

Abstract
The estimated test error of a learned classifier is the most commonly reported measure of classifier performance. However, constructing a high quality point estimator of the test error has proved to be very difficult. Furthermore, common interval estimators (e.g. confidence intervals) are based on the point estimator of the test error and thus inherit all the difficulties associated with the point estimation problem. As a result, these confidence intervals do not reliably deliver nominal coverage. In contrast we directly construct the confidence interval by use of smooth data-dependent upper and lower bounds on the test error. We prove that for linear classifiers, the proposed confidence interval automatically adapts to the non-smoothness of the test error, is consistent under fixed and local alternatives, and does not require that the Bayes classifier be linear. Moreover, the method provides nominal coverage on a suite of test problems using a range of classification algorithms and sample sizes.
Keywords: Classification, Test Error, Pretesting, Confidence Intervals, Non-Regular Asymptotics
1 Introduction
In classification problems, we observe a training set of (feature, label) pairs, . The goal is use this sample to construct a classifier, say , so that when presented with a new feature, X, will accurately predict the unobserved label, Y . Accurate prediction corresponds to small test error; recall that the test error is given by where denotes expectation over the distribution P of (X, Y) only, and not the distribution of the training set. The test error is a functional of and thus is a random quantity. For this reason is sometimes referred to as the conditional test error (Efron 1997; Hastie et al. 2009; Chung and Han 2009). Estimation of the test error typically employs resampling. Most commonly, the leave-one-out or k-fold cross-validated test error is reported in practice. Bootstrap estimates of the test error were suggested by Efron (1983) and later refinements were given by Efron and Tibshirani (1995, 1997). There have been a number of simulation studies comparing these approaches; some references include (Efron 1983; Chernick et al. 1985; Kohavi 1995; Krzanowksi and Hand 1996). A nice survey of estimators is given by Schiavo and Hand (2000). However many have documented that estimators of the test error are plagued by bias and high variance across training sets (Zhang 1995; Isaakson 2008; Hastie et al. 2009) and consequently the test error is accepted to be a difficult quantity to estimate accurately. Two reasons for this problematic behavior are that some classification algorithms result in a that is a non-smooth functional of the training set, and, even when is a smooth functional of the training set, the test error is the expectation of a non-smooth function of .
An alternative to point estimation is interval estimation (e.g. a confidence interval). However, this approach has also been problematic likely because researchers have followed what we call the “point estimation paradigm”: as a first step a point estimator of the test error is constructed, and as a second step, the distribution of this estimator is approximated. The problem with this approach is that a problematic point estimator of the test error makes the second step very difficult. The point estimation paradigm was employed by Efron and Tibshirani (1997) where the standard error of their smoothed leave-one-out estimator was approximated using the nonparametric delta method. Efron and Tibshirani noted that this approach would not work, however, for their more refined .632 (or .632+) estimators because of non-smoothness. Yang (2006) follows this paradigm as well, using a normal approximation to the repeated split cross-validation estimator. In practice, the point estimation paradigm is often applied by simply bootstrapping the estimator of the test error (see Jiang et al., 2008; Chung and Han 2009). These methods, while intuitive, lack theoretical justification.
We consider interval estimators for linear classifiers constructed from training sets in which the number of features is less than the training set size (p << n). As will be seen, even in this simple setting, natural approaches to constructing interval estimators for the test error can perform poorly. Instead of using the point estimation paradigm, we directly construct the confidence interval by use of smooth data-dependent upper and lower bounds on the test error. These bounds are sufficiently smooth so that their bootstrap distribution can be used to construct valid confidence intervals. Moreover, these bounds are adaptive in the sense that under certain settings exact coverage is delivered.
The outline of this paper is as follows. In Section 2 we illustrate the small sample problems that motivate the use of approximations in a non-regular asymptotic framework. Section 3 introduces the Adaptive Confidence Interval (ACI). The ACI is shown to be consistent under fixed and local alternatives. Section 4 addresses the computational issues involved in constructing the ACI. A computationally efficient (polynomial time) convex relaxation of the ACI is developed and shown to provide nearly identical results to exact computation. Section 5 provides a large experimental study of the ACI and several competitors. A variety of classifiers and sample sizes are considered on a suite of ten examples. The ACI is shown to provide correct coverage while being shorter in length than competing methods. Section 6 discusses a number of generalizations and directions for future research. Most proofs are left to the online supplement.
2 Motivation
Throughout we assume that the training set is an iid sample drawn from some unknown joint distribution P. The features X are assumed to take values in while the labels are coded . To construct the linear classifier we fit a linear model by minimizing a convex criterion function. That is, we construct where is the empirical measure and L(X, Y, β) is a convex function of β (e.g., hinge loss with an L2 penalty in the case of linear support vector machines). The classifier is the sign of the linear fit; that is, the predicted label y at input x is assigned according to (define sign(0) = 1). Recall that the test error of the learned classifier is defined as
where P denotes expectation with respect to X and Y .
As discussed in the introduction, the test error is a non-smooth functional of the training data. To see this and to gain a clearer understanding of the test error note
| (1) |
where . Recall that sign(2q(x) − 1) is the Bayes classifier. Then
| (2) |
where denotes the expectation over iid training sets of size n drawn from P. The form of reveals that there are two scenarios in which is highly variable. The first occurs when is likely to be small relative to over a large range of x where q(x) ≠ 1/2. Notice that this might occur when the classifier does well but is subject to overfitting. The second scenario occurs when is likely to be small relative to over a small range of x where q(x) is far from 1/2. In this scenario there may be little overfitting but the classifier may be far from the Bayes rule and hence of poor quality. Note that poor classifier performance and overfitting are hallmarks of small samples. In either case, need not concentrate around .
In order to provide good intuition for the small sample case, we require an asymptotic framework wherein the test error does not concentrate about , even in large samples. One way of achieving this is to permit P(Xtβ* = 0) to be positive where . This ensures that for all that satisfy xtβ* = 0, the indicator function never settles down to a constant but rather converges to a non-degenerate distribution. Furthermore, if for a non-null subset of these x’s we have q(x) ≠ 1/2, then does not converge to zero. Hereafter we refer to this as the non-regular framework. This language is consistent with that of Bickel et al. (2001). However, unlike the usual notion of non-regularity the limiting distribution of depends not only on the value of β* but also the marginal distribution of X.
To see why it is useful to consider approximations that are valid even in the non-regular asymptotic framework we consider simulated data, which we call the quadratic example. Here the generative model satisfies P(Xtβ* = 0) = 0. Data are generated according to the following mechanism
The working classifier is given by where is constructed using squared error loss . In this example so that the continuity of X1 and X2 ensures that the regularity condition P(Xtβ* = 0) = 0 is satisfied. Consider two seemingly reasonable, and commonly employed methods for constructing a confidence set. The first is the centered percentile bootstrap (CPB). The CPB confidence set is formed by bootstrapping the centered and scaled in-sample error . Note that where is the in-sample error. More specifically, let and be the 1 − γ/2 and γ/2 percentiles of
| (3) |
where is the bootstrap empirical measure with weights and . Then the 1 − γ CPB interval is given by . The second approach is based on the asymptotic approximation
| (4) |
Thus the normal approximation confidence set is given by (see the binomial approximation in Chung and Han 2009). If P(Xtβ* = 0) = 0 then both methods can be shown to be consistent.
The left hand side of Figure 1 shows the estimated coverage using 1000 Monte Carlo iterations of the CPB with 1000 bootstrap resamples, and the normal approximation. Both methods severely undercover in small samples. This is especially troubling since (i) the problem is low-dimensional, (ii) the linear classifier is of relatively high quality, (for example if n = 30 the expected test error ) and (iii) the regularity condition P(Xtβ* = 0) = 0 is satisfied. Why do these methods fail? Neither method correctly captures the additional variation in the test error across training samples due to the non-smoothness of the test error. Since the generative model satisfies the condition P(Xtβ* = 0) = 0, the variation across training sets eventually becomes negligible and the methods deliver the desired coverage for n large.
Figure 1.

Left: Coverage of centered percentile bootstrap and normal approximations for constructing confidence sets for . Right: Coverage of centered percentile bootstrap with smoothed target for varying values of a; a value of a = ∞ corresponds to . Results are based on 1000 Monte Carlo iterations, target coverage is .950. The performance of the ACI on this example can found in Section 5 under the example labeled “quad.”
To illustrate the effect of non-smoothness on the coverage consider the problem of finding a confidence interval for the functional , where a is a positive free parameter. Notice that the size of a varies inversely with the smoothness of . A value of a > 0 gives the expectation of a sigmoid function and a value of a = ∞ corresponds to ). Coverage for a = 0.1, 1.0, and 10 are given in the right hand side of Figure 1. Notice that coverage increases with the smoothness of the target . The dramatic difference in coverage between a = .1 and a = ∞ suggests that a large component of the anti-conservatism is indeed attributable to non-smoothness.
Operating in the regular framework there is no indication that these methods may not work well. In the non-regular framework, however, both of these methods are inconsistent. To see this in the case of the CPB, write
| (5) |
The first term on the right hand side of (5) appears because we allow P(Xtβ* = 0) > 0 in the non-regular framework; conditioned on the data the term does not have a limit and consequently the CPB is inconsistent. A detailed proof is omitted (see for example Shao 1994). The inconsistency of the normal approximation can be seen by examining the limiting distribution of in the non-regular framework. This limit is given in Theorem 3.1.
3 Adaptive confidence interval
In this section we introduce our method for constructing a confidence interval for the test error. This section is organized as follows. We begin by constructing adaptive confidence interval. Next, we establish the theoretical underpinnings of the method under fixed alternatives. Following this we provide a (heuristic) justification for our method using local alternatives. Finally, we discuss the choice of a tuning parameter required by the method.
3.1 Construction of the ACI
We propose an method of constructing a confidence interval that is consistent in the non-regular framework. We refer to this method as the Adaptive Confidence Interval (ACI) because, it is adaptive in two ways. First, unlike the CPB, the ACI provides asymptotically valid confidence intervals regardless of the true parameter values; intuitively the ACI achieves this by adapting to the amount of non-smoothness in the test error. Second, in settings (see Corollary 3.4) in which the CPB is consistent, the upper and lower limits of the ACI are adaptive in that these limits have the same distribution as the upper and lower limits of the CPB.
The ACI is based on bootstrapping an upper bound of the functional . This upper bound is constructed by first partitioning the training data into two groups (i) points that are far from the boundary xtβ* = 0, and (ii) points that are too close to delineate from being on the boundary. The upper bound is constructed by taking the supremum over all possible classifications of the points that we cannot distinguish from lying on the boundary. More precisely, under the non-regular framework the scaled and centered test error can be decomposed as
| (6) |
where . The first term on the right hand side of (6) corresponds to points on the decision boundary xtβ* = 0, and the second term corresponds to points that are not on this boundary. That is, the domain of X is partitioned into two-sets. We operationalize this partitioning using a series of hypothesis tests. For each X = x we test H0 : xtβ* = 0 against a two-sided alternative. Let Σ denote the asymptotic covariance of (see below). Then the test rejects when the statistic is large. The bounds are obtained by computing the supremum (infemum) over all classifications of points for which the test fails to reject. In particular, an upper bound on is given by
| (7) |
and an lower bound is given by
| (8) |
The choice of an, is discussed at the end of this Section. Put to see that (7) and (8) are upper and lower bounds, respectively.
Suppose we want to construct a 1 − δ% confidence interval for the test error. We have that
We approximate the distribution of , by bootstrap. The bootstrap is shown to be consistent later in this section. Denote the 1 − δ/2 percentile of the bootstrap distribution of by u1–δ/2 and the δ/2 percentile of the bootstrap distribution of by lδ/2. The 1 − δ% ACI is given by
| (9) |
3.2 Properties of the ACI
In the remainder of the paper we verify that the ACI is asymptotically of the correct size even if the problem is non-regular (e.g. P(Xtβ* = 0) > 0) and we evaluate the performance of the ACI in small samples. A method for efficiently approximating the ACI is given and shown to be almost identical to exact computation on a suite of examples. Most proofs are deferred to the online supplement.
First we provide the asymptotic distribution of and . Throughout we make the following assumptions.
-
(A1)
L(X, Y, β) is convex with respect to β for each fixed .
-
(A2)
exists and is finite for all .
-
(A3)
exists and is unique.
-
(A4)
Let g(X, Y, β) be a sub-gradient of L(X, Y, β). Then for all β in a neighborhood of β* .
-
(A5)
Q(β) is twice continuously differentiable at β* and is positive definite.
-
(A6)
.
These assumptions are quite mild and hold for most commonly used loss functions (e.g., exponential loss, squared error loss, hinge loss–if P has a smooth density at 1, logistic loss, etc.). Recall that a subgradient satisfies for all and, . All convex functions have a measurable subgradient. Let Ω be the covariance matrix of the sub-gradient of L(x, y, β) at β*. Under (A1)-(A5) Haberman (1989; see also Niemiro, 1992) proved that converges with probability one to β* and converges in distribution to .
Let be a Brownian-Bridge indexed by with the variance-covariance function
| (10) |
Furthermore, let denote a mean zero normal random variable with variance .
Theorem 3.1. Let and z∞ be as above. Assume (A1)-(A6). Then
,
.
Note that the limiting distributions of , and have the same regular component ; the three limits differ only in the non-regular component. Note also that the form of the covariance function of given in (10) and the form of the limiting distribution of (or ) shows that if the margin condition P(Xtβ* = 0) = 0 holds, then and similarly for . That is, if the margin condition holds, the limiting distribution of the functional used to construct the ACI is the same as the limiting distribution of the functional . From a practical point of view this means that for problems where the regular framework is applicable, for example, if the sample size is large or points are well separated from the boundary, the ACI is asymptotically exact.
Another scenario in which the limiting distribution of , and are the same is when the Bayes decision boundary is linear. In this case q(x) = 1/2 if xtβ* = 0 where q(x) = P(Y = 1|X = x). (Here, we assume that the loss function is classification-calibrated (Bartlett 2005). All loss functions mentioned in this paper are classification-calibrated.) Then for any fixed we have
The form of the variance of and the above series of equalities show that if the Bayes decision boundary is linear then for all . Therefore, if the Bayes decision is linear
where the first and last equalities follow from Theorem 3.1, and the second and third equalities follow since is constant across all indices. We have proved the following result.
Corollary 3.2. Assuming (A1)-(A6) hold then if either (i) the Bayes decision boundary is sign(Xtβ*) or (ii) P (Xtβ* = 0) = 0 then , and have the same limiting distribution.
The implication of the above theorem and corollary is that when either of the above conditions hold the ACI should provide the nominal coverage. When neither event holds then the ACI may be conservative. In simulations we shall see that the degree of conservatism is small.
The ACI in (9) utilizes a bootstrap approximation to the distribution of , . The next theorem concerns the consistency of the bootstrap distributions. Let be a weakly consistent estimator of Σ (e.g. the plug-in estimator). Define to be the space of bounded Lipschitz-1 functions on and let denote the expectation with respect to the bootstrap weights.
Theorem 3.3. Assume (A1)-(A6). Then and converge to the same limiting distribution in probability. That is,
converges in probability to zero.
Thus the ACI provides asymptotically valid confidence intervals. Moreover we have the following.
Corollary 3.4. Assuming (A1)-(A6) hold then if either (i) the Bayes decision boundary is sign(Xtβ*) or (ii) P(Xtβ* = 0) = 0 then and converge to the same limiting distribution, in probability.
Thus, the ACI is also adaptive in the sense that in settings where the centered percentile bootstrap would be consistent, , and have the same limiting distribution.
3.3 Local Alternatives
In Section 2 we motivated the use of a non-regular asymptotic framework in order to gain intuition for small samples. An alternative strategy for developing intuition for non-regular problems is to study the limiting behavior of under local alternatives. This strategy has roots in Econometrics.
In econometrics, a common strategy to constructing procedures with good small sample properties in non-regular settings is to utilize alternatives local to the parameter values that cause the non-regularity (Andrews 2000; Cheng 2008; Xie 2009). To see this recall that in small samples a non-negligible proportion of the inputs x are in a -neighborhood of the decision boundary xtβ* = 0 which causes the indicator function to become unstable. In the prior sections we assumed that there was a non-null probability that an input lies exactly on the boundary in order to retain the instability of the indicator function even in large samples. Another way to maintain this instability is by considering local alternatives.
The ACI can be seen as arising as an asymptotic approximation under local alternatives in the following way. In particular, suppose that a training set is drawn iid from distribution Pn for which
| (11) |
for some . In addition, we assume that P(Xtβ* = 0) > 0 (while Pn(Xtβn* = 0) > 0 may or may not hold). A general tactic is to derive the limiting distribution of an estimator which will depend on the local parameter Γ and then take a supremum over this parameter to construct a confidence interval. As a first step in following this approach we might expect that
under Pn. Note that is equal to the first term on the right hand side of (7). Hence, is the supremum over all local alternatives of the form given in (11). Also taking the supremum over we obtain
which is the limiting distribution of (see Theorem 3.1). Thus, the ACI can be seen as arising as an asymptotic approximation under local alternatives. This result is formalized below.
Theorem 3.5. Assume that is drawn iid from distribution Pn for which:
-
(B1)
for some ,
-
(B2)
if is any uniformly bounded Donsker class and under P, then ,
-
(B3), (1), where . Assume (A1)-(A6). Then:
Thus the limiting distribution of is unchanged under local alternatives and hence might be expected to perform well in small samples. A similar result can be proved for . This result is underscored by the empirical results in Section 5.
3.4 Choice of Tuning Parameter an
Use of the ACI requires the choice of the tuning parameter an. We use a simple heuristic for choosing the value of this parameter. The method described here performed well on all of the examples in Section 5. We begin with the presumption that undercoverage is a greater sin than conservatism. Recall that we can view the ACI as a two step procedure where at the first stage we test the null hypothesis H0: xtβ* = 0 against a two-sided alternative. The test of H0 used in constructing the ACI rejects when . The form of in (7) shows that too small (e.g. large Type I error) results in too few points being deemed “near the boundary.” Consequently the resulting interval may be too small since the supremum does not affect enough of the training points. Conversely, too large (e.g. large Type II error) puts too many points in the region on non-regularity, resulting in an interval that may be too wide because the supremum affects too many of the training points. Given our presumption, controlling Type I error is of primary importance. Let . Then let and we have for any and xtβ* = 0
Thus, the suggested an controls the Type I error to be no more than γ. Moreover, it is clear from the above display that the Type I error decreases to zero as n tends to infinity. In all of the experiments in this paper we choose, rather arbitrarily, to use γ = .005. Simulations results, given in Table 5 of the online supplement, show that the performance (measured in terms of width and coverage) of the ACI appears to be insensitive to choices of γ in the range .001 to .01 for a sample size of around 30. For larger sample sizes, the choice of γ is unimportant since except for extremely small values of γ.
Table 5.
Comparison of computation time (in seconds) between ACI, Yang’s CV and Jiang’s BCCV P – BR for squared error loss. Examples where at least the nominal coverage was not attained are omitted
| Sample Size | n = 30 | n = 100 | n = 250 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Data Set / Method | ACI | Yang | Jiang | ACI | Yang | Jiang | ACI | Yang | Jiang |
| ThreePt | .734 | .762 | 1.37 | ||||||
| Magic | 1.24 | .0392 | 1.59 | 1.40 | .0834 | 11.1 | 1.90 | 0.178 | 60.66 |
| Mam. | 1.37 | .0185 | .697 | 6.03 | .0383 | 5.52 | 12.8 | .0800 | .26.3 |
| Ion. | 2.13 | .0331 | 1.32 | 6.42 | .0702 | 10.0 | 16.7 | .147 | 52.62 |
| Donut | 2.00 | .00930 | 4.33 | 2.16 | 11.6 | 10.84 | |||
| Bal. | .977 | .0160 | .575 | 1.05 | .0315 | 3.50 | 1.23 | .0660 | 20.9 |
| Liver | 1.16 | .0222 | .859 | 1.44 | .0461 | 6.25 | 1.78 | .0978 | 33.7 |
| Spam | 1.38 | .0348 | 1.37 | 1.53 | 0.744 | 10.5 | 1.72 | .159 | 57.9 |
| Quad | .983 | .00918 | .125 | 1.11 | .0191 | 1.43 | 1.24 | .0398 | 6.96 |
| Heart | 1.06 | .0317 | 1.25 | 1.15 | .0660 | 8.00 | 1.42 | .139 | 23.6 |
4 Computation
To implement the ACI we need to calculate, for each bootstrap sample, the supremum and infimum in and respectively. The required optimization, as stated, is a Mixed Integer Program (MIP) because of the discrete nature of the indicator function. In this section, we develop a convex relaxation that can be solved in polynomial time. The details for the infimum are provided below; a similar approach is used to find the supremum by writing and using the relationship: supz g(z) = −in fz − g(z). Let (mn1, mn2, … , mnn) be a realization of the bootstrap weights . For each such realization, construction of the infemum in the ACI requires computing
| (12) |
where . In this form, the optimization is clearly seen to be an MIP. Reliably solving an MIP requires the use specialized software (we use CPLEX) and quickly becomes computationally burdensome as the size of the problem grows. The following convex relaxation of (12) is (i) computationally efficient requiring roughly the same amount of computation as fitting a linear SVM and (ii) can be solved without specialized software (e.g. R or matlab).
As the initial step write
Then replace the indicator function with convex surrogate and upper bound where (z)+ denotes the positive part of z. Similarly, replace the function with convex surrogate and upper bound . The indicator functions and their respective surrogates are shown in Figure 2. The relaxed optimization problem is then
| (13) |
where the −1 in the relaxation of has been omitted since it does not depend on u. The optimization problem in (13) can be cast as a linear program and hence solved in polynomial time. See the next section for an empirical comparison of the relaxed and MIP solutions to (12).
Figure 2.

Relaxation of the indicator functions. Left panel: indicator function replaced with convex surrogate . Right panel: indicator function replaced with convex surrogate .
5 Empirical study
In this section we compare solution quality between the relaxed and MIP solutions to (12); as will be seen the relaxed solution to (12) can be computed much more quickly while little is lost in terms of solution quality. Next using the relaxed solution to (12) the empirical performance of the ACI is compared with two recent methods proposed in the literature. Ten data sets are used in these comparisons; three are simulated and the remaining seven data sets are taken from the UCI machine learning repository (www.ics.uci.edu/~mlearn/MLRepository.html) and thus the true generative model is unknown. In this case, the empirical distribution function of the data set is treated as the generative model. A summary of the data sets are given in Table 2.
Table 2.
Test data sets used to evaluate confidence interval performance. The last three columns record the average test error for a linear classifier trained using a training set of size n = 100 and loss function: squared error loss (SE), binomial deviance (BD), and ridged hinge loss (SVM)
| Name | Features | Source | |||
|---|---|---|---|---|---|
| ThreePt | 2 | Simulated | .500 | .500 | .500 |
| Quad | 3 | Simulated | .0997 | .109 | .101 |
| Donut | 3 | Simulated | .235 | .249 | .232 |
| Magic | 11 | UCI | .264 | .231 | .252 |
| Mam. | 6 | UCI | .192 | .190 | .203 |
| Ion. | 9 | UCI | .151 | .147 | .149 |
| Bal. | 5 | UCI | .054 | .050 | .061 |
| Liver | 7 | UCI | .342 | .342 | .334 |
| Spam | 10 | UCI | .190 | .183 | .181 |
| Heart | 9 | UCI | .167 | .173 | .174 |
To assess the difference in solution quality between the relaxed and MIP solutions to (12) we perform the following procedure for each of the 10 examples listed in Table 2. We generate 1000 training sets of size n = 30, and for each training set we compute 1000 bootstrap resamples. For each resample we compute (12) exactly using the MIP and approximately using the convex relaxation described above. Here we illustrate the results when the loss function used to construct and is chosen to be L(X, Y, γ) = (1 − Y Xtγ)2. Let and denote the MIP and relaxed solution to (12) for the bth bootstrap resample of the tth training set. Table 1 reports the 50, 75, 95, and 99 percentiles of for each example. Notice that for each example we considered, the relaxed and MIP solutions agree exactly on more than half of the resampled pairs. Moreover, on more than 95 percent of the resampled pairs, we observe that , implying that the two solutions differed by at most the activation of a single indicator function. Table 1 also reports the estimated coverage of confidence sets constructed using the MIP and relaxed formulations. For each of the 10 data sets, estimated coverage using the two methods is not significantly different. The final bit of information in Table 1 regards computation time. The last two columns report the average time in seconds that it takes to construct a single confidence interval using the MIP and relaxed formulations. Computations were performed using a 3.06 GHz intel processor with 4 GB 1067 MHz DDR3. It is clear that even in the n = 30 case significant computational gain can be made by using the relaxed formulation. However, this gain becomes more pronounced as sample size increases. Figure 3 compares the computation time for the ThreePt data set (this data set is decribed in Laber and Murphy 2009) as a function of sample size using squared error loss. As claimed, the computation time for the relaxed construction scales much more efficiently than the MIP formulation. In the examples presented in the next section we use the convex relaxation to compute the confidence interval.
Table 1.
Comparison of MIP and relaxed versions of the ACI. For each data set the table was constructed using 1000 training sets each with 1000 bootstrap iterations for a total of 1,000,000 computations of the optimization problem given in (12)
| Data Set | Coverage | Difference in width | Computation time | |||||
|---|---|---|---|---|---|---|---|---|
| Relaxed | MIP | p.99 | p.95 | p.75 | p.5 | Relaxed | MIP | |
| ThreePt | .948 | .948 | .0334 | 0.00 | 0.00 | 0.00 | .734 | 3.11 |
| Magic | .944 | .945 | .0334 | .0334 | 0.00 | 0.00 | 1.24 | 1.94 |
| Mam. | .957 | .958 | .0334 | 0.00 | 0.00 | 0.00 | .904 | 1.88 |
| Ion. | .954 | .954 | .0334 | 0.00 | 0.00 | 0.00 | 1.33 | 3.06 |
| Donut. | .967 | .968 | .0667 | .0334 | .0334 | 0.00 | .917 | 2.94 |
| Bal. | .969 | .969 | 0.00 | 0.00 | 0.00 | 0.00 | .977 | 1.69 |
| Liver | .956 | .956 | .0333 | .0333 | 0.00 | 0.00 | 1.61 | 2.50 |
| Spam | .984 | .987 | .0333 | .0333 | 0.00 | 0.00 | 1.54 | 3.01 |
| Quad | .959 | .962 | .0333 | 0.00 | 0.00 | 0.00 | .983 | 1.37 |
| Heart | .960 | .961 | .0333 | 0.00 | 0.00 | 0.00 | 1.06 | 3.27 |
Figure 3.
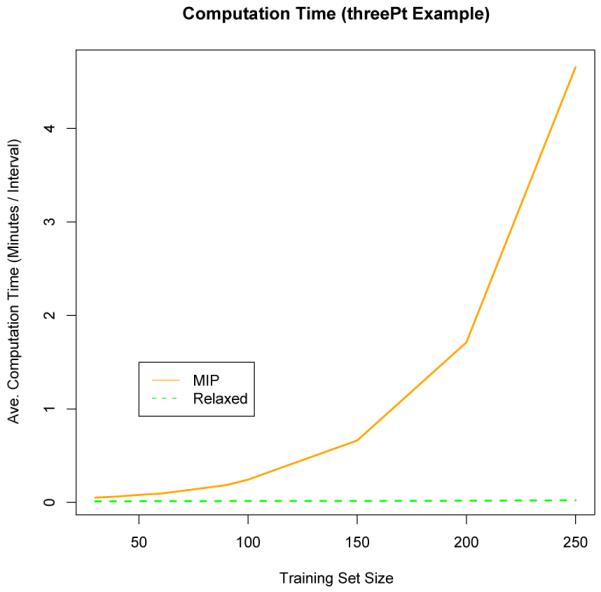
Computation time for MIP and relaxed construction of ACI using the ThreePt data set and squared error loss.
5.1 Competing methods
As competitors we consider a repeated-split normal approximation suggested by (Yang 2006) and the recently proposed Bootstrap Case Cross-Validated Percentile with Bias Reduction (BCCVP-BR) method of (Jiang 2008). These methods represent the best we could find in terms of consistent coverage. Both methods substantially outperform standard approaches like the bootstrap and normal approximation which are discussed in Section 2. To provide a baseline for comparison, the performance of the Centered Percentile Bootstrap (CPB) is included in the online supplement.
Briefly, Yang’s method repeatedly partitions the training data into two equal halves and . A classifier is trained on and then evaluated on . The mean and variance of the number of misclassified points in is recorded. This mean and variance are then aggregated and used in a normal approximation. Jiang’s method can be roughly described as leave one out cross validation with bootstrap resamples. However, since a bootstrap resample can have multiple copies of a single training example, leave one out cross-validation will no longer have disjoint training and testing sets. Instead, for each unique training example (xi, yi) the bootstrap resample is partitioned into two sets, one with all copies of (xi, yi) call this , and the second contains the remainder of the resample call this . The classifier is trained on and evaluated on . The average error over all sets is recorded within each bootstrap resample and the percentiles form the endpoints of a confidence interval. As a final step Jiang provides a bias correction. A full description of these methods can be found in the referenced works. While these methods are intuitive, they lack theoretical justification. Yang’s method was developed for use with a hold-out set; when such a hold-out set does not exist, the method is inconsistent. Jiang offers no justification other than intuition.
5.2 Results
We examine the performance of the ACI and competing methods using the following three metrics (i) coverage (ii) interval width and (iii) computational expense. These metrics are recorded using ten data sets, three sample sizes, and three loss functions. Three of the examples use simulated datasets and hence the test error can be computed exactly. The remaining seven data sets are taken from the UCI machine learning repository (www.ics.uci.edu/~mlearn/MLRepository.html) and thus the true generative model is unknown. In this case, the empirical distribution function of the data set is treated as the generative model. Results using squared error loss are listed here while the results using binomial deviance and ridged hinge loss (support vector machines) are given in the online supplement. A summary of the data sets are given in Table 2.
Coverage results for squared error loss are given in Table 3. The adaptive confidence interval is the only method to attain at least nominal coverage on all ten test sets. Yang’s method is either extremely conservative or anti-conservative. Jiang’s interval attains the nominal coverage on eight of ten data sets in the n = 30 case and nine of ten data sets for larger sample sizes. Table 4 shows the width of the constructed confidence intervals. When n = 30 the ACI is smallest in width for eight of the ten data sets. For larger sample sizes Jiang’s method and the ACI display comparable widths; Yang’s method is always the widest. Another important factor is computation time. Table 5 shows the average amount of time required in seconds to construct a single confidence interval. All methods used 1000 resamples. That is, 1000 bootstrap resamples for the ACI and Jiang’s method, and 1000 repeated splits for Yang’s method. Table 5 shows that Yang’s method is the most computationally efficient. However, it is also clear that Jiang’s method is significantly slower than the ACI for moderate sample sizes. For the Magic data set Jiang’s method takes more than 30 times longer than the ACI. It is most important, however, to notice the trend in computation time across sample sizes. Computation time for Yang’s method and the ACI grow slowly with sample size while the computational cost of Jiang’s method increases much more quickly. The reason for this is that Jiang’s method performs leave-one-out cross validation for each bootstrap resample thus increasing the computation time by a factor of n. Results for ridged hinge loss and binomial deviance loss are similar and can be found in the technical report (Laber and Murphy, 2010).
Table 3.
Coverage comparison between ACI, Yang’s CV and Jiang’s BCCV P – BR for squared error loss, target coverage is .950. Coverage is starred if observed coverage is significantly different from .950 at .01 level
| Sample Size | n = 30 | n = 100 | n = 250 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Data Set / Method | ACI | Yang | Jiang | ACI | Yang | Jiang | ACI | Yang | Jiang |
| ThreePt | .948 | .930* | .863* | .937 | .537* | .925* | .935 | .387* | .930* |
| Magic | .944 | .996* | .979* | .973* | .991* | .969* | .962 | .996* | .974* |
| Mam. | .957 | .989* | .966 | .937 | .996* | .964 | .960 | .995* | .968 |
| Ion. | .941 | .996* | .972* | .961 | .992* | .964 | .952 | .996* | .949 |
| Donut | .965 | .967 | .908* | .970* | .866* | .974* | .974* | .895* | .988* |
| Bal. | .976* | .989* | .966 | .962 | .995* | .969* | .946 | .991* | .963 |
| Liver | .956 | .997* | .970* | .963 | .992* | .966 | .971* | .996* | .984* |
| Spam | .984* | .998* | .975* | .967 | .996* | .967 | .979* | .996* | .958 |
| Quad | .959 | .983* | .945 | .957 | .989* | .938 | .965 | .999* | .940 |
| Heart | .960 | .995* | .976* | .949 | .991* | .979* | .971* | .989* | .974* |
Table 4.
Comparison of interval width between ACI, Yang’s CV and Jiang’s BCCV P – BR for squared error loss. Smallest observed width is starred. Examples where at least the nominal coverage was not attained are omitted
| Sample Size | n = 30 | n = 100 | n = 250 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Data Set / Method | ACI | Yang | Jiang | ACI | Yang | Jiang | ACI | Yang | Jiang |
| ThreePt | .385* | .198* | .193* | ||||||
| Magic | .498* | .528 | .501 | .238 | .257 | .214* | .125 | .157 | .122* |
| Mam. | .374* | .456 | .383 | .191 | .226 | .178* | .112 | .140 | .105* |
| Ion. | .313* | .466 | .388 | .175 | .213 | .172* | .103 | .127 | .100* |
| Donut | .424* | .483 | .217* | .258 | .123* | .201 | |||
| Bal. | .217* | .350 | .232 | .101* | .138 | .103 | .0623 | .0772 | .0620* |
| Liver | .534 | .527 | .500* | .262 | .274 | .241* | .152 | .172 | .143* |
| Spam | .428 | .496 | .418* | .219 | .229 | .184* | .125 | .140 | .108* |
| Quad | .246* | .360 | .267 | .142* | .171 | .144 | .0811* | .104 | .0885 |
| Heart | .367* | .476 | .404 | .184* | .219 | .184* | .106* | .132 | .110 |
6 Discussion
Many statistical procedures in use today are justified by a combination of asymptotic approximations and high quality simulation performance. As exemplified here, the choice of asymptotic framework may be crucial in obtaining reliably good performance in small samples. In this paper a non-regular asymptotic framework in which the limiting distribution of the test error changes abruptly with changes in the true, underlying data generating distribution is used to develop a confidence interval. In particular, asymptotic non-regularity occurs due to the non-smooth test error in connection with particular combinations of β* values and the X distribution. It is common practice to “eliminate” this asymptotic non-regularity by assuming that these problematic combinations of β* values and the X distribution cannot occur. However, small samples are unable to precisely discriminate between settings that are close to the problematic β* values/X distribution from settings in which the β* values/X distribution are exactly problematic. As a result, asymptotic approximations that depend on assuming away these problematic settings can be of poor quality; this is the case here.
The validity of proposed adaptive confidence interval presented here does not depend on assuming away problematic scenarios; instead the ACI detects and then accommodates settings that are sufficiently close to the problematic β* values/X distribution. In this sense the ACI adapts to the non-smoothness in the test error. Specifically, in settings in which standard asymptotic procedures fail, the ACI provides asymptotically valid, albeit conservative, confidence intervals. Moreover, the ACI delivers exact coverage if either (i) the model space is correct or (ii) a margin condition holds. Practically, this means that in a setting where standard asymptotic procedures (e.g. the bootstrap) are applicable, the ACI is asymptotically equivalent to these methods. Experimental performance of the ACI is also quite promising. On a suite of 10 examples, three loss functions and three classification algorithms, the ACI delivered nominal coverage. In addition, the ACI generally had a smaller length than competing methods. The ACI can be computed efficiently with algorithms scaling polynomially in dimension and sample size.
Two important extensions of the ACI are: first, to extend the ACI to construct valid confidence intervals for the difference in test error between two linear classifiers and, second, to extend these ideas to the setting in which the number of features is comparable or larger than the sample size. The former extension is straightforward and can be achieved by enlarging the set over which the supremum is taken in (7) to include the points on the classification boundaries of both classifiers. The latter is more difficult. In the estimation of classifiers in the p >> n setting, it is important to avoid overfitting. A typical approach to reduce the amount of overfitting is regularization which effectively reduces the space of available classifiers to choose from. Similarly, the supremum in (7) must be taken over a restricted set of classifiers to avoid being unnecessarily wide. Extending the theory and computation to this setting is left to another paper.
Supplementary Material
Acknowledgments
This research is supported by NIH grants R01 MH080015 and P50 DA10075. The authors thank Min Qian, Zhigou Li, Diane Lambert, Kerby Shedden, and Vijay Nair for insightful comments and criticisms. In addition, the authors wish to thank the Editor and anonymous reviewers for criticisms and insights that made for a much better paper.
References
- Anthony MM, Bartlett P. Learning in Neural Networks: Theoretical Foundations. Cambridge University Press; New York, NY, USA: 1999. [Google Scholar]
- Bartlett P, Jordan M, McAuliffe J. Convexity, classification, and risk bounds. Journal of the American Statistician. 2005;101:138–156. [Google Scholar]
- Bickel P, Klaassen A, Ritov Y, Wellner J. Efficient and adaptive inference in semi-parametric models. Johns Hopkins University Press; Baltimore: 1993. [Google Scholar]
- Bose A, Chatterjee S. Tech. rep. Indian Statistical Institute; 2000. Generalized bootstrap for estimators of minimizers of convex functionals. [Google Scholar]
- Bose A. Generalized bootstrap for estimators of minimizers of convex functions. Journal of Statistical Planning and Inference. 2003;117:225–239. [Google Scholar]
- Cheng X. Robust Confidence Intervals in Nonlinear Regression Under Weak Identification. Job Market Paper. 2008 [Google Scholar]
- Chernick M, Murthy V, Nealy C. Application of Bootstrap and Other Resampling Techniques: Evaluation of Classifier Performance. PRL. 1985;3:167–178. [Google Scholar]
- Chung H-C, Han C-P. Conditional confidence intervals for classification error rate. Computational Statistics and Data Analysis. 2009;53:4358–4369. [Google Scholar]
- Donald DW. Testing when a parameter is on the Boundary of the Maintained Hypothesis. Econometrica. 2001;69:683–734. [Google Scholar]
- Efron B. Estimating the Error Rate of a Prediction Rule: Improvement on Cross-Validation. Journal of the American Statistical Association. 1983;78:316–331. [Google Scholar]
- Efron B, Tibshirani R. Cross-Validation and the Bootstrap: Estimating the Error Rate of a Prediction Rule. Stanford; 1995. Tech. Rep. 172. [Google Scholar]
- Efron B. Improvements on Cross-Validation: The .632+ Bootstrap Method. Journal of the American Statistical Association. 1997;92:548–560. [Google Scholar]
- Haberman S. Concavity and Estimation. Annals of Statistics. 1989;17:1631–1661. [Google Scholar]
- Hastie T, Tibshirani R, Friedman J. The Elements of Statistical Learning, Springer Series in Statistics. Springer New York Inc.; New York, NY, USA: 2009. [Google Scholar]
- Isaksson A, Wallman M, Gransson H, Gustafsson M. Cross-validation and bootstrapping are unreliable in small sample classification. Pattern Recognition Letters. 2008;29:1960–1965. [Google Scholar]
- Jiang W, Varma S, Simon R. Calculating confidence intervals for prediction error in microarray classification using resampling. Statistical Applications in Genetics and Molecular Biology. 2008;7 doi: 10.2202/1544-6115.1322. [DOI] [PubMed] [Google Scholar]
- Kohavi R. IJCAI. Morgan Kaufmann; 1995. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection; pp. 1137–1145. [Google Scholar]
- Kosorok M. Introduction to empirical processes and semiparametric inference. Springer Verlag; 2008. [Google Scholar]
- Krzanowski W, Hand D. Assessing Error Rate Estimators: The Leave-One-Out Method Reconsidered. PRL. 1985;3:167–178. [Google Scholar]
- Laber EB, Murphy SA. Small Sample Inference for Generalization Error in Classification Using the CUD Bound; Proceedings of the Proceedings of the Twenty-Fourth Conference Annual Conference on Uncertainty in Artificial Intelligence (UAI-08); Corvallis, Oregon: AUAI Press. 2008; pp. 357–365. [PMC free article] [PubMed] [Google Scholar]
- Laber EB. Adaptive Confidence Intervals for the Test Error in Classification. University of Michigan; 2009. Tech. Rep. 497. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Niemiro W. Asymptotics for M-Estimators defined by convex minimization. Annals of Statistics. 1992;20:1514–1533. [Google Scholar]
- Schiavo RA, Hand D. Ten More Years of Error Rate Research. International Statistical Review. 2000;68:295–310. [Google Scholar]
- Van der Vaart A, Wellner J. Weak convergence and empirical processes: with applications to statistics. Springer Verlag; 1996. [Google Scholar]
- Xie M, Singh K, Zhang C-H. Confidence Intervals for Population Ranks in the Presence of Ties and Near Ties. Journal of the American Statistical Association. 2009;104:775–788. [Google Scholar]
- Yang Y. Comparing Learning Methods for Classification. Statistica Sinica. 2006;16:635–657. [Google Scholar]
- Zhang P. APE and Models for Categorical Panel Data. Scandinavian Journal of Statistics. 1995:83–94. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.