

Abstract
We construct a descriptive toy model that considers quantum effects on biological evolution starting from Chaitin's classical framework. There are smart evolution scenarios in which a quantum world is as favorable as classical worlds for evolution to take place. However, in more natural scenarios, the rate of evolution depends on the degree of entanglement present in quantum organisms with respect to classical organisms. If the entanglement is maximal, classical evolution turns out to be more favorable.
Ever since its development by Darwin1, the theory of evolution stands up as the landmark of fundamental knowledge in life sciences. In this sense, it is a theory of everything that unifies all species with a common origin. The driving principle of evolution is the ’survival of the fittest’. This leads to a common origin to all species and biological diversity. Before it, biology was conceived as static through history. After it, biological effects are given a dynamical framework.
As it stands, evolution is now considered the basic principle of biology and has the same character as a physical law: it is true as long of all pieces of experimental evidence support it. However, this does not preclude raising the fundamental question as to why living organism evolve. This question also arises in physical laws and the underlying issue is the search for more fundamental principles.
In a recent work, G. Chaitin2,3,4 has challenged the status of evolution and asked the question: is it possible to give a mathematical proof of evolution? As well as why is it that living organisms evolve.
It is apparent that in addressing such deep questions one cannot take into account all the details that are present in a living organism, whether it is highly evolved or not. One needs to abstract the basic features and come up with a toy model in order to be able to work with it. Chaitin has followed this method and he uses a very basic definition of what a living organism is and a remarkable notion of a mutation. His model and insight are inspired by his earlier works on Algorithmic Information Theory (AIT)5,6. We will refer to it as the Chaitin model and we shall describe it in Sect. I A.
A natural and challenging problem is how to introduce quantum effects in the classical model of Chaitin, and then try to evaluate its consequences. This is the purpose of this paper. Related to this, an interesting questions is: What is more favorable, to evolve in a quantum world or in a classical world?
The answer to this question is relevant in several ways since it could shed some light to other fundamental questions:
Biological evolution was formulated as a basic feature of classical living organisms for our world is classical at the macroscopic level. However, there could have been an earlier time previous to our current ‘classical era’ in which quantum effects may have played a role in evolution. Thus, was there a quantum evolution epoch before classical evolution took place?
Alternatively, there is also the possibility that classical and quantum evolution coexists at different scales. Is this possible or favorable?
A basic assumption of our quantum model for biological evolution will be the Turing barrier: a quantum computer can not compute a problem that is uncomputable for a classical computer, i.e. for a Turing machine (TM). For example, the Turing halting problem7 is also uncomputable for a quantum Turing machine. In his famous paper on quantum simulators, Feynman's argues that this barrier is unsurmountable8 and this is the widely accepted status on these quantum limits9, despite several attempts to beat the Turing barrier10,11. We leave for the Discussion section the interesting analysis on the possible consequences of beating the Turing barrier for the quantum Chaitin model of biological evolution.
It is very deep and insightful the use of non-computability as something positive as opposed to how it is appreciated in more pragmatical approaches to the foundations of the theory of computation. In mathematics, there is also intrinsic randomness, and Chaitin uses non-computability as a resource to have an appropriate fitness function to challenge organism to evolve, thereby improving and becoming more advanced. This is elaborated further in the Discussion section, Sec.II.
Schrödinger was the precursor of studying quantum effects in DNA12 and he thought about the possibility that mutations were originated by some sort of quantum fluctuations. The notion of mutation introduced here, Sec.I C, is far more general.
When addressing the issue of quantum effects in Chaitin biological evolution, it is crucial to bear in mind the following fact:
Complexity classes are affected by quantum effects and they are different than in the classical case.
Computability remains the same for both quantum and classical cases (this is the Turing barrier).
Thus, as the Chaitin model is based on non-computability as a resource for driving evolution, then apparently there should not be any quantum effects. However, the key point is that Chaitin defines an organism as a finite-size program software. Once its size N is fixed, thus being finite, it is also computable, thereby becoming a complexity problem. Thus, the way out to this apparent paradox is to realize that for finite N-size problem, there is no computability issue. What it is true is that ∀N, it is not possible to compute the fitness functions of Chaitin based on non-computability.
The version of algorithmic complexity introduced by Kolmogorov is not prefix-free (self-delimiting programs) and does not allow to formulate halting probabilities as in Chaitin's version of algorithmic complexity. This is why we use the latter.
This paper is organized as follows: in Sect.I A we review the classical model introduced by Chaitin to study classical evolution scenarios using the formalism and results of AIT; in Sect.I C the quantum versions of organisms, mutations and fitness functions are formulated on very general grounds; in Sect.I D a choice of quantum algorithmic complexity has to be made and we review the known results for entangled and separable quantum states; in Sect.I E we introduce quantum Ω numbers which play a central role in defining mutations in a quantum world; in Sect.I F we analyze the total evolution time and its scaling with the number of time-steps, for several quantum evolution scenarios and quantum organisms; Sect.II is devoted to discussion, prospects and further explanations. The Methods section III explains some basic notions of AIT and in particular, prefix-free bit-strings and its coding that are necessary to compute the complexity of quantum mutations.
Results
A. Classical chaitin model. 1. The model. The fundamental notion in Chaitin model is to consider life as evolving software. This will be specified below. To this end, let us recall some basic notions from AIT that are needed to define the model. Let 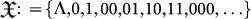 be the set of finite strings of binary bits, with Λ denoting the blank space symbol. The size or number of bits is |x|. The set of infinite bit-strings is denoted as
be the set of finite strings of binary bits, with Λ denoting the blank space symbol. The size or number of bits is |x|. The set of infinite bit-strings is denoted as  . A classical computer is an application
. A classical computer is an application 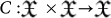 that takes an input data
that takes an input data  and a program
and a program 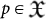 and acts on the input to produce an output string
and acts on the input to produce an output string 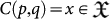 which is the result of the computation, assuming it halts. The concrete structure and functioning of C is given by the classical Turing Machine5,6. When the input data is empty, we simply write C(p) = x and when the output is simply stopping the computer with no output, we write C(p) : halts. A universal Turing Machine (UTM) U is one that can simulate the functioning of any other TM C.
which is the result of the computation, assuming it halts. The concrete structure and functioning of C is given by the classical Turing Machine5,6. When the input data is empty, we simply write C(p) = x and when the output is simply stopping the computer with no output, we write C(p) : halts. A universal Turing Machine (UTM) U is one that can simulate the functioning of any other TM C.
The notion of complexity is basic in computability theory. It tells us whether a program 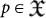 or input/output data q,
or input/output data q, 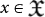 have a simple structure or not. Throughout this paper, we shall be using the notion of algorithmic complexity H(x) of a generic string of bits
have a simple structure or not. Throughout this paper, we shall be using the notion of algorithmic complexity H(x) of a generic string of bits 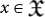 . It was studied independently by Solomonoff13, Kolmogorov14 and Chaitin15, and sometimes is referred to as Kolmogorov complexity. It is defined as the shortest program that can reproduce a given string x in a universal TM:
. It was studied independently by Solomonoff13, Kolmogorov14 and Chaitin15, and sometimes is referred to as Kolmogorov complexity. It is defined as the shortest program that can reproduce a given string x in a universal TM:
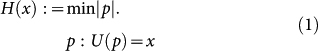 |
This notion of complexity grasp the concept that the information content of a string is more related to its intrinsic computational structure rather than to its mere size. For example, a string like x = 0101010101010101… may be very large, but its structure is very simple; x = (01)n, for a certain integer n. The same goes for other periodic strings or structured strings. Its complexity is bounded by a constant; H(x) < c. On the other side of the complexity are the random strings xr that are those without internal structure. This is represented by a complexity H(xr) ≥ |xr|, for the best thing a TM can do is to output the same input string xr.
A remark is in order. The algorithmic complexity H(x) is not computable because of the existence of the Halting problem and it is defined through a optimization process. Nevertheless, this is no obstacle to produce good and rigorous upper bounds that are enough to quantify the complexity of programs, data etc.
The classical Chaitin model is characterized by a triplet of elements 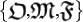 , whose definitions are:
, whose definitions are:
Living Organism
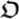 : it is a classical program, i.e., a piece of software that can be fed in a universal Turing Machine and produce a certain output, or just halt or even not halt. If the program
: it is a classical program, i.e., a piece of software that can be fed in a universal Turing Machine and produce a certain output, or just halt or even not halt. If the program 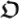 halts, then the output is a string of classical bits x. In the theory of classical computation, a program
halts, then the output is a string of classical bits x. In the theory of classical computation, a program 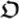 can also be characterized by a certain bit-string whose size is denoted as
can also be characterized by a certain bit-string whose size is denoted as 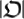 . Thus,
. Thus, 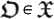 .
The rationale behind this choice is an abstract process that reduces an organism to pure information encoded in its DNA. The rest of the organism such as its body, functionalities etc are disregarded as far as being essential to evolution is concerned. This is an oversimplification that is inherent to this toy model and so far it is necessary in order to be able to apply tools from classical information theory (AIT).
.
The rationale behind this choice is an abstract process that reduces an organism to pure information encoded in its DNA. The rest of the organism such as its body, functionalities etc are disregarded as far as being essential to evolution is concerned. This is an oversimplification that is inherent to this toy model and so far it is necessary in order to be able to apply tools from classical information theory (AIT).Mutation
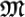 : it is a classical algorithm that transforms a given organism
: it is a classical algorithm that transforms a given organism 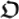 into a mutated organism
into a mutated organism 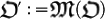 . Thus, it represents a transformation of the DNA by the action of external agents to the classical code. Thus,
. Thus, it represents a transformation of the DNA by the action of external agents to the classical code. Thus, 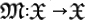 .
This notion of mutation is an algorithmic mutation as opposed to other more typical mutations called point-wise mutation that are common to population genetics studies. What is remarkable is that an algorithmic mutation is far richer than other notions of mutations considered thus far, and in this context, it appears as the most general change that we can consider on a given living organism (classical code).
Consider the following two very different mutations acting on a n-string in bitwise notation
.
This notion of mutation is an algorithmic mutation as opposed to other more typical mutations called point-wise mutation that are common to population genetics studies. What is remarkable is that an algorithmic mutation is far richer than other notions of mutations considered thus far, and in this context, it appears as the most general change that we can consider on a given living organism (classical code).
Consider the following two very different mutations acting on a n-string in bitwise notation  . One is a point-wise mutation
. One is a point-wise mutation 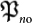 defined as
defined as
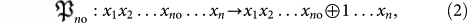 and the other is a bit-wise mutation
and the other is a bit-wise mutation 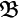
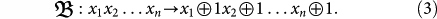 While
While 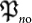 represents a local change in the classical code (DNA),
represents a local change in the classical code (DNA), 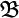 affects globlally to a all the code.
affects globlally to a all the code. 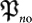 is a typical mutation in population genetics since it is more likely to change one single base of the genetic code than multiple changes which are exponentially unlikely. On the contrary, the bit-wise mutation produces a drastic change in the genetic code. It turns out to be useful since it may lead to a change of specie for example. Both mutations are necessary and they find a common framework in the algorithmic treatment of evolution. They have similar amounts of complexity
is a typical mutation in population genetics since it is more likely to change one single base of the genetic code than multiple changes which are exponentially unlikely. On the contrary, the bit-wise mutation produces a drastic change in the genetic code. It turns out to be useful since it may lead to a change of specie for example. Both mutations are necessary and they find a common framework in the algorithmic treatment of evolution. They have similar amounts of complexity 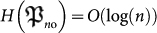 and
and 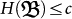 . In fact, for conditional complexities we also have
. In fact, for conditional complexities we also have 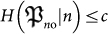 . Therefore, having a big mutation is not penalized during the whole history of evolution.
The evolution is a process that starts with the simplest organism
. Therefore, having a big mutation is not penalized during the whole history of evolution.
The evolution is a process that starts with the simplest organism 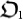 and it evolves towards more complex organisms
and it evolves towards more complex organisms 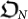 after the action of a series of mutations
after the action of a series of mutations 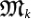 , k = 1, 2, …, N. The algorithmic complexity
, k = 1, 2, …, N. The algorithmic complexity 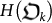 measures how the new successful organisms are becoming more advanced.
It is the action of a mutation what defines the notion of time in this model and it is given by the time-step k. The total evolution time would be N.
measures how the new successful organisms are becoming more advanced.
It is the action of a mutation what defines the notion of time in this model and it is given by the time-step k. The total evolution time would be N.Fitness Function
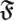 : this is a cost function that evaluates whether a mutated organism has improved with respect to the original. Thus,
: this is a cost function that evaluates whether a mutated organism has improved with respect to the original. Thus, 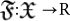 .
.
Let 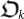 be a given organism and time-step. Then, in the next step the organism is mutated to
be a given organism and time-step. Then, in the next step the organism is mutated to 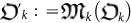 . The fitness function selects whether the new organism survives or fails:
. The fitness function selects whether the new organism survives or fails:
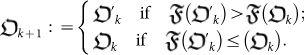 |
Chaitin's deep insight into the problem of biological evolution is the choice of the fitness function from AIT. The idea is to see life as evolving software, such that a living organism is tested after a mutation has occurred. The idea is to use a testing function that is an endless resource. This way, evolution will never be exhausted, will ever go on. In AIT there are several functions with this remarkable property that make them specially well-suited for this task: quantities that are definable but not computable. One example is the Busy Beaver function16
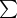 . Another example is Chaitin's Ω number6,17,18 that represents the halting probability of self-delimiting TMs.
. Another example is Chaitin's Ω number6,17,18 that represents the halting probability of self-delimiting TMs.
For the Busy Beaver function 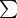 there are several variants which are equally good for the purposes of fitness function, that measures the rate of evolution. For instance,
there are several variants which are equally good for the purposes of fitness function, that measures the rate of evolution. For instance, 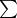 can be defined as the maximum number of 1′s output by a TM U after it halts starting from a blank input data q = Λ. To work with
can be defined as the maximum number of 1′s output by a TM U after it halts starting from a blank input data q = Λ. To work with 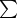 it is convenient to specify the maximum size N that the programs
it is convenient to specify the maximum size N that the programs 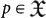 operated by U and define the output as the largest integer
operated by U and define the output as the largest integer 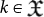 in binary form that is computed after halting U. Thus, a N-th Busy Beaver function is denoted
in binary form that is computed after halting U. Thus, a N-th Busy Beaver function is denoted  and defined
and defined
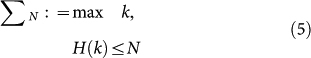 |
where the algorithmic complexity (1) is defined for programs p that compute k = U(p) without input and halting. This is a well-defined function 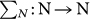 but it is noncomputable: it grows faster than any computable function
but it is noncomputable: it grows faster than any computable function 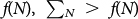 for sufficiently large N. Therefore,
for sufficiently large N. Therefore,  cannot be bounded in the form of
cannot be bounded in the form of 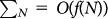 . This is the property that makes
. This is the property that makes 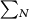 a good candidate for fitness function since it is an endless source of creativity that enable us to test a new organism, a program
a good candidate for fitness function since it is an endless source of creativity that enable us to test a new organism, a program 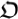 , and see whether it is smarter by checking whether it can name a bigger number. Thus, we can use (4) with
, and see whether it is smarter by checking whether it can name a bigger number. Thus, we can use (4) with 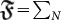 and ask how the total mutation time TN behaves as N grows. Let us mention in passing that naming increasingly bigger numbers requires lots of creativity in the form of new functions and ways to name new numbers bigger and bigger.
and ask how the total mutation time TN behaves as N grows. Let us mention in passing that naming increasingly bigger numbers requires lots of creativity in the form of new functions and ways to name new numbers bigger and bigger.
A more manageable and systematic choice for fitness function is Chaitin's Ω number. To define it, it is convenient to introduce the notion of universal probability PU(x) of a given string 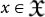 :
:
which is the probability that a program randomly drawn as a sequence of fair coin flips p = p1p2… will compute the string x. That this is a well-defined probability distribution is a central result in AIT. It relies on some technical details: a) the programs p are not arbitrary, but self-delimiting; b) convergence of the series is guaranteed by the Kraft inequality19. A self-delimiting program is a program that knows when to stop by itself, without additional stopping symbols. It is constructed from a set of prefix-free strings of bits: strings that are not prefix of any other string in the set (see Methods section III). In AIT, the algorithmic complexity and the universal probability of strings are related by a Shannon type of equation:
The Ω number can be defined from the universal probability once we drop any reference to any particular output string:
It is considered as the halting probability in the theory of TMs. It measures the probability that a randomly chosen program p will halt when run in a UTM that halts. Thus, it is defined on the set of prefix-free halting programs, not for arbitrary programs. Interestingly enough, Chaitin proved that universal TM exist for self-delimiting programs. This technical condition guarantees that 0 < Ω < 1: there are always programs that halt, but not all of them will halt due to the halting problem. Again, Ω is well-defined and noncomputable. It hosts an inexhaustible amount of knowledge and it is thus suited for a fitness function. In short, if Ω were computable it would imply that there is no halting problem, which is false. Like 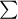 , it is convenient to truncate Chaitin's number up to programs of size N computed in time less than N:
, it is convenient to truncate Chaitin's number up to programs of size N computed in time less than N:
These ΩN are lower bounds to the actual Ω. This truncation also produces an unbounded function ΩN that reflects its non-computability.
Chaitin uses Ωk to define an organism 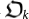 and a mutation
and a mutation 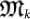 at time-step k, as well as the fitness function
at time-step k, as well as the fitness function 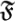 . Namely, an organism is defined by means of the first N(k) binary digits ωi of Ωk:
. Namely, an organism is defined by means of the first N(k) binary digits ωi of Ωk:
To complete the construction of the organism 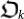 from the proto-organism
from the proto-organism 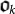 , we need two more ingredients. One is to make it a self-delimiting program by including a prefix string 1N(k)0 (see Methods section III) and the other one is to prefix a program pΩ to read the fitness of the resulting organism. Altogether, the organism looks like:
, we need two more ingredients. One is to make it a self-delimiting program by including a prefix string 1N(k)0 (see Methods section III) and the other one is to prefix a program pΩ to read the fitness of the resulting organism. Altogether, the organism looks like:
The mutation acts on the organism by trying to improve the lower bounds on Ω. According to AIT, a natural move is
Notice that this mutation induces, in turn, a mutation in the organism 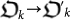 by the rules specified in its construction above. These mutations represent challenging an organism to find a better a better lower bound of Ω which amounts to an ever increasing source of knowledge. To this end, the fitness function
by the rules specified in its construction above. These mutations represent challenging an organism to find a better a better lower bound of Ω which amounts to an ever increasing source of knowledge. To this end, the fitness function 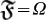 is introduced as follows:
is introduced as follows:
To understand this selection, notice that no truncation Ωk can be greater that the real Ω and thus, this represents a failure. On the contrary, if the new truncation 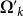 is still less than Ω, we have increased our knowledge of how many programs will halt upon running a UTM
is still less than Ω, we have increased our knowledge of how many programs will halt upon running a UTM 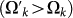 . As Chaitin notices, this implies the use of an oracle2,3,4.
. As Chaitin notices, this implies the use of an oracle2,3,4.
It is possible to define a variant of the Busy Beaver function 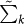 in terms of ΩN as the least N for which the first k bits of the binary string of ΩN are correct. In AIT it can be proved that both Busy Beavers are approximately equal,
in terms of ΩN as the least N for which the first k bits of the binary string of ΩN are correct. In AIT it can be proved that both Busy Beavers are approximately equal,
B. Chaitin's Evolution Scenarios. Let us denote TN the total mutation time, i.e., the number of mutations tried in order to evolve an initial organism 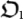 up to a certain more fitted organism
up to a certain more fitted organism 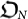 . Depending on the strategy followed by Nature, Chaitin considers three scenarios and computes the scaling of TN with N. In this way, one can assess which is the best evolutionary scenario. The results are the following:
. Depending on the strategy followed by Nature, Chaitin considers three scenarios and computes the scaling of TN with N. In this way, one can assess which is the best evolutionary scenario. The results are the following:
Scenario I: Exhaustive Search.
This scenario represents that there is no strategy in Nature and every possible organism is tested regardless which was the previous organism that originated it. Thus, there is no effective application of a fitness function but Nature explores all possible codes available in the phase space. As from AIT we know that in a given set of strings 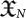 of length up to N there are 2N − 1 strings, then the order of the evolution time is
of length up to N there are 2N − 1 strings, then the order of the evolution time is
It takes an exponential time to reach a certain organism 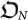 .
.
Scenario II: Intelligent Design.
This scenario is the opposite to the previous one. Now, Nature is not dumb but assumed to be intelligent enough so as to know about AIT and this model of evolution. The initial proto-organism is 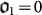 . The best strategy is to apply a process of interval halving to track down better lower bounds to O by applying mutations
. The best strategy is to apply a process of interval halving to track down better lower bounds to O by applying mutations 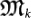 , k = 1, 2, …, N in this increasing order. Thus the mutation time takes of the order of N trials:
, k = 1, 2, …, N in this increasing order. Thus the mutation time takes of the order of N trials:
Thus, by selecting intelligently the order of the mutations, since we assume that Natures knows the structure of Ω, then the total evolution time for an organism grows linearly in N.
Scenario III: Cumulative Evolution at Random.
A more natural assumption is that Nature choses randomly the mutations 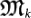 among the set of possible mutations. It is a random walk in the space of mutations. Remarkably enough, the evolution time grows in between quadratic and cubic in N:
among the set of possible mutations. It is a random walk in the space of mutations. Remarkably enough, the evolution time grows in between quadratic and cubic in N:
Although this is worse than scenario II, it is still a polynomial growth and far from the exponential growth of scenario I.
C. Quantum Chaitin Model. The following definitions are we well-motivated when trying to bring concepts from Quantum Information Theory (QIT) into Chaitin's classical model. They can be made even more general as discussed in Sect.II.
Quantum Organism
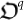 : it is a pure quantum state in a Hilbert space
: it is a pure quantum state in a Hilbert space 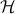 of infinitely countable qubits:
of infinitely countable qubits: 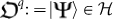 . In practice, we shall be dealing with a finite truncation to a number of qubits N denoted as
. In practice, we shall be dealing with a finite truncation to a number of qubits N denoted as 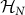 .The meaning of this choice is motivated by the notion of classical organism as a program for a TM. Now, the quantum version is a pure state that encodes the information of a quantum program. This is meaningful since we have adhered to an abstraction process in which a living organism is divested of everything except its genetic code that is represented by a classical program. Thus, a quantum organism is not a form of quantum life, but represents quantum effects in the classical code of DNA.
.The meaning of this choice is motivated by the notion of classical organism as a program for a TM. Now, the quantum version is a pure state that encodes the information of a quantum program. This is meaningful since we have adhered to an abstraction process in which a living organism is divested of everything except its genetic code that is represented by a classical program. Thus, a quantum organism is not a form of quantum life, but represents quantum effects in the classical code of DNA.Quantum Mutation
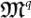 : it is a quantum algorithm that transforms the original quantum organism
: it is a quantum algorithm that transforms the original quantum organism 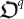 into a mutated quantum organism
into a mutated quantum organism 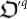 :
:

Quantum Fitness
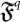 : it is a cost function that selects a mutated organism when it is fittest than the original.
: it is a cost function that selects a mutated organism when it is fittest than the original.
The traditional characters of Quantum Information20,21 Alice A and Bob B, can be adapted to the quantum evolution scenario: Alice is the organism before the mutation 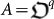 and Bob is the mutated organism
and Bob is the mutated organism 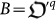 . Then,
. Then, 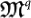 will success or fail depending on the fitness of the pair (A, B).
will success or fail depending on the fitness of the pair (A, B).
In order to complete the above quantum definitions we need to specify how to choose a triplet 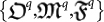 in the quantum case. We shall follow the classical model and try to find a quantum version of organisms as lower bounds to some Ω number to be specify. Once this is done, the quantum notions of mutation and fitness function will also follow. All this can be done by defining a notion of quantum algorithmic complexity.
in the quantum case. We shall follow the classical model and try to find a quantum version of organisms as lower bounds to some Ω number to be specify. Once this is done, the quantum notions of mutation and fitness function will also follow. All this can be done by defining a notion of quantum algorithmic complexity.
D. Quantum Algorithmic Complexity. The quantumness of the Ω number that we are searching for our definition of quantum organism will depend on the notion of quantum algorithmic complexity Hq that we decide to use. In fact, there are several versions of Hq22,23,24,25 and not all of them are equivalent. We shall choose the definition of Mora and Briegel25 that is called network complexity Hnet because of the following properties25,26,27:
Hnet is a classical algorithmic complexity associated to a quantum state. It describes how many classical bits of information are required to describe a quantum state of N qubits. Being classical, it will allow us to compare to previous evolution rates on equal footing.
Hnet has the special property that it requires an exponential number of classical bits for the description of generic quantum states. In particular, it detects a sharp difference between multipartite entangled states and separable states.
The network complexity is a description that Alice does of a quantum state 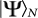 she has and she wants to send this information to Bob through a classical channel so that Bob could eventually reproduce that state on his side. It describes the classical effort Bob would have to do. In order to define network complexity, we need several operational elements: a) a universal set of quantum gates
she has and she wants to send this information to Bob through a classical channel so that Bob could eventually reproduce that state on his side. It describes the classical effort Bob would have to do. In order to define network complexity, we need several operational elements: a) a universal set of quantum gates 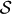 ; b) an alphabet to code circuit operations
; b) an alphabet to code circuit operations 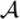 , and c) a fidelity or degree of precision ε ∈ (0,1). With the aid of these elements, we can construct a mapping from quantum states in
, and c) a fidelity or degree of precision ε ∈ (0,1). With the aid of these elements, we can construct a mapping from quantum states in 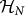 to finite strings
to finite strings 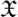 , such that
, such that
and then,
The first equality represents our choice of quantum algorithmic complexity while the second is the definition of network complexity (1).
The mapping 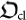 (19) is constructed from the elements a)-c) as follows: let us select a universal finite set of gates for example, the one generated by the gates
(19) is constructed from the elements a)-c) as follows: let us select a universal finite set of gates for example, the one generated by the gates 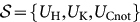 28, i.e., the Hadamard gate, the π/8-phase gate and the Cnot gate, respectively. Then, Alice sets up a quantum circuit of gates called U by concatenating gates from
28, i.e., the Hadamard gate, the π/8-phase gate and the Cnot gate, respectively. Then, Alice sets up a quantum circuit of gates called U by concatenating gates from 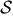 , and constructs a state, namely,
, and constructs a state, namely, 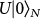 , from an initialization state
, from an initialization state 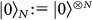 . This prepared state can approximate the desired state
. This prepared state can approximate the desired state 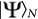 with precision given by
with precision given by
In all what follows, ε will be a fixed parameter once and for all from the beginning.
Next, Alice needs to use the alphabet 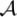 in order to code all the operations in the circuit U and preparation of the state with ε-precision (21). This is represented by a certain string of bits
in order to code all the operations in the circuit U and preparation of the state with ε-precision (21). This is represented by a certain string of bits 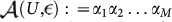 , where M is the length of the resulting bit-string and is a certain function of the number of qubits N. Then, the mapping (19) is given by
, where M is the length of the resulting bit-string and is a certain function of the number of qubits N. Then, the mapping (19) is given by
With this, the network complexity (20) is well-defined. An additional minimization process is assumed in (1) since the circuit U is not unique and it is natural to request to use the minimal circuit that prepares the state with the desired precission.
Our choice of quantum algorithmic complexity has very important consequences for studying quantum effects in biological evolution:
According to this definition of quantum algorithmic complexity in terms of a classical network complexity, we realize that the set of quantum states is mapped onto the set of bit-strings. Thus, while the former is uncountable, the latter is infinitely denumerable.
By virtue of this mapping we are complying with the Turing barrier.
The fact that the network complexity is classical will make that our quantum Ωq will be also real numbers and not quantum states or operators. However, we can make classical definitions of Ω numbers that represent different types of quantum states (see later).
In a traditional quantum information scenario, Bob needs to agree with Alice on which alphabet to use in order to communicate. In a quantum evolution scenario, there is no need to agree on a common language for the description since there are not two observers, but a single organism that evolves.
We shall use the following fundamental results from network complexity and quantum states25. As a consequence of the Solovay-Kitaev theorem20,29,30, the number of gates (bit-string) M of the circuit needed to construct a given multipartite state 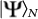 grows exponentially with N for a fixed accuracy ε.
grows exponentially with N for a fixed accuracy ε.
Furthermore, the network complexity quantifies very differently the complexity of separable and entangled states25:
Separable States
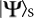 :
:
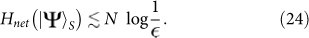
Maximally Entangled States
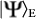 :
:
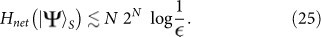
Generic States:
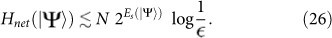
where 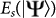 is the Schmidt measure which quantifies the degree of entanglement in the multipartite pure state31.
is the Schmidt measure which quantifies the degree of entanglement in the multipartite pure state31.
The fact that separable states are less complex than entangled states means that separable states are more likely: If we type a random bit-string at a computer, most likely it will correspond to a separable state. This raises a fundamental question: can we use the higher complexity of entangled states to accelerate the rate of biological evolution? To answer this question we need to introduce the corresponding quantum Ω numbers and different scenarios for mutations evolution in which evolution will develop.
E. Quantum Omega Numbers. In order to describe different types of quantum organisms we need to define different types of Ω numbers associated to quantum states. Thus, we shall use the basic results on network complexity Hnet. However, we can define Omega numbers associated to selected classes of states. As we know from the geometry of the Hilbert space of states that the set of separable states does not intersect the set of truly entangled (maximally) states, we can define Ω numbers by restricting the sum on the programs originated by the mapping (19) to those yielding either separable or entangled states. By construction, these sets are discrete since we are using a discrete set of universal quantum gates 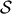 .
.
Separable
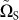 number:
number:
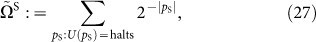
where pS is a program that describes the network complexity of a separable state |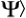 S. To do this sum, we construct all possilble separable states and apply the mapping (19) to perform the sum. As the method is constructive, the separable states are obtained on demand.
S. To do this sum, we construct all possilble separable states and apply the mapping (19) to perform the sum. As the method is constructive, the separable states are obtained on demand.
Entangled (maximally)
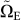 number:
number:
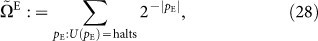
where pE is a program that describes the network complexity of a maximally entangled state |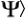 E. To do this sum, we fix the accuracy ε which behaves as an overhead factor, then we construct all posilble maximally entangled states and apply the mapping (19) to perform the sum. The decision problem of whether a given constructed state is maximally entangled is solved by computing its Schmidt measure and testing that it is maximal. We take this as an operational definition of maximally entangled state in this context.
E. To do this sum, we fix the accuracy ε which behaves as an overhead factor, then we construct all posilble maximally entangled states and apply the mapping (19) to perform the sum. The decision problem of whether a given constructed state is maximally entangled is solved by computing its Schmidt measure and testing that it is maximal. We take this as an operational definition of maximally entangled state in this context.
In both sums, the programs pS and pE are assumed to be prefix-free in order to guarantee their convergence. The typical behaviour of their general terms are 2N and 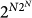 , repectively. We drop off the overhead factor from now on. From the viewpoint of AIT, we may use another equivalent definitions in terms of the network complexity explicitly:
, repectively. We drop off the overhead factor from now on. From the viewpoint of AIT, we may use another equivalent definitions in terms of the network complexity explicitly:
The above quantum Ω numbers are introduced relying on the choice of quantum algorithmic complexity in terms of network complexity. Other choices of quantum complexity may lead to different definitions of quantum Ω numbers that may become quantum states32,33 or even quantum operators.
F. Quantum Evolution Scenarios. We want to compare quantum evolution in a world of maximally entangled quantum organisms w.r.t. a classical world both in intelligent design and cumulative evolution scenarios.
In order to study quantum effects in evolution scenarios as in Sect.I A, (15) (16) (17), we need to define a triplet 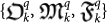 . This is achieved by introducing truncated versions of the quantum Ω numbers in (29), as follows. For separable states, we have
. This is achieved by introducing truncated versions of the quantum Ω numbers in (29), as follows. For separable states, we have
where the sum runs over truncations up to N qubits, 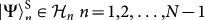 , corresponding to the construction process described in (27), (29). The quantum separable organism is a lower bound to (31). The key distinctive feature is that the typical behaviour of one element in this truncated sum decreases as 2−k. Thus, the corresponding mutation is defined such as to produce a significant change in the organisms as
, corresponding to the construction process described in (27), (29). The quantum separable organism is a lower bound to (31). The key distinctive feature is that the typical behaviour of one element in this truncated sum decreases as 2−k. Thus, the corresponding mutation is defined such as to produce a significant change in the organisms as
Therefore, the analysis of the evolution rates for the quantum evolution scenarios dealing with separable states are similar to those with classical organisms in (15), (16), (17). A classical state is a state that can be prepared classically, thus it can evolve classically. The same treatment as with the classical scenarios in Sect.I A reproduces the same evolution rates.
A different result will be obtained with maximally entangled organisms. Now, let us introduce the truncated entangled Ω number as
This allows us to obtain a quantum version of the triplet 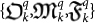 . In particular, the quantum entangled organism
. In particular, the quantum entangled organism 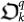 at time step k is defined by the same process in Sect.I A, (11) of producing lower bounds but now with the truncated quantum Ω number (33).
at time step k is defined by the same process in Sect.I A, (11) of producing lower bounds but now with the truncated quantum Ω number (33). 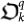 yields a lower bound to
yields a lower bound to 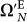 defined above (33).
defined above (33).
Next, we introduce a mutation 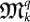 that tries to make this quantum organism
that tries to make this quantum organism 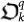 to progress. A significative progress will occur if we try to increase the form of the quantum Ω number (33) according to the typical behaviour of its terms in the sum. This is given by
to progress. A significative progress will occur if we try to increase the form of the quantum Ω number (33) according to the typical behaviour of its terms in the sum. This is given by 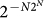 for spaces up to N qubits. Thus, now we define an entangled version of the mutation as
for spaces up to N qubits. Thus, now we define an entangled version of the mutation as
Notice that this choice of move in the space of quantum organisms is motivated by the typical behaviour of quantum circuits representing quantum algorithms acting on quantum states. This is the natural scale for quantum mutations to occur at the level of quantum organisms.
The fitness function is determined by the oracle of ΩE which decides whether the mutated organism 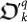 with (34) succeeds or fails according to the criteria (13).
with (34) succeeds or fails according to the criteria (13).
Now, we have all the ingredients to analyze the rates for different quantum evolution scenarios, mainly with entangled organisms.
1. Quantum Exhaustive Search
As indicated by its name, this strategy is defined by searching all classical possible programs that can be generated quantum states available in the Hilbert space 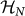 of N qubits by means of the mapping (19). For a strings of length M we know this grows as 2M. In turn, the length of these strings is related to the number of qubits as M ≈ 2N. Thus, as in this evolution scenario each mutation is exhaustive, i.e., it tries every possible quantum organism regardless which original organism may be, then the evolution rate behaves as
of N qubits by means of the mapping (19). For a strings of length M we know this grows as 2M. In turn, the length of these strings is related to the number of qubits as M ≈ 2N. Thus, as in this evolution scenario each mutation is exhaustive, i.e., it tries every possible quantum organism regardless which original organism may be, then the evolution rate behaves as
2. Quantum Intelligent Design
This strategy is like climbing a hill via the optimal path, knowing such a path before hand. In such a way that each step is always better than the previous one. There is no backtracking. A more proper name would be Quantum Optimal Evolution.
Now, we have to use the quantum mutations (34). If we produce an optimal ordered sequence of these mutations 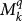 as follows: k = 1, 2, …, N we shall reach the first N valid digits of
as follows: k = 1, 2, …, N we shall reach the first N valid digits of 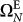 , by construction, and then the evolution rate is:
, by construction, and then the evolution rate is:
Thus, quantum intelligent design behaves linear in the number of trials N in a maximally entangled world. This behaviour is equal as the intelligent design in a classical world (16). Notice that the quantum mutations have a different growth rate than classical mutations, but nevertheless the evolution time is the same: they are optimal.
3. Quantum Cumulative Evolution
This strategy is like climbing a hill, but now we do not have a priori knowledge of the best strategy to improve the lower bounds of the quantum number. Thus, a natural strategy is to mutate by means of a random walk in the space of quantum mutations given by (34). In this case, the quantum mutations must be drawn at random and often enough so as to produce the same final quantum organism.
The quantum mutation is characterized by the growth k2k. For simplicity, we shall take it as the leading behaviour 2k. As the we have chosen the network complexity as our measure for quantum algorithmic complexity, we can now use classical formulas and Methods section III, (45) to estimate the complexity of a quantum mutation associated to a maximally entangled state:
Its probability is 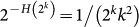 and its frequency is k22k. The total evolution time TN is of the order of
and its frequency is k22k. The total evolution time TN is of the order of
which grows exponentially up to polynomial factors,
Thus, quantum cumulative evolution in a maximally entangled world behaves exponentially worse than cumulative evolution in a classical world. Quite likely, it is more favorable to evolve in a classical world than in a quantum world. This may explain why we live in a classical world at the macroscopic level. We should remark that this conclusion does not contradicts the fact that quantum algorithms can be more efficient than classical algorithms since our conclusions refer to algorithmic complexity, while quantum algorithms deal with computational complexity (time and space resources for computation).
Discussion
We have studied quantum effects on biological evolution by means of a descriptive toy model based on quantum algorithmic complexity. This is an adequate option when studying biological evolution from a broad perspective and in a very large time scale, so large that any type of quantum mutation (18) can take place and not just point-wise mutation that only affect a base in the DNA code. In quantum evolution terms, the quantum complexity is a measure of how difficult has been for Nature to ‘prepare’ the quantum organism. The results obtained in Sect.I F for the rates in quantum evolution scenarios are based not on the notion of runtime complexity, but on the notion of mutation time, as well as what a typical quantum mutation move is.
The halting problem and other noncomputable functions are preceded by an aura of being a pathology, a nuisance … eventually, something negative. This is the perspective of non-specialists. On the contrary, we may consider this undecidability as a sort of intrinsic randomness in Mathematics. This is analogous to the intrinsic randomness that quantum theory brought to Physics even earlier in the history of Science. Now we know from Quantum Information Theory (QIT) that this randomness can be used to our benefit, in a large variety of ways. Similarly, It is very remarkable how Chaitin turns the problem of non-computability in algorithmic complexity into a source of creativity in order to challenge living organisms to evolve by becoming increasingly more advanced. This process of challenging by means of mutations is endless precisely because the fitness function employed is non-computable and cannot be bounded when truncated, as we learn from AIT. Thus, non-computability is given a positive role in a descriptive version of biological evolution.
We have adopted the same perspective when formulating a quantum version of an algorithmic model for biological evolution. This has motivated us to use a quantum notion of complexity based on the network complexity. In this way, We can still work with lower bounds of quantum Ω numbers as prototype of quantum effects in DNA code. This perspective is non-trivial in the quantum case since it implicitly assumes the existence of the Turing barrier also in the quantum realm. This is still an open problem. While a classical Turing Machine works with data and programs that are infinite but countable, a quantum Turing Machine works with non-countable sets like complex numbers. Thus, we could argue that the classical halting problem does not apply since now the number of quantum TMs is uncountable. However, let us recall that Turing's halting problem is just one instance, very remarkable, of Gödel's incompleteness theorem. Thus, if we believe that Gödel's incompleteness theorem applies beyond Arithmetic, we may accept that there are uncomputable problems in quantum TMs also, and likely something equivalent to a quantum Turing halting problem. Moreover, in our case, we have employed a finite set of universal quantum gates and a transformation to bit-strings from network complexity. This implies that we are not considering a quantum TM as a continuous system, but we are dealing effectively with a countable set of gates up to a fixed precision ε. T his seems the simplest generalization of the classical scenario.
It is interesting to realize that the Turing barrier has important consequences in a quantum evolution scenario of this kind. In case that barrier could be beaten by quantum effects, that would imply that we cannot use real quantum non-computability as a source of creativity in quantum evolution as in the classical Chaitin model. We could not justify quantum effects on biological evolution on the same theoretical grounds.
The evolution rates in quantum scenarios are understood up to an overhead factor arising from the accuracy factor that we want to use. This is fixed and thus removed from the expressions for simplicity. However, this ε parameter is new in the quantum evolution case and does not exist in the classical case. Something similar could be introduced in a classical evolution by invoking the existence of classical errors during evolution, but this is not standard in AIT. The reason for the existence of ε is because the universal gate set 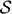 is finite. With a continuous universal gate set20,21,34 it is possible to get rid of it, but that would imply that Nature would had an infinite amount of resources, something which we do not consider reasonable. The fundamental origin of this difference is the fact that the set of classical strings is countable while the set of quantum states is uncountable. Thus, working with a classical universal set of gates does not need an ε parameter. In this regard, the quantum complexity is more ‘natural’ than the classical where something like ε is absent at the very fundamental level. In other words, the classical universal Turing machine and the finite universal quantum gate set are not on equal footing, but the quantum case is more ‘natural’ since Nature can also make errors.
is finite. With a continuous universal gate set20,21,34 it is possible to get rid of it, but that would imply that Nature would had an infinite amount of resources, something which we do not consider reasonable. The fundamental origin of this difference is the fact that the set of classical strings is countable while the set of quantum states is uncountable. Thus, working with a classical universal set of gates does not need an ε parameter. In this regard, the quantum complexity is more ‘natural’ than the classical where something like ε is absent at the very fundamental level. In other words, the classical universal Turing machine and the finite universal quantum gate set are not on equal footing, but the quantum case is more ‘natural’ since Nature can also make errors.
Alternatively, we can think of this parameter as a grid or lattice spacing but in the space of quantum states, rather than in real space. It is a discretization. In this sense, we always work with a finite lattice or grid, and that is why we drop this dependence. We never take the continuum limit.
The network complexity is formulated in terms of a finite universal gate set 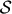 , instead of a quantum Turing Machine which would seem more natural if we see how the classical algorithmic complexity is defined explicitly in terms of a classical Turing Machine. However, this is not an obstacle since we are using the Solovay-Kitaev theorem to reconstruct arbitrary quantum unitary gate to a given precision. Furthermore, we also know that the quantum circuit model is equivalent to the quantum Turing Machine model due to the Yao theorem35. Moreover, we have also identified that the choice of a coding language in network complexity to transform a quantum circuit in a bit-string (19) is irrelevant for quantum evolution, since Alice and Bob are replaced by the original organism and the mutated organism, respectively.
, instead of a quantum Turing Machine which would seem more natural if we see how the classical algorithmic complexity is defined explicitly in terms of a classical Turing Machine. However, this is not an obstacle since we are using the Solovay-Kitaev theorem to reconstruct arbitrary quantum unitary gate to a given precision. Furthermore, we also know that the quantum circuit model is equivalent to the quantum Turing Machine model due to the Yao theorem35. Moreover, we have also identified that the choice of a coding language in network complexity to transform a quantum circuit in a bit-string (19) is irrelevant for quantum evolution, since Alice and Bob are replaced by the original organism and the mutated organism, respectively.
The simple quantum toy model of Sec.I C can be thought of as a first step towards more realistic models and it does not exhaust all necessary ingredients to describe quantum effects in biological evolution, even from a algorithmic information viewpoint. For example, we can mention a series of extensions that this model still allows:
Fitness Functions: instead of using lower bounds to quantum Ω numbers, there are other options considered by Chaitin in his classical model that it is worthwhile to find its instance in the quantum model.
Creation of Hierarchies: classical evolution favors the formation of hierarchies of living organisms. Are they compatible with quantum evolutions?
Mixed States: in all our analysis, quantum organisms have been represented by means of pure quantum states and mutations by quantum algorithms. There is a natural extension to mixed quantum states where the lack of purity here may represent the action of an external environment on the organism, i.e., its genetic code. This degree of freedom may influence the evolution rates and it is also a way to model the presence of errors during evolution.
Continuous Variables (CV): we may also choose the Hilbert space of states not to be represented by qubits, but for continuous variable states36, like Gaussian states. This is still a well-defined model for quantum computation and it remains a challenge to study its properties from the algorithmic complexity perspective and in the context of evolution.
Quantum Complexity: as we have mentioned, there are other notions of quantum algorithmic complexity that are not equivalent to network complexity. It is still possible to keep a version of this toy model in Sect.I C and investigate the consequences in quantum evolution of these other choices. In particular, quantum Ω numbers can be replaced by quantum states or even quantum operators. This may affect the evolution rates. However, it is important to justify conceptually these other choices.
Methods
Size of Self-Delimiting Bit-Strings in Algorithmic Complexity Theory (AIT)
The size of an integer k ∈ N is defined as
where 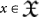 is the finite bit-string representation of k.
is the finite bit-string representation of k.
In AIT, it is technically necessary to work with self-delimiting, i.e., prefix-free strings of bits in order to have a well-defined halting probability Ω that be convergent. Let x denote a n-bit string: x = x1x2…xn. The set of 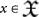 strings is not self-delimiting. For example, for n = 2 then
strings is not self-delimiting. For example, for n = 2 then 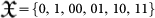 has a 0 that is a prefix of 00 and 01 and so on.
has a 0 that is a prefix of 00 and 01 and so on.
Given a set of strings 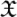 we can make them into a set of self-delimiting strings by the following procedure:
we can make them into a set of self-delimiting strings by the following procedure:
i.e., we put n 0s before the string and use a 1 to separate it from the given n-bit string x. In the context of evolution, this is called a proto-organism. As the Turing Machine has to read the input string bit by bit, then this way we are telling the TM the length of the string x ahead of time (before the TM reads it). Another example for n = 3 bit-strings is
and now we do not have prefix strings anymore.
The size of self-delimiting strings enters in the definition of the Chaitin numbers and we need to compute its size. Denote |x| the size in bits of a string 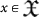 . In our case, |x| = n. Then, the size of its self-delimiting extension (41) is
. In our case, |x| = n. Then, the size of its self-delimiting extension (41) is
However, we realize that the coding of the size of the string x in the above self-delimiting procedure is highly inefficient since we are using the unary code. We can improve this coding by using the fact that an integer like |x| can be coded with log n bits, for x large (40). Thus, let us define a better encoded self-delimiting string x′ as follows
where 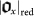 here is the string of bits representing the log of the size of
here is the string of bits representing the log of the size of  , and appears before x. Now, its size is (43)
, and appears before x. Now, its size is (43)
Acknowledgments
M.A.M.-D. thanks the Spanish MICINN grant FIS2009-10061, CAM research consortium QUITEMAD S2009-ESP-1594, European Commission PICC: FP7 2007-2013, Grant No. 249958, UCM-BS grant GICC-910758.
References
- Darwin Ch. On the Origin of Species by Means of Natural Selection, or the Preservation of Favoured Races in the Struggle for Life, (1959). [PMC free article] [PubMed] [Google Scholar]
- Chaitin G. J. To a mathematical theory of evolution and biological creativity; preprint (2011). Paper presented Monday 10 January 2011 at a workshop on. ÒRandomness, Structureand Causality: Measures of Complexity from Theory to Applications Ôorganized by Jim Crutchel. [Google Scholar]
- Chaitin G. J. Proving Darwin, Pantheon, New York, (2012). [Google Scholar]
- Chaitn G. J. Life as evolving software, in H. Zenil, A Computable Universe, World Scientific, Singapore., (2012).
- Chaitin G. J. A theory of program size formally identical to information theory. J. ACM 22, 329, –340 (1975). [Google Scholar]
- Chaitin G. J. Algorithmic Information Theory, Cambridge University Press, (1987). [Google Scholar]
- Turing A. M. On computable numbers, with an application to the Entscheidungsproblem, Proc. London Math. Soc. 42, 230–265 (1936–37); Correction, ibid. 43, 544–546 (1937). [Google Scholar]
- Feynman R. P., Simulating physics with computers. Int. J. Theor. Phys. 21, 467 –488 (1982). [Google Scholar]
- Bernstein E. & Vazirani U. Quantum complexity theory. SIAM J. Comput. 26, 1411 (1997). [Google Scholar]
- Calude C. S. & Pavlov B. Coins, Quantum Measurements, and Turing. ÕsBarrier, Quantum Information Processing, 1, Nos.1/2, (2002). [Google Scholar]
- Kieu T. D. Quantum Algorithm for HilbertÕsTenthProblem, arXiv:quant-ph/0310052v2. (2003).
- Schrödinger E. What Is Life? The Physical Aspect of the Living Cell. Cambridge University Press, Cambridge (1944). [Google Scholar]
- Solomonoff R. A Formal Theory of Inductive Inference Part I. 7 . Information and Control 7 (1): 1–22 (1964). [Google Scholar]
- Kolmogorov A. N. Three Approaches to the Quantitative Definition of Information. Problems Inform. Transmission 1, 1–7 (1965). [Google Scholar]
- Chaitin G. J. On the length of programs for computing finite binary sequences. Journal of the ACM 13, 547–569 (1966). [Google Scholar]
- Radó T. On non-computable functions, Bell. System Technical Journal, 41, No. 3, 877–884 (1962). [Google Scholar]
- Chaitin G. J. The Limits of Mathematics, Springer-Verlag, London, (2003). [Google Scholar]
- Calude C. C., Dinneen M. J. & Shu C.-K. Computing a glimpse of randomness. Exper. Math., 11, 361–370 (2002). [Google Scholar]
- Cover T. M. & Thomas J. A. Elements of Information Theory, Second Edition, John Wiley & Sons, Inc. New Jersey (2006), [Google Scholar]
- Nielsen M. A. & Chuang I. L. Quantum Computation and Quantum Information, Cambridge University Press, UK, (2000). [Google Scholar]
- Galindo A. & Martin-Delgado M. A. Information and Computation: Classical and Quantum Aspects.. Rev. Mod. Phys. 74, 347–423, (2002); arXiv:quant-ph/0112105. [Google Scholar]
- Vitanyi P. Three Approaches to the Quantitative Definition of Information in an Individual Pure Quantum State., arXiv: quant-ph/9907035 (2000).
- Berthiaume A., Dam W. & Laplante S. Quantum Kolmogorov Complexity., arXiv: quant-ph/005018 (2000).
- Gács P. Quantum Algorithmic Entropy., arXiv: quantph/0011046 v2 (2001).
- Mora C. & Briegel H. J. Algorithmic complexity and entanglement of quantum states., Phys. Rev. Lett. 95, 20 (2005). [DOI] [PubMed] [Google Scholar]
- Mora C. & Briegel H. J. Algorithmic complexity of quantum states., arXiv:quant-ph/0412172. (2004). [DOI] [PubMed]
- Mora C., Briegel H. J. & Kraus B. Quantum Kolmogorov complexity and its applications, arXiv:quant-ph/0610109. (2006).
- Boykin P. O., Mor T., Pulver M., Roychowdhury, & F. Vatan F. On Universal and Fault-Tolerant Quantum Computing. Information Processing Letters 75, 101 (2000). [Google Scholar]
- Solovay R. unpublished manuscript (1995). [Google Scholar]
- Kitaev A. Y. Quantum computations:algorithms and error correction. Russ. Math. Surv. 52, 1191–1249 (1997). [Google Scholar]
- Eisert J. & Briegel H. J. Schmidt measure as a tool for quantifying multiparticle entanglement. Phys. Rev. A 64 (2001). [Google Scholar]
- Svozil K. Quantum algorithmic information theory, eprint. arXiv:quant-ph/9510005, (1995).
- Svozil K. Halting probability amplitude of quantum computers. Journal of Universal Computer Science 1, nr. 3 (1995)
- Barenco A., et al. Elementary gates for quantum computation. Phys. Rev. A. 52, 3457. (1995). [DOI] [PubMed] [Google Scholar]
- Yao A. Proceedings of the 34th IEEE Symposium on the Foundations of Computer Science (IEEE Computer Society, Los Alamitos, CA), p. 352. (1993). [Google Scholar]
- Braunstein S. L. & Pati A. K. (Eds) Quantum Information with Continuous Variables; Kluwer Academic Publishers, The Netherlands (2003). [Google Scholar]