

Abstract
It is rather challenging for current variable selectors to handle situations where the number of covariates under consideration is ultra-high. Consider a motivating clinical trial of the drug bortezomib for the treatment of multiple myeloma, where overall survival and expression levels of 44760 probesets were measured for each of 80 patients with the goal of identifying genes that predict survival after treatment. This dataset defies analysis even with regularized regression. Some remedies have been proposed for the linear model and for generalized linear models, but there are few solutions in the survival setting and, to our knowledge, no theoretical support. Furthermore, existing strategies often involve tuning parameters that are difficult to interpret. In this paper we propose and theoretically justify a principled method for reducing dimensionality in the analysis of censored data by selecting only the important covariates. Our procedure involves a tuning parameter that has a simple interpretation as the desired false positive rate of this selection. We present simulation results and apply the proposed procedure to analyze the aforementioned myeloma study.
Keywords: Cox model, Multiple myeloma, Sure independence screening, Ultra-high-dimensional covariates, Variable selection
1. Introduction
An urgent need has emerged in the field of biomedicine for statistical procedures capable of analyzing and interpreting vast quantities of data. Selecting the best predictors of an outcome is a key step in this process, but traditional methods of variable selection, such as best subset selection or backward selection, have been found to be unstable and inaccurate when the dimension of the covariates is close to the number of observations. Furthermore, when there are more covariates than observations, as is often the case in genomic studies, these methods can fail completely.
To address these issues, recent work has focused on regularized regression procedures such as the lasso [1] and adaptive lasso [2], the elastic net [3], the smoothly clipped absolute deviation estimator [4], and the Dantzig selector [5]. These methods can handle the high-dimension-low-sample-size paradigm, have superior predictive accuracy, and under certain conditions can achieve the oracle property [4]: they are as accurate and efficient as an estimator that knows a priori which variables are truly important.
However, these procedures only work well with a moderate number of covariates. When the dimension of the covariates is ultra-high, both traditional and regularization methods have problems with speed, stability, and accuracy [6]. For example, many of the bounds on the accuracy of these methods involve factors of log pn, where pn is the dimension of the covariates [5, 7]. Thus the theoretical performance of these methods degrades as pn becomes very large, yet this ultra-high dimensionality characterizes many real-world biological datasets. Our work in this paper is motivated by one such dataset, in the area of multiple myeloma.
Multiple myeloma is the world’s second-most common hematological cancer and patients often present with bone lesions, immunological disorders, and renal failure. An effective treatment is still being sought, as only about 10% of patients survive 10 years after diagnosis. A deeper understanding of the molecular etiology of this disease would lead to novel therapeutic targets and more accurate risk classification systems. We studied overall survival for 80 multiple myeloma patients enrolled in a clinical trial of bortezomib [8]. With expression level measurements on 44760 probesets, this dataset defies analysis even with regularized regression.
Without tools to deal with this type of ultra-high dimensionality, many analysts employ an initial univariate screening step to reduce the number of covariates under consideration. The remaining covariates could then be fed to one of the more sophisticated regularization techniques in a second stage. But it was only recently that Fan and Lv [6] placed this ad-hoc practice on firm theoretical ground, showing that that screening could indeed improve the performance of regularization methods. They suggested fitting marginal regression models for each covariate, choosing a threshold, and retaining those covariates for which the magnitudes of the parameter estimates are above the threshold. When the data come from an ordinary linear model with normal errors, Fan and Lv [6] showed that this pre-screening procedure, which they termed sure independence screening (SIS), has desirable theoretical properties. Fan and Song [9] later gave theoretical justification for using SIS with generalized linear models.
But two important problems remain. First, one common type of outcome data seen in clinical settings, including in our myeloma dataset, is survival time, which is subject to censoring. Regularized regression methods for censored observations have been studied, as reviewed in Li [10], but these are subject to the same issues mentioned above when the dimension of the covariates is ultra-high. There is thus a need for a pre-screening procedure in this setting, but the results of Fan and Lv [6] and Fan and Song [9] cannot be applied because the issue of censoring is not addressed. Several ad-hoc solutions are available from Tibshirani [11] and Fan et al. [12], but none of these proposals has much theoretical support. The extension of the theoretical sure screening results to censored data is not immediate because it turns out that certain conditions on the relationship between the covariates and the censoring distribution are required for screening to have good theoretical properties, an issue which does not emerge with uncensored data.
The second problem is that existing screening procedures require choosing a threshold to dictate how many variables to retain, but there are no principled methods for making such a choice, making the resulting screened models difficult to evaluate. The threshold can be thought of as a regularization parameter, which in the regression setting is ordinarily chosen by optimizing out-of-sample prediction error using cross-validation or generalized cross-validation. However, this approach is unavailable for screening procedures because no prediction rule is ever generated.
In this paper we provide a screening method for censored survival data with ultra-high-dimensional covariates. We also propose a new, principled method for choosing the number of covariates to retain based on specifying the desired false positive rate. Finally, we give, to our knowledge, the first theoretical justifications of the sure independence screening procedure for censored data. Under the asymptotic framework where the number of covariates can grow with the sample size, we show that with probability going to 1, our procedure will select all of the important variables with a false positive rate close to the prespecified level.
Our paper is organized as follows. We briefly review sure independence screening for generalized linear models in Section 2. In Section 3 we discuss the implementation and the theoretical properties of our principled sure independence screening procedure, and present simulation results in Section 4. Section 5 describes our analysis of the myeloma dataset, and we conclude with a discussion in Section 6. All proofs are given in the Appendix.
2. Sure independence screening in generalized linear models
We first review the sure independence screening formulation of Fan and Song [9]. For subjects i = 1, …, n let Zi = (Zi1, …, Zipn) be the pn- dimensional covariate vector. Assuming that observations Yi come from an exponential family, we model E(Yi | Zi) as some function of a linear predictor with parameter vector α0 = (α01, …, α0pn). When pn is much larger than n we are unable to estimate α0 with conventional procedures. To reduce pn, sure independence screening proceeds by regressing Yi on each Zij individually to calculate marginal maximum likelihood estimates β̂j. The final screened model retains all covariates j : |β̂j| ≥ γn for some prespecified constant cutoff γn.
Fan and Song [9] showed that under certain conditions, if γn follows an ideal rate, this procedure has two desirable properties, namely the sure screening property and the size control property. The former guarantees that the screened model will contain the true model with a probability approaching 1. The latter states that if log(pn) = o(n1–2κ) where κ < 1/2, the probability that the size of the screened model will be at most O{n2κλmax(Σ)} will also go to 1, where Σ = var(Zi) and λmax(Σ) is the largest eigenvalue of Σ.
These results, however, are restricted to non-censored generalized linear models. Furthermore, it is difficult to translate the ideal rate for γn into a method for selecting the cutoff in practice. Fan and Lv [6] suggest n/log(n) or n − 1 as the number of covariates to retain after screening, but without theoretical justification. To address these issues, we investigate here a reliable pre-screening procedure in a survival setting, where the outcomes are subject to right censoring, and propose a principled method for choosing γn based on controlling the false positive rate.
3. Principled Cox sure independence screening
3.1. Method
In the context of survival analysis, we assume that the underlying survival times Ti follow a Cox model [13] with the true hazard function
| (1) |
where λ0(x) is unspecified. Let C̃i be potential censoring times, which are independent of Ti conditional on Zi. Furthermore let τ > 0 be the finite study duration such that P{min(C̃i, τ) < Ti} < 1, ensuring that enough events will be observed over [0, τ]. The effective censoring times are thus Ci = min(C̃i, τ). We observe Xi = min(Ti, Ci), and δi = I(Ti ≤ Ci). Without loss of generality, we assume throughout that E(Zij) = 0 for all j.
To perform an initial screening procedure, we propose to fit marginal Cox regressions, possibly misspecified, for each Zij, namely . Let Ni(t) = I(Xi ≤ t, δi = 1) be independent counting processes for each subject i and Yi(t) = I(Xi ≥ t) be the at-risk processes. For κ = 0, 1, …, define
Then the maximum marginal partial likelihood estimator β̂j solves the estimating equation
| (2) |
Finally, let β0j be the solution to the limiting estimation equation
| (3) |
Define the information matrix to be Ij(β) = −∂Uj/∂β at β̂j. We will denote the final screened model by
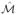 = {j : Ij(β̂j)1/2|β̂j| ≥ γn}. We would like a practical way of choosing γn such that we can achieve the sure screening property while controlling the false positive rate, or the proportion of unimportant covariates we incorrectly include in
. If the true model
= {j : Ij(β̂j)1/2|β̂j| ≥ γn}. We would like a practical way of choosing γn such that we can achieve the sure screening property while controlling the false positive rate, or the proportion of unimportant covariates we incorrectly include in
. If the true model
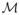 = {j : α0j ≠ 0} has size |
| = sn, then the expected false positive rate can be written as
= {j : α0j ≠ 0} has size |
| = sn, then the expected false positive rate can be written as
| (4) |
We can show that Ij(β̂j)1/2 β̂j has an asymptotically standard normal distribution, so we see that γn corresponds to controlling the expected false positive rate at 2{1 − Φ (γn)}, where Φ(·) is the standard normal cumulative distribution function.
However, we would like the false positive rate to decrease to 0 as pn increases with n, though it can never exactly equal 0 or else γn = ∞. One sensible way to do this would be to first fix the number of false positives f that we are willing to tolerate, which would correspond to a false positive rate of f/(pn−sn). Because sn is unknown, we can be conservative by letting γn = Φ−1{1 − qn/2)} where qn = f/pn, so that the expected false positive rate is 2{1 − Φ (γn)} = qn ≤ f/(pn − sn). We can show that this procedure maintains the sure screening property, and more precise arguments will be given later (Theorems 4 and 5).
We term this method a principled Cox sure independence screening procedure (abbreviated PSIS), as the cutoff γn is selected to control the false positive rate. Specifically, PSIS is implemented as follows:
Fit a marginal Cox model for each of the covariates according to equation (2) to get parameter estimates β̂j and variance estimates Ij(β̂j)−1.
Fix the false positive rate qn = f/pn and let γn = Φ−1(1 − qn/2).
Retain covariates j : Ij(β̂j)1/2|β̂j| ≥ γn.
Our cutoff selection procedure is related to false discovery rate (FDR) methods [14, 15]. In particular, the FDR is defined as |
∩
 |/|
|, which is simply the product of the false positive rate in (4) and |
|/|
|, which is less than pn/|
|. Therefore, controlling the false positive rate at qn = f/pn is equivalent to controlling the FDR at f/|
|, conditional on |
|. Bunea et al. [16] have in fact shown that FDR methods can also have the sure screening property, though only in the linear regression case.
|/|
|, which is simply the product of the false positive rate in (4) and |
|/|
|, which is less than pn/|
|. Therefore, controlling the false positive rate at qn = f/pn is equivalent to controlling the FDR at f/|
|, conditional on |
|. Bunea et al. [16] have in fact shown that FDR methods can also have the sure screening property, though only in the linear regression case.
Our screening procedure resembles the “marginal ranking” methods for censored outcome data proposed by various authors [12, 11]. However, to our knowledge, none of these proposals has much theoretical support. A much more aggressive method of control has been proposed by Fan et al. [12]. We show below that our proposed procedure maintains the sure screening property, and will also control the false positive rate at close to the nominal level. Fan and Lv [6] also proposed an iterative sure independence screening procedure (ISIS) for linear models, which they showed can perform better than SIS. However, they were unable to offer theoretical support. In this paper we focus on first understanding non-iterative screening for the Cox model.
3.2. Theoretical properties
First, under certain assumptions, we find that we can distinguish α0j, j ∈
from α0j, j ∈
in the presence of censoring. It is this guarantee that makes the marginal screening approach possible.
Theorem 1
Under Assumptions 1–8 in the Appendix, β0j = 0 if and only if α0j = 0, for all j = 1, …, pn.
Following Struthers and Kalbfleisch [17] and under Assumptions 1 and 2 in the Appendix, we know that the β̂j are consistent for β0j. It is therefore natural to ask how accurate these estimates are.
Theorem 2
Under Assumptions 1–8 in the Appendix,
for all j = 1, …, pn, where K is the bound on the covariates Zij for all j, is bounded by Assumption 4, A is the bound on the parameters α0j for all j, L = || α0 ||1 and is bounded by Assumption 3, and H is defined in Assumption 5.
Theorem 2 is important as it suggests that |β̂j−β0j| is at most on the order of n−1/2 with high probability. Hence in order to detect covariate j ∈
, we need |β0j| to be at least O(n−1/2), which is indeed the case as shown by the following theorem.
Theorem 3
Under Assumptions 1–8 in the
Appendix, there is a constant c2 > 0 such that minj∈
|β0j| ≥ c2n−κ, where κ < 1/2.
Because the |β0j| are large enough to be detected with our marginal Cox regressions, and because they reflect the importance of the Zij in the true joint model, we can prove that our procedure maintains the sure screening property and controls the false positive rate at close to the nominal level.
Theorem 4 (Sure screening property)
Under Assumptions 1–8 in the Appendix, if we choose γn = Φ−1 (1 − qn/2), then for κ < 1/2 and log(pn) = O(n1/2−κ), there exists a constant c3 > 0 such that
Theorem 5 (False positive control property)
Under Assumptions 1– 8 in the Appendix, if we choose γn = Φ−1(1 − qn/2), then there exists some c4 > 0 such that
where |
∩
|/|
| can be interpreted as the false positive rate.
It is often assumed that the true model is sparse and sn is small [5], in which case Theorem 4 indicates that we will be able to retain all important covariates with high probability. The probability bound will converge to 1 if log(pn) = O(n1/2−κ), which is comparable to the rates allowed in Fan and Lv [6] and Fan and Song [9]. That pn is allowed to incease exponentially justifies the use of sure independence screening in the Cox model when pn is ultra-high-dimensional.
4. Simulations
To evaluate the finite-sample performance of our sure screening and false positive control properties, we performed PSIS on simulated datasets generated from Cox models and examined its average false positive and negative rates. We simulated 200 datasets, each consisting of pn = 20000 covariates and n = 100 subjects. We generated the covariates from a multivariate normal distribution where the mean was 0 and the correlation between components Zij and Zik was ρ|j−k| for ρ = 0.5, and 0.9. We next generated survival times from Cox models with baseline hazards of λ0(x) = 1 and linear predictors for different parameter vectors α0. We let the number of non-zero elements of α0 be either sn = 10 or 20 and set the first sn components of α0 to be either all equal to 0.35 or all equal to 0.7. Finally, we generated censoring times from a uniform and an exponential distribution, which gave bounded and unbounded censoring times respectively. Under each censoring mechanism, we considered censoring rates of approximately 20%, 50%, and 70%.
To explore how the variable selection performance of a few popular regularized regression techniques were affected by PSIS with different values of qn, we followed PSIS by either lasso [18], adaptive lasso [19], or SCAD [20]. Since the initial parameter estimates required by adaptive lasso do not exist when pn > n, we first applied ordinary lasso to reduce pn and calculated the initial estimates using the remaining covariates. We implemented lasso and adaptive lasso using a coordinate descent algorithm [21] with the R package glmnet, and we implemented SCAD using the one-step estimator of Zou and Li [22] with the package SIS. We tuned each regularized regression with BIC to achieve selection consistency, and we denote these two-stage procedures by PSIS-L, PSIS-L-A, and PSIS-S, respectively.
Tables 1 and 2 report numerical results for our sure screening and false positive control properties when sn = 20, α0j = 0.35, and when censoring times were generated from an exponential distribution. The results when sn = 10, α0j = 0.7, or when the censoring times were uniformly distributed are similar and are omitted for the sake of space. We considered qn = 10r for r = −6, …,−2, and also ranging from 0.1 to 1 (corresponding to no screening) in increments of 0.1. The results support our principled cutoff procedure: the observed false positive rates closely match the nominal qn when ρ = 0.5 for all censoring rates. When ρ = 0.9, the observed false positive rates can be higher than the nominal qn for qn ≤ 10−4, but since pn = 20000 here, qn = 10−4 corresponds to only 2 false positives. In other words, even when the nominal qn underestimates the true false positive rate, the absolute number of false positives selected by PSIS is still fairly small.
Table 1.
Simulation results for Cox models with sn = 20, α0j = 0.35, and ρ = 0.5 under exponential censoring
| % censoring | qn | |
| |
PSIS | PSIS-L | PSIS-A | PSIS-S | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| FN | FP | FN | FP | FN | FP | FN | FP | |||
| 20 | 1e-6 | 0.86 | 0.96 | 3e-7 | 0.96 | 0.00 | 0.96 | 0.00 | 0.96 | 0.00 |
| 20 | 1e-5 | 2.45 | 0.89 | 1e-5 | 0.89 | 0.00 | 0.89 | 0.00 | 0.90 | 0.00 |
| 20 | 1e-4 | 7.29 | 0.74 | 1e-4 | 0.75 | 0.00 | 0.75 | 0.00 | 0.78 | 0.00 |
| 20 | 1e-3 | 30.74 | 0.52 | 1e-3 | 0.56 | 0.00 | 0.57 | 0.00 | 0.80 | 0.00 |
| 20 | 0.01 | 223.46 | 0.27 | 0.01 | 0.50 | 0.00 | 0.51 | 0.00 | 0.60 | 0.00 |
| 20 | 0.10 | 2066.62 | 0.07 | 0.10 | 0.45 | 0.00 | 0.46 | 0.00 | 0.64 | 0.00 |
| 20 | 0.20 | 4084.34 | 0.04 | 0.20 | 0.45 | 0.00 | 0.46 | 0.00 | 1.00 | 0.00 |
| 20 | 0.30 | 6085.28 | 0.03 | 0.30 | 0.45 | 0.00 | 0.46 | 0.00 | 1.00 | 0.00 |
| 20 | 0.40 | 8087.81 | 0.02 | 0.40 | 0.45 | 0.00 | 0.46 | 0.00 | 1.00 | 0.00 |
| 20 | 0.50 | 10076.05 | 0.01 | 0.50 | 0.45 | 0.00 | 0.46 | 0.00 | 1.00 | 0.00 |
| 20 | 0.60 | 12063.53 | 0.01 | 0.60 | 0.45 | 0.00 | 0.46 | 0.00 | 1.00 | 0.00 |
| 20 | 0.70 | 14049.73 | 0.01 | 0.70 | 0.45 | 0.00 | 0.46 | 0.00 | 1.00 | 0.00 |
| 20 | 0.80 | 16035.60 | 0.00 | 0.80 | 0.45 | 0.00 | 0.46 | 0.00 | 1.00 | 0.00 |
| 20 | 0.90 | 18018.92 | 0.00 | 0.90 | 0.45 | 0.00 | 0.46 | 0.00 | 1.00 | 0.00 |
| 20 | 1.00 | 19999.97 | 0.00 | 1.00 | 0.45 | 0.00 | 0.46 | 0.00 | 1.00 | 0.00 |
| 50 | 1e-6 | 0.46 | 0.98 | 8e-7 | 0.98 | 0.00 | 0.98 | 0.00 | 0.98 | 0.00 |
| 50 | 1e-5 | 1.48 | 0.93 | 9e-6 | 0.93 | 0.00 | 0.93 | 0.00 | 0.94 | 0.00 |
| 50 | 1e-4 | 5.53 | 0.82 | 1e-4 | 0.83 | 0.00 | 0.83 | 0.00 | 0.87 | 0.00 |
| 50 | 1e-3 | 27.48 | 0.64 | 1e-3 | 0.69 | 0.00 | 0.70 | 0.00 | 0.84 | 0.00 |
| 50 | 0.01 | 218.90 | 0.37 | 0.01 | 0.70 | 0.00 | 0.71 | 0.00 | 0.80 | 0.00 |
| 50 | 0.10 | 2055.34 | 0.11 | 0.10 | 0.84 | 0.00 | 0.84 | 0.00 | 0.82 | 0.00 |
| 50 | 0.20 | 4066.57 | 0.06 | 0.20 | 0.85 | 0.00 | 0.86 | 0.00 | 1.00 | 0.00 |
| 50 | 0.30 | 6072.90 | 0.04 | 0.30 | 0.86 | 0.00 | 0.87 | 0.00 | 1.00 | 0.00 |
| 50 | 0.40 | 8071.28 | 0.03 | 0.40 | 0.86 | 0.00 | 0.87 | 0.00 | 1.00 | 0.00 |
| 50 | 0.50 | 10061.46 | 0.02 | 0.50 | 0.87 | 0.00 | 0.87 | 0.00 | 1.00 | 0.00 |
| 50 | 0.60 | 12055.20 | 0.02 | 0.60 | 0.87 | 0.00 | 0.87 | 0.00 | 1.00 | 0.00 |
| 50 | 0.70 | 14048.17 | 0.01 | 0.70 | 0.87 | 0.00 | 0.87 | 0.00 | 1.00 | 0.00 |
| 50 | 0.80 | 16034.58 | 0.00 | 0.80 | 0.87 | 0.00 | 0.87 | 0.00 | 1.00 | 0.00 |
| 50 | 0.90 | 18018.47 | 0.00 | 0.90 | 0.87 | 0.00 | 0.87 | 0.00 | 1.00 | 0.00 |
| 50 | 1.00 | 19999.97 | 0.00 | 1.00 | 0.87 | 0.00 | 0.87 | 0.00 | 1.00 | 0.00 |
| 70 | 1e-6 | 0.04 | 1.00 | 1e-6 | 1.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 |
| 70 | 1e-5 | 0.33 | 0.99 | 7e-6 | 0.99 | 0.00 | 0.99 | 0.00 | 0.99 | 0.00 |
| 70 | 1e-4 | 2.33 | 0.96 | 8e-5 | 0.96 | 0.00 | 0.96 | 0.00 | 0.97 | 0.00 |
| 70 | 1e-3 | 20.34 | 0.86 | 9e-4 | 0.89 | 0.00 | 0.89 | 0.00 | 0.95 | 0.00 |
| 70 | 0.01 | 200.62 | 0.63 | 0.01 | 0.98 | 0.00 | 0.98 | 0.00 | 0.97 | 0.00 |
| 70 | 0.10 | 2036.15 | 0.28 | 0.10 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.20 | 4056.93 | 0.17 | 0.20 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.30 | 6073.71 | 0.11 | 0.30 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.40 | 8074.10 | 0.08 | 0.40 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.50 | 10069.87 | 0.06 | 0.50 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.60 | 12061.20 | 0.04 | 0.60 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.70 | 14053.00 | 0.03 | 0.70 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.80 | 16036.78 | 0.02 | 0.80 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.90 | 18018.22 | 0.01 | 0.90 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 1.00 | 19999.98 | 0.00 | 1.00 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
Table 2.
Simulation results for Cox models with sn = 20, α0j = 0.35, and = 0.9 under exponential censoring
| % censoring | qn | |
| |
PSIS | PSIS-L | PSIS-A | PSIS-S | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| FN | FP | FN | FP | FN | FP | FN | FP | |||
| 20 | 1e-6 | 20.57 | 0.03 | 6e-5 | 0.26 | 0.00 | 0.27 | 0.00 | 0.65 | 0.00 |
| 20 | 1e-5 | 22.00 | 0.01 | 1e-4 | 0.25 | 0.00 | 0.26 | 0.00 | 0.64 | 0.00 |
| 20 | 1e-4 | 25.39 | 0.00 | 3e-4 | 0.26 | 0.00 | 0.27 | 0.00 | 0.65 | 0.00 |
| 20 | 1e-3 | 46.84 | 0.00 | 1e-3 | 0.29 | 0.00 | 0.32 | 0.00 | 0.68 | 0.00 |
| 20 | 0.01 | 237.31 | 0.00 | 0.01 | 0.43 | 0.00 | 0.45 | 0.00 | 0.65 | 0.00 |
| 20 | 0.10 | 2069.38 | 0.00 | 0.10 | 0.39 | 0.00 | 0.41 | 0.00 | 0.69 | 0.00 |
| 20 | 0.20 | 4082.82 | 0.00 | 0.20 | 0.37 | 0.00 | 0.40 | 0.00 | 1.00 | 0.00 |
| 20 | 0.30 | 6085.60 | 0.00 | 0.30 | 0.38 | 0.00 | 0.40 | 0.00 | 1.00 | 0.00 |
| 20 | 0.40 | 8080.28 | 0.00 | 0.40 | 0.38 | 0.00 | 0.40 | 0.00 | 1.00 | 0.00 |
| 20 | 0.50 | 10072.06 | 0.00 | 0.50 | 0.38 | 0.00 | 0.40 | 0.00 | 1.00 | 0.00 |
| 20 | 0.60 | 12063.09 | 0.00 | 0.60 | 0.38 | 0.00 | 0.39 | 0.00 | 1.00 | 0.00 |
| 20 | 0.70 | 14052.35 | 0.00 | 0.70 | 0.38 | 0.00 | 0.40 | 0.00 | 1.00 | 0.00 |
| 20 | 0.80 | 16041.30 | 0.00 | 0.80 | 0.38 | 0.00 | 0.39 | 0.00 | 1.00 | 0.00 |
| 20 | 0.90 | 18017.65 | 0.00 | 0.90 | 0.38 | 0.00 | 0.39 | 0.00 | 1.00 | 0.00 |
| 20 | 1.00 | 19999.98 | 0.00 | 1.00 | 0.38 | 0.00 | 0.40 | 0.00 | 1.00 | 0.00 |
| 50 | 1e-6 | 19.38 | 0.07 | 4e-5 | 0.35 | 0.00 | 0.37 | 0.00 | 0.72 | 0.00 |
| 50 | 1e-5 | 21.08 | 0.03 | 8e-5 | 0.34 | 0.00 | 0.36 | 0.00 | 0.71 | 0.00 |
| 50 | 1e-4 | 24.35 | 0.01 | 2e-4 | 0.34 | 0.00 | 0.36 | 0.00 | 0.72 | 0.00 |
| 50 | 1e-3 | 44.27 | 0.00 | 1e-3 | 0.30 | 0.00 | 0.32 | 0.00 | 0.74 | 0.00 |
| 50 | 0.01 | 229.40 | 0.00 | 0.01 | 0.50 | 0.00 | 0.53 | 0.00 | 0.69 | 0.00 |
| 50 | 0.10 | 2059.74 | 0.00 | 0.10 | 0.51 | 0.00 | 0.54 | 0.00 | 0.78 | 0.00 |
| 50 | 0.20 | 4075.78 | 0.00 | 0.20 | 0.51 | 0.00 | 0.55 | 0.00 | 1.00 | 0.00 |
| 50 | 0.30 | 6082.62 | 0.00 | 0.30 | 0.51 | 0.00 | 0.55 | 0.00 | 1.00 | 0.00 |
| 50 | 0.40 | 8076.19 | 0.00 | 0.40 | 0.51 | 0.00 | 0.54 | 0.00 | 1.00 | 0.00 |
| 50 | 0.50 | 10069.25 | 0.00 | 0.50 | 0.51 | 0.00 | 0.54 | 0.00 | 1.00 | 0.00 |
| 50 | 0.60 | 12056.07 | 0.00 | 0.60 | 0.51 | 0.00 | 0.54 | 0.00 | 1.00 | 0.00 |
| 50 | 0.70 | 14049.39 | 0.00 | 0.70 | 0.51 | 0.00 | 0.55 | 0.00 | 1.00 | 0.00 |
| 50 | 0.80 | 16035.47 | 0.00 | 0.80 | 0.52 | 0.00 | 0.55 | 0.00 | 1.00 | 0.00 |
| 50 | 0.90 | 18016.56 | 0.00 | 0.90 | 0.52 | 0.00 | 0.55 | 0.00 | 1.00 | 0.00 |
| 50 | 1.00 | 19999.99 | 0.00 | 1.00 | 0.52 | 0.00 | 0.55 | 0.00 | 1.00 | 0.00 |
| 70 | 1e-6 | 17.07 | 0.17 | 2e-5 | 0.49 | 0.00 | 0.51 | 0.00 | 0.78 | 0.00 |
| 70 | 1e-5 | 19.29 | 0.09 | 6e-5 | 0.45 | 0.00 | 0.47 | 0.00 | 0.77 | 0.00 |
| 70 | 1e-4 | 22.88 | 0.04 | 2e-4 | 0.40 | 0.00 | 0.43 | 0.00 | 0.76 | 0.00 |
| 70 | 1e-3 | 42.52 | 0.01 | 1e-3 | 0.35 | 0.00 | 0.39 | 0.00 | 0.74 | 0.00 |
| 70 | 1e-2 | 225.35 | 0.00 | 0.01 | 0.63 | 0.00 | 0.66 | 0.00 | 0.78 | 0.00 |
| 70 | 0.10 | 2047.36 | 0.00 | 0.10 | 0.65 | 0.00 | 0.68 | 0.00 | 0.86 | 0.00 |
| 70 | 0.20 | 4061.41 | 0.00 | 0.20 | 0.65 | 0.00 | 0.68 | 0.00 | 1.00 | 0.00 |
| 70 | 0.30 | 6066.76 | 0.00 | 0.30 | 0.65 | 0.00 | 0.68 | 0.00 | 1.00 | 0.00 |
| 70 | 0.40 | 8069.35 | 0.00 | 0.40 | 0.65 | 0.00 | 0.68 | 0.00 | 1.00 | 0.00 |
| 70 | 0.50 | 10063.83 | 0.00 | 0.50 | 0.65 | 0.00 | 0.68 | 0.00 | 1.00 | 0.00 |
| 70 | 0.60 | 12052.45 | 0.00 | 0.60 | 0.65 | 0.00 | 0.68 | 0.00 | 1.00 | 0.00 |
| 70 | 0.70 | 14041.27 | 0.00 | 0.70 | 0.65 | 0.00 | 0.68 | 0.00 | 1.00 | 0.00 |
| 70 | 0.80 | 16029.24 | 0.00 | 0.80 | 0.65 | 0.00 | 0.68 | 0.00 | 1.00 | 0.00 |
| 70 | 0.90 | 18015.47 | 0.00 | 0.90 | 0.65 | 0.00 | 0.68 | 0.00 | 1.00 | 0.00 |
| 70 | 1.00 | 19999.99 | 0.00 | 1.00 | 0.65 | 0.00 | 0.68 | 0.00 | 1.00 | 0.00 |
Figure 1 plots the average false negative rates for PSIS against qn, which increase as qn decreases but generally don’t rise dramatically until qn ≈ 0.1. For a given qn the false negative rates decrease with larger α0j. The performance of PSIS actually improves when ρ = 0.9, perhaps because in our simulated data the correlation between the important covariates increases with ρ, making the marginal β̂j estimates for those covariates more likely to be similar in magnitude. Higher censoring rates exhibit worse performance, as expected. These results suggest that qn can be set fairly low and the false negative rate will not suffer much, as long as the amount of censoring is not too high.
Figure 1.

False negative rates for Cox models with α0j = 0.35 (dashes) and α0j = 0.7 (solid) under exponential censoring.
The average false negative rates for PSIS-L, PSIS-L-A, and PSIS-S are also plotted in Figure 1. The corresponding false positive rates are all very low and so are not plotted (see Tables 1 and 2). The PSIS-S results give false negative rates of 1 for large qn because the SCAD algorithm fails when the number of covariates is too large, so we already see the usefulness of PSIS in facilitating computations. For all methods, higher values of α0j exhibit lower false negative rates, and as before we see better performance when the covariates are more correlated.
Interestingly, with 50% censoring, when qn is small the PSIS-L, PSISL- A, and PSIS-S false negative rates are noticeably lower than those after running lasso, lasso-adaptive lasso, or SCAD alone (i.e. qn = 1). This supports the use of PSIS prior to running regularized regression. However, when the censoring rate is fairly low (20%) or fairly high (70%), this effect diminishes, to the point where PSIS actually degrades the performance of the regularized regressions when ρ = 0.5 at 20% censoring. This could be because with low censoring, there might already be sufficient data for the regularized regressions to select from the pn = 20000 covariates, even in the absence of PSIS. At the other extreme, when there is 70% censoring, there might be so little data (with n = 100) that no regularized method, with or without PSIS, would perform well.
To assess the robustness of our procedure, we also generated 200 datasets from log-normal models. Each dataset had n = 100 and pn = 20000, and covariates Zi were generated using the same procedure as above, for ρ = 0.5 or 0.9. Survival times Ti were generated according to , where ∈i followed a standard normal distribution and α0 had sn = 10 or 20 nonzero elements all equal to either 0.35 or 0.7. Censoring times were generated using the same schemes and rates as before.
Tables 3 and 4 and Figure 2 show that PSIS can still perform very well when the Cox model is misspecified. Again, the numerical results when sn = 10, α0j = 0.7, or the censoring times were uniformly distributed are omitted from the tables to save space. These results follow the same trends as those of the correctly specified simulations discussed above. In particular, the principled cutoff procedure still shows good performance, and using PSIS when qn is small can still lead to lower false negative rates than when qn = 1.
Table 3.
Simulation results for log-normal models with sn = 20, α0j = 0.35, and ρ = 0.5 under exponential censoring
| % censoring | qn | |
| |
PSIS | PSIS-L | PSIS-A | PSIS-S | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| FN | FP | FN | FP | FN | FP | FN | FP | |||
| 20 | 1e-6 | 1.07 | 0.95 | 5e-7 | 0.95 | 0.00 | 0.95 | 0.00 | 0.95 | 0.00 |
| 20 | 1e-5 | 2.92 | 0.86 | 1e-5 | 0.87 | 0.00 | 0.87 | 0.00 | 0.88 | 0.00 |
| 20 | 1e-4 | 7.83 | 0.71 | 1e-4 | 0.72 | 0.00 | 0.72 | 0.00 | 0.76 | 0.00 |
| 20 | 1e-3 | 31.64 | 0.50 | 1e-3 | 0.54 | 0.00 | 0.54 | 0.00 | 0.74 | 0.00 |
| 20 | 0.01 | 225.09 | 0.25 | 0.01 | 0.45 | 0.00 | 0.46 | 0.00 | 0.54 | 0.00 |
| 20 | 0.10 | 2072.03 | 0.07 | 0.10 | 0.38 | 0.00 | 0.39 | 0.00 | 0.58 | 0.00 |
| 20 | 0.20 | 4086.02 | 0.04 | 0.20 | 0.38 | 0.00 | 0.39 | 0.00 | 1.00 | 0.00 |
| 20 | 0.30 | 6091.88 | 0.02 | 0.30 | 0.38 | 0.00 | 0.39 | 0.00 | 1.00 | 0.00 |
| 20 | 0.40 | 8096.85 | 0.01 | 0.40 | 0.38 | 0.00 | 0.39 | 0.00 | 1.00 | 0.00 |
| 20 | 0.50 | 10084.36 | 0.01 | 0.50 | 0.38 | 0.00 | 0.39 | 0.00 | 1.00 | 0.00 |
| 20 | 0.60 | 12071.20 | 0.01 | 0.60 | 0.38 | 0.00 | 0.39 | 0.00 | 1.00 | 0.00 |
| 20 | 0.70 | 14053.60 | 0.00 | 0.70 | 0.38 | 0.00 | 0.39 | 0.00 | 1.00 | 0.00 |
| 20 | 0.80 | 16035.81 | 0.00 | 0.80 | 0.38 | 0.00 | 0.39 | 0.00 | 1.00 | 0.00 |
| 20 | 0.90 | 18014.10 | 0.00 | 0.90 | 0.38 | 0.00 | 0.39 | 0.00 | 1.00 | 0.00 |
| 20 | 1.00 | 19999.96 | 0.00 | 1.00 | 0.38 | 0.00 | 0.39 | 0.00 | 1.00 | 0.00 |
| 50 | 1e-6 | 0.58 | 0.97 | 2e-6 | 0.97 | 0.00 | 0.97 | 0.00 | 0.97 | 0.00 |
| 50 | 1e-5 | 1.68 | 0.92 | 8e-6 | 0.92 | 0.00 | 0.92 | 0.00 | 0.93 | 0.00 |
| 50 | 1e-4 | 5.74 | 0.80 | 9e-5 | 0.81 | 0.00 | 0.81 | 0.00 | 0.85 | 0.00 |
| 50 | 1e-3 | 28.12 | 0.61 | 1e-3 | 0.66 | 0.00 | 0.66 | 0.00 | 0.82 | 0.00 |
| 50 | 0.01 | 217.45 | 0.35 | 0.01 | 0.63 | 0.00 | 0.65 | 0.00 | 0.74 | 0.00 |
| 50 | 0.10 | 2053.91 | 0.10 | 0.10 | 0.79 | 0.00 | 0.80 | 0.00 | 0.79 | 0.00 |
| 50 | 0.20 | 4066.55 | 0.05 | 0.20 | 0.81 | 0.00 | 0.82 | 0.00 | 1.00 | 0.00 |
| 50 | 0.30 | 6071.31 | 0.03 | 0.30 | 0.81 | 0.00 | 0.82 | 0.00 | 1.00 | 0.00 |
| 50 | 0.40 | 8071.39 | 0.02 | 0.40 | 0.82 | 0.00 | 0.82 | 0.00 | 1.00 | 0.00 |
| 50 | 0.50 | 10067.45 | 0.01 | 0.50 | 0.82 | 0.00 | 0.83 | 0.00 | 1.00 | 0.00 |
| 50 | 0.60 | 12061.88 | 0.01 | 0.60 | 0.82 | 0.00 | 0.83 | 0.00 | 1.00 | 0.00 |
| 50 | 0.70 | 14045.89 | 0.00 | 0.70 | 0.82 | 0.00 | 0.83 | 0.00 | 1.00 | 0.00 |
| 50 | 0.80 | 16030.90 | 0.00 | 0.80 | 0.82 | 0.00 | 0.83 | 0.00 | 1.00 | 0.00 |
| 50 | 0.90 | 18017.08 | 0.00 | 0.90 | 0.82 | 0.00 | 0.83 | 0.00 | 1.00 | 0.00 |
| 50 | 1.00 | 19999.99 | 0.00 | 1.00 | 0.82 | 0.00 | 0.83 | 0.00 | 1.00 | 0.00 |
| 70 | 1e-6 | 0.07 | 1.00 | 8e-7 | 1.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 |
| 70 | 1e-5 | 0.45 | 0.98 | 7e-6 | 0.98 | 0.00 | 0.98 | 0.00 | 0.99 | 0.00 |
| 70 | 1e-4 | 2.62 | 0.95 | 8e-5 | 0.95 | 0.00 | 0.95 | 0.00 | 0.96 | 0.00 |
| 70 | 1e-3 | 20.59 | 0.83 | 9e-4 | 0.86 | 0.00 | 0.87 | 0.00 | 0.93 | 0.00 |
| 70 | 0.01 | 201.80 | 0.59 | 0.01 | 0.98 | 0.00 | 0.98 | 0.00 | 0.96 | 0.00 |
| 70 | 0.10 | 2032.38 | 0.24 | 0.10 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.20 | 4057.72 | 0.15 | 0.20 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.30 | 6071.12 | 0.10 | 0.30 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.40 | 8075.48 | 0.07 | 0.40 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.50 | 10069.12 | 0.05 | 0.50 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.60 | 12056.30 | 0.04 | 0.60 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.70 | 14044.67 | 0.03 | 0.70 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.80 | 16029.99 | 0.02 | 0.80 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 0.90 | 18015.69 | 0.01 | 0.90 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
| 70 | 1.00 | 19999.99 | 0.00 | 1.00 | 0.99 | 0.00 | 0.99 | 0.00 | 1.00 | 0.00 |
Table 4.
Simulation results for log-normal models with sn = 20, α0j = 0.35, and ρ = 0.9 under exponential censoring
| % censoring | qn | |
| |
PSIS | PSIS-L | PSIS-A | PSIS-S | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| FN | FP | FN | FP | FN | FP | FN | FP | |||
| 20 | 1e-6 | 20.63 | 0.03 | 6e-5 | 0.25 | 0.00 | 0.25 | 0.00 | 0.63 | 0.00 |
| 20 | 1e-5 | 21.98 | 0.01 | 1e-4 | 0.23 | 0.00 | 0.24 | 0.00 | 0.62 | 0.00 |
| 20 | 1e-4 | 24.94 | 0.00 | 2e-4 | 0.23 | 0.00 | 0.25 | 0.00 | 0.63 | 0.00 |
| 20 | 1e-3 | 45.60 | 0.00 | 1e-3 | 0.26 | 0.00 | 0.29 | 0.00 | 0.65 | 0.00 |
| 20 | 0.01 | 232.98 | 0.00 | 0.01 | 0.35 | 0.00 | 0.37 | 0.00 | 0.54 | 0.00 |
| 20 | 0.10 | 2064.58 | 0.00 | 0.10 | 0.31 | 0.00 | 0.33 | 0.00 | 0.64 | 0.00 |
| 20 | 0.20 | 4079.41 | 0.00 | 0.20 | 0.30 | 0.00 | 0.33 | 0.00 | 1.00 | 0.00 |
| 20 | 0.30 | 6089.45 | 0.00 | 0.30 | 0.30 | 0.00 | 0.32 | 0.00 | 1.00 | 0.00 |
| 20 | 0.40 | 8089.52 | 0.00 | 0.40 | 0.30 | 0.00 | 0.32 | 0.00 | 1.00 | 0.00 |
| 20 | 0.50 | 10075.52 | 0.00 | 0.50 | 0.30 | 0.00 | 0.33 | 0.00 | 1.00 | 0.00 |
| 20 | 0.60 | 12064.03 | 0.00 | 0.60 | 0.30 | 0.00 | 0.32 | 0.00 | 1.00 | 0.00 |
| 20 | 0.70 | 14048.61 | 0.00 | 0.70 | 0.30 | 0.00 | 0.32 | 0.00 | 1.00 | 0.00 |
| 20 | 0.80 | 16031.75 | 0.00 | 0.80 | 0.30 | 0.00 | 0.33 | 0.00 | 1.00 | 0.00 |
| 20 | 0.90 | 18014.60 | 0.00 | 0.90 | 0.31 | 0.00 | 0.33 | 0.00 | 1.00 | 0.00 |
| 20 | 1.00 | 19999.98 | 0.00 | 1.00 | 0.31 | 0.00 | 0.33 | 0.00 | 1.00 | 0.00 |
| 50 | 1e-6 | 19.65 | 0.06 | 4e-5 | 0.32 | 0.00 | 0.34 | 0.00 | 0.68 | 0.00 |
| 50 | 1e-5 | 21.14 | 0.02 | 8e-5 | 0.30 | 0.00 | 0.32 | 0.00 | 0.68 | 0.00 |
| 50 | 1e-4 | 24.32 | 0.01 | 2e-4 | 0.30 | 0.00 | 0.32 | 0.00 | 0.68 | 0.00 |
| 50 | 1e-3 | 44.18 | 0.00 | 1e-3 | 0.24 | 0.00 | 0.25 | 0.00 | 0.69 | 0.00 |
| 50 | 0.01 | 229.64 | 0.00 | 0.01 | 0.43 | 0.00 | 0.46 | 0.00 | 0.63 | 0.00 |
| 50 | 0.10 | 2056.83 | 0.00 | 0.10 | 0.46 | 0.00 | 0.50 | 0.00 | 0.72 | 0.00 |
| 50 | 0.20 | 4067.93 | 0.00 | 0.20 | 0.47 | 0.00 | 0.50 | 0.00 | 1.00 | 0.00 |
| 50 | 0.30 | 6075.55 | 0.00 | 0.30 | 0.47 | 0.00 | 0.50 | 0.00 | 1.00 | 0.00 |
| 50 | 0.40 | 8067.98 | 0.00 | 0.40 | 0.47 | 0.00 | 0.50 | 0.00 | 1.00 | 0.00 |
| 50 | 0.50 | 10065.84 | 0.00 | 0.50 | 0.47 | 0.00 | 0.51 | 0.00 | 1.00 | 0.00 |
| 50 | 0.60 | 12059.20 | 0.00 | 0.60 | 0.46 | 0.00 | 0.50 | 0.00 | 1.00 | 0.00 |
| 50 | 0.70 | 14048.42 | 0.00 | 0.70 | 0.46 | 0.00 | 0.50 | 0.00 | 1.00 | 0.00 |
| 50 | 0.80 | 16028.41 | 0.00 | 0.80 | 0.47 | 0.00 | 0.50 | 0.00 | 1.00 | 0.00 |
| 50 | 0.90 | 18014.56 | 0.00 | 0.90 | 0.47 | 0.00 | 0.50 | 0.00 | 1.00 | 0.00 |
| 50 | 1.00 | 19999.97 | 0.00 | 1.00 | 0.47 | 0.00 | 0.50 | 0.00 | 1.00 | 0.00 |
| 70 | 1e-6 | 17.46 | 0.14 | 2e-5 | 0.41 | 0.00 | 0.44 | 0.00 | 0.75 | 0.00 |
| 70 | 1e-5 | 19.54 | 0.07 | 5e-5 | 0.37 | 0.00 | 0.39 | 0.00 | 0.73 | 0.00 |
| 70 | 1e-4 | 22.92 | 0.03 | 2e-4 | 0.32 | 0.00 | 0.35 | 0.00 | 0.72 | 0.00 |
| 70 | 1e-3 | 43.28 | 0.01 | 1e-3 | 0.35 | 0.00 | 0.38 | 0.00 | 0.69 | 0.00 |
| 70 | 0.01 | 229.22 | 0.00 | 0.01 | 0.57 | 0.00 | 0.60 | 0.00 | 0.75 | 0.00 |
| 70 | 0.10 | 2062.75 | 0.00 | 0.10 | 0.63 | 0.00 | 0.65 | 0.00 | 0.86 | 0.00 |
| 70 | 0.20 | 4080.23 | 0.00 | 0.20 | 0.63 | 0.00 | 0.65 | 0.00 | 1.00 | 0.00 |
| 70 | 0.30 | 6083.23 | 0.00 | 0.30 | 0.62 | 0.00 | 0.65 | 0.00 | 1.00 | 0.00 |
| 70 | 0.40 | 8080.86 | 0.00 | 0.40 | 0.62 | 0.00 | 0.65 | 0.00 | 1.00 | 0.00 |
| 70 | 0.50 | 10073.59 | 0.00 | 0.50 | 0.62 | 0.00 | 0.65 | 0.00 | 1.00 | 0.00 |
| 70 | 0.60 | 12067.05 | 0.00 | 0.60 | 0.62 | 0.00 | 0.65 | 0.00 | 1.00 | 0.00 |
| 70 | 0.70 | 14053.72 | 0.00 | 0.70 | 0.62 | 0.00 | 0.65 | 0.00 | 1.00 | 0.00 |
| 70 | 0.80 | 16038.41 | 0.00 | 0.80 | 0.62 | 0.00 | 0.65 | 0.00 | 1.00 | 0.00 |
| 70 | 0.90 | 18019.44 | 0.00 | 0.90 | 0.62 | 0.00 | 0.65 | 0.00 | 1.00 | 0.00 |
| 70 | 1.00 | 19999.99 | 0.00 | 1.00 | 0.62 | 0.00 | 0.65 | 0.00 | 1.00 | 0.00 |
Figure 2.

False negative rates for log-normal models with sn = 20, α0j = 0.35 (dashes), and α0j = 0.7 (solid) under exponential censoring.
5. Analysis of the myeloma study
Recent advances in understanding the biological mechanisms underlying multiple myeloma have offered new possibilities for therapy [23]. Time-to-event outcomes offer information about the progression of the disease, and in this vein several studies have examined the relationship between gene expression levels and survival [24]. In one such study conducted by Millennium Pharmaceuticals [8], mRNA expression levels were collected using Affymetrix U133A/B arrays from myeloma cells of 80 patients enrolled in a clinical trial of bortezomib (accession number GSE9782, trial 39). Median survival time was 684 days after randomization, and 50% of the observations were censored. We applied our methods to this data.
Expression values were measured for 44760 probesets, encompassing more than 22000 genes, and were log2-transformed. We performed PSIS and chose qn = 1/44760, for two reasons. First, our simulation results suggest that for large ρ, the true false positive rate can be larger than our nominal level, and genetic datasets are probably highly correlated. Second, gene expression levels are very likely related to the survival outcomes, but only weakly so. Many of our genes are probably not sufficiently important, in the sense of Assumption 7, so allowing even a small false positive rate would result in including a huge number of genes. For these reasons, we want to control the false positive rate to the extent possible, but on the other hand we cannot allow f = 0 or else γn = ∞. Thus we considered f = 1, which leads to our choice of qn.
We could not directly evaluate the performance of PSIS without knowing which genes are “truly” important. Instead, we ran PSIS to get a screened model
and also randomly selected |
| probesets. We then compared the prediction accuracies of PSIS-L, PSIS-L-A, and PSIS-S to those obtained by fitting lasso, lasso-adaptive lasso, and SCAD on the randomly selected probesets. Using random genes as negative controls is common in these type of experiments [25, 26, 12]. We also fit the regularized regression procedures on the full dataset, without any screening (i.e. qn = 1).
For each of these methods, we randomly partitioned the data into a 60- patient training set and a 20-patient testing set. We then used the models fit in the training set to calculate scores for each subject in the testing set, and evaluated the predictive performance using the C-statistic [27]. We repeated this entire process 200 times. Better performances from the screened methods would provide evidence that PSIS is indeed finding predictively important genes.
Table 5 reports the average C-statistics and model sizes obtained by our different methods. We see that PSIS-L, PSIS-L-A, and PSIS-S perform much better than the corresponding regressions fit using randomly selected probesets. When we do not screen the data, SCAD fails, and lasso and lasso-adaptive lasso do not perform as well as the screened versions.
Table 5.
Predictive accuracies using myeloma data
| PSIS, qn = 0.0001 | Random probesets | All probesets | ||||
|---|---|---|---|---|---|---|
| Method | C-stat (SD) | Size (SD) | C-stat (SD) | Size (SD) | C-stat (SD) | Size (SD) |
| Lasso | 0.60 (0.09) | 11.43 (9.18) | 0.15 (0.25) | 3.33 (10.74) | 0.33 (0.33) | 20.91 (24.07) |
| Lasso-alasso | 0.60 (0.09) | 11.13 (8.97) | 0.15 (0.25) | 3.29 (10.60) | 0.33 (0.33) | 18.86 (21.74) |
| SCAD | 0.60 (0.09) | 7.13 (6.67) | 0.33 (0.28) | 2.48 (7.43) | — | — |
Because of the selection consistency of the adaptive lasso [2, 19], we next applied PSIS-L-A with qn = 1/44760 to all 80 patients. Table 6 gives the probesets we found to have nonzero parameter estimates, as well as their estimated coefficients. Indeed, our results include some genes previously found to be related to myeloma, e.g. IGHV3-23 [28] and PRKDC [29]. Finally, we evaluated the predictive performance of this model using an independent validation dataset (accession number GSE9782, trials 24, 25, and 40). The model in Table 6 achieved a C-statistic of 0.59, which matches the cross-validation estimate of Table 5. These results indicate that PSIS is an effective way to identify predictively important genes while controlling the false positive rate, and that implementing PSIS before regularized regression can lead to more computationally amenable, interpretable models with high predictive power.
Table 6.
Genes found using PSIS-L-A, qn = 0.0001
| Probeset | Gene | Description | Coefficient |
|---|---|---|---|
| 219999_at | MAN2A2 | mannosidase, alpha, class 2A, member 2 | −0.27 |
| 207677_s_at | NCF4 | neutrophil cytosolic factor 4, 40kDa | −0.14 |
| 216510_x_at | IGHV3-23 | immunoglobulin heavy variable 3–23 | −0.35 |
| 222610_s_at | S100PBP | S100P binding protein | 0.15 |
| 203550_s_at | FAM189B | family with sequence similarity 189, member B | 0.06 |
| 208694_at | PRKDC | protein kinase, DNA-activated, catalytic polypeptide | 0.12 |
| 223277_at | C3orf75 | chromosome 3 open reading frame 75 | 0.18 |
| 234980_at | TMEM56 | transmembrane protein 56 | −0.37 |
| 213893_x_at | PMS2L5 | postmeiotic segregation increased 2-like 5 | 0.26 |
| 217518_at | MYOF | myoferlin | −0.13 |
| 202587_s_at | AK1 | adenylate kinase 1 | −0.11 |
| 232452_at | LOC148824 | hypothetical LOC148824 | 0.42 |
| 209217_s_at | WDR45 | WD repeat domain 45 | −1.29 |
| 226692_at | SERF2 | small EDRK-rich factor 2 | −1.15 |
| 223114_at | COQ5 | coenzyme Q5 homolog, methyltransferase | 0.29 |
6. Discussion
This paper advances the field in three distinct ways. First, we have demonstrated that with censored outcomes, sure independence screening using marginal Cox regressions is a theoretically justified, effective way to reduce ultra-high-dimensional data to moderate sizes before applying more sophisticated variable selection procedures. In particular, we have described new, necessary condition on the dependence between the covariates and the censoring distribution. Second, we have provided a simple, principled method to select the number of variables to retain after screening and illustrated its effectiveness with simulated data. Our procedure could be easily extended to other screening methods. Finally, we have demonstrated through the motivating myeloma example that pre-screening may improve risk classification and identify predictive genes. There are a number of ways to broaden the scope of our method. So far we have dealt only with covariates that are constant in time, and we have not considered tied observations. Our method could also be extended to multivariate survival, competing risks, and other extensions of the Cox model.
While our simulations suggest that PSIS performs well even with correlated covariates, it would be interesting to explore other screening methods proposed specifically to deal with this situation. One approach is the ISIS method of Fan and Lv [6], which starts with an initial model of potentially important covariates, regresses the residuals from the working model on each of the remaining covariates to expand the working model, and iterates this process in order to capture any important covariates that would be missed in univariate screening. Residuals are unavailable with censored observations, but Fan et al. [12] generalized this iterative idea by working instead with log-likelihood ratios. Their formulation is easily applied to the log-partial likelihood of the Cox model, which they have implemented in the R package SIS. However, the theoretical properties of this procedure have not been investigated.
Finally, our theoretical analysis of sure independence screening touches on some philosophical questions about notions of variable importance. Biological phenomena often arise from the complex interactions of genes and other factors whose individual effects can be fairly weak but still non-zero. Thus merely having a non-zero contribution to the model is not a useful notion of importance, because then nearly every variable would be important. It may be more useful to conceive of importance as a finite sample property, in the sense that covariates whose signals are higher than the noise level of the estimator being used are to be considered important. In our method, for instance, the so-called important covariates satisfy Theorem 3, or else they could not be detected by marginal Cox regressions. Perhaps a good variable selection technique is one that, instead of selecting every variable with a non-zero contribution to the outcome, retains only those variables that, for a given n, meet the finite-sample definition of importance as defined in Theorem 3. The sure screening property of our method indicates that as n increases, we get closer to achieving this goal.
Acknowledgments
We thank Professor Jianqing Fan for reading an earlier version of this article and for many helpful suggestions that substantially improved the manuscript.
Appendix A. Assumptions
Let the true hazard function λ(x;Zi) be given by (1), and denote the true survival functions of Ti and Ci as and SC(x;Zi) = P(Ci > x|Zi), where the cumulative baseline hazard function . To conserve space we will write these as ST and SC. For simplicity we will drop the subject-specific subscripts i, except in the proof of Theorem 2. We will also need the following assumptions. We use notation introduced in Section 3.1.
Assumption 1
There exists a neighborhood B of β0j such that for each t < ∞,
in probability as n → ∞, is bounded away from zero on B × [0, t], and and are bounded on B × [0, t].
Assumption 2
For each t < ∞ and j = 1, …, pn, .
Assumption 3
The true parameter vector α0 belongs to a compact set such that each component α0j is bounded by a constant A > 0. Furthermore, || α0 ||1 is bounded by a constant L > 0.
Assumption 4
With τ (the study duration) as defined in Section 3.1, λ0(τ) is bounded by a positive constant.
Assumption 5
There is some constant H > 0 such that n−1|Uj(β̂j) − Uj(β0j)| ≥ H|β̂j − β0j | for all j = 1, …, pn.
Assumptions 1 and 2 are standard in survival analysis. Assumption 3 controls the total effect size of the covariates, which intuitively should be bounded and independent of sample size. The bounded cumulative baseline hazard function required by Assumption 4 usually holds in practice. Finally, Assumption 5 is reasonable because by the mean value theorem, we know that n−1|Uj(β̂j)−Uj(β0j)| = |n−1Ij(β*)||β̂j −β0j | for some β* between β̂j and β0j. It can be shown that Ij(β*) converges to the absolute value of the limiting information −∂uj(β)/∂β evaluated at the true β0j [30], and it is reasonable to assume that this limiting information is bounded from below away from zero. Thus for n sufficiently large, we can take H = inf β,j |∂uj(β)/∂β| such that H ≠ 0.
Our PSIS method will have good theoretical properties if the covariates Zi also satistify the following reasonable assumptions. Versions of these assumptions have been previously proposed [6, 9], but modifications are required when working with censored data.
Assumption 6
The Zij are independent of time and bounded by a constant K > 0, and E(Zij) = 0 for all j.
Assumption 7
If FT (x;Zi) is the cumulative distribution function of Ti given
Zi, then for constants c1 > 0 and κ < 1/2, minj∈
|cov[Zij, E{FT (Ci;Zi) | Zi}]| ≥ c1n−κ.
Assumption 8
The Zij, j ∈
are independent of the Zij, j ∈
and of Ci.
The validity of our proposed screening procedure hinges on whether the misspecified marginal Cox regressions can reflect the importance of the corresponding covariates in the joint model. In general it is difficult to directly link the true α0j to the marginal β0j because of the phenomenon of unfaithfulness [31], where the marginal correlation of Zij with the outcome can be zero even if α0j is large, due to correlated covariates. Assumption 7 protects against unfaithfulness. Though the outcome is unobservable under censoring, FT (Ci;Zi) is the probability of observing a failure given Zi and is a sensible surrogate. Assumption 8 is similar to the partial orthogonality assumption introduced in Fan and Song [9].
Appendix B. Proof of Theorem 1
We first relate β0j to cov[Zj, E{FT (C; Z) | Z}]. Assumptions 7 and 8 will then relate the covariance to α0j.
First, integration by parts gives that
Next, we define the function
Then since β0j is the solution to the estimating equation uj(β) (3), we know that cov[Zj, E{FT (C;Z) | Z}] = f(β0j). We can use the Cauchy- Schwarz inequality to show that ∂f(β)/∂β ≥ 0, with equality if and only
if P{Zj exp(βZj/2)(ST SC)1/2 = c exp(βZj/2)(ST SC )1/2} = 1 for some constant c. Since this will not hold if Zj is not constant, we see that f (β) is a monotone-increasing function in β.
Now suppose α0j = 0 so that j ∈
. By Assumption 8, Zj is independent of E{FT (C; Z) | Z}, so that f (β0j) = cov[Zj, E{FT (C; Z) | Z}] = 0. However, we also have that f(0) = 0, since E{ZjST SC} = E(Zj)E(ST SC) = 0 by Assumption 6 and because Zj and C are independent for j ∈
. Because f(β) is monotone we know that there is only one value of β such that f(β) = 0, so that β0j = 0. Similarly, suppose that a0j ≠ 0 so that j ∈
. Then by Assumption 7, |f(β0j)| = |cov[Zj, E{FT (C; Z) | Z}]| > c1n−κ. Therefore β0j ≠ 0 by monotonicity, and we can conclude that α0j = 0 if and only if β0j = 0.
Appendix C. Proof of Theorem 2
We first bound |Uj(β̂j)−Uj(β0j)| by the supremum of an empirical process, where Uj(β) was defined in (2). We then use the concentration theorem of Massart [32] to derive a maximal inequality. We will conclude by using Assumption 5 to extend this inequality to |β̂j − β0j|.
First, let Ūj(β) = n−1Uj(β). Since we still have Ūj(β̂j) = 0, we can write |Ūj(β̂j) − Ūj(β0j)| = |Ūj(β0j)|. Because Ūj(β0j) is not a sum of independent terms, we cannot directly apply empirical process techniques. However, we know from Lin and Wei [33] that , where
and the are independent. Furthermore, it is easy to show that . If we let En denote the empirical measure, then we can . Thus |Ūj(β̂j) − Ūj(β0j)| is bounded by the sum of the supremum of an empirical process and a term that converges to zero in probability.
To derive a maximal inequality for this process, we first find a bound on uniform over β and j = 1, …, pn. Using Assumptions 3, 4, and 6, we can write that for j = 1, …, pn. Next, we must find a bound on the expected value of our supremum. Let εi, i = 1, …, n be an independent, identically distributed sequence of random variables taking values ±1 with probability 1/2. In particular, they are independent of Z. Then , by Lemma 2.3.1 of van der Vaart and Wellner [34]. But by the Cauchy-Schwarz inequality, independence of εi and Zi, and the bound on | | derived above, we can show that the right side is bounded by . Then from the concentration theorem of Massart [32], we know that
| (C.1) |
Finally, we can relate this inequality back to |β̂j − β0j | with Assumption 5, though we must also deal with the op(1) term. Using a previously proven inequality, , so we can write
| (C.2) |
But for any ε > 0, P(A + B ≥ c) ≤ P(A ≥ c − ε) + P(B ≥ ε), where A and B are random variables and c is a constant. We conclude by combining this with (C.1) and (C.2) and taking ε arbitrarily close to 0.
Appendix D. Proof of Theorem 3
From Theorem 1, we know that β0j ≠ 0 if j ∈
. Then by Theorem 2.1 of Struthers and Kalbfleisch [17] and the mean value theorem, we know that
for some β* between β0j and 0, where
. We will first bound
and then use Assumption 7 to conclude.
Integrating by parts, we can show that . But E{ST (C; Z) | Z} is bounded by 1, so
Because ST SC is the probability of being at risk at time x, we can intuitively see, and also prove, that E(ZjST SC) = cov(Zj, ST SC) and cov[Zj, E{FT (C; Z) | Z}] have opposite signs. This implied that j ∈
, |β0j| ≥ 0.5K−2|cov[Zj, E{FT (C; Z) | Z}]|, and Assumption 7 gives minj∈
|β0j| ≥ c2n−κ for c2 = 0.5K−2c1.
Appendix E. Proof of Theorem 4
We first derive a probability bound for the standardized marginal regression parameters. We can then use this bound to find P(
⊆
).
Let 1+t = c2Hn1/2−κ/(8K[1+ Λ0(τ ) exp{2K(A + L)}]), with c2 and κ as defined in Theorem 3 and K, Λ0(τ), A, and L as defined in Theorem 2. Then by Theorem 2 there exists a constant c3 such that P(|β̂j − β0j| ≥ c2n−κ/2) ≤ exp(−c3n1−2κ).
If we now set our cutoff γn = Φ−1(1 − qn/2), then we can write the probability of retaining the important covariates as 1 − P{minj∈
Ij(β̂j)1/2|β̂j| < γn} ≥ 1 − P{minj∈
|β̂j| ≤ γn(Hn)−1/2}. Using Theorem 3 we can show that c2n−κ − |β̂j| ≤ |β0j − β̂j|, j ∈ M, so P{minj∈
|β̂j| ≤ γn(Hn)−1/2} ≤ P{maxj∈
|β̂j − β0j| ≥ c2n−κ − γn(Hn)−1/2}. If we have γn ≤ c2H1/2n1/2−κ/2, then the probability bound above gives P(
⊆
) ≥ 1 − exp(−c3n1−2κ).
Finally, since qn = f/pn, the requirement on γn can be rewritten as pn ≤ (f/2){1 − Φ(c2H1/2n1/2−κ/2)}−1. Using the fact that 1 − Φ(x) ≤ x−1 exp(−x2/2), this inequality can be satisfied if . Thus the sure screening property holds as long as log(pn) = O(n1-2κ).
Appendix F. Proof of Theorem 5
We first show that for j ∈
, Uj(β) evaluated at the true β0j can be approximated by a sum of continuous-time martingales, just as it can in a correctly specified Cox regression. We can then appeal to an Edgeworth expansion by Gu [35] to conclude.
By Theorem 1 we know that β0j = 0 for j ∈
. Thus we can rewrite
(2) as
where is a continuous martingale in x.
Now let , where
Note that E(ξm | Sm−1) = E{E(ξm | Sm−1, Zm) | Sm−1}, and
Given Sm−1, the conditional expectation on the right-hand side above is a random variable in Zmk, k ∈
only, and by Assumption 8 is independent of Zmj, j ∈
. Since E(Zmj | Sm−1) = E(Zlj) = 0 by Assumption 6, we find that E(ξm | Sm−1) = 0, implying that Sm is a discrete martingale in m. Then when m = n, by the inequality of Dharmadhikari et al. [36] we have that E(|n−1Sn|p) = Dn−p/2 for p ≥ 2, where we can show that D does not depend on j.
We have shown that for j ∈
,
where n−1Sn satisfies the same conditions as R1, n in (4.3) of Gu (1992). We can therefore extend the proof of Theorem 2.1 in Gu (1992) to show that
where c4 does not depend on j. Then (4) implies
The result follows if we choose γn = & Φ−1(1 − qn/2).
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- 1.Tibshirani RJ. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society, Ser B. 1996;58:267–288. [Google Scholar]
- 2.Zou H. The adaptive lasso and its oracle properties. Journal of the American Statistical Association. 2006;101:1418–1429. [Google Scholar]
- 3.Zou H, Hastie T. Regression shrinkage and selection via the elastic net with application to microarrays. Journal of the Royal Statistical Society, Ser B. 2005;67:301–320. [Google Scholar]
- 4.Fan J, Li R. Variable selection via noncave penalized likelihood and its oracle properties. Journal of the American Statistical Association. 2001;96:1348–1360. [Google Scholar]
- 5.Candès E, Tao T. The Dantzig selector: statistical estimation when p is much larger than n. The Annals of Statistics. 2007;35:2313–2351. [Google Scholar]
- 6.Fan J, Lv J. Sure independence screening for ultrahigh dimensional feature space. Journal of the Royal Statistical Society, Ser B. 2008;70:849–911. doi: 10.1111/j.1467-9868.2008.00674.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Wainwright MJ. Sharp thresholds for high-dimensional and noisy recovery using ℓ1-constrained quadratic programming (lasso) IEEE Transactions on Information Theory. 2009;55:2183–2202. [Google Scholar]
- 8.Mulligan G, Mitsiades C, Bryant B, Zhan F, Chng WJ, Roels S, Koenig E, Fergus A, Huang Y, Richardson P, Trepicchio WL, Broyl A, Sonneveld P, Shaughnessy JD, Bergsagel PL, Schenkein D, Esseltine DL, Boral A. Gene expression profiling and correlation with outcome in clinical trials of the proteasome inhibitor bortezomib. Blood. 2007;109:3177–3188. doi: 10.1182/blood-2006-09-044974. [DOI] [PubMed] [Google Scholar]
- 9.Fan J, Song R. Sure independence screening in generalized linear models and NP-dimensionality. The Annals of Statistics. 2010;38:3567–3604. [Google Scholar]
- 10.Li H. Censored data regression in high-dimensional and low-sample-size settings for genomic applications. In: Biswas A, Datta S, Fine J, Segal M, editors. Statistical Advances in Biomedical Sciences: State of the Art and Future Directions. Wiley; Hoboken: 2008. pp. 384–403. [Google Scholar]
- 11.Tibshirani RJ. Univariate shrinkage in the Cox model for high dimensional data. Statistical Applications in Genetics and Molecular Biology. 2009;8:21. doi: 10.2202/1544-6115.1438. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Fan J, Feng Y, Wu Y. High-dimensional variable selection for Cox’s proportional hazards model. In: Berger JO, Cai T, John-stone I, editors. Borrowing Strength: Theory Powering Applications – A Festschrift for Lawrence D Brown. Institute of Mathematical Statistics; Beachwood, OH: 2010. pp. 70–86. [Google Scholar]
- 13.Cox DR. Regression models and life tables (with discussion) Journal of the Royal Statistical Society, Ser B. 1972;34:187–220. [Google Scholar]
- 14.Benjamini Y, Hochberg Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society, Ser B. 1995;57:289–300. [Google Scholar]
- 15.Benjamini Y, Yekutieli D. The control of the false discovery rate in multiple testing under dependency. The Annals of Statistics. 2001;29:1165–1188. [Google Scholar]
- 16.Bunea F, Wegkamp M, Auguste A. Consistent variable selection in high dimensional regression via multiple testing. Journal of Statistical Planning and Inference. 2006;136:4349–4364. [Google Scholar]
- 17.Struthers CA, Kalbfleisch JD. Misspecified proportional hazard models. Biometrika. 1986;73:363–369. [Google Scholar]
- 18.Tibshirani RJ. The lasso method for variable selection in the Cox model. Statistics in Medicine. 1997;16:385–395. doi: 10.1002/(sici)1097-0258(19970228)16:4<385::aid-sim380>3.0.co;2-3. [DOI] [PubMed] [Google Scholar]
- 19.Zhang HH, Lu W. Adaptive lasso for Cox’s proportional hazards model. Biometrika. 2007;94:691–703. [Google Scholar]
- 20.Fan J, Li R. Variable selection for Cox’s proportional hazards model and frailty model. The Annals of Statistics. 2002;30:74–99. [Google Scholar]
- 21.Friedman J, Hastie T, Hoefling H, Tibshirani R. Pathwise coordinate optimization. The Annals of Applied Statistics. 2007;2:302–332. [Google Scholar]
- 22.Zou H, Li R. One-step sparse estimates in nonconcave penalized likelihood models (with discussion) The Annals of Statistics. 2008;36:1509–1533. doi: 10.1214/009053607000000802. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Hideshima T, Mitsiades C, Tonon G, Richardson P, Anderson KC. Understanding multiple myeloma pathogenesis in the bone marrow to identify new therapeutic targets. Nature Reviews Cancer. 2007;7:585–598. doi: 10.1038/nrc2189. [DOI] [PubMed] [Google Scholar]
- 24.Decaux O, Lodé L, Magrangeas F, Charbonnel C, Gouraud W, Jézéquel P, Attal M, Harousseau JL, Moreau P, Bataille R, Campion L, Avet-Loiseau H, Minvielle S. Prediction of survival in multiple myeloma based on gene expression profiles reveals cell cycle and chromosome instability signatures in high-risk patients and hyperdiploid signatures in low-risk patients: a study of the Intergroupe Francophone du Myélome. Journal of Clinical Oncology. 2008;26:4798–4805. doi: 10.1200/JCO.2007.13.8545. [DOI] [PubMed] [Google Scholar]
- 25.Hofmann WK, de Vos S, Komor M, Hoelzer D, Wachsman W, Koeffer HP. Characterization of gene expression of CD34+ cells from normal and myelodysplastic bone marrow. Blood. 2002;100:3553–3560. doi: 10.1182/blood.V100.10.3553. [DOI] [PubMed] [Google Scholar]
- 26.Aerts S, Lambrechts D, Maity S, Van Loo P, Coessens B, De Smet F, Tranchevent LC, De Moor B, Marynen P, Hassan B, Carmeliet P, Moreau Y. Gene prioritization through genomic data fusion. Nature Biotechnology. 2006;24:537–544. doi: 10.1038/nbt1203. [DOI] [PubMed] [Google Scholar]
- 27.Uno H, Cai T, Pencina MJ, D’Agostino RB, Wei LJ. On the C-statistics for evaluating overall adequacy of risk prediction procedures with censored survival data. Statistics in Medicine. 2011;30:1105–1117. doi: 10.1002/sim.4154. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Hadzidimitriou A, Stamatopoulos K, Belessi C, Lalayianni C, Stavroyianni N, Smilevska T, Hatzi K, Laoutaris N, Anagnos-topoulos A, Kollia P, Fassas A. Immunoglobulin genes in multiple myeloma: expressed and non-expressed repertoires, heavy and light chain pairings and somatic mutation patterns in a series of 101 cases. Haematologica. 2006;91:781–787. [PubMed] [Google Scholar]
- 29.Shaughnessy JD, Barlogie B. Interpreting the molecular biology and clinical behavior of multiple myeloma in the context of global gene expression profiling. Immunological Reviews. 2003;194:140–163. doi: 10.1034/j.1600-065x.2003.00054.x. [DOI] [PubMed] [Google Scholar]
- 30.Fleming TR, Harrington DP. Counting Processes and Survival Analysis. Wiley; Hoboken, NJ: 2005. [Google Scholar]
- 31.Wasserman L, Roeder K. High dimensional variable selection. The Annals of Statistics. 2009;37:2178–2201. doi: 10.1214/08-aos646. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Massart P. About the constants in Talagrand’s concentration inequalities for empirical processes. The Annals of Statistics. 2000;28:863–884. [Google Scholar]
- 33.Lin DY, Wei LJ. The robust inference for the cox proportional hazards model. Journal of the American Statistical Association. 1989;84:1074–1078. [Google Scholar]
- 34.van der Vaart AW, Wellner JA. Weak Convergence and Empirical Processes. Springer; New York: 1996. [Google Scholar]
- 35.Gu M. On the Edgeworth expansion and bootstrap approximation for the Cox regression model under random censorship. Canadian Journal of Statistics. 1992;20:399–414. [Google Scholar]
- 36.Dharmadhikari SW, Fabian V, Jogdeo K. Bounds on the moments of martingales. The Annals of Mathematical Statistics. 1968;39:1719–1723. [Google Scholar]