. doi: 10.1093/scan/nsl030. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pelli DG. The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision. 1997;10:437–442. [PubMed] [Google Scholar]
- Pelphrey KA, Sasson N, Reznick JS, Paul G, Goldman BD, Piven J. Visual scanning of faces in autism. Journal of Autism and Developmental Disorders. 2002;32:249–261. doi: 10.1023/a:1016374617369. [DOI] [PubMed] [Google Scholar]
- Riby DM, Hancock PJB. Viewing it differently: Social scene perception in Williams syndrome and autism. Neuropsychologia. 2008;46:2855–2860. doi: 10.1016/j.neuropsychologia.2008.05.003. [DOI] [PubMed] [Google Scholar]
- Smith ML, Cottrell GW, Gosselin F, Schyns PG. Transmitting and decoding facial expressions. Psychological Science. 2005;16:184–189. doi: 10.1111/j.0956-7976.2005.00801.x. [DOI] [PubMed] [Google Scholar]
- Spezio ML, Huang PY, Castelli F, Adolphs R. Amygdala damage impairs eye contact during conversations with real people. Journal of Neuroscience. 2007;27:3994–3997. doi: 10.1523/JNEUROSCI.3789-06.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Whalen PJ. The uncertainty of it all. TICS. 2007;11:499–500. doi: 10.1016/j.tics.2007.08.016. [DOI] [PubMed] [Google Scholar]
- Whalen PJ, Kagan J, Cook RG, Davis FC, Kim H, Polis S, et al. Human amygdala responsivity to masked fearful eye whites. Science. 2004;306:2061. doi: 10.1126/science.1103617. [DOI] [PubMed] [Google Scholar]
- Yarbus AL. Eye movements and vision (Translated by Basil Haigh) Plenum Press; New York: 1967. Originally published in Russian in 1965. [Google Scholar]